JPA技术总结
jparepositoryimplementation原理

jparepositoryimplementation原理JParepository是Spring Data JPA提供的一种抽象接口,用于简化数据库访问和数据持久化的操作。
JParepository实现了一组通用的CRUD (增加、读取、更新和删除)操作,允许开发人员通过定义一个简单的Java接口来实现数据访问,而无需编写具体的数据库访问代码。
JParepository的原理如下:1.定义实体:首先,需要定义一个实体类,用于映射数据库表。
实体类使用注解来标识属性和关系,以便与数据库表字段进行映射。
2. 定义接口:接下来,需要定义一个接口,该接口继承自JParepository。
该接口中可以定义一些通用的CRUD操作方法,如save、findAll、findById等。
可以使用注解来定义查询语句,也可以使用Spring Data JPA中提供的查询方法名称约定来定义查询方法。
3. 实现接口:然后,需要编写一个接口的实现类,以实现接口中定义的方法。
在该实现类中,可以使用Spring Data JPA提供的一组基本的数据库操作方法来执行CRUD操作。
4.注入接口:最后,将该接口的实现类注入到需要访问数据库的服务类中。
通过调用接口中的方法,可以实现对数据库的访问和操作。
JParepository实现的原理是通过Java Persistence API(JPA)和Hibernate来实现数据库访问和数据持久化。
JPA是Java EE的一部分,用于管理对象与关系数据库之间的映射。
Hibernate是一个开源的JPA实现,提供了一组强大的对象-关系映射技术,可以通过配置文件或注解来对实体类和数据库表进行映射。
JParepository实现了数据库访问和数据持久化的抽象,使开发人员可以通过编写简单的接口和方法来实现对数据的操作,而无需关心具体的数据库操作和SQL语句。
Spring Data JPA会根据接口的方法名称和注解来生成SQL语句,并通过Hibernate来执行这些SQL语句。
jpa save方法原理

jpa save方法原理JPA(Java Persistence API)是Java EE平台的一个规范,用于管理Java对象与数据库之间的映射关系。
在JPA中,save方法是用于将一个对象持久化到数据库中的方法。
本文将介绍save方法的原理及其在JPA中的作用。
我们需要了解JPA中的实体类。
在JPA中,实体类是指与数据库表对应的Java类。
JPA通过注解或XML配置的方式,将实体类的属性与数据库表的字段进行映射。
通过这种映射关系,JPA可以实现对象与数据库之间的转换和持久化。
save方法是JPA中一个用于保存对象的方法。
它的原理是将实体对象转换为对应的数据库操作语句,然后通过数据库连接执行这些语句,最终将对象保存到数据库中。
具体而言,save方法的原理包括以下几个步骤:1. 获取实体对象的信息:save方法首先需要获取实体对象的信息,包括对象的类名、属性名和属性值等。
这些信息可以通过反射机制获取。
2. 构建INSERT语句:根据实体对象的信息,save方法会构建一个INSERT语句,用于将实体对象的数据插入到数据库表中。
INSERT 语句包括表名和字段名,以及对应的值。
3. 执行INSERT语句:save方法通过数据库连接执行INSERT语句,将实体对象的数据插入到数据库表中。
在执行INSERT语句之前,需要先建立数据库连接,并将INSERT语句发送给数据库。
4. 返回保存结果:执行INSERT语句后,save方法会返回一个保存结果,用于表示保存操作是否成功。
保存结果可以是一个布尔值或一个表示保存成功的标识。
通过上述步骤,save方法可以将实体对象持久化到数据库中。
在执行保存操作时,JPA会根据实体对象的状态来判断是执行插入操作还是更新操作。
如果实体对象的主键为空,JPA会执行插入操作;如果实体对象的主键不为空,JPA会执行更新操作。
save方法在JPA中的作用非常重要。
通过save方法,我们可以将业务逻辑中的Java对象保存到数据库中,从而实现数据的持久化。
jpa expression 多表达式

JPA是Java持久化API的缩写,是一种用于管理Java应用程序持久化数据的标准。
JPA提供了多种查询方式,其中JPA表达式是一个非常常用的查询方法。
它允许开发人员以一种非常规范的方式编写数据库查询语句,而不需要直接使用SQL语句。
在JPA中,表达式可以用于多表关联查询,通过在实体类之间建立关联关系来实现多表查询。
在使用JPA表达式进行多表查询时,可以使用以下几种方法:1. 使用关联实体类的属性进行查询当实体类之间建立了关联关系时,可以直接使用关联实体类的属性进行查询。
如果有一个订单实体类和一个客户实体类,订单实体类中有一个customer属性,表示该订单所属的客户,那么可以使用customer属性进行查询客户相关的订单信息。
2. 使用连接查询在JPA中,可以使用JOIN关键字进行连接查询,将多个实体类进行关联查询。
如果需要查询订单和客户的相关信息,可以使用连接查询将订单表和客户表进行关联,并根据条件进行筛选。
