数据挖掘1-
第1章 《数据挖掘》PPT绪论

Knowledge
Information
Data
3 of 43
1.1数据挖掘基本概念
第一章 绪论
1.1.1 数据挖掘的概念
数据挖掘、数据库、人工智能
• 数据挖掘是从数据中发掘知识的过程,在这个过程中人工智能和数据库技术可以作 为挖掘工具,数据可以被看作是土壤,云平台可以看作是承载数据和挖掘算法的基 础设施 。在挖掘数据的过程中需要用到一些挖掘工具和方法,如机器学习的方法。 当挖掘完毕后,数据挖掘还需要对知识进行可视化和展现。
21 of 43
1.3数据挖掘常用工具
第一章 绪论
1.3.2 开源工具
• WEKA WEKA 是一个基于JAVA 环境下免费开源的数据挖掘工作平台,集合了大量能承担数据 挖掘任务的机器学习算法,包括对数据进行预处理,分类,回归、聚类、关联规则以及 在新的交互式界面上的可视化。
22 of 43
1.3数据挖掘常用工具
•R • Weka • Mahout • RapidMiner • Python • Spark MLlib
第一章 绪论
20 of 43
1.3数据挖掘常用工具
第一章 绪论
1.3.2 开源工具
•R R是用于统计分析和图形化的计算机语言及分析工具,提供了丰富的统计分析和数据挖 掘功能,其核心模块是用C、C++和Fortran编写的。
为了提高系统的决策支持能力,像ERP、SCM、HR等一些应用系统也逐渐与数据 挖掘集成起来。多种理论与方法的合理整合是大多数研究者采用的有效技术。
12 of 43
1.2 数据挖掘起源及发展历史
第一章 绪论
3 数据挖掘面临的新挑战
随着物联网、云计算和大数据时代的来临,在大数据背景下数据挖掘要面临的挑 战,主要表现在以下几个方面:
数据挖掘1

联机分析处理需具备的功能特征:
• • • • • 给出数据的多维视图 可交互查询对数据分析 提供分析建模功能 生成概括数据、聚集和层次 检查并显示二维或三维表格、图形,并能容易的 变换基准轴 • 具有多维数据存储引擎,按阵列存储数据
2.数据挖掘技术和工具 数据挖掘(Data Mining,DM)是从超大型数据库 (VLDB)或数据仓库中发现并提取隐藏在内部的信息 的一种新技术。目的是帮助决策者寻找数据间潜在 的关系,发现经营者被忽略的要素,而这些要素对 预测趋势、决策行为也许是十分有用的信息。 数据挖掘技术是可以满足和解决当前“数据太 多,信息不足”的技术。
3.数据库系统(DataBase System,DBS)
数据库系统是指在计算机系统中 引入数据库后的系统。 数据库系统由数据库管理系统进 行管理。
4.数据库管理系统
随着计算机软、硬件和相应技术的发展,数 据管理经历了三个阶段。 人工管理 文件系统 数据库系统
1.1.2数据库系统的特点 1. 2. 3. 4. 数据的结构化 数据的共享性 数据的独立性 数据统一由DBMS管理和控制 (1)数据的安全性 (2)数据的完整性 (3)并发控制 (4)数据库恢复
开放式数据库连接(ODBC) 是一种应用程序接口规范,它定义了 一个标准例程集,应用程序使用它们可以 访问数据库中的数据。
图1-4 数据库系统
应用程序 ODBC API
ODBC 驱动程序管理器
ODBC 驱动程序
ODBC 驱动程序
ODBC 驱动程序
数据库
数据库
数据库
(3)面向对象数据库 面向对象数据库系统是数据库技术与面向 对象程序设计方法相结合的产物。 面向对象数据库的三个发展方向:
第一章 数据挖掘的概念

1.3.2 数据收集
数据如何收集,有两种截然不同的可能: 1)当数据产生过程在专家的控制下时,称为 “设计实验”。 2)专家不能影响数据产生过程,称为“观察 法”,数据随机产生。 通常收集完成后取样的分布也是完全未知 的,或者是在数据收集过程中部分或者不明确 地给出,但要理解数据收集是怎样影响它的理 论分布的,这一点相当重要。
1.5数据仓库
虽然数据仓库的存在并不是数据挖掘的先 决条件,但通过对数据仓库的访问,数据挖 掘任务变得容易多了,尤其是大公司或医院。
定义:数据仓库是一个集成的,面向主 题的、设计用于决策功能(DSF)的数据库 的集合,数据中的每一个数据单元在时间上 都是和某个时刻相关的。
•构建数据仓库时应该注意的两 个方面: 第一是数据仓库中存储的特殊数 据类型(分类) 第二是为了使数据有利于决策而 把它准备成最终形式所要进行 的转换。
• 数据仓库包括以下的数据类别:
(1)过去细节数据 (2)当前细节数据 (3)轻度综合数据 (4)高度综合数据 (5)元数据(数据目录或向导) 在数据仓库中进行这5种基本类型或导出 数据的准备。
• 数据基本类型的4种转换方式:
1.简单转换:它一次只集中在一个字段 上,而不考虑相关字段的值。 2.清洁和净化:确保一个字段或相关字 段格式和使用的一致性。 3.集成:对一个或多个来源的操作型数 据进行处理,进行字段到字段的映射, 形成一个新的数据结构的过程。 4.聚合和总结:将操作型环境中的数据 实例浓缩成更小的数据仓库环境中实例 的方法。
数据挖掘的两个根本目标:预测和描述 预测涉及到使用数据集中的一些变量或域 来预测其他我们关心的变量的未知或未 来的值;描述关注的则是找出描述可由 人类解释的数据格式。 1)预测性数据挖掘:生成已知数据集的系统 模型。 2)描述性数据挖掘:在数据集上生成新的、 非同寻常的信息。
数据挖掘概念与技术第一章PPT课件

