数据库脚本部署说明
如何在Shell脚本中使用数据库

如何在Shell脚本中使用数据库Shell脚本是一种用于自动化任务和处理系统操作的脚本语言。
在与数据库交互时,Shell脚本可以用来连接数据库、执行SQL语句、处理查询结果等。
本文将介绍如何在Shell脚本中使用数据库,并提供几个示例来展示常见的数据库操作。
一、连接数据库在Shell脚本中使用数据库,首先需要连接数据库。
一般来说,常用的关系型数据库有MySQL、Oracle和PostgreSQL等,不同的数据库连接方法有所差异。
1. 连接MySQL数据库:使用命令"mysql -h 主机名 -P 端口号 -u 用户名 -p"连接MySQL数据库。
其中,主机名为数据库服务器的IP地址或主机名,端口号为数据库服务监听的端口,默认情况下为3306,用户名为数据库的登录用户名,"-p"表示需要输入密码。
示例:```shell#!/bin/bash# 连接MySQL数据库mysql -h 127.0.0.1 -P 3306 -u root -p```通过使用Oracle提供的sqlplus工具连接Oracle数据库。
命令格式为"sqlplus 用户名/密码@数据库实例名",其中,用户名为数据库的登录用户名,密码为登录密码,数据库实例名为数据库的实例名称。
示例:```shell#!/bin/bash# 连接Oracle数据库sqlplus scott/tiger@orcl```3. 连接PostgreSQL数据库:使用pgcli或psql命令来连接PostgreSQL数据库。
命令格式为"pgcli -h 主机名 -p 端口号 -U 用户名 -W 数据库名"或"psql -h 主机名 -p 端口号 -U 用户名 -W 数据库名",其中,主机名为数据库服务器的IP地址或主机名,端口号为数据库服务监听的端口,默认情况下为5432,用户名为数据库的登录用户名,"-W"表示需要输入密码,数据库名为要连接的数据库名称。
安装部署手册

第一部分数据库服务器的安装 (2)1 介绍 (2)1.1引言 (2)1.2术语解释 (2)1.3数据结构 (3)2安装Oracle数据库服务器 (3)2.1 查看安装的产品 (4)2.2 开始安装 (5)3安装Oracle客户端 (7)4 配置Oracle数据库 (8)4.1将数据库添加到树 (8)4.2创建数据库DBA用户及方案库 (9)4.3创建系统数据库表并建立初始数据 (11)4.4、数据库备份与恢复 (13)4.4.1数据库备份—数据导出 (13)4.4.2数据库恢复---数据导入 (13)第二部分W AS 服务器的安装配置 (14)5 W AS的安装与配置 (14)5.1 安装W AS软件 (14)5.2 W AS配置 (19)5.2.1 配置JDBC数据源 (19)5.2.2 发布应用 (27)5.2.3 设置websphere与数据库的连接 (28)5.2.4 发布 (33)6 停止和启动websphere注意事项 (38)6.1 停止websphere (38)7.设置IP地址跳转和页面访问 (40)7.1 设置ip地址跳转 (40)7.2访问地址 (41)第一部分数据库服务器的安装1 介绍1.1引言内网信息共享平台使用的数据库是oracle,这里我们选择安装ORACLE9i作为数据库服务器。
1.2术语解释导向库:是办公自动化系统的一个全局数据库,主要功能如下:1)保存所有地区用户的信息2)保存各地区数据库的导向信息3)保存用户与所在地区的关联信息4)保存系统及各子系统的全局参数地区库:主要功能包括系统用户管理、组织架构管理、服务器管理、数据字典管理、权限管理、应用系统管理和工作日期管理等七部分内容。
为办公自动化系统的各个功能模块提供用户与组织架构信息、向系统提供各模块的数据库服务器信息等基本信息。
WAS:WebSphere Application Server的缩写。
1.3数据结构建库SQL语句参考以下文件:导向库.sql导向库初始化脚本.txt地区库_管理工具.sql地区库_引擎.sql地区库_工作流触发器.sql地区库初始化脚本.txt2安装Oracle数据库服务器安装oracle前需要准备好oracle的安装文件。
数据库脚本管理与发布流程

