编译原理(11)
编译原理第十一章解析

26
此处要用到的有向图,是一种其结点带有下述标记或附 加信息的DAG: ① 图的叶结点,即无后继的结点,以一标识符(变 量名)或常数作为标记,表示这个结点代表该变量或常数 的值。如果叶结点用来代表某变量A的地址,则用addr (A)作为这个结点的标记。通常把叶结点上作为标记的 标识符加上下标0,以表示它是该变量的初值。 ② 图的内部结点,即有后继的结点,以一运算符作为 标记,表示这个结点代表应用该运算符对其后继结点所代 表的值进行运算的结果。 ③ 图中各个结点上可能附加一个或多个标识符,表 示这些变量具有该结点所代表的值。
30
下面是仅含0,1,2型四元式的基本块的DAG构造算法。
首先,DAG为空。 对基本块的每一四元式,依次执行: 1. 如果NODE(B)无定义,则构造一标记为B的叶结点并定 义NODE(B)为这个结点; 如果当前四元式是0型,则记NODE(B)的值为n,转4。 如果当前四元式是1型,则转2.(1)。 如果当前四元式是2型,则:(Ⅰ)如果NODE(C)无定义, 则构造一标记为C的叶结点并定义NODE(C)为这个结点,(Ⅱ) 转2.(2)。 2. (1) 如果NODE(B)是标记为常数的叶结点,则转2.(3), 否则转3.(1)。 (2) 如果NODE(B)和NODE(C)都是标记为常数的叶结 点,则转2.(4),否则转3.(2 (3) 执行op B(即合并已知量),令得到的新常数为P。如 果NODE(B)是处理当前四元式时新构造出来的结点,则删除它。 如果NODE(P)无定义,则构造一用P做标记的叶结点n。置NODE (P)=n,转4.。 (4) 执行B op C(即合并已知量),令得到的新常数为P。如 果NODE(B)或NODE(C)是处理当前四元式时新构造出来的结 点,则删除它。如果NODE(P)无定义,则构造一用P做标记的叶 结点n。置NODE(P)=n,转4.。
编译原理第六章到第十一章课后习题答案
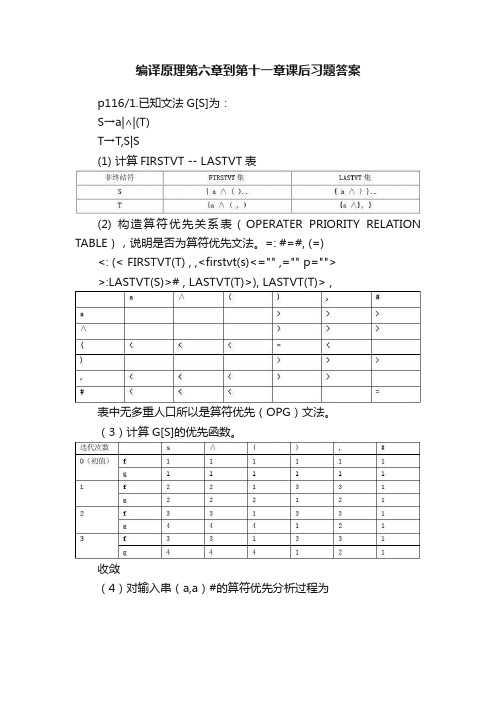
编译原理第六章到第十一章课后习题答案p116/1.已知文法G[S]为:S→a|∧|(T)T→T,S|S(1) 计算FIRSTVT -- LASTVT表(2) 构造算符优先关系表(OPERATER PRIORITY RELATION TABLE),说明是否为算符优先文法。
=: #=#, (=)<: (< FIRSTVT(T) , ,<firstvt(s)<="" ,="" p="">>:LASTVT(S)># , LASTVT(T)>), LASTVT(T)> ,表中无多重人口所以是算符优先(OPG)文法。
(3)计算G[S]的优先函数。
收敛(4)对输入串(a,a)#的算符优先分析过程为Success!3.有文法G(S):s->Vv->T/ViTT->F/T+FF->)V*|((1)(+(i(的规范推导S=>V=>ViT=>ViF=>Vi(=>Ti(=>T+Fi(=>T+(i(=>F+(i(=>(+(i((2)F+Fi(的短语、句柄、素短语。
短语S: F+Fi(T1:F+F (素短语)T2:F (句柄)F:( (素短语)(3) G(S)是否为OPG?若是,给出(1)中句子的分析过程!S’->#S# S->V V->T/ViT T->F/T+F F->)V*|(算符优先关系表(OPERATER PRIORITY RELATION TABLE)对输入串(+(I(的算符优先分析过程为:p152/2文法:S→L.L|LL→LB|BB→0|1拓广文法为G′,增加产生式S′→SI3若产生式排序为:0 S' →S1 S →L.L2 S →L3 L →LB4 L →B5 B →06 B →1由产生式知:First (S' ) = {0,1}First (S ) = {0,1}First (L ) = {0,1}First (B ) = {0,1}Follow(S' ) = {#}Follow(S ) = {#}Follow(L ) = {.,0,1,#}Follow(B ) = {.,0,1,#}G′的LR(0)项目集族及识别活前缀的DFA如下图所示:I5B →.0和B →.1为移进项目,S →L.为归约项目,存在移进-归约冲突,因此所给文法不是LR(0)文法。
《编译原理》期末复习资料(完整版)
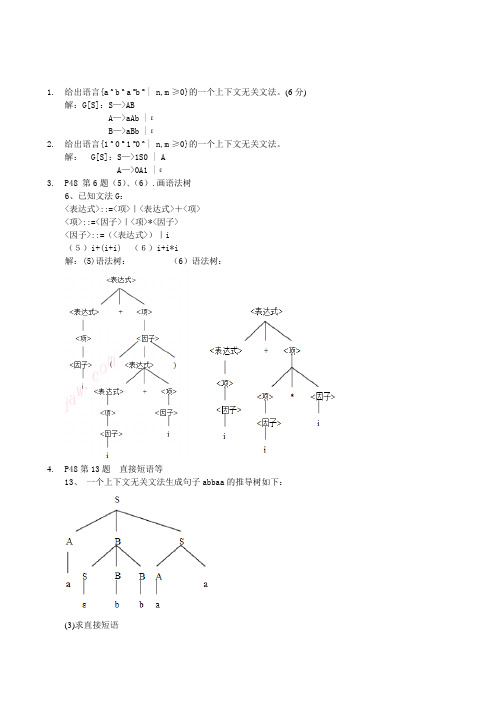
1.给出语言{a n b n a m b m | n,m≥0}的一个上下文无关文法。
(6分)解:G[S]:S—>ABA—>aAb |εB—>aBb |ε2.给出语言{1 n 0 m 1 m0 n | n,m≥0}的一个上下文无关文法。
解:G[S]:S—>1S0 | AA—>0A1 |ε3.P48 第6题(5)、(6).画语法树6、已知文法G:<表达式>::=<项>|<表达式>+<项><项>::=<因子>|<项>*<因子><因子>::=(<表达式>)|i(5)i+(i+i) (6)i+i*i解:(5)语法树:(6)语法树:4.P48第13题直接短语等13、一个上下文无关文法生成句子abbaa的推导树如下:(3)求直接短语解:直接短语有:a ε bP102例题6.1及其分析.( 后加画语法树)例6.1 设文法G[S]为:(1)S—>aAcBe(2)A—>b(3)A—>Ab(4)B—>d对输入串abbcde#进行分析,检查该符号串是否是G[S]的句子。
步骤符号栈输入符号串动作(1)# abbcde# 移进(2)#a bbcde# 移进(3)#ab bcde# 归约(A—>b)(4)#aA bcde#移进(5)#aAb cde# 归约(A—>Ab)(6)#aA cde# 移进(7)#aAc de# 移进(8)#aAcd e# 归约(B—>d)(9)#aAcB e# 移进(10)#aAcBe # 归约(S—>aAcBe)(11)#S # 接受一、计算分析题(60%)1、正规式→ NFA→ DFA→最简DFAP72第1题(1)、(4);第一题1、构造下列正规式相应的DFA.(1)1(0|1)*101解:先构造NFA0 1S AA A ABAB AC ABAC A ABZABZ AC AB除S,A外,重新命名其他状态,令AB为B、AC为C、ABZ为D,因为D含有Z(NFA的终态),所以0 1S AA A BB C BC A DD C B(4) b((ab)*|bb)*ab解:先构造NFA得到DFA如下所示:P72第4题(a)4、把下图确定化和最小化解:确定化:a b0 01 101 01 11 0、{1},其中A为初态,A,B为终态,因此有:a bA B CB B CC A最小化::初始分划得终态组{A,B},非终态组{C}Π0:{A,B},{C},对终态组进行审查,判断A和B是等价的,故这是最后的划分。
编译原理课后答案-第二版
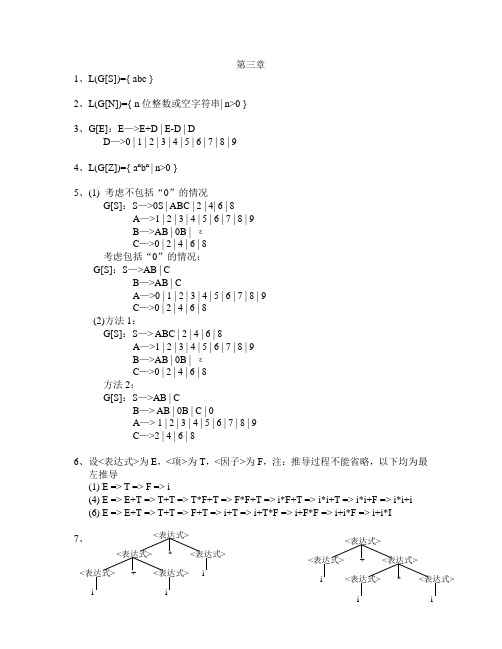
第三章1、L(G[S])={ abc }2、L(G[N])={ n位整数或空字符串| n>0 }3、G[E]:E—>E+D | E-D | DD—>0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 94、L(G[Z])={ a n b n | n>0 }5、(1) 考虑不包括“0”的情况G[S]:S—>0S | ABC | 2 | 4| 6 | 8A—>1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9B—>AB | 0B | εC—>0 | 2 | 4 | 6 | 8考虑包括“0”的情况:G[S]:S—>AB | CB—>AB | CA—>0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9C—>0 | 2 | 4 | 6 | 8(2)方法1:G[S]:S—> ABC | 2 | 4 | 6 | 8A—>1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9B—>AB | 0B | εC—>0 | 2 | 4 | 6 | 8方法2:G[S]:S—>AB | CB—> AB | 0B | C | 0A—> 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9C—>2 | 4 | 6 | 86、设<表达式>为E,<项>为T,<因子>为F,注:推导过程不能省略,以下均为最左推导(1) E => T => F => i(4) E => E+T => T+T => T*F+T => F*F+T => i*F+T => i*i+T => i*i+F => i*i+i(6) E => E+T => T+T => F+T => i+T => i+T*F => i+F*F => i+i*F => i+i*I7、<表达式><表达式>*<表达式><表达式>+<表达式>i i i<表达式><表达式>+<表达式>i <表达式>*<表达式>i i8、是有二义性的,因为句子abc 有两棵语法树(或称有两个最左推导或有两个最右推导)最左推导1:S => Ac => abc 最左推导2:S => aB => abc 9、(1)(2) 该文法描述了变量a 和运算符+、*组成的逆波兰表达式10、(1) 该文法描述了各种成对圆括号的语法结构(2) 是有二义性的,因为该文法的句子()()存在两种不同的最左推导: 最左推导1:S => S(S)S => (S)S => ()S => ()S(S)S => ()(S)S => ()()S => ()()最左推导2:S => S(S)S => S(S)S(S)S => (S)S(S)S=> ()S(S)S => ()(S)S => ()()S => ()()11、(1) 因为从文法的开始符E 出发可推导出E+T*F ,推导过程如下:E => E+T =>E+T*F ,所以E+T*F 是句型。
编译原理课后答案