数据淹没,但却缺乏知识
信息技术的进化
···
数据挖掘的自动化分析的海量数据集 文件处理->数据库管理系统->高级数据库:系统高级数据分析
2021
3
定义:从大量的数据中提取有趣的(非平凡的,隐 含的,以前未知的和潜在有用的)模式或知识。
“数据中发现知识”(KDD)
2021
4
选择和变换
评估和表示
第一章 引论
2021
1
1.1 为什么进行数据挖掘 1.2 什么是数据挖掘 1.3 可以挖掘什么类型的数据 1.4 可以挖掘什么类型的模式 1.5 使用什么技术 1.6 面向什么类型的应用 1.7 数据挖掘的主要问题 1.8 小结
2021
2
数据爆炸
海量数据,爆炸式增长
来源:网络,电子商务,个人 类型:图像,文本···
设想网上购物的一次交易,其付款过程至少包括以下几步数据库操作:
一、更新客户所购商品的库存信息 二、保存客户付款信息--可能包括与银行系统的交互 三、生成订单并且保存到数据库中 四、更新用户相关信息,例如购物数量等等
2021
9
其他类型的数据
股票交易数据 文本 图像 音频视频 未知的
2021
10
1.4.1 类/概念描述:特征化与区分
类/概念
数据特征化
目标数据的一般特性或特征汇总
数据区分
将目标类数据对象的一般性与一个或多个 对比类对象的一般特性进行比较
特征化和区分
2021
11
1.4.2 挖掘频繁模式、关联和相关性
频繁模式是在数据中频繁出现的模式
1.频繁项集、频繁子序列、频繁子结构 2.挖掘频繁模式可以发现数据中的关联和相关性 例如:单维与多维关联
数据挖掘概念、技术--数据挖掘原语、语言和系统结构1

数据挖掘语言分类
数据挖掘查询语言;
• DBMiner中定义的原语 DBMiner中定义的原语
数据挖掘建模语言; 通用数据挖掘语言。 第一阶段的数据挖掘语言一般属于查询语 言;PMML属于建模语言;OLE 言;PMML属于建模语言;OLE DB for DM属于通用数据挖掘语言。 DM属于通用数据挖掘语言。
置信度
• confidence factor (or predictive accuracy) • P(A^B)/P(A)
Piatetsky-Shapiro’st three principles for rule interestingness (RI)
如果P(A^B)=P(A)P(B),那么RI=O; 如果P(A^B)=P(A)P(B),那么RI=O; 当其它参数固定时,Rl随着P(A^B)的增加 当其它参数固定时,Rl随着P(A^B)的增加 单调递增; 当其它参数固定时,RI随着P(A)或P(B)的 当其它参数固定时,RI随着P(A)或P(B)的 增加单调递减。
提供匹配的模式模版(元模式,元规则,元查询) 指导发现过程。 P(X:customer,W)^Q(X,Y)=>buys(X,Z)
背景知识
关于挖掘领域的知识。概念分层允许在多个抽象 层次上发现知识。 概念分层定义了一组由底层概念集到高层概念集 的映射。 概念分层结构可以由系统用户,领域专家,知识 工程师,自动发现,统计分析获得
简洁性
要求规则的前件和后件(主要是前件) 要求规则的前件和后件(主要是前件)包含的 属性的项数不要太多。即A 属性的项数不要太多。即A的属性数目越少 规则越简洁,客观兴趣度越高。
• 一般地,A包含的属性越少P(A)越大。 一般地,A包含的属性越少P(A)越大。
《网络数据挖掘》实验一

《网络数据挖掘》实验一一、实验目的在SQL Server2005上构建数据仓库二、实验内容1.每个学生按自己的学号创建一个空的数据库。
2.将“浙江经济普查数据”目录下的11个城市的生产总值构成表导入该数据库。
要求表中列的名称为EXCEL表中抬头的名称,表的名称分别为对应的excel文件名。
往城市表中输入前面导入的11个城市名称和城市ID(注意不能重复),5.仔细阅读excel表格,分析产业结构的层次,找出产业、行业大类、行业中类的关系。
有些行业的指标值为几个子行业的累加。
比如:第一产业→农林牧渔业第二产业→工业→采矿业、制造业、电力、燃气及水的生产和供应业类ID可按顺序编写。
8.创建一个新表汇总11个城市的生产总值,表的名称为“按城市和行业分组的生产总值表”。
表中的列名和第二步导入表的列名相同,同时添加一个新列(放在第一列),列名为“城市ID”,数据类型为整型;再添加一个新列(放在第二列),列名为“行业中类ID”,数据类型为整型。
9.将11个城市的生产总值构成表导入到第6步创建的新表中,注意不同的城市,要用不同的城市ID代入,行业中类ID可暂时为空值。
10.将行业门类表中的行业中类ID值输入至表“按城市和行业分组的生产总值表”中的“行业中类ID”列上。
11.检查3个表:“按城市和行业分组的生产总值表”、“城市表”、“行业门类表”中主键和外键是否一致(可通过关联查询检查)。
12.删除“按城市和行业分组的生产总值表”中除了行业中类纪录以外的其他高层次的记录,如指标为“第一产业”的行等等(如果不删除,将在汇总中出错)。
13.删除“按城市和行业分组的生产总值表”中原有的“指标”列(由于这列在行业门类表中已存在,因此是冗余的)。
14. 建立以下查询,和原EXCEL文件中的数据对比a)查询杭州市第二产业工业大类下各行业中类的总产出、增加值、劳动者报酬、营业盈余b)分别查询11个城市的第二产业总产出汇总值c)分别查询11个城市的工业劳动者报酬汇总值d)分别查询11个城市的第三产业增加值14.使用SSIS创建一个包,来完成第9步和第10步的过程,执行包,检查数据是否一致。
数据挖掘--分类完整1ppt课件

