Java实现文件下载并解决中文文件名乱码
Java中文乱码的解决方案

Java中文乱码的解决方案jsp+Servlet的形式,在jsp页面向后台发送的请求里包含中文时,后台采用String name = request.getParameter("name")接收到的是乱码,我在网上找了很多资料,有网友说request.getParameter是默认采用ISO8859-1来编码的,必须进行转换:我总结了一下,解决中文乱码大概有以下几种方式:1、采用decode()方法.URLDecoder.decode(s)2、采用设置字符集的方式request.setCharacterEncoding("utf-8");3、在页面上定义charset的字符集<%@ page language="java" contentType="text/html; charset=utf-8"pageEncoding="utf-8"%><meta http-equiv="Content-Type" content="text/html; charset=utf-8">4、在web.xml文件里定义编码,同时在CoreFilter类里定义编码为utf-8<filter><filter-name>encodingFilter</filter-name><filter-class>com.demo.filter.CoreFilter</filter-class><init-param><param-name>encoding</param-name><param-value>utf-8</param-value></init-param></filter><filter-mapping><filter-name>encodingFilter</filter-name><url-pattern>/*</url-pattern></filter-mapping>5、在form表单里定义编码accept-charset="utf-8" onsubmit="document.charset='utf-8';"6、更改ContentTypes的值改变myeclipse里ContentTypes的值为utf-87、改变tomcat字符集通过改变server.xml文件里的字符集来接收中文8、采用转码的方式nameCode = new String(request.getParameter("name").getBytes("ISO8859-1"),"UTF-8");补充:如果是Servlet向页面发送的数据中包含中文,可以采用如下方式解决:response.setContentType("text/html;charset=utf-8");。
java中文乱码解决方法

java中文乱码解决方法Java是一种强大的编程语言,它可以为不同的计算机平台提供稳定可靠的软件开发环境,它也在处理文本文件上有着独特的优势。
但在使用Java处理中文文件时,乱码就成为了一个重大问题,如果不能很好地处理乱码,会影响到Java应用软件的正常使用。
本文给出了3种常用的Java中文乱码解决方案,以帮助相关开发人员快速解决乱码问题。
首先,使用正确的字符集编码将文件保存为指定的编码格式,这可以有效防止中文乱码的出现。
首先,应确保将文本文件保存为国际标准字符集UNIX UTF-8编码。
这是一种任何平台及系统都能够正确执行的字符集,比如Windows系统可以使用ANSI编码,但是在Linux 中会出现乱码问题。
其次,在字符编码方面应尽量使用UTF-8,它可以支持多种字符集,可以为用户提供更丰富的文本文件内容。
此外,为了完全解决Java中文乱码问题,开发者可以利用相关的API来设置不同的编码格式。
例如,开发者可以使用System.setProperty()方法来指定程序的编码格式,即指定文件使用的字符集。
以下是一个简单的示例代码:System.setProperty(file.encoding UTF-8另外,Java还提供了更加强大的控制功能。
它可以为用户提供一种可以自行设置和识别字符集的文件编码类。
例如,使用InputStreamReader和OutputStreamWriter类,开发者可以指定输入和输出的字符集,以进行不同的输入和输出操作,从而得到更加准确的结果,避免出现乱码问题。
以下是一个使用InputStreamReader 和OutputStreamWriter设置字符集的简单示例:InputStreamReader isr = new InputStreamReader(inputStream, UTF-8OutputStreamWriter osw = newOutputStreamWriter(outputStream, UTF-8最后,用户还可以使用相关的第三方软件来解决Java中文乱码问题,这些软件专门设计用于解决文本文件字符集编码的问题,可以自动识别文件的编码格式,并将其转换成指定的编码格式。
java文件下载以及中文乱码解决

