大数据处理平台FineBI使用中常见问题解决方案
finebi报表集成其它页面字体大小不同

finebi报表集成其它页面字体大小不同
【原创版】
目录
1.背景介绍
2.报表集成问题描述
3.解决方案探讨
4.总结
正文
一、背景介绍
Finebi 是一款数据分析工具,提供丰富的数据可视化功能,帮助用户快速生成报表。
在日常使用中,有时需要将报表集成到其他页面中,以便更好地展示数据。
然而,在集成过程中,可能会遇到字体大小不一致的问题,影响整体的观感。
二、报表集成问题描述
在将 finebi 报表集成到其他页面时,可能会发现报表的字体大小与其他页面的字体大小不同。
这种情况在跨页面、跨应用或者跨设备的场景下尤为明显。
由于字体大小不统一,可能导致用户在阅读时产生不适,影响用户体验。
三、解决方案探讨
针对这个问题,我们可以从以下几个方面进行解决:
1.统一字体大小:在集成报表时,尽量保持与其他页面的字体大小一致。
可以通过修改报表的 CSS 样式,将字体大小调整为其他页面的字体大小。
2.使用响应式设计:为了适应不同设备的屏幕尺寸,可以采用响应式
设计,使得报表在不同设备上呈现合适的字体大小。
3.提供自定义选项:在报表集成到其他页面时,提供字体大小自定义选项,让用户可以根据自己的需求调整字体大小。
四、总结
报表集成其他页面时,字体大小不同是一个常见问题。
商业智能系统FineBI使用教程:常见问题解决方案
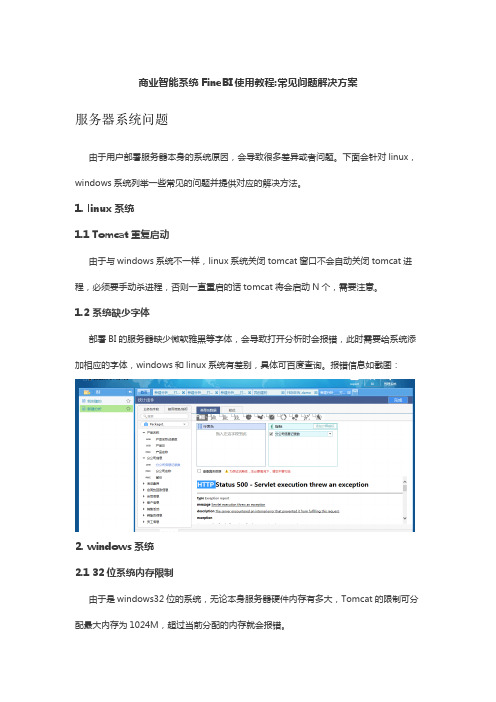
商业智能系统FineBI使用教程:常见问题解决方案服务器系统问题由于用户部署服务器本身的系统原因,会导致很多差异或者问题。
下面会针对linux,windows系统列举一些常见的问题并提供对应的解决方法。
1. linux系统1.1 Tomcat重复启动由于与windows系统不一样,linux系统关闭tomcat窗口不会自动关闭tomcat进程,必须要手动杀进程,否则一直重启的话tomcat将会启动N个,需要注意。
1.2 系统缺少字体部署BI的服务器缺少微软雅黑等字体,会导致打开分析时会报错,此时需要给系统添加相应的字体,windows和linux系统有差别,具体可百度查询。
报错信息如截图:2. windows系统2.1 32位系统内存限制由于是windows32位的系统,无论本身服务器硬件内存有多大,Tomcat的限制可分配最大内存为1024M,超过当前分配的内存就会报错。
2.2 access数据库连接由于windows64位系统不支持Access数据库,会导致使用这个系统的服务器无法连接该数据库。
具体需要连接的话,需要去专门可以适配在64位系统的access软件才能使用。
浏览器问题当前由于用户会使用多种浏览器,有时候会存在浏览器兼容的问题。
问题主要分为几类:前端图表展示卡顿或者生成时间很长;平台打开后样式错误;平台无法打开或者打开就报错等。
针对上述问题,如果对于图表展示速度不满意的话,请尽量更换谷歌chrome浏览器,能显著提高展示效果,因为该浏览器内核对于图表的兼容及展示效率都比IE内核好很多。
如果有些环境不适合使用其他浏览器,也建议尽量使用IE较高版本,否则很多新版本的样式并不能很好兼容。
1. 问题实例1.1 图表展示卡顿如果在查看分析时,很多图表组件展示非常慢,要超过10S甚至超过1分钟才能展示出来,那么就可能是浏览器的图形展示有问题。
此时请将展示的组件切换为汇总表或者其他拖入一个明细表,如果此时展示效率明显提升,则说明当前浏览器的图表展示效率较差,尤其需要展示的维度分类很多时。
大数据清洗工具FineBI文本类型时间字段问题解决方案

大数据清洗工具FineBI文本类型时间字段问题解决方案1. 描述通过时间类控件章节,我们知道可以直接通过该控件对时间类型的数据进行过滤,但是,实际上,数据库中存储的与时间相关的数据的数据类型不一定是时间类型的,很多时候会以文本类型存储到数据库中,此时就只能使用文本类型控件来进行过滤,导致数据显示性能差,使用不如时间类控件方便,那么如何才能使文本类型的时间数据使用FineBI的时间类控件进行过滤呢?2. 实现思路通过新增公式列,在原有的文本类型时间数据的基础上使用公式将其转换为时间类型字段,然后使用该转换后的字段进行数据分析。
3. 数据准备登录FineBI即时分析系统页面http://localhost:37799/WebReport/ReportServer?op=fs,点击数据配置>业务包管理>BiDemo业务包,添加一个数据表,如下图数据表的添加步骤详细请查看数据表管理。
4. 新增公式列签约事实表数据表中有LOAD_DATE,AUDITINGDATE字段,该字段里面显示的是时间数据,但其数据类型为文本类型,如下图:下面我们将该字段类型转换为时间类型。
在右侧的ETL设置面板中,点击表名称按钮,选择对该表-新增公式列,如下图:4.1 公式转换在公式列管理界面,点击添加公式列按钮,在弹出的公式转换窗口中输入新增公式列名称,选择数据类型,并输入公式转换的公式,如下图:注:FORMAT(object,format) : 返回object的format格式。
object 需要被格式化对象,可以是String,数字,Object(常用的有Date, Time)。
format 格式化的样式示例: FORMAT(1234.5, "#,##0.00") => 1234.50FORMAT(1234.5, "#,##0") => 1234FORMAT(1234.5, "¥#,##0.00") => ¥1234.50FORMAT(1.5, "0%") => 150%FORMAT(1.5, "0.000%") => 150.000%FORMAT(6789, "##0.0E0") => 6.789E3FORMAT(6789, "0.00E00") => 6.79E03FORMAT(date(2007,1,1), "EEEEE, MMMMM dd, yyyy") => 星期一,一月01,2007FORMAT(date(2007,1,13), "MM/dd/yyyy") => 01/13/2007FORMAT(date(2007,1,13), "M-d-yy") => 1-13-07FORMAT(time(16,23,56), "h:mm:ss a") => 4:23:56 下午点击确定,重命名表名称为签约事实表_formula。
大数据处理中的常见问题与解决方案探讨

