2019年最新-数据挖掘章概念描述特征化与比较-精选文档
数据挖掘基本概念解说

效的、新颖的、潜在有用的,以及最终可理解的模式的非平凡过程。
知识发现就是从数据源中抽取感兴趣的数据,并把这些数据组织成符合挖掘
的组织形式,然后利用相应的算法、模型生成想要的知识模式,最后对生成
的知识模式进行评估,并把有价值的知识集成到应用系统当中。
常用KDD过程模型 (KDD process model)
式为直接电邮,考虑到多数用户可能不会对理财产品感兴趣,所以 销售目标为用户群中对产品兴趣度最高的前20%
数据表
有效字段
客户表
姓名、职业、性别、生日、收入
日期对照表
日期的各种转化形式
账号信息表
账号类型,月费、透支额度等
交易信息表
交易类型、交易日期、交易金额
1
19
三、数据挖掘案例
流程
数据评
价
数据预处
理
1995年底美国计算机年会。 开始把数据挖掘认为是KDD过
程中对数据真正应用算法抽取 知识的一个基本步骤。
1995年第一届知识发现和 数据挖掘国际学术会议。首次 提出数据挖掘的概念。
如今各种各样的 数据挖掘软件和算法。
1
6
一、数据挖掘的基本概念
4.数据挖掘基本流程
Data
跨 行 业
Business Understanding
度为C=3/5=0.6,假如设计支持度最小为0.5,置信度为0.6,那么网球
拍和网球的关联关系就是有意义的一对关联关系。
1
16
二、数据挖掘方法分类
5.关联规则(Affinity grouping or association rules)
1
17
三、数据挖掘案例
1
18
数据挖掘 第二章 认识数据总结

第二章认识数据数据的统计描述概念:数据对象,属性类型,属性(维,特征,变量,标称<分类,枚举,二元/序数>/数值<区间标度/比率标度>,定性/定量,连续/离散)。
数据对称性和中心趋势度量:(1)均值(Mean):x算术均值,xi是观测值/样本,数值型;受极端值,倾斜数据影响(2)加权均值:x加权算术均值,权值wi描述对应观测值的意义,重要性或出现频率等;优劣同上。
截尾均值:丢弃高低极端值后的均值(3)中位数(Median):应用于数值数据,把所有数值数据排序,位于有序队伍正中的数据;计算时间复杂度高于算术均值,不受极端值影响;(4)众数(Mode):多个众数,单峰/多峰,每个数据出现一次,则没有众数;不受极端值影响,计算简单,多用于非数值型数据,可靠性差;(5)中列数(Midrange):最大和最小值的均值;易受极端值影响,计算简单,应用于数值型数据数据对称性:算术均值和众数之差用来度量偏态(正负),偏态skewness = Mean − Mode数据散布度量:(1)第k个q分位数:把排好序的样本,均分为q等分,子集的边界可能就是分位数;在有序样本中的下标计算:⌈Nkq⌉,取上整,k = 1, 2,..., q-1。
单个值描述分布;中位数,四分位数,百分位数常使用,Q3-Q1四分位数极差(IRQ,用于判定盒图的离群点);(2)五数概括:最小值,Q1,Q2,Q3,最大值;用均匀分布的5个点来描述分布,不是单个值;用于描述倾斜数据的分布;(3)盒图:盒的上下边界是Q3,Q1,中位数是盒内线,盒外胡须可延伸到;可以看成是直观地表示了五数概括;计算时间O(nlogn);(4)方差:(5)标准差:当均值作为中心趋势度量时,适用。
大部分观测样本,其偏离中心不会超过很多倍标准差;统计描述的图形显示:(1)分位数图:用来观察单变量数据分布,数据值低于或等于在一个单变量分布中独立的变量的粗略百分比。
数据挖掘概念与技术

