TXC-TRAIN-GT-ITR-120-01-20080424-简报技巧_附件_麦肯锡图表汇总
【原创】R语言文本挖掘tf-idf,主题建模,情感分析,n-gram建模研究分析案例报告(附代码数据)

务(附代码数据),咨询QQ:3025393450有问题到百度搜索“大数据部落”就可以了欢迎登陆官网:/datablogR语言挖掘公告板数据文本挖掘研究分析## Registered S3 methods overwritten by 'ggplot2':## method from## [.quosures rlang## c.quosures rlang## print.quosures rlang我们对1993年发送到20个Usenet公告板的20,000条消息进行从头到尾的分析。
此数据集中的Usenet公告板包括新闻组用于政治,宗教,汽车,体育和密码学等主题,并提供由许多用户编写的丰富文本。
该数据集可在/~jason/20Newsgroups/(该20news-bydate.tar.gz文件)上公开获取,并已成为文本分析和机器学习练习的热门。
1预处理我们首先阅读20news-bydate文件夹中的所有消息,这些消息组织在子文件夹中,每个消息都有一个文件。
我们可以看到在这样的文件用的组合read_lines(),map()和unnest()。
请注意,此步骤可能需要几分钟才能读取所有文档。
library(dplyr)library(tidyr)library(purrr)务(附代码数据),咨询QQ:3025393450有问题到百度搜索“大数据部落”就可以了欢迎登陆官网:/databloglibrary(readr)training_folder <- "data/20news-bydate/20news-bydate-train/"# Define a function to read all files from a folder into a data frameread_folder <-function(infolder) {tibble(file =dir(infolder, s =TRUE)) %>%mutate(text =map(file, read_lines)) %>%transmute(id =basename(file), text) %>%unnest(text)}# Use unnest() and map() to apply read_folder to each subfolderraw_text <-tibble(folder =dir(training_folder, s =TRUE)) %>%unnest(map(folder, read_folder)) %>%transmute(newsgroup =basename(folder), id, text)raw_text## # A tibble: 511,655 x 3## newsgroup id text## <chr> <chr> <chr>## 1 alt.atheism 49960 From: mathew <mathew@>## 2 alt.atheism 49960 Subject: Alt.Atheism FAQ: Atheist Resources## 3 alt.atheism 49960 Summary: Books, addresses, music -- anything related to atheism## 4 alt.atheism 49960 Keywords: FAQ, atheism, books, music, fiction, addresses, contacts## 5 alt.atheism 49960 Expires: Thu, 29 Apr 1993 11:57:19 GMT## 6 alt.atheism 49960 Distribution: world## 7 alt.atheism 49960 Organization: Mantis Consultants, Cambridge. UK.## 8 alt.atheism 49960 Supersedes: <19930301143317@>## 9 alt.atheism 49960 Lines: 290## 10 alt.atheism 49960 ""## # … with 511,645 more rows请注意该newsgroup列描述了每条消息来自哪20个新闻组,以及id列,用于标识该新闻组中的唯一消息。
Python机器学习库LightGBM入门学习使用LightGBM进行机器学习的基本技巧

Python机器学习库LightGBM入门学习使用LightGBM进行机器学习的基本技巧LightGBM是由微软开源的一款机器学习库,它是目前最快的梯度提升决策树(Gradient Boosting Decision Tree,简称GBDT)框架之一。
它具有高效、易用和灵活等特点,被广泛应用于各种机器学习任务中。
本文将介绍如何使用LightGBM进行入门学习,包括数据准备、模型训练和性能优化等基本技巧。
一、数据准备在使用LightGBM进行机器学习之前,首先需要准备好训练数据。
数据准备包括数据清洗、特征工程和数据划分等步骤。
1. 数据清洗在进行数据清洗时,需要处理缺失值和异常值。
可以使用LightGBM提供的函数来处理缺失值,如fillna()函数可以用来填充缺失值;通过设置参数outliers可以过滤掉异常值。
2. 特征工程特征工程是指根据已有数据构造新的特征以提高模型的性能。
LightGBM可以处理多种类型的特征,包括数值型、类别型和组合型特征。
可以使用One-Hot编码将类别型特征转换为数值特征;通过离散化将连续型特征转换为类别特征;利用特征交叉构造新的特征等。
3. 数据划分将准备好的数据分为训练集和测试集。
一般情况下,将数据按照70%的比例划分为训练集,30%的比例划分为测试集。
可以使用train_test_split()函数来完成数据划分。
二、模型训练准备好数据后,就可以使用LightGBM进行模型训练了。
以下是使用LightGBM进行模型训练的基本步骤:1. 构建训练集和测试集将准备好的数据分别作为训练集和测试集输入到LightGBM中。
2. 设置模型参数设置模型的超参数,包括学习率、决策树的最大深度、叶子节点的最小样本数等。
这些参数会直接影响模型的性能。
3. 模型训练调用LightGBM提供的train()函数进行模型训练。
在训练过程中,可以设置早停策略,即当模型在验证集上的性能不再提升时,停止训练。
P r e d i c t i o n 算 法 使 用

提升方法AdaBoost算法完整python代码提升方法AdaBoost算法完整python代码提升方法简述俗话说,“三个臭皮匠顶个诸葛亮”,对于一个复杂的问题,一个专家的判断往往没有多个专家的综合判断来得好。
通常情况下,学习一个弱学习算法比学习一个强学习算法容易得多,而提升方法研究的就是如何将多个弱学习器转化为强学习器的算法。
强学习算法:如果一个多项式的学习算法可以学习它,而且正确率很高,那就是强可学习的。
弱学习算法:如果一个多项式的学习算法可以学习它,正确率仅仅比随机猜测略好,那就是弱可学习的。
AdaBoost算法简述=未正确分类的样本数目所有样本数目epsilon=frac{未正确分类的样本数目}{所有样本数目}α=12ln(1?)alpha=frac{1}{2}ln(frac{1-epsilon}{epsilon})如果某个样本被正确分类,权重更改为:Dt+1i=Dti?αSum(D)D^{t+1}_i=frac{D^t_iepsilon^{-alpha}}{Sum(D)}如果某个样本被分类错误,权重更改为:Dt+1i=Dti?αSum(D)D^{t+1}_i=frac{D^t_iepsilon^{alpha}}{Sum(D)}直到训练错误率为0或者达到指定的训练次数为止。
单层决策树弱分类器单层决策树(decision stump)也叫决策树桩,是一种简单的决策树,仅基于单个特征做决策。
将最小错误率minError设为+∞对数据集中的每一个特征(第一层循环):对每个步长(第二层循环):对每个不等号(第三层循环):建立一棵单层决策树并利用加权数据集对它进行测试如果错误率低于minError,则将当前单层决策树设为最佳单层决策树返回最佳单层决策树代码实现弱分类器核心部分from numpy import *#通过比较阈值进行分类#threshVal是阈值 threshIneq决定了不等号是大于还是小于defstumpClassify(dataMatrix,dimen,threshVal,threshIneq): retArray = ones((shape(dataMatrix)[0],1)) #先全部设为1 if threshIneq == 'lt': #然后根据阈值和不等号将满足要求的都设为-1retArray[dataMatrix[:,dimen] = threshVal] = -1.0retArray[dataMatrix[:,dimen] threshVal] = -1.0return retArray#在加权数据集里面寻找最低错误率的单层决策树#D是指数据集权重用于计算加权错误率def buildStump(dataArr,classLabels,D):dataMatrix = mat(dataArr); labelMat = mat(classLabels).T m,n = shape(dataMatrix) #m为行数 n为列数numSteps = 10.0; bestStump = {}; bestClasEst = mat(zeros((m,1)))minError = inf #最小误差率初值设为无穷大for i in range(n): #第一层循环对数据集中的每一个特征 n 为特征总数rangeMin = dataMatrix[:,i].min(); rangeMax = dataMatrix[:,i].max()stepSize = (rangeMax-rangeMin)-numStepsfor j in range(-1,int(numSteps)+1): #第二层循环对每个步长for inequal in ['lt','gt']: #第三层循环对每个不等号threshVal = rangeMin + float(j) * stepSize#计算阈值predictedVals =stumpClassify(dataMatrix,i,threshVal,inequal)#根据阈值和不等号进行预测errArr = mat(ones((m,1)))#先假设所有的结果都是错的(标记为1)errArr[predictedVals == labelMat] = 0#然后把预测结果正确的标记为0weightedError = D.T*errArr#计算加权错误率#print 'split: dim %d, thresh %.2f, thresh inequal: %s, # the weightederror is %.3f' % (i,threshVal,inequal,weightedError)if weightedError minError: #将加权错误率最小的结果保存下来minError = weightedErrorbestClasEst = predictedVals.copy()bestStump['dim'] = ibestStump['thresh'] = threshValbestStump['ineq'] = inequalreturn bestStump, minError, bestClasEst准备了一个简单的数据集来测试算法#加载数据集def loadSimpleData():dataMat = matrix([[1.,2.1],[2.,1.1],[1.3,1.],[1.,1.],[2.,1.]])classLabels = [1.0,1.0,-1.0,-1.0,1.0]return dataMat,classLabels#绘制数据集def pltData(dataMat,classLabels):for index,item in enumerate(dataMat): #enumrate的参数为一个可以遍历的东西,返回值为索引和该项if classLabels[index] 0:plt.plot(item[0,0],item[0,1],'or') #'or' 表示画红点plt.plot(item[0,0],item[0,1],'ob') #'ob' 表示画蓝点plt.show()导入数据集并绘制dataMat, classLabels=loadSimpleData()pltData(dataMat, classLabels)测试算法D = mat(ones((5,1))-5)buildStump(dataMat, classLabels, D)完整AdaBoost算法实现基于上面写的树桩弱分类器,实现完整的AdaBoost算法。
