双表查询,SQL语句使用
最全MySQL数据库表的查询操作

最全MySQL数据库表的查询操作 序⾔ 1、 2、 本节⽐较重要,对数据表数据进⾏查询操作,其中可能⼤家不熟悉的就对于INNER JOIN(内连接)、LEFT JOIN(左连接)、RIGHT JOIN(右连接)等⼀些复杂查询。
通过本节的学习,可以让你知道这些基本的复杂查询是怎么实现的,但是建议还是需要多动⼿去敲,虽然理解了什么是内连接等,但是从理解到学会,是完全不⼀样的感觉。
--WZY⼀、单表查询 1.1、查询所有字段 1.2、查询指定字段 1.3、查询指定记录 1.4、带IN关键字的查询 1.5、带BETWEEN AND 的范围查询 1.6、带LIKE的字符匹配查询 1.7、查询空值 1.8、带AND的多条件查询 1.9、带OR的多条件查询 1.10、关键字DISTINCT(查询结果不重复) 1.11、对查询结果排序 1.12、分组查询(GROUP BY) 1.13、使⽤LIMIT限制查询结果的数量 集合函数查询 1.14、COUNT()函数 1.15、SUM()函数 1.16、AVG()函数 1.17、MAX()函数 1.18、MIN()函数 ⼆、多表查询 ⼩知识 为表取别名 为字段取别名 基于两张表 2.1、普通双表连接查询 2.2、内连接查询 2.3、外连接查询 2.3.1、左外连接查询 2.3.2、右外连接查询 2.4、复合条件连接查询 ⼦查询 2.5、带ANY、SOME关键字的⼦查询 2.6、带ALL关键字的⼦查询 2.7、带EXISTS关键字的⼦查询 2.8、带IN关键字的⼦查询 2.9、带⽐较运算符的⼦查询 合并结果查询 2.10、UNION[ALL]的使⽤三、使⽤正则表达式查询 3.1、查询以特定字符或字符串开头的记录 3.2、查询以特定字符或字符串结尾的记录 3.3、⽤符号"."来替代字符串中的任意⼀个字符 3.4、使⽤"*"和"+"来匹配多个字符 3.5、匹配指定字符串 3.6、匹配指定字符中的任意⼀个 3.7、匹配指定字符以外的字符 3.8、使⽤{n,}或者{n,m}来指定字符串连续出现的次数四、综合案例练习数据表查询操作 4.1、搭建环境 省略 4.2、查询操作 省略 4.3、在已经创建好的employee表中进⾏如下操作 4.3.1、计算所有⼥员⼯(F)的年龄 4.3.2、使⽤LIMIT查询从第3条记录开始到第六条记录 4.3.3、查询销售⼈员(SALSEMAN)的最低⼯资 4.3.4、查询名字以字母N或者S结尾的记录 4.3.5、查询在BeiJing⼯作的员⼯的姓名和职务 4.3.6、使⽤左连接⽅式查询employee和dept表 4.3.7、查询所有2001~2005年⼊职的员⼯的信息,查询部门编号为20和30的员⼯信息并使⽤UNION合并两个查询结果 4.3.8、使⽤LIKE查询员⼯姓名中包含字母a的记录 4.3.9、使⽤REGEXP查询员⼯姓名中包含T、C或者M 3个字母中任意1个的记录 想直接做题的,跳过讲解,直接到练习区。
2023年教师资格之中学信息技术学科知识与教学能力提升训练试卷A卷附答案

2023年教师资格之中学信息技术学科知识与教学能力提升训练试卷A卷附答案单选题(共60题)1、在Flash中,填充变形工具可以对所填颜色的范围、方向和角度等进行调节以获得特殊的效果。
其中,要改变填充高光区的位置应该使用()。
A.大小手柄B.旋转手柄C.焦点手柄D.中心点手柄【答案】 D2、2019年9月18日,国家计算机病毒应急处理中心发布了第十八次计算机病毒和移动终端病毒疫情调查报告。
调查显示,2018年我国计算机病毒感染率和移动终端病毒感染率均呈现上升态势。
网络安全问题呈现出易变性、不确定性、规模性和模糊性等特点,网络安全事件发生成为大概率事件,信息泄漏、勒索病毒等重大网络安全事件多有发生。
下列关于计算机病毒传播特征的叙述,正确的是()。
A.只要不上网计算机就不会感染病毒B.在计算机中安装杀毒软件就能确保计算机不感染病毒C.在开机状态下插入U盘可能会导致计算机感染病毒D.感染过病毒的计算机具有对该病毒的免疫性【答案】 C3、在浏览标题为学习强国的网页时,需要保存当前页面,若使用默认文件保存,则以下描述正确的是()。
A.可以得到一个文件名为index.htm网页文件和index.files文件夹B.可以得到一个文件名为学习强国.htm网页文件和index.files文件夹C.可以得到一个文件名为index.htm网页文件和学习强国.files文件夹D.可以得到一个文件名为学习强国.htm网页文件和学习强国.files文件夹【答案】 D4、在一款概念汽车的设计、测试和生产过程中,最不可能用到的是()A.CADB.CATC.CAMD.CAI【答案】 D5、下列不属于高中信息技术课程基本理念的是()A.关注全体学生,建设有特色的信息技术课程B.营造良好的信息环境,打造终身学习的平台C.强化学生的手脑并用,发展学生的实践能力D.注重交流与合作,共同构建健康的信息文化【答案】 C6、在电影《头号玩家》中,人们沉浸在一个被称为“绿洲”的游戏世界里。
sql查询之双重notexists实现关系代数除运算
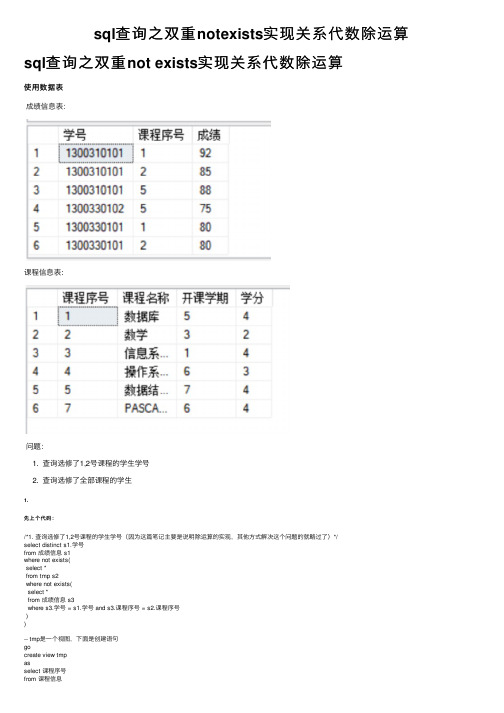
sql查询之双重notexists实现关系代数除运算sql查询之双重not exists实现关系代数除运算使⽤数据表成绩信息表:课程信息表:问题:1. 查询选修了1,2号课程的学⽣学号2. 查询选修了全部课程的学⽣1.先上个代码:/*1. 查询选修了1,2号课程的学⽣学号(因为这篇笔记主要是说明除运算的实现,其他⽅式解决这个问题的就略过了)*/select distinct s1.学号from 成绩信息 s1where not exists(select *from tmp s2where not exists(select *from 成绩信息 s3where s3.学号 = s1.学号 and s3.课程序号 = s2.课程序号))-- tmp是⼀个视图,下⾯是创建语句gocreate view tmpasselect 课程序号from 课程信息where 课程序号 in ('1', '2');goselect * from tmp;先来看看这个视图,得到的结果如下:很明显,这只是为了创建⼀个只含有1,2课程号的表,当然可以通过其他⽅式创建,⽐如直接创建⼀个表,然后插⼊数据接着看看这个查询,这⾥⽤到了两重not exists,第⼀重是对成绩信息表进⾏的扫描,select 可以列举成对表的每⼀个元组的枚举,对于not exists可以理解成exists的结果取反,即true变false, false变true,还有即使别名s1是为了⽅便写起的然后就是第⼆层not exists,这个是对创建的那个视图的扫描。
也就是在第⼀重扫描时,没扫描⼀个元组,就会进⼊第⼆层的扫描,即第⼀层每次执⾏⼀次,就会执⾏⼀次这个代码select *from tmp s2.../*后⾯第⼆个not exists先忽略*/扫描过程就是类似图中这样,类似于for循环再将第⼆个扫描的not exists那部分加进来select *from tmp s2where not exists(select *from 成绩信息 s3where s3.学号 = s1.学号 and s3.课程序号 = s2.课程序号)加了条件之后对于tmp的扫描进⾏了⼀个筛选,第⼆重not exists中的条件很好理解,就是拿s2(tmp视图)中的课程序号, s1 (成绩信息表)的学号去s3中做⼀个筛选,当s1中的学号和s2中的课程序号在s3表中找得到时,第⼆重not exists中的条件就会返回的是true, 经过第⼆重的not exists之后就是false,那么对第⼆重扫描(也就是第⼆个select)扫描到的这个结果就会被抛弃,然后就是继续第⼆层扫描(select)。
oracle_plsql语句大全

