(完整版)统计软件期中试卷.doc
四川大学期中考试概率与数理统计试卷

四川大学期中考试试卷一、填空(每空3分,共15分)1.设A 、B 、C 是三随机事件,已知41)()()(===C P B P A P ,0=)(AB P ,91)()(==BC P AC P ,则=)(C B A P 3617.3617)]()()()()()()([1)(1)(:=+---++-=⋃⋃-=ABC P BC P AC P AB P C P B P A P C B A P C B A P 解 2.一袋中有4个红球,6个白球,随机地取出3球,则其中至少有1个红球的概率是65.656111)0(1)1(:31036=-=-==-=≥C C X P X P X 为:红球个数,则所求概率设解3. 设随机变量X 有分布函数23),(+=X Y x F ,则Y 有分布函数)32(-y F X .)32()32()23()()(:-=-≤=≤+=≤=y F y X P y X P y Y P y F X Y 解5. 设随机变量X 在[1,4]上服从均匀分布,则概率=≤)(32X P 313-.31331)()3(31322-===≤⎰⎰≤dx dx x f X P x 解法一: ⎪⎩⎪⎨⎧≤≤≤≤=⎪⎩⎪⎨⎧≤>-+==⎪⎩⎪⎨⎧≤≤=其它则可得令其它解法二:,0)41(161,610,00)],()([21)(,,041,31)(2y y yy y y f y f yy f X Y x x f X X Y X ⎰-==≤=≤31231361)3()3(dy yY P X P 故 二、单项选择(每空3分,共15分)1. 设A 、B 是事件,且B A ⊂,则下式正确的是 D . (A )P (AB )=P (B )(B )P (B | A )=P (B )(C ))()(A P A B P =(D ))()(A P B P ≤ 2. 设A ,B 是事件,31==)()(B P A P ,61|=)(B A P ,则 =)(B A P | B .127)(1|=⋃-⋃==)(=)()()()()(解:B P B A P B P B A P B P B A P B A P(A )125(B )127(C )31(D )43 3. 甲、乙二人独立地向目标射击一次,其命中率分别为0.6,0.5,现已知目标被击中,则它只是由乙击中的概率是 C .(A )52 B )92 C )41 D )21418.02.0)()()())(())(|(==⋃=⋃⋃=⋃B A P B A P B A P B A B A P B A B A P B A B A 独立,则所求概率为与标,分别表示甲、乙射中目、设解: 4. 设随机变量X 有密度⎩⎨⎧<<=其它010,4)(3x x x f则使概率)()(a X P a X P <=>的常数=a A .(A )421 (B )42(C )321 (D )4211-440321214)(21)()()(1)(====≤≤<=≤-=>⎰a a dx x a X P a X P a X P a X P a X P a解得而=得由解:5. 已知),,(~2a a N X 且b aX Y +=服从标准正态分布)1,0(N 则 B 成立.(A )⎩⎨⎧==11b a(B )⎩⎨⎧-==11b a(C )⎩⎨⎧-=-=11b a(D )⎩⎨⎧=-=11b a1,1)1,0(~-==-b a N aaX 知由正态变量的标准化解:三、解答题1. (9分)设每张体育彩票是一个7位数,求在某次摇奖时,(1)出现7位数全不相同的概率;(2)至少有两位数字相同的概率;(3)恰好三个位置上数字相同,其余位置上数字全都不相同的概率。
统计学期中考试试卷

统计学期中考试试卷考试时间:120分钟总分:100分一、选择题(每题2分,共20分)1. 统计学中,描述数据集中趋势的度量是:A. 方差B. 标准差C. 平均数D. 众数2. 下列哪项不是统计学中的抽样方法?A. 简单随机抽样B. 分层抽样C. 系统抽样D. 整体抽样3. 假设检验中,如果原假设为H0:μ = 50,备择假设为H1:μ ≠ 50,当检验结果拒绝原假设时,说明:A. 样本均值等于50B. 样本均值不等于50C. 样本方差等于50D. 样本方差不等于50...(此处省略剩余选择题)二、填空题(每空1分,共10分)请根据题目所给的数据,计算下列统计量:1. 平均数()2. 中位数()3. 众数()4. 方差()5. 标准差()...(此处省略剩余填空题)三、简答题(每题10分,共20分)1. 请简述相关系数和回归系数的区别。
2. 请解释什么是置信区间,并说明其在统计推断中的作用。
四、计算题(每题15分,共30分)1. 给定一组数据:23, 28, 31, 36, 40, 42, 49, 55, 58, 62。
请计算这组数据的平均数、中位数、众数、方差和标准差。
2. 假设某工厂生产的产品,其重量服从正态分布,平均重量为50克,标准差为2克。
如果从这批产品中随机抽取100件产品,请计算这100件产品的平均重量的95%置信区间。
五、论述题(20分)请论述统计学在数据分析中的重要性,并举例说明统计方法在实际问题中的应用。
考试结束,请考生停止答题并交卷。
[注:本试卷仅为示例,具体题目和内容应根据实际教学大纲和课程内容进行调整。
]。
《统计学》期中考试试卷10-11第二学期[2]
![《统计学》期中考试试卷10-11第二学期[2]](https://img.taocdn.com/s3/m/10073e70a26925c52cc5bfc3.png)
一、填空:(10分)1. 平均指标和变异指标(或σ和x )。
2.统计中,标志的承担者是总体单位 。
3.抽样平均误差的实质是样本平均数 的标准差。
4.由组距数列计算平均数,由组中值代表各组标志值的水平,其假定前提是组内标志值均匀分布 。
5.负责向上报告调查内容的单位,称为报告单位 。
6.在统计调查方法体系中,以普查为基础,以抽样调查 为主体。
7.现象总体在轻微偏态情况下,中位数与平均数的距离是平均数与众数距离的 1/3 。
8.社会经济统计学的研究对象是研究大量社会经济现象 总体 的数量方面。
9.在组距数列的条件下,众数的计算公式是 。
10.反映总体中各个组成部分之间数量对比关系的指标是比例相对 指标。
二、单项选择(20分)1.攻读某专业硕士学位的四位研究生英语成绩分别为75分、78分、85分、和88分,这四个数字是:( D )A.指标B.标志C.变量D.标志值2.已知:∑2x =2080,∑x =200,总体单位数为20。
则标准差为( B )A.1B.2C.4D.103.调查某地区1010户农民家庭,按儿童数分配的资料如下:根据上述资料计算的中位数为( B )A. 380B. 2C. 2.5D. 5054.某地区为了了解小学生发育状况,把全地区各小学按地区排队编号,然后按排队编号顺序每隔20个学校抽取一个学校,对抽中学校所有学生都进行调查,这种调查是( D )厦门大学《统计学》2010~2011第二学期期中试卷____学院____系____年级____专业主考教师: 试卷类型:(A 卷)A. 简单随机抽样B. 等距抽样(系统抽样)C. 分层抽样D. 整群抽样5.统计工作中,搜集原始资料,获得感性知识的基础环节是(B )A.统计设计B.统计调查C.统计整理D.统计分析6.人口普查的调查单位是( B )A.全部人口B.每个人C.全部人口数D.每户家庭7.对两工厂工人工资做纯随机不重复抽样,调查的工人数一样,两工厂工资方差一样,但第二个工厂工人数多一倍,则抽样平均误差:( B )A.第一个工厂大B.第二个工厂大C.两个工厂一样大D.不能做结论8.必要的样本容量不受下面哪个因素影响( B )。