2020/5/21
.
16
K-近邻分类算法
大部分分类器都输出一个实数值(可以看作概率),通过变 换阈值可以得到多组TPR与FPR的值。
2020/5/21
.
11
第三章 分类方法
分类的基本概念与步骤 基于距离的分类算法 决策树分类方法 贝叶斯分类 实值预测 与分类有关的问题
内容提要
2020/5/21
.
12
基于距离的分类算法的思路
第三章 分类方法
分类的基本概念与步骤 基于距离的分类算法 决策树分类方法 贝叶斯分类 实值预测 与分类有关的问题
内容提要
2020/5/21
.
1
分类的流程
根据现有的知识,我们得到了一些关于爬行动物和鸟类的信息, 我们能否对新发现的物种,比如动物A,动物B进行分类?
2020/5/21
.
2
f(xi1 ,xi2 ,xi3 ,..x.i)n. .y.i ,
步骤三:建立分类模型或分类器(分类)。
分类器通常可以看作一个函数,它把特征映射到类的空间 上
2020/5/21
.
5
如何避免过度训练
分类也称为有监督学习(supervised learning), 与之相对于的是无监督学习(unsupervised learning),比如聚类。
2020/5/21
.
7
分类模型的评估
真阳性(True Positive): 实际为阳性 预测为阳性 真阴性(True Negative):实际为阴性 预测为阴性 假阳性(False Positive): 实际为阴性 预测为阳性 假阴性(False Negative):实际为阳性 预测为阴性
预测是否正确 预测结果 比如预测未知动物是鸟类还是爬行动物,阳性代表爬
数据挖掘的方法和工具

数据挖掘的方法和工具随着计算机技术的快速发展,数据的存储和获取变得越来越容易。
随之而来的是一个庞大的数据集,其中包含了各式各样的信息。
大数据时代的到来,使得针对这些海量数据的分析和挖掘工作显得格外重要。
数据挖掘技术,作为一种高效的数据处理方法,成为了当今实现数据价值、探讨未知领域的工具之一。
数据挖掘技术的目的数据挖掘技术通过大数据的分析、整合和挖掘,从中发现其中存在的潜在模式、关系和趋势。
从而对数据集的结构和特征进行分析和评估,为数据决策提供支撑和保障。
为了达成这一目标,需采用一系列方法和工具。
下面我们将介绍一些常用的数据挖掘方法和工具。
基于聚类的数据挖掘方法基于聚类的数据挖掘方法,是将大量数据集中在一起,类似于物以类聚,依据数据之间的相似性以及差异性,将其归属到不同的类别之中。
这种方法可以从大量的数据中提取有用的信息,从而为数据分析和决策提供支撑。
在实际应用中,一些聚类算法,如k-means算法、DBSCAN算法、层次聚类算法等,被广泛应用于数据分组和数据分类领域。
基于关联规则的数据挖掘方法基于关联规则的数据挖掘方法,通过分析大量数据之间的关联关系,建立各组数据之间的关联规则,从而利用判断和推理方式对各种数据进行预测和分析。
该方法可以有效地发现数据之间的极强关联,并为数据分析和决策提供一定的支撑。
Apriori算法、FP-growth算法等,是主流的关联规则数据挖掘算法。
基于分类的数据挖掘方法通过分类算法描述数据样本之间的客观差异和相似性,然后将数据分类,并对其进行相关性、差异性分析,从而找出数据的属性和属性值,并使用分类器将该数据应用于相应的分类或预测中。
这种方法适用于数据建模、分类、预测、聚类和分类验证等常见领域。
朴素贝叶斯算法、决策树算法、支持向量机等,是主流的基于分类的数据挖掘算法。
数据挖掘工具与上述算法相关的数据挖掘工具,可以帮助用户高效的进行数据分析和挖掘。
例如R语言具有强大的统计分析功能,是进行数据统计和分析的首选工具之一。
数据挖掘1——精选推荐

