spss统计练习题及答案
《统计分析与SPSS的应用》课后练习答案

《统计分析与SPSS的应用》课后练习答案在学习《统计分析与 SPSS 的应用》这门课程后,通过课后练习能够帮助我们更好地掌握所学知识,并将其应用到实际的数据分析中。
以下是针对部分课后练习的答案及解析。
一、选择题1、在 SPSS 中,用于描述数据集中变量分布特征的统计量是()A 均值B 标准差C 中位数D 众数答案:ABCD解析:均值、标准差、中位数和众数都是描述数据分布特征的常用统计量。
均值反映了数据的集中趋势;标准差反映了数据的离散程度;中位数是将数据排序后位于中间位置的数值;众数则是数据集中出现次数最多的数值。
2、进行独立样本 t 检验时,需要满足的前提条件是()A 样本来自正态分布总体B 两样本方差相等C 两样本相互独立D 以上都是答案:D解析:独立样本 t 检验要求样本来自正态分布总体、两样本方差相等以及两样本相互独立。
只有在这些条件满足的情况下,t 检验的结果才是可靠的。
3、以下哪种方法适用于多组数据的比较()A 单因素方差分析B 配对样本 t 检验C 相关分析D 回归分析答案:A解析:单因素方差分析用于比较三个或三个以上组别的数据是否存在显著差异。
配对样本 t 检验适用于配对数据的比较;相关分析用于研究变量之间的线性关系;回归分析用于建立变量之间的预测模型。
二、简答题1、请简述 SPSS 中数据录入的基本步骤。
答:SPSS 中数据录入的基本步骤如下:(1)打开 SPSS 软件,选择“新建数据文件”。
(2)在变量视图中定义变量的名称、类型、宽度、小数位数等属性。
(3)切换到数据视图,按照定义好的变量逐行录入数据。
(4)录入完成后,保存数据文件。
2、解释相关分析和回归分析的区别。
答:相关分析主要用于研究两个或多个变量之间的线性关系程度和方向,但它并不确定变量之间的因果关系。
相关分析的结果通常用相关系数来表示,如皮尔逊相关系数。
回归分析则不仅可以确定变量之间的关系,还可以建立数学模型来预测因变量的值。
《spss统计软件》练习题库及答案

华中师范大学网络教育学院《SPSS统计软件》练习题库及答案(本科)一、选择题(选择类)1、在数据中插入变量的操作要用到的菜单是:AInsertVariable; BInsertCase;CGotoCase; DWeightCases2、在原有变量上经过必定的计算产生新变量的操作所用到的菜单是:ASortCases ;BSelectCases ;CCompute ;DCategorizeVariables(C)3、Transpose菜单的功能是:对数据进行分类汇总;对数据进行加权办理;对数据进行队列转置;按某变量切割数据(A)4、用One-WayANOVA进行大、中、小城市16岁男性青年均匀身高的比较,结果给出sig.=,说明:A.依据明显性水平,拒绝H0,说明三种城市的均匀身高有差异;三种城市身高没有差其他可能性是;三种城市身高有差其他可能性是;说明城市不是身高的一个影响要素(B)5、下边的例子能够用Paired-SamplesTTest 过程进行剖析的是:A家庭主妇和女大学生对同种商品爱好的差异;服用某种药物前后病情的改变状况;服用药物和没有服用药物的病人身体状况的差异;D性别和年纪对雇员薪资的影响二、填空题(填空类)6、MergeFiles 菜单用于归并数据库有两种状况:假如两数据库变量同样,是_观察对象__的归并;假如不一样,则是_变量__的归并。
7、用于对计数资料和有序分类资料进行统计描绘和简单的统计推测,在剖析时能够产生二维或多维列联表,在统计推断时能进行卡方查验的菜单是_ Crosstabs __。
8、One-SamplesTTest 过程用于进行样本所在整体均数___与__已知整体均数_的比较。
三、名词解说(问答类)9、RepeatedMeasures:重复丈量的方差剖析,指的是一个因变量被重复丈量好几次,进而同一个个体的几次察看结果间存在有关,这样就不知足一般剖析的要求,需要用重复丈量的方差剖析模型来解决。
统计软件应用基础(SPSS)试卷测试题及答案

统计软件应用基础(SPSS)试卷测试题及答案一、单项选择题(8分)1、下列变量中,属于有效spss变量名的是(B)A.5bB.ageC.table aD.my house2、以下变量属于字符型变量的是(A)A.“学历”,大专B.“收入”50000C.“价格”:300D.“日期”:20130503.SPSS文件保存的默认格式是(A)A.*.savB.*.txtC.*.datD.*.xls4、“职业”变量是属于(A)A.定类尺度B.定序尺度C.定距尺度D.定比尺度5、在SPSS输出中,峰度系数g2>0.此时表示(B)A.峰的形状比正态分布平坦B.峰的形状比正态分布陡峭C.峰的形状为正态峰D.以上都不是6、在消费者信心指数调查中,想要分析不同月份的消费者信心指数变化情况,适合选用(C)。
A.Q-Q图B.面积图C.直方图D.P-P图7如希望比较蚂蚁和大象的体重变异,直接比较其标准差显然不合理,通常采用(C).A.均值B.方差C.变异系数D.调和均数8.一组数据中最大值与最小值之差是(A)A.全距B.百分位距C.极端值D.异常值二、填空题(4分)1.在变量的测量尺度中,___定距尺度__,不仅可以排序,而且可以准确指出不同类别的差距是多少,通常以自然或物理单位为计算尺度。
2、在SPSS多项选择题的录入方式中,常用的两种方式分别是:___多重二分法___、___多重分类法___。
3、假设检验中的第一类错误通常被称之为___α错误(弃真错误)__三、判断改错题:(供6分,2分/题,请判断下列句子的正误,并在括号内打“小”或"X",错误的需要改正。
)1.t检验最多只能完成两组均数的比较。
(√)2.使用非参数检验时,可以不考虑样本的分布情况。
(×)可以不考虑总体的分布情况3、卡方检验只能用于无需分类变量的统计推断,对于检验某个连续变量的分布与某种理论分布是否一致的检验则无能为力。
spss统计分析期末考试题及答案