java⽂件下载以及中⽂乱码解决 在客户端下载⽂件时替换下载⽂件的名称,但是当名称是中⽂时浏览器会出现乱码,解决代码如下: public org.springframework.http.ResponseEntity<InputStreamResource> handleExcel(HttpServletRequest request) throws Exception {String fileName = "模板下载.xsls";//解决浏览器下载汉字乱码的兼容问题String userAgent = request.getHeader("User-Agent");byte[] bytes = userAgent.contains("MSIE") ? fileName.getBytes() : fileName.getBytes("UTF-8");// 各浏览器基本都⽀持ISO编码String name = new String(bytes, "ISO-8859-1");//⽹络资源⽂件//可以替换为⽹络资源⽂件//本地⽂件PathResource file = new PathResource(FileUtil.getNewFileName(fileName));HttpHeaders headers = new HttpHeaders();headers.add("Cache-Control", "no-cache, no-store, must-revalidate");headers.add("Content-Disposition", "attachment;fileName=" + name);headers.add("Pragma", "no-cache");headers.add("Expires", "0");org.springframework.http.ResponseEntity<InputStreamResource> entity = org.springframework.http.ResponseEntity.ok().headers(headers).contentLength(file.contentLength()).contentType(MediaType.parseMediaType("application/octet-stream")).body(new InputStreamResource(file.getInputStream()));return entity;}。
Java Web项目开发中的中文乱码问题与对策

Java Web项目开发中的中文乱码问题与对策作者:张彦芳来源:《电脑知识与技术》2020年第09期摘要:在当下的网络时代,Java Web技术发展迅速,已经成为市场上主流的web开发技术之一,为越来越多的web应用开发人员所使用。
但是,在进行Java Web项目开发时,经常出现的中文乱码问题给应用开发带来了不少的麻烦。
该文具体分析了Java Web项目开发中常见的中文乱码问题,并给出了相应的对策。
关键词:中文乱码;编码;解码;Servlet中图分类号:TP311 文献标识码:A文章编号:1009-3044(2020)09-0096-021 引言目前,网络高速发展,web开发应用非常广泛,Java Web成为市场上非常流行的web开发技术之一,越来越多的人开始学习并使用Java web开发项目。
但是,我们在使用Java web技术开发项目时不可避免用到中文,在Java web中使用中文经常会出现中文乱码问题,严重影响了项目的开发与应用,解决中文乱码问题迫不及待。
本文具体分析了实际应用中遇到的中文乱码问题,并给出了相应的对策。
2 产生中文乱码的原因计算机中存储数据都是以二进制的形式存储。
当我们输入中文字符时,需要把中文字符转换成二进制进行存储,这时就会发生字符和字节之间的转换。
将字符转换成字节的过程,我们称为编码,将字节转换成字符的过程称为解码。
无论是编码还是解码,字符与字节之间的转换都是通过查码表来完成的,如果在解码时采用的码表和编码时采用的码表不一致,就会产生乱码的问题。
3 Java Web中常见的中文乱码问题与对策3.1访问JSP页面时出现中文乱码通过浏览器访问JSP页面时,经常会在浏览器中看到乱码,出现乱码的根本原因是使用的编码不支持中文。
在JSP页面中使用的编码默认为“IS0-8859-1”,这种编码方式不兼容中文字符。
常用的支持中文字符的编码有GB2312,GBK和UTF-8。
我们可以在JSP文件的page指令中将编码修改为支持中文的编码即可。
Java Web项目开发中的中文乱码问题与对策

Java Web项目开发中的中文乱码问题与对策在Java Web项目开发中,遇到中文乱码问题是比较常见的。
中文乱码问题的根本原因是Java中使用的是Unicode编码,而在HTTP传输过程中使用的是ISO-8859-1编码,这两种编码不兼容,导致中文字符无法正确显示。
中文乱码问题通常会出现在以下几个方面:1. 数据库存储:如果数据库的字段类型是varchar而不是utf8类型,就无法正确存储中文字符,导致乱码问题。
解决办法是将数据库的字段类型修改为utf8。
2. 请求参数传递:如果浏览器向服务器发送的请求参数中包含中文字符,而服务器没有正确解析编码,就会导致中文字符乱码。
解决办法是在服务器端对请求参数进行编码转换,通常使用的是UTF-8编码。
3. 响应结果显示:如果服务器向浏览器返回的响应结果中包含中文字符,而没有正确设置响应头的编码,浏览器无法正确解析中文字符,就会显示乱码。
解决办法是在服务器端设置响应头的Content-Type为text/html;charset=UTF-8。
针对中文乱码问题,我们可以采取以下对策:1. 统一字符编码:在整个项目中都使用UTF-8编码,包括数据库、服务器、浏览器等各个环节,确保数据的正确传输和显示。
2. 在项目中添加字符编码过滤器:通过在web.xml文件中配置字符编码过滤器,可以对请求和响应的字符编码进行统一处理,确保中文字符能够正确传输和显示。
