性能测试监控点一览
列出cpu常见的监控指标

列出cpu常见的监控指标CPU(中央处理器)是计算机中最重要的组件之一,其性能和运行状态对整个系统的稳定性和效率有着直接影响。
为了监控和评估CPU的运行情况,人们通常会关注一系列指标。
下面我们将列举一些常见的CPU监控指标,以帮助读者更好地了解CPU的运行状态。
1. CPU使用率(CPU Usage)CPU使用率是指CPU在特定时间段内工作的百分比。
它是衡量CPU负载的重要指标,通常以百分比形式表示。
较高的CPU使用率表示CPU正在高负载运行,可能会导致系统响应缓慢或出现卡顿现象。
2. CPU温度(CPU Temperature)CPU温度是指CPU芯片的温度,它是衡量CPU工作状态的重要指标。
较高的CPU温度可能会导致系统性能下降、稳定性问题甚至硬件损坏。
因此,及时监控CPU温度并采取适当的散热措施是非常必要的。
3. CPU时钟频率(CPU Clock Speed)CPU时钟频率是指CPU每秒钟执行的时钟周期数。
它决定了CPU 处理指令的速度,是衡量CPU性能的重要指标。
通常以GHz为单位表示,较高的时钟频率意味着更快的处理速度。
4. CPU核心数(CPU Cores)CPU核心数是指CPU中独立运行的处理单元个数。
每个核心都可以独立执行任务,较多的CPU核心数通常意味着更好的多任务处理能力。
5. CPU缓存(CPU Cache)CPU缓存是CPU内部用于临时存储数据的高速存储器。
它的容量和访问速度直接影响CPU的性能。
较大的缓存容量和较快的访问速度能够提高CPU的运行效率。
6. 中断率(Interrupt Rate)中断率是指CPU在特定时间内接收和处理中断的次数。
中断是外部事件(如硬件设备请求、时钟中断等)打断CPU正常运行的信号。
较高的中断率可能意味着系统中存在大量的外部事件,需要CPU频繁地切换任务。
7. 上下文切换(Context Switch)上下文切换是指CPU从一个任务切换到另一个任务时,保存和恢复相关的执行环境和状态信息的过程。
性能测试中的资源监控和管理方法

性能测试中的资源监控和管理方法性能测试是软件开发过程中非常重要的一项工作,它用于评估系统的性能以及性能瓶颈,并针对性地优化系统。
在进行性能测试的过程中,资源监控和管理是不可或缺的环节。
本文将介绍一些常用的性能测试中的资源监控和管理方法。
一、资源监控1. CPU监控在性能测试中,CPU的使用率是衡量系统性能的重要指标之一。
通过监控CPU的使用率,我们可以了解系统在不同负载下的处理能力和性能瓶颈。
通常可以使用系统自带的性能监控工具,如Windows系统的任务管理器或Linux系统的top命令来实时监控CPU的使用率。
2. 内存监控内存的使用情况对系统性能有着重要的影响。
在进行性能测试时,需要监控系统的内存使用情况,包括内存占用量、内存峰值等指标。
可以使用操作系统的性能监控工具或第三方监控工具,如JConsole、Grafana等来监控系统的内存使用情况。
3. 磁盘IO监控磁盘IO是性能测试中的另一个重要指标,它反映了系统对存储资源的利用情况。
通过监控磁盘IO,可以了解系统在不同负载下的IO操作能力和性能瓶颈。
类似地,可以使用操作系统的性能监控工具或第三方监控工具来监控系统的磁盘IO情况。
4. 网络带宽监控对于网络应用来说,网络带宽是一个关键的性能指标。
在进行性能测试时,需要监控系统的网络带宽使用情况,包括带宽利用率、吞吐量等指标。
可以使用网络监控工具,如Wireshark等来实时监控系统的网络带宽使用情况。
二、资源管理1. 资源分配在进行性能测试时,需要合理地分配系统资源,以模拟真实的运行环境。
根据被测系统的特点和性能测试的目标,可以合理配置CPU、内存、磁盘和网络等资源。
例如,可以通过修改系统设置或使用虚拟化技术来控制资源的分配。
2. 资源优化性能测试的目的之一是发现系统的性能瓶颈并进行优化。
在进行资源优化时,可以通过监控系统资源的使用情况,找到资源使用过高或过低的情况,并进行相应的调整。
例如,可以通过调整系统参数、优化代码或增加硬件设备等方式来提高系统的性能。
除了RPS和错误率,性能测试还需要关注这些指标