第二章 高级语言及其语法描述4.令+、*和↑代表加,乘和乘幂,按如下的非标准优先级和结合性质的约定,计算1+1*2↑2*1↑2的值:(1) 优先顺序(从高至低)为+,*和↑,同级优先采用左结合。
(2) 优先顺序为↑,+,*,同级优先采用右结合。
解:(1)1+1*2↑2*1↑2=2*2↑1*1↑2=4↑1↑2=4↑2=16 (2)1+1*2↑2*1↑2=1+1*2*1=2*2*1=2*2=46.令文法G6为 N →D|NDD →0|1|2|3|4|5|6|7|8|9 (1) G6 的语言L (G6)是什么?(2) 给出句子0127、34和568的最左推导和最右推导。
解:(1)L (G6)={a|a ∈∑+,∑=﹛0,1,2,3,4,5,6,7,8,9}}(2)N =>ND => NDD => NDDD => DDDD => 0DDD => 01DD => 012D => 0127 N => ND => N7=> ND7=> N27=> ND27=> N127=> D127=> 0127 N => ND => DD => 3D => 34 N => ND => N4=> D4 =>34N => ND => NDD => DDD => 5DD => 56D => 568 N => ND => N8=> ND8=> N68=> D68=> 5687.写一个文法,使其语言是奇数集,且每个奇数不以0开头。
解:A →SN, S →+|-|∑, N →D|MDD →1|3|5|7|9, M →MB|1|2|3|4|5|6|7|8|9 B →0|1|2|3|4|5|6|7|8|9 8. 文法:E T E T E T TF T F T F F E i→+-→→|||*|/()| 最左推导:E E T T TF T i T i T F i F F i i F i i i E T T F F F i F i E i E T i T T i F T i i T i i F i i i ⇒+⇒+⇒+⇒+⇒+⇒+⇒+⇒+⇒⇒⇒⇒⇒⇒+⇒+⇒+⇒+⇒+⇒+********()*()*()*()*()*()*()最右推导:E E T E TF E T i E F i E i i T i i F i i i i i E T F T F F F E F E T F E F F E i F T i F F i F i i i i i ⇒+⇒+⇒+⇒+⇒+⇒+⇒+⇒+⇒⇒⇒⇒⇒+⇒+⇒+⇒+⇒+⇒+⇒+**********()*()*()*()*()*()*()*()语法树:/********************************EE FTE +T F F T +iiiEEFTE-T F F T -iiiE EFT+T F FTiii*i+i+ii-i-ii+i*i*****************/9.证明下面的文法是二义的:S → iSeS|iS|I解:因为iiiiei 有两种最左推导,所以此文法是二义的。
编译原理课后习题答案

