生物信息学复习资料 整理(双语)
大学生物信息学专业-复习资料整理

大学生物信息学专业-复习资料整理一、名词解释:生物信息学:研究大量生物数据复杂关系的学科,其特征是多学科交叉,以互联网为媒介,数据库为载体。
利用数学知识建立各种数学模型;利用计算机为工具对实验所得大量生物学数据进行储存、检索、处理及分析,并以生物学知识对结果进行解释。
二级数据库:在一级数据库、实验数据和理论分析的基础上针对特定目标衍生而来,是对生物学知识和信息的进一步的整理。
FASTA序列格式:是将DNA或者蛋白质序列表示为一个带有一些标记的核苷酸或者氨基酸字符串,大于号(>)表示一个新文件的开始,其他无特殊要求。
genbank序列格式:是GenBank数据库的基本信息单位,是最为广泛的生物信息学序列格式之一。
该文件格式按域划分为4个部分:第一部分包含整个记录的信息(描述符);第二部分包含注释:第三部分是引文区,提供了这个记录的科学依据;第四部分是核苷酸序列本身,以“//”结尾。
Entrez检索系统:是NCBI开发的核心检索系统,集成了NCBI的各种数据库,具有链接的数据库多,使用方便,能够进行交叉索引等特点。
BLAST:基本局部比对搜索工具,用于相似性搜索的工具,对需要进行检索的序列与数据库中的每个序列做相似性比较。
P94查询序列(querysequence):也称被检索序列,用来在数据库中检索并进行相似性比较的序列。
P98打分矩阵(scoringmatrix):在相似性检索中对序列两两比对的质量评估方法。
包括基于理论(如考虑核酸和氨基酸之间的类似性)和实际进化距离(如PAM)两类方法。
P29空位(gap):在序列比对时,由于序列长度不同,需要插入一个或几个位点以取得最佳比对结果,这样在其中一序列上产生中断现象,这些中断的位点称为空位。
P29空位罚分:空位罚分是为了补偿插入和缺失对序列相似性的影响,序列中的空位的引入不代表真正的过化事件,所以要对其进行罚分,空位罚分的多少直接影响对比的结果。
生物信息复习资料

生物信息复习资料生物信息复习资料生物信息学是一门综合性学科,涉及生物学、计算机科学和统计学等多个领域。
它的出现和发展,为我们深入研究生物体的基因组、蛋白质组以及其他生物大数据提供了强有力的工具和方法。
在生物信息学的学习和研究过程中,我们需要掌握一些基本的概念、技术和工具。
下面,我将为大家整理一些生物信息学的复习资料,希望能够对大家的学习有所帮助。
一、基本概念1. 生物信息学:生物信息学是一门研究生物体内信息的获取、存储、处理和分析的学科。
它通过运用计算机科学和统计学的方法,挖掘和解释生物体内的基因、蛋白质等分子信息,从而揭示生物体内的生命规律和机制。
2. 基因组学:基因组学是研究生物体基因组结构、功能和演化的学科。
它通过对生物体DNA序列的测定和分析,揭示基因组的组成、基因的定位和功能等信息。
3. 蛋白质组学:蛋白质组学是研究生物体蛋白质组成、结构和功能的学科。
它通过对生物体蛋白质的测定和分析,揭示蛋白质的组成、互作关系和功能等信息。
4. 基因表达谱:基因表达谱是指在特定条件下,生物体内基因的表达水平和模式。
通过对基因表达谱的分析,可以了解基因在不同组织、不同发育阶段或者不同环境条件下的表达情况,从而揭示基因的功能和调控机制。
二、常用技术和工具1. DNA测序技术:DNA测序技术是获取生物体基因组序列的重要方法。
常见的DNA测序技术包括Sanger测序、高通量测序和单分子测序等。
其中,高通量测序技术如Illumina测序和Ion Torrent测序,具有高通量、高准确性和低成本的特点,广泛应用于基因组学和转录组学研究。
2. 生物信息学数据库:生物信息学数据库是存储和管理生物学数据的重要资源。
常见的生物信息学数据库包括GenBank、EMBL、DDBJ、NCBI、Ensembl和Uniprot等。
这些数据库提供了丰富的生物学数据,如基因序列、蛋白质序列、基因表达数据等,为生物信息学的研究和分析提供了基础。
生物信息学,复习资料

第一章生物信息学是生命科学、计算机科学、现代信息科学、数学、物理学以及化学等多个学科交叉结合形成的一门新学科,是利用信息技术和数学方法对生命科学研究中的生物信息进行存储。
检索和分析的科学。
1982年创建了GenBank数据库。
(1)序列数据资源:储存了生物信息学研究的原始数据,是生物信息学存在和发展的基础。
(2)序列比对与比对搜索:相似性分析是生物信息学最早涉及的问题之一。
常用的分析方法是序列比对。
(3)基因组结构注释(4)分子系统发生分析:系统发生关系是表示物种进化关系的参考依据。
通过分析分子水平的序列数据,可以了解物种系统发生的关系,目前常用树的形式来表示不同物种间的进化关系。
(5)蛋白质结构:蛋白质的空间结构是其行使功能的基础。
(6)蛋白质序列分析与功能预测。
(7)微阵列数据分析:微阵列是一种重要的基因表达高通量检测技术。
(8)蛋白质组数据分析:高通量的蛋白质组工程能够大范围地确定蛋白质功能,能确定蛋白质在哪种特殊的生理条件下会出现,还能确定那些蛋白质之间有相互作用。
(9)疾病相关研究:寻找疾病相关基因是认识疾病发生机理、研制疾病的基因诊断与防治手段的基础,也是人类基因组研究的重要手段。
(10)SNP芯片及深度测序数据分析。
视黄醇结合蛋白是一个相对分子质量小、被大量分泌的蛋白质,能结合血液中的视黄醇。
性质:①在多个物种中有许多蛋白质和RBP4同源,包括人、小鼠和鱼总的蛋白质。
②也有许多人类蛋白质额RBP4紧密相关,它们和RBP4的家族成为lipocalin家族——一群多样的小配体结合蛋白,它们倾向于分泌到细胞外空间。
③有细南的lipealin 蛋白,它们在对抗生素的抗性中起作用。
编码细菌lipocalin 的基因可能是一古老基因,它通过水平基因转移的过程进人真核生物基因组。
④些lipocalin 蛋白的表达水平受到显著的调控。
⑤lipealin 蛋白小而丰富,并且是可溶性的,它们的生物化学性质已被详细研究,许多蛋白质的三维结构也以x线晶体街射的方法被解析出来。
分子生物学双语复习知识点