除了RPS和错误率,性能测试还需要关注这些指标背景最近发现交给外包做的性能测试,外包⼈员除了看RPS、错误率,其他指标完全不看。
我陷⼊了思考,现在很多公司为了降低性能测试的门槛,内部会针对⼀些开源框架进⾏⼆次开发,以⽤户⾮常友好的WEB页⾯呈现出来。
因此,在很多测试⼈员看来,所谓的性能测试不就是调⼀下并发,看看页⾯显⽰的RPS,哪⾥报错,就找开发定位。
这么简单,哪有什么神秘感?真的是这样吗?如果是这样,为什么性能测试专家这么吃⾹?为什么有⼀些⼈可以在性能测试领域深耕多年甚⾄超过⼗年?换⼀个思路,当你进⾏性能摸底,发现某个节点,RPS就上不去了,你不好奇为什么吗?为什么不懂得去看看系统指标,确定哪⾥是瓶颈?反正我觉得性能测试最有意思的就是测试过程的问题定位、排查,性能测试结束之后的瓶颈分析、结论分析。
所以,写了这篇⽂章,想告诉⼤家除了RPS和错误率,你还可以关注什么。
施压端RPS:即吞吐量,每秒钟系统可以处理的请求数、任务数。
请求响应时间服务处理⼀个请求或者任务的耗时,包括⽹络链路耗时。
分类:平均值、99分位数、中位数、最⼤值最⼩值错误率:⼀批请求中结果出错的请求所占⽐例。
被测服务CPU内⽹IO wait⽹络带宽Load:负载TOP:1min、5min、15minLinux系统的CPU统计维度us:⽤户态使⽤的cpu时间百分⽐sy:系统胎使⽤的cpu时间百分⽐sy过⾼意味着被测服务在⽤户态和系统态之间切换⽐较频繁,此时系统整体性能会有⼀定下降在使⽤多核CPU的服务器上,CPU0负责CPU各核之间的调度,CPU0的使⽤率过⾼会导致其他CPU核⼼之间的调度效率变低。
ni:⽤做nice加权的进程分配的⽤户态cpu时间百分⽐⼀般来说,被测服务和服务器整体的ni值不会很⾼,如果测试过程中nic的值⽐较⾼,需要从服务器Linux系统配置、被测服务运⾏参数查找原因。
id:空闲的cpu时间百分⽐线上服务运⾏过程,需要保留⼀定的idle冗余来应对突发的流量激增。
性能测试通常需要监控的指标

性能测试通常需要监控的指标在进行性能测试时,需要监控以下指标以评估系统的性能和效率:1.响应时间:响应时间是衡量系统响应请求的速度。
它是从发送请求到收到相应的时间间隔。
较短的响应时间表示系统运行速度快,用户获得结果的等待时间短。
2.吞吐量:吞吐量是单位时间内系统处理的请求数量。
它表示系统的处理能力,较高的吞吐量意味着系统能够同时处理更多的请求。
3.并发用户数:并发用户数指同时访问系统的用户数量。
它反映了系统能够同时支持的用户数量,较高的并发用户数表示系统能够处理更多的并发请求。
4.CPU使用率:CPU使用率表示当前系统的CPU利用率。
它反映了系统的负载情况,较高的CPU使用率可能导致系统性能下降。
5.内存使用率:内存使用率表示当前系统的内存利用率。
它反映了系统内存的负载情况,较高的内存使用率可能导致系统出现内存不足的情况。
6.网络延迟:网络延迟是从发送请求到接收到响应的时间间隔。
它反映了网络传输的速度和稳定性,较短的网络延迟表示网络传输速度快。
7.数据库响应时间:对于涉及数据库的系统,需要监控数据库的响应时间。
较短的数据库响应时间表示数据库访问效率高。
8.磁盘I/O:磁盘I/O是指磁盘的读写操作。
需要监控磁盘的读写速度和响应时间,较高的磁盘I/O可能影响系统的性能和效率。
9.错误率:错误率表示系统处理请求时出现错误的比率。
较低的错误率表示系统稳定性高,较高的错误率可能表示系统存在问题。
10.带宽利用率:带宽利用率表示当前网络带宽的利用率。
较高的带宽利用率可能导致网络拥堵和传输速度下降。
11.日志记录:性能测试还需要监控系统的日志记录,以便分析和诊断问题。
需要记录系统的运行日志、错误日志和性能日志等。
通过监控这些指标,可以评估系统的性能和效率,并及时发现和解决潜在的性能问题。
性能测试常用监控工具简介

一、 LINUX监控工具--NMON
NMON简介
● Nmon是一种在Aix与Linux操作系统上 广泛使用的监控与分析工具
● Nmon所记录的信息非常全面 ● Nmon可以产生数据文件与图形化结果
NMON监控内容
● cpu占用率 ● 内存使用情况 ● 磁盘I/O速度、传输和读写比率 ● 文件系统的使用率 ● 网络I/O速度、传输和读写比率、错误统计率与传输包的大小 ● 消耗资源最多的进程 ● 计算机详细信息和资源 ● 页面空间和页面I/O速度 ● 用户自定义的磁盘组 ● 网络文件系统
Spotlight on oracle监控top session
TopSessions面板可以查看当前哪个session当前占用了大量的资源;单 击session列表,会在session Information中显示该会话的所有详细信息 ,可以查看执行计划,判断是否存在全表扫描
Spotlight on oracle监控top sql
● 举例:./nmon –F test.nmon –s 5 –c 1000
NMON生成数据文件
● nmon analyser生成数据文件 ● 需要将nmon analyser的宏安全模式调至低
NMON数据文件分析
NMON数据文件分析
主要关注TAB: ● SYSSUM ● CPU_ALL ● CPU_SUMM ● DISK_SUMM ● DISKBUSY ● MEM ● NET
Jconsole启动
服务器端启动:
在catalina.sh的JAVA_OPTS参数中添加-Djava.awt.headless=true 在Xshell的参数选项中,将X11连接选中:
Jconsole启动
远程连接:
性能测试系列四压测常见的关注指标以及监控分析工具