数据挖掘概念与技术数据挖掘概念与技术一. 什么是数据挖掘,数据挖掘的知识体系及应用范围1. 定义:又称数据中的知识发现,从大量的数据中挖掘有趣模式和知识的过程。
知识发现的过程:1). 数据清理:除噪声和删除不一致数据2). 数据集成:多种数据源的组合3). 数据选择:取和分析与任务相关的数据4). 数据变换:数据变换和统一成适合挖掘的形式5). 数据挖掘:使用智能方法提取数据格式6). 模式评估:识别代表知识的有趣模式7). 知识表示:使用可视化和知识表示技术,向用户提供挖掘的知识2. 为什么要进行数据挖掘未来将是大数据时代,IDC(国际数据公司)研究报告指出2012年全球信息资料量为2.8ZB (2的40次方GB),而在2020年预计会达到40ZB,平均每人拥有5247GB的数据。
庞大的数据量背后隐藏着巨大的潜在价值,人们手握巨量的数据却没有很好的手段去充分挖掘其中的价值,因此对数据挖掘的研究可以帮助我们将数据转化成知识。
3. 数据挖掘的知识体系数据库的用户为数据库专业人员、处理日常操作,而数据仓库为主管和分析人员,为决策提供支持。
3). 数据仓库体系架构:底层数据,中间层OLAP服务器,顶层前端工具4). 数据仓库模型:企业仓库:提供企业范围内的数据集成,企业范围的数据集市:包含企业范围数据的一个子集,对特定的用户群,咸鱼选定的主题,部门范围的。
虚拟仓库:操作数据库上视图的集合2. 数据仓库建模数据立方体:允许以多维数据建模和观察,由维(属性)和事实(数值)定义方体:给定诸维的每个可能的自己产生一个方体,结果形成方体的格,方体的格称作数据立方体。
多维模型:星形模式:包括一个大的中心表(事实表)、一组小的附属表(维表),维表围绕中心表雪花模式:是星形的表变种,某些维表被规范化费解到附加的表中,用于数据集市事实星座:多个事实表分享维表,用于复杂的应用,常用于企业数据仓库3. 典型OLAP操作:上卷:沿一个维的概念分层向上攀升或通过维规约进行聚集,如由city上卷到country下钻:沿维的概念分层向下或引入附加的维来实现,如由季度数据到更详细的月数据切片:在立方体的一个维上进行选择,定义一个子立方体,如选择季度一的数据切块:在立方体的两个或多个维上进行选择,定义子立方体,如选择季度为一和商品类型为计算机的数据转轴:转动数据视角,或将3D立方变换成2D 平面序列物化:完全物化(完全立方体):计算定义数据立方体的格中所有的方体,需要过多存储空间,导致维灾难部分物化:选择性计算子立方体冰山立方体:一个数据立方体,只存放其聚集值大于某个最小支持度阈值的立方体单元。
数据挖掘的基本概念与方法

数据挖掘的基本概念与方法数据挖掘是一种从大量数据中发现模式、提取知识的过程。
随着信息技术的飞速发展,各行各业都积累了海量的数据资源,但如何从中发现有用的信息成为了一项重要任务。
数据挖掘通过运用统计学、机器学习和数据库技术等手段,帮助人们从数据中挖掘出有用的信息并为决策提供参考。
数据挖掘的基本概念1. 数据源:数据挖掘的第一步是确定数据源。
数据可以来自于各种渠道,如企业的数据库、互联网上的数据、传感器采集的数据等。
2. 数据清洗:数据清洗是为了提高数据质量,包括删除重复数据、处理缺失值、处理异常值等。
清洗后的数据更有利于挖掘有用的信息。
3. 特征选择:在数据挖掘过程中,特征选择是非常重要的一步。
通过选择和提取与挖掘目标相关的特征,可以减少维度灾难,提高模型的准确性和效率。
4. 模型构建:在选择好特征后,需要构建合适的模型来完成挖掘任务。
常用的模型有分类模型、聚类模型、关联规则模型等。
5. 模型评估:模型评估是检验模型质量的重要步骤,可以通过交叉验证、混淆矩阵等方法进行评估。
评估结果可以帮助我们进一步优化模型。
数据挖掘的基本方法1. 关联规则挖掘:通过挖掘数据中的项集之间的关联关系,找到频繁项集和关联规则。
例如,在超市购物数据中,可以发现“尿布”和“啤酒”之间存在关联,进而为超市的陈设和促销策略提供一定的依据。
2. 分类:通过训练分类器,将新的数据样本分到已知类别中。
分类可以应用于很多领域,如医学诊断、垃圾邮件过滤等。
3. 聚类:聚类是将数据划分成若干互不重叠的类别,类别内的数据相似度较高,类别间的数据相似度较低。
聚类可以用于市场细分、推荐系统等。
4. 预测:基于现有的数据模型,对未知数据进行预测。
预测可以帮助机构制定未来发展策略,如金融行业的违约预测等。
5. 异常检测:通过对数据进行异常值的判断和识别,找出潜在的异常行为。
异常检测可以应用于网络安全、诈骗检测等。
总结:数据挖掘作为一项重要的技术手段,已经广泛应用于各行各业。
数据挖掘技术手册

数据挖掘技术手册数据挖掘技术是在大规模数据集中寻找、挖掘出有价值信息的过程。
它应用于各个领域,如商业、科学、医疗等,为决策制定提供了有效的支持。
本手册将介绍有关数据挖掘的基本概念、常用算法和实践技巧。
一、数据挖掘概述数据挖掘是一项复杂的技术,它结合了多个学科领域,如数据库管理、统计学和机器学习等。
其主要目标是通过分析大规模数据集,发现隐藏在其中的模式和关联规则。
数据挖掘不仅仅是简单地提取数据,还需要对数据进行预处理、选择合适的算法和模型,并对结果进行解释和验证。
二、数据挖掘过程1. 数据理解:对数据进行初步的探索和分析,了解数据的结构、特征和问题。
2. 数据清洗:对数据进行清洗和去噪,消除缺失值和异常值。
3. 特征选择:选择对分析任务有用的特征,减少计算复杂度。
4. 模型选择:选择适合问题的数据挖掘模型,如分类、聚类、关联规则等。
5. 模型构建:根据所选的数据挖掘模型,构建相应的算法和模型。
6. 模型评估:评估模型的性能和准确度,进行模型的调整和优化。
7. 模型应用:将模型应用于实际问题中,获得有用的信息和结果。
三、常用的数据挖掘算法1. 分类算法:用于将数据集中的样本分为不同的类别,如决策树、支持向量机等。
2. 聚类算法:将数据集中的样本分为多个组,使同一组内的样本相似度更高,组间的差异较大,如K-means、DBSCAN等。
3. 关联规则算法:通过挖掘数据集中项之间的关联规则,发现事物之间的联系和依赖关系,如Apriori算法。
4. 预测算法:利用历史数据建立模型,预测未来的趋势和结果,如线性回归、时间序列分析等。
四、数据挖掘的实践技巧1. 数据采集:选择合适的数据源,进行数据爬取和收集,保证数据的质量和完整性。
2. 特征工程:对原始数据进行预处理和特征抽取,选择合适的特征表示方式。
3. 参数调优:对选定的数据挖掘模型进行参数调优,使其在特定任务中表现更好。
4. 模型解释:对模型的结果进行解释和验证,确保结果的可靠性和可解释性。
数据挖掘功能及各自方法总结

