hadoop平台搭建 多节点详细教程 一次就能搭建成功
hadoop3.2环境搭建分步骤说明

这里要注意 jdk 版本问题,是否支持 hadoop 组件 还有就是配置 JAVA_HOME 这个变量非常重要,因为在 hadoop 启动 的时候,有很多.sh 的脚本需要配置 JAVA_HOME 的绝对路径,这里需 要配置很清楚,到底安装在哪里。 yum install java(yum 不好用就重新安装 yum) 配置环境变量 默认 jre jdk 安装路径是/usr/lib/jvm 下面
最后多节点启动成功这样子
使用环境 WMware 虚拟机(版本没有太多区别) Centos7(不同版本 systemctl 命令有不同) Java1.8(直接 yum 安装的) Hadoop-3.2.0(官网下载) 前几个步骤虚拟机建立,网上带图的配置说明很多,我就不在发 图了,比较简单。需要时刻记住最终搭建是三节点,所以系统配置的 时候 3 台机器都要配置好(如果熟悉可以 1 台复制 3 台改),我的 3 台机器都是 root 用户。
Hadoop3.2 环境搭建(详细步骤)
唾沫星冲锋枪 曾经 2009 年的时候跟着 Yahoo 的展会初识了 hadoop,因为一直 在金融领域 IT 混,也没有真正实践机会,这方面通信、互联网领域 还是比较快。最近因为工作中用的了 hdfs 等相关的东西,所以自己 尝试搭建 hadoop 环境。细致记录搭建过程的每个环节和坑(包含了很 详细的虚拟机配置和 linux 配置,hdfs 单节点或 hadoop 多节点配置) 分享一下,我自己踩坑的配置也都高亮标记黄色。 首先是展示目录(操作时每个步骤都是单独记录的)
hadoop5-linux 关闭防火墙
centos7 命令 停防火墙 service firewalld stop 永久关闭 systemctl disable firewalld 恢复防火墙 systemctl enable firewalld
如何使用Docker构建一个多节点的Hadoop集群

如何使用Docker构建一个多节点的Hadoop集群Hadoop作为一个分布式计算框架,在大数据领域受到广泛应用。
为了实现更加高效的数据处理和存储,构建一个多节点的Hadoop集群至关重要。
本文将介绍如何使用Docker来构建一个多节点的Hadoop集群。
1. 安装Docker首先,我们需要安装Docker。
Docker是一个开源的容器化平台,能够将应用程序和其依赖项打包为一个可移植的容器,方便部署和管理。
安装Docker非常简单,可以参考Docker官方文档来完成。
2. 准备Hadoop镜像在构建Hadoop集群之前,我们需要准备Hadoop的Docker镜像。
可以从Docker Hub上搜索并下载现有的Hadoop镜像,也可以通过编写Dockerfile来构建自定义的Hadoop镜像。
在这里,我们选择下载现有的Hadoop镜像。
3. 创建一个Hadoop网络在Docker中,我们可以使用Docker网络来连接多个容器。
在创建Hadoop集群之前,我们需要创建一个自定义的Docker网络。
通过以下命令创建一个名为"hadoop_net"的网络:```docker network create --driver bridge hadoop_net```4. 创建Hadoop主节点容器接下来,我们可以创建Hadoop集群的主节点容器。
在这里,我们使用Hadoop 的NameNode和ResourceManager角色来代表主节点。
通过以下命令创建一个运行Hadoop的容器,并将其连接到"hadoop_net"网络:```docker run -itd --name master --network hadoop_net hadoop_image```5. 创建Hadoop从节点容器除了主节点,我们还需要创建多个从节点来构建完整的Hadoop集群。
从节点主要负责数据的存储和计算。
一步步教你Hadoop多节点集群安装配置

⼀步步教你Hadoop多节点集群安装配置1、集群部署介绍1.1 Hadoop简介Hadoop是Apache软件基⾦会旗下的⼀个开源分布式计算平台。
以Hadoop分布式⽂件系统HDFS(Hadoop Distributed Filesystem)和MapReduce(Google MapReduce的开源实现)为核⼼的Hadoop为⽤户提供了系统底层细节透明的分布式基础架构。
对于Hadoop的集群来讲,可以分成两⼤类⾓⾊:Master和Salve。
⼀个HDFS集群是由⼀个NameNode和若⼲个DataNode组成的。
其中NameNode作为主服务器,管理⽂件系统的命名空间和客户端对⽂件系统的访问操作;集群中的DataNode管理存储的数据。
MapReduce框架是由⼀个单独运⾏在主节点上的JobTracker和运⾏在每个从节点的TaskTracker共同组成的。
主节点负责调度构成⼀个作业的所有任务,这些任务分布在不同的从节点上。
主节点监控它们的执⾏情况,并且重新执⾏之前的失败任务;从节点仅负责由主节点指派的任务。
当⼀个Job被提交时,JobTracker接收到提交作业和配置信息之后,就会将配置信息等分发给从节点,同时调度任务并监控TaskTracker的执⾏。
从上⾯的介绍可以看出,HDFS和MapReduce共同组成了Hadoop分布式系统体系结构的核⼼。
HDFS在集群上实现分布式⽂件系统,MapReduce在集群上实现了分布式计算和任务处理。
HDFS在MapReduce任务处理过程中提供了⽂件操作和存储等⽀持,MapReduce 在HDFS的基础上实现了任务的分发、跟踪、执⾏等⼯作,并收集结果,⼆者相互作⽤,完成了Hadoop分布式集群的主要任务。
1.2 环境说明我的环境是在虚拟机中配置的,Hadoop集群中包括4个节点:1个Master,2个Salve,节点之间局域⽹连接,可以相互ping通,节点IP地址分布如下:虚拟机系统机器名称IP地址Ubuntu 13.04Master.Hadoop192.168.1.141Ubuntu 9.11Salve1.Hadoop192.168.1.142Fedora 17Salve2.Hadoop192.168.1.137Master机器主要配置NameNode和JobTracker的⾓⾊,负责总管分布式数据和分解任务的执⾏;3个Salve机器配置DataNode和TaskTracker的⾓⾊,负责分布式数据存储以及任务的执⾏。
Hadoop的多节点部署