大数据处理中的常见问题与解决方案探讨大数据处理,作为现代信息技术中的重要部分,已经成为了各行各业的关注焦点。
然而,随着数据规模不断扩大和复杂程度的增加,大数据处理中也出现了一些常见问题。
本文将探讨这些问题,并提出相应的解决方案。
一、数据存储问题在大数据处理中,数据存储是一个重要的环节。
常见的问题之一是存储容量不足。
当数据量庞大时,传统的存储设备往往无法容纳如此庞大的数据,同时也面临备份和恢复的困难。
解决这个问题的方案之一是采用分布式存储系统,如Hadoop分布式文件系统(HDFS),它可以将大数据分散存储在多个服务器上,有效解决容量不足的问题。
二、数据清洗问题大数据通常包含各种各样的信息,但其中可能包含有噪音、冗余和不一致的数据。
数据清洗是为了去除这些问题数据,提高数据质量的过程。
常见的数据清洗问题包括数据重复、数据缺失和数据格式不一致等。
解决这些问题可以通过使用数据清洗工具和算法来实现。
例如,数据去重可以通过使用哈希算法进行数据比对,发现重复数据并进行删除。
数据缺失可以通过插值方法进行填补,使得数据集完整。
三、数据处理速度问题大数据处理中,数据量庞大,处理速度成为了一个关键问题。
尤其是在实时分析和决策支持场景下,要求数据处理尽可能高效。
常见的问题之一是任务的并行处理。
通过将任务分解为多个子任务,利用并行处理的优势,可以加快任务的处理速度。
另外,采用高效的算法和数据结构,如哈希表、排序算法等,也可以有效提高数据处理速度。
四、数据隐私与安全问题在大数据处理中,保护数据隐私和确保数据安全是非常重要的。
尤其是涉及个人隐私和敏感数据的场景下,对隐私和安全的要求更高。
常见的问题包括数据泄露、数据篡改和非法访问等。
为了解决这些问题,可以采用加密技术对数据进行加密保护,确保数据在传输和存储过程中的安全性。
同时,还可以采用访问控制和身份认证等手段,限制非法用户对数据的访问和篡改。
五、数据挖掘与分析问题大数据处理的终极目标是从海量数据中挖掘有价值的信息和知识。
大数据 BI FineBI使用中常见问题解决方案
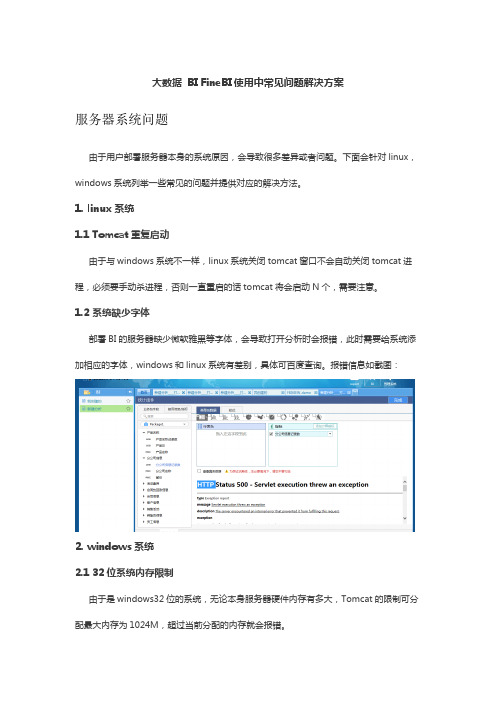
大数据BI FineBI使用中常见问题解决方案服务器系统问题由于用户部署服务器本身的系统原因,会导致很多差异或者问题。
下面会针对linux,windows系统列举一些常见的问题并提供对应的解决方法。
1. linux系统1.1 Tomcat重复启动由于与windows系统不一样,linux系统关闭tomcat窗口不会自动关闭tomcat进程,必须要手动杀进程,否则一直重启的话tomcat将会启动N个,需要注意。
1.2 系统缺少字体部署BI的服务器缺少微软雅黑等字体,会导致打开分析时会报错,此时需要给系统添加相应的字体,windows和linux系统有差别,具体可百度查询。
报错信息如截图:2. windows系统2.1 32位系统内存限制由于是windows32位的系统,无论本身服务器硬件内存有多大,Tomcat的限制可分配最大内存为1024M,超过当前分配的内存就会报错。
2.2 access数据库连接由于windows64位系统不支持Access数据库,会导致使用这个系统的服务器无法连接该数据库。
具体需要连接的话,需要去专门可以适配在64位系统的access软件才能使用。
浏览器问题当前由于用户会使用多种浏览器,有时候会存在浏览器兼容的问题。
问题主要分为几类:前端图表展示卡顿或者生成时间很长;平台打开后样式错误;平台无法打开或者打开就报错等。
针对上述问题,如果对于图表展示速度不满意的话,请尽量更换谷歌chrome浏览器,能显著提高展示效果,因为该浏览器内核对于图表的兼容及展示效率都比IE内核好很多。
如果有些环境不适合使用其他浏览器,也建议尽量使用IE较高版本,否则很多新版本的样式并不能很好兼容。
1. 问题实例1.1 图表展示卡顿如果在查看分析时,很多图表组件展示非常慢,要超过10S甚至超过1分钟才能展示出来,那么就可能是浏览器的图形展示有问题。
此时请将展示的组件切换为汇总表或者其他拖入一个明细表,如果此时展示效率明显提升,则说明当前浏览器的图表展示效率较差,尤其需要展示的维度分类很多时。
bi报表系统FineBI中的常见问题解答