《概率论与数理统计》期中考试试题汇总,DOC

《概率论与数理统计》期中考试试题(一)一、选择题(本题共6小题,每小题2分,共12分)1.某射手向一目标射击两次,A i 表示事件“第i 次射击命中目标”,i =1,2,B 表示事件“仅第一次射击命中目标”,则B =( )A .A 1A 2B .21A AC .21A AD .21A A2345C 68.将3个球放入5个盒子中,则3个盒子中各有一球的概率为=________.9.从a 个白球和b 个黑球中不放回的任取k 次球,第k 次取的黑球的概率是=.10.设随机变量X ~U (0,5),且21Y X =-,则Y 的概率密度2f Y (y )=________.11.设二维随机变量(X ,Y )的概率密度f (x ,y )=⎩⎨⎧≤≤≤≤,y x ,其他,0,10,101则P {X +Y ≤1}=________. 12.设二维随机变量(,)X Y 的协方差矩阵是40.50.59⎛⎫ ⎪⎝⎭,则相关系数,X Y ρ=________. 13.二维随机变量(X ,Y )(1,3,16,25,0.5)N -,则X ;Z X Y =-+.(-1,31),(2,0),且取这些值的概率依次为61,a ,121,125. 求(1)a =?并写出(X ,Y )的分布律;(2)(X ,Y )关于X ,Y 的边缘分布律;问X ,Y 是否独立;(3){0}P X Y +<;(4)1X Y =的条件分布律;(5)相关系数,X Y ρ18.(8分)设测量距离时产生的随机误差X ~N (0,102)(单位:m),现作三次独立测量,记Y 为三次测量中误差绝对值大于19.6的次数,已知Φ(1.96)=0.975.(1)求每次测量中误差绝对值大于19.6的概率p ;(2)问Y 服从何种分布,并写出其分布律;求E (Y ).1取出的3件中恰有一件次品的概率为( )A .601B .457C .51D .157 2.下列选项不正确的是()A .互为对立的事件一定互斥B .互为独立的事件不一定互斥C .互为独立的随机变量一定是不相关的D .不相关的随机变量一定是独立的3.某种电子元件的使用寿命X (单位:小时)的概率密度为42100,100;()0,100,x p x x x ⎧≥⎪=⎨⎪<⎩任取一只电子元件,则它的使用寿命在150小时以内的概率为( )A .41B .31C .21D .32 4.若随机变量,X Y 不相关,则下列等式中不成立的是.A5A 6A 79.设随机变量X ~E (1),且21Y X =-,则Y 的概率密度f Y (y )=________.10.设随机变量X ~B (4,32),则{}1P X <=___________. 11.已知随机变量X 的分布函数为0,6;6(),66121,6,x x F x x x ≤-⎧⎪+⎪=-<<⎨⎪≥⎪⎩,则X 的概率密度p (x )=______________.12.设二维随机变量(,)X Y 的协方差矩阵是90.60.625⎛⎫⎪⎝⎭,则相关系数,X Y ρ=________. 13.二维随机变量(X ,Y )(2,3,9,16,0.4)N -,则X;Z X Y =-+. 14.随机变量X 的概率密度函数为,0()0,0x X e x f x x -⎧>=⎨≤⎩,Y 的概率密度函数为1,12()3Y y f y ⎧-<<⎪=⎨,,X Y 相互独立,且Z X Y =+的概率密度函数为()z f z = 试求:(1)常数α,β;(2)(X ,Y )关于X ,Y 的边缘分布律;问X ,Y 是6否独立;(3)X 的分布函数F(x);(4){1}P X Y +<;(5)1X Y =的条件分布律;(6)相关系数,X Y ρ18.(8分)设顾客在某银行窗口等待服务的时间X (单位:分钟)具有概率密度()3103x e x p x -⎧>⎪=⎨,;某顾客在窗口等待服务,若超过9分钟,他就离视机,厂方获得利润50万元,但如果因销售不出而积压在仓库里,则每一万台需支付库存费10万元,问29寸彩色电视机的年产量应定为多少台,才能使厂方的平均收益最大?《概率论与数理统计》期中试卷试题(五)一、选择题(共5题,每题2分,共计12分)1.下列选项正确的是()A.互为对立事件一定是互不相容的B.互为独立的事件一定是互不相容的C.互为独立的随机变量一定是不相关的 D.不相关的随机变量不二、填空题:(每小题2分,共18分)7.同时扔4枚均匀硬币,则至多有一枚硬币正面向上的概率为________.8.将3个球放入6个盒子中,则3个盒子中各有一球的概率为=________.89.从a 个白球和b 个黑球中不放回的任取3次球,第3次取的黑球的概率是=.10.公共汽车站每隔5分钟有一辆汽车到站,乘客到站的时刻是任意的,则一个乘客候车时间不超过3分钟的概率为 (1,2,9,16,0)N -;2Z X =-. 率密度函数51,050,0x e x x ->≤的概率密,(,)X Y 相互独立,且X Y +的概率密度函数为(z f 在某区域有一架飞机,雷达以99%的概率探测到并报警。
(完整版)《统计学》期中试卷含答案
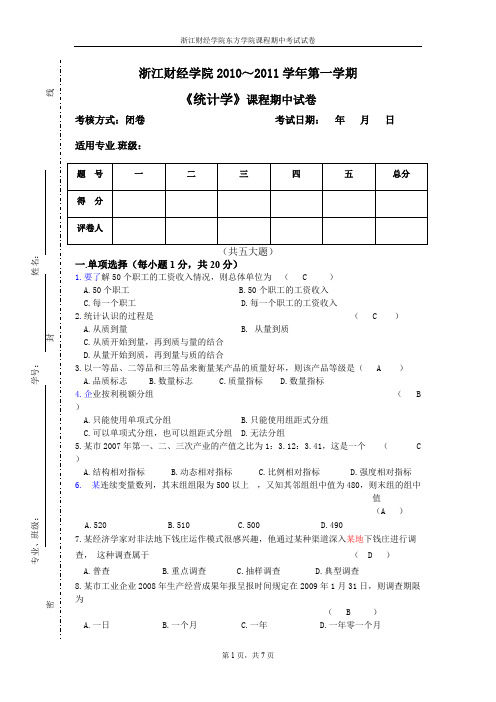
i nt he i rb a re go o浙江财经学院2010~2011学年第一学期《统计学》课程期中试卷考核方式:闭卷 考试日期: 年 月 日适用专业.班级:题 号一二三四五总分得 分评卷人(共五大题)一.单项选择(每小题1分,共20分)1.要了解50个职工的工资收入情况,则总体单位为 ( C )A.50个职工B.50个职工的工资收入C.每一个职工D.每一个职工的工资收入2.统计认识的过程是 ( C )A.从质到量 B. 从量到质 C.从质开始到量,再到质与量的结合 D.从量开始到质,再到量与质的结合3.以一等品、二等品和三等品来衡量某产品的质量好坏,则该产品等级是( A )A.品质标志 B.数量标志 C.质量指标 D.数量指标4.企业按利税额分组 ( B )A.只能使用单项式分组B.只能使用组距式分组C.可以单项式分组,也可以组距式分组D.无法分组5.某市2007年第一、二、三次产业的产值之比为1:3.12:3.41,这是一个 ( C )A.结构相对指标B.动态相对指标C.比例相对指标D.强度相对指标6. 某连续变量数列,其末组组限为500以上 ,又知其邻组组中值为480,则末组的组中值 (A )A.520B.510C.500D.4907.某经济学家对非法地下钱庄运作模式很感兴趣,他通过某种渠道深入某地下钱庄进行调查, 这种调查属于 ( D )A.普查 B.重点调查 C.抽样调查 D.典型调查8.某市工业企业2008年生产经营成果年报呈报时间规定在2009年1月31日,则调查期限为( B )A.一日 B.一个月 C.一年 D.