sql语句的编程手册SQL PLUS一、SQL PLUS1 引言SQL命令以下17个是作为语句开头的关键字:alter drop revokeaudit grant rollback*commit* insert selectcomment lock updatecreate noaudit validatedelete rename这些命令必须以“;”结尾带*命令句尾不必加分号,并且不存入SQL缓存区。
SQL中没有的SQL*PLUS命令这些命令不存入SQL缓存区@ define pause# del quit$ describe remark/ disconnect runaccept document saveappend edit setbreak exit showbtitle get spoolchange help sqlplusclear host startcolumn input timingcompute list ttitleconnect newpage undefinecopy---------2 数据库查询数据字典TAB 用户创建的所有基表、视图和同义词清单DTAB 构成数据字典的所有表COL 用户创建的基表的所有列定义的清单CA TALOG 用户可存取的所有基表清单select * from tab;describe命令描述基表的结构信息describe deptselect *from emp;select empno,ename,jobfrom emp;select * from deptorder by deptno desc;逻辑运算符= !=或<> > >= < <=inbetween value1 and value2like%_in nullnotno in,is not null谓词in和not in有哪些职员和分析员select ename,jobfrom empwhere job in ('clerk','analyst');select ename,jobfrom empwhere job not in ('clerk','analyst');谓词between和not between哪些雇员的工资在2000和3000之间select ename,job,sal from empwhere sal between 2000 and 3000;select ename,job,sal from empwhere sal not between 2000 and 3000;谓词like,not likeselect ename,deptno from empwhere ename like 'S%';(以字母S开头)select ename,deptno from empwhere ename like '%K';(以K结尾)select ename,deptno from empwhere ename like 'W___';(以W开头,后面仅有三个字母)select ename,job from empwhere job not like 'sales%';(哪些雇员的工种名不以sales开头)谓词is null,is not null没有奖金的雇员(即commision为null)select ename,job from empwhere comm is null;select ename,job from empwhere comm is not null;多条件查询select ename,jobfrom empwhere deptno=20and job!='clerk';表达式+ - * /算术表达式选择奖金高于其工资的5%的雇员select ename,sal,comm,comm/sal from emp where comm>.05*salorder by comm/sal desc;日期型数据的运算add two days to 6-Mar-876-Mar-87 + 2 = 8-Mar-87add two hours to 6-Mar-876-Mar-87 + 2/24 = 6-Mar-87 and 2hrsadd 15 seconds to 6-Mar-876-Mar-87 + 15/(24*60*60) = 6-Mar-87 and 15 secs列名的别名select ename employee from empwhere deptno=10;(别名:employee)select ename,sal,comm,comm/sal "C/S RATIO" from empwhere comm>.05*salorder by comm/sal desc;SQL命令的编辑list or l 显示缓冲区的内容list 4 显示当前SQL命令的第4行,并把第4行作为当前行,在该行号后面有个*。
实验3-SQL语言查询操作

实验3:SQL语言操作一、实验目的:1.熟悉SQL语言的基本语法和规则2.了解CREATE、DROP语句的使用。
3.掌握INSERT、UPDA TE、DELETE语言的基本语法和规则4.掌握在查询分析器或企业管理器中执行INSERT、UPDATE、DELETE操作的方法5.掌握SQL语言函数、程序控制语句的使用二、基本原理:SQL语言的基本语法规则和相关SQL程序结构控制语法理论。
三、实验仪器设备:1.硬件:PC台/人(内存:256M以上,cpu:P4)2.软件:SQL Server2000四、实验内容:1.用Create创建表名为class和student,2.利用select和Insert语句向表中插入记录3.利用UPDATE语句更新class和student记录4.利用DELETE删除class表中的记录5.利用DROP语句删除表6.依据SQL语法,编写SQL程序执行数据库相关操作。
五、实验步骤:1).在企业管理器中用Create创建数据库或表,名为student和class,并用ALTER修改数据库和表。
建立一个名为test的数据库,可以输入如下的SQL语句:CREATE DATABASE test例如,要创建一个销售数据库,并设定数据文件为d:\销售.LDF,大小为5MB,最大为20MB,每次增长5MB。
事务日志文件为d:\ 销售.LDF,大小为5MB,最大为10MB,每次增长为1MB。
则创建的SQL语句为:CREATE DATABASE【TABLE】销售数据库ON (NAME = 销售数据,FILENAME = 'd:\Program Files\Microsoft SQL Server\MSSQL\data\销售数据.MDF',SIZE = 10MB,MAXSIZE = 50MB,FILEGROWTH = 10MB)LOG ON(NAME = 销售数据日志,FILENAME = 'd:\Program Files\Microsoft SQL Server\MSSQL\data\销售数据日志.LDF',SIZE = 10MB,MAXSIZE = 20MB,FILEGROWTH = 5MB)2)例如,为销售数据库新增一个逻辑名为“销售数据2”的数据文件,其大小及其最大值分别为10MB和50MB。
使用sql语句查询日期的方法