3. 使用子查询JPA表达式还支持使用子查询进行多表查询。
子查询是指在查询语句中嵌套另一个查询语句,可以根据外部查询的结果来进行内部查询的条件筛选。
使用子查询可以在不使用连接查询的情况下,实现多表的关联查询。
4. 使用Fetch关键字在JPA中,可以使用Fetch关键字来指定查询时关联实体类的加载方式。
通过Fetch关键字,可以指定关联实体类在查询时是立即加载还是延迟加载,从而提高查询的性能。
5. 使用Criteria查询JPA还提供了Criteria查询的方式,通过CriteriaBuilder和CriteriaQuery来构建查询条件,可以实现动态查询、多条件查询等功能,非常灵活。
总结JPA表达式是JPA中进行多表查询的常用方法,通过使用JPA表达式,开发人员可以以一种非常规范的方式编写多表查询语句,而不需要直接使用SQL语句。
在实际开发中,根据业务需求和性能考虑,可以选择适合的多表查询方式,并结合JPA提供的其他查询功能,构建高效、灵活的数据库查询操作。
jparepository save and flush

jparepository save and flushjpaRepository是Spring Data JPA的一部分,提供了一套高级的、面向对象的数据访问抽象。
它简化了与数据库的交互,实现了常见的CRUD操作。
save()和flush()是jpaRepository中经常使用的两个方法,本文将对这两个方法进行详细讨论。
1. save()方法save()方法用于保存或更新实体对象。
它有多种重载形式,可以接受一个实体对象作为参数,也可以接受一个实体对象的集合作为参数。
它的返回值类型可以根据具体的需求选择,常用的有如下几种:- void:不返回任何值,可以通过实体对象的主键来判断操作是否成功。
- T:返回保存或更新后的实体对象,可以通过该对象获取自动生成的主键或其他需要的信息。
- Iterable<T>:返回保存或更新后的实体对象集合。
save()方法的内部实现是通过调用EntityManager的persist()方法来执行持久化操作。
如果实体对象是新创建的(没有ID),那么会进行插入操作;如果实体对象已经存在(有ID),那么会进行更新操作。
2. flush()方法flush()方法用于将持久化上下文(Persistence Context)中的所有挂起的修改操作同步到数据库中。
它的调用方式很简单,只需要通过jpaRepository实例调用flush()方法即可。
flush()方法的主要作用是强制将挂起的修改操作同步到数据库,从而保证数据的一致性。
在实际开发中,可能存在一些需要立即生效的业务场景,比如在保存多个实体对象后立即进行查询操作。
此时,可以使用flush()方法来确保保存操作生效后立即能查询到数据。
另外,flush()方法并不会提交事务,只是将挂起的修改操作同步到数据库中。
如果想要将修改操作提交到数据库并结束当前事务,可以使用@Transactional注解标记事务的边界,或显式调用EntityManager的flush()和commit()方法。
jpa命名规则

jpa命名规则JavaPersistenceAPI(JPA)是JavaEE平台提供的数据库持久化技术。
它通过定义一套灵活、通用的持久性规范,可以让开发人员使用它来管理持久化数据。
在使用JPA进行数据持久化时,要遵守JPA 的命名规则,这些命名规则是持久化操作的基础。
首先,JPA的命名规则规定了数据库表和字段的命名格式。
在JPA 规范中,表的命名规则要求使用大写字母加下划线的格式,例如:USER_INFO,字段必须以小写字母开始,每个单词之间使用下划线分隔,例如:user_name。
其次,JPA还规定了实体类的命名规则。
在JPA中,实体类应该以一般的单词作为名称,使用驼峰命名规则,首字母应该大写,每个单词的首字母应该大写,例如:UserInfo。
还有,JPA规定实体类中的属性也要遵循特定的命名规则,属性的名称也应该使用驼峰命名法,属性的第一个字母应该小写,每个单词的首字母应该大写,例如:userName。
此外,JPA还是规定一些其它的字段命名规则,例如,主键字段应该以id或者ID开头,外键字段应该以外键名称开头,例如:userId;外键字段的类型应该定义为外键引用的实体类的类型,而不是其他类型;字段的命名应该有语义,而不是使用乱七八糟的字符。
最后,JPA还规定了实体类和其他类之间映射关系的命名规则。
在JPA中,实体类之间映射关系具有一定的规律性,通常情况下,一个实体类名称加一个`s`就可以得到它与另一个实体类之间映射关系的名称,例如:user_info表与user_role表之间的映射关系名称为usersRoles。
以上就是JPA的命名规则,遵循这些规则可以有效地管理数据库中的数据,从而使程序的代码更加简洁、清晰,而且易于维护和管理。
jpa实现原理

jpa实现原理JPA(Java Persistence API)是Java EE的持久化标准,提供了一种统一的方式,使得开发人员可以方便地进行对象关系映射(ORM)操作。