性能测试系列四压测常见的关注指标以及监控分析⼯具前⾯的⽂章,我们分析了压测的时机,压测的指标,那么这次呢,我们来看下,我们这些压测的指标,常见的都需要性能压测中观测点,有了对指标的梳理,我们才有重点的关注点,下⾯,我列举⼀些常见的指标。
•服务器cpu•服务器内存•服务器load•数据库连接池•Redis 连接池•Tomcat连接池•TPS•⽹络带宽•响应时间•GC•错误率这些都是⼀些常见的指标了,当然了,还有⼀些其他的指标,需要我们根据⾃⼰的实际的业务去选择,这些关注点,⼤家都可以去搭建⼀些监控平平台,展⽰分析使⽤,例如⽕焰图,zabbix,Grafana,InfluxDB,prometheus等⼯具。
都可以成为我们监控分析的利器。
这些⼯具呢,都是⼀些在压测中常见呢,我们来介绍下⽕焰图这是官⽅的github给我们的。
由底部到顶部可以追溯⼀个唯⼀的调⽤链,下⾯的⽅块是上⾯⽅块的⽗调⽤。
同⼀⽗调⽤的⽅块从左到右以字母序排列。
⽅块上的字符表⽰⼀个调⽤名称,括号内是⽕焰图指向的调⽤在⽕焰图中出现的次数和这个⽅块占最底层⽅块的宽度百分⽐。
⽅块的颜⾊没有实际意义,相邻⽅块的颜⾊差只为了便于查看。
⽕焰图则适合⽤在:代码循环分析:如果代码中有很⼤的循环或死循环代码,那么从⽕焰图的顶部或接近项部的地⽅会有很明显的”平顶”,表⽰代码频繁地在某个线程栈上下切换。
但需要注意的是,如果循环的总耗时不长,在⽕焰图上不会很明显。
IO 瓶颈/锁分析:在我们的应⽤代码中,我们的调⽤普遍都是同步的,也就是说在进⾏⽹络调⽤、⽂件 I/O 操作或未成功获得锁时,线程会停留在某个调⽤上等待 I/O 响应或锁,如果这个等待⾮常耗时,会导致线程在某个调⽤上⼀直 hang 住,这在⽕焰图上表现得会⾮常清晰。
与此相对的是,我们应⽤线程构成的⽕焰图⽆法准确地表达 CPU 的消耗,因为应⽤线程内没有系统的调⽤栈,在应⽤线程栈hang 住时,CPU 可能去做其他事了,导致我们看到耗时很长,⽽ CPU 却很闲。
常用的性能测试方法和测试要点

常用的性能测试方法和测试要点2008-12-16 13:58:04 / 个人分类:转载好东西常用的性能测试方法和测试要点1、明确用户的性能需求(显示的和隐式的),性能测试点,找出瓶颈1)用户直接需求的和使用过程中(行业经验)可能遇到的性能瓶颈点必须测试和分析到。
当然,客户不需要的,也没有必要去花时间和精力。
2)从中获取相应的性能测试参数,峰值和平均值。
3)客户的性能容忍度和系统所能承受的容忍度同样重要。
4)确认系统运行的最低硬件环境要求(虽然硬件便宜的多了,但客户能不能改造自己的环境还得客户说了算)5)如果可以的话,将系统的容错性做为性能测试的一部分进行测试2、测试对象和性能负载分布1)基本的3个对对像:C/S、B/S中的客户端和服务器,其中还有网络进行连接或中间件。
2)服务端可能分为数据端、业务端和服务容器。
3)跟据实际的测试结果合理的进行相应的性能负载分布。
3、负载、容量和压力测试逐一进行(如果需要)1)更多的情况下,性能测试中出现的问题是最初的设计时应存在的问题。
如果可能,建议对相应的性能提前做测试和优化。
2)够用就好,不是所有的系统都要进行性能测试,一切以客户需求和实际需要为准。
4、测试点1)CPU和内存使用(系统自身的原因)。
是否可以正常的使用和释放,是否存在内存溢出。
2)访问的速度(客户需求或是实际的应用要求说了算)3)网络。
网络传输速度,网络传输丢包率。
(找些工具,有免费的)4)服务器。
指令、服务应答响应时间,服务器对信息处理的时效性,服务器对峰值的处理(建议进行服务器优化或是进行服务负载均衡,有大量的文档对此进行描述)5)中间件。
中间件在信息传递中的处理性能及信息处理的正确性。
5、测试和监控数据1)均值下的持续运行(通过分析对整体的性能进行预测和评估)2)短时间的峰值运行(分析系统的处理能力)3)最低配置和最佳配置下的性能对比4)多用户。
同时访问,同时提交。
5)对4 中的数据进行记录和监控6、选择测试工具现有的测试工具太多了,不在一一列举。
服务器性能监控主要内容主要服务器的各项指标监控

服务器性能监控主要内容主要服务器的各项指标监控主要服务器的各项指标监控包括以下几个方面:1.CPU使用率监控:CPU是服务器的核心组件之一,负责处理各种计算任务。
通过监控CPU使用率,我们可以了解服务器的计算负载情况,及时发现CPU瓶颈或过载的情况。
2.内存使用率监控:内存是服务器用于存储运行中程序和数据的地方,也是服务器性能的重要指标之一、通过监控内存使用率,我们可以了解服务器内存的使用情况,包括空闲内存、已分配内存和已用内存等,以及及时发现内存泄露或不足的问题。
3.磁盘使用率监控:磁盘是用于存储数据的重要硬件设备。
通过监控磁盘使用率,我们可以了解服务器磁盘的容量、使用情况和剩余空间等,以及及时发现磁盘过载、写入速度慢或文件系统损坏等问题。
4.网络带宽监控:网络是服务器与外界通信的通道,对于网络性能的监控十分重要。
通过监控服务器的网络带宽使用率,我们可以了解服务器的上行和下行速度,及时发现网络拥堵、带宽不足或网络故障等问题。
5.进程和服务监控:服务器上运行的进程和服务对于服务器功能的实现至关重要。
通过监控进程和服务的运行状态、CPU使用率、内存使用率和网络通信情况等,可以及时发现进程崩溃、服务停止或占用过多资源等问题。
6.负载均衡监控:对于负载均衡服务器,监控其负载均衡策略的运行情况也是必要的。
通过监控负载均衡服务器的连接数、负载情况和响应时间等,可以保证负载均衡的稳定性和性能。
7.日志文件监控:服务器的日志文件中包含了大量的系统和应用程序信息。
通过监控日志文件的大小、更新时间和错误日志等,可以及时发现系统错误、安全漏洞和异常情况,以便进行及时的处理和修复。
总之,服务器性能监控主要关注CPU、内存、磁盘、网络、进程和服务等关键指标,通过收集和分析这些指标的数据,可以及时发现和解决服务器性能问题,保证服务器的稳定性和高效运行。
关键物料重点监控项目一览表

