(7,4)汉明码编译码程序说明
线性分组码(7,4)码设计说明书

言
设计数字通信系统时,应首先合理选择信道编译码码组种类,这样才可以在信号的 传输,以及接收环节达到较好的效果,线性分组码具有编译码简单,封闭性好等特点, 采用差错控制编码技术是提高数字通信可靠性的有效方法,是目前较为流行的差错控制 编码技术。 分组码是一组固定长度的码组,可表示为(n , k) ,通常它用于前向纠错。在分组 码中,监督位被加到信息位之后,形成新的码。在编码时,k 个信息位被编为 n 位码组 长度,而 n-k 个监督位的作用就是实现检错与纠错。 对于长度为 n 的二进制线性分组码,它有种可能的码组,从种码组中,可以选择 M= 个码组(k<n)组成一种码。这样,一个 k 比特信息的线性分组码可以映射到一个长度 为 n 码组上, 该码组是从 M=个码组构成的码集中选出来的, 这样剩下的码组就可以对这 个分组码进行检错或纠错。
上述方法构造的能纠正单个误码的线性分组码又称为汉明码。它具有以下一些特 点:码长 n=2m-1,最小码距为 d=3,信息码长 k=2n-m-1,纠错能力 t=1,监督码 长 r=n-k=m。这里 m 为≥2 的正整数。给定 m 后,就可构造出汉明码(n,k)。
5
第三章 推导过程
3.1 编码过程
监督阵 H 与生成矩阵 G 的关系: 由 H 与 G 的分块表示的矩阵形式 H [ P I n k ]
其中 A 为纠错输出码序列,E 为错码矩阵,B 为信道输出码。 对接收到的信息进行改正求出正确的编码,从而再提去更正后的接收序列的前四 位来提取信息位,以至获得信息矩阵 I。
8
第四章 仿真过程及结果分析
4.1 程序流程图
4.1.1 主程序流程图 主程序一开始就有欢迎界面,并对用户显示出了选择提示语句,可以选择编码器、 译码器、退出三种选择,当用户做出选择后便会进入各自的子程序,执行相应的功能, 整个主程序的流程如下:
用MCS-51实现(7,4)汉明码的译码方法

20 0 6年第 1 1期 总 秉 2 6 2
用 MC 一 1 S 5 实现(,) 74汉明码的译码方法
贾培 军 , 世 平 杨
( 安 大学 物 理 与 电 子 信 息 学 院 延 陕 西 延 安 76 0 ) 1 0 0
摘
要 : 字信 号在 传输过程 中需要用信道编码 来降低误 码率 , 高数 字通信的 可靠性 , 数 提 汉明码 正是 一种编码 效率 高且
s s e , i i lsg a r c s i g lc la e e wo k I h s p p r c d n t o f i l me t g( , ) a y t m d g t in lp o e sn , o a r a n t r . n t i a e , o ig me h d o mp e n i a n 7 4 H mmi g b s d o n ae n
关 键 词 : 明 码 ; 片机 MC 汉 单 S一5 ; 道 ; 码 1信 译 中图分类号 : TN9 1 1 文 献标 识码 : B 文 章 编 号 :0 4 7X(0 6 1 —0 9 2 10 —3 3 2 0 ) 1 5 —0
C d n eh fI lme t g ( , ) Ha mi gB C o i gM t o o mp e n i d n 74 m n y M S一5 1
M CS 一 51 i nt o c d. S i r du e
K y r s: mmi g; CS一5 ; h n e ; o i g e wo d Ha n M c a n lc dn 1
l 引
言
两个错误 。
在 当今 和 未来 的 信 息 化 社 会 中 , 字 通 信 已成 为 信 息 数 传 输 的重 要 手 段 , 球 数 字 化 已 成 为 当今 社 会 的 主 要 潮 全
基于FPGA汉明码编译码器设计

基于FPGA汉明码编译码器设计汉明码是一种能够检测和纠正错误的编码方式。
在FPGA(Field Programmable Gate Array)中,我们可以使用FPGA来设计并实现一个基于(7,4)汉明码的编码器和解码器。
1.编码器设计:编码器将4位数据编码为7位汉明码。
下面是一个基于FPGA的(7,4)汉明码编码器的设计步骤:-设置一个4位输入端口和一个7位输出端口。
-创建一个4×7的矩阵,用于存储所有可能输入与对应汉明码的关系。
每行代表一个输入,每列代表一个汉明码位。
-在FPGA中,使用逻辑门(如XOR门和AND门)来实现矩阵的功能。
根据矩阵,依次设计逻辑门电路来计算每个汉明码位。
例如,对于第一个汉明码位,使用四个输入位的异或门计算出结果。
-将每个汉明码位的结果输出到对应的输出端口。
2.解码器设计:解码器将7位汉明码解码为4位数据。
下面是一个基于FPGA的(7,4)汉明码解码器的设计步骤:-设置一个7位输入端口和一个4位输出端口。
-创建一个7×4的矩阵,用于存储所有可能的汉明码与对应的输出数据的关系。
每行代表一个汉明码,每列代表一个输出数据位。
-同样,使用逻辑门来实现矩阵的功能。
根据矩阵,依次设计逻辑门电路来计算每个输出数据位。
例如,对于第一个数据位,使用七个输入位的与门计算出结果。
-将每个输出数据位的结果输出到对应的输出端口。
3.性能分析和优化:可以通过FPGA的资源利用率和时钟频率等指标对设计进行性能评估。
通过仔细设计逻辑电路,合理分配资源和优化电路,可以提高编码器和解码器的性能。
可以考虑使用并行计算、流水线等技术来提高时钟频率和减少时延。
另外,还可以在FPGA中使用多个编码器和解码器来实现更高级的错误检测和纠正功能。
可以考虑使用更高级的汉明码,如(15,11)汉明码或(31,26)汉明码,来提高错误检测和纠正能力。
可以结合其他编码技术,如校验和,奇偶校验等,来增加冗余度和提高系统的可靠性。
74汉明码编码译码函数matlab

74汉明码编码译码函数matlab73汉明码简介73汉明码(Hamming Code),是由理查德·哈明(Richard W. Hamming)于1950年提出的一种能够纠错的编码方式。
在数据的通信和储存中,由于比特位(Bit)的传输或存储可能出错,使用汉明码可以检测和纠正错误,保证数据的可靠性。
而且,它具有编码效率高、纠错能力强等优越性。
74汉明码编码原理74汉明码是由7个数据位加上3个校验位组成的码。
通过在7个数据位中插入3个校验位,使得每个校验位都对特定的数据位进行检验,并在校验位位上调整,使其满足校验规则。
74汉明码编码规则如下:1. 将数据位插入到编码位中:将数据位a1、a2、a3、a4、a5、a6、a7插入到编码位b1、b2、b3、c1、c2、c3、c4中,并按照如下公式进行计算:b1 = a1b2 = a2b3 = a3c1 = a4c2 = a5c3 = a6c4 = a72. 计算每个校验位的值:每个校验位都要对特定的数据位进行检验,并在校验位位上调整,使其满足校验规则。
校验位p1:检验b1、 b2、 c1 是否为1的个数是否为奇数。
校验位p2:检验b1、 b3、 c2 是否为1的个数是否为奇数。
校验位p3:检验b2、 b3、 c3 是否为1的个数是否为奇数。
3. 将所有编码位合并得到74汉明码:将校验位及数据位组成新的编码位,形成74汉明码。
74汉明码译码原理74汉明码译码的规则如下:1. 监测码:检测接受到的数据中是否存在错误。
利用4个校验位检测数据中的错误。
校验位p1:检验b1、 b2、 c1 是否为1的个数是否为奇数。
校验位p2:检验b1、 b3、 c2 是否为1的个数是否为奇数。
校验位p3:检验b2、 b3、 c3 是否为1的个数是否为奇数。
校验位p4:检验数据位a1、 a2、 a3、 a4、 a5、 a6、 a7以及校验位p1、 p2、 p3是否为1的个数是否为奇数。
74汉明码编码原理