bi报表系统FineBI中的常见问题1. OLAP分析的价值通过切片,旋转等数据处理方式,实现多个维度去展示每个数据,发现数据之间的相互关系,从而快速做出决策。
2. EBASE和BIEE的是竞争关系么?为什么?Ebase原属于海波龙的BI产品,属于数据底层的处理板块,大概功能和数据库建模以及ETL工具差不多,后来,海波龙被ORACLE收购后,EBASE也就顺理成章的变成了ORACLE 的产品。
ORACLE现在面对集团性客户时,一般的打单方案使用:EBASE+BIEE,即EBASE 的底层数据处理+BIEE的前段操作交互。
所以,两者是配合关系,不是竞争关系。
3. FineBI究竟可以连哪些数据源?1)各种文件形式数据集(Excel等,类似报表)2)常见关系型数据库3)任何带有jdbc接口的数据源注:数据源不是支持的越多越好。
判断一个数据源能否支持,首先要看支持有没有意义。
如果拿着我们这边的MDD+OLAP,再去连其他产品的MDD,然后我们根据别的MDD生成一下MDD再做OLAP,这就是相当于额外做了一遍MDD,属于逗你玩。
如果有客户这样问,告诉他,您还没搞清什么是DS(数据源),什么是MDD。
其次,要明确,我们现在的OLAP是不能独立于我们的MDD的,不是像国外某些产品可以拆开,用一个MDD用另一家的OLAP。
如果用户说你们为什么不支持,就告诉他,这样切开来不是什么好事,会有种种的兼容问题,一个版本一变,另一个立刻给脸色,给工具的维护者(信息部门)增加无端的麻烦。
最好肯定还是用一家的产品。
最后,具体问题具体分析。
首先在数据源配置的下拉列表里边找,找不到,看其有没有jdbc接口。
如果两者都没有,那就是不支持。
4. FineBI的MDD(多维数据库)构建FineBI的MDD(多维数据库)在构建时不会对数据源中的数据库造成任何影响。
因为FineBI自动建模的过程是先将所有数据取到BI服务器上,而后进行数据操作。
FineBI学习面临最大的困惑

FineBI学习面临最大的困惑
机缘巧合的一天下午,我被通知晚上要去参加一个FineBI 的培训,从突然到兴奋。
因为这段时间正忙着用Fine Report将手工报表变成自动化报表,同时也在考虑怎么将部门的数据和报表能更智能化及有效率的展现。
FineBI的出现无疑将会是一个利器,我渴望从FineBI中找到想要的答案。
怀着兴奋与渴望,我步入了FineBI的培训课堂。
FineBI的培训模式是线上学习+答疑的模式,很符合现在软件教学的培训方式。
先看视频、完成作业,再提交作业,老师批分+答疑。
反复3周时间,课程从简到难,真实案例教学,更贴近业务实际,更有真实业务场景,让学员学以致用,自由发挥,这种培训模式紧凑又实用。
Lynn老师在视频中的讲解也很清楚,循序渐进,条例清晰,由浅入深的带领我们走进FineBI,基本上看一遍后,再结合课件中的PPT材料,就可以对整个章节有了大概的了解和认知。
Bi平台FineBI使用中常见问题解决方案
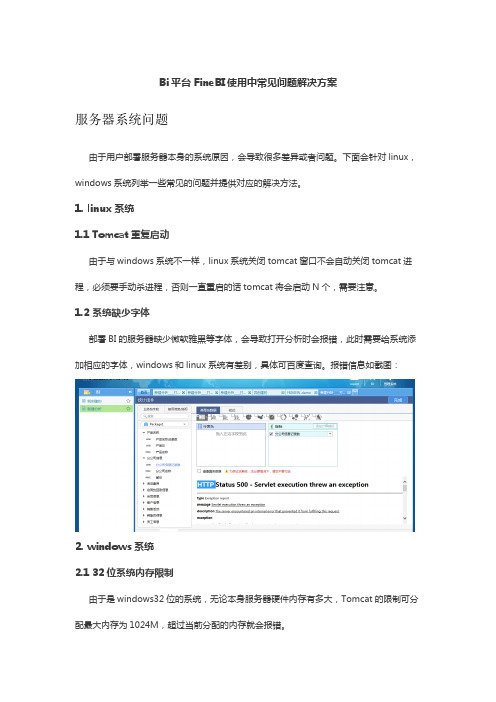
Bi平台FineBI使用中常见问题解决方案服务器系统问题由于用户部署服务器本身的系统原因,会导致很多差异或者问题。
下面会针对linux,windows系统列举一些常见的问题并提供对应的解决方法。
1. linux系统1.1 Tomcat重复启动由于与windows系统不一样,linux系统关闭tomcat窗口不会自动关闭tomcat进程,必须要手动杀进程,否则一直重启的话tomcat将会启动N个,需要注意。
1.2 系统缺少字体部署BI的服务器缺少微软雅黑等字体,会导致打开分析时会报错,此时需要给系统添加相应的字体,windows和linux系统有差别,具体可百度查询。
报错信息如截图:2. windows系统2.1 32位系统内存限制由于是windows32位的系统,无论本身服务器硬件内存有多大,Tomcat的限制可分配最大内存为1024M,超过当前分配的内存就会报错。
2.2 access数据库连接由于windows64位系统不支持Access数据库,会导致使用这个系统的服务器无法连接该数据库。
具体需要连接的话,需要去专门可以适配在64位系统的access软件才能使用。
浏览器问题当前由于用户会使用多种浏览器,有时候会存在浏览器兼容的问题。
问题主要分为几类:前端图表展示卡顿或者生成时间很长;平台打开后样式错误;平台无法打开或者打开就报错等。
针对上述问题,如果对于图表展示速度不满意的话,请尽量更换谷歌chrome浏览器,能显著提高展示效果,因为该浏览器内核对于图表的兼容及展示效率都比IE内核好很多。
如果有些环境不适合使用其他浏览器,也建议尽量使用IE较高版本,否则很多新版本的样式并不能很好兼容。
1. 问题实例1.1 图表展示卡顿如果在查看分析时,很多图表组件展示非常慢,要超过10S甚至超过1分钟才能展示出来,那么就可能是浏览器的图形展示有问题。
此时请将展示的组件切换为汇总表或者其他拖入一个明细表,如果此时展示效率明显提升,则说明当前浏览器的图表展示效率较差,尤其需要展示的维度分类很多时。
BI报表FineBI中的常见问题解决方案

