spark集群三种部署模式的区别
spark入门及实践

2010’NJUPT
纲要
1
Spark综述 核心技术
5
2
Spark安装部署
Spark应用实例 Scala简介
3
Spark架构
6
4
BDAS简介
7
2010’NJUPT
三、Spark体系架构
1
架构组成
Master Worker
2010’NJUPT
三、Spark体系架构
2
架构图
2010’NJUPT
2010’NJUPT
一、Spark综述
3
Spark与Hadoop
3、执行策略 MapReduce在数据shuffle之前总是花费大量时间来 排序。Spark支持基于Hash的分布式聚合,在需要的时候 再进行实际排序。
4、任务调度的开销 MapReduce上的不同作业在同一个节点运行时,会 各自启动一个JVM。而Spark同一节点的所有任务都可以 在一个JVM上运行。
1
Spark是什么
Spark是基于内存计算的大数据并行 计算框架。Spark基于内存计算,提 高了在大数据环境下数据处理的实 时性,同时保证了高容错性和高可 伸缩性,允许用户将Spark部署在大 量廉价硬件之上,形成集群。 Spark于2009年诞生于加州大学伯 克利分校AMPLab。并且于2010年 Matai zaharia 开源。2013年6月Spark进入 Apache孵化器。目前,已经成为 /matei/ Apache软件基金会旗下的顶级开源 项目。
2010’NJUPT
纲要
1
Spark综述 核心技术
5
2
Spark安装部署
Spark应用实例 Scala简介
3
spark之Standalone模式部署配置详解

spark之Standalone模式部署配置详解spark运⾏模式Spark 有很多种模式,最简单就是单机本地模式,还有单机伪分布式模式,复杂的则运⾏在集群中,⽬前能很好的运⾏在Yarn和 Mesos 中,当然 Spark 还有⾃带的 Standalone 模式,对于⼤多数情况 Standalone 模式就⾜够了,如果企业已经有Yarn 或者 Mesos 环境,也是很⽅便部署的。
1.local(本地模式):常⽤于本地开发测试,本地还分为local单线程和local-cluster多线程;2.standalone(集群模式):典型的Mater/slave模式,不过也能看出Master是有单点故障的;Spark⽀持ZooKeeper来实现HA3.on yarn(集群模式):运⾏在 yarn 资源管理器框架之上,由 yarn 负责资源管理,Spark 负责任务调度和计算4.on mesos(集群模式):运⾏在 mesos 资源管理器框架之上,由 mesos 负责资源管理,Spark 负责任务调度和计算5.on cloud(集群模式):⽐如 AWS 的 EC2,使⽤这个模式能很⽅便的访问 Amazon的 S3;Spark ⽀持多种分布式存储系统:HDFS 和 S3Spark Standalone集群部署准备⼯作1.这⾥我下载的是Spark的编译版本,否则需要事先⾃⾏编译2.Spark需要Hadoop的HDFS作为持久化层,所以在安装Spark之前需要安装Hadoop,这⾥Hadoop的安装就不介绍了,给出⼀个教程3.实现创建hadoop⽤户,Hadoop、Spark等程序都在该⽤户下进⾏安装4.ssh⽆密码登录,Spark集群中各节点的通信需要通过ssh协议进⾏,这需要事先进⾏配置。
通过在hadoop⽤户的.ssh⽬录下将其他⽤户的id_rsa.pub公钥⽂件内容拷贝的本机的authorized_keys⽂件中,即可事先⽆登录通信的功能5.Java环境的安装,同时将JAVA_HOME、CLASSPATH等环境变量放到主⽬录的.bashrc,执⾏source .bashrc使之⽣效部署配置这⾥配置⼯作需要以下⼏个步骤:1.解压Spark⼆进制压缩包2.配置conf/spark-env.sh⽂件3.配置conf/slave⽂件下⾯具体说明⼀下:配置Spark的运⾏环境,将spark-env.sh.template模板⽂件复制成spark-env.sh,然后填写相应需要的配置内容:export SPARK_MASTER_IP=hadoop1export SPARK_MASTER_PORT=7077export SPARK_WORKER_CORES=1export SPARK_WORDER_INSTANCES=1export SPARK_WORKER_MEMORY=3g其他选项内容请参照下⾯的选项说明:# Options for the daemons used in the standalone deploy mode:# - SPARK_MASTER_IP, to bind the master to a different IP address or hostname# - SPARK_MASTER_PORT / SPARK_MASTER_WEBUI_PORT, to use non-default ports for the master# - SPARK_MASTER_OPTS, to set config properties only for the master (e.g. "-Dx=y")# - SPARK_WORKER_CORES, to set the number of cores to use on this machine# - SPARK_WORKER_MEMORY, to set how much total memory workers have to give executors (e.g. 1000m, 2g)# - SPARK_WORKER_PORT / SPARK_WORKER_WEBUI_PORT, to use non-default ports for the worker# - SPARK_WORKER_INSTANCES, to set the number of worker processes per node# - SPARK_WORKER_DIR, to set the working directory of worker processes# - SPARK_WORKER_OPTS, to set config properties only for the worker (e.g. "-Dx=y")# - SPARK_HISTORY_OPTS, to set config properties only for the history server (e.g. "-Dx=y")conf/slave⽂件⽤户分布式节点的配置,这⾥只需要在slave⽂件中写⼊该节点的主机名即可将以上内容都配置好了,将这个spark⽬录拷贝到各个节点scp -r spark hadoop@hadoop2:~接下来就可以启动集群了,在Spark⽬录中执⾏sbin/start-all.sh,然后可以通过netstat -nat命令查看端⼝7077的进程,还可以通过浏览器访问hadoop1:8080了解集群的概况Spark Client部署Spark Client的作⽤是,事先搭建起Spark集群,然后再物理机上部署客户端,然后通过该客户端提交任务给Spark集群。
Spark及Spark-Streaming核心原理及实践