数据库脚本管理与发布流程1.脚本开发脚本开发是指开发人员根据需求编写操作数据库的脚本。
在开发之前,需要确定脚本所需的数据库版本,并在开发环境中创建相应的数据库。
编写脚本时,应考虑到脚本的可重复性和可撤销性,确保脚本的执行结果是可预期的。
2.脚本版本管理版本管理是指对数据库脚本进行版本控制,包括脚本的提交、追踪和回退。
通常使用版本控制系统(如Git)来管理数据库脚本。
每个脚本需要有一个唯一的标识符,可以使用自动生成的序列号或时间戳来标识。
开发人员在提交脚本时,需要将脚本文件添加到版本控制系统中,并添加相应的注释说明修改的内容、原因和影响。
3.脚本测试脚本测试是确保脚本执行的正确性和稳定性的关键步骤。
测试包括单元测试和集成测试。
单元测试是针对单个脚本的测试,验证脚本的语法和逻辑是否正确。
集成测试是将多个脚本进行组合测试,验证脚本之间的依赖关系是否正确。
测试结果应该被记录和审查,发现问题需要及时修复。
4.脚本发布脚本发布是指将开发和测试通过的脚本应用于生产环境。
在发布之前,需要对脚本进行备份,以防止出现意外问题。
发布过程中,需要确保数据库处于维护模式,以防止用户对数据库的操作干扰到脚本的执行。
发布后,需要进行验证和监控,确保脚本的执行结果符合预期。
5.脚本回滚脚本回滚是指在脚本发布后出现问题时恢复到之前的状态。
在脚本发布之前,应该制定相应的回滚策略,包括如何回退脚本和如何还原数据。
回滚过程中需要确保数据的一致性和完整性。
6.脚本文档和培训对于每个数据库脚本,都应该编写相应的文档,包括脚本的用途、功能、参数和配置项。
文档应该更新并与脚本一起存档。
此外,在脚本发布之前,应该对相关人员进行培训,确保他们了解脚本的工作原理和操作流程。
总结:数据库脚本的管理与发布流程是一个重要的环节,它涉及到数据库的稳定性和数据的一致性。
通过以上的流程,可以保证脚本的开发、版本管理、测试和发布的质量和稳定性。
同时,脚本的回滚和文档的编写也能有效地处理脚本发布过程中出现的问题,并提供进一步的支持和培训。
mysql-canal-rabbitmq安装部署超详细教程
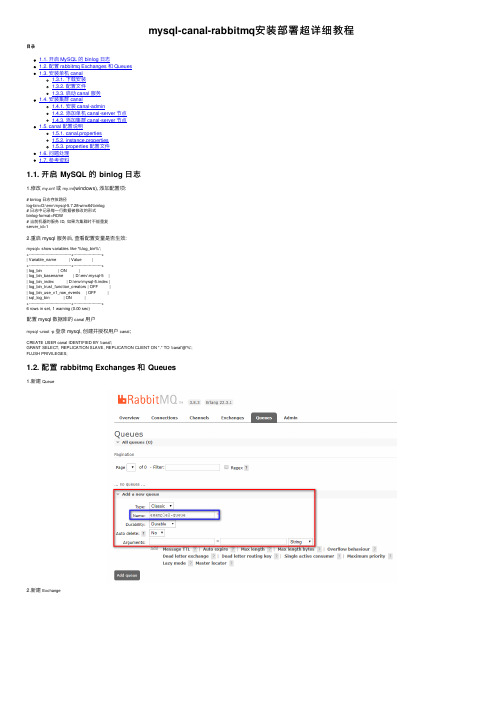
mysql-canal-rabbitmq安装部署超详细教程⽬录1.1. 开启 MySQL 的 binlog ⽇志1.2. 配置 rabbitmq Exchanges 和 Queues1.3. 安装单机 canal1.3.1. 下载安装1.3.2. 配置⽂件1.3.3. 启动 canal 服务1.4. 安装集群 canal1.4.1. 安装 canal-admin1.4.2. 添加单机 canal-server 节点1.4.3. 添加集群 canal-server 节点1.5. canal 配置说明1.5.1. canal.properties1.5.2. instance.properties1.5.3. properties 配置⽂件1.6. 问题处理1.7. 参考资料1.1. 开启 MySQL 的 binlog ⽇志1.修改f或my.ini(windows), 添加配置项:# binlog ⽇志存放路径log-bin=D:\env\mysql-5.7.28-winx64\binlog# ⽇志中记录每⼀⾏数据被修改的形式binlog-format=ROW# 当前机器的服务 ID, 如果为集群时不能重复server_id=12.重启 mysql 服务后, 查看配置变量是否⽣效:mysql> show variables like '%log_bin%';+---------------------------------+----------------------+| Variable_name | Value |+---------------------------------+----------------------+| log_bin | ON || log_bin_basename | D:\env\mysql-5 || log_bin_index | D:\env\mysql-5.index || log_bin_trust_function_creators | OFF || log_bin_use_v1_row_events | OFF || sql_log_bin | ON |+---------------------------------+----------------------+6 rows in set, 1 warning (0.00 sec)配置 mysql 数据库的canal⽤户mysql -uroot -p登录 mysql, 创建并授权⽤户canal;CREATE USER canal IDENTIFIED BY 'canal';GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';FLUSH PRIVILEGES;1.2. 配置 rabbitmq Exchanges 和 Queues1.新建Queue2.新建Exchange3.设置 Queue ⾥的 Bindings, 填写Exchange名称, 以及路由Routing key;1.3. 安装单机 canal1.3.1. 下载安装并解压缩;sudo wget https:///alibaba/canal/releases/download/canal-1.1.4/canal.deployer-1.1.4.tar.gzsudo tar -zxvf canal.deployer-1.1.4.tar.gz最新版本1.1.5的安装sudo wget https:///alibaba/canal/releases/download/canal-1.1.5-alpha-1/canal.deployer-1.1.5-SNAPSHOT.tar.gz sudo tar -zxvf canal.deployer-1.1.5-SNAPSHOT.tar.gz1.3.2. 配置⽂件1.3.2.1. 节点配置⽂件 canal.properties# tcp bind ip, 当前节点的 IP 地址canal.ip = 192.168.2.108# register ip to zookeeper, 注册到 ZK 的 IP 地址, 如下图1.canal.register.ip = 192.168.2.108canal.zkServers = zk集群# tcp, kafka, RocketMQ, 最新版本 1.1.5 可以直接连接 rabbitmqcanal.serverMode = rabbitmq# destinations, 当前 server 上部署的 instance 列表, 对应各个实例⽂件夹(../conf/<instance_name>)名称canal.destinations = example2# 设置 mq 服务器地址, 此处为 rabbitmq 的服务器地址# !! 此处下载后默认的配置是有配置IP:端⼝的# rabbitmq 此处则不需要配置端⼝canal.mq.servers = 192.168.208.100# ⼀下⼏项均为 1.1.5 新版本新增⽀持 rabbitmq 的配置canal.mq.vhost=/canal.mq.exchange=example2-ex # 指定 rabbitmq 上的 exchange 名称, "新建 `Exchange`" 步骤新建的名称ername=admin # 连接 rabbitmq 的⽤户名canal.mq.password=**** # 连接 rabbitmq 的密码canal.mq.aliyunuid=1.3.2.2. 实例配置⽂件 instance.properties# position info, 数据库的连接信息canal.instance.master.address=192.168.2.108:3306# 以下两个配置, 需要在上⾯配置的 address 的数据库中执⾏ `SHOW MASTER STATUS` 获取的 `File` 和 `Position` 两个字段值=mysql-5.7canal.instance.master.position=674996# table meta tsdb info, 禁⽤ tsdb 记录 table meta 的时间序列版本canal.instance.tsdb.enable=false# username/password, 实例连接数据的⽤户名和密码canal.instance.dbUsername=canalcanal.instance.dbPassword=canal# table regex, 正则匹配需要监听的数据库表canal.instance.filter.regex=ysb\\.useropcosttimes_prod# mq config, 指定 rabbitmq 设置绑定的路由, 详见"配置rabbitmq"步骤⾥的第三步配置的`Routing key`canal.mq.topic=example2-routingkey1.3.3. 启动 canal 服务Linux 对应的启动脚本./bin/startup.sh, Windows 对应的启动脚本./bin/startup.bat; 以 Windows 为例:λ .\startup.batstart cmd : java -Xms128m -Xmx512m -XX:PermSize=128m -Djava.awt.headless=true .preferIPv4Stack=true -Dapplication.codeset=UTF-8 -Dfile.encoding=UTF-8 -server -Xdebug -Xnoagent piler=NONE -Xrunjdwp:transport=dt_socket,add Java HotSpot(TM) Server VM warning: ignoring option PermSize=128m; support was removed in 8.0Listening for transport dt_socket at address: 9099最后⼿动修改数据库数据, 或者等待其他的修改, 再查看⼀下 rabbitmq 上的监控即可知道流程是否⾛通了.1.4. 安装集群 canal1.4.1. 安装 canal-admin1.4.1.1. 下载安装并解压缩sudo wget https:///alibaba/canal/releases/download/canal-1.1.5-alpha-1/canal.admin-1.1.5-SNAPSHOT.tar.gzsudo tar -zxvf canal.admin-1.1.5-SNAPSHOT.tar.gz1.4.1.2. 配置⽂件application.ymlserver:port: 8089spring:jackson:date-format: yyyy-MM-dd HH:mm:sstime-zone: GMT+8spring.datasource:address: 192.168.2.108:3306database: canal_managerusername: canalpassword: canaldriver-class-name: com.mysql.jdbc.Driver# 数据库连接字符串末尾需添加`serverTimezone=UTC`, 否则启动时会报时区异常;url: jdbc:mysql://${spring.datasource.address}/${spring.datasource.database}?useUnicode=true&characterEncoding=UTF-8&useSSL=false&serverTimezone=UTChikari:maximum-pool-size: 30minimum-idle: 1canal:# 配置 canal-admin 的管理员账号和密码adminUser: adminadminPasswd: 123456canal_manager.sql在管理canal-admin数据的数据库中执⾏该 sql 脚本, 初始化⼀些表;1.4.1.3. 启动 canal-admin 服务Linux 对应的启动脚本./bin/startup.sh, Windows 对应的启动脚本./bin/startup.bat; 以 Windows 为例:λ .\startup.batstart cmd : java -Xms128m -Xmx512m -Djava.awt.headless=true .preferIPv4Stack=true -Dapplication.codeset=UTF-8 -Dfile.encoding=UTF-8 -DappName=canal-admin -classpath "D:\env\green\canal-1.1.5-admin\bin\\..\conf\..\lib\*;D:\env\green\canal-2020-04-13 20:01:39.495 [main] INFO com.alibaba.otter.canal.admin.CanalAdminApplication - Starting CanalAdminApplication on Memento-PC with PID 50696 (D:\env\green\canal-1.1.5-admin\lib\canal-admin-server-1.1.5-SNAPSHOT.jar started by Memento in 2020-04-13 20:01:39.527 [main] INFO com.alibaba.otter.canal.admin.CanalAdminApplication - No active profile set, falling back to default profiles: default2020-04-13 20:01:39.566 [main] INFO o.s.b.w.s.c.AnnotationConfigServletWebServerApplicationContext - Refreshing org.springframework.boot.web.servlet.context.AnnotationConfigServletWebServerApplicationContext@13a5bf6: startup date [Mon Apr 13 20:01 2020-04-13 20:01:41.149 [main] INFO o.s.boot.web.embedded.tomcat.TomcatWebServer - Tomcat initialized with port(s): 8089 (http)2020-04-13 20:01:41.166 [main] INFO org.apache.coyote.http11.Http11NioProtocol - Initializing ProtocolHandler ["http-nio-8089"]2020-04-13 20:01:41.176 [main] INFO org.apache.catalina.core.StandardService - Starting service [Tomcat]2020-04-13 20:01:41.177 [main] INFO org.apache.catalina.core.StandardEngine - Starting Servlet Engine: Apache Tomcat/8.5.29...2020-04-13 20:01:42.996 [main] INFO org.apache.coyote.http11.Http11NioProtocol - Starting ProtocolHandler ["http-nio-8089"]2020-04-13 20:01:43.007 [main] INFO .NioSelectorPool - Using a shared selector for servlet write/read2020-04-13 20:01:43.019 [main] INFO o.s.boot.web.embedded.tomcat.TomcatWebServer - Tomcat started on port(s): 8089 (http) with context path ''2020-04-13 20:01:43.024 [main] INFO com.alibaba.otter.canal.admin.CanalAdminApplication - Started CanalAdminApplication in 3.919 seconds (JVM running for 5.241)1.4.1.4. 注意事项canal-admin连接数据库的账号, 必须有建表, 读写数据的权限, 如果还是采⽤上⽂中创建的canal账号, 需要另外扩展⼀下权限:GRANT ALL PRIVILEGES ON *.* TO 'canal'@'%' ;1.4.2. 添加单机 canal-server 节点1.4.2.1. 启动 canal-server 节点服务单机 canal-server 照常启动, 此时, canal-server 默认加载的../conf/canal.properties⾥的配置信息, 可以从../bin/startup.bat[startup.sh]脚本中获悉, 获取从执⾏的脚本命令提⽰⾥获悉;1.4.2.2. 新建单机 server在canal-admin中新建⼀个单机server该server会⾃动识别已启动的canal-server节点, 但是此时由admin接管后, 不会⾃动加载../conf/canal.properties的配置⽂件, 点击最右侧的操作-配置查看, 该 server 加载的是默认的配置信息需要⼿动将1.3.2中配置好的../conf/canal.properties⾥的配置信息拷贝到该配置⾥进⾏覆盖!1.4.2.3. 新建实例 instance⼿动在canal-admin中新建⼀个instance, 对应单机canal-server配置下的实例example2; 同样, 需要⼿动将./conf/<实例名称>/instance.properies配置⽂件⼿动拷贝到 admin 中!!注意在新建或启动instance实例时, 先删除实例⽂件夹下的meta.dat⽂件, 并更新=..., canal.instance.master.position=...两个配置项;1.4.3. 添加集群 canal-server 节点1.4.3.1. 新建集群需要指定集群名称, 以及配置集群绑定的zookeeper集群地址;新建成功后, 在最右侧的操作-主配置中配置集群的通⽤ server 配置信息此处也可以将之前配置的../conf/canal.properties配置直接拷贝过来, 稍微修改⼀下就可以⽤了# canal admin configcanal.admin.manager = 192.168.2.108:8089canal.instance.global.mode = manager1.4.3.2. 新建 server指定所属集群, 为1.4.3.1中设定的集群名称;如果先前已经启动了canal-server节点服务, 则新建的 server 会⾃动识别为启动状态, 否则为断开状态;这⾥有⼀点需要⼗分注意的地⽅细⼼的⼈可能会发现, 除了canal.properties配置⽂件, 还有⼀个canal_local.properties的配置⽂件, 后者⽐前者的内容少了很多, 因为这个⽂件就是⽤于搭建canal集群时, 本地节点的配置⽂件, ⽽前者配置⽂件⾥的其他信息都是交由canal-admin集中配置管理的;在./bin/startup.bat[startup.sh]启动脚本⾥, 默认是加载canal.properties配置⽂件, 即以单机形式启动的服务;windows 在搭建canal集群时, 需要⼿动修改startup.bat, 蓝⾊标注处是加载%canal_conf%变量的配置⽂件路径, 所以需要将红⾊框内的变量调整为:@rem set canal_conf=...set canal_conf=%conf_dir%\canal_local.properties使启动时加载canal_local.properties的配置⽂件1.4.3.3. 新建 instance此处配置也可以基于单机 server 中的实例1.4.2.3配置进⾏调整使⽤;# 2. position info, 指定 mysql 开始同步的 binlog 位置信息canal.instance.master.address=192.168.0.25:63306=mysql-bin.001349canal.instance.master.position=198213313# 3. username/password, 设置同步 mysql 的数据库⽤户名和密码canal.instance.dbUsername=xxxxcanal.instance.dbPassword=xxx# 4. table regex, 正则匹配需要同步的数据表canal.instance.filter.regex=xxxx# 5. mq config, 指定 mysql 上的路由绑定, 见 `1.2.3`canal.mq.topic=example2-routingkey保存后即可在操作中启动该实例后话如果此处的 instance ⽆法启动, 按⼀下⼏个步骤检查操作⼀下试试:检查集群⾥的主配置⾥的canal.destinations是否包含新建的实例instance名称;检查canal-server节点是否加载的canal_local.properties配置⽂件;删除实例⽂件夹下的.db, .bat⽂件, 更新实例配置⽂件中的canal.instance.master.position的binglog位置后, 启动instance;1.5. canal 配置说明1.5.1. canal.properties1. canal.ip, 该节点 IP2. canal.register.ip, 注册到 zookeeper 上的 IP3. canal.zkServers, zk 集群4. 是否启⽤ tsdb, 开启 table meta 的时间序列版本记录功能5. // 5. canal.serverMode, 设置为 rabbitmq, 默认为 tcpcanal.instance.tsdb.enable = truecanal.instance.tsdb.dir = ${canal.file.data.dir:../conf}/${canal.instance.destination:}canal.instance.tsdb.url = jdbc:h2:${canal.instance.tsdb.dir}/h2;CACHE_SIZE=1000;MODE=MYSQL;canal.instance.tsdb.dbUsername = canalcanal.instance.tsdb.dbPassword = canal5.canal.destinations, 当前集群上部署的 instance 列表6.canal.mq.servers, 设置 Rabbitmq 集群地址, !! 此处不可以加上端⼝1.5.2. instance.properties1. canal.instance.master.address, master 数据库地址2. , 在数据库中执⾏show master status的File值3. canal.instance.master.position, 在数据库中执⾏show master status的Position值4. canal.instance.tsdb.enable=false, 禁⽤ tsdb5. canal.instance.dbUsername, 实例数据库⽤户名6. canal.instance.dbPassword, 实例数据库密码7. canal.instance.filter.regex, 匹配需要同步的表8. canal.mq.topic, canal 注册 mq 的 topic 名称1.5.3. properties 配置⽂件properties配置分为两部分canal.properties (系统根配置⽂件)instance.properties (instance 级别的配置⽂件, 每个实例⼀份)1.canal.propertiescanal.destinations # 当前 server 上部署的 instance 列表canal.conf.dir # conf ⽬录所在路径canal.auto.scan # 开启 instance ⾃动扫描# 如果配置为 true, canal.conf.dir ⽬录下的 instance 配置变化会⾃动触发# 1. instance ⽬录新增: 触发 instance 配置载⼊, lazy 为 true 时则⾃动启动;# 2. instance ⽬录删除: 卸载对应 instance 配置, 如已启动则进⾏关闭;# 3. instance.properties ⽂件变化: reload instance 配置, 如已启动则⾃动进⾏重启操作;canal.auto.scan.interval # instance ⾃动扫描间隔时间, 单位 scanal.instance.global.mode # 全局配置加载⽅式zy # 全局 lazy 模式canal.instance.global.manager.address # 全局的 manager 配置⽅式的链接信息canal.instance.global.spring.xml # 全局的 spring 配置⽅式的组件⽂件canal.instance.example.modezycanal.instance.example.spring.xml# instance 级别的配置定义, 如有配置, 会⾃动覆盖全局配置定义模式canal.instance.tsdb.enable # 是否开启 table meta 的时间序列版本记录功能canal.instance.tsdb.dir # 时间序列版本的本地存储路径, 默认为 instance ⽬录canal.instance.tsdb.url # 时间序列版本的数据库连接地址, 默认为本地嵌⼊式数据库canal.instance.tsdb.dbUsername # 时间序列版本的数据库连接账号canal.instance.tsdb.dbPassword # 时间序列版本的数据库连接密码2.instance.propertiescanal.id # 每个 canal server 实例的唯⼀标识canal.ip # canal server 绑定的本地 IP 信息, 如果不配置, 默认选择⼀个本机 IP 进⾏启动服务canal.port # canal server 提供 socket 服务的端⼝canal.zkServers # canal server 连接 zookeeper 集群的连接地址, 例如: 10.20.144.22:2181,10.20.144.23:2181canal.zookeeper.flush.period # canal 持久化数据到 zookeeper 上的更新频率, 单位 mscanal.instance.memory.batch.mode # canal 内存 store 中数据缓存模式# 1. ITEMSIZE: 根据 buffer.size 进⾏限制, 只限制记录的数量# 2. MEMSIZE: 根据 buffer.size * buffer.memunit 的⼤⼩, 限制缓存记录的⼤⼩;canal.instance.memory.buffer.size # canal 内存 store 中可缓存 buffer 记录数, 需要为 2 的指数canal.instance.memory.buffer.memunit # 内存记录的单位⼤⼩, 默认为 1KB, 和 buffer.size 组合决定最终的内存使⽤⼤⼩canal.instance.transactions.size # 最⼤事务完整解析的长度⽀持, 超过该长度后, ⼀个事务可能会被拆分成多次提交到 canal store 中, ⽆法保证事务的完整可见性canal.instance.fallbackIntervalInSeconds # canal 发⽣ mysql 切换时, 在新的 mysql 库上查找 binlog 时需要往前查找的时间, 单位 s# 说明: mysql 主备库可能存在解析延迟或者时钟不⼀致, 需要回退⼀段时间, 保证数据不丢canal.instance.detecting.enable # 是否开启⼼跳检查canal.instance.detecting.sql # ⼼跳检查 sql, insert into retl.xdual values(1,now()) on duplicate key update x=now()canal.instance.detecting.interval.time # ⼼跳检查频率, 单位 scanal.instance.detecting.retry.threshold # ⼼跳检查失败重试次数canal.instance.detecting.heatbeatHaEnable # ⼼跳检查失败后, 是否开启 mysql ⾃动切换# 说明: ⽐如⼼跳检查失败超过阈值后, 如果该配置为 true, canal 会⾃动连到 mysql 备库获取 binlog 数据work.receiveBufferSize # ⽹络连接参数, SocketOptions.SO_RCVBUFwork.sendBufferSize # ⽹络连接参数, SocketOptions.SO_SNDBUFwork.soTimeout # ⽹络连接参数, SocketOptions.SO_TIMEOUT1.5.4. canal.mq.dynamicTopic1.6. 问题处理1.windows 下执⾏startup.bat启动 canal 时, 出现如下异常Failed to instantiate [ch.qos.logback.classic.LoggerContext]Reported exception:ch.qos.logback.core.LogbackException: Unexpected filename extension of file [file:/D:/env/green/canal/conf/]. Should be either .groovy or .xmlat ch.qos.logback.classic.util.ContextInitializer.configureByResource(ContextInitializer.java:79)at ch.qos.logback.classic.util.ContextInitializer.autoConfig(ContextInitializer.java:152)at org.slf4j.impl.StaticLoggerBinder.init(StaticLoggerBinder.java:85)at org.slf4j.impl.StaticLoggerBinder.<clinit>(StaticLoggerBinder.java:55)at org.slf4j.LoggerFactory.bind(LoggerFactory.java:141)at org.slf4j.LoggerFactory.performInitialization(LoggerFactory.java:120)at org.slf4j.LoggerFactory.getILoggerFactory(LoggerFactory.java:331)at org.slf4j.LoggerFactory.getLogger(LoggerFactory.java:283)at org.slf4j.LoggerFactory.getLogger(LoggerFactory.java:304)at com.alibaba.otter.canal.deployer.CanalLauncher.<clinit>(CanalLauncher.java:29)解决⽅法:将startup.bat⾥的⼀下这⾏代码注释打开@rem set logback_configurationFile=%conf_dir%\logback.xml注, 新版1.1.5不存在该问题, 1.1.5这个⽂件中的这⼀⾏是没有注释掉的.1.1.5新版本canal-admin启动时出现如下异常:2020-04-10 18:55:40.406 [main] ERROR com.zaxxer.hikari.pool.HikariPool - HikariPool-1 - Exception during pool initialization.java.sql.SQLException: The server time zone value '�й��� ʱ��' is unrecognized or represents more than one time zone. You must configure either the server or JDBC driver (via the serverTimezone configuration property) to use a more specifc time zone value if you want to utilize time zone support.解决⽅法spring.datasource.url配置的 mysql 连接地址后⾯加上参数&serverTimezone=UTCInstance⽇志⾥出现异常errno = 1236, sqlstate = HY000 errmsg = log event entry exceeded max_allowed_packet;2020-04-13 13:06:09.507 [destination = example3 , address = /192.168.2.108:3306 , EventParser] ERROR mon.alarm.LogAlarmHandler -destination:example3[java.io.IOException: Received error packet: errno = 1236, sqlstate = HY000 errmsg = log event entry exceeded max_allowed_packet; Increase max_allowed_packet on master; the first event 'mysql-5.7' at 671745, the last event read from 'D:\env\mysql-5.7' at 673181, the last byte read from 'D:\env\mysql-5.7' at 673200.at com.alibaba.otter.canal.parse.inbound.mysql.dbsync.DirectLogFetcher.fetch(DirectLogFetcher.java:102)at com.alibaba.otter.canal.parse.inbound.mysql.MysqlConnection.dump(MysqlConnection.java:235)at com.alibaba.otter.canal.parse.inbound.AbstractEventParser$3.run(AbstractEventParser.java:265)at ng.Thread.run(Unknown Source)]解决⽅法删除canal/conf下对应实例⾥的meta.dat⽂件, 让canal-admin⾃动再⽣成即可;1.7. 参考资料到此这篇关于mysql-canal-rabbitmq 安装部署超详细教程的⽂章就介绍到这了,更多相关mysql-canal-rabbitmq 安装部署内容请搜索以前的⽂章或继续浏览下⾯的相关⽂章希望⼤家以后多多⽀持!。
数据库部署方案