数据挖掘功能的特点及主要挖掘方法一、数据挖掘功能的特点及主要挖掘方法数据挖掘的目标是从数据库中发现隐含的、有意义的知识,主要有以下几类功能:(1)概念描述概念描述又称数据总结,其目的是对数据进行浓缩,给出它的综合描述,或者将它与其它对象进行对比。
通过对数据的总结,可以实现对数据的总体把握。
最简单的概念描述就是利用统计学中的传统方法,计算出数据库中各个数据项的总和、均值、方差等,或者利用OLAP(0n Line Processing,联机分析处理技术)实现数据的多维查询和计算,或者绘制直方图、折线图等统计图形。
(2)关联分析关联分析就是从大量数据中发现项集之间有趣的关联或相关联系。
随着大量数据不停地收集和存储,许多业界人士对于从他们的数据库中挖掘关联规则越来越感兴趣。
从大量商务事务记录中发现有趣的关联关系,可以帮助许多商务决策的制定。
关联分析的主要方法有Apriori算法、AprioriTid算法、FP-growth算法等。
(3)分类和预测分类和预测是两种数据分析形式,可以用于提取描述重要数据类的模型或预测数据未来的趋势。
就是研究已分类资料的特征,分析对象属性,据此建立一个分类函数或分类模型,然后运用该模型计算总结出的数据特征,将其他未经分类或新的数据分派到不同的组中。
计算结果通常简化为几个离散值,常用来对资料作筛选工作。
分类和预测的应用十分广泛,例如,可以建立一个分类模型,对银行的贷款客户进行分类,以降低贷款的风险;也可以通过建立分类模型,对工厂的机器运转情况进行分类,用来预测机器故障的发生。
分类的主要方法有ID3算法、C4.5算法、SLIQ算法、SPRINT算法、RainForest 算法、Bayes分类算法、CBA(Classification Based on Association)算法、MIND(Mining in Database)算法、神经网络方法、粗糙集理论方法、遗传算法等。
(4)聚类分析当要分析的数据缺乏描述信息,或是无法组成任何分类模式时就采用聚类的方法,将异质母体区隔为较具同构性的群(Cluster),即将组之间的差异识别出来,并对个别组内的相似样本进行挑选,实现同组数据相近,不同组数据相异。
数据挖掘概念与技术ppt课件