Spark及Spark Streaming核心原理及实践导语:Spark已经成为广告、报表以及推荐系统等大数据计算场景中首选系统,因效率高,易用以及通用性越来越得到大家的青睐,我自己最近半年在接触spark以及spark streaming之后,对spark技术的使用有一些自己的经验积累以及心得体会,在此分享给大家。
本文依次从spark生态,原理,基本概念,spark streaming原理及实践,还有spark 调优以及环境搭建等方面进行介绍,希望对大家有所帮助。
Spark 特点运行速度快=> Spark拥有DAG执行引擎,支持在内存中对数据进行迭代计算。
官方提供的数据表明,如果数据由磁盘读取,速度是Hadoop MapReduce的10倍以上,如果数据从内存中读取,速度可以高达100多倍。
适用场景广泛=> 大数据分析统计,实时数据处理,图计算及机器学习易用性=> 编写简单,支持80种以上的高级算子,支持多种语言,数据源丰富,可部署在多种集群中容错性高。
Spark引进了弹性分布式数据集RDD (Resilient Distributed Dataset) 的抽象,它是分布在一组节点中的只读对象集合,这些集合是弹性的,如果数据集一部分丢失,则可以根据“血统”(即充许基于数据衍生过程)对它们进行重建。
另外在RDD计算时可以通过CheckPoint来实现容错,而CheckPoint有两种方式:CheckPoint Data,和Logging The Updates,用户可以控制采用哪种方式来实现容错。
Spark的适用场景目前大数据处理场景有以下几个类型:复杂的批量处理(Batch Data Processing),偏重点在于处理海量数据的能力,至于处理速度可忍受,通常的时间可能是在数十分钟到数小时;基于历史数据的交互式查询(Interactive Query),通常的时间在数十秒到数十分钟之间基于实时数据流的数据处理(Streaming Data Processing),通常在数百毫秒到数秒之间Spark成功案例目前大数据在互联网公司主要应用在广告、报表、推荐系统等业务上。
sparkcore入门到实战之(1)spark基础入门

sparkcore⼊门到实战之(1)spark基础⼊门第1章Spark 概述1.1 什么是Spark Sp a r k的产⽣背景 Sp a r k是⼀种快速、通⽤、可扩展的⼤数据分析引擎,2009年诞⽣于加州⼤学伯克利分校A M P La b,2010年开源,2013年6⽉成为A p a c h e孵化项⽬,2014年2⽉成为A p a c h e顶级项⽬。
项⽬是⽤Sc a l a进⾏编写。
⽬前,Sp a r k⽣态系统已经发展成为⼀个包含多个⼦项⽬的集合,其中包含Sp a r k SQ L、Sp a r k St r e a m in g、G r a p h X、M Lib、Sp a r k R等⼦项⽬,Sp a r k是基于内存计算的⼤数据并⾏计算框架。
除了扩展了⼴泛使⽤的M a p R e d u c e计算模型,⽽且⾼效地⽀持更多计算模式,包括交互式查询和流处理。
Sp a r k适⽤于各种各样原先需要多种不同的分布式平台的场景,包括批处理、迭代算法、交互式查询、流处理。
通过在⼀个统⼀的框架下⽀持这些不同的计算,Sp a r k使我们可以简单⽽低耗地把各种处理流程整合在⼀起。
⽽这样的组合,在实际的数据分析过程中是很有意义的。
不仅如此,Sp a r k的这种特性还⼤⼤减轻了原先需要对各种平台分别管理的负担。
⼤⼀统的软件栈,各个组件关系密切并且可以相互调⽤,这种设计有⼏个好处: 1、软件栈中所有的程序库和⾼级组件都可以从下层的改进中获益。
2、运⾏整个软件栈的代价变⼩了。
不需要运⾏5到10套独⽴的软件系统了,⼀个机构只需要运⾏⼀套软件系统即可。
系统的部署、维护、测试、⽀持等⼤⼤缩减。
3、能够构建出⽆缝整合不同处理模型的应⽤。
Sp a r k的内置项⽬如下: S p a r k C o r e:实现了Sp a r k的基本功能,包含任务调度、内存管理、错误恢复、与存储系统交互等模块。
Sp a r k C o r e中还包含了对弹性分布式数据集(r e s il ie n t d is t r ib u t e d d a t a s e t,简称R D D)的A P I定义。
Spark学习总结

Spark学习总结Spark是用于大数据处理的集群计算框架,没有使用MapReduce作为执行引擎,而是使用了自研的分布式运行环境(DAG引擎)在集群上执行工作。
Spark可以在YARN上运行,并支持Hadoop文件及HDFS。
Spark最突出的表现在于它能将作业与作业之间产生的大规模的工作数据集存储在内存中,在性能上要优于等效的MapReduce工作流,通常可以高出一个数量级。
因为MapReduce的数据集始终需要从磁盘上加载。
•Spark与MapReduce一样,也有作业(job)的概念,Spark的作业比MapReduce的作业更为通用,Spark作业是由任意的多阶段(stages)有向无环图(DAG)构成,其中每个阶段相当于MapReduce中的map阶段或者reduce阶段。
•这些阶段在Spark运行环境中被分解成多个任务(task),任务并行运行在分布于集群中的RDD(弹性分布式数据集Resilient Distributed Dataset)分区上。
像MapReduce中的任务一样。
•Spark作业始终运行在应用上下文中(applicationContext,用实例SparkContext表示),它提供了RDD分组以及共享变量。
一个应用(application)可以串行或者并行运行多个作业,并为这些作业提供访问由同一应用的先前作业所缓存的RDD的机制。
弹性分布式数据集RDDRDD是Spark最核心的概念,它是在集群中跨多个机器分区存储的一个只读的对象集合。
在典型的Spark程序中,首先要加载一个或多个RDD,作为输入再通过一系列转换得到一组目标RDD,然后对这些目标RDD执行一个动作,如计算出结果或者写入持久存储器。
“弹性分布式数据集”中的“弹性”指的是Spark可以通过重新安排计算来自动重建丢失的分区。
加载RDD或者执行转换不会立即触发任何数据处理操作,只是重建了一个计算的计划。
大数据spark经典面试题目与参考答案总结