spss统计分析期末考试题及答案一、选择题(每题2分,共20分)1. 在SPSS中,数据视图和变量视图分别对应于:A. 变量列表和数据表B. 数据表和变量列表C. 数据集和变量集D. 变量集和数据集答案:B2. SPSS中用于描述数据分布特征的统计量不包括:A. 平均值B. 中位数C. 众数D. 方差答案:D3. 在SPSS中进行独立样本T检验时,需要满足的假设条件不包括:A. 独立性B. 正态性C. 方差齐性D. 线性答案:D4. 下列哪个选项不是SPSS中的数据类型?A. 数值型B. 字符串型C. 日期型D. 图片型答案:D5. 在SPSS中,进行相关分析时,通常使用的统计方法是:A. 回归分析B. 方差分析C. 卡方检验D. 皮尔逊相关系数答案:D6. SPSS中,用于创建新变量的命令是:A. COMPUTEB. DESCRIPTIVESC. T-TESTD. FREQUENCIES答案:A7. 在SPSS中,执行因子分析时,通常使用的方法是:A. 主成分分析B. 聚类分析C. 回归分析D. 判别分析答案:A8. SPSS中,用于检验两个分类变量之间关系的统计方法是:A. 相关分析B. 回归分析C. 卡方检验D. 方差分析答案:C9. 在SPSS中,进行多变量回归分析时,需要满足的假设条件不包括:A. 线性关系B. 误差项独立C. 误差项同方差性D. 变量之间独立答案:D10. SPSS中,用于创建数据集的命令是:A. GET FILEB. SAVEC. OPEN DATAD. NEW答案:D二、简答题(每题10分,共40分)1. 简述SPSS中数据清洗的常用步骤。
答案:数据清洗的常用步骤包括:数据导入、数据预览、缺失值处理、异常值检测、数据转换和数据编码。
2. 解释SPSS中因子分析的目的和基本步骤。
答案:因子分析的目的是将多个变量简化为几个不相关的因子,以揭示变量之间的内在关系。
基本步骤包括:确定因子数量、提取因子、旋转因子和因子得分计算。
第4章 SPSS基本统计分析(课后练习参考)

第4章 SPSS基本统计分析(课后练习参考)1、利用习题二第6题数据,采用SPSS数据筛选功能将数据分成两份文件。
其中,第一份数据文件存储常住地是“沿海或中心繁华城市”且本次存款金额在1000至5000之间的调查数据;第二份数据文件是按照简单随机抽样所选取的70%的样本数据。
第一份文件:选取数据数据——选择个案——如果条件满足——存款>=1000&存款<5000&常住地=沿海或中心繁华城市。
第二份文件:选取数据数据——选择个案——随机个案样本——输入70。
2、利用习题二第6题数据,将其按常住地(升序)、收入水平(升序)、存款金额(降序)进行多重排序。
排序数据——排序个案——把常住地、收入水平、存款金额作为排序依据分别设置排列顺序。
3、利用习题二第4题的完整数据,对每个学生计算得优课程数和得良课程数,并按得优课程数的降序排序。
计算转换——对个案内的值计数输入目标变量及目标标签,把所有课程选取到数字变量,定义值——设分数的区间,之后再排序。
4、利用习题二第4题的完整数据,计算每个学生课程的平均分以及标准差。
同时,计算男生和女生各科成绩的平均分。
方法一:利用描述性统计,数据——转置学号放在名称变量,全部课程放在变量框中,确定后,完成转置。
分析——描述统计——描述,将所有学生变量全选到变量框中,点击选项——勾选均值、标准差。
先拆分数据——拆分文件按性别拆分,分析——描述统计——描述,全部课程放在变量框中,选项——均值。
方法二:利用变量计算,转换——计算变量分别输入目标变量名称及标签——均值用函数mean完成平均分的计算,标准差用函数SD完成标准差的计算。
数据——分类汇总——性别作为分组变量、全部课程作为变量摘要、(创建只包含汇总变量的新数据集并命名)——确定5、利用习题二第6题数据,大致浏览存款金额的数据分布状况,并选择恰当的组限和组距进行组距分组。
根据存款金额排序,观察其最大值与最小值,算出组数和组距。
spss大学考试题及答案

spss大学考试题及答案一、选择题(每题2分,共20分)1. 在SPSS中,以下哪项不是数据视图(Data View)中的数据属性?A. 数字B. 日期C. 图片D. 标签答案:C2. SPSS中,用于描述性统计分析的命令是:A. AnalyzeB. TransformC. GraphD. File答案:A3. 在SPSS中,要进行t检验,应该选择以下哪个菜单?A. Analyze > Compare MeansB. Analyze > RegressionC. Analyze > Descriptive StatisticsD. Analyze > Nonparametric Tests答案:A4. 在SPSS中,如果需要计算一个变量的总和,应该使用以下哪个功能?A. ComputeB. AggregateC. AlgebraicD. Recode答案:B5. 在SPSS中,以下哪个命令用于因子分析?A. FactorB. ClusterC. Reliability AnalysisD. Canonical Correlation答案:A6. 要在SPSS中创建一个频率分布表,应该选择以下哪个命令?A. Analyze > Descriptive Statistics > FrequenciesB. Analyze > Descriptive Statistics > DescriptivesC. Analyze > Descriptive Statistics > ExploreD. Analyze > Descriptive Statistics > Crosstabs答案:A7. 在SPSS中,如果需要对数据进行排序,应该使用以下哪个命令?A. Sort CasesB. Rank CasesC. Order CasesD. Arrange Cases答案:A8. 在SPSS中,要进行卡方检验,应该选择以下哪个菜单?A. Analyze > Descriptive Statistics > CrosstabsB. Analyze > Compare Means > Independent-Samples T TestC. Analyze > Nonparametric Tests > Chi-SquareD. Analyze > Regression > Binary Logistic答案:C9. 在SPSS中,以下哪项不是数据录入时的变量属性?A. 变量类型B. 变量标签C. 缺失值D. 数据格式答案:D10. 在SPSS中,要进行相关性分析,应该选择以下哪个命令?A. Analyze > CorrelationB. Analyze > RegressionC. Analyze > FactorD. Analyze > Cluster答案:A二、简答题(每题5分,共30分)1. 描述SPSS中的数据录入过程。
SPSS数据统计与分析考试习题集(附答案淮师)