数据库部署方案目录1. 简介1.1 什么是数据库部署方案1.1.1 数据库部署方案的作用1.1.2 数据库部署方案的重要性1.2 数据库部署方案的种类1.2.1 本地部署1.2.2 云端部署1.2.3 混合部署1.简介数据库部署方案是指根据需求和条件制定的数据库部署计划,旨在实现数据库系统在不同环境下的最佳性能和稳定性。
通过有效的数据库部署方案,可以提高数据库系统的管理效率,确保数据安全性和可靠性。
1.1 什么是数据库部署方案数据库部署方案是为了在数据库系统上部署服务、应用程序或其他软件而规划和实施的整体方法。
它包括硬件配置、软件安装、数据备份和恢复等方面的考虑,旨在为用户提供高性能、高可用性的数据库服务。
1.1.1 数据库部署方案的作用数据库部署方案的作用主要是为了规划和实施数据库系统的部署过程,确保系统能够按照预期的要求和性能需求正常运行。
它还可以提高系统的安全性和可靠性,降低系统出现故障的风险。
1.1.2 数据库部署方案的重要性数据库部署方案的重要性在于它可以帮助用户制定合理的部署策略,提高系统的灵活性和可维护性。
一个好的数据库部署方案可以确保系统在不同环境下都能够正常运行,并能够及时调整和优化系统的性能。
1.2 数据库部署方案的种类数据库部署方案主要分为本地部署、云端部署和混合部署三种。
1.2.1 本地部署本地部署是指将数据库系统部署在用户自己的本地服务器上,用户可以直接控制和管理数据库系统,但需要投入大量的硬件资源和人力成本。
1.2.2 云端部署云端部署是将数据库系统部署在云端服务器上,用户可以根据需要进行灵活的扩展和缩减,减少了硬件维护和管理的成本,但也带来了网络延迟和安全问题。
1.2.3 混合部署混合部署是将数据库系统部署在本地和云端服务器上,结合了本地部署和云端部署的优点,既可以获得本地资源的控制和灵活性,又可以享受云端部署的便捷和高可用性特点。
ORACLE数据库部署手册范本