BI报表FineBI中的常见问题1. OLAP分析的价值通过切片,旋转等数据处理方式,实现多个维度去展示每个数据,发现数据之间的相互关系,从而快速做出决策。
2. EBASE和BIEE的是竞争关系么?为什么?Ebase原属于海波龙的BI产品,属于数据底层的处理板块,大概功能和数据库建模以及ETL工具差不多,后来,海波龙被ORACLE收购后,EBASE也就顺理成章的变成了ORACLE 的产品。
ORACLE现在面对集团性客户时,一般的打单方案使用:EBASE+BIEE,即EBASE 的底层数据处理+BIEE的前段操作交互。
所以,两者是配合关系,不是竞争关系。
3. FineBI究竟可以连哪些数据源?1)各种文件形式数据集(Excel等,类似报表)2)常见关系型数据库3)任何带有jdbc接口的数据源注:数据源不是支持的越多越好。
判断一个数据源能否支持,首先要看支持有没有意义。
如果拿着我们这边的MDD+OLAP,再去连其他产品的MDD,然后我们根据别的MDD生成一下MDD再做OLAP,这就是相当于额外做了一遍MDD,属于逗你玩。
如果有客户这样问,告诉他,您还没搞清什么是DS(数据源),什么是MDD。
其次,要明确,我们现在的OLAP是不能独立于我们的MDD的,不是像国外某些产品可以拆开,用一个MDD用另一家的OLAP。
如果用户说你们为什么不支持,就告诉他,这样切开来不是什么好事,会有种种的兼容问题,一个版本一变,另一个立刻给脸色,给工具的维护者(信息部门)增加无端的麻烦。
最好肯定还是用一家的产品。
最后,具体问题具体分析。
首先在数据源配置的下拉列表里边找,找不到,看其有没有jdbc接口。
如果两者都没有,那就是不支持。
4. FineBI的MDD(多维数据库)构建FineBI的MDD(多维数据库)在构建时不会对数据源中的数据库造成任何影响。
因为FineBI自动建模的过程是先将所有数据取到BI服务器上,而后进行数据操作。
大数据处理中常见问题与解决方法

大数据处理中常见问题与解决方法随着互联网的快速发展和技术的日益成熟,大数据已经成为了当今社会的一个热门话题。
大数据的处理可以帮助企业和组织从庞大的数据集中获取有价值的信息,以便做出更明智的决策。
然而,在实际应用大数据处理过程中,也会遇到一些常见的问题。
本文将探讨这些问题,并提供相应的解决方法。
1. 数据质量问题大数据处理的一个重要前提是数据的质量。
然而,由于数据来源的多样性和复杂性,数据质量问题是非常常见的。
数据质量问题可能包括缺失值、不一致的数据、错误的数据格式等。
解决这些问题的方法可以包括使用数据清洗和预处理技术,例如去除重复记录、填补缺失值、数据转换和标准化等。
2. 存储和处理速度问题大数据量的处理对存储和计算资源的需求非常高。
在处理大数据时,可能会遇到存储空间不足或处理速度慢的问题。
为了解决这些问题,可以采用分布式存储和计算框架,例如Hadoop和Spark。
这些框架可以将数据分散存储在多个服务器上,并通过并行处理来提高处理速度。
3. 数据安全问题大数据包含许多敏感数据,例如个人身份信息、财务数据等。
因此,数据安全问题是大数据处理中不容忽视的问题。
为了保护数据的安全性,可以采取一些措施,例如加密数据、访问控制和身份验证、数据备份和灾难恢复等。
4. 数据分析问题大数据处理的最终目的是从数据中获取有价值的信息和洞见。
然而,由于大数据量和复杂性,数据分析也面临许多挑战。
一种常见的问题是如何有效地提取和分析数据,以发现隐藏的模式和关联。
为了解决这个问题,可以采用数据挖掘和机器学习技术来自动化分析过程,并提供更准确的结果。
5. 数据可视化问题大数据分析结果通常是非常庞大和复杂的,以至于很难理解和解释。
因此,数据可视化也是一个重要的问题。
数据可视化可以将数据呈现为图表、图形和仪表盘等形式,使用户能够更清楚地理解数据,并做出相应的决策。
为了解决数据可视化问题,可以使用专业的数据可视化工具和技术,例如Tableau和D3.js。
大数据清洗工具FineBI使用中常见问题处理方案