74汉明码编码1. 线性分组码是一类重要的纠错码,应用很广泛。
在(n ,k )分组码中,若 冗余位是按线性关系模2相加而得到的,则称其为线性分组码。
现在以(7,4)分组码为例来说明线性分组码的特点。
其主要参数如下:码长:21m n =-信息位:21m k m =--校验位:m n k =-,且3m ≥最小距离:min 03d d ==其生成矩阵G (前四位为信息位,后三位为冗余位)如下:系统码可分为消息部分和冗余部分两部分,根据生成矩阵,输出码字可按下式计算:所以有信息位 冗余位由以上关系可以得到(7,4)汉明码的全部码字如下所示。
1000110010001100101110001101G ⎡⎤⎢⎥⎢⎥=⎢⎥⎢⎥⎣⎦3210321010001100100011(,,,)(,,,)00101110001101b a a a a G a a a a ⎡⎤⎢⎥⎢⎥=•=•⎢⎥⎢⎥⎣⎦63524130b a b a b a b a ====231013210210b a a a b a a a b a a a =⊕⊕=⊕⊕=⊕⊕2.用C++编写(7,4)汉明码的思路如下:16个不同信息序列的产生:调用stidlib包中的rand()产生二进制伪随机序列,为了产生16个不同信息序列,共分两步产生:第一步:先产生一个伪随机序列并保留,将它赋给第一个信息序列V[0];i=0;for(j=0;j<4;j++)v[i][j]=rand()%2;第二步:同样产生一个序列,产生后要与在它以前产生的信息序列相比较,如果产生的信息序列与前面的序列都不同,则保留这个信息序列,并进行产生下一个信息序列;如果产生的信息序列与前面的序列有相同的,则此次产生的序列无效,需从新产生信息序列。
此过程中需定义一个比较函数进行比较,其代码如下:for(i=1;i<16;i++){Lable:for(j=0;j<4;j++)v[i][j]=rand()%2;for(k=0;k<i;k++){ //判断随机产生的信息序列与前面的信息序列是否相同if( vedict( v[i],v[k]))continue; //如果产生的信息序列与前面的序列都不同,则保留这个信息序列,并进行产生下一个信息序列elsegoto lable; //如果产生的信息序列与前面的序列有相同的,则此次产生的序列无效,跳转到标签lable处,从新产生信息序列}}进行判断的函数为:bool vedict(int a[],int b[]){int m;for(m=0;m<4;m++){switch(m){case 0:if(a[m]!=b[m])return true;else continue;break;case 1:if(a[m]!=b[m])return true;elsecontinue;break;case 2:if(a[m]!=b[m])return true;else continue;break;case 3:if(a[m]!=b[m])return true;elsereturn false;}}}74汉明码的生成:利用线性关系式 : 信息位冗余位用两个for 循环,并分两部分求解:前四位用信息位方程,后三位用 冗余位方程(通过异或运算求得);其代码如下:for(i=0;i<16;i++){for(j=0;j<7;j++){if(j<4)u[i][j]= v[i][j];if(j==4)u[i][j]=(v[i][0]^v[i][2])^v[i][3];if(j==5)u[i][j]=(v[i][0]^v[i][1])^v[i][2];if(j==6)u[i][j]=(v[i][1]^v[i][2])^v[i][3];cout << u[i][j] << " ";}cout << endl;}3. 其总代码为:#include<iostream.h>#include<stdlib.h>void main(){int g[4][7]={{1,0,0,0,1,1,0},{0,1,0,0,0,1,1},{0,0,1,0,1,1,1},{0,0,0,1,1,0,1}};//声明生成矩阵63524130b a b a b a b a ====231013210210b a a a b a a a b a a a =⊕⊕=⊕⊕=⊕⊕int v[16][4];//声明信息序列int u[16][7];int i,j,k;cout << "生成矩阵为:" << endl;//输出生成矩阵for(i=0;i<4;i++){for(j=0;j<7;j++)cout << g[i][j] << " ";cout << endl;}bool vedict(int a[],int b[]);//声明判断函数cout << "消息序列:"<< endl;//随机产生信息位序列i=0;for(j=0;j<4;j++)v[i][j]=rand()%2;for(i=1;i<16;i++){lable:for(j=0;j<4;j++)v[i][j]=rand()%2;for(k=0;k<i;k++){ //判断随机产生的信息序列与前面的信息序列是否相同if( vedict( v[i],v[k]))continue; //如果产生的信息序列与前面的序列都不同,则保留这个信息序列,并进行产生下一个信息序列elsegoto lable; //如果产生的信息序列与前面的序列有相同的,则此次产生的序列无效,跳转到标签lable处,从新产生信息序列}}for(i=0;i<16;i++){ //输出信息序列for(j=0;j<4;j++)cout << v[i][j] << " ";cout << endl;}cout << "74汉明码为:" <<endl;for(i=0;i<16;i++){for(j=0;j<7;j++){if(j<4)u[i][j]= v[i][j];if(j==4)u[i][j]=(v[i][0]^v[i][2])^v[i][3];if(j==5)u[i][j]=(v[i][0]^v[i][1])^v[i][2];if(j==6)u[i][j]=(v[i][1]^v[i][2])^v[i][3];cout << u[i][j] << " ";}cout << endl;}}bool vedict(int a[],int b[]){int m;for(m=0;m<4;m++){switch(m){case 0:if(a[m]!=b[m])return true;else continue;break;case 1:if(a[m]!=b[m])return true;elsecontinue;break;case 2:if(a[m]!=b[m])return true;else continue;break;case 3:if(a[m]!=b[m])return true;elsereturn false;}}}编译、运行结果为:。
实验报告书汉明码设计与实现
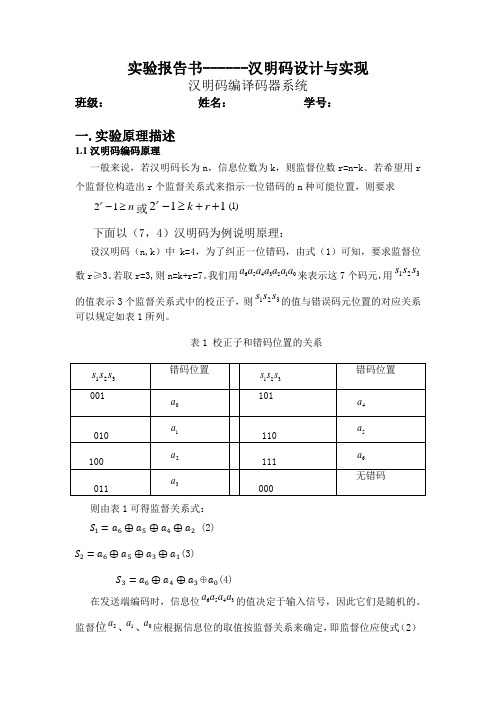
实验报告书------汉明码设计与实现汉明码编译码器系统班级: 姓名: 学号:一.实验原理描述1.1汉明码编码原理一般来说,若汉明码长为n ,信息位数为k ,则监督位数r=n-k 。
若希望用r 个监督位构造出r 个监督关系式来指示一位错码的n 种可能位置,则要求21r n -≥或211rk r -≥++(1)下面以(7,4)汉明码为例说明原理:设汉明码(n,k )中k=4,为了纠正一位错码,由式(1)可知,要求监督位数r ≥3。
若取r=3,则n=k+r=7。
我们用6543210a a a a a a a 来表示这7个码元,用123s s s 的值表示3个监督关系式中的校正子,则123s s s 的值与错误码元位置的对应关系可以规定如表1所列。
表1 校正子和错码位置的关系则由表1可得监督关系式: S 1=a 6⊕a 5⊕a 4⊕a 2 (2)S 2=a 6⊕a 5⊕a 3⊕a 1(3)S 3=a 6⊕a 4⊕a 3⊕a 0(4) 在发送端编码时,信息位6543a a a a 的值决定于输入信号,因此它们是随机的。
监督位2a 、1a 、0a 应根据信息位的取值按监督关系来确定,即监督位应使式(2)~式(4)中1s 、2s 、3s的值为0(表示编成的码组中应无错码){a 6⊕a 5⊕a 4⊕a 2=0a 6⊕a 5⊕a 3⊕a 1=0a 6⊕a 4⊕a 3⊕a 0=0(5)式(5)经过移项运算,接触监督位{a 2=a 6⊕a 5⊕a 4a 1=a 6⊕a 5⊕a 3a 0=a 6⊕a 4⊕a 3(6)式(5)其等价形式为: [1 1 1 0 1 0 01 1 0 1 0 1 01 0 1 1 0 0 1][ a 6a 5a 4a 3a 2a 1a 0]=[000](7)式(6)还可以简记为H ∙A T =0T 或A ∙H T =0 (8)其中H =[1 1 1 0 1 0 01 1 0 1 0 1 01 0 1 1 0 0 1]A =[a 6a 5a 4a 3a 2a 1a 0]P =[1 1 1 01 1 0 11 0 1 1]I r =[1 0 00 1 00 0 1]0=[0 0 0]所以有H =[PI r ](9)式(6)等价于[a 2a 1a a ]=[a 6 a 5 a 4 a 3][1 1 11 1 01 0 10 1 1]=[a 6 a 5 a 4a 3]Q (10)其中Q 为P 的转置,即T Q P (11)式(10)表示,信息位给定后,用信息位的行矩阵乘矩阵Q 就产生出监督位。
单片机实现(7,4)汉明码的编码毕业设计

单片机实现(7,4)汉明码的编码摘要在当今和未来的信息化社会中,数字通信已成为信息传输的重要手段,全球数字化已成为当今世界的主要潮流。
但是,数字信号在传输过程中,加性噪声,码间串扰等都会产生误码,因此需要用信道编码来降低误码率,提高数字通信的可靠性。
随着差错控制编码技术的蓬勃发展,作为信道传输过程抗干扰的有效手段,其中较为成熟的编码方法如汉明码、奇偶校验码、循环冗余码等编码技术,被广泛应用于计算机、电子通信、控制等领域。
其中汉明码是一种能够纠正一位错误且编码效率较高的线性分组码。
由于它的编译码在工程上较易实现,所以应用广泛。
与其他的错误校验码类似,汉明码也利用了奇偶校验位的概念,通过在数据位后面增加一些比特,可以验证数据的有效性。
利用一个以上的校验位,汉明码不仅可以验证数据是否有效,还能在数据出错的情况下指明错误位置。
在接受端通过纠错译码自动纠正传输中的差错来实现码纠错功能,称为前向纠错FEC。
在数据链路中存在大量噪音时,FEC可以增加数据吞吐量。
通过在传输码列中加入冗余位(也称纠错位)可以实现前向纠错。
但这种方法比简单重传协议的成本要高。
汉明码利用奇偶块机制降低了前向纠错的成本。
软件实现下面给出基于最常用的MCS-51单片机汇编语言的汉明码测试程序。
它的有效信息占到了总编码长度的70%,测试程序中自动生成11个字节的原始数据。
原始数据块的长度、存放地址可根据实际情况由用户自己确定,只要将本测试程序的汉明码编码、解码子程序嵌入用户应用程序中,就可直接使用。
本课题就是研究利用C8051F系列单片机来实现(7,4)汉明码的编码。
关键词:单片机;线性分组码;(7,4)汉明码C8051F series MCU(7,4)hamming code encodingABSTRACTIn today's and future information society, digital communication has become an important means of information transmission, the global digital has become a major trend in today's world. However, the digital signal in the transmission process, the additive noise, intersymbol interference, and this will result in error, channel coding, therefore need to reduce the error rate and improve the reliability of digital communications. With the error control coding techniques flourished as the transmission channel interference and effective means by which the more mature coding methods, such as Hamming codes, parity bits, cyclic redundancy code and other coding techniques are widely used in computers, electronics communication, control and other fields. Hamming code which is able to correct a mistake and the code more efficient linear block codes. Encoding and decoding in the project because of its easier to achieve, so widely used. With other similar error check code, Hamming code parity bit also use the concept, followed by an increase in the number of bits of data bits, the validity of data can be verified. Use more than one parity bit, Hamming codes can not only verify the data is valid, but also in the caseof data error location specified in the error. By error correction decoding in a receiver automatically correct the transmission errors to achieve error correction code, known as forward error correction FEC. There are a lot of data-link noise, FEC can increase data throughput. Transmission code in the column by adding redundant bits (also known as error correction bits) can be achieved FEC. However, this method than a simple retransmission protocol to the high cost. Hamming code parity block mechanism reduces the use of forward error correction costs. Software are given below based on the most popular MCS-51 microcontroller Hamming code assembly language test program. It accounts for effective information length of 70% of the total coding and testing program automatically generates 11 bytes of raw data. The length of the original data block, or hold the actual situation according to the user to determine if the Hamming code of the test program encoding and decoding routines embedded in user applications, can be used directly.This topic is to study the use of C8051F MCU to achieve (7,4) hamming code encoding.Keywords:MCU;linear block codes; (7,4) hamming code目录第1章绪论 (1)第2章实验的软硬件环境 (2)2.1 VHDL语言的概述 (2)2.1.1 VHDL语言的发展历史 (2)2.1.2 VHDL语言的特点 (2)2.1.3 VHDL语言的开发流程 (3)2.1.4 VHDL的程序结构 (5)2.1.5 逻辑芯片的分类 (5)2.2 MAX+plusⅡ的使用 (9)第3章基于CPLD的PCM解码电路的设计 (12)3.1 PCM的概述 (13)3.2 解调PCM码的基本原理 (18)3.2.1 位同步的实现 ..................................................................错误!未定义书签。
74循环汉明码编码及译码

74循环汉明码编码及译码clear all;close all;%-------------(7,4)循环汉明码的编码----------------- n=7;k=4;p=cyclpoly(n,k,'all');[H,G]=cyclgen(n,p(1,:));Msg=[0 0 0 0;0 0 0 1;0 0 1 0;0 1 0 0;0 1 0 1];C=rem(Msg*G,2)M=input('M=');disp( '输入信源序列:');Msg=input('Msg=');C=rem(Msg*G,2) %编码结果R=7/4*log2(2) %计算码元信息率%----------- (7,4)循环码的译码------------------- M=input('M=');disp( '输入接收序列:');Msg=input('Msg=');S=mod(Msg*H',2)for i=1:Mif S(i)==[0 0 0]disp('接收码元无错');Rsg=Msgelseif S(i)==[1 0 0]disp('监督元a0位错');if Msg(0)==0Msg(0)=1;elseif Msg(0)==1Msg(0)=0;endRsg=Msgelseif S(i)==[0 1 0] disp('监督元a1位错'); if Msg(1)==0Msg(1)=1;elseif Msg(1)==1 Msg(1)=0;endRsg=Msgelseif S(i)==[0 0 1] disp('监督元a2位错'); if Msg(2)==0Msg(2)=1;elseif Msg(2)==1 Msg(2)=0;endRsg=Msgelseif S(i)==[1 0 1] disp('信息元第1位错'); if Msg(3)==0Msg(3)=1;elseif Msg(3)==1 Msg(3)=0;endRsg=Msgelseif S(i)==[1 1 1] disp('信息元第2位错'); if Msg(4)==0Msg(4)=1;elseif Msg(4)==1 Msg(4)=0;endRsg=Msgelseif S(i)==[1 1 0] disp('信息元第3位错'); if Msg(5)==0Msg(5)=1;elseif Msg(5)==1 Msg(5)=0;endRsg=Msgelseif S(i)==[0 1 1] disp('信息元第4位错'); if Msg(6)==0Msg(6)=1;elseif Msg(6)==1 Msg(6)=0;endRsg=Msgelsedisp('无法纠错');Rsg=MsgendendH =1 0 0 1 1 1 00 1 0 0 1 1 10 0 1 1 1 0 1G =1 0 1 1 0 0 0 1 1 1 0 1 0 0 1 1 0 0 0 1 0 0 1 1 0 0 0 1。
基于simulink的(7,4)汉明吗的编码与译码讲解

引言在实际信道中传输数字信号时,由于信道特性不理想及加性噪声的影响,接收端所收到的数字信号不可避免的的会产生错码,影响通信质量。
为了使数字通信系统达到一定的误比特率指标,首先应合理设计基带信号,选择合适的调制方式、解调方式,采用均衡,提高发信功率等,但如果误比特率指标仍不能满足要求,则必须采用信道编码。
信道编码也称差错控制编码或纠错编码,它是提高数字通信系统可靠的重要方法。
1948年,香农在他的开创性论文《通信的数学理论》中首次阐明了在有扰信道中实现可靠通信的方法,提出了著名的有扰信道编码定理,奠定了纠错编码的基石。
如今的纠错编码已有几十年的历史,从早期的线性分组码,BCH码,到后来的RS码、卷积码,级联码、Turbo码;从原来的代数译码,到后来的门限译码、软判决译码,到Viterbi译码等;从注重数学模型、理论研究,到注重纠错编码的使用化问题,并且通过计算机仿真、搜索好码。
无论是从编码方法、译码方法还有研究方法上,纠错编码研究都取得了长足的发展,并广泛应用于各种通信系统。
如今,纠错编码技术已开始渗透带很多领域,如移动通信中大量利用纠错编码,计算机通信系统中也大量应用纠错编码。
汉明码是1950年由Hamming首先构造的,他是一个能够纠正单个错误的线性分组码,即SEC(Sing Error Correcting)码,它不仅性能好,而且编译电路非常简单,易于实现。
从20世纪50年代问世以来,在提高系统可靠性方面获得了广泛的应用。
最先用于磁芯存储器,60年代初用于大型计算机,70年代在MOS存储器得到应用,后来在中小型计算机中普遍采用,目前常用在RFID系统中多位错误的纠正。
汉明码是在原编码的基础上附加一部分代码,使其满足纠错码的条件,原编码我们可将它称为信息码,附加码称为校验码(又可称为监督码或冗余码)。
汉明码的最小码间距为3,所以只能够检测到2个错误或纠正1个错误,编码效率最高。
它属于线性分组码,由于线性码的编码和译码容易实现,至今仍是应用最广泛的一类码。
7-4汉明码

7,4汉明码及8,4扩展汉明码的实现(2012-12-16 15:32:02)分类:FPGA标签:fpga扩展汉明码一、汉明码汉明码是1950 年由美国贝尔实验室提出来的,是第一个设计用来纠正错误的线性分组码,汉明码及其变型已广泛应用于数字通信和数据存储系统中作为差错控制码。
汉明码是一种线性分组码。
线性分组码是指将信息序列划分为长度为k的序列段,在每一段后面附加r位的监督码,且监督码和信息码之间构成线性关系,即它们之间可由线性方程组来联系。
这样构成的抗干扰码称为线性分组码。
编码原理设码长为n,信息位长度为k,监督位长度为r=n-k。
如果需要纠正一位出错,因为长度为n的序列上每一位都可能出错,一共有n种情况,另外还有不出错的情况,所以我们必须用长度为r的监督码表示出n+1种情况。
而长度为r的监督码一共可以表示2^r种情况。
因此2^r>=n+1,即r>=log(n+1)我们以一个例子来说明汉明码。
假设k=4,需要纠正一位错误,则2^r>=n+1=k+r+1=4+r+1解得r>=3。
我们取r=3,则码长为3+4=7。
用a6,a5,...a0表示这7个码元。
用S1,S2,S3表示三个监关系式中的校正子。
我们作如下规定(这个规定是任意的):S1S2S3错码的位置001a0010a1100a2011a3101a4110a5111a6000无错按照表中的规定可知,仅当一个错码位置在a2,a4,a5或a6时校正子S1为1,否则S1为0。
这就意味着a2,a4,a5,a6四个码元构成偶校验关系:S1=a6⊕a5⊕a4⊕a2(1)式同理,可以得到:S2=a6⊕a5⊕a3⊕a1(2)式S3=a6⊕a4⊕a3⊕a0(3)式在发送信号时,信息位a6,a5,a4,a3的值取决于输入信号,是随机的。
监督为a2,a1,a0应该根据信息位的取值按照监督关系决定,即监督位的取值应该使上述(1)(2)(3)式中的S1,S2,S3为0,这表示初始情况下没有错码。
通原实验课设(7、4汉明码)