使用sql语句查询日期的方法使用sql语句查询日期的方法篇一:使用sql语句查询日期使用sql语句查询日期select * from ShopOrder where datediff(week,ordTime,getdate()-1)=0 //查询当天日期在一周年的数据--查询当天:select * from info where DateDiff(dd,datetime,getdate())=0 --查询24小时内的:select * from info where DateDiff(hh,datetime,getDate())<=24--info为表名,datetime为数据库中的字段值--查询当天:select * from info where DateDiff(dd,datetime,getdate())=0 --查询24小时内的:select * from info where DateDiff(hh,datetime,getDate())<=24 --info为表名,datetime为数据库中的字段值Sql代码--查询当天记录另类的方法SELECT *FROM j_GradeShopWHERE (GAddTime BETWEEN CONVERT(datetime, LEFT(GETDATE(), 10) + ' 00:00:00.000')AND CONVERT(datetime, LEFT(GETDATE(), 10) + ' 00:00:00.000') + 1) ORDER BY GAddTime DESC--查询当天记录另类的方法SELECT *FROM j_GradeShopWHERE (GAddTime BETWEEN CONVERT(datetime, LEFT(GETDATE(), 10) + ' 00:00:00.000')AND CONVERT(datetime, LEFT(GETDATE(), 10) + ' 00:00:00.000') + 1) ORDER BY GAddTime DESCDATEDIFF 函数:语法:DATEDIFF ( datepart , startdate , enddate )备注:enddate 减去 startdate。
Access第三章_数据查询

右键快捷菜单:添加用于查 询的数据源
3.2.2
通过设计视图编辑或创建查询
查询设计视图中的工具栏
视图 运行 显示表 上限值 生成器 新对象
查询类型
合计
属性
数据库窗口
3.2.2
通过设计视图编辑或建查询
打开已有查询的设计视图:单击 “设计”按钮
3.2.2 通过设计视图编辑或创建查询
在设计视图中创建查询
3.2.1
用简单查询向导生成查询
【例3-2】 基于“导师”和“研究生”两个表生成 “导师-研究生”查询,显示每位导师的编号、姓 名、职称及其所带研究生的学号、姓名和入学分数。
前提:“导师”表和“研究生”表应建立一对多关系 本章中的例题以“导师”表、“研究生”表和 “系”表作为查询的数据源,为不失一般性,删除研究生
马力、李卫星和赵小刚的导师编号,使他们暂时无导师,
同时让“导师”表中的李小严不带研究生 。
3.2.1
用简单查询向导生成查询
(1)在简单查询向导第一个对话框,选择数据源及字段:
在“表/查 询”下拉列表框中, 依次选择“导师” 表 和“研究生”表, 并在 “可用字段” 列表框中,选中需 查询字段,将其送 入“选定的字段” 列表框中。
查询执行结果:
3.2.2
通过设计视图编辑或创建查询
【例3-4】在查询设计视图中新建一个查询,要求 能够显示各个系的系名、系中导师的姓名和导师 所带研究生的姓名。
打开的查询设 计视图,在视 图上半部分添 加查询数据源 (应为三个 表) ,在视 图下半部分, 设置好用于查 询的字段。
3.2.2
查询结果
'考古学' Or '会计学'
3.2.3 条件查询
5.使用SQL语句进行连接查询

实验使用SQL语句进行多表查询●目标✓完成本实验,将能够:使用SQL语句对数据表进行连接查询和子查询操作,掌握连接查询语句和子查询的使用方法。
●实验预估时间:60 min练习使用SQL 语句进行连接查询在本练习中,将使用SQL语句完成对数据表的单表的连接查询操作。
实验步骤:1)启动SQL Server20052)登录数据库服务器3)完成数据库和数据表的构建工作:打开并运行在服务器上共享的数据库构建文件Initialsize.sql文件,具体方法为:a)将服务器上共享的Initialsize.sql文件复制到本地磁盘b)双击本地磁盘中的Initialsize.sql文件,并在弹出的“连接服务器”对话框中点击“连接”按钮。
c)按键盘上的“F5”键运行Initialsize.sql文件中的数据库和数据表的SQL构建语句。
4)查询所有学生的详细信息与选课信息。
5)分别使用连接查询和子查询的方式检索所有选修了2号课程的学生的姓名。
6)分别使用连接查询和子查询的方式检索所有与“刘琳”在一个系学习的学生的姓名。
注:数据SQL语句格式:数据查询:SELECT [ALL|DISTINCT] <目标列表达式> [,<目标列表达式>] …FROM <表名或视图名>[,<表名或视图名> ] …[ WHERE <条件表达式> ][ORDER BY <列名> [ASC|DESC] [,<列名> [ASC|DESC]…] ]子查询:SELECT [ALL|DISTINCT] <目标列表达式> [,<目标列表达式>] …FROM <表名或视图名>[,<表名或视图名> ] …WHERE <列名> IN(SELECT <列名>FROM <表名>[ WHERE <条件表达式> ])。
执行SQL语句的方式

执⾏SQL语句的⽅式JDBC不仅可执⾏查询,也可以执⾏DDL,DML等SQL语句,从⽽允许通过JDBC最⼤限度地控制数据库。
使⽤executeUpdate或者使⽤executeLargeUpdate⽅法来执⾏DDL和DML语句: 编写程序,通过executeUpdate⽅法在mysql当前数据库下创建⼀个数据库表⽰范:public class JDBC {String driver;String url;String user;String password;//查询该数据库是否有对应的表,有则返回ture,没有返回falsepublic boolean tableIsExists(String tableName){try{Connection conn =DriverManager.getConnection(url,user,password);Statement statement =conn.createStatement();String sql = "select table_name from information_schema.tables where table_schema='test'";ResultSet resultSet = statement.executeQuery(sql);while(resultSet.next()){String queryTableName = resultSet.getString(1);System.out.println(queryTableName);if(queryTableName.equals("tb_test")){return true;}}}catch(Exception e){}return false;}public void createTableJDBC(String tableName){try{Connection conn =DriverManager.getConnection(url,user,password);Statement statement =conn.createStatement();if(!tableIsExists(tableName)){System.out.println("当前数据库没有"+tableName+"表格,将创建"+tableName+"数据库表");String sql = "create table "+tableName+"("+ "test_id int auto_increment primary key,"+ "test_name varchar(255),"+ "test_desc text)";int result = statement.executeUpdate(sql);}else{System.out.println("当前数据库有"+tableName+"表格,不创建"+tableName+"数据库表");}}catch(Exception e){}}public static void main(String[] args) {// TODO Auto-generated method stubJDBC jdbc = new JDBC();jdbc.initParam("mysql.properties");jdbc.createTableJDBC("tb_test");}} 第⼀次运⾏结果如下:tb_adminusertb_user当前数据库没有tb_test表格,将创建tb_test数据库表 第⼆此运⾏结果如下(假如没有操作mysql数据的话):tb_adminusertb_test当前数据库有tb_test表格,不创建tb_test数据库表 编写程序,对上述新增表添加数据:public class JDBC {String driver;String url;String user;String password;public void initParam(String paramFile){try{Properties props = new Properties();props.load(new FileInputStream(paramFile));driver = props.getProperty("driver");url = props.getProperty("Url");user = props.getProperty("user");password = props.getProperty("password");}catch(Exception e){}}public void addData(String table,String sql){try{Connection conn =DriverManager.getConnection(url,user,password);Statement statement =conn.createStatement();int resultRow = statement.executeUpdate(sql);System.out.println("对"+table+"表添加了1条数据,该表受影响⾏数为"+resultRow);}catch(Exception e){}}public static void main(String[] args) {// TODO Auto-generated method stubJDBC jdbc = new JDBC();jdbc.initParam("mysql.properties");String table = "tb_test";String sql = "insert into "+table+"(test_name,test_desc) values('hjl','0');";jdbc.addData(table, sql);}} 运⾏的效果为:对tb_test表添加了1条数据,该表受影响⾏数为1 通过两个代码进⾏测试可以得知,使⽤executeUpdate(String sql) 是可以对数据库进⾏DML语句与DDL语句操作的,不同的是,DDL语句因为不是对表中内容进⾏操作,因此返回的值为0;⽽DML语句是对表格内容进⾏操作的,因此返回影响表格内容的⾏数。
JPA如何使用nativequery多表关联查询返回自定义实体类