品种号
1
2
3
4
5
6
7
8
9
10
电渗处理/mg
22.23
23.42
23.25
21.28
24.45
22.42
24.37
21.75
19.82
22.56
对照/mg
18.04
20.32
19.64
16.38
21.37
20.43
18.45
20.04
17.38
18.42
9.某猪场从10窝大白猪的仔猪中,每窝抽出性别相同、体重接近的仔猪2头,将每窝两头仔猪随机地分配到两个饲料组,进行饲料对比试验,试验时间30天,增重结果见下表。试检验两种饲料喂饲的仔猪平均增重差异是否显著?双个样本成对
1976
1977
1978
1979
1980
,4月下旬平均气温(℃)
19.3
26.6
18.1
17.4
17.5
16.9
16.9
19.1
17.9
17.5
18.1
19.0
,5月上旬50株棉苗蚜虫数
86
197
8
29
28
29
23
12
14
64
50
112
3.采用碘量法测定还原糖,用0.05mol/L浓度硫代硫酸钠滴定标准葡萄糖溶液,记录耗用硫代硫酸钠体积数(mL),得到下表数据,试求y对x的线性回归方程。
2.随机抽测了10只兔的直肠温度,其数据为:38.7、39.0、38.9、39.6、39.1、39.8、38.5、39.7、39.2、38.4(℃),已知该品种兔直肠温度的总体平均数为39.5(℃),试检验该样本平均温度与该品种兔直肠温度的总体平均数是否存在显著差异?单个样本显著值0.027<0.05
spss习题及其答案

spss习题及其答案
SPSS习题及其答案
SPSS(Statistical Package for the Social Sciences)是一种统计分析软件,广泛应用于社会科学和商业研究。
它可以帮助研究人员对数据进行分析、建模和预测。
在学习和使用SPSS的过程中,习题和答案是非常重要的,可以帮助我们更好地理解和掌握SPSS的使用方法和技巧。
下面是一些常见的SPSS习题及其答案,供大家参考:
1. 问题:如何在SPSS中导入数据?
答案:在SPSS中,可以通过“文件”菜单中的“打开”选项来导入数据,也可以直接拖拽数据文件到SPSS的工作区。
2. 问题:如何计算变量的描述性统计量?
答案:在SPSS中,可以使用“分析”菜单中的“描述统计”选项来计算变量的描述性统计量,包括均值、标准差、最大值、最小值等。
3. 问题:如何进行相关性分析?
答案:在SPSS中,可以使用“分析”菜单中的“相关”选项来进行相关性分析,可以计算变量之间的皮尔逊相关系数或斯皮尔曼相关系数。
4. 问题:如何进行回归分析?
答案:在SPSS中,可以使用“回归”选项来进行回归分析,可以进行简单线性回归、多元线性回归等不同类型的回归分析。
5. 问题:如何进行因子分析?
答案:在SPSS中,可以使用“因子”选项来进行因子分析,可以帮助研究人员发现变量之间的潜在结构和关联。
通过以上习题及其答案的学习和实践,我们可以更好地掌握SPSS的使用方法,提高数据分析的效率和准确性。
希望大家在学习SPSS的过程中能够多多练习,不断提升自己的数据分析能力。
SPSS习题及其答案是我们学习的好帮手,也是我们进步的动力。
spss考试题及答案

spss考试题及答案1. 单选题:在SPSS中,以下哪个选项不是数据清洗的步骤?A. 缺失值处理B. 异常值检测C. 数据转换D. 数据备份答案:D2. 多选题:在SPSS中进行描述性统计分析时,可以输出哪些统计量?A. 均值B. 中位数C. 众数D. 标准差E. 方差答案:A, B, C, D, E3. 判断题:在SPSS中,使用“描述统计”功能可以计算出数据的峰度。
对错答案:错4. 填空题:在SPSS中,进行相关性分析时,可以使用_________菜单下的“相关性”选项。
答案:分析5. 简答题:请简述SPSS中因子分析的步骤。
答案:因子分析的步骤包括:a. 确定分析变量b. 进行KMO和Bartlett的球形度检验c. 选择提取方法(如主成分分析或因子分析)d. 确定因子数量e. 进行因子旋转(如需要)f. 解释因子6. 案例分析题:某研究者收集了一组数据,想要使用SPSS进行方差分析。
请描述方差分析的一般步骤。
答案:方差分析的一般步骤如下:a. 确定研究假设b. 选择合适的方差分析类型(如单因素方差分析或多因素方差分析)c. 输入数据并设置因子和因变量d. 进行方差分析e. 检查方差齐性f. 进行后续多重比较(如果需要)g. 解释结果7. 操作题:使用SPSS进行回归分析,并解释回归系数的意义。
答案:进行回归分析的步骤包括:a. 选择分析菜单下的回归选项b. 选择线性回归c. 设置因变量和自变量d. 运行回归分析e. 查看输出结果f. 解释回归系数,即自变量每变化一个单位,因变量预期的变化量以上即为SPSS考试题及答案的排版及格式。
spss统计练习题及答案