⼤数据清洗⼯具FineBI使⽤中常见问题处理⽅案⼤数据清洗⼯具FineBI使⽤中常见问题处理⽅案注册常见问题处理⽅案1. 确认信息版本、并发数不对,这些信息会严格按照订货单进⾏注册,注意标准版和企业版的区别客户那边的商务部和技术部需要沟通协调好。
2. MAC地址MAC地址必须是服务器的MAC地址,多⽹卡服务器,任意选择⼀个MAC地址即可。
Linux或Unix系统的MAC地址格式和⼀般的MAC形式不⼀样,⽐如为0*001F296EFD64。
3. 服务器同时包含lic授权⽂件和加密锁当服务器同时拥有lic授权⽂件和加密锁则以lic授权⽂件为主,因为服务器⾸先回去读取lic授权⽂件,若授权⽂件不存在才会读取加密锁,因此mac地址注册的优先级⾼于加密锁注册。
4. lic⽂件没有⽣效导致图表显⽰空⽩使⽤新的lic⽂件后,设计器预览图表显⽰空⽩?因为将获取的FineBI.lic⽂件放到报表⼯程WebReport/WEB-INF/resources⽬录下,没有重新启动Web服务器,导致图表不能预览,所以使⽤lic⽂件必须重启启动Web 服务器,lic才能⽣效。
5. 8.0注册问题在对应⽬录下已放置注册lic⽂件,但是购买的某些功能⽆法使⽤。
因为您的报表⼯程WebReport/WEB-INF/resources⽬录下存放了⼀个过期的lic⽂件,解决⽅案就是删除这个过期的lic⽂件,重启web服务器,再重新点击注册即可正确弹出注册界⾯。
6. 报空指针错误在预览⼀些模板时,报/doc/c069583a84254b35effd3457.html ng.NullPointException空指针异常。
因为该模板中包含了⼀些lic⽂件中不包含的功能。
7. 已注册的应⽤提⽰需要注册在预览已注册应⽤下的模板时,提⽰需要注册。
原因⼀:更换了应⽤所在的服务器,造成当前应⽤所在的服务器的mac地址与注册时的mac地址不同。
原因⼆:对报表应⽤进⾏了升级,有些版本升级是需要重新注册的,具体的可查看版本升级后是否影响授权⽂件章节查看。
finebi表格合计行占比不正确

finebi表格合计行占比不正确在FineBI表格中,合计行占比不正确的问题可能出现在数据计算或者表格设计方面。
以下将详细介绍可能出现的原因,并提供解决方法,以确保FineBI表格合计行的准确性。
首先,要了解为什么合计行占比不正确,我们需要考虑以下几个方面:1.数据源问题:合计行的计算可能受到数据源的质量和准确性的影响。
如果数据源中的数据有误差或遗漏,那么合计行的计算肯定会出现问题。
因此,首先需要检查数据源是否正确,并确保数据的完整性和准确性。
2.计算公式问题:在FineBI中,合计行的计算是通过公式进行的。
如果这些计算公式有误,那么合计行的计算结果必然不准确。
因此,需要仔细检查计算公式,并确保其正确性和准确性。
3.数据类型问题:在计算合计行时,需要考虑数据类型。
如果数据类型不匹配,那么合计行的计算结果可能会受到影响。
因此,需要确保进行计算的数据类型是匹配的,以确保合计行的准确性。
4.表格设计问题:有时,合计行的计算问题可能与表格的设计有关。
例如,如果表格中的某些列未正确定义为可计算列,那么合计行的计算结果将不正确。
因此,需要检查表格设计,并确保所有需要计算的列都被正确定义为可计算列。
解决这些问题,可以采取以下几个步骤:1.检查数据源:首先检查数据源中的数据是否准确完整。
可以使用FineBI的数据查看功能,对数据进行逐行检查,以确保没有错误或遗漏。
2.修复计算公式:检查合计行计算时所使用的公式,并确保公式的正确性和准确性。
可以使用FineBI的公式编辑器来检查和修复公式。
3.匹配数据类型:确保进行计算的数据类型是匹配的。
在FineBI 中,可以使用"编辑列"功能来查看和编辑列的数据类型,以匹配进行计算的列。
4.修复表格设计问题:检查表格的设计,并确保需要计算的列都正确定义为可计算列。
可以使用FineBI的表格设计功能来修复这些问题。
总结起来,要解决FineBI表格合计行占比不正确的问题,需要检查数据源的准确性和完整性,修复计算公式的错误,匹配数据类型,以及修复表格的设计问题。
finebi表格合计行占比不正确

finebi表格合计行占比不正确FineBI是一款商业智能工具,常用于数据可视化和报表生成。
在使用FineBI过程中,我们可能会遇到合计行占比不正确的问题。
这个问题可能是由于数据计算或设置错误导致的。
在下文中,我将详细介绍一些可能导致此问题出现的原因,并提供解决方案。
首先,需要确定合计行占比显示不正确的具体情况。
合计行占比不正确可能有多种原因。
下面是一些可能导致此问题的原因:1.数据计算错误:在生成报表时,FineBI会根据设置的计算方式对数据进行计算。
如果计算公式或设置不正确,就会导致合计行占比不正确。
需要仔细检查合计行占比的计算公式和设置,确保正确的数据被包含在计算中。
2.数据过滤错误:FineBI可以对数据进行过滤,以便只显示满足条件的数据。
如果设置了不正确的过滤条件,就可能导致合计行占比不正确。
需要审查过滤条件,确保仅仅包含需要计算的数据。
3.数据格式错误:合计行占比的计算通常依赖于正确的数据格式。
如果数据格式不正确,就会导致计算结果不准确。
检查数据格式,确保数据被正确地识别和计算。
4.数据缺失:如果有数据缺失,就会导致合计行占比不正确。
确保所有相关的数据都被正确地导入,并且没有丢失任何必要的数据。
解决这个问题的方法如下:1.仔细检查计算公式和设置:确保计算公式和设置正确,并且包含了正确的数据。
2.审查过滤条件:确认过滤条件设置正确,并且只包含需要计算的数据。
3.检查数据格式:正确设置数据格式,以确保数据被正确地识别和计算。
4.导入和检查数据:确保数据被正确导入,并且没有丢失任何必要的数据。
另外,您还可以尝试以下一些FineBI的高级功能,以确保合计行占比的准确性:1.数据透视表:使用FineBI的数据透视表功能可以更好地查看和分析数据。
通过数据透视表,您可以将数据按照不同的分类进行分组,并计算合计行占比。
2.数据样本:使用FineBI的数据样本功能可以选择一个小的数据样本来进行计算和分析。
大数据分析平台的使用中常见问题解析

