实验一、BP及RBP神经网络逼近
BP神经网络逼近非线性函数

3、 试用BP 神经网络逼近非线性函数f(u) =)5.0u (9.1e+-sin(10u) 其中,u ∈[-0.5,0.5](1)解题步骤:①网络建立:使用“net=newff(minmax(x), [20, 1], {'tansig ’,’ purelin' });,语句建立个前馈BP 神经网络。
该BP 神经网络只含个隐含层,且神经元的个数为20。
隐含层和输出层神经元的传递函数分别为tansig 和pure-lin 。
其他参数默认。
②网络训练:使用“net=train (net, x , y) ;”语句训练建立好的BP 神经网络。
当然在网络训练之前必须设置好训练参数。
如设定训练时间为50个单位时间,训练目标的误差小于0.01,用“net.trainParam.epochs=50; net.train-Param.goal=0.01;”,语句实现。
其他参数默认。
③网络仿真:使用“y1=sim(net, x); y2=sim(net, x};”语句仿真训练前后的BP 神经网络。
(2)程序如下:clear all ;x=[-0.5:0.01:0.5];y=exp(-1.9*(0.5+x)).*sin(10*x);net=newff(minmax(x),[20,1],{'tansig' 'purelin'});y1=sim(net,x); %未训练网络的仿真结果 net.trainParam.epochs=50;net.trainParam.goal=0.01;net=train(net,x,y);y2=sim(net,x); %训练后网络的仿真结果 figure;plot(x,y,'-',x,y1,'-',x,y2,'--')title('原函数与网络训练前后的仿真结果比较');xlabel('x');ylabel('y');legend('y','y1','y2');grid on(3)仿真结果如图:图1图1为原函数y与网络训练前后(y1,y2)的仿真结果比较图。
BP神经网络实现函数逼近python实现

机器学习作业一BP神经网络实现函数逼近一.算法描述BP(Back Propagation)神经网络是1986年由Rumelhart和McCelland为首的科学家小组提出,是一种按误差逆传播算法训练的多层前馈网络,是目前应用最广泛的神经网络模型之一。
BP网络能学习和存贮大量的输入-输出模式映射关系,而无需事前揭示描述这种映射关系的数学方程。
它的学习规则是使用梯度下降法,通过反向传播来不断调整网络的权值和阈值,使网络的误差平方和最小。
BP神经网络模型拓扑结构包括输入层(input)、隐层(hidden layer)和输出层(output layer)。
二.数据描述逼近函数y = sin(x)三.算法参数输入学习率,迭代次数,逼近函数,神经网络规模输出逼近的函数四.实验流程反向传播算法(Back Propagation)分二步进行,即正向传播和反向传播。
这两个过程简述如下:1.正向传播输入的样本从输入层经过隐单元一层一层进行处理,传向输出层;在逐层处理的过程中。
在输出层把当前输出和期望输出进行比较,如果现行输出不等于期望输出,则进入反向传播过程。
2.反向传播反向传播时,把误差信号按原来正向传播的通路反向传回,逐层修改连接权值,以望代价函数趋向最小。
输入层输入向量(n维):X=(x1,x2,…,xi,…,xn)T隐层输出向量(隐层有m个结点):Y=(y1,y2,…,yj,…,ym)T输出层输出向量(l维):O=(o1,o2,…,ok,…,ol)T期望输出向量:d=(d1, d2,…,dk,…,dl)T输入层到隐层之间的权值矩阵:V=(V1,V2,…,Vj,…,Vm)隐层到输出层之间的权值矩阵用:W=(W1,W2,…,Wk,…,Wl)对输出层第k个结点和隐含层的第j个结点有如下关系:激活函数f(x)常用sigmoid函数(一个在生物学中常见的S型的函数,也称为S 形生长曲线)或者tanh(双曲正切)函数。
BP神经网络实验报告

作业8编程题实验报告(一)实验内容:实现多层前馈神经网络的反向传播学习算法。
使用3.2节上机生成的数据集对神经网络进行训练和测试,观察层数增加和隐层数增加是否会造成过拟合。
(二)实验原理:1)前向传播:以单隐层神经网络为例(三层神经网络),则对于第k 个输出节点,输出结果为:在实验中采用的激励函数为logistic sigmoid function 。
考虑每一层节点中的偏差项,所以,在上式中:)()(00,1l l j b w x ==在实验中,就相应的需要注意矢量形式表达式中,矢量大小的调整。
2)BP 算法:a) 根据问题,合理选择输入节点,输出节点数,确定隐层数以及各隐层节点数;b) 给每层加权系数,随机赋值;c) 由给定的各层加权系数,应用前向传播算法,计算得到每层节点输出值,并计算对于所有训练样本的均方误差;d) 更新每层加权系数:其中,⎪⎩⎪⎨⎧⋅⋅⋅-=∑+j i ji l i l i i i l i a h w a h d y 其它层,最后一层)('(),(')()1()()(δδe) 重复c),d )迭代过程,直至迭代步数大于预设值,或者每次迭代误差变化值小于预设值时,迭代结束,得到神经网络的各层加权系数。
(三)实验数据及程序:1)实验数据处理:a) 训练样本输入节点数据:在实验中,所用数据中自变量x 的取值,为0—1的25个随机值,为了后续实验结果的分析,将其从小到大排序,并加上偏差项,神经网络的输出节点最终训练结果,即为训练得到的回归结果;b) 训练样本标签值:在实验中,采用的激励函数为logistic sigmoid function ,其值域为[0,1],所以,在神经网络训练前,需要对训练样本标签值进行归一化处理;c) 神经网络输出节点值:对训练样本标签值进行了归一化处理,相应的,对于输出节点,需要反归一化处理。
2)实验程序:实现函数:[Theta]=BP(input_layer_size,hidden_layer_size,hidden_layer_num,num_labels,Niter,leta,X,Y)输入参数:input_layer_size:输入节点数;hidden_layer_size:隐层节点数(对于单隐层,输入值为一数值,对于多隐层,为一矢量);hidden_layer_num:隐层数;num_labels:输出节点数;Niter:为预设的迭代步数;leta:学习速率,即更新步长;X,Y:分别为训练样本输入特征值以及标签值。
BP神经网络仿真实验指导书