ORACLE数据库部署手册1.Oracle简介Oracle Database,又名Oracle RDBMS,或简称Oracle。
是甲骨文公司的一款关系数据库管理系统。
它是在数据库领域一直处于领先地位的产品。
可以说Oracle数据库系统是目前世界上流行的关系数据库管理系统,系统可移植性好、使用方便、功能强,适用于各类大、中、小、微机环境。
它是一种高效率、可靠性好的适应高吞吐量的数据库解决方案。
2.Oracle安装医院部署数据库要求使用Oracle 11G R2(64Bit)正版数据库,建议使用医院采购的正版oracle11g数据库软件。
本文档详细介绍Oracle11gR2的安装步骤、常用服务、日常使用等。
本文档主要介绍Oracle11gR2数据库的安装步骤,关于不同应用程序的具体数据库配置,则在对应的应用程序的产品手册中详细描述。
2.1.安装环境的要求2.2.安装步骤1)运行安装文件打开安装包后,双击setup.exe文件;稍等片刻后,出现如下所示的安装界面;如下图1所示:图 12)配置安全更新等oracle安装程序启动以后,第二步就进入了【配置安全更新】环节,这一步可将自己的电子信息填写进去点击“下一步”;如下图2所示:图 23)选择安装选项安装选项有三种选择:新部署数据库时选择“创建和配置数据库”,点击下一步;当安装完毕数据库管理软件后,系统会自动创建一个数据库实例,点击“下一步”;如下图3所示:图 34)系统类选项设置进入“系统类选项设置”,系统类选项设置分为桌面类和服务器类两种;如下图4所示:桌面类:使用桌面类系统安装。
使用WINDOWS系统则使用此类典型安装。
服务器类:适合linux服务器环境下的高级安装。
图 45)典型安装配置选择桌面类之后,默认为典型安装,填写完成后,点击“下一步”继续;如下图5所示:Oracle基目录:目录路径不要含有中文或其它的特殊字符软件位置:也即是实例存储的目录数据库文件位置:放置数据库文件的位置数据库版本:这里选择使用企业版字符集:选择默认值ZHS16GBK字符集(此处字符集一定要选择这个)全局数据库名称(即实例名称)和口令:全局数据库名(数据库名称):orcl,管理口令(密码):根据需要设置注:此处实例名称和口令十分重要(相当于SQL数据库的登录名和密码),请单独记录保存。
mysql分布式部署方案