⼤数据spark经典⾯试题⽬与参考答案总结⼀、简答题1.Spark master使⽤zookeeper进⾏HA的,有哪些元数据保存在Zookeeper?答:spark通过这个参数spark.deploy.zookeeper.dir指定master元数据在zookeeper中保存的位置,包括Worker,Driver和Application以及Executors。
standby节点要从zk中,获得元数据信息,恢复集群运⾏状态,才能对外继续提供服务,作业提交资源申请等,在恢复前是不能接受请求的。
另外,Master切换需要注意2点1)在Master切换的过程中,所有的已经在运⾏的程序皆正常运⾏!因为Spark Application在运⾏前就已经通过Cluster Manager获得了计算资源,所以在运⾏时Job本⾝的调度和处理和Master是没有任何关系的!2)在Master的切换过程中唯⼀的影响是不能提交新的Job:⼀⽅⾯不能够提交新的应⽤程序给集群,因为只有Active Master 才能接受新的程序的提交请求;另外⼀⽅⾯,已经运⾏的程序中也不能够因为Action操作触发新的Job的提交请求;2.Spark master HA 主从切换过程不会影响集群已有的作业运⾏,为什么?答:因为程序在运⾏之前,已经申请过资源了,driver和Executors通讯,不需要和master进⾏通讯的。
3.Spark on Mesos中,什么是的粗粒度分配,什么是细粒度分配,各⾃的优点和缺点是什么?答:1)粗粒度:启动时就分配好资源,程序启动,后续具体使⽤就使⽤分配好的资源,不需要再分配资源;好处:作业特别多时,资源复⽤率⾼,适合粗粒度;不好:容易资源浪费,假如⼀个job有1000个task,完成了999个,还有⼀个没完成,那么使⽤粗粒度,999个资源就会闲置在那⾥,资源浪费。
2)细粒度分配:⽤资源的时候分配,⽤完了就⽴即回收资源,启动会⿇烦⼀点,启动⼀次分配⼀次,会⽐较⿇烦。
spark的容错分析

Standalone部署的节点组成介绍Spark的资料中对于RDD这个概念涉及的比较多,但对于RDD如何运行起来,如何对应到进程和线程的,着墨的不是很多。
在实际的生产环境中,Spark总是会以集群的方式进行运行的,其中standalone的部署方式是所有集群方式中最为精简的一种,另外是Mesos和YARN,要理解其内部运行机理,显然要花更多的时间才能了解清楚。
standalone cluster的组成standalone集群由三个不同级别的节点组成,分别是∙Master 主控节点,可以类比为董事长或总舵主,在整个集群之中,最多只有一个Master 处在Active状态∙Worker 工作节点,这个是manager,是分舵主,在整个集群中,可以有多个worker,如果worker为零,什么事也做不了∙Executor 干苦力活的,直接受worker掌控,一个worker可以启动多个executor,启动的个数受限于机器中的cpu核数这三种不同类型的节点各自运行于自己的JVM进程之中。
Driver Application提交到standalone集群的应用程序称之为Driver Applicaton。
Standalone集群启动及任务提交过程详解上图总结了正常情况下Standalone集群的启动以及应用提交时,各节点之间有哪些消息交互。
下面分集群启动和应用提交两个过程来作详细说明。
集群启动过程正常启动过程如下所述step 1: 启动master$SPARK_HOME/sbin/start-master.shstep 2: 启动worker./bin/spark-class org.apache.spark.deploy.worker.Workerspark://localhost:7077worker启动之后,会做两件事情1.将自己注册到Master, RegisterWorker2.定期发送心跳消息给Master任务提交过程step 1: 提交application利用如下指令来启动spark-shellMASTER=spark://127.0.0.1:7077$SPARK_HOME/bin/spark-shell运行spark-shell时,会向Master发送RegisterApplication请求日志位置: master运行产生的日志在$SPARK_HOME/logs目录下step 2: Master处理RegisterApplication的请求之后收到RegisterApplication请求之后,Mastet会做如下处理1.如果有worker已经注册上来,发送LaunchExecutor指令给相应worker2.如果没有,则什么事也不做step 3: 启动ExecutorWorker在收到LaunchExecutor指令之后,会启动Executor进程step 4: 注册Executor启动的Executor进程会根据启动时的入参,将自己注册到Driver中的SchedulerBackend日志位置:executor的运行日志在$SPARK_HOME/work目录下step 5: 运行TaskSchedulerBackend收到Executor的注册消息之后,会将提交到的Spark Job分解为多个具体的Task,然后通过LaunchTask指令将这些Task分散到各个Executor上真正的运行如果在调用runJob的时候,没有任何的Executor注册到SchedulerBackend,相应的处理逻辑是什么呢?1.SchedulerBackend会将Task存储在TaskManager中2.一旦有Executor注册上来,就将TaskManager管理的尚未运行的task提交到executor中3.如果有多个job处于pending状态,默认调度策略是FIFO,即先提交的先运行测试步骤1.启动Master2.启动spark-shell3.执行sc.textFile("README.md").count4.启动worker5.注意worker启动之后,spark-shell中打印出来的日志消息Job执行结束任务运行结束时,会将相应的Executor停掉。
spark-1.2.1部署应用模式总结