西安工业大学现代通信原理实验课程设计报告题目:(7,4)汉明码编译码系统CPLD实现系(部):电子信息工程学院专业:电子信息工程班级:姓名:学号:2011 年5 月29 日1[设计目的]通过本课程设计巩固并扩展通信原理课程的基本概念、基本理论、分析方法和实现方法。
结合EDA技术、数字通信技术和微电子技术,学习现代数字通信系统的建模和设计方法,使学生能有效地将理论和实际紧密结合,培养创新思维和设计能力,增强软件编程实现能力和解决实际问题的能力。
⑴熟悉数字电路设计的一般方法,熟练地运用通信理论,进行数字基带信号、数字信号频带传输系统设计,掌握对数字基带信号的处理方法,并进行通信系统建模。
⑵熟悉和掌握QUARTUS软件的使用,按设计要求进行建模;⑶设计完成后,按学校规范统一书写格式撰写课程设计报告一份,包括:设计目的、设计要求、逻辑分析、设计总体电路、模块设计、模块程序(含对程序的说明)、仿真波形、实验结果分析、心得体会(不少于500字)、参考文献(不少于5篇)等。
3. [逻辑分析](7,4)汉明码的编码思路分析(7,4)汉明码的编码就是将输入的四位信息码编成七位的汉明码,即加入三位监督位。
根据式(2.2.0)A = [a6 a5a4a3] ·G可知,信息码与生成矩阵G的乘积就是编好以后的(7,4)汉明码,而生成矩阵G又是已知的,由式(1.1.9)得1 0 0 0 1 1 1G = 0 1 0 0 1 1 00 0 1 0 1 0 10 0 0 1 0 1 1所以,可以得出如下方程组a6 = a6a5 = a5a4 = a4a3 = a3a2 = a6+ a5+ a4a1 = a6+ a5+ a3a0 = a6+ a4+ a3根据上式就可以编出编码程序了。
2. [设计要求](7,4)汉明码的编码程序设计根据(7,4)汉明码的编码原理,首先画出程序设计的流程图:编码流程图输入信息码a 3a 2a 1a 0,输出(7,4)汉明码b 6b 5b 4b 3b 2b 1b 0。
(完整版)(7,4)汉明码编译码程序说明

(7,4)汉明码编译码原理程序说明书1、线性分组码假设信源输出为一系列二进制数字0和1.在分组码中,这些二进制信息序列分成固定长度的消息分组(message blocks )。
每个消息分组记为u ,由k 个信息位组成。
因此共有2k 种不同的消息。
编码器按照一定的规则将输入的消息u 转换为二进制n 维向量v ,这里n>k 。
此n 维向量v 就叫做消息u 的码字(codeword )或码向量(code vector )。
因此,对应于2k 种不同的消息,也有2k 种码字。
这2k 个码字的集合就叫一个分组码(block code )。
一个长度为n ,有2k 个码字的分组码,当且仅当其2k 个码字构成域GF (2)上所有n维向量空间的一个k 维子空间时被称为线性(linear )(n ,k )码。
对于线性分组码,希望它具有相应的系统结构(systematic structure ),其码字可分为消息部分和冗余校验部分两个部分。
消息部分由k 个未经改变的原始信息位构成,冗余校验部分则是n-k 个奇偶校验位(parity-check )位,这些位是信息位的线性和(linear sums )。
具有这样的结构的线性分组码被称为线性系统分组码(linear systematic block code )。
本实验以(7,4)汉明码的编译码来具体说明线性系统分组码的特性。
其主要参数如下:码长:21mn =-信息位:21mk m =-- 校验位:m n k =-,且3m ≥ 最小距离:min 03d d ==由于一个(n ,k )的线性码C 是所有二进制n 维向量组成的向量空间n V 的一个k 维子空间,则可以找到k 个线性独立的码字,0,1,1k g g g -…… ,使得C 中的每个码字v 都是这k 个码字的一种线性组合。
(7,4)汉明码的生成矩阵如下,前三位为冗余校验部分,后四位为消息部分。
0123 1 1 0 1 0 0 00 1 1 0 1 0 01 1 1 0 0 1 01 0 1 0 0 0 1g g G g g ⎧⎫⎧⎫⎪⎪⎪⎪⎪⎪⎪⎪==⎨⎬⎨⎬⎪⎪⎪⎪⎪⎪⎪⎪⎩⎭⎩⎭如果()0123u u u u u =是待编码的消息序列,则相应的码字可如下给出:()0101230011223323g g v u G u u u u u g u g u g u g g g ⎧⎫⎪⎪⎪⎪===+++⎨⎬⎪⎪⎪⎪⎩⎭编码结构即码字()0123456v v v v v v v v =,对于(7,4)线性分组码汉明码而言,3456,,,v v v v 为所提供的消息序列,而0356v v v v =⊕⊕,1345v v v v =⊕⊕,2456v v v v =⊕⊕。
基于matlab的(7.4)汉明码编译码仿真.

I
1.引言
MATLAB(Matrix Laboratory,矩阵实验室是Mathwork公司推出的一套高效率的数值计算和可视化软件。其中,MATLAB通信工具箱是一套用于在通信领域进行理论研究、系统开发、分析设计和仿真的专业化工具软件包。MATIAB通信工具箱由两大部分组成:通信系统功能函数库和SIMULINK通信系统仿真模型库。
规定如表1所列。
表1校正子和错码位置的关系
则由表1可得监督关系式: 16542s a a a a =⊕⊕⊕ (2
2653s a a a a =⊕⊕⊕ (3 36430s a a a a =⊕⊕⊕ (4
在发送端编码时,信息位6543a a a a的值决定于输入信号,因此它们是随机的。
监督位2a、1a、0a应根据信息位的取值按监督关系来确定,即监督位应使式(2~式(4中1s、2s、3s的值为0(表示编成的码组中应无错码
1
0001
000
1r I ⎡⎤⎢⎥=⎢
⎥⎢⎥⎣⎦
所以有
[]
r H PI = (9
式(6等价于
[][][]2106
54
3654
3111110101011a a a a a a a a a a a Q
⎡⎤⎢⎥
⎢
⎥==⎢⎥⎢⎥⎣⎦
(10
其中Q为P的转置,即
T Q P = (11
式(10表示,信息位给定后,用信息位的行矩阵乘矩阵Q就产生出监督位。我们将Q的左边加上一个k ×k阶单位方阵,就构成一个矩阵G
21r n -≥或211r
k r -≥++ (1
下面以(7,4汉明码为例说明原理:
设汉明码(n,k中k=4,为了纠正一位错码,由式(1可知,要求监督位数r ≥3。若取r=3,则n=k+r=7。我们用6543210a a a a a a a来表示这7个码元,用123s s s的
74汉明码编码原理

74汉明码编码原理汉明码(Hamming Code)是一种用于检错和纠错的编码方式。
它是由美国数学家理查德·汉明(Richard Hamming)在1950年提出的。
汉明码的设计目标是,通过在发送的数据中附加冗余位(校验位)来检测和纠正传输错误。
汉明码的原理是利用了冗余位与数据位之间的异或运算。
在汉明码编码中,将n个数据位编码为m个码字,其中m>n,并在码字中加入冗余位。
通过校验位的计算与比较,可以检测错误的发生位置,并进行纠正,使得接收方可以准确地恢复原始数据。
汉明码的编码过程如下:1.确定数据位的数量n和校验位的数量m。
汉明码要求数据位的数量n加上校验位的数量m等于码字的位数,即m+n=k,其中k是码字的位数。
2.确定校验位的位置。
校验位的位置有两种方式:水平位置和垂直位置。
在水平位置编码中,校验位出现在码字的最左边,依次向右排列。
在垂直位置编码中,校验位出现在码字的最上方,依次向下排列。
3.计算校验位的值。
校验位的计算方法是使得每个校验位对应的数据位加上校验位的数量等于偶数个1例如,对于一个校验位对应两个数据位的汉明码,校验位的值是根据对应的两个数据位的奇偶性进行计算的。
若两个数据位中1的个数为奇数,则校验位的值为1;若两个数据位中1的个数为偶数,则校验位的值为0。
4.将数据位和校验位合并形成码字。
将数据位和校验位按照一定的顺序合并形成码字。
合并的方式可以采用水平合并或垂直合并。
5.发送码字。
将编码后的码字发送给接收方。
汉明码的解码过程如下:1.接收码字。
接收方接收到发送方发送的码字。
2.计算校验位的值。
对接收到的码字,按照相同的校验位计算方法重新计算校验位的值。
3.比较校验位的值。
将接收到的校验位的值与重新计算得到的校验位的值进行比较,如果两者不一致,则说明发生了错误。
4.纠正错误。
如果发现错误发生,则根据校验位的位置和计算出的校验位值,确定错误的位置,并进行纠正。
5.提取数据位。
通信原理设计报告(7-4)汉明码的编解码设计