生命基本特征(本质):生命是生物体所表现出来的复合现象,包括:自身繁殖,生长发育,新陈代谢,遗传变异,对刺激产生反应等生物学Biology:是一门研究生命的现象与本质及活动规律的科学。
它包揽了生命的各个方面,从生命的化学组成,细胞的结构与功能,个体生物学,生物的多样性,到生物的遗传、进化及生态等方面的完整知识体系。
分子生物学Molecular Biology:它是研究核酸、蛋白质等生物大分子的结构与功能,并从分子水平上阐述蛋白质与核酸、蛋白质与蛋白质之间相互作用的关系及其基因表达调控机制的学科,是人类从分子水平上真正揭开生物世界的奥秘,由被动地适应自然界转向主动地改造和重组自然界的基础学科。
Is a subject to understand the five basic cell behavior patterns (growth, division, specialization, movement, and interaction) in terms of the various molecules that are responsible for them.That is, molecular biology wants to generate a complete description of the structure, function, and interrelationships of the cell’s macromolecules, and thereby to understand why living cells behave the way they do.分子生物学的研究内容Research Contents of Molecular Biology :生物大分子的结构功能研究(结构部分,又称结构分子生物学):包括基因、基因组的结构;DNA 复制、转录、翻译(功能部分);基因表达调控研究(调控部分);DNA重组技术(又称基因工程)Structure and Function of Macromolecules (Structural Part, Also Known as Structural & Molecular Biology);DNA Replication, Transcription, Translation (Functional Part);Regulation of Gene Expression (Control Section);Recombinant DNA Technology (Genetics)F.Miescher就发现了核素(nuclein);Boyer 和Berg等发展了重组DNA技术,完成了第一个细菌基因的克隆;Sanger 等发明了DNA测序技术;Sanger、Maxam和Gilbert先后发明了三种DNA序列的快速测定法;Mullis等发明的聚合酶链式反应(PCR);90年代全自动核酸序列测定仪问世;生物芯片技术是生命科学研究中继基因克隆技术、PCR技术、基因自动测序技术后的又一次革命性技术突破;分子遗传学基本理论建立者Jacob和Monod最早提出的操纵元学说分子生物学的3条基本原理:构成生物体各类有机大分子的单体在不同生物中都是相同的;生物体内一切有机大分子的建成都遵循共同的规则;某一特定生物体所拥有的核酸及蛋白质分子决定了它的属性。
分子生物学双语版本复习资料

细胞分类原核生物(prokaryote):最简单的活细胞直径1-10um 细胞膜、细胞壁(most)、环状染色体、质粒、RNA、核糖体、鞭毛、纤毛包括真细菌和古细菌真细菌(eubacteria):可为单细胞或多细胞 E.coli古细菌(archaea):膜脂由醚键连接而不是酯键真核生物(eukaryote):动物、植物、真菌(fungi)、原生生物(protists)直径10-100um分化(differentiation):拥有相同DNA但转录不同基因亚细胞器细胞核(nuclei):DNA的转录和RNA的加工场所核仁:rRNA合成和核糖体进行部分组装的场所线粒体:直径1-2um 内含一个小的环状DNA分子、线粒体特异RNA、合成线粒体蛋白的核糖体叶绿体:内膜腔内有第三膜体系---类囊体内质网:与核膜相连光面内质网:脂类物质合成和生物异源物质代谢,含解毒的酶粗面内质网:膜蛋白和分泌蛋白的合成微体:溶酶体—含降解性水解酶过氧化物酶体:高活性自由基和氢过氧化物的代谢乙醛酸酶体:植物的过氧化物酶体进行乙醛酸循环细胞器的分离:渗透压冲击、可控制的机械剪切和某些非离子去污作用可以破坏质膜差速离心法:根据沉降系数的不同分离细胞器密度梯度离心法:分离密度相似的细胞器生物大分子蛋白质:起结构和功能双重作用氨基酸聚合体核酸:核苷酸的聚合体多糖:单糖以糖苷键共价连接几丁质是N-乙酰胺基葡糖的聚合体(真菌细胞壁和节肢动物外骨骼中)黏多糖:结缔组织的重要组成部分脂类:饱和与不饱和脂肪酸的三酰甘油磷脂:两分子脂肪酸和一分子磷酸以酯键与甘油相结合鞘磷脂:磷脂胆碱+脑胺复杂大分子:核蛋白—核酸+蛋白质(端粒酶、核糖核酸酶P)糖蛋白、蛋白多糖(蛋白质+黏多糖)—糖类与蛋白质共价相连脂连接蛋白:共价相连脂蛋白:非共价相连大分子的组装蛋白质复合体:微管(微管蛋白构成)、微丝(肌动蛋白和肌球蛋白构成)、中间纤维(多种蛋白质构成)细胞骨架(一系列蛋白质微丝)微管蛋白:110kDa的球形蛋白是细胞骨架、鞭毛、纤毛的主要组分核蛋白:细菌70s核糖体由一个50s大亚基(23sRNA、5sRNA、31种蛋白质)和一个30s小亚基(16sRNA和21种蛋白质)组成真核生物的80s核糖体含有60s(28SRNA、5.8sRNA、多种5sRNA)和40s(18sRNA)两个亚基膜:膜磷脂和鞘磷脂形成了极性基团在外部、烃链在内部的双分子层膜蛋白的功能:1、信号分子的受体2、酶3、转运时的孔或通道4、细胞间相互作用的介质非共价相互作用:弱相互作用电荷与电荷、电荷与偶极、偶极与偶极之间的相互作用氢键疏水作用力氨基酸的分类20种常见氨基酸都有一个与质子、氨基、羟基相连的手性α-碳原子和侧链酸性氨基酸:Glu、Asp 带负电碱性氨基酸:Lys、His、Arg 带正电中性氨基酸:Ser、Thr、Asn、Gln、Cys 不带电荷非极性氨基酸:Gly、Pro、Ala、Val、Leu、Ile、Met芳香族氨基酸:Phe、Tyr、Typ(可吸收紫外光280nm处最大)蛋白质的结构与功能球蛋白:可溶性蛋白多数酶纤维蛋白:重要的结构蛋白如丝蛋白、角蛋白一级结构:α-氨基与α-羧基以肽键相连的氨基酸顺序二级结构:α-螺旋(每圈3.6个氨基酸,右手螺旋,链内氢键)β-折叠(平行与反向平行)β-转角无规则卷曲三级结构:不同二级结构区域和连接区的组合非共价相互作用亲水性氨基酸在外面,疏水性氨基酸在内部二硫键氢键范德华力疏水作用力伴娘蛋白:保证肽链的正确折叠四级结构:多个肽链亚基的组合别构效应(亚基间的相互作用)辅基:提供额外化学功能的非蛋白质分子NAD+、血红素、金属离子蛋白质的功能:1、酶2、信号传递3、转运与储存(血红蛋白转铁蛋白脂蛋白铁蛋白)4、结构与运动(胶原蛋白角蛋白肌动蛋白肌球蛋白)5、营养(酪蛋白卵清蛋白)6、免疫(抗体)7、调节结构域:同一多肽中有限的高度有序结构片段相连(由外显子编码)结构基序motif(超二级结构):蛋白质家族中从共同祖先进化过程中保留下来的保守的结合位点或催化位点的必要部分相似的结构基序可以在没有序列相似性的蛋白质中发现直向同源:不同物种的具有相同功能、承担相同生化角色的蛋白质家族成员共生同源:进化不同但功能相似的蛋白蛋白质分析法蛋白质纯化依据:凝胶过滤层析---蛋白质大小等电聚焦(形成PH梯度)、电泳、离子交换层析---所带离子电荷疏水作用层析---疏水性亲和层析---酶或受体与配体的特殊亲和性Edman降解法:从N端对多肽进行测序抗体:脊椎动物的免疫系统为了应对外来物质(抗原)入侵而产生的蛋白质,对抗原有很高的结合亲和力与特异性X射线衍射确定蛋白质结晶的三级结构蛋白质功能分析方法:分离纯化、研究突变体的表现核酸结构碱基:嘌呤为双环结构,嘧啶为单环结构核苷:碱基共价结合于戊糖分子的1位,DNA中的为2-脱氧核糖碱基+糖分子=核苷(糖苷键相连)核苷酸:一个或多个磷酸基团结合到核苷的3位、5位、2位上碱基+糖分子+磷酸分子=核苷酸NTP 5-三磷酸核糖核苷磷酸二酯键:前一个核糖的5-羟基与下一个核糖的3-羟基通过磷酸基团共价相连核酸序列:DNA或RNA链中的碱基A、C、G、T(或U)排列顺序由5端写至3端DNA双螺旋:两条独立的反向平行的单链DNA以右手螺旋缠绕,糖-磷酸骨架在外,氢键、碱基堆积力每螺旋10个碱基对标准的DNA双螺旋---B型,A型---右手螺旋(RNA链)每圈11个碱基对Z型---左手螺旋每圈12个碱基对RNA的二级结构:局部分子内碱基配对和其他氢键相互作用而维持的局部互补的螺旋结构DNA修饰:A和C的甲基化核酸的理化性质核酸螺旋的稳定性由疏水作用和堆积在碱基对间的偶极矩作用决定酸效应:强酸---核酸水解为碱基、糖和磷酸中度酸---脱嘌呤核酸碱效应:变性----碱基的互变异构态改变,特异碱基被破坏某些化学试剂破坏碱基间的疏水作用力使核酸变性DNA的水溶液具有高黏性平衡密度梯度离心(等密度梯度离心):分离DNA(RNA)与蛋白质DNA的密度梯度为1.7g/cm3。
[整理]《生物信息学》学生复习资料.
![[整理]《生物信息学》学生复习资料.](https://img.taocdn.com/s3/m/233dedc8f524ccbff1218491.png)
《生物信息学》复习资料陈芳宋东光教材:《生物信息学简明教程》(钟扬编)1 绪论分子生物学与计算机、信息科学的结合-生物信息学(Bioinformatics);Bioinformatics is the science of storing, extracting, organizing, analyzing, interpreting, and utilizing information from biological sequences and molecules.生物信息学及其分支学科分子生物信息学(molecular informatics)-即狭义的生物信息学,指应用信息技术储存和分析基因组测序所产生的分子序列及其相关数据;生物信息学(bioinformatics)-广义的生物信息学指生命科学与数学、计算机科学和信息科学等交叉形成的一门边缘学科,对各种生物信息(主要是分子生物学信息)的获取、储存、处理、分析和阐释;生物信息学是广义的计算生物学的分支,在为生物学系统建模中应用了量化分析技术;计算分子生物学(computational molecular biology)-开发和使用数学和计算机技术以帮助解决分子生物学中的问题,侧重于发展理论模型和有效算法;分子计算(molecular computing)-将DNA作为一种信息储存器,应用PCR 技术和生物芯片等来进行计算。
生物信息学的主要目的不是分子发展最精致的算法,其目的是发现生物体以怎样的方式生存。
生物信息学和计算生物学研究包括从生物系统的性质抽象出为数学或物理模型,到实现数据分析的新算法,以及开发数据库和访问数据库的Web工具。
生物信息学的功能是表示、存储和分布数据。
开发从数据中发现知识的分析工具处于第二位。
生物信息学发展阶段与研究方向前基因组时代-数据库建立、检索工具的开发和蛋白质序列分析;基因组时代-基因寻找和识别、网络数据库系统的建立如EST数据库及电子克隆等;后基因组时代-大规模基因组分析、蛋白质组分析、各种数据的比较和整合。
生物信息学复习整理loh

