北邮数据结构平衡二叉树报告概论
北邮数据结构实验报告

北邮数据结构实验报告北京邮电大学信息与通信工程学院2009级数据结构实验报告实验名称:实验三哈夫曼编/解码器的实现学生姓名:陈聪捷日期:2010年11月28日1.实验要求一、实验目的:了解哈夫曼树的思想和相关概念;二、实验内容:利用二叉树结构实现哈夫曼编/解码器1.初始化:能够对输入的任意长度的字符串s进行统计,统计每个字符的频度,并建立哈夫曼树。
2.建立编码表:利用已经建好的哈夫曼树进行编码,并将每个字符的编码输出。
3.编码:根据编码表对输入的字符串进行编码,并将编码后的字符串输出。
4.译码:利用已经建好的哈夫曼树对编码后的字符串进行译码,并输出译码结果。
5.打印:以直观的方式打印哈夫曼树。
6.计算输入的字符串编码前和编码后的长度,并进行分析,讨论哈夫曼编码的压缩效果。
7.用户界面可以设计成“菜单”方式,能进行交互,根据输入的字符串中每个字符出现的次数统计频度,对没有出现的字符一律不用编码。
2.程序分析2.1存储结构二叉树templateclassBiTree{public:BiTree();//构造函数,其前序序列由键盘输入~BiTree(void);//析构函数BiNode*Getroot();//获得指向根结点的指针protected:BiNode*root;//指向根结点的头指针};//声明类BiTree及定义结构BiNodeData:二叉树是由一个根结点和两棵互不相交的左右子树构成data:HCode*HCodeTable;//编码表inttSize;//编码表中的总字符数二叉树的节点结构templatestructBiNode//二叉树的结点结构{Tdata;//记录数据Tlchild;//左孩子Trchild;//右孩子Tparent;//双亲};编码表的节点结构structHCode{chardata;//编码表中的字符charcode[100];//该字符对应的编码};待编码字符串由键盘输入,输入时用链表存储,链表节点为structNode{charcharacter;//输入的字符unsignedintcount;//该字符的权值boolused;//建立树的时候该字符是否使用过Node*next;//保存下一个节点的地址};示意图:2.2关键算法分析1.初始化函数(voidHuffmanTree::Init(stringInput))算法伪代码:1.初始化链表的头结点2.获得输入字符串的第一个字符,并将其插入到链表尾部,n=1(n 记录的是链表中字符的个数)3.从字符串第2个字符开始,逐个取出字符串中的字符3.1将当前取出的字符与链表中已经存在的字符逐个比较,如果当前取出的字符与链表中已经存在的某个字符相同,则链表中该字符的权值加1。
数据结构中平衡二叉树的定义

数据结构中平衡二叉树的定义平衡二叉树?哎呦,这个名字一听就让人有点晕,搞得我差点以为是个什么高深的数学公式,其实不然,它就是一种数据结构。
你想象一下,平衡二叉树就像一个超级讲究的家庭,每个人都必须保持“平衡”,不然就容易乱套。
这个家庭的成员,或者说是“节点”,总共有两个子节点,而且它们的“家务活”分配要特别均匀,不能有一个子节点忙得像打了鸡血,另一个却轻松得像度假。
说白了,平衡二叉树就是告诉你,“兄弟姐妹”们得公平分工,不能让某个“孩子”走得太远,另一个就被落下。
我们得弄清楚什么是“二叉树”。
嘿,其实二叉树就是每个节点最多只能有两个子节点的树形结构,简单点说,就是每个人最多只能有两个“孩子”,并且这两个“孩子”得排排坐,不能一个高一个矮,那样看起来就不和谐了。
可要是左边的“孩子”特别高,右边的又短得跟个小矮人一样,那也不行,得保持两边差不多高。
嘿,听起来像什么?就像家里有两个孩子,一个高得过头,一个低得不行,结果谁都不开心。
平衡二叉树特别讲究左右子树的“差距”。
差距得控制在一定范围内,通常说是不能超过1。
就是说,如果左边的子树高出了1层,右边的子树就不能高出2层。
否则呢,这个二叉树就不平衡了,像你站在一只跛脚的板凳上,随时可能摔倒。
再简单点说,平衡二叉树就像我们家常见的“八仙过海,各显神通”,每个节点都有各自的位置和作用,位置偏离太多就得重新调整调整,确保大家的体力和位置保持均衡。
有的朋友可能会问,既然这么讲究“平衡”,那它怎么判断自己是否平衡呢?嘿,这里就要用到一个神奇的“高度差”了。
我们通常用每个节点的左右子树的高度差来判断。
如果某个节点的左右子树的高度差超过了1,说明它就失去平衡了。
那么我们该怎么办呢?就像你掉进了泥潭,要不是用力蹬两下,要不就是找人来拉一把,二叉树也是一样,得“旋转”一下才能恢复平衡。
平衡二叉树一旦出现不平衡,就得做旋转操作。
别想歪了,旋转不是让树开个舞会,而是指用一种特别的方式重新安排节点的位置。
北邮数据结构平衡二叉树报告概论

数据结构实验报告实验名称:平衡二叉树1.实验目的和内容根据平衡二叉树的抽象数据类型的定义,使用二叉链表实现一个平衡二叉树。
二叉树的基本功能:1、平衡二叉树的建立2、平衡二叉树的查找3、平衡二叉树的插入4、平衡二叉树的删除5、平衡二叉树的销毁6、其他:自定义操作编写测试main()函数测试平衡二叉树的正确性。
2. 程序分析2.1 存储结构struct node{int key; //值int height; //这个结点的父节点在这枝最长路径上的结点个数node *left; //左孩子指针node *right; //右孩子指针node(int k){ key = k; left = right = 0; height = 1; } //构造函数};2.2 程序流程2.3 关键算法分析(由于函数过多,在此只挑选部分重要函数)算法1:void AVL_Tree::left_rotate(node *&x)[1] 算法功能:对 R-R型进行调整[2] 算法基本思想:将结点右孩子进行逆时针旋转[3] 算法空间、时间复杂度分析:都为0(1)[4] 代码逻辑node *y = x->right; y为x的右孩子x->right = y->left; 将y的左孩子赋给x的右孩子 y->left = x; x变为y的左孩子fixheight(x); 修正x,y的height值fixheight(y);x = y; 使x的父节点指向y 算法2:void A VL_Tree::right_rotate(node *&x)[1] 算法功能:对L-L型进行调整[2] 算法基本思想:将左孩子进行顺时针旋转[3] 算法空间、时间复杂度分析:都为0(1)[4] 代码逻辑node *y = x->left; //y为x的左孩子 x->left = y->right; y的右孩子赋给x的左孩子y->right = x; x变为y的右孩子fixheight(x); 修正x和y的height值fixheight(y);x = y; 使x的父节点指向y算法3:node*& A VL_Tree::balance(node *&p)[1] 算法功能:对给定结点进行平衡操作[2] 算法基本思想:通过平衡因子判断属于哪种情况,再依照情况进行平衡[3] 算法空间、时间复杂度分析:没有递归和循环,都为O(1)[4] 代码逻辑fixheight(p); //修正P的height值if (bfactor(p) == 2) 平衡因子为2,为L-?型if (bfactor(p->left) < 0) P的左孩子平衡因子<0时,为L-R型,执行left_rotate(p->left); 相关平衡操作,若>0,为L-L型。
数据结构程序的设计报告(平衡二叉树)

