数据挖掘r语言总结报告
RStudioR语言与统计分析实验报告

RStudioR语言与统计分析实验报告1. 实验目的本实验旨在介绍RStudio软件和R语言在统计分析中的应用。
通过本实验,可以了解RStudio的基本功能和操作,掌握R语言的基本语法和常用函数,并在实际数据分析中应用所学知识。
2. 实验环境与工具本实验使用RStudio软件进行实验操作。
RStudio是一个集成开发环境(IDE),专门用于R语言编程和统计分析。
它提供了代码编辑器、调试器、数据可视化工具等一系列功能,便于用户进行数据处理和分析。
3. 实验步骤本实验分为以下几个步骤:3.1 安装R和RStudio在开始实验之前,需要先安装R语言和RStudio软件。
R语言是一种统计分析和数据挖掘的编程语言,而RStudio是R语言的集成开发环境。
3.2 RStudio界面介绍在打开RStudio后,可以看到主要分为四个区域:代码编辑器、控制台、环境和帮助。
代码编辑器用于编写R语言代码,控制台用于执行和查看代码运行结果,环境用于查看和管理数据对象,帮助用于查阅R语言文档和函数说明。
3.3 R语言基础研究R语言的基本语法和常用函数是使用RStudio进行统计分析的基础。
实验中将介绍R语言的数据类型、赋值操作、条件语句、循环语句等基本概念,并演示常用函数的使用方法。
3.4 实际数据分析应用通过实际数据分析案例,将R语言和RStudio运用到实际问题中。
根据给定的数据,使用R语言进行数据处理、探索性分析和统计模型建立,并通过可视化工具展示分析结果。
4. 实验总结通过完成本实验,我们了解了RStudio软件和R语言在统计分析中的应用。
掌握了RStudio的基本功能和操作,熟悉了R语言的基本语法和常用函数。
通过实际数据分析案例的应用,提高了数据处理和统计分析能力。
5. 参考资料。
数据挖掘_实习报告

数据挖掘_实习报告数据挖掘实习报告一、实习目的进入大学以来,我一直在学习数据挖掘的相关理论知识,包括统计学、机器学习、数据库管理等。
为了将理论应用于实践,提升自己的专业技能,我选择了在XX公司进行数据挖掘实习。
二、实习内容在实习期间,我主要参与了以下几个项目:1. 用户画像构建:通过对用户历史数据的分析,提取用户的特征和兴趣点,构建用户画像。
这涉及到数据清洗、特征工程、标签制定等环节。
2. 推荐系统开发:基于用户画像,开发推荐算法,为用户提供个性化的商品或服务推荐。
这需要对推荐算法有深入的理解,并熟悉相关工具和平台。
3. 广告投放策略优化:通过数据分析和机器学习算法,优化广告投放策略,提高广告的点击率和转化率。
这涉及到数据处理、模型训练、AB测试等环节。
三、实习过程在实习过程中,我遇到了很多挑战和问题。
其中最大的挑战是如何将理论知识与实际应用相结合,我对数据挖掘的知识有了深入的理解,但在实际应用中,却发现自己对某些概念的理解还不够深入。
为了解决这个问题,我主动向同事请教,并阅读了大量相关文档和资料。
我还积极参加团队讨论和分享会,与其他同事交流经验和看法,不断加深对数据挖掘的理解和应用。
除了技术层面的挑战外,我还面临了时间管理和工作压力的挑战。
由于项目进度紧张和任务繁重,我需要在有限的时间内完成大量的工作和学习任务。
为了应对这些挑战,我制定了详细的工作计划和时间表,并学会合理安排时间和优先级。
我也积极调整自己的心态和情绪,保持积极乐观的态度,以应对工作中的压力和挑战。
四、实习收获通过这次实习,我不仅提升了自己的专业技能和实践能力,还学会了如何将理论知识与实际应用相结合,解决实际问题。
我还培养了自己的团队协作能力和沟通能力,学会了如何与他人合作完成任务。
在未来的学习和工作中,我将更加注重理论与实践的结合,不断提升自己的专业素养和实践能力。
五、总结与展望这次实习是一次非常宝贵的学习和成长经历,通过这次实习,我不仅掌握了数据挖掘的基本理论和技能,还提升了自己的实践能力和团队协作能力。
R语言学习总结

R语言学习总结第一篇:R语言学习总结R语言学习总结经过接近一个学期的学习,从对R语言的完全陌生,到现在对其有了一些粗浅的认识,其中经历了遇到困难苦思冥想的艰辛,也有解决问题以后豁然开朗的畅快。
在学习的过程中,以前掌握的数理基础给我带来了不少便利,而认真地态度和踏实的性格也使我获益匪浅。
在这个学期中,我学会了R语言的基本操作和语法,以及针对具体的统计学问题相应的解决方法。
并按时完成老师布置的课后作业,以达到学以致用的目的,也加强了对R语言操作的熟练度。
一、初识R软件R软件是一套完整的数据处理、计算和制图软件系统。
其功能包括:据存储和处理,数组运算,完整连贯的统计分析工具,优秀的统计制图功能已及简便而强大编程语言。
接触R语言以后,我的第一感觉就是方便和强大。
R语言中有非常多的函数和包,我们几乎不用自己去编一些复杂的算法,而往往只需要短短几行代码就能解决很复杂的问题,这给我们的使用带来了极大地方便;于此同时,它又可操纵数据的输入输出,实习分支、循环,使用者可以自定义功能,这就意味着当找不到合适的函数或包来解决所遇的问题时,我们又可以自己编程去实现各种具体功能,这也正是R语言的强大之处。
二、学习心得在学习该书的过程中,我不仅加深了对统计学方法的理解,同时也掌握了R软件的编程方法和基本技巧,了解了各种函数的意义和用法,并能把两者结合起来,解决实际中的统计问题。
1、R语言的基本语法及技巧R语言不仅可以进行基础的数字、字符以及向量的运算,内置了许多与向量运算有关的函数。
而且还提供了十分灵活的访问向量元素和子集的功能。
R语言中经常出现数组,它可以看作是定义了维数(dim属性)的向量。
因此数组同样可以进行各种运算,以及访问数组元素和子集。
二维数组(矩阵)是比较重要和特殊的一类数组,R可以对矩阵进行内积、外积、乘法、求解、奇异值分解及最小二乘拟合等运算,以及进行矩阵的合并、拉直等。
apply()函数可以在对矩阵的一维或若干维进行某种计算,例如apply(A,1,mean)表示对A按行求和。
数据挖掘工具使用心得分享