Hadoop的多节点部署这里用的是Hadoop-0.20.2的版本,不过加上了Hypertable-0.9.4.3的patch.1.部署节点分布:10.250.8.19dev110.250.8.21dev310.20.137.11dev4将以上这些信息放入到/etc/hosts中,并在各个机器上可以相互ping通主机名我们将在dev3上部署(NameNode,DataNode),而dev1,dev4分别作为slave的DataNode2.ssh免登录的配置在hdfs运行时,需要从master控制slave.所以需要控制master免密码ssh登录slave,这里即从dev3面密码登录dev1和dev41)dev3上ssh-keygen-t rsa-P“”-f~/.ssh/id_rsascp~/.ssh/id_rsa.pub itlanger@dev1:/tmp;scp~/.ssh/id_rsa.pub itlanger@dev2:/tmp;2)dev1,dev4,dev3上cat/tmp/id_rsa.pub》/home/itlanger/.ssh/authorized_keys(追加方式添加)cat/tmp/id_rsa.pub》/home/itlanger/.ssh/authorized_keyscat~/.ssh/id_rsa.pub》~/.ssh/authorized_keys(比较重要,这样就不用在启动dev3的NameNode和DataNode时输入密码了,哈哈!)3)确保无密码登录:ssh dev1;ssh dev4;ssh dev33.确保统一的java环境JAVA_HOME=/usr/java/jdk1.6.0_234.Hadoop配置:(三台机器一样做)下载源代码和解压,这个就不说了。
修改文件$HADOOP_HOME/conf/hadoop-env.shexport JAVA_HOME=/usr/java/jdk1.6.0_23修改文件$HADOOP_HOME/conf/core-site.xml设置文件系统为HDFS文件系统,并指定访问host和port<configuration><property><name></name><value>hdfs://dev3:9000</value></property></configuration>修改文件$HADOOP_HOME/conf/hdfs-site.xml设置HDFS文件系统NameNode和DataNode的本地存储位置,并指定复制份数<configuration><property><name>.dir</name><value>/home/itlanger/project/hadoop/hadoop_filesystem/name</value> </property><property><name>dfs.data.dir</name><value>/home/itlanger/project/hadoop/hadoop_filesystem/data</value></property><property><name>dfs.replication</name><value>2</value></property></configuration>5.修改文件$HADOOP_HOME/conf/slaves(仅在dev3上配置)localhost#这里也可以写为dev3dev1dev4同理conf/master文件也可以写为:dev3,效果和localhost没有区别6.格式化NameNode文件系统:(dev3,dev1,dev4)$HADOOP_HOME/bin/hadoop namenode-format7.启动Hadoop:(dev3)$HADOOP_HOME/bin/start-dfs.sh#如果要启动mapreduce则可以用start-all.sh使用浏览器通过“HDFS Web UI”查看HDFS状态:http://dev3:50070/#(需要在本机中的/etc/hosts中也配置dev3,dev1,dev4的解析)注:在Cluster Summary中,可以看到Live Nodes数目为2,HDFS成功启动;浏览HDFS 文件系统,可以看到当前根目录下只存在/tmp文件夹。
hadoop集群安装配置的主要操作步骤-概述说明以及解释

hadoop集群安装配置的主要操作步骤-概述说明以及解释1.引言1.1 概述Hadoop是一个开源的分布式计算框架,主要用于处理和存储大规模数据集。
它提供了高度可靠性、容错性和可扩展性的特性,因此被广泛应用于大数据处理领域。
本文旨在介绍Hadoop集群安装配置的主要操作步骤。
在开始具体的操作步骤之前,我们先对Hadoop集群的概念进行简要说明。
Hadoop集群由一组互联的计算机节点组成,其中包含了主节点和多个从节点。
主节点负责调度任务并管理整个集群的资源分配,而从节点则负责实际的数据存储和计算任务执行。
这种分布式的架构使得Hadoop可以高效地处理大规模数据,并实现数据的并行计算。
为了搭建一个Hadoop集群,我们需要进行一系列的安装和配置操作。
主要的操作步骤包括以下几个方面:1. 硬件准备:在开始之前,需要确保所有的计算机节点都满足Hadoop的硬件要求,并配置好网络连接。
2. 软件安装:首先,我们需要下载Hadoop的安装包,并解压到指定的目录。
然后,我们需要安装Java开发环境,因为Hadoop是基于Java 开发的。
3. 配置主节点:在主节点上,我们需要编辑Hadoop的配置文件,包括核心配置文件、HDFS配置文件和YARN配置文件等。
这些配置文件会影响到集群的整体运行方式和资源分配策略。
4. 配置从节点:与配置主节点类似,我们也需要在每个从节点上进行相应的配置。
从节点的配置主要包括核心配置和数据节点配置。
5. 启动集群:在所有节点的配置完成后,我们可以通过启动Hadoop 集群来进行测试和验证。
启动过程中,我们需要确保各个节点之间的通信正常,并且集群的各个组件都能够正常启动和工作。
通过完成以上这些操作步骤,我们就可以成功搭建一个Hadoop集群,并开始进行大数据的处理和分析工作了。
当然,在实际应用中,还会存在更多的细节和需要注意的地方,我们需要根据具体的场景和需求进行相应的调整和扩展。
Hadoop集群的搭建方法与步骤

Hadoop集群的搭建方法与步骤随着大数据时代的到来,Hadoop作为一种分布式计算框架,被广泛应用于数据处理和分析领域。
搭建一个高效稳定的Hadoop集群对于数据科学家和工程师来说至关重要。
本文将介绍Hadoop集群的搭建方法与步骤。
一、硬件准备在搭建Hadoop集群之前,首先要准备好适合的硬件设备。
Hadoop集群通常需要至少三台服务器,一台用于NameNode,两台用于DataNode。
每台服务器的配置应该具备足够的内存和存储空间,以及稳定的网络连接。
二、操作系统安装在选择操作系统时,通常推荐使用Linux发行版,如Ubuntu、CentOS等。
这些操作系统具有良好的稳定性和兼容性,并且有大量的Hadoop安装和配置文档可供参考。
安装操作系统后,确保所有服务器上的软件包都是最新的。
三、Java环境配置Hadoop是基于Java开发的,因此在搭建Hadoop集群之前,需要在所有服务器上配置Java环境。
下载最新版本的Java Development Kit(JDK),并按照官方文档的指引进行安装和配置。
确保JAVA_HOME环境变量已正确设置,并且可以在所有服务器上运行Java命令。
四、Hadoop安装与配置1. 下载Hadoop从Hadoop官方网站上下载最新的稳定版本,并将其解压到一个合适的目录下,例如/opt/hadoop。
2. 编辑配置文件进入Hadoop的安装目录,编辑conf目录下的hadoop-env.sh文件,设置JAVA_HOME环境变量为Java的安装路径。
然后,编辑core-site.xml文件,配置Hadoop的核心参数,如文件系统的默认URI和临时目录。
接下来,编辑hdfs-site.xml文件,配置Hadoop分布式文件系统(HDFS)的相关参数,如副本数量和数据块大小。
最后,编辑mapred-site.xml文件,配置MapReduce框架的相关参数,如任务调度器和本地任务运行模式。
hadoop集群搭建步骤