opencv adaboost人脸检测训练程序阅读笔记(LBP特征)

1、训练程序整体流程(1)读输入参数并打印相关信息(2)进入训练程序最外层入口classifier.train1)读正负样本,将正负样本放入imgLiast中,先读正样本,后读负样本2)load( dirName )判断之前是否有已训练好的xml文件,若有,不在重新训练该stage的xml文件,没有返回false,初始化参数3)计算requiredLeafFARate = pow(maxFalseAlarm,numStages)/max_depth,该参数是stage停止条件(利用训练样本集来计算tempLeafFARate,若tempLeafFARate小于这一参数,则退出stage训练循环);4)Stage训练循环5)更新训练样本集,计算tempLeafFARate(负样本被预测为正样本的个数除以读取负样本的次数,第一次没有训练之前,这个比值为1,因为没训练之前,所有负样本都被预测成了正样本,当第一层训练好以后,负样本采集时会先用第一层的分类器预测一次,若能分类,则不选用,选用负样本的数目是固定的,但选用这么多负样本总共要选的次数会随着层数的增多而加大,因为层数越大,分类器的分类能力也要求越大,说需要的样本就是前面分类器所不恩呢该识别的,故在采集时也比较困难。
)6)判断stage是否退出训练,若tempLeafFARate<requiredLeafFARate则退出stage训练,否则继续;7)强训练器训练入口tempStage->train()a.建立训练数据data = new CvCascadeBoostTrainData(主要是一些参数的设置,还有特征值的计算)b.初始化样本权重update_weights( 0 );c.弱分类器训练循环i)tree->train—》do_trainai) 根节点的初始root = data->subsample_data( _subsample_idx );(主要是对根节点的一些参数进行初始化,parent 0,count 1,split 0,value 0,class_idx 0,maxlr 0,left = right = 0,等等)bi) CV_CALL( try_split_node(root)),根据根节点计算整颗数的各节点的参数配置aii) calc_node_value( node );计算节点的回归值,类似于分类投票值sum(w*class_lable),正样本的class_lable取,负样本的class_lable取-1;计算节点的风险值node_risk,noderisk is the sum of squared errors: sum_i((Y_i -<node_value>)^2)bii) 判断节点是否可以分裂(判断依据:样本值和设计的节点最大深度);再利用node_risk与regression_accuracy,如果这个节点的所有训练样本的节点估计值的绝对差小于这个参数,节点不再进行分裂cii) 找出最佳分裂best_split = find_best_split(node);aiii) 定义DTreeBestSplitFinder finder( this, node );biii) parallel_reduce(cv::BlockedRange(0, data->var_count), finder);此时调用DTreeBestSplitFinder类的操作符DTreeBestSplitFinder::operator()(constBlockedRange& range)aiv) 遍历所有特征vi = vi1; vi< vi2; vi++biv) res = tree->find_split_cat_reg()得到特征为split->var_idx = vi的最佳分裂的质量split->quality(split->quality越大越好)av) 将特征为vi所有样本的特征值返回到cat_labelsbv) 计算每个特征值取值不权值和和响应和,例如特征值为,则将所有特征值列表中特征值为的样本权值相加,LBP的特征值范围是0~255,故有256个categorycv) 计算每个category的平均响应值,即将每个category的响应和除以每个category的样本权值和dv) icvSortDblPtr( sum_ptr, mi, 0 );把256个值进行升序排序,注意sum_ptr里存的是sum[i]的地址,这里排序的依据是特征值还是按照每个特征值的平均响应来排序???个人感觉是按特征值的平均响应来排序fv) 将每个特征值的平均响应值乘以该特征值的总权值得到每个特征值的总响应gv) 遍历subset_i = 0; subset_i< mi-1; subset_i++avi) 计算索引是subset_i在排序前的idxbvi) 获取索引idx对应的样本总权重cvi) 获取索引idx对应的样本总响应dvi) 以subset_i为分裂点,计算分裂质量(sumL*sumL)/ weightL +(sumR*sumR)/ weightRfvi) 若最佳分裂质量小于这个质量,则更新最佳分裂质量hv) 经过训练得到最佳分裂点和最佳分裂质量,将遍历得到的值更新到split结构体各参数。
r语言lstm代码

r语言lstm代码R语言LSTM代码实现文本生成LSTM(Long Short-Term Memory)是一种常用的循环神经网络(Recurrent Neural Network,RNN)架构,主要用于处理序列数据。
它在自然语言处理领域中被广泛应用,尤其是在文本生成任务中。
本文将介绍如何使用R语言实现LSTM模型,并利用该模型生成文本。
1. 数据预处理为了实现文本生成,首先需要准备一些用于训练的文本数据。
可以选择一篇较长的文章或者一本书籍作为训练数据。
然后,将文本内容进行分词,将每个词作为一个训练样本。
可以使用R语言中的`text`包或`tm`包来进行文本处理和分词。
2. 构建LSTM模型在R语言中,可以使用`keras`包来构建LSTM模型。
首先,需要安装`keras`包,并加载所需的库:```Rinstall.packages("keras")library(keras)```然后,可以使用以下代码构建LSTM模型:```Rmodel <- keras_model_sequential()model %>%layer_lstm(units = 128, input_shape = list(1, vocab_size)) %>%layer_dense(units = vocab_size) %>%layer_activation("softmax")```在这个例子中,LSTM模型包含一个LSTM层(具有128个隐藏单元)和一个全连接层(用于输出预测结果),并使用softmax函数作为激活函数。
3. 编译和训练模型在训练模型之前,需要对模型进行编译,指定损失函数和优化器。
在这里,可以选择交叉熵作为损失函数,并使用Adam优化器。
```Rmodel %>% compile(loss = "categorical_crossentropy",optimizer = optimizer_adam(),metrics = c("accuracy"))```然后,可以使用以下代码训练模型:```Rmodel %>% fit(x = X_train,y = y_train,batch_size = 128,epochs = 10,validation_data = list(X_test, y_test))```在这个例子中,`X_train`和`y_train`是训练数据和标签,`X_test`和`y_test`是验证数据和标签。
利用随机森林构建分类模型,并用十折交叉验证。r语言教程

利用随机森林构建分类模型,并用十折交叉验证。
r语言教程在R语言中,我们可以使用`caret`包中的`train`函数进行模型的训练,并使用`caret`包的`createDataPartition`函数进行十折交叉验证。
以下是使用随机森林构建分类模型的示例代码:首先,确保你已经安装了必要的包。
如果没有,你可以使用以下命令进行安装:```r("caret")("randomForest")```然后,加载这些包:```rlibrary(caret)library(randomForest)接下来,我们需要加载数据。
假设我们有一个名为`data`的数据框,其中包含我们的特征和目标变量:```rdata <- ("your_") 请将"your_"替换为你的数据文件路径```然后,我们将使用`createDataPartition`函数进行十折交叉验证的数据分割:```r(123) 为了结果的可重复性control <- rbind(trainControl(method = "cv", number = 10), 10折交叉验证trainControl(method = "oob") 用于随机森林的外部验证)```接着,我们将使用`train`函数训练我们的模型:(123) 为了结果的可重复性rf_model <- train(target ~ ., data = data, trControl = control, method = "rf") 使用随机森林方法训练模型```最后,我们可以输出模型的详细信息:```rprint(rf_model)```以上代码演示了如何使用随机森林和十折交叉验证在R语言中构建分类模型。
请注意,你可能需要根据自己的数据和需求对代码进行一些调整。
【目标检测】用FasterR-CNN训练自己的数据集超详细全过程

【⽬标检测】⽤FasterR-CNN训练⾃⼰的数据集超详细全过程⽬录:⼀、环境准备⼆、训练步骤三、测试过程四、计算mAP寒假在家下载了Faster R-CNN的源码进⾏学习,于是使⽤⾃⼰的数据集对这个算法进⾏实验,下⾯介绍训练的全过程。
⼀、环境准备我这⾥的环境是win10系统,pycharm + python3.7⼆、训练过程1、下载Faster R-CNN源码2、安装扩展包下载的源码中有⼀个 requirements.txt⽂件,列出了需要安装的扩展包名字。
可以在cmd中直接运⾏以下代码:pip install -r requirements.txt或者使⽤pip命令⼀个⼀个安装,所需要的扩展包有:cython、opencv-python、easydict、Pillow、matplotlib、scipy。
如果使⽤conda管理,按conda的下载⽅式也可以。
3、下载并添加预训练模型源码中预训练模型使⽤的是VGG16,VGG16模型可点开下⽅链接直接下载:下载的模型名字应该是vgg_16.ckpt,重命名为vgg16.ckpt 后,把模型保存在data\imagenet_weights\⽂件夹下。
也可以使⽤其他的模型替代VGG16,其他模型在下⽅链接中下载:4、修改训练参数打开源码的lib\config⽂件夹下的config.py⽂件,修改其中⼀些重要参数,如:(1)network参数该参数定义了预训练模型⽹络,源码中默认使⽤了vgg16模型,我们使⽤vgg16就不需修改,如果在上⼀步中使⽤其他模型就要修改。
(2)learning_rate这个参数是学习率,如果设定太⼤就可能产⽣振荡,如果设定太⼩就会使收敛速度很慢。
所以我们可以先默认为源码的0.001进⾏实验,后期再取0.01或0.0001等多次实验,找到运⾏后的相对最优值。
(3)batch_size该参数表⽰梯度下降时数据批量⼤⼩,⼀般可以取16、32、64、128、256等。
【原创】R语言使用特征工程泰坦尼克号数据分析应用案例数据分析报告论文(含代码数据)

咨询QQ:3025393450有问题百度搜索“”就可以了欢迎登陆官网:/datablogR语言使用特征工程泰坦尼克号数据分析应用案例数据分析报告来源:大数据部落| 有问题百度一下“”就可以了特征工程对于模型的执行非常重要,即使是具有强大功能的简单模型也可以胜过复杂的算法。
实际上,特征工程被认为是决定预测模型成功或失败的最重要因素。
特征工程真正归结为机器学习中的人为因素。
通过人类的直觉和创造力,您对数据的了解程度可以带来不同。
那么什么是特征工程?对于不同的问题,它可能意味着许多事情,但在泰坦尼克号的竞争中,它可能意味着砍伐,并结合我们在Kaggle的优秀人员给予的不同属性来从中榨取更多的价值。
通常,机器学习算法可以更容易地从工程学习算法中消化和制定规则,而不是从其导出的变量。
获得更多机器学习魔力的最初嫌疑人是我们上次从未发送到决策树的三个文本字段。
票号,舱位和名称都是每位乘客独有的; 也许可以提取这些文本字符串的一部分以构建新的预测属性。
让我们从名称字段开始。
如果我们看一下第一位乘客的名字,我们会看到以下内容:> train$Name[1][1] Braund, Mr. Owen Harris891 Levels: Abbing, Mr. Anthony Abbott, Mr. Rossmore Edward ... Zimmerman, Mr. Leo以前我们只通过子集化访问乘客组,现在我们通过使用行号1作为索引来访问个人。
好吧,船上没有其他人有这个名字,这几乎可以肯定,但他们还有什么共享?好吧,我确信船上有很多先生。
也许人物头衔可能会给我们更多的洞察力。
咨询QQ:3025393450有问题百度搜索“”就可以了欢迎登陆官网:/datablog如果我们滚动数据集,我们会看到更多的标题,包括Miss,Mrs,Master,甚至是Countess!标题“大师”现在有点过时,但在这些日子里,它被保留给未婚男孩。
基于SVD Entropy和SVM联合算法的列控系统态势感知技术研究

第43卷第1期2021年1月Vol.43No.1January2021铁道学报journal of the china railway society文章编号:1001-8360(2021)01-0100-07基于SVD Entropy和SVM联合算法的列控系统态势感知技术研究李其昌1,2,步兵打赵骏逸打李冈『(1.北京交通大学轨道交通控制与安全国家重点实验室,北京100044;2.中国铁道科学研究院集团有限公司通信信号研究所,北京100081)摘要:列控系统态势感知是指对可能引起列控系统信息安全态势发生变化的态势要素进行获取、理解、评价以及预测的过程°提岀一种基于SVD Entropy和SVM联合算法的列控系统态势感知技术,以识别信息安全风险,避免列控系统安全事故发生°该联合算法能够处理列控系统多源异构数据集,通过设定奇异值熵阈值,完成多源异构数据的降维与特征提取;再结合支持向量机多分类算法,实现数据的分类与融合°仿真实验表明,当奇异值熵阈值设定为0.85时,在保持分类精度基本不变的前提下,SVD Entropy和SVM联合算法能有效压缩系统运算时间,具有较高的计算实时性°该联合算法为后续实时在线处理数据,完成态势评价、预测提供了理论支持°关键词:列控系统;信息安全;态势感知;奇异值熵;支持向量机中图分类号:U283.2文献标志码:A doi:10.3969/j.issn.l001-8360.2021.01.012Research on Situation Awareness of Train Control System Based onSVD Entropy and SVM Joint AlgorithmLI Qichang',2,BU Bing1,ZHAO Junyi1,LI Gang2(1.State Key Laboratory of Rail Traffic Control and Safety,Beijing Jiaotong University,Beijing100044,China;2.Signal and Communication Research Institute,China Academy of Railway Sciences Corporation Limited,Beijing100081,China)Abstract:Situation awareness of train control system refers to the process of acquiring,understanding,evaluating and predicting the situation elements that may cause changes in the information security situation of the train control system.A situational awareness technology based on the SVD Entropy and SVM joint algorithm was proposed for train control systems to identify information security risks and avoid security accidents of the train control system.The joint algorithm can process multi-source heterogeneous data sets of train control system,and achieve the dimensionality reduction and feature extraction of multi-source heterogeneous data by setting the singular value entropy bined with support vector machine multi-classification algorithm,data classification and fusion were realized.The simulation experiments show that when the singular value entropy threshold is set at0.85,under the precondition of keeping the classification accuracy basically unchanged,the SVD Entropy and SVM joint algorithm can effectively compress the system operation time with high real-time calculation performance.The joint algorithm provides a theoretical basis for the subsequent real-time online data processing as well as the situation evaluation and forecast process.Key words:train control system;information security;situational awareness;SVD Entropy;SVM收稿日期;2020-07-20;修回日期:2020-09-25基金项目:城市轨道交通北京实验室资助(I18H100010);交控科技创新基金(9907006507);北京交通大学基本科研业务费(2020YJS199)第一作者:李其昌(1992—),男,黑龙江鹤岗人,助理研究员,博士研究生°E-mail-liqichang@通信作者:步兵(1974—),男,河南新乡人,教授,博士°E-mail:bbu@城市轨道交通作为典型的工业控制系统以及重要的城市基础设施,为缓解和解决城市化进程带来的交通压力和人民日益增长的交通需求,应运发展了基于通信的列车运行控制系统(Communication Based Train Control,CBTC)°CBTC系统广泛融合了计算机、通信和控制等领域的先进技术,是一个复杂的分布式、实时第1期李其昌等:基于SVD Entropy和SVM联合算法的列控系统态势感知技术研究101控制系统[1]°随着列控系统信息化与自动化的深度融合,实现了自管理信息层延伸至现场设备的一致性识别、通信和控制°然而,在轨道交通信息化、智能化融合的同时,来自列控系统内部和外部的威胁也逐渐增大,其面临的信息安全风险日益加剧[2]°一方面,列控系统采用标准通信协议与通用计算设备,使得列控系统更易遭到黑客的攻击,如恶意木马植入、洪水攻击等;另一方面,列控系统与其他系统的数据共享、设备互联、业务协作,使得系统难以做到真正的“完全封闭”,进一步加剧了列控系统的信息安全风险。
P r e d i c t i o n 算 法 使 用

链路预测(Link prediction)中常用的评价指标(evaluation metrics)前提:链路预测只能预测边,不能预测节点。
只预测边!!!论文中提出两种链路预测的评价指标:AUC和精确度(Precision)1、 AUC:AUC指标的具体计算方法:首先我们知道衡量一个算法的好坏,需要把数据集划分为训练集和测试集,如何划分?比如可以删除10%的边(只删除边),那么这10%就是测试集,其余的90%的边和网络的全部节点就为训练集。
那么还有其它的边吗?我想绝大数现实的网络都不是完全图吧,所以肯定有两个节点之间没有连边的情况,那这部分边,我们称之为不存在的边。
一个算法(如CN)经过训练集训练得到网络中每一对节点之间的一个相似值(包括训练集中的边也会得到,测试集的边以及不存在的边显然也会得到)。
AUC指标就是比较测试集中的边的相似值? 与? 不存在的边的相似性的大小。
如果测试集中边的相似值大于不存在边的相似值,就说明效果好啊,+ 1呗;如果测试集中边的相似值等于不存在边的相似值,就说明跟随机选择差不多啊,那就+ 0.5呗,没啥意义,还不如不用算法;如果测试集中边的相似值小于不存在边的相似值,就说明你这算法也太差了吧,随机的都比不过,反其道行之啊兄弟,+ 0吧;那么分母就是测试集中的边与不存在中的边的比较次数,比如测试集中2条边,不存在中3条边,那么比较次数就是6次啦。
2、精确度(Precision)注意:这里提到的精确度和你之前听到的二分类问题的precision、accuracy、recall、F1都毫无关系!!!那么这种精确度怎样计算呢?算法(如CN)不是得到每一个节点对之间的相似值了嘛,这时候去掉训练集中的边,还剩什么了?就剩测试集中的边和不存在的边以及边对应的相似值,按相似值的大小倒序排列这些边。
排序后取前L个(比如给它赋值50,即L=50),看一看这里有几个是测试集中的啊,比如有20个,那么精确度就等于20-50。
特征工程中数据预处理方法总结

特征工程中数据预处理方法总结特征工程是机器学习中非常重要的一步,它对于模型的性能和结果具有重要影响。
在进行特征工程之前,我们通常需要对数据进行预处理,以便使其适用于模型的训练和应用。
数据预处理是特征工程的第一步,它的目的是清洗和转换原始数据,以提取有用的特征并改善模型性能。
下面将总结一些常用的数据预处理方法。
1.数据清洗:数据清洗是指处理缺失值、异常值和重复值等问题。
缺失值处理可以用均值、中位数或者一个特定的值来填充缺失值,也可以通过回归模型或者KNN方法进行预测。
异常值可以通过箱线图和Z分数进行识别和处理。
重复值可以直接删除或进行合并处理,以避免对模型产生不良影响。
2. 数据标准化:数据标准化是指将数据转化为具有零均值和单位方差的分布。
常见的数据标准化方法有Z-score标准化和Min-Max标准化。
Z-score标准化通过减去均值并除以标准差来实现,使得数据分布在正态分布的0均值和1标准差范围内。
Min-Max标准化则通过将数据线性转化到指定范围内,通常是0到1之间。
3.数据归一化:数据归一化是将数据转化到相同的尺度上,以消除不同特征之间的量纲差异。
常用的数据归一化方法有离差标准化和归一化。
离差标准化通过减去最小值并除以最大值与最小值之差来实现,将数据映射到0到1之间。
归一化方法则通过将数据划分为多个区间并进行映射来实现。
4. One-Hot编码:One-Hot编码是一种将离散特征表示为二进制向量的方法。
将离散特征转换为二进制向量可以解决模型无法处理的问题,并且能够更好地表示特征之间的关系。
在进行One-Hot编码之前需要将离散特征转换为整数类型。
5.特征选择:特征选择是指从原始特征中选择最重要的特征子集。
它可以排除无关的特征,并减少冗余特征,从而提高模型的泛化能力和解释能力。
常用的特征选择方法有过滤法、包装法和嵌入法等。
过滤法通过统计指标(如相关系数和卡方检验)对特征进行排序或打分,然后选择最重要的特征。
基于CNN-ResNet-LSTM模型的城市短时交通流量预测算法

2020年10月第43卷第5期北京邮电大学学报Journal of Beijing University of Posts and TelecommunicationsOct.2020Vol.43No.5文章编号:1007-5321(2020)05-0009-06DOI :10.13190/j.jbupt.2019-243基于CNN-ResNet-LSTM 模型的城市短时交通流量预测算法蒲悦逸1,王文涵1,朱强1,陈朋朋1,2(1.中国矿业大学计算机科学与技术学院,徐州221116;2.中国矿业大学矿山数字化教育部工程研究中心,徐州221116)摘要:针对交通流量特性和外部因素对交通流量预测结果的影响,提出了一种对城市短时交通流量预测的模型CNN-ResNet-LSTM ,将卷积神经网络(CNN )、残差神经单元(ResNet )和长短期记忆循环神经网络(LSTM )集成到一个端到端的网络框架.利用卷积神经网络来捕获城市区域间交通流量的局部空间特征,并在卷积神经网络中加入多个残差神经单元来加深网络深度,可提高预测的准确性;利用长短期记忆循环神经网络来捕获交通流量数据的时间特征;利用相应的权重将2个网络的输出结果融合,得到通过轨迹数据预测的结果;最后与外部因素融合,得到城市区域的交通流量预测值.用北京市轨迹交通数据对该模型进行验证,CNN-ResNet-LSTM 模型不仅在准确率方面比传统模型高,而且在保证预测准确率的情况下,模型使用的参数也少.关键词:短时交通流量预测;深度学习;长短期记忆循环神经网络;卷积神经网络中图分类号:TP18文献标志码:A收稿日期:2019-11-26基金项目:徐州市科技计划项目(KC18061);国家自然科学基金项目(51674255)作者简介:蒲悦逸(1994—),男,硕士生.通信作者:陈朋朋(1983—),男,教授,E-mail :chenp@cumt.edu.cn.Urban Short -Term Traffic Flow Prediction AlgorithmBased on CNN -ResNet -LSTM ModelPU Yue-yi 1,WANG Wen-han 1,ZHU Qiang 1,CHEN Peng-peng 1,2(1.School of Computer Science and Technology ,China University of Mining and Technology ,Xuzhou 221116,China ;2.Mine Digitization Engineering Research Center of the Ministry of Education ,China University of Mining and Technology ,Xuzhou 221116,China )Abstract :With the continuous advancement of smart city construction ,urban short-term traffic flow fore-casting becomes more and more important.According to the influence of traffic flow characteristics and external factors on traffic flow forecast results ,the model CNN-ResNet-LSTM for urban short-term traffic flow forecasting is proposed.The model integrates convolutional neural networks (CNN ),residual neuralunits (ResNet )and long-short-term memory networks (LSTM )into an end-to-end network framework.The convolutional neural network is used to capture the local spatial characteristics of traffic flow ,and multiple residual neural units are added to deepen the network depth and improve the prediction accura-cy.On the other hand ,the long short-term memory-cycle neural network is used to capture temporal characteristics of traffic flow data.The output results of the two networks are combined by the correspond-ing weights to obtain the predicted results through the trajectory data.Finally ,the traffic flow prediction values of the urban areas are obtained by fusing with external factors.Through the verification of theCNN-ResNet-LSTM model by Beijing data,the model is not only higher in accuracy than the traditional model,but also has fewer parameters in the case of ensuring the accuracy of prediction.Key words:traffic flow forecasting;deep learning;long short-term memory network;convolutional neu-ral network智能交通系统(ITS,intelligent traffic system)的完善是建设智能城市的主要环节[1],智能交通系统能缓解交通拥堵,减少车辆尾气排放,提高交通运营效率[2].通过将卷积神经网络(CNN,convolutionalneural networks)、残差神经单元(ResNet,residualneural units)和长短期记忆循环神经网络(LSTM,long-short-term memory networks)集成到一个端到端的深度学习网络CNN-ResNet-LSTM,能同时考虑轨迹数据和外部因素对交通流量的影响,从而进行短时预测.经实验结果验证,模型在保证预测准确率的情况下,减少了模型的参数.传统的流量预测方法很难对大规模的数据进行准确预测[3-4].深度学习已在许多领域被证明取得了成功,例如图像、音频和语言学习任务[5],单一神经网络模型无法充分提取交通流量数据时空特征[6-8].为了充分发挥各模型的优势,Bates和Granger[9]提出了组合预测的思想.众多研究人员开始用组合模型对交通流量进行预测[10-12].1短时交通流量预测问题短时交通流量预测问题定义为:在一个确定的时间间隙内预测某一观测点在下一个时间间隙的交通流量,时间间隙通常选择5 30min,第i个观测点在第t个时间间隙的流量记作f i,t,在间隙T时,交通流量序列F={f i,t|i∈D,t=1,2,…,T}(D是预测区域中全部的观测点),此时流量预测任务为预测间隙T+1的交通流量f i,T+1或者T+n的交通流量fi,T+n.然而,精确的预测受3个因素影响,设某一时间间隙的交通流量为X.1)临近性Xc =(Xt0-T h+3,Xt0-T h+2,Xt0-T h+1,…,Xt0)∈R2ˑMˑK其中R为轨迹集合,即每一个时间间隙的交通流量往往受前一个时间间隙流量的影响,同时也会影响下一个时间间隙的流量.随着人群上下班,一天中城市交通流量最为活跃的时间段分别为早、晚高峰.图1所示为北京市一天中进入某一区域的交通流量,可以看出,9:00、12:00、17:30的交通流量较多.图1北京市一天的交通流量2)趋势性Xt=(Xt0-T m+3,Xt0-T m+2,Xt0-T m+1,…,Xt0)∈R2ˑMˑK 图2所示为北京市某一区域2015-03-12—2015-06-12连续4个月在12号11:30—12:00的出租车流量,能够看出,人们喜欢在天气凉爽的月份出行,随着温度升高,人们越来越喜欢待在家里.图2北京市交通流量趋势性3)周期性Xp=(Xt0-T d+3,Xt0-T d+2,Xt0-T d+1,…,Xt0)∈R2ˑMˑK 由预测时间间隙之前多天与预测时间间隙相同的序列组成.城市区域的交通流量具有周期性,即同一月份中每一天相同时间间隙的车流大致相同,图3为2013-07-01—2013-07-07期间北京市从周一到周日12:30—13:00时的出租车入流的趋势图.可以看到,在工作日时进入该区域的出租车数量相近,而节假日进入该区域的出租车数量明显多于工作日.01北京邮电大学学报第43卷图3北京市交通流量周期性为了更好地考虑空间和时间上各因素对交通流量的影响,将城市区域根据经纬度划分成一个MˑN的网格地图,其中1个网格表示1个区域.第m 行第k列网格(m,k)的入流和出流定义为x in,m,k t =∑T r∈R|{n>1|hn-1(m,k)∧h n∈(m,k)}|(1)x out,m,k t =∑T r∈R|{n≥1|hn∈(m,k)∧h n+1 (m,k)}|(2)图4CNN-ResNet-LSTM网络结构其中:T r:h1→h2→…→h Tr为R中的一个轨迹,h n为地理位置的坐标,h i∈(m,k)为点h n在网格(m,k)中.对每个时间间隙t,将MˑN个区域的入流(Xt)0,m,k=x in,m,kt和出流(X t)1,m,k=x out,m,kt为X t,Xt∈R2ˑMˑK.采取的时间间隙为30min,即每30min统计一次城市区域内所有网格的入流与出流情况,并建立时空矩阵P t为Pt=Xlon1,lat1…Xlon1,lat kXlon m,lat1…Xlon m,latk(3)2网络模型通过将卷积神经网络、残差神经单元和长短期记忆循环神经网络集成到一个端到端的深度学习网络,网络结构如图4所示.一方面使用卷积神经网路来捕获城市区域内交通数据的局部空间特征,并使用残差神经单元来加深网络的深度从而提高预测的准确性;另一方面,使用长短期记忆循环神经网络来捕获交通流量间数据的时间特征,然后将2个网络的输出利用相应的权重矩阵融合,最后与外部因素(天气、温度、风速等)融合,从而实现预测每个区域短时的交通流量.2.1卷积神经网络首先构建X c,X t和X p三个模块.这3个模块通过一个相同的二维卷积神经网络结构以模拟时间临11第5期蒲悦逸等:基于CNN-ResNet-LSTM模型的城市短时交通流量预测算法近性、趋势性以及周期性.卷积算子定义为f(W*X+b)(4)其中:f为激活函数,*为卷积运算,W为权重矩阵,b为偏置值.临近性、趋势性、周期性3个模块的卷积算子分别为X(l)c=(f∑l c j=1W(l)c_j*X t-j+b(l))c(5)X(l)t=(f∑l t j=1W(l)t_j*X t-j+b(l))t(6)X(l)p=(f∑l p j=1W(l)p_j*X t-j+b(l))p(7)2.2残差神经元通过加入多个残差单元以解决模型过拟合问题,如式(8)所示,在卷积层的基础上增加了M个残差单元.X(l+1)c =X(l)c+ (X(l)c;θ(l)c),l=1,2,…,M(8)其中: 为残差函数,θ(l)c为在l层的残差单元所有能够学习的参数.2.3长短期记忆循环神经网络LSTM的输入通常是序列数据,因此需要对初始输入数据进行处理,首先将卷积神经网络的每个输入,即图中的X c,X t,X p展开成一维矩阵,然后将其转换成适合LSTM网络的输入形式.通过不同门的功能,使得LSTM网络能够处理具有长期依赖性的交通流量数据.2.4融合在进行多源数据融合时,首先将X c,X t,X p利用权重矩阵进行融合得到轨迹数据X tra.Xtra =WcX c+W t X t+W p X p(9)其中 为哈达马积.其次将外部数据X ext与轨迹数据X tra利用tanh 函数融合得到最终时间间隙t的交通流量预测值为槇X=tanh(Xext +Xtra)(10)其中:tanh为双曲正切函数,确保最终结果在[-1,1].3实验3.1数据集描述利用北京市数据[13]对CNN-ResNet-LSTM模型进行验证,北京市数据由出租车自带GPS设备收集的出租车轨迹数据和北京市的外部因素数据组成,信息如表1所示.表1数据集信息参数数值数据类型出租车GPS数据时间跨度2013-07-01—2013-10-302014-03-01—2014-09-302015-03-01—2015-09-302015-11-01—2016-04-10时间间隙/min30外部因素天气情况16种天气类型(晴天,下雪等)温度/ħ[-24.6,41.0]风速/(mile·h-1)[0,48.6]3.2评价标准利用均方根误差(RMSE,root mean square er-ror)和平均绝对百分比误差(MAPE,mean absolute percentage error)对模型进行评价,RMSE和MAPE 是常见量化模型优劣的重要标准,其值分别为rRMSE=1n∑ni=1(yi槇-yi)槡2(11)mMAPE=1n∑ni=1yi-槇yiyiˑ100(12)3.3超参数影响模型自身参数的改变同样会影响最终的预测结果.因此,为得到最好的预测结果,对模型使用的参数进行了自身的对比实验.首先,对卷积核尺寸大小从2ˑ2增加到7ˑ7时分别进行了实验,实验结果如图5(a)所示.当卷积核尺寸大小从2ˑ2到3ˑ3时,RMSE下降明显;当卷积核尺寸大小从3ˑ3变化到6ˑ6时,RMSE变化不很明显;而卷积核尺寸大小为7ˑ7时,RMSE变大.由于模型训练时长通常随着卷积核额的增大而加长,所以将卷积核尺寸大小设置为3ˑ3;其次,对残差神经单元的个数从7 13分别进行了实验,实验结果如图5(b)所示.随着残差神经单元从7增加到11,模型深度加深,RMSE一直减小.但是,当深度继续加深,即残差神经单元从11增加到13时,RMSE反而增大.因此选择的残差单元数为11.最后,对实验迭代次数进行比较,RMSE和MAPE的值分别如图5(c)和(d)所示,RMSE和MAPE均在150次时取得最小值.21北京邮电大学学报第43卷图5超参数影响3.4实验结果将提出的CNN-ResNet-LSTM模型与其他模型进行了比较,如表2所示.从预测结果来看,模型ARIMA和循环神经网络(SimpleRNN,GRU,LSTM)对最终流量的预测误差比较大,由于提出的CNN-ResNet-LSTM模型充分考虑了交通流量的时空特征,所以CNN-ResNet-LSTM模型与其他6个模型在交通流量的短时预测相比,表现出了较好的结果,其RMSE值为16.10,MAPE值为1.699.从模型复杂程度上看,CNN-ResNet-LSTM模型在保证较好预测结果的基础上大大降低了模型的复杂程度,其参数数量为281054.表2实验结果对比模型模型参数参数数量RMSE MAPE ARIMA无无20.29 4.370 CNN2层CNN,参数与CNN-ResNet-LSTM相同4278420.38 2.179 CNN3层CNN,参数与CNN-ResNet-LSTM相同15356819.51 2.070 SimpleRNN3层SimpleRNN,参数与CNN-ResNet-LSTM相同566699.9313.980 GRU3层GRU,参数与CNN-ResNet-LSTM相同1686680.9813.719 LSTM3层LSTM,参数与CNN-ResNet-LSTM相同2246674.1514.020 ConvLSTM2层ConvLSTM,参数与CNN-ResNet-LSTM相同55000218.65 2.030 ST-ResNet[13]2层CNN,参数与CNN-ResNet-LSTM相同226652816.69 1.910 CNN-ResNet-LSTM—28105416.10 1.6994结束语提出了一种新的能够对短时交通流量进行准确预测的组合学习模型CNN-ResNet-LSTM,可根据历史轨迹数据,结合外部因素对城市各个区域交通流量的变化进行预测.该模型将卷积神经网络与长短31第5期蒲悦逸等:基于CNN-ResNet-LSTM模型的城市短时交通流量预测算法期记忆循环神经网络集成到一个端到端的网络框架,分别捕获城市交通流量数据的局部空间特征和长依赖性之间的相关特征,并通过增加残差神经单元个数加深网络深度,以提高模型的预测准确性.为了验证模型的性能,利用北京市出租车GPS数据对模型进行了评估,并通过与多个常用的预测方法(ARIMA,CNN,BasicRNN,LSTM,GRU,ST-ResNET,ConvLSTM)进行比较,证实了提出的模型拥有较高的准确性.因只按照经纬度将北京市进行网格划分,并未考虑交通路网的复杂性,下一步的研究将考虑复杂的交通路网信息,对具体的路段和地区进行分类研究,同时对其他城市的数据进行分析,从而增强模型的泛化能力,提高算法的普适性.参考文献:[1]陈湘军,阮雅端,陈启美,等.车辆图像稀疏特征表示及其监控视频应用[J].北京邮电大学学报,2016(S1):81-86.Chen Xiangjun,Ruan Yaduan,Chen Qimei,et al.Sparse feature representation of vehicle images and itssurveillance video application[J].Journal of BeijingUniversity of Posts and Telecommunications,2016(S1):81-86.[2]Zhang Nan,Wang Feiyue,Zhu Fenghua,et al.Dyna-CAS:computational experiments and decision support forITS[J].IEEE Intelligent Systems,2008,23(6):19-23.[3]Sun Bin,Cheng Wei,Goswami Prashant,et al.Short-term traffic forecasting using self-adjusting k-nearestneighbours[J].IET Intelligent Transport Systems,2017,12(1):41-48.[4]Castro-Neto M,Jeong Y S,Jeong M K,et al.Online-SVRfor short-term traffic flow prediction under typicaland atypical traffic conditions[J].Expert Systems withApplications,2009,36(3):6164-6173.[5]Schmidhuber J.Deep learning in neural networks:an overview[J].Neural Networks,2015,61:85-117.[6]Huang Wenhao,Song Guojie,Hong Haikun,et al.Deeparchitecture for traffic flow prediction:deep belief net-works with multitask learning[J].IEEE Transactions onIntelligent Transportation Systems,2014,15(5):2191-2201.[7]Lu Wenqi,Luo Dongyu,Yan Menghua.A model of traf-fic accident prediction based on convolutional neural net-work[C]∥20172nd IEEE International Conference onIntelligent Transportation Engineering(ICITE).Singa-pore:IEEE,2017:198-202.[8]Zhao Zheng,Chen Weihai,Wu Xingming,et al.LSTM network:a deep learning approach for short-term trafficforecast[J].IET Intelligent Transport Systems,2017,11(2):68-75.[9]Bates J M,Granger C W J.The combination of forecasts [J].Journal of the OperationalResearch Society,1969,20(4):451-468.[10]Shi Xingjian,Chen Zhourong,Wang Hao,et al.Convo-lutional LSTM network:a machine learning approach forprecipitation nowcasting[C]∥Advances in Neural Infor-mation Processing Systems.Montreal:Neural Informa-tion Processing Systems Foundation,2015:802-810.[11]段宗涛,张凯,杨云,等.基于深度CNN-LSTM-Res-Net组合模型的出租车需求预测[J].交通运输系统工程与信息,2018,18(4):215-223.Duan Zongtao,Zhang Kai,Yang Yun,et al.Taxi de-mand prediction based on deep CNN-LSTM-ResNet com-bined model[J].Journal of Transportation Systems En-gineering and Information Technology,2018,18(4):215-223.[12]Wu Yuankai,Tan Huachun,Qin Lingqiao,et al.A hy-brid deep learning based traffic flow prediction methodand its understanding[J].TransportationResearch PartC:Emerging Technologies,2018,90:166-180.[13]He Kaiming,Zhang Xiangyu,Ren Shaoqing,et al.Deep residual learning for image recognition[C]∥Pro-ceedings of the IEEE Conference on Computer Visionand PatternRecognition.Las Vegas:IEEE ComputerSociety,2016:770-778.41北京邮电大学学报第43卷。
dataset用法python

dataset用法python摘要:1.数据集(dataset)的定义和作用2.Python 中处理数据集的方法和常用库3.使用Python 操作数据集的实例正文:1.数据集(dataset)的定义和作用数据集(dataset)是指一组数据的集合,通常用于机器学习、数据挖掘和统计分析等领域。
数据集可以帮助研究人员和开发者训练模型、测试算法和优化程序。
数据集的质量和多样性对于模型的准确性和泛化能力至关重要。
2.Python 中处理数据集的方法和常用库Python 作为一门广泛应用于数据科学领域的编程语言,提供了丰富的库和方法来处理数据集。
以下是一些常用的Python 库:- Pandas:一个功能强大的数据处理库,可以轻松地处理数据表和混合数据(例如CSV、Excel、SQL 等文件格式)。
- NumPy:一个用于数值计算的库,提供了高效的多维数组对象和相关操作函数。
- Matplotlib:一个用于绘制数据图形的库,可以生成各种图表,如折线图、散点图、直方图等。
- Scikit-learn:一个用于机器学习的库,提供了许多常用的数据处理、特征提取和模型评估方法。
3.使用Python 操作数据集的实例下面是一个使用Python 操作数据集的简单实例,主要涉及数据的读取、处理和可视化。
首先,需要安装相关库:```pip install pandas numpy matplotlib scikit-learn```然后,编写代码:```pythonimport pandas as pdimport numpy as npimport matplotlib.pyplot as pltfrom sklearn.model_selection import train_test_split# 读取数据集data = pd.read_csv("iris.data", names=["sepal_length","sepal_width", "petal_length", "petal_width", "species"])# 数据预处理data = data.dropna() # 删除缺失值X = data[["sepal_length", "sepal_width", "petal_length","petal_width"]]y = data["species"]# 数据集划分X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 可视化数据plt.scatter(X_train[:, 0], X_train[:, 1], c=y_train, cmap="viridis", edgecolors="k", label="训练数据")plt.scatter(X_test[:, 0], X_test[:, 1], c=y_test, cmap="viridis", edgecolors="k", label="测试数据")plt.legend()plt.show()# 建立模型from sklearn.svm import SVCmodel = SVC(kernel="linear", C=1)model.fit(X_train, y_train)# 模型评估y_pred = model.predict(X_test)score = model.score(X_test, y_test)print(f"模型准确率:{score:.2f}")```上述代码首先从CSV 文件中读取数据集,然后进行预处理,如删除缺失值。
基于RepGT损失的改进Faster_R-CNN的包裹检测算法

[收稿日期]2022-02-21[作者简介]范海红(1981-),女,硕士研究生,讲师,主要研究方向:机器学习的算法研究和应用。
doi:10.3969/j.issn.1005-152X.2022.05.017基于RepGT 损失的改进Faster R-CNN 的包裹检测算法范海红(浙江邮电职业技术学院管理信息学院,浙江绍兴312000)[摘要]针对目前我国快递包裹中转中心面临的快递包裹文件数量密集型问题以及包裹辨识检测算法技术,提供了一个经过改进的Faster R-CNN辨识检测算法。
通过修改Faster R-CNN算法中的损失函数,用RepGT损失函数替代原回归项中的损失函数,使得选取的包裹候选框更接近包裹目标框,完成图像检测。
通过数据实验发现,改进后的算法比传统的Faster R-CNN在精度上提升了2.38AP,同时发现当损失函数中参数σ=1时,检测精确度达到最高。
[关键词]包裹检测;卷积神经网络;Faster R-CNN;RepGT 损失[中图分类号]F259.23;TP391.41;TP183[文献标识码]A[文章编号]1005-152X(2022)05-0078-04Improved Faster R-CNN Parcel Detection Algorithm Based on RepGT LossFAN Haihong(Department of Management &Information,Zhejiang Post &Telecommunication College,Shaoxing 312000,China)Abstract:In this paper,aiming at the problems faced by the express parcel transfer centers in China,we proposed an improved Faster R-CNN identification and detection algorithm.Next,by modifying the loss function in the Faster R-CNN algorithm and replacing the loss function in the original regression with the RepGT loss function,we arrived at parcel identification frames closer to the target frames to complete the image detection.At the end,through a numerical example,it is found that the improved algorithm is 2.38AP more accurate than the traditional Faster R-CNN algorithm,and also identified the parameterization of the loss function to realize the highest detection accuracy.Keywords:parcel detection;convolutional neural network;Faster R-CNN;RepGT loss0引言近几年,随着电子商务迅速发展,相应的物流产业也快速发展,包裹数量远超欧美国家的总和。
中文NER的那些事儿1.Bert-Bilstm-CRF基线模型详解代码实现

中⽂NER的那些事⼉1.Bert-Bilstm-CRF基线模型详解代码实现这个系列我们来聊聊序列标注中的中⽂实体识别问题,第⼀章让我们从当前⽐较通⽤的基准模型Bert+Bilstm+CRF说起,看看这个模型已经解决了哪些问题还有哪些问题待解决。
以下模型实现和评估脚本,详见。
Repo⾥上传了在MSRA上训练好的bert_bilstm_crf, bilstm_crf模型以及serving相关的代码, 可以开箱即⽤哟~NER问题抽象实体识别需要从⽂本中抽取两类信息,不同类型的实体本⾝token组合的信息(实体长啥样),以及实体出现的上下⽂信息(实体在哪⾥)⼀种解法就是通过序列标注把以上问题转化成每个字符的分类问题,label主要有两种其中BIO更常见些BIO:B标记实体的开始,I标记其余部分,⾮实体是OBMOES:B标记开始,E标记结束,中间是M,单字实体是S,⾮实体是O主流中⽂实体识别任务都是字符级输⼊,考虑后⾯会⽤到Bert-finetune统⼀⽤bert-tokenizer做字符到ID的映射。
不以中⽂分词作为输⼊粒度的原因也很简单,其⼀分词本⾝的准确率限制了NER的天花板,其⼆不同领域NER的词粒度和分词的粒度会存在差异进⼀步影响模型表现。
如何引⼊中⽂词粒度信息,之后会通过词汇增强的⽅式来实现。
以下是训练数据的Demo<img src="https:///user/8955/7858a82f-d1d0-4061-bbd1-5a21e4976aa2.png" heigh="200" ,="" width="500">NER评估NER评估分为Tag级别(B-LOC,I-LOC)和Entity级别(LOC),⼀般以entity的micro F1-score为准。
因为tag预测准确率⾼但是抽取出的entity有误,例如边界错误,在实际应⽤时依旧抽取的是错误的实体。
Fast RCNN 训练自己的数据集(3训练和检测)

Fast RCNN 训练自己的数据集(3训练和检测)转载请注明出处,楼燚(yì)航的blog,/louyihang-loves-baiyan/https:///YihangLou/fast-rcnn-train-another-datas et 这是我在github上修改的几个文件的链接,求星星啊,求星星啊(原谅我那么不要脸~~)在之前两篇文章中我介绍了怎么编译Fast RCNN,和怎么修改Fast RCNN的读取数据接口,接下来我来说明一下怎么来训练网络和之后的检测过程先给看一下极好的检测效果https:///YihangLou/fast-rcnn-train-another-datas et1.预训练模型介绍首先在data目录下,有两个目录就是之前在1中解压好fast_rcnn_models/imagenet_models/fast_rcnn_model文件夹下面是作者用fast rcnn训练好的三个网络,分别对应着小、中、大型网络,大家可以试用一下这几个网络,看一些检测效果,他们训练都迭代了40000次,数据集都是pascal_voc的数据集。
caffenet_fast_rcnn_iter_40000.caffemodelvgg_cnn_m_1024_fast_rcnn_iter_40000.caffemodelvgg16_fast_rcnn_iter_40000.caffemodelimagenet_model文件夹下面是在Imagenet上训练好的通用模型,在这里用来初始化网络的参数CaffeNet.v2.caffemodelVGG_CNN_M_1024.v2.caffemodelVGG16.v2.caffemodel在这里我比较推荐先用中型网络训练,中型网络训练和检测的速度都比较快,效果也都比较理想,大型网络的话训练速度比较慢,我当时是5000多个标注信息,网络配置默认,中型网络训练大概两三个小时,大型网络的话用十几个小时,需要注意的是网络训练最好用GPU,CPU的话太慢了,我当时用的实验室的服务器,有16块Tesla K80,用起来真的是灰常爽!2. 修改模型文件配置模型文件在models下面对应的网络文件夹下,在这里我用中型网络的配置文件修改为例子比如:我的检测目标物是car ,那么我的类别就有两个类别即background 和car因此,首先打开网络的模型文件夹,打开train.prototxt修改的地方重要有三个分别是个地方首先在data层把num_classes 从原来的21类20类+背景,改成2类车+背景接在在cls_score层把num_output 从原来的21 改成2在bbox_pred层把num_output 从原来的84 改成8,为检测类别个数乘以4,比如这里是2类那就是2*4=8OK,如果你要进一步修改网络训练中的学习速率,步长,gamma值,以及输出模型的名字,需要在同目录下的solver.prototxt中修改。
lstm车辆行驶轨迹预测python代码

lstm车辆行驶轨迹预测python代码LSTM车辆行驶轨迹预测Python代码随着人们对交通安全和交通效率的要求越来越高,车辆行驶轨迹预测成为了一个重要的研究方向。
在这个领域中,LSTM(长短时记忆网络)被广泛应用于车辆行驶轨迹预测。
本文将介绍如何使用Python代码实现LSTM车辆行驶轨迹预测。
1. 数据准备我们需要准备数据。
在这个例子中,我们将使用Kaggle上的一个数据集,该数据集包含了纽约市出租车的行驶轨迹。
我们将使用其中的一部分数据进行训练和测试。
我们需要导入必要的库:```import pandas as pdimport numpy as npimport matplotlib.pyplot as pltfrom sklearn.preprocessing import MinMaxScaler```然后,我们可以读取数据:```data = pd.read_csv('data.csv')```接下来,我们需要对数据进行预处理。
首先,我们需要将时间戳转换为日期时间格式:```data['datetime'] = pd.to_datetime(data['timestamp'])```然后,我们可以将日期时间格式的数据转换为时间戳:```data['timestamp'] = data['datetime'].astype(np.int64) // 10**9 ```接下来,我们需要将数据按照时间戳排序:```data = data.sort_values(by=['timestamp'])```然后,我们可以将数据划分为训练集和测试集:```train_data = data[:8000]test_data = data[8000:]```我们需要对数据进行归一化处理:```scaler = MinMaxScaler()train_data = scaler.fit_transform(train_data)test_data = scaler.transform(test_data)```2. 构建LSTM模型接下来,我们需要构建LSTM模型。
特征矩阵构造方法在高速列车故障诊断中的应用

特征矩阵构造方法在高速列车故障诊断中的应用赵莹莹;谭献海【摘要】The Two-dimensional Feature Fusion (2DFF) method based on two-dimensional feature matrix,i.e.,twodimensional principal component analysis can the goal of feature fusion by decreasing the dimensions of the feature matrix,but it performs well got only when the difference in the dimensions of feature vectors is small.Some zeros after every single feature vector to get a two-dimensional feature matrix in the construction method of feature matrix of traditional 2DFF,which may change attributes of original feature vector at the condition that the difference in dimension of each feature vectors is huge and decreases the identification rate.Since the disadvantage above,a new construction method of feature matrix based on Singular Value Decomposition (SVD) is proposed.The new method groups all feature vectors end to end as a new one-dimensional feature vector which is decomposed into a two-dimensional feature matrix by keeping the phase of the signal unchanged based on the decomposition feature of SVD.Experimental result shows that the new method has a higher identification rate than traditional 2DFF feature construction method difference in the dimensions of feature vectors.%基于二维特征矩阵的二维特征融合(2DFF)方法——二维主成分分析法能够降低特征矩阵的维数,达到特征融合的目的,但该方法仅在特征向量维数相近的情况下效果较好.传统2 DFF特征矩阵构造方法需要在每个特征向量后补0以形成二维特征矩阵,在特征向量维数相差较大时补0个数较多,破坏原始特征向量属性,使最终识别率降低.针对该问题,提出一种基于奇异值分解(SVD)的二维特征矩阵构造方法,该方法将所有特征向量首尾相接组合成一维特征向量,利用SVD的分解特性,在保持特征信号相位不变的情况下,将一维综合特征向量分解成二维特征矩阵,避免大量补0导致信号特性的改变.实验结果表明,该方法在各特征向量维数相差较大的情况下,可获得比在向量后直接补0的特征矩阵构造方法更高的识别率.【期刊名称】《计算机工程》【年(卷),期】2017(043)002【总页数】6页(P21-25,32)【关键词】状态识别;高速列车故障诊断;特征融合;二维特征矩阵;主成分分析【作者】赵莹莹;谭献海【作者单位】西南交通大学信息科学与技术学院,成都610031;西南交通大学信息科学与技术学院,成都610031【正文语种】中文【中图分类】TP391信息融合技术是模式识别的一项重要技术。
机器学习之手写数字识别-小数据集
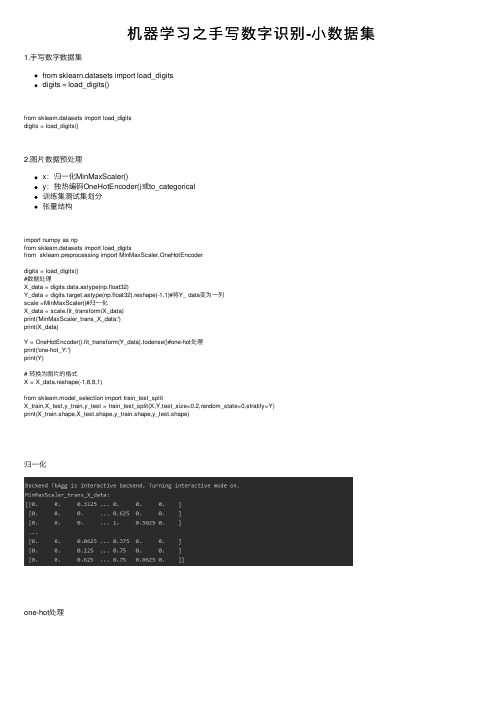
机器学习之⼿写数字识别-⼩数据集1.⼿写数字数据集from sklearn.datasets import load_digitsdigits = load_digits()from sklearn.datasets import load_digitsdigits = load_digits()2.图⽚数据预处理x:归⼀化MinMaxScaler()y:独热编码OneHotEncoder()或to_categorical训练集测试集划分张量结构import numpy as npfrom sklearn.datasets import load_digitsfrom sklearn.preprocessing import MinMaxScaler,OneHotEncoderdigits = load_digits()#数据处理X_data = digits.data.astype(np.float32)Y_data = digits.target.astype(np.float32).reshape(-1,1)#将Y_ data变为⼀列scale =MinMaxScaler()#归⼀化X_data = scale.fit_transform(X_data)print('MinMaxScaler_trans_X_data:')print(X_data)Y = OneHotEncoder().fit_transform(Y_data).todense()#one-hot处理print('one-hot_Y:')print(Y)# 转换为图⽚的格式X = X_data.reshape(-1,8,8,1)from sklearn.model_selection import train_test_splitX_train,X_test,y_train,y_test = train_test_split(X,Y,test_size=0.2,random_state=0,stratify=Y)print(X_train.shape,X_test.shape,y_train.shape,y_test.shape)归⼀化one-hot处理图⽚格式划分测试集与训练集3.设计卷积神经⽹络结构4.模型训练#导⼊相关包from tensorflow.keras.models import Sequentialfrom yers import Dense,Dropout,Flatten,Conv2D,MaxPool2D#建⽴模型model = Sequential()ks = (3, 3)# 第⼀层卷积# 第⼀层输⼊数据的shape要指定外,其他层的数据的shape框架会⾃动推导model.add(Conv2D(filters=16, kernel_size=ks, padding='same', input_shape=X_train.shape[1:],activation='relu'))# 池化层model.add(MaxPool2D(pool_size=(2, 2)))# 防⽌过拟合model.add(Dropout(0.25))# 第⼆层卷积model.add(Conv2D(filters=32, kernel_size=ks, padding='same', activation='relu'))# 池化层model.add(MaxPool2D(pool_size=(2, 2)))model.add(Dropout(0.25))# 第三层卷积model.add(Conv2D(filters=64, kernel_size=ks, padding='same', activation='relu'))# 第四层卷积model.add(Conv2D(filters=128, kernel_size=ks, padding='same', activation='relu'))# 池化层model.add(MaxPool2D(pool_size=(2, 2)))model.add(Dropout(0.25))model.add(Flatten())# 平坦层model.add(Dense(128, activation='relu'))# 全连接层model.add(Dropout(0.25))model.add(Dense(10, activation='softmax'))# 激活函数softmaxmodel.summary()pile(loss='categorical_crossentropy',optimizer='adam',metrics=['accuracy'])train_history = model.fit(x=X_train,y=y_train,validation_split=0.2,batch_size=300,epochs=10,verbose=2) score = model.evaluate(X_test, y_test)print(score)训练运⾏结果如下:5.模型评价model.evaluate()交叉表与交叉矩阵pandas.crosstabseaborn.heatmapimport seaborn as snsimport pandas as pdresults = model.evaluate(X_test, y_test)print('评估结果:', results)# 预测值y_pred = model.predict_classes(X_test)print('预测值:', y_pred[:10])# 交叉表与交叉矩阵y_test1 = np.argmax(y_test, axis=1).reshape(-1)y_true = np.array(y_test1)[0]# 交叉表查看预测数据与原数据对⽐c=pd.crosstab(y_true, y_pred, rownames=['true'], colnames=['predict'])# 交叉矩阵y_test1 = y_test1.tolist()[0]a = pd.crosstab(np.array(y_test1), y_pred, rownames=['Lables'], colnames=['Predict']) df = pd.DataFrame(a)#转换成属dataframesns.heatmap(df, annot=True, cmap="RdGy", linewidths=0.2, linecolor='G')plt.show()交叉表预测数据与原数据预测数据与原数据热⼒图如下具体代码如下:# -*- coding:utf-8 -*-# 班级:17软件⼯程⼀班# 开发⼈员:爱飞的⼤⽩鲨# 开发时间:2020/6/8 10:20# ⽂件名称:⼿写数据集及预处理.pyimport numpy as npfrom sklearn.datasets import load_digitsfrom sklearn.preprocessing import MinMaxScaler,OneHotEncoderdigits = load_digits()#数据处理X_data = digits.data.astype(np.float32)Y_data = digits.target.astype(np.float32).reshape(-1,1)#将Y_ data变为⼀列scale =MinMaxScaler()#归⼀化X_data = scale.fit_transform(X_data)print('MinMaxScaler_trans_X_data:')print(X_data)Y = OneHotEncoder().fit_transform(Y_data).todense()#one-hot处理print('one-hot_Y:')print(Y)# 转换为图⽚的格式X = X_data.reshape(-1,8,8,1)from sklearn.model_selection import train_test_splitX_train,X_test,y_train,y_test = train_test_split(X,Y,test_size=0.2,random_state=0,stratify=Y) print(X_train.shape,X_test.shape,y_train.shape,y_test.shape)#导⼊相关包from tensorflow.keras.models import Sequentialfrom yers import Dense,Dropout,Flatten,Conv2D,MaxPool2D#建⽴模型model = Sequential()ks = (3, 3)# 第⼀层卷积# 第⼀层输⼊数据的shape要指定外,其他层的数据的shape框架会⾃动推导model.add(Conv2D(filters=16, kernel_size=ks, padding='same', input_shape=X_train.shape[1:], activation='relu'))# 池化层model.add(MaxPool2D(pool_size=(2, 2)))# 防⽌过拟合model.add(Dropout(0.25))# 第⼆层卷积model.add(Conv2D(filters=32, kernel_size=ks, padding='same', activation='relu'))# 池化层model.add(MaxPool2D(pool_size=(2, 2)))model.add(Dropout(0.25))# 第三层卷积model.add(Conv2D(filters=64, kernel_size=ks, padding='same', activation='relu'))# 第四层卷积model.add(Conv2D(filters=128, kernel_size=ks, padding='same', activation='relu'))# 池化层model.add(MaxPool2D(pool_size=(2, 2)))model.add(Dropout(0.25))model.add(Flatten())# 平坦层model.add(Dense(128, activation='relu'))# 全连接层model.add(Dropout(0.25))model.add(Dense(10, activation='softmax'))# 激活函数softmaxmodel.summary()pile(loss='categorical_crossentropy',optimizer='adam',metrics=['accuracy'])train_history = model.fit(x=X_train,y=y_train,validation_split=0.2,batch_size=300,epochs=10,verbose=2) score = model.evaluate(X_test, y_test)print(score)train_history.historyimport matplotlib.pyplot as pltplt.rcParams['font.sans-serif'] = ['FangSong'] # 指定字体def show_train_history(train_history, train, validation):plt.plot(train_history.history[train])plt.plot(train_history.history[validation])plt.ylabel('train')plt.xlabel('epoch')plt.legend(['train', 'validation'], loc='upper left')plt.show()p = plt.figure(figsize=(15, 15))a1 = p.add_subplot(2, 1, 1)show_train_history(train_history, 'accuracy', 'val_accuracy')plt.title("准确率")a2 = p.add_subplot(2, 1, 2)show_train_history(train_history, 'loss', 'val_loss')plt.title("损失率")plt.show()import seaborn as snsimport pandas as pdresults = model.evaluate(X_test, y_test)print('评估结果:', results)# 预测值y_pred = model.predict_classes(X_test)print('预测值:', y_pred[:10])# 交叉表与交叉矩阵y_test1 = np.argmax(y_test, axis=1).reshape(-1)y_true = np.array(y_test1)[0]# 交叉表查看预测数据与原数据对⽐c=pd.crosstab(y_true, y_pred, rownames=['true'], colnames=['predict'])# 交叉矩阵y_test1 = y_test1.tolist()[0]a = pd.crosstab(np.array(y_test1), y_pred, rownames=['Lables'], colnames=['Predict'])df = pd.DataFrame(a)#转换成属dataframesns.heatmap(df, annot=True, cmap="RdGy", linewidths=0.2, linecolor='G')plt.show()。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
LINEAR F
Unit of measure
Text
Unit of measure Text Text Text Text Text
Text
* 资料来源:
34
GBUTtem
SPIRAL1 3D
Unit of measure
* 资料来源:
35
GBUTtem
SPIRAL2 3D
Unit of measure
Brakes
Spiral
* 资料来源:
Tube in tube
* 资料来源:
39
GBUTtem
WIRE CUBES
Unit of measure
Text
Text
* 资料来源:
40
GBUTtem
ARROWS
Unit of measure
Text
Text
Text Text Text Text
Text
* 资料来源:
41
GBUTtem
LEVEL 1
Unit of measure
Text
Text
Text
Text
* 资料来源:
12
GBUTtem
FORCES AT WORK
Unit of measure
New entrant
Suppliers
Industry competitors
Buyers
Substitute s
* 资料来源:
13
GBUTtem
JOINT
Unit of measure
* 资料来源:
52
GBUTtem
FLOW 4 TITLE
Unit of measure
Header
Text Text
Header
Text
Header
Text
Header
Text
* 资料来源:
53
GBUTtem
FLOW 5
Unit of measure Header Text Header Text Header Text Header Text Header Text
CYCLE 7
Unit of measure
Text
Text
Text
Text
Text Text
Text
* 资料来源:
67
GBUTtem
CYCLE 8
Unit of measure
Text TeLeabharlann tTextText
Text Text Text
Text
* 资料来源:
68
GBUTtem
INCOMING
Text Text Text Text Text
Text Text Text Text
Text
* 资料来源:
14
GBUTtem
LEVEL SEPARATE 4
Unit of measure
Text
Text
Text
Text
* 资料来源:
15
GBUTtem
LINEAR A 3D
Unit of measure
GBUTtem
FLOW 2
Unit of measure Header Text Header Text
* 资料来源:
48
GBUTtem
FLOW 2 TITLE
Unit of measure
Header
Text Text
Header
Text
* 资料来源:
49
GBUTtem
FLOW 3
Unit of measure Header Text Header Text Header Text
Text
Text
* 资料来源:
61
GBUTtem
CYCLE 2
Unit of measure
Text
Text
* 资料来源:
62
GBUTtem
CYCLE 3
Unit of measure Text
Text Text
* 资料来源:
63
GBUTtem
CYCLE 4
Unit of measure
Text Text
* 资料来源:
71
GBUTtem
UPON 2
Unit of measure Text
Text
* 资料来源:
72
GBUTtem
CONTINUOUS
Unit of measure
Text
Text Text Text
Text Text Text Text
* 资料来源:
73
GBUTtem
CUTOUT
Unit of measure
Text
Text Text
* 资料来源:
4
GBUTtem
2X2 TOWER
Unit of measure
* 资料来源:
5
GBUTtem
5Ps MARKETING
Unit of measure
Product offering
Product
Package
Place
Price
Positioning promotion
* 资料来源:
50
GBUTtem
FLOW 3 TITLE
Unit of measure
Header
Text Text
Header
Text
Header
Text
* 资料来源:
51
GBUTtem
FLOW 4
Unit of measure Header Text Header Text Header Text Header Text
* 资料来源:
6
GBUTtem
7S
Unit of measure
Style
Strategy Shared values
Skills
Staff
Systems
Structure
* 资料来源:
7
GBUTtem
ARROW 3D
Unit of measure
* 资料来源:
8
GBUTtem
CUBES1 3D
36
GBUTtem
SPOTLIGHT
Unit of measure
Text
Text
Text
Text
* 资料来源:
37
GBUTtem
STAIRCASE
Unit of measure
Text Text Text Text Text Text
* 资料来源:
38
GBUTtem
Stars 3D
Unit of measure
* 资料来源:
56
GBUTtem
FLOW 6 TITLE
Unit of measure Header Text Text Header Text Header Text Header Text Header Text Header Text
* 资料来源:
57
GBUTtem
BLADES
Unit of measure
–
Text
Text Text
High Low
Text
Text
Text
* 资料来源:
1
GBUTtem
EXHIBIT TITLE
* 资料来源:
2
GBUTtem
Unit of measure
* 资料来源:
3
GBUTtem
2X2 CUBED
Unit of measure
Text
Text
Text Text Text
Unit of measure
Text Text
Text
* 资料来源:
19
GBUTtem
LINEAR E 3D
Unit of measure
Text
Text
Text
Text
* 资料来源:
20
GBUTtem
LINEAR G 3D
Unit of measure
Text
Text
Text
* 资料来源:
21
GBUTtem
LINEAR I 3D
Unit of measure
Text
Text
* 资料来源:
22
GBUTtem
LINEAR J 3D
Unit of measure
Text Text Text
Text
* 资料来源:
23
GBUTtem
LINEAR N 3D
Unit of measure
Text
Text
Text
Text
* 资料来源:
24
GBUTtem
LINEAR P 3D
Unit of measure
Text Text Text
* 资料来源:
25
GBUTtem
LINEAR Q 3D
Unit of measure
Text
Text
* 资料来源:
26
GBUTtem
LINEAR Q 3D
Unit of measure
Text
Text
Text
Text
* 资料来源:
74
GBUTtem
LINEAR A
Unit of measure
Text
Text
Text
* 资料来源:
75