3
委外 委外 委外 委外 自测
材质成份 铜管及铜制件,黄铜 4 机械性能 制件 耐压性 应力测试 5 商标及户外标贴件 光老化试验 6 内胆部件(含附件) 寿命测试 吸水率 7 发泡料(组合料) 收缩率 保湿性能 导热系数 8 导热硅脂 铜铝腐蚀性 9 安全阀/T/P阀 寿命测试 10 电气(器)件 寿命测试
关键物料重点监控项目一览表
序号 物料 重点监控项目 材质成份 监控频次成分即 可 委外 备注 不锈钢板每三个月抽样测试一次,不锈钢二次冶炼加工制件每月测试一 按国标 次
1
2
每月抽样不锈钢制件(含二次冶炼及加工件,焊接件)检测一次;有针 不锈钢板及制件(含 中性盐雾试验 1000H 对性取样进行测试(如焊接部位,拉伸部位,冲压部位,表层破坏部位 无缝钢管,焊管,波 腐蚀测试(点 每月抽样不锈钢制件(含二次冶炼及加工件,焊接件)检测一次;有针 纹管等) 24H 蚀) 对性取样进行测试(如焊接部位,拉伸部位,冲压部位,表层破坏部位 腐蚀测试(晶 每季度抽样不锈钢制件(含二次冶炼及加工件,焊接件)检测一次;有 间腐蚀,电位 针对性取样进行测试(如焊接部位,拉伸部位,冲压部位,表层破坏部 按国标 腐蚀等) 位等) 中性盐雾试验 常规喷涂颜色每周抽样一次,非常用颜色每批抽样。 500H 钣金喷涂件(含粉 末);彩板,覆膜板 光老化试验 每三个月测试一次,测试含三个月内生产所有颜色,日常来料抽样。 500H 户外塑料件(整体机 光老化试验 专用塑料件,提手, 装饰圈等) 机械性能 每三个月测试一次。含所有材质、颜色、供方样品。 每三个月测试一次。含所有材质、颜色、供方样品。 每三个月测试一次。含所有材质、供方样品。 每三个月测试一次。含所有材质、供方样品。 每三个月测试一次。含所有材质、供方样品。 每三个月测试一次。含所有材质、供方样品。 每三个月测试一次。含所有材质、供方样品。 每周测试一次,含安全阀、T/P阀、排污管、法兰等附件。 每月测试一次。 每月测试一次。 每半年测试一次。 每三个月测试一次。 每三个月测试一次。 每三个月测试一次。 每三个月测试一次。 500H 按国标 按国标 按国标 按国标 按国标 500H 十万次 按国标 按国标 按国标 按国标 按国标 100000次 100000次
性能测试监控指标说明
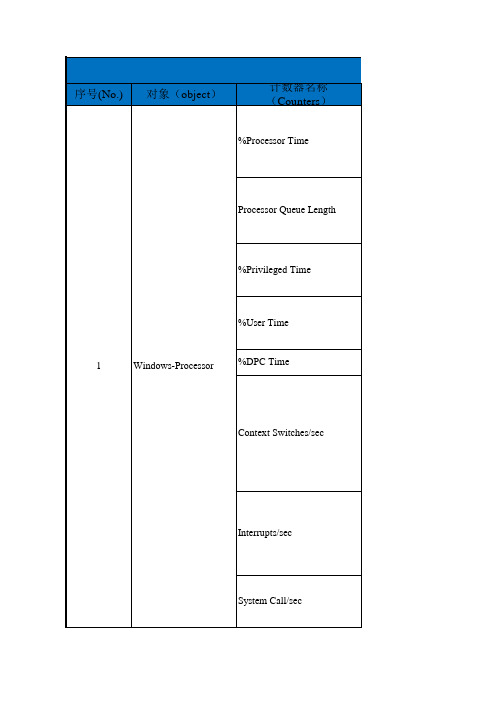
Current Disk Queue Length
4
Windows-Thread
Threads %Process Time Page Faults/sec Working Set
5
Windows-Process Private Bytes
%Total Processor Time
6
Windows-System
6
Windows-System
File Data Operations/Sec Processor Queue Length Total Interrupts/sec
7
Windows-NetWork Interface
Bytes Total/sec
Hale Waihona Puke 服务器性能计数器说明 描述(Description)
显示出当前空闲的物理内存总量,它等于分配给待机 (缓存的)、空闲和零分页列表内存的总和。 空闲内存可以马上使用;清零内存是由零值填满的内 存页,用来防止后续进程获得旧进程使用的数据;待 机内存是从进程工作集(其物理内存)中删除然后进入磁 盘的内存,但是该内存仍然可以收回。该指标仅显示 最后一次观察到的值,不是平均值。 以字节表示的确认虚拟内存。确认内存磁盘页面文件 上保留了空间的物理内存。每个物理磁盘上可以有一 个或一个以上的页面文件。这个计数器只显示上一回 观察到的值,它不是一个平均值。其实就是指有多少 虚拟内存正在被使用。虚拟内存是占用硬盘空间的内 存,和物理内存无关。 指为解决硬页错误从磁盘读取或写入磁盘的页数。这 个计数器是可以显示导致系统范围延缓类型错误的主 要指示器。它是 Memory\Pages Input/sec 和 Memory\Pages Output/sec 的总和。是用页数计算的,以 便在不用做转换的情况下就可以同其他页计数如: Memory\Page Faults/sec 做比较,这个值包括为满足错 误而在文件系统缓存(通常由应用程序请求)的非缓存映 非分页池中的字节数,指可供操作系统组件完成指定 任务后从其中获得空间的系统内存区域。非分页池页 面不可以退出到分页文件中。它们自分配以来就始终 位于主内存中。 指读取磁盘以解析硬页面错误的次数。它显示读取操 作的数量,它并不考虑每个操作的页面数量。当一个 进程引用一个虚拟内存的页面,而此虚拟内存位于工 作集以外或物理内存的其他位置,并且此页面必须从 磁盘检索时,就会发生硬页面错误。此计数器是引起 系统范围内延迟的主要指示器。它包含读取操作以满 足文件系统缓存(通常由应用程序请求)和非缓存映射内 存文件的错误。比较内存的值\PagesReads/sec 与内存的 值\PagesInput/sec 来决定每个操作取读的平均页面数量 。 通俗含义:指页面的硬故障,是Page/sec的子集,为了
软件系统运维技术使用中的性能监控要点