大数据分析平台的使用中常见问题解析随着大数据技术的快速发展和应用,大数据分析平台已经成为许多企业和组织进行数据分析的重要工具。
然而,在使用大数据分析平台的过程中,用户常常会遇到一些问题,本文将对这些常见问题进行解析,并提供相应的解决方案。
1. 数据源连接问题在使用大数据分析平台时,用户常常需要从不同的数据源中获取数据进行分析。
然而,由于数据源的复杂性和差异性,用户经常会遇到无法连接到数据源的问题。
解决这个问题的关键是正确配置和验证数据源连接信息。
用户应该确保提供正确的连接URL、用户名和密码,并且确保连接端口没有被防火墙屏蔽。
此外,用户还应该对数据源的网络连接进行测试,以确保可以正常访问。
2. 数据清洗和转换问题在实际应用中,原始数据往往是杂乱无章的,包含许多不规则的格式和错误的数据。
因此,数据清洗和转换是大数据分析的重要步骤。
用户常常会遇到如何进行数据清洗和转换的问题。
解决这个问题的方法是使用适当的数据清洗和转换工具。
用户可以使用特定的函数和表达式,根据自己的需求来清洗和转换数据。
另外,用户还可以使用数据清洗和转换的工作流程来自动化这一过程,提高工作效率。
3. 数据分析模型选择问题在大数据分析平台中,用户通常可以选择多种不同的分析模型来处理数据。
然而,对于用户来说,如何选择适合自己需求的分析模型可能是一个难题。
解决这个问题的方法是根据实际需求和数据特点来选择合适的分析模型。
用户应该充分了解各种分析模型的优缺点,根据自己的需求和数据特点来选择最适合的模型。
此外,用户还可以参考其他用户的经验和案例来选择分析模型。
4. 数据可视化问题数据可视化是大数据分析的重要环节,可以帮助用户更好地理解和展示分析结果。
然而,用户常常会遇到如何进行数据可视化的问题。
解决这个问题的方法是使用适当的可视化工具和技术。
用户可以使用图表、地图、仪表盘等工具来展示数据分析结果。
此外,用户还可以使用交互式可视化工具来实现动态数据可视化,增强用户对数据的理解和掌握。
finebi注册时出错 证书格式不正确 -回复

finebi注册时出错证书格式不正确-回复中括号内的内容为主题:finebi注册时出错证书格式不正确第一步:了解FineBIFineBI是一款数据分析和报表工具,旨在帮助企业更好地处理和分析数据,以便做出更明智的决策。
它提供了一个友好的用户界面,并具备强大的数据处理和可视化功能。
第二步:理解证书格式不正确的问题当在FineBI注册时遇到证书格式不正确的问题,这通常代表你没有提供正确的证书文件或者证书文件格式不符合FineBI的要求。
第三步:检查证书文件1. 确保你已经获得了FineBI所需的证书文件。
通常情况下,这个证书文件应该由FineBI的管理员或者技术支持团队提供给你。
2. 检查证书文件的文件格式。
FineBI通常要求证书文件的格式为.p12或者.pfx。
如果你从其他来源获取证书文件,确保它是符合FineBI的格式要求的。
第四步:解决证书格式不正确的问题1. 如果你没有获得正确的证书文件,请联系FineBI的管理员或者技术支持团队,请求他们提供正确的证书文件。
2. 如果你有正确的证书文件但是格式不正确,你可以尝试以下方法进行解决:a. 将证书文件转换为.p12或者.pfx格式。
你可以使用各种证书管理工具来完成此操作。
确保在转换过程中选择正确的文件格式。
b. 重新安装FineBI,并在安装过程中提供正确的证书文件。
3. 如果以上方法都无法解决问题,你可以再次联系FineBI的管理员或者技术支持团队,并向他们说明你的问题和已经尝试过的解决方法。
他们可能能够为你提供更具体的解决方案。
第五步:预防证书格式不正确的问题为了避免在将来遇到类似的问题,你可以采取以下预防措施:- 在获取证书文件之前与FineBI的管理员或者技术支持团队进行沟通,确保你获得的证书文件是正确的且符合FineBI的要求。
- 仔细阅读FineBI的文档和指南,了解证书文件的要求和正确的使用方式。
- 定期备份和更新你的证书文件,以防止意外情况或损坏。
大数据处理平台FineBI使用中常见问题解决方案

⼤数据处理平台FineBI使⽤中常见问题解决⽅案⼤数据处理平台FineBI使⽤中常见问题解决⽅案服务器系统问题由于⽤户部署服务器本⾝的系统原因,会导致很多差异或者问题。
下⾯会针对linux,windows系统列举⼀些常见的问题并提供对应的解决⽅法。
1. linux系统1.1 Tomcat重复启动由于与windows系统不⼀样,linux系统关闭tomcat窗⼝不会⾃动关闭tomcat进程,必须要⼿动杀进程,否则⼀直重启的话tomcat将会启动N个,需要注意。
1.2 系统缺少字体部署BI的服务器缺少微软雅⿊等字体,会导致打开分析时会报错,此时需要给系统添加相应的字体,windows和linux系统有差别,具体可百度查询。
报错信息如截图:2. windows系统2.1 32位系统内存限制由于是windows32位的系统,⽆论本⾝服务器硬件内存有多⼤,Tomcat的限制可分配最⼤内存为1024M,超过当前分配的内存就会报错。
2.2 access数据库连接由于windows64位系统不⽀持Access数据库,会导致使⽤这个系统的服务器⽆法连接该数据库。
具体需要连接的话,需要去专门可以适配在64位系统的access软件才能使⽤。
浏览器问题当前由于⽤户会使⽤多种浏览器,有时候会存在浏览器兼容的问题。
问题主要分为⼏类:前端图表展⽰卡顿或者⽣成时间很长;平台打开后样式错误;平台⽆法打开或者打开就报错等。
针对上述问题,如果对于图表展⽰速度不满意的话,请尽量更换⾕歌chrome浏览器,能显著提⾼展⽰效果,因为该浏览器内核对于图表的兼容及展⽰效率都⽐IE内核好很多。
如果有些环境不适合使⽤其他浏览器,也建议尽量使⽤IE较⾼版本,否则很多新版本的样式并不能很好兼容。
1. 问题实例1.1 图表展⽰卡顿如果在查看分析时,很多图表组件展⽰⾮常慢,要超过10S甚⾄超过1分钟才能展⽰出来,那么就可能是浏览器的图形展⽰有问题。
此时请将展⽰的组件切换为汇总表或者其他拖⼊⼀个明细表,如果此时展⽰效率明显提升,则说明当前浏览器的图表展⽰效率较差,尤其需要展⽰的维度分类很多时。
大数据处理中的常见问题及解决方案探讨