JPA如何使⽤nativequery多表关联查询返回⾃定义实体类⽬录JPA nativequery多表关联查询返回⾃定义实体类JPA多表关联的实现⽅式优缺点对⽐使⽤sql并返回⾃定义实体类JPA多表关联动态查询(⾃定义sql语句)实体类注解解释测试类打印结果TestVo实体接收类JPA nativequery多表关联查询返回⾃定义实体类JPA官⽅推荐的多表关联查询使⽤不便,接触的有些项⽬可能会使⽤JPA 做简单查询,Mybaits做复杂查询。
所以想要寻找⼀种好⽤的解决⽅案。
JPA多表关联的实现⽅式1.使⽤Specification实现映射关系匹配,如@ManyToOne等2.使⽤NativeQuery等sql或hql来实现优缺点对⽐1.映射关系是hibernate的⼊门基础,很多⼈都会习惯去使⽤。
个⼈不太喜欢这种⽅式,复⽤性太弱,且不灵活特别是在多表复杂业务情况下。
2.使⽤Specification⽅式需要继承JpaSpecificationExecutor接⼝,构造对应的⽅法后传⼊封装查询条件的Specification对象。
逻辑上简单易懂,但是构造Specification 对象需要拼接格式条件⾮常繁琐。
3.直接使⽤NativeQuery等⽅式实现复杂查询个⼈⽐较喜欢,直观且便利,弊端在于⽆法返回⾃定义实体类。
需要⼿动封装⼯具类来实现Object到⽬标对象的反射。
使⽤sql并返回⾃定义实体类个⼈⽐较喜欢的实现⽅式,不多说看代码import org.springframework.stereotype.Repository;import javax.persistence.EntityManager;import javax.persistence.PersistenceContext;import javax.transaction.Transactional;@Repositorypublic class EntityManagerDAO {@PersistenceContextprivate EntityManager entityManager;/*** ⼈员列表排序* @return*/@Transactionalpublic List<BackstageUserListDTO> listUser(){String sql = "select a.create_time createTime," +"a.mobilephone phoneNum," +"a.email email,a.uid uid," +"a.enabled enabled," +"c.id_number idNumber," +" (case b.`status` when 1 then 1 else 0 end) status " +"from tbl_sys_user a " +"LEFT JOIN user_high_qic b on a.uid=b.u_id" +"LEFT JOIN user_qic c on a.uid=c.uid " +"ORDER BY status desc";SQLQuery sqlQuery = entityManager.createNativeQuery(sql).unwrap(SQLQuery.class);Query query =sqlQuery.setResultTransformer(Transformers.aliasToBean(BackstageUserListDTO.class));List<BackstageUserListDTO> list = query.list();entityManager.clear();return list;}}public class BackstageUserListDTO implements Serializable{private static final long serid = 1L;private String createTime;private String phoneNum;private String email;private BigInteger uid;private Integer enabled;private String idNumber;private BigInteger status;//GETTER SETTER}这样⼀个需求如果使⽤前两种⽅式实现,⽆疑会⾮常⿇烦。
sql语句两张表嵌套查询

sql语句两张表嵌套查询篇一:s ql子查询嵌套SE LE CT语句s ql子查询嵌套SE LE CT语句嵌套S EL EC T语句也叫子查询,一个SE LE CT语句的查询结果能够作为另一个语句的输入值。
子查询不但能够出现在Wh er e子句中,也能够出现在f ro m子句中,作为一个临时表使用,也能够出现在s el ec tli st中,作为一个字段值来返回。
1、单行子查询:单行子查询是指子查询的返回结果只有一行数据。
当主查询语句的条件语句中引用子查询结果时可用单行比较符号(=,,,=,=,)来进行比较。
例:s el ec ten am e,de pt no,s alf ro mem pwh er ede pt no=(se le ctd ep tn ofr omd ep twh er elo c=N EWY OR K);2、多行子查询:多行子查询即是子查询的返回结果是多行数据。
当主查询语句的条件语句中引用子查询结果时必须用多行比较符号(IN,A LL,A NY)来进行比较。
其中,IN的含义是匹配子查询结果中的任一个值即可(I N操作符,能够测试某个值是否在一个列表中),A LL则必须要符合子查询的所有值才可,AN Y要符合子查询结果的任何一个值即可。
而且须注意A LL和AN Y操作符不能单独使用,而只能与单行比较符(=、、、=、=、)结合使用。
两表关联查询的sql语句

两表关联查询的sql语句在数据库中,当我们需要从多个表中检索数据时,就需要使用到关联查询。
关联查询是通过匹配两个或多个表中的共同字段来检索数据的一种方法。
在这篇文章中,我们将探讨两表关联查询的SQL语句的使用和优化。
关联查询最常用的两种语句是内连接(INNER JOIN)和外连接(OUTER JOIN)。
在内连接中,只有在两个表中都存在匹配行的情况下,才会返回结果。
而在外连接中,即使某个表中没有匹配行,也会返回结果。
下面是一个内连接的例子。
假设我们有两个表,一个是顾客表(customers),另一个是订单表(orders)。
这两个表都有一个共同字段,即顾客ID(customer_id)。
我们想要检索出所有有订单的顾客信息,可以使用如下SQL语句:SELECT customers.customer_id, customers.customer_nameFROM customersINNER JOIN ordersON customers.customer_id = orders.customer_id;上述语句中,我们先指定要检索的字段,然后使用INNER JOIN关键字指定要连接的表。
ON关键字后面是我们需要匹配的字段。
对于外连接,我们可以使用LEFT JOIN和RIGHT JOIN关键字。
左外连接(LEFT JOIN)表示左边的表是主导表,即使右表没有匹配行,也会返回结果;而右外连接(RIGHT JOIN)则表示右边的表是主导表。
下面是一个左外连接的例子:SELECT customers.customer_id, customers.customer_name,orders.order_idFROM customersLEFT JOIN ordersON customers.customer_id = orders.customer_id;在这个例子中,我们使用LEFT JOIN关键字来连接两个表,以顾客表作为主导表(左边的表)。
a5sql使用技巧