软件系统运维技术使用中的性能监控要点在软件系统运维的过程中,性能监控是一个至关重要的环节。
通过对系统的性能参数进行监控,可以及时发现和解决潜在的性能问题,确保系统稳定可靠地运行。
下面将介绍一些在软件系统运维中使用的性能监控的要点。
首先,合理选择监控指标。
要对软件系统的性能进行监控,就需要明确监控哪些指标。
常见的性能指标包括CPU使用率、内存使用率、网络流量、磁盘IO等。
根据具体的系统需求和性能特点,选取相应的监控指标进行监测,避免盲目监控或监控过于庞杂,浪费资源。
其次,建立合适的监控系统。
在进行性能监控时,需要选择适合自己的监控系统。
常见的监控系统有Zabbix、Nagios等。
这些监控系统能够采集和展示监控数据,同时提供告警和报警功能,方便运维人员及时发现并处理性能问题。
通过在监控系统中设置合适的阈值,当性能指标超出阈值时,监控系统会自动发出警报,提醒相关人员进行处理。
此外,还应定期进行性能测试。
通过定期进行性能测试,可以了解系统在不同负载情况下的性能表现。
可以通过负载测试工具模拟用户访问系统,观察系统的各项性能指标,如响应时间、吞吐量等。
通过性能测试可以发现系统的瓶颈和性能问题,并及时采取相应的优化措施。
另外,注意实时监控和历史数据分析。
在性能监控中,不仅需要实时监控系统运行状态,还需要对历史数据进行分析。
实时监控可以即时发现异常和故障,及时采取措施进行处理。
而历史数据分析可以帮助运维人员了解系统的发展趋势,预测潜在问题,并进行容量规划,以确保系统的可扩展性和可靠性。
此外,应注意合理配置监控策略。
不同系统的性能特点不同,对监控的要求也不同。
因此,在进行性能监控时,应根据实际情况合理配置监控策略。
可以根据系统的关键指标和重要业务进行重点监控,避免监控过于繁琐而忽略了关键信息。
最后,要关注监控数据的可视化和报告。
监控数据可视化可以帮助运维人员直观地了解系统性能情况,通过图表和报告展现,可以更好地分析和解读数据。
性能测试中的监控和数据分析方法

性能测试中的监控和数据分析方法性能测试是软件测试过程中非常重要的环节之一,旨在评估系统在不同负载条件下的表现和稳定性。
在进行性能测试时,监控和数据分析方法的有效应用能够帮助我们更准确地评估系统的性能,并及时发现潜在的问题。
本文将介绍性能测试中常用的监控和数据分析方法。
一、监控方法1. 实时监控实时监控是指通过使用性能监控工具,实时收集系统的关键指标数据,以了解系统当前的性能情况。
监控对象可以包括服务器的硬件指标、操作系统的性能指标以及应用程序的性能指标等。
通过实时监控,我们可以快速获得系统的实时状态,并及时发现性能瓶颈和异常情况。
2. 日志监控日志监控是指通过分析系统生成的日志文件,从中提取关键指标数据,以了解系统的性能情况。
在性能测试过程中,系统会生成大量的日志信息,包括请求的响应时间、错误信息等。
通过对日志的监控和分析,我们可以全面了解系统的性能表现,并发现潜在的问题。
二、数据分析方法1. 数据采集在性能测试过程中,我们需要采集大量的数据,包括系统的负载情况、响应时间、吞吐量等指标。
数据采集可以通过使用性能测试工具和监控工具来实现,将收集到的数据存储在数据库或者文件中,以便后续进行数据分析和报告生成。
2. 数据清洗与处理采集到的原始数据通常会存在一些异常值或者噪声数据,需要进行数据清洗和处理。
数据清洗的目的是去除异常值和噪声数据,使得数据更加准确和可靠。
数据处理的目的是对原始数据进行计算、求平均值、求标准差等操作,从而得到更具有代表性的数据。
3. 数据分析与可视化数据分析是指通过使用统计学和数据挖掘的方法,对采集到的数据进行分析和解读。
常用的数据分析方法包括趋势分析、归因分析、聚类分析等。
数据分析的结果可以通过可视化的方式呈现,比如使用折线图、柱状图、饼状图等形式展示数据分析结果,便于人们更直观地理解和解读数据。
4. 数据报告数据报告是性能测试的最终成果之一,可以通过报告的方式将性能测试的结果和分析结论进行总结和呈现。
软件性能知识点总结