说明✓Spark版本为:spark-1.2.1-bin-hadoop2.4,已经做了相应的环境配置,比如linux的免鉴权登录等。
✓在on yarn 模式下,已经安装hadoop2.6.0并正确配置。
Running the Examples and Shellbin/run-example:运行spark提供的例子,仅指定Local模式。
./bin/run-example SparkPi 10./bin/run-example org.apache.spark.examples.SparkPi 4Spark-shell:采用交互方式运行spark应用。
执行后,进入scala模式。
[hadoop@Master spark-1.2.1-bin-hadoop2.4]$ ./bin/spark-shell --master local[2]scala>scala> :quit[hadoop@Master spark-1.2.1-bin-hadoop2.4]$ ./bin MASTER=local bin/spark-shellscala>scala> :quitscala> val file = sc.textFile("hdfs://192.168.2.200:9000/tmp/test.txt")scala> val count = file.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey(_+_)scala> count.collect()Cluster ModeSpark的运行模式分为单机模式和集群模式。
在单机上既可以以本地模式运行,也可以以伪分布式模式运行。
Apache Spark支持三种分布式部署方式,并各自有对应的manager,分别是standalone、spark on mesos和spark on YARN,当以分布式的方式运行在Cluster集群中时,底层的资源调度可以使用Mesos 或者是Hadoop Yarn 2 ,也可以使用Spark自带的Standalone Deploy模式Spark componentStandalone modeStarting a ClusterStarting a Cluster Manually如果没有配置文件conf/spark-env.sh,则采用默认方式启动master。
Spark集群-Standalone模式

Spark集群-Standalone模式Spark 集群相关来源于官⽅, 可以理解为是官⽅译⽂, 外加⼀点⾃⼰的理解. 版本是2.4.4本篇⽂章涉及到:集群概述master, worker, driver, executor的理解打包提交,发布 Spark applicationstandalone模式SparkCluster 启动及相关配置资源, executor分配开放⽹络端⼝⾼可⽤(Zookeeper)名词解释Term(术语) | Meaning(含义)| - | -Application | ⽤户构建在 Spark 上的程序。
由集群上的⼀个 driver 程序和多个 executor 组成。
Driver program | 该进程运⾏应⽤的 main() ⽅法并且创建了 SparkContext。
Cluster manager | ⼀个外部的⽤于获取集群上资源的服务。
(例如,Standlone Manager,Mesos,YARN)Worker node | 任何在集群中可以运⾏应⽤代码的节点。
Executor | ⼀个为了在 worker 节点上的应⽤⽽启动的进程,它运⾏ task 并且将数据保持在内存中或者硬盘存储。
每个应⽤有它⾃⼰的Executor。
Task | ⼀个将要被发送到 Executor 中的⼯作单元。
Job | ⼀个由多个任务组成的并⾏计算,并且能从 Spark action 中获取响应(例如 save,collect); 您将在 driver 的⽇志中看到这个术语。
Stage | 每个 Job 被拆分成更⼩的被称作 stage(阶段)的 task(任务)组,stage 彼此之间是相互依赖的(与 MapReduce 中的 map 和 reduce stage 相似)。
您将在 driver 的⽇志中看到这个术语。
概述参考链接:中⽂链接:Spark Application 在集群上作为独⽴的进程组来运⾏,在 main程序(称之为 driver 程序)中通过 SparkContext 来协调。
大数据技术,Spark任务调度原理四种集群部署模式介绍
大数据技术,Spark任务调度原理四种集群部署模式介绍一、spark-submit任务提交机制spark-submit \--class org.apache.spark.examples.SparkPi \--master spark://ns1.hadoop:7077 \--executor-memory 1G \--total-executor-cores 2 \/usr/local/spark/examples/jars/spark-examples_2.11-2.1.1.jar 上面是spark在集群提交任务最常见的命令,其中:--class 是程序的主入口,和main方法类似。
--master 指定spark的运行模式,yarn、standalone等模式--executor-memory 指定计算节点的内存大小,spark是基于内存运算的。
--total-executor-cores 指定运行任务的核数,你可以理解为线程数。
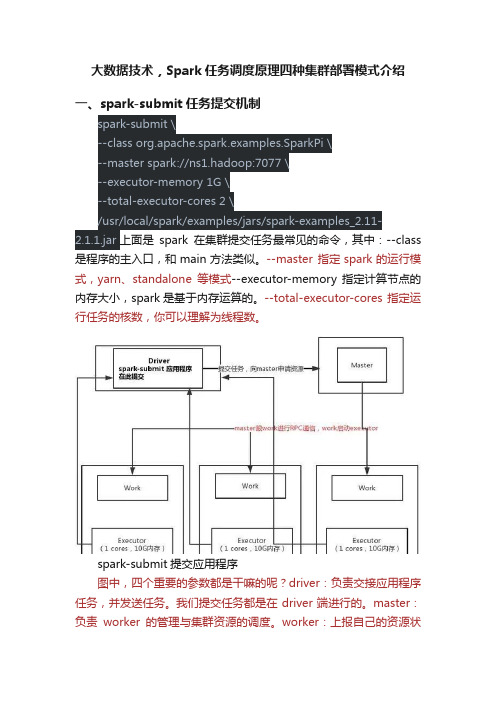
spark-submit提交应用程序图中,四个重要的参数都是干嘛的呢?driver:负责交接应用程序任务,并发送任务。
我们提交任务都是在driver端进行的。
master:负责worker的管理与集群资源的调度。
worker:上报自己的资源状态、存活情况,启动并管理。
executor:负责执行任务,真正用来做计算的节点。
spark-submit提交任务的,启动计算的过程:1,在driver端提交spark-submit任务,任务提交以后会向master申请资源。
2,master会启动worker,worker在启动executor,executor是真正用来计算任务的。
3,executor启动以后,反向连接driver。
通过master->worker->executor反向找到driver在哪里。
4,driver生成taskset任务集,之后把任务发送给executor,executor启动计算程序。
saprk