一年零一个月9.某企业A 产品本年计划降低成本5%,实际超额2.11%完成计划,则实际成本比上年( C )A.降低2.75%B.降低3%C.降低7%D.提高2.83%10.简单表和分组表的区别在于 ( A )A.主词是否分组 B.宾词是否分组 C.分组标志的多少 D.分组标志是否重叠11.某组数据呈正态分布,它的算术平均数为100,众数为74,则这组数据的分布呈( B )A.左偏分布B.右偏分布C.对成分布D.无法判断12.分配数列各组标志值和每组次数均增加20%,则加权算术平均数的数值 ( B)A.减少20%B.增加20%C.不变化D.增加40%13.已知某企业产值连续四年的环比增长速度分别为8%、7.5%、8.3%、9%,则该企业产值平均每年增长速度为 ( D )A. 4/%)9%3.8%5.7%8(+++B.1%)109%3.108%5.107%108(-⨯⨯⨯C.1%9%3.8%5.7%84-⨯⨯⨯D.1%109%3.108%5.107%1084-⨯⨯⨯14.某企业生产某种产品,若产量逐期增长量每年相等,则其各年的环比发展速度( A )A.年年下降B.年年增长C.年年保持不变D.无法判断15.下列指标中属于相对指标的是 ( B )A.某商品平均价格 B.某地区按人口平均的粮食产量 C.某企业生产工人劳动生产率 D.某公司职工人均工资16.平均差与标准差的主要区别在于 ( C )A.计算条件不同 B.指标意义不同 C.数学处理方法不同 D.计算结果不同17.已知某企业7月、8月、9月、10月的平均职工人数分别为1200人、1250人、1208人和1230人。
实用统计软件试题及答案

实用统计软件试题及答案# 实用统计软件试题及答案一、选择题1. 在统计分析中,SPSS软件主要用于处理以下哪类数据?A. 图像数据B. 音频数据C. 定量数据D. 文本数据答案:C2. Excel中,以下哪个功能用于创建数据的频率分布表?A. 数据透视表B. 排序C. 筛选D. 条件格式答案:A3. R语言中,以下哪个命令用于安装新的包?A. `library()`B. `install.packages()`C. `require()`D. `source()`答案:B4. 在统计学中,描述数据集中趋势的度量是:A. 方差B. 标准差C. 均值D. 极差答案:C5. 以下哪个统计软件是开源的?A. SPSSB. SASC. RD. Stata答案:C二、判断题1. 在使用Excel进行数据分析时,数据透视表可以用于计算数据的中位数。
(对/错)答案:错2. R语言中,所有的数据集默认都是以列表的形式存储。
(对/错)答案:对3. 统计分析软件中,散点图可以用来展示两个变量之间的相关性。
(对/错)答案:对4. 在SPSS中,可以直接使用鼠标拖拽来完成数据的排序。
(对/错)答案:对5. 所有的统计软件都支持进行假设检验。
(对/错)答案:错三、简答题1. 描述Excel中数据透视表的基本功能。
答案:Excel中的数据透视表是一种强大的数据汇总工具,它允许用户快速地对大量数据进行分组、排序和筛选,以及执行多维度的汇总计算。
用户可以通过数据透视表来计算数据的总和、平均值、最大值、最小值、计数等,并且能够动态地改变汇总的方式和显示的数据分组,从而深入分析数据。
2. 解释R语言中数据框(data frame)的结构特点。
答案:R语言中的数据框是一种二维数据结构,类似于Excel中的表格。
数据框由多列组成,每列可以是不同的数据类型(数值、字符、逻辑等)。
数据框的行通常代表观测值,列代表变量。
数据框中的数据可以通过列名进行访问和操作,这使得数据操作和分析变得非常灵活和高效。
统计中级试题及答案

统计中级试题及答案统计学是应用数学的一个分支,它通过收集、分析、解释和展示数据来帮助我们理解数据背后的模式和趋势。
以下是一套中级统计学的试题及答案,旨在帮助学生巩固和检验他们对统计学概念的理解。
# 统计中级试题一、选择题(每题2分,共20分)1. 以下哪项不是描述性统计的组成部分?A. 均值B. 方差C. 标准差D. 抽样分布2. 一个总体的标准差是10,样本量是100,样本均值是50。
根据中心极限定理,样本均值的分布接近:A. 正态分布B. 二项分布C. 泊松分布D. 几何分布3. 以下哪个选项是衡量数据集中趋势的度量?A. 方差B. 标准差C. 均值D. 极差4. 相关系数的取值范围是:B. 0 到 1C. -∞ 到∞D. 1 到∞5. 一个变量的偏度是-1.5,这表明:A. 变量是对称分布的B. 变量是正偏态分布的C. 变量是负偏态分布的D. 变量是均匀分布的6. 以下哪个选项是统计推断的一部分?A. 计算均值B. 计算方差C. 计算标准差D. 假设检验7. 一个正态分布的总体,均值为100,标准差为15。
如果从中抽取一个样本,样本均值的期望值是多少?A. 85B. 100C. 115D. 无法确定8. 以下哪个选项是统计学中的实验设计?A. 随机抽样B. 配对比较C. 回归分析D. 描述性统计9. 以下哪个选项是用于度量变量之间线性关系的统计方法?B. 相关分析C. 卡方检验D. t检验10. 一个样本的均值为50,标准差为10,样本量为100。
样本均值的95%置信区间的宽度是多少?A. 5B. 10C. 15D. 20二、简答题(每题10分,共30分)1. 解释什么是正态分布,并列出其三个主要特征。
2. 描述什么是假设检验,并解释其基本步骤。
3. 解释什么是置信区间,并说明为什么它在统计推断中很重要。
三、计算题(每题25分,共50分)1. 假设你有一个样本数据集,包含以下年龄(单位:岁):23, 27, 30, 34, 37, 40, 42, 45, 50, 55。
统计学基础期中试卷

《统计学基础》期中试卷一、单项选择题(20分)1、在研究总体中出现频数最多的标志值是( )A.算术平均数B.几何平均数C.众数D.中位数2、下列情况属于连续变量的是( )A.汽车台数B.工人人数C.工厂数D.工业总产值3、要了解某班学生的学习情况,则总体单位是( )A.全班学生B.全班学生的学习成绩C.每个学生D.每个学生的学习成绩4、统计研究的数量必须是()A、抽象的量B、具体的量C、连续不断的量D、可直接相加的量5、统计总体最基本的特征是()A、数量性B、同质性C、综合性D、差异性6、统计总体的同质性是指()A、总体单位各标志值不应有差异B、总体的各项指标都是同类性质的指标C、总体全部单位在所有标志上具有同类性质D、总体全部单位在所有某一个或几个标志上具有同类性质7、一个统计总体()A、只能有一个标志B、只能有一个指标C、可以有多个标志D、可以有多个指标8、总体和总体单位不是固定不变的,由于研究目的不同()A、总体单位有可能变换为总体,总体也有可能变换为总体单位B、总体只能变换为总体单位,总体单位不能变换为总体C、总体单位只能变换为总体,总体不能变换为总体单位D、任何一对总体和总体单位都可以互相变换9、某小组学生数学考试分别为60分、68分、75分和85分。