用户 GUI API 数据立方体 API
挖掘结果
第4层 用户界面
OLAP 引擎
第3层 OLAP/OLAM
21.05.2020
.
17
KDD过程的步骤(续)
选择挖掘算法 数据挖掘: 搜索有趣的模式 模式评估和知识表示
可视化, 变换, 删除冗余模式, 等.
发现知识的使用
21.05.2020
.
18
数据挖掘和商务智能
提高支持商务决策的潜能
制定决策
数据表示 可视化技术
数据挖掘 信息发现
21.05.2020
我们正被数据淹没,但却缺乏知识 解决办法: 数据仓库与数据挖掘
数据仓库与联机分析处理(OLAP) 从大型数据库的数据中提取有趣的知识(规则, 规律性, 模
式, 限制等)
21.05.2020
.
6
数据处理技术的演进
1960s: 数据收集, 数据库创建, IMS 和网状 DBMS
1970s: 关系数据库模型, 关系 DBMS 实现
顾客分类(Customer profiling)
数据挖掘能够告诉我们什么样的顾客买什么产品(聚类或分类)
识别顾客需求
对不同的顾客识别最好的产品 使用预测发现什么因素影响新顾客
提供汇总信息
各种多维汇总报告 统计的汇总信息 (数据的中心趋势和方差)
21.05.2020
.
11
法人分析和风险管理
搜索有趣的模式可视化变换删除冗余模式发现知识的使用2105202019提高支持商务决策的潜能最终用户商务分析人员数据分析人员dba制定决策数据表示可视化技术数据挖掘信息发现数据探查olapmda统计分析查询和报告数据仓库数据集市数据源文字记录文件信息提供者数据库系统oltp系统2105202020数据仓库数据清理数据集成过滤数据库数据库或数据仓库数据挖掘引擎模式评估图形用户界面知识库21052020www21052020概念描述
数据挖掘概论(复习大纲)
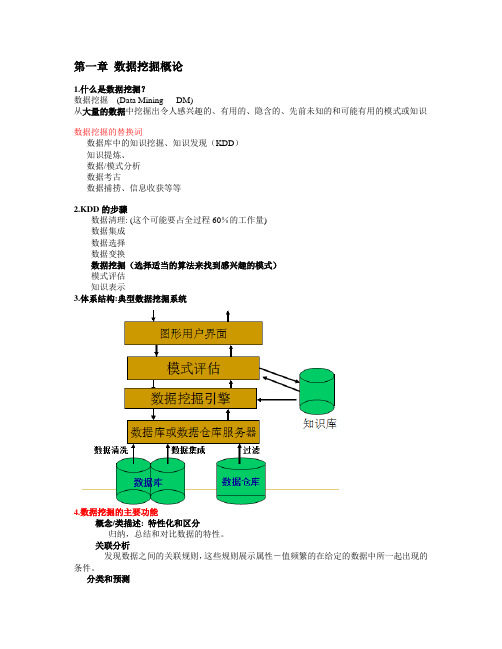
第一章数据挖掘概论1.什么是数据挖掘?数据挖掘(Data Mining DM)从大量的数据中挖掘出令人感兴趣的、有用的、隐含的、先前未知的和可能有用的模式或知识数据挖掘的替换词数据库中的知识挖掘、知识发现(KDD)知识提炼、数据/模式分析数据考古数据捕捞、信息收获等等2.KDD的步骤数据清理: (这个可能要占全过程60%的工作量)数据集成数据选择数据变换数据挖掘(选择适当的算法来找到感兴趣的模式)模式评估知识表示3.体系结构:典型数据挖掘系统4.数据挖掘的主要功能概念/类描述: 特性化和区分归纳,总结和对比数据的特性。
关联分析发现数据之间的关联规则,这些规则展示属性-值频繁的在给定的数据中所一起出现的条件。
分类和预测通过构造模型(或函数)用来描述和区别类或概念,用来预测类型标志未知的对象类。
聚类分析将类似的数据归类到一起,形成一个新的类别进行分析。
孤立点分析通常孤立点被作为“噪音”或异常被丢弃,但在欺骗检测中却可以通过对罕见事件进行孤立点分析而得到结论。
趋势和演变分析描述行为随时间变化的对象的发展规律或趋势5.数据挖掘系统与DB或DW系统的集成方式不耦合松散耦合半紧密耦合紧密耦合概念P23第三章数据仓库和OLAP技术1.什么是数据仓库?数据仓库的定义很多,但却很难有一种严格的定义.“数据仓库是一个面向主题的、集成的、随时间而变化的、不容易丢失的数据集合,支持管理部门的决策过程.”—W. H. Inmon(数据仓库构造方面的领头设计师)2.数据仓库关键特征数据仓库关键特征一——面向主题数据仓库关键特征二——数据集成数据仓库关键特征三——随时间而变化数据仓库关键特征四——数据不易丢失3.数据仓库与异种数据库集成传统的异种数据库集成:在多个异种数据库上建立包装程序和中介程序采用查询驱动方法——当从客户端传过来一个查询时,首先使用元数据字典将查询转换成相应异种数据库上的查询;然后,将这些查询映射和发送到局部查询处理器缺点:复杂的信息过虑和集成处理,竞争资源数据仓库: 采用更新驱动将来自多个异种源的信息预先集成,并存储在数据仓库中,供直接查询和分析高性能.4.从关系表和电子表格到数据立方体数据仓库和数据仓库技术基于多维数据模型。
数据挖掘5概念描述特征化与比较

2019/10/22
4
特征化和比较
什么是概念描述? 数据概化和基于汇总的特征化 分析特征化: 分析属性之间的关联性 挖掘类比较:获取不同类之间的不同处 在大型数据库中挖掘描述统计度量 讨论 总结
2019/10/22
5
数据概化和基于汇总的特征化
数据概化
将大量的相关数据从一个较低的概念层次抽象、转化到 一个比较高的层次
from student
where status in “graduate”
相应的SQL:
Select name, gender, major, birth_place, birth_date,
residence, phone#, gpa
from student
where status in {“Msc”, “MBA”, “PhD” }
2019/10/22
19
相关性度量标准
相关性度量标准决定了如何对属性进行判断的标 准
方法 信息增益information gain (ID3) 增益比gain ratio (C4.5) Gini索引gini index 不确定性 相关系数
2019/10/22
20
Entropy 和 Information Gain
2019/10/22
21
一个例子(131页例5.9)
任务 使用分析特征化来了解研究生的一般特征
属性名称 gender, major, birth_place, birth_date, phone#, and gpa
Gen(ai) = concept hierarchies on ai Ui = attribute analytical thresholds for ai Ti = attribute generalization thresholds for ai R = attribute relevance threshold
数据挖掘概念与技术word版