a5sql使用技巧A5SQL使用技巧1. 安装和配置•安装A5SQL:下载A5SQL的安装程序,双击运行并按照提示完成安装。
•配置连接:打开A5SQL,点击“连接管理”按钮,在弹出的对话框中配置数据库连接信息,包括主机名、端口、用户名和密码等。
2. 基本操作•新建查询:点击“新建查询”按钮或使用快捷键Ctrl+N,即可打开一个新的查询窗口。
•执行查询:在查询窗口中编写SQL语句,点击工具栏上的“执行”按钮或使用快捷键F5,即可执行查询并显示结果。
•保存查询:点击工具栏上的“保存”按钮或使用快捷键Ctrl+S,即可将当前查询保存为一个文件。
3. 查询优化技巧•使用索引:在查询中使用适当的索引可以提高查询性能。
可以通过查看表的索引信息,选择合适的索引来优化查询。
•避免全表扫描:尽量避免在查询中使用不带索引的条件,这样会导致全表扫描,降低查询性能。
可以通过对字段添加索引或重新编写查询条件来避免全表扫描。
•使用JOIN优化查询:使用合适的JOIN语句可以减少查询的数据量和查询时间。
在多表查询时,要注意选择适当的JOIN类型,避免产生笛卡尔积。
4. 结果处理技巧•导出结果:在查询结果窗口中,点击工具栏上的“导出”按钮,即可将查询结果导出为CSV、Excel等格式的文件。
•分页显示:对于大量数据的查询结果,可以通过设置分页参数来分批显示数据,避免加载过多的数据。
•数据过滤:在查询结果窗口中,可以使用过滤功能按条件过滤数据,只显示满足条件的数据,方便快速定位所需数据。
5. 其他实用技巧•快捷键:A5SQL提供了丰富的快捷键,如F5执行查询、Ctrl+S 保存查询等,熟练掌握这些快捷键可以提高工作效率。
•语法检查:A5SQL内置了SQL语法检查功能,可以及时发现语法错误并给出提示,帮助减少调试时间。
•自动补全:A5SQL支持SQL语句的自动补全功能,可以快速填充关键字、表名、字段名等,减少编写SQL语句的时间。
数据库系统原理实验报告-SQL查询语句

数据库系统原理实验报告-SQL查询语句数据库系统原理实验报告姓名:xxx学号:xxxxxxxx专业:xxxxx⽇期:xxxxxLab2⼀、实验⽬的进⼀步熟悉关系数据库标准语⾔SQL。
⼆、实验环境1)Windows 102)SQL Server 2017三、实验内容给定如学⽣表、课程表和学⽣作业表所⽰的信息。
表2 课程表表3 学⽣作业表K0020529707085 K0020531808080 K0020538657585 K0020592758585 K0060531808090 K0060591808080 M0010496707080 M0010591657575 S0010531808080 S00105386080写出如下SQL语句:1.查询数据库中有哪些专业班级。
(5分)Sql语句:SELECT专业班级FROM学⽣表;查询结果截图:2.查询在1986年出⽣的学⽣的学号、姓名和出⽣⽇期。
(5分)Sql语句:SELECT学号,姓名,出⽣⽇期FROM学⽣表WHERE出⽣⽇期LIKE'1986%';查询结果截图:3.查询05级的男⽣信息。
(5分)Sql语句:SELECT*FROM学⽣表WHERE学号LIKE'05%'AND性别='男';查询结果截图:4.查询没有作业成绩的学号和课程号。
(5分)Sql语句:SELECT学号,课程号FROM学⽣作业表WHERE作业1成绩IS NULL OR作业2成绩IS NULL OR作业3成绩IS NULL;查询结果截图:5.查询选修了K001课程的学⽣⼈数。
(5分)Sql语句:SELECT COUNT(DISTINCT学号)FROM学⽣作业表WHERE课程号='K001';查询结果截图:6.查询数据库中共有多少个班级。
(5分)Sql语句:SELECT COUNT(DISTINCT专业班级)FROM学⽣表;查询结果截图:7.查询选修三门以上(含三门)课程的学⽣的学号和作业1平均分、作业2平均分和作业3平均分。
sqlyog使用方法

sqlyog使用方法SQLyog是一款基于Windows平台上的MySQL数据库管理工具,它提供了方便的图形化用户界面,方便用户对数据库进行管理和操作。
本文将为大家介绍SQLyog的使用方法。
一、安装SQLyog:请在官网下载SQLyog安装包,双击打开后进行安装,并接受软件条款和协议。
二、连接数据库:打开SQLyog后,点击“新连接”图标,在出现的窗口中填写数据库所在的IP地址、端口号、用户名和密码等信息,点击“连接”按钮即可完成连接。
三、查看数据库:连接成功后,您可以在左侧“ 数据库(Databases)”窗口中看到您的数据库列表。
如果要查看特定数据库的详细信息,只需在左侧窗口中单击该数据库即可。
四、创建表格:在SQLyog中,您可以使用“新建表格”按钮创建新的数据库表格。
打开新建窗口后,您需要输入表的名称以及列的名称、类型、长度、精度等信息。
五、填充表格:在SQLyog中,您可以通过使用“填充表格”按钮来手动添加数据。
如果要快速填充表格,您可以右键单击该表并单击“导入数据”以从文件中导入数据。
六、执行语句:在SQLyog中,您可以使用查询编辑器来编写SQL 语句并执行它们。
在查询编辑器中输入SQL语句,然后单击“执行”按钮以运行该语句。
七、备份数据库:在SQLyog中,您可以使用“备份”功能来创建数据库的备份。
只需在左侧窗口中单击要备份的数据库,并单击“备份”按钮即可。
八、查询日志文件:在SQLyog中,您可以使用“日志文件”功能来查看数据库的错误日志。
只需在左侧窗口中单击要查看的数据库,然后单击“日志文件”按钮即可。
九、优化表格:在SQLyog中,您可以使用“优化表格”功能来优化表格的性能。
只需在左侧窗口中单击要优化的表格并单击“优化表格”按钮即可。
十、退出SQLyog:在SQLyog中,您可以使用“退出”按钮来退出应用程序。
只需单击“退出”按钮即可关闭SQLyog。
总之,SQLyog是一款功能强大的MySQL数据库管理工具,可以提供用户方便的图形化用户界面,使用SQLyog,您可以轻松管理和操作数据库,为您的工作提供帮助。
sqlmap使用教程(超详细)