这四个数字是()A、标志B、指标C、标志值D、变量10、对某企业500名职工的工资状况进行调查,则总体是()A.500名职工 B.每一个职工的工资 C.每一个职工 D.500名职工的工资总额11、对某地区10家生产相同产品的企业的产品进行质量检查,则总体单位是()A.每一个企业 B.每一件产品 C.所有10家企业每一件产品 D.每一个企业产品12、某班学生数学考试成绩分别为65分、71分、80分、87分,这四个数字是()A.指标 B.标志 C.变量 D.标志值13、商业企业的职工数、商品销售额是()A.连续变量 B.离散变量C.前者是连续变量后者是离散变量D.前者是离散变量后者是连续变量14、某厂的劳动生产率,计划比去年提高5%,执行结果提高10%,则劳动生产率的计划完成程度为()A.104.76%B.95.45%C.200%D.4.76%15、当简单算术平均数和加权算术平均数在计算结果上相同,是因为()A.权数不等B.权数相等C.变量值相同D.变量值不同16、总量指标数值大小通常会随着总体范围()A.扩大而增加B.扩大而减少C.缩小而增加D.与总体范围大小无关17、已知4 个水果店苹果的单价和销售额,要求计算4 店的平均单价,应用()A.简单算术平均数B.加权算术平均数C.加权调和平均数D.几何平均数18、反映总体各单位数量特征的标志值汇总得出的指标是()。
统计学期中考试作业参考资料

统计学期中考试作业参考资料统计学期中考试复习参考资料一、判断题(正确的填T,错误的填F)1.统计分组的关键是确定组距和组数。
( )2.假设检验指的是对样本均值、样本成数、样本方差的检验。
( )3.双尾检验的原假设H的陈述表达式用“=”号。
( )4.假设检验中犯第一类错误的概率就是显著性水平α。
()5.抽样极限误差总是大于抽样平均误差。
()6.指标和标志一样,都是由名称和数值两部分组成的。
()7.重点调查和抽样调查都是非全面调查,其调查结果都可以用于推算总体指标。
()8.恩格尔系数属定类数据。
()9.加权算术平均数和加权调和平均数都用变量值所出现的次数作为权数。
()10.所有可能的样本平均数的平均数,等于总体平均数。
()11.单边检验中,由于所提出的原假设的不同,可分为左边检验和右边检验。
()12.样本均值的方差大于总体方差。
( )13.众数<中位数< 平均数是正偏分布。
( )14.对全国粮食生产基本情况进行调查最有效的调查方法是重点调查。
( ) 15.相对指标属定序数据。
( )16.总体参数是唯一确定的常量。
( )17.调查某地区工业企业生产设备的利用情况,该地区的工业企业,既是调查单位,又是报告单位。
()18.各变量值的次数相同时,众数不存在。
()19.平均指标反映总体的离中趋势,标志变异指标反映总体的集中趋势。
()如果总体平均数落在区间[960,1040] 内的概率保证程度为0.9545,则抽样平均误差等于30。
()假设检验中,显著性水平为0.01时原假设被拒绝,则用0.05的显著性水平时原假设一定会被拒绝。
()二、单项选择题1.下列指标中属于数量指标是()A.劳动生产率B.产量C.人口密度D.利润率2.在全国人口普查中,总体单位是()A.每一户B.每个人C.每个地区的人D.全国总人口3.某市调查100个企业的职工工资情况,则调查对象是()A.100个企业B.100个企业的职工C.100个企业职工的工资D.每个企业的职工工资4.如果要定期取得我国国民经济基本统计资料,采用的基本组织方式是()A.重点调查B.抽样调查C.专门调查D.统计报表 5.今有4位工人的月工资分别为:400元、600元、700元、900元,计算4人月平均工资,应采用的计算方法是()A.简单算术平均数 B.加权算术平均数 C.简单调和平均数 D.加权调和平均数6.有两个变量数列,甲数列:100,12.8X σ==甲甲;乙数列:14.5, 3.7X σ==乙乙。
《统计学》期中试卷(15上)

《统计学》期中试卷〔15上〕浙江财经学院课程期中考试试卷浙江财经学院2022~2022学年第二学期密封线《统计学》课程期中试卷考核方式:闭卷考试日期:年月日适用专业、班级:题号得分评卷人一二三四五总分专业、班级:学号:姓名:〔共五大题〕一、单项选择〔每题1分,共20分〕1、以杭州的全部工业企业为总体,那么娃哈哈集团公司的工业增加值是〔〕A、数量标志B、品质标志C、质量指标D、数量指标2、以下属于时点数列的是〔〕 A、某厂各年工业产值 B、某厂各年劳动生产率 C、某厂各年生产工人占全部职工的比重 D、某厂各年年初职工人数3、某市统计局欲对该市职工2022年8月15日至21日一周的时间安排进行调查。
要求此项调查在9月底完成。
那么调查时间是〔〕 A、8月15日 B、8月15日至21日 C、8月底 D、9月底4、分组标志一经选定〔〕A、就掩盖了总体在此标志下的性质差异B、就突出了总体在此标志下的性质差异C、就突出了总体在其他标志下的性质差异D、就使得总体内部的差异消失了 5、某班学生的平均年龄为20.8岁,21岁的人数最多,那么该分布属于〔〕A、正态分布B、左偏分布C、右偏分布D、无法判断6、某工业局所属企业职工的平均工资和职工人数资料,要计算该工业局职工的平均工资,应选择的权数是〔〕 A、职工人数 B、平均工资 C、工资总额 D、职工人数或工资总额7、某企业生产三批产品,第一批产品废品率为1%,第二批产品废品率为1.5%,第三批产品废品率为2%。
第一批产品数量占总数的25%,第二批产品数量占总数的30%,那么平均废品率为〔〕 A、1.5% B、1.75% C、1.6% D、1.55%8、逐日登记资料的时点数列计算序时平均数应采用〔〕 A、几何平均法 B、加权算术平均法 C、简单算术平均法 D、首末折半法 9、以下有关典型调查的表述不正确的选项是〔〕 A、可以检验全面调查数据的真实性 B、能够补充全面调查资料的缺乏 C、必须同其他调查结果结合起来使用 D、不容易受人们主观认识上的影响10、由组距数列确定众数时,如果众数组相邻两组的次数相等,那么〔〕 A、众数为零 B、众数组的组中值就是众数第1页,共5页浙江财经学院课程期中考试试卷C、众数不能确定D、众数组的组限就是众数11、某产品单位本钱方案规定比基期下降3%,实际比基期下降3.5%,那么单位本钱降低方案完成程度为〔〕 A、116.7% B、100.5% C、99.5% D、85.5% 12、以下指标中属于相对指标的是〔〕 A、某商品平均价格 B、某地区按人口平均的粮食产量 C、某企业生产工人劳动生产率 D、某公司职工人均工资13、某公司2022年管理人员年均收入6.5万元,生产人员为5.5万元;2022年各类人员年均收入水平不变,但管理人员增加15%,生产人员增加25%,那么两类人员平均的年收入2022年比2022年〔〕 A、持平 B、提高 C、下降 D、无法判断14、重点调查中重点单位是指〔〕 A、标志总量在总体中有很大比重的单位B、具有典型意义或代表性的单位C、那些具有反映事物属性差异的品质标志的单位D、能用以推算总体标志总量的单位 15、某城市2022年-2022年各年6月30号统计的从业人员数资料如下。
统计期中试卷及答案(中职)【2024版】

可编辑修改精选全文完整版《统计基础知识》期中试卷姓名:__________ 学号:__________ 成绩:__________注意事项:1.本试卷共6道大题,共99分,外加卷面分1分。
2.考试时间为90分钟。