一、讨论下列每项活动是否是数据挖掘任务,为什么?数据挖掘任务有两类:1、预测性挖掘任务:在当前的数据上进行判断,以进行预测。
2、描述性挖掘任务:刻划数据库中数据的一些特性(相关趋势,聚类,异常等等。
)四种主要的数据挖掘任务及概念。
1、预测建模a、分类:用于预测离散的目标变量。
b、回归:用于预测连续的目标变量。
2、关联分析:用来发现描述数据中强关联特征的模式。
所发现的模式,通常用蕴涵规则或特征子集的形式表示目标,以有郊的方式提取最有趣的模式。
3、聚类分析:旨在发现紧密相关的观测值组群,使得与属于不同的观测值相比,属于同一簇的观测值相互之间尽可能类似。
4、异常检测:又称孤立点分析,其任务是识别其特征显著不同于其它数据的观测值,这样的观测值称为异常点或离群点。
(a)根据性别划分公司的顾客。
答:属于聚类分析,是数据挖掘任务。
(b)根据可赢利性划分公司的顾客。
答:属于聚类分析,是数据挖掘任务。
(c)计算公司的总销售额。
答:不满足上述的任何一种,不是数据挖掘任务。
(d)按学生的标识号对学生数据库排序。
答:不满足上述的任何一种,不是数据挖掘任务。
(e)预测掷一对骰子的结果。
答:属于预测建模中的分类,是数据挖掘任务(f)使用历史记录预测某公司未来的股票价格。
答:属于预测建模中的回归,是数据挖掘任务(g)监测分析病人心率的异常变化。
答:属于异常检测,是数据挖掘任务。
(h)监测分析地震活动的地震波。
答:属于关联分析,是数据挖掘任务。
(i)提取声波的频率。
答:属于关联分析,是数据挖掘任务。
(j)根据数据对象属性描述数据对像特征。
答:不满足上述的任何一种,不是数据挖掘任务。
二、将下列属性分类成二元的、离散的或连续的,并将它们分类成定性的(标称的或序数的)或定量的(区间的或比率的)。
某些情况下可能有多种解释,因此如果你认为存在多义性,请给出。
例如:年龄。
回答:离散的,定量的、比率的。
答:二元变量只有两个状态,0或1,0表示该变量为空,1表示该变量存在。
数据挖掘的基本步骤

数据挖掘的基本步骤引言概述:数据挖掘是一种从大量数据中提取有价值信息的过程,它可以匡助企业和组织发现隐藏在数据暗地里的模式和规律。
在进行数据挖掘之前,我们需要了解一些基本的步骤,以确保我们能够正确地应用数据挖掘技术并得到准确的结果。
本文将介绍数据挖掘的基本步骤,包括问题定义、数据采集、数据清洗、特征选择和模型训练。
一、问题定义:1.1明确挖掘目标:在进行数据挖掘之前,我们需要明确我们的挖掘目标是什么。
例如,我们可能希翼预测客户购买某种产品的可能性,或者发现导致销售额下降的原因。
明确挖掘目标有助于我们选择适当的数据挖掘方法和技术。
1.2确定数据挖掘问题的范围:在问题定义阶段,我们需要确定我们要解决的具体问题的范围。
这有助于我们集中精力解决特定的问题,同时避免陷入无关的细节。
1.3制定评估标准:在问题定义的过程中,我们还需要制定评估标准来衡量我们的数据挖掘结果。
这可以是预测准确率、模型的召回率或者其他适当的指标。
制定评估标准有助于我们评估我们的模型的性能和效果。
二、数据采集:2.1确定数据来源:在数据挖掘之前,我们需要确定我们将从哪里获取数据。
数据可以来自各种来源,包括数据库、日志文件、传感器等。
确定数据来源有助于我们了解数据的可用性和可行性。
2.2采集数据:一旦确定了数据来源,我们就需要采集数据。
这可以通过数据抓取、数据采样或者其他方法来完成。
在采集数据时,我们应该确保数据的完整性和准确性,以避免对后续分析产生不良影响。
2.3整理数据:在数据采集之后,我们需要对数据进行整理和组织。
这包括去除重复数据、处理缺失值、处理异常值等。
整理数据有助于我们准确地分析和挖掘数据。
三、数据清洗:3.1数据预处理:在进行数据挖掘之前,我们需要对数据进行预处理。
这包括数据的归一化、标准化、离散化等。
数据预处理有助于我们消除数据中的噪声和冗余,提高数据挖掘的准确性和可靠性。
3.2特征选择:在数据清洗的过程中,我们还需要进行特征选择。
数据挖掘导论--第1章绪论

数据挖掘导论--第1章绪论数据挖掘导论-第⼀章-绪论为什么会出现数据挖掘?1. 因为随着社会不断快速发展,信息量在不断增加,由于**信息量太⼤** ,⽽⽆法使⽤传统的数据分析⼯具和技术处理它们;2. 即使数据集相对较⼩,但由于数据本⾝有⼀些**⾮传统特点**,也不能使⽤传统的⽅法进⾏处理。
什么是数据挖掘?数据挖掘是⼀种技术,它将传统的数据分析⽅法与处理⼤量数据的复杂算法相结合。
数据挖掘是在⼤型数据存储库中,⾃动地发现有⽤信息的过程。
数据挖掘是数据库中知识发现(knowledge discovery in database,KDD)不可缺少的⼀部分。
数据挖掘要解决的问题可伸缩⾼维性异种数据和复杂数据数据的所有权与分布⾮传统的分析数据挖掘任务通常,数据挖掘任务分为下⾯两⼤类预测任务:这些任务的⽬标是根据其他属性的值,预测特定属性的值。
被预测的属性⼀般称为⽬标变量或因变量⽤来做预测的属性称说明变量或⾃变量描述任务:其⽬标是导出概括数据中潜在联系的模式(相关、趋势、聚类、轨迹和异常)。
本质上,描述性数据挖掘任务通常是探查性的,并且常常需要后处理技术验证和解释结果下图展⽰了其余部分讲述的四种主要数据挖掘任务预测建模:以说明变量函数的⽅式为⽬标变量建⽴模型。
有两类预测建模任务:分类(classification):⽤于预测离散的⽬标变量回归(regression):⽤于预测连续的⽬标变量关联分析:⽤来发现描述数据中强关联特征的模式。
所发现的模式通常⽤蕴涵规则或特征⼦集的形式表⽰聚类分析:旨在发现紧密相关的观测值组群,使得与属于不同簇的观测值相⽐,属于同⼀簇的观测值相互之间尽可能类似异常检测:任务是识别其特征显著不同于其他数据的观测值。
这样的观测值称为异常点或离群点## 参考⽂献: 1. 数据挖掘导论(完整版)。
数据挖掘CHAPTER1引言