数学与计算机科学学院数据结构程序设计报告平衡二叉树学生姓名:学号:班级:指导老师:报告日期:1.题目与要求1). 问题的提出编写已个平衡二叉树,主要是对插入一个元素导致树不平衡的情况进行平衡化处理以及相关的处理。
2)设计的知识点队列的插入,删除,二叉树的建立于销毁,平衡树的平衡化,以及C语言中基础应用于结构等。
3)功能要求(1).通过不断插入的方式创建一棵平衡二叉树,包括输入结点的关键字和相关信息。
(2)按要求输出创建的平衡二叉树结点,包括顺序(中序)输出和按层次输出。
(3)插入新增的结点,若结点不存在则插入平衡二叉树,并进行相关调整。
(4)销毁二叉树。
(5)退出菜单界面如下:2.功能设计算法设计选择创建平衡二叉树后,利用循环不断插入结点,并进行调整,当输入节点为0时停止进入菜单界面。
在平横二叉树排序树BSTree上插入一个新的数据元素e的递归算法可如下描述:(1)若BSTree为空树,则插入一个数据元素为e的新结点作为BSTree的根结点,树的深度增1;(2)若e的关键字和BSTree的根节点的关键字相等,则不进行插入;(3)若e的关键字小于BSTree的根结点的关键字,而且在其左子树中不存在和e形同的关键字的结点,则将e插入在其左子树上,并且当插入之后的左子树的深度加1时,分别就下列不同情况处理之:a.BSTree的跟结点的平衡因子为-1(右子树的深度大于左子树的深度):则将跟结点的平衡因子更改为0,BBST的深度不变;b.BBST的根结点的平衡因子为0(左,右子树的深度相等):则将根结点的平衡因子更改为1,BBST的深度增1;c.BBST的根结点的平衡因子为1(左子树的深度大于右子树的深度):若BBST的左子树根结点的平衡因子为1,则需进行向左旋平衡处理,并且在右旋之后,将根节点和其右子树根节点的平衡因子更改为0,树的深度不变;若BBST的左子树根结点的平衡因子为-1,则需进行向左,向右的双向旋转平衡处理,并且在旋转处理之后,修改根结点和其左右子树的平衡因子,数的深度不变;(4)若e的关键字大于BBST的根结点的关键字,而且在BBST的右子树中不存在和e有相同的关键字的的节点,则将e插入在BBST的右子树上,并且当插入之后的右子树深度增加(+1)时,分别就不同情况处理之。
平衡二叉树的实现及分析

平衡二叉树的实现及分析平衡二叉树(Balanced Binary Tree),也称为AVL树,是一种自平衡二叉查找树。
它的每个节点都包含一个额外的平衡因子,即左子树的高度减去右子树的高度,取值为-1、0或1、通过维护这个平衡因子,AVL树可以在查找、插入和删除操作中自动保持平衡,从而保证了较高的性能。
AVL树的实现基于二叉查找树(Binary Search Tree),它的插入和删除操作与二叉查找树相同。
然而,当进行插入或删除操作后,AVL树需要通过旋转操作保持平衡,这是AVL树与普通二叉查找树的主要区别。
AVL树的平衡性保证了树的高度不超过O(log n),这使得查找、插入和删除的平均时间复杂度都为O(log n)。
具体而言,当插入或删除操作导致树不再平衡时,需要进行以下四种旋转操作之一来恢复平衡:1. 左旋(Left Rotation):以当前节点为支点,将其右子节点变为新的根节点,并将原根节点作为新根节点的左子节点。
2. 右旋(Right Rotation):以当前节点为支点,将其左子节点变为新的根节点,并将原根节点作为新根节点的右子节点。
3. 左右旋(Left-Right Rotation):先对当前节点的左子节点进行左旋操作,然后再对当前节点进行右旋操作。
4. 右左旋(Right-Left Rotation):先对当前节点的右子节点进行右旋操作,然后再对当前节点进行左旋操作。
具体的实现中,需要对每个节点保存其高度信息。
在进行插入和删除操作时,先按照二叉查找树的规则进行操作,并更新节点的高度信息。
然后,逐级向上检查每个节点的平衡因子,如果平衡因子不在[-1,0,1]的范围内,就进行相应的旋转操作。
完成旋转后,需要更新相关节点的高度信息。
AVL树的平衡性能保证了在最坏情况下的时间复杂度为O(log n),不过由于维护平衡需要进行旋转操作,相对于普通的二叉查找树,AVL树的插入和删除操作可能会较慢一些。
实验报告平衡二叉树

实习报告一、需求分析1、问题描述利用平衡二叉树实现一个动态查找表。
(1)实现动态查找表的三种基本功能:查找、插入和删除。
(2)初始时,平衡二叉树为空树,操作界面给出查找、插入和删除三种操作供选择。
每种操作均要提示输入关键字。
在查找时,如果查找的关键字不存在,则把其插入到平衡二叉树中。
每次插入或删除一个结点后,应更新平衡二叉树的显示。
(3)每次操作的关键字都要从文件中读取,并且关键字的集合限定为短整型数字{1,2,3······},关键字出现的顺序没有限制,允许出现重复的关键字,并对其进行相应的提示。
(4)平衡二叉树的显示采用图形界面画出图形。
2、系统功能打开数据文件,用文件中的关键字来演示平衡二叉树操作的过程。
3、程序中执行的命令包括:(1)(L)oad from data file //在平衡的二叉树中插入关键字;(2)(A)ppend new record //在平衡的二叉树中查找关键字;(3)(U)pate special record //显示调整过的平衡二叉树;(4)(D)elete special record //删除平衡二叉树中的关键字;(5)(Q)uit //结束。
4、测试数据:平衡二叉树为:图 1 插入关键字10之前的平衡二叉树插入关键字:10;调整后:图 2 插入关键字10之后的平衡二叉树删除关键字:14;调整后:图 3 删除关键字14后的平衡二叉树查找关键字:11;输出:The data is here!图 3 查找关键字11后的平衡二叉树二、概要设计本次实验目的是为了实现动态查找表的三种基本功能:查找、插入和删除。
动态查找表可有不同的表示方法,在此次实验中主要是以平衡二叉树的结构来表示实现的,所以需要两个抽象数据类型:动态查找表和二叉树。
1、动态查找表的抽象数据类型定义为:ADT DynamicSearchTable{数据对象D :D是具有相同特性的数据元素的集合。
数据结构二叉树实验报告