目前Spark在全球已有广泛的应用,其中包括阿里巴巴、 Cloudera、Databricks、IBM、Intel、雅虎等。
Spark自2013年6月进入Apache的孵化器以来,已经有来自25个 组织的120多位开发者参与贡献。
二 与Hadoop对比
1, Spark的中间数据放到内存中,一次创建数据集,可以多次迭代运 算,减少了IO的开销,对于迭代运算效率更高。
2, Spark更适合于迭代运算比较多的ML和DM运算。因为在Spark里 面,有RDD的抽象概念。
三 运行模式
总之,这四种分布式部署方式各有利弊,通常需要根据公司情况 决定采用哪种方案。进行方案选择时,往往要考虑公司的技术路线( 采用Hadoop生态系统还是其他生态系统)、服务器资源(资源有限的 话就不要考虑standalone模式了)、相关技术人才el(pregel on spark):Bagel是基于Spark的轻量级的 Pregel(Pregel是Google鼎鼎有名的图计算框架)的实现。
5,对机器学习算法,图计算能力有很好的支持。
二.1 运算模型对比
(1)传统Hadoop数据抽取运算模型
数据的抽取运算基于磁盘,中间结果也是存储在磁盘上。MR运算伴随着大量的磁 盘IO。
二.1 运算模型对比
(2)Spark 则使用内存代替了传统HDFS存储中间结果
简述:第一代的Hadoop完全使用Hdfs存储中间结果,第二带的Hadoop加入了 cache来保存中间结果。而Spark则基于内存的中间数据集存储。可以将Spark理 解为Hadoop的升级版本,Spark兼容了Hadoop的API,并且能够读取Hadoop的 数据文件格式,包括HDFS,Hbase等。
Spark基础知识详解

Spark基础知识详解Apache Spark是⼀种快速通⽤的集群计算系统。
它提供Java,Scala,和R中的⾼级API,以及⽀持通⽤执⾏图的优化引擎。
它还⽀持⼀组丰富的⾼级⼯具,包括⽤于SQL和结构化数据处理的Spark SQL,⽤于机器学习的MLlib,⽤于图形处理的GraphX和Spark Streaming。
Spark优点:减少磁盘I/O:随着实时⼤数据应⽤越来越多,Hadoop作为离线的⾼吞吐、低响应框架已不能满⾜这类需求。
HadoopMapReduce的map端将中间输出和结果存储在磁盘中,reduce端⼜需要从磁盘读写中间结果,势必造成磁盘IO成为瓶颈。
Spark允许将map端的中间输出和结果存储在内存中,reduce端在拉取中间结果时避免了⼤量的磁盘I/O。
Hadoop Yarn中的ApplicationMaster申请到Container后,具体的任务需要利⽤NodeManager从HDFS的不同节点下载任务所需的资源(如Jar包),这也增加了磁盘I/O。
Spark将应⽤程序上传的资源⽂件缓冲到Driver本地⽂件服务的内存中,当Executor执⾏任务时直接从Driver的内存中读取,也节省了⼤量的磁盘I/O。
增加并⾏度:由于将中间结果写到磁盘与从磁盘读取中间结果属于不同的环节,Hadoop将它们简单的通过串⾏执⾏衔接起来。
Spark把不同的环节抽象为Stage,允许多个Stage 既可以串⾏执⾏,⼜可以并⾏执⾏。
避免重新计算:当Stage中某个分区的Task执⾏失败后,会重新对此Stage调度,但在重新调度的时候会过滤已经执⾏成功的分区任务,所以不会造成重复计算和资源浪费。
可选的Shuffle排序:HadoopMapReduce在Shuffle之前有着固定的排序操作,⽽Spark则可以根据不同场景选择在map端排序或者reduce端排序。
灵活的内存管理策略:Spark将内存分为堆上的存储内存、堆外的存储内存、堆上的执⾏内存、堆外的执⾏内存4个部分。
spark的四种模式,spark比MapReduce快的原因

spark的四种模式,spark比MapReduce快的原因2018年09月05日 20:09:05 wyqwilliamSpark 是美国加州大学伯克利分校的AMP 实验室(主要创始人lester 和 Matei)开发的通用的大数据处理框架。
λApache Spark™ is a fast and general engine for large-scale data processing.λ Apache Spark is an open source cluster computing system that aims to make data analyticsfast,both fast to run and fast to wrtieSpark 应用程序可以使用 R 语言、Java、Scala 和 Python 进行编写,极少使用 R 语言编写 Spark 程序,Java 和 Scala 语言编写的 Spark 程序的执行效率是相同的,但 Java 语言写的代码量多,Scala 简洁优雅,但可读性不如 Java,Python 语言编写的 Spark 程序的执行效率不如 Java 和 Scala。
Spark 有 4 中运行模式:1. local 模式,适用于测试2. standalone,并非是单节点,而是使用 spark 自带的资源调度框架3. yarn,最流行的方式,使用 yarn 集群调度资源4. mesos,国外使用的多Spark 比 MapReduce 快的原因1. Spark 基于内存迭代,而 MapReduce 基于磁盘迭代MapReduce 的设计:中间结果保存到文件,可以提高可靠性,减少内存占用,但是牺牲了性能。
Spark 的设计:数据在内存中进行交换,要快一些,但是内存这个东西,可靠性比不过MapReduce。
2. DAG 计算模型在迭代计算上还是比 MR 的更有效率。
spark集群三种部署模式的区别