SPSS统计练习题及答案一、选择题(选择类)(A)1、在数据中插入变量的操作要用到的菜单是:A Insert Variable;B Insert Case;C Go to Case;D Weight Cases(C)2、在原有变量上通过一定的计算产生新变量的操作所用到的菜单是:A Sort Cases;B Select Cases;C Compute;D Categorize Variables(C)3、Transpose菜单的功能是:A 对数据进行分类汇总;B 对数据进行加权处理;C 对数据进行行列转置;D 按某变量分割数据(A)4、用One-Way ANOVA进行大、中、小城市16岁男性青年平均身高的比较,结果给出sig.=0.043,说明:A. 按照0.05显著性水平,拒绝H0,说明三种城市的平均身高有差别;B. 三种城市身高没有差别的可能性是0.043;C. 三种城市身高有差别的可能性是0.043;D. 说明城市不是身高的一个影响因素(B)5、下面的例子可以用Paired-Samples T Test过程进行分析的是:A 家庭主妇和女大学生对同种商品喜好的差异;B 服用某种药物前后病情的改变情况;C 服用药物和没有服用药物的病人身体状况的差异;D性别和年龄对雇员薪水的影响二、填空题(填空类)6、Merge Files菜单用于合并数据库有两种情况:如果两数据库变量相同,是_观测对象__的合并;如果不同,则是_变量__的合并。
7、用于对计数资料和有序分类资料进行统计描述和简单的统计推断,在分析时可以产生二维或多维列联表,在统计推断时能进行卡方检验的菜单是_ Crosstabs __。
8、One-Samples T Test过程用于进行样本所在总体均数___与__已知总体均数_的比较。
三、名词解释(问答类)9、Repeated Measures:重复测量的方差分析,指的是一个因变量被重复测量好几次,从而同一个个体的几次观察结果间存在相关,这样就不满足普通分析的要求,需要用重复测量的方差分析模型来解决。
spss第二版习题及答案

spss第二版习题及答案SPSS第二版习题及答案SPSS(Statistical Package for the Social Sciences)是一种统计分析软件,广泛应用于社会科学领域的数据分析和研究中。
对于学习SPSS的人来说,掌握习题并查看答案是提高技能的重要途径之一。
本文将为大家介绍一些SPSS第二版习题及其答案,希望能够帮助读者更好地理解和应用SPSS。
一、描述统计学习题1. 对于以下数据集,请计算平均数、中位数、众数、标准差和极差。
数据集:12,15,18,20,22,25,25,27,30,30答案:平均数:23.4,中位数:24,众数:25和30,标准差:6.89,极差:18 2. 对于以下数据集,请计算四分位数和箱线图。
数据集:10,12,15,18,20,22,25,25,27,30,30,32,35,40,45答案:第一四分位数(Q1):18.5,第二四分位数(Q2):25,第三四分位数(Q3):32.5,箱线图:参考附图1。
二、假设检验学习题1. 一个研究人员想要确定一种新的药物是否对治疗抑郁症有效。
他随机选择了100名患有抑郁症的患者,并将他们分为两组:实验组和对照组。
实验组接受新药物治疗,对照组接受安慰剂。
请使用SPSS进行假设检验,判断新药物是否显著改善了患者的抑郁症状。
答案:使用t检验进行假设检验。
设定零假设(H0):新药物对抑郁症状无显著改善;备择假设(H1):新药物对抑郁症状有显著改善。
根据样本数据计算得到t值和p值,如果p值小于设定的显著性水平(通常为0.05),则拒绝零假设,认为新药物对抑郁症状有显著改善。
三、相关性分析学习题1. 一个市场研究人员想要确定广告投入和销售额之间的相关性。
他收集了10个不同广告投入和销售额的数据。
请使用SPSS进行相关性分析,并解释结果。
答案:使用Pearson相关系数进行相关性分析。
根据样本数据计算得到相关系数r,r的取值范围为-1到1,如果r接近1,则表示广告投入和销售额之间存在正相关关系;如果r接近-1,则表示存在负相关关系;如果r接近0,则表示不存在线性相关关系。
spss统计分析习题答案

spss统计分析习题答案SPSS统计分析习题答案在统计学中,SPSS(Statistical Package for the Social Sciences)是一种常用的统计分析软件。
它提供了一系列功能强大的工具,用于数据处理、数据可视化和统计分析。
对于学习和实践统计分析的人来说,掌握SPSS的使用是非常重要的。
在学习SPSS统计分析过程中,我们常常会遇到一些习题,用以巩固和应用所学的知识。
下面,我将提供一些SPSS统计分析习题的答案,希望能对你的学习和实践有所帮助。
习题一:假设你有一份关于某个班级学生的成绩数据,包括数学成绩、语文成绩和英语成绩。
请使用SPSS计算每个学生的总分,并计算班级的平均总分。
答案:首先,打开SPSS软件并导入数据集。
然后,依次点击"Transform"、"Compute Variable"。
在弹出的对话框中,输入一个新的变量名,比如"Total_Score",然后在"Numeric Expression"框中输入数学成绩、语文成绩和英语成绩的变量名,并使用"+"符号将它们连接起来,最后点击"OK"按钮。
这样,SPSS将会计算每个学生的总分,并将结果保存在新的变量"Total_Score"中。
接下来,点击"Analyze"、"Descriptive Statistics"、"Frequencies"。
在弹出的对话框中,将"Total_Score"变量拖动到"Variables"框中,并点击"OK"按钮。
SPSS将会计算班级的平均总分,并在输出结果中显示。
习题二:假设你有一份关于某个公司员工的工资数据,包括性别、年龄和工资水平。
spss试题及答案