编译原理课后习题答案第一章1.典型的编译程序在逻辑功能上由哪几部分组成?答:编译程序主要由以下几个部分组成:词法分析、语法分析、语义分析、中间代码生成、中间代码优化、目标代码生成、错误处理、表格管理。
2. 实现编译程序的主要方法有哪些?答:主要有:转换法、移植法、自展法、自动生成法。
3. 将用户使用高级语言编写的程序翻译为可直接执行的机器语言程序有哪几种主要的方式?答:编译法、解释法。
4. 编译方式和解释方式的根本区别是什么?答:编译方式:是将源程序经编译得到可执行文件后,就可脱离源程序和编译程序单独执行,所以编译方式的效率高,执行速度快;解释方式:在执行时,必须源程序和解释程序同时参与才能运行,其不产生可执行程序文件,效率低,执行速度慢。
第二章1.乔姆斯基文法体系中将文法分为哪几类?文法的分类同程序设计语言的设计与实现关系如何?答:1)0型文法、1型文法、2型文法、3型文法。
2)2. 写一个文法,使其语言是偶整数的集合,每个偶整数不以0为前导。
答:Z→SME | BS→1|2|3|4|5|6|7|8|9M→ε | D | MDD→0|SB→2|4|6|8E→0|B3. 设文法G为:N→ D|NDD→ 0|1|2|3|4|5|6|7|8|9请给出句子123、301和75431的最右推导和最左推导。
答:N?ND?N3?ND3?N23?D23?123N?ND?NDD?DDD?1DD?12D?123N?ND?N1?ND1?N01?D01?301N?ND?NDD?DDD?3DD?30D?301N?ND?N1?ND1?N31?ND31?N431?ND431?N5431?D5431?7 5431N?ND?NDD?NDDD?NDDDD?DDDDD?7DDDD?75DDD?754 DD?7543D?75431 4. 证明文法S→iSeS|iS| i是二义性文法。
答:对于句型iiSeS存在两个不同的最左推导:S?iSeS?iiSesS?iS?iiSeS所以该文法是二义性文法。
编译原理课后第十一章答案

对假设(2) B:=3 D:=A+C E:=A*C F:=D+E K:=B*5 L:=K+F
计算机咨询网()陪着您
10
《编译原理》课后习题答案第十一章
第7题 分别对图 11.25 和 11.26 的流图: (1) 求出流图中各结点 n 的必经结点集 D(n)。 (2) 求出流图中的回边。 (3) 求出流图中的循环。
(1) (2) (3) (4) (5) (6) (7) (8) (9) (10) (11) (12) (13)
i:=m-1 j:=n t1:=4*n v:=a[t1] i:=i+1 t2:=4*i t3:=a[t2] if t3< v goto (5) j:=j-1 t5:=4*j t5:=a[t4] if t5> v goto (9) if i >=编译原理》课后习题答案第十一章
第 5 题: 如下程序流图(图 11.24)中,B3 中的 i∶=2 是循环不变量,可以将其提到前置结点吗? 你还能举出一些例子说明循环不变量外移的条件吗?
图 11.24 答案: 不能。因为 B3 不是循环出口 B4 的必经结点。 循环不变量外移的条件外有: (a)(I)s 所在的结点是 L 的所有出口结点的必经结点 (II)A 在 L 中其他地方未再定值 (III)L 中所有 A 的引用点只有 s 中 A 的定值才能到达 (b)A 在离开 L 之后不再是活跃的,并且条件(a)的(II)和(III)成立。所谓 A 在离开 L 后不再是活跃的是指,A 在 L 的任何出口结点的后继结点的入口处不是活跃的(从此点后 不被引用) (3)按步骤(1)所找出的不变运算的顺序,依次把符合(2)的条件(a)或(b)的 不变运算 s 外提到 L 的前置结点中。如果 s 的运算对象(B 或 C)是在 L 中定值的,则只有 当这些定值四元式都已外提到前置结点中时,才可把 s 也外提到前置结点。
编译原理(龙书)课后习题解答(详细)