数据结构二叉树实验报告二叉树是一种常用的数据结构,它在计算机科学中有着广泛的应用。
本文将介绍二叉树的定义、基本操作以及一些常见的应用场景。
一、二叉树的定义和基本操作二叉树是一种特殊的树形结构,它的每个节点最多有两个子节点。
一个节点的左子节点称为左子树,右子节点称为右子树。
二叉树的示意图如下:```A/ \B C/ \D E```在二叉树中,每个节点可以有零个、一个或两个子节点。
如果一个节点没有子节点,我们称之为叶子节点。
在上面的示例中,节点 D 和 E 是叶子节点。
二叉树的基本操作包括插入节点、删除节点、查找节点和遍历节点。
插入节点操作可以将一个新节点插入到二叉树中的合适位置。
删除节点操作可以将一个指定的节点从二叉树中删除。
查找节点操作可以在二叉树中查找指定的节点。
遍历节点操作可以按照一定的顺序遍历二叉树中的所有节点。
二、二叉树的应用场景二叉树在计算机科学中有着广泛的应用。
下面将介绍一些常见的应用场景。
1. 二叉搜索树二叉搜索树是一种特殊的二叉树,它的每个节点的值都大于其左子树中的节点的值,小于其右子树中的节点的值。
二叉搜索树可以用来实现快速的查找、插入和删除操作。
它在数据库索引、字典等场景中有着重要的应用。
2. 堆堆是一种特殊的二叉树,它的每个节点的值都大于或小于其子节点的值。
堆可以用来实现优先队列,它在任务调度、操作系统中的内存管理等场景中有着重要的应用。
3. 表达式树表达式树是一种用来表示数学表达式的二叉树。
在表达式树中,每个节点可以是操作符或操作数。
表达式树可以用来实现数学表达式的计算,它在编译器、计算器等场景中有着重要的应用。
4. 平衡二叉树平衡二叉树是一种特殊的二叉树,它的左子树和右子树的高度差不超过1。
平衡二叉树可以用来实现高效的查找、插入和删除操作。
它在数据库索引、自平衡搜索树等场景中有着重要的应用。
三、总结二叉树是一种常用的数据结构,它在计算机科学中有着广泛的应用。
本文介绍了二叉树的定义、基本操作以及一些常见的应用场景。
北京邮电大学 数据结构 实验二 二叉树 可视化设计

数据结构实验报告实验名称:实验2——二叉树的构造学生姓名:XXXXNB班级:XXXXXX班内序号:学号:XXXXXXX日期:XXXXXXXX1.实验要求根据二叉树的抽象数据类型的定义,使用二叉链表实现一个二叉树。
二叉树的基本功能:1、二叉树的建立2、前序遍历二叉树3、中序遍历二叉树4、后序遍历二叉树5、按层序遍历二叉树6、求二叉树的深度7、求指定结点到根的路径8、二叉树的销毁9、其他:自定义操作编写测试main()函数测试线性表的正确性2.程序分析2.1 存储结构采用二叉树的存储结构,其中每个二叉树的结点定义了一个结构体,该结构体包含三个元素,分别是一个T 类型的数据域data,一个指向T 类型的指针左孩子,一个指向T 类型的指针右孩子,示意图如图所示:2.2 关键算法分析代码描述:1.构造函数template < class T >void BiTree<T>::Creat(BiNode<T>*&R, T data[], int i,int n)//i表示位置,从1开始,n表示数组长度{if (i <= n&&data[i - 1]){R = new BiNode < T > ;//创建根节点R->data = data[i - 1];Creat(R->LChild, data, 2 * i, n);//创建左子树Creat(R->RChild, data, 2 * i + 1, n);//创建右子树}else R = NULL;}template<class T>BiTree<T>::BiTree(T data[], int n){Creat(Root, data, 1, n);//利用递归循环构造}2.前序遍历//前序遍历,递归template<class T>void BiTree<T>::PreOrder(BiNode<T>*R)//前序遍历,递归//R都是源自于一开始构造所产生的根节点//根->左->右{if (R != NULL){cout << R->data<<" ";//访问结点PreOrder(R->LChild);//遍历左子树PreOrder(R->RChild);//遍历右子树}}//前序遍历,非递归template<class T>void BiTree<T>::PreOrderNormal(BiNode<T>*R)//用栈模板进行非递归操作{stack<BiNode<T>*> s;//结构栈BiNode<T>* p = R;//从根结点开始循环while (p != NULL || !s.empty()){while (p != NULL){cout << p->data << " ";s.push(p);p = p->LChild;//先压栈,再更改指针域}if (!s.empty())//检验栈是否为空,栈为空后,遍历结束{p = s.top();s.pop();p = p->RChild;}}}3.中序遍历//中序遍历,递归template<class T>void BiTree<T>::InOrder(BiNode<T>*R)//左->根->右//递归,中序遍历{if (R != NULL){InOrder(R->LChild);//遍历左子树cout << R->data<<" ";//访问节点InOrder(R->RChild);//遍历右子树}}4.后序遍历//后序遍历,递归template<class T>void BiTree<T>::PostOrder(BiNode<T>*R)//递归,后序遍历//左->右->根{if (R != NULL){PostOrder(R->LChild);//遍历左子树PostOrder(R->RChild);//遍历右子树cout << R->data<<" ";//访问节点}}时间复杂度:O(n)5.层序遍历template<class T>void BiTree<T>::LevelOrder(BiNode<T>*R)//层序遍历{queue<BiNode<T>*> q;BiNode<T>* p = R;//从根结点开始循环if(p!=NULL) q.push(p);while (!q.empty()){p = q.front();cout << p->data<<" ";q.pop();if (p->LChild != NULL) q.push(p->LChild);if (p->RChild != NULL) q.push(p->RChild);}}6.析构函数//析构函数template<class T>void BiTree<T>::Release(BiNode<T>*R){if (R != NULL){Release(R->LChild);//释放左子树Release(R->RChild);//释放右子树delete R;//释放根节点}}template<class T>BiTree<T>::~BiTree(){Release(Root);//释放二叉树}7.求二叉树深度template<class T>int BiTree<T>::Depth(BiNode<T>*R)//输出二叉树的深度{if (R == NULL) return 0;else{int m = Depth(R->LChild);int n = Depth(R->RChild);return m >= n ? m + 1:n + 1;}}时间复杂度:O(n)8.求路径template<class T>bool BiTree<T>::Findpath(BiNode<T>*R, T s)//找出指定元素到根节点的路径{if (R == NULL){return false;}else{if (R->data == s)//当前元素等于e,输出该节点{cout << R->data<<" ";return true;}else if (Findpath(R->LChild, s))//经过该结点的左孩子能到达e,输出该结点{cout << R->data<<" ";return true;}else if (Findpath(R->RChild, s))//经过该结点的右孩子能到达e,输出该结点{cout << R->data << " ";return true;}elsereturn false;}}template<class T>void BiTree<T>::Detect(BiNode<T>*R, T s){if (!(Findpath(R, s))){throw"输入元素有误!";}}3. 程序运行结果主函数流程图:测试截图:初始化二叉树,菜单创建执行功能:4. 总结.调试时出现了一些问题如:异常抛出的处理,书中并未很好的提及异常处理,通过查阅资料,选择用try catch 函数对解决。
数据结构实验报告——树

