R常用函数表格汇总
R语言常用的数据操作函数整理

R语言常用的数据操作函数整理R语言是一种用于数据分析和统计建模的编程语言,它提供了许多强大且便捷的数据操作函数。
本文将整理R语言常用的数据操作函数,以帮助读者更好地进行数据处理。
1.载入数据在R语言中,可以使用`read.csv(`函数来从CSV文件中读取数据,`read.table(`函数可以读取其他格式的数据,如文本文件。
另外,还可以使用`read.xlsx(`函数读取Excel文件,通过`readRDS(`函数读取R数据集。
以下是一些常用的数据载入函数:- `read.csv(file, header=TRUE)`:从CSV文件中读取数据。
- `read.table(file, header=TRUE)`:从文本文件中读取数据。
- `read.xlsx(file)`:从Excel文件中读取数据。
2.数据查看在进行数据操作前,我们常常需要先了解数据的结构和内容。
以下是一些常用的数据查看函数:- `head(data, n=6)`:显示数据的前n行,默认为6行。
- `tail(data, n=6)`:显示数据的后n行,默认为6行。
- `str(data)`:显示数据的结构和类型。
- `summary(data)`:提供数据的描述性统计信息。
3.数据选择在R语言中,可以使用不同的方式选择数据的子集。
以下是一些常用的数据选择函数:- `[rows, cols]`:通过行索引和列索引选择数据。
- `$column_name`:通过列名选择数据。
- `subset(data, condition)`:根据条件选择数据子集。
4.数据过滤对于大型数据集,我们常常需要根据一些条件过滤数据。
以下是一些常用的数据过滤函数:- `filter(data, condition)`:根据条件筛选出符合条件的数据。
- `slice(data, indices)`:通过索引选择数据。
- `arrange(data, column)`:按照指定列对数据进行排序。
R语言常用函数整理
求时间序列描述统计量(包括均值、标准差、偏度、峰度等) FinTS 检验时间序列均值是否为零(实际上可作单、双样本检验) stats ARMA 相关函数 转换为时间序列格式 将多个时间序列联合起来 将时间相同的列合并,区别不同时间的行 stats stats stats
R 语言常用函数整理 window ts.plot diff.ts as.Date acf pacf Box.test ar arima ARIMA arma predict tsdiag adf.test urdfTest kpss.test pp.test Arima.sim FitAR Auto.arima 提取符合某个时间段的数据 作时序图 时序差分 把非时间向量转为时间向量 求自相关函数和作偏自相关函数图 求偏自相关函数和作偏自相关函数图 作序列自相关 B-P 和 L-B 检验
R 语言常用函数整理
方匡南
R 语言常用函数整理
提示:碰到不懂的函数可以输入“?函数名” ,前提条件是需要先安装包,使用命令 “ istall.packages(“ 包名” ) 或菜单安装。再载入包,除了几个基本包外,其他的包需要用 “library(包名)”载入。
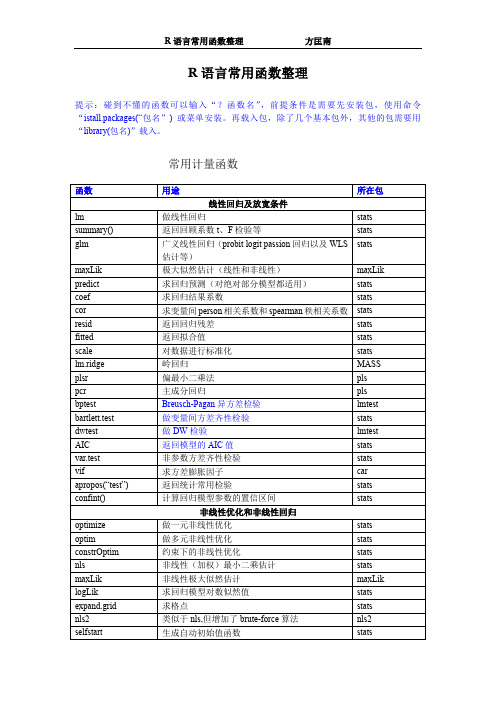
常用计量函数
函数 lm summary() glm maxLik predict coef cor resid fitted scale lm.ridge plsr pcr bptest bartlett.test dwtest AIC var.test vif apropos(“test”) confint() optimize optim constrOptim nls maxLik logLik expand.grid nls2 selfstart 用途 线性回归及放宽条件 做线性回归 返回回顾系数 t、F 检验等 广义线性回归(probit logit passion 回归以及 WLS 估计等) 极大似然估计(线性和非线性) 求回归预测(对绝对部分模型都适用) 求回归结果系数 求变量间 person 相关系数和 spearman 秩相关系数 返回回归残差 返回拟合值 对数据进行标准化 岭回归 偏最小二乘法 主成分回归 Breusch-Pagan 异方差检验 做变量间方差齐性检验 做 DW 检验 返回模型的 AIC 值 非参数方差齐性检验 求方差膨胀因子 返回统计常用检验 计算回归模型参数的置信区间 非线性优化和非线性回归 做一元非线性优化 做多元非线性优化 约束下的非线性优化 非线性(加权)最小二乘估计 非线性极大似然估计 求回归模型对数似然值 求格点 类似于 nls,但增加了 brute-force 算法 生成自动初始值函数 stats stats stats stats maxLik stats stats nls2 stats stats stats stats maxLik stats stats stats stats stats stats MASS pls pls lmtest stats lmtest stats stats car stats stats 所在包
R语言常用函数汇总

R语言常用函数汇总R语言是一种强大的统计计算语言,拥有丰富的函数和包。
下面是常用的R语言函数的汇总(按照字母顺序排列)。
1. abs(x): 返回x的绝对值。
2. append(x, values): 向向量x中追加值values。
3. apply(X, MARGIN, FUN): 在矩阵X的指定维度上应用函数FUN。
4. args(function): 返回指定函数的参数列表。
5. as.character(x): 将对象x转化为字符型。
6. as.data.frame(x): 将对象x转化为数据框。
7. as.factor(x): 将对象x转化为因子型。
8. as.matrix(x): 将对象x转化为矩阵。
9. as.numeric(x): 将对象x转化为数值型。
10. barplot(height): 绘制条形图。
11.c(x,...):将x与其他对象合并为一个向量。
12. colnames(x): 返回矩阵或数据框x的列名。
13. cor(x, y): 计算x和y的相关系数。
14. cut(x, breaks): 将向量x划分为几个离散区间。
15. plot(x, y): 绘制散点图。
16. density(x): 生成x的密度图。
17. diff(x): 计算向量x的差值。
18. dim(x): 返回矩阵或数据框x的维度。
19. mean(x): 计算向量x的平均值。
20. median(x): 计算向量x的中位数。
21. min(x): 返回向量x的最小值。
22. max(x): 返回向量x的最大值。
23. names(x): 返回对象x的变量名。
24. paste(x, ...): 将x和其他对象合并为一个字符型。
25. print(x): 打印对象x。
26. range(x): 返回向量x的范围。
27. read.csv(file): 从CSV文件中读取数据。
28. rownames(x): 返回矩阵或数据框x的行名。
R语言常用函数汇总

