第六章 stata语言中的常用函数
stata real函数

stata real函数Stata是一种统计分析软件,具有强大的数据处理和分析功能。
其中的real函数是Stata中用于处理实数的函数之一。
在本文中,我们将重点介绍Stata中的real函数及其应用。
我们来了解一下real函数的基本功能。
real函数用于将字符串或其他类型的数据转换为实数。
它可以用于将字符型变量转换为数值型变量,或者用于提取字符串中的数字部分。
real函数的基本语法如下:real(expression)其中,expression是一个Stata表达式,可以是一个字符串、数值、变量名或其他Stata函数的组合。
real函数将expression中的数据转换为实数,并返回转换后的结果。
在实际应用中,real函数常常被用于数据清洗和处理。
例如,当我们从外部数据源导入数据时,可能会遇到一些数据类型不匹配的问题。
使用real函数可以将字符串型的数据转换为数值型,从而方便后续的数据分析和计算。
除了将字符串转换为实数,real函数还可以用于提取字符串中的数字部分。
例如,我们有一个包含数字和文字的字符串变量,如"123abc",可以使用real函数提取其中的数字部分,即123。
实际操作中,我们可以将real函数与其他Stata函数和命令结合使用,以实现更复杂的数据处理和分析任务。
例如,我们可以使用real函数将字符串型的变量转换为数值型,并使用summarize命令对这些变量进行统计分析;或者我们可以使用real函数提取字符串中的数字部分,并使用generate命令创建新的变量。
总结一下,Stata的real函数是一个非常实用的函数,它可以将字符串或其他类型的数据转换为实数。
在数据清洗和处理过程中,real 函数可以帮助我们解决数据类型不匹配的问题,提取字符串中的数字部分,并方便后续的数据分析和计算。
通过上述对Stata real函数的介绍,我们可以看到它在数据处理和分析中的重要性和实用性。
stata函数

stata函数Stata是一种用于统计分析和数据管理的软件,拥有强大的数据分析能力和丰富的函数库。
本文将介绍一些常用的Stata函数及其使用方法,帮助读者更好地理解和使用Stata进行数据分析。
1. summarize函数summarize函数用于对数值型变量进行描述性统计分析,包括计算变量的均值、标准差、最小值、最大值等。
例如,对于一个名为"income"的变量,可以使用以下命令进行描述性统计分析:summarize income该函数的输出结果包括均值、标准差、最小值、最大值、缺失值个数等信息。
2. generate函数generate函数用于创建新的变量,并对其赋值。
例如,可以使用以下命令创建一个新的变量"age_squared",并将"age"的平方赋值给它:generate age_squared = age^2该函数可以根据已有的变量进行计算,并将结果保存为新的变量。
3. sort函数sort函数用于对数据集按照指定变量进行排序。
例如,可以使用以下命令对数据集按照"age"变量进行升序排序:sort age该函数可以方便地对数据集进行排序,便于后续的数据分析操作。
4. merge函数merge函数用于将两个数据集按照指定变量进行合并。
例如,假设有两个数据集分别为"dataset1"和"dataset2",并且它们都有一个名为"ID"的变量,可以使用以下命令将两个数据集按照"ID"变量进行合并:merge dataset1 dataset2 using ID该函数可以将两个数据集中的相同"ID"值的观测合并到一起,方便进行分析和比较。
5. regress函数regress函数用于进行线性回归分析。
例如,可以使用以下命令对一个因变量"y"和两个自变量"x1"和"x2"进行线性回归分析:regress y x1 x2该函数可以得到回归系数、截距、残差等回归结果,并进行显著性检验和拟合优度分析。
Stata命令整理

Stata 命令语句格式:[by varlist:] command [varlist] [=exp] [if exp] [in range] [weight] [, options] 1、[by varlist:]*如果需要分别知道国产车和进口车的价格和重量,可以采用分类操作来求得,sort foreign //按国产车和进口车排序. by foreign: sum price weight*更简略的方式是把两个命令用一个组合命令来写。
. by foreign, sort: sum price weight如果不想从小到大排序,而是从大到小排序,其命令为gsort。
. sort - price //按价格从高到低排序. sort foreign -price /*先把国产车都排在前,进口车排在后面,然后在国产车内再按价格从大小到排序,在进口车内部,也按从大到小排序*/2、[=exp]赋值运算. gen nprice=price+10 //生成新变量 nprice,其值为 price+10/*上面的命令 generate(略写为 gen) 生成一个新的变量,新变量的变量名为nprice,新的价格在原价格的基础上均增加了 10 元。
. replace nprice=nprice-10 /*命令 replace 则直接改变原变量的赋值, nprice 调减后与 price 变量取值相等*/3、[if exp]条件表达式. list make price if foreign==0*只查看价格超过 1 万元的进口车(同时满足两个条件),则. list make price if foreign==1 & price>10000*查看价格超过 1 万元或者进口车(两个条件任满足一个). list make price if foreign==1 | price>100004、[in range]范围筛选sum price in 1/5注意“1/5”中,斜杠不是除号,而是从 1 到 5 的意思,即 1,2,3,4,5。
常用stata命令-好用