sqlmap使⽤教程(超详细)-u 指定⽬标URL (可以是http协议也可以是https协议)-d 连接数据库--dbs 列出所有的数据库--current-db 列出当前数据库--tables 列出当前的表--columns 列出当前的列-D 选择使⽤哪个数据库-T 选择使⽤哪个表-C 选择使⽤哪个列--dump 获取字段中的数据--batch ⾃动选择yes--smart 启发式快速判断,节约浪费时间--forms 尝试使⽤post注⼊-r 加载⽂件中的HTTP请求(本地保存的请求包txt⽂件)-l 加载⽂件中的HTTP请求(本地保存的请求包⽇志⽂件)-g ⾃动获取Google搜索的前⼀百个结果,对有GET参数的URL测试-o 开启所有默认性能优化--tamper 调⽤脚本进⾏注⼊-v 指定sqlmap的回显等级--delay 设置多久访问⼀次--os-shell 获取主机shell,⼀般不太好⽤,因为没权限-m 批量操作-c 指定配置⽂件,会按照该配置⽂件执⾏动作-data data指定的数据会当做post数据提交-timeout 设定超时时间-level 设置注⼊探测等级--risk 风险等级--identify-waf 检测防⽕墙类型--param-del="分割符" 设置参数的分割符--skip-urlencode 不进⾏url编码--keep-alive 设置持久连接,加快探测速度--null-connection 检索没有body响应的内容,多⽤于盲注--thread 最⼤为10 设置多线程--delay有些web服务器请求访问太过频繁可能会被防⽕墙拦截,使⽤--delay就可以设定两次http请求的延时--safe-url有的web服务器会在多次错误的访问请求后屏蔽所有请求,使⽤--safe-url 就可以每隔⼀段时间去访问⼀个正常的页⾯。
--tamper语法:--tamper ["脚本名称"]当调⽤多个脚本的时候,脚本之间⽤逗号隔开,调⽤的脚本在 sqlmap⽂件夹下的 tamper ⽂件夹中脚本信息apostrophemask.py ⽤UTF-8全⾓字符替换单引号字符apostrophenullencode.py ⽤⾮法双字节unicode字符替换单引号字符appendnullbyte.py 在payload末尾添加空字符编码base64encode.py 对给定的payload全部字符使⽤Base64编码between.py 分别⽤“NOT BETWEEN 0 AND #”替换⼤于号“>”,“BETWEEN # AND #”替换等于号“=”bluecoat.py 在SQL语句之后⽤有效的随机空⽩符替换空格符,随后⽤“LIKE”替换等于号“=”chardoubleencode.py 对给定的payload全部字符使⽤双重URL编码(不处理已经编码的字符)charencode.py 对给定的payload全部字符使⽤URL编码(不处理已经编码的字符)charunicodeencode.py 对给定的payload的⾮编码字符使⽤Unicode URL编码(不处理已经编码的字符)concat2concatws.py ⽤“CONCAT_WS(MID(CHAR(0), 0, 0), A, B)”替换像“CONCAT(A, B)”的实例equaltolike.py ⽤“LIKE”运算符替换全部等于号“=”greatest.py ⽤“GREATEST”函数替换⼤于号“>”halfversionedmorekeywords.py 在每个关键字之前添加MySQL注释ifnull2ifisnull.py ⽤“IF(ISNULL(A), B, A)”替换像“IFNULL(A, B)”的实例lowercase.py ⽤⼩写值替换每个关键字字符modsecurityversioned.py ⽤注释包围完整的查询modsecurityzeroversioned.py ⽤当中带有数字零的注释包围完整的查询multiplespaces.py 在SQL关键字周围添加多个空格nonrecursivereplacement.py ⽤representations替换预定义SQL关键字,适⽤于过滤器overlongutf8.py 转换给定的payload当中的所有字符percentage.py 在每个字符之前添加⼀个百分号randomcase.py 随机转换每个关键字字符的⼤⼩写randomcomments.py 向SQL关键字中插⼊随机注释securesphere.py 添加经过特殊构造的字符串sp_password.py 向payload末尾添加“sp_password” for automatic obfuscation from DBMS logsspace2comment.py ⽤“/**/”替换空格符space2dash.py ⽤破折号注释符“--”其次是⼀个随机字符串和⼀个换⾏符替换空格符space2hash.py ⽤磅注释符“#”其次是⼀个随机字符串和⼀个换⾏符替换空格符space2morehash.py ⽤磅注释符“#”其次是⼀个随机字符串和⼀个换⾏符替换空格符space2mssqlblank.py ⽤⼀组有效的备选字符集当中的随机空⽩符替换空格符space2mssqlhash.py ⽤磅注释符“#”其次是⼀个换⾏符替换空格符space2mysqlblank.py ⽤⼀组有效的备选字符集当中的随机空⽩符替换空格符space2mysqldash.py ⽤破折号注释符“--”其次是⼀个换⾏符替换空格符space2plus.py ⽤加号“+”替换空格符space2randomblank.py ⽤⼀组有效的备选字符集当中的随机空⽩符替换空格符unionalltounion.py ⽤“UNION SELECT”替换“UNION ALL SELECT”unmagicquotes.py ⽤⼀个多字节组合%bf%27和末尾通⽤注释⼀起替换空格符宽字节注⼊varnish.py 添加⼀个HTTP头“X-originating-IP”来绕过WAFversionedkeywords.py ⽤MySQL注释包围每个⾮函数关键字versionedmorekeywords.py ⽤MySQL注释包围每个关键字xforwardedfor.py 添加⼀个伪造的HTTP头“X-Forwarded-For”来绕过WAF-v ["x"]使⽤sqlmap注⼊测试时,可以使⽤ -v [x] 参数来指定回显信息的复杂程度, x 的取值范围为[0~6]:等级解释0只显⽰python错误以及严重信息1同时显⽰基本信息和警告信息2同时显⽰debug信息3同时显⽰注⼊的pyload4同时显⽰HTTP请求5同时显⽰HTTP相应头6同时显⽰HTTP相应页⾯--levellevel有5个等级,默认等级为1,进⾏Cookie测试时使⽤--level 2 ,进⾏use-agent或refer测试时使⽤--level 3 ,进⾏ host 测试时使⽤--level 5–-os-cmd=["命令"] 或 --os-shell=["命令"] 执⾏系统命令利⽤sql-labs-less1测试 whoami 命令sqlmap -u "http://192.168.0.6/sqli-labs-master/Less-1/?id=1" --os-cmd=whoami选择web服务器⽀持的语⾔选择web服务器的可写⽬录[1] 使⽤默认的[2] ⾃定义位置[3] ⾃定义⽬录列表⽂件[4] 暴⼒搜索我在本地测试,节省时间,我选择2 ,⾃定义路径,然后把路径输⼊在下⾯执⾏命令后的返回结果以下关卡均可⽤get型的⽅法,常规注⼊step1:sqlmap -u ["URL"] //测试是否存在注⼊step2:sqlmap -u ["URL"] -current-db //查询当前数据库step3:sqlmap -u ["URL"] -D ["数据库名"] --tables //查询当前数据库中的所有表step4:sqlmap -u ["URL"] -D ["数据库名"] -T ["表名"] --columns //查询指定库中指定表的所有列(字段)step5:sqlmap -u ["URL"] -D ["数据库名"] -T ["表名"] -C ["列名"] --dump //打印出指定库中指定表指定列中的字段内容GET型关卡类型sql-labs-less1GET单引号字符型注⼊sql-labs-less2 数字型注⼊sql-labs-less3有括号的单引号报错注⼊sql-labs-less4有括号的双引号报错注⼊sql-labs-less5单引号⼆次注⼊sql-labs-less6双引号⼆次注⼊sql-labs-less7⽂件导⼊导出sql-labs-less8布尔型盲注sql-labs-less9时间型盲注sql-labs-less10双引号时间盲注sql注⼊检测get型:语法:sqlmap -u ["url"]sqlmap -u http://192.168.0.6/sqli-labs-master/Less-1/?id=1post型:先使⽤bp把提交的数据包保存下来或者直接加上post提交的参数语法:sqlmap -r ["请求包的txt⽂件"]sqlmap -r "/root/.sqlmap/post.txt"sql-labs -less1~sql-labs-less9获取当前数据库名称:语法:sqlmap -u [“url”] --current-dbsqlmap -u "http://192.168.0.6/sqli-labs-master/Less-1/?id=1" --current-db获取指定数据库的表名:语法:sqlmap -u [“url”] -D [‘数据库名’] --tablessqlmap -u "192.168.0.6/sqli-labs-master/Less-1/?id=1" -D security --tables获取指定数据库指定表中的字段:语法:sqlmap -u [“url”] -D [‘数据库名’] -T[‘表名’] --columnssqlmap -u "192.168.0.6/sqli-labs-master/Less-1/?id=1" -D security -T users --columns获取指定数据库指定表的指定字段的字段内容:语法:sqlmap -u [“url”] -D [‘数据库名’] -T [‘表名’] -C [‘字段名1,字段名2,…’] --dumpsqlmap -u "192.168.0.6/sqli-labs-master/Less-1/?id=1" -D security -T users -C password --dumpsql-labs-less10sqlmap -u "http://192.168.0.6/sqli-labs-master/Less-10/?id=1" --current-db提升等级 -level 2sqlmap -u "http://192.168.0.6/sqli-labs-master/Less-10/?id=1" -level 2 --current-dbsql-labs-less11~less17常规 POST 注⼊step1:sqlmap -r ["请求头⽂本"] //测试是否存在注⼊step2:sqlmap -r ["请求头⽂本"] --current-db //查询当前数据库step3:sqlmap -r ["请求头⽂本"] -D ["数据库名"] --tables //查询当前数据库的所有表step4:sqlmap -r ["请求头⽂本"] -D ["数据库名"] -T ["表名"] --columns //查询指定库指定表的所有列step5:sqlmap -r ["请求头⽂本"] -D ["数据库名"] -T ["表名"] -C ["列名"] --dump //打印出指定库指定表指定列的所有字段内容POST关卡类型sql-labs-less11基于错误的单引号字符型注⼊sql-labs-less12基于错误的双引号字符型注⼊sql-labs-less13单引号变形双注⼊sql-labs-less14双引号变形双注⼊sql-labs-less15Bool型时间延迟单引号盲注sql-labs-less16Bool型时间延迟双引号盲注sql-labs-less17更新查询注⼊sql-labs-less18Uagent注⼊sql-labs-less19Referer注⼊sql-labs-less20Cookie注⼊sql-labs-less18Header injection - Uagentsqlmap 在对user-agent 注⼊的时候,得在⽂件中的user-agent的参数后⾯加上 *或者不加 * 号,调⽤ --level参数,将等级调⾄ 3级,只有等级为 3级即以上时才能对 user-agent进⾏注⼊sqlmap -r "/root/.sqlmap/post.txt" -level 3sql-labs-less19Header injection - Referer对Referer注⼊和User-agent相同,要么是在Referer后⾯加上 *或者将 level 调⾄ 3 级sql-labs-less20Header injection -Cookie语法:sqlmap -u [“url”] --cookie ["cookie信息"] --level 2sqlmap -u "http://192.168.0.6/sqli-labs-master/Less-20/index.php" --cookie "pma_lang=zh_CN;pma_mcrypt_iv=AoXpKxU5KcY%3D;pmaUser-1=7%2FwV%2BDOfbmI%3D;uname=admin;" --level 2。
SQL查询基础