摘要随着计算机和网络的发展,对于大数据需要数据分析,在分析数据的时候,数据挖掘的过程也叫知识发现的过程,它是一门涉及面很广的交叉性新兴学科,涉及到数据库、人工智能、数理统计、可视化、并行计算等领域。
本文主要综述了数据挖掘中常用的一些关联规则,分类和聚类的算法。
关键字:数据挖掘;分类;聚类;关联规则1 引言1.1 数据挖掘介绍近年来,数据挖掘引起了信息产业界的极大关注,其主要原因是存在大量数据,可以广泛使用,并且迫切需要将这些数据转换成有用的信息和知识。
获取的信息和知识可以广泛用于各种应用,包括商务管理,生产控制,市场分析,工程设计和科学探索等[1]。
数据挖掘出现于20世纪80年代后期,是数据库研究中一个很有应用价值的新领域,是一门交叉性学科,融合了人工智能、数据库技术、模式识别、机器学习、统计学和数据可视化等多个领域的理论和技术.数据挖掘作为一种技术,它的生命周期正处于沟坎阶段,需要时间和精力去研究、开发和逐步成熟,并最终为人们所接受。
20世纪80年代中期,数据仓库之父W.H.In-mon在《建立数据仓库》(Building the Data Warehouse)一书中定义了数据仓库的概念,随后又给出了更为精确的定义:数据仓库是在企业管理和决策中面向主题的、集成的、时变的以及非易失的数据集合。
与其他数据库应用不同的是,数据仓库更像一种过程—对分布在企业内部各处的业务数据的整合、加工和分析的过程。
传统的数据库管理系统(database management system,DBMS)的主要任务是联机事务处理(on-line transaction processing,OLTP);而数据仓库则是在数据分析和决策方面提供服务,这种系统被称为联机分析处理(on-line analyticalprocessing,OLAP).OLAP的概念最早是由关系数据库之父E.F.Codd于1993年提出的。
当时,Codd认为OLTP已不能满足终端用户对数据库查询分析的需要,结构化查询语言(structured query language,SQL)对数据库进行的简单查询也不能满足用户分析的需求.用户的决策分析需要对关系数据库进行大量计算才能得到结果,因此Codd提出了多维数据库和多维分析的概念[2]。
1 数据挖掘每章知识范文

第一章1.数据挖掘定义:从大量的、不完全的、有噪声的、模糊的、随机的数据中,提取隐含在其中的、人们事先不知道的、但又是潜在有用的信息和知识的过程。
2.不能在原数据库上做决策而要建造数据仓库的原因:传统数据库的处理方式和决策分析中的数据需求不相称,主要表现在:⑴决策处理的系统响应问题⑵决策数据需求的问题⑶决策数据操作的问题3.数据仓库的定义W.H.Inmon的定义:数据仓库是一个面向主题的、集成的、非易失的且随时间变化的数据集合,用来支持管理人员的决策。
公认的数据仓库概念基本上采用了W.H.Inmon的定义:数据仓库是面向主题的、集成的、不可更新的(稳定性)随时间不断变化(不同时间)的数据集合,用以支持经营管理中的决策制定过程。
4.数据仓库与数据挖掘的关系:⑴数据仓库系统的数据可以作为数据挖掘的数据源。
数据仓库系统能够满足数据挖掘技术对数据环境的要求,可以直接作为数据挖掘的数据源。
⑵数据挖掘的数据源不一定必须是数据仓库系统。
数据挖掘的数据源不一定必须是数据仓库,可以是任何数据文件或格式,但必须事先进行数据预处理,处理成适合数据挖掘的数据。
5. 数据挖掘的功能——7个方面:⑴概念描述:对某类对象的内涵进行描述,并概括这类对象的有关特征。
①特征性描述②区别性描述⑵关联分析:若两个或多个变量间存在着某种规律性,就称为关联。
关联分析的目的就是找出数据中隐藏的关联网。
⑶分类与预测①分类②预测⑷聚类分析:客观的按被处理对象的特征分类,将有相同特征的对象归为一类。
⑸趋势分析:趋势分析——时间序列分析,从相当长的时间的发展中发现规律和趋势。
⑹孤立点分析:孤立点:数据库中包含的一些与数据的一般行为或模型不一致的数据。
⑺偏差分析:偏差分析——比较分析,是对差异和极端特例的描述,揭示事物偏离常规的异常现象。
6. 数据挖掘常用技术:⑴数据挖掘算法是数据挖掘技术的一部分⑵数据挖掘技术用于执行数据挖掘功能。
⑶一个特定的数据挖掘功能只适用于给定的领域。
概念描述