BP神经网络设计指导书一、实验目的1. 熟悉神经网络的特征、结构以及学习算法2. 了解神经网络的结构对控制效果的影响3. 掌握用MATLAB实现神经网络控制系统仿真的方法。
二、实验原理人工神经网络ANN(Artificial Neural Network)系统由于具有信息的分布存储、并行处理以及自学习能力等优点,已经在信息处理、模式识别、智能控制及系统建模等领域得到越来越广泛的应用。
尤其是基于误差反向传播(Back Propagation) 算法的多层前馈网络(Muhiple-LayerFeedforward Network),即BP网络,可以以任意精度逼近任意连续函数,所以广泛地应用于非线性建模、函数逼近和模式分类等方面。
1.BP网络算法实现BP算法属于delta算法,是一种监督式的学习算法。
其主要思想是:对于M个输人学习样本,已知与其对应的输出样本。
学习的目的是用网络的实际输出与目标矢量之间的误差来修改其权值,使实际与期望尽可能地接近,即使网络输出层的误差平方和达到最小,他是通过连续不断地在相对于误差函数斜率下降的方向上计算网络权值和偏差的变化而逐渐逼近目标的。
每一次权值和偏差的变化都与网络误差的影响成正比,并以反向传播的方式传递到每一层。
2.BP网络的设计在MATLAB神经网络工具箱中.有很方便的构建神经网络的函数。
对于BP网络的实现.其提供了四个基本函数:newff,init.train和sim.它们分别对应四个基本步骤.即新建、初始化、训练和仿真(1)初始化前向网络初始化是对连接权值和阈值进行初始化。
initff函数在建立网络对象的同时,自动调用初始化函数,根据缺省的参数对网络的连接权值和阈值进行初始化。
格式:[wl,bl,w2,b2]=initff(p,sl,fl,s2,f2)其中P表示输入矢量,s表示神经元个数,f表示传递函数,W表示权值,b表示阈值。
(2)训练网络BP网络初始化以后,就可对之进行训练了。
BP神经网络实验报告

BP神经网络实验报告一、引言BP神经网络是一种常见的人工神经网络模型,其基本原理是通过将输入数据通过多层神经元进行加权计算并经过非线性激活函数的作用,输出结果达到预测或分类的目标。
本实验旨在探究BP神经网络的基本原理和应用,以及对其进行实验验证。
二、实验方法1.数据集准备本次实验选取了一个包含1000个样本的分类数据集,每个样本有12个特征。
将数据集进行标准化处理,以提高神经网络的收敛速度和精度。
2.神经网络的搭建3.参数的初始化对神经网络的权重和偏置进行初始化,常用的初始化方法有随机初始化和Xavier初始化。
本实验采用Xavier初始化方法。
4.前向传播将标准化后的数据输入到神经网络中,在神经网络的每一层进行加权计算和激活函数的作用,传递给下一层进行计算。
5.反向传播根据预测结果与实际结果的差异,通过计算损失函数对神经网络的权重和偏置进行调整。
使用梯度下降算法对参数进行优化,减小损失函数的值。
6.模型评估与验证将训练好的模型应用于测试集,计算准确率、精确率、召回率和F1-score等指标进行模型评估。
三、实验结果与分析将数据集按照7:3的比例划分为训练集和测试集,分别进行模型训练和验证。
经过10次训练迭代后,模型在测试集上的准确率稳定在90%以上,证明了BP神经网络在本实验中的有效性和鲁棒性。
通过调整隐藏层结点个数和迭代次数进行模型性能优化实验,可以发现隐藏层结点个数对模型性能的影响较大。
随着隐藏层结点个数的增加,模型在训练集上的拟合效果逐渐提升,但过多的结点数会导致模型的复杂度过高,容易出现过拟合现象。
因此,选择合适的隐藏层结点个数是模型性能优化的关键。
此外,迭代次数对模型性能也有影响。
随着迭代次数的增加,模型在训练集上的拟合效果逐渐提高,但过多的迭代次数也会导致模型过度拟合。
因此,需要选择合适的迭代次数,使模型在训练集上有好的拟合效果的同时,避免过度拟合。
四、实验总结本实验通过搭建BP神经网络模型,对分类数据集进行预测和分类。
实训神经网络实验报告

一、实验背景随着人工智能技术的飞速发展,神经网络作为一种强大的机器学习模型,在各个领域得到了广泛应用。
为了更好地理解神经网络的原理和应用,我们进行了一系列的实训实验。
本报告将详细记录实验过程、结果和分析。
二、实验目的1. 理解神经网络的原理和结构。
2. 掌握神经网络的训练和测试方法。
3. 分析不同神经网络模型在特定任务上的性能差异。
三、实验内容1. 实验一:BP神经网络(1)实验目的:掌握BP神经网络的原理和实现方法,并在手写数字识别任务上应用。
(2)实验内容:- 使用Python编程实现BP神经网络。
- 使用MNIST数据集进行手写数字识别。
- 分析不同学习率、隐层神经元个数对网络性能的影响。
(3)实验结果:- 在MNIST数据集上,网络在训练集上的准确率达到98%以上。
- 通过调整学习率和隐层神经元个数,可以进一步提高网络性能。
2. 实验二:卷积神经网络(CNN)(1)实验目的:掌握CNN的原理和实现方法,并在图像分类任务上应用。
(2)实验内容:- 使用Python编程实现CNN。
- 使用CIFAR-10数据集进行图像分类。
- 分析不同卷积核大小、池化层大小对网络性能的影响。
(3)实验结果:- 在CIFAR-10数据集上,网络在训练集上的准确率达到80%以上。
- 通过调整卷积核大小和池化层大小,可以进一步提高网络性能。
3. 实验三:循环神经网络(RNN)(1)实验目的:掌握RNN的原理和实现方法,并在时间序列预测任务上应用。
(2)实验内容:- 使用Python编程实现RNN。
- 使用Stock数据集进行时间序列预测。
- 分析不同隐层神经元个数、学习率对网络性能的影响。
(3)实验结果:- 在Stock数据集上,网络在训练集上的预测准确率达到80%以上。
- 通过调整隐层神经元个数和学习率,可以进一步提高网络性能。
四、实验分析1. BP神经网络:BP神经网络是一种前向传播和反向传播相结合的神经网络,适用于回归和分类问题。
BP神经网络逼近非线性函数