当S=000时,则无错。
第4章(7,4)汉明码编码器旳设计
4.1(7,4)汉明码编码措施
(7,4)汉明码旳编码就是将输入旳4位信息码M=[ ]加上3位监督码 从而编成7位汉明码[ ],编码输出B=[ ].由式A = M·G=[ ]·G可知,信息码M与生成矩阵G旳乘积就
(3)VHDL语句旳行为描述能力和程序构造决定了他具有支持大规模设计旳分解和已有设计旳再运用功能。符合市场需求旳大规模系统高效,高速旳完毕必须有多人甚至多种代发组共同并行工作才干实现。
(4)对于用VHDL完毕旳一种拟定旳设计,可以运用EDA工具进行逻辑综合和优化,并自动旳把VHDL描述设计转变成门级网表。
使用组合编译方式可一次完毕整体设计流程。
自动定位编译错误、
高效旳器件编程与验证工具。
可读入原则旳EDIF网表文献、VHDL网表文献和Verilog网表文献。
能生成第三方EDA软件使用旳VHDL网表文献和Verilog网表文献。
●VHDL语言
VHDL语言重要用于描述数字系统旳构造、行为、功能和接口,除了具有许多具有硬件特性旳语句外,VHDL旳语言形式和描述风格与句法是十分类似于一
体会与建议.......................................................19
附录..............................................................20
前言
汉明(Hamming)码是一种可以纠正一位错码或检测两位错码旳一种效率较高旳线性分组码。本次课程设计旳任务就是运用EDA技术在Quartus II软件下用VHDL语言实现(7,4)汉明码旳编译码旳设计和仿真。从而进一步加深对汉明码编译码原理旳理解。
对语音进行74汉明码编译码

对语音进行74汉明码编译码汉明码是一种用于检错的编码方式,常用于数据传输和存储领域。
它可以通过在数据中添加冗余的校验位来检测和纠正传输或存储过程中出现的错误。
汉明码的编码过程如下:1. 确定要传输的数据。
假设我们要传输一个k位的消息。
2. 确定校验位的数量。
校验位的数量r可以通过以下公式进行计算:2^r >= k + r + 1。
这个公式确保了校验位足够多以检测和纠正错误。
3. 将数据位和校验位进行排列。
将k位的数据位和r位的校验位按照某种方式进行排列。
一种常见的排列方式是将校验位插入到数据位的特定位置。
4. 计算校验位的值。
校验位的值可以通过以下步骤来计算:a. 将每一个校验位作为一个索引。
b. 对于每一个校验位,将目标位中索引所指的位进行异或运算。
c. 将异或结果作为校验位的值。
5. 将数据位和校验位传输或存储。
汉明码的解码过程如下:1. 接收数据位和校验位。
2. 计算每一个校验位的值。
校验位的值可以通过以下步骤来计算:a. 将每一个校验位作为一个索引。
b. 对于每一个校验位,将接收到的数据位中索引所指的位进行异或运算。
c. 将异或结果作为校验位的值。
3. 比较计算得到的校验位的值与接收到的校验位的值。
如果两者相等,则说明传输或存储过程中没有错误发生。
如果两者不相等,则说明可能存在错误。
4. 如果存在错误,根据所在位置的校验位的索引,进行纠正。
将该位的值进行翻转即可。
需要注意的是,汉明码可以检测错误的位置,并在发生错误时进行纠正,但是它有限制和缺陷。
它只能检测和纠正1位的错误,并且无法检测多位错误。
此外,汉明码的编码和解码过程相对复杂,可能会增加传输或存储的开销。
总结起来,汉明码是一种用于检错的编码方式,可以在数据传输或存储过程中检测和纠正错误。
通过添加校验位并进行异或运算,可以实现错误的检测和纠正。
然而,汉明码只能检测和纠正1位的错误,且编码和解码过程相对复杂。
74汉明码卷积码编码和译码程序

《差错控制编码》编译码作业说明文档学号: 2012211502 学生姓名:李小喜邮箱:lixiaoxi@专业班级:通信工程12-1班完成地点:逸夫楼406室提交时间: 2014年12月22日计算机与信息学院通信工程系前言笔者共花费了大约三周的时间来完成此次的编译码程序,所有程序均为原创,基于VC6.0,若有疑问可随时通过以上邮箱联系本人。
本次提交的编译码作业主要可分为四个部分:分别包括7-4汉明码的简单的编译码、利用7-4汉明码对文本文档的编译码、卷积码的简单的编译码和利用卷积码对文本文档的编译码。
首先是7-4汉明码的简单的编译码程序,是利用生成矩阵和校验矩阵来实现编码和得到矫正子的,比直接利用信息位来获得校验位再和信息位组合成七位码字的方法复杂一些。
其次是在简单汉明码的编译码上提升了一个层次,实现了对一个由ASCII码组成的文本文档进行编码,并最终译码出原文档,该程序原则上只能处理英文的字符,但经验证发现也可以处理中文,它是把中文字符当做两个ASCII来处理的,深层原因笔者并未深究。
然后就是(2,1,3)卷积码的简单的编译码程序,其中译码程序是采用Viterbi译码,也就是利用网格图采用最小汉明距离译码,本程序适用的是(2,1,3)卷积码,寄存器有8个状态,要比(2,1,2)卷积码或(3,1,2)卷积码要复杂的多,它们只有4个状态。
最后是利用(2,1,3)卷积码对文本文档进行处理。
由于能力和课程时间的限制,此次作业难免有“不够人性化”“考虑不周”“报告格式不严谨”等等小错误,欢迎提出指正,望谅解。
目录前言 (2)17-4汉明码简单的编译码 (4)1.1操作说明 (4)1.2程序详细设计 (4)1.3附C++源代码 (6)2利用7-4汉明码处理文档 (8)2.1操作说明 (8)2.2程序详细设计 (8)2.3附源代码 (9)3 (2,1,3)卷积码的简单编译码 (13)3.1操作说明 (13)3.2程序详细设计 (13)3.3附C++源代码 (17)4 利用(2,1,3)卷积码处理文档 (22)4.1操作说明 (22)4.2程序详细设计 (22)4.3附C++源代码 (23)5 参考文献 (30)17-4汉明码简单的编译码1.1操作说明输入待编码序列或输入待译码序列时,应该按照“1 0 0 1”或“1 1 1 0 1 0”的格式输入二进制序列,因为程序中是使用数组保存的。
汉明码编码译码实验报告(信息论与编码)及源程序