JPA的实现原理主要包括以下几个方面:1. 实体类的定义:JPA通过注解(如@Entity、@Table等)来标识实体类,并将其映射到数据库表中。
实体类中的属性与数据库表中的字段进行映射。
2. 数据库连接和事务管理:JPA需要通过数据源获取数据库连接,然后使用连接执行SQL语句并操作数据库。
事务管理是保证数据操作的一致性和完整性的重要机制。
3. 对象关系映射:JPA通过配置文件或注解来定义实体类与数据库表之间的映射关系。
对于一对一、一对多、多对多等关联关系,可以使用@OneToOne、@OneToMany、@ManyToMany等注解进行定义。
4. 查询语言:JPA提供了一种面向对象的查询语言JPQL(Java Persistence Query Language),可以通过编写类似于SQL的查询语句来操作数据库。
JPQL将查询结果封装为实体对象,方便开发人员进行操作。
5. 缓存管理:JPA提供了缓存机制,可以将查询结果缓存起来,提高查询性能。
当对数据库进行更新操作时,缓存会相应地进行更新或清除。
6. 对象状态管理:JPA维护了实体对象的状态,包括新增(new)、持久化(managed)、脱管(detached)和删除(removed)等状态。
开发人员可以通过JPA的API对实体对象进行状态管理。
总体而言,JPA的实现原理是通过对象关系映射技术将实体类与数据库表进行映射,并提供了一套API和查询语言来对数据库进行操作和查询。
同时,JPA还提供了事务管理、缓存管理等机制,方便开发人员进行数据持久化操作。
jpa缓存机制

jpa缓存机制JPA缓存机制JPA(Java Persistence API)是Java EE规范中的一部分,用于简化Java应用程序与数据库的交互。
在JPA中,缓存机制是一个重要的特性,它可以提高数据库访问的性能,并减少对数据库的频繁访问。
缓存是一种在内存中存储数据的技术,它可以加快数据的读取速度。
在JPA中,缓存机制可以分为两种类型:一级缓存和二级缓存。
一级缓存是在EntityManager对象的范围内有效的缓存,它存储了应用程序在当前事务中查询的实体对象。
通过使用一级缓存,应用程序可以避免多次查询相同的实体对象,从而提高性能。
一级缓存是默认开启的,不需要额外的配置。
二级缓存是在EntityManagerFactory对象的范围内有效的缓存,它存储了应用程序中所有的实体对象。
通过使用二级缓存,应用程序可以减少对数据库的访问次数,从而提高性能。
二级缓存需要额外的配置,可以使用第三方的缓存提供者,如Ehcache或Redis。
JPA缓存机制的工作原理如下:当应用程序查询实体对象时,首先会检查一级缓存中是否存在该实体对象。
如果存在,则直接返回缓存中的对象;如果不存在,则从数据库中查询该实体对象,并将其存储到一级缓存中。
当应用程序提交事务时,JPA会将一级缓存中的所有实体对象同步到数据库中,保持数据的一致性。
在查询实体对象时,JPA也会检查二级缓存中是否存在该实体对象。
如果存在,则直接返回缓存中的对象;如果不存在,则从数据库中查询该实体对象,并将其存储到二级缓存中。
JPA还提供了一些注解和配置项,用于控制缓存的行为。
例如,可以使用@Cacheable注解标记实体对象,表示该对象可以被缓存。
还可以使用@CacheEvict注解标记方法,表示该方法执行后会清空缓存。
此外,还可以通过配置文件修改缓存的过期时间和大小等参数。
JPA缓存机制的优点包括:1. 提高性能:通过使用缓存,可以减少对数据库的访问次数,从而提高应用程序的性能。
JPA_官方文档
@GeneratedValue:主键的产生策略,通过 strategy 属性指定。默认情况下,JPA 自 动选择一个最适合底层数据库的主键生成策略,如 SqlServer 对应 identity,MySql 对应 auto increment。在 javax.persistence.GenerationType 中定义了以下几种可供选 择的策略:
JOINED:父子类相同的部分保存在同一个表中,不同的部分分开存放,通过表连 接获取完整数据;
TABLE_PER_CLASS:每一个类对应自己的表,一般不推荐采用这种方式。
关联关系
我们再继续对 PollTopic 进行注解,进一步了解实体继承的 JPA 映射定义:
代码清单 3:PollTopic 映射描述
1) IDENTITY:表自增键字段,Oracle 不支持这种方式;
2) AUTO: JPA 自动选择合适的策略,是默认选项;
3) SEQUENCE:通过序列产生主键,通过@SequenceGenerator 注解指定序列名, MySql 不支持这种方式;
4) TABLE:通过表产生主键,框架借由表模拟序列产生主键,使用该策略可以使 应用更易于数据库移植。不同的 JPA 实现商生成的表名是不同的,如 OpenJPA 生 成 openjpa_sequence_table 表 Hibernate 生成一个 hibernate_sequences 表,而 TopLink 则生成 sequence 表。这些表都具有一个序列名和对应值两个字段,如 SEQ_NAME 和 SEQ_COUNT。