数据挖掘工具使用心得分享数据挖掘是现代信息时代的关键技术之一,而数据挖掘工具则是数据挖掘实现的重要途径。
数据挖掘工具越来越多,越来越强大,让数据挖掘变得越来越简单,也越来越普及。
在实际的应用中,不同的数据挖掘工具可以拥有不同的优势,这也就需要使用者有所取舍并掌握不同工具的使用技巧。
一、R语言R语言是自由软件,是一种适用于数据分析、统计建模的编程语言和软件环境。
它是许多统计模型的实现者之一,提供了许多的算法和统计方法。
R语言在统计分析和数据可视化方面能够发挥巨大的优势,很多数据科学家认为它在数据挖掘中发挥的作用是不可替代的。
R语言的学习曲线略高,但是只要你掌握好了它的实现方式,你就可以从中获得大量的选项和自由度。
二、PythonPython是另一种流行的用于数据挖掘和机器学习的编程语言,具有简单的语法和清晰的代码风格。
它的强大之处在于可以轻松访问和处理数据,并配备了各种语言库、工具和框架,可以针对各种不同的挖掘和模型训练算法。
Python拥有功能强大的数据分析库,例如NumPy、SciPy和Pandas,这些库可以支持数据的统计分析和处理,因此在数据分析领域中得到了广泛的使用。
三、SQLSQL(Structured Query Language)是一种标准化的数据库语言,几乎所有的数据库都支持SQL,这也就使SQL成为非常重要的数据挖掘工具之一。
通过SQL,可以对数据库进行许多数据运算和操作,例如数据提取、数据分析、数据整合和数据建模等。
SQL具有读取、分析和处理大量信息的能力,而这些信息可以来自不同的来源,例如企业的ERP和CRM系统,这使得它成为进行大规模数据挖掘的理想工具。
四、WEKAWEKA是一个开放源代码的数据挖掘工具,它提供了一系列的数据挖掘算法,例如分类、聚类、关联规则挖掘、数据预处理和可视化。
WEKA不仅能够自动化数据挖掘过程,而且可以支持自定义算法和数据处理流程,帮助让用户快速开发数据挖掘解决方案。
【原创】R语言UCI数据挖掘报告:先验知识对概念获取的影响:实验和计算结果

先验知识对概念获取的影响:实验和计算结果1.研究背景与目的以前的研究表明,背景知识对概念学习有明显的影响。
在本实验中,背景知识的作用被作为各种偶然的学习任务以及有意的学习任务的函数。
通过比较概念上相关的编码与概念上不相关的共现的编码来研究先验知识的影响。
通过偶然编码观察到的先验知识的精确影响,以及概念相关性,我们发现与有意的学习任务一样具有偶然的影响。
结果表明,许多类型的基于知识的影响不会作为编码策略的函数而变化。
我们讨论了背景知识对概念学习的影响的普遍性,通过决策树模型来分析气球试验的结果,最后证实背景知识对结果是否具有影响。
2.试验假设纯粹的经验发现技术在概念获取期间不利用先验知识。
仅仅依靠基于解释的学习的人类学习模型不能解释这样的事实,即在没有任何领域知识的情况下,受试者能够学习概念。
此外,当前的解释学习方法假定领域理论是完整的、正确的,这一假设不能对人类受试者的现有知识做出(Nisbett k Ross,1978)。
实验还指出当前基于解释的学习方法的不足。
基于解释的学习假设背景理论足够强,以证明为什么特定的结果发生。
相反,似乎并不出现对象的背景知识对于创建这样的证据是有效的。
换句话说,“背景知识似乎能够识别什么因素的情况可能影响膨胀气球的结果。
然而,受试者需要几个例子来确定这些因素中的哪些是相关的,以及这些因素是必要的还是适当的。
3.模型建立和理论背景为了开发学习任务的计算模型,必须理解领域理论是完整和正确的基于解释的学习的假设。
基于解释的学习中的完全,不完全和不正确的领域理论问题(Kajamoney k DeJong,不考虑,我认为决策树理论,是一种特定类型的不完全理论。
在这样的理论中,几个因素的影响是已知的,但领域理论没有指定一个系统的方法来组合这些因素。
此外,不假定域理论识别所有的影响因素。
决策树(decision tree)一般都是自上而下的来生成的。
每个决策或事件(即自然状态)都可能引出两个或多个事件,导致不同的结果,把这种决策分支画成图形很像一棵树的枝干,故称决策树。
R语言ablone数据集数据挖掘预测分析报告

R语言ablone数据集数据挖掘预测分析报告●介绍●数据集描述●检测异常值并构建清洁数据集●清洁数据分析●结论介绍鲍鱼是铁和泛酸的极佳来源,是澳大利亚,美国和东亚地区的营养食品资源和农业。
100克鲍鱼每日摄取这些营养素的量超过20%。
鲍鱼的经济价值与年龄呈正相关。
因此,准确检测鲍鱼的年龄对于农民和消费者确定其价格非常重要。
然而,目前用来决定年龄的技术是相当昂贵和低效的。
农民通常通过显微镜切割贝壳并计数环以估计鲍鱼的年龄。
这种复杂的方法增加了成本并限制了它的普及。
我们的目标是找出预测戒指的最佳指标,然后找出鲍鱼的年龄。
数据集描述数据集描述在这个项目中,数据集Abalone是从UCI Machine Learning Repository(1995)获得的。
该数据集包含1995年12月由澳大利亚塔斯马尼亚州主要工业和渔业部海洋研究实验室Taroona记录的4177只鲍鱼的物理测量结果。
有9个变量,分别是性别,长度,直径和身高,体重,体重,内脏重量,外壳重量和戒指。
随着年龄等于戒指数量,变量戒指与鲍鱼年龄呈线性相关加1.5。
检测异常值并构建清洁数据集library(ggplot2)library(plyr)library(nnet)library(MASS)library(gridExtra)## Loading required package: gridlibrary(lattice)library(RColorBrewer)library(xtable)Data = read.csv("abalone.csv")# Import Dataprint(str(Data))# Structure of the Data## 'data.frame': 4177 obs. of 9 variables:## $ Sex : Factor w/ 3 levels "F","I","M": 3 3 1 3 2 2 1 1 3 1 ...## $ Length : num 0.455 0.35 0.53 0.44 0.33 0.425 0.53 0.545 0.475 0.55 ...## $ Diameter : num 0.365 0.265 0.42 0.365 0.255 0.3 0.415 0.425 0.37 0.44 ...## $ Height : num 0.095 0.09 0.135 0.125 0.08 0.095 0.15 0.125 0.125 0.15 ...## $ Whole.weight : num 0.514 0.226 0.677 0.516 0.205 ...## $ Shucked.weight: num 0.2245 0.0995 0.2565 0.2155 0.0895 ...## $ Viscera.weight: num 0.101 0.0485 0.1415 0.114 0.0395 ...## $ Shell.weight : num 0.15 0.07 0.21 0.155 0.055 0.12 0.33 0.26 0.165 0.32 ...## $ Rings : int 15 7 9 10 7 8 20 16 9 19 ...## NULL有4种不同的体重衡量标准,即Whole.weight,Shucked.weight,Viscera.weight和Shell.weight。
基于R语言的数据分析和挖掘方法总结——中位数检验