方法: OLAP方法: 面向属性的归纳
city street
Data Mining: Concepts and Techniques
7
OLAP方法
在数据立方体上进行计算和存储结果 优点
效率高
能够计算多种汇总 如:count,average,sum,min,max
还可以使用roll-down和roll-up操作 限制
概念描述
特征化和比较
Data Mining: Concepts and Techniques
1
概念描述: 特征化和比较(定性与对比)
什么是概念描述? 数据概化和基于汇总的特征化 分析特征化: 分析属性之间的关联性 挖掘类比较: 获取不同类之间的不同处 在大型数据库中挖掘描述统计度量
Data Mining: Concepts and Techniques
只能处理非数值化数据和数值数据的简单汇总。 只能分析,不能自动的选择哪些字段和相应的概念层次
Data Mining: Concepts and Techniques
8
面向属性的归纳
KDD Workshop(89)中提出 不限制于种类字段和特定的汇总方法 方法介绍:
使用某一方法(如SQL)收集相关数据 通过数据删除和数据概化来实现概化 聚集通过合并相等的广义元组,并累计他们对
相关性分析
Sort and select the most relevant dimensions and levels.
面向属性的类描述(AOI)
On selected dimension/level
Data Mining: Concepts and Techniques
19
相关性度量标准
数据挖掘的基本概念

数据挖掘的基本概念数据挖掘的基本概念数据挖掘是一种从大量数据中提取有用信息的过程。
它是一种利用计算机技术和统计学方法来分析数据并发现其中规律和模式的过程。
在当今信息爆炸的时代,数据挖掘已成为企业、政府和科学研究等领域中不可或缺的工具。
一、数据挖掘的定义数据挖掘是指从大量数据中自动或半自动地发现非显然、有效且新颖的模式和关系的过程,也可以理解为对大量数据进行分析,以发现其中隐藏的规律和趋势。
二、数据挖掘的目标1. 预测性任务:通过历史数据来预测未来事件。
2. 描述性任务:通过对现有数据进行分析,得出对于该领域或问题相关变量之间关系描述。
三、数据挖掘的步骤1. 数据预处理:包括去除异常值、填补缺失值、特征选择等。
2. 数据转换:将原始数据转换成可用于建模或分析的形式,如数值化、离散化等。
3. 模型构建:根据问题类型和目标选择适当算法,并进行参数调整。
4. 模型评估:使用测试数据集来评估模型的性能。
5. 模型应用:将模型应用于新数据,得出预测结果或新的知识。
四、数据挖掘的技术1. 分类:对分类问题进行建模,如决策树、朴素贝叶斯等。
2. 聚类:对无标签数据进行分组,如k-means聚类、层次聚类等。
3. 关联规则挖掘:发现数据中的关联规则,如Apriori算法等。
4. 异常检测:发现不符合预期的数据点,如LOF算法、孤立森林算法等。
5. 时间序列分析:分析时间序列数据中的趋势和周期性变化,如ARIMA模型等。
五、数据挖掘在实际中的应用1. 金融领域:风险评估、信用评估等。
2. 零售业:市场细分、推荐系统等。
3. 医疗领域:疾病诊断、药物研发等。
4. 社交网络领域:社交网络分析、舆情监测等。
六、数据挖掘面临的问题1. 数据隐私保护问题2. 数据质量问题3. 模型可解释性问题七、数据挖掘的发展趋势1. 深度学习技术的应用2. 大数据处理技术的发展3. 可解释性机器学习的研究结语:数据挖掘是一种强大的工具,它可以帮助我们从海量数据中提取出有价值的信息,为我们提供更好的决策支持和业务优化。
【最新文档】数据挖掘笔记-word范文 (11页)

本文部分内容来自网络整理,本司不为其真实性负责,如有异议或侵权请及时联系,本司将立即删除!== 本文为word格式,下载后可方便编辑和修改! ==数据挖掘笔记篇一:数据挖掘概念与技术读书笔记1、可以挖掘的数据类型:数据库数据,数据仓库(是一个从多个数据源收集的信息存储库,存放在一致的模式下,并且通常驻留在单个站点上,通常数据仓库用称作数据立方体的多维数据结构建模,数据立方体有下钻(往下细分)和上卷(继续记性总和归纳)操作),事务数据,时间先关或序列数据(如历史记录,股票交易数据等),数据流、空间数据、工程设计数据,超文本和多媒体数据2、可以挖掘什么类型的模型数据挖掘功能包括特征化与区分、频繁模式、关联和相关性挖掘分类与回归、聚类分析、离群点分析。
数据挖掘功能用于指定数据挖掘任务发现的模式。
一般而言,这些任务可以分为两类:描述性和预测性。
描述性挖掘任务刻画目标数据中数据的一般性质。
预测性挖掘任务在当前数据上进行归纳,以便做出预测。
特征化与区分:数据特征化(如查询某类产品的特征)、数据区分(将目标类数据对象的一般特性与一个或多个对比类对象的一般特性进行比较,如把具有不同特性的产品进行对比区分)。
挖掘频繁模式、关联和相关性:频繁模式是在数据中频繁出现的模式(频繁项集、频繁子序列和频繁子结构)用于预测分析的分类与回归:分类是找出描述和区分数据类或概念的模型,以便能够使用模型预测类标号未知的对象的类标号。
到处模型是基于对训练数据集的分析。
该模型用来预测类标号未知的对象类标号。
表现形式有:分类规则(IF-THEN)、决策树、数学公式和神经网络。
分类预测类别标号,而回归简历连续值函数模型,而不是离散的类标号。
相关分析可能需要在分类和回归之前进行,他试图识别与分类和回归过程显著相关的属性。
聚类分析:聚类分析数据对象,而不考虑类标号。
离群分析:数据集中可能包含一些数据对象,他么对数据的一般行为或模型不一致。
这些数据时利群点。
数据挖掘章概念描述特征化与比较

F o r m a jo r= ” S c ie n c e ” :
S11= 8 4
F o r m a jo r= ” E n g in e e rin g ” : S 12= 3 6
F o r m a jo r= ” B u sin e ss” : S 13= 0
F
Business Canada
<=20
Fair
20
M
Business Canada
<=20
Fair
22
F
Science Canada
21-25 Fair
24
M
Engineerin Foreign
g
F
Engineerin Canada
g
21-25 <=20
Very_good 22 Excellent 24
j1
s
Ga iIn(1 ,(ss2,A .s.m )). ,E(A)
2019/10/4
21
一个例子(131页例5.9)
任务 使用分析特征化来了解研究生的一般特征
属性名称 gender, major, birth_place, birth_date, phone#, and gpa
量化特征规则: (上表与136页例4.26)
ge ( x ) n " m " d a elr e b_ i rr e ( t x ) g h " C io " a [ t: 5 n % n 3 b a _ ] i r d r e ( a t x ) g h " fo io " [ t r : 4 n % e .7 ig
数据挖掘CHAPTER概念描述:特征与比较

第五章概念描述:特征与比较从数据分析的角度,数据挖掘可以分为两类:描述式数据挖掘和预测式数据挖掘。
描述式数据挖掘以简洁概要的方式描述数据,并提供数据的有趣的一般性质。
预测式数据挖掘分析数据,建立一个或一组模型,并试图预测新数据集的行为。
数据库通常存放大量的细节数据。
然而,用户通常希望以简洁的描述形式观察汇总的数据集。
这种数据描述可以提供一类数据的概貌,或将它与对比类相区别。
此外,用户希望方便、灵活地以不同的粒度和从不同的角度描述数据集。
这种描述性数据挖掘称为概念描述,它是数据挖掘的一个重要部分。
本章,你将学习概念描述如何有效地进行。
5.1 什么是概念描述?描述性数据挖掘的最简单类型是概念描述。
概念通常指数据的汇集,如frequent_buyers, graduate_students等。
作为一种数据挖掘任务,概念描述不是数据的简单枚举。
概念描述产生数据的特征和比较描述。
当被描述的概念涉及对象类时,有时也称概念描述为类描述。
特征提供给定数据汇集的简洁汇总,而概念或类的比较(也称为区分)提供两个或多个数据汇集的比较描述。
由于概念描述涉及特征和比较,我们将逐一研究这些任务的实现技术。
概念描述与数据泛化密切相关。
给定存放在数据库中的大量数据,能够以简洁的形式在更一般的(而不是在较低的)抽象层描述数据是很有用的。
允许数据集在多个抽象层泛化,便于用户考察数据的一般行为。
例如,给定AllElectronics数据库,销售经理可能不想考察每个顾客的事务,而愿意观察泛化到高层的数据。
如,根据地区按顾客的分组汇总,观察每组顾客的购买频率和顾客的收入。
这种多维、多层数据泛化类似于数据仓库中的多维数据分析。
在这种意义下,概念描述类似于第2章讨论的数据仓库的联机分析处理(OLAP)。
“大型数据库的概念描述和数据仓库的联机分析处理有何不同?”二者之间的主要差别如下:复杂的数据类型和聚集:数据仓库和OLAP工具基于多维数据模型,将数据看作数据方形式,由维(或属性)和度量(聚集函数)组成。
第1章 数据挖掘的概念