我常用到的stata命令最重要的两个命令莫过于help和search了。
即使是经常使用stata的人也很难,也没必要记住常用命令的每一个细节,更不用说那些不常用到的了。
所以,在遇到困难又没有免费专家咨询时,使用stata自带的帮助文件就是最佳选择。
stata的帮助文件十分详尽,面面俱到,这既是好处也是麻烦。
当你看到长长的帮助文件时,是不是对迅速找到相关信息感到没有信心?闲话不说了。
help和search都是查找帮助文件的命令,它们之间的区别在于help用于查找精确的命令名,而search是模糊查找。
如果你知道某个命令的名字,并且想知道它的具体使用方法,只须在stata的命令行窗口中输入help空格加上这个名字。
回车后结果屏幕上就会显示出这个命令的帮助文件的全部内容。
如果你想知道在stata下做某个估计或某种计算,而不知道具体该如何实现,就需要用search命令了。
使用的方法和help类似,只须把准确的命令名改成某个关键词。
回车后结果窗口会给出所有和这个关键词相关的帮助文件名和链接列表。
在列表中寻找最相关的内容,点击后在弹出的查看窗口中会给出相关的帮助文件。
耐心寻找,反复实验,通常可以较快地找到你需要的内容。
下面该正式处理数据了。
我的处理数据经验是最好能用stata的do文件编辑器记下你做过的工作。
因为很少有一项实证研究能够一次完成,所以,当你下次继续工作时。
能够重复前面的工作是非常重要的。
有时因为一些细小的不同,你会发现无法复制原先的结果了。
这时如果有记录下以往工作的do文件将把你从地狱带到天堂。
因为你不必一遍又一遍地试图重现做过的工作。
在stata窗口上部的工具栏中有个孤立的小按钮,把鼠标放上去会出现“bring do-file editor to front”,点击它就会出现do文件编辑器。
为了使do文件能够顺利工作,一般需要编辑do文件的“头”和“尾”。
这里给出我使用的“头”和“尾”。
/*(标签。
stata函数

stata函数一、简介stata是一款功能强大的统计分析软件,广泛应用于各个领域的数据分析。
stata提供了丰富的函数和命令,可以帮助用户进行数据的整理、探索、统计分析和模型建立等工作。
本文将介绍一些常用的stata函数,以及它们在数据分析中的应用。
二、描述统计1. summarize函数summarize函数用于计算数据的基本统计量,包括均值、标准差、最小值、最大值等。
例如,我们可以使用以下命令计算变量x的基本统计量:```summarize x```2. tabulate函数tabulate函数用于计算分类变量的频数和比例,并生成交叉表。
例如,我们可以使用以下命令生成变量x和y的交叉表:```tabulate x y```三、数据整理1. merge函数merge函数用于将两个数据集按照共同的变量进行合并。
例如,我们可以使用以下命令将数据集A和数据集B按照变量id进行合并:```merge 1:1 id using A B```2. reshape函数reshape函数用于改变数据集的结构,将宽数据集转换为长数据集或者将长数据集转换为宽数据集。
例如,我们可以使用以下命令将宽数据集转换为长数据集:```reshape long x, i(id) j(year)```四、统计分析1. regress函数regress函数用于进行线性回归分析。
例如,我们可以使用以下命令进行简单线性回归分析:```regress y x```2. logistic函数logistic函数用于进行逻辑回归分析。
例如,我们可以使用以下命令进行二分类逻辑回归分析:```logistic y x```3. anova函数anova函数用于进行方差分析。
例如,我们可以使用以下命令进行单因素方差分析:```anova y x```五、图表绘制1. histogram函数histogram函数用于绘制直方图。
例如,我们可以使用以下命令绘制变量x的直方图:```histogram x```2. scatter函数scatter函数用于绘制散点图。
stata 语法

stata 语法Stata 语法及其应用一、Stata 语法简介Stata 是一种统计分析软件,它具有强大的数据处理、统计分析和图形展示功能。
Stata 的语法简洁明了,便于用户使用和学习。
本文将介绍 Stata 的基本语法和一些常用的命令,以及它们在实际数据分析中的应用。
二、数据导入和整理1. 导入数据使用 Stata 导入数据的命令是 "use",其语法为:use "数据文件路径\文件名"。
例如,导入名为 "data.dta" 的 Stata 数据文件的命令是:use "C:\data.dta"。
2. 查看数据使用 Stata 查看数据的命令是 "browse",其语法为:browse。
该命令可以显示数据文件中的部分或全部观测值。
3. 数据清理对于数据清理,Stata 提供了一系列的命令,如"drop"、"replace" 和 "generate" 等。
其中,"drop" 命令可以删除变量或观测值,"replace" 命令可以替换变量的值,"generate" 命令可以生成新的变量。
三、数据分析1. 描述性统计描述性统计是对数据集的基本特征进行概括和分析。
Stata 提供了多种命令来计算和展示数据的描述性统计量,如 "summarize"、"tabulate" 和 "histogram" 等。
2. 回归分析回归分析是一种常用的统计方法,用于研究变量之间的关系。
在Stata 中,进行回归分析的命令是 "regress",其语法为:regress 因变量自变量1 自变量2 ...。
例如,进行一元线性回归分析的命令是:regress y x。
stata概率函数

stata概率函数
Stata是一种统计和数据分析软件,它提供了多种概率函数,用于进行各种概率计算和统计分析。
以下是一些常用的Stata概率函数:
1.binomial:二项分布概率函数,用于计算在n次独立伯努利试验中成功k次
的概率。
2.normal:正态分布概率函数,用于计算正态分布下的概率值。
3.tdist:t分布概率函数,用于计算t分布下的概率值。
4.chisqdist:卡方分布概率函数,用于计算卡方分布下的概率值。
5.fdist:F分布概率函数,用于计算F分布下的概率值。
6.beta:Beta分布概率函数,用于计算Beta分布下的概率值。
这些函数通常接受相应的参数,例如平均值、标准差、自由度等,以计算对应的概率值。
请注意,这只是Stata中可用的概率函数的一部分,具体可用的函数取决于Stata的版本和安装的插件。
stata函数命令