SQL查询基础SELECT语句基础算术运算符和⽐较运算符逻辑运算符本章重点本章将会和⼤家⼀起学习查询前⼀章创建的Product表中数据的 SQL 语句。
这⾥使⽤的SELECT 语句是 SQL 最基本也是最重要的语句。
请⼤家在实际运⾏书中的SELECT语句时,亲⾝体验⼀下其书写⽅法和执⾏结果。
执⾏查询操作时可以指定想要查询数据的条件(查询条件)。
查询时可以指定⼀个或多个查询条件,例如“某⼀列等于这个值”“某⼀列计算之后的值⼤于这个值”等。
2-1 SELECT语句基础列的查询查询出表中所有的列为列设定别名常数的查询从结果中删除重复⾏根据WHERE语句来选择记录注释的书写⽅法2-2 算术运算符和⽐较运算符算术运算符需要注意NULL⽐较运算符对字符串使⽤不等号时的注意事项不能对NULL使⽤⽐较运算符2-3 逻辑运算符NOT运算符AND运算符和OR运算符使⽤括号强化处理逻辑运算符和真值含有NULL时的真值2-1 SELECT语句基础学习重点使⽤SELECT语句从表中选取数据。
为列设定显⽰⽤的别名。
SELECT语句中可以使⽤常数或者表达式。
通过指定DISTINCT可以删除重复的⾏。
SQL语句中可以使⽤注释。
可以通过WHERE语句从表中选取出符合查询条件的数据。
列的查询从表中选取数据时需要使⽤SELECT语句,也就是只从表中选出(SELECT)必要数据的意思。
通过SELECT语句查询并选取出必要数据的过程称为匹配查询或查询(query)。
KEYWORDSELECT语句匹配查询查询SELECT语句是 SQL 语句中使⽤最多的最基本的 SQL 语句。
掌握了SELECT语句,距离掌握SQL 语句就不远了。
SELECT语句的基本语法如下所⽰。
语法 2-1 基本的SELECT语句SELECT <列名>,……FROM <表名>;该SELECT语句包含了SELECT和FROM两个⼦句(clause)。
sql查询 double 数值 是科学计数法 -回复