基于R语⾔的数据分析和挖掘⽅法总结——中位数检验3.1 单组样本符号秩检验(Wilcoxon signed-rank test)3.1.1 ⽅法简介此处使⽤的统计分析⽅法为美国统计学家Frank Wilcoxon所提出的⾮参数⽅法,称为Wilcoxon符号秩 (signed-rank)检验,当数据中仅有单⼀组样本时,可⽤这种⽅法检验数据的中位数是否⼤于、⼩于或等于某⼀特定数值。
当你的样本数较⼤时(通常样本个数≧30的样本可视为样本数较⼤),建议改以单组样本均值t检验(one-sample t-test)检验总体均值。
注:总体中位数经常和均值⼀样, 因此检验中位数即检验均值。
3.1.2 公式3.1.3 实现范例1. 范例A-2:⽯油定价差异的分析物价不断上涨,各项与民⽣问题有关的物品都会受到关注,⽽每⽇上班需使⽤到交通⼯具使⽤的汽油与柴油也是⼤众⽣活的重要⽀出。
由于⽯油是⼀种同时具备战略考虑与民⽣问题双重属性的特殊物品,因此油价的波动会影响民⽣问题,为了推动国内油价市场的公平性与合理性,降低⾮经济因素的影响,使国内油价能回归市场机制,负责部门于2007年1⽉开始实施浮动油价的机制,经过多次的修订与调整,该计价制度推⾏⾄今。
由于近⼏个⽉来国际油价的波动剧烈,进⽽影响到⼀般百姓最关⼼的汽柴油价格,某研究民⽣议题的机构想了解该国主要两个⽯油公司A⽯油公司及B⽯化公司的浮动油价是否有差异,由北⾄南收集了A公司与B公司在该国9个地区的加油站油价(元/升),如下表所⽰。
问题:在浮动油价制度制定之前,国内的汽油价格为30元/升,研究机构想了解在实施浮动油价制度后,国内的平均油价是否⾼于实施之前,并以A 公司的数据加以⽐较。
问题解析:此问题可讨论A公司的平均油价与制度实施前油价加以⽐较,故讨论"A公司的平均油价是否⼤于30元/升?"。
统计⽅法:此问题中变量为⽯油公司的油价,为单⼀变量(⼀个变量,建议选择单变量分析);想了解A公司的油价,视为⼀组样本且仅有样本量9个,⼩于30笔;可采⽤分析⽅法:单组样本中位数检验(Wilcoxon signed-rank test),检验"A公司的平均油价是否⾼于30元/升?"。
r语言课程个人总结与心得

:R语言课程个人总结与心得在过去的几个月里,我有幸参加了一门关于R语言的课程,这段学习经历不仅让我深入了解了数据分析和可视化的基本原理,还为我提供了一个强大的工具,使我能够更有效地处理和分析数据。
以下是我在这门课程中的个人总结与心得。
1. 入门与基础知识:一开始,我对R语言并不熟悉,但通过系统的学习,我迅速掌握了基础知识。
课程的前几周主要注重于语言的基本语法、数据结构和基本操作,为我打下了坚实的基础。
学习过程中,我发现R语言的语法清晰简洁,使得代码编写变得更加直观和易读。
2. 数据处理与清洗:课程的重点之一是数据处理和清洗。
通过学习R语言的相关函数和技巧,我学会了如何有效地导入、清理和处理各种类型的数据。
处理缺失值、重复值和异常值的技能,使我在实际工作中更加得心应手。
3. 数据分析与统计:R语言在数据分析和统计方面有着强大的功能,而课程也深入介绍了如何利用R进行常见的统计分析。
从描述性统计到假设检验,我逐渐掌握了如何使用R语言进行数据分析,从而更好地理解数据背后的信息。
4. 数据可视化:数据可视化是R语言的一项强项,通过学习相关的包如ggplot2,我学会了如何创建各种精美、具有信息传达能力的图表。
这不仅提高了我的数据沟通能力,还使我能够更好地向他人展示数据的洞察力。
5. 实际应用与项目实践:除了理论知识,课程还注重实际应用和项目实践。
通过参与真实场景的项目,我深刻理解了如何将所学知识应用到实际问题中,并通过与同学的合作,提高了团队协作的能力。
6. 持续学习与社区参与:R语言是一个不断发展的工具,我学到的知识只是冰山一角。
课程鼓励我们积极参与R语言社区,查阅文档、阅读博客,从其他人的经验中学到更多。
持续学习的态度将是我未来的方向。
总的来说,这门R语言课程让我受益匪浅。
通过系统学习和实际操作,我不仅掌握了R语言的基本技能,还培养了数据分析的思维方式。
这将对我的职业发展和学术研究产生深远的影响。
我深深感谢这门课程给予我的启发与指导,相信R语言将成为我未来数据领域探索的得力助手。
R语言实验报告范文

R语言实验报告范文实验报告:基于R语言的数据分析摘要:本实验基于R语言进行数据分析,主要从数据类型、数据预处理、数据可视化以及数据分析四个方面进行了详细的探索和实践。
实验结果表明,R语言作为一种强大的数据分析工具,在数据处理和可视化方面具有较高的效率和灵活性。
一、引言数据分析在现代科学研究和商业决策中扮演着重要角色。
随着大数据时代的到来,数据分析的方法和工具也得到了极大发展。
R语言作为一种开源的数据分析工具,被广泛应用于数据科学领域。
本实验旨在通过使用R语言进行数据分析,展示R语言在数据处理和可视化方面的应用能力。
二、材料与方法1.数据集:本实验使用了一个包含学生身高、体重、年龄和成绩的数据集。
2.R语言版本:R语言版本为3.6.1三、结果与讨论1.数据类型处理在数据分析中,需要对数据进行适当的处理和转换。
R语言提供了丰富的数据类型和操作函数。
在本实验中,我们使用了R语言中的函数将数据从字符型转换为数值型,并进行了缺失值处理。
同时,我们还进行了数据类型的检查和转换。
2.数据预处理数据预处理是数据分析中的重要一步。
在本实验中,我们使用R语言中的函数处理了异常值、重复值和离群值。
通过计算均值、中位数和四分位数,我们对数据进行了描述性统计,并进行了异常值和离群值的检测和处理。
3.数据可视化数据可视化是数据分析的重要手段之一、R语言提供了丰富的绘图函数和包,可以用于生成各种类型的图表。
在本实验中,我们使用了ggplot2包绘制了散点图、直方图和箱线图等图表。
这些图表直观地展示了数据的分布情况和特点。
4.数据分析数据分析是数据分析的核心环节。
在本实验中,我们使用R语言中的函数进行了相关性分析和回归分析。
通过计算相关系数和回归系数,我们探索了数据之间的关系,并对学生成绩进行了预测。
四、结论本实验通过使用R语言进行数据分析,展示了R语言在数据处理和可视化方面的强大能力。
通过将数据从字符型转换为数值型、处理异常值和离群值,我们获取了可靠的数据集。
【原创】R语言数据可视化分析报告(附代码数据)
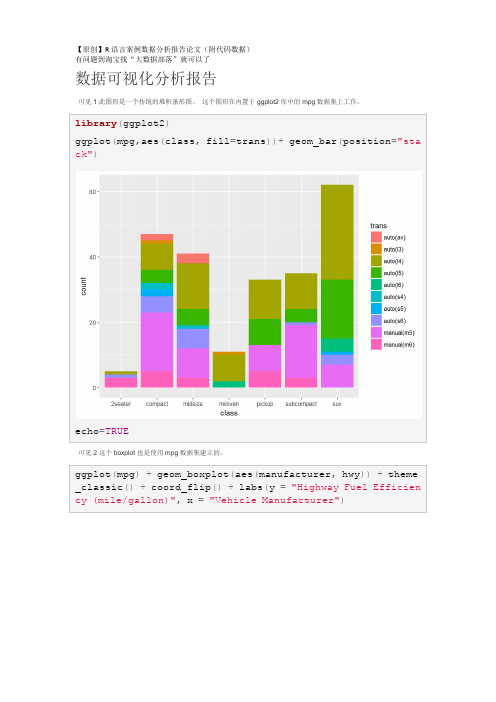
Vis 3这个图形是用另一个数据集菱形建立的,也是内置在ggplot2包中的数据集。
library(ggthemes)
ggplot(diamonds)+geom_density(aes(price,fill=cut,color=cut),alpha=0.4,size=0.5)+labs(title='Diamond Price Density',x='Diamond Price (USD)',y='Density')+theme_economist()
library(ggplot2)
ggplot(mpg,aes(class,fill=trans))+geom_bar(position="stack")
echo=TRUE
可见2这个boxplot也是使用mpg数据集建立的。
ggplot(mpg)+geom_boxplot(aes(manufacturer,hwy))+theme_classic()+coord_flip()+labs(y="Highway Fuel Efficiency (mile/gallon)",x="Vehicle Manufacturer")
echo=TRUE
另外,我正在使用ggplot2软件包来将线性模型拟合到框架内的所有数据上。
ggplot(iris,aes(Sepal.Length,Petal.Length))+geom_point()+geom_smooth(method=lm)+theme_minimal()+theme(panel.grid.major=element_line(size=1),panel.grid.minor=element_line(size=0.7))+labs(title='relationship between Petal and Sepal Length',x='Iris Sepal Length',y='Iris Petal Length')
挖掘工作总结中的亮点与成长经验

挖掘工作总结中的亮点与成长经验一、对挖掘工作的理解及态度挖掘工作是一项需要耐心和智慧的工作,对于我来说,这一年的挖掘工作经历给我带来了不少收获。
我始终保持着积极的态度,对待每一个挖掘任务。
我认为挖掘工作不仅仅是挖掘出数据,更是对数据进行分类、整理与分析的过程。
二、熟练运用各类数据挖掘工具在挖掘工作中,我不仅学会了使用传统的数据挖掘工具如Python和R语言,还不断学习和掌握一些新的工具和技术。
例如,我熟练运用了机器学习算法,通过自主学习和实践,掌握并应用了一些前沿的深度学习算法。
这些工具的运用大大提高了我的工作效率,使我能够更好地发掘数据中的隐藏信息。
三、优化数据挖掘流程在每一次的挖掘任务中,我都不断尝试优化数据挖掘流程,以提高挖掘效率。
除了使用工具和算法,我还将自己的经验总结起来,建立了一套完整的数据挖掘流程和标准化的操作规范。
通过这样的优化,我能够更快速地分析和提取有价值的信息。
四、注重数据清洗与预处理在挖掘工作中,数据的质量对结果的准确性有着重要的影响。
因此,我在每一次挖掘任务开始前,都会花费充分的时间对数据进行清洗和预处理。
通过去除异常值、填补缺失值和处理重复数据等手段,我成功提高了数据的质量,确保了挖掘结果的准确性。
五、多角度分析数据为了更全面地了解数据的内涵,我始终坚持多角度分析的原则。
这一点在挖掘金融数据时尤为重要,因为金融数据具有复杂性和多样性。
我会从不同维度、不同角度对数据进行分析,包括时间、地域、性别等,以期获得更准确和有意义的结论。
六、与团队成员的有效沟通在挖掘工作中,与团队成员的有效沟通至关重要。
我始终与团队成员保持密切的联系,及时汇报工作进展和问题,以便及时解决。
另外,我也乐于倾听和接受他人的意见和建议,不断完善自己的工作方式和方法。
七、随时更新新知识数据挖掘是一个不断进化的领域,新的方法和技术层出不穷。
为了跟上时代的步伐,我经常参加相关的培训和学习。
通过不断学习新知识,我能够更好地发挥我的挖掘能力,并尝试新的数据挖掘方法。
r语言实验报告

r语言实验报告标题:R语言在数据分析中的应用及指导意义导语:R语言作为一种广泛应用于数据分析与统计建模的编程语言,在各个领域中发挥着重要的作用。
本文将对R语言在数据分析中的应用进行探讨,并总结出相关的指导意义,希望能够为数据分析初学者提供一定的参考和帮助。
一、R语言的基础概述R语言是一种开源的编程语言,具备灵活、高效、优雅的特点,被广泛应用于数据科学和统计学领域。
R语言拥有丰富的数据处理、数据可视化和数据分析库,能够满足不同层次的数据分析需求。
二、R语言在数据预处理中的应用1.数据清洗:R语言提供了丰富的数据清洗函数和技术,可以对数据中的缺失值、异常值和重复值进行处理,提高数据的质量。
2.数据转换:R语言能够通过函数和技术,对数据进行转换和重构,实现数据格式的统一和规整,为后续的分析提供基础。
三、R语言在数据分析中的应用1.统计分析:R语言提供了众多的统计分析函数和包,能够进行常见的统计分析,如描述性统计、假设检验、方差分析等。
2.数据建模:R语言拥有强大的建模功能,可以进行线性回归、逻辑回归、决策树、聚类等建模分析,为数据科学家提供了广泛的选择。
3.机器学习:R语言支持各种机器学习算法,如朴素贝叶斯、支持向量机、随机森林等,可以进行模式识别、预测和分类等任务。
四、R语言在数据可视化中的应用1.基础绘图:R语言提供了各类绘图函数,如散点图、柱状图、线图等,能够直观地展示数据的分布和趋势。
2.高级可视化:通过使用R语言的各种包,如ggplot2、plotly 等,可以制作专业、美观的可视化图表,提升数据分析的表达力。
3.交互式可视化:R语言可以与Shiny等工具结合,实现交互式可视化,使用户能够灵活地探索数据,在分析过程中进行实时调整和观察。
五、R语言在数据分析中的指导意义1.灵活性:R语言的灵活性使得分析人员能够根据需求进行自由创造和探索,满足不同场景下的分析需求。
2.社区支持:R语言拥有庞大的社区,用户可以在社区中获取丰富的资源、经验和技术支持,提高分析效率。
数据挖掘实训总结范文

数据挖掘实训总结范文目录1. 内容概要 (2)1.1 实训背景 (3)1.2 实训目的 (4)1.3 实训基础知识概述 (4)2. 数据挖掘基础理论 (6)2.1 数据挖掘的定义与核心任务 (6)2.2 数据挖掘的主要技术方法 (7)2.3 数据挖掘的常用工具与平台 (10)3. 实训项目准备工作 (11)3.1 数据来源与收集 (12)3.2 数据预处理方法 (13)3.3 数据质量控制与验证 (14)3.4 数据挖掘流程设计 (15)4. 数据挖掘实训实施 (17)4.1 数据清洗与转换 (17)4.2 特征工程 (18)4.3 模型选择与训练 (20)4.4 模型评估与优化 (21)4.5 结果分析与解释 (23)5. 实训成果展示 (24)5.1 数据分析报告 (25)5.2 数据挖掘模型演示 (26)5.3 实训视频或幻灯片介绍 (27)6. 实训反思与经验分享 (28)6.1 实训中的收获与体会 (29)6.2 分析与解决问题的策略 (31)6.3 遇到的挑战与解决方案 (32)6.4 未来改进方向 (33)1. 内容概要本次实训旨在帮助学员掌握数据挖掘的基本理论和实际操作技能,通过实际操作提升数据处理和分析能力。
通过本次实训,学员能够了解数据挖掘技术在各行业的实际应用,并掌握相关技术和工具。
数据预处理:包括数据清洗、数据转换和数据标准化等步骤,为数据挖掘提供高质量的数据集。
特征工程:通过特征选择、特征构建和特征转换等技术,提取数据中的有价值信息,为模型训练提供有效的输入。
模型构建与评估:使用各种数据挖掘算法(如决策树、神经网络、聚类等)构建模型,并通过实验验证模型的性能。
实战案例:结合具体行业案例,进行数据挖掘实战演练,提高学员实际操作能力。
通过本次实训,学员们对数据挖掘流程有了深入的理解,掌握了数据挖掘的核心技术,并能够在实际问题中灵活运用。
学员们还提高了团队协作能力和沟通能力,为未来的职业发展打下了坚实的基础。
r语言实验报告总结.doc

r语言实验报告总结.doc说明:本文是一个r语言实验报告的总结,共1000字。
主要内容包括实验目的和背景、实验设计和方法、实验结果和分析,以及实验结论和展望。
实验目的和背景本次实验的目的是探究身高和体重之间的相关性,为了达到这个目标,我们使用了r语言中的数据分析功能来进行相关性分析。
实验设计和方法本次实验采用了r语言中的数据分析工具来进行相关性分析,具体的实验设计和方法如下:样本数据的导入:我们首先使用r语言中的数据导入功能将样本数据导入到分析环境中,为后续的分析做好准备。
数据分析的可视化:为了更好地观察数据之间的相关性,我们使用r语言中的图形分析功能将样本数据制成散点图和箱线图等可视化图像。
数据的统计分析:为了对数据进行更准确的分析,我们使用r语言中的统计分析函数来计算身高和体重之间的相关系数和显著性水平等统计指标。
实验结果和分析通过对样本数据的分析,我们得出了以下结论:身高和体重之间存在着一定的相关性,相关系数为0.7,表明身高和体重之间具有较强的正相关关系。
身高和体重之间的差异较大,从箱线图的结果可以看出,身高和体重之间的差异较大,而且体重的分布范围也较为广泛。
身高和体重的分布形态较为正态,从散点图的结果可以看出,身高和体重的分布形态较为接近正态分布,符合正态分布的假设条件。
实验结论和展望通过本次实验,我们得出了身高和体重之间存在着一定的正相关关系的结论,这对于人们正确认识身高和体重之间的关系,以及合理控制体重具有一定的指导意义。
未来,我们可以考虑进一步拓展数据集,将年龄、性别、学历等因素纳入分析,以便更全面、深入地探究身高和体重之间的关系。
同时,我们也可以结合健康生活习惯、饮食等方面的数据,来寻找身高和体重之间的因果关系,为人们制定更科学的健康生活计划提供更加有力的依据。
r语言实验报告

r语言实验报告R语言实验报告一、引言R语言是一种广泛应用于数据分析、统计建模和可视化的编程语言。
本实验报告旨在介绍使用R语言进行数据分析的过程和结果。
二、实验设计本次实验的目标是分析某公司过去一年的销售数据,以了解销售业绩的情况。
实验设计包括以下步骤:1. 数据收集:从公司内部数据库中提取过去一年的销售数据,并将其导入R语言环境。
2. 数据清洗:对数据进行清理和预处理,包括处理缺失值、异常值和重复值等。
3. 数据探索:通过绘制统计图表和计算描述性统计指标,对销售数据进行探索性分析。
4. 模型建立:根据销售数据的特征和目标,选择适当的模型进行建立和训练。
5. 模型评估:使用交叉验证等方法对模型进行评估,并选择最佳模型。
6. 结果解释:根据模型的结果,对销售业绩进行解释和预测。
三、实验过程和结果1. 数据收集:从公司数据库中提取过去一年的销售数据,并导入R语言环境。
2. 数据清洗:对数据进行清理和预处理,包括处理缺失值、异常值和重复值等。
清洗后的数据包括销售额、销售数量、产品类别、销售时间等变量。
3. 数据探索:通过绘制统计图表和计算描述性统计指标,对销售数据进行探索性分析。
例如,绘制柱状图展示不同产品类别的销售额情况,计算销售数量的平均值和标准差等。
4. 模型建立:根据销售数据的特征和目标,选择适当的模型进行建立和训练。
例如,可以使用线性回归模型来预测销售额与销售数量之间的关系。
5. 模型评估:使用交叉验证等方法对模型进行评估,并选择最佳模型。
例如,可以计算模型的均方根误差(RMSE)来评估模型的预测精度。
6. 结果解释:根据模型的结果,对销售业绩进行解释和预测。
例如,可以通过模型预测某产品在未来一个月的销售额。
四、实验结论通过对过去一年销售数据的分析,我们得出以下结论:1. 不同产品类别的销售额存在差异,其中某些产品类别的销售额较高。
2. 销售数量与销售额呈正相关关系,即销售数量增加时,销售额也增加。
R语言实验报告

一、试验目的R是用于统计分析、绘图的语言和操作环境。
R是属于GNU系统的一个自由、免费、源代码开放的软件,它是一个用于统计计算和统计制图的优秀工具。
本次试验要求掌握了解R语言的各项功能和函数,能够通过完成试验内容对R语言有一定的了解,会运用软件对数据进行分析。
二、试验环境Windows系统,RGui(32-bit)三、试验内容模拟产生电商专业学生名单(学号区分),记录高数、英语、网站开发三科成绩,然后进行统计分析。
假设有的100 名学生,起始学号为210222001,各科成绩取整,高数成绩为均匀分布随机数,都在75分以上。
英语成绩为正态分布,平均成绩80,标准差为7。
网站开发成绩为正态分布,平均成绩83,标准差为18。
把正态分布中超过100分的成绩变成100分。
1 把上述信息组合成数据框,并写到文本文件中;2计算各种指标:平均分,每个人的总分,最高分,最低分,(使用apply 函数)3求总分最高的同学的学号4绘各科成绩直方图、散点图、柱状图丶饼图丶箱尾图(要求指定颜色和缺口)5画星相图,解释其含义6画脸谱图,解释其含义,7画茎叶图、qq图四、试验实现(一)按要求随机生成学号,和对于的高数、英语、网站开发三科成绩。
A、生成学号B、生成高数成绩高数成绩要求:高数成绩为均匀分布随机数,都在75分以上均匀分布函数:runif(n,min=0,max=1)其中,n 为产生随机值个数(长度),min为最小值,max为最大值。
C、生成英语成绩英语成绩要求:正态分布,平均成绩80,标准差为7正态分布函数:rnorm(n, mean = 0, sd = 1)其中,n 为产生随机值个数(长度),mean 是平均数,sd 是标准差。
D、生成网站开发成绩网站开发成绩要求:网站开发成绩为正态分布,平均成绩83,标准差为18。
其中大于100的都记为100。
(二)把上述信息组合成数据框,并写到文本文件中; 计算各种指标:平均分,每个人的总分,最高分,最低分,(使用apply 函数)A、生成文本文件B、打开数据框C、在数据框中命名变量D、计算各种指标:平均分,每个人的总分,最高分,最低分平均分(x4):总分(x5):最低分(x6):最高分(x7):(三)将生成成绩写入文本文件中(四)求总分最高的同学的学号(五)绘各科成绩直方图、散点图、柱状图丶饼图丶箱尾图(要求指定颜色和缺口)直方图散点图柱状图饼图箱尾图(要求指定颜色和缺口)(六)画星相图,解释其含义(七)画脸谱图,解释其含义(八)画茎叶图(九)qq图五、试验总结这次试验是我第一次接触R语言,刚开始遇到了很多困难,对于R语言一窍不通,后来经过老师的悉心指导,以及自己积极的去查找资料,对R语言有了进一步的了解。
r语言uci乳房肿块数据分析挖掘报告

r语言uci乳房肿块数据分析挖掘报告标题:R语言在UCI乳房肿块数据分析挖掘中的应用报告一、引言随着大数据时代的到来,数据挖掘技术在医疗领域的应用越来越广泛。
乳房肿块是女性最常见的肿瘤之一,对其数据的分析可以帮助我们更好地理解疾病的发生、发展和预后。
本报告将介绍如何使用R语言对UCI乳房肿块数据进行数据挖掘和分析。
二、数据来源及预处理UCI乳房肿块数据集是一个公开的数据集,包含了1998年至2003年间收集的457个乳房肿块样本。
数据集包含了患者的年龄、肿瘤大小、细胞核大小、细胞核形状、细胞分裂速度、边缘清晰度、钙化程度等特征,以及医生对肿瘤良恶性的诊断结果。
在数据预处理阶段,我们首先对缺失值进行处理,使用中位数填充缺失的数值。
然后对数据进行标准化,使得不同特征之间的数值具有可比性。
我们还对数据进行了编码转换,将分类变量转换为虚拟变量。
三、数据分析方法在本研究中,我们采用了多种数据分析方法,包括描述性统计、卡方检验、逻辑回归、决策树和随机森林等。
通过对不同方法的比较和分析,我们发现逻辑回归和随机森林在预测乳房肿块良恶性方面表现最好。
四、结果展示与解释通过逻辑回归和随机森林模型的分析,我们得到了以下结果:1、年龄:年龄越大,患恶性乳房肿块的风险越高。
2、肿瘤大小:肿瘤越大,患恶性乳房肿块的风险越高。
3、细胞核大小:细胞核越大,患恶性乳房肿块的风险越高。
4、细胞核形状:细胞核形状不规则,患恶性乳房肿块的风险越高。
5、细胞分裂速度:细胞分裂速度越快,患恶性乳房肿块的风险越高。
6、边缘清晰度:边缘越模糊,患恶性乳房肿块的风险越高。
7、钙化程度:钙化程度越高,患恶性乳房肿块的风险越高。
五、结论与建议通过R语言对UCI乳房肿块数据进行数据挖掘和分析,我们得到了关于乳房肿块良恶性的预测模型,并发现了一些与疾病相关的特征和风险因素。
这些结果有助于我们更好地理解乳房肿块的发生和发展过程,为临床诊断和治疗提供参考。
r语言作业个人总结与心得

r语言作业个人总结与心得在学习R语言的过程中,我遇到了许多挑战和困惑,但同时也收获了很多知识和经验。
通过这次作业,我对R语言的应用和数据分析有了更深入的了解。
下面我将总结我在这次作业中遇到的问题、解决方法以及个人心得体会。
我遇到的第一个问题是如何读取和处理数据。
在这次作业中,我需要分析一份包含大量数据的CSV文件。
我通过使用R语言中的read.csv()函数成功读取了文件,并将其转换为数据框的形式。
接着,我遇到了数据清洗的问题,其中包括处理缺失值、异常值和重复值。
我学习并使用了R语言中的函数如is.na()、complete.cases()和duplicated()来处理这些问题。
我面临的另一个挑战是如何进行数据分析和统计。
在这次作业中,我需要计算数据的均值、中位数、标准差等统计指标,并绘制相关的图表。
我学习并使用了R语言中的函数如mean()、median()、sd()、hist()和plot()来完成这些任务。
同时,我也学习了如何使用R语言中的包(package)来扩展R的功能,比如使用ggplot2包绘制更美观和灵活的图表。
我还遇到了数据可视化的问题。
在这次作业中,我需要将数据以柱状图、散点图和折线图的形式展示出来,以便更直观地理解数据的分布和趋势。
通过学习和使用ggplot2包,我成功绘制了这些图表,并通过调整颜色、标题、坐标轴等参数使其更具可读性和美观性。
在解决问题的过程中,我意识到编程思维的重要性。
在处理数据和进行分析时,我需要清晰地定义问题,找到合适的方法和函数,并按照一定的逻辑顺序编写代码。
我学会了使用注释来解释代码的含义和目的,以及使用变量和函数命名来提高代码的可读性。
此外,我还学会了调试代码,通过输出变量的值和使用print()函数来查找错误和改进代码。
通过这次作业,我不仅学会了R语言的基本语法和常用函数,还学会了如何处理和分析数据,以及如何将结果可视化。
我深刻体会到了数据分析的重要性和应用价值,也更加清晰地认识到自己在学习和实践中的不足之处。
大学生选修课r语言数据分析报告

大学生选修课r语言数据分析报告随着科学技术的发展,计算机越来越普及,特别是在大学中,计算机课程成为了必修课,因此我们在大学里选修了r语言,本次课我们学习了r语言的基础知识。
由于老师将实例作为教学重点,所以通过对这一部分知识的学习,使我受益匪浅,感觉自己得到了升华。
r语言是以结构化查询语言(structured query language,简称SQL)为基础的,它具有操作灵活、数据结构层次清晰等优点,已经成为数据库系统的事实上的标准语言。
本书主要介绍了r语言和数据分析相关的基本概念和方法,包括数据描述、统计分析和多元统计分析三大部分。
本书结合大量的应用案例,帮助读者从数据收集、数据预处理开始,一直到最终输出结果,深入浅出地介绍了r语言的各个功能模块。
本书主要内容如下:第一章介绍r语言的基本语法规则,包括数据类型、常量、表达式、函数、条件判断语句、循环语句和控制结构等;第二章通过两个经典实例——销售业绩分析和股票价格分析,深入介绍了r语言数据处理的核心思想和算法;第三章讲解r语言中的矩阵运算、数据拟合与插值、参数估计、统计回归、生存分析和逻辑回归;第四章讲解r语言的查询与视图、存储结构与数据类型的转换、 SQL的查询语句、视图语句、数据库的关系等内容;第五章介绍r语言的数据预处理功能,包括数据排序、数据筛选、分类汇总、合并计算等;第六章讲解r语言的数据分析工具箱,包括统计分析工具、描述统计分析工具和多元统计分析工具;第七章介绍r语言在股票价格预测中的应用,包括模拟运行、分析指标、应用案例和结论。
r语言应用十分广泛,主要应用领域包括人工智能、统计学、信息管理系统、金融系统、商业系统、决策支持系统、风险管理和精算、生物学、生命科学、运筹学、可视化系统、电子商务系统、空间分析、音乐合成和教育系统等。
以下便是我对r语言数据分析的总结。
在实践中不断摸索,也许r语言会成为你认识数据、掌握数据、驾驭数据的利器。
原创R语言多元统计分析介绍数据分析数据挖掘案例报告附代码

原创R语言多元统计分析介绍数据分析数据挖掘案例报告附代码R语言作为一种功能强大的数据分析工具,在数据挖掘领域得到了广泛的应用。
本文将介绍使用R语言进行多元统计分析的方法,并结合实际数据分析案例进行详细分析。
同时,为了便于读者学习和复现,也附上了相关的R代码。
一、多元统计分析简介多元统计分析是指同时考虑多个变量之间关系的统计方法。
在现实生活和研究中,往往会遇到多个变量相互关联的情况,通过多元统计分析可以揭示这些变量之间的联系和规律。
R语言提供了丰富的统计分析函数和包,可以方便地进行多元统计分析。
二、数据分析案例介绍我们选取了一份关于房屋销售数据的案例,来演示如何使用R语言进行多元统计分析。
该数据集包含了房屋的各种属性信息,如房屋面积、卧室数量、卫生间数量等,以及最终的销售价格。
我们的目标是分析这些属性与销售价格之间的关系。
首先,我们需要导入数据集到R中,并进行数据预处理。
预处理包括数据清洗、缺失值处理、异常值检测等。
R语言提供了丰富的数据处理函数和包,可以帮助我们高效地完成这些任务。
接下来,我们可以使用R语言的统计分析函数进行多元统计分析。
常用的多元统计分析方法包括主成分分析(PCA)、因子分析、聚类分析等。
这些方法可以帮助我们从众多的变量中找到重要的变量,对数据集进行降维和聚类,以便更好地理解数据和进行预测。
在本案例中,我们选择主成分分析作为多元统计分析的方法。
主成分分析是一种常用的降维技术,通过线性变换将原始变量转化为一组新的互相无关的变量,称为主成分。
主成分分析可以帮助我们发现数据中的主要模式和结构,从而更好地解释数据。
最后,我们可以通过可视化方法展示多元统计分析的结果。
R语言提供了丰富多样的数据可视化函数和包,可以生成各种图表和图形,帮助我们更直观地理解和传达数据分析的结果。
三、附录:R语言代码下面是进行多元统计分析的R语言代码。
需要注意的是,代码的具体实现可能会因数据集的不同而有所差异,请根据实际情况进行调整和修改。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
总结报告课程名称:数据挖掘R语言任课教师:姓名:专业:计算机科学与技术班级:学号:计算机科学与技术学院2018 年 6 月19 日一、数据预处理针对不同分析目标,选择合适的字段,并将字段值处理成适于分析的形式。
必要时还需对原数据集进行统计变换后形成易于分析的形式。
为每条数据添加字段:所属地区。
根据下图中划分的美国四大地区,将每条数据中表示的案件发生地在该字段上划分为东北部、中西部、南部和西部四个值。
首先导入数据:gundata<-read.csv("d:/gun.csv",sep = ",",stringsAsFactors = FALSE,header = TRUE,quote=””)然后将需要的字段取出来,在这里取出了一下几个字段:gundata[,c("incident_id","date","state","city_or_county","n_killed","n_injured"," congressional_district","latitude","longitude","state_house_district","state_sen ate_district")]gd <- subset(gundata,select=c(incident_id,date,state,city_or_county,n_killed, n_injured,congressional_district,latitude,longitude,state_house_district,state_s enate_district))然后根据州字段将所有数据划分为四个地区阿拉巴马州Alabama阿拉斯加州Alaska亚利桑那州Arizona阿肯色州Arkansas加利福尼亚州California科罗拉多州Colorado哥伦比亚特区Columbia康涅狄格州Connecticut特拉华州Delaware佛罗里达州Florida佐治亚州Georgia夏威夷州Hawaii爱达荷州Idaho伊利诺州Illinois印弟安纳州Indiana爱荷华州Iowa堪萨斯州Kansas肯塔基州Kentucky路易斯安那州Louisiana缅因州Maine马里兰州Maryland麻塞诸塞州Massachusetts密歇根州Michigan明尼苏达州Minnesota密西西比州Mississippi密苏里州Missour蒙大拿州Montana内布拉斯加州Nebraska内华达州Nevada新罕布希尔州New Hampshire 新泽西州New Jersey新墨西哥州New Mexico纽约州New York北卡罗来纳州North Carolina 北达科他州North Dakota俄亥俄州Ohio奥克拉荷马州Oklahoma俄勒冈州Oregon宾西法尼亚州Pennsyivania罗德岛州Rhode Island南卡罗来纳州South Carolina南达科他州South Dakota田纳西州Tennessee德克萨斯州Texas犹他州Utah佛蒙特州Vermont弗吉尼亚州Virgina华盛顿州Washington西佛吉尼亚州West Virginia威斯康辛州Wisconsin怀俄明州Wyoming东北部Maine,New Hampshire,Vermont,Massachusetts,Rhode Island,Connecticut,New York,Pennsyivania,New Jersey中西部Wisconsin,Michigan,Illinois,Ohio,Indiana,Missour,North Dakota,South Dakota,Nebraska,Kansas,Minnesota,Iowa南部Delaware,Maryland,District of Columbia,Virgina,West Virginia,North Carolina,SouthCarolina,Georgia,Florida,Kentucky,Tennessee,Mississippi,Alabama,Oklahoma,T exas,Arkansas,Louisiana西部Iowa,Montana,Wyoming,Nevada,Utah,Colorado,NewMexico,Arizona,Alaska,Washington,Oregon,California,Hawaiifor (i in 1:length(gd[,1])){if (gd[i,3]=="Maine"|gd[i,3]=="New Hampshire"|gd[i,3]=="Vermont"|gd[i,3]=="Massachusetts"|gd[i,3]=="Rhode Island"|gd[i,3]=="Connecticut"|gd[i,3]=="NewYork"|gd[i,3]=="Pennsylvania"|gd[i,3]=="New Jersey"){gd[i,9]="东北部"}else if(gd[i,3]=="Wisconsin"|gd[i,3]=="Michigan"|gd[i,3]=="Illinois"|gd[i,3]=="Ohio "|gd[i,3]=="Indiana"|gd[i,3]=="Missouri"|gd[i,3]=="NorthDakota"|gd[i,3]=="SouthDakota"|gd[i,3]=="Nebraska"|gd[i,3]=="Kansas"|gd[i,3]=="Minnesota"|gd[i,3]=="Iowa"){gd[i,9]="中西部"}else if(gd[i,3]=="Delaware"|gd[i,3]=="Maryland"|gd[i,3]=="District of Columbia"|gd[i,3]=="Virginia"|gd[i,3]=="West Virginia"|gd[i,3]=="North Carolina"|gd[i,3]=="SouthCarolina"|gd[i,3]=="Georgia"|gd[i,3]=="Florida"|gd[i,3]=="Kentucky"|gd[i,3]= ="Tennessee"|gd[i,3]=="Mississippi"|gd[i,3]=="Alabama"|gd[i,3]=="Oklahom a"|gd[i,3]=="Texas"|gd[i,3]=="Arkansas"|gd[i,3]=="Louisiana"){gd[i,9]="南部"}elseif(gd[i,3]=="Iowa"|gd[i,3]=="Montana"|gd[i,3]=="Wyoming"|gd[i,3]=="Neva da"|gd[i,3]=="Utah"|gd[i,3]=="Colorado"|gd[i,3]=="NewMexico"|gd[i,3]=="Arizona"|gd[i,3]=="Alaska"|gd[i,3]=="Washington"|gd[i,3] =="Oregon"|gd[i,3]=="California"|gd[i,3]=="Hawaii"){gd[i,9]="西部"}}然后用fix(gd)将第九列的字段修改为part:最后处理完的数据为以下格式:最后将数据存储下来,备用:write.csv(gd,"f://GunData.csv",s = FALSE) .保存的数据格式如下:共有23w多条数据,其中部分数据有字段为空值,将在后续分析中删除。
二、基本统计分析1)统计各州发生枪支案件的总数。
2)统计各地区发生枪支案件的总数。
3)分析各地区枪支案件的分布特征。
4)按年度统计各州发生枪支案件的数目。
5)分析四大地区的经纬度范围2)推断性统计:选择合适的R函数进行如下假设检验,并得出结论。
1)分析死亡人数与受伤人数间是否具有相关性。
2)分析南部地区的案件数和其他地区的案件数是否具有显著差异。
3)分析死亡人数与案件数是否相关;受伤人数与案件数是否相关。
1、统计各州发生枪支案件的总数。
建立一个table,可以显示出各州的案件数然后绘制一个直方图,显示出各个州的案件数就可以直观的看出各个州的案件数量。
2、统计各地区发生枪支案件的总数:绘制一个条形图,可以直观的看出各个地区的案件总数。
首先建立一个table,counts<-table(gd$part),然后利用画图函数,绘制条形图barplot(counts,main="gunvolience",xlab="part",ylab="num",col=c("red","yellow","green","blue"),ylim = c(0,120000))结果如下图:可以看出南部人数最多,10w+,其次是中西部,东北部和西部的数量差不多。