R语言常用函数汇总R语言有众多常用函数,以下是其中一部分:1.数据导入和导出函数- read.csv(:读取CSV文件的数据- read.table(:读取表格数据- read.xlsx(:读取Excel文件的数据- write.csv(:将数据写入CSV文件- write.table(:将数据写入表格文件2.数据处理函数- subset(:根据条件筛选数据- merge(:合并数据集- aggregate(:按照指定变量对数据进行聚合- ifelse(:根据条件进行向量元素的赋值- transform(:对数据进行变换3.数据探索函数- summary(:提供数据的基本统计描述- table(:生成频数统计表- hist(:绘制直方图- boxplot(:绘制箱线图- scatterplot(:绘制散点图4.数据清洗函数- na.omit(:去除包含缺失值的行- na.fill(:填充缺失值- duplicates(:删除重复的行- cut(:将连续变量分组- normalize(:对数据进行标准化5.数据分析函数- lm(:线性回归模型拟合- glm(:广义线性模型拟合- t.test(:进行t检验- cor(:计算变量之间的相关系数- anova(:进行方差分析6.绘图函数- plot(:绘制二维散点图- barplot(:绘制条形图- pie(:绘制饼图- boxplot(:绘制箱线图- hist(:绘制直方图7.矩阵和数组操作函数- matrix(:创建矩阵- array(:创建数组- dim(:返回矩阵或数组的维度-t(:转置矩阵- solve(:求解线性方程组8.字符串处理函数- paste(:将多个字符串拼接在一起- grep(:根据模式匹配字符串- sub(:替换字符串中的部分内容- toupper(:将字符串转换为大写- tolower(:将字符串转换为小写9.时间和日期处理函数- as.Date(:将字符转换为日期格式- format(:格式化日期输出- months(:返回英文月份名称- weekdays(:返回英文星期几名称10.循环和条件控制函数- for(:执行循环操作- while(:执行循环操作,条件为真时执行- if(:执行条件判断- else(:if条件为假时执行- break(:跳出循环。
r语言基本函数

r语言基本函数作为一种数据分析和统计学的软件, R 语言已经成为了数据分析领域中不可或缺的一部分。
R 语言拥有丰富的函数库,这是其实现数据分析和建模的基础。
本文将介绍R 语言中的基本函数,从而为读者提供使用 R 进行统计分析的基础知识和指导。
R 语言的基本函数主要分为三大类:数据操作函数、数据处理函数和统计函数。
在使用这些函数之前,我们需要先安装 R 语言软件并导入所需的数据集。
一、数据操作函数数据操作函数主要用于对数据的读取、转化、合并等操作。
下面是一些常见的数据操作函数:1. read.table():用于从文件中读取表格数据并生成数据框。
2. cbind() 和 rbind():分别用于对数据框进行列合并和行合并。
3. subset():用于选取数据框的子集。
4. merge():用于根据一个或多个变量来合并两个数据框。
5. aggregate():用于对数据框中的某一列进行分组并进行统计分析。
6. transform():用于根据已有的变量生成新的变量。
7. arrange():根据指定的变量对数据框进行排序。
以上是数据操作函数的部分应用,这些函数的使用有助于我们对数据进行更好的处理和操作。
二、数据处理函数数据处理函数主要用于对数据进行清洗、规整、筛选、统计等操作。
下面是一些常见的数据处理函数:1. summary():用于生成数据框的统计概要。
2. na.omit():用于删除数据框中具有缺失值的行或列。
3. na.fill():用于使用指定的值或方法填充数据框中的缺失值。
4. scale():用于对数据框中的变量进行标准化。
5. cor():用于计算数据框中各变量之间的相关性。
6. subset():用于筛选数据框中满足条件的行或列。
以上是数据处理函数的一些应用,这些函数可以使我们更好、更快、更精准地对数据进行处理。
三、统计函数统计函数主要用于数据的描述和探索性分析,可以帮助我们快速地了解数据的分布、变量之间的关系等。
R语言时间序列有关各种函数总结

R语言时间序列有关各种函数总结R语言是一种强大的统计分析和数据可视化工具,提供了许多时间序列分析的函数和方法。
下面是一些重要的时间序列分析函数的总结:1. ts(函数:用于创建时间序列对象。
可以指定时间序列的起始时间、结束时间、时间间隔等。
例如,创建从1990年1月到1999年12月的月度时间序列对象可以使用以下代码:```Rts_data <- ts(data, start=c(1990, 1), end=c(1999, 12), frequency=12)``````R```3. stl(函数:基于季节性-趋势-随机性分解的局部回归方法,用于进行季节调整。
该函数可以根据时间序列的特性自动选择适当的分解模型。
以下是使用stl(函数进行季节调整的示例:```Rseasonally_adjusted <- stl(ts_data, s.window="periodic")```4. forecast(函数:用于时间序列的预测。
可以根据历史数据拟合不同的模型,例如ARIMA模型、指数平滑模型等,并生成未来一段时间的预测结果。
以下是使用forecast(函数生成未来12个月的预测结果的示例:```Rforecast_result <- forecast(ts_data, h=12)```5. autocorrelation(函数:用于计算时间序列的自相关系数。
自相关系数可以帮助我们了解时间序列的固定模式和周期性。
以下是计算时间序列的自相关系数的示例:```Racf_result <- autocorrelation(ts_data)```6. arima(函数:用于建立自回归移动平均模型(ARIMA)来拟合时间序列。
ARIMA模型是一种常用的时间序列预测模型,可以预测时间序列的未来值。
以下是使用arima(函数拟合ARIMA模型的示例:```Rarima_model <- arima(ts_data, order=c(p, d, q))```7. ets(函数:用于指数平滑时间序列模型的拟合和预测。
R语言常用函数

R语言常用函数数学函数:1、round() #四舍五入例:x <- c(3.1416, 15.377, 269.7)round(x, 0) #保留整数位round(x, 2) #保留两位小数round(x, -1) #保留到十位2、signif() #取有效数字(跟学过的有效数字不是一个意思) 例:略3、trunc() #取整floor() #向下取整ceiling() #向上取整例:xx <- c(3.60, 12.47, -3.60, -12.47)trunc(xx)floor(xx)ceiling(xx)4、logb(a, b) #以b为底的对数,省略b表示自然对数log() #自然对数log10() #以10为底的常用对数例:logb(8, 2)log(8); logb(8)log10(100); logb(100, 10)5、sqrt() #平方根exp() #指数6、sin() #正弦cos() #余弦tan() #正切asin() #反正弦acos() #反余弦atan() #反正切sinh() #双曲正弦tanh() #双曲正切7、nchar() #字符长度例:xx <- 'China is a great country'nchar(xx)8、substring() #取子字符串例:substring(xx, 1, 5)9、paste() #连接字符语法是:paste(..., sep = " ", collapse = NULL)例1:x <- 'I'; y <- 'am'; z <- 'a'; d <- 'student' paste(x, y, z, d)例2:paste(c('x', 'y'), 1:4, sep = '')例3:paste('x', 1:4, sep = '', collapse = '+') 10、计算+, -, *, /, ^, %%, %/%:四则运算ceiling,floor,round,signif,trunc,zapsmall:舍入max,min,pmax,pmin:最大最小值 range:最大值和最小值sum,prod:向量元素和,积cumsum,cumprod,cummax,cummin:累加、累乘sort:排序 approx和approx fun:插值diff:差分sign:符号函数11、自己写函数程序流程一、控制结构if,else,ifelse,switch:分支for,while,repeat,break,next:循环apply,lapply,sapply,tapply,sweep:替代循环的函数。
R语言常用函数

R语言常用函数This model paper was revised by the Standardization Office on December 10, 2020R语言常用函数基本一、数据管理vector:向量 numeric:数值型向量 logical:逻辑型向量character;字符型向量list:列表:数据框c:连接为向量或列表 length:求长度 subset:求子集seq,from:to,sequence:等差序列rep:重复 NA:缺失值 NULL:空对象sort,order,unique,rev:排序unlist:展平列表attr,attributes:对象属性 mode,typeof:对象存储模式与类型names:对象的名字属性二、字符串处理character:字符型向量 nchar:字符数 substr:取子串format,formatC:把对象用格式转换为字符串paste,strsplit:连接或拆分charmatch,pmatch:字符串匹配grep,sub,gsub:模式匹配与替换三、复数complex,Re,Im,Mod,Arg,Conj:复数函数四、因子factor:因子 codes:因子的编码 levels:因子的各水平的名字nlevels:因子的水平个数 cut:把数值型对象分区间转换为因子table:交叉频数表 split:按因子分组aggregate:计算各数据子集的概括统计量tapply:对“不规则”数组应用函数数学一、计算+, -, *, /, ^, %%, %/%:四则运算ceiling,floor,round,signif,trunc,zapsmall:舍入max,min,pmax,pmin:最大最小值 range:最大值和最小值sum,prod:向量元素和,积cumsum,cumprod,cummax,cummin:累加、累乘sort:排序approx和approx fun:插值diff:差分sign:符号函数二、数学函数abs,sqrt:绝对值,平方根log, exp, log10, log2:对数与指数函数sin,cos,tan,asin,acos,atan,atan2:三角函数sinh,cosh,tanh,asinh,acosh,atanh:双曲函数beta,lbeta,gamma,lgamma,digamma,trigamma,tetragamma,pentagamma,choose ,lchoose:与贝塔函数、伽玛函数、组合数有关的特殊函数fft,mvfft,convolve:富利叶变换及卷积polyroot:多项式求根poly:正交多项式spline,splinefun:样条差值 besselI,besselK,besselJ,besselY,gammaCody:Bessel函数deriv:简单表达式的符号微分或算法微分三、数组array:建立数组 matrix:生成矩阵:把数据框转换为数值型矩阵:矩阵的下三角部分:生成矩阵或向量t:矩阵转置 cbind:把列合并为矩阵 rbind:把行合并为矩阵diag:矩阵对角元素向量或生成对角矩阵aperm:数组转置 nrow, ncol:计算数组的行数和列数dim:对象的维向量 dimnames:对象的维名row/colnames:行名或列名 %*%:矩阵乘法crossprod:矩阵交叉乘积(内积) outer:数组外积kronecker:数组的Kronecker积 apply:对数组的某些维应用函数tapply:对“不规则”数组应用函数sweep:计算数组的概括统计量aggregate:计算数据子集的概括统计量 scale:矩阵标准化matplot:对矩阵各列绘图 cor:相关阵或协差阵Contrast:对照矩阵 row:矩阵的行下标集col:求列下标集四、线性代数solve:解线性方程组或求逆 eigen:矩阵的特征值分解svd:矩阵的奇异值分解backsolve:解上三角或下三角方程组chol:Choleski分解 qr:矩阵的QR分解chol2inv:由Choleski分解求逆五、逻辑运算,=,==,!=:比较运算符!,&,&&,|,||,xor():逻辑运算符logical:生成逻辑向量 all,any:逻辑向量都为真或存在真ifelse():二者择一 match,%in%:查找unique:找出互不相同的元素 which:找到真值下标集合duplicated:找到重复元素六、优化及求根optimize,uniroot,polyroot:一维优化与求根程序设计一、控制结构if,else,ifelse,switch:分支for,while,repeat,break,next:循环apply,lapply,sapply,tapply,sweep:替代循环的函数。
r语言常用函数

r语言常用函数r语言是一种用于处理统计和计算的非常受欢迎的编程语言。
它具有许多强大的函数,可以帮助统计学家们非常快速地解决问题。
以下是r语言常用函数的列表:1. c():它用于将多个值合并成一个向量。
2. dim():它可以用于查看对象的维数。
3. seq():这个函数可以用于生成一个指定范围的有序数字序列。
4. apply():它用于在数据框或数组上应用函数,而不必遍历它们。
5. aggregate():统计数据分组之后,这是一种快速汇总函数。
6. lm():它用于建立线性回归模型,可以为数据样本中特定自变量拟合参数模型。
7. plot():这是一个绘制图形所需的核心函数,并可用于绘制散点图,折线图,箱线图和条形图等。
8. mean():这是r语言中函数计算均值的函数,它可用于计算输入向量的平均值。
9. summary():这是一个快速的汇总函数,它可以提供有关数据分布的大量信息,包括均值,中位数,最大值,最小值,标准差等。
10. log():该函数可以用来计算指定数字的对数值。
11. sd():这个函数可以查看样本标准差值。
12. cor():它可以用于检查两个变量间的线性相关性。
13. table():这是一个用于创建交叉表的函数,可用于检查表中分类变量之间的关系。
14. which():它用来查找符合条件的索引值。
15. order():这是一个常用的函数,用于排序,它可以按顺序或倒序对给定向量进行排序。
16. not():它用来查看给定向量的某元素是否满足给定的条件。
17. ifelse():这个函数可以返回由条件判断结果产生的新向量。
18. diff():它用于计算向量中连续元素间的差值。
19. is.na():它可以检测向量中是否存在缺失值。
20. split():它可以用来将数据框拆分为多个新的数据框。
R语言常用函数

基本一、数据管理vector:向量numeric:数值型向量logical:逻辑型向量character;字符型向量list:列表data.frame:数据框c:连接为向量或列表length:求长度subset:求子集seq,from:to,sequence:等差序列rep:重复NA:缺失值NULL:空对象sort,order,unique,rev:排序unlist:展平列表attr,attributes:对象属性mode,typeof:对象存储模式与类型names:对象的名字属性二、字符串处理character:字符型向量nchar:字符数substr:取子串format,formatC:把对象用格式转换为字符串paste,strsplit:连接或拆分charmatch,pmatch:字符串匹配grep,sub,gsub:模式匹配与替换三、复数complex,Re,Im,Mod,Arg,Conj:复数函数四、因子factor:因子codes:因子的编码levels:因子的各水平的名字nlevels:因子的水平个数cut:把数值型对象分区间转换为因子table:交叉频数表split:按因子分组aggregate:计算各数据子集的概括统计量tapply:对“不规则”数组应用函数数学一、计算+, -, *, /, ^, %%, %/%:四则运算ceiling,floor,round,signif,trunc,zapsmall:舍入max,min,pmax,pmin:最大最小值range:最大值和最小值sum,prod:向量元素和,积cumsum,cumprod,cummax,cummin:累加、累乘sort:排序approx和approx fun:插值diff:差分sign:符号函数二、数学函数abs,sqrt:绝对值,平方根log, exp, log10, log2:对数与指数函数sin,cos,tan,asin,acos,atan,atan2:三角函数sinh,cosh,tanh,asinh,acosh,atanh:双曲函数beta,lbeta,gamma,lgamma,digamma,trigamma,tetragamma,pentagamma,choose ,lchoose:与贝塔函数、伽玛函数、组合数有关的特殊函数fft,mvfft,convolve:富利叶变换及卷积polyroot:多项式求根poly:正交多项式spline,splinefun:样条差值besselI,besselK,besselJ,besselY,gammaCody:Bessel函数deriv:简单表达式的符号微分或算法微分三、数组array:建立数组matrix:生成矩阵data.matrix:把数据框转换为数值型矩阵lower.tri:矩阵的下三角部分mat.or.vec:生成矩阵或向量t:矩阵转置cbind:把列合并为矩阵rbind:把行合并为矩阵diag:矩阵对角元素向量或生成对角矩阵aperm:数组转置nrow, ncol:计算数组的行数和列数dim:对象的维向量dimnames:对象的维名row/colnames:行名或列名%*%:矩阵乘法crossprod:矩阵交叉乘积(内积)outer:数组外积kronecker:数组的Kronecker积apply:对数组的某些维应用函数tapply:对“不规则”数组应用函数sweep:计算数组的概括统计量aggregate:计算数据子集的概括统计量scale:矩阵标准化matplot:对矩阵各列绘图cor:相关阵或协差阵Contrast:对照矩阵row:矩阵的行下标集col:求列下标集四、线性代数solve:解线性方程组或求逆eigen:矩阵的特征值分解svd:矩阵的奇异值分解backsolve:解上三角或下三角方程组chol:Choleski分解qr:矩阵的QR分解chol2inv:由Choleski分解求逆五、逻辑运算<,>,<=,>=,==,!=:比较运算符!,&,&&,|,||,xor():逻辑运算符logical:生成逻辑向量all,any:逻辑向量都为真或存在真ifelse():二者择一match,%in%:查找unique:找出互不相同的元素which:找到真值下标集合duplicated:找到重复元素六、优化及求根optimize,uniroot,polyroot:一维优化与求根程序设计一、控制结构if,else,ifelse,switch:分支for,while,repeat,break,next:循环apply,lapply,sapply,tapply,sweep:替代循环的函数。
R语句常用函数汇总

R语句常用函数汇总以下是一些在R语言中常用的函数:1.基础函数:- `print(`:打印输出结果。
- `c(`:创建向量(vector)。
- `length(`:计算向量的长度。
- `class(`:显示对象的类型。
- `typeof(`:显示对象的存储模式。
- `is.na(`:判断元素是否为缺失值。
- `is.null(`:判断对象是否为NULL。
- `is.factor(`:判断对象是否为因子(factor)。
- `is.character(`:判断对象是否为字符型(character)。
- `is.numeric(`:判断对象是否为数值型(numeric)。
- `is.vector(`:判断对象是否为向量(vector)。
2.数据管理函数:- `mean(`:计算向量或矩阵的均值。
- `sum(`:计算向量或矩阵的和。
- `min(`:计算向量或矩阵的最小值。
- `max(`:计算向量或矩阵的最大值。
- `median(`:计算向量或矩阵的中位数。
- `var(`:计算向量或矩阵的方差。
- `sd(`:计算向量或矩阵的标准差。
- `quantile(`:计算向量或矩阵的分位数。
- `sort(`:对向量或矩阵进行排序。
- `table(`:创建频数表。
- `subset(`:根据条件筛选数据。
- `merge(`:根据指定的列合并数据框。
- `aggregate(`:根据指定的变量对数据进行聚合。
3.数据操作函数:- `unique(`:返回向量的唯一值。
- `duplicated(`:判断向量是否有重复值。
- `na.omit(`:删除包含缺失值的观察值。
- `na.exclude(`:排除缺失值。
- `names(`:获取或设置对象的名称。
- `as.factor(`:将向量转换为因子(factor)。
- `as.character(`:将向量转换为字符型(character)。
- `as.numeric(`:将向量转换为数值型(numeric)。
R软件画图常用函数及参数

R软件画图常用函数及参数R语言是一种强大的统计和绘图语言,它提供了丰富的函数和参数来进行数据可视化。
下面是一些常用的R软件画图函数及其参数的介绍:1. plot(函数:plot(函数是R中最基本的绘图函数之一,可以绘制散点图、折线图、柱状图等各种类型的图形。
参数:-x:要绘制的数据的x轴值-y:要绘制的数据的y轴值- type:图形类型,例如"p"代表散点图,"l"代表折线图- main:图形的主标题- col:点或线的颜色- pch:点的形状- lwd:线的宽度- xlim:x轴的范围- ylim:y轴的范围2. hist(函数:hist(函数用于绘制直方图,可以展示数据的分布情况。
参数:-x:要绘制直方图的数据- breaks:直方图的分割数,或者是分割点的向量- main:图形的主标题- col:直方图的颜色- xlim:x轴的范围- ylim:y轴的范围3. boxplot(函数:boxplot(函数用于绘制箱线图,可以显示数据的分布、中位数、四分位数等统计信息。
参数:-x:要绘制箱线图的数据- main:图形的主标题- col:箱线图的颜色- xlim:x轴的范围- ylim:y轴的范围4. barplot(函数:barplot(函数用于绘制柱状图,可以展示不同组别之间的比较。
参数:-x:柱状图的高度或数据- main:图形的主标题- col:柱状图的颜色- xlim:x轴的范围- ylim:y轴的范围5. plotly(函数:plotly(函数用于创建交互式的图形,可以通过鼠标和键盘进行缩放、旋转和放大等操作。
参数:-x:要绘制的数据的x轴值-y:要绘制的数据的y轴值- type:图形类型,例如"scatter"代表散点图,"line"代表折线图- mode:交互模式,例如"lines"代表线条,"markers"代表点- marker:点的样式参数,如颜色、大小等- hoverinfo:鼠标悬停时显示的信息。
r语言数据整理常用函数

r语言数据整理常用函数R语言是一种流行的数据分析和统计建模工具,它提供了许多强大的函数和包,用于数据整理和处理。
在本文中,我们将介绍一些常用的R语言数据整理函数,以帮助您更有效地处理和分析数据。
1. dplyr包。
dplyr包是R语言中最流行的数据整理包之一,它提供了一组简单而一致的函数,用于对数据进行筛选、排序、汇总和变换。
其中一些常用的函数包括:filter(),用于筛选数据集中满足特定条件的观测值。
select(),用于选择数据集中的特定变量。
mutate(),用于创建新的变量,或者修改现有的变量。
summarise(),用于对数据进行汇总统计。
这些函数使得数据整理变得更加直观和简单,同时也提高了代码的可读性和可维护性。
2. tidyr包。
tidyr包是另一个常用的数据整理包,它提供了一些函数,用于对数据进行重塑和整理。
其中一些常用的函数包括:gather(),用于将宽格式数据转换为长格式数据。
spread(),用于将长格式数据转换为宽格式数据。
separate()和unite(),用于对一个变量进行拆分或者合并。
这些函数可以帮助您轻松地处理不同格式的数据,使得数据整理更加灵活和高效。
3. reshape2包。
reshape2包也提供了一些函数,用于数据的重塑和整理。
其中最常用的函数是melt()和dcast(),它们分别用于将数据从宽格式转换为长格式,以及从长格式转换为宽格式。
总结。
在本文中,我们介绍了一些常用的R语言数据整理函数和包,包括dplyr、tidyr和reshape2。
这些函数和包提供了丰富的功能,可以帮助您更加高效地处理和整理数据,使得数据分析工作变得更加简单和愉快。
希望本文对您有所帮助,谢谢阅读!。
R语言常用函数汇总

R语言常用函数汇总今天把R常用函数大体汇总了一下,其中包括一般数学函数,统计函数,概率函数,字符处理函数,以及一些其他函数;1. 数学函数函数作用abs() 绝对值sqrt() 平方根ceiling(x) 不小于x的最小整数floor(x) 不大于x的最大整数round(x, digits=n) 将x舍入为指定位的小数signif(x, digits=n) 将X舍入为指定的有效数字位数2. 统计函数函数作用mean(x) 平均值median(x) 中位数sd(x) 标准差var(x) 方差quantile(x, probs) 求分位数,x为待求分位数的数值型向量,probs是一个由[0,1]的概率值组成的数值型向量range(x) 求值域sum(x) 求和min(x) 求最小值max(x) 求最大值scale(x, center=TRUE,scale=TRUE) 以数据对象x按列进行中心化或标准化,center=TRUE表示数据中心化,scale=TRUE表示数据标准化diff(x, lag=n) 滞后差分,lag用以指定滞后几项,默认为1difftime(time1,time2,units=c(“auto”,”secs”,”mins”,”hou rs”,”days”,”weeks”))计算时间间隔,并以星期,天,时,分,秒来表示3. 概率函数分布名称缩写beta分布beta 二项分布binom 柯西分布Cauchy 卡方分布chisp 指数分布expF分布 fgamma分布gamma几何分布geom超几何分布hyper对数正态分布lnormlogistics分布logis多项分布multinom负二项分布nbinom正态分布norm泊松分布poisWilcoxon分布signrankt分布t均匀分布unifweibull分布weibullWilcoxon秩和分布W ilcox在R中,函数函数行如:[x][function]。
R语言常用函数参考

R语言常用函数参考基本一、数据管理vector:向量numeric:数值型向量logical:逻辑型向量character;字符型向量list:列表data.frame:数据框c:连接为向量或列表length:求长度subset:求子集seq,from:to,sequence:等差序列rep:重复NA:缺失值NULL:空对象sort,order,unique,rev:排序unlist:展平列表attr,attributes:对象属性mode,typeof:对象存储模式与类型names:对象的名字属性二、字符串处理character:字符型向量nchar:字符数substr:取子串format,formatC:把对象用格式转换为字符串paste,strsplit:连接或拆分charmatch,pmatch:字符串匹配grep,sub,gsub:模式匹配与替换三、复数complex,Re,Im,Mod,Arg,Conj:复数函数四、因子factor:因子codes:因子的编码levels:因子的各水平的名字nlevels:因子的水平个数cut:把数值型对象分区间转换为因子table:交叉频数表split:按因子分组aggregate:计算各数据子集的概括统计量tapply:对“不规则”数组应用函数数学一、计算+, -, *, /, ^, %%, %/%:四则运算ceiling,floor,round,signif,trunc,zapsmall:舍入max,min,pmax,pmin:最大最小值range:最大值和最小值sum,prod:向量元素和,积cumsum,cumprod,cummax,cummin:累加、累乘sort:排序approx和approx fun:插值diff:差分sign:符号函数二、数学函数abs,sqrt:绝对值,平方根log, exp, log10, log2:对数与指数函数sin,cos,tan,asin,acos,atan,atan2:三角函数sinh,cosh,tanh,asinh,acosh,atanh:双曲函数beta,lbeta,gamma,lgamma,digamma,trigamma,tetragamma,pentagamma,choose ,lchoose:与贝塔函数、伽玛函数、组合数有关的特殊函数fft,mvfft,convolve:富利叶变换及卷积polyroot:多项式求根poly:正交多项式spline,splinefun:样条差值besselI,besselK,besselJ,besselY,gammaCody:Bessel函数deriv:简单表达式的符号微分或算法微分三、数组array:建立数组matrix:生成矩阵data.matrix:把数据框转换为数值型矩阵lower.tri:矩阵的下三角部分mat.or.vec:生成矩阵或向量t:矩阵转置cbind:把列合并为矩阵rbind:把行合并为矩阵diag:矩阵对角元素向量或生成对角矩阵aperm:数组转置nrow, ncol:计算数组的行数和列数dim:对象的维向量dimnames:对象的维名row/colnames:行名或列名%*%:矩阵乘法crossprod:矩阵交叉乘积(内积)outer:数组外积kronecker:数组的Kronecker积apply:对数组的某些维应用函数tapply:对“不规则”数组应用函数sweep:计算数组的概括统计量aggregate:计算数据子集的概括统计量scale:矩阵标准化matplot:对矩阵各列绘图cor:相关阵或协差阵Contrast:对照矩阵row:矩阵的行下标集col:求列下标集四、线性代数solve:解线性方程组或求逆eigen:矩阵的特征值分解svd:矩阵的奇异值分解backsolve:解上三角或下三角方程组chol:Choleski分解qr:矩阵的QR分解chol2inv:由Choleski分解求逆五、逻辑运算<,>,<=,>=,==,!=:比较运算符!,&,&&,|,||,xor():逻辑运算符logical:生成逻辑向量all,any:逻辑向量都为真或存在真ifelse():二者择一match,%in%:查找unique:找出互不相同的元素which:找到真值下标集合duplicated:找到重复元素六、优化及求根optimize,uniroot,polyroot:一维优化与求根程序设计一、控制结构if,else,ifelse,switch:分支for,while,repeat,break,next:循环apply,lapply,sapply,tapply,sweep:替代循环的函数。
摘抄-R语言常用数学函数

摘抄-R语⾔常⽤数学函数R语⾔常⽤数学函数(2013-01-04 22:09:00)转载▼标签:杂谈分类:R语⾔语⾔的数学运算和⼀些简单的函数整理如下:向量可以进⾏那些常规的算术运算,不同长度的向量可以相加,这种情况下最短的向量将被循环使⽤。
> x <- 1:4> a <- 10> x * a[1] 10 20 30 40> x + a[1] 11 12 13 14> sum(x) #对x中的元素求和[1] 10> prod(x) #对x中的元素求连乘积[1] 24> prod(2:8) #8的阶乘[1] 40320> prod(2:4) #4的阶乘[1] 24> max(x) #x中元素的最⼤值[1] 4> min(x) #x中元素的最⼩值[1] 1> which.max(x) #返回x中最⼤元素的下标[1] 4> which.min(x) #返回x中最⼩元素的下标[1] 1> x <- 4:1 #对向量x重新赋值> x[1] 4 3 2 1> which.min(x)[1] 4> which.max(x)[1] 1> range(x) #与c(min(x), max(x))作⽤相同[1] 1 4> mean(x) #x中元素的均值[1] 2.5> median(x) #x中元素的中位数[1] 2.5> var(x) #x中元素的的⽅差(⽤n-1做分母)[1] 1.666667> x[1] 4 3 2 1> rev(x) #对x中的元素取逆序[1] 1 2 3 4> sort(x) #将x中的元素按升序排列;[1] 1 2 3 4> x[1] 4 3 2 1> cumsum(x) #求累积和,返回⼀个向量,它的第i个元素是从x[1]到x[i]的和[1] 4 7 9 10> cumsum(rev(x))[1] 1 3 6 10> y <- 11:14> pmin(x,y) #返回⼀个向量,它的第i个元素是x[i], y[i], . . .中最⼩值[1] 4 3 2 1> x <- rev(x) #重新赋值> pmin(x,y)[1] 1 2 3 4> pmax(x,y) #返回⼀个向量,它的每个元素是向量x和y在相应位置的元素的最⼤者[1] 11 12 13 14> cumprod(x) #求累积(从左向右)乘积[1] 1 2 6 24> cummin(x) #求累积最⼩值(从左向右)[1] 1 1 1 1> cummax(x) #求累积最⼤值(从左向右)[1] 1 2 3 4> match(x, y) #返回⼀个和x的长度相同的向量,表⽰x中与y中元素相同的元素在y中的位置(没有则返回NA)[1] NA NA NA NA> y[c(2,4)] <- c(2,4)> y[1] 11 2 13 4> match(x, y)[1] NA 2 NA 4na.omit(x)函数忽略有缺失值(NA)的观察数据(如果x是矩阵或数据框则忽略相应的⾏)> na.omit(match(x,y))[1] 2 4attr(,"na.action")[1] 1 3attr(,"class")[1] "omit"> na.fail(match(x,y)) #na.fail(x) 如果x包含⾄少⼀个NA则返回⼀个错误消息错误于na.fail.default(match(x,y)) : 对象⾥有遺漏值which()函数返回⼀个包含x符合条件(当⽐较运算结果为真(TRUE)的下标的向量,在这个结果向量中数值i说明x[i] == a(这个函数的参数必须是逻辑型变量)> which( x == 2)[1] 2> which( x <= 2)[1] 1 2求组合数> choose(4,2)[1] 6> choose(3,1)[1] 3> choose(-3,1)[1] -3> choose(-4,2)[1] 10> y <- c(1:4, rep(4,1))> y[1] 1 2 3 4 4> unique(y) #如果y是⼀个向量或者数据框,则返回⼀个类似的对象但是去掉所有重复的元素(对于重复的元素只取⼀个)[1] 1 2 3 4> table(y) #返回⼀个表格,给出y中重复元素的个数列表(尤其对于整数型或者因⼦型变量)y1 2 3 41 1 1 2> subset(x, x>2) #返回x中的⼀个满⾜特定条件...的⼦集[1] 3 4> sample(x, 2) #从x中⽆放回抽取size个样本,选项replace= TRUE表⽰有放回的抽样[1] 1 2> sample(x, 2, replace = TRUE) #有放回的抽样[1] 2 3R中⽤来处理数据的函数太多了⽽不能全部列在这⾥。
R常用函数表格汇总