spss试题及答案SPSS(Statistical Package for the Social Sciences)是一种用于统计分析和数据处理的软件工具,被广泛应用于社会科学领域。
本文将为您提供一些SPSS试题及答案,帮助您巩固和扩展SPSS的应用知识。
1. 选择题1.1 SPSS是以下哪种类型的软件?A. 文字处理软件B. 统计分析软件C. 图像处理软件D. 电子表格软件答案:B. 统计分析软件1.2 SPSS可以用于哪些数据类型的处理?A. 数值型数据B. 文字型数据C. 图像数据D. 所有类型的数据答案:D. 所有类型的数据1.3 SPSS的输入数据文件的扩展名是什么?A. .xlsB. .docC. .csvD. .spss答案:D. .spss2. 判断题2.1 在SPSS中,可以使用语法来进行数据操作和分析。
答案:正确2.2 SPSS中的数据视图是用来展示数据分析结果的。
答案:错误2.3 SPSS只适用于Windows操作系统。
答案:错误3. 简答题3.1 请解释“变量”在SPSS中的概念。
答:在统计学中,变量是指可变化的属性或特征。
在SPSS中,变量用于表示数据的不同维度或特征,例如性别、年龄、收入等。
变量在SPSS中可以是数值型或文字型,根据数据的属性选择合适的变量类型进行存储和分析。
3.2 请描述一下SPSS中数据分析的流程。
答:SPSS中数据分析的流程通常包括数据导入、数据清洗、数据转换、数据分析和结果报告等步骤。
首先,将待分析的数据导入SPSS软件中,可以选择打开Excel、CSV等格式的数据文件。
然后,对数据进行清洗,包括去除异常值、缺失值处理等。
接下来,可以进行数据转换,如计算新的变量、合并数据集等。
最后,进行具体的数据分析,例如描述性统计、相关分析、回归分析等。
完成数据分析后,生成结果报告并进行解释和讨论。
4. 计算题4.1 请利用SPSS计算以下数据的均值和标准差:样本数据:10, 8, 12, 15, 11, 9, 13, 14, 10, 9答:使用SPSS的描述性统计功能,计算得到均值为 11.1,标准差为 2.21。
SPSS统计分析练习及答案
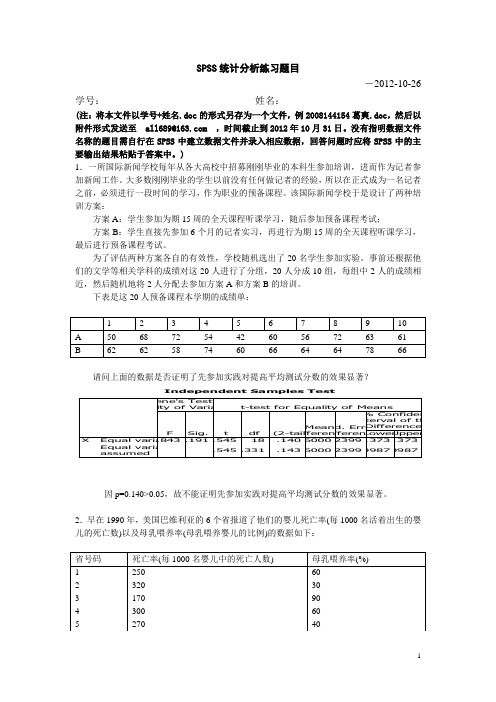
4000
3000
2000
Y人 均 消 费
1000
2000
3000
4000
5000
6000
7000
8000
9000
X人均 国民收 入
4.某餐饮业连锁店对店员服务效率进行随机抽查,以下是店员 A、B、C、D 完成配餐的三
3
次时间记录(单位:秒)。根据下面的数据计算方差分析表,以及相应的概率值。
A
B
C
D
喂 养 率 -2.346 .518
-.897 -4.529
a.Dependent Variable: 死 亡 率
Sig. .000 .006
ANOVbA
Model
Sum of Squares
1
Regre1s4s3io1n1.54
Resid3u4a8l 8.462
Total17800.00
df Mean Square F 114311.538 20.513 5 697.692 6
等级
节目 乙 甲 乙 乙 乙 甲 乙 乙 甲 乙 甲 乙 甲 甲 甲 甲
类型
根据实验数据,检验节目乙是否比节目甲效果更好?
P>0.05,因此不能认为乙节目效果比甲节目好。
Hale Waihona Puke 8.某公司在 15 个商业地区销售一种化妆品,有关销售量、目标人口以及人均可支配收入的 数据如下表所示。为了用目标人口和人均可支配收入来预测商业地区的销售量,要拟合一个 Y 对 X1 和 X2 的二元线性回归方程。试利用 SPSS 求解这一方程。
本题采用秩相关系数比较合适,r=0.9021
6.大学和研究生毕业的一个随机样本给出了学生所获取学位类别与性别的分类数据,如下
spss统计软件练习题及答案