编译原理(龙书)课后习题解答(详细)编译原理(龙书)课后题解答第一章1.1.1 :翻译和编译的区别?答:翻译通常指自然语言的翻译,将一种自然语言的表述翻译成另一种自然语言的表述,而编译指的是将一种高级语言翻译为机器语言(或汇编语言)的过程。
1.1.2 :简述编译器的工作过程?答:编译器的工作过程包括以下三个阶段:(1) 词法分析:将输入的字符流分解成一个个的单词符号,构成一个单词符号序列;(2) 语法分析:根据语法规则分析单词符号序列中各个单词之间的关系,确定它们的语法结构,并生成抽象语法树;(3) 代码生成:根据抽象语法树生成目标程序(机器语言或汇编语言),并输出执行文件。
1.2.1 :解释器和编译器的区别?答:解释器和编译器的主要区别在于执行方式。
编译器将源程序编译成机器语言或汇编语言等,在运行时无需重新编译,程序会一次性运行完毕;而解释器则是边翻译边执行,每次执行都需要进行一次翻译,一次只执行一部分。
1.2.2 :Java语言采用的是解释执行还是编译执行?答:Java一般是编译成字节码的形式,然后由Java虚拟机(JVM)进行解释执行。
但是,Java也有JIT(即时编译器)的存在,当某一段代码被多次执行时,JIT会将其编译成机器语言,提升代码的执行效率。
第二章2.1.1 :使用BNF范式定义简单的加法表达式和乘法表达式答:<加法表达式> ::= <加法表达式> "+" <乘法表达式> | <乘法表达式><乘法表达式> ::= <乘法表达式> "*" <单项式> | <单项式><单项式> ::= <数字> | "(" <加法表达式> ")"2.2.3 :什么是自下而上分析?答:自下而上分析是指从输入字符串出发,自底向上构造推导过程,直到推导出起始符号。
编译原理课后习题答案(陈火旺+第三版)

编译原理课后习题答案(陈火旺+第三版)第二章P36-6(1)L G ()1是0~9组成的数字串(2) 最左推导:N ND NDD NDDD DDDD DDD DD D N ND DD D N ND NDD DDD DD D ⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒0010120127334556568最右推导:N ND N ND N ND N D N ND N D N ND N ND N D ⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒⇒77272712712701274434886868568P36-7G(S)O N O D N S O AO A AD N→→→→→1357924680|||||||||||P36-8文法:E T E T E T TF T F T F F E i→+-→→|||*|/()|最左推导:E E T T TF T i T i T F i F F i i F i i i E T T F F F i F i E i E T i T T i F T i i T i i F i i i ⇒+⇒+⇒+⇒+⇒+⇒+⇒+⇒+⇒⇒⇒⇒⇒⇒+⇒+⇒+⇒+⇒+⇒+********()*()*()*()*()*()*()最右推导:E E T E TF E T i E F i E i i T i i F i i i i i E T F T F F F E F E T F E F F E i F T i F F i F i i i i i ⇒+⇒+⇒+⇒+⇒+⇒+⇒+⇒+⇒⇒⇒⇒⇒+⇒+⇒+⇒+⇒+⇒+⇒+**********()*()*()*()*()*()*()*()语法树:/********************************EE FTE +T F F T +iiiEEFTE-T F F T -iiiEEFT+T F FTiii*i+i+ii-i-ii+i*i*****************/P36-9句子iiiei 有两个语法树: S iSeS iSei iiSei iiiei S iS iiSeS iiSei iiiei ⇒⇒⇒⇒⇒⇒⇒⇒P36-10/**************)(|)(|S T T TS S →→***************/1 ε ε 1 0 11 确定化:1 1111 1 最小化:{,,,,,},{}{,,,,,}{,,}{,,,,,}{,,,}{,,,,},{},{}{,,,,}{,,}{,,,},{},{},{}{,,,}{,012345601234513501234512460123456012341350123456012310100==== 3012312401234560110112233234012345610101}{,,,}{,,}{,},{,}{},{},{}{,}{}{,}{,}{,}{}{,}{}{},{},{,},{},{},{}=====0 1111 1P64–8(1) 01)0|1(*(2))5|0(|)5|0()9|8|7|6|5|4|3|2|1|0)(9|8|7|6|5|4|3|2|1(*(3)******)110|0(01|)110|0(10P64–12(a)aa确定化:给状态编号:aaa b b ba0 1最小化:{,},{,}{,}{}{,}{}{,}{,}{,}{}{,},{},{}012301101223032330123a ba b ====aabb ab (b)b baa baa baa a已经确定化了,进行最小化最小化:{{,}, {,,,}}012345011012423451305234523452410243535353524012435011012424{,}{}{,}{,}{,,,}{,,,}{,,,}{,,,}{,}{,}{,}{,}{,}{,}{,}{,}{{,},{,},{,}}{,}{}{,}{,}{,}a b a b a b a b a b a =============={,}{,}{,}{,}{,}{,}{,}10243535353524 b a baa baP64–14(1) 00 (2):(|)*0100 1 ε确定化:给状态编号:1 0110 最小化:{,},{,}{,}{}{,}{}{,}{,}{,}{}{,},{},{}0123011012231323301230101====1 11第四章P81–1(1) 按照T,S 的顺序消除左递归ε|,)(||^)(T S T T S T T a S S G '→''→→'递归子程序: procedure S; beginif sym='a' or sym='^' then abvance else if sym='(' then beginadvance;T;if sym=')' then advance;else error;endelse errorend;procedure T;beginS;'Tend;procedure 'T;beginif sym=','then beginadvance;S;'Tendend;其中:sym:是输入串指针IP所指的符号advance:是把IP调至下一个输入符号error:是出错诊察程序(2)FIRST(S)={a,^,(} FIRST(T)={a,^,(} FIRST('T )={,,ε} FOLLOW(S)={),,,#} FOLLOW(T)={)} FOLLOW('T )={)} 预测分析表是LL(1)文法P81–2文法:|^||)(|*||b a E P F F F P F T T T F T E E E T E →'→''→→''→+→''→εεε(1)FIRST(E)={(,a,b,^} FIRST(E')={+,ε}FIRST(T)={(,a,b,^} FIRST(T')={(,a,b,^,ε} FIRST(F)={(,a,b,^} FIRST(F')={*,ε} FIRST(P)={(,a,b,^} FOLLOW(E)={#,)} FOLLOW(E')={#,)} FOLLOW(T)={+,),#} FOLLOW(T')={+,),#} FOLLOW(F)={(,a,b,^,+,),#} FOLLOW(F')={(,a,b,^,+,),#} FOLLOW(P)={*,(,a,b,^,+,),#} (2)考虑下列产生式:'→+'→'→'→E E T T F F P E a b||*|()|^||εεεFIRST(+E)∩FIRST(ε)={+}∩{ε}=φ FIRST(+E)∩FOLLOW(E')={+}∩{#,)}=φ FIRST(T)∩FIRST(ε)={(,a,b,^}∩{ε}=φ FIRST(T)∩FOLLOW(T')={(,a,b,^}∩{+,),#}=φFIRST(*F')∩FIRST(ε)={*}∩{ε}=φFIRST(*F')∩FOLLOW(F')={*}∩{(,a,b,^,+,),#}=φFIRST((E))∩FIRST(a) ∩FIRST(b) ∩FIRST(^)=φ所以,该文法式LL(1)文法.(3)(4)procedure E;beginif sym='(' or sym='a' or sym='b' or sym='^'then begin T; E' endelse errorendprocedure E';beginif sym='+'then begin advance; E endelse if sym<>')' and sym<>'#' then errorendprocedure T;beginif sym='(' or sym='a' or sym='b' or sym='^'then begin F; T' endelse errorendprocedure T';beginif sym='(' or sym='a' or sym='b' or sym='^'then Telse if sym='*' then errorendprocedure F;beginif sym='(' or sym='a' or sym='b' or sym='^'then begin P; F' endelse errorendprocedure F';beginif sym='*'then begin advance; F' endendprocedure P;beginif sym='a' or sym='b' or sym='^'then advanceelse if sym='(' thenbeginadvance; E;if sym=')' then advanceelse errorendelse error end;P81–3/***************(1) 是,满足三个条件。
编译原理习题答案

1、正规文法又称 DA、0型文法B、1型文法C、2型文法D、3型文法2、对于无二义性的文法,规范归约是 BA. 最左推导B. 最右推导的逆过程C.最左归约的逆过程D.最右归约的逆过程。
3、扫描器的任务是从源程序中识别出一个个单词符号。
4、程序所需的数据空间在程序运行前就可确定,称为 A 管理技术。
A 静态存储B 动态存储C 栈式存储D 堆式存储5、编译过程中,语法分析器的任务是(B)。
①分析单词是怎样构成的②分析单词串是如何构成语句和说明的③分析语句和说明是如何构成程序的④分析程序的结构A、②③B、②③④C、①②③D、①②③④6、文法G:E→E+T|T T→T*P|P P→ (E)| i则句型P+T+i的句柄和最左素短语分别为 B 。
A、P+T和iB、P和P+TC、i和P+T+iD、P和P7、四元式之间的联系是通过B实现的A.指示器B.临时变量C.符号表D.程序变量8、程序语言的单词符号一般可以分为保留字、标识符、常数、运算符、界符等等。
9、下列 B 优化方法是针对循环优化进行的。
A.删除多余运算B.删除归纳变量C.合并已知量D.复写传播10、若文法G 定义的语言是无限集,则文法必然是 AA、递归的B、前后文无关的C、二义性的D、无二义性的11、文法G 产生的D的全体是该文法描述的语言。
A、句型B、终结符集C、非终结符集D、句子12、Chomsky 定义的四种形式语言文法中,0 型文法又称为 A文法;1 型文法又称为 C 文法。
A.短语文法B.上下文无关文法C.上下文有关文法D.正规文法A.短语文法B.上下文无关文法C.上下文有关文法D.正规文法13、语法分析最常用的两类方法是自顶向下和自底向上分析法。
14、一个确定的有穷自动机DFA是一个 A 。
A 五元组(K,∑,f, S, Z)B 四元组(V N,V T,P,S)C 四元组(K,∑,f,S)D 三元组(V N,V T,P)A、语法B、语义C、代码D、运行15、 B不属于乔姆斯基观点分类的文法。
编译原理课后习题答案+清华大学出版社第二版

注意:如果问编译程序有哪些主要构成成分,只要回答六部分就可以。如果搞不清楚, 就回答八部分。
第 2题
若 PL/0 编译程序运行时的存储分配策略采用栈式动态分配,并用动态链和静态链的方
式分别解决递归调用和非局部变量的引用问题,试写出下列程序执行到赋值语句 b∶=10
时运行栈的布局示意图。 var x,y; procedure p; var a; procedure q; var b;
begin (q)
答案:
PL/0 编译程序所产生的目标代码中有 3 条非常重要的特殊指令,这 3 条指令在 code 中的位置和功能以及所完成的操作说明如下:
INT 0 A 在过程目标程序的入口处,开辟 A 个单元的数据段。A 为局部变量的个数+3。 OPR 0 0
3
《编译原理》课后习题答案第二章
在过程目标程序的出口处,释放数据段(退栈),恢复调用该过程前正在运行的过程的数 据段基址寄存器 B 和栈顶寄存器 T 的值,并将返回地址送到指令地址寄存器 P 中,以使调 用前的程序从断点开始继续执行。
3
《编译原理》课后习题答案第一章
第6题
计算机执行用高级语言编写的程序有哪些途径?它们之间的主要区别是什么?
答案:计算机执行用高级语言编写的程序主要途径有两种,即解释与编译。 像 Basic 之类的语言,属于解释型的高级语言。它们的特点是计算机并不事先对高级语
言进行全盘翻译,将其变为机器代码,而是每读入一条高级语句,就用解释器将其翻译为一 条机器代码,予以执行,然后再读入下一条高级语句,翻译为机器代码,再执行,如此反 复。
编译原理小题答案解析

《编译原理》常见题型一、填空题1.编译程序的工作过程一般可以划分为词法分析,语法分析,中间代码生成______ ,,代码优化(可省)_,目标代码生成等几个基本阶段。
2.若源程序是用高级语言编写的,目标程序是机器语言程序或汇编程序—,则其翻译程序称为编译程序.3.编译方式与解释方式的根本区别在于是否生成目标代码__________5.对编译程序而言,输入数据是源程序_______ ,输出结果是目标程序7.若源程序是用高级语言编写的,目标程序是机器语言程序或汇编程序,则其翻译程序称为编译程序。
8.一个典型的编译程序中,不仅包括词法分析、语法分析、中间代码生成、代码优化、目标代码生成等五个部分,还应包括一表格处理和出错处理—。
其中,词法分析器用于识别单词一。
10.一个上下文无关文法所含四个组成部分是一组终结符号_________ 、, 一组非终结符号―、一个开始符号、一组产生式___________ 。
12.产生式是用于定义语法成分______ 的一种书写规则。
13.设G[S]是给定文法,则由文法G所定义的语言14)可描述为:L(G)= {x| S=>*x.x£ VT*} 。
*14.设G是一个给定的文法,S是文法的开始符号,如果5n x (其中x£V*),则称x是文法的一个.句型。
*15.设G是一个给定的文法,S是文法的开始符号,如果5n x(其中x£V T*),则称x是文法的一个句子一。
16.扫描器的任务是从源程序中识别出一个个单词符号_________ 。
17.语法分析最常用的两类方法是自上而下一和自下而上分析法。
18.语法分析的任务是识别给定的终结符串是否为给定文法的句子_。
19.递归下降法不允许任一非终结符是直接上—递归的。
20.自顶向下的语法分析方法的关键是如何选择候选式________ 的问题。
21.递归下降分析法是自.顶向下分析方法。
22.自顶向下的语法分析方法的基本思想是:从文法的开始符号—开始,根据给定的输入串并按照文法的产生式一步一步的向下进行直接推导,试图推导出文法的句子—,使之与给定的输入串匹配。
编译原理

自底向上分析方法是从给定的单词串开始,试图归约(推导的逆操作)为文法的开始符,如果能归约到文法 开始符,则确认单词串是正确的程序,否则是错误的程序。
自底向上语法分析要解决的问题是如何快速、确定的找到合适的归约过程(如果存在),用于其的方法有简 单优先法、算符优先法、LR分析法等。
语义处理
在计算机上执行一个高级语言源程序一般分为两步:一是通过编译程序把源程序 翻译成机器语言程序,也叫目标程序;二是执行目标程序。但是对高级语言源程序的 处理也可以采用边翻译边执行的解释执行方式。这种方式下的翻译程序称为解释程序。
解释程序与编译程序的比较
编译程序 解释程序
执行方式
将源程序翻译成目标语言程
序,然后在计算机上运行目 标程序
或者直接解释执行源程序,
或者将源程序翻译成某种中 间表示形式后再加以执行
处理程序 翻译源程序
机器上运行的是与源程序等 价的目标程序,源程序和编 译程序都不再参与目标程序
的执行过程
将源程序翻译成独立的目标 程序
解释程序和源程序(或某种等 价表示)要参与到程序的运行 过程中,运行程序的控制权
编译程序也称为编译器,是指把用高级程序设计语言书写的源程序,翻译成等价的 机器语言格式目标程序的翻译程序。编译程序属于采用生成性实现途径实现的翻译程序。 它以高级程序设计语言书写的源程序作为输入,而以汇编语言或机器语言表示的目标程 序作为输出。编译出的目标程序通常还要经历运行阶段,以便在运行程序的支持下运行, 加工初始数据,算出所需的计算结果。
语法分析
语法分析就是确认作为词法分析结果的单 词序列是否为给定语言的一个正确序列。在语 法分析中,给定语言用文法表示,如果给定的 程序能够与该文法相匹配,则认为程序是正确 的,否则程序是错误的。单词序列与给定文法 匹配的方式有两种:自顶向下分析法和自底向 上分析法。
北语17春《编译原理》作业11满分答案

17春《编译原理》作业1
试卷总分:100 得分:100
一、单选题 (共 6 道试题,共 24 分)
1. 如果文法G是无二义的,则它的任何句子α_____。
A. 最左推导和最右推导对应的语法树必定相同
B. 最左推导和最右推导对应的语法树可能不同
C. 最左推导和最右推导必定相同
D. 可能存在两个不同的最左推导,但它们对应的语法树相同
满分:4 分
正确答案:A
2. 编译程序是将高级语言程序翻译成( )。
A. 高级语言程序
B. 机器语言程序
C. 汇编语言程序
D. 汇编语言或机器语言程序
满分:4 分
正确答案:D
3. 正规式MI和M2等价是指_____。
A. MI和M2的状态数相等
B. Ml和M2的有向弧条数相等。
C. M1和M2所识别的语言集相等
D. Ml和M2状态数和有向弧条数相等
满分:4 分
正确答案:C
4. 文法分为四种类型,即0型、1型、2型、3型。
其中0型文法是_____。
A. 短语文法
B. 正则文法
C. 上下文有关文法
D. 上下文无关文法
满分:4 分
正确答案:A
5. 用高级语言编写的程序经编译后产生的程序叫_____。
A. 源程序
B. 目标程序
C. 连接程序
D. 解释程序。
编译原理名词解释

编译原理名词解释1. 词法分析器(Lexer):也称为扫描器(Scanner),用于将源代码分割成一个个单词(Token)。
2. 语法分析器(Parser):将词法分析器生成的单词序列转换成语法树(Parse Tree)或抽象语法树(Abstract Syntax Tree)。
3. 语法树(Parse Tree):表示源代码的语法结构的树状结构,它由语法分析器根据语法规则生成。
4. 抽象语法树(Abstract Syntax Tree):比语法树更加简化和抽象的树状结构,用于表示源代码的语义结构。
5. 语义分析器(Semantic Analyzer):对抽象语法树进行语义检查,并生成中间代码或目标代码。
6. 中间代码(Intermediate code):一种介于源代码和目标代码之间的中间表示形式,可以被不同的优化器和代码生成器使用。
7. 目标代码生成器(Code Generator):将中间代码转换成特定目标平台的机器代码。
8. 优化器(Optimizer):用于对中间代码进行优化,以提高代码的执行效率和资源利用率。
9. 符号表(Symbol Table):用于存储程序中的标识符(变量、函数等)的信息,包括名称、类型等。
10. 语言文法(Grammar):定义了一种语言的语法规则,常用的形式包括上下文无关文法和正则文法。
11. 上下文无关文法(Context-free Grammar):一种形式化的语法表示方法,由产生式和非终结符组成,描述一种语言的句子结构。
12. 语言解释器(Interpreter):将源代码逐行解释执行的程序,不需要生成目标代码。
13. 回溯法(Backtracking):一种递归式的算法,用于在语法分析过程中根据产生式进行选择。
14. 正则表达式(Regular Expression):用于描述一类字符串的表达式,可以用于词法分析中的模式匹配。
15. 自顶向下分析(Top-down Parsing):从文法的起始符号开始,按照语法规则逐步构建语法树的过程。
编译原理考试知识点复习