5. 在文件上传和下载时进行编码转换:在上传和下载文件时,对文件名进行编码转换,通常使用的是URL编码,确保文件名中的中文字符能够正确传输和显示。
遇到中文乱码问题时,需要在不同的环节进行编码转换和设置,确保中文字符能够正确传输和显示。
通过统一字符编码、设置响应头的字符编码、对请求参数进行编码转换等对策,可以有效解决中文乱码问题,提高项目的可用性和用户体验。
java中文乱码解决方法

java中文乱码解决方法1、解决文件中文乱码:1.1、修改文件字符编码:由于不同系统,比如Unix下用GBK格式编辑的文件,在Windows中就会乱码,此时可以使用Notepad++(记事本插件),将文件编码转换为系统默认的utf-8,8为Unicode编码。
1.2、修改系统语言及字符编码:此外,也可以通过改变操作系统的语言及字符编码,这种方法我们可以在控制面板-区域和语言的地方进行修改,再次点击其中的管理,在点击详细设置,这时候就可以看到字符集,将其设置为utf-8。
2、解决程序中文乱码:2.1、使用unicod-8格式编码:在这种情况下,一定要注意程序代码的编码格式,一定要以utf-8格式进行编码,而不是GBK,否则一样会出现乱码。
2.2、设置字符集:有时候,可以在程序中设置语言字符集,例如:response.setContentType("text/html;charset=utf-8");用于普通的JSP页面编码设置,也可以在web.xml中设置characterEncoding3、修改Tomcat的默认编码:可以修改tomcat的server.xml文件,将其默认编码为utf-8,在相应的位置加上URIEncoding="utf-8"。
4、前端乱码解决方法:也可以到浏览器中去修改编码,比如:Firefox浏览器中,可以按Ctrl + U,Chrome可以按Ctrl + U,IE下可以第一个菜单栏中点击View,然后选择Encoding,转换为相应的编码即可。
5、对数据库使用正确的编码:在不同的数据库中当我们有gbk的字符编码的时候,一定要创建数据库时候指定好字符编码,让数据库与整个程序保持一致,如果仅仅程序有编码时,数据库没有则容易出现乱码。
总之,我们在解决Java中文乱码的问题是要以系统- web页面-程序-数据库为关键点进行检查,以确保编码的一致性。
java读取文件里面部分汉字内容乱码的解决方案

java读取⽂件⾥⾯部分汉字内容乱码的解决⽅案java读取⽂件⾥⾯部分汉字内容乱码读取⼀个txt⽂件,到代码中打印出来,发票有部分汉字的内容是乱码的。
我开始的⽅式是这样的, 如下,这是完全错误的,汉字是两个字节的,如果每次读固定个字节,可能会把汉字截断。
就会出现部分乱码的情况。
package susq.path;import java.io.File;import java.io.FileInputStream;import java.io.IOException;/*** @author susq* @since 2018-05-18-19:28*/public class WrongMethodReadTxt {public static void main(String[] args) throws IOException {ClassLoader classLoader = WrongMethodReadTxt.class.getClassLoader();String filePath = classLoader.getResource("").getPath() + "/expect1.txt";System.out.println(filePath);File file = new File(filePath);try (FileInputStream in = new FileInputStream(file)) {byte[] bytes = new byte[1024];StringBuffer sb = new StringBuffer();int len;while ((len = in.read(bytes)) != -1) {sb.append(new String(bytes, 0, len));}System.out.println(sb.toString());}}}如果存在汉字,就要按字符的⽅式读取:package susq.path;import java.io.BufferedReader;import java.io.File;import java.io.FileReader;import java.io.IOException;/*** @author susq* @since 2018-05-18-17:39*/public class SysPath {public static void main(String[] args) throws IOException {ClassLoader classLoader = SysPath.class.getClassLoader();String filePath = classLoader.getResource("").getPath() + "/expect1.txt";System.out.println(filePath);File file = new File(filePath);try (BufferedReader br = new BufferedReader(new FileReader(file))) {StringBuffer sb = new