stata函数命令Stata是一种广泛使用的统计软件,它提供了许多函数命令来支持数据分析和建模。
在本文中,我们将为您介绍一些常用的Stata函数命令。
一、描述统计量命令1. summarize命令Summarize命令提供了基本的描述性统计信息,例如平均值、标准偏差、最小值、最大值等。
语法:summarize var1 var2 var3 ...2. tabulate命令Tabulate命令提供了分类变量的频率统计信息。
它可以将分类变量按不同的组合列出。
语法:tabulate var1 var2, row column3. correlate命令Correlate命令提供了变量之间的相关系数,并生成相关系数矩阵。
它可以帮助分析变量之间的关系。
语法:correlate var1 var2 var3 ...二、数据处理命令1. generate命令Generate命令可以创建新的变量或改变原始变量的值。
它可以计算变量的平均值、差异、百分位数、标准化等。
语法:generate newvar = function(oldvar)2. drop命令Drop命令可以删除Stata数据集中的变量。
它可以删除一列或多列变量。
语法:drop var1 var2 var3 ...3. keep命令Keep命令可以仅保留数据集中的变量。
它可以保留一列或多列变量。
语法:keep var1 var2 var3 ...三、数据分析和建模命令1. regress命令Regress命令可以用来拟合一个线性回归模型,它可以根据数据集的给定变量来预测因变量。
语法:regress depvar indepvar1 indepvar2 ...2. logistic命令Logistic命令可以用来拟合一个逻辑回归模型,它可以预测二元变量的概率。
语法:logistic depvar indepvar1 indepvar2 ...3. cluster命令Cluster命令可以用来构建聚类分析模型,它可以将样本分成互不干扰的群组。
零基础小白STATA数据分析实用常见命令整理

STATA基础入门零基础实用命令整理第一章数据的读入与熟悉1.读入文件中的部分变量. use[变量] using [文件名]Eg . use age sex height weight using [文件名]2.读入文件中的部分观察量. use[文件名] in X/Y. use "I:\stata\chapter3.dta" in 601/1000软件只读入从第601个观察到第1000个观察之间的400个观察量3.描述、管理数据的基本命令命令功能. describe描述数据的基本情况:样本总量、变量总数、变量的格式等. list. list [变量名]-列出数据中所有变量的分布,从第一个样本到最后一个样本-列出选定变量的分布. list [变量名] in X/Y 列出数据中被选定的变量分布。
in限定数据的观察值范围。
比如,若只想查看第100个-200个观察值的分布,则将X/Y替换成100/200. order [变量名]按选定变量排序。
比如,样本的编号、年龄、性别、教育程度,……,等. aorder 将所有变量从 a-z 排序. label variable给变量贴上标签命令功能. sort [变量名] -将某个变量的数值进行排序。
一般情况下,排序的方式是从小到大-可同时排序多个变量-Stata将缺失值描述为最大数值,故排列在最后. sort [变量名] [in] 对某些变量的某个取值范围进行排序;没有指定的取值范围保持在原地方. gsort [+|-][变量名] -可从小到大和从大到小-若变量名前没有任何符号或加上+号,则按升序排列;若在变量名前加上-号,则按降序排列-变量可以是数值型、也可以是字符型. gsort [+|-][变量名] ,mfirst -mfirst指定将缺失值置于所有有效数值之前. gsort -age第二章变量的生成与处理1.离散和连续测量离散方式(discrete measure):由定性测量和定序测量组成;适用于低层次数据连续方式(continuous measure):由定距测量和定比测量组成。
stata函数与操作大全

Stata 函数与操作大全e “…(路径+文件)”, clear 打开一个文件进行处理a) e.g. use "D:\Stata9\auto.dta", clear2.edit 编辑这一个处理的文件(也可以用页面上方的查看按钮)3.将review窗口执行过的命令储存为可执行文件:a)右键review窗口b)选择“Save All”c)这样就生成了一个.do文件4.打开Do文件编辑器:Window – Do-file editor – New5.四则运算:dia)di 5+9 di 5-9b)di 5*9 di 10/2c)di 10^2 di exp(0)d)di ln(1) di sqrt(4)6.sum 函数: e.g. sum price; 会出现五个值。
sum是summarize简写。
a)Obs 观察值个数b)Mean 平均数c)Std. Dev. 标准差d)Min 最小值e)Max 最大值7.散点图:scatter price weight 以price为y轴,weight为x轴画散点图。
8.折线图:line price weight, sort以price为y轴,weight为x轴,将x轴的点按照从小到大排序后画折线图。
注意:如果没有sort,就不排序,直接按照数据的顺序画图。
9.在command窗口的每行语句前加“. “可以使得执行完这一句语句后不显示结果。
10.生成新的数据. clear. set obs 1000 将数据指针定位到1000处. gen x=_n 生成新的数据x, x = 1,2,3,…,1000. gen y=x^2 生成新的y. scatter y x 将y,x画成散点图注: gen 是generate的缩写;obs是observation的缩写11.控制结果输出显示list x显示完一屏后会停住,此时按回车键和”l”会显示下一行;按”q”会终止命令,或者使用ctrl+break;按其他键会显示下一页。
第六章-stata语言中的常用函数

第六章stata语言中的常用函数本章重点:Stata系统是一个统计分析系统,stata语言是实现stata系统功能的基础,因此它其中包括了各种各样的函数。
在stata系统中,函数的自变量可以是一个常数,可以是一个变量,或者是一连串的变量。
在调用这些函数的时候,只要将函数中定义中的这些变量替换为相应值即可。
这一章,介绍一下这些函数的定义以及使用方法。
6.1函数概览函数只不过是一些编号的小程序,它会按一定的规则进行处理,之后报告结果。
实际上,谁也记不住这么多函数,因此,首先要学会查找函数的帮助,当记不住的时候,随时去查寻帮助。
记住下面的命令才是最关键的。
. help function弹出来的对话框告诉我们,STATA包括八类函数,分别是数学函数,分布函数,随机数函数,字符函数,程序函数,日期函数,时间序列函数和矩阵函数。
本章主要介绍数学函数和字符函数,日期函数,随机函数等常用函数,其他函数可以参考stata 帮助功能。
6.2数学函数Abs(x) x的绝对值●Acos(x)反余弦函数例如:arcos (0.5)=1.57 arcos(1)=0●Asin(x) 反正弦函数●Atan(x) 反正切函数●atanh(x) 反双曲正切函数●ceil(x) 返回大于或等于自变量的最小的整数。
例如:ceil(0.7)=1 ceil(3)=3 ceil(-0.7)=0●Floor(x) 返回小于或等于自变量的最大的整数例如:floor(0.7)=0 floor(3)=3 floor(-0.7)=-1●Int(x) 返回自变量的整数部分例如:int(0.7)=0 int(2.9)=2 int(-2.55)=-2●Round(x,y) 返回与y的单位最接近的数x,x为真数,y为近似单位例如:round(5.2,1)= round(4.8,1)=5 round(2.234,0.1)=2.2 round(2.234,0.01)=2.23round(2.234,0.001)=2.234 round(28,5)=30●cloglog(x) 返回ln{-ln(1-x)}的值●comb(n,k) 从n中取k个的组合,即comb(n,k)=n!/{k!(n - k)!}例如:comb(10,5)=252 comb(6,2)=15●cos(x) 余弦函数●digamma(x) 返回digamma函数值,这是lngamma(x)的一阶导数●exp(x) 指数函数例如:exp(0)=1 exp(3)= 20.085537●invcloglog(x) 返回invcloglog(x) = 1 - exp{-exp(x)}的值●ln(x) 自然对数函数●lnfactorial(n) 返回N阶乘的自然对数,即lnfactorial(n)= ln(n!) ,计算n!时用round(exp(lnfactorial(n)),1)函数保证得出的结果是一个整数。
stata基本运算 -回复