生物信息学复习整理大乐名词翻译STS:序列标签位点EST:表达序列标签GSS:基因组短序列ORTHOLOGS:直系同源PARALOGS:旁系同源CDS:编码序列EXON:外显子ORF:开放阅读框PHI-BLAST:模式识别BLASTPSI-BLAST:位置特异的迭代BLASTSNP:单核苷酸多态性MMDB:分子模型数据库MeSH:医学主题词BLAST :基本局部相似性比对搜索工具PMD (蛋白质突变数据库)PDB Retriever (PDB镜像)SS-Thread (二级结构预测)LIBRA (三级结构预测)ExPASy专家级蛋白质分析系统NLM:美国国立医学图书馆名词解释1)Fasta格式:FASTA格式又称Pearson的格式,该种序列格式要求序列的标题行以大于号">"开头,下一行起为具体的序列。
一般建议每行的字符数不超过80个,以比对程序的处理。
2)医学主题词MeSH是Medical Subject Headings的缩略词,即医学主题词,是用规范化的医学术语来描述生物医学概念。
NIH的工作人员按MeSH词表规定,浏览生物医学期刊全文后标引出每篇文献中的MeSH主题词,其中论述文献中心的主题词称主要主题词(major topic headings),论述主题某一方面的内容的词称为副主题词。
3)直系同源:Orthologs是指来自于不同物种的由垂直家系(物种形成)进化而来的蛋白,并且典型的保留与原始蛋白有相同的功能。
4)序列模体(motif):通常指蛋白序列中相邻或相近的一组具有保守性的残基,与蛋白质分子及家族的功能有关。
5)计分矩阵(scoring matrix):记分矩阵是描述残基(氨基酸或碱基)在比对中出现的概率值的表。
在记分矩阵中的值是两种概率比值的对数,一个是在序列比对中氨基酸随机发生的概率。
这个值只是指出每个氨基酸出现的独立几率的概率。
另一个是在序列比对中,一对残基的出现的有意义的概率。
生物信息学复习资料

生物信息学复习资料第一章1、什么是生物信息学?生物信息学是一门交叉科学,它包含了生物信息的获取、加工、存储、分配、分析、解释等在内的所有方面,它综合运用数学、计算机科学和生物学的各种工具来阐明和理解大量数据所包含的生物学意义2、BIOINFORMATICS这个词是谁提出的?林华安3、生物信息学的发展经过了哪些阶段?前基因组时代、基因组时代、后基因组时代4、HGP是什么意思?什么时候开始?什么时候全部结束?人类基因组计划、1990.10、20035、生物信息学的研究对象是什么?6、生物信息学的研究内容有哪些?获取人和各种生物的完整基因组、新基因的发现、SNP分析(单核苷酸多态性:single nucleotide polymorphism,SNP)、非编码区信息结构与分析、生物进化;全基因组的比较研究、蛋白质组学研究、基因功能预测、新药设计、遗传疾病的研究以及关键基因鉴定、生物芯片7、学习生物信息学的目的是什么?阐明和理解大量数据所包含的生物学意义第二章1、生物信息数据库有哪些要求?时间性、注释、支撑数据、数据质量、集成性2、生物信息数据库分为哪几级,每一级是如何让定义的,每一级各包含哪些数据库?一级数据库二级数据库;一级数据库:数据库中的数据直接来源于实验获得的原始数据,只经过简单的归类整理和注释二级数据库:对原始生物分子数据进行整理、分类的结果,是在一级数据库、实验数据和理论分析的基础上针对特定的应用目标而建立的一级数据库:包括基因组数据库、核酸和蛋白质一级结构数据库、生物大分子(主要是蛋白质)三维空间结构数据库二级数据库:根据生命科学不同研究领域的实际需要,对基因组图谱、核酸和蛋白质序列、蛋白质结构以及文献等数据进行分析、整理、归纳、注释,构建具有特殊生物学意义和专门用途的数据库3、请列出至少三个国际知名生物信息中心网站、至少三个核酸数据库、至少三个蛋白数据库。
网站:NCBI、EBI、SIB、HGMP、CMBI、ANGIS、NIG、BIC核酸数据库:EMBL、DDBJ、GenBank蛋白质序列数据库:PIR(Protein Information Resource)、SWISS-PROT、TrEMBL、UniProt、NCBI生物大分子数据库:PDB(Protein Data Bank)蛋白质结构分类数据库SCOP、蛋白质二级结构数据库DSSP、蛋白质同源序列比对数据库HSSP4、NCBI和EBI使用的搜索引擎分别是什么?NCBI提取工具:Entrez EBI提取工具:SRS65、GENBANK使用的基本信息单位是什么,包括哪几个部分,最后以什么字符结尾?基本信息单位:GBFF(GenBank flatfile, GenBank平面文件)格式:GBFF是GenBank数据库的基本信息单位,是最为广泛使用的生物信息学序列格式之一哪几个部分:头部包含整个记录的信息(描述符)、第二部分包含了注释这一记录的特性、第三部分是核苷酸序列本身最后字符:所有序列数据库记录都在最后一行以“//”结尾6、什么是Refseq?The Reference Sequence database 参考序列数据库RefSeq数据库,即RefSeq参考序列数据库,美国国家生物信息技术中心(NCBI)提供的具有生物意义上的非冗余的基因和蛋白质序列7、FASTA格式有哪些部分组成,以什么字符开始?8.NCBI的在线和离线序列提交软件是什么?在线提交软件:Bankit 离线提交软件:Sequin第三章1、什么是同源、直系同源、旁系同源?同源性和相似性有什么区别?同源性:两条序列有一个共同的进化祖先,那么它们是同源的相似性:序列间相似性的量度同源性和相似性的区别:同源性是序列同源或者不同源的一种论断,而相似性或者一致性是一个序列相关性的量化,是两个不同的概念直系同源(orthology):不同物种内的同源序列旁系同源(paralogy):同一物种内的同源序列2、什么是序列比对、全局比对、局部比对?序列比对的关键问题是什么?序列比对:根据特定的计分规则,将两个或多个符号序列按位置比较排列后,得到最具相似性的排列的过程。
生物信息学复习总结

生物信息期末总结1.生物信息学(Bioinformatics)定义:(第一章)★生物信息学是一门交叉科学,它包含了生物信息的获取、加工、存储、分配、分析、解释等在内的所有方面,它综合运用数学、计算机科学和生物学的各种工具来阐明和理解大量数据所包含的生物学意义。
(或:)生物信息学是运用计算机技术和信息技术开发新的算法和统计方法,对生物实验数据进行分析,确定数据所含的生物学意义,并开发新的数据分析工具以实现对各种信息的获取和管理的学科。
(NSFC)2. 科研机构及网络资源中心:NCBI:美国国立卫生研究院NIH下属国立生物技术信息中心;EMBnet:欧洲分子生物学网络;EMBL-EBI:欧洲分子生物学实验室下属欧洲生物信息学研究所;ExPASy:瑞士生物信息研究所SIB下属的蛋白质分析专家系统;(ExpertProtein Analysis System)Bioinformatics Links Directory;PDB (Protein Data Bank);UniProt 数据库3. 生物信息学的主要应用:1.生物信息学数据库;2.序列分析;3.比较基因组学;4.表达分析;5.蛋白质结构预测;6.系统生物学;7.计算进化生物学与生物多样性。
4.什么是数据库:★1、定义:数据库是存储与管理数据的计算机文档、结构化记录形式的数据集合。
(记录record、字段field、值value)2、生物信息数据库应满足5个方面的主要需求:(1)时间性;(2)注释;(3)支撑数据;(4)数据质量;(5)集成性。
3、生物学数据库的类型:一级数据库和二级数据库。
库等;DDBJ核酸库和EMBL数据库、Genbank(国际著名的一级核酸数据库有.蛋白质序列数据库有SWISS-PROT等;蛋白质结构库有PDB等。
)★4、一级数据库与二级数据库的区别:1)一级数据库:包括:a.基因组数据库----来自基因组作图;b.核酸和蛋白质一级结构序列数据库;c.生物大分子(主要是蛋白质)的三维空间结构数据库,(来自X-衍射和核磁共振结构测定);2)二级数据库:是对原始生物分子数据进行整理、分类的结果,是在一级数据库、实验数据和理论分析的基础上针对特定的应用目标而建立的。
生物专业英语复习资料
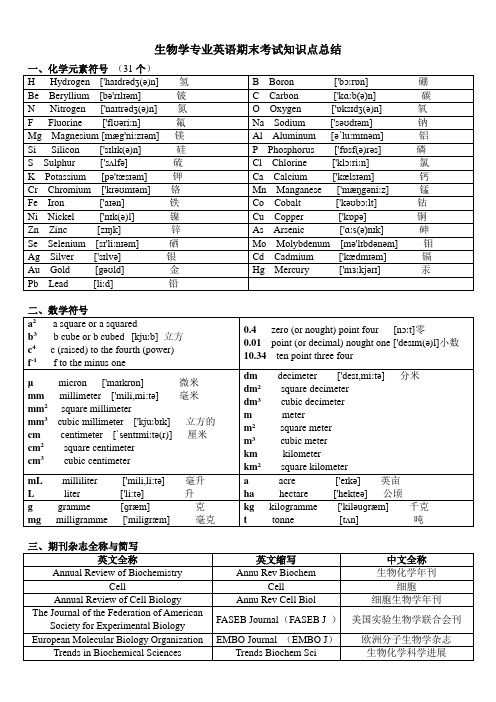
生物学专业英语期末考试知识点总结一、化学元素符号(31个)H Hydrogen ['haɪdrədʒ(ə)n] 氢 B Boron ['bɔːrɒn] 硼Be Beryllium [bə'rɪlɪəm] 铍 C Carbon ['kɑːb(ə)n]碳N Nitrogen ['naɪtrədʒ(ə)n] 氮O Oxygen ['ɒksɪdʒ(ə)n] 氧F Fluorine ['flʊəriːn] 氟Na Sodium ['səʊdɪəm] 钠Mg Magnesium [mæg'niːzɪəm] 镁Al Aluminum [əˈluːmɪnəm] 铝Si Silicon ['sɪlɪk(ə)n] 硅P Phosphorus ['fɒsf(ə)rəs] 磷S Sulphur ['sʌlfə] 硫Cl Chlorine ['klɔːriːn] 氯K Potassium [pə'tæsɪəm] 钾Ca Calcium ['kælsɪəm] 钙Cr Chromium ['krəʊmɪəm] 铬Mn Manganese ['mæŋgəniːz] 锰Fe Iron ['aɪən] 铁Co Cobalt ['kəʊbɔːlt] 钴Ni Nickel ['nɪk(ə)l] 镍Cu Copper ['kɒpə] 铜Zn Zinc [zɪŋk]锌As Arsenic ['ɑːs(ə)nɪk] 砷Se Selenium [sɪ'liːnɪəm] 硒Mo Molybdenum [mə'lɪbdənəm] 钼Ag Silver ['sɪlvə] 银Cd Cadmium ['kædmɪəm] 镉Au Gold [gəʊld] 金Hg Mercury ['mɜːkjərɪ] 汞Pb Lead [liːd] 铅二、数学符号a2 a square or a squaredb3 b cube or b cubed[kjuːb] 立方c4 c (raised) to the fourth (power)f-1 f to the minus one 0.4 zero (or nought) point four [nɔːt]零0.01point (or decimal) nought one ['desɪm(ə)l]小数10.34ten point three fourμ micron ['maɪkrɒn] 微米mm millimeter ['mili,mi:tə] 毫米mm2 square millimetermm3cubic millimeter ['kjuːbɪk] 立方的cm centimeter [ˈsentɪmiːtə(r)] 厘米cm2square centimetercm3cubic centimeter dm decimeter ['desɪ,miːtə] 分米dm2square decimeterdm3cubic decimeterm meterm2square meterm3cubic meterkm kilometerkm2square kilometermL milliliter ['mili,li:tə] 毫升L liter ['li:tə] 升a acre ['eɪkə] 英亩ha hectare ['hekteə] 公顷g gramme [ɡræm] 克mg milligramme ['miligræm] 毫克kg kilogramme ['kiləuɡræm] 千克t tonne [tʌn] 吨三、期刊杂志全称与简写英文全称英文缩写中文全称Annual Review of Biochemistry Annu Rev Biochem 生物化学年刊Cell Cell 细胞Annual Review of Cell Biology Annu Rev Cell Biol 细胞生物学年刊The Journal of the Federation of AmericanSociety for Experimental BiologyFASEB Journal (FASEB J )美国实验生物学联合会刊European Molecular Biology Organization EMBO Journal (EMBO J)欧洲分子生物学杂志Trends in Biochemical Sciences Trends Biochem Sci 生物化学科学进展Molecular and Cellular Biology Mol Cell Biol 分子与细胞生物学杂志Journal of Biological Chemistry J Biol Chem 生物化学期刊Plant Cell Plant Cell 植物细胞Molecular Pharmacology Mol Pharmacol 分子药理学DNA Cell Biology DNA Cell Biol DNA细胞生物学Journal of Molecular Biology J Mol Biol 分子生物学期刊Biochemistry Biochemistry 生物化学Cell Growth and Differentiation Cell Growth Differ 细胞生长与分化Methods in Enzymology Method Enzymol 酶学方法Molecular Microbiology Mol Microbiol 分子微生物学Journal of Neurochemistry J Neurochem 神经化学杂志Progress in Biophysics & MolecularBiologyProg Biophys Mol Biol 生物物理和分子生物学进展Advances in Microbial Physiology Adv Microb Physiol 微生物生理学进展Molecular Biology and Evolution Mol Bio Evol 分子生物学与进化Journal of Cellular Biochemistry J Cell Biochem 细胞生物化学杂志Molecular Biology and Medicine Mol Biol Med 分子生物学与药学Federation of European BiochemistrySociety FEBS Letters ( FEBS Lett)欧洲生物化学学会联合会杂志Plant Molecular Biology Plant Mol Biol 植物分子生物学Journal of Molecular Evolution J Mol Evol 分子进化杂志Analytical Biochemistry Anal Biochem 分析生物化学Molecular Immunology Mol Immunol 分子免疫学Neurochemical Research Neurochem Res 神经化学研究Molecular and Cellular Biochemistry Mol Cell Biochem 分子与细胞生物化学Molecular Biology Report Mol Biol Rep 分子生物学报告Proceedings of National Academy ofsciences USA PROC NATL ACADSCI USA美国国家科学院院刊四、作文1. Topic or title or head.2. Authors and their institutes.3. Abstract4. Introduction5. Materials and Methods6. Results7. Discussion8. References or literatures cited.How to write a report or paperA paperconsists of 8partsEnglish description英文叙述Chinese narrative中文叙述Part1.Topic or titleor head.(主题/标题/头)Concise and informative 简洁而信息量丰富Part2.Authors and their institutes. (作者及其所在研究机构)The name(s) of the auther(s)The affiliation(s) and address(es) of the auther(s)The e-mail address,telephone and fax numbers of the corresponding auther作者姓名作者的隶属机构和地址通讯作者的电子邮件地址,电话号码以及传真号。
生物信息学复习总结