hadoop集群搭建步骤Hadoop集群搭建步骤Hadoop是一个开源的分布式计算框架,被广泛应用于大数据处理。
搭建Hadoop集群可以提供高可用性、高性能的分布式计算环境。
下面将介绍Hadoop集群的搭建步骤。
1. 硬件准备需要准备一组具有较高性能的服务器作为集群中的节点。
这些服务器需满足一定的硬件要求,包括处理器、内存和存储空间等。
通常情况下,建议使用至少3台服务器来搭建一个最小的Hadoop集群。
2. 操作系统安装在每台服务器上安装合适的操作系统,例如CentOS、Ubuntu等。
操作系统应该是最新的稳定版本,并且需要进行基本的配置,如网络设置、安装必要的软件和工具等。
3. Java环境配置Hadoop是基于Java开发的,因此需要在每台服务器上安装Java 开发环境。
确保安装的Java版本符合Hadoop的要求,并设置好相应的环境变量。
4. Hadoop安装和配置下载Hadoop的最新稳定版本,并将其解压到指定的目录。
然后,需要进行一些配置来启动Hadoop集群。
主要的配置文件包括hadoop-env.sh、core-site.xml、hdfs-site.xml和mapred-site.xml等。
在hadoop-env.sh文件中,可以设置一些全局的环境变量,如Java路径、Hadoop日志目录等。
在core-site.xml文件中,配置Hadoop的核心设置,如Hadoop的文件系统类型(HDFS)和默认的文件系统地址等。
在hdfs-site.xml文件中,配置HDFS的相关设置,如副本数量、数据块大小等。
在mapred-site.xml文件中,配置MapReduce的相关设置,如任务调度方式、任务跟踪器地址等。
5. 配置SSH免密码登录为了实现集群中各节点之间的通信,需要配置SSH免密码登录。
在每台服务器上生成SSH密钥,并将公钥添加到所有其他服务器的授权文件中,以实现无需密码即可登录其他服务器。
HADOOP大数据平台配置方法(懒人版)

HADOOP大数据平台配置方法(完全分布式,懒人版)一、规划1、本系统包括主节点1个,从节点3个,用Vmware虚拟机实现;2、主节点hostname设为hadoop,IP地址设为192.168.137.100;3、从节点hostname分别设为slave01、slave02,slave03,IP地址设为192.168.137.201、192.168.137.202、192.168137.203。
今后如要扩充节点,依此类推;基本原理:master及slave机器的配置基本上是一样的,所以我们的操作方式就是先配置好一台机器,然后克隆3台机器出来。
这样可以节省大量的部署时间,降低出错的概率。
安装配置第一台机器的时候,一定要仔细,否则一台机器错了所有的机器都错了。
二、前期准备1、在Vmware中安装一台CentOS虚拟机;2、设置主机名(假设叫hadoop)、IP地址,修改hosts文件;3、关闭防火墙;4、删除原有的JRE,安装JDK,设置环境变量;5、设置主节点到从节点的免密码登录(此处先不做,放在第七步做);三、安装Hadoop在hadoop机上以root身份登录系统,按以下步骤安装hadoop:1、将hadoop-1.0.4.tar.gz复制到/usr 目录;2、用cd /usr命令进入/usr目录,用tar –zxvf hadoop-1.0.4.tar.gz进行解压,得到一个hadoop-1.0.4目录;3、为简单起见,用mv hadoop-1.0.4 hadoop命令将hadoop-1.0.4文件夹改名为hadoop;4、用mkdir /usr/hadoop/tmp命令,在hadoop文件夹下面建立一个tmp目录;5、用vi /etc/profile 修改profile文件,在文件最后添加以下内容:export HADOOP_HOME=/usr/hadoopexport PATH=$PATH:$HADOOP_HOME/bin6、用source /usr/profile命令使profile 立即生效;四、配置HadoopHadoop配置文件存放在/usr/hadoop/conf目录下,本次有4个文件需要修改。
Hadoop分布式集群搭建详细教程

hadoop1hadoop2hadoop3HDFS NameNodeDataNodeDataNodeSecondaryNameNodeDataNodeYARN NodeManager ResourceManagerNodeManagerNodeManager Hadoop分布式集群搭建详细教程本教程是基于CentOS-7-x86_64的Hadoop完全分布式搭建1、搭建前的准备1)CentOS-7虚拟机3台(hadoop1、hadoop2、hadoop3)2)hadoop-3.3.0包3)jdk-8u144-linux-x64包2、整体部署3、基本步骤1)修改3台虚拟机的名称2)关闭、禁⽌开机⾃启防⽕墙3)配置静态ip4)修改/etc/hosts⽂件(hadoop1、hadoop2、hadoop3)5)配置免密登录(hadoop1、hadoop2、hadoop3)6)安装JDK及配置相应环境变量(hadoop1)7)安装Hadoop及配置相应环境变量(hadoop1)8)修改配置⽂件(hadoop1)9)拷贝(hadoop1-->hadoop2,hadoop1-->hadoop3)10)远程同步/etc/profile⽂件(hadoop1)11)格式化NameNode12)启动和关闭Hadoop集群13)通过浏览器访问Hadoop集群14)测试集群,上传⽂件4、详细步骤操作1)修改3台虚拟机的名称#hostname #查看主机名称hostnamectl set-hostname 主机名 #修改主机名称#reboot #重启虚拟机【注】:修改主机名称后需重启才能⽣效2)关闭、禁⽌开机⾃启防⽕墙#systemctl status firewalld #查看防⽕墙状态#systemctl stop firewalld #关闭防⽕墙#systemctl disable firewalld #关闭防⽕墙开机⾃启#vim /etc/selinux/config #修改selinux配置⽂件SELINUX=enforcing 修改为 SELINUX=disabled3)配置静态ip#cd /etc/sysconfig/network-scripts/#vim ifcfg-ens33BOOTPROTO=none 改为 BOOTPROTO=staticIPADDR也进⾏修改【注】:因为3台虚拟机都是克隆完成的,ip地址⼀致,故在此对ip进⾏修改4)修改/etc/hosts⽂件(hadoop1、hadoop2、hadoop3)192.168.150.14 hadoop1192.168.150.15 hadoop2192.168.150.16 hadoop3#reboot5)配置免密登录(hadoop1、hadoop2、hadoop3)#ssh-keygen -t rsa #⽣成ssh密钥,不提⽰输⼊密码三次回车键#ssh-copy-id hadoop1#ssh-copy-id hadoop2#ssh-copy-id hadoop3 #将密钥拷贝到各节点#ssh hadoop1#ssh hadoop2#ssh hadoop3 #测试免密登录6)安装JDK及配置相应环境变量(hadoop1)#cd /opt/#mkdir modules #创建modules⽂件夹#mkdir tar_packages #创建tar_packages⽂件夹#cd tar_packages/ #进⼊tar_packages⽂件夹将hadoop-3.3.0.tar.gz和jdk-8u144-linux-x64.tar.gz包导⼊tar_packages⽂件夹中导⼊⽅法较多,可⽤Xshell,可⽤命令wget xxxxx下载,亦可命令rz导⼊#tar -zxvf jdk-8u144-linux-x64.tar.gz -C /opt/modules/ #将压缩包解压到/opt/modules/⽂件夹下#cd /opt/modules/jdk1.8.0_144/#pwd/opt/modules/jdk1.8.0_144 #复制此路径#vim /etc/profile/ #修改配置⽂件,加⼊环境变量在⽂件末尾加⼊#JAVA_HOMEexport JAVA_HOME=/opt/modules/jdk1.8.0_144export PATH=$PATH:$JAVA_HOME/bin#source /etc/profile #⽴即⽣效#java#javac#javadoc #测试java环境7)安装Hadoop及配置相应环境变量(hadoop1)#cd /opt/tar_packages/#tar -zxvf hadoop-3.3.0.tar.gz -C /opt/modules #将压缩包解压到/opt/modules/⽂件夹下#cd /opt/modules/hadoop-3.3.0#pwd/opt/modules/hadoop-3.3.0 #复制此路径#vim /etc/profile #修改配置⽂件,加⼊环境变量在⽂件末尾加⼊#HADOOP_HOMEexport HADOOP_HOME=/opt/modules/hadoop-3.3.0export PATH=$PATH:$HADOOP_HOME/binexport PATH=$PATH:$HADOOP_HOME/sbin#source /etc/profile #⽴即⽣效#hadoop #测试hadoop8)修改配置⽂件(hadoop1)1、修改hadoop-env.sh⽂件#cd /opt/modules/hadoop-3.3.0/etc/hadoop#vim hadoop-env.sh在⽂件中加⼊export JAVA_HOME=/opt/modules/jdk1.8.0_1442、修改yarn-env.sh⽂件#vim yarn-env.sh在⽂件中加⼊export JAVA_HOME=/opt/modules/jdk1.8.0_1443、修改mapred-env.sh⽂件#vim mapred-env.sh在⽂件中加⼊export JAVA_HOME=/opt/modules/jdk1.8.0_1444、修改core-site.xml#vim core-site.xml在<configuration></configuration>间加⼊<!-- 指定HDFS中NameNode的地址 --><property><name>fs.defaultFS</name><value>hdfs://hadoop1:9000</value><!-- 指定Hadoop运⾏时产⽣⽂件的存储⽬录 --><property><name>hadoop.tmp.dir</name><value>/opt/modules/hadoop-3.3.0/data/tmp</value></property>5、修改hdfs-site.xml⽂件# vim hdfs-site.xml在<configuration></configuration>间加⼊<!-- 指定Hadoop副本个数 --><property><name>dfs.replication</name><value>2</value></property><!-- 指定Hadoop辅助名称节点主机配置 --><property><name>node.secondary.http-address</name><value>hadoop3:50090</value></property>6、修改yarn-site.xml⽂件#vim yarn-site.xml在<configuration></configuration>间加⼊<!-- Reducer获取数据的⽅式 --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><!-- 指定YARN的ResourceManager的地址 --><property><name>yarn.resourcemanager.hostname</name><value>hadoop2</value></property>7、修改mapred-site.xml⽂件#vim mapred-site.xml在<configuration></configuration>间加⼊<!-- 指定MR运⾏在Yarn上 --><property><name></name><value>yarn</value></property>8、修改workers⽂件#vim workers修改为3个主机名称hadoop1hadoop2hadoop3【注】:我这⾥的hadoop-3.3.0版本⽂件名为workers,hadoop-2.x.x版本⽂件名为slaves9)拷贝(hadoop1-->hadoop2,hadoop1-->hadoop3)#scp -r /opt/modules/ root@hadoop2:/opt/#scp -r /opt/modules/ root@hadoop3:/opt/ #将hadoop1主节点下opt⽬录下的modules⽂件夹分别拷贝到hadoop2和hadoop3节点的opt⽬录下10)远程同步/etc/profile⽂件(hadoop1)#rsync -rvl /etc/profile root@hadoop2:/etc/profile#rsync -rvl /etc/profile root@hadoop3:/etc/profile #远程同步,将hadoop1主节点上的配置⽂件分别拷贝到hadoop2和hadoop3节点#tail /etc/profile #显⽰已修改的配置⽂件(/etc/profile)内容,查看是否同步成功#source /etc/profile #⽴即⽣效#javadoc #测试#hadoop #测试#cat /opt/modules/hadoop-3.3.0/etc/hadoop/workers #查看workers⽂件内容是否⼀致11)格式化NameNodecd /opt/modules/hdoop-3.3.0#hadoop namenode -format #格式化NameNode12)启动和关闭Hadoop集群#启动集群#cd /opt/modules/hadoop-3.3.0/sbin/#start-dfs.sh先在hadoop1节点下执⾏上述命令start-dfs.sh#cd /opt/modules/hadoop-3.3.0/sbin/等hadoop1主节点下start-dfs.sh命令执⾏结束后,在hadoop2节点下执⾏命令start-yarn.sh#jps #hadoop1、hadoop2、hadoop3⼀起查看启动的进程#关闭集群#stop-yarn.sh先在hadoop2节点下执⾏命令stop-yarn.sh#stop-dfs.sh等hadoop2节点下stop-yarn.sh命令执⾏结束后,在hadoop1主节点下执⾏命令stop-dfs.sh【注】:启动集群和关闭集群顺序是相反的,启动时先hadoop1,关闭时后hadoop1【注】:因hadoop版本不同,hadoop-2.x.x下启动正常,hadoop-3.x.x下可能出现如下错误:[root@hadoop1 sbin]# start-dfs.shStarting namenodes on [hadoop1]ERROR: Attempting to operate on hdfs namenode as rootERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation.Starting datanodesERROR: Attempting to operate on hdfs datanode as rootERROR: but there is no HDFS_DATANODE_USER defined. Aborting operation.Starting secondary namenodes [hadoop3]ERROR: Attempting to operate on hdfs secondarynamenode as rootERROR: but there is no HDFS_SECONDARYNAMENODE_USER defined. Aborting operation.[root@hadoop1 sbin]# start-dfs.shWARNING: HADOOP_SECURE_DN_USER has been replaced by HDFS_DATANODE_SECURE_USER. Using value of HADOOP_SECURE_DN_USER.解决办法为:在start-dfs.sh和stop-dfs.sh⽂件⾸部加⼊如下部分1 HDFS_DATANODE_USER=root2 HDFS_DATANODE_SECURE_USER=hdfs3 HDFS_NAMENODE_USER=root4 HDFS_SECONDARYNAMENODE_USER=root在start-yarn.sh和stop-yarn.sh⽂件⾸部加⼊如下部分1 YARN_RESOURCEMANAGER_USER=root2 HADOOP_SECURE_DN_USER=yarn3 YARN_NODEMANAGER_USER=root这样这个问题就解决了,记得看清楚⾃⼰hadoop的版本号13)通过浏览器访问Hadoop集群在浏览器输⼊:192.168.150.14(主节点ip):9870访问Hadoop⽂件系统【注】:hadoop-3.x.x,服务器端⼝改为了9870,并不是原来的50070,看清⾃⼰的Hadoop版本可在Windows下配置主机节点映射,配置完成后即可在浏览器输⼊:hadoop1(主节点名称):9870访问Hadoop⽂件系统具体映射配置:在C:\Windows\System32\drivers\etc\hosts⽂件后,加⼊与在虚拟机/etc/hosts配置⼀致的内容,即:#192.168.150.14 hadoop1#192.168.150.15 hadoop2#192.168.150.16 hadoop314)测试集群,上传⽂件#hadoop fs -mkdir -p /root/ #创建root⽬录#hadoop fs -put /opt/tar_packages/jdk-8u144-linux-x64.tar.gz /root/ #将/opt/tar_packages/⽬录下的jdk-8u144-linux-x64.tar.gz压缩包上传到刚才创建的root⽬录下⾄此,分布式集群搭建完成!PS:搭建过程中需要的⼯具我整理了⼀下,需要的请⾃取哦!(提取码:u240)如果搭建过程遇到了什么难以解决的问题,欢迎留⾔,毕竟多⼀个⼈⼀起百度可能会快⼀点!。
Hadoop安装配置超详细步骤

Hadoop安装配置超详细步骤Hadoop的安装1、实现linux的ssh无密码验证配置.2、修改linux的机器名,并配置/etc/hosts3、在linux下安装jdk,并配好环境变量4、在windows下载hadoop 1.0.1,并修改hadoop-env.sh,core-site.xml,hdfs-site.xml,mapred-site.xml,masters,slaves文件的配置5、创建一个给hadoop备份的文件。
6、把hadoop的bin加入到环境变量7、修改部分运行文件的权限8、格式化hadoop,启动hadoop注意:这个顺序并不是一个写死的顺序,就得按照这个来。
如果你知道原理,可以打乱顺序来操作,比如1、2、3,先哪个后哪个,都没问题,但是有些步骤还是得依靠一些操作完成了才能进行,新手建议按照顺序来。
一、实现linux的ssh无密码验证配置(1)配置理由和原理Hadoop需要使用SSH协议,namenode将使用SSH协议启动namenode和datanode进程,(datanode向namenode传递心跳信息可能也是使用SSH协议,这是我认为的,还没有做深入了解)。
大概意思是,namenode 和datanode之间发命令是靠ssh来发的,发命令肯定是在运行的时候发,发的时候肯定不希望发一次就弹出个框说:有一台机器连接我,让他连吗。
所以就要求后台namenode和datanode 无障碍的进行通信。
以namenode到datanode为例子:namenode作为客户端,要实现无密码公钥认证,连接到服务端datanode上时,需要在namenode上生成一个密钥对,包括一个公钥和一个私钥,而后将公钥复制到datanode上。
当namenode通过ssh连接datanode时,datanode就会生成一个随机数并用namenode的公钥对随机数进行加密,并发送给namenode。
hadoop安装指南(非常详细,包成功)

➢3.10.2.进程➢JpsMaster节点:namenode/tasktracker(如果Master不兼做Slave, 不会出现datanode/TasktrackerSlave节点:datanode/Tasktracker说明:JobTracker 对应于NameNodeTaskTracker 对应于DataNodeDataNode 和NameNode 是针对数据存放来而言的JobTracker和TaskTracker是对于MapReduce执行而言的mapreduce中几个主要概念,mapreduce整体上可以分为这么几条执行线索:jobclient,JobTracker与TaskTracker。
1、JobClient会在用户端通过JobClient类将应用已经配置参数打包成jar文件存储到hdfs,并把路径提交到Jobtracker,然后由JobTracker创建每个Task(即MapTask和ReduceTask)并将它们分发到各个TaskTracker服务中去执行2、JobTracker是一个master服务,软件启动之后JobTracker接收Job,负责调度Job的每一个子任务task运行于TaskTracker上,并监控它们,如果发现有失败的task就重新运行它。
一般情况应该把JobTracker部署在单独的机器上。
3、TaskTracker是运行在多个节点上的slaver服务。
TaskTracker主动与JobTracker通信,接收作业,并负责直接执行每一个任务。
TaskTracker都需要运行在HDFS的DataNode上3.10.3.文件系统HDFS⏹查看文件系统根目录:Hadoop fs–ls /。
大数据分析平台Hadoop的部署教程

大数据分析平台Hadoop的部署教程随着互联网和信息技术的发展,大数据分析已经成为企业决策和发展的重要工具。
而Hadoop作为目前应用最广泛的大数据分析平台之一,成为众多企业和组织的首选。
本文将为您提供一份简单而全面的Hadoop部署教程,帮助您快速搭建属于自己的大数据分析平台。
1. 硬件和系统配置在开始部署Hadoop之前,首先需要确保您的硬件配置和操作系统满足最低要求。
对于一般的开发和测试环境,您可以考虑使用至少4核CPU、16GB内存和100GB硬盘空间的机器。
操作系统方面,Hadoop支持Linux和Windows操作系统,我们推荐使用Linux,比如Ubuntu或CentOS。
2. 安装Java Development Kit(JDK)Hadoop是基于Java开发的,因此在部署Hadoop之前,需要先安装Java Development Kit(JDK)。
您可以从官方网站上下载最新版本的JDK。
下载完成后,请按照安装向导一步步进行安装。
安装完成后,设置JAVA_HOME环境变量,并将Java的bin目录添加到PATH变量中,以便在命令行中能够使用Java命令。
3. 下载和配置Hadoop在准备好硬件和操作系统之后,接下来需要下载和配置Hadoop。
您可以从Hadoop官方网站上下载最新版本的Hadoop。
下载完成后,解压缩文件到您的安装目录中。
接下来,您需要对Hadoop进行一些基本配置。
在Hadoop的安装目录中,可以找到core-site.xml、hdfs-site.xml和mapred-site.xml等配置文件的模板。
您需要将这些模板文件复制一份,并将其重命名为core-site.xml、hdfs-site.xml和mapred-site.xml。
然后,您可以编辑这些文件,根据您的需求进行配置。
4. 配置Hadoop集群Hadoop是一个分布式系统,可以通过配置多台机器来搭建一个Hadoop集群。
大数据Hadoop学习之搭建Hadoop平台(2.1)

⼤数据Hadoop学习之搭建Hadoop平台(2.1) 关于⼤数据,⼀看就懂,⼀懂就懵。
⼀、简介 Hadoop的平台搭建,设置为三种搭建⽅式,第⼀种是“单节点安装”,这种安装⽅式最为简单,但是并没有展⽰出Hadoop的技术优势,适合初学者快速搭建;第⼆种是“伪分布式安装”,这种安装⽅式安装了Hadoop的核⼼组件,但是并没有真正展⽰出Hadoop的技术优势,不适⽤于开发,适合学习;第三种是“全分布式安装”,也叫做“分布式安装”,这种安装⽅式安装了Hadoop的所有功能,适⽤于开发,提供了Hadoop的所有功能。
⼆、介绍Apache Hadoop 2.7.3 该系列⽂章使⽤Hadoop 2.7.3搭建的⼤数据平台,所以先简单介绍⼀下Hadoop 2.7.3。
既然是2.7.3版本,那就代表该版本是⼀个2.x.y发⾏版本中的⼀个次要版本,是基于2.7.2稳定版的⼀个维护版本,开发中不建议使⽤该版本,可以使⽤稳定版2.7.2或者稳定版2.7.4版本。
相较于以前的版本,2.7.3主要功能和改进如下: 1、common: ①、使⽤HTTP代理服务器时的⾝份验证改进。
当使⽤代理服务器访问WebHDFS时,能发挥很好的作⽤。
②、⼀个新的Hadoop指标接收器,允许直接写⼊Graphite。
③、与Hadoop兼容⽂件系统(HCFS)相关的规范⼯作。
2、HDFS: ①、⽀持POSIX风格的⽂件系统扩展属性。
②、使⽤OfflineImageViewer,客户端现在可以通过WebHDFS API浏览fsimage。
③、NFS⽹关接收到⼀些可⽀持性改进和错误修复。
Hadoop端⼝映射程序不再需要运⾏⽹关,⽹关现在可以拒绝来⾃⾮特权端⼝的连接。
④、SecondaryNameNode,JournalNode和DataNode Web UI已经通过HTML5和Javascript进⾏了现代化改造。
3、yarn: ①、YARN的REST API现在⽀持写/修改操作。
Hadoop集群搭建详细简明教程

Linux 操作系统安装
利用 vmware 安装 Linux 虚拟机,选择 CentOS 操作系统
搭建机器配置说明
本人机器是 thinkpadt410,i7 处理器,8G 内存,虚拟机配置为 2G 内存,大家可以 按照自己的机器做相应调整,但虚拟机内存至少要求 1G。
会出现虚拟机硬件清单,我们要修改的,主要关注“光驱”和“软驱”,如下图: 选择“软驱”,点击“remove”移除软驱:
选择光驱,选择 CentOS ISO 镜像,如下图: 最后点击“Close”,回到“硬件配置页面”,点击“Finsh”即可,如下图: 下图为创建all or upgrade an existing system”
执行 java –version 命令 会出现上图的现象。 从网站上下载 jdk1.6 包( jdk-6u21-linux-x64-rpm.bin )上传到虚拟机上 修改权限:chmod u+x jdk-6u21-linux-x64-rpm.bin 解压并安装: ./jdk-6u21-linux-x64-rpm.bin (默认安装在/usr/java 中) 配置环境变量:vi /etc/profile 在该 profile 文件中最后添加:
选择“Skip”跳过,如下图:
选择“English”,next,如下图: 键盘选择默认,next,如下图:
选择默认,next,如下图:
输入主机名称,选择“CongfigureNetwork” 网络配置,如下图:
选中 system eth0 网卡,点击 edit,如下图:
选择网卡开机自动连接,其他不用配置(默认采用 DHCP 的方式获取 IP 地址), 点击“Apply”,如下图:
在三台虚拟机上部署多节点Hadoop

cd /etc/networkvi interfaces进入vi后,编辑auto eth0iface eth0 inet staticaddress IP地址netmask 掩码gateway 网关重启SSH:serivce ssh restart重启网卡:/etc/init.d/networking restart取得root权限:sudo passwdsu1.硬件环境共有3台机器,均使用的linux系统,Java使用的是openjdk-6-jdk sudo apt-get updatesudo apt-get install openjdk-6-jdk修改主机名:suvi /etc/hostnameIP配置如下:hadoop1:192.168.75.132(NameNode)hadoop2:192.168.75.131(DataNode)hadoop3:192.168.75.133 (DataNode)这里有一点需要强调的就是,务必要确保每台机器的主机名和IP地址之间能正确解析。
一个很简单的测试办法就是ping一下主机名,比如在hadoop1上ping hadoop2,如果能ping通就OK!若不能正确解析,可以修改/etc/h osts文件,如果该台机器作Namenode用,则需要在hosts文件中加上集群中所有机器的IP地址及其对应的主机名;如果该台机器作Datanode用,则只需要在hosts文件中加上本机IP地址和Namenode机器的IP地址。
以本文为例,hadoop1(NameNode)中的/etc/hosts文件看起来应该是这样的:vi /etc/hosts127.0.0.1hadoop1localhost192.168.75.132hadoop1hadoop1192.168.75.131hadoop2hadoop2192.168.75.133hadoop3hadoop3hadoop2(DataNode)中的/etc/hosts文件看起来就应该是这样的:127.0.0.1hadoop2localhost192.168.75.132hadoop1hadoop1192.168.75.131hadoop2hadoop2hadoop3(DataNode)中的/etc/hosts文件看起来就应该是这样的:127.0.0.1hadoop3localhost192.168.75.132hadoop1hadoop1192.168.75.133hadoop3hadoop3对于Hadoop来说,在HDFS看来,节点分为Namenode和Datanode,其中Namenode只有一个,Datanode可以是很多;在MapReduce看来,节点又分为Jobtracker和Tasktracker,其中Jobtracker只有一个,Tasktr acker可以是很多。
三节点Hadoop集群搭建
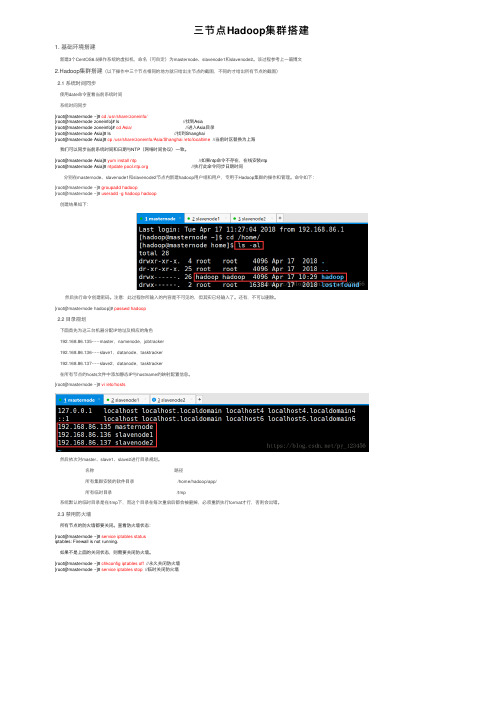
三节点Hadoop集群搭建1. 基础环境搭建新建3个CentOS6.5操作系统的虚拟机,命名(可⾃定)为masternode、slavenode1和slavenode2。
该过程参考上⼀篇博⽂2.Hadoop集群搭建(以下操作中三个节点相同的地⽅就只给出主节点的截图,不同的才给出所有节点的截图)2.1 系统时间同步使⽤date命令查看当前系统时间系统时间同步[root@masternode ~]# cd /usr/share/zoneinfo/[root@masternode zoneinfo]# ls //找到Asia[root@masternode zoneinfo]# cd Asia/ //进⼊Asia⽬录[root@masternode Asia]# ls //找到Shanghai[root@masternode Asia]# cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime //当前时区替换为上海我们可以同步当前系统时间和⽇期与NTP(⽹络时间协议)⼀致。
[root@masternode Asia]# yum install ntp //如果ntp命令不存在,在线安装ntp[root@masternode Asia]# ntpdate //执⾏此命令同步⽇期时间 分别在masternode、slavenode1和slavenode2节点内新建hadoop⽤户组和⽤户,专⽤于Hadoop集群的操作和管理。
命令如下:[root@masternode ~]# groupadd hadoop[root@masternode ~]# useradd -g hadoop hadoop创建结果如下: 然后执⾏命令创建密码。
注意:此过程你所输⼊的内容是不可见的,但其实已经输⼊了。
还有,不可以删除。
[root@masternode hadoop]# passwd hadoop2.2 ⽬录规划下⾯⾸先为这三台机器分配IP地址及相应的⾓⾊192.168.86.135-----master,namenode,jobtracker192.168.86.136-----slave1,datanode,tasktracker192.168.86.137-----slave2,datanode,tasktracker在所有节点的hosts⽂件中添加静态IP与hostname的映射配置信息。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Hadoop平台搭建说明1.Hadoop节点规划本次安装规划使用三个节点,每个节点都使用centos系统。
三个节点的hostname分别规划为:centoshadoop1、centoshadoop2、centoshadoop3(此处为本教程参数,可根据实际环境情况修改)三个节点的ip地址分别规划为:192.168.65.57、192.168.65.58、192.168.65.59(此处为本教程参数,根据实际环境情况修改)2.平台搭建使用的软件下载如下软件操作系统安装包:Centos6.3_x64Jdk安装包:jdk-6u37-linux-x64.binHadoop安装包:hadoop-1.1.2.tar.gz3.安装centos操作系统安装三个节点的操作系统,安装过程省略。
4.配置centoshadoop1节点4.1.修改节点hostname[root@localhost ~]# vi /etc/sysconfig/networkHOSTNAME=centoshadoop1[root@localhost ~]# vi /etc/hosts……192.168.65.57 centoshadoop1192.168.65.58centoshadoop2192.168.65.59centoshadoop3[root@localhost ~]#reboot4.2.关闭iptables防火墙[root@centoshadoop1~]#service iptables stop注意每次操作系统重启后都要操作4.3.建立无ssh密码登陆生成签名文件[root@centoshadoop1~]#cd /root[root@centoshadoop1~]#ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa[root@centoshadoop1~]#cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys [root@centoshadoop1~]#测试本地SSH无密码登录[root@centoshadoop1~]#sshcentoshadoop14.4.安装jdk上传jdk-6u37-linux-x64.bin到/root目录下[root@centoshadoop1~]#chmod 777 jdk-6u37-linux-x64.bin[root@centoshadoop1~]#./jdk-6u37-linux-x64.bin[root@centoshadoop1~]#ll查看生成jdk-6u37-linux-x64目录4.5.安装hadoop软件上传hadoop-1.1.2.tar.gz到/root目录下[root@centoshadoop1~]#tar -zvxf hadoop-1.1.2.tar.gz[root@centoshadoop1~]#ll查看生成hadoop-1.1.2目录[root@centoshadoop1~]#vi /conf/core-site.xml<?xml version="1.0"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><!-- Put site-specific property overrides in this file. --><configuration><property><name></name><value>hdfs://192.168.65.57:9000</value></property><property><name>hadoop.tmp.dir</name><value>/root/hadoop-1.1.2/tmp</value></property></configuration>[root@centoshadoop1~]#vi hdfs-site.xml<?xml version="1.0"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Put site-specific property overrides in this file. --><configuration><property><name>dfs.replication</name><value>1</value></property></configuration>[root@centoshadoop1~]#vi mapred-site.xml<?xml version="1.0"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Put site-specific property overrides in this file. --><configuration><property><name>mapred.job.tracker</name><value>192.168.65.57:9001</value></property></configuration>4.6.