StringBuffer();while (br.ready()) {sb.append(br.readLine());}System.out.println(sb);}}}java的IO流读取数据时,解决中⽂乱码,还有个别中⽂乱码问题情况:⽤IO流读取数据时,若是不设置编码格式,出来的数据未必是我们所要的解决:读取数据时,设置编码代码:(字符串设置对应的编码即可,但这种⽅式,会导致个别中⽂乱码,貌似是byte[]导致的)//这⾥我通过socket⽅式,获取流,并读取数据//代理需要外置配置(代理配置需要判断,若有配置,则添加,若⽆配置,则不添加)Socket socket = new Socket("192.168.99.100", 80);String url = "GET " + href + " HTTP/1.1\r\n\r\n";socket.getOutputStream().write(new String(url).getBytes());InputStream is = socket.getInputStream();byte[] bs = new byte[1024];int i;StringBuilder str = new StringBuilder();while ((i = is.read(bs)) > 0) {//⼀定要加编码,不然,在输出到⽂件时,部分数据会乱str.append(new String(bs, 0, i,"UTF-8"));//由于socket读取不会断开,所以只能⾃断开连接读取if(new String(bs, 0, i,"UTF-8").contains("</html>")){break;}}解决个别中⽂乱码问题:代码://代理需要外置配置(代理配置需要判断,若有配置,则添加,若⽆配置,则不添加)Socket socket = new Socket("192.168.99.100", 80);//Socket socket = new Socket();String url = "GET " + href + " HTTP/1.1\r\n\r\n";socket.getOutputStream().write(new String(url).getBytes());InputStream is = socket.getInputStream();//解决个别中⽂乱码StringBuilder str = new StringBuilder("");InputStreamReader isr = new InputStreamReader(is,"UTF-8");BufferedReader br = new BufferedReader(isr);String line = null;while ((line = br.readLine()) != null) {str.append(line + "\n");if(line.contains("</html>")){break;}}以上为个⼈经验,希望能给⼤家⼀个参考,也希望⼤家多多⽀持。
Java Web项目开发中的中文乱码问题与对策

Java Web项目开发中的中文乱码问题与对策在Java Web项目开发中,中文乱码问题是一个常见的挑战。
当我们接收、处理和展示中文数据时,如果不正确地处理字符编码,就可能导致中文乱码的问题。
下面是一些常见的中文乱码问题及其对策。
1. 请求参数中的中文乱码:当浏览器发送一个带有中文参数的请求时,服务器端可能无法正确解析中文字符。
解决方案是在服务器端对请求参数进行解码。
可以通过在Tomcat的server.xml中配置URIEncoding属性来确保正确的解码,例如将URIEncoding 设为"UTF-8"。
2. 数据库中的中文乱码:当我们将中文数据存储到数据库中时,如果数据库的字符编码与传入的数据的字符编码不一致,就会出现中文乱码。
解决方案是在创建数据库表时指定正确的字符编码,并在连接数据库时设置正确的连接字符编码。
可以在创建数据库表时指定字符集为utf8mb4,然后在连接MySQL数据库时将连接字符集设为utf8mb4。
3. 页面展示中的中文乱码:在JSP页面中,如果不指定正确的字符编码,就可能出现中文乱码。
解决方案是在JSP页面的头部指定正确的字符编码,例如设置contentType为"text/html; charset=UTF-8"。
4. 中文文件名的乱码:当我们下载一个中文文件时,浏览器可能无法正确解析中文文件名,导致乱码。
解决方案是通过在响应的header中设置Content-Disposition属性来指定正确的文件名编码。
可以将Content-Disposition的值设置为"attachment; filename*=utf-8''文件名",其中文件名是经过URL编码的。
6. 处理中文乱码的过滤器:为了统一处理中文乱码问题,可以在项目中添加一个字符编码过滤器,将所有的请求和响应的字符编码都统一为UTF-8。
Java Web项目开发中的中文乱码问题与对策

Java Web项目开发中的中文乱码问题与对策【摘要】在Java Web项目开发中,中文乱码问题一直是开发者们头痛的难题。
本文旨在探讨中文乱码问题的原因及解决方案。
通过分析中文乱码问题的根源,可以明确乱码产生的原因。
探讨了在Java Web项目中如何正确设置字符编码以避免乱码问题的发生。
介绍了使用过滤器处理乱码的方法,通过过滤器可以有效地解决乱码问题。
本文通过对中文乱码问题的分析和解决方案提出了一些有效的对策,希望能够帮助开发者更好地处理中文乱码问题。