stata基本运算-回复Stata基本运算Stata是一款强大的统计分析软件,广泛应用于各个领域的数据分析和研究。
在Stata中,基本运算是进行数据处理和分析的首要步骤之一。
本文将针对Stata中的基本运算概念和使用方法,以及如何进行一些常见的基本运算进行详细解析,希望能帮助读者更好地掌握Stata软件的基本操作和数据处理能力。
首先,我们需要明确什么是基本运算。
在Stata中,基本运算包括加法、减法、乘法和除法等数学运算,还包括一些更加复杂的运算,例如指数函数、对数函数等。
这些运算可以用于计算和分析各种类型的数据,从简单的数据操作到复杂的统计分析都离不开这些基本运算。
在Stata中,基本运算可以直接在命令窗口进行,也可以在do文件或者程序中编写。
比如,我们可以在命令窗口中输入以下命令进行加法运算:statadi 2 + 3其中,`di`是display(显示)的缩写,用于在命令窗口中显示计算结果。
这样,Stata会将2和3相加的结果5显示在命令窗口中。
类似地,我们也可以进行减法、乘法和除法运算。
例如:statadi 5 - 2di 2 * 3di 6 / 2上述命令分别计算了5减去2的结果3、2乘以3的结果6,以及6除以2的结果3。
此外,Stata还提供了一些用于处理数据的函数,如`exp()`(指数函数)和`ln()`(对数函数)。
这些函数可以对数据进行各种运算和变换。
statadi exp(1) 计算e的指数di ln(3) 计算以e为底的对数注意,在Stata中,乘号和除号可以省略不写,例如`2 * 3`可以简写成`23`,`6 / 2`可以简写成`6 2`。
除了在命令窗口中进行基本运算,我们还可以在do文件或者程序中编写基本运算的代码。
假设我们在程序中定义了变量a和b,并进行了一系列基本运算。
我们可以通过`disp`命令将计算结果显示出来,如下所示:stataprogram define myprogramsyntax, [varname1(string)] [varname2(string)] 定义输入参数local result1 = `varname1' + `varname2' 定义运算结果1local result2 = `varname1' - `varname2' 定义运算结果2disp "`varname1' + `varname2'的结果为:`result1'"disp "`varname1' - `varname2'的结果为:`result2'"end在上述示例中,`program define`用于定义程序名称,`syntax`用于定义输入参数,`local`用于定义局部变量,`disp`用于显示计算结果。
stata笔记常用