2008级数据结构实验报告实验名称:实验三树学生姓名:班级:班内序号:学号:日期:2009年11月23日1.实验要求a. 实验目的通过选择两个题目之一进行实现,掌握如下内容:掌握二叉树基本操作的实现方法了解赫夫曼树的思想和相关概念学习使用二叉树解决实际问题的能力b. 实验内容利用二叉树结构实现赫夫曼编/解码器。
基本要求:1、初始化(Init):能够对输入的任意长度的字符串s进行统计,统计每个字符的频度,并建立赫夫曼树2、建立编码表(CreateTable):利用已经建好的赫夫曼树进行编码,并将每个字符的编码输出。
3、编码(Encoding):根据编码表对输入的字符串进行编码,并将编码后的字符串输出。
4、译码(Decoding):利用已经建好的赫夫曼树对编码后的字符串进行译码,并输出译码结果。
5、打印(Print):以直观的方式打印赫夫曼树(选作)6、计算输入的字符串编码前和编码后的长度,并进行分析,讨论赫夫曼编码的压缩效果。
2. 程序分析2.1 存储结构存储结构:二叉树示意图如下:2.2 关键算法分析核心算法思想:1.哈夫曼编码(Huffman Coding)是可变字长编码。
编码时借助哈夫曼树,也即带权路径长度最小的二叉树,来建立编码。
2.哈夫曼编码可以实现无损数据压缩。
单个字符用一个特定长度的位序列替代:在字符串中出现频率高的符号,使用短的位序列,而那些很少出现的符号,则用较长的位序列。
关键算法思想描述和实现:关键算法1:统计字符出现的频度,记录出现的字符及其权值,对未出现的字符不予统计编码。
将统计的叶子节点编制成数组。
为创建哈夫曼树作准备。
C++实现:for(int i=0;str[i]!='\0';i++) //统计频度frequency[(short)str[i]]++;此处以一个一维的下标表示ascII编码,以元素之表示字符频度,解决统计字符的问题。
for(int j=0;j<128;j++) //统计叶子节点个数if(frequency[j]!=0) leaf++;此处扫描一遍上面建立的数组得到叶子节点的个数,则由(leaf*2-1)得到总的节点个数。
数据结构二叉树实验报告

数据结构二叉树实验报告1. 引言二叉树是一种常见的数据结构,由节点(Node)和链接(Link)构成。
每个节点最多有两个子节点,分别称为左子节点和右子节点。
二叉树在计算机科学中被广泛应用,例如在搜索算法中,二叉树可以用来快速查找和插入数据。
本实验旨在通过编写二叉树的基本操作来深入理解二叉树的特性和实现方式。
2. 实验内容2.1 二叉树的定义二叉树可以用以下方式定义:class TreeNode:def__init__(self, val):self.val = valself.left =Noneself.right =None每个节点包含一个值和两个指针,分别指向左子节点和右子节点。
根据需求,可以为节点添加其他属性。
2.2 二叉树的基本操作本实验主要涉及以下二叉树的基本操作:•创建二叉树:根据给定的节点值构建二叉树。
•遍历二叉树:将二叉树的节点按照特定顺序访问。
•查找节点:在二叉树中查找特定值的节点。
•插入节点:向二叉树中插入新节点。
•删除节点:从二叉树中删除特定值的节点。
以上操作将在下面章节详细讨论。
3. 实验步骤3.1 创建二叉树二叉树可以通过递归的方式构建。
以创建一个简单的二叉树为例:def create_binary_tree():root = TreeNode(1)root.left = TreeNode(2)root.right = TreeNode(3)root.left.left = TreeNode(4)root.left.right = TreeNode(5)return root以上代码创建了一个二叉树,根节点的值为1,左子节点值为2,右子节点值为3,左子节点的左子节点值为4,左子节点的右子节点值为5。
3.2 遍历二叉树二叉树的遍历方式有多种,包括前序遍历、中序遍历和后序遍历。
以下是三种遍历方式的代码实现:•前序遍历:def preorder_traversal(root):if root:print(root.val)preorder_traversal(root.left)preorder_traversal(root.right)•中序遍历:def inorder_traversal(root):if root:inorder_traversal(root.left)print(root.val)inorder_traversal(root.right)•后序遍历:def postorder_traversal(root):if root:postorder_traversal(root.left)postorder_traversal(root.right)print(root.val)3.3 查找节点在二叉树中查找特定值的节点可以使用递归的方式实现。
北邮数据结构实验报告

北邮数据结构实验报告北邮数据结构实验报告一、引言数据结构是计算机科学中的重要基础知识,对于计算机程序的设计和性能优化起着至关重要的作用。
本报告旨在总结北邮数据结构实验的相关内容,包括实验目的、实验设计、实验过程和实验结果等。
二、实验目的本次实验旨在通过实践操作,加深对数据结构的理解和应用能力。
具体目的如下:1. 掌握线性表、栈和队列等基本数据结构的实现方法;2. 熟悉二叉树、图等非线性数据结构的构建和遍历算法;3. 学会使用递归和非递归算法解决实际问题;4. 培养编程实践能力和团队合作意识。
三、实验设计本次实验包括以下几个部分:1. 线性表实验:设计一个线性表类,实现线性表的基本操作,如插入、删除和查找等。
通过实验,了解线性表的顺序存储和链式存储结构的特点和应用场景。
2. 栈和队列实验:设计栈和队列类,实现栈和队列的基本操作,如入栈、出栈、入队和出队等。
通过实验,掌握栈和队列的应用,如括号匹配、迷宫求解等。
3. 二叉树实验:设计二叉树类,实现二叉树的创建、遍历和查找等操作。
通过实验,熟悉二叉树的前序、中序和后序遍历算法,并了解二叉树的应用,如表达式求值等。
4. 图实验:设计图类,实现图的创建、遍历和最短路径等操作。
通过实验,掌握图的邻接矩阵和邻接表表示方法,并了解图的深度优先搜索和广度优先搜索算法。
四、实验过程1. 线性表实验:根据实验要求,首先选择线性表的存储结构,然后设计线性表类,实现插入、删除和查找等基本操作。
在实验过程中,遇到了一些问题,如边界条件的处理和内存管理等,通过团队合作,最终解决了这些问题。
2. 栈和队列实验:根据实验要求,设计栈和队列类,实现入栈、出栈、入队和出队等基本操作。
在实验过程中,我们发现了栈和队列在实际应用中的重要性,如括号匹配和迷宫求解等,通过实验加深了对栈和队列的理解。
3. 二叉树实验:根据实验要求,设计二叉树类,实现二叉树的创建、遍历和查找等操作。
在实验过程中,我们发现了二叉树在表达式求值和排序等方面的应用,通过实验加深了对二叉树的理解。
《数据结构》课程设计--二叉排序树调整为平衡二叉树