第一章:编译过程的六个阶段:词法分析,语法分析,语义分析,中间代码生成,代码优化,目标代码生成解释程序:把某种语言的源程序转换成等价的另一种语言程序——目标语言程序,然后再执行目标程序。
解释方式是接受某高级语言的一个语句输入,进行解释并控制计算机执行,马上得到这句的执行结果,然后再接受下一句。
编译程序:就是指这样一种程序,通过它能够将用高级语言编写的源程序转换成与之在逻辑上等价的低级语言形式的目标程序(机器语言程序或汇编语言程序)。
解释程序和编译程序的根本区别:是否生成目标代码第三章:Chomsky对文法中的规则施加不同限制,将文法和语言分为四大类:0型文法(PSG)◊ 0型语言或短语结构语言文法G的每个产生式α→β中:若α∈V*VNV*, β∈(VN∪VT)* ,则G是0型文法,即短语结构文法。
1型文法(CSG)◊ 1型语言或上下文有关语言在0型文法的基础上:若产生式集合中所有|α|≤|β|,除S→ε(空串)外,则G是1型文法,即:上下文有关文法另一种定义:文法G的每一个产生式具有下列形式:αAδ→αβδ,其中α、δ∈V*,A∈VN,β∈V+;2型文法(CFG)◊ 2型语言或上下文无关语言文法G的每个产生式A→α,若A∈VN ,α∈(VN∪VT)*,则G是2型法,即:上下文无关文法。
3型文法(RG)◊ 3型语言或正则(正规)语言若A、B∈VN,a∈VT或ε,右线性文法:若产生式为A→aB或A→a左线性文法:若产生式为A→Ba或A→a都是3型文法(即:正规文法)最左(最右)推导在推导的任何一步α⇒β,其中α、β是句型,都是对α中的最左(右)非终结符进行替换规范推导:即最右推导。
规范句型:由规范推导所得的句型。
句子的二义性(这里的二义性是指语法结构上的。
)文法G[S]的一个句子如果能找到两种不同的最左推导(或最右推导),或者存在两棵不同的语法树,则称这个句子是二义性的。
文法的二义性一个文法如果包含二义性的句子,则这个文法是二义文法,否则是无二义文法。
编译原理课后作业参考答案

作业参考答案第二章 高级语言及其语法描述6、(1)L (G 6)={0,1,2,......,9}+(2)最左推导:N=>ND=>NDD=>NDDD=>DDDD=>0DDD=>01DD=>012D=>0127 N=>ND=>DD=>3D=>34N=>ND=>NDD=>DDD=>5DD=>56D=>568 最右推导:N=>ND =>N7=>ND7=>N27=>ND27=>N127=>D127=>0127 N=>ND=>N4=>D4=>34N=>ND=>N8=>ND8=>N68=>D68=>568 7、G:S →ABC | AC | CA →1|2|3|4|5|6|7|8|9B →BB|0|1|2|3|4|5|6|7|8|9C →1|3|5|7|98、(1)最左推导:E=>E+T=>T+T=>F+T=>i+T=>i+T*F=>i+F*F=>i+i*F=>i+i*iE=>T=>T*F=>F*F=>i*F=>i*(E)=>i*(E+T)=>i*(T+T)=>i*(F+T)=>i*(i+T)=>i*(i+F)=>i*(i+i) 最右推导:E=>E+T=>E+T*F=>E+T*i=>E+F*i=>E+i*i=>T+i*i=>F+i*i=>i+i*iE=>T=>T*F=>T*(E)=>T*(E+T)=>T*(E+F)=>T*(E+i)=>T*(T+i)=>T*(F+i)=>T*(i+i)=>F*(i+i)=>i*(i+i) (2)9、证明:该文法存在一个句子iiiei 有两棵不同语法分析树,如下所示,因此该文法是二义的。
编译原理期末复习