}
printf("经过译码后变为: \n");
for(i=0;i<N/4;i++)
{for(j=0;j<3;j++)
{f[j]=0;
for(k=A;k<A+7;k++)
f[j]+=w[k]*H[k-A][j];/////计算伴随式
}
for(m=0;m<7;m++)
{for(j=0;j<3;j++)
printf("%d",ww[A+m]);//没有出错的地方
}
}
A=A+7;//向后移动7位
L=8;//复位
M=0;///清零,复位
printf("\n");
}
}
4
5
这次的实验是实现汉明码的编码与译码,达到纠错功能。通过信息论的课程,我基本了解了汉明码编译的原理和方法,但在编程的过程中遇到了不小的困难。首先还是理解汉明码概念的问题,因为还存在纠错的功能,所以汉明码的编码方式和以前学的哈夫曼编码或Fano编码比起来要复杂不少,开始的时候理解起来有些困难。不过通过仔细看PPT,很快就弄懂了汉明码的原理。但是最开始编出来的程序运行的结果总是不正确,和书上的码字不一样,后来发现是在校验矩阵上出了问题,自己对矩阵方面的知识一直把握得不是很好。经过调试,程序很快就能够正确运行了。
if((f[j]%2)==H[m][j])M=M+1;
if(M==3)L=m ;
M=0;//清零
} ///根据伴随式找到出错的位置
for(m=0;m<7;m{ww[A+m]=(w[A+m]+1)%2;//将出错的地方更正
汉明码的编码和译码(含有源程序)