1、去年某企业每天平均生产元件105个,今年改进了生产技术随机抽取15天进行测量,结果为208 112 202 108 210 106 206 204 118 112116 210 114 104 214假定生产从正态分布,能否判断今年的产量是否是去年的两倍(a=0.05)步骤:输入数据后,从菜单栏选择“分析”→“比较均值”→“单样本T检验”命令,打开“单样本T检验”对话框。
(1)将变量产量选入“检验变量”列表框。
(2)在“检验值”框中输入已知去年元件产量的平均数105。
(3)单击“确定”按钮,完成设置并执行上述操作。
单个样本统计量N 均值标准差均值的标准误元件个数15 156.27 50.005 12.911分析:样本数量为15,均值为156.27,标准差为50.005,均值的标准误差为12.911分析:显著性水平为0.001小于0.05,所以认为今年的产量不是去年的两倍。
2、一生产商想比较两种汽车轮胎A和B的磨损质量。
在比较中,选A和B型轮胎组成一对后任意安装在7辆汽车的后轮上,然后让汽车运行指定的英里数,记录下每只轮胎的磨损量。
数据如下:汽车 1 2 3 4 5 6 7轮胎A 9.6 10.8 11.3 10.7 8.2 9.0 11.2轮胎B 8.2 9.4 11.8 9.1 9.3 11.0 13.1这两种轮胎的平均磨损质量存在显著差异吗?步骤:(1)输入数据,执行“分析”→“比较均值”→“配对样本T检验”命令,打开“配对样本T检验”对话框。
(2)在“置信区间百分比”框内输入置信度95%,然后单击“继续”按钮确认,返回主对话框。
(3)单击“确定”按钮,完成设置并执行配对样本T检验。
成对样本统计量均值N 标准差均值的标准误对 1 轮胎A 10.114 7 1.1950 .4517轮胎B 10.271 7 1.7433 .6589轮胎A的均值10.114 小于轮胎B的均值10.271。
相关系数为0.457,认为轮胎之间相关性大显著性水平为0.804,大于0.01,接受原假设,认为两个轮胎的平均磨损质量之间无显著性差异。
华师15春《SPSS 统计软件》在线作业100分答案

华师《SPSS 统计软件》在线作业
一、单选题(共20 道试题,共40 分。
)
1. 频数分析中常用的统计图包括()
A. 直方图
B. 柱形图
C. 饼图
D. 树形图
正确答案:C
2. ()的功能是定义SPSS 数据的结构、录入编辑和管理待分析的数据。
A. 数据编辑窗口
B. 结果输出窗口
C. 数据视图
D. 变量视图
正确答案:A
3. SPSS 中进行参数检验应选择()主窗口菜单。
A. 视图
B. 编辑
C. 文件
D. 分析
正确答案:D
4. 下面偏度系数的值表明数据分布形态是正态分布的是()
A. 1.429
B. 0
C. -3.412
D. 1
正确答案:B
5. SPSS 的()就是将数据编辑窗口中数据的行列互换
A. 数据转置
B. 加权处理
C. 数据才分
D. 以上不都是
正确答案:A。
spss统计试题及答案

spss统计试题及答案SPSS统计试题及答案1. 单项选择题- 1.1 SPSS中,用于进行数据描述性分析的命令是()。
- A. DESCRIPTIVES- B. FREQUENCIES- C. MEANS- D. T-TEST- 答案:A- 1.2 在SPSS中,要进行方差分析,应该使用以下哪个命令?() - A. DESCRIPTIVES- B. ANOVA- C. REGRESSION- D. CROSSTABS- 答案:B2. 多项选择题- 2.1 下列哪些选项是SPSS中的数据类型?()- A. Numeric- B. String- C. Date- D. Time- 答案:A、B、C、D- 2.2 在SPSS中,进行相关性分析可以使用以下哪些命令?()- A. CORRELATIONS- B. REGRESSION- C. CROSSTABS- D. MEANS- 答案:A、B3. 简答题- 3.1 简述SPSS中如何进行数据的导入和导出。
- 答案:在SPSS中,数据的导入可以通过“文件”菜单下的“打开”选项,选择“数据”并导入不同格式的数据文件。
数据的导出则可以通过“文件”菜单下的“另存为”选项,选择导出为SPSS、Excel、CSV等格式。
- 3.2 解释在SPSS中进行回归分析的步骤。
- 答案:在SPSS中进行回归分析的步骤包括:打开数据文件,选择“分析”菜单下的“回归”选项,选择“线性”或“逻辑”回归,指定因变量和自变量,点击“确定”进行分析。
4. 计算题- 4.1 假设有一组数据:10, 15, 20, 25, 30。
计算这组数据的平均值和标准差。
- 答案:平均值 = (10+15+20+25+30)/5 = 20;标准差 =√[(10-20)²+(15-20)²+(20-20)²+(25-20)²+(30-20)²]/5 =7.071。
《统计分析与SPSS的应用》课后练习答案

《统计分析与SPSS的应用》课后练习答案在学习《统计分析与 SPSS 的应用》这门课程后,通过课后练习,我们对所学知识有了更深入的理解和掌握。
以下是针对课后练习的详细答案及相关解释。
一、单选题1、在 SPSS 中,用于描述数据集中变量分布特征的命令是()A FrequenciesB DescriptivesC ExploreD Crosstabs答案:B解释:Descriptives 命令可以提供变量的集中趋势、离散程度等分布特征的统计量。
2、进行独立样本 t 检验时,需要满足的前提条件是()A 样本来自正态分布总体B 两样本方差相等C 以上都是D 以上都不是答案:C解释:独立样本 t 检验要求样本来自正态分布总体,且两样本方差相等。
3、用于分析两个变量之间线性关系强度的统计量是()A 相关系数B 决定系数C 方差D 标准差答案:A解释:相关系数用于衡量两个变量之间线性关系的密切程度。
二、多选题1、以下哪些是 SPSS 中的数据类型()A 数值型B 字符型C 日期型D 以上都是答案:D解释:SPSS 中的数据类型包括数值型、字符型和日期型。
2、方差分析的基本假定包括()A 正态性B 方差齐性C 独立性D 以上都是答案:D解释:方差分析需要满足正态性、方差齐性和独立性这三个基本假定。
三、简答题1、请简述 SPSS 中数据录入的基本步骤。
答:首先打开 SPSS 软件,在变量视图中定义变量的名称、类型、宽度、小数位数等属性。
然后切换到数据视图,逐行录入数据。
在录入过程中,要注意数据的准确性和完整性。
2、解释均值、中位数和众数的含义及适用情况。
答:均值是所有数据的算术平均值,反映数据的集中趋势,但容易受极端值影响。
适用于数据分布较为对称、不存在极端值的情况。
中位数是将数据从小到大排序后位于中间位置的数值,不受极端值影响,适用于数据分布偏态或存在极端值的情况。
众数是数据中出现次数最多的数值,适用于描述数据的集中趋势,尤其在类别数据中常用。
spss练习题及答案