(8) E=E+F
(9) Write (E)
(10)Halt
(11)L1: E=B*
(12)F=F+2
(13)E=E+F
(14)Write (E)
(15)If E>100 goto L2
(16)halt
(17)L2:F=F-1
(18)goto L1
47
48
49
50
语句(1)—语句(5)、(6)—(10)、语句(11)— (15)、语句(16)、语句(17)和(18)分别是 一个基本块 设语句(1)—语句(5)为① 语句(6)—语句(10)为② 语句(11)—语句(15)为③ 语句(16)为④ 语句(17)和(18)为⑤、
A. S→Sx|xy
B. S→xy|xSy
C. S→xx|yxx
D. S→Sy|x
CH4 语法分析——自下而上分析
练习:
下列文法中 是LL(1)文法…………( )
A. S→aSb|ab
B. S→aS|b
C. S→ab|Sab
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
8
9
B2
T6:=T5[T1]
T7:=T3*T6 T1=T1+4
B2
10 P:=P+T7 3‘ 12 If T1<=80 goto (5)
经过优化以后执行效率大大提高
12
11.2 局部优化
局部优化是指基本块内的优化。
基本块定义:
1. 2. 3. 指程序中一顺序执行的语句序列; 只有一个入口语句和一个出口语句。 执行时只能从入口语句进入,从出口语句退出。
2.
代码外提
此优化的目的在于减少循环中代码总数。 把循环中不变运算,即其结果独立于循环执行次数的表达 式,提到循环外(前面)。 使之只在循环外计算一次。 将(4)和(7)提到循环外
6
经过删除公共子表达式和外提代码后的中间代码
1 2 P:=0 I:=1
B1
4
7
虽然仍然是12行中间代码 存贮空间没有省。
19
用 DAG 进行基本块的优化
四元式
0型: A:=B(:=,B, —,A)
DAG结点
n1 n1
A
B
n2 n2 A
1型:
A:=op B(op,B, —,A)
op n1 n1 B
n3
A op n1 n1 B
n2 n2
2型: A:=B
op C(op, B, C,A)
C
20
用 DAG 进行基本块的优化
范围
依据优化所涉及的程序范围,优化可分为局部优化、循环优化和全 局优化。
3
11.1 优化技术简介
局部优化:指的是在只有一个入口、一个出口的基本程序块上进行的优 化。(基本块优化,通过DAG图优化。)
循环优化:是对循环中的代码进行优化。(依据控制流,循环中代码优 化,包括代码外提和强度消弱等。)
2
2. 知识要点
11.1 优化技术简介
定义
所谓优化,实质上是对代码进行等价变换,使得变换后的代码运行 结果与变换前代码运行结果相同,而运行速度加大或占用存贮空间 减少。 优化可在编译的不同阶段进行,对同一阶段,涉及的程序范围也有 所不同,在同一范围内,可进行多种优化。
阶段
优化工作阶段可在中间代码生成后或目标代码生成后进行。对中间 代码优化相对要简单(与机器无关的优化);对目标代码优化相对 要复杂,因为目标代码是针对具体计算机的(依赖计算机的优化)。
T4:=T1
T6:=T5[T4] T7:=T3*T6 P:=P+T7 I:=I+1 T1=T1+4 If I<=20 goto (5)
8
B2
4.
变换循环控制条件
中间代码中,I和T1始终保持T1=4*I的线性关系; 把四元式(12)的循环控制条件I≤20变换成T1≤80, 这样整个程序的运行结果不变。 这种变换称为变换循环控制条件。 变换后,循环中I的值在循环后不会被引用,四元式 (11)成为多余运算,可以从循环中删除。 变换循环控制条件可以达到代码优化的目的。
10
6. 删除无用赋值
(6)对T4赋值,但T4未被引用; (2)和(11)对I赋值,但只有(11)引用I。
(6),(2)和(11)对程序的运行结果无任何作用。
我们称之为无用赋值,无用赋值可以从程序中删除。
11
中间代码
1
1 2 P:=0 I:=1
P:=0
T2:=addr(A)-4 T5:=addr(B)-4 T1:=4
14
3.
程序的控制流图 把一个程序划分成若干基本块后,可以按 照程序的执行过程用有向边把基本块连接 起来,这就构成了程序的控制流图。 流图是一个具有唯一首结点的有向图。 流图G可以表示为:G=(N,E,n0)。
1. N是流图的所有的结点的集合,流图中的结点 就是基本块; 2. n0是流图的首结点; 3. E是流图的所有的有向边组成的集合。
3.
4.
如果当前四元式是1型,则转2(1)。
如果当前四元式是2型,则:如果NODE(1)无定义,则构造一标 记为C的叶结点并定义NODE(1) 为这个结点;转2 (2)
将DAG定义为一个特殊的数据结构:在其中存放着DAG的各个结点信息,包括
每个结点的标注信息(常数或者运算符)和附加信息(变量名称)。
一个基本块,可用一个DAG来表示。
各种四元式及相对应的DAG的结点形式。 图中ni为结点编号,结点下面的符号(运算符、标 识符或常数)是各结点的标记;
n1 n1
A
B
n2 n2 A
各结点右边的标识符是结点的附加标识符。
各种形式的四元式按其对应结点的后继个数分为四类。 a. 0个后继结点的四元式称为0型; b. 1个后继结点的四元式称为1型; c. 2个后继结点的四元式称为2型; d. 3个后继结点的四元式称为3型。
16
例题:
1 2 3 4 5 6 7 8 9 10 11 Read(limit) I:=1 If I>limit goto(11) Read(j) If I=1 goto(8) Sum:=sum+j Goto(9) Sum:=j I:=I+1 Goto(3) Write(sum)
上述程序中,入口语句分别为1、3、4、6、 8、9、11。 该程序共有7个基本块。 其中语句1、2为1块; 3语句为2块; 4、5语句为3块; 6、7语句为4块; 8语句为5块; 9、10语句为6块; 11语句为7块。 根据执行过程可以构成控制流图如下:
B1
B1
4 7 3
3 4 5 6 7 8 9 10 11 12
T1:=4*I T2:=addr(A)-4 T3:=T2[T1] T4:=4*I T5:=addr(B)-4 T6:=T5[T4] T7:=T3*T6 P:=P+T7 I:=I+1 If I<=20 goto (3)
5
T3:=T2[T1]
对于一个给定程序,可以划分出一系列基本块。
13
11.2 局部优化
基本块划分: 入口语句:
1. 2. 3. 程序的第一个语句; 或者,条件转移语句或无条件转移语句的转移目标语句; 或者,紧跟在条件转移语句后面的语句。
基本块划分算法:
1. 2. 求出各个入口语句; 对每个入口语句,构造其所属的基本块。即由该入口语句 到下一个入口语句(不包含该语句),或到一转移语句 (包含该语句),或到一停语句(包含该语句)之间的语 句序列组成。 凡是未被纳入某个基本块中的语句,都是程序控制流程中 无法到达的语句,也是不会被执行的语句,因此,可以删 除掉。
如果有向图中任一个通路都不是环路,则称该有向图为无环 路有向图。简称DAG。
18
基本块的DAG表示
DAG图中的结点带有标记或者附加信息。
图的叶节点:即无后继的节点,以一标识符(变量名)或常数作为标记, 表示该节点代表该变量或常数。
图的内部节点:即有后继的节点,以一运算符作为标记,表示该节点代 表应用该运算符对其后继节点所代表的值进行运算的结果。 图中各个节点上可能附加一个或多个标识符,表示这些变量具有该节 点所代表的值。 DAG可以用来描述计算过程。 一个基本块,可用一个DAG来表示
9
5.
合并已知量和复写传播
四元式(3)计算4*I时,I必为1。 4*I的两个运算对象都是编码时的已知量,可在编译时计算 出它的值,即四元式(3)可变为T1=4,这种变换称为合 并已知量。 四元式(6)把T1的值复写到T4中,四元式(8)要引用T4的 值,而从四元式(6)到四元式(8)之间未改变T4和T1的 值,则将四元式(8)改为T6∶=T5[T1], 这种变换称为复写传播.复写传播之后运算结果保持不变。
22
基本块的DAG构造算法
第二步骤, 1. 如果NODE(B)是标记为常数的叶结点 ,则转2(3),否 则转3(1)。 2. 如果NODE(B)和NODE(C)都是标记为常数的叶结点,则 转2(4),否则转3(2)。 3. 执行op B(即合并已知量),令得到的新常数为P。 如果NODE(B)是处理当前四元式时新构造出来的结点, 则删除它。如果NODE(P)无定义,则构造一用P做标记 的叶结点n。置NODE(P)=n,转4。 4. 执行B op C(即合并已知量),令得到的新常数为P。 如果NODE(B)或NODE(C)是处理当前四元式时新构造出 来的结点,则删除它。如果NODE(P)无定义,则构造 一用P做标记的叶结点n。置NODE(P)=n,转4。
2
3 4 5
I:=1
T1:=4*I T2:=addr(A)-4 T3:=T2[T1]
6
对源程序编译后得到中间代码 中间代码由B1和B2两部分组成 B2为循环部分。 对中间代码可以进行相应优化。
T4:=4*I
T5:=addr(B)-4 T6:=T5[T4]
B2
7 8
9
10 11 12
T7:=T3*T6
全局优化:是整个程序范围内进行优化。(依据数据流,大范围的优化, 主要分析变量的定值点和引用点。)
源代码
前段
中间代码
代码生成
目标代码
无论在哪个阶段进行优化都 可以通过上述三个方式实现。
中间代码优化
目标代码优化
编译的优化工作阶段
4
优化技术举例(中间代码优化)
源程序
中间代码 B1
1
P:=0
P:=0 for I:=1 to 20 do P:=P+A[I]*B[I];
1 2 3 7 4 5 6
17
基本块的DAG表示
一个有向图中有n个节点。对于任意一个有向边ni→nj,ni为 前驱(父节点),nj为后继(子节点)。 对于任意一个有向边序列,n1→n2、 n2→n3、„..、 nk1→nk ,称为从节点n1到nk的的一条通路。如果n1=nk ,则称 该通路为环路。