软件性能知识点总结软件性能是衡量软件系统质量的重要指标,它可以影响到软件系统的稳定性、可靠性、效率和用户体验。
在软件开发和运维过程中,了解并掌握软件性能知识点,对于提高软件系统的整体质量和性能优化具有重要意义。
本文将对软件性能的相关知识进行总结,包括性能测试、性能优化、性能监控等方面的知识点,并为读者提供全面的参考和指导。
一、性能测试1. 性能测试概念性能测试是指通过一系列模拟真实用户场景的测试,来评估系统的性能,包括系统的响应时间、并发用户量、吞吐量和资源利用率等指标。
性能测试可以帮助开发人员和运维人员发现系统中的性能瓶颈和问题,为性能优化提供依据。
2. 性能测试类型(1)负载测试:通过模拟高负载的系统访问量来测试系统的稳定性和性能表现。
负载测试可以评估系统在高负载下的响应时间、资源消耗和吞吐量等指标。
(2)压力测试:通过逐渐增加系统负载并观察系统响应情况,以测试系统的极限容量和承载能力。
压力测试可以帮助发现系统的性能瓶颈和容量限制。
(3)并发测试:模拟多个并发用户同时访问系统,并观察系统的并发用户能力、资源竞争和性能表现。
并发测试可以评估系统在多用户并发访问下的性能和稳定性。
3. 性能测试工具(1)LoadRunner:是一款功能强大的性能测试工具,可以模拟真实用户场景进行负载测试、压力测试和并发测试,支持多种协议和环境。
(2)JMeter:是一款开源的性能测试工具,可以进行负载测试和压力测试,支持多种协议和插件扩展。
(3)Gatling:是一款基于Scala语言的性能测试工具,具有高性能和易用性,可以进行负载测试和压力测试。
二、性能优化1. 性能优化概念性能优化是指通过调整系统架构、算法或代码实现,来提升系统的响应速度、资源利用率和用户体验。
性能优化可以帮助系统更加高效地运行,减少资源浪费和提升系统稳定性。
2. 性能优化技术(1)代码优化:通过改进代码复杂度、算法效率和资源利用率,来提升程序的性能。
APP性能测试指标

1、响应2、内存3、CPU4、FPS(app使用的流畅度)5、GPU渲染6、电量7、流量一、响应响应时间和响应速度直接影响到用户的体验度,进而影响到产品的日活、留存。
应用程序的响应时间包括安装、卸载、启动、切换各功能页面的耗时。
主要测试点:1.冷启动:首次启动app的时间间隔(只是启动时间,不包括页面加载)2、热启动:非首次启动app的时间间隔(只是启动时间,不包括页面加载)3、完全启动:从启动到首页完全加载出来的时间间隔在项目中,主要测试关注点是冷启动,热启动二.内存在Android系统中,每个APP进程除了同其他进程共享内存(Shareddirty)外,还独用私有内存(PriVatedirty),通常使用PSS(私有内存+比例分配共享内存)来衡量一个APP的内存开销。
移动设备的内存资源是非常有限,为每个APP进程分配的私有内存也是有限制,如果内存消耗过大就会造成应用卡顿或者闪退。
正常情况下,应用不应占用过多的内存资源,且能够及时释放内存,以免发生内存泄漏。
测试点:1.空闲状态:切换至后台或者启动后不做任]可操作,消耗内存最少2、中强度状态:时间偏长的操作应用3、高强度状态:高强度使用应用4、应用内存峰值5、应用内存泄露6、应用是否常驻内存7、压力测试后的内存使用三、CPU手机CPU,即中央处理器是手机最重要的硬件指标,它是整台手机的控制中枢系统。
应用程序占用的CPU大小直接影响了系统性能。
CPU测试,主要关注的是CPU的占用率。
CPU 使用率过高,导致手机发烫发热,手机响应变慢,用户体验就会很差。
测试点:1.在空闲时间(切换至后台)的消耗(CPU占用率0%)2、在运行一些应用的情况下,观察应用程序占用cpu的情况(cpu占用率50%)3、在高负荷的情况下看CPU的表现(CPU占用率80%以上)具体场景:1.应用空闲状态运行监测CPU占用率空闲状态:应用按Home键退到后台,不再占用系统的状态(通常是灭屏半分钟后)CPU占用率=0%2、应用中等规格运行监测CPU占用率中等规格:模拟用户最常见的使用场景CPU占用率≤30%3、应用满规格长时间正常运行监测CPU占用率CPU占用率≤30%4、应用正常运行期间监测CPU占用率峰值应用正常运行:打开应用进行基本操作CPU占用率≤50%四、FPS(应用的使用流畅度)FPS是图像领域中的定义,是指画面每秒传输帧数,通俗来讲就是指动画或视频的画面数。
软件评测的性能监控与分析