第一章引言本书是一个导论,介绍什么是数据挖掘,什么是数据库中知识发现。
书中的材料从数据库角度提供,特别强调发现隐藏在大型数拯集中有趣数据模式的数据挖掘基本概念和技术。
所讨论的实现方法主要而向可规模化的、有效的数据挖掘工具开发。
本章,你将学习数据挖掘如何成为数据库技术自然进化的一部分,为什么数据挖掘是重要的,以及如何左义数据挖掘。
你将学习数据挖掘系统的一般结构,并考察挖掘的数据种类,可以发现的数据类型,以及什么样的模式提供有用的知识。
除学习数据挖掘系统的分类之外,你将看到建立未来的数据挖掘工具所面临的挑战性问题。
1.1什么激发数据挖掘?为什么它是重要的?需要是发明之母。
近年来,数据挖掘引起了信息产业界的极大关注,其主要原因是存在大量数据,可以广泛使用.并且迫切需要将这些数据转换成有用的信息和知识。
获取的信息和知识可以广泛用于各种应用,包括商务管理、生产控制.市场分析、工程设计和科学探索等。
数据挖掘是信息技术自然进化的结果。
进化过程的见证是数据库工业界开发以下功能(图1.1):数据收集和数据库创建,数据管理(包括数拯存储和提取.数据库事务处理),以及数据分析与理解(涉及数据仓库和数据挖掘)。
例如,数据收集和数据库创建机制的早期开发已成为稍后数据存储和提取、査询和事务处理有效机制开发的必备基础。
随着提供查询和事务处理的大量数据库系统广泛付诸实践,数据分析和理解自然成为下一个目标。
自60年代以来,数据库和信息技术已经系统地从原始的文件处理进化到复杂的、功能强大的数拯库系统。
自70年代以来,数据库系统的研究和开发已经从层次和网状数据库发展到开发关系数据库系统(数据存放在关系表结构中;见1・3・1小节)、数据建模工具、索引和数据组织技术。
此外,用户通过查询语言、用户界面・优化的査询处理和事务管理,可以方便、灵活地访问数据。
联机事务处理(0LTP)将查询看作只读事务,对于关系技术的发展和广泛地将关系技术作为大量数据的有效存储、提取和管理的主要工具作出了重要贡献。
数据挖掘--数据可视化技术简介(1)
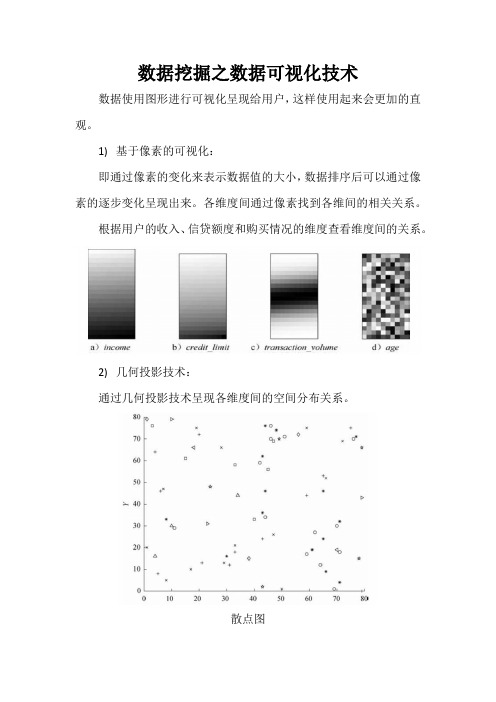
数据挖掘之数据可视化技术
数据使用图形进行可视化呈现给用户,这样使用起来会更加的直观。
1)基于像素的可视化:
即通过像素的变化来表示数据值的大小,数据排序后可以通过像素的逐步变化呈现出来。
各维度间通过像素找到各维间的相关关系。
根据用户的收入、信贷额度和购买情况的维度查看维度间的关系。
2)几何投影技术:
通过几何投影技术呈现各维度间的空间分布关系。
散点图
三维矩阵图
3)基于图符的可视化技术:
通过图符来表示数据的维度,切尔诺夫脸:
人物线条画:
4)标签云:
通过使用标签的大小来呈现标签的使用次数和数量的多少。
根据标签的使用次数,通过标签的大小呈现。
根据词语的搜索量或使用量的多少,将标签以不同的大小呈现。
《数据挖掘导论》教材配套教学PPT——第1章 认识数据挖掘