展望未来,我们可以进一步研究和优化解决方案,以提升中文乱码问题的处理效率和准确性。
【关键词】Java Web项目开发、中文乱码问题、对策、引言、背景介绍、研究目的、正文、乱码问题分析、乱码原因分析、解决方案探讨、字符编码设置、使用过滤器处理乱码、结论、总结分析、展望未来。
1. 引言1.1 背景介绍在Java Web项目开发中,中文乱码问题一直是开发者们头疼的难题。
随着中文内容在互联网中的普及和应用不断增加,中文乱码问题也变得越发严重。
由于在网络传输过程中,数据的编码格式可能会发生变化,导致中文字符显示时出现乱码现象。
这给用户的浏览体验造成了影响,也给开发人员带来了困扰。
为了更好地解决Java Web项目开发中的中文乱码问题,本文旨在对中文乱码问题进行深入分析,并探讨解决方案。
首先我们将分析中文乱码问题出现的原因,进一步讨论乱码问题的解决方案。
在具体实践中,我们将重点讨论字符编码设置和使用过滤器处理乱码的方法,希望为开发者们提供实用的技术指导。
通过本文的研究和探讨,希望能够为Java Web项目开发中的中文乱码问题提供有效的解决方案,提升项目的稳定性和用户体验,为开发者们的工作带来便利。
1.2 研究目的研究目的是为了解决Java Web项目开发中出现的中文乱码问题,提高系统的稳定性和用户体验。
通过深入分析中文乱码问题的原因,探讨相关的解决方案,并探讨如何正确设置字符编码以及使用过滤器来处理乱码,最终达到消除乱码问题的目的。
关于java文件下载文件名乱码问题解决方案
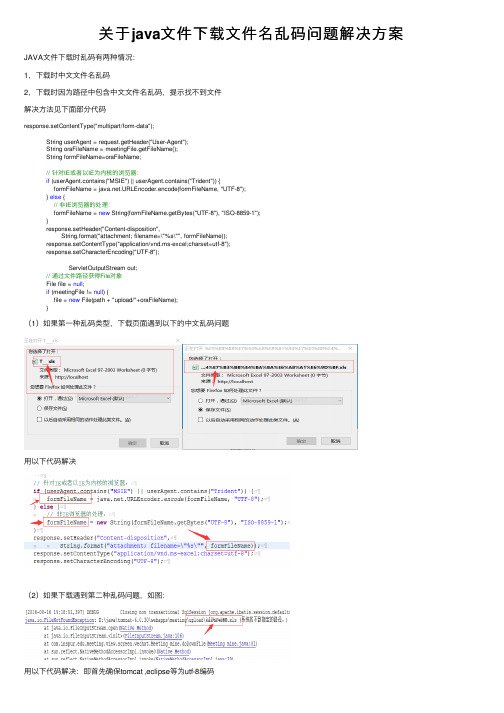
关于java⽂件下载⽂件名乱码问题解决⽅案JAVA⽂件下载时乱码有两种情况:1,下载时中⽂⽂件名乱码2,下载时因为路径中包含中⽂⽂件名乱码,提⽰找不到⽂件解决⽅法见下⾯部分代码response.setContentType("multipart/form-data");String userAgent = request.getHeader("User-Agent");String oraFileName = meetingFile.getFileName();String formFileName=oraFileName;// 针对IE或者以IE为内核的浏览器:if (userAgent.contains("MSIE") || userAgent.contains("Trident")) {formFileName = .URLEncoder.encode(formFileName, "UTF-8");} else {// ⾮IE浏览器的处理:formFileName = new String(formFileName.getBytes("UTF-8"), "ISO-8859-1");}response.setHeader("Content-disposition",String.format("attachment; filename=\"%s\"", formFileName));response.setContentType("application/vnd.ms-excel;charset=utf-8");response.setCharacterEncoding("UTF-8");ServletOutputStream out;// 通过⽂件路径获得File对象File file = null;if (meetingFile != null) {file = new File(path + "upload/"+oraFileName);}(1)如果第⼀种乱码类型,下载页⾯遇到以下的中⽂乱码问题⽤以下代码解决(2)如果下载遇到第⼆种乱码问题,如图:⽤以下代码解决:即⾸先确保tomcat ,eclipse等为utf-8编码然后JAVA中这样与第⼀种对⽂件名编码分开,使它们分别编码,互不影响。
Java中文乱码解决办法

中文乱码解决办法
保持字符集统一,在此采用统一字符集“UTF-8”
1.新建web工程时采用统一的编码格式
1.1工程更改编码格式
右击“工程名”
设置编码为
“UTF-8”
1.2文件更改编码
右击“文件名”
2jsp
文件中更改编码
3.servlet 中处理中文乱码的问题
3.1doPost 方法中处理乱码问题
3.1.1在获取页面数据之前设置编码
设置编码为
“UTF-8”
3.1.2打开传输流之前设置编码
3.2doGet方法中处理乱码问题
3.2.1在获取页面数据之前设置编码
3.2.2打开传输流之前设置编码
3.2.3更改Tomcat配置文件
Tomcat安装目录下----》conf文件夹下--》server.xml中----》
4数据库乱码问题解决<MySql为例>
MySql安装目录----------》my.ini---------------》
以上解决办法仅供参考......。
文件下载中文名称乱码问题