表1帮助函数 (2)表2用于管理R工作空间的函数 (2)表3处理数据对象和变量的实用函数 (4)表4日期格式 (7)表 5 数据类型转换函数 (8)表6用于保存图形输出的函数 (8)表7图形输出函数 (9)表8算术运算符 (12)表9逻辑运算符 (12)表10字符处理函数 (13)表11其它使用函数(字符与数字) (15)表12数学函数 (15)表13统计函数 (16)表14概率分布 (16)表15常用控制流语句 (18)表16基本图形 (18)表17基本统计分析函数 (19)表18中级统计分析函数 (22)表19对拟合线性模型非常有用的其它函数 (23)表1帮助函数注:函数RSiteSearch()可在在线帮助手册和R-Help邮件列表的讨论存档中搜索指定主题,并在浏览器中返回结果。
由函数vignette()函数返回的vignette文档一般是PDF格式的实用介绍性文章。
不过,并非所有的包都提供了vignette文档。
表2用于管理R工作空间的函数注:①注意setwd()命令的路径中使用了正斜杠。
R将反斜杠(\)作为一个转义符。
②我通常会在启动一个R会话时使用setwd()命令指定到某一个项目的路径,后接不加选项的load()命令,这样就能继续上一次的会话。
③如果filename中不包含路径,R将假设此文件在当前工作目录中。
④表3处理数据对象和变量的实用函数注:①在R中,对象(object)是指可以赋值给变量的任何事物,包括常量、数据结构、函数,甚至图形。
②R中的五种数据结构:向量、矩阵、数组、数据框、列表;对应c(),matrix(),arry(),data.frame(),list();另外有factor()。
③read.table()中name必须是file中存在的变量,且无重复值。
④R中没有标量。
标量以单元素向量的形式出现。
⑤R中的下标不从0开始,而从1开始。
在上述向量中,x[1]的值为8。
r语言处理excel常见函数