stata笔记常用Stata: 输出regression table到word和excel1. 安装estout。
最简单的方式是在stata的指令输入:ssc install estout, replaceEST安装的指导网址是:2.跑你的regression3.写下这行指令esttab using test.rtf,然后就会出现个漂亮的表格给你(WORD文档)。
只要再小幅修改,就可以直接用了。
这个档案会存在my document\stata下。
如果你用打开的是一个stata do file,结果会保存到do文件所在文件夹中。
如果要得到excel文件,就把后缀改为.xls或者.csv就可以了4.跑多个其实也不难,只要每跑完一个regression,你把它取个名字存起来:est store m1。
m1是你要改的,第一个model所以我叫m1,第二个的话指令就变成est store m2,依次类推。
5.运行指令:esttab m1 m2 ... using test.rtf就行了。
异方差的检验:Breusch-Pagan test in STATA:其基本命令是:estat hettest var1 var2 var3其中,var1 var2 var3 分别为你认为导致异方差性的几个自变量。
是你自己设定的一个滞后项数量。
同样,如果输出的P-Value 显著小于0.05,则拒绝原假设,即不存在异方差性。
White检验:其基本命令是在完成基本的OLS 回归之后,输入imtest, white如果输出的P-Value 显著小于0.05,则拒绝原假设,即不存在异方差性处理异方差性问题的方法:方法一:WLSWLS是GLS(一般最小二乘法)的一种,也可以说在异方差情形下的GLS就是WLS。
在WLS下,我们设定扰动项的条件方差是某个解释变量子集的函数。
之所以被称为加权最小二乘法,是因为这个估计最小化的是残差的加权平方和,而上述函数的倒数恰为其权重。
stata学习资料-第六章
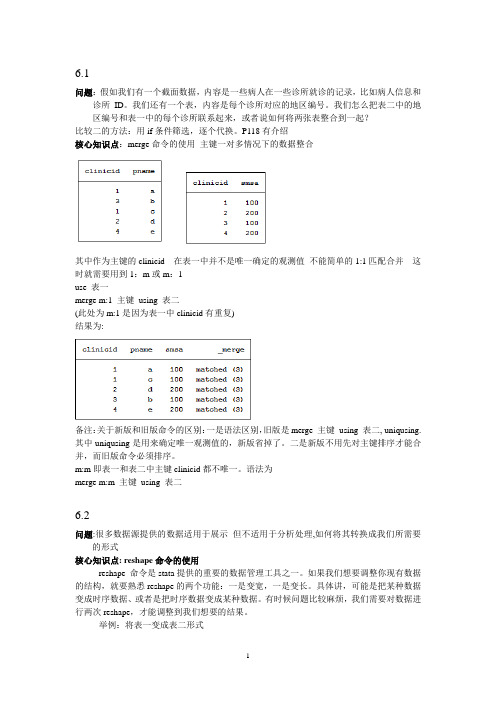
6.1问题:假如我们有一个截面数据,内容是一些病人在一些诊所就诊的记录,比如病人信息和诊所ID。
我们还有一个表,内容是每个诊所对应的地区编号。
我们怎么把表二中的地区编号和表一中的每个诊所联系起来,或者说如何将两张表整合到一起?比较二的方法:用if条件筛选,逐个代换。
P118有介绍核心知识点:merge命令的使用主键一对多情况下的数据整合其中作为主键的clinicid 在表一中并不是唯一确定的观测值不能简单的1:1匹配合并这时就需要用到1:m或m:1use 表一merge m:1 主键using 表二(此处为m:1是因为表一中clinicid有重复)结果为:备注:关于新版和旧版命令的区别:一是语法区别,旧版是merge 主键using 表二, uniqusing. 其中uniqusing是用来确定唯一观测值的,新版省掉了。
二是新版不用先对主键排序才能合并,而旧版命令必须排序。
m:m即表一和表二中主键clinicid都不唯一。
语法为merge m:m 主键using 表二6.2问题:很多数据源提供的数据适用于展示但不适用于分析处理,如何将其转换成我们所需要的形式核心知识点: reshape命令的使用reshape 命令是stata提供的重要的数据管理工具之一。
如果我们想要调整你现有数据的结构,就要熟悉reshape的两个功能:一是变宽,一是变长。
具体讲,可能是把某种数据变成时序数据、或者是把时序数据变成某种数据。
有时候问题比较麻烦,我们需要对数据进行两次reshape,才能调整到我们想要的结果。
举例:将表一变成表二形式表一有四个变量,分别是country,tradeflow, Yr1990, Yr1991.其中tradeflow是作为一个变量主体,分为imports和exports,而1990和1991的贸易流是作为两个并列的变量主体。
我们要把它转成面板数据,分两步。
第一是Yr1990和Yr1991改成时间序列,tradeflow暂时不变。
stata基本运算 -回复

stata基本运算-回复Stata基本运算:一步一步解析在数据分析领域中,Stata被广泛用来进行统计分析和数据处理。
它提供了许多功能强大的基本运算函数,可以帮助研究人员高效地进行数据管理、数据清洗和数据分析等操作。
本文将详细介绍Stata中一些常用的基本运算,包括数值运算、逻辑运算和字符串运算等,旨在帮助读者更好地理解和使用Stata进行数据分析。
一、数值运算1. 加法和减法:Stata中的数值加法和减法运算非常简单。
例如,要计算两个变量X和Y之和,可以使用“generate sum = X + Y”指令,其中“sum”是一个新变量。
类似地,可以用减法来执行相应的运算。
2. 乘法和除法:乘法和除法运算与加法和减法类似。
例如,要计算变量X 和Y的乘积,可以使用“generate product = X * Y”指令。
同样,如果要计算变量X除以变量Y的结果,可以使用“generate quotient = X / Y”指令。
3. 幂运算:Stata还提供幂运算的功能。
例如,要计算变量X的平方,可以使用“generate square = X^2”指令。
4. 取余数和取整:在某些情况下,需要对数值进行取余数和取整操作。
Stata提供了相应的函数来实现这些功能。
例如,可以使用“generate remainder = mod(X, Y)”来计算变量X除以Y的余数。
类似地,可以使用“generate integer = int(X)”指令来将变量X取整。
二、逻辑运算1. 等于运算:逻辑运算在数据分析中起着非常重要的作用。
Stata中的等于运算使用“==”符号表示。
例如,要判断变量X是否等于变量Y,可以使用“generate flag = (X == Y)”指令。
生成的新变量“flag”将包含布尔值,如果X等于Y,则为1,否则为0。
2. 不等于运算:不等于运算与等于运算相反,使用“!=”符号表示。
例如,要判断变量X是否不等于变量Y,可以使用“generate flag = (X != Y)”指令。
第六章 stata语言中的常用函数

第六章stata语言中的常用函数本章重点:Stata系统是一个统计分析系统,stata语言是实现stata系统功能的基础,因此它其中包括了各种各样的函数。
在stata系统中,函数的自变量可以是一个常数,可以是一个变量,或者是一连串的变量。
在调用这些函数的时候,只要将函数中定义中的这些变量替换为相应值即可。
这一章,介绍一下这些函数的定义以及使用方法。
6.1函数概览函数只不过是一些编号的小程序,它会按一定的规则进行处理,之后报告结果。
实际上,谁也记不住这么多函数,因此,首先要学会查找函数的帮助,当记不住的时候,随时去查寻帮助。
记住下面的命令才是最关键的。
. help function弹出来的对话框告诉我们,STATA包括八类函数,分别是数学函数,分布函数,随机数函数,字符函数,程序函数,日期函数,时间序列函数和矩阵函数。
本章主要介绍数学函数和字符函数,日期函数,随机函数等常用函数,其他函数可以参考stata 帮助功能。
6.2数学函数Abs(x) x的绝对值●Acos(x)反余弦函数例如:arcos (0.5)=1.57 arcos(1)=0●Asin(x) 反正弦函数●Atan(x) 反正切函数●atanh(x) 反双曲正切函数●ceil(x) 返回大于或等于自变量的最小的整数。
例如:ceil(0.7)=1 ceil(3)=3 ceil(-0.7)=0●Floor(x) 返回小于或等于自变量的最大的整数例如:floor(0.7)=0 floor(3)=3 floor(-0.7)=-1●Int(x) 返回自变量的整数部分例如:int(0.7)=0 int(2.9)=2 int(-2.55)=-2●Round(x,y) 返回与y的单位最接近的数x,x为真数,y为近似单位例如:round(5.2,1)= round(4.8,1)=5 round(2.234,0.1)=2.2 round(2.234,0.01)=2.23round(2.234,0.001)=2.234 round(28,5)=30●cloglog(x) 返回ln{-ln(1-x)}的值●comb(n,k) 从n中取k个的组合,即comb(n,k)=n!/{k!(n - k)!}例如:comb(10,5)=252 comb(6,2)=15●cos(x) 余弦函数●digamma(x) 返回digamma函数值,这是lngamma(x)的一阶导数●exp(x) 指数函数例如:exp(0)=1 exp(3)= 20.085537●invcloglog(x) 返回invcloglog(x) = 1 - exp{-exp(x)}的值●ln(x) 自然对数函数●lnfactorial(n) 返回N阶乘的自然对数,即lnfactorial(n)= ln(n!) ,计算n!时用round(exp(lnfactorial(n)),1)函数保证得出的结果是一个整数。
stata指数函数命令