• 数据实例(Instance)
– 用于有指导学习的样本数据
• 训练实例(Training Instance)
– 用于训练的实例
• 检验实例(Test Instance)
– 分类模型建立完成后,经过检验实例进行检验,判断模型是否 能够很好地应用在未知实例的分类或预测中。
2022年3月23日星期三
第10页,共65页
Knowledge)
2022年3月23日星期三
第21页,共65页
1.4 专家系统
清华大学出版社
专家系统(Expert System)
• 一种具有“智能”的计算机软件系统。 • 能够模拟某个领域的人类专家的决策过程,解决那些需要人类专家
处理的复杂问题。 • 一般包含以规则形式表示的领域专家的知识和经验,系统就是利用
• 决策树有很多算法(第2章)
Sore-throat Yes Cooling-effect
Not good
Unknown Good
No
Cold Type=Viral (3/0)
Cold Type=Bacterial (4/1)
Cold Type=Viral (2/0)
Cold Type=Bacterial (1/0)
Sore-
throat 咽痛
Cooling-
effect 退热效果
Group 群体发病
Cold-type 感冒类型
1
Yes
2
No
3
Yes
4
Yes
5
No
6
No
7
No
8
Yes
9
Yes
10
Yes
No
Yes
数据挖掘第一章

CS512 Coverage (Chapters 11, 12, 13 + More Advanced Topics)
Cluster Analysis: Advanced Methods (Chapter 11) Outlier Analysis (Chapter 12) Mining data streams, time-series, and sequence data Mining graph data Mining social and information networks Mining object, spatial, multimedia, text and Web data Mining complex data objects Spatial and spatiotemporal data mining Multimedia data mining Text and Web mining Additional (often current) themes if time permits
Database Systems:
Text information systems
Bioinformatics
Yahoo!-DAIS seminar (CS591DAIS—Fall and Spring. 1 credit unit)
2
CS412 Coverage (Chapters 1-10, 3rd Ed.)
Summary
7
Why Data Mining?
Tfrom terabytes to petabytes
数据挖掘:概念与技术--笔记1--度量数据的相似性与相异性

数据挖掘:概念与技术--笔记1--度量数据的相似性与相异性基本概念数据矩阵表⽰ n个对象 × p个属性相异性矩阵表⽰n个对象两两之间的临近度 n×n的矩阵d(i,j)表⽰对象i与对象j之间的相异性1 标称属性的临近性度量计算公式:m: 匹配的数⽬(即i和j取值相同状态的属性数)p: 刻画对象的属性总数令p=1 (主要⽬的是使相异矩阵的值在[0,1]之间),相同时为1,不同时为0相异矩阵为:相似性:2 ⼆元属性的临近性度量(1)对称的⼆元相异性其中q,r,s,t的含义见表2.3(2)⾮对称的⼆元相异性可以看出⾮对称的⼆元相异性是忽略t的,即忽略属性均为0的例:y(yes) p(positive) 值为1,n(no, negative) 值为0其中name是对象标⽰符,gender是对称属性,其余均为⾮对称属性对于⾮对称属性进⾏计算:d(Jack,Jim)=(1+1)/(1+1+1)=0.67d(Jack,Mary)=(0+1)/(2+0+1)=0.33d(Jim,Mary)=(1+2)/(1+1+2)=0.753 数值属性的相异性介绍⼏个基本概念⼀般计算距离之前数据应该规范化欧⼏⾥得距离加权的欧⼏⾥得距离曼哈顿(城市块)距离闵可夫斯基距离其中h是实数 h≥1上确界距离(1)序数属性的临近性度量计算步骤:第⼀步:把test-2的每个值替换为它的排位,则四个对象将分别被赋值为3,1,2,3第⼆步:按照公式 M f表⽰总的排位,r if表⽰第i个对象的排位(此公式的⽬的是将每个属性的值域映射到[0.0,1.0])所以排位1的值为0,排位2的值为0.5,排位3的值为1第三步:可以使⽤⽐如欧⼏⾥得距离算出相异性矩阵(2)数值属性的临近性度量对test-3计算max h x h=64,min h x h=224 混合类型属性的相异性把所有有意义的属性转换到共同的区间[0.0,1.0]上结果5 余弦相似性对于稀疏矩阵,例⽐较⽂档或针对给定的查询词向量对⽂档排序例:。
数据挖掘实验报告1-weka

Southwest university of science and technology 数据挖掘实验报告实验一学院名称计算机科学与技术专业名称软件1201学生姓名李亚才学号********指导教师吴珏二〇一五年十一月一、实验要求掌握weka中聚类算法并分析结果二、实验平台Xp weka三、实验内容1、Weka 工具初步认识(掌握weka程序运行环境)2、实验数据预处理。
(掌握weka中数据预处理的使用)对weka自带测试用例数据集weather.nominal.arrf文件,进行一下操作。
1)、加载数据,熟悉各按钮的功能。
2)、熟悉各过滤器的功能,使用过滤器Remove、Add对数据集进行操作。
3)、使用weka.unsupervised.instance.RemoveWithValue过滤器去除humidity属性值为high 的全部实例。
4)、使用离散化技术对数据集glass.arrf中的属性RI和Ba进行离散化(分别用等宽,等频进行离散化)。
四、实验步骤和结果打开weather.nominal.arff文件:进行remove操作:在choose列表中选择weka.unsupervised.instance.RemoveWithValue过滤器:运行结果如下:加载glass文件:对RI,Ba进行离散化,结果如下:五、思考与分析1、使用数据集编辑器打开weather.nominal.arrf文件,实例编号为2的分类属性值是多少?答:实例2类属性有hot,mild,cool三个2、加载weather.nomina.arrf文件后,temperature属性可以有哪些合法值?答:有hot,mild,cool。
大数据本科系列教材PPT课件之《数据挖掘》:第1章 绪论