应用BP神经网络逼近非线性函一、实验要求1、逼近的非线性函数选取为y=sin(x1)+cos(x2),其中有两个自变量即x1,x2,一个因变量即y。
2、逼近误差<5%,即:应用测试数据对网络进行测试时,神经网络的输出与期望值的最大误差的绝对值小于期望值的5%。
3、学习方法为经典的BP算法或改进形式的BP算法,鼓励采用改进形式的BP算法。
4、不允许采用matlab中现有的关于神经网络建立、学习、仿真的任何函数及命令。
二、实验基本原理2.1 神经网络概述BP神经网络是一种多层前馈神经网络,该网络的主要特点是信号前向传播,误差反向传播。
在前向传递中,输入信号从输入层经隐含层逐层处理,直至输出层。
每一层的神经元状态只影响下一层神经元状态。
如果输出层得不到期望输出,则转入反向传播,根据预判误差调整网络权值和阈值,从而使BP神经网络预测输出不断逼近期望输出。
BP神经网络的拓扑结构如图所示。
2.2 BP神经网络训练步骤BP神经网络预测前首先要训练网络,通过训练使网络具有联想记忆和预测能力。
BP神经网络的训练过程包括以下几个步骤。
步骤1:网络初始化。
根据系统输入输出序列(X,Y)确定网络输入层节点数n、隐含层节点数l、输出层节点数m,初始化输入层、隐含层和输出层神经元之间的连接权值ωij,ωjk,初始化隐含层阈值a,输出层阈值b,给定学习速率和神经元激励函数。
步骤2:隐含层输出计算。
根据输入变量X,输入层和隐含层间连接权值ωij以及隐含层阈值a,计算隐含层输出H。
j1(a )nj ij ii H f x ω==-∑ j=1,2,…,l式中,l 为隐含层节点数,f 为隐含层激励函数,该函数有多种形式,一般选取为1(x)1xf e-=+ 步骤3:输出层输出计算。
根据隐含层输出H ,连接权值ωjk 和阈值b ,计算BP 神经网络预测输出O 。
1lk j jk k j O H b ω==-∑ k=1,2,…,m步骤4:误差计算。
BP神经网络逼近非线性函数

应用BP神经网络逼近非线性函一、实验要求1、逼近的非线性函数选取为y=sin(x1)+cos(x2),其中有两个自变量即x1,x2,一个因变量即y。
2、逼近误差<5%,即:应用测试数据对网络进行测试时,神经网络的输出与期望值的最大误差的绝对值小于期望值的5%。
3、学习方法为经典的BP算法或改进形式的BP算法,鼓励采用改进形式的BP算法。
4、不允许采用matlab中现有的关于神经网络建立、学习、仿真的任何函数及命令。
二、实验基本原理2.1 神经网络概述BP神经网络是一种多层前馈神经网络,该网络的主要特点是信号前向传播,误差反向传播。
在前向传递中,输入信号从输入层经隐含层逐层处理,直至输出层。
每一层的神经元状态只影响下一层神经元状态。
如果输出层得不到期望输出,则转入反向传播,根据预判误差调整网络权值和阈值,从而使BP神经网络预测输出不断逼近期望输出。
BP神经网络的拓扑结构如图所示。
2.2 BP神经网络训练步骤BP神经网络预测前首先要训练网络,通过训练使网络具有联想记忆和预测能力。
BP神经网络的训练过程包括以下几个步骤。
步骤1:网络初始化。
根据系统输入输出序列(X,Y)确定网络输入层节点数n、隐含层节点数l、输出层节点数m,初始化输入层、隐含层和输出层神经元之间的连接权值ωij,ωjk,初始化隐含层阈值a,输出层阈值b,给定学习速率和神经元激励函数。
步骤2:隐含层输出计算。
根据输入变量X,输入层和隐含层间连接权值ωij以及隐含层阈值a,计算隐含层输出H。
j 1(a )nj ij i i H f x ω==-∑ j=1,2,…,l式中,l 为隐含层节点数,f 为隐含层激励函数,该函数有多种形式,一般选取为1(x)1xf e-=+步骤3:输出层输出计算。
根据隐含层输出H ,连接权值ωjk 和阈值b ,计算BP 神经网络预测输出O 。
1lk j jk k j O H b ω==-∑ k=1,2,…,m步骤4:误差计算。
BP神经网络实验

实验名称:班级名称: 专业:姓名:学号:联系电话:计算智能实验报告BP神经网络算法实验一、实验目的1)编程实现BP神经网络算法;2)探究BP算法中学习因子算法收敛趋势、收敛速度之间的关系;3)修改训练后BP神经网络部分连接权值,分析连接权值修改前和修改后对相同测试样本测试结果,理解神经网络分布存储等特点。
二、实验要求按照下面的要求操作,然后分析不同操作后网络输出结果。
1)可修改学习因子2)可任意指定隐单元层数3)可任意指定输入层、隐含层、输出层的单元数4)可指定最大允许误差e5)可输入学习样本(增加样本)6)可存储训练后的网络各神经元之间的连接权值矩阵;7)修改训练后的BP神经网络部分连接权值,分析连接权值修改前和修改后对相同测试样本测试结果。
三、实验原理1明确BP神经网络算法的基本思想如下:2明确BP神经网络算法步骤和流程如下:四、实验内容和分析1.. 实验时建立三层BP神经网络,输入节点2个,隐含层节点2个,输出节点1个,输入训练样本如下表:学习因子分别为0.5和0.6,最大允许误差0.012.训练结果:训练次数3906 ,全局误差0.0099955输入层与隐含层连接权值为-5.25626 5.04393-5.35186 5.43925隐含层与输出层连接权值为7.79517 -7.43036隐含层神经元阈值为-2.77105 2.78374输出层神经元阈值为3.480783.输入测试样本为0.05 0.10.2 0.90.86 0.95输出测试结果为0.046 0.7860.043可见网络性能良好,输出结果基本满足识别要求。
4.改变学习因子学习因子决定每一次循环训练中所产生的权值变化量。
大的学习因子可能导致系统的不稳定;但小的学习因子导致较长的训练时间,可能收敛很慢,不过能保证网络的误差值不跳出误差表面的低谷而最终趋于误差最小值。
所以一般情况下倾向于选取较小的学习速率以保证系统的稳定性。
5.改变输入层、隐含层、输出层的单元数当隐含层节点个数为3时,相同训练样本和测试样本,得到测试结果为0.0450.7990.039训练次数3742 ,全局误差0.0099959可见,改变输入层、隐含层、输出层的单元数,即改变网络结构,可以改善网络性能,增加隐含层节点个数可以更好的提取模式特征,识别结果更精确,但网络复杂度增加,可能不稳定。
BP神经网络——逼近应用
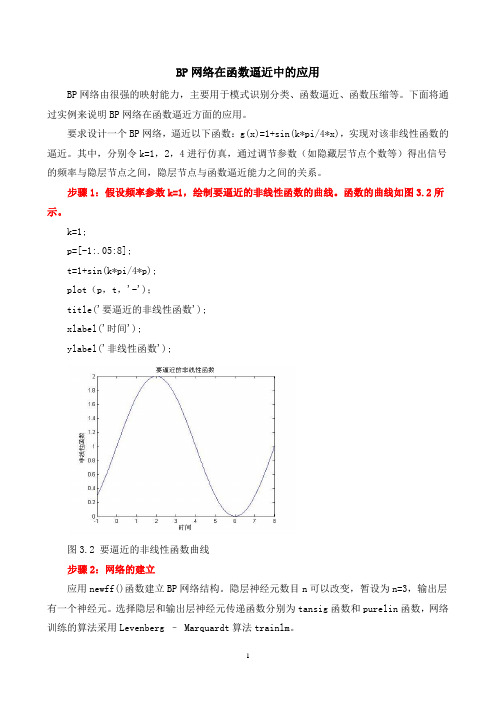
BP网络在函数逼近中的应用BP网络由很强的映射能力,主要用于模式识别分类、函数逼近、函数压缩等。
下面将通过实例来说明BP网络在函数逼近方面的应用。
要求设计一个BP网络,逼近以下函数:g(x)=1+sin(k*pi/4*x),实现对该非线性函数的逼近。
其中,分别令k=1,2,4进行仿真,通过调节参数(如隐藏层节点个数等)得出信号的频率与隐层节点之间,隐层节点与函数逼近能力之间的关系。
步骤1:假设频率参数k=1,绘制要逼近的非线性函数的曲线。
函数的曲线如图3.2所示。
k=1;p=[-1:.05:8];t=1+sin(k*pi/4*p);plot(p,t,'-');title('要逼近的非线性函数');xlabel('时间');ylabel('非线性函数');图3.2 要逼近的非线性函数曲线步骤2:网络的建立应用newff()函数建立BP网络结构。
隐层神经元数目n可以改变,暂设为n=3,输出层有一个神经元。
选择隐层和输出层神经元传递函数分别为tansig函数和purelin函数,网络训练的算法采用Levenberg – Marquardt算法trainlm。
n=3;net = newff(minmax(p),[n,1],{'tansig' 'purelin'},'trainlm');对于初始网络,可以应用sim()函数观察网络输出。
y1=sim(net,p);figure;plot(p,t,'-',p,y1,':')title('未训练网络的输出结果');xlabel('时间');ylabel('仿真输出--原函数-');同时绘制网络输出曲线,并与原函数相比较,结果如图3.3所示。
图3.3 未训练网络的输出结果因为使用newff( )函数建立函数网络时,权值和阈值的初始化是随机的,所以网络输出结构很差,根本达不到函数逼近的目的,每次运行的结果也有时不同。
bp神经网络进行多项式函数的逼近 吐血推荐1