stata指数函数命令Stata是一个专业的统计分析软件,它提供了丰富的命令和函数,以满足数据处理、分析和可视化的需求。
其中,指数函数是在数学分析、金融计算和经济学等领域中常用的函数之一。
下面,我们将介绍Stata中的指数函数命令。
一、exp函数命令exp函数是Stata中的指数函数命令之一,它可以计算一个值的以自然常数e为底的指数函数。
其语法格式如下:exp(number)其中,number表示要求指数函数的数值,可以是标量、宏或向量。
二、对数函数命令对数函数是指数函数的反函数,其值代表了底数为e的指数函数的指数部分。
Stata中提供了以下三种对数函数命令:1. ln函数:计算一个数的以e为底的自然对数。
其语法格式如下:ln(number)其中,number表示要计算自然对数的数值。
2. log10函数:计算一个数的以10为底的对数。
其语法格式如下:log10(number)其中,number表示要计算对数的数值。
3. log函数:计算一个数的以指定底数为底的对数。
其语法格式如下:log(number, base)其中,number表示要计算对数的数值,而base则表示指定的底数。
三、示例分析以下是一个示例分析,展示了如何在Stata中使用指数函数命令进行数学计算。
我们以自然指数函数exp(x)为例,计算不同x取值下的指数函数值。
1. 打开Stata软件,并输入以下命令:clearset mem 500mset obs 102. 生成测试数据。
我们使用以下命令生成10组测试数据:gen x = _n3. 计算指数函数值。
我们使用以下命令计算不同x取值下的指数函数值:gen y = exp(x)4. 输出数据。
我们使用以下命令查看计算结果:list x y运行以上命令后,Stata会输出x和y的值。
其中,y表示以自然常数e为底的指数函数值。
四、总结指数函数是一个常用的数学函数,在统计分析、金融计算和经济学等领域中具有广泛的应用。
stata 字符串函数

stata 字符串函数Stata是一款在数据分析和统计上非常强大的软件,它提供了很多函数和命令来处理和分析数据,其中字符串函数在数据处理过程中也非常重要。
本文将介绍Stata中常用的字符串函数以及它们的中文解释。
1. substrsubstr函数用于提取字符串的一部分,第一个参数是字符串本身,第二个参数是提取的起始位置,第三个参数是提取的长度。
例如:substr("Hello World", 3, 5)返回的结果是 "llo W",因为从第三个字符开始取了五个字符。
2. replacereplace函数用于替换字符串中的字符或子串,第一个参数是原字符串,第二个参数是需要替换的字符或子串,第三个参数是用来替换的字符或子串,第四个参数是可选的,指定需要替换的位置。
例如:返回的结果是 "Hezzo Worzd",因为将原字符串中的所有'l'替换成'z'。
4. split返回的结果是 "Hello" 和 "World" 两个子串。
5. toupper/tolowertoupper和tolower函数用于将字符串全部转化为大写或小写字母,其中toupper将所有字母转化为大写,tolower将所有字母转化为小写。
例如:返回的结果是 "HELLO WORLD"。
6. regexr7. destringdestring("1234", int)返回的结果是 1234,表示整数类型的数据。
8. strtrimstrtrim函数用于去除字符串中的前导和末尾的空格符,第一个参数是字符串本身。
例如:。
stata real函数