《数据结构》课程设计--二叉排序树调整为平衡二叉树2013-2014学年第一学期《数据结构》课程设计报告题目:二叉排序树调整为平衡二叉树专业:网络工程班级:二姓名:汪杰指导教师:刘义红成绩:计算机与信息工程系2013年 1 月 2日目录1、问题描述………………………………………2、设计思路(数学模型的选择) ……………3、二叉排序树和平衡二叉树定义…………………………4、程序清单……………………………5.程序功能说明……………………………5.运行与调试分析………………………6.总结…………………………………1.问题描述输入带排序序列生成二叉排序树,并调整使其变为平衡二叉树,运行并进行调试。
2.设计思路平衡二叉树的调整方法平衡二叉树是在构造二叉排序树的过程中,每当插入一个新结点时,首先检查是否因插入新结点而破坏了二叉排序树的平衡性,若是,则找出其中的最小不平衡子树,在保持二叉排序树特性的前提下,调整最小不平衡子树中各结点之间的链接关系,进行相应的旋转,使之成为新的平衡子树。
具体步骤如下:⑴每当插入一个新结点,从该结点开始向上计算各结点的平衡因子,即计算该结点的祖先结点的平衡因子,若该结点的祖先结点的平衡因子的绝对值均不超过1,则平衡二叉树没有失去平衡,继续插入结点;⑵若插入结点的某祖先结点的平衡因子的绝对值大于1,则找出其中最小不平衡子树的根结点;⑶判断新插入的结点与最小不平衡子树的根结点的关系,确定是哪种类型的调整;⑷如果是LL型或RR型,只需应用扁担原理旋转一次,在旋转过程中,如果出现冲突,应用旋转优先原则调整冲突;如果是LR型或LR型,则需应用扁担原理旋转两次,第一次最小不平衡子树的根结点先不动,调整插入结点所在子树,第二次再调整最小不平衡子树,在旋转过程中,如果出现冲突,应用旋转优先原则调整冲突;3.二叉排序树和平衡二叉树定义二叉排序树二叉排序树(Binary Sort Tree)又称二叉查找树。
数据结构实验报告二叉树

数据结构实验报告二叉树二叉树是一种重要的数据结构,广泛应用于计算机科学和算法设计中。
在本次实验中,我们通过实际编程实践,深入理解了二叉树的基本概念、性质和操作。
一、二叉树的定义和基本性质二叉树是一种特殊的树结构,每个节点最多有两个子节点。
它具有以下基本性质:1. 根节点:二叉树的顶部节点称为根节点,它没有父节点。
2. 子节点:每个节点最多有两个子节点,分别称为左子节点和右子节点。
3. 叶节点:没有子节点的节点称为叶节点。
4. 深度:从根节点到某个节点的路径长度称为该节点的深度。
5. 高度:从某个节点到其叶节点的最长路径长度称为该节点的高度。
6. 层次遍历:按照从上到下、从左到右的顺序遍历二叉树的节点。
二、二叉树的实现在本次实验中,我们使用C++语言实现了二叉树的基本操作,包括创建二叉树、插入节点、删除节点、查找节点等。
通过这些操作,我们可以方便地对二叉树进行增删改查。
三、二叉树的遍历二叉树的遍历是指按照某种顺序访问二叉树的所有节点。
常用的遍历方式有三种:前序遍历、中序遍历和后序遍历。
1. 前序遍历:先访问根节点,然后依次递归遍历左子树和右子树。
2. 中序遍历:先递归遍历左子树,然后访问根节点,最后递归遍历右子树。
3. 后序遍历:先递归遍历左子树,然后递归遍历右子树,最后访问根节点。
四、二叉树的应用二叉树在计算机科学和算法设计中有广泛的应用。
以下是一些常见的应用场景:1. 二叉搜索树:二叉搜索树是一种特殊的二叉树,它的左子树的值都小于根节点的值,右子树的值都大于根节点的值。
它可以高效地支持插入、删除和查找操作,常用于有序数据的存储和检索。
2. 堆:堆是一种特殊的二叉树,它的每个节点的值都大于(或小于)其子节点的值。
堆常用于实现优先队列等数据结构。
3. 表达式树:表达式树是一种用二叉树表示数学表达式的方法。
通过对表达式树的遍历,可以实现对数学表达式的计算。
4. 平衡树:平衡树是一种特殊的二叉树,它的左右子树的高度差不超过1。
北邮数据结构实验报告3二叉树含源码