生物信息期末总结1.生物信息学(Bioinformatics)定义:(第一章)★生物信息学是一门交叉科学,它包含了生物信息的获取、加工、存储、分配、分析、解释等在内的所有方面,它综合运用数学、计算机科学和生物学的各种工具来阐明和理解大量数据所包含的生物学意义。
(或:)生物信息学是运用计算机技术和信息技术开发新的算法和统计方法,对生物实验数据进行分析,确定数据所含的生物学意义,并开发新的数据分析工具以实现对各种信息的获取和管理的学科。
(NSFC)2。
科研机构及网络资源中心:NCBI:美国国立卫生研究院NIH下属国立生物技术信息中心;EMBnet:欧洲分子生物学网络;EMBL-EBI:欧洲分子生物学实验室下属欧洲生物信息学研究所;ExPASy:瑞士生物信息研究所SIB下属的蛋白质分析专家系统;(Expert Protein Analysis System)Bioinformatics Links Directory;PDB (Protein Data Bank);UniProt 数据库3. 生物信息学的主要应用:1.生物信息学数据库;2.序列分析;3.比较基因组学;4.表达分析;5.蛋白质结构预测;6.系统生物学;7.计算进化生物学与生物多样性.4.什么是数据库:★1、定义:数据库是存储与管理数据的计算机文档、结构化记录形式的数据集合。
(记录record、字段field、值value)2、生物信息数据库应满足5个方面的主要需求:(1)时间性;(2)注释;(3)支撑数据;(4)数据质量;(5)集成性。
3、生物学数据库的类型:一级数据库和二级数据库。
(国际著名的一级核酸数据库有Genbank数据库、EMBL核酸库和DDBJ库等;蛋白质序列数据库有SWISS—PROT等;蛋白质结构库有PDB等。
)4、一级数据库与二级数据库的区别:★1)一级数据库:包括:a.基因组数据库--—-来自基因组作图;b.核酸和蛋白质一级结构序列数据库;c。
生物信息学复习资料

生物信息学复习资料生物信息学复习资料第一讲生物信息学绪论1、生物信息学诞生于计算机初创时期,1956年在美国田纳西州的Gatlinburg召开了首次―生物学中的信息理论讨论会‖2、20世纪80年代末―林华安‖博士创造了‖bioinformatics‖一词3、数据库的构建:1979年美国Genbank数据库;1982年欧洲分子生物实验室EMBL核酸序列数据库;1984年日本国家级核酸序列数据库DDBJ4、专业机构:1988年美国成立了―生物技术信息中心‖(NCBI);欧洲生物信息学研究所(EBI)于1993年构建.5、生物信息学产生的背景(1)、传统生物学和现代生物学都是一门实验学科,生物学的发展需要数学模型的介入(2)、海量生物学数据信息的产生(2002年8月,Genbank中的序列量已达18197000,而碱基对数达22617000000,且以每秒220对的速度增加),数据的分析处理成为生物学发展的―瓶颈‖(3)、新的生物学研究模式的出发点应是理论:从理论出发,再回到实验中追踪或验证这些理论假设6、生物信息学定义(广义):应用信息科学的方法和技术,研究生物体系和生命过程中信息的存贮、信息的内涵和信息的传递,研究和分析生物体细胞、组织、器官的生理、病理、药理过程中的各种生物信息,或者也可以说成是生命科学中的信息科学。
狭义:应用信息科学的理论、方法和技术,管理、分析和利用生物分子数据。
一般提到的―生物信息学‖是就指这个狭义的概念,更准确地说,应该是分子生物信息学(Molecular Bioinformatics)7、生物信息学研究的主要对象——两种信息载体:DNA分子和蛋白质分子(1)遗传信息的载体——DNA遗传信息的载体主要是DNA,控制生物体性状的基因是一系列DNA片段,生物体生长发育的本质就是遗传信息的传递和表达(2)蛋白质的结构决定其功能蛋白质功能取决于蛋白质的空间结构,蛋白质结构决定于蛋白质的序列(这是目前基本共认的假设),蛋白质结构的信息隐含在蛋白质序列之中。
生物信息学总结复习题包括答案陶士珩