mysql分布式部署方案随着互联网应用的快速发展,对于数据库的需求也越来越大。
传统的单机数据库在面对高并发、大量数据的场景下已经无法满足需求,因此分布式数据库逐渐成为了一种趋势。
MySQL作为目前最常用的关系型数据库之一,也提供了一些分布式部署方案,本文将介绍几种常见的MySQL分布式部署方案。
一、主从复制主从复制是MySQL自带的一种分布式部署方案,通过将主数据库的数据同步到从数据库上,实现读写分离,提高数据库的并发处理能力。
主从复制适用于以读操作为主的场景,可以有效利用从数据库的读能力,减轻主数据库的读压力。
主从复制的基本原理是:主库记录变更操作,将变更信息写入二进制日志,从库连接主库,将主库的日志应用到自己的数据上。
二、分片分片是将一个数据库按照某种规则拆分成多个片段,并将这些片段分布在不同的数据库服务器上。
分片可以水平扩展数据库,提高存储容量和读写能力。
常见的分片规则有哈希分片和范围分片两种。
哈希分片可以根据某个字段的哈希值来决定数据属于哪个片段,范围分片则是根据某个字段的取值范围来决定数据属于哪个片段。
三、MySQL ClusterMySQL Cluster是MySQL的一种高可用性、高扩展性的分布式数据库解决方案。
它采用了多主复制的架构,每个节点都是一个MySQL 实例,节点之间通过同步复制来实现数据的一致性。
MySQL Cluster可以提供高可用性和高可靠性的数据库服务,支持水平扩展以及故障自动恢复。
四、MySQL ProxyMySQL Proxy是一个支持分布式部署的数据库代理工具,它可以根据需求在多个MySQL服务节点之间进行连接路由和负载均衡。
MySQL Proxy可以实现读写分离、分片等功能,从而提高数据库的性能和可扩展性。
它可以对数据库的请求进行拦截和处理,实现一些自定义的逻辑。
MySQL Proxy常用于应用层与数据库之间的中间层,可以提供更灵活和高效的数据库访问方式。
Phabricator部署手册