数据结构实验报告实验名称:实验三——树题目一学生姓名:申宇飞班级:2012211103班内序号:03学号:2012210064日期:2013年12月3日1.实验要求掌握二叉树基本操作的实现方法根据二叉树的抽象数据类型的定义,使用二叉链表实现一个二叉树。
二叉树的基本功能:1、二叉树的建立2、前序遍历二叉树3、中序遍历二叉树4、后序遍历二叉树5、按层序遍历二叉树6、求二叉树的深度7、求指定结点到根的路径8、二叉树的销毁9、其他:自定义操作编写测试main()函数测试线性表的正确性2. 程序分析2.1 存储结构采用二叉树的存储结构,其中每个二叉树的结点定义了一个结构体,该结构体包含三个元素,分别是一个T类型的数据域data,一个指向T类型的指针左孩子,一个指向T 类型的指针右孩子,示意图如图所示。
采用了队列的存储结构。
示意图如图所示:对于二叉树中每个结点的data 域的赋值,我们事先把这些data 储存在一个数组中,通过对数组元素的调用事先对二叉树中每个结点的data 域的赋值。
2.2 关键算法分析 一:二叉树的建立: A . 自然语言描述:1首先判断调用的数组是否为空,如果为空,直接将一个已经初始化好的根节点置为空。
2 如果该数组不为空,则把调用的数组的第一个元素的赋给根节点的data 域。
3 采用递归的思想,分别将根节点的左右孩子作为根节点,递归调用该函数。
完成对左右子树的赋值。
B . 代码详细分析:template <class T> void BiTree<T>::Create(Node<T> *&R,T* buf,int i) {if (buf[i-1]==0) R = NULL; else {R=new Node<T>; R->data = buf[i-1];Create(R->lch, buf, 2*i); Create(R->rch, buf, 2*i+1); }lchdata rchlchdata rchlchdata rchlchdata rchlchdata rchlchdata rchlch data rchA[2*i]A[2*i+1] lch data rch lch data rch二:前序遍历二叉树:A. 自然语言描述:1:建立栈2:判断该栈是否为空并且根节点是否为空指针3:如果根节点不是空指针,则输出它的data域,并且是它入栈4:入栈后将根节点指针指向它的左孩子5:如果根节点是空指针6:则根节点出栈,并且指向根节点的指针指向它的右孩子B.代码详细分析:template <class T> void BiTree<T>::Preorder(Node<T> *R){Stack<Node<T>*> S;while(!S.IsEmpty() || (R!=NULL)){if (R!=NULL){Print(R->data);S.Push(R);R=R->lch;}else{R=S.Pop();R=R->rch;}}}三:中序遍历二叉树:A.自然语言描述:1:建立栈2:判断该栈是否为空并且根节点是否为空指针3:如果根节点不是空指针,将它入栈4:入栈后将根节点指针指向它的左孩子5:如果根节点是空指针6:则根节点出栈,输出该节点的data域,并且指向根节点的指针指向它的右孩子B. 代码详细分析:template <class T> void BiTree<T>::Inorder(Node<T> *R){Stack<Node<T>*> S;while(!S.IsEmpty() || (R!=NULL)){if (R!=NULL){S.Push(R);R=R->lch;}else{R=S.Pop();Print(R->data);R=R->rch;}}}四:后序遍历二叉树:A.自然语言描述:1:判断根节点是否为空2:如果根节点不为空3:递归调用后续遍历函数,函数的参数改为根节点的左孩子 4:递归调用后续遍历函数,函数的参数改为根节点的右孩子 5:输出根节点的data域B.代码详细分析:template <class T> void BiTree<T>::Postorder(Node<T> *R) {if (R!=NULL) {Postorder(R->lch);Postorder(R->rch);Print(R->data);}}}}123五:层序遍历二叉树:A.自然语言描述:1:判断根节点是否为空2:如果根节点不为空3:输出根节点的data域4:递归调用层续遍历函数,函数的参数改为根节点的左孩子5:递归调用层序遍历函数,函数的参数改为跟结点的右孩子B.代码详细分析:template <class T> void BiTree<T>::Levelorder(Node<T> *R){Queue<Node<T>*> Q;while(!Q.IsEmpty() || (R!=NULL)){if (R!=NULL){Print(R->data);Q.EnQueue(R->lch);Q.EnQueue(R->rch);}R=Q.DelQueue();}}}123六:求二叉树的深度:A.自然语言描述:1:判断根节点是否为空,如果根节点为空,返回02:如果根节点不为空但是根节点的左右孩子同时为空,返回13:如果以上两个条件都不成立4:递归调用求二叉树的深度,函数的参数改为根节点的左孩子,并且深度初始化为1 5:递归调用求二叉树的深度,函数的参数改为跟结点的右孩子,并且深度初始化为0 6:返回4与5步中得出深度较大的那个数作为二叉树的深度数B.代码详细分析:template <class T> int BiTree<T>::GetDepth(Node<T> *R,int d){if (R==NULL) return d;if ((R->lch==NULL) && (R->rch==NULL))return d+1;else{int m = GetDepth(R->lch,d+1); int n = GetDepth(R->rch,d+1); return n>m? n:m; } }七:二叉树的销毁 A.自然语言描述:1:判断根节点是否为空 2:如果根节点不为空3:递归调用二叉树的销毁函数,参数改为根节点的左孩子 4:递归调用二叉树的销毁函数,参数改为根节点的右孩子 5:释放根节点指向的内存 B.代码详细分析:template <class T> void BiTree<T>::Destroy(Node<T> *R) {if (R!=NULL) { Destroy(R->lch); Destroy(R->rch); delete R; } }}:123八:求二叉树的叶子结点数: A.自然语言描述:1:判断根节点是否为空,如果为空,返回02:如果根节点不为空,切根节点的左右孩子同时为空,返回13:递归调用求二叉树的叶子节点数函数,参数改为根节点的左孩子 4:递归调用求二叉树的叶子结点数函数,参数改为根节点的右孩子 5:返回根节点的左右子树的叶子结点数之和 B.代码详细分析:template <class T> int BiTree<T>::LeafNodeCount(Node<T> *R) {if (R==NULL) return 0;if ((R->lch==NULL) && (R->rch==NULL)) return 1; else {int n=LeafNodeCount(R->lch); int m=LeafNodeCount(R->rch); return m+n; } }九:求二叉树的结点数: A.自然语言描述:} }123}1231:判断根节点是否为空,如果为空,返回02:如果根节点不为空3:递归调用求二叉树的结点数的函数,参数改为根节点的左孩子4:递归调用求二叉树的结点数的函数,参数改为根节点的右孩子5:返回根节点的左右字数的结点数之和B.代码详细分析:template <class T> int BiTree<T>::NodeCount(Node<T> *R){if (R==NULL) return 0;else{int m=NodeCount(R->lch);}}int n=NodeCount(R->rch); return m+n+1;}1232.3 其他对二叉树的操作上,前序遍历与中序遍历采用了非递归算法,后续遍历,层序遍历,求二叉树深度,求二叉树叶子结点数,求二叉树结点数等函数采用了递归算法。
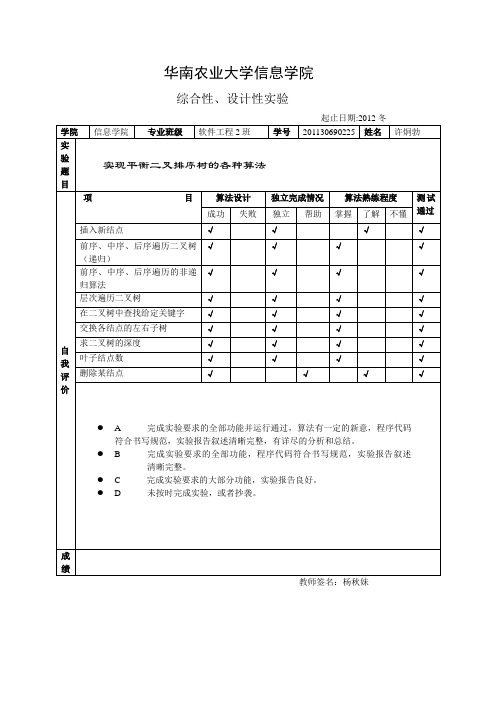
平衡二叉排序树实验报告
s.pop()//出栈
s.empty()//判断栈是否为空,是空时返回TRUE
s.top()//返回栈顶元素
q.push(SElemType e)//入队列
q.pop()//出队列
q.empty()//判断队列是否为空,是空时返回TRUE
q.front()//返回队头元素
T->data=e;
T->lchild=T->rchild=NULL;
T->bf=EH;
taller=true;
}
else{
if(e==T->data){
taller=false;
return 0;
}
if(e<T->data){
if(!InsertAVL(T->lchild,e,taller)) return 0;
p->rchild=rc->lchild;
rc->lchild=p;
p=rc;
}
void Left_Balance(BSTree &T){ //插入结点时向左平衡
BSTree lc,rd;
lc=T->lchild;
switch(lc->bf){
case LH:T->bf=lc->bf=EH;R_Rotate(T);break;
if(Visit(T->data))
if(PreOrderTraverse(T->lchild,Visit))
if(PreOrderTraverse(T->rchild,Visit)) return OK;
return ERROR;
数据结构-chap9 (3)平衡二叉树