sql查询double 数值是科学计数法-回复SQL查询中使用科学计数法的双精度数值是一个重要的主题。
本文将一步一步回答有关这个主题的问题,并详细解释如何在SQL查询中使用科学计数法的双精度数值。
一、什么是双精度数值?双精度数值是计算机科学中一种表示浮点数的数据类型。
它可以存储非常大或非常小的数值,并且具有较高的精度。
双精度数值在SQL中常用于存储和处理科学计数法表示的数值。
二、什么是科学计数法表示法?科学计数法是一种方便表示非常大或非常小数值的方法。
它将一个数值表示为两个部分:尾数和指数。
尾数是一个在1和10之间的数字,而指数表示移动尾数的小数点的位数。
科学计数法可用于非常大的数值(如10的幂)或非常小的数值(如10的负幂)。
例如,数值1000可以用科学计数法表示为1e3,其中1是尾数,3是指数。
同样,数值0.001可以表示为1e-3,其中1是尾数,-3是指数。
科学计数法可以在存储和计算大量数据时非常有用。
三、如何在SQL查询中使用科学计数法的双精度数值?在SQL查询中使用科学计数法的双精度数值需要按照以下步骤进行:1. 创建表格并定义列的数据类型为DOUBLE。
CREATE TABLE example (value DOUBLE);2. 插入科学计数法的双精度数值。
INSERT INTO example (value) VALUES (1e3);INSERT INTO example (value) VALUES (1e-3);3. 查询表格中的数据,并将科学计数法的双精度数值转换为普通的数值格式。
SELECT FORMAT(value, 2) AS formatted_value FROM example;- FORMAT函数用于将数值转换为指定格式的字符串。
在这个例子中,指定了使用2个小数位的格式。
- AS关键字用于为查询结果中的列指定别名,将其命名为formatted_value。
4. 查看查询结果,即转换后的科学计数法的双精度数值。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
insert into Student (Sno,Sname,Ssex,Sdept) values('aaa','mary','f','172');
将int型的Sno字段设置成自增长后
insert into Student (Sname,Ssex,Sdept) values('mary1','f','172');
例如如下这句,就是增加一条记录。
Select aid, a1, a2 from [表a]
union all
Select bid, b1, b2 from [表b]
Union
select 0, '111', '222'
如下会出错,因为第一个Select中的字段 111 为整型,会造成[表b]的b1字段内容强行向整型转换,转换会失败:将 varchar 值 'b11' 转换为数据类型为 int 的列时发生语法错误。
查找指定的字段的其他字段
select Sdept,Ssex,Sname
from Student
where Sno=3;
(where Sname='mary1';或则where Sname like 'mary1';)
在between语句查询的都是在and之间的所有值而IN语句则必须是in括号里面的值.
select distinct name from table 表示将返回table表中name字段不重复的所有字段的集合。
注:distinct必须放在开头,select id distinct name from table 是错误的!
-------------------------------------------------------------------------------------
默认是ASC。
按表中哪个字段倒叙排序:
select * from Student order by Sno desc;
注意:要排序的字段必须是int型。
设置成自增长的字段在插入数据的时候不需要插入该字段的值:
select * from Student order by Sno d字中间有mary的所有名字对应的的Sno和Ssex值.
select Sno,Ssex from Student where Sdept >= 170 and Sname like '%mary%';
注:mary1,1mary,marydsajdh,等.
注意:and or not 用的时候,and是用在连接并列条件的2个不同的字段
select count(*) userid from Student;
查询字段的平均值:
selecet avg(Sno) from Student;
select avg(字段名)from 表名;
给出查询的字段的平均值取别名:
select avg(字段名) as (别名) from (表名);
建立索引:
create unique index Sno on Student(Sno);
索引的一点好处:在查询时候比较方便,在存在的所有记录中查找一个Sno=1的时候!建立索引的表中就直接查找Sno项比较它是否=1找到后查相关的记录就比较快。没有建立索引的需要把所有信息都查找一遍,再在其中找Sno字段,再比较其值=1的相关记录。
select 0, 111, '222'
Union
Select bid, b1, b2 from [表b]
二、union all中的“All”不加的话,是自动剔除重复的记录(重复的记录只保留1条),加上“All”则会保留所有数据。
---------------------------------
--关键点:SELECT INTO 必须是包含 UNION 运算符的 SQL 语句中的第一个查询。
2)增加查询条件:
Select aid, a1, a2 from [表a] where a2 like '%22'
union all
Select bid, b1, b2 from [表b] where b2 like '%22'
看能否从现有数据中的某一列通过某种计算得到一个貌似自增的结果。类似:
select *, 一个公式(某列) as MyID from [tablename]
--------------------------------------------------------------------------------------
select Sno,Ssex,Sname from Student where Sdept between 180 and 190;
select Sno,Ssex,Sname from Student where Sdept in (172,190);
查询Student表中的所有的名字中的Sno和Ssex值.
在表中的排序如下:
Sno Sname Ssex Sdept
1 mary1 f 172
2 mar1y f 172
3 ma1ry f 172
4 m1ary f 172
/*********************************************************************************
Insert into [NewTABLE](oid,A,B) Select bid, b1, b2 from [表b]
Go
----------------------------------
“单纯的查询时候定义自增列”,这个据我所知是不行的,不知SQL 2005是否有此功能。因为查询的结果总是来源于现有数据或常数,且SQL的记录是没有行号概念的。
删除记录:
delete from Student where Sno = 'aaa';
注:只需要删除一个主键就可以了。其他的记录会相应的删除掉。
删除表中一个字段:
ALTER TABLE Student DROP column Ssex; 列名;
修改表中的那一行数据:
原来的记录:
insert into Student (Sname,Ssex,Sdept) values('mar1y','f','172');
insert into Student (Sname,Ssex,Sdept) values('ma1ry','f','172');
insert into Student (Sname,Ssex,Sdept) values('m1ary','f','172');
按问题补充:1)让查询结果添加到一张新表里面;2)按某个条件查询,比如查询出结尾为22的数据。显示a22 b22:
只需要增加几个子句就可以了:
1)将查询结果放到新表:
Select aid, a1, a2 into [新表名] from [表a]
union all
Select bid, b1, b2 from [表b]
Sno Sname Ssex Sdept
aaa mary f 172
update Student set Sname='mary1', Ssex='m' where Sno='aaa';
修改后:
Sno Sname Ssex Sdept
aaa mary1 m 172
desc倒叙排列:
2006.7.20
*********************************************************************************/
查询表中记录总数:(无字段名字)
select count() from usertable;
或:(userid 为字段名字,结果是字段的总行数)
select distinct(name1) from test_1
结果:
name1
aaa
bbb
ccc
ddd
eee
distinct这个关键字来过滤掉多余的重复记录只保留一条,但往往只用它来返回不重复记录的集合,而不是用它来返回不重记录的所有值。其原因是distinct只能返回它的目标字段,而无法返回其它字段,即上表中只能返回name1字段的所有不重复记录集合。
双表查询,SQL语句使用
2009/04/17 09:59 A.M.
Select aid, a1, a2 from [表a]
union all
Select bid, b1, b2 from [表b]
使用Union的关键点:
一、查询结果是一个数据集,它的字段名以第1个Select后面的字段列表为准,后面的Select的字段列表需要与第1个的对齐(字段个数和数据类型相同,名称无所谓)
Insert into [新表名] Select bid, b1, b2 from [表b]
如果还超时,那就复杂了,可能数据量太大、其他性能、索引、等综合检查了。
对于增加自增长字段的问题,是这样的,在Select into这种方式生成新表时,是无法指定自增长字段的。所以办法就是:先建立好表,再用Insert into的方式向里面插入数据: