spss上机报告3
spss 上机实验报告

spss 上机实验报告
《SPSS上机实验报告》
在当今社会,数据分析已经成为了各行各业中不可或缺的一部分。
而SPSS作为一款功能强大的统计分析软件,被广泛应用于科研、商业、教育等领域。
本次
实验旨在通过SPSS软件进行数据分析,以探讨数据的规律性和相关性,为进一步的研究和决策提供科学依据。
实验一:描述性统计分析
首先,我们对所收集到的数据进行了描述性统计分析。
通过SPSS软件,我们得出了数据的平均值、标准差、最大值、最小值等指标,从而对数据的分布情况
有了更清晰的了解。
这些统计指标为我们提供了数据的基本特征,为后续的分
析奠定了基础。
实验二:相关性分析
接下来,我们利用SPSS软件进行了相关性分析。
通过相关系数的计算,我们发现了数据之间的相关程度,并得出了相关性显著性检验的结果。
这些分析为我
们揭示了数据之间的内在联系,为我们理解数据背后的规律性提供了重要线索。
实验三:多元回归分析
最后,我们进行了多元回归分析,以探讨不同自变量对因变量的影响程度。
通
过SPSS软件的模型拟合和显著性检验,我们得出了各个自变量的回归系数,并对模型的拟合程度进行了评估。
这些结果为我们提供了对因变量影响因素的深
入理解,为我们在实际应用中进行预测和决策提供了重要参考。
通过以上实验,我们不仅掌握了SPSS软件的基本操作技能,还深入了解了数据分析的方法和原理。
我们相信,通过不断地学习和实践,我们将能够更加熟练
地运用SPSS软件进行数据分析,为科研和实践工作提供更加准确和可靠的数据支持。
SPSS上机实验报告就此结束。
spss 上机实验报告

spss 上机实验报告SPSS上机实验报告引言:SPSS(统计软件包,Statistical Package for the Social Sciences)是一种常用的统计分析软件,被广泛应用于社会科学、医学、经济学等领域的数据分析和研究中。
本文将对SPSS上机实验进行报告,介绍实验目的、实验设计、数据处理和结果分析等内容。
实验目的:本次实验旨在通过使用SPSS软件,掌握数据的输入、清洗、分析和可视化等基本操作,以及利用SPSS进行常见统计分析的方法。
实验设计:本次实验使用了一份虚构的调查问卷数据,包含了参与者的性别、年龄、教育程度、收入水平以及对某产品的满意度等指标。
通过对这些指标进行分析,我们可以了解不同因素对满意度的影响。
数据处理:首先,我们需要将数据导入SPSS软件中。
通过点击菜单栏的“文件”选项,选择“导入数据”,然后选择数据文件并进行导入。
导入后,我们可以查看数据的整体情况,包括变量的名称、类型、取值范围等。
接下来,我们对数据进行清洗,以确保数据的准确性和一致性。
例如,我们可以检查是否有缺失值,如果有,可以选择删除或填充缺失值。
此外,还可以进行异常值检测,排除数据中的异常观测点。
结果分析:在数据清洗完成后,我们可以进行统计分析。
首先,我们可以计算各个变量的描述性统计量,如均值、标准差、最大最小值等,以了解数据的分布情况。
通过点击菜单栏的“分析”选项,选择“描述性统计”,然后选择需要计算的变量即可。
接着,我们可以进行相关性分析,以探究不同因素之间的关系。
通过点击菜单栏的“分析”选项,选择“相关”或“回归”等选项,然后选择需要分析的变量。
相关性分析可以帮助我们了解变量之间的线性关系,并进行进一步的分析。
另外,我们可以进行T检验或方差分析等统计检验,以比较不同组别之间的差异。
通过点击菜单栏的“分析”选项,选择“比较均值”或“方差分析”等选项,然后选择需要比较的变量和组别。
统计检验可以帮助我们判断不同组别之间是否存在显著差异。
spss软件上机实训报告8页word