Phabricator部署⼿册概述phabricator,由facebook公司开发,是⼀个开源的代码审查系统,帮助软件公司建⽴更好的软件。
该系统能够部署在多数linux发⾏版以及os x系统上。
本⽂档仅是该系统部署的⼀个简单指导,详细内容请查看官⽹说明和解释,本说明的部署仅针对Ubuntu 14.04 LTS版本操作系统。
安装脚本安装时,需要先选定安装路径,因为安装脚本是默认使⽤当前⼯作路径安装的,当然,你也可以修改脚本上的安装路径。
启动安装脚本,按照提⽰⼀步⼀步的执⾏。
安装时会检查系统是否已安装必须的组件(MYSQL、APACHE2等),如果没有安装,则脚本会⾃动安装。
安装到最后会提⽰是否修复问题(Fix issue),选择修复并继续执⾏,执⾏完成后,即已安装完成。
安装过程中会从github中克隆出该系统的源码和相关⽂件,这个过程可能会⽐较耗时,需要耐⼼等待。
安装完成后安装⽬录会出现⼀个phabricator⽬录,该⽬录包含了该系统的所有⽂件以及源码。
安装完成后请检查MySQL以及Apache2是否安装成功,以及服务是否可以正常启动。
部署webserverPhabricator安装完成后需要将其使⽤Apache2部署,部署时应该特别注意配置,在不同的操作系统中配置项以及配置⽂件可能不同,这⾥使⽤的是Ubuntu 14.04 LTS版本的Apache2 2.4.7版本。
在/etc/apache2⽬录需要注意如下路径:ports.conf:web站点可⽤的端⼝,默认为80,使⽤不同端⼝时需要修改或者该⽂件中的监听端⼝。
sites-avaliable:web站点虚拟主机的配置⽂件存在路径。
sites-enabled:sites-avaliable配置⽂件对应的连接⽂件路径。
如果使⽤默认路径时需要在sites-avaliable路径下禁⽤默认的虚拟主机,此时对应的连接⽂件将会被删除;启⽤新的虚拟主机时需要创建对应的连接⽂件。
达梦数据库安装部署文档release

达梦数据库安装部署文档一.数据库安装(重点说明linux安装)1. Windows环境安装配置好每个页面后点击“下一步”,默认安装即可,安装路径根据自己的要求选择。
在使用达梦数据库配置助手dbca工具初始化库的过程中,需要将下图红色框选部分改为如图所示。
详细的安装细节可以参考DM7_Install_zh.pdf文档或咨询本区域资深服务工程师。
注意:页大小(page_size)除去Clob、Blob等大字段外,数据库中一行记录的所有字段的实际长度的和不能超过页大小的一半;日志文件的大小(log_size)数据库redo日志文件的大小,单位为M。
(正式环境日志文件的大小一般设置为2048);字符串比较大小写敏感(case_sensitive)默认为大小写敏感的,根据具体情况进行设置。
迁移实施中针对原始库Oracle数据库是大小写敏感的,SQL Server和MySQL数据库默认对大小写是不敏感的,所以在数据库安装的过程中需要根据具体情况来选择。
建议:在开发环境和测试环境的页大小、字符串大小写敏感等初始化参数一定要保持一致,避免使用.bak文件还原的时候,因为初始化参数不一致导致无法还原。
2. Linux环境安装2.1 预设场景执行程序:/opt/dmdbms数据文件:/opt /dmdataOS:中标麒麟64位linux2.1 检查安装环境用户首先以root用户登录,进行以下安装前的准备工作1.检查安装程序的临时目录的硬盘需求安装程序产生的临时文件,默认使用/tmp目录。
为了安装程序能够正常运行,用户应该保证/tmp有大于600M的剩余空间。
用户可以使用以下命令进行查询:df -h /tmp 如果/tmp目录的剩余空间不足,用户可以扩充/tmp目录的空间,也可以通过设置环境变量DM_INSTALL_TMPDIR指定安装程序的临时目录。
2.建议关闭防火墙service iptables stop2.2 Linux系统使用非root用户进行安装(建议使用)为了减少对操作系统的影响,用户不应该以root用户来安装和运行达梦数据库。
2024sybase建库sybase数据库使用教程

sybase建库sybase数据库使用教程contents •Sybase数据库简介•Sybase数据库安装与配置•Sybase数据库基本操作•Sybase数据库高级功能•Sybase数据库性能优化•Sybase数据库备份与恢复•Sybase数据库安全管理目录01Sybase数据库简介Sybase 数据库提供了高性能的数据处理能力,支持大量并发用户和数据操作。
高性能Sybase 数据库具有良好的可伸缩性,可以根据业务需求进行扩展或缩减。
可伸缩性Sybase 数据库提供了多种安全机制,包括身份验证、访问控制、数据加密等,确保数据的安全性和完整性。
安全性Sybase 数据库提供了丰富的开发和管理工具,使得数据库的开发、部署和维护变得更加容易。
易用性Sybase 数据库特点03互联网应用Sybase 数据库也适用于互联网应用,如电商、社交等,能够应对高并发、大数据量的挑战。
01企业级应用Sybase 数据库适用于大型企业级应用,如ERP 、CRM 等,能够满足复杂业务流程和数据处理需求。
02移动应用Sybase 数据库支持移动应用的后端数据库,为移动应用提供高效、稳定的数据存储和处理能力。
早期阶段发展壮大被收购与整合Sybase数据库最早由Sybase公司开发,是一款基于关系型数据库的管理系统。
随着市场需求的不断增长,Sybase数据库不断进行技术创新和产品升级,逐渐发展成为一款功能强大的企业级数据库产品。
后来,Sybase公司被SAP公司收购,Sybase数据库也成为了SAP产品线中的重要组成部分,与SAP的其他产品进行了深度整合和优化。
02Sybase数据库安装与配置安装Sybase 数据库软件按照安装向导的指示完成软件的安装过程,选择适当的安装选项和配置设置。
验证安装安装完成后,可以通过命令行界面或图形用户界面验证Sybase 数据库软件是否成功安装。
下载Sybase 数据库软件安装包从官方网站或可信赖的下载站点获取适用于您的操作系统的Sybase 数据库软件安装包。
2024版TCM脚本使用教程

0102TCM脚本是一种基于文本的配置管理工具,用于管理和自动化网络设备的配置任务。
它通过提供一套简洁易懂的脚本语言,使得用户可以方便地编写和执行配置脚本,实现对网络设备的批量配置、自动化部署和监控等功能。
TCM脚本定义与作用03TCM 脚本可以应用于大规模网络设备的批量配置,提高配置效率,减少手动操作的工作量。
网络设备批量配置通过编写和执行TCM 脚本,可以实现网络设备的自动化部署和运维,降低运维成本,提高网络稳定性。
自动化部署与运维TCM 脚本还可以用于网络设备的监控和故障排查,帮助用户及时发现和解决网络问题。
网络监控与故障排查TCM 脚本应用场景TCM 脚本语言采用简洁明了的语法结构,使得用户可以快速上手并编写出高效的配置脚本。
简单易学TCM 脚本可以在不同的操作系统和网络设备上运行,具有良好的跨平台支持能力。
跨平台支持TCM 脚本提供了丰富的内置函数和库,支持多种网络协议和设备类型,可以满足用户各种复杂的配置需求。
强大的功能TCM 脚本在执行过程中会对配置操作进行严格的权限控制和安全性检查,确保配置任务的安全可靠。
安全性高TCM 脚本优势与特点1 2 3确保代码清晰、易读、易于维护。
遵循标准的编程规范通过适当的缩进和空行,使代码结构更加清晰。
使用缩进和空行在关键部分添加注释,解释代码的功能和实现思路。
注释的使用编写规则与规范输出信息到控制台。
echo条件判断语句,根据条件执行不同的操作。
if设置变量的值。
set循环语句,用于遍历列表或执行重复操作。
for常用命令及功能01变量命名规则变量名只能包含字母、数字和下划线,且不能以数字开头。
02数据类型TCM脚本支持字符串、数字、布尔值等数据类型。
03变量赋值使用等号(=)进行变量赋值操作。
变量与数据类型使用`if`语句进行条件判断,根据条件执行相应的代码块。
条件判断循环语句嵌套语句使用`for`循环语句遍历列表或执行重复操作,可以使用`break`和`continue`控制循环流程。
腾讯云 TDSQL MySQL版(私有云)安装手册说明书