生物信息学复习题名词解说1.Homology ( 同源 ): 根源于共同先人的序列相像的序列及同源序列。
序列相像序列其实不必定是同源序列。
2.Orthologs (直系同源):指因为物种形成的特别事件来自一个共同先人的不一样物种中的同源序列,它们拥有相像的功能。
3.Paralogs (旁系(并系)同源):指同一个物种中拥有共同先人,经过基因复制产生的一组基因,这些基因在功能上的可能发生了改变。
基因复制事件是促使新基因进化的重要推进力。
4.Xenologs ( 异同源 ) :经过横向转移,根源于共生或病毒侵染而产生的相像的序列,为异同源。
Score : The sum of the number of identical matches and conservative(high scoring) substitutions in a sequence alignment divided by the total number ofaligned sequence characters. Gap老是不计入总数中。
6.点矩阵( dot matrix ):建立一个二维矩阵,其 X 轴是一条序列, Y 轴是另一个序列,而后在 2个序列相同碱基的对应地点( x,y)加点,假如两条序列完整相同则会形成一条主对角线,假如两条序列相像则会出现一条或许几条直线;假如完整没有相像性则不可以连成直线。
7.E 值:得分大于等于某个分值S 的不一样的比对的数目在随机的数据库搜寻中发生的可能性。
权衡序列之间相像性能否明显的希望值。
E 值大小说了然能够找到与查问序列(query )相般配的随机或没关序列的概率, E 值越小意味着序列的相像性有时发生的时机越小,也即相像性越能反应真切的生物学意义, E 值越靠近零,越不行能找到其余般配序列。
8.P 值:得分为所要求的分值比对或更好的比对随机发生的概率。
它是将观察获取的比对得分 S,与相同长度和构成的随机序列作为查问序列进行数据库搜寻进行比较获取的HSP(高分片段对)得分的希望散布联系起来计算的。
生物信息学复习资料

生物信息学复习资料生物信息学是一门融合了生物学、计算机科学、数学和统计学等多个学科的交叉领域。
它的出现和发展为我们理解生命的奥秘提供了强大的工具和方法。
以下是对生物信息学的一些关键知识点的复习。
一、生物信息学的定义和范畴生物信息学主要是研究如何获取、处理、存储、分析和解释生物数据的学科。
这些数据包括但不限于基因组序列、蛋白质结构、基因表达数据等。
它的应用范围广泛,涵盖了从基础生物学研究到临床诊断和药物研发等多个领域。
二、生物数据的获取(一)测序技术现代测序技术的发展使得我们能够快速而准确地获取大量的生物序列信息。
第一代测序技术如 Sanger 测序法,虽然准确性高,但成本较高、通量较低。
而新一代测序技术如 Illumina 测序、Ion Torrent 测序等,则大大提高了测序的通量和速度,降低了成本,但在准确性上可能略有不足。
(二)基因芯片技术基因芯片可以同时检测成千上万个基因的表达水平,为研究基因表达模式和调控机制提供了重要的数据。
(三)蛋白质组学技术质谱技术是蛋白质组学研究中的重要手段,能够鉴定蛋白质的种类和修饰状态。
三、生物数据的存储和管理面对海量的生物数据,高效的数据存储和管理至关重要。
常用的数据库包括 GenBank、UniProt、PDB 等。
这些数据库采用了特定的数据格式和管理系统,以确保数据的完整性、准确性和可访问性。
四、生物数据的分析方法(一)序列比对序列比对是生物信息学中最基本的分析方法之一,用于比较两个或多个生物序列的相似性。
常见的比对算法包括全局比对(如NeedlemanWunsch 算法)和局部比对(如 SmithWaterman 算法)。
(二)基因预测通过对基因组序列的分析来预测基因的位置和结构。
常用的方法有基于同源性的预测、基于信号特征的预测等。
(三)蛋白质结构预测包括从头预测法和基于同源建模的方法。
从头预测法基于物理化学原理来构建蛋白质的三维结构,而同源建模法则利用已知结构的同源蛋白质来推测目标蛋白质的结构。
《生物信息学》复习资料

《生物信息学》复习资料《生物信息学》先锋版中译本第二版科学出版社打分政策:60% 期末考试(70%掌握内容、25% 熟悉内容、5% 理解内容)(请注意红体与黑体字)A: 生物信息学概述1. 生物信息学:生物信息学是生物学和信息技术的结合,是现代科学的又一个分支学科,它利用计算机对大量生物数据进行分析处理。
生物信息学把用于存储和搜索数据的数据库开发,与用于分析和确定大分子序列、结构、表达模式和生化途径等生物数据集之间的关系的统计工具和算法的开发结合在一起。
数据库生物信息学主要由三大部分组成算法与统计工具分析与解释测序策略:逐个克隆法、全基因组鸟枪法计算机在生物信息学中的作用:生物信息学需要计算机快速、可靠地执行重复任务的能力以及处理问题的能力。
然而,生物信息学中涉及的许多问题仍需要专家的人工处理,同时原始数据的完整性和质量也很关键。
生物信息学课程范围:使初学者理解生物信息学的基本原理,并获得相应的应用能力。
具体包括生物信息学的一些关键领域:数据库使用、序列和结构分析工具、注释工具、表达分析以及生化和分子途径分析。
2. 生物信息学实例:——数据库界面Genbank/EMBL/DDBJ, Medline, SwissProt, PDB, …——序列搜索与比对BLAST, FASTA, Clustal, MultAlin, DiAlign ——基因搜索Genscan, GenomeScan, GeneMark, GRAIL——蛋白结构域分析与鉴定pfam, BLOCKS, ProDom,——基因调控元件的计算机模式识别Gibbs Sampler, AlignACE,MEME——蛋白折叠预测PredictProtein, SwissModeler生物信息学网站:包括生物信息学资源、各种数据库和生物信息学分析工具的网站3. 五个必须知道的生物信息学网站:(详细参考书本p9)NCBI (The National Center for Biotechnology Information)/EBI (The European Bioinformatics Institute)/The Canadian Bioinformatics Resource http://www.cbr.nrc.ca/SwissProt/ExPASy (Swiss Bioinformatics Resource)http://expasy.cbr.nrc.ca/sprot/PDB (The Protein Databank)/PDB/B: 数据采集一、DNA, RNA和蛋白质测序1. DNA测序原理:DNA测序是采用全自动的链终止反应完成的,这一技术通过加入限量的双脱氧核苷酸来产生有特定终止碱基的嵌套DNA片段。
生物信息学词汇双语通解

生物信息学词汇双语通解什么是生物信息学?生物信息学是一门研究生物信息的学科,旨在探索基因、蛋白质和其他生物分子的结构和功能。
它结合了生物学、医学、计算机科学、数学和其他多领域的知识,以更好地理解生物系统。
生物信息学有助于研究药物发现、基因组学、分子进化、基因表达分析等研究对象。
生物信息学词汇是生物信息学领域中经常使用到的词汇,包括生物学、医学、计算机科学和数学等技术领域。
这些词汇出现在生物信息学文献、新闻报道、学术会议和科普文章中。
有些词汇只有在生物信息学中才有定义,而有些词汇可能是生物学、医学、计算机科学和数学等技术领域中通用的词汇。
为了帮助读者更好地理解生物信息学,本文将介绍一些常见的生物信息学词汇,并为其提供双语解释,以便读者更好地理解生物信息学的概念。
一、基因基因是一种由DNA序列构成的核酸分子,用于保存和传输遗传信息。
它是一个在生物系统中传播生物特征的基本单位,是实现生物多样性的关键。
基因在英文中的意思是gene,在汉语中的意思是基因。
二、染色体染色体是一种由DNA和蛋白质组成的结构体,用于保存、传输和表达遗传信息。
染色体在英文中的意思是chromosome,在汉语中的意思是染色体。
三、DNADNA是一种细胞内的核酸,是遗传信息的载体。
它由碱基对组成,它们通过链接在一起形成DNA链。
DNA在英文中的意思是deoxyribonucleic acid,在汉语中的意思是脱氧核糖核酸。
四、蛋白质蛋白质是一种从基因编码的大分子,它们可以调节和控制细胞的各种功能。
蛋白质在英文中的意思是protein,在汉语中的意思是蛋白质。
五、RNARNA是一种核酸,它们可以把基因编码的信息从DNA复制到蛋白质。
RNA在英文中的意思是ribonucleic acid,在汉语中的意思是核糖核酸。
六、序列序列是一种按照一定次序排列的字符串,它们用于描述基因、蛋白质和其他生物分子的结构和功能。
序列在英文中的意思是sequence,在汉语中的意思是序列。
生物信息学复习资料全