第1章数据挖掘的概念本章目标●理解对大型的、复杂的和信息丰富的数据集进行分析的必要性。
●明确数据挖掘过程的目标和首要任务。
●描述数据挖掘技术的起源。
●认识数据挖掘过程所具有的迭代特点,说明数据挖掘的基本步骤。
●解释数据的质量对数据挖掘过程的影响。
●建立数据仓库和数据挖掘之间的联系。
1.1 概述现代科学和工程建立在用“首要原则模型(first-principle models)”来描述物理、生物和社会系统的基础上。
这种方法从基础的科学模型入手,如牛顿运动定律或麦克斯韦的电磁公式,然后基于模型来建立机械工程或电子工程方面的各种应用。
在这种方法中,用实验数据来验证基本的“首要原则模型”,以及对一些难以直接测量或者根本不可能直接测量的参数进行评估。
但是在许多领域,基本的“首要原则模型”往往是未知的,或者研究的系统太复杂而难以进行数学定型,随着计算机的广泛应用,像这样的复杂系统生成了大量的数据。
在没有“首要原则模型”时候,可以利用这些易得的可用数据,通过对系统变量之间可以利用的关系(即未知的输入输出相关性)进行评估来导出模型。
这样,传统的建模及基于“首要原则模型”进行分析的方法与开发模型及直接对数据进行相应分析的方法之间普遍存在着范型变换。
我们都逐渐习惯面对这样的一个事实——超量的数据充斥着我们的电脑、网络和生活,政府机构、科研机构和企业都投入大量的资源去收集和存储数据。
实际上,这些数据中只有一小部分将会被用到,因为在很多情况下,要么数据量简直太大了,难于管理,要么就是数据结构太复杂,不能进行有效的分析。
这种情况是怎么发生的呢?根本的原因是人们创建一个数据集时往往把精力都集中在如数据的存储效率的问题上,而没有去考虑数据最终是怎样使用和分析的。
对大型的、复杂的、信息丰富的数据集的理解实际上是所有的商业、科学、工程领域的共同需要,在商务领域,公司和顾客的数据逐渐被认为是一种战略资产。
在当今的竞争世界中,吸取隐藏在这些数据后面的有用知识并利用这些知识的能力变得愈加重要。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
2019/4/13
8
基本方法
数据聚焦:选择和当前分析相关的数据,包括维。
属性删除: 如果某个属性包含大量不同值,但是
1)在该属性上没有概化操作,
或者2)它的较高层概念用其它属性表示。
属性概化:如果某个属性包含大量不同值,同时在 该属性上有概化操作符,则运用该操作符进行概化。
属性阈值控制: typical 2-8, specified/default.
1 2 5A u s t inA v e ., B u r n a b y …
P h o n e#
G P A
L a c h a n c e L a u r aL e e F … …
R e m o v e d R e t a in e d
V a n c o u v e r ,B C , 8 1 2 7 6 C a n a d a C S M o n t r e a l, Q u e , 2 8 7 7 5 C a n a d a e a t t le ,W A ,U S A 2 P h y s ic s S 5 8 7 0 … … …
概化关系阈值控制: 控制最终关系的大小
2019/4/13
9
基本算法
InitialRel: 得到相关数据,形成初始关系表
PreGen: 通过统计不同属性的含有的不同值的个数 决定是丢弃该属性还是对其进行汇总。
PrimeGen:根据上一步的计算结果,对属性概化到相 应的层次,计算汇总值,得到主概化关系。
5
2019/4/13
数据概化和基于汇总的特征化
数据概化
将大量的相关数据从一个较低的概念层次抽象、转化到 一个比较高的层次 方法: OLAP方法: 面向属性的归纳
2019/4/13
6
OLAP方法
在数据立方体上进行计算和存储结果 优点
效率高
能够计算多种汇总
如:count,average,sum,min,max
Prime Generalized Relation
M F …
S c i e n c e S c i e n c e …
Birth_Region Canada Gender M F Total
2019/4/13
S c i,E n g , B u s
6 8 7 4 5 9 8 3 .6 7 2 5 3 9 1 0 6 3 .7 0 4 2 0 5 2 3 2 3 .8 3 … … R e m o v e d E x c l, V G ,..
C o u n t 1 6 2 2 …
C o u n t r y
A g er a n g e
相应的SQL: Select name, gender, major, birth_place, birth_date, residence, phone#, gpa from student where status in {“Msc”, “MBA”, “PhD” }
11
2019/4/13
别
概念描述: 能够处理复杂的数据类型和各种汇总方法 更加自动化 OLAP: 只能限制于少量的维度和数据类型 用户控制的流程
2019/4/13
4
特征化和比较
什么是概念描述?
数据概化和基于汇总的特征化 分析特征化: 分析属性之间的关联性 挖掘类比较:获取不同类之间的不同处 在大型数据库中挖掘描述统计度量 讨论 总结
概念描述
2019/4/13
1
特征化和比较
什么是概念描述?
数据概化和基于汇总的特征化 解析特征化: 分析属性之间的关联性 挖掘类比较:获取不同类之间的不同处 在大型数据库中挖掘描述统计度量 讨论 总结
2
2019/4/13
什么是概念描述?
描述性 vs. 预测性 数据挖掘 描述性数据挖掘: 预测性数据挖掘: 概念描述: 特征化:对所选择的数据集给出一个简单明了的 描述,汇总 比较:提供对于两个或多个数据集进行比较的描 述
结果的表示:概化关系、交叉表、3D立方体
2019/4/13
10
示例
DMQL: use Big_University_DB mine characteristics as “Science_Students” in relevance to name, gender, major, birth_place, birth_date, residence, phone#, gpa from student where status in “graduate”
C it y
G e n d e r M a j o r
B i r t h _ r e g i o n A g e _ r a n g e R e s i d e n c e G P A C a n a d a F o r e i g n … 2 0 2 5 2 5 3 0 … R i c h m o n d V e r y g o o d B u r n a b y E x c e l l e n t … …
还可以使用roll-down和roll-up操作 只能处理非数值化数据和数值数据的简单汇总。 只能分析,不能自动的选择哪些字段和相应的概念层次
限制
2019/4/13
7
面向属性的归纳
KDD Workshop(89)中提出 不限制于种类字段和特定的汇总方法 方法介绍: 使用SQL等收集相关数据 通过数据属性值删除和属性值概化来实现概化 聚集通过合并相等的广义元组,并累计他们对 应的计数值进行 和使用者之间交互式的呈现方式.