package com.hs.es.action;import java.io.File;import mons.io.FileUtils;import org.apache.struts2.ServletActionContext;import com.hs.es.GlobalVar.GlobalVar;import com.hs.es.business.TaskBusiness;import com.hs.es.filter.AppcontextEvent;public class FileUpLoad extends ActionClass{private static final long serialVersionUID = 572146812454l;/************************************************ 类属性区**************************************************/private static final int BUFFER_SIZE = 16 * 1024;// 流反冲区大小private File myFile;// 文件private String contentType;// 文件类型private String fileName;// 文件名private String imageFileName;// 文件最终路径和名称private String caption;private Integer userid;// 用户IDprivate Integer taskid;// 任务id// private String fileContentType;//文件类型// private String fileFileName;//文件名/**************************************************** get set 方法区*******************************************/// 特别方法public void setMyFileContentType(String contentType) {this.contentType = contentType;}// 特别方法public void setMyFileFileName(String fileName) {this.fileName = fileName;}public File getMyFile() {return myFile;}public void setMyFile(File myFile) {this.myFile = myFile;}public String getImageFileName() {return imageFileName;}public void setImageFileName(String imageFileName) {this.imageFileName = imageFileName;}public String getCaption() {return caption;}public void setCaption(String caption) {this.caption = caption;}public Integer getUserid() {return userid;}public void setUserid(Integer userid) {erid = userid;}public Integer getTaskid() {return taskid;}public void setTaskid(Integer taskid) {this.taskid = taskid;}/**************************************************** 业务逻辑方法区******************************************//*** 拷贝文件到另外的位置*/// 添加产品文件(后台)@Overridepublic String execute() throws Exception {String separator = System.getProperty("file.separator");//文件分隔符// System.out.println("上传文件类型:"+contentType);System.out.println(separator);if(checkSession() == null)return LOGIN;clearErrorsAndMessages(); //????// ProductpictureBusiness obj = (ProductpictureBusiness) IOC.SellMgr_IOC.get(ProductpictureBusiness.class.getName());// 定位到项目发布的相对服务器路径Gardens项目名称String url = ServletActionContext.getRequest().getRequestURL().toString();System.out.println("url : " + url);url = url.substring(0,stIndexOf("/"))+"/UploadFiles/";if(AppcontextEvent.getFilepath()==null)AppcontextEvent.setFilepath(url);//设置文件保存路径到外部文件中去// 得到项目下webroot 这个路径是在服务器上的System.out.println(ServletActionContext.getServletContext().getRealPath("/UploadFiles"));System.out.println(ServletActionContext.getServletContext().getRealPath("/UploadFiles").replace All("/", separator));File ff = new File(ServletActionContext.getServletContext().getRealPath("/UploadFiles").replaceAll("/", separator));if (!ff.exists()) {boolean df = ff.mkdirs(); //创建此抽象路径名指定的目录,包括所有必需但不存在的父目录。
Java的各种中文乱码解决方法

Java的各种中⽂乱码解决⽅法⼀、Servlet输出乱码1. ⽤servlet.getOutStream字节流输出中⽂,假设要输出的是String str ="钓鱼岛是中国的,⽆耻才是⽇本的"。
1.1 若是本地服务器与本地客户端这种就不⽤说了,直接可以out.write(str.getBytes())可以输出没有问题。
因为服务器中⽤str.getBytes()是采⽤默认本地的编码,⽐如GBK。
⽽浏览器也解析时也⽤本地默认编码,两者是统⼀的,所以没有问题。
1.1 若服务器输出时⽤了, out.write(str.getBytes("utf-8"))。
⽽本地默认编码是GBK时(⽐例在中国),那么⽤浏览器打开时就会乱码。
因为服务器发送过来的是utf-8的1010数据,⽽客户端浏览器⽤了gbk来解码,两者编码不统⼀,肯定是乱码。
当然,你也可以⾃⼰将客户端浏览器的编码⼿⼯调⽤下(IE菜单是:查询View->编码encoding->utf-8),但是这种操作很烂,最好由服务器输出响应头告诉,浏览器⽤哪种编码来解码。
所以要在服务器的servlet中,增加response.setHeader("content-type","text/html;charset=utf-8"),当然也可直接⽤简单的response.setContentType("text/hmtl;charset=utf-8")。
两种的操作是⼀样⼀样的。
2. ⽤servlet.getWirter字符流输出中⽂,假设要输出的是String str ="钓鱼岛是中国的,⽆耻才是⽇本的"。
2.1 若写成out.print(str)输出时,客户端浏览器显⽰的将全是多个的字符,代表在编码表中肯定就找不到相应的字符来显⽰。
原因是:servlet.getWriter()得到的字符输出流,默认对字符的输出是采⽤ISO-8859-1,⽽ISO-8859-1肯定是不⽀持中⽂的。
文件下载 response.setHeader()下载中文文件名乱码问题 解决办法

response.setHeader()下载中文文件名乱码问题[转]首先展示我的解决问题的代码:response.setHeader("Content-Disposition", "attachment; filename=" + .URLEncoder.encode(fileName, "UTF-8"));1. HTTP消息头(1)通用信息头即能用于请求消息中,也能用于响应信息中,但与被传输的实体内容没有关系的信息头,如Data,Pragma主要: Cache-Control , Connection , Data , Pragma , Trailer , T ransfer-Encoding , Upgrade(2)请求头用于在请求消息中向服务器传递附加信息,主要包括客户机可以接受的数据类型,压缩方法,语言,以及客户计算机上保留的信息和发出该请求的超链接源地址等.主要: Accept , Accept-Encoding , Accept-Language , Host ,(3)响应头用于在响应消息中向客户端传递附加信息,包括服务程序的名称,要求客户端进行认证的方式,请求的资源已移动到新地址等.主要: Location , Server , WWW-Authenticate(认证头)(4)实体头用做实体内容的元信息,描述了实体内容的属性,包括实体信息的类型,长度,压缩方法,最后一次修改的时间和数据的有效期等.主要: Content-Encoding , Content-Language , Content-Length , Content-Location , Content-Type (4)扩展头主要:Refresh, Content-Disposition2. 几个主要头的作用(1)Content-Type的作用该实体头的作用是让服务器告诉浏览器它发送的数据属于什么文件类型。
JavaWeb实现文件下载和乱码处理方法

JavaWeb实现⽂件下载和乱码处理⽅法⽂件上传和下载是web开发中常遇到的问题,这⼏天在做⼀个项⽬⼜⽤到了⽂件下载,之前也零零散散记了些笔记,今天来做⼀下整理。
⽂件上传还有待进⼀步测试,这⾥先说⼀下⽂件下载。
⼀、⽂件下载处理流程⽂件下载处理流程其实很清晰,即:1、根据⽂件名或者⽂件路径定位⽂件,具体的策略主要根据⾃⼰的需求,总之需要系统能找到的⽂件全路径。
2、获取输⼊流,从⽬标⽂件获取输⼊流。
3、获取输出流,从response中获取输出流。
4、从输⼊流读⼊⽂件,通过输出流输出⽂件。
这是真正的下载执⾏过程。
5、关闭IO流。
主要流程就是这个,另外就是⼀些必要的属性设置,⽐如⽐较重要的有设置⽂件的contentType类型等。
⼆、不啰嗦了了,上代码我是⽤Springmvc做的,但其实⽤其他的也⼀样,主要需要HttpServletResponse对象和有效的⽬标⽂件。
1、前台代码/** 下载上传的⽂件*/function downloadFromUpload(fileName){window.location.href = path + "/download?dir=upload&fileName="+encodeURI(encodeURI(fileName));}/** 普通下载*/function download(fileName){window.location.href = path + "/download?dir=download&fileName="+encodeURI(encodeURI(fileName));}2、controller代码/*** ⽂件下载(从上传路径下载)** @param request* @param response* @throws IOException*/@ResponseBody@RequestMapping(value = "/download")public void downloadFile(HttpServletRequest request,HttpServletResponse response, FileModel model) throws Exception {String fileName = URLDecoder.decode(model.getFileName(), "UTF-8");/** 限制只有upload和download⽂件夹⾥的⽂件可以下载*/String folderName = "download";if (!StringUtils.isEmpty(model.getDir())&& model.getDir().equals("upload")) {folderName = "upload";} else {folderName = "download";}String fileAbsolutePath = request.getSession().getServletContext().getRealPath("/")+ "/WEB-INF/" + folderName + "/" + fileName;FileTools.downloadFile(request, response, fileAbsolutePath);log.warn("⽤户Id:"+ (Integer) (request.getSession().getAttribute("userId"))+ ",⽤户名:"+ (String) (request.getSession().getAttribute("username"))+ ",下载了⽂件:" + fileAbsolutePath);}这⾥的下载逻辑是,前台只需要请求/download,并给出⽂件名参数即可。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
response.reset();//如果有换行,对于文本文件没有什么问题,但是对于其它格
//式,比如AutoCAD、Word、Excel等文件下载下来的文件中就会多出一些换行符//0x0d和0x0a,这样可能导致某些格式的文件无法打开,有些也可以正常打开。同//时response.reset()这种方式也能清空缓冲区, 防止页面中的空行等输出到下载内容里去
ServletOutputStream sos = response.getOutputStream();
FileInputStream fis = null;
File d = new File(filepath);
if (d.exists())
{
fis = new FileInputStream(filபைடு நூலகம்path);//
Java实现文件下载并解决中文文件名乱码
2010-08-12 【群组讨论】 【进入论坛】
关键词: Java;文件下载;中文文件名;文件名乱码 字体:大 中 小
“中华诵”经典诵读行动“感念师恩”短信赢礼品全国高校人才引进数据分析报告职场办公软件技能提升用Excel函数查找重复项
response.setContentType("application/octet-stream");
response.setHeader("Content-Disposition", "attachment;filename=\"" + filename + "\"");
response.setHeader("Connection", "close");
filename = new String(filename.getBytes("UTF-8"), "ISO8859-1");//firefox浏览器
else if (request.getHeader("User-Agent").toUpperCase().indexOf("MSIE") > 0)
String filepath = "c:/";//需要下载的文件路径
String filename = "文档.doc";//需要下载的文件名字
//解决中文文件名乱码问题
if (request.getHeader("User-Agent").toLowerCase().indexOf("firefox") > 0)
fis.close();
sos.flush();
sos.close();
}
byte b[] = new byte[1000];
int j;
while ((j = fis.read(b)) != -1)
{
try
{
sos.write(b, 0, j);
}
catch (IOException exp)
{
}
}