一、名词解释(31个)1.生物信息学:广义:应用信息科学的方法和技术,研究生物体系和生物过程息的存贮、信息的涵和信息的传递,研究和分析生物体细胞、组织、器官的生理、病理、药理过程中的各种生物信息,或者也可以说成是生命科学中的信息科学。
狭义:应用信息科学的理论、方法和技术,管理、分析和利用生物分子数据。
2.二级数据库:对原始生物分子数据进展整理、分类的结果,是在一级数据库、实验数据和理论分析的根底上针对特定的应用目标而建立的。
3.多序列比对:研究的是多个序列的共性。
序列的多重比对可用来搜索基因组序列的功能区域,也可用于研究一组蛋白质之间的进化关系。
4.系统发育分析:是研究物种进化和系统分类的一种方法,其常用一种类似树状分支的图形来概括各种〔类〕生物之间的亲缘关系,这种树状分支的图形称为系统发育树。
5.直系同源:如果由于进化压力来维持特定模体的话,模体中的组成蛋白应该是进化保守的并且在其他物种中具有直系同源性。
指的是不同物种之间的同源性,例如蛋白质的同源性,DNA序列的同源性。
〔来自百度〕6.旁系〔并系〕同源:是那些在一定物种中的来源于基因复制的蛋白,可能会进化出新的与原来有关的功能。
用来描述在同一物种由于基因复制而别离的同源基因。
〔来自百度〕7.FASTA序列格式:将一个DNA或者蛋白质序列表示为一个带有一些标记的核苷酸或氨基酸字符串。
8.开放阅读框〔ORF〕:是结构基因的正常核苷酸序列,从起始密码子到终止密码子的阅读框可编码完整的多肽链,其间不存在使翻译中断的终止密码子。
〔来自百度〕9.结构域:大分子蛋白质的三级结构常可分割成一个或数个球状或纤维状的区域,折叠得较为严密,各行其功能,称为结构域。
10.空位罚分:序列比对分析时为了反映核酸或氨基酸的插入或缺失等而插入空位并进展罚分,以控制空位插入的合理性。
〔来自百度〕11.表达序列标签:通过从cDNA文库中随机挑选的克隆进展测序所获得的局部cDNA的3’或5’端序列。
《生物信息学》复习提纲