JPA 教程
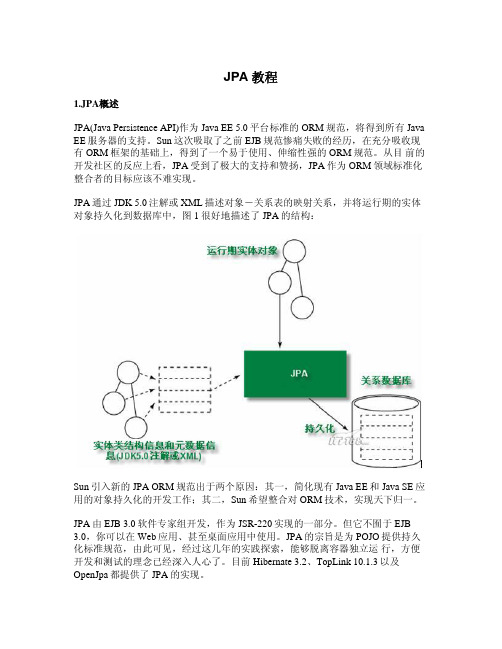
1.JPA概述 JPA(Java Persistence API)作为 Java EE 5.0 平台标准的 ORM 规范,将得到所有 Java EE 服务器的支持。Sun 这次吸取了之前 EJB 规范惨痛失败的经历,在充分吸收现 有 ORM 框架的基础上,得到了一个易于使用、伸缩性强的 ORM 规范。从目 前的 开发社区的反应上看,JPA 受到了极大的支持和赞扬,JPA 作为 ORM 领域标准化 整合者的目标应该不难实现。 JPA 通过 JDK 5.0 注解或 XML 描述对象-关系表的映射关系,并将运行期的实体 对象持久化到数据库中,图 1 很好地描述了 JPA 的结构:
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
EntityManager em=getEntityManagerFactory().createEntityManager(); try { Query q=em.createQuery("select ac from RcAccount ac",RcAccount.class); List<RcAccount> acList=q.getResultList(); for (int i=0;i<acList.size();i++) { ….. ….. } } finally { em.close(); }
可以在EntityManager中设置该参数,如下:
em.setProperty( "javax.persistence.cache.retrieveMode", CacheRetrieveMode.BYPASS);
也可以在具体的提取数据操作中设置该参数,如下:
// Before executing a query: query.setHint("javax.persistence.cache.retrieveMode", CacheRetrieveMode.BYPASS); // For retrieval by type and primary key: em.find(MyEntity2.class, Long.valueOf(1), Collections.<String,Object>singletonMap( "javax.persistence.cache.retrieveMode", CacheRetrieveMode.BYPASS));
JPA中,对象的状态有多个状态: •新建(New)状态 新建( 新建 )状态:当对象用new操作符创建时,对象处于该状态,此时,对象不受任何管理。 •被管理(Managed)状态 被管理( 被管理 )状态:当新建(New)或已被删除(Removed)的对象被持久化(persist)后,即处于被管理 的状态,此外,经由EntityManager从数据库中获取(retrieve,find ,query……)的对象也处于被管理状态。调用 EntityManager对象的 对象的contains(entity)方法来判别对象处于被管理(Managed)状态,非Managed状态的对象均返 对象的 状态的对象均返 回false,代码如下: Boolean isManaged = em.contains(employee); •已删除 已删除(Removed)状态 状态:当被管理的(Managed)的对象被删除(remove)后,即处于此状态。 已删除 状态 •脱管(Detached)状态 脱管( 脱管 )状态:当EntityManager关闭(lcose)或者清空(clear)时,已删除(Removed)和被管理 (Managed)对象的状态变为脱管状态(Detached)。 。 •对所有管理(Managed)状态或者已删除(Removed)状态执行flush或commit命令,则变化会反映到数据库中。
EntityTransaction Persistence EntityManagerFactory EntityManager Query
为给定“名字”的“持 久化单元”创建 EntityManager。 。
其实例代表对数据库的一个连接。 一个数据库连接中最多只能有一个活动的事务 对象—EntityTransaction。 。
JPA的缓存
• • • • persistence context 是所有受EntityManager管理的实体对象的集合。 persistence context 的主要职责就是确保数据库中的实体对象,在同一个EntityManager中,最多只有一个 数据库中的实体对象, 数据库中的实体对象 内存实体对象与之对应。 内存实体对象 每个EntityManager都有自己的persistence context 。同一个数据库实体对象在不同 EntityManager的persistence context中可能有多个内存实体对象与之对应。 中可能有多个内存实体对象与之对应。 中可能有多个内存实体对象与之对应 persistence context范围内的内存实体对象是一级缓存 范围内的内存实体对象是一级缓存(Leve1)。 范围内的内存实体对象是一级缓存 。 EntityManagerFactory创建的所有EntityManager都共享的缓存就是二级缓存。二级缓存 也被称为”共享缓存( sharedCache )” 。 EntityManagerFactory EntityManager 创建 私有 Shared Cache persistence context EntityManager 1 一级缓存(必须) 二级缓存(可配置) 访问 …… EntityManager N 拥有 创建