目录序言 (1)第1章 QuartusⅡ与VHDL简介 (2)1.1 QuartusⅡ软件简介 (2)1.2 VHDL简介 (3)第2章 (7,4)汉明码的原理 (4)2.1 基本概念 (4)2.2 监督矩阵H.. 52.3 生成矩阵G.. 52.4 伴随式(校正子)S. 6第3章 (7,4)汉明码编解码器的设计 (7)3.1 (7,4)汉明码的编码思路及程序设计 (7)3.1.1 (7,4)汉明码的编码思路 (7)3.1.2 (7,4)汉明码的编码程序设计 (7)3.2 (7,4)汉明码的译码思路及程序设计 (8)3.2.1 (7,4)汉明码的译码思路 (8)3.2.2 (7,4)汉明码的译码程序设计 (10)第4章编译程序的调试与分析 (12)4.1 (7,4)汉明码的编码程序调试与分析 (12)4.1.1 (7,4)汉明码的编码程序的编译 (12)4.1.2 (7,4)汉明码的编码程序的仿真分析 (12)4.2 (7,4)汉明码的编译码程序分析及调试 (13)4.2.1 (7,4)汉明码的译码程序的编译 (13)4.2.2 (7,4)汉明码的译码程序的仿真分析 (13)参考文献 (15)体会与建议 (16)附录 (17)序言EDA ( Elect ronics Design Automation) 技术是随着集成电路和计算机技术飞速发展应运而生的一种高级、快速、有效的电子设计自动化工具。
目前,VHDL语言已经成为EDA的关键技术之一,VHDL 是一种全方位的硬件描述语言,具有极强的描述能力,能支持系统行为级、寄存器传输级和逻辑门级三个不同层次的设计,支持结构、数据流、行为三种描述形式的混合描述,覆盖面广,抽象能力强,因此在实际应用中越来越广泛。
VHDL语言具有功能强大的语言结构,可用明确的代码描述复杂的控制逻辑设计,并且具有多层次的设计描述功能,支持设计库和可重复使用的元件的生成。
近几十年来,EDA技术获得了飞速发展。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
(7,4)汉明码编译码原理程序说明书1、线性分组码假设信源输出为一系列二进制数字0和1.在分组码中,这些二进制信息序列分成固定长度的消息分组(message blocks )。
每个消息分组记为u ,由k 个信息位组成。
因此共有2k 种不同的消息。
编码器按照一定的规则将输入的消息u 转换为二进制n 维向量v ,这里n>k 。
此n 维向量v 就叫做消息u 的码字(codeword )或码向量(code vector )。
因此,对应于2k 种不同的消息,也有2k 种码字。
这2k 个码字的集合就叫一个分组码(block code )。
一个长度为n ,有2k 个码字的分组码,当且仅当其2k 个码字构成域GF (2)上所有n维向量空间的一个k 维子空间时被称为线性(linear )(n ,k )码。
对于线性分组码,希望它具有相应的系统结构(systematic structure ),其码字可分为消息部分和冗余校验部分两个部分。
消息部分由k 个未经改变的原始信息位构成,冗余校验部分则是n-k 个奇偶校验位(parity-check )位,这些位是信息位的线性和(linear sums )。
具有这样的结构的线性分组码被称为线性系统分组码(linear systematic block code )。
本实验以(7,4)汉明码的编译码来具体说明线性系统分组码的特性。
其主要参数如下:码长:21mn =-信息位:21mk m =-- 校验位:m n k =-,且3m ≥ 最小距离:min 03d d ==由于一个(n ,k )的线性码C 是所有二进制n 维向量组成的向量空间n V 的一个k 维子空间,则可以找到k 个线性独立的码字,0,1,1k g g g -…… ,使得C 中的每个码字v 都是这k 个码字的一种线性组合。
(7,4)汉明码的生成矩阵如下,前三位为冗余校验部分,后四位为消息部分。
0123 1 1 0 1 0 0 00 1 1 0 1 0 01 1 1 0 0 1 01 0 1 0 0 0 1g g G g g ⎧⎫⎧⎫⎪⎪⎪⎪⎪⎪⎪⎪==⎨⎬⎨⎬⎪⎪⎪⎪⎪⎪⎪⎪⎩⎭⎩⎭如果()0123u u u u u =是待编码的消息序列,则相应的码字可如下给出:()0101230011223323g g v u G u u u u u g u g u g u g g g ⎧⎫⎪⎪⎪⎪===+++⎨⎬⎪⎪⎪⎪⎩⎭编码结构即码字()0123456v v v v v v v v =,对于(7,4)线性分组码汉明码而言,3456,,,v v v v 为所提供的消息序列,而0356v v v v =⊕⊕,1345v v v v =⊕⊕,2456v v v v =⊕⊕。
由以上关系可以得到(7,4)汉明码的全部码字如下所示:2、用C++编写(7,4)汉明码编译码程序的思路如下: (1)编码程序循环输入待编码消息序列()0123u u u u u =,首先判断输入是否符合输入条件:输入必须是4位0,1序列,共有42种情况。
编码程序如下:(本人水平有限,使用直接赋值的方法,望见笑) for(j=0;j<7;j++) {if(j==3) v[j]= u[0];if(j==4) v[j]= u[1];if(j==5) v[j]= u[2];if(j==6) v[j]= u[3]; if(j==0)v[j]= ((u[0]^u[2])^u[3]); //异或运算 if(j==1)v[j]= ((u[0]^u[1])^u[2]); //异或运算 if(j==2)v[j]= ((u[1]^u[2])^u[3]); //异或运算 cout << v[j] << " "; }cout<<endl;编码的思想为: 30v u =41v u = 52v u =0356v v v v =⊕⊕ 1345v v v v =⊕⊕ 2456v v v v =⊕⊕(2)译码程序:循环输入待译码的码字序列()0123456v v v v v v v v =,第一步判断输入是否符合输入条件:输入必须是7位0,1序列,共有72种情况。
但是72种情况中只有42即16个有效码字,那么第二步则是要判断是否是42即16个有效码字,这也是编码的一个检错方式,利用其奇偶校验矩阵TH ,校正子s ,接收到的码字序列为r ,判断*Ts r H =是否等于0。
若等于0,则证明是有效码字;若不等于0,则证明不属于16个有效码字的一个。
● 奇偶校验矩阵100101101011100010111H ⎧⎫⎪⎪=⎨⎬⎪⎪⎩⎭● 奇偶校验矩阵100010001110011111101TH ⎧⎫⎪⎪⎪⎪⎪⎪⎪⎪=⎨⎬⎪⎪⎪⎪⎪⎪⎪⎪⎩⎭以下为纠错的关键程序:for(j=0;j<3;j++){a=(v[0]*ht[0][j])^(v[1]*ht[1][j])^(v[2]*ht[2][j])^(v[3]*ht[3][j])^(v[4]*ht[4][j])^(v[5]*ht[5][j])^(v[6]*ht[6][j]);result=result+a;}if(result!=0){cout<<"输入的是无效的字码"<<endl;goto loop;}else cout<<"输入字码有效"<<endl;cout<<"您所输入的待译码的码字序列为:";接下来便是译码的两个主要方法:第一个方法为查表法:程序中check_table()函数便是查表法。
第二个方法编码方法便是:系统码直接取信息位译码程序如下:for(j=0;j<4;j++){if(j==0)u[j]= v[3];if(j==1)u[j]= v[4];if(j==2)u[j]= v[5];if(j==3)u[j]= v[6];cout << u[j] << " ";}3、程序附录//(7,4)编译码程序#include <iostream>using namespace std;void check_table();//编码程序int main(){intg[4][7]={{1,1,0,1,0,0,0},{0,1,1,0,1,0,0},{1,1,1,0,0,1,0},{1,0,1,0,0,0,1}};//声明生成矩阵G,即4个线性独立的码字,可以使码本C中的码字v都是这k个码字的一种线性组合,int h[3][7]={{1,0,0,1,0,1,1},{0,1,0,1,1,1,0},{0,0,1,0,1,1,1}};//声明校验矩阵H,int ht[7][3]={{1,0,0},{0,1,0},{0,0,1},{1,1,0},{0,1,1},{1,1,1},{1,0,1}};//声明校验矩阵H的转置矩阵HT(这里的T是H 的上标)int u[4]; //声明待编码的消息序列,即未编码前的信息序列int v[7]; //声明编码后的码字序列//int s[7];int i,j,k;//顺序输入待编码4位信息序列lable: cout<<"请输入4位待编码消息序列:"<<endl;for(i=0;i<4;i++){cin>>u[i];}//判断是否输入正确数据for(i=0;i<4;i++){if((u[0]==0|u[0]==1)&(u[1]==0|u[1]==1)&(u[2]==0|u[2]==1)&(u[3]==0|u[3]==1)) {cout<<"您所输入的待编码消息序列为:";for(i=0;i<4;i++){cout<<u[i];}cout<<endl;}else{cout<<"输入错误!请输入正确的二进制4位0,1信息序列!"<<endl;goto lable;}}cout<<endl;//输出生成矩阵cout <<"(7,4)汉明码的生成矩阵G为:"<<endl;for(i=0;i<4;i++){for(j=0;j<7;j++)cout <<g[i][j]<< " ";cout << endl;}cout << endl;//编码程序//码字的系统结构分为冗余校验部分和消息部分,结构形式:v(x)={v0,v1,v2,v3,v4,v5,v6} //编码序列中v3,v4,v5,v6均为所提供的消息序列,对于(7,4)汉明码:// v0=v3^v5^v6;// v1=v3^v4^v5;// v2=v4^v5^v6; cout<<" 等待编码中…… "<<endl;cout<<"编码成功!编码后的码字序列为:"<<" ";for(j=0;j<7;j++){if(j==3)v[j]= u[0];if(j==4)v[j]= u[1];if(j==5)v[j]= u[2];if(j==6)v[j]= u[3];if(j==0)v[j]= ((u[0]^u[2])^u[3]); //异或运算if(j==1)v[j]= ((u[0]^u[1])^u[2]); //异或运算if(j==2)v[j]= ((u[1]^u[2])^u[3]); //异或运算cout << v[j] << " ";}cout<<endl;//顺序输入7位待译码有效码字序列loop:int a,result=0;cout<<"请输入7位待译码有效的消息序列:"<<endl;for(i=0;i<7;i++){cin>>v[i];}cout<<endl;for(i=0;i<7;i++){cout<<v[i];}//1.判断是否输入正确0,1序列if((v[0]==0|v[0]==1)&(v[1]==0|v[1]==1)&(v[2]==0|v[2]==1)&(v[3]==0|v[3]==1)&(v[4]==0|v[4]==1)&(v[5]==0|v[5]==1)&(v[6]==0|v[6]==1)){cout<<"输入字码合法"<<endl;}else{cout<<"输入错误!请输入正确的二进制7位0,1码字序列!"<<endl;goto loop;}//2.判断是否为有效码字for(j=0;j<3;j++){a=(v[0]*ht[0][j])^(v[1]*ht[1][j])^(v[2]*ht[2][j])^(v[3]*ht[3][j])^(v[4]*ht[4][j])^(v[5]*ht[5][j])^(v[6]*ht[6][j]);result=result+a;}if(result!=0){cout<<"输入的是无效的字码"<<endl;goto loop;}else cout<<"输入字码有效"<<endl;cout<<"您所输入的待译码的码字序列为:";for(i=0;i<7;i++){cout<<v[i];}cout<<endl;//输出校验矩阵Hcout <<"(7,4)汉明码的校验矩阵H为:"<<endl;for(i=0;i<3;i++){for(j=0;j<7;j++)cout <<h[i][j]<< " ";cout << endl;}cout << endl;//输出校验矩阵HT(这里的T为H 的上标,代表转置),目的是为了利用校正子进行编码检测s=r*HT;cout <<"(7,4)汉明码的校验矩阵H的转置矩阵为:"<<endl;for(i=0;i<7;i++){for(j=0;j<3;j++)cout <<ht[i][j]<< " ";cout << endl;}cout << endl;//检错算法check_table();//查表法cout<<"译码方法二:系统码直接取信息位译码 "<<endl;cout<<" 等待译码中…… "<<endl;cout<<"译码成功!译码后的消息序列为:"<<" ";for(j=0;j<4;j++){if(j==0)u[j]= v[3];if(j==1)u[j]= v[4];if(j==2)u[j]= v[5];if(j==3)u[j]= v[6];cout << u[j] << " ";}cout<<endl;system("pause");return 0;}//查表法函数void check_table(){cout<<"译码方法一:查表法"<<endl;cout<<" k=4,n=7的线性分组码的全部码字 "<<endl;cout<<" 消息码字 | 消息码字"<<endl;cout<<"(0000) (0000000) | (0001) (1010001)"<<endl;cout<<"(1000) (1101000) | (1001) (0111001)"<<endl;cout<<"(0100) (0110100) | (0101) (1100101)"<<endl;cout<<"(1100) (1011100) | (1101) (0001101)"<<endl;cout<<"(0010) (1110010) | (0011) (0100011)"<<endl;cout<<"(1010) (0011010) | (1011) (1001011)"<<endl;cout<<"(0110) (1000110) | (0111) (0010111)"<<endl;cout<<"(1110) (0101110) | (1111) (1111111)"<<endl; }运行结果如下:编码结果为:译码结果为:。