(b)调整后恢复平衡
RL型调整的三个例子
-1 310 47-2 311 47 0 40 0 31
0 40
0 47 0 25
-1 31
0 47 0 40 0 0 25 0 69 0 36
-2 31
1 47 1 40 0 69 0 25 0 31
0 40 -1 47 0 36 0 69
(a) RL(0)型调整
最佳二叉排序树
定义 :平均查找长度最小的二叉排序树。
举例:形如满二叉树或完全二叉树的二叉排序树。
非常难于构造。
折中:平衡二叉树。
第九章
9.0
9.1 9.2
查 找
概述
静态查找表 动态查找表
二叉排序树 平衡二叉树
B-树和B+树
9.3
哈希表
平衡二叉树概念
平衡二叉树或者是一棵空树,或者是具有下列性质的二叉树: 它的左子树和右子树都是平衡二叉树,且左子树和右子树的深 度之差的绝对值不超过1. 平衡因子(BF):该结点的左子树的深度减去它的右子树的深度 平衡二叉树上所有结点的平衡因子只可能是-1,0,和1.
(1) 二叉排序树; (2) 平衡二叉排序树; (3) 最佳二叉排序树 分别求其在等概率的情况下查找成功的平均查找长度。
自测题 5
二叉查找树的查找效率与二叉树的( (1) )有关, 在 ((2) )时
其查找效率最低 (1) A. 高度 B. 结点的多少 C. 树型
D. 结点的位置
(2) A. 结点太多 B. 完全二叉树
2 A 1 B AR BL BR 0 B A AR
BL S
BR
(a)插入结点S后失去平衡
(b)调整后恢复平衡
数据结构之平衡二叉树

数据结构之平衡⼆叉树from https:///zhujunxxxxx/p/3348798.htmlAVL树是根据它的发明者G.M. Adelson-Velsky和E.M. Landis命名的。
它是最先发明的⾃平衡⼆叉查找树,也被称为⾼度平衡树。
相⽐于"⼆叉查找树",它的特点是:AVL树中任何节点的两个⼦树的⾼度最⼤差别为1。
它是⼀种⾼度平衡的⼆叉排序树。
⾼度平衡?意思是说,要么它是⼀棵空树,要么它的左⼦树和右⼦树都是平衡⼆叉树,且左⼦树和右⼦树的深度之差的绝对值不超过1。
将⼆叉树上结点的左⼦树深度减去右⼦树深度的值称为平衡因⼦BF,那么平衡⼆叉树上的所有结点的平衡因⼦只可能是-1、0和1。
只要⼆叉树上有⼀个结点的平衡因⼦的绝对值⼤于1,则该⼆叉树就是不平衡的。
平衡⼆叉树的前提是它是⼀棵⼆叉排序树。
距离插⼊结点最近的,且平衡因⼦的绝对值⼤于1的结点为根的⼦树,称为最⼩不平衡⼦树。
如下图所⽰,当插⼊结点37时,距离它最近的平衡因⼦的绝对值超过1的结点是58。
1、平衡⼆叉树实现原理平衡⼆叉树构建的基本思想就是在构建⼆叉排序树的过程中,每当插⼊⼀个结点时,先检查是否因插⼊⽽破坏了树的平衡性,若是,则找出最⼩不平衡⼦树。
在保持⼆叉排序树特性的前提下,调整最⼩不平衡⼦树中各结点之间的链接关系,进⾏相应的旋转,使之成为新的平衡⼦树。
下⾯讲解⼀个平衡⼆叉树构建过程的例⼦。
现在⼜a[10] = {3, 2, 1, 4, 5, 6, 7, 10, 9, 8}需要构建⼆叉排序树。
在没有学习平衡⼆叉树之前,根据⼆叉排序树的特性,通常会将它构建成如下左图。
虽然完全符合⼆叉排序树的定义,但是对这样⾼度达到8的⼆叉树来说,查找是⾮常不利的。
因此,更加期望构建出如下右图的样⼦,⾼度为4的⼆叉排序树,这样才可以提供⾼效的查找效率。
现在来看看如何将⼀个数组构成出如上右图的树结构。
对于数组a的前两位3和2,很正常地构建,到了第个数“1”时,发现此时根结点“3”的平衡因⼦变成了2,此时整棵树都成了最⼩不平衡⼦树,需要进⾏调整,如下图图1(结点左上⾓数字为平衡因⼦BF值)。
北邮数据结构哈夫曼树报告之欧阳理创编