一、单项选择题(2×18=36分)1.统计工作的决定性环节是()A.统计设计B.统计调查C.统计整理 D统计分析2.对某市学校教师情况进行研究,总体是()A.该市全部学校B.每个学校C.该市全部学校的全部教师D.每个学校的全部教师3.属于数量标志的是()A.性别B.年龄C.文化程度D.政治面貌4.属于质量指标的是()A.人口总数B.工业生产总值C.优质品率D.职工总数5.属于离散变量的是()A.工人数B.产值C.工资D.身高6.某实物的重量为20.15g,则该数据为()A.分类数据B.顺序数据C.计量值数据D.计数值数据7.2011年我国各地区的国内生产总值是()A.分类数据B.顺序数据C.截面数据D.时间序列数据8.两组工人加工同样的零件,第一组工人日产量为:32、25、29、28、26;第二组工人日产量为:30、25、22、36、27。
这两组工人日产量的差异程度()A.第一组差异程度大于第二组 B.第一组差异程度小于第二组C.两组差异程度相同D.无法比较9.按调查组织方式不同,可分为()A.全面调查和非全面调查B.统计报表调查和专门调查C. 经常性调查和一次性调查D.重点调查和抽样调查10.2016年农业普查是()A.普查B.重点调查C.抽样调查D.典型调查11.在全市小学生健康状况调查中,全市的每一个小学生都是()A.调查对象B.调查单位C.报告单位D.统计指标12.调查时间是()A.调查工作进行的时间B.调查工作登记的时间C.调查资料的报送时间D.调查资料所属的时间13.为了解居民对小区物业服务的意见和看法,管理人员随机抽取100户居民,上门通过问卷进行调查。
这种数据的收集方法是()A.科学实验法B.直接观察法C.邮寄访问法D.入户访问法14.某村农民人均收入最高为377,最低为248,据此分为八个组,形成闭口式等距数列,则组距应为()A.27B.36C.31D.4215.一个容量为80的样本,最小值为80,最大值为173,组距为10,则可分为()组。
统计学原理_期中考试试卷

08-09统计学原理期中考试试卷班级__________ 学号__________ 姓名__________ 成绩_______一、判断题(每题2分,共20分)1、在全国工业普查中,全国企业数是统计总体,每个工业企业是总体单位。
()2、数量指标是由数量标志汇总来的,质量指标是由品质标志汇总来的。
()3、在统计调查中,调查标志的承担者是调查单位。
()4、我国人口普查的总体单位和调查单位都是同一人,而填报单位是户。
()5、从全部总体单位中按照随机原则抽取部分单位组成样本,只可能组成一个样本。
()6、在一个总体中,算术平均数、众数、中位数可能相等。
()7、对我国主要粮食作物产区进行调查,以掌握全国主要粮食作物生长的基本情况,这种调查是典型调查。
()8、计算结构相对指标时,总体各部分数值与总体数值对比求得的比重之和一定为100%。
()9、标志变异指标数值越大,说明总体中各单位标志值的变异程度就越大,则平均指标的代表性就越小。
()10、相对指标可以反映总体规模的大小。
()二、单项选择题(每题2分,共12分)1、某班学生的平均年龄为22岁,这里的22岁为( )。
A.指标值B.标志值C.变量值D.数量标志值2、统计分组的关键是( )。
A.确定组数和组距B.抓住事物本质C.选择分组标志和划分各组界限D.统计表的形式设计3、构成总体的个别事物称为()。
A.调查总体 B.标志值C.品质标志 D.总体单位4、某地区农民家庭年人均纯收入最高为2600 元,最低为1000 元,据此分为八组形成闭口式等距数列,各组的组距为()。
A.300 B.200C.1600 D.1005、下列指标中属于结构相对数的指标是()。
A.计划完成程度B.劳动生产率C.人口密度D.食品消费支出占全部消费支出的比重6、权数对算术平均数的影响作用,实质上取决于()。
A、作为权数的各组单位数占总体单位数比重的大小B、各组标志值占总体标志总量比重的大小C、标志值本身的大小D、标志值数量的多少三、多项选择题(每题2分,共8分)1、抽样调查()A.是一种非全面调查B.其目的是根据抽样结果推断总体数量特征C.它具有经济性、时效性、准确性和灵活性等特点D.其调查单位是随机抽取的E.抽样推断的结果往往缺乏可靠性2、要了解某地区全部成年人口的就业情况,那么()。
统计学期中试卷
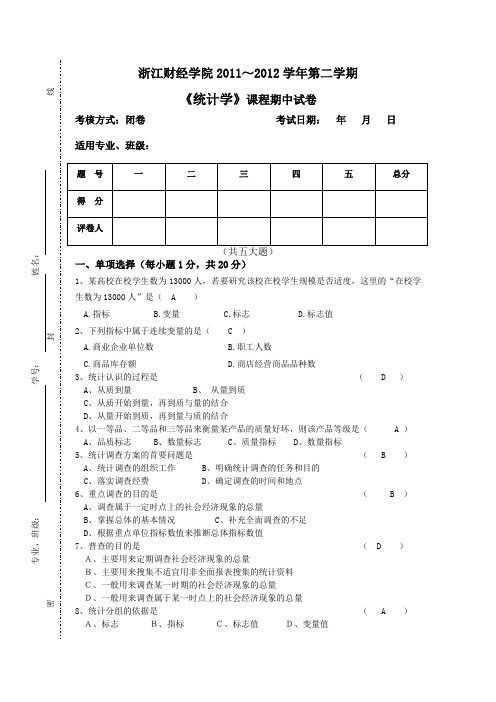
《统计学》课程期中试卷考核方式:闭卷考试日期:年月日适用专业、班级:一、单项选择(每小题1分,共20分)1、某高校在校学生数为13000人,若要研究该校在校学生规模是否适度,这里的“在校学生数为13000人”是( A )A.指标B.变量C.标志D.标志值2、下列指标中属于连续变量的是( C )A.商业企业单位数B.职工人数C.商品库存额D.商店经营商品品种数3、统计认识的过程是( D )A、从质到量B、从量到质C、从质开始到量,再到质与量的结合D、从量开始到质,再到量与质的结合4、以一等品、二等品和三等品来衡量某产品的质量好坏,则该产品等级是( A )A、品质标志B、数量标志C、质量指标D、数量指标5、统计调查方案的首要问题是( B )A、统计调查的组织工作B、明确统计调查的任务和目的C、落实调查经费D、确定调查的时间和地点6、重点调查的目的是( B )A、调查属于一定时点上的社会经济现象的总量B、掌握总体的基本情况C、补充全面调查的不足D、根据重点单位指标数值来推断总体指标数值7、普查的目的是( D )A、主要用来定期调查社会经济现象的总量B、主要用来搜集不适宜用非全面报表搜集的统计资料C、一般用来调查某一时期的社会经济现象的总量D、一般用来调查属于某一时点上的社会经济现象的总量8、统计分组的依据是( A )A、标志B、指标C、标志值D、变量值9、统计分组的关键在于 ( D ) A 、正确选择分布数列种类 B 、正确确定各组组限和组中值 C 、正确确定组数和组距 D 、正确选择分组标志10、简单表和分组表的区别在于 ( A ) A 、主词是否分组 B 、宾词是否分组 C 、分组标志的多少 D 、分组标志是否重叠11、某组距式分组,其起始组是开口组,上限为100,又知相邻组的组距为50,则起始组的组距可以视为( A ).75 C12、不受极端数值影响的是 ( D ) A 、算术平均数 B 、调和平均数 C 、几何平均数 D 、众数13、某企业A 产品本年计划降低成本5%,实际超额%完成计划,则实际成本比上年( C )A 、降低%B 、降低3%C 、降低7%D 、提高% 14、在加权算术平均数公式中,若各个变量值都扩大2倍,而频数都减少为原来的三分之一,则平均数 ( B ) A 、不变 B 、扩大2倍 C 、扩大3倍 D 、减少3倍15、下列指标中属于相对指标的是 ( B ) A 、某商品平均价格 B 、某地区按人口平均的粮食产量 C 、某企业生产工人劳动生产率 D 、某公司职工人均工资16、平均差与标准差的主要区别在于 ( C ) A 、计算条件不同 B 、指标意义不同 C 、数学处理方法不同 D 、计算结果不同17、累计增长量是 ( A ) A 、本期水平减固定基期水平 B 、本期水平减前期水平C 、本期逐期增长量减前期增长量D 、本期逐期增长量加前期逐期增长量 18、已知各期环比增长速度分别为%、%、%和%,则定基增长速度( D )A 、7.1% 3.4% 3.6% 5.3%⨯⨯⨯B 、(7.1% 3.4% 3.6% 5.3%)1⨯⨯⨯-C 、107.1%103.4%103.6%105.3%⨯⨯⨯D 、(107.1%103.4%103.6%105.3%)1⨯⨯⨯-19、如果动态数列指标数值的二级增长量大体相同,可拟合 ( B ) A 、直线 B 、抛物线 C 、指数曲线 D 、双曲线20、某企业2011年第二季度A 商品销售额为150万元,根据前三年分季资料测算,二、三季度的季节指数分别为%和%,则第三季度的A 商品销售额的预测值为( D )A 、万元B 、万元C 、万元D 、万元二、多项选择(每小题2分,共20分)1、要了解某地区的就业情况 ( ABDE ) A 、全部成年人是研究总体 B 、成年人口总数是统计指标C 、成年人口的就业率是数量标志D 、反映每个人特征的职业是品质标志E 、某人职业是律师为标志表现2、下列标志中,属于数量标志的有( BC )A、性别B、出勤人数C、产品产量D、八级工资制E、文化程度3、一时调查可以有( BCDE )A、定期统计报表B、普查C、重点调查D、典型调查E、抽样调查4、普查属于( ACE )A、专门组织的调查B、非全面调查C、全面调查D、经常调查E、一时调查5、变量数列中( CDE )A、各组频率大于0B、各组频率大于1C、各组频率之和等于1D、总次数一定时频数与频率成正比E、频数越大该组标志值起的作用越大6、下列属于强度相对指标的有( ABD )A、全员劳动生产率B、人均拥有的绿化面积C、学生到课率D、人口自然增长率E、男女性别比7、与变量计量单位相同的标志变异指标有( ABC )A、全距B、平均差C、标准差D、平均差系数E、标准差系数8、比较两个单位的资料时发现,甲的标准差大于乙的标准差,甲的平均数小于乙的平均数,由此可推断( ADE )A、乙单位的平均数代表性大于甲单位B、甲单位的平均数代表性大于乙单位C、甲单位的工作均衡性好于乙单位D、乙单位的工作均衡性好于甲单位E、甲单位的标准差系数比乙单位大9、下列平均指标,属于序时平均数的有( ACE )A、第一季度职工平均月工资B、企业产品单位成本C、“十五”期间GDP年平均增长率D、某企业某年第四季度人均产值E、“十五”期间某企业产值年平均增长量10、相对数动态数列可以是(ABC )A、两个时期数列之比B、两个时点数列之比C、一个时期数列和一个时点数列之比D、两个单项数列之比E、两个组距数列之比三、判断(每小题1分,共10分)1、统计总体具有大量性、同质性和差异性三个基本特征。
统计软件模拟试题及答案

统计软件模拟试题及答案一、单项选择题(每题2分,共10分)1. SPSS中用于描述性统计分析的命令是:A. DESCRIPTIVESB. FREQUENCIESC. DESCRIPTIVED. DESCRIPT答案:A2. 在R语言中,用于创建数据框的函数是:A. data.frame()B. dataframe()C. data.frameD. dataframe答案:A3. Excel中,用于计算一组数据平均值的函数是:A. AVERAGEB. MEANC. AVGD. MEDIAN答案:A4. SAS中,用于输出结果的命令是:A. PRINTB. PROC PRINTC. OUTPUTD. LIST答案:B5. 在Stata中,用于进行线性回归分析的命令是:A. REGB. LINEARC. REGRESSIOND. REGRESS答案:D二、多项选择题(每题3分,共15分)1. 下列哪些软件属于统计分析软件?A. SPSSB. ExcelC. SASD. R答案:ABCD2. 在R语言中,下列哪些函数用于数据导入?A. read.csv()B. read.table()C. readRDS()D. read.xlsx()答案:ABCD3. Excel中,下列哪些函数用于数据排序?A. SORTB. RANKC. SMALLD. LARGE答案:ABC4. SAS中,下列哪些命令用于数据清洗?A. PROC MEANSB. PROC CONTENTSC. PROC FREQD. PROC SQL答案:BCD5. Stata中,下列哪些命令用于数据转换?A. reshapeB. generateC. replaceD. merge答案:ABC三、判断题(每题2分,共10分)1. 在SPSS中,可以通过“Transform”菜单进行数据转换。
(对)2. R语言中,向量的长度必须是固定的。
(错)3. Excel中,可以通过“数据”菜单进行数据透视表的创建。
统计试题及答案doc

统计试题及答案doc一、单项选择题(每题2分,共20分)1. 以下哪个选项是描述统计数据集中趋势的度量?A. 方差B. 标准差C. 平均数D. 极差答案:C2. 在统计学中,标准差是衡量数据集的:A. 中心趋势B. 离散程度C. 偏态分布D. 峰态分布答案:B3. 以下哪个选项不是描述统计学中的分布类型?A. 正态分布B. 二项分布C. 泊松分布D. 线性分布答案:D4. 相关系数的取值范围是:A. -1到1B. 0到1C. 1到10D. -10到10答案:A5. 以下哪个选项是描述统计数据离散程度的度量?A. 均值B. 方差C. 众数D. 极差答案:B6. 统计学中的置信区间是用来:A. 预测未来事件B. 估计总体参数C. 描述样本数据D. 进行假设检验答案:B7. 以下哪个选项是描述统计数据偏态的度量?A. 均值B. 方差C. 偏度D. 峰度答案:C8. 假设检验中,零假设通常表示:A. 研究假设成立B. 研究假设不成立C. 研究假设是正确的D. 研究假设是错误的答案:B9. 以下哪个选项是描述统计数据峰态的度量?A. 均值B. 方差C. 偏度D. 峰度答案:D10. 统计学中,数据的收集方法不包括:A. 观察法B. 实验法C. 调查法D. 推理法答案:D二、多项选择题(每题3分,共15分)1. 以下哪些是描述统计学中的分布类型?A. 正态分布B. 二项分布C. 泊松分布D. 线性分布答案:ABC2. 以下哪些是描述统计数据集中趋势的度量?A. 平均数B. 方差C. 众数D. 中位数答案:ACD3. 以下哪些是描述统计数据离散程度的度量?A. 均值B. 方差C. 标准差D. 极差答案:BCD4. 以下哪些是描述统计数据偏态的度量?A. 均值B. 偏度C. 方差D. 峰度答案:B5. 以下哪些是描述统计数据峰态的度量?A. 均值B. 峰度C. 方差D. 偏度答案:B三、简答题(每题5分,共10分)1. 请简述什么是正态分布,并说明其特点。
实用统计软件试题及答案

实用统计软件试题及答案一、单项选择题(每题2分,共40分)1. SPSS软件中,用于描述数据集中趋势的统计量是()。
A. 平均值B. 方差C. 标准差D. 众数答案:A2. 在R语言中,用于创建向量的函数是()。
A. vector()B. list()C. matrix()D. array()答案:A3. Excel中,计算一组数据的标准差的函数是()。
A. AVERAGEB. STDEV.PC. STDEV.SD. MEDIAN答案:B4. 在统计学中,用于衡量数据离散程度的指标是()。
A. 均值B. 方差C. 标准差D. 众数答案:C5. MATLAB中,用于生成随机数的函数是()。