《生物信息学》主要知识点一、基本名词和概念1、bioinformatics 生物信息学,狭义的生物信息学是指将计算机科学和数学应用于生物大分子信息的获取、加工、存储、分类、检索与分析,以达到理解这些生物大分子信息的生物学意义的一门交叉学科。
广义上的生物信息学是指运用计算机技术,处理、分析生物学数据,以揭示生物学数据背后蕴藏的意义的所有知识体系。
2、ORF Open Reading Frame,开放阅读框,是指在给定的阅读框架中,不包含终止密码子的一串DNA序列3、CDS Coding sequence,基因的编码区(也叫Coding region),是指DNA或RNA中由外显子组成,编码蛋白质的部分。
4、UTR Untranslated Regions,即非翻译区,是指mRNA分子两端的非编码片段,包括5'-UTR(或称“前导序列”)和3'-UTR(或称“尾随序列”)5、genome 基因组,是指包含在一种生物的单倍体细胞中的全套染色体DNA(部分病毒是RNA)中的全部遗传信息,包括基因和非编码DNA。
6、proteomics 蛋白质组学,对特定的通路、细胞器、细胞、组织、器官和肌体中包含的所有蛋白质,进行鉴定、表征和定量,提供关于该系统准确和全面数据的学科。
7、transcriptome 转录组,也称为“转录物组”,广义上指在相同环境(或生理条件)下的一个细胞、组织或生物体中出现的所有RNA的总和,包括mRNA、rRNA、tRNA及非编码RNA;狭义上则指细胞所能转录出的所有mRNA。
8、metabonomics 代谢组学,属于系统生物学的一个重要组成部分,效仿基因组学和蛋白质组学的研究思想,对生物体内所有代谢物进行定量分析,从而研究生命体对外界刺激、病理生理变化、以及本身基因突变而产生的其体内代谢物水平的多元动态反应。
其研究对象大都是相对分子质量1000以内的小分子物质。
9、functional genomics 功能基因组学,是一门利用结构基因组学研究所得到的各种信息,建立和发展各种技术和实验模型来测定基因和基因组非编码序列的生物学功能的学科。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
基因表达gene expression:是基因中的DNA序列生产出蛋白质的过程。
步骤大致从DNA 转录成mRNA开始,一直到对于蛋白质进行后转译修饰为止。
基因水平转移horizontal gene transfer:指生物将遗传物质传递给其他细胞而非其子代的过程,基因水平转移是一个重要的现象。
人工神经网络(Artificial Neural Networks)人工神经网络是一种应用类似于大脑神经突触联接的结构进行信息处理的数学模型。
序列比对sequence alignment:序列比对指将两个或多个序列排列在一起,标明其相似之处。
序列中可以插入间隔。
对应的相同或相似的符号(在核酸中是A, T(或U), C, G,在蛋白质中是氨基酸残基的单字母表示)排列在同一列上。
这一方法常用于研究由共同祖先进化而来的序列,特别是如蛋白质序列或DNA序列等生物序列。
在比对中,错配与突变相应,而空位与插入或缺失对应。
可变剪接alternative splicing :通过不同的剪接位点,从一个单独的前体mRNA生成两个或多个mRNA成熟分子的现象。
启动子(promotor): 指一段能使基因进行转录的DNA序列。
启动子可以被RNA聚合酶辨认,并开始转录。
在RNA合成中,启动子可以和决定转录开始的转录因子产成相互作用,继而控制细胞开始转录翻译蛋白质。
增强子Enhancer:是DNA上一小段可与转录因子蛋白结合的区域,结合之后,基因的转录作用将会加强。
强化子可能位于基因上游,也可能位于下游。
分支约束法branch and bound method :一种对最大简约树进行逐层搜索的智能高效的方法,包括两个步骤:一、将上边界确定为数据集的最大简约树的长度;二、每次增加一个分支,逐步生成一棵树,以此描述部分被考虑序列的相互关系。
趋同演化(Convergency):在演化生物学中指的是两种不具亲缘关系的动物长期生活在相同或相似的环境,或曰生态系统中,它们因应需要而发展出相同功能的器官的现象。
Chou-Fasman 参数Chou-Fasman parameter:表示与α螺旋、β折叠以及发夹环各个位置相关的氨基酸二级结构经验观察趋势的一系列数值参量。
位置特异性打分矩阵position-specific scoring matrix:一个矩阵,矩阵中的每一个数表示某个特定的氨基酸占据多序列比对中某个位置的频率。
基因芯片(gene chip),又称DNA微阵列(microarray),是由大量cDNA或寡核苷酸探针密集排列所形成的探针阵列,其工作的基本原理是通过杂交检测信息。
系统生物学system biology:是一个试图整合不同层次信息以理解生物系统如何行使功能的学术领域。
通过研究某生物系统各不同部分之间的相互关系和相互作用(例如,与细胞信号传导,代谢通路,细胞器,细胞,生理系统与生物等相关的基因和蛋白网络),系统生物学期望最终能够建立整个系统的可理解模型。
请阐述生物信息学研究的主要内容。
The main contents of bioinformatics research.生物信息学作为一门新的交叉学科,其研究范畴是以基因组DNA序列的信息分析作为出发点,分析基因组结构,寻找或发现新基因,分析基因调控信息,并在此基础上研究基因的功能,研究基因的产物即蛋白质,模拟和预测蛋白质的空间结构,分析蛋白质的性质,其结果将为基于靶分子结构的药物分子设计和蛋白质分子改性设计提供依据。
当前,生物信息学已在理论生物学领域占有了核心的地位。
生物信息学主要有以下几个方面的研究内容。
(1)生物分子数据的收集与管理;(2)数据库搜索及序列比较;(3)基因组序列分析;(4)基因表达数据的分析和处理;(5)蛋白质结构预测。
从生物分子数据的收集和管理到数据库搜索,从基因组序列和基因表达数据分析到蛋白质结构与功能的研究形成生物信息学研究的主线,进一步的工作还包括药物分子设计和蛋白质设计。
简述分子生物学中的“中心法则”。
A brief description of the "Central Dogma" in molecular biology.DNA是遗传物质,是携带遗传信息的载体。
信息从基因的核苷酸序列中被提取出,用来指导蛋白质合成的过程对地球上的所有生物都是相同的,分子生物学家称之为中心法则(central dogma)。
“中心法则”的核心:DNA分子中的遗传信息转录(transcription)到RNA分子中(即RNA聚合酶以DNA为模板合成RNA),再由RNA翻译(translation)生成体内各种蛋白质,行使特定的生物功能。
国际上有哪几个著名的核酸序列数据库?The three well-known international nucleotide sequence database.核酸序列是了解生物体结构、功能、发育和进化的出发点。
国际上权威的核酸序列数据库有三个,分别是美国生物技术信息中心(NCBI)的GenBank (/Web/Genbank/index.html),欧洲分子生物学实验室的EMBL-Bank(简称EMBL,/embl/index.html),日本遗传研究所的DDBJ (http://www.ddbj.nig.ac.jp/)。
三个组织相互合作,各数据库中的数据基本一致,仅在数据格式上有所差别,对于特定的查询,三个数据库的响应结果一样。
这三个数据库是综合性的DNA和RNA序列数据库,其数据来源于众多的研究机构和核酸测序小组,来源于科学文献。
用户可以通过各种方式将核酸序列数据提交给这三个数据库系统。
数据库中的每条记录代表一个单独、连续、附有注释的DNA或RNA片段。
简述Alignment基本原理。
The basic principles of Alignment.两条序列的比对(alignment)是指这两条序列中各个字符的一种一一对应关系,或字符对比排列。
序列的比对是一种关于序列相似性的定性描述,它反映在什么部位两条序列相似,在什么部位两条序列存在差别。
最优比对揭示两条序列的最大相似程度,指出序列之间的根本差异。
对两条序列进行编辑操作,通过字符匹配和替换,或者插入和删除字符,使得两条序列达到一样的长度,并使两条序列中相同的字符尽可能地一一对应。
设两条序列分别是s和t,在s或t中插入空位符号,使s和t达到一样的长度。
在进行序列比对时,可根据实际情况选用代价函数或得分函数。
两条序列s和t的比对的得分(或代价)等于将s转化为t所用的所有编辑操作的得分(或代价)总和,s和t的最优比对是所有可能的比对中得分最高(或代价最小)的一个比对,s和t的真实距离应该是在得分函数p值(或代价函数w值)最优时的距离。
请简要介绍基因组序列分析步骤。
The steps of genome sequence analysis.基因组序列分析步骤一般如下:(1)发现重复元素。
这是重要的一步,因为重复元素会给DNA序列分析带来许多问题。
所以,一般先寻找并屏蔽重复的和低复杂性的序列,然后寻找基因以及与其相关的调控区域。
(2)数据库搜索。
通过数据库搜索,发现相似序列或者同源序列,根据相似序列具有相似结构及相似功能的原理,通过类比,得到关于待分析序列的初步信息,指导进一步的详细序列分析。
(3)分析功能位点。
其主要目的是识别DNA序列上存在的序列信号,具体地说,就是特殊的片段。
这些片段与基因及调控信息有关,如转录剪切位点、启动子、起始密码子等。
对于基因识别问题来说,信号识别有助于确定基因所在的区域。
(4)序列组成统计分析。
蛋白质编码区域与非编码区域在DNA序列组成上具有明显不同的统计特征,编码序列具有三联周期性,编码区域多联核苷酸出现频率与非编码区域不同。
因而,可以通过统计分析预测基因的编码区域,预测一段DNA序列成为编码区域的可能性,寻找可能的基因外显子。
(5)综合分析。
综合数据库搜索、功能位点分析、序列组成分析等的阶段性结果,检查这些结果的相容性,经过整理,最终得到一致性的分析结果。
请简要介绍基因识别及主要原理。
The gene recognition and main methods.由于DNA测序技术的迅速发展,我们已经得到一些完整的基因组序列,有效地解决基因识别问题显得越来越迫切。
基因识别中的一个关键问题是预测编码区域。
所谓编码区域预测,一般是指预测DNA序列中编码蛋白质的部分,即基因的外显子部分。
而基因识别的最终目标是预测完整的基因结构,正确地识别出一个基因的所有外显子及其边界。
识别DNA序列中蛋白质编码区域的方法主要有两类。
一类是基于特征信号的识别。
真核基因外显子(编码区域)具有一些特别的序列信号,如内部的外显子被剪切接受体位点和给体位点所界定,5’-端的外显子一定是在核心启动子(例如TA TA盒)的下游,而3’-端的外显子的下游包含多聚A信号和终止编码。
根据这些序列特征信号确定外显子的边界,从而达到识别编码区域的目的。
然而没有一个算法在预测基因时仅仅检测这些信号,因为这些信号的强度太弱,它们缺乏统计的显著性。
另一类是基于统计度量的方法,对编码区进行统计特性分析。
通过统计而获得的经验说明,DNA中密码子的使用频率不是平均分布的,某些密码子会以较高的频率使用,而另一些则较少使用。
这样就使得编码区的序列呈现出可察觉的统计特异性,即“密码子偏好性”。
利用这一特性对未知序列进行统计学分析可以发现编码区的粗略位置。
基因识别方法又可以分成两大类,即从头算方法(或基于统计的方法)和基于同源序列比较的方法。
从头算方法根据蛋白质编码基因的一般性质和特征进行识别,通过统计值区分外显子、内含子及基因间区域。
基于同源的方法利用数据库中现有与基因有关的信息(如EST序列、蛋白质序列),通过同源比较,帮助发现新基因。
最理想的方法是综合两大类方法的优点,开发混合算法。
请阐述基因组测序技术及其发展。
The genome sequencing technologies and their development.DNA测序(DNA sequencing)是指分析特定DNA片段的碱基序列,也就是腺嘌呤(A)、胸腺嘧啶(T)、胞嘧啶(C)與鳥嘌呤的(G)排列方式。
一、传统的DNA测序技术——Sanger测序法Sanger双脱氧链终止法是Sanger于1975年发明的。
测序过程需要先做一个聚合酶连锁反应(PCR)。
PCR过程中,DNA分子可能随机的被加入到正在合成中的DNA片段里。
由于双脱氧核糖核酸多脱了一个氧原子,一旦它被加入到DNA链上,这个DNA链就不能继续增加长度。
最终的结果是获得所有可能获得的、不同长度的DNA片段。