Spark三种集群部署模式的比较目前Apache Spark支持三种分布式部署方式,分别是standalone、spark on mesos和spark on YARN,其中,第一种类似于MapReduce 1.0所采用的模式,内部实现了容错性和资源管理,后两种则是未来发展的趋势,部分容错性和资源管理交由统一的资源管理系统完成:让Spark运行在一个通用的资源管理系统之上,这样可以与其他计算框架,比如MapReduce,公用一个集群资源,最大的好处是降低运维成本和提高资源利用率(资源按需分配)。
本文将介绍这三种部署方式,并比较其优缺点。
1. standalone模式,即独立模式,自带完整的服务,可单独部署到一个集群中,无需依赖任何其他资源管理系统。
从一定程度上说,该模式是其他两种的基础。
借鉴Spark开发模式,我们可以得到一种开发新型计算框架的一般思路:先设计出它的standalone模式,为了快速开发,起初不需要考虑服务(比如master/slave)的容错性,之后再开发相应的wrapper,将stanlone模式下的服务原封不动的部署到资源管理系统yarn或者mesos上,由资源管理系统负责服务本身的容错。
目前Spark在standalone模式下是没有任何单点故障问题的,这是借助zookeeper实现的,思想类似于Hbase master单点故障解决方案。
将Spark standalone与MapReduce比较,会发现它们两个在架构上是完全一致的:1) 都是由master/slaves服务组成的,且起初master均存在单点故障,后来均通过zookeeper解决(Apache MRv1的JobTracker仍存在单点问题,但CDH版本得到了解决);2) 各个节点上的资源被抽象成粗粒度的slot,有多少slot就能同时运行多少task。
不同的是,MapReduce将slot分为map slot和reduce slot,它们分别只能供Map Task和Reduce Task使用,而不能共享,这是MapReduce资源利率低效的原因之一,而Spark则更优化一些,它不区分slot类型,只有一种slot,可以供各种类型的Task使用,这种方式可以提高资源利用率,但是不够灵活,不能为不同类型的Task定制slot资源。
sparkdeploymode的client和cluster的区别

sparkdeploymode的client和cluster的区别spark deploy mode 的client和cluster的区别一般来说,如果提交任务的节点(即Master)和Worker集群在同一个网络内,此时client mode比较合适。
如果提交任务的节点和Worker集群相隔比较远,就会采用cluster mode来最小化Driver和Executor之间的网络延迟。
2015070313355的信鸽是的鸽子2015是鸽子的年份,07为吉林省信鸽协会足环全国统一代码,应该是吉林省信鸽协会某会员的鸽子,0313355是鸽子的编码具体是谁的,要求逐级查询相应鸽会的足环分配记录。
衣服的的近义词服装的近义词•装束:①整理行装:装束完毕,马上出发。
②服饰的打扮装束•打扮:1.使容貌和衣着好看;装饰。
2.指打扮出来的打扮写事的作文250~300字的我期盼已久的寒假终于到了,我迫不及待地把作业写完。
怀着满怀的好心情,来到了我姨家。
刚一进门,弟弟马上跑了过来,拽着我去观看他的玩具。
在他房间里的小桌上,放着一件精美的艺术品。
下面是一个“金字塔”形的底座,底座上面是雕刻精美、栩栩如生的一只老鹰。
老鹰的尖嘴在金字塔上,奇怪的是不论飞快地转动它,还是猛按它的身体,老鹰在金字塔上就是不掉下来。
这就像是一只真的老鹰在展翅飞翔一样,非常逼真。
更奇怪的是还可以把老鹰的尖嘴放在手上或别的东西上,都能在上面转动也不掉下来。
这种东西既好看又好玩,还真是一项伟大的发明呀!我觉得挺纳闷,这是什么原因呢?我就掂了掂老鹰,发觉它的头部特别重,好像有一快铁在里面似的;它的两翅及尾部特别轻。
但我还是不很明白,就去问爸爸。
爸爸说:“这是利用重心的原理,这只老鹰的重心在它的嘴尖上,因此无论怎样动它,但它的重心都不会变,所以不会从支持它的物体上掉下来。
”我听后似懂非懂的,以后我一定要好好学习科学知识,长大了做出更好的玩具和艺术品来娱乐和美化人们的生活,这件艺术品让我永久不忘。
大数据Spark部署模式DeployMode
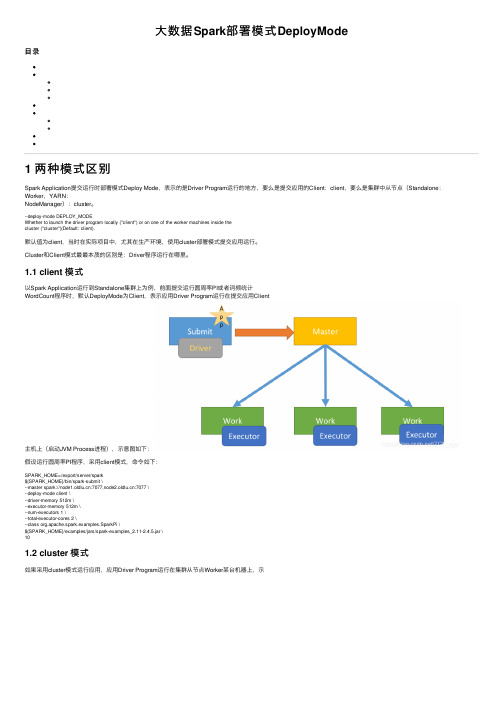
⼤数据Spark部署模式DeployMode⽬录1 两种模式区别Spark Application提交运⾏时部署模式Deploy Mode,表⽰的是Driver Program运⾏的地⽅,要么是提交应⽤的Client:client,要么是集群中从节点(Standalone:Worker,YARN:NodeManager):cluster。
--deploy-mode DEPLOY_MODEWhether to launch the driver program locally ("client") or on one of the worker machines inside thecluster ("cluster")(Default: client).默认值为client,当时在实际项⽬中,尤其在⽣产环境,使⽤cluster部署模式提交应⽤运⾏。
Cluster和Client模式最最本质的区别是:Driver程序运⾏在哪⾥。
1.1 client 模式以Spark Application运⾏到Standalone集群上为例,前⾯提交运⾏圆周率PI或者词频统计WordCount程序时,默认DeployMode为Client,表⽰应⽤Driver Program运⾏在提交应⽤Client主机上(启动JVM Process进程),⽰意图如下:假设运⾏圆周率PI程序,采⽤client模式,命令如下:SPARK_HOME=/export/server/spark${SPARK_HOME}/bin/spark-submit \--master spark://:7077,:7077 \--deploy-mode client \--driver-memory 512m \--executor-memory 512m \--num-executors 1 \--total-executor-cores 2 \--class org.apache.spark.examples.SparkPi \${SPARK_HOME}/examples/jars/spark-examples_2.11-2.4.5.jar \101.2 cluster 模式如果采⽤cluster模式运⾏应⽤,应⽤Driver Program运⾏在集群从节点Worker某台机器上,⽰意图如下:假设运⾏圆周率PI程序,采⽤cluster模式,命令如下:SPARK_HOME=/export/server/spark${SPARK_HOME}/bin/spark-submit \--master spark://:7077,:7077 \--deploy-mode cluster \--supervise \--driver-memory 512m \--executor-memory 512m \--num-executors 1 \--total-executor-cores 2 \--class org.apache.spark.examples.SparkPi \${SPARK_HOME}/examples/jars/spark-examples_2.11-2.4.5.jar \101.3 两者⽐较Cluster和Client模式最最本质的区别是:Driver程序运⾏在哪⾥。
spark学习(基础篇)--(第三节)Spark几种运行模式