神经网络及应用实验报告院系:电气工程学院班级:adf3班姓名:adsf学号:20sdf实验二、基于BP网络的多层感知器一:实验目的:1. 理解多层感知器的工作原理2. 通过调节算法参数了解参数的变化对于感知器训练的影响3. 了解多层感知器局限性二:实验原理:BP的基本思想:信号的正向传播误差的反向传播–信号的正向传播:输入样本从输入层传入,经各隐层逐层处理后,传向输出层。
–误差的反向传播:将输入误差以某种形式通过隐层向输入层逐层反传,并将误差分摊给各层的所有单元,从而获得各层单元的误差信号来作为修正各单元权值的依据。
1.基本BP算法的多层感知器模型:2.BP学习算法的推导:当网络输出与期望输出不等时,存在输出误差E将上面的误差定义式展开至隐层,有进一步展开至输入层,有调整权值的原则是使误差不断地减小,因此应使权值的调整量与误差的梯度下降成正比,即η∈(0,1)表示比例系数,在训练中反应学习速率BP算法属于δ学习规则类,这类算法被称为误差的梯度下降(Gradient Descent)算法。
三:实验内容:Hermit多项式如下式所示:f(x)=1.1(1-x+2x^2)exp(-x^2/2)采用BP算法设计一个单输入单输出的多层感知器对该函数进行逼近。
训练样本按以下方法产生:样本数P=100,其中输入样本xi服从区间[-4,4]内的均匀分布,样本输出为F(xi)+ei ,ei为添加的噪声,服从均值为0,标准差为0.1的正态分布。
隐层采用Sigmoid激活函数f(x)=1/(1+1/e^x),输出层采用线性激活函数f(x)=x。
注意:输出层采用的线性激活函数,不是Sigmoid激活函数,所以迭代公式需要根据前面的推导过程重新推导。
四:实验步骤:1. 用Matlab编程,实现解决该问题的单样本训练BP网络,设置一个停止迭代的误差Emin和最大迭代次数。
在调试过程中,通过不断调整隐层节点数,学习率η,找到收敛速度快且误差小的一组参数。
BP神经网络实验