软件评测的性能监控与分析在当今高度数字化的时代,软件的性能评测成为了决定用户体验和产品竞争力的重要指标之一。
对于软件开发者和品牌商来说,了解和分析软件的性能状况至关重要。
为此,性能监控和分析成为了软件评测中不可或缺的环节。
一、性能监控的重要性软件的性能监控旨在评估软件在使用过程中的表现,并通过监控多个关键指标来获取全面的性能数据。
监控软件的性能有助于开发团队和品牌商了解软件的稳定性、响应速度、资源利用情况等关键指标,从而及时发现和解决潜在问题,提升用户体验。
二、性能监控的指标1. 响应时间:衡量软件处理用户请求的速度,包括页面加载时间、数据查询时间等。
较短的响应时间能够提升用户体验,减少用户等待时间,而较长的响应时间则可能导致用户流失。
2. 并发量:指软件在同一时间内可以处理的用户请求数量。
并发量过大可能导致软件崩溃或运行缓慢,而并发量过小则可能导致资源浪费。
3. 错误率:衡量软件在运行过程中出现错误的频率。
较低的错误率可以增强软件的稳定性和可靠性。
4. 资源利用率:包括CPU利用率、内存利用率等,衡量软件在运行过程中对硬件资源的占用情况。
过高的资源利用率可能导致软件运行缓慢或崩溃。
三、性能分析的方法1. 基准测试:在事先设定好的条件下对软件进行测试,通过对比测试前后的性能数据,得出软件的性能改进情况。
基准测试可以帮助开发团队了解软件在不同环境下的表现,并找出性能瓶颈。
2. 负载测试:通过模拟大量用户同时访问软件,测试软件在高负载情况下的性能表现。
负载测试可以帮助开发团队确定软件的并发处理能力和资源利用情况,从而优化软件性能。
3. 实时监控:通过监控工具对软件的关键指标进行实时监控,及时发现和解决潜在问题。
实时监控可以帮助开发团队发现软件在运行中的异常情况并及时采取措施,保证软件的稳定性和可用性。
四、性能监控与分析工具1. APM工具:Application Performance Management,可对软件的性能数据进行全面监控和分析,包括响应时间、错误率、并发量等。
性能测试监控指标说明

性能测试监控指标说明1. 响应时间(Response Time)响应时间是指从用户发出请求到系统返回结果所花费的时间。
较低的响应时间通常被认为是系统性能好的一个重要指标。
响应时间可以分为平均响应时间、95th或99th百分位响应时间等,用来表示系统在不同负载条件下的性能表现。
2. 吞吐量(Throughput)吞吐量是指系统在单位时间内处理的请求数量。
较高的吞吐量意味着系统可以高效地处理更多的请求,是一个衡量系统性能的重要指标。
吞吐量通常以每秒请求数(QPS)或每秒事务数(TPS)来表示。
3. 并发用户数(Concurrent Users)并发用户数是指同时访问系统的用户数量。
并发用户数是评估系统容量的重要指标之一,它可以帮助确定系统能够支持的最大负载量。
4. CPU 使用率(CPU Utilization)CPU使用率是指系统中CPU资源的利用率。
较高的CPU使用率可能意味着系统负载过高或存在性能问题。
通过监控CPU使用率,可以评估系统的处理能力和资源利用效率。
5. 内存使用率(Memory Utilization)内存使用率是指系统中内存资源的利用率。
过高的内存使用率可能导致系统缓慢、崩溃或出现其他性能问题。
通过监控内存使用率,可以评估系统的内存容量和资源管理效果。
6. 磁盘 I/O(Disk IO)磁盘I/O是指系统中磁盘读写操作的速度和效率。
通过监控磁盘I/O,可以评估系统对持久化数据的读写能力,以及磁盘的性能和健康状况。
7. 网络延迟(Network Latency)网络延迟是指通过网络传输数据所需的时间。
较高的网络延迟可能会导致系统响应变慢或数据丢失。
通过监控网络延迟,可以评估系统对网络条件的适应性和网络性能。
8. 错误率(Error Rate)错误率是指系统在处理请求过程中产生的错误数量。
较低的错误率通常表示系统可靠性高,能够稳定地处理用户请求。
监控错误率可以帮助我们及时发现和解决系统的错误和异常情况。
性能测试指标

浅谈软件性能测试中关键指标的监控与分析一、软件性能测试需要监控哪些关键指标?软件性能测试的目的主要有以下三点:评价系统当前性能,判断系统是否满足预期的性能需求。
寻找软件系统可能存在的性能问题,定位性能瓶颈并解决问题。
判定软件系统的性能表现,预见系统负载压力承受力,在应用部署之前,评估系统性能。
而对于用户来说,则最关注的是当前系统:是否满足上线性能要求?系统极限承载如何?系统稳定性如何?因此,针对以上性能测试的目的以及用户的关注点,要达到以上目的并回答用户的关注点,就必须首先执行性能测试并明确需要收集、监控哪些关键指标,通常情况下,性能测试监控指标主要分为:资源指标和系统指标,如下图所示,资源指标与硬件资源消耗直接相关,而系统指标则与用户场景及需求直接相关。
性能测试监控关键指标说明:资源指标CPU使用率:指用户进程与系统进程消耗的CPU时间百分比,长时间情况下,一般可接受上限不超过85%。
内存利用率:内存利用率=(1-空闲内存/总内存大小)*100%,一般至少有10%可用内存,内存使用率可接受上限为85%。
磁盘I/O: 磁盘主要用于存取数据,因此当说到IO操作的时候,就会存在两种相对应的操作,存数据的时候对应的是写IO操作,取数据的时候对应的是是读IO操作,一般使用% Disk Time(磁盘用于读写操作所占用的时间百分比)度量磁盘读写性能。
网络带宽:一般使用计数器Bytes Total/sec来度量,Bytes Total/sec表示为发送和接收字节的速率,包括帧字符在内。
判断网络连接速度是否是瓶颈,可以用该计数器的值和目前网络的带宽比较。
系统指标:并发用户数:某一物理时刻同时向系统提交请求的用户数。
在线用户数:某段时间内访问系统的用户数,这些用户并不一定同时向系统提交请求。
平均响应时间:系统处理事务的响应时间的平均值。
事务的响应时间是从客户端提交访问请求到客户端接收到服务器响应所消耗的时间。
对于系统快速响应类页面,一般响应时间为3秒左右。
性能测试监控策略汇总