1.3.1 商用工具
• SAS Enterprise Miner Enterprise Miner是一种通用的数据挖掘工具,按照“抽样-探索-修改-建模-评价”的方 法进行数据挖掘,它把统计分析系统和图形用户界面(GUI)集成起来,为用户提供了用 于建模的图形化流程处理环境。
19 of 43
1.3数据挖掘常用工具
3 of 43
1.1数据挖掘基本概念
第一章 绪论
1.1.1 数据挖掘的概念
数据挖掘的定义
• 数据挖掘(Data Mining,DM),是从大量的、有噪声的、不完全的、模糊和随机 的数据中,提取出隐含在其中的、人们事先不知道的、具有潜在利用价值的信息和 知识的过程。
• 这个定义包含以下几层含义: ✓ 数据源必须是真实的、大量的、含噪声的; ✓ 发现的是用户感兴趣的知识; ✓ 发现的知识要可接受、可理解、可运用; ✓ 不要求发现放之四海皆准的知识,仅支持特定的问题
•R • Weka • Mahout • RapidMiner • Python • Spark MLlib
第一章 绪论
21 of 43
1.3数据挖掘常用工具
第一章 绪论
1.3.2 开源工具
•R R是用于统计分析和图形化的计算机语言及分析工具,提供了丰富的统计分析和数据挖 掘功能,其核心模块是用C、C++和Fortran编写的。
8 of 43
1.1数据挖掘基本概念
第一章 绪论
1.1.3 大数据挖掘的特性
• 在大数据时代,数据的产生和收集是基础,数据挖掘是关键,即数据挖掘是大数据 中最关键、最有价值的工作。
大数据挖掘的特性:
• 应用性 • 工程性 • 集合性
9 of 43
数据挖掘导论第一章