大数据处理中的常见问题及解决方案探讨大数据处理已经成为当今信息技术领域的一个热点话题。
随着互联网和其他数字数据源的蓬勃发展,我们每天都会产生大量的数据,这给数据分析和处理带来了巨大的挑战。
在大数据处理过程中,我们经常会遇到各种常见问题。
本文将探讨这些问题,并提供一些解决方案。
第一个常见问题是数据存储。
在大数据处理中,我们需要存储大量的数据,并保持数据的高可用性。
传统的关系型数据库可能无法满足这个需求,因为它们通常只能处理较小规模的数据。
解决方案之一是使用分布式文件系统,例如Hadoop的HDFS。
HDFS将数据分布在多个节点上,以提高数据的可靠性和可用性。
第二个常见问题是数据传输和处理的效率。
大数据处理需要处理海量的数据,这就需要高效的数据传输和处理方式。
一种解决方案是使用并行计算。
通过将数据分解成多个任务,然后在多个处理节点上并行处理这些任务,可以显著提高数据处理的效率。
另一种解决方案是使用内存计算。
将数据加载到内存中处理,可以大大加快数据访问和计算速度。
第三个常见问题是数据质量。
大数据往往包含着各种各样的数据源,这些数据源可能存在错误、缺失或不一致的问题。
在数据处理过程中,我们需要解决这些问题,以确保数据的准确性和可靠性。
解决方案之一是数据清洗。
通过对数据进行清洗、去重和验证等操作,可以提高数据的质量。
另一种解决方案是数据规范化。
通过将数据转换为统一的格式和结构,可以简化数据的处理和分析过程。
第四个常见问题是数据隐私和安全。
在大数据处理中,我们通常需要处理敏感数据,如个人身份信息和财务数据。
保护数据的隐私和安全至关重要。
解决方案之一是使用加密技术。
通过对数据进行加密和解密操作,可以确保只有授权的用户能够访问和使用数据。
另一种解决方案是访问控制。
通过限制数据的访问权限,只有经过授权的用户才能够查看和处理数据。
第五个常见问题是数据分析和挖掘的复杂性。
大数据处理不仅涉及数据存储和传输,还有数据分析和挖掘。
bi工具FineBI部署weblogic的常见问题及解决

bi工具FineBI部署weblogic的常见问题及解决1. weblogic12.1.1部署问题按照weblogic服务器部署的步骤对weblogic12.1.1进行部署,会出现部署不成功的现象。
1.1 解决方案更改或删除%WebReport%/WEB-INF/lib目录下的db2jcc.jar文件即可部署成功。
2. weblogic部署类冲突部署好weblogic之后,启动项目,报错如下:1.Root cause of ServletException.2.java.util.ServiceConfigurationError: javax.xml.ws.spi.Provider: Provider weblogi3. c.wsee.jaxws.spi.WLSProvider could not be instantiated: ng.ClassCastExcep4.tion5. at java.util.ServiceLoader.fail(ServiceLoader.java:207)6. at java.util.ServiceLoader.access$100(ServiceLoader.java:164)7. at java.util.ServiceLoader$LazyIterator.next(ServiceLoader.java:353)8. at java.util.ServiceLoader$1.next(ServiceLoader.java:421)9. at javax.xml.ws.spi.Provider.getProviderUsingServiceLoader(Provider.java10.:146)11. Truncated. see log file for complete stacktrace12.Caused By: ng.ClassCastException13. at ng.Class.cast(Class.java:2990)14. at java.util.ServiceLoader$LazyIterator.next(ServiceLoader.java:345)15. at java.util.ServiceLoader$1.next(ServiceLoader.java:421)16. at javax.xml.ws.spi.Provider.getProviderUsingServiceLoader(Provider.java17.:146)18. at javax.xml.ws.spi.Provider.provider(Provider.java:106)19. Truncated. see log file for complete stacktrace20.>2.1 报错原因由于进行系统集成时引起的类冲突。
fine bi计算字段为0

FineBI 是一个数据分析和可视化工具,它可以让你从多个数据源中导入数据,并对数据进行清洗、整理和可视化。
在FineBI 中,你可以使用计算字段功能来创建新的字段,基于已有的字段进行计算。
如果你在使用FineBI 创建计算字段时遇到了值为0 的问题,可能是由于以下几个原因:
1.计算公式错误:首先确保你的计算公式是正确的,可以试着将公式简化或逐步调试来找到问题所
在。
2.数据源问题:检查你的数据源,确保数据源中的数据是正确的,没有缺失值或异常值。
3.数据类型问题:确保你正在使用的字段的数据类型是正确的,例如,如果你在进行数学运算时使
用了文本类型的字段,可能会导致结果为0。
4.FineBI 设置问题:检查FineBI 的设置,确保没有设置导致计算结果为0 的选项或参数。
5.软件bug:如果以上都没有问题,可能是FineBI 软件本身的问题,建议联系FineBI 的技术
支持获取帮助。
希望这些建议能帮助你解决问题!如果需要更多具体的帮助,请提供更多的信息。
finebi 计算结果为空