A. rand()B. randn()C. randi()D. all of the above答案:D6. Python中,用于计算相关系数的函数是()。
A. corr()B. cov()C. mean()D. median()答案:A7. 在统计分析中,用于检验两个独立样本均值差异显著性的统计方法是()。
A. t检验B. 方差分析C. 卡方检验D. 回归分析答案:A8. SAS中,用于数据清洗的步骤是()。
A. PROC CONTENTSB. PROC FREQC. PROC MEANSD. PROC STANDARD答案:A9. 在统计软件中,用于创建数据框的函数是()。
A. data.frame()B. matrix()C. list()D. array()答案:A10. 用于绘制箱线图的R语言函数是()。
A. boxplot()B. hist()C. plot()D. barplot()答案:A二、多项选择题(每题3分,共30分)1. 下列哪些软件属于统计分析软件?()A. SPSSB. ExcelC. MATLABD. Photoshop答案:ABC2. R语言中,用于数据可视化的函数包括()。
A. plot()B. hist()C. boxplot()D. barplot()答案:ABCD3. Excel中,可以用于描述数据分布的函数有()。
中级统计考试试题

中级统计考试试题一、选择题(每题2分,共20分)1. 下列哪项不是描述性统计的主要功能?A. 数据分类B. 数据描述C. 数据推断D. 数据展示2. 总体均值用哪个希腊字母表示?A. αB. βC. μD. σ3. 在统计学中,一个数据集中的中位数是指:A. 数据集中数值最小的数B. 数据集中数值最大的数C. 将数据集分为两个相等部分的数值D. 数据集中出现次数最多的数值4. 标准差和方差之间的关系是:A. 标准差是方差的平方B. 方差是标准差的平方C. 标准差和方差相等D. 标准差和方差无关5. 下列哪项不是概率分布的类型?A. 离散型分布B. 连续型分布C. 二项分布D. 正态分布6. 抽样分布是什么的分布?A. 总体中所有个体的分布B. 样本均值的分布C. 样本中某一个体的分布D. 总体中某一个体的分布7. 相关系数的取值范围是:A. -1 到 1B. 0 到 1C. -∞ 到+∞D. 1 到+∞8. 在回归分析中,哪个统计量用于衡量自变量对因变量的解释程度?A. R²B. t 统计量C. F 统计量D. p 值9. 一个统计量的值越小,表示其抽样分布越集中,这个统计量是:A. 方差B. 标准差C. 变异系数D. 均值10. 下列哪项是统计学中的基本概念?A. 置信区间B. 假设检验C. 标准误差D. 所有选项都是二、简答题(每题5分,共30分)11. 解释什么是“中心极限定理”并说明其在实际应用中的重要性。
12. 描述一下“抽样误差”是什么,并给出一个可能影响抽样误差大小的因素。
13. 解释“参数估计”和“置信区间”的概念,并说明它们之间的关系。
14. 什么是“假设检验”?请列出进行假设检验的基本步骤。
15. 说明“相关性”和“因果关系”之间的区别,并给出一个可能混淆这两者的例子。
16. 什么是“回归分析”?在什么情况下使用线性回归分析?三、计算题(每题10分,共40分)17. 给定一组数据:3, 5, 7, 9, 11, 13, 15, 17, 19, 21。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
4南京师范大学2013-2014 学年第一学期数科院统计学专业11 年级《统计软件》课程期中试卷班级:任课教师:高启兵学号:姓名:要求:第 1-10 要写出程序,第11-16 题要给出较为完整统计问题解答和程序。
数据:假设我们随机抽取某班18 名同学的部分信息,如下所示,为纯文本格式score1.txt ,含义分别为姓名 name、性别 gender 、语文成绩 chin 、数学成绩 math。
Zhangyu m 89 88xuzhi m 87 86lixiao f 88 89xiaohan f 90 89minghui f 93 91huizheng m 84 86guolei m 99 95yuqiang m 90 91mazheng m 93 96yuanhua f 79 80xiuqiang f 87 85daolu m 82 83wanger m 84 86sungao m 83 82zhangqi f 94 91shifang f 86 89xingming f 87 85weiwei f 85 871.将该文本文件转换成 d:\sdata 下永久 SAS数据集 score1 ,并写出查看相应库的属性程序。
(4 分)Libname sdata‘ d:\sdata’;Data sdata.score1;Infile ‘d:\score1.txt’;Input name$ gender$ chin math;Proc print data= sdata.score1;Run;Proc datasets lib=sdata;Run;2.试将数据放在数据步中并用逗号分隔然后读入到临时数据集score1 。
(4 分 ) Data score1;Infile datalines dlm=”,”;Input name$ gender$ chin math;Datalines;Run;Proc print data=score1;Run;3.建立 excel 文件 score1.xls, 然后用 import 过程将该 excel 文件转换成临时SAS数据集 score1; 查看该数据集 score1 的属性并将变量名分别改为 name, gender chin 和 math 。
(4 分)Proc importDatafile=”d:\score.xls”Out=score1Dbms=excel2000 replace;GETNAMES=YES;DATAROW=2;RANGE(sheet)="Sheet1$";Run;Proc contents data=score1;Run;Data score1 (rename=(zhangy=name m=gender F3=chin F4=math));Set score1;Run;PROC IMPORT OUT= WORK.aaDATATABLE= "username"DBMS=ACCESS REPLACE;DATABASE="D:\info.mdb";RUN;例/* 链接 DataBaseName数据库*/ libname DataBaseName oracleuser=MyUserNamepassword=MyPassWordpath='orcl'schema=DataBaseName;4.上题中的的数据文件 score1.xls 建立数据视图。
(4 分)也可以用 sqlProc access dbms=xls;Create work.score1.access;Path=’d:\score1.xls’;Create work.score1.view;Select all;List view;Run;Proc sql;Select *from ;例 ACCESS过程将数据视窗转换为数据集。