性能测试监控策略汇总监控类别监控指标监控⼯具或命令
APP前端响应时间、吞吐量、TPS、点击率、超时概率、错误概
率、页⾯性能⼯具:ddms25、
页⾯⼯具:YSlow3.1、ChromDevTools(基于Chrome57)综合⼯具:GT、Emmagee
应⽤服务器(jvm和配置)JVM、最⼤线程数、DB连接数、full gc频率、是否有异
常⽇志、是否有OOM、内存泄露、代码异常、线程死锁
⼯具:jvisualvm(基于jdk1.7)
⼯具:MemoryAnalyzer1.6
命令:jps jinfo jstat jcmd
数据库(mysql5.5)系统负载、CPU占⽤率、内存使⽤率、磁盘、数据库连
接数、是否有慢查询SQL、SQL死锁
命令:show processlist
命令:mysqldumpslow
命令:explain
操作系统(linux3.1)系统负载、CPU占⽤率、内存使⽤率、磁盘、⽹络带宽
(⽆丢包、⽆延迟、⽆阻塞)
命令:top uptime free vmstat
命令:iostat sar netstat
命令:tcpdump dstat。
性能测试工具Loadrunner中监控指标的名词解释

性能测试工具Loadrunner中监控指标的名词解释Transactions(用户事务分析)用户事务分析是站在用户角度进行的基础性能分析。
1、Transation Sunmmary(事务综述)对事务进行综合分析是性能分析的第一步,通过分析测试时间内用户事务的成功与失败情况,可以直接判断出系统是否运行正常。
2、Average Transaciton Response Time(事务平均响应时间)“事务平均响应时间”显示的是测试场景运行期间的每一秒内事务执行所用的平均时间,通过它可以分析测试场景运行期间应用系统的性能走向。
例:随着测试时间的变化,系统处理事务的速度开始逐渐变慢,这说明应用系统随着投产时间的变化,整体性能将会有下降的趋势。
3、Transactions per Second(每秒通过事务数/TPS)“每秒通过事务数/TPS”显示在场景运行的每一秒钟,每个事务通过、失败以及停止的数量,使考查系统性能的一个重要参数。
通过它可以确定系统在任何给定时刻的时间事务负载。
分析TPS主要是看曲线的性能走向。
将它与平均事务响应时间进行对比,可以分析事务数目对执行时间的影响。
例:当压力加大时,点击率/TPS曲线如果变化缓慢或者有平坦的趋势,很有可能是服务器开始出现瓶颈。
4、Total Transactions per Second(每秒通过事务总数)“每秒通过事务总数”显示在场景运行时,在每一秒内通过的事务总数、失败的事务总署以及停止的事务总数。
5、Transaction Performance Sunmmary(事务性能摘要)“事务性能摘要”显示方案中所有事务的最小、最大和平均执行时间,可以直接判断响应时间是否符合用户的要求。
重点关注事务的平均和最大执行时间,如果其范围不在用户可以接受的时间范围内,需要进行原因分析。
6、Transaction Response Time Under Load(事务响应时间与负载)“事务响应时间与负载”是“正在运行的虚拟用户”图和“平均响应事务时间”图的组合,通过它可以看出在任一时间点事务响应时间与用户数目的关系,从而掌握系统在用户并发方面的性能数据,为扩展用户系统提供参考。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
处理器瓶颈
处理器出现瓶颈可能是由于处理器本身没有足够的能力,或由于应用程序效率低下导致处理器能力不足。
必须仔细检查处理器是否由于物理内存不足而不得不花费大量时间来执行分页。
内存瓶颈
内存不足通常是由于RAM 不足、内存泄漏或内存开关被放置在boot.ini 中而导致的。
在讨论内存计数器之前,我先介绍一下/3GB 开关。
内存越多,磁盘I/O 活动就越少,而应用程序的性能也会因此得以改善。
在Windows NT® 中引入了/3GB 开关,用于为用户模式程序提供更多的内存。
Windows 使用4GB 的虚拟地址空间(与系统拥有的物理RAM 大小无关)。
默认情况下,下面的2GB 是为用户模式程序保留的,而上面的2GB 是为内核模式程序保留的。
通过使用/3GB 开关,可将3GB 用于用户模式进程。
当然,这样做的代价是内核内存仅剩1GB 的虚拟地址空间。
这可能会产生一些问题,因为Pool Non-Paged Bytes、Pool Paged Bytes、Free System Page Tables Entries 和桌面堆都争用这1GB 的空间。
因此,必须在环境中进行全面测试后才能使用/3GB 开关。
如果怀疑自己遇到了与内存相关的瓶颈,可以考虑一下这一点。
硬盘瓶颈
由于磁盘系统存储和处理服务器上的程序和数据,因此影响磁盘使用情况和运行速度的瓶颈会极大地影响服务器的整体性能。
网络瓶颈
网络瓶颈顾名思义会影响服务器通过网络发送和接收数据的能力。
原因可能是服务器的网卡存在问题,或者网络处于满负荷状态,需要对其进行分段。
进程瓶颈
如果进程异常或未经优化,服务器性能将会受到严重影响。
线程和句柄泄漏最终会使服务器
速度减慢,过度使用处理器会使服务器变为爬行速度。
在诊断与进程相关的瓶颈时,需要使用以下计数器。