spss练习题及答案SPSS练习题及答案SPSS(Statistical Package for the Social Sciences)是一款广泛应用于数据分析和统计的软件工具。
它提供了丰富的功能和强大的统计算法,帮助研究者和数据分析师快速、准确地处理和分析大量数据。
为了帮助大家更好地掌握SPSS的使用技巧,下面将给出一些SPSS练习题及答案,供大家参考。
练习题一:描述性统计分析某公司对员工的工资进行了调查,收集了100位员工的薪资数据,请根据以下数据,使用SPSS进行描述性统计分析。
薪资数据:5000,5500,6000,6500,7000,7500,8000,8500,9000,9500,10000,10500,11000,11500,12000,12500,13000,13500,14000,14500,15000,15500,16000,16500,17000,17500,18000,18500,19000,19500,20000,20500,21000,21500,22000,22500,23000,23500,24000,24500,25000,25500,26000,26500,27000,27500,28000,28500,29000,29500,30000答案:1. 打开SPSS软件,新建数据集,将薪资数据输入到数据集中。
2. 在菜单栏选择"分析",然后选择"描述统计",再选择"频数"。
3. 将薪资数据变量拖动到"变量"框中,点击"统计"按钮,在弹出的对话框中勾选"平均值"、"中位数"、"标准差"、"最小值"、"最大值"等选项,点击"确定"。
4. 点击"图表"按钮,选择"直方图",点击"确定"。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
SPSS统计练习题及答案一、选择题(选择类)(A)1、在数据中插入变量的操作要用到的菜单是:AInsertVariable; BInsert Case; C Go to Case; DWeightCases(C)2、在原有变量上通过一定的计算产生新变量的操作所用到的菜单是:A Sort Cases;B Select Cases;C Compute; DCategorizeVariables(C)3、Transpose菜单的功能是:A 对数据进行分类汇总;B 对数据进行加权处理;C对数据进行行列转置;D按某变量分割数据(A)4、用One-Way ANOVA进行大、中、小城市16岁男性青年平均身高的比较,结果给出sig.=0.043,说明: A.按照0.05显著性水平,拒绝H0,说明三种城市的平均身高有差别;B.三种城市身高没有差别的可能性是0.043;C.三种城市身高有差别的可能性是0.043;D.说明城市不是身高的一个影响因素(B)5、下面的例子可以用Paired-Samples TTest过程进行分析的是:A家庭主妇和女大学生对同种商品喜好的差异;B服用某种药物前后病情的改变情况;C 服用药物和没有服用药物的病人身体状况的差异;D性别和年龄对雇员薪水的影响二、填空题(填空类)6、Merge Files菜单用于合并数据库有两种情况:如果两数据库变量相同,是_观测对象__的合并;如果不同,则是_变量__的合并。
7、用于对计数资料和有序分类资料进行统计描述和简单的统计推断,在分析时可以产生二维或多维列联表,在统计推断时能进行卡方检验的菜单是_ Crosstabs __。
8、One-Samples TTest过程用于进行样本所在总体均数___与__已知总体均数_的比较。
三、名词解释(问答类)9、RepeatedMeasures:重复测量的方差分析,指的是一个因变量被重复测量好几次,从而同一个个体的几次观察结果间存在相关,这样就不满足普通分析的要求,需要用重复测量的方差分析模型来解决。
10、Chi-Squaretest:卡方检验,它是非参数检验的一种方法,来检验变量的几个取值所占百分比是否和我们期望的比例没有统计学差异。
比如我们在人群中抽取了一个样本,可以用该方法来分析四种血型所占的比例是否相同(都是25%),或者是否符合我们所给出的一个比例(如分别为10%、30%、40%和20%)。
四、简答题(问答类)11、用SPSS对数据进行分析的基本流程是什么?答:(1)、将数据输入SPSS,并保存;(2)、进行必要的预分析(分布图、均数标准差等的描述等),以确定应采用的检验方法;(3)、按题目要求进行统计分析;(4)、保存和导出分析结果。
12、对数据进行方差分析时,Univariate菜单和Multivariate菜单最大的区别是什么?答:当因变量只有一个时,使用Univariate菜单,当因变量不止一个时,使用Multivariate菜单。
13、简述SPSS打开其它格式数据的几种方法?答:(1)、直接打开:选择菜单File==>Open==>Data或直接单击快捷工具栏上的打开按钮;(2)、使用数据库查询打开:选择菜单File==>OpenDatabase==>New Query,根据向导打开数据;(3)、使用文本向导读入文本文件:选择菜单File==>Read TextData14、指定数据按某个变量进行排序需要用到哪个菜单?答:Date==>Sort Cases15、两因素以上的方差分析在SPSS中用什么来完成?答:这些方差分析一律可归入一般线性模型,所以在SPSS中都被归入了GeneralLineal Model子菜单。
16、简述Descriptive Statistics菜单的组成和功能。
答:描述性统计分析是统计分析的第一步,做好这第一步是下面进行正确统计推断的先决条件。
SPSS中专门为该目的而设计的几个模块集中在DescriptiveStatistics菜单中,最常用的是列在最前面的四个过程:(1)、Frequencies过程的特色是产生频数表(2)、Descriptives过程进行一般性的统计描述;(3)、Explore过程用于对数据概况不清时的探索性分析;(4)、Crosstabs过程则完成计数资料和等级资料的统计描述和一般的统计检验,我们常用的卡方检验也在其中完成。