配置hadoop数据节点[root@centoshadoop1~]#vi /root/hadoop-1.1.2/conf/masters 192.168.65.57 #secondaryNameNode[root@centoshadoop1~]#vi /root/hadoop-1.1.2/conf/slaves 192.168.65.58 #datanode192.168.65.59 #datanode4.7.添加环境变量[root@centoshadoop1~]#cd /root[root@centoshadoop1~]#vi /etc/profileexport JAVA_HOME=/root/jdk1.6.0_37export JRE_HOME=/root/jdk1.6.0_37/jreexport HADOOP_HOME=/root/hadoop-1.1.2export HADOOP_HOME_WARN_SUPPRESS=1export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib:$HADOOP_HOME/lib:$CLASSPATH export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$HADOOP_HOME/bin:$PATH[root@centoshadoop1~]#vi ~/.bashrcexport JAVA_HOME=/root/jdk1.6.0_37export JRE_HOME=/root/jdk1.6.0_37/jreexport HADOOP_HOME=/root/hadoop-1.1.2export HADOOP_DEV_HOME=/root/hadoop-1.1.2export HADOOP_COMMON_HOME=/root/hadoop-1.1.2export HADOOP_HDFS_HOME=/root/hadoop-1.1.2export HADOOP_CONF_DIR=/root/hadoop-1.1.2/conf[root@centoshadoop1~]#vi /root/hadoop-1.1.2/conf/hadoop-env.shexport JAVA_HOME=/root/jdk1.6.0_37export HADOOP_HOME_WARN_SUPPRESS=1export HADOOP_CLASSPATH=/root/hadoop-1.1.2:/root/hadoop-1.1.2/lib5.配置centoshadoop2节点5.1.修改节点hostname[root@localhost ~]# vi /etc/sysconfig/networkHOSTNAME=centoshadoop2[root@localhost ~]# vi /etc/hosts……192.168.65.57 centoshadoop1192.168.65.58 centoshadoop2192.168.65.59 centoshadoop3[root@localhost ~]#reboot5.2.关闭iptables防火墙[root@centoshadoop1~]#service iptables stop注意每次操作系统重启后都要操作5.3.建立无ssh密码登陆将centoshadoop1节点上/root/.ssh目录下的authorized_keys、known_hosts 、id_rsa.pub、id_rsa四个文件拷贝到本机的/root/.ssh目录下5.4.安装jdk上传jdk-6u37-linux-x64.bin到/root目录下[root@centoshadoop1~]#chmod 777 jdk-6u37-linux-x64.bin[root@centoshadoop1~]#./jdk-6u37-linux-x64.bin[root@centoshadoop1~]#ll查看生成jdk-6u37-linux-x64目录5.5.安装hadoop软件上传hadoop-1.1.2.tar.gz到/root目录下[root@centoshadoop1~]#tar -zvxf hadoop-1.1.2.tar.gz[root@centoshadoop1~]#ll查看生成hadoop-1.1.2目录[root@centoshadoop1~]#vi /conf/core-site.xml<?xml version="1.0"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><!-- Put site-specific property overrides in this file. --><configuration><property><name></name><value>hdfs://192.168.65.57:9000</value></property><property><name>hadoop.tmp.dir</name><value>/root/hadoop-1.1.2/tmp</value></property></configuration>[root@centoshadoop1~]#vi hdfs-site.xml<?xml version="1.0"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><!-- Put site-specific property overrides in this file. --><configuration><property><name>dfs.replication</name><value>1</value></property></configuration>[root@centoshadoop1~]#vi mapred-site.xml<?xml version="1.0"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><!-- Put site-specific property overrides in this file. --><configuration><property><name>mapred.job.tracker</name><value>192.168.65.57:9001</value></property></configuration>5.6.添加环境变量[root@centoshadoop1~]#cd /root[root@centoshadoop1~]#vi /etc/profileexport JAVA_HOME=/root/jdk1.6.0_37export JRE_HOME=/root/jdk1.6.0_37/jreexport HADOOP_HOME=/root/hadoop-1.1.2export HADOOP_HOME_WARN_SUPPRESS=1export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib:$HADOOP_HOME/lib:$CLASSPATH export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$HADOOP_HOME/bin:$PATH[root@centoshadoop1~]#vi ~/.bashrcexport JAVA_HOME=/root/jdk1.6.0_37export JRE_HOME=/root/jdk1.6.0_37/jreexport HADOOP_HOME=/root/hadoop-1.1.2export HADOOP_DEV_HOME=/root/hadoop-1.1.2export HADOOP_COMMON_HOME=/root/hadoop-1.1.2export HADOOP_HDFS_HOME=/root/hadoop-1.1.2export HADOOP_CONF_DIR=/root/hadoop-1.1.2/conf[root@centoshadoop1~]#vi /root/hadoop-1.1.2/conf/hadoop-env.shexport JAVA_HOME=/root/jdk1.6.0_37export HADOOP_HOME_WARN_SUPPRESS=1export HADOOP_CLASSPATH=/root/hadoop-1.1.2:/root/hadoop-1.1.2/lib6.配置centoshadoop3节点6.1.修改节点hostname[root@localhost ~]# vi /etc/sysconfig/networkHOSTNAME=centoshadoop3[root@localhost ~]# vi /etc/hosts……192.168.65.57 centoshadoop1192.168.65.58 centoshadoop2192.168.65.59 centoshadoop3[root@localhost ~]#reboot关闭iptables防火墙、建立无ssh密码登陆、安装jdk、安装hadoop软件、添加环境变量等操作跟“配置centoshadoop2节点”完全相同7.启动运行hadoop平台7.1.首先执行格式化[root@centoshadoop1~]#hadoop namenode –format注意:core-site.xml、hdfs-site.xml、mapred-site.xml等配置文件变化后都需要执行格式化7.2.启动hadoop[root@centoshadoop1~]#start-all.sh7.3.停止hadoop[root@centoshadoop1~]#stop-all.sh7.4.查看hadoop运行状态查看hadoop启动的进程[root@centoshadoop1~]#jps查看hadoop集群状态[root@centoshadoop1~]#hadoop dfsadmin -report 查看hadoop中的目录情况[root@centoshadoop1~]#hadoop fs –ls /。