TDSQL MySQL版(私有云)安装手册产品文档【版权声明】©2013-2022 腾讯云版权所有本文档(含所有文字、数据、图片等内容)完整的著作权归腾讯云计算(北京)有限责任公司单独所有,未经腾讯云事先明确书面许可,任何主体不得以任何形式复制、修改、使用、抄袭、传播本文档全部或部分内容。
前述行为构成对腾讯云著作权的侵犯,腾讯云将依法采取措施追究法律责任。
【商标声明】及其它腾讯云服务相关的商标均为腾讯云计算(北京)有限责任公司及其关联公司所有。
本文档涉及的第三方主体的商标,依法由权利人所有。
未经腾讯云及有关权利人书面许可,任何主体不得以任何方式对前述商标进行使用、复制、修改、传播、抄录等行为,否则将构成对腾讯云及有关权利人商标权的侵犯,腾讯云将依法采取措施追究法律责任。
【服务声明】本文档意在向您介绍腾讯云全部或部分产品、服务的当时的相关概况,部分产品、服务的内容可能不时有所调整。
您所购买的腾讯云产品、服务的种类、服务标准等应由您与腾讯云之间的商业合同约定,除非双方另有约定,否则,腾讯云对本文档内容不做任何明示或默示的承诺或保证。
【联系我们】我们致力于为您提供个性化的售前购买咨询服务,及相应的技术售后服务,任何问题请联系 4009100100。
文档目录安装手册10.3.19.1.x部署简介规划设计部署前准备部署必选组件安装必选组件完成监控库配置安装MC部署其他(可选)组件概述安装HDFS安装LVS其他组件安装授权LICENSE集群验收安全收尾安装过程常见问题与排障指引安装回滚安装手册10.3.19.1.x部署简介最近更新时间:2021-11-15 14:57:04部署方案介绍本文档适用于基于TDSQL一键部署包分别在基于x86(64)芯片、基于ARM(鲲鹏920)系列芯片上的CentOS7.8、7.9,银河麒麟操作系统V10,如下表。
TDSQL一键部署包版本号CPU操作系统V10.3.19.1.0、10.3.19.2.0X86_64CentOS 7.8、7.9(含补丁)V10.3.19.1.2、10.3.19.2.2ARM(aarch64) 鲲鹏920系列银河麒麟V10(含补丁)部署流程示意本产品部署过程至少包括以下几个步骤规划设计部署前准备部署必选组件部署可选组件授权license集群验收规划设计最近更新时间:2021-11-15 14:57:12警告:本产品(含业内主流商用数据库)不建议在任何虚拟机(云服务器)中安装、运行本产品作为业务系统生产数据库。
图书管理SQLServer建库脚本

USex char(2) not null default '男' check(USex in ('男','女')), --用户性别
UAddress varchar(50) not null, --用户地址
)
GO
grant select,alter,insert,update,delete on dbo.Book to center
grant select on dbo.Book to opac
--创建系部表
if exists(select * from sysobjects where [name]='xibu')
BIntime varchar(10) not null, ---图书的入库时间
BookGood int not null, ---图书的好坏程度/////--------------修改(成熟新在1至10之间)
BookState tinyint not null ---图书可借否(bit)1表示可借 0表示不可借
LOG ON
( NAME = N'mylibriry_log' , FILENAME = N'D:\mylibriry.ldf' , SIZE = 2MB , MAXSIZE = 20GB , FILEGROWTH = 10%)
COLLATE Chinese_PRC_CI_AS
GO
RECONFIGURE
GO
--允许执行xp_cmdshell
EXEC sp_configure 'xp_cmdshell', 1
数据库使用说明范文

数据库使用说明范文一、数据库的相关概念数据库是计算机系统中的一种数据存储结构,用于组织和存储数据。
数据库系统包括数据库管理系统(DBMS)和数据库。
数据库管理系统是指对数据库进行管理、维护和操作的软件系统,它提供了各种操作接口和功能。
而数据库则是指一个或多个相关数据的集合,可以是文本、数字、图像、音频等。
二、数据库的安装和配置2.安装数据库软件并按照安装向导进行配置。
配置过程包括设置数据库存储路径、端口号、管理员用户名和密码等。
根据具体的需求进行设置,确保数据库能够正常运行。
3.启动数据库服务。
在安装目录下找到对应的启动程序,双击启动或通过命令行方式启动。
启动成功后,数据库服务会在后台运行并等待连接。
三、数据库的创建和管理1.创建数据库在数据库管理系统中,可以使用SQL语句来创建数据库。
语法如下:```CREATE DATABASE database_name;```其中,database_name为要创建的数据库名称。
执行该语句后,系统会自动创建一个新的数据库。
2.数据表的创建在数据库中,数据以表格的形式组织,表格包含行和列,每个列都有一个特定的数据类型。
创建数据表的语法如下:```CREATE TABLE table_namecolumn1 datatype1 constraint,column2 datatype2 constraint,...```其中,table_name为要创建的表格名称,column1、datatype1等为列名和对应的数据类型。
可以在每个列上设置约束,用于限制数据的类型、输入范围等。
3.数据库的备份和恢复为了防止数据丢失或损坏,需要定期备份数据库。
数据库备份可以使用数据库管理系统提供的工具或者编写脚本实现。
一般来说,备份数据库包括两个步骤:备份数据文件和备份事务日志。
恢复数据库时,可以使用备份文件将数据库恢复到一些特定的时间点。
4.数据库的优化和性能调优为了提高数据库的性能,可以进行以下优化措施:-设定合适的索引:索引可以提高数据的检索速度,但索引过多会增加插入和删除数据的开销,需权衡取舍。
数据库脚本编写与优化技巧

数据库脚本编写与优化技巧随着企业和组织的数据规模不断增长,数据库管理变得愈发重要。
在日常的数据库管理工作中,数据库脚本编写和优化是一项关键任务。
本文将介绍数据库脚本编写和优化的技巧,旨在帮助管理员提高数据库的性能和效率。
一、数据库脚本编写技巧1. 使用注释:在编写脚本时,使用注释将有助于他人理解和修改脚本。
注释应包括对脚本功能的简要描述、作者信息、修改历史等。
注释还可以用于解释复杂逻辑或关联关系。
2. 使用格式化和缩进:良好的格式化和缩进可以提高脚本的可读性。
在脚本中使用适当的空格、缩进和换行符来使代码清晰易懂,避免出现歧义。
3. 合理命名:命名是一个重要的编程习惯,对于数据库脚本也同样适用。
使用有意义的名称来命名表、列、存储过程和函数等,可以提高代码可读性和可维护性。
4. 使用事务:对于需要多个操作的数据库脚本,应该使用事务来确保数据的完整性和一致性。
通过在脚本开始时开启事务,在脚本结束时提交或回滚事务,可以有效地处理意外的中断或错误。
5. 异常处理:在数据库脚本中,适当处理异常非常重要。
合理使用TRY-CATCH块或错误处理语句来捕获和处理异常情况,确保脚本的稳定性和可靠性。
二、数据库脚本优化技巧1. 选择合适的数据类型:正确选择每个列的数据类型是数据库脚本优化的一项关键任务。
使用最小的数据类型来节省存储空间,避免使用过大或过小的数据类型。
优化数据类型将减少磁盘空间和内存消耗,并提高查询性能。
2. 创建索引:索引的创建是数据库脚本优化的一个重要步骤。
适当地创建索引可以加快数据的检索速度,特别是当表中有大量数据时。
在选择索引列时,考虑到经常用于查询的列,并避免在不必要的列上创建索引。
3. 避免全表扫描:全表扫描是数据库脚本中的一个性能瓶颈。
为了提高查询效率,应该尽量避免全表扫描。
通过创建合适的索引,使用WHERE条件过滤数据,或者使用JOIN操作来优化查询,可以避免全表扫描。
4. 正确使用JOIN操作:JOIN操作在数据库脚本中常常用于关联多个表的数据。
数据库技术的分布式部署方案