PROC ACCESS VIEWDESC=s000001 OUT=stk000001;Run;5.从score1数据集中将男生(m)信息资料取出建立数据集male; 取出女生信息资料建立数据集female 。
(4 分)Data male female;Set score1;Select(gender);When(‘m’ ) output male;When(‘female ’) output female;End;run;6.请分别从数据集 score1 中将数学成绩变量去除,建立语文成绩数据集 chin ,保留数学成绩变量建立数据集 math 并将数据集 chin 保存为数据间用逗号分隔的文本文件。
(4 分)Data chin(drop=math);Set score1;run;Print data;run;Data math(drop=chin);Set score1;run;Print data;run;proc import out=t1;datafiles= ””;dbms=csv replace;sheet= ”” ;getnames=yes;datarow=2;run;Proc export data=chinOutfile=chinDbms=csv Replace;Run;7.由数据集 score1 产生总成绩 ( 语文和数学之和 ) , 并根据总成绩由高到低排序,结果放在数据集 socre2 中。
(4 分)Data t;Set score1;Sum=sum(chin,math);Run;Proc sort data=t out=score2;By descending sum;Run;Proc print data=score2;Run;8. 请将总成绩≧ 180 者定义为成绩评价(变量 eval )为 A, 总成绩≦ 150 者定义为成绩评价( eval )为 C,二者之间者定义为 B,结果放在数据集 score3 中。
(4 分)Data score3;Set score2;If sum>=189 then eval=’A’;Esle if sum<=150 then eval=’C’;Else eval= ’B’;Run;Proc print data score3;Run;9.假设还有这 18 名同学的英语成绩表数据 , 数据集名为 score4, 结构与 socre1 相同。
请将 score1 和 score4 合并起来构成这 18 名学生姓名 , 性别及语数外的成绩信息数据集 score5 。
( 用两种方法 , 并要求其中一种方法产生的数据集 score5 中含变量表示相应记录来自哪个数据集和重复观测的首条记录和末条记录 ) (8分)1\ proc sort data=score4;by name;run;Data score5;Merge score1(in=a) score4(in=bi);By name;Ina=a; inb=bi;If then first=1;If then last=1;Run;2\proc sql ;Select ,score1.gender,chin,math,english From score1,score4Where=&score1.gender=score4.gender Quit;10.假设还有另外 18 名同学的信息 , 数据集名为 score6, 格式与 score5 相同 , 请将 score5 和 score6 连接起来构成数据集 score7 。
( 用两种方法 ) (6 分) Data score7;Set score5 score6;Run;Proc print data=score7;Run;Proc sql;Create table score7 asSelect *From score5Select *From score6;Quit;11-16 先要有假设,检验,估计,分析!11.请分析 score1 数据集中 18 名学生的语文和数学成绩有无相关关系。
(4 分) CorrProc corr data =score1 var spearman pearson;Var chin math;Run;12.试问数据集 score1 中 18 同学的语文平均成绩同88 分有无显著性差异。
(10 分)UnivaribleMeans(均值为 0)Data tem ;Set score1 ;Chinew=chin-88 ;Proc means data=tem mean stderr t probt;Var chinew ;Run;proc univariate data =scorel1mu0= 88 alpha=0.05;var chin;run ;13.请分析 score1 中数学与语文成绩有无差异? (10 分)Proc ttest data=score1;Var math chi;Run;转化数据!可以先对应相减;或者 anova重新建立数据集,自行加一列分类变量14.请分析 score1 数据集中 18 名学生的语文和数学成绩进行回归分析(给出参数估计和检验的 p 值,并指出它们之间是否有线性回归关系)。
(10 分)RegProc reg data=score;Model chi=math;Run;15.若得到 36 名学生的成绩等级 A、 B、 C 如下表所示,问性别与等级间是否相关? (10 分 )性别 A B C 合计男8 7 3 18女 5 8 5 18 Freqdatadata temp;do i= 1 to 2;do j= 1 to 3;input x @@;output ;end ;end ;cards ;8 7 35 8 5;run ;proc freq data =temp ;table i*j/ chisq ;weight x;run ;16. 某人研究北京机关工作人员血脂水平,随机抽取不同年龄男性各10 名受试者,检测他们的总胆固醇(TC)的含量 (mmol/L) ,其结果如下:青年组 5.00 4.85 4.93 5.18 4.95 4.78 5.18 4.89 5.07 5.21 中年组5.12 5.13 4.89 5.20 4.99 5.14 5.16 4.98 5.16 5.25 老年组5.24 5.26 5.23 5.10 5.31 5.23 5.21 4.98 5.15 5.19请问:三个年龄组的总胆固醇平均含量之间的差别是否具有统计学意义?(10 分)Anovadata TC;do i= 1 to 3;do j= 1 to 10 ;input x@@;output ;end ;end ;datalines ;5.00 4.85 4.93 5.18 4.95 4.78 5.18 4.89 5.07 5.215.12 5.13 4.89 5.20 4.99 5.14 5.16 4.98 5.16 5.255.24 5.26 5.23 5.10 5.31 5.23 5.21 4.98 5.15 5.19;run ;proc print data =TC;run ;proc anova data =TC;class i;model x=i;run ;。