stata real函数Stata Real函数:简介与应用Stata是一种常用的统计软件,广泛应用于统计分析、数据管理和数据可视化等领域。
其中,Real函数是Stata中的一个重要函数,可以用于处理和转换数值数据,具有广泛的应用价值。
Real函数可以将字符串类型的数据转换为数值类型,使得我们可以对这些数据进行数值计算和分析。
在实际应用中,我们经常遇到需要将字符串类型的变量转换为数值类型的情况,例如将一个表示年龄的字符串变量转换为数值变量,以便进行统计分析。
使用Real函数非常简单,只需要在Stata命令窗口中输入"real()",并将需要转换的变量名放在括号中即可。
例如,如果我们有一个名为"age"的字符串变量,表示年龄,我们可以使用以下命令将其转换为数值变量:```gen age_num = real(age)```上述命令中,"age_num"是新生成的数值变量,它将原始的字符串变量"age"转换为数值类型。
除了将字符串转换为数值,Real函数还可以处理一些特殊的数值数据。
例如,当我们需要将一个表示百分比的字符串变量转换为小数类型时,可以使用Real函数。
以下是一个示例:```gen percent = "50%"gen percent_num = real(subinstr(percent, "%", "", .))```上述命令中,我们首先创建了一个名为"percent"的字符串变量,表示一个百分比。
然后,使用Subinstr函数将百分号去除,并使用Real函数将字符串转换为数值类型。
在实际应用中,Real函数还可以与其他Stata函数和命令结合使用,进行更复杂的数据处理和分析。
例如,我们可以使用If条件语句和Real函数来进行数据筛选和计算。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第六章stata语言中的常用函数本章重点:Stata系统是一个统计分析系统,stata语言是实现stata系统功能的基础,因此它其中包括了各种各样的函数。
在stata系统中,函数的自变量可以是一个常数,可以是一个变量,或者是一连串的变量。
在调用这些函数的时候,只要将函数中定义中的这些变量替换为相应值即可。
这一章,介绍一下这些函数的定义以及使用方法。
6.1函数概览函数只不过是一些编号的小程序,它会按一定的规则进行处理,之后报告结果。
实际上,谁也记不住这么多函数,因此,首先要学会查找函数的帮助,当记不住的时候,随时去查寻帮助。
记住下面的命令才是最关键的。
. help function弹出来的对话框告诉我们,STATA包括八类函数,分别是数学函数,分布函数,随机数函数,字符函数,程序函数,日期函数,时间序列函数和矩阵函数。
本章主要介绍数学函数和字符函数,日期函数,随机函数等常用函数,其他函数可以参考stata 帮助功能。
6.2数学函数Abs(x) x的绝对值●Acos(x)反余弦函数例如:arcos (0.5)=1.57 arcos(1)=0●Asin(x) 反正弦函数●Atan(x) 反正切函数●atanh(x) 反双曲正切函数●ceil(x) 返回大于或等于自变量的最小的整数。
例如:ceil(0.7)=1 ceil(3)=3 ceil(-0.7)=0●Floor(x) 返回小于或等于自变量的最大的整数例如:floor(0.7)=0 floor(3)=3 floor(-0.7)=-1●Int(x) 返回自变量的整数部分例如:int(0.7)=0 int(2.9)=2 int(-2.55)=-2●Round(x,y) 返回与y的单位最接近的数x,x为真数,y为近似单位例如:round(5.2,1)= round(4.8,1)=5 round(2.234,0.1)=2.2 round(2.234,0.01)=2.23round(2.234,0.001)=2.234 round(28,5)=30●cloglog(x) 返回ln{-ln(1-x)}的值●comb(n,k) 从n中取k个的组合,即comb(n,k)=n!/{k!(n - k)!}例如:comb(10,5)=252 comb(6,2)=15●cos(x) 余弦函数●digamma(x) 返回digamma函数值,这是lngamma(x)的一阶导数●exp(x) 指数函数例如:exp(0)=1 exp(3)= 20.085537●invcloglog(x) 返回invcloglog(x) = 1 - exp{-exp(x)}的值●ln(x) 自然对数函数●lnfactorial(n) 返回N阶乘的自然对数,即lnfactorial(n)= ln(n!) ,计算n!时用round(exp(lnfactorial(n)),1)函数保证得出的结果是一个整数。
求n的阶乘的对数比单纯求阶乘更有用,因为存在溢出值问题。
●lngamma(x) 返回.gamma函数的自然对数●log10(x) 以10为底对数函数●logit(x) 返回logit函数值logit(x)= ln{x/(1-x)}●max(x1,x2,...,xn) 求x1, x2, ..., xn中的最大值例如:max(1,2,3)=3●min(x1,x2,...,xn) 求x1, x2, ..., xn中的最小值例如:min(1,2,3)=3●mod(x,y) 求x除以y的余数, 即mod(x,y) = x - y*int(x/y)例如:mod(7,4)=3●reldif(x,y) 返回x,y的相对差异值,reldif(x,y)= |x-y|/(|y|+1).如果x和y都是相同类型的缺失值,则返回0;如果只有一个为缺失值或x、y为不同类型的缺失值,则返回缺失值。
●sign(x) 求x的符号,如果为负数,则返回-1;如果为0,则返回0;如果为正数,则返回1;如果是缺失值,则返回缺失值●sin(x) 正弦函数●sqrt(x) 求x的平方根,x只能为非负数例如:sqrt(100)=10●sum(x) 返回x的和,将缺失值看成是0●tan(x) 正切函数●tanh(x) 双曲正切函数●trigamma(x) 返回lngamma(x)的二阶导数●trunc(x) 将数据截为特定的长度6.3 概率分布和密度函数●betaden(a,b,x) 返回β分布的概率密度,a,b为参数,如果x < 0或者x > 1,返回0●binomial(n,k,p) n次贝努里试验,取得成功次数小于或等于k次的概率,其中一次p为事件成功的概率若k<0 返回1 ;若k>n 返回0●binomialtail(n,k,p) n次贝努里试验,取得成功次数大于或等于k次的概率,其中一次p为事件成功的概率若k<0 返回1 ;若k>n 返回0●binormal(h,k,r) 返回自由度为n的卡方的分布,chi2(n,x) =gammap(n/2,x/2)。
若x<0 ,则返回0●chi2tail(n,x) chi2tail(n,x) = 1 - chi2(n,x)。
若x<0 ,则返回1●dgammapda(a,x) 返回gammap(a,x)分布函数关于a的偏微分,a>0.若x<0 ,则返回0●dgammapdada(a,x) 返回gammap(a,x)分布函数关于a的二阶偏微分,a>0. 若x<0 ,则返回0●dgammapdadx(a,x) 返回gammap(a,x)分布函数关于a和x的二阶偏微分,a>0. 若x<0 ,则返回0●dgammapdx(a,x) 返回gammap(a,x)分布函数关于x的偏微分,a>0.若x<0 ,则返回0●dgammapdxdx(a,x) 返回gammap(a,x)分布函数关于x的二阶偏微分,a>0. 若x<0 ,则返回0●F(n1,n2,f) 返回分子自由度为n1,分母自由度为n2的F分布函数。
若f<0 ,则返回0●Fden(n1,n2,f) 分子自由度为n1,分母自由度为n2的F分布函数的概率密度函数。