在R语言中,处理Excel文件的主要库是`readxl`和`openxlsx`。
以下是一些常用的函数:1. **readxl::read_excel()**: 这是最常用的函数,用于从Excel 文件中读取数据。
```Rlibrary(readxl)data <- read_excel("path/to/your/file.xlsx")```2. **openxlsx::read.xlsx()**: 这个函数与`read_excel()`类似,但有一些额外的功能,如选择工作表和范围。
```Rlibrary(openxlsx)data <- read.xlsx("path/to/your/file.xlsx", sheet = 1) # 读取第一个工作表```3. **writexl::write_excel()**: 这个函数用于将数据写入Excel 文件。
```Rlibrary(writexl)write_excel(data, "path/to/your/new_file.xlsx")```4. **openxlsx::write.xlsx()**: 这个函数也用于将数据写入Excel文件,但有一些额外的功能,如选择工作表和范围。
```Rlibrary(openxlsx)write.xlsx(data, "path/to/your/new_file.xlsx", sheetName = "Sheet1") # 写入到名为"Sheet1"的工作表```5. **openxlsx::addDataFrame()**: 这个函数用于向现有的Excel 工作表中添加数据框。
```Rlibrary(openxlsx)addDataFrame(data, "path/to/your/existing_file.xlsx",sheetName = "Sheet2") # 添加到名为"Sheet2"的工作表```6. **openxlsx::addGrob()**: 这个函数用于向现有的Excel工作表中添加复杂的图形对象。
R软件画图常用函数及参数Word版

R的基本画图函数非常容易学,看上去也很普通。
然而适当的参数设置,有意义的颜色设置,不同基本图间的互相组合,会使你的图更漂亮也更有力的表达数据。
下面介绍一些R基本包里画图函数的参数:hist(): breaks设置每个柱的间距;freq柱图表示count或frequency;polt设置是否画图;density和angle可以设置柱上的斜线;axes设置是否需要画坐标轴; cor设置柱图的颜色;border设置柱图边界的颜色;xlim设置横轴范围;ylim设置纵轴范围。
R的许多函数都有类似的参数名,这些函数往往有同样的功能。
因此后面就只介绍比较特殊的参数。
layout():mat用矩阵设置窗口的划分,矩阵的0元素表示该位置不画图,非0元素必须包括从1开始的连续的整数值,比如:1……N,按非0元素的大小设置图形的顺序。
widths用来设置窗口不同列的宽度,heights设置不同行的高度。
par()的mfcol,和mfrow参数也有类似layout的功能,不过相对layout就逊色多了。
par():mar设置图离四个边缘的距离;bg设置背景颜色;xaxt 和yaxt设置坐标轴标签的类型(=”n”表示不画轴标签);xlim 和ylim设置坐标轴的范围。
axis():las设置坐标轴标签的方式(水平,垂直……)。
mtext():为四个坐标轴添加标签。
text():在给定坐标的位置写字。
lines():lty设置线的类型;lwd设置线的宽度。
points():pch设置点的类型。
plot():最简单的画图函数。
type设置画图的类型(type=”n”表示不画数据);axes设置是否画坐标轴。
常用的参数还有:xlim 和ylim,xaxt和yaxt。
barplot():space设置bar图间的间距;horiz设置bar的方向是垂直或水平;beside设置height为矩阵时,每列元素的bar 排列方式;add设置是否将barplot加在当前已有的图上。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
表1帮助函数 (2)
表2用于管理R工作空间的函数 (2)
表3处理数据对象和变量的实用函数 (4)
表4日期格式 (7)
表 5 数据类型转换函数 (8)
表6用于保存图形输出的函数 (8)
表7图形输出函数 (9)
表8算术运算符 (12)
表9逻辑运算符 (12)
表10字符处理函数 (13)
表11其它使用函数(字符与数字) (15)
表12数学函数 (15)
表13统计函数 (16)
表14概率分布 (16)
表15常用控制流语句 (18)
表16基本图形 (18)
表17基本统计分析函数 (19)
表18中级统计分析函数 (22)
表19对拟合线性模型非常有用的其它函数 (23)
表1帮助函数
注:函数RSiteSearch()可在在线帮助手册和R-Help邮件列表的讨论存档中搜索指定主题,并在浏览器中返回结果。
由函数vignette()函数返回的vignette文档一般是PDF格式的实用介绍性文章。
不过,并非所有的包都提供了vignette文档。
表2用于管理R工作空间的函数
注:①注意setwd()命令的路径中使用了正斜杠。
R将反斜杠(\)作为一个转义符。
②我通常会在启动一个R会话时使用setwd()命令指定到某一个项目的路径,后接不加选项的load()命令,这样就能继续上一次的会话。
③如果filename中不包含路径,R将假设此文件在当前工作目录中。
④
表3处理数据对象和变量的实用函数
注:①在R中,对象(object)是指可以赋值给变量的任何事物,包括常量、数据结构、函数,甚至图形。
②R中的五种数据结构:向量、矩阵、数组、数据框、列表;对应c(),matrix(),arry(),data.frame(),list();另外有factor()。
③read.table()中name必须是file中存在的变量,且无重复值。
④R中没有标量。
标量以单元素向量的形式出现。
⑤R中的下标不从0开始,而从1开始。
在上述向量中,x[1]的值为8。
⑥变量无法被声明。
它们在首次被赋值时生成。
⑦若干程序包都提供了实用的变量重编码函数,特别地,car包中的recode()函数可以十分简便地重编码数值型、字符型向量或因子。
而doBy包提供了另外一个很受欢迎的函数recodevar()。
最后,R中也自带了cut(),可将一个数值型变量按值域切割为多个区间,并返回一个因子。
⑧使用一个统计函数时,需要阅读help,注意它是怎样处理缺失值的
⑨日期格式:yyyy-mm-dd 写作%Y-%m-%d
表4日期格式
⑩R的内部在存储日期时,是使用自1970年1月1日以来的天数表示的,更早的日期则表示为负数。
表 5 数据类型转换函数
表6用于保存图形输出的函数
表7图形输出函数
注:①创建自定义坐标轴时,你应当禁用高级绘图函数自动生成的坐标轴。
参数axes=FALSE将禁用全部坐标轴(包括坐标轴框架线,除非你添加了参数frame.plot=TRUE)。
参数xaxt="n"和yaxt="n"将分别禁用X轴或Y轴(会留下框架线,只是去除了刻度)。
②不加参数地执行par()将生成一个含有当前图形参数设置的列表,并显示在workspace上。
添加参数no.readonly=TRUE可以生成一个可以修改的当前图形参
数列表,就是说par(),会将之前的图形的参数存储,添加了参数no.readonly=TRUE,只是表明之前的图形的参数可以修改了,之后用par(参数,参数)去修改就可以了(opar<-par(no.readonly=TRUE)不会在workspace上显示参数列表,par(no.readonly=TRUE)会显示),plot(dose,drugA,type = "b")就可以显示修改之后的图形了;par(opar)只是再将参数重置为修改之前的值,再plot(dose,drugA,type = "b")就可以显示最初的图形。
表8算术运算符
表9逻辑运算符
注:类似于其他科学计算语言,在R中比较浮点型数值时请慎用==,以防出现误判。
表10字符处理函数
注:函数grep()、sub()和strsplit()能够搜索某个文本字符串(fixed=TRUE)或某个正则表达式(fixed=FALSE,默认值为FALSE)。
正则表达式为文本模式的匹配提供了一套清晰而简练的语法。
例如,正则表达式:^[hc]?at
可匹配任意以0个或1个h或c开头、后接at的字符串。
因此,此表达式可以匹配hat、cat和at,但不会匹配bat。
要了解更多,请参考维基百科的regular
expression(正则表达式)条目。
表11其它使用函数(字符与数字)
表12数学函数
表13统计函数
表14概率分布
注:R中概率函数形式如:
例:pnorm(1.96)等于0.975
表15常用控制流语句
表16基本图形
表17基本统计分析函数
此函数可用来检验:某种相关系数的显
著性;两个独立相关系数的差异是否显
著;两个基于一个共享变量得到的非独
立相关系数的差异是否显著;两个基于完
全不同的变量得到的非独立相关系数的差
异是否显著。
注:①psych包和Hmisc包均提供了名为describe()的函数。
R如何知道该
使用哪个呢?简言之,如代码清单7-5所示,最后载入的程序包优先。
在这里,psych在Hmisc之后被载入,然后显示了一条信息,提示Hmisc包中的describe()函数被psych包中的同名函数所屏蔽(masked)。
键入describe()后,R 在搜索这个函数时将首先找到psych包中的函数并执行它。
如果你想改而使用Hmisc包中的版本,可以键入Hmisc::describe(mt)。
②doBy包和psych包也提供了分组计算描述性统计量的函数,如doBy包中summaryBy()函数,psych包中的describe.by();reshape包中的melt()和cast()联合运用也能。
③table()函数默认忽略缺失值(NA)。
要在频数统计中将NA视为一个有效的类别,请设定参数useNA="ifany".gmodels包中的CrossTable()函数也可创建二维列联表,并且有很多选项:如计算(行、列、单元格)的百分比;指定小数位数;进行卡方、Fisher和McNemar独立性检验;计算期望和(皮尔逊、标准化、调整的标准化)残差;将缺失值作为一种有效值;进行行和列标题的标注;生成SAS或SPSS风格的输出。
④table2flat()的代码:
表18中级统计分析函数
注:①car包中的scatterplot()函数,它可以很容易、方便地绘制二元关系图②
表19对拟合线性模型非常有用的其它函数
③多元回归分析中,第一步最好检查一下变量间的相关性。
cor()函数提供了二变量之间的相关系数,car包中scatterplotMatrix()函数则会生成散点图矩阵
④在k 重交叉验证中,样本被分为k个子样本,轮流将k1个子样本组合作为训练集,另外1个子样本作为保留集。
这样会获得k 个预测方程,记录k 个保留样本的预测表现结果,然后求其平均值。
[当n 是观测总数目,k 为n 时,该方法又称作刀切法(jackknifing)。
]。