2020/9/29
数据挖掘导论
3
2020/9/29
数据挖掘导论
4
2020/9/29
数据挖掘导论
5
Jiawei Han
在数据挖掘领域做出杰出贡献的郑州大学校友——韩家炜
2020/9/29
数据挖掘导论
6
第1章 绪论
?
No
S in g le 4 0 K
?
No
M a rrie d 8 0 K
?
10
Training Set
Learn Classifier
Test Set
Model
2020/9/29
数据挖掘导论
23
分类:应用1
Direct Marketing Goal: Reduce cost of mailing by targeting a set of consumers likely to buy a new cell-phone product. Approach: Use the data for a similar product introduced before. We know which customers decided to buy and which decided otherwise. This {buy, don’t buy} decision forms the class attribute. Collect various demographic, lifestyle, and company-interaction related information about all such customers. Type of business, where they stay, how much they earn, etc. Use this information as input attributes to learn a classifier model.
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Part I:1. Suppose that the data for analysis include the attribute age. The age values for the data tuples are (in increasingv order):13,15,16,16,19,20,20,21,22,22,25,25,25,25,30,33,33,35,35,35,35,36,40,45,46,52,70. (a) use min-max normalization to transform the value 35 for age onto the rang[0.0,1.0].(b) use z-score normalization to transform the value 35 for age ,where the standard deviation of age is 12.94 years.(c) Use normalization by decimal scaling to transform the value 35 for age. (d) Comment on which method you would prefer to use for the given data ,giving reasons sa to why.(a) Given that the minmum age value is 13 and the maxmun value is 70, we cantransform the value 35 for age onto the rang[0.0,1.0] by min-max normalization as follows:min '(max min )min max min 3513(10)070130.39age age age ageage agev v new new new -=-+--=-+-=(b) Given that the standard deviation of age is 12.94 years ,we may use z-scorenormalization to transform the value 35 for age:80929.9627age == 3529.96'0.3912.94agev agev σ--===(c) By decimal scaling normalization,we transform the value 35 for age as 35'0.35(max(')1)10100j v v j v ===<为使得的最小整数(d) 我更倾向于使用小数定标规范化。
对于最小-最大规范化。
如果今后的输入值落在age 的原始数据至于之外,该方法可能会面临“越界”错误,而z-dcore 规范化则额外计算并保存平均值和标准差这两个参数。
由于age 的值基本上都是不超过二位数,因而j 可以统一取2,即用100初每个数即可。
2.A database has four transaction. Let min_sup=60%and min_conf=80%.(a) At the granularity of item_category(eg.item;could be “milk ”),for the following rule template,123,(,)(,)(,)[,]X transaction buys X item buys X item buys X item s c ∀∈∧⇒ List the frequent k itemset - for the largest k and all of the strong association rules (with their support s and confidence c)containing the frequentk itemset - for the largest k .相对支持度为min_sup=60%,那么可以求得绝对支持度为 min_sup=0.64 2.4⨯={ milk,cheese },{ cheese,bread },{ milk, bread },{ milk },{ cheese },{ bread }。
得出关联规则如下,每个都列出置信度:milk cheese bread 3/3100%confidence ∧⇒== cheese bread milk 3/3100%confidence ∧⇒== milk bread cheese 3/475%confidence ∧⇒== milk bread cheese 3/475%confidence ⇒∧== cheese milk bread 3/3100%confidence ⇒∧== bread milk cheese3/475%confidence ⇒∧==已知最小置信度为min_conf=80%,故强关联规则有:,(,milk)(,cheese)(,bread)[75%,100%]X transaction buys X buys X buys X s c ∀∈∧⇒==,(,cheese)(,bread)(,milk)[75%,100%]X transaction buys X buys X buys X s c ∀∈∧⇒== ,(,cheese)(,milk)(,bread)[75%,100%]X transaction buys X buys X buys X s c ∀∈⇒∧==(b) At the granularity of brand-item_category(e.g. item; could be “sunset-milk ”), for the following rule temple,123,(,)(,)(,)X customer buys X item buys X item buys X item ∀∈∧⇒List the frequent k itemset - for the largest k . Note:do not print any rule.从1L 可以看出,k 最大为1,故频繁k 项集为l ={ Wonder-bread }3. When mining cross-level association rules, suppose it is found that the itemset“{IBM home computer, printer}”dose not satisfy minimum support. Can this information be used to prune the mining of a “descendent”itemset such as“{IBM home computer, /b printer}”? Given a general rule explaining how this information may be used for pruning the search space.如果对于所有层使用一致的最小支持度,根据祖先是其后代超集的知识,采用Aprioti性质:频繁项集的所有非空子集也必须是频繁的,在这种情况下,如果祖先不满足最小支持度,那么我们可以停止对其后代的探查。
如果在较低层使用递减的最小支持度,即每个抽象层都有自己的最小支持度,且抽象层越低,对应的阈值越小,此时有可能在祖先不满足最小支持度的前提下,但是其后代却满足,此时Aprioti性质不能成立,我们不能停止对其后代的探查。
4. 假定数据仓库中包含4个维:date, product, vendor, location;和两个度量:sale_number和sales_cost。
(a) 画出该数据仓库的星形模式图(b) 由基本方体[date, product, vendor, location]开始,列出vendor Wal-Mart每年在Los Angles的所有sales_cost。
(c) 对于数据仓库,位图索引是有用的。
以该立方体为例,简略讨论使用位图索引结构的优点和问题。
(a)数据仓库的星形模式图(b)所需的OLAP操作:沿着Date维由Day上卷到year;对vendor=Wal-Mart进行切片;沿着Location 维由Street上卷到City;对City=Los Angles切片;最后沿着product维由每种产品上卷到all。
(c)该立方体一共有四个维(或属性),只需要为这四个为分别维护一张位图索引表,当属性的域的基数较小时,因为比较、连接和聚集操作都变成了位运算,大大减少了处理时间。
由于用来表示具体事务的字符串可以用单个二进位表示,位图索引显著降低了空间和I/O开销。
但是如果属性的域的基数很大时,可能会浪费存储空间来存储大量的数据0.5. 下面是一个超市某种商品连续24个月的销售数据(单位为百元)21,16,19,24,27,23,22,21,20,17,16,20,23,22,18,24,26, 25,20,26,23,21,15,17(a)对以上数据进行深度为6的Equal-depth binning,然后分别采用bin median及bin boundaries两种方法进行平滑。
(b)请写出采用min-max方法,将16和23规范化到[0,1] 区间后的结果。
对24个月的销售数据排序后为15,16,16,17,17,18,19,20,20,20,21,21,21,22,22,23,23,23,24,24,25,26,26,27(a)划分为(等深)箱:箱1:15,16,16,17,17,18箱2:19,20,20,20,21,21箱3:21,22,22,23,23,23箱4:24,24,25,26,26,27用bin median进行平滑:箱1:16.5,16.5,16.5,16.5,16.5,16.5箱2:20,,20,20,20,20,20箱3:22.5,22.5,22.5,22.5,22.5,22.5箱4:25.5,25.5,25.5,25.5,25.5,20.5 用bin boundaries 进行平滑: 箱1:15,15,15,18,18,18 箱2:19,19,19,19,21,21 箱3:21,21,21,23,23,23 箱4:24,24,24,27,27,27 (b)对16采用min-max 方法规范化min '(max min )min max min 1615(10)027150.08age age age ageage agev v new new new -=-+--=-+-=对23采用min-max 方法规范化min '(max min )min max min 2315(10)027150.67age age age ageage agev v new new new -=-+--=-+-=6. Consider the data set shown in Table 1, (min_sup = 40%, min_conf=75%) (a) Find all frequent itemsets using Apriori and FP-growth, respectively,bytreating each transaction ID as a market basket. Compare the efficiency of the two mining processes.(b) Use the results in part (a) to compute the confidence for the association rules {a,d}→{e} and {e}→{a, d}. Is confidence a symmetric measure?(c) List all of the strong association rules (with support s and confidence c)matching the following metarule, where X is a variable representing customers, and item i denotes variables representing items (e.g. “A”, “B”,etc.):Table 1. Example of market basket transactions.(a)⑴Apriori1.扫描数据库,对每个候选1项集计数得C12.由min_sup = 40%可知最小支持度计数为0.4*10=4,从而确定频繁1项集L1,它满足最小支持度计数的C1中的所有候选项集组成:L13.令L1与自身连接产生候选2项集的集合C2,由于C2中的候选2项集的每个子集必定是频繁的,所以不需要删除操作。