若f<0 ,则返回0●gammap(a,x) gamma分布●ibeta(a,b,x) β分布●normal(z) 正态分布函数●normalden(z) 标准正态分布密度函数●tden(n,t) t分布的概率密度函数6.4 随机数函数●uniform() 产生服从均匀分布的随机数●invnormal(uniform()) 标准正态分布的随机数6.5字符函数●char(n) 返回字符的ASCII码●indexnot(s1,s2) 返回s1中第一个在s2中找不到的字母的位置,若s1所有的字母在s2中均可以找到,则返回0例如:indexnot("12disxl","2fsd1")=4 indexnot("12disxl","2fsd1ixs")=7 indexnot("12disxl","2fsd1lixs")=0●itrim(s) 将字符间多于一个空格缩减为一个空格例如:itrim("hello there") = "hello there"●length(s) 返回字符串s的长度例如:length("ab") = 2●lower(s) 将s中的字母变为xiaoxie例如:lower("THIS") = "this"●ltrim(s) 将字符串s中首字母之前的空格去掉例如:ltrim(" this") = "this"●plural(n,s) or plural(n,s1,s2)如果n!=+/-1, plural(n,s)就是将"s"加到s后。
如果s2前有"+",表示将s2加到s1后,如果s2前为"-",则返回s1中去掉s2 字符串后剩下的字符串。
如果s2前既没有"+"也没有"-",则plural(n,s1,s2)=s2.例如:plural(1, "horse") = "horse"plural(2, "horse") = "horses"plural(2, "glass", "+es") = "glasses"plural(1, "mouse", "mice") = "mouse"plural(2, "mouse", "mice") = "mice"plural(2, "abcdefg", "-efg") = "abcd"●proper(s) 将首字母大写,而且将紧接着非字母字符后的字母大写,其他的字母小写例如:proper("mR. joHn a. sMitH") = "Mr. John A. Smith"proper("jack o'reilly") = "Jack O'Reilly"proper("2-cent's worth") = "2-Cent'S Worth"●real(s) 将s字符串转化为数字后返回,或返回“.”例如:real("5.2")+1 = 6.2real("hello") = .●reverse(s) 将字符串颠倒过来例如:reverse("hello") = "olleh"●rtrim(s) 去掉字符串末尾的空格例如:rtrim("this ") ="this".●string(n) 将数字n转化为字符串例如:string(4)+"F" = "4F"string(1234567) = "1234567"string(12345678) = "1.23e+07"string(.) = "."●string(n,s) 将数字n转化为字符串例如:string(4,"%9.2f") = "4.00"string(123456789,"%11.0g") = "123456789"string(123456789,"%13.0gc" = "123,456,789"string(0,"%td") = "01jan1960"string(225,"%tq") = "2016q2"string(225,"not a format") = ""●strmatch(s1,s2) s2与s1的形式相同则返回1,否则返回0例如:strmatch("17.4","1??4")=1 在s2中?代表此处有一个字符,*表示0或更多的字符●strpos(s1,s2) s2在s1中第一次找到的位置,否则为0例如:strpos("this","is") = 3strpos("this","it") = 0●subinstr(s1,s2,s3,n) 返回s1,将s1中第n次出现s2时的s2替换成s3 ,若n为”.”,则将所有s1中的s2字符串替换成s3例如:subinstr("this is this","is","X",1) = "thX is this"subinstr("this is this","is","X",2) = "thX X this"subinstr("this is this","is","X",.) = "thX X thX"●substr(s,n1,n2) 返回s1的子集,从s1中第n1个字符开始抽取,抽n2个字符例如: substr("abcdef",2,3) = "bcd"substr("abcdef",-3,2) = "de"substr("abcdef",2,.) = "bcdef"substr("abcdef",-3,.) = "def"substr("abcdef",2,0) = ""substr("abcdef",15,2) = ""●trim(s) 将字符串s的首字母之前和末尾的空格去掉例如:trim(" this ") ="this"●upper(s) 将字符串s中的字母变为大写例如:upper("this") ="THIS"●word(s,n) s中第n个单词例如:word("glass tass a td",2)=tassword("glass tass a td",.)=.●wordcount(s) s中单词数例如:wordcount("glass tass a td")=46.6 日期时间函数●date(date, mask) 返回date与1960年1月1日相距的天数,其中mask的形式为“MDY”或“YMD”或“DMY”,表示date中年月日的顺序●weekly(date, mask) 返回date与1960年1月1日相距的星期数●monthly(date, mask) 返回date与1960年1月1日相距的月数●quarterly(date, mask) 返回date与1960年1月1日相距的季度数●halfyearly(date, mask) 返回date与1960年1月1日相距的星期数●yearly(date, mask) 返回date与1960年1月1日相距有多少个半年●clock(date, mask) 返回date与1960年1月1日相距的秒数●mdyhms(M, D, Y, h, m, s) 从年月日,小时,分钟,秒得到stata日期时间值●dhms(td, h, m, s) 从日期,小时,分钟,秒得到stata日期时间值●hms(h, m, s) 从小时,分钟,秒返回一个stata日期时间值●mdy(M, D, Y) 从月,日,年中得到一个stata日期值●yw(Y, W) 从年,星期得到一个stata日期值,表示距1960年1月1日有多少个星期●ym(Y, M) 从年,月得到一个stata日期值,表示距1960年1月1日有多少个月●yq(Y, Q) 从年,季度得到一个stata日期值,表示距1960年1月1日有多少个季度●yh(Y, H) 从年,半年得到一个stata日期值,表示距1960年1月1日有多少个半年●year(d) 从stata日期中得到年份●month(d) 从stata日期中得到月份●day(d) 从stata日期中得到当前日期(一个月内的日期)●doy(d) 从stata日期中得到当前日期(一年内的日期)●quarter(d) 从stata日期中得到当前季度●week(d) 从stata日期中得到当前星期●dow(d) 从stata日期中得到当前星期几,其中0为星期天,3为星期三例:请算算你活了多少天?示例:一个生于1975 年12 月27 日的家伙,他活了?.di date(“1975/12/27”,”YMD”)。