实验算法BP神经网络实验【实验名称】BP神经网络实验【实验要求】掌握BP神经网络模型应用过程,根据模型要求进行数据预处理,建模,评价与应用;【背景描述】神经网络:是一种应用类似于大脑神经突触联接的结构进行信息处理的数学模型。
BP神经网络是一种按照误差逆向传播算法训练的多层前馈神经网络,是目前应用最广泛的神经网络。
其基本组成单元是感知器神经元。
【知识准备】了解BP神经网络模型的使用场景,数据标准。
掌握Python/TensorFlow数据处理一般方法。
了解keras神经网络模型搭建,训练以及应用方法【实验设备】Windows或Linux操作系统的计算机。
部署TensorFlow,Python。
本实验提供centos6.8环境。
【实验说明】采用UCI机器学习库中的wine数据集作为算法数据,把数据集随机划分为训练集和测试集,分别对模型进行训练和测试。
【实验环境】Pyrhon3.X,实验在命令行python中进行,或者把代码写在py脚本,由于本次为实验,以学习模型为主,所以在命令行中逐步执行代码,以便更加清晰地了解整个建模流程。
【实验步骤】第一步:启动python:命令行中键入python。
第二步:导入用到的包,并读取数据:(1).导入所需第三方包import pandas as pdimport numpy as npfrom keras.models import Sequentialfrom yers import Denseimport keras(2).导入数据源,数据源地址:/opt/algorithm/BPNet/wine.txtdf_wine = pd.read_csv("/opt/algorithm/BPNet/wine.txt", header=None).sample(frac=1) (3).查看数据df_wine.head()第三步:数据预处理(1).划分60%数据p = 0.6cut = int(np.ceil(len(df_wine) * p))(2).划分数据集df_wine_train = df_wine.iloc[:cut]df_wine_test = df_wine.iloc[cut:](3).类别标识编码(深度学习常用手段,类别1 = (1,0),类别2 = (0,1),类别3 = (0,0)) label_train = pd.DataFrame(df_wine_train[0])label_train["one-hot_1"] = label_train[0].map(lambda x: 1 if (x == 1) else 0) label_train["one-hot_2"] = label_train[0].map(lambda x: 1 if (x == 2) else 0) label_train["one-hot_3"] = [1]*len(label_train)(4).数据标准化,获取每列均值,标准差avg_col = df_wine_train.mean()td_col = df_wine_train.std()(5).标准化结果df_train_norm = (df_wine_train - avg_col) / td_col(6).整理数据df_train_norm=df_train_norm.drop([0], axis=1).join(label_train[["one-hot_1", "one-hot_2"]]) (7).构建神经网络需要的数据结构df_train_net = np.array(df_train_norm)train_data_x = df_train_net[:, 0:13]train_data_y = df_train_net[:, 13:]第四步:搭建神经网络(1).构建神经网络,模型为13->10->20->2 网络model = Sequential()(2).建立全连接层-首层需要指定输入层维度model.add(Dense(units=10, # 输出维度,即本层节点数input_shape=(13,), # 输入维度activation="sigmoid", # 激活函数use_bias=True, # 使用偏置kernel_regularizer=keras.regularizers.l2(0.001) # 正则化))model.add(Dense(units=20, # 输出维度,即本层节点数输入维度自动适配上一层activation="sigmoid", # 激活函数use_bias=True, # 使用偏置kernel_regularizer=keras.regularizers.l2(0.001) # 正则化))model.add(Dense(units=2, # 输出维度,即本层节点数输入维度自动适配上一层activation="sigmoid", # 激活函数,use_bias=True, # 使用偏置kernel_regularizer=keras.regularizers.l2(0.001) # 正则化))第五步:定义模型训练方法,损失函数,停止规则以及训练参数并训练网络(1).建立评估函数,优化方法:随机梯度下降法SGDsgd = keras.optimizers.SGD(lr=0.01, # 学习速率decay=1e-7, # 每次更新后的学习率衰减值momentum=0.8, # 学习动量nesterov=True # 确定是否使用Nesterov动量)(2).设计目标误差函数,以及训练方法pile(loss='mean_squared_error', optimizer=sgd)(3).提前结束训练的阈值,下面参数,观察误差,连续5次无改善.则结束训练early_stopping = keras.callbacks.EarlyStopping(monitor='loss', patience=5, verbose=0, mode='auto')(4).模型训练,写入数据,目标,迭代次数,批数,训练详情(0不显示),训练提早结束条件model.fit(train_data_x, train_data_y, epochs=1000, batch_size=32, verbose=1, callbacks=[early_stopping])第六步:模型应用于测试集,并输出准确率(1).模型预测label_test = pd.DataFrame(df_wine_test[0])label_test["one-hot_1"] = label_test[0].map(lambda x: 1 if (x == 1) else 0)label_test["one-hot_2"] = label_test[0].map(lambda x: 1 if (x == 2) else 0)(2).标准化结果df_test_norm = (df_wine_test - avg_col) / td_col(3).整理数据df_test_norm = df_test_norm.drop([0], axis=1).join(label_test[["one-hot_1", "one-hot_2"]]) (4).构建神经网络需要的数据结构df_test_net = np.array(df_test_norm)test_data_x = df_test_net[:, 0:13]test_data_y = df_test_net[:, 13:]predicted = model.predict(test_data_x)F1 = pd.DataFrame(predicted)F1.columns = ["predicted_1", "predicted_2"]F1["predicted_1"] = F1["predicted_1"].map(lambda x: 1.0 if (x > 0.5) else 0.0)F1["predicted_2"] = F1["predicted_2"].map(lambda x: 1.0 if (x > 0.5) else 0.0)F2 = pd.DataFrame(test_data_y)F2.columns = ["test_1", "test_2"]F = F1.join(F2)acc = len(F[(F["predicted_1"] == F["test_1"]) & (F["predicted_2"] == F["test_2"])]) * 1.0 / len(F)(5).输出准确率print("准确率%s " % (acc))第七步:可以通过以下命令执行python文件,查看最终结果python /opt/algorithm/BPNet/BPNet.py。
BP神经网络算法实验报告

计算各层的输入和输出
es
计算输出层误差 E(q)
E(q)<ε
修正权值和阈值
结
束
图 2-2 BP 算法程序流程图
3、实验结果
任课教师: 何勇强
日期: 2010 年 12 月 24 日
中国地质大学(北京) 课程名称:数据仓库与数据挖掘 班号:131081 学号:13108117 姓名:韩垚 成绩:
任课教师: 何勇强
(2-7)
wki
输出层阈值调整公式:
(2-8)
ak
任课教师: 何勇强
E E netk E ok netk ak netk ak ok netk ak
(2-9)
日期: 2010 年 12 月 24 日
中国地质大学(北京) 课程名称:数据仓库与数据挖掘 隐含层权值调整公式: 班号:131081 学号:13108117 姓名:韩垚 成绩:
Ep
系统对 P 个训练样本的总误差准则函数为:
1 L (Tk ok ) 2 2 k 1
(2-5)
E
1 P L (Tkp okp )2 2 p 1 k 1
(2-6)
根据误差梯度下降法依次修正输出层权值的修正量 Δwki,输出层阈值的修正量 Δak,隐含层权 值的修正量 Δwij,隐含层阈值的修正量
日期: 2010 年 12 月 24 日
隐含层第 i 个节点的输出 yi:
M
yi (neti ) ( wij x j i )
j 1
(2-2)
输出层第 k 个节点的输入 netk:
q q M j 1
netk wki yi ak wki ( wij x j i ) ak
神经网络激活函数[BP神经网络实现函数逼近的应用分析]
![神经网络激活函数[BP神经网络实现函数逼近的应用分析]](https://img.taocdn.com/s3/m/6f4ac08759f5f61fb7360b4c2e3f5727a5e924b1.png)
神经网络激活函数[BP神经网络实现函数逼近的应用分析]神经网络激活函数是神经网络中非常重要的组成部分,它决定了神经网络的非线性特性,并且对于神经网络的求解效果和性能有着重要的影响。
本文将对神经网络激活函数进行详细的分析和探讨,并以BP神经网络实现函数逼近的应用为例进行具体分析。
1.神经网络激活函数的作用(1)引入非线性:神经网络通过激活函数引入非线性,使其具备处理非线性问题的能力,能够更好的逼近任意非线性函数。
(2)映射特征空间:激活函数可以将输入映射到另一个空间中,从而更好地刻画特征,提高神经网络的表达能力,并且可以保留原始数据的一些特性。
(3)增强模型的灵活性:不同的激活函数具有不同的形状和性质,选择合适的激活函数可以增加模型的灵活性,适应不同问题和数据的特点。
(4)解决梯度消失问题:神经网络中经常会遇到梯度消失的问题,通过使用合适的激活函数,可以有效地缓解梯度消失问题,提高神经网络的收敛速度。
2.常用的神经网络激活函数(1)Sigmoid函数:Sigmoid函数是一种常用的激活函数,它的输出值范围在(0,1)之间,具有平滑性,但是存在梯度消失问题。
(2)Tanh函数:Tanh函数是Sigmoid函数的对称形式,它的输出值范围在(-1,1)之间,相对于Sigmoid函数来说,均值为0,更符合中心化的要求。
(3)ReLU函数:ReLU函数在输入为负数时输出为0,在输入为正数时输出为其本身,ReLU函数简单快速,但是容易出现神经元死亡问题,即一些神经元永远不被激活。
(4)Leaky ReLU函数:Leaky ReLU函数是对ReLU函数的改进,当输入为负数时,输出为其本身乘以一个小的正数,可以解决神经元死亡问题。
(5)ELU函数:ELU函数在输入为负数时输出为一个负有指数衰减的值,可以在一定程度上缓解ReLU函数带来的神经元死亡问题,并且能够拟合更多的函数。
3.BP神经网络实现函数逼近的应用BP神经网络是一种常用的用于函数逼近的模型,它通过不断调整权重和偏置来实现对目标函数的拟合。
基于BP神经网络和RBF网络的非线性函数逼近问题比较研究