spark学习(基础篇)--(第三节)Spark⼏种运⾏模式spark应⽤执⾏机制分析前段时间⼀直在编写指标代码,⼀直采⽤的是--deploy-mode client⽅式开发测试,因此执⾏没遇到什么问题,但是放到⽣产上采⽤--master yarn-cluster⽅式运⾏,那问题就开始陆续暴露出来了。
因此写⼀篇⽂章分析并记录⼀下spark 的⼏种运⾏⽅式。
1.spark应⽤的基本概念spark运⾏模式分为:Local(本地idea上运⾏),Standalone,yarn,mesos等,这⾥主要是讨论⼀下在yarn上的运⾏⽅式,因为这也是最常见的⽣产⽅式。
根据spark Application的Driver Program是否在集群中运⾏,spark应⽤的运⾏⽅式⼜可以分为Cluster模式和Client模式。
spark应⽤涉及的⼀些基本概念:1.mater:主要是控制、管理和监督整个spark集群2.client:客户端,将⽤应⽤程序提交,记录着要业务运⾏逻辑和master通讯。
3.sparkContext:spark应⽤程序的⼊⼝,负责调度各个运算资源,协调各个work node上的Executor。
主要是⼀些记录信息,记录谁运⾏的,运⾏的情况如何等。
这也是为什么编程的时候必须要创建⼀个sparkContext的原因了。
4.Driver Program:每个应⽤的主要管理者,每个应⽤的⽼⼤,有⼈可能问不是有master么怎么还来⼀个?因为master是集群的⽼⼤,每个应⽤都归⽼⼤管,那⽼⼤疯了。
因此driver负责具体事务运⾏并跟踪,运⾏Application的main()函数并创建sparkContext。
5.RDD:spark的核⼼数据结构,可以通过⼀系列算⼦进⾏操作,当Rdd遇到Action算⼦时,将之前的所有的算⼦形成⼀个有向⽆环图(DAG)。
再在spark中转化成为job,提交到集群执⾏。
理解Spark运行模式(三)(STANDALONE和Local)