上机实训报告前言中国汽车行业现状中国车市异军突起,北汽控股收购萨博整车平台等技术、保时捷收购不成反被收购大众收购保时捷49.9%股份、长安与中航合并央企首例汽车业重组诞生长安跻身前三甲、中国汽车2009第1000万辆在一汽隆重下线、汽车振兴规划细则公布1.6升及以下排量减收购置税、吉利收购沃尔沃。
据中国汽车工业协会(下称“中汽协”)发布的数据显示,去年国内汽车销售了1364.48万辆,同比增幅46.15%,中国确定成为全球第一大汽车市场,将昔日霸主美国远远甩在身后,美国去年销量为1043万辆。
由于今年政府依然实施刺激汽车消费的购置税优惠、汽车下乡补贴等政策,国内车企普遍预测,2019年国内汽车销量增幅约为15%。
,根据主要汽车企业制订的最新产销计划和目标,2019年国内汽车销量有望达到1600万辆,接近美国金融危机爆发前的每年汽车销量。
其中,上汽预计今年销量可达300万辆,北汽预计为170万辆,广汽为72万辆,比亚迪为80万辆,华晨为45万辆,吉利为40万辆。
中汽协公布的数据称,2009年国内汽车销量1364.48万辆,同比增长46.15%。
其中乘用车销量为1033.13万辆,同比增长52.93%。
商用车销量331.35万辆,同比增长28.39%。
与2019年相比,不仅乘用车市场取得惊人增长,商用车也走出谷底。
2009年国内销量前十位的汽车公司分别是上汽、一汽、东风、长安、北汽、广汽、奇瑞、比亚迪、华晨和吉利,上述十家企业共销售汽车1189.33万辆,占汽车销售总量的87%。
一个易见的事实是,国内汽车市场上目前仍是在排队加价销售状态中。
实训概述一、实训目的(1)掌握SPSS中基本的数据处理方法;(2)学会使用SPSS进行单变量多选题次数分布表的制作,能以此方式独立完成相关作业。
二、实训要求1、已学习教材相关内容,理解数据整理中的统计计算问题;理解统计表和统计图的制作方法;已阅读本次实训指导书,了解SPSS中相关的统计命令。
SPSS第3次实验报告

过程:
H0:用该方法测量所得的结果与标准浓度值相同 H1:用该方法测量所得的结果与标准浓度值不同 使用 SPSS 得出下表
表中显示 N=11,均值为,标准差为;在检验值为,置信水平为的数值下的 t 统计量为,不在
(,)之内;P 值=<
所以拒绝 H0,暂时接受 H1
表3 单个样本统计量
N
均值
标准
差
均值的标 准误
分析:干预前后的数据可以当成是来自两个不同总体的配对样本,推断两个总体的 均值是否存在显着差异。
过程:
H0:干预前后该地区贫血儿童血红蛋白(%)平均水平有变化
H1:干预前后该地区贫血儿童血红蛋白(%)平均水平没有变化
结果:表所示为配对样本 T 检验分析的结果,干预前的均值为,标准差为,干预后 的均值为,标准差为,说明干预后该地区贫血儿童血红蛋白(%)平均水平有增长,且 波动幅度不大。
2. 步骤: 1) 提出零假设 2) 选择检验统计量 A. 当量总体方差未知且相等,即σ1=σ2 时,采用合并的方差作为 两个总体的方差估计,数学定义为:(t 统计量服从个自由度的 t 分布)
B. 当量总体方差未知且不相等,即σ1≠σ2 时,分别采用各自的 方差,此时两样本均值差的抽样分布的方差σ212 为:(t 统计量服从修正 自由度的 t 分布)
浓 11
度
.32186
t
浓 度
表4 单个样本检验 检验值 =
df
Sig.(
均值
双侧)
差值
.9836
10
.012
4
差分的 95% 置信区 间
下限
上限
.2665
(二) 独立样本 T 检验 1. 原理:
利用两个总体的独立样本,推断两个总体的均值是否存在显着差异。这个检验的前 提要求是:(1)独立。两组数据相互独立,互不相关;(2)正态,剂量组样本来自的总 体符合正态分布;(3)方差齐性。即两组方差相等。
统计学spss上机实验报告
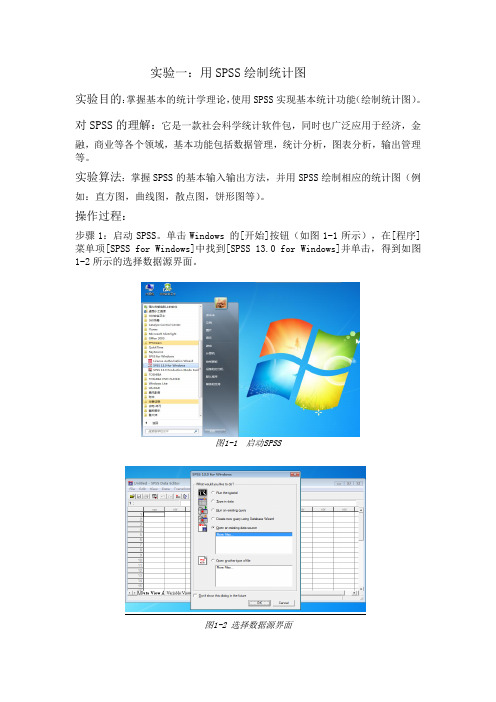
实验一:用SPSS绘制统计图实验目的:掌握基本的统计学理论,使用SPSS实现基本统计功能(绘制统计图)。
对SPSS的理解:它是一款社会科学统计软件包,同时也广泛应用于经济,金融,商业等各个领域,基本功能包括数据管理,统计分析,图表分析,输出管理等。
实验算法:掌握SPSS的基本输入输出方法,并用SPSS绘制相应的统计图(例如:直方图,曲线图,散点图,饼形图等)。
操作过程:步骤1:启动SPSS。
单击Windows 的[开始]按钮(如图1-1所示),在[程序]菜单项[SPSS for Windows]中找到[SPSS 13.0 for Windows]并单击,得到如图1-2所示的选择数据源界面。
图1-1 启动SPSS图1-2 选择数据源界面步骤2 :打开一个空白的SPSS数据文件,如图1-3。
启动SPSS 后,出现SPSS 主界面(数据编辑器)。
同大多数Windows 程序一样,SPSS 是以菜单驱动的。
多数功能通过从菜单中选择完成。
图1-3 空白的SPSS数据文件步骤3:数据的输入。
打开SPSS以后,直接进入变量视图窗口。
SPSS的变量视图窗口分为data view和variable view两个。
先在variable view中定义变量,然后在data view里面直接输入自定义数据。
命名为“我的文件”并保存在桌面。
如图1-4所示。
图1-4数据的输入步骤4:调用Graphs菜单的Bar功能,绘制直条图。
直条图用直条的长短来表示非连续性资料(该资料可以是绝对数,也可以是相对数)的数量大小。
步骤5:数据准备。
步骤6:选Graphs菜单的Bar过程,弹出Bar Chart定义选项。
在定义选项框的下方有一数据类型栏,系统提供3种数据类型:Summaries for groups of cases:以组为单位体现数据;Summaries of separate variables:以变量为单位体现数据;Values of individual cases:以观察样例为单位体现数据。
spss上机实验报告

spss上机实验报告I. 实验目的本实验旨在通过使用SPSS软件进行数据分析,加深对SPSS软件的理解和掌握,巩固和深化统计分析的基础知识。
II. 实验内容本实验使用了SPSS软件对一组数据进行了统计分析。
数据包括了100名学生的语文成绩、数学成绩、英语成绩、性别和年龄等信息。
实验内容如下:1. 数据导入和检查将数据文件导入SPSS软件中,并对数据进行检查,排除异常数据。
2. 数据描述性统计分析使用SPSS软件对数据进行描述性统计分析,包括均值、中位数、标准差等统计指标的计算。
3. 方差分析使用SPSS软件对数据进行方差分析,分析不同性别和年龄段学生的语文、数学和英语成绩之间的差异。
III. 实验结果1. 数据导入和检查数据文件成功导入SPSS软件中,并且通过检查,排除了部分异常数据。
2. 数据描述性统计分析经过计算,该组数据的语文平均分为75.3分,数学平均分为78.6分,英语平均分为80.2分,标准差分别为8.5、7.9、6.8。
3. 方差分析通过方差分析,发现女生的语文成绩平均值显著高于男生,F(1,98)=10.76,p<0.01;年龄在18岁以下的学生数学成绩平均值显著高于18岁以上的学生,F(1,98)=3.94, p<0.05;年龄在18岁以上的学生英语成绩平均值显著高于18岁以下的学生,F(1,98)=6.19,p<0.05。
IV. 结论通过本实验,我们进一步掌握了SPSS软件的使用技巧,并且运用统计学基础知识对一组数据进行了分析,得出了有意义的结论。
在以后的学习和工作中,我们将会更加熟练地使用SPSS软件,为我们的研究和工作提供更多的支持和帮助。
spss统计学上机报告

一、用两种定义变量的方法绘制直方图某学院两个专业,各抽取24名学生,他们某门课考试成绩资料如下:甲专业乙专业成绩(分)学生数成绩(分)学生数60以下7 60-70 960-70 11 70-90 1270-90 6 90以上 3合计24 合计24方法1:SPSS操作步骤:⑴定义“成绩”、“学生数”和“专业”三个变量。
⑵在定义变量窗口对“专业”做变量值标签,令1=甲专业,2=乙专业。
⑶在录入数据窗口依次录入表中数据。
⑷选择数据下拉菜单中的加权个案子菜单,频率变量选学生数。
⑸选择分析下拉菜单中的描述统计子菜单,选择频率模块。
操作结果图如下:方法2:SPSS操作步骤:⑴定义“成绩”、“专业学生数”两个变量。
⑵在录入数据窗口依次录入表中数据。
⑶根据已存在的变量产生新变量。
选择转换下拉菜单中的计算变量,计算总人数。
总人数=甲专业学生数+乙专业学生数。
⑷选择数据下拉菜单中的加权个案子菜单,频率变量选总人数。
⑸选择分析下拉菜单中的描述统计子菜单,选择频率模块。
操作结果图如下:二、一个总体均值的区间估计和两个总体均值差的假设检验某学院两个专业,各抽取24名学生,他们某门课考试成绩资料如下:甲专业乙专业成绩(分)学生数成绩(分)学生数60以下7 60-70 960-70 11 70-90 1270-90 6 90以上 3合计24 合计241、以95%的概率保证程度推断该学院所有学生该门课考试成绩为多少?2、以95%的概率保证程度推断两个专业学生的平均成绩是否有显著性差异。
第一问SPSS操作步骤:⑴定义“成绩”、“专业学生数”两个变量。
⑵在录入数据窗口依次录入表中数据。
⑶根据已存在的变量产生新变量。
选择转换下拉菜单中的计算变量,计算总人数。
总人数=甲专业学生数+乙专业学生数。
⑷选择数据下拉菜单中的加权个案子菜单,频率变量选总人数。
⑸选择分析下拉菜单中的描述统计子菜单,选择探索模块。
操作结果图如下:分析:由题可知这是一个总体方差未知时均值的区间估计,由表可知所有学生的考试成绩的置信区间为(67.9428,74.7655),所以95%的把握认为该学院所有学生该门课考试成绩为(67.9428,74.7655)。
SPSS统计软件实验报告实验三

One-Sample Kolmogorov-Smirnov Test
频数
N
10
Uniform Parametersa
Minimum
66
Maximum
92
Most Extreme Differences
Absolute
.169
Positive
.162
Negative
-.169
Kolmogorov-Smirnov Z
配对检验结果表明t为4.210,自由度为7,显著值为0.004,差别具高度显著性意义,即饲料中缺乏维生素E对鼠肝中维生素A含量有影响。
4.录入数据后,analyze->nonparametric tests->1-sample k-s,频数选入test variable list,再选uniform,得到结果:
–与样本在相同点的累计频率进行比较.如果相差较小,则认为样本所代表的总体符合指定的总体分布.
教师评语:
2.录入数据后,analyze—compare means—independent-samples t test,打开对话框,排出量选入test variable,别类(1为病人,2为健康人)选入grouping variable,打开Define Groups对话框,在Group1输入1,Group2输入2,单击Continue,再单击OK,得到结果:
.535
Asymp. Sig. (2-tailed)
.937
结果:sig=0.937,即频数不服从均匀分布。
5.录入数据:
先做加权:Data ->Weight cases,然后进行二项分布检验analyze->nonparametric test->Binomial,在test proportion里填入0.95,得到结果:
《市场调研》SPSS上机实验报告

《市场调研》SPSS上机实验报告一、实验目的本次实验的主要目的是通过运用 SPSS 软件对市场调研数据进行分析,掌握数据分析的基本方法和流程,提高对市场现象的理解和洞察能力,为决策提供科学依据。
二、实验内容1、数据录入与整理首先,将收集到的市场调研数据录入到 SPSS 软件中。
在录入过程中,需要确保数据的准确性和完整性。
同时,对数据进行初步的整理,如缺失值处理、异常值检查等。
2、描述性统计分析运用 SPSS 中的描述性统计分析功能,计算数据的均值、中位数、标准差、最小值、最大值等统计指标,以了解数据的集中趋势和离散程度。
3、相关性分析通过相关性分析,探究不同变量之间的线性关系。
例如,研究产品价格与销售量之间是否存在显著的相关性。
4、假设检验根据研究问题提出假设,并运用 SPSS 进行 t 检验、方差分析等,以验证假设是否成立。
5、因子分析运用因子分析对多个相关变量进行降维,提取主要的公共因子,以便更简洁地描述数据结构。
6、聚类分析通过聚类分析将样本数据分为不同的类别,以便发现潜在的市场细分群体。
三、实验步骤1、打开 SPSS 软件,新建数据文件。
2、将收集到的数据按照变量的定义依次录入到数据文件中。
3、选择“分析”菜单中的相应功能,如“描述统计”、“相关性”、“假设检验”等,进行相应的数据分析。
4、根据分析结果,解读数据所反映的市场现象和规律。
四、实验数据本次实验使用的是一份关于消费者对某品牌手机满意度的市场调研数据。
数据包括消费者的年龄、性别、收入水平、购买渠道、使用体验等方面的信息。
五、实验结果与分析1、描述性统计分析结果通过描述性统计分析,我们得到了消费者年龄的均值为 30 岁,中位数为 28 岁,标准差为 8 岁。
这表明消费者年龄分布较为均匀,主要集中在 20 40 岁之间。
2、相关性分析结果产品价格与销售量的相关性分析结果显示,两者之间存在显著的负相关关系(r =-065,p < 005),即价格越高,销售量越低。
中南财大-SPSS-实验报告-3

5.点击确定按钮,等待输出结果。
结果分析:
1.从表中可以看出,样本总共有60个,全部参加分析,没有缺失值。
表1案例处理基本统计表
2.变量统计结果表:
表2变量统计结果表
3.从表可以看出,学生态度得分的均值为47.00,标准值为13.629。
第二问
操作步骤
1.回到数据视图,选择“分析”→“比较均值”→“单样本T检验”,弹出如下图对话框:
第二问:
操作步骤:
1.对数据进行分组。点击“数据”→“分割文件”,进入分割文件对话框。选择“method”,点击中间的向右箭头,使之成为分组方式。如图:
图14分割文件
2.点击确定完成分组设置。单击“分析”→“描述统计”→“频率”,弹出频率对话框。选中scoreadd变量,单击向右箭头使之进入变量列表框。如下图:
图10单样本T检验
点击选项,在置信区间百分比输入“95”,即设置显著性水平为5%。在“缺失值”选项组中选中“按分析顺序排除个案”,也就是说,只有分析计算涉及到该记录缺失的变量时,才删去该记录。如下图:
图11单样本T检验:选项
4.设置完毕,点击“继续”按钮返回“单样本T检验”对话框。单击“确定”按钮,等待结果输出。
表7统计量
第三问:
操作步骤:
1.点击“分析”→“比较均值”→“独立样本T检验”,选中“socreadd”并点击右侧第一个向右箭头,使之进入检验变量列表框;选中“method”,单击右侧第二个向右箭头,使之进入分组变量列表框。如图:
图16独立样本T检验
2.单击定义组,在组1(1)输入“1.00”,在组2(2)输入“2.00”。单击继续,如图:
图5单样本T检验对话框
2.将变量态度反应得分(x)移动到右侧的检测变量对话框中,并在“检测值”列表框中输入47.00,作为目标值。
《市场调研》SPSS上机实验报告

《市场调研》SPSS上机实验报告市场调研的SPSS上机实验报告一、实验目的本实验旨在通过SPSS(社会科学统计软件包)对市场调研数据进行统计分析,从而了解市场状况、消费者需求和行为特征,为企业的市场决策提供数据支持。
二、实验数据实验数据来源于某次市场调研,包括被调查者的基本信息、购买行为、品牌评价等相关数据。
数据共包含500份有效问卷,其中男性被调查者250人,女性被调查者250人。
三、实验步骤1、打开SPSS软件,导入实验数据。
2、对数据进行描述性统计分析,包括均值、标准差、最大值、最小值等指标。
3、进行独立样本T检验,分析男性和女性被调查者在购买行为和品牌评价方面是否存在显著差异。
4、进行相关性分析,探究被调查者基本信息、购买行为和品牌评价之间的相关关系。
5、利用因子分析法,提取影响消费者购买决策的主要因素。
6、根据分析结果,提出针对性的市场策略建议。
四、实验结果1、描述性统计分析结果通过对实验数据进行描述性统计分析,我们得到了被调查者在购买行为和品牌评价方面的基本情况。
具体数据如下:(1)购买行为方面:被调查者在过去一年内购买该类产品的次数集中在1-3次之间,平均每次消费金额集中在50-100元之间。
(2)品牌评价方面:被调查者对目标品牌的认知度较高,平均得分在70-80分之间,对其他竞品的认知度相对较低,平均得分在60-70分之间。
2、独立样本T检验结果在实验数据中,我们将被调查者按照性别进行分类,利用独立样本T检验分析男性和女性在购买行为和品牌评价方面是否存在显著差异。
结果显示,男女在购买行为和品牌评价方面均无显著差异。
21、相关性分析结果通过相关性分析,我们发现被调查者基本信息(如年龄、收入等)与购买行为和品牌评价之间存在一定的相关关系。
具体如下:(1)年龄与购买行为:随着年龄的增长,被调查者购买该类产品的次数逐渐增加。
(2)收入与购买行为:随着收入的增加,被调查者购买该类产品的次数和每次消费金额均有所增加。
SPSS上机实验报告参考模板

四川理工学院SPSS上机实验报告课程名称:SPSS统计分析高级教程专业班级:2012级统计2班姓名:雷鹏程学号:12071050204指导教师:林旭东实验日期: 2014年12月15日实验名称:多因素方差分析模型一、实验案例分析超市的规模、货架的位置与销量的关系,具体数据如下表1所示:超市规模货物摆放位置A B C D小型45、50 56、63 65、71 48、53 中型57、65 69、78 73、80 60、57 大型70、78 75、82 82、89 71、75表1超市购物数据二、实验预分析本案例是分析超市的规模、与货架的位置与销量的问题,由于从数据表知道超市的位置与超市规模是分类变量,所以不考虑回归模型了,我初步模型是方差分析模型,并且采用多因素方差分析模型。
三、实验目的3.1、掌握利用SPSS进行多因素方差分析。
3.2、解释运行结果。
3.3、得出最终的实验结论。
四、实验操作步骤及实验描述4.1、初步拟合模型(1)在SPSS选择“”-“”- “”菜单项。
(2)将“sale”选入“”,将“size、position”选入“”。
(3)点击“ok”。
在输出表中得到以下表2、3,如下表所示:Between-Subjects FactorsValue Label N超市规模 1 小型82 中型83 大型8摆放位置 A 6B 6Between-Subjects FactorsValue Label N超市规模 1 小型82 中型83 大型8摆放位置 A 6B 6C 6C 6D 6表2组间变量描述Tests of Between-Subjects Effects Dependent Variable:周销售量Source Type III Sum ofSquares df Mean Square F Sig.Corrected Model 3019.333a11 274.485 12.767 .000108272.667 1 108272.667 5.036E3 .000size 1828.083 2 914.042 42.514 .000position 1102.333 3 367.444 17.090 .000size * position 88.917 6 14.819 .689 .663Error 258.000 12 21.500Total 111550.000 24Corrected Total 3277.333 23a. R Squared = .921 (Adjusted R Squared = .849)表3主体间效应的检验结果解释:表2是两个因素的总和统计。
SPSS实验分析报告(三)

SPSS实验分析报告三一、同只小鼠不同饲料关于钙留存量实验分析报告(一)、提出假设原假设H0=“不同饲料喂养下的同只小鼠体内的钙留存量无显著差异”备选假设H1 =“不同饲料喂养下的同只小鼠体内的钙留存量差异显著”(二)、两独立样本t检验结果及分析表 1-1 不同种类饲料喂食同只小鼠的钙留存量的基本描述统计量群统计资料饲料种类N 平均数标准偏差均值的标准误差钙留存量饲料一9 32.5778 3.81077 1.27026饲料二9 34.2667 5.59933 1.86644表 1-2 不同种类饲料喂食同只小鼠的钙留存量的两独立样本t检验结果独立样本检定方差方程的Levene检验均值方程的t检验F 显著性T df显著性(双侧)均值差值标准误差值差分的95%的置信区间下限上限钙留存量假设方差相等1.410 .252 -.748 16 .465 -1.688892.25769 -6.474983.09720 假设方差不相等-.748 14.102 .467 -1.68889 2.25769 -6.52787 3.15009结果分析:由表1-1可以看出,饲料一喂养的钙留存量与饲料二喂养的钙留存量的样本平均值有一定的差距。
通过检验应判断这种差异是有抽样误差造成的还是系统性的。
对于表1-2,做两步分析。
第一步,两总体方差是否相等的F实验。
在该实验中,检验的F统计量的观测值为1.410,对应的P-值为0.252。
此时的显著性水平α为0.05,由于概率P-值大于0.05,可以认为两个总体的方差无显著差异。
第二步,两总体均值的检验。
在第一步中,由于两总体方差有显著差异,因此应该看第一列(假设方差相等)t检验的结果。
其中,t统计量的观测值为-0.748,对应的双侧概率P-值为0.465。
此时的显著性水平α为0.05,p/2大于0.05,不能拒绝原假设,即没有充分的证据和理由认为不同饲料喂养条件下的钙留存量有显著差异;同时,由于0落在两总体均值差的95%的置信区间内,也从另一个角度证明了对于同只小鼠,不同种类饲料的喂养条件对于钙留存量无显著影响,也即原假设成立。
SPSS上机实验报告

SPSS上机实验报告一、引言SPSS(Statistical Package for the Social Sciences)是一种统计分析软件,被广泛应用于社会科学领域的研究中。
本实验旨在通过使用SPSS软件进行数据分析,掌握SPSS的基本操作和数据分析方法。
本报告将介绍实验的目的、方法、结果和讨论,并对实验过程中的问题进行总结和分析。
二、实验目的1.掌握SPSS软件的基本操作;2.熟悉数据导入、数据清洗和数据整理的方法;3.学习使用SPSS进行描述性统计、频率分析、相关分析等数据分析方法;4.训练对实验结果进行合理解读和分析。
三、实验方法1.数据收集:本实验使用公开数据集进行分析。
数据集为包含1000个样本的数据集,其中包含了身高(Height)、体重(Weight)和性别(Gender)三个变量。
数据以Excel文件的形式存储。
2.数据导入:打开SPSS软件,选择“打开文件”功能,导入Excel文件。
3.数据清洗:对于身高(Height)和体重(Weight)两个变量,检查是否有缺失值和异常值,如果有则进行删除或修正。
4.数据整理:对于性别(Gender)变量,将其转换为数值型变量(例如1表示男性,2表示女性),以便后续分析。
5.数据分析:进行描述性统计,计算身高和体重的均值、标准差、最大值和最小值,了解数据的整体情况。
进行频率分析,计算性别的分布情况,并绘制柱状图展示。
进行相关分析,计算身高和体重之间的相关系数,了解二者之间的关系。
四、实验结果1.描述性统计:身高的均值为170.5cm,标准差为10.2cm,最大值为190cm,最小值为150cm;体重的均值为65kg,标准差为8.5kg,最大值为80kg,最小值为50kg。
2.频率分析:男性占样本的50%,女性占样本的50%。
柱状图展示了男女性别在样本中的分布情况。
3.相关分析:身高和体重之间的相关系数为0.8,表示二者有较强的正相关关系。
统计学的上机实训报告

一、实习背景随着科学技术的飞速发展,统计学在各个领域的应用日益广泛。
为了提高我们对统计学软件的熟练程度,加深对统计学理论知识的理解,我们进行了为期两周的统计学上机实训。
本次实训以SPSS软件为主要工具,通过实际操作,掌握统计学数据处理和分析的基本技能。
二、实习目的1. 熟练掌握SPSS软件的基本操作,包括数据录入、数据管理、数据转换等。
2. 学习运用SPSS进行描述性统计、推断性统计和多元统计分析。
3. 培养统计学思维,提高数据分析和解决问题的能力。
三、实习内容1. 数据录入与数据管理(1)在SPSS中录入数据,包括数值型数据和分类数据。
(2)学习数据管理的基本操作,如数据筛选、排序、合并等。
(3)了解SPSS的数据视图和变量视图,掌握变量的定义和编辑。
2. 描述性统计(1)学习SPSS进行描述性统计,包括计算均值、标准差、中位数等。
(2)掌握描述性统计图表的制作,如直方图、饼图、散点图等。
(3)学习描述性统计的假设检验,如t检验、方差分析等。
3. 推断性统计(1)学习SPSS进行推断性统计,包括参数估计、假设检验等。
(2)掌握t检验、方差分析、卡方检验等常用统计方法。
(3)学习如何根据实际需求选择合适的统计方法,并进行结果解释。
4. 多元统计分析(1)学习SPSS进行多元统计分析,包括相关分析、回归分析等。
(2)掌握相关系数、回归系数等参数的计算方法。
(3)学习如何根据实际需求进行回归分析,并进行结果解释。
四、实习过程1. 前期准备(1)熟悉SPSS软件界面和基本操作。
(2)收集实际数据,进行数据预处理。
2. 实训操作(1)按照实习内容,依次进行数据录入、数据管理、描述性统计、推断性统计和多元统计分析。
(2)在操作过程中,遇到问题及时查阅资料,与同学和老师交流。
3. 结果分析与总结(1)对统计结果进行解释,分析数据背后的规律和现象。
(2)总结实训过程中的经验和教训,提高统计学应用能力。
五、实习成果1. 熟练掌握了SPSS软件的基本操作,能够独立进行数据录入、数据管理和统计分析。
【免费下载】SPSS上机实验报告

湖北科技学院市场营销调研SPSS上机操作实验报告姓名:李果学号: XXXXXXX专业:11工商管理方向: 市场营销2013年12月01日实验名称:频数分布成绩:实验目的和要求:绘制频数分布表、频数分布直方图并分析集中趋势指标、差异性指标和分布形状指标实验内容:绘制频数分布表和频数分布直方图并分析实验记录、问题处理:频数分布直方图集中趋势指标、差异性指标和分布形状指标实验结果分析:从统计量表可以看出有效样本数有30个,没有缺失值。
平均销售额是106.8333,标准差为21.78592。
从频数分布表可以看出样本值、频数占总数的百分比、累计百分比。
从带正态曲线的直方图可以看出销售额集中在110实验名称:列联表成绩:实验目的和要求:绘制频数表、相对频数表并进行显著性检验和关系强度分析实验内容:绘制频数表、相对频数表并分析实验结果分析:从卡方检验看出sig>0.05,不显著。
所以男生女生对满意与否评价没有差异实验名称:方差分析成绩:实验目的和要求:单因子方差分析、多因子方差和协方差分析实验内容:进行单因子方差分析并输出方差分析表、显著性检验及解释结果、多因子方差和协方差分析并输出方差分析表和协方差分析表、显著性检验及解释结果。
实验记录、问题处理:单因子方差分析分析——比较均值,单因素——键入销售额为因变量,键入促销力度为因子——两两比较打钩L检验,选项方差齐性检验打钩得:多因子方差分析分析——一般线性模型,单变量——键入店内促销和赠券状态为固定因子,销售额为因变量——两两比较打钩L检验,选项方差齐性协方差分析分析——一般线性模型,单变量——键入店内促销和赠券状态为固定因子,销售额为因变量,键入客源排序为协变量——两两比较打钩L检验,选项方差齐性检验打钩,得:实验结果分析:单因子:组间显著性为0.000,小于0.05,显著影响。
多因子:店内促销和赠券状态显著性分别都为0.000,小于0.05,显著影响。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
统计分析软件(spss)实验报告3
聚类表
群集组合系数首次出现阶群集下一阶群集 1 群集 2 群集 1 群集 2
11 5 8 8909339.143 0 6 22
12 2 7 8924771.443 0 7 17
13 10 19 11295059.756 0 0 25
14 22 28 16150669.103 0 0 21
15 4 21 16307806.114 4 0 20
16 6 15 26791380.109 10 0 18
17 2 3 30236391.656 12 0 20
18 6 13 44818134.028 16 0 23
19 9 18 54973236.917 0 0 25
20 2 4 55207713.466 17 15 26
21 14 22 61526555.347 0 14 24
22 5 24 124477353.091 11 9 24
23 6 27 176631641.509 18 0 26
24 5 14 488781146.909 22 21 28
25 9 10 775967399.508 19 13 27
26 2 6 1032818251.122 20 23 28
27 9 17 2293476117.021 25 0 29
28 2 5 3395790865.556 26 24 29
29 2 9 12287019144.16
8
28 27 30
30 1 2 89868157406.33
2
0 29 0
所以,分类为:
第一类:北京
第二类:天津、河北、山西、辽宁、吉林、浙江、安徽、福建、山东、海南、四川、陕西第三类:内蒙古、黑龙江、江西、河南、广西、重庆、贵州、云南、西藏、甘肃、宁夏、新疆
第四类:湖南
(3)
单因素方差分析
平方和df 均方 F 显著性
投入人年数组间59778341.196 3 19926113.732 26.428 .000 组内20357294.159 27 753973.858
总数80135635.355 30
投入高级职称的人年数组间16485966.820 3 5495322.273 34.553 .000 组内4294074.147 27 159039.783
总数20780040.968 30
投入科研事业费(百元)组间
132451401880.8
84
3 44150467293.62
8
324.318 .000 组内3675602946.794 27 136133442.474
总数
136127004827.6
77
30
课题总数组间16470536.564 3 5490178.855 32.181 .000 组内4606273.436 27 170602.720
总数21076810.000 30
专著数组间7203690.385 3 2401230.128 61.327 .000 组内1057167.809 27 39154.363
总数8260858.194 30
论文数组间219675698.219 3 73225232.740 17.693 .000 组内111743385.717 27 4138643.915
总数331419083.935 30
获奖数组间169882.049 3 56627.350 3.619 .026 组内422436.790 27 15645.807
总数592318.839 30
案例与其类别中心之间的距离组间
16021705187.52
7
3 5340568395.842 45.175 .000 组内3191932471.180 27 118219721.155
总数
19213637658.70
7
30
(3)、广西瑶族与广西侗族、贵州苗族、基诺族为一类,土家族与崩龙族、白族为一类,湖南侗族自成一类
4、
初始聚类中心
群集成员
案例 3 群集1:天 1 2:辽 1 3:吉 1 4:江 1 5:浙 2 6:山 1 7:黑 3 8:安 1 9:福 1 10:江 1 11:湖 1 12:湖 1 13:广 1 14:四 1 15:贵 3 16:新 3 17:河 3 18:山 3 19:内 3 20:河 3 21:云 3 22:陕 3 23:甘 3 24:青 3 25:宁 3。