EntityManagerFactory emf= Persistence.createEntityManagerFactory("JPA_ Hibernate");
EntityManager em = emf.createEntityManager(); try { // TODO: Use the EntityManager to access the database } Finally { em.close(); }
javax.persistence.sharedCache.mode 属性可以设置为以下值: •NONE –不启用缓存. •ENABLE_SELECTIVE – 缓存只对特定的实体类(标注为@Cacheable(true) )起作用。 @Cacheable // or @Cacheable(true) @Entity public class MyCacheableEntityClass { } •DISABLE_SELECTIVE – 缓存只对特定的实体类(标注为@Cacheable(false) )不起作用。 @Cacheable(false) @Entity public class MyNonCacheableEntityClass extends MyCacheableEntityClass {}
EntityTransaction Persistence EntityManagerFactory EntityManager Query 持久化配置文件persistence.xml 持久化配置文件
<?xml version="1.0" encoding="UTF-8"?> <persistence version="2.0" xmlns="/xml/ns/persistence" xmlns:xsi="/2001/XMLSchema-instance" xsi:schemaLocation="/xml/ns/persistence 其实例表示对对数据库的 /xml/ns/persistence/persistence_2_0.xsd"> 连接 <persistence-unit name="JPA_Hibernate"> <provider>org.hibernate.ejb.HibernatePersistence</provider> <class>com.neusoft.right.entity.RcAccount</class> <properties> <property name="hibernate.connection.driver_class" value="com.microsoft.sqlserver.jdbc.SQLServerDriver"/> <property name="hibernate.connection.url" value="jdbc:sqlserver://localhost:1433;DatabaseName=BS_DLERP;SelectMethod=Cursor"/> <property name="ername" value="sa"/> <property name="hibernate.connection.password" value="111111"/> <property name="hibernate.dialect" value="org.hibernate.dialect.SQLServerDialect"/> <property name="hibernate.show_sql" value="true"/> </properties> </persistence-unit> <persistence-unit name="JPA_OpenJPA"> …….. </persistence-unit> </persistence>
实体类定义和使Βιβλιοθήκη —实体类实体类就是普通的Java类,其实例可以被持久化到数据库中,声明实体类最简单的办法就 是使用Entity 注解。如下:
import javax.persistence.Entity; @Entity public class MyEntity { }
JPA对实体类要求如下: 对实体类要求如下: 对实体类要求如下 1.是一个顶级类,不能是嵌入类。 2.必须有一个public 或protected 的无参数构造函数。 3. 不能声明为final,也不能有final 方法或者 final 实例变量.