理解Spark运行模式(三)(STANDALONE和Local)前两篇介绍了Spark的yarn client和yarn cluster模式,本篇继续介绍Spark的STANDALONE模式和Local模式。
下面具体还是用计算PI的程序来说明,examples中该程序有三个版本,分别采用Scala、Python和Java语言编写。
本次用Java程序JavaSparkPi做说明。
1 package org.apache.spark.examples;23 import org.apache.spark.api.java.JavaRDD;4 import org.apache.spark.api.java.JavaSparkContext;5 import org.apache.spark.sql.SparkSession;67 import java.util.ArrayList;8 import java.util.List;910 /**11 * Computes an approximation to pi12 * Usage: JavaSparkPi [partitions]13 */14 public final class JavaSparkPi {1516 public static void main(String[] args) throws Exception {17 SparkSession spark = SparkSession18 .builder()19 .appName("JavaSparkPi")20 .getOrCreate();2122 JavaSparkContext jsc = new JavaSparkContext(spark.sparkContext());2324 int slices = (args.length == 1) ? Integer.parseInt(args[0]) : 2;25 int n = 100000 * slices;26 List<Integer> l = new ArrayList<>(n);27 for (int i = 0; i < n; i++) {28 l.add(i);29 }3031 JavaRDD<Integer> dataSet = jsc.parallelize(l, slices);3233 int count = dataSet.map(integer -> {34 double x = Math.random() * 2 - 1;35 double y = Math.random() * 2 - 1;36 return (x * x + y * y <= 1) ? 1 : 0;37 }).reduce((integer, integer2) -> integer + integer2);3839 System.out.println("Pi is roughly " + 4.0 * count / n);4041 spark.stop();42 }43 }程序逻辑与之前的Scala和Python程序一样,就不再多做说明了。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Spark三种集群部署模式的比较
目前Apache Spark支持三种分布式部署方式,分别是standalone、spark on mesos和spark on YARN,其中,第一种类似于MapReduce 1.0所采用的模式,内部实现了容错性和资源管理,后两种则是未来发展的趋势,部分容错性和资源管理交由统一的资源管理系统完成:让Spark运行在一个通用的资源管理系统之上,这样可以与其他计算框架,比如MapReduce,公用一个集群资源,最大的好处是降低运维成本和提高资源利用率(资源按需分配)。
本文将介绍这三种部署方式,并比较其优缺点。
1. standalone模式,即独立模式,自带完整的服务,可单独部署到一个集群中,无需依赖任何其他资源管理系统。
从一定程度上说,该模式是其他两种的基础。
借鉴Spark开发模式,我们可以得到一种开发新型计算框架的一般思路:先设计出它的standalone模式,为了快速开发,起初不需要考虑服务(比如master/slave)的容错性,之后再开发相应的wrapper,将stanlone模式下的服务原封不动的部署到资源管理系统yarn或者mesos上,由资源管理系统负责服务本身的容错。
目前Spark在standalone模式下是没有任何单点故障问题的,这是借助zookeeper实现的,思想类似于Hbase master单点故障解决方案。
将Spark standalone与MapReduce比较,会发现它们两个在架构上是完全一致的:
1) 都是由master/slaves服务组成的,且起初master均存在单点故障,
后来均通过zookeeper解决(Apache MRv1的JobTracker仍存在单点问题,但CDH版本得到了解决);
2) 各个节点上的资源被抽象成粗粒度的slot,有多少slot就能同时运行
多少task。
不同的是,MapReduce将slot分为map slot和reduce slot,它们分别只能供Map Task和Reduce Task使用,而不能共享,这是MapReduce资源利率低效的原因之一,而Spark则更优化一些,它不区分slot类型,只有一种slot,可以供各种类型的Task使用,这种方式可以提高资源利用率,但是不够灵活,不能为不同类型的Task定制slot资源。
总之,这两种方式各有优缺点。
2. Spark On Mesos模式。
这是很多公司采用的模式,官方推荐这种模式(当然,原因之一是血缘关系)。
正是由于Spark开发之初就考虑到支持Mesos,因此,目前而言,Spark运行在Mesos上会比运行在YARN上更加灵活,更加自然。
目前在Spark On Mesos环境中,用户可选择两种调度模式之一运行自己的应用程序(可参考Andrew Xia的“Mesos Scheduling Mode on Spark”):
1) 粗粒度模式(Coarse-grained Mode):每个应用程序的运行环境由一
个Dirver和若干个Executor组成,其中,每个Executor占用若干资源,内部可运行多个Task(对应多少个“slot”)。
应用程序的各个任务正式运行之前,需要将运行环境中的资源全部申请好,且运行过程中要一直占用这些资源,即使不用,最后程序运行结束后,回收这些资源。
举个例子,比如你提交应用程序时,指定使用5个executor运行你的应用程序,每个executor占用5GB 内存和5个CPU,每个executor内部设置了5个slot,则Mesos需要先为executor分配资源并启动它们,之后开始调度任务。
另外,在程序运行过程中,mesos的master和slave并不知道executor内部各个task的运行情况,executor直接将任务状态通过内部的通信机制汇报给Driver,从一定程度上
可以认为,每个应用程序利用mesos搭建了一个虚拟集群自己使用。
2) 细粒度模式(Fine-grained Mode):鉴于粗粒度模式会造成大量资源
浪费,Spark On Mesos还提供了另外一种调度模式:细粒度模式,这种模式类似于现在的云计算,思想是按需分配。
与粗粒度模式一样,应用程序启动时,先会启动executor,但每个executor占用资源仅仅是自己运行所需的资源,不需要考虑将来要运行的任务,之后,mesos会为每个executor动态分配资源,每分配一些,便可以运行一个新任务,单个Task运行完之后可以马上释放对应的资源。
每个Task会汇报状态给Mesos slave和Mesos Master,便于更加细粒度管理和容错,这种调度模式类似于MapReduce调度模式,每个Task完全独立,优点是便于资源控制和隔离,但缺点也很明显,短作业运行延迟大。
3. Spark On YARN模式。
这是一种很有前景的部署模式。
但限于YARN自身的发展,目前仅支持粗粒度模式(Coarse-grained Mode)。
这是由于YARN上的Container资源是不可以动态伸缩的,一旦Container启动之后,可使用的资源不能再发生变化,不过这个已经在YARN计划中了。
spark on yarn 的支持两种模式:
1) yarn-cluster:适用于生产环境;
2) yarn-client:适用于交互、调试,希望立即看到app的输出
yarn-cluster和yarn-client的区别在于yarn appMaster,每个yarn app实例有一个appMaster进程,是为app启动的第一个container;负责从ResourceManager 请求资源,获取到资源后,告诉NodeManager为其启动container。
yarn-cluster 和yarn-client模式内部实现还是有很大的区别。
如果你需要用于生产环境,那么请选择yarn-cluster;而如果你仅仅是Debug程序,可以选择yarn-client。
总结:
这三种分布式部署方式各有利弊,通常需要根据实际情况决定采用哪种方案。
进行方案选择时,往往要考虑公司的技术路线(采用Hadoop生态系统还是其他生态系统)、相关技术人才储备等。
上面涉及到Spark的许多部署模式,究竟哪种模式好这个很难说,需要根据你的需求,如果你只是测试Spark Application,你可以选择local模式。
而如果你数据量不是很多,Standalone 是个不错的选择。
当你需要统一管理集群资源(Hadoop、Spark等),那么你可以选择Yarn或者mesos,但是这样维护成本就会变高。
·从对比上看,mesos似乎是Spark更好的选择,也是被官方推荐的
·但如果你同时运行hadoop和Spark,从兼容性上考虑,Yarn是更好的选择。
·如果你不仅运行了hadoop,spark。
还在资源管理上运行了docker,Mesos 更加通用。
·Standalone对于小规模计算集群更适合!。