Oracle内置函数、高级查询、事务
ORACLE_分析函数大全

ORACLE_分析函数大全Oracle分析函数是一种高级SQL函数,它可以在查询中实现一系列复杂的分析操作。
这些函数可以帮助我们在数据库中执行各种数据分析和报表生成任务。
本文将介绍Oracle数据库中的一些常用分析函数。
1.ROW_NUMBER函数:该函数为查询结果中的每一行分配一个唯一的数字。
可以用它对结果进行排序或分组。
例如,可以使用ROW_NUMBER函数在结果集中为每个员工计算唯一的编号。
2.RANK和DENSE_RANK函数:这两个函数用于计算结果集中每个行的排名。
RANK函数返回相同值的行具有相同的排名,并且下一个排名值将被跳过。
DENSE_RANK函数类似,但是下一个排名值不会被跳过。
G和LEAD函数:LAG函数返回结果集中指定列的前一个(上一个)行的值,而LEAD函数返回后一个(下一个)行的值。
这些函数通常用于计算增长率或发现趋势。
4.FIRST和LAST函数:这两个函数用于返回结果集中分组的第一个和最后一个行的值。
可以与GROUPBY子句一起使用。
5.CUME_DIST函数:该函数用于计算给定值的累积分布。
它返回值的累积分布在结果集中的位置(百分比)。
6.PERCENT_RANK函数:该函数用于计算结果集中每个行的百分位数排名。
它返回值的百分位数排名(0到1之间的小数)。
7. NTILE函数:该函数用于将结果集分成指定数量的桶(Bucket),并为每个行分配一个桶号。
通常用于将数据分组为更小的块。
8.LISTAGG函数:该函数将指定列的值连接成一个字符串,并使用指定的分隔符分隔每个值。
可以用它将多个值合并在一起形成一个字符串。
9.AVG、SUM、COUNT和MAX/MIN函数:这些是常见的聚合函数,可以在分析函数中使用。
它们用于计算结果集中的平均值、总和、计数和最大/最小值。
以上只是Oracle数据库中的一些常用分析函数。
还有其他一些分析函数,如PERCENTILE_CONT、PERCENTILE_DISC等可以用于更高级的分析计算。
oracle最全函数大全(分析函数-聚合函数-转换函数-日期型函数-字符型函数-数值型函数-其他函数)

oracle函数大全(分析函数,聚合函数,转换函数,日期型函数,字符型函数,数值型函数,其他函数)oracle函数大全 (1)oracle分析函数--SQL*PLUS环境 (1)oracle 10g函数大全--聚合函数 (19)oracle 10g函数大全--转换函数 (23)oracle 10g函数大全--日期型函数 (40)oracle 10g函数大全--字符型函数 (45)oracle 10g函数大全--数值型函数 (55)oracle 10g函数大全--其他函数 (58)oracle分析函数--SQL*PLUS环境一、总体介绍1.1.分析函数如何工作语法 FUNCTION_NAME(<参数>,…) OVER (<PARTITION BY 表达式,…> <ORDER BY 表达式 <ASC DESC> <NULLS FIRST NULLS LAST>> <WINDOWING子句>) PARTITION子句ORDER BY子句 WINDOWING子句缺省时相当于RANGE UNBOUNDED PRECEDING1. 值域窗(RANGE WINDOW)RANGE N PRECEDING 仅对数值或日期类型有效,选定窗为排序后当前行之前,某列(即排序列)值大于/小于(当前行该列值–/+ N)的所有行,因此与ORDER BY子句有关系。
2. 行窗(ROW WINDOW)ROWS N PRECEDING 选定窗为当前行及之前N行。
还可以加上BETWEEN AND 形式,例如RANGE BETWEEN m PRECEDING AND n FOLLOWING 函数 AVG(<distinct all> eXPr)一组或选定窗中表达式的平均值 CORR(expr, expr) 即COVAR_POP(exp1,exp2) / (STDDEV_POP(expr1) * STDDEV_POP(expr2)),两个表达式的互相关,-1(反相关) ~1(正相关),0表示不相关COUNT(<distinct> <*> <expr>) 计数COVAR_POP(expr, expr) 总体协方差COVAR_SAMP(expr, expr) 样本协方差CUME_DIST 累积分布,即行在组中的相对位置,返回0 ~ 1DENSE_RANK 行的相对排序(与ORDER BY搭配),相同的值具有一样的序数(NULL计为相同),并不留空序数FIRST_VALUE 一个组的第一个值LAG(expr, <offset>, <default>) 访问之前的行,OFFSET是缺省为1 的正数,表示相对行数,DEFAULT是当超出选定窗范围时的返回值(如第一行不存在之前行)LAST_VALUE 一个组的最后一个值LEAD(expr, <offset>, <default>) 访问之后的行,OFFSET是缺省为1 的正数,表示相对行数,DEFAULT是当超出选定窗范围时的返回值(如最后行不存在之前行)MAX(expr) 最大值MIN(expr) 最小值NTILE(expr) 按表达式的值和行在组中的位置编号,如表达式为4,则组分4份,分别为1 ~ 4的值,而不能等分则多出的部分在值最小的那组PERCENT_RANK 类似CUME_DIST,1/(行的序数 - 1)RANK 相对序数,答应并列,并空出随后序号RATIO_TO_REPORT(expr) 表达式值 / SUM(表达式值)ROW_NUMBER 排序的组中行的偏移STDDEV(expr) 标准差STDDEV_POP(expr) 总体标准差STDDEV_SAMP(expr) 样本标准差SUM(expr) 合计VAR_POP(expr) 总体方差VAR_SAMP(expr) 样本方差VARIANCE(expr) 方差REGR_ xxxx(expr, expr) 线性回归函数REGR_SLOPE:返回斜率,等于COVAR_POP(expr1, expr2) / VAR_POP(expr2) REGR_INTERCEPT:返回回归线的y截距,等于AVG(expr1) - REGR_SLOPE(expr1, expr2) * AVG(expr2)REGR_COUNT:返回用于填充回归线的非空数字对的数目REGR_R2:返回回归线的决定系数,计算式为:If VAR_POP(expr2) = 0 then return NULLIf VAR_POP(expr1) = 0 and VAR_POP(expr2) != 0 then return 1If VAR_POP(expr1) > 0 and VAR_POP(expr2 != 0 thenreturn POWER(CORR(expr1,expr),2)REGR_AVGX:计算回归线的自变量(expr2)的平均值,去掉了空对(expr1, expr2)后,等于AVG(expr2)REGR_AVGY:计算回归线的应变量(expr1)的平均值,去掉了空对(expr1, expr2)后,等于AVG(expr1)REGR_SXX:返回值等于REGR_COUNT(expr1, expr2) * VAR_POP(expr2)REGR_SYY:返回值等于REGR_COUNT(expr1, expr2) * VAR_POP(expr1)REGR_SXY: 返回值等于REGR_COUNT(expr1, expr2) * COVAR_POP(expr1, expr2) 首先:创建表及接入测试数据create table students(id number(15,0),area varchar2(10),stu_type varchar2(2),score number(20,2));insert into students values(1, '111', 'g', 80 );insert into students values(1, '111', 'j', 80 );insert into students values(1, '222', 'g', 89 );insert into students values(1, '222', 'g', 68 );insert into students values(2, '111', 'g', 80 );insert into students values(2, '111', 'j', 70 );insert into students values(2, '222', 'g', 60 );insert into students values(2, '222', 'j', 65 );insert into students values(3, '111', 'g', 75 );insert into students values(3, '111', 'j', 58 );insert into students values(3, '222', 'g', 58 );insert into students values(3, '222', 'j', 90 );insert into students values(4, '111', 'g', 89 );insert into students values(4, '111', 'j', 90 );insert into students values(4, '222', 'g', 90 );insert into students values(4, '222', 'j', 89 ); commit;二、具体应用:1、分组求和:1.2.GROUP BY子句1.2.1.GROUPING SETSselect id,area,stu_type,sum(score) scorefrom studentsgroup by grouping sets((id,area,stu_type),(id,area),id) order by id,area,stu_type;/*--------理解grouping setsselect a, b, c, sum( d ) from tgroup by grouping sets ( a, b, c )等效于select * from (select a, null, null, sum( d ) from t group by a union allselect null, b, null, sum( d ) from t group by b union allselect null, null, c, sum( d ) from t group by c )*/1.2.2.ROLLUPselect id,area,stu_type,sum(score) scorefrom studentsgroup by rollup(id,area,stu_type)order by id,area,stu_type;1.2.3.rollupselect a, b, c, sum( d )from tgroup by rollup(a, b, c);等效于select * from (select a, b, c, sum( d ) from t group by a, b, c union allselect a, b, null, sum( d ) from t group by a, b union allselect a, null, null, sum( d ) from t group by a union allselect null, null, null, sum( d ) from t)*/1.2.4.CUBEselect id,area,stu_type,sum(score) scorefrom studentsgroup by cube(id,area,stu_type)order by id,area,stu_type;/*--------理解cubeselect a, b, c, sum( d ) from tgroup by cube( a, b, c)等效于select a, b, c, sum( d ) from tgroup by grouping sets(( a, b, c ),( a, b ), ( a ), ( b, c ),( b ), ( a, c ), ( c ),() )*/1.2.5.GROUPING/*从上面的结果中我们很容易发现,每个统计数据所对应的行都会出现null,如何来区分到底是根据那个字段做的汇总呢,grouping函数判断是否合计列!*/select decode(grouping(id),1,'all id',id) id,decode(grouping(area),1,'all area',to_char(area)) area,decode(grouping(stu_type),1,'all_stu_type',stu_type) stu_type, sum(score) scorefrom studentsgroup by cube(id,area,stu_type)order by id,area,stu_type;1.3.OVER()函数的使用1.3.1.统计名次1.3.1.1.D ENSE_RANK(),允许并列名次、名次不间断,如122344456将score按ID分组排名:dense_rank() over(partition by id order by score desc)将score不分组排名:dense_rank() over(order by score desc)select id,area,score,dense_rank() over(partition by id order by score desc) 分组id排序, dense_rank() over(order by score desc) 不分组排序from students order by id,area;1.3.1.2.R OW_NUMBER(),不允许并列名次、相同值名次不重复,结果如123456……将score按ID分组排名:row_number() over(partition by id order by score desc)将score不分组排名:row_number() over(order by score desc)select id,area,score,row_number() over(partition by id order by score desc) 分组id排序,row_number() over(order by score desc) 不分组排序from students order by id,area;1.3.1.3.r ank(),允许并列名次、复制名次自动空缺,结果如12245558……将score按ID分组排名:rank() over(partition by id order by score desc) 将score不分组排名:rank() over(order by score desc)select id,area,score,rank() over(partition by id order by score desc) 分组id排序,rank() over(order by score desc) 不分组排序from students order by id,area;1.3.1.4.c ume_dist(),名次分析——-最大排名/总个数函数:cume_dist() over(order by id)select id,area,score,cume_dist() over(order by id) a, --按ID最大排名/总个数cume_dist() over(partition by id order by score desc) b, --ID分组中,scroe最大排名值/本组总个数row_number() over (order by id) 记录号from students order by id,area;1.3.1.5.c ume_dist(),允许并列名次、复制名次自动空缺,取并列后较大名次,结果如22355778……将score按ID分组排名:cume_dist() over(partition by id order by score desc)*sum(1) over(partition by id)将score不分组排名:cume_dist() over(order by score desc)*sum(1) over() select id,area,score,sum(1) over() as 总数,sum(1) over(partition by id) as 分组个数,(cume_dist() over(partition by id order by score desc))*(sum(1)over(partition by id)) 分组id排序,(cume_dist() over(order by score desc))*(sum(1) over()) 不分组排序from students order by id,area1.3.1.6.s um(),max(),avg(),RATIO_TO_REPORT()--分组统计select id,area,sum(1) over() as 总记录数,sum(1) over(partition by id) as 分组记录数,sum(score) over() as 总计 ,sum(score) over(partition by id) as 分组求和,sum(score) over(order by id) as 分组连续求和,sum(score) over(partition by id,area) as 分组ID和area求和,sum(score) over(partition by id order by area) as 分组ID并连续按area求和,max(score) over() as 最大值,max(score) over(partition by id) as 分组最大值,max(score) over(order by id) as 分组连续最大值,max(score) over(partition by id,area) as 分组ID和area求最大值,max(score) over(partition by id order by area) as 分组ID并连续按area求最大值,avg(score) over() as 所有平均,avg(score) over(partition by id) as 分组平均,avg(score) over(order by id) as 分组连续平均,avg(score) over(partition by id,area) as 分组ID和area平均,avg(score) over(partition by id order by area) as 分组ID并连续按area平均,RATIO_TO_REPORT(score) over() as "占所有%",RATIO_TO_REPORT(score) over(partition by id) as "占分组%",score from students;3、LAG(COL,n,default)、LEAD(OL,n,default) --取前后边N条数据取前面记录的值:lag(score,n,x) over(order by id)取后面记录的值:lead(score,n,x) over(order by id)参数:n表示移动N条记录,X表示不存在时填充值,iD表示排序列select id,lag(score,1,0) over(order by id) lg,score from students; select id,lead(score,1,0) over(order by id) lg,score from students;4、FIRST_VALUE()、LAST_VALUE()取第起始1行值:first_value(score,n) over(order by id)取第最后1行值:LAST_value(score,n) over(order by id)select id,first_value(score) over(order by id) fv,score from students; select id,last_value(score) over(order by id) fv,score from students;sum(...) over ...【功能】连续求和分析函数【参数】具体参示例【说明】Oracle分析函数NC示例:select bdcode,sum(1) over(order by bdcode) aa from bd_bdinfo【示例】1.原表信息: SQL> break on deptno skip 1 -- 为效果更明显,把不同部门的数据隔段显示。
Oracle中常用的函数与表达式

14.1.8
instr()函数——获得字符串出现的 位置
instr()函数用于获得子字符串在父字符串中出现的位置 。 select instr('big big tiger', 'big') from dual; 可以指定额外的参数,以命令该函数从指定位置开始 搜索。 select instr('big big tiger', 'big', 2) from dual;
14.1.3
lower()函数——返回小写字符串
lower()函数用于返回字符串的小写形式。lower()函数 在查询语句中经常扮演重要角色。例如,对于用户名和密码 的校验来说,用户名一般并不区分大小写,用户无论输入了 大写还是小写形式,都被认为是合法用户。因此,在数据库 查询时,应该将数据库中用户名与用户输入的用户名进行统 一。
14.2.2
round ()函数——返回数字的“四舍 五入”值
round()函数用于返回某个数字的四舍五入值。为了使 用该函数,除了提供原始值之外,还应提供精确到的位数。 精确位数可以为正整数、0和负整数。 select round(2745.173, 2) result from dual; 如果不使用第二个参数,那么,相当于使用了参数0, 即精确到整数。 select round(2745.173) result from dual; 如果第二个参数为负数,那么,相当于将数值精确到 小数点之前的位数。
14.2
Oracle中的数学函数
Oracle提供的数学函数可以处理日常使用到的大多数 数学运算。本小节将讲述Oracle中常用的几种数学函数。
14.2.1
abs ()函数——返回数字的绝对值
oracle的nvl函数用法

oracle的nvl函数用法Oracle是一个关系型数据库管理系统软件,提供了很多内置函数,其中包括NVL函数,意为“null value replacement”。
这个函数是用来将NULL值替换为一个指定的值。
NVL函数的语法如下:NVL( expr1, expr2 )expr1和expr2都是表达式,如果表达式是NULL,则NVL函数返回expr2的值。
如果expr1不是NULL,则返回expr1的值。
下面是一个简单的NVL函数示例,它将一个表示客户税务ID的列(TAX_ID)转换为字符串,如果该值为NULL,则用“未知”替代:SELECT CUSTOMER_NAME, NVL(TO_CHAR(TAX_ID), '未知') as TAX_IDFROM CUSTOMERS;在上述语句中,如果TAX_ID列是NULL,则将其替换为“未知”。
除了常规用法之外,NVL函数还可以在连接表达式中使用,以避免在连接中出现NULL值并保留结果的完整性。
例如:SELECT EMPLOYEE_NAME, DEPARTMENT_NAME, NVL(SALARY, 0) as SALARYFROM EMPLOYEESJOIN DEPARTMENTS ON EMPLOYEES.DEPARTMENT_ID = DEPARTMENTS.DEPARTMENT_ID;在这个查询中,如果某些员工的薪资(SALARY)未知,则用0替换它。
这样可以确保查询结果仍然包含所有未知薪资的员工。
NVL函数还可以在UPDATE语句中使用,以更新NULL值。
例如:UPDATE EMPLOYEESSET SALARY = NVL(SALARY, 0) + 1000;在这个UPDATE语句中,如果某个员工的薪资是NULL,则将其替换为0,然后再给该员工增加1000的薪水。
这能确保所有员工的薪水都得到更新。
NVL函数是一个非常有用和强大的Oracle内置函数,它可以帮助开发人员处理数据库中的NULL值问题,保持查询结果的完整性和正确性。
ORACLE高级技巧 高级查询

!Oracle高级技巧,高级查询1.删除表的注意事项在删除一个表中的全部数据时,须使用TRUNCATE TABLE表名;因为用DROP TABLE,DELETE*FROM表名时,TABLESPACE表空间该表的占用空间并未释放,反复几次DROP,DELETE操作后,该TABLESPACE上百兆的空间就被耗光了。
2.having子句的用法having子句对group by子句所确定的行组进行控制,having子句条件中只允许涉及常量,聚组函数或group by子句中的列.3.外部联接"+"的用法外部联接"+"按其在"="的左边或右边分左联接和右联接.若不带"+"运算符的表中的一个行不直接匹配于带"+"预算符的表中的任何行,则前者的行与后者中的一个空行相匹配并被返回.若二者均不带’+’,则二者中无法匹配的均被返回.利用外部联接"+",可以替代效率十分低下的not in运算,大大提高运行速度.例如,下面这条命令执行起来很慢用外联接提高表连接的查询速度在作表连接(常用于视图)时,常使用以下方法来查询数据:SELECT PAY_NO,PROJECT_NAMEFROM AWHERE A.PAY_NO NOT IN(SELECT PAY_NO FROM B WHERE VALUE>=120000);----但是若表A有10000条记录,表B有10000条记录,则要用掉30分钟才能查完,主要因为NOT IN要进行一条一条的比较,共需要10000*10000次比较后,才能得到结果。
该用外联接后,可以缩短到1分左右的时间:SELECT PAY_NO,PROJECT_NAMEFROM A,BWHERE A.PAY_NO=B.PAY_NO(+)AND B.PAY_NO IS NULLAND B.VALUE>=12000;4.set transaction命令的用法在执行大事务时,有时oracle会报出如下的错误:ORA-01555:snapshot too old(rollback segment too small)这说明oracle给此事务随机分配的回滚段太小了,这时可以为它指定一个足够大的回滚段,以确保这个事务的成功执行.例如set transaction use rollback segment roll_abc;delete from table_name where...commit;回滚段roll_abc被指定给这个delete事务,commit命令则在事务结束之后取消了回滚段的指定.5.数据库重建应注意的问题在利用import进行数据库重建过程中,有些视图可能会带来问题,因为结构输入的顺序可能造成视图的输入先于它低层次表的输入,这样建立视图就会失败.要解决这一问题,可采取分两步走的方法:首先输入结构,然后输入数据.命令举例如下(uesrname:jfcl,password:hfjf,host sting:ora1,数据文件:expdata.dmp):imp jfcl/hfjf@ora1file=empdata.dmp rows=Nimp jfcl/hfjf@ora1file=empdata.dmp full=Y buffer=64000commit=Y ignore=Y第一条命令输入所有数据库结构,但无记录.第二次输入结构和数据,64000字节提交一次.ignore=Y选项保证第二次输入既使对象存在的情况下也能成功.select a.empno from emp a where a.empno not in(select empno from emp1where job=’SALE’);倘若利用外部联接,改写命令如下:select a.empno from emp a,emp1bwhere a.empno=b.empno(+)and b.empno is nulland b.job=’SALE’;可以发现,运行速度明显提高.6.从已知表新建另一个表:CREATE TABLE bAS SELECT*(可以是表a中的几列)FROM aWHERE a.column=...;7.查找、删除重复记录:法一:用Group by语句此查找很快的select count(num),max(name)from student--查找表中num列重复的,列出重复的记录数,并列出他的name属性group by numhaving count(num)>1--按num分组后找出表中num列重复,即出现次数大于一次delete from student(上面Select的)这样的话就把所有重复的都删除了。
Oracle内置函数大全

Oracl e SQL 内置函数大全(一)整理时间[2005-10-14] 阅读次数[6224]导读:Oracle SQL 内置函数大全(一)Oracle SQL 内置函数大全(二)Oracle SQL 内置函数大全(三)________________________________________文字大小:【大】【中】【小】SQL中的单记录函数1.ASCII返回与指定的字符对应的十进制数;SQL> select ascii('A') A,ascii('a') a,ascii('0') zero,ascii(' ') space from dual;A a ZERO SPACE--------- --------- --------- ---------65 97 48 322. 2.CHR给出整数,返回对应的字符;SQL> select chr(54740) zhao,chr(65) chr65 from dual;ZH C-- -赵A3. 3.CONCAT连接两个字符串;SQL> select concat('010-','88888888')||'转23' 高乾竞电话from dual; 高乾竞电话----------------010-********转234. 4.INITCAP返回字符串并将字符串的第一个字母变为大写;SQL> select initcap('smith') upp from dual;UPP-----Smith5. 5.INSTR(C1,C2,I,J)在一个字符串中搜索指定的字符,返回发现指定的字符的位置;C1 被搜索的字符串C2 希望搜索的字符串I 搜索的开始位置,默认为1J 出现的位置,默认为1(第一次?)SQL> select instr('oracle traning','ra',1,2) instring from dual;INSTRING---------96. 6.LENGTH返回字符串的长度;SQL> selectname,length(name),addr,length(addr),sal,length(to_char(sal))from .nchar_tst; NAME LENGTH(NAME) ADDR LENGTH(ADDR) SALLENGTH(TO_CHAR(SAL))------ ------------ ---------------- ------------ --------- --------------------高乾竞 3 北京市海锭区 6 9999.99 7。
第三章 Oracle内置函数、高级查询、事务(理论)

2. 如果表DEMO里面有一个字段经常都有空值,在日常开发过 程中,要将该空值指定为一个固定的值,可以使用什么函数 来完成?
SQL>SELECT NVL(COMM,0) FROM EMP;
3. 使用联合查询查询出SCOTT.EMP表中员工编号为7788的上 司姓名。
数据操纵语言 数据定义语言 数据控制语言 事务控制语言
UPDATE INSERT SELECT DELETE SAVEPOINT CREATE ALTER DROP COMMIT REVOKE ROLLBACK GRANT
Oracle 数据类型
Oracle内置的SQL语言数据类型类别:
数据类型
字符
Oracle 数据类型
日期时间数据类型存储日期和时间值,包括年、月、日, 数值数据类型 小时、分钟、秒 可以存储整数、浮点数和实数 主要的日期时间类型有: 最高精度为 38 位 DATE - 存储日期和时间部分,精确到整个的秒 数值数据类型的声明语法: TIMESTAMPp[,存储日期、时间和时区信息,秒值精确到小 NUMBER [( - s])] 数点后6位 P表示精度,S表示小数点的位数
其它函数
以下是几个用来转换空值的函数:
NVL NVL2 NULLIF
SELECT itemdesc, NVL(re_level,0) FROM itemfile; SELECT itemdesc, NVL2(re_level,re_level,max_level) FROM itemfile; SELECT itemdesc, NULLIF(re_level,max_level) FROM itemfile;
11
oracle 查询高级语法

Oracle 查询高级语法:深入解析与应用一、引言Oracle 数据库作为业界领先的关系型数据库管理系统,提供了丰富而强大的查询功能。
要充分利用这些功能,深入了解和掌握Oracle 查询的高级语法至关重要。
本文将详细解析Oracle 查询高级语法的核心概念、特点和应用场景,帮助读者提升查询效率和准确性。
二、基本查询语句在深入探讨高级语法之前,我们首先回顾一下基本的查询语句。
SELECT 语句是Oracle 查询的核心,用于从数据库表中检索数据。
其基本语法结构如下:sql复制代码SELECT column1, column2, ...FROM table_nameWHERE condition;其中,SELECT 关键字用于指定要检索的列,FROM 关键字用于指定要查询的表,WHERE 关键字用于设置筛选条件。
三、高级语法:多表连接查询内连接(INNER JOIN):内连接是最常用的连接类型,它返回两个表中匹配条件的行。
语法如下:sql复制代码SELECT column1, column2, ...FROM table1INNER JOIN table2ON table1.column = table2.column;左连接(LEFT JOIN):左连接返回左表中的所有行,以及右表中匹配条件的行。
如果右表中没有匹配的行,则结果集中对应字段为NULL。
语法如下:sql复制代码SELECT column1, column2, ...FROM table1LEFT JOIN table2ON table1.column = table2.column;右连接(RIGHT JOIN):右连接与左连接相反,返回右表中的所有行,以及左表中匹配条件的行。
如果左表中没有匹配的行,则结果集中对应字段为NULL。
语法如下:sql复制代码SELECT column1, column2, ...FROM table1RIGHT JOIN table2ON table1.column = table2.column;全连接(FULL JOIN):全连接返回左表和右表中的所有行,如果某侧没有匹配的行,则结果集中对应字段为NULL。
oracle高级语法(事物、函数、存储过程、触发器、异常)

数据的完整性:
Student:
id
name
classNo(fk)
1
zhangsan
10
Class:
cid
cname
10
class10
-------------------------
使用约束,维护数据的完整性 约束:限定不能做什么! !!
Oracle 的约束:
非空 not null : 字段输入必须有值
Xmanager 工具 : 可以远程的调用,在本地显示一个图形化。 。。 -------------------------tnsnames.ora vi $ORACLE_HOME/network/admin/tnsnames.ora 在 Linux 中,如何图形化配置网络服务名: 进入 oracle 用户 ----------- netmgr ----------------------------------------------------Oracle--> SID(实例 )删除重装 数据库配置助手 dbca --》一般来说一个 Oracle 服务器只有一个实例 Transaction Processing(事务处理) ... step 10 : 选择字符集编码 ---------------------------------------------------------------------------------------------------------------------------
如果在数据量激增的情况,后面推荐使用
重新建立索引
1、创建索引: create index 索引名 on 表名(字段)
2、删除索引 drop index 索引名 ;
Oracle的函数与SQL高级查询
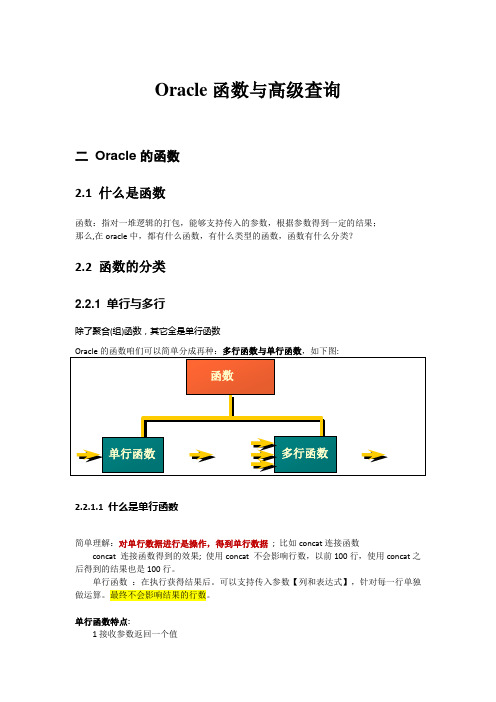
Oracle函数与高级查询二Oracle的函数2.1 什么是函数函数:指对一堆逻辑的打包,能够支持传入的参数,根据参数得到一定的结果;那么,在oracle中,都有什么函数,有什么类型的函数,函数有什么分类?2.2 函数的分类2.2.1 单行与多行除了聚合(组)函数,其它全是单行函数Oracle的函数咱们可以简单分成再种:多行函数与单行函数,如下图:函数单行函数多行函数2.2.1.1 什么是单行函数简单理解:对单行数据进行是操作,得到单行数据; 比如concat连接函数concat 连接函数得到的效果; 使用concat 不会影响行数,以前100行,使用concat之后得到的结果也是100行。
单行函数:在执行获得结果后。
可以支持传入参数【列和表达式】,针对每一行单独做运算。
最终不会影响结果的行数。
单行函数特点:1接收参数返回一个值2对每一行返回行起作用3每一行返回一个结果4可以修改数据类型5可以使用嵌套concat(concat(col1,col2),col2)除了concat 这样的单行函数以外,还有其他的单行函数,比如字符处理函数;比如有时要求用户名全部大写或者小写,或者需要得到一个人的姓,这些都需要字符函数进行处理,字符函数中,也存在分类2.2.1.2 什么是多行函数多行函数:简单理解对多行数据进行操作,最后返回一个数据比如count函数:Count 针对过滤后的结果支持传入表的列名或者常量,对所有行的记录统一处理。
最终只会得到一个结果,会影响结果行数;多行函数: 在执行获得结果后。
可以支持传入参数【列和表达式】,针对每一行整体统计做运算。
最终只会产生1行数据咱们所说的单行与多行是指这个函数操作的数据是单行还是多行(不是说的结果)2.2.1.3 单行、多行分别用在哪?扩展理解与练习比如concat 用在哪里? 可以放在select 后,把它的姓和名连接起来;单行函数:select 关键字之后where 之后的条件上(where 之后单行函数如下)姓名中有e或者a的员工?把姓名组合起来查询select*from employeeswhere first_name || last_name like'%e%'or first_name || last_name like'%a%'使用函数Select * from employeesWhere concat(first_name,last_name) like ‘%e%’Or first_name || last_name like ‘%a%’;多行函数:针对Select 关键之后;比如count函数统计所有行,放在select之后使用多行函数得到就一个结果,那我放在where 后面有意义吗?Where 是针对每一行,而多行函数返回结果只有一行,如果放在where 之后,执行一次,是一个结果,执行二次还是同一个结果,所以没有意义.2.2.2 函数功能分类可以分为:字符函数、数字函数,转换函数,日期函数,组函数,其它函数字符(串)函数:拼接字符串,截取字符串,全变大写,全变小写,首字母大写...数字(number)函数:四舍五入,舍掉转换函数:字符《--》日期字符《--》数字日期函数:拿到年,月,日,时,分,秒组函数:sum,count,max....其它函数:2.3 字符函数字符函数分为大小写转换函数与字符处理函数2.3.1 大小写转换函数大小写转换函数:Lower(列|表达式) 全部转换小写Upper(列|表达式) 全部转换大写Initcap(列|表达式) 首字母大写练习案例:select 'Hello world' from dual;大写:select upper('Hello world') from dual;小写:select lower('Hello world') from dual;练习案例:1,查询first_name为randall的员工工资;分析:我们查询的时候不需要关心名称中的大小写问题select * from employees where lower(first_name) ='randall';练习案例:2,客户在输入名字的时候,可以不会在意名称的大小写,比如,Wang Xiaoer,假设现在在发送邮件,需要按照正规的格式输出姓名;请使用SQL处理分析:我们可以插入一条小写的名字,然后使用首字母大写查询出来,格式更完整insert into employees(employee_id,first_name,last_name,email,phone_number,hire_date,job_id)values(300,'wang','xiaoer','xxx@','1895236541',sysdate,'SH_CLERK')查询:select initcap(first_name)||' '||initcap(last_name) from employees;2.3.2 字符处理函数1、CONCAT(strexp, strexp): 连接两个字符串2、Substr(str,start_index,length) :从指定的位置截取指定长度的字符串3、LENGTH(strexp):返回字符串的长度LENGTHB(strexp):返回字节的长度4、LPAD( string1, padded_length, [ pad_string ] ) 在列的左边粘贴字符其中string1是需要粘贴字符的字符串* padded_length是返回的字符串的数量,如果这个数量比原字符串的长度要短,lpad 函数将会把字符串截取成padded_length;* pad_string是个可选参数,这个字符串是要粘贴到string1的左边,如果这个参数未写,lpad函数将会在string1的左边粘贴空格。
oracle查询函数内容

oracle查询函数内容Oracle查询函数内容1. 什么是Oracle查询函数Oracle查询函数是一组用于在查询语句中执行特定操作或计算的内置函数。
它们可以用于选择、过滤、排序和组合数据,以及执行各种数值、字符串和日期操作。
2. Oracle常用的查询函数•COUNT函数:用于计算满足查询条件的行数。
•SUM函数:用于计算指定列的总和。
•AVG函数:用于计算指定列的平均值。
•MAX函数:用于找到指定列中的最大值。
•MIN函数:用于找到指定列中的最小值。
•UPPER函数:将指定字符串中的小写字母转换为大写字母。
•LOWER函数:将指定字符串中的大写字母转换为小写字母。
•LENGTH函数:用于计算指定字符串的长度。
•SUBSTR函数:从指定字符串中提取子字符串。
•TRIM函数:从指定字符串的开头和结尾删除指定字符。
•TO_CHAR函数:将数值、日期或时间转换为字符格式。
3. 示例代码以下是一些使用Oracle查询函数的示例代码:•使用COUNT函数计算employees表中的员工总数:SELECT COUNT(*) FROM employees;•使用SUM函数计算sales表中的销售总额:SELECT SUM(amount) FROM sales;•使用AVG函数计算products表中的平均价格:SELECT AVG(price) FROM products;•使用MAX函数找到orders表中的最新订单日期:SELECT MAX(order_date) FROM orders;•使用UPPER函数将customers表中的last_name列转换为大写:SELECT UPPER(last_name) FROM customers;•使用SUBSTR函数提取description列中的前10个字符:SELECT SUBSTR(description, 1, 10) FROM pro ducts;•使用TRIM函数删除employees表中first_name列值的首尾空格:SELECT TRIM(first_name) FROM employees;•使用TO_CHAR函数将order_date列中的日期转换为字符格式:SELECT TO_CHAR(order_date, 'YYYY-MM-DD') F ROM orders;4. 结论Oracle查询函数提供了丰富的功能,可以在查询语句中执行各种操作和计算。
oralce函数

oralce函数Oracle函数是一种可重复使用的程序单元,它可以在SQL语句中调用并执行特定的任务。
Oracle函数可以返回一个值或一个结果集,它可以接收一个或多个参数,并可以在SQL语句的任何地方使用。
Oracle函数分为系统函数和用户自定义函数。
系统函数是Oracle提供的一些内置函数,包括数学函数、字符串函数、日期函数等,用户可以直接调用使用。
用户自定义函数是用户根据自己的需求编写的函数,可以根据需要返回一个值或结果集。
在Oracle中,函数的语法如下:CREATE [OR REPLACE] FUNCTION function_name(parameter_name [IN | OUT | IN OUT] data_type [, parameter_name [IN | OUT | IN OUT] data_type]...)RETURN return_data_typeIS[local_variable_declaration;...]BEGINSQL_statements;[EXCEPTIONexception_handler;...]END [function_name];其中,function_name是函数的名称,parameter_name是函数的参数名称,data_type是参数的数据类型,return_data_type是函数返回值的数据类型。
在函数体中可以使用SQL语句和PL/SQL语句来实现特定的功能。
如果函数执行过程中出现异常,可以使用EXCEPTION 块来处理异常。
Oracle函数的使用可以帮助我们提高SQL语句的复用性和可维护性,减少代码的冗余和复杂度,提高代码的执行效率和性能。
同时,函数也可以方便地实现一些特殊的计算和处理需求,提高开发效率和数据处理效率。
oracle自带函数大全及例子

oracle⾃带函数⼤全及例⼦Oracle已经内建了许多函数,不同的函数有不同的作⽤和⽤法,有的函数只能作⽤在⼀个记录⾏上,有的能够作⽤在多个记录⾏上,不同的函数可能处理不同的数据类型。
常见的有两类,单⾏函数和分组函数。
单⾏函数:单⾏函数分类函数功能⽰例字符函数LPAD(,[,])在字符串c1的左边添加字符串c2直到c1字符串的长度等于i。
SELECT LPAD(‘Hello!’,8,’ ’)leftpad,RPAD(‘Hello!’,8,’ ’) rightpadFROM DUAL;RPAD(,[,])在字符串c1的右边添加字符串c2直到c1字符串的长度等于i。
LOWER()把字符串c1转换为⼩写SELECT LOWER(ename) one,UPPER(ename)two, INITCAP(ename) FROM EMP;UPPER()把字符串c1转换为⼤写INITCAP()把c1字符串的每⼀个单词的第⼀个字母转换成⼤写字母LENGTH()返回字符串c1的长度SELECT LENGTH(‘How are you’) FROM DUAL; SUBSTR(,[,])返回字符串c1中从第i个位置开始的j个字符(向右)。
如果省略j,则返回c1中从第i个位置开始的所有字符。
如果j为负,则返回字符串c1中从第i个位置开始的j个字符(向左)。
SELECT SUBSTR(‘Hello,World’,1,5) FROMDUAL;INSTR(,[,[,]])在c1中从位置i开始查找c2在c1中出第j次的位置,i可以为负(此时,从c1的尾部开始)。
SELECT INSTR(‘Mississippi’,’i’,3,3) FROMDUAL; 返回结果11。
SELECT INSTR(‘Mississippi’,’i’,-2,3) FROMDUAL; 返回结果2。
LTRIM(,)从c1前⾯开始去掉出现在c2的中任何前导字符集。
oracle统计查询方法

oracle统计查询方法Oracle是一种强大的关系型数据库管理系统,它提供了丰富的统计查询方法,用于帮助用户对数据库中的数据进行分析和统计。
本文将介绍一些常用的Oracle统计查询方法,帮助读者更好地利用Oracle进行数据分析和统计。
一、基本统计查询方法1. COUNT函数:COUNT函数用于统计某个列或表中的记录数。
例如,可以使用SELECT COUNT(*) FROM table_name来统计表中的记录数。
2. SUM函数:SUM函数用于计算某个列的总和。
例如,可以使用SELECT SUM(salary) FROM employees来计算员工表中的薪水总和。
3. AVG函数:AVG函数用于计算某个列的平均值。
例如,可以使用SELECT AVG(salary) FROM employees来计算员工表中的平均薪水。
4. MAX函数和MIN函数:MAX函数和MIN函数分别用于计算某个列的最大值和最小值。
例如,可以使用SELECT MAX(salary) FROM employees来计算员工表中的最高薪水。
二、分组统计查询方法1. GROUP BY子句:GROUP BY子句用于按照某个列的值进行分组,并对每个分组进行统计。
例如,可以使用SELECT department_id, COUNT(*) FROM employees GROUP BY department_id来统计每个部门的员工人数。
2. HAVING子句:HAVING子句用于对分组后的结果进行条件过滤。
例如,可以使用SELECT department_id, COUNT(*) FROM employees GROUP BY department_id HAVING COUNT(*) > 10来统计员工人数大于10人的部门。
三、高级统计查询方法1. JOIN操作:JOIN操作用于将多个表按照某个列进行关联,从而进行联合查询和统计。
Oracle函数及其查询PPT(23张)

INSTR (char1,char2[,m[,n]])
LPAD (char1,n[,char2])
RPAD (char1,n[,char2])
TRIM(leading|trailing|both,trim_char FROM trim_source)
REPLACE (char1,char2 [,char3])
•
2、身材不好就去锻炼,没钱就努力去赚。别把窘境迁怒于别人,唯一可以抱怨的,只是不够努力的自己。
•
3、大概是没有了当初那种毫无顾虑的勇气,才变成现在所谓成熟稳重的样子。
•
4、世界上只有想不通的人,没有走不通的路。将帅的坚强意志,就像城市主要街道汇集点上的方尖碑一样,在军事艺术中占有十分突出的地位。
•
2.Top-n查询
Top-n用于取某列数据中最大或最小的n个值
Top-n分析语法 SELECT [ column_list ], ROWNUM FROM ( SELECT [column_list ] FROM table ORDER BY Top-N_column [ ASC | DESC ]) WHERE ROWNUM <= N ;
1.单行函数
日期函数
MONTHS_BETWEEN (d1,d2) ADD_MONTHS (d,n) NEXT_DAY (d,s) LAST_DAY (d) ROUND (date,fmt) TRUNC (date,fmt)
1.单行函数
Oracle使用内部的数值格式表示日期和时间
默认的日期显示格式是DD-MON-RR (日-月-年) 可设定掩码指定日期型数据的格式
•
9、别再去抱怨身边人善变,多懂一些道理,明白一些事理,毕竟每个人都是越活越现实。
Oracle10g空间管理

BINARY_DOUBL 9字节,其中有一长度字 64位双精度浮点数类型。 E 节。
14
Oracle数据类型
3. 时间、时间间隔类型
时间字段可取值范围:
时间字段
YEAR
时间类型有效值
-4712至9999,包括0
时间间隔类型有效值
任何整数
MONTH
DAY HOUR MINUTE SECOND
01至12
默认1字节,n值最大为 末尾填充空格以达到指定长度,超过最大 2000 长度报错。默认指定长度为字节数,字符 长度可以从1字节到四字节。
默认1字符,最大存储 末尾填充空格以达到指定长度,n为 内容2000字节 Unicode字符数。默认为1字节。 最大长度必须指定,最 变长类型。n为Unicode字符数 大存储内容4000字节 最大长度必须指定,至 变长类型。超过最大长度报错。默认存储 少为1字节或者1字符, 的是长度为0的字符串。 n值最大为4000 同VARCHAR2 不建议使用
为什么要使用视图?视图的优点在什么地方?
为了简化数据查询操作。 视图的优点: 视图限制数据的访问,因为视图能够选择性的显示表中的列。 视图可以用来构成简单的查询以取回复杂查询的结果。例如,视图能用 于从多表中查询信息,而用户不必知道怎样写连接语句。 视图对特别的用户和应用程序提供数据独立性,一个视图可以从几个表 中取回数据。 视图提供用户组按照他们的特殊标准访问数据。
DDL
数据库模式定义语言DDL(Data Definition Language),是用 于描述数据库中要存储的现实世界实体的语言。一个数据库 模式包含该数据库中所有实体的描述定义。 常见的DDL语句:
CREATE DATABASE CREATE TABLE ALTER TABLE DROP TABLE CREATE VIEW ALTER VIEW DROP VIEW TRUNCATE TABLE
oracle语句大全及用法

oracle语句大全及用法Oracle语句是Oracle数据库中用于管理和操作数据的SQL语句。
以下是一些常用的Oracle语句及其用法:1. 数据定义语句(DDL)CREATE DATABASE:用于创建新的数据库。
CREATE TABLE:用于创建新的表。
语法如下:sql`CREATE TABLE table_name (column1 datatype1, column2 datatype2, ...);`ALTER TABLE:用于修改现有的表结构,如添加、删除或修改列。
DROP TABLE:用于删除现有的表。
CREATE INDEX:用于在表上创建索引,以提高查询性能。
2. 数据操纵语句(DML)SELECT:用于从表中查询数据。
语法如下:sql`SELECT column1, column2, ... FROM table_name;`INSERT INTO:用于向表中插入新的数据行。
语法如下:sql`INSERT INTO table_name (column1, column2, ...) VALUES (value1, value2, ...);`UPDATE:用于修改表中的现有数据。
DELETE:用于从表中删除数据。
3. 数据控制语句(DCL)GRANT:用于授予用户或角色对数据库对象的访问权限。
REVOKE:用于撤销用户或角色对数据库对象的访问权限。
4. 事务控制语句(TCL)COMMIT:用于提交当前事务,使所做的更改永久生效。
ROLLBACK:用于撤销当前事务,恢复到事务开始前的状态。
SAVEPOINT:用于在事务中设置保存点,以便在之后的某个时刻可以回滚到该点。
5. 其他常用语句DECLARE:用于声明变量或常量,并为其分配数据类型和初始值。
BEGIN ... END:用于定义PL/SQL代码块的开始和结束。
IF ... THEN ... ELSE:用于条件判断,根据条件执行不同的操作。
Oracle数据库,查询语句、内置函数

Oracle数据库,查询语句、内置函数
⼀、数据库的查询语句:
1、查询整个表: select * from 表名
例:
2、通过条件查询某⼀⾏数据: select * from 表名 where 字段名
例:
3、某⼀列数据去重查询: select distinct 字段名 from 表名
例:
4、查询的结果按某个字段升序或倒序排列: select * from 表名 order by 字段名; 在字段名的后⾯加desc为降序顺序排列
例:
5、查询某⼀列在某个范围内的数据: select * from 表名 where 字段名>n and 字段名<m;
例: select* from 表名 where between 较⼩值 and 较⼤值;表⽰在某个区间内较⼩值<=字段<=较⼤值
⼆、内置函数:在查询中添加,查询到我们需要⽤的结果
1、count()统计某⼀列字段⾮空数据的个数书写⽅式: select count()from 表名
例:
2、max()查询某⼀列的最⼤值书写⽅式: select max(列名) from 表名
例:
3、min()查询某⼀列的最⼩值书写⽅式: select min(列名) from 表名
例:
4、avg()查询某⼀列的平均值书写⽅式:select agv(列名) from 表名
例:
5、查询的嵌套使⽤思路:把查询到的某个数据当做条件,继⽽查询其他数据
例:。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
【作业】
单行函数
1.显示系统时间
2.查询员工表emp中员工号empno,姓名ename,工资sal,以及工资提高百分之20%后的
结果
3.
4.查询各员工的姓名ename,并显示出各员工在公司工作的月份数(即:与当前日期比较,
该员工已经工作了几个月)。
5.查询员工的姓名和工资,按下面的形式显示
6.查询员工的姓名ename和工资数sal,条件限定为工资数必须大于1200,并对查询结果
7.做一个查询,产生下面的结果
8.做一个查询,产生类似下面的结果
9.使用decode函数,按照下面的条件:
job grade
PRESIDENT A
MANAGER B
ANALYST C
SALESMAN D
CLERK E
产生类似下面形式的结果
DECODE(value, if1, then1, if2,then2, if3,then3, . . . else )
Value 代表某个表的任何类型的任意列或一个通过计算所得的任何结果。
当每个value 值被测试,如果value的值为if1,Decode 函数的结果是then1;如果value等于if2,Decode函数结果是then2;等等。
事实上,可以给出多个if/then 配对。
如果value 结果不等于给出的任何配对时,Decode 结果就返回else 。
需要注意的是,这里的if、then及else 都可以是函数或计算表达式
12.将英文小写字母的ascii码返回。
14.将“上海世博会”替换成“上海世界博览会”。
15.将字符串“iljfljsaiejvnvlaljlovejldjfeijfyou”截取成i love you的字符串。
17.将4^20开方。
18.取得5550的余弦值。
21.将系统时间转换成字符串。
格式:‘YYYY"年" fmMM"月" fmDD"日" HH24:MI:SS’。
多表查询
1.
2.
3.选择所有有奖金comm的员工的ename , dname , loc
4.选择在DALLAS工作的员工的ename , job , deptno, dname
5.选择所有员工的姓名ename,员工号deptno,以及他的管理者mgr的姓名ename和员工
号deptno,结果类似于下面的格式:
12.查询各部门员工姓名和他们所在位置,结果类似于下面的格式
子查询
1.查询和scott相同部门的员工姓名ename和雇用日期hiredate。
2.查询工资比公司平均工资高的所有员工的员工号empno,姓名ename和工资sal。
3.查询和姓名中包含字母u的员工在相同部门的员工的员工号empno和姓名ename
4.查询在部门的loc为newYork的部门工作的员工的员工姓名ename,部门名称dname和
5.。