数据结构实验报告实验名称:哈夫曼树学生姓名:袁普班级:2013211125班班内序号:14号学号:2013210681日期:2014年12月1.实验目的和内容利用二叉树结构实现哈夫曼编/解码器。
基本要求:1、初始化(Init):能够对输入的任意长度的字符串s 进行统计,统计每个字符的频度,并建立哈夫曼树2、建立编码表(CreateTable):利用已经建好的哈夫曼树进行编码,并将每个字符的编码输出。
3、编码(Encoding):根据编码表对输入的字符串进行编码,并将编码后的字符串输出。
4、译码(Decoding):利用已经建好的哈夫曼树对编码后的字符串进行译码,并输出译码结果。
5、打印(Print):以直观的方式打印哈夫曼树(选作)6、计算输入的字符串编码前和编码后的长度,并进行分析,讨论赫夫曼编码的压缩效果。
7、可采用二进制编码方式(选作)测试数据:I love data Structure, I love Computer。
I will try my bestto study data Structure.提示:1、用户界面可以设计为“菜单”方式:能够进行交互。
2、根据输入的字符串中每个字符出现的次数统计频度,对没有出现的字符一律不用编码2. 程序分析2.1 存储结构用struct结构类型来实现存储树的结点类型struct HNode{int weight; //权值int parent; //父节点int lchild; //左孩子int rchild; //右孩子};struct HCode //实现编码的结构类型{char data; //被编码的字符char code[100]; //字符对应的哈夫曼编码};2.2 程序流程2.3算法1:void Huffman::Count()[1] 算法功能:对出现字符的和出现字符的统计,构建权值结点,初始化编码表[2] 算法基本思想:对输入字符一个一个的统计,并统计出现次数,构建权值数组,[3] 算法空间、时间复杂度分析:空间复杂度O(1),要遍历一遍字符串,时间复杂度O(n)[4] 代码逻辑:leaf=0; //初始化叶子节点个数int i,j=0;int s[128]={0}; 用于存储出现的字符for(i=0;str[i]!='\0';i++) 遍历输入的字符串s[(int)str[i]]++; 统计每个字符出现次数for(i=0;i<128;i++)if(s[i]!=0){data[j]=(char)i; 给编码表的字符赋值weight[j]=s[i]; 构建权值数组j++;}leaf=j; //叶子节点个数即字符个数for(i=0;i<leaf;i++)cout<<data[i]<<"的权值为:"<<weight[i]<<endl;算法2:void Init();[1] 算法功能:构建哈弗曼树[2] 算法基本思想:根据哈夫曼树构建要求,选取权值最小的两个结点结合,新结点加入数组,再继续选取最小的两个结点继续构建。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
数据结构
实
验
报
告
实验名称:平衡二叉树
1.实验目的和内容
根据平衡二叉树的抽象数据类型的定义,使用二叉链表实现一个平衡二叉树。
二叉树的基本功能:
1、平衡二叉树的建立
2、平衡二叉树的查找
3、平衡二叉树的插入
4、平衡二叉树的删除
5、平衡二叉树的销毁
6、其他:自定义操作
编写测试main()函数测试平衡二叉树的正确性。
2. 程序分析
2.1 存储结构
struct node
{
int key; //值
int height; //这个结点的父节点在这枝最长路径上的结点个数
node *left; //左孩子指针
node *right; //右孩子指针
node(int k){ key = k; left = right = 0; height = 1; } //构造函数};
2.2 程序流程
2.3 关键算法分析(由于函数过多,在此只挑选部分重要函数)
算法1:void AVL_Tree::left_rotate(node *&x)
[1] 算法功能:对 R-R型进行调整
[2] 算法基本思想:将结点右孩子进行逆时针旋转
[3] 算法空间、时间复杂度分析:都为0(1)
[4] 代码逻辑
node *y = x->right; y为x的右孩子
x->right = y->left; 将y的左孩子赋给x的右孩子 y->left = x; x变为y的左孩子
fixheight(x); 修正x,y的height值
fixheight(y);
x = y; 使x的父节点指向y 算法2:void A VL_Tree::right_rotate(node *&x)
[1] 算法功能:对L-L型进行调整
[2] 算法基本思想:将左孩子进行顺时针旋转
[3] 算法空间、时间复杂度分析:都为0(1)
[4] 代码逻辑
node *y = x->left; //y为x的左孩子 x->left = y->right; y的右孩子赋给x的左孩子
y->right = x; x变为y的右孩子
fixheight(x); 修正x和y的height值
fixheight(y);
x = y; 使x的父节点指向y
算法3:node*& A VL_Tree::balance(node *&p)
[1] 算法功能:对给定结点进行平衡操作
[2] 算法基本思想:通过平衡因子判断属于哪种情况,再依照情况进行平衡
[3] 算法空间、时间复杂度分析:没有递归和循环,都为O(1)
[4] 代码逻辑
fixheight(p); //修正P的height值
if (bfactor(p) == 2) 平衡因子为2,为L-?型
if (bfactor(p->left) < 0) P的左孩子平衡因子<0时,为L-R型,执行left_rotate(p->left); 相关平衡操作,若>0,为L-L型。
right_rotate(p);
}
else if (bfactor(p) == -2) 平衡因子为2 ,为R-?型
{
if (bfactor(p->right)>0) P的右孩子平衡因子>0,为R-L型
right_rotate(p->right); 小于0时,为R-R型
left_rotate(p);
}
fixheight(p); 修正平衡后的P的height值
return p;
算法4:node* A VL_Tree::remove(node *&p, int k)
[1] 算法功能:删除给定key值的结点
[2] 算法基本思想:首先通过递归找到待删除结点,如果其没有右孩子,直接将其
删除,将其左孩子链上去。
若有右孩子,找到右枝中的最小结点代替待删除结
点,对改变后的结点进行平衡。
注意右孩子要删除其中的最小结点
[3] 算法空间、时间复杂度分析:有递归,递归次数最多为深度,时间复杂度0
(nlogn),空间复杂度0(logn)
[4] 代码逻辑
if (k < p->key) K小于根节点,在左枝中寻找p->left=remove(p->left, k); 递归
else if (k>p->key) K大于根节点,在右枝中寻找p->right=remove(p->right, k); 递归
else 找到待删除结点
{
node *q = p->left; q为删除结点的左孩子
node *r = p->right; p为删除结点右孩子
delete p;
if (!r) //没有右子树
return q; 直接将左孩子返回,相当于直接删除p node* min = findmin(r); //有右子树时,找到右枝中的最小值
min->right=removein(r); 使删除最小值后的右枝变为min的右枝
min->left = q; p的左孩子变为min的左孩子,相当于删除了p,
balance(min); 对min进行balance操作
return min;
}
balance(p); 每次递归完都对p进行平衡操作
return p;
算法5:void A VL_Tree::insert(node *&p, int k)
[1] 算法功能:一边插入结点一边进行平衡
[2] 算法基本思想:按照构建排序二叉树的方法插入结点,每插入一次后判断是否
需要平衡
[3] 算法空间、时间复杂度分析:插入节点寻找位置需要递归,时间复杂度O(logn)
空间复杂度O(logn)
[4] 代码逻辑
if (!p) 如果是插入第一个节点
p = new node(k); 直接构造一个结点
else if (k < p->key) 插入值小于根节点,在左枝中寻找
{
insert(p->left, k);
if (height(p->left) - height(p->right) == 2) p的平衡因子为2
{
if (k<p->left->key)
right_rotate(p); //LL型
else
left_right_rotate(p); //L-R型
}
}
else if (k>p->key) 寻找值大于根节点,在右枝中寻找{
insert(p->right, k);
if (height(p->left) - height(p->right) == -2) 平衡因子为-2
{
if (k > p->right->key)
left_rotate(p); R-R型
else
right_left_rotate(p); R-L型
}
}
else;
fixheight(p); 修正P的height值
算法6:node* A VL_Tree::findvalue(int key)
[1] 算法功能:查找key的位置
[2] 算法基本思想:根据排序二叉树的规则进项查找
[3] 算法空间时间复杂度分析:没有递归,时间复杂度0(logn),空间复杂度O(1)
[4] 代码逻辑
node *r = root; 初始化r为根节点,进行移动查找
while (r != NULL)
{
if (key < r->key) 小于根节点,在左枝中寻找
r = r->left;
else if (key>r->key) 大于根节点,在后枝中寻找
r = r->right;
else return r;
}
throw "无此值";
2.4 其他
使用了结构类型和类的知识。
使用了STL中的算法,直接调用其寻找两个值中最小值的函数min,大大节约了时间
3.程序运行结果分析
程序运行没有问题。
编写了主函数进行了测试,测试结果正确
4.总结
4.1实验的难点和关键点
本实验的难点和关键点在于大量的递归函数以及删除结点这两个方面,递归函数一定要注意递归返回的值,而删除结点时一定要注意是属于哪种情况。
4.2心得体会
本次实验让我对递归函数有了更加深刻的理解,递归函数的难点在于递归返回,我们一定要深刻的理解递归。
递归可以使代码变得异常简洁,但是也可能带来一些问题,在编写递归的时候一定要仔细思考,注意返回值与跳出。
相信以后的编程我可以做的更好。