基于BP神经网络和RBF网络的非线性函数逼近问题比较研究丁德凯摘要:人脑是一个高度复杂的、非线性的和并行的计算机器,人脑可以组织神经系统结构和功能的基本单位,即神经元,以比今天已有的最快的计算机还要快很多倍的速度进行特定的计算,例如模式识别、发动机控制、感知等。
神经网络具有大规模并行、分布式存储和处理、自组织、自适应和自学习,以及很强的非线性映射能力,所以它在函数(特别是非线性函数)逼近方面得到了广泛的应用。
BP神经网络和RBF神经网络,都是非线性多层前向网络,本文分别用BP(Back Propagation)网络和RBF(Radial Basis Function)网络对非线性函数f=sin(t)+cos(t)进行逼近,结果发现后者的学习速度更快,泛化能力更强,而前者的程序设计相对比较简单。
关键词:BP神经网络,RBF神经网络,函数逼近0 引言人工神经网络(Artificial Neural Networks,ANN)[1]是模仿生物神经网络功能的一种经验模型。
生物神经元受到传入的刺激,其反应又从输出端传到相联的其它神经元,输入和输出之间的变换关系一般是非线性的,且对输入信号有功能强大的反应和处理能力。
神经网络是由大量的处理单元(神经元)互相连接而成的网络。
为了模拟大脑的基本特性,在神经科学研究的基础上,提出了神经网络的模型。
但是,实际上神经网络并没有完全反映大脑的功能,只是对生物神经网络进行了某种抽象、简化和模拟。
神经网络的信息处理通过神经元的互相作用来实现,知识与信息的存储表现为网络元件互相分布式的物理联系。
神经网络的学习和识别取决于各种神经元连接权系数的动态演化过程。
神经网络的发展与神经科学、数理科学、认知科学、计算机科学、人工智能、信息科学、控制论、机器人学、微电子学、心理学、微电子学、心理学、光计算、分子生物学等有关,是一门新兴的边缘交叉学科。
当前,它在许多领域有重要的作用。
例如,模式识别和图像处理;印刷体和手写字符识别、语音识别、签字识别、指纹识别、人体病理分析、目标检测与识别、图像压缩和图像复制等。
(完整word版)BP神经网络实验报告

BP 神经网络实验报告一、实验目的1、熟悉MATLAB中神经网络工具箱的使用方法;2、经过在MATLAB下面编程实现BP网络逼近标准正弦函数,来加深对BP网络的认识和认识,理解信号的正向流传和误差的反向传达过程。
二、实验原理由于传统的感知器和线性神经网络有自己无法战胜的弊端,它们都不能够解决线性不能分问题,因此在实质应用过程中碰到了限制。
而BP 网络却拥有优异的繁泛化能力、容错能力以及非线性照射能力。
因此成为应用最为广泛的一种神经网络。
BP 算法的根本思想是把学习过程分为两个阶段:第一阶段是信号的正向流传过程;输入信息经过输入层、隐层逐层办理并计算每个单元的实质输出值;第二阶段是误差的反向传达过程;假设在输入层未能获取希望的输出值,那么逐层递归的计算实质输出和希望输出的差值〔即误差〕,以便依照此差值调治权值。
这种过程不断迭代,最后使得信号误差到达赞同或规定的范围之内。
基于 BP 算法的多层前馈型网络模型的拓扑结构如上图所示。
BP 算法的数学描述:三层BP 前馈网络的数学模型如上图所示。
三层前馈网中,输入向量为: X ( x1 , x2 ,..., x i ,..., x n )T;隐层输入向量为:Y( y1 , y2 ,..., y j ,...y m ) T;输出层输出向量为: O (o1 , o2 ,..., o k ,...o l )T;希望输出向量为:d(d1 ,d 2 ,...d k ,...d l )T。
输入层到隐层之间的权值矩阵用 V 表示,V(v1 , v2 ,...v j ,...v m ) Y,其中列向量v j为隐层第 j 个神经元对应的权向量;隐层到输出层之间的权值矩阵用W 表示,W( w1 , w2 ,...w k ,...w l ) ,其中列向量 w k为输出层第k个神经元对应的权向量。
下面解析各层信号之间的数学关系。
对于输出层,有y j f (net j ), j1,2,..., mnet j v ij x i , j1,2,..., m对于隐层,有O k f (net k ), k1,2,...,lm net k wjkyi, k1,2,...,lj0以上两式中,转移函数 f(x) 均为单极性Sigmoid 函数:1f ( x)x1 ef(x) 拥有连续、可导的特点,且有 f ' (x) f ( x)[1 f ( x)]以上共同构成了三层前馈网了的数学模型。
实验一、BP及RBP神经网络逼近

实验一、BP及RBF神经网络逼近一、实验目的1、了解MATLAB集成开发环境2、了解MATLAB编程基本方法3、熟练掌握BP算法的原理和步骤4、掌握工具包入口初始化及调用5、加深BP、RBF神经网络对任意函数逼近的理解二、实验内容1、MATLAB基本指令和语法。
2、BP算法的MATLAB实现三、实验步骤1、熟悉MATLAB开发环境2、输入参考程序3、设置断点,运行程序,观察运行结果四、参考程序1. BP算法的matlab实现程序%lr为学习步长,err_goal期望误差最小值,max_epoch训练的最大次数,隐层和输出层初值为零lr=0.05;err_goal=0.0001;max_epoch=10000;a=0.9;Oi=0;Ok=0;%两组训练集和目标值X=[1 1;-1 -1;1 1];T=[1 1;1 1];%初始化wki,wij(M为输入节点j的数量;q为隐层节点i的数量;L为输出节点k的数量)[M,N]=size(X);q=8;[L,N]=size(T);wij=rand(q,M);wki=rand(L,q);wij0=zeros(size(wij));wki0=zeros(size(wki));for epoch=1:max_epoch%计算隐层各神经元输出NETi=wij*X;for j=1:Nfor i=1:qOi(i,j)=2/(1+exp(-NETi(i,j)))-1;endend%计算输出层各神经元输出NETk=wki*Oi;for i=1:Nfor k=1:LOk(k,i)=2/(1+exp(-NETk(k,i)))-1;endend%计算误差函数E=((T-Ok)'*(T-Ok))/2;if (E<err_goal)break;end%调整输出层加权系数deltak=Ok.*(1-Ok).*(T-Ok);w=wki;wki=wki+lr*deltak*Oi';wki0=w;%调整隐层加权系数deltai=Oi.*(1-Oi).*(deltak'*wki)';w=wij;wij=wij+lr*deltai*X';wij0=w;endepoch %显示计算次数%根据训练好的wki,wij和给定的输入计算输出X1=X;%计算隐层各神经元的输出NETi=wij*X1;for j=1:Nfor i=1:qOi(i,j)=2/(1+exp(-NETi(i,j)))-1;endend%计算输出层各神经元的输出NETk=wki*Oi;for i=1:Nfor k=1:LOk(k,i)=2/(1+exp(-NETk(k,i)))-1;endendOk %显示网络输出层的输出2、BP逼近任意函数算法的matlab实现程序⏹X=-4:0.08:4;⏹T=1.1*(1-X+2*X.^2).*exp(-X.^2./2);⏹net=newff(minmax(X),[20,1],{'tansig','purelin'});⏹net.trainParam.epochs=15000;⏹net.trainParam.goal=0.001;⏹net=train(net,X,T);⏹X1=-1:0.01:1;⏹y=sim(net,X1);⏹figure;⏹plot(X1,y,'-r',X,T,':b','LineWidth',2);3.RBF能够逼近任意的非线性函数⏹X=-4:0.08:4;⏹T=1.1*(1-X+2*X.^2).*exp(-X.^2./2);⏹net=newrb(X,T,0.002,1);⏹X1=-1:0.01:1;⏹y=sim(net,X1);⏹figure;⏹plot(X1,y,'-r',X,T,':b','LineWidth',3);五、思考题1. 将结果用图画出。
基于BP神经网络算法的函数逼近

基于BP神经网络算法的函数逼近神经网络是一种基于生物神经元工作原理构建的计算模型,可以通过学习和调整权重来逼近非线性函数。
其中,基于误差反向传播算法(BP)的神经网络是最常见和广泛应用的一种,其能够通过反向传播来调整网络的权重,从而实现对函数的近似。
BP神经网络的算法包括了前馈和反向传播两个过程。
前馈过程是指输入信号从输入层经过隐藏层传递到输出层的过程,反向传播过程是指将网络输出与实际值进行比较,并根据误差来调整网络权重的过程。
在函数逼近问题中,我们通常将训练集中的输入值作为网络的输入,将对应的目标值作为网络的输出。
然后通过反复调整网络的权重,使得网络的输出逼近目标值。
首先,我们需要设计一个合适的神经网络结构。
对于函数逼近问题,通常使用的是多层前馈神经网络,其中包括了输入层、隐藏层和输出层。
隐藏层的神经元个数和层数可以根据具体问题进行调整,一般情况下,通过试验和调整来确定最优结构。
然后,我们需要确定误差函数。
对于函数逼近问题,最常用的误差函数是均方误差(Mean Squared Error)。
均方误差是输出值与目标值之间差值的平方和的均值。
接下来,我们进行前馈过程,将输入值通过网络传递到输出层,并计算出网络的输出值。
然后,我们计算出网络的输出与目标值之间的误差,并根据误差来调整网络的权重。
反向传播的过程中,我们使用梯度下降法来最小化误差函数,不断地调整权重以优化网络的性能。
最后,我们通过不断训练网络来达到函数逼近的目标。
训练过程中,我们将训练集中的所有样本都输入到网络中,并根据误差调整网络的权重。
通过反复训练,网络逐渐优化,输出值逼近目标值。
需要注意的是,在进行函数逼近时,我们需要将训练集和测试集分开。
训练集用于训练网络,测试集用于评估网络的性能。
如果训练集和测试集中的样本有重叠,网络可能会出现过拟合现象,导致在测试集上的性能下降。
在神经网络的函数逼近中,还有一些注意事项。
首先是选择适当的激活函数,激活函数能够在网络中引入非线性,使网络能够逼近任意函数。
BP神经网络的仿真实验
BP神经网络的仿真实验一、实验目的学会用matlab的神经网络工具箱(Nntool)来完成神经网络可逼近函数的功能。
二、实验任务设计一个两层的BP神经网络。
输入范围为[-1 1],样本输入x和目标输出y为:x=-1:0.01:1;y=(1-x2)1/2训练该网络使输出在区间[-1 1] 内逼近该函数。
三、实验要求:通过仿真画出y=(1-x2)1/2 和在样本输入x的情况下神经网络输出的图形,分析你所设计的神经网络的逼近性能如何?四、实验步骤及结果1实验步骤1) 在Matlab的命令窗口下键入Nntool,2) 我们就进入了神经网络工具箱的Network/Data Manager窗口:2)点击Network/Data Manager窗口下部的New Network,3)进入Create New Network窗口,4)该窗口的每一个设置参数如图所示:3)输入神经网络的输入向量和目标向量:在Matlab命令窗口中定义好所需要的输入向量和目标向量,再传送到工具箱中,具体操作为在命令窗口键入以下命令行:>> x=-1:0.01:1;>> y=sqrt(1-x.^2);这样就定义好了输入向量和目标向量。
点击Network/Data Manager窗口下的Import 按钮,进入Import or Load to Network/Data Manager窗口:由于数据来自于工作空间,所以Source项取默认值;如果数据来自于disk,则选择Load from disk file。
在Select a variable中选择想要传送的数据x,再在destination项中键入名字x,同时import as中的选项被激活了,选择其中的Inputs,最后点击Import,这样就完成了输入向量从工作空间向工具箱的传送,在Network/Data Manager窗口下的Inputs列表中出现了新输入的输入向量的名字x;同理可以输入目标向量y。
实验一、BP及RBP神经网络逼近
实验一、BP及RBF神经网络逼近一、实验目的1、了解MATLAB集成开发环境2、了解MATLAB编程基本方法3、熟练掌握BP算法的原理和步骤4、掌握工具包入口初始化及调用5、加深BP、RBF神经网络对任意函数逼近的理解二、实验内容1、MATLAB基本指令和语法。
2、BP算法的MATLAB实现三、实验步骤1、熟悉MATLAB开发环境2、输入参考程序3、设置断点,运行程序,观察运行结果四、参考程序1. BP算法的matlab实现程序%lr为学习步长,err_goal期望误差最小值,max_epoch训练的最大次数,隐层和输出层初值为零lr=0.05;err_goal=0.0001;max_epoch=10000;a=0.9;Oi=0;Ok=0;%两组训练集和目标值X=[1 1;-1 -1;1 1];T=[1 1;1 1];%初始化wki,wij(M为输入节点j的数量;q为隐层节点i的数量;L为输出节点k的数量)[M,N]=size(X);q=8;[L,N]=size(T);wij=rand(q,M);wki=rand(L,q);wij0=zeros(size(wij));wki0=zeros(size(wki));for epoch=1:max_epoch%计算隐层各神经元输出NETi=wij*X;for j=1:Nfor i=1:qOi(i,j)=2/(1+exp(-NETi(i,j)))-1;endend%计算输出层各神经元输出NETk=wki*Oi;for i=1:Nfor k=1:LOk(k,i)=2/(1+exp(-NETk(k,i)))-1;endend%计算误差函数E=((T-Ok)'*(T-Ok))/2;if (E<err_goal)break;end%调整输出层加权系数deltak=Ok.*(1-Ok).*(T-Ok);w=wki;wki=wki+lr*deltak*Oi';wki0=w;%调整隐层加权系数deltai=Oi.*(1-Oi).*(deltak'*wki)';w=wij;wij=wij+lr*deltai*X';wij0=w;endepoch %显示计算次数%根据训练好的wki,wij和给定的输入计算输出X1=X;%计算隐层各神经元的输出NETi=wij*X1;for j=1:Nfor i=1:qOi(i,j)=2/(1+exp(-NETi(i,j)))-1;endend%计算输出层各神经元的输出NETk=wki*Oi;for i=1:Nfor k=1:LOk(k,i)=2/(1+exp(-NETk(k,i)))-1;endendOk %显示网络输出层的输出2、BP逼近任意函数算法的matlab实现程序⏹X=-4:0.08:4;⏹T=1.1*(1-X+2*X.^2).*exp(-X.^2./2);⏹net=newff(minmax(X),[20,1],{'tansig','purelin'});⏹net.trainParam.epochs=15000;⏹net.trainParam.goal=0.001;⏹net=train(net,X,T);⏹X1=-1:0.01:1;⏹y=sim(net,X1);⏹figure;⏹plot(X1,y,'-r',X,T,':b','LineWidth',2);3.RBF能够逼近任意的非线性函数⏹X=-4:0.08:4;⏹T=1.1*(1-X+2*X.^2).*exp(-X.^2./2);⏹net=newrb(X,T,0.002,1);⏹X1=-1:0.01:1;⏹y=sim(net,X1);⏹figure;⏹plot(X1,y,'-r',X,T,':b','LineWidth',3);五、思考题1. 将结果用图画出。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
实验一、BP 及RBF 神经网络逼近
一、实验目的
1、了解MATLAB 集成开发环境
2、了解MATLAB 编程基本方法
3、熟练掌握BP 算法的原理和步骤
4、掌握工具包入口初始化及调用
5、加深BP、RBF 神经网络对任意函数逼近的理解
二、实验内容
1、MATLAB 基本指令和语法。
2、BP 算法的MATLAB 实现
三、实验步骤
1、熟悉MATLAB 开发环境
2、输入参考程序
3、设置断点,运行程序,观察运行结果
四、参考程序
1. BP算法的matlab实现程序
%lr为学习步长,err_goal期望误差最小值,max_epoch训练的最大次数,隐层和输岀层初值为零lr=0.05; err_goal=0.0001; max_epoch=10000;
a=0.9;
Oi=0;
Ok=0;
%两组训练集和目标值
X=[1 1;-1 -1;1 1];
T=[1 1;1 1];
%初始化wki , wij ( M为输入节点j的数量;q为隐层节点i的数量;L为输岀节点k的数量) [M,N]=size(X); q=8;
[L,N]=size(T);
wij=rand(q,M);
wki=rand(L,q);
wij0=zeros(size(wij)); wki0=zeros(size(wki));
for epoch=1:max_epoch
% 计算隐层各神经元输岀
NETi=wij*X;
for j=1:N
for i=1:q Oi(i,j)=2/(1+exp(-NETi(i,j)))-1;
end
end
% 计算输出层各神经元输出NETk=wki*Oi;
for i=1:N
for k=1:L Ok(k,i)=2/(1+exp(-NETk(k,i)))-1;
end
end
% 计算误差函数E=((T-Ok)'*(T-Ok))/2;
if (E<err_goal) break ;
end
% 调整输出层加权系数deltak=Ok.*(1-Ok).*(T-Ok); w=wki;
wki=wki+lr*deltak*Oi';
wki0=w;
% 调整隐层加权系数deltai=Oi.*(1-Oi).*(deltak'*wki)'; w=wij;
wij=wij+lr*deltai*X';
wij0=w;
end
epoch % 显示计算次数
%根据训练好的wki ,wij 和给定的输入计算输出X1=X;
%计算隐层各神经元的输出NETi=wij*X1;
for j=1:N
for i=1:q Oi(i,j)=2/(1+exp(-NETi(i,j)))-1;
end
end
%计算输出层各神经元的输出NETk=wki*Oi;
for i=1:N
for k=1:L Ok(k,i)=2/(1+exp(-NETk(k,i)))-1;
end end
Ok % 显示网络输出层的输出
2、BP逼近任意函数算法的matlab实现程序
X=-4:0.08:4;
T=1.1*(1-X+2*X.A2).*exp(-X.A2./2);
net=newff(minmax(X),[20,1],{'tansig','purelin'});
net.trainParam.epochs=15000;
net.trainParam.goal=0.001;
net=train(net,X,T);
X1=-1:0.01:1;
y=sim(net,X1);
figure;
plot(X1,y,'-r',X,T,':b','LineWidth',2);
3.RBF能够逼近任意的非线性函数
X=-4:0.08:4;
T=1.1*(1-X+2*X.A2).*exp(-X.A2./2);
net=newrb(X,T ,0.002,1);
X1=-1:0.01:1;
y=sim(net,X1);
figure;
plot(X1,y,'-r',X,T ,':b','LineWidth',3);
五、思考题
1. 将结果用图画出。
2•假设训练样本X=[1 -1;1 -1;-1 1] ,目标输出T=[1 1;1 1],建立一个3个输入,单隐层8个神经元,输出层2个神经元的网络结构,其中隐层、输出层神经元的传递函数均为sigmoid函数,
(1)试利用BP学习算法实现该网络的训练过程;
( 3)观察两种学习算法的运行结果,比较两种算法的优缺点。