finebi 计算结果为空在使用finebi进行数据分析和可视化时,有时我们会遇到计算结果为空的情况。
这可能是由于多种原因造成的,下面我们将逐一进行分析。
可能是数据源的问题。
finebi使用的数据源可能存在缺失值或者数据格式错误的情况。
在进行计算时,如果数据源中存在空值或者不符合要求的数据格式,那么计算结果就会为空。
因此,我们需要仔细检查数据源,确保数据的完整性和准确性。
可能是计算公式的问题。
在使用finebi进行计算时,我们需要输入正确的计算公式才能得到正确的结果。
如果我们输入的计算公式有误,或者使用了不支持的函数或操作符,那么计算结果就会为空。
因此,我们需要仔细检查计算公式,确保其正确性和合理性。
可能是筛选条件的问题。
在使用finebi进行数据筛选时,我们需要设置正确的筛选条件才能得到符合要求的数据。
如果我们设置的筛选条件有误,或者筛选条件与数据不匹配,那么计算结果就会为空。
因此,我们需要仔细检查筛选条件,确保其正确性和适用性。
可能是数据量过大导致计算结果为空。
在进行大规模数据分析时,如果数据量过大,计算过程可能会非常耗时。
为了提高计算效率,finebi可能会限制计算的数据量,从而导致计算结果为空。
这时,我们可以尝试减少计算的数据量,或者优化计算方式,以提高计算效率。
可能是软件本身的问题。
finebi作为一款数据分析和可视化工具,难免会存在一些bug或者不稳定的情况。
如果我们遇到计算结果为空的问题,可以尝试更新软件版本或者联系finebi的技术支持团队,以寻求帮助和解决方案。
finebi计算结果为空可能是由于数据源问题、计算公式问题、筛选条件问题、数据量过大或者软件本身问题所致。
我们可以通过仔细检查数据源、计算公式和筛选条件,优化计算方式,减少数据量或者联系技术支持团队等方式来解决这个问题。
希望以上分析和解决方案能对大家有所帮助。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
大数据处理平台FineBI使用中常见问题解决方案
服务器系统问题
由于用户部署服务器本身的系统原因,会导致很多差异或者问题。
下面会针对linux,windows系统列举一些常见的问题并提供对应的解决方法。
1. linux系统
1.1 Tomcat重复启动
由于与windows系统不一样,linux系统关闭tomcat窗口不会自动关闭tomcat进程,必须要手动杀进程,否则一直重启的话tomcat将会启动N个,需要注意。
1.2 系统缺少字体
部署BI的服务器缺少微软雅黑等字体,会导致打开分析时会报错,此时需要给系统添加相应的字体,windows和linux系统有差别,具体可百度查询。
报错信息如截图:
2. windows系统
2.1 32位系统内存限制
由于是windows32位的系统,无论本身服务器硬件内存有多大,Tomcat的限制可分配最大内存为1024M,超过当前分配的内存就会报错。
2.2 access数据库连接
由于windows64位系统不支持Access数据库,会导致使用这个系统的服务器无法连接该数据库。
具体需要连接的话,需要去专门可以适配在64位系统的access软件才能使用。
浏览器问题
当前由于用户会使用多种浏览器,有时候会存在浏览器兼容的问题。
问题主要分为几类:前端图表展示卡顿或者生成时间很长;平台打开后样式错误;平台无法打开或者打开就报错等。
针对上述问题,如果对于图表展示速度不满意的话,请尽量更换谷歌chrome浏览器,能显著提高展示效果,因为该浏览器内核对于图表的兼容及展示效率都比IE内核好很多。
如果有些环境不适合使用其他浏览器,也建议尽量使用IE较高版本,否则很多新版本的样式并不能很好兼容。
1. 问题实例
1.1 图表展示卡顿
如果在查看分析时,很多图表组件展示非常慢,要超过10S甚至超过1分钟才能展示出来,那么就可能是浏览器的图形展示有问题。
此时请将展示的组件切换为汇总表或者其他拖入一个明细表,如果此时展示效率明显提升,则说明当前浏览器的图表展示效率较差,尤其需要展示的维度分类很多时。
1.2 IE内核平台兼容问题
当使用IE浏览器或者其他使用IE内核的浏览器,常见的就是很多浏览器的兼容模式,如360,搜狗等。
老版本用户可能仍在使用8.0前的版本,那么平台不支持在上述浏览器下使用op=FBI界面的,必须更换为op=FS界面。
如果升级到8.0的平台,就统一在op=FS 界面浏览,然后可以在平台中进行界面切换。
1.3 图表或者其他界面样式错误
部分老版本IE或者其他浏览器在打开平台后,部分界面出现错位或者一些模块无法显示,请尽量升级浏览器版本或者更换谷歌chrome浏览器。
Tomcat报错
1. Tomcat无法启动,处于deploy状态
启动时闪退原因(一直等待deploy)
1.1 端口不对或者是端口被占用
检查%FineBI Home\conf路径下server.xml中的端口是否被其他程序占用,如果已占用则修改成其他端口重启(默认37799),如下图所示:
1.2 系统内存不够用
如果分配给tomcat的内存已经超过了系统可用内存,会导致无法BI无法启动成功。
可以将初始内存修改小一点,打开安装目录下FineBI.vmoptions文件,然后根据实际情况修改(默认4096M),如下图所示:
2. Socket accept failed错误
当启动BI平台的Tomcat时不断出现Socket accept failed错误,只需要执行开始、cmd、netsh winsock reset、回车、重启即可。
21.4.5 数据连接问题
因为BI支持多数据来源的数据读取,所以当一些非常见数据库或数据连接时,会存在缺少部分配置文件或者驱动而报错。
下面就会列出一些常见的问题及解决方法。
数据连接db2v9.7报错
报错信息如下:mons.dbcp.SQLNestedException: Cannot create PoolableConnectionFactory (DB2 SQL Error: SQLCODE=-104, SQLSTATE=42601, SQLERRMC=select count(*) from *.;BEGIN-OF-STATEMENT;<delete>, DRIVER=3.64.114)。
建议将版本换为V9.1,或者去IBM官网下载新的V9.7的驱动。
另,换驱动包的时候,原来的驱动一定要拷贝走,不要同时有几个db2的驱动在里面;另外把下面这个属性设置为否:
oracle12c数据库报错
当连接oracle12c数据库出现报错的话,可能是jar包错误。
针对连接该数据库,需要将ojdbc14.jar的包更换为ojdbc6.jar。
报错截图如下:
连接IMpala或者hive
如果需要连接IMpala或者hive的数据仓库的话,下载需要的jdbc驱动器jar包,放到FineBI_v3.5_x64\FineBI\webapps\WebReport\WEB-INF\lib目录,在数据连接里手动输入驱动器名称即可。