17、简述在多元线性回归分析中,SPSS筛选自变量进入回归方程的四种方法。
答:这四种方法是:强迫法、逐步法、向前法、向后法。
(1)逐步回归法(stepwise),是运用甚为广泛的复回归分析方法之一,也是多元回归分析报告中出现几率最多的一种预测变量的方法。
它结合“向前法”(forward selection)和“向后法”(backwardelimination)二种方式的优点。
(2)向前法是自变量一个一个进入回归模式中,而向后法是先将所有的自变量纳入回归模式中,之后再逐一将对模式贡献最小的预测变量移除,直到所有的自变量均达到标准为止。
(3)强迫回归法(Enter)也是一种常见的方法,强迫所有变量有顺序进入回归方程。
18. 试说明多元线性回归分析中的“共线性”问题及判断标准。
答:多元回归分析中要留意“共线性”(collinarity)问题,它是指由于自变量间的相关太高,造成回归分析的情境困扰,使回归模式的参数不能完全被估计出来。
自变量间的共线性问题可由容忍度(tolerance)、变异数膨胀因素(VIF)和条件指针(condition index;CI)。
一般而言,容忍度越接近0、VIF越大或条件指针越大(大于15),则越有可能存在共线性问题。
19、下表是不同职业与工作满意感之间相关分析的结果,试判断不同职业与满意感之间是否有相关,如果有,相关系数是多少?答:由于显著性水平P=0.662>0.05,说明二者之间不存在显著性相关。
五、分析题(问答类)20、某克山病区测得11例克山病患者与13名健康人的血磷值(mmol/L)如下:患者: 0.84 1.051.20 1.20 1.391.53 1.67 1.80 1.87 2.07 2.11健康:0.54 0.640.64 0.750.760.81 1.16 1.20 1.34 1.35 1.481.56 1.87 (1)将数据录入SPSS,保存为li1_1.sav;(2)分析该地克山病患者和健康人的血磷脂是否不同;(3)保存结果。
21、在数据li1_1.sav中生成新变量temp,当血磷值小于1.5时取值为1,1.5~2时取值为2,大于2时取值为3,并保存结果。
答:操作步骤如下:(1)、OutputVariable框:选入x;(2)、Output Variable Name框:键入temp,单击Change钮;(3)、选中x->temp:单击Old and New Values钮;(4)、Range:Lowest through*单选钮:键入1.5;NewV alueValue单选钮:键入1;单击Add钮;(5)、Range:*through*单选钮:两侧分别键入1.5、2;New ValueValue单选钮:键入2;单击Add钮; (6)、Range:All othervalues单选钮;New Value Value单选钮:键入3;单击Add钮;(7)、单击Continue;(8)、单击OK;22、数据li3_1.sav记录的是某班50名学生语、数、外三门科目的考试成绩,分别作出三科得分频数表、计算均数、标准差、中位数、P2.5和P97.5,并画出直方图。
答:操作步骤如下:(1).Analyze==>Descriptive Statistics==>Frequencies;(2).Variables框:选入变量engl(外)、chin(语)、math(数);(3).单击Statistics钮;(4).选中Mean、Std.deviation、Median复选框;(5).单击Percentiles:输入2.5:单击Add;输入97.5:单击Add;(6)单击Continue钮;(7).单击Charts钮;(8).选中Bar charts;(9).单击Continue钮;(10).单击OK;23、根据数据li3_1.sav分析该班男、女生在语、数、外三科得分上有无差异。
答:(1).Analyze==>CompareMeans==>Independent-SamplesT Test;(2)Test Variables框:选入变量engl(外)、chin(语)、math(数);(3)Grouping Variable框:选入变量gender;(3)单击Define Groups钮;(4)选择Usespecified Values,在group1中填1,在group2中填2;(5)单击Continue钮;(6)单击OK。
24、某驾校学校欲购进一批驾驶模拟训练器,为了知道它们的效果,进行了一次实验。
从新学员中随机抽取12名进行训练,训练前和训练后分别对学员驾驶技能进行测试,结果如下:训练前66.068.070.0 65.0 67.0 82.0 60.559.0 71.077.0 66.0 70.5 训练后62.585.070.0 73.065.0 63.560.5 76.075.5 65.0 62.5 72.0试问模拟器训练的效果如何?答:用Paired-SampleTTest分析(1)、录入数据:设变量x1,x2 分别代表训练前和训练后值,在SPSS 中输入数据。
(2)、统计分析:依次选择Analyze-Compare means-Paired samplesT test(配对t检验),弹出对话框,将变量x1、x2同时选入Paired Variables框(同时选中x1、x2)。
在Options子对话框中可定义可信区间和缺失值的处理。
单击OK键提交执行即可得结果。
25、美国国家计算机产品公司在亚特兰大、达拉斯以及西雅图都设有工厂,生产传真机与打印机。
为了确定这三个工厂的工人的产品质量管理意识水平,特意从每个工厂随机选取10个工人,对他们进行质量意识考试,员工考试的结果如下。
请问这三个工厂员工的质量管理意识水平有无显著差异?若有显著差异,根据统计结果直接观察,哪个工厂最低? 亚特兰大85 7582 767185 79 83 7478达拉斯7175 7374 6982 74 787668西雅图59 646269756766 62 69 70答:数据已经输好,分组变量为group,三组取值分别为1、2、3,结果变量为X。