数据库技术的分布式部署方案随着互联网行业的迅猛发展和数据规模的不断增长,传统的单机数据库已经无法满足大规模应用的需求。
在这样的背景下,分布式数据库技术应运而生。
分布式数据库指的是将数据分布在不同的节点上进行存储与计算,从而提高整个系统的性能和可伸缩性。
在本文中,我将介绍一些常见的数据库分布式部署方案。
1. 主从复制主从复制是一种简单且常用的数据库分布式部署方式。
该方案通过一个主节点和多个从节点的组合来实现数据的冗余备份和读写分离。
主节点负责接收和处理所有的写操作,然后将写操作日志传输给从节点进行执行。
此外,从节点可以处理读操作,从而降低主节点的负载压力。
主从复制方案的优势在于简单易用,但是它存在单点故障和数据一致性的问题。
2. 分区与分片分区与分片是一种常见的增加数据库可伸缩性的方案。
分区指的是将数据分割成不同的分区,每个分区可以放置在不同的节点上进行存储和计算。
分区可以根据数据的某种特性进行划分,例如按照用户ID、地理位置等进行划分。
分片是指将一个表按照某种规则进行划分成多个片,每个片可以放置在不同的节点上。
多个节点之间可以通过共享数据字典来进行查询,或者使用路由机制来保证数据的一致性。
分区与分片方案的优势在于增加了数据库的并发处理能力和数据存储空间,但是也增加了数据分布与数据查询的复杂性。
3. 垂直切分与水平切分垂直切分和水平切分是两种常见的数据库分布式部署策略。
垂直切分指的是将一个大型的数据库中的表按照某种规则拆分成多个子库,每个子库包含一部分表。
垂直切分可以根据不同的业务需求将数据存放在不同的节点上,从而提高效率和灵活性。
水平切分是指根据数据的某种特性将表中的数据划分成多个片,然后将每个片存放在不同的节点上。
水平切分的优势在于提高了数据库的并发处理能力和存储空间,但是也会增加数据查询的复杂性。
4. 分布式事务在分布式部署的数据库中,事务的处理是一个重要的问题。
传统的单机数据库可以通过锁机制来保证事务的一致性和隔离性,但是在分布式数据库中,由于数据分布在不同的节点上,锁机制无法直接应用。
数据同步Datax与Datax_web的部署以及使用说明

数据同步Datax与Datax_web的部署以及使⽤说明⼀、DataX3.0概述DataX 是⼀个异构数据源离线同步⼯具,致⼒于实现包括关系型数据库(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定⾼效的数据同步功能。
请看下图:设计理念:为了解决异构数据源同步问题,DataX将复杂的⽹状的同步链路变成了星型数据链路,DataX作为中间传输载体负责连接各种数据源。
当需要接⼊⼀个新的数据源的时候,只需要将此数据源对接到DataX,便能跟已有的数据源做到⽆缝数据同步。
当前使⽤状况:DataX在阿⾥巴巴集团内被⼴泛使⽤,承担了所有⼤数据的离线同步业务,并已持续稳定运⾏了6年之久。
⽬前每天完成同步8w多道作业,每⽇传输数据量超过300TB。
⼆、DataX3.0框架设计DataX本⾝作为离线数据同步框架,采⽤Framework + plugin架构构建。
将数据源读取和写⼊抽象成为Reader/Writer插件,纳⼊到整个同步框架中。
1、Reader:Reader为数据采集模块,负责采集数据源的数据,将数据发送给Framework。
2、Writer: Writer为数据写⼊模块,负责不断向Framework取数据,并将数据写⼊到⽬的端。
3、Framework:Framework⽤于连接reader和writer,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等核⼼技术问题。
三、插件体系DataX⽬前已经有了⽐较全⾯的插件体系,主流的RDBMS数据库、NOSQL、⼤数据计算系统都已经接⼊。
DataX⽬前⽀持数据如下:四、DataX3.0核⼼架构DataX 3.0 开源版本⽀持单机多线程模式完成同步作业运⾏,按⼀个DataX作业⽣命周期的时序图,从整体架构设计⾮常简要说明DataX各个模块相互关系。
1、DataX完成单个数据同步的作业,我们称之为Job,DataX接受到⼀个Job之后,将启动⼀个进程来完成整个作业同步过程。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
系统脚本部署说明
一、数据库基础部署
说明:数据库基础部署部分主要包括数据库用户、表空间、日志表的创建;以及新建数据库用户权限的修改;数据库基础参数的修改等。
1、进入DataBase_Initialize_Scripts文件夹
2、使用记事本打开Initialize_Database.bat
3、根据现场视情况,修改Initialize_Database.bat文件,如下图红色圈选部分:
(注:SYS_PASSWORD修改为对应需要初始化用户的数据库的SYS用户密码
GLOBAL_EZLINKDIR为连接数据库的连接串:IP地址:端口号/实例名(这里的实例名是真正的数据库实例名,而不是TNS网络实例名))
4、双击Initialize_Database.bat执行
5、确认无报错,安装正确后,重启数据库。
二、各系统数据库脚本部署
完成步骤一中的数据库基础部署工作后,根据现场实际情况,选择需要的各系统数据库脚本进行部署。
在执行各系统的数据库脚本时,需注意数据库用户与各系统的对应关系如下:
各系统数据库脚本部署顺序:
(1)部署系统管理中心系统的数据库到EHL_PUBLIC用户下。
(2)部署运维系统(设备设施管理系统)数据库到EHL_PLUBIC用户下。
(3)部署警力资源管理系统至EHL_PUBLIC用户下。
(4)根据现场需要部署交通流数据库到EHL_TFM用户下。
(5)执行\DataBase_Initialize_Scripts\Global_Scripts文件夹下的CrtSyn.sql脚本,创建7个数据库之间的同义词。
(临时方案)
(6)执行\DataBase_Initialize_Scripts\Global_Scripts文件夹下的Grant_Privilege_Temp.sql脚本,补充已建同义词的相关权限。
(临时方案)
(7)根据现场需要,执行其它系统的数据库脚本。
各系统数据库脚本执行步骤如下:
1、生成bat脚本(两种方式选择其一)
<1> 使用工具生成各系统的bat脚本(自动化生成步骤),生成后无需修改。
(暂不支持)
<2> 手动修改bat脚本,如下图红色圈选部分:
2、双击bat文件进行安装
3、核对log,保证安装正确。