编译原理预测分析表方法实验报告
编译原理预测分析法实验报告

编译原理实验预测分析法姓名**学号**班级**完成日期**1.实验目的加深对语法分析器工作过程的理解;加强对预测分析法实现语法分析程序的掌握;能够采用一种编程语言实现简单的语法分析程序;能够使用自己编写的分析程序对简单的程序段进行语法翻译。
2.实验要求1.对语法规则有明确的定义;2.编写的分析程序能够对实验一的结果进行正确的语法分析;3. 3.对于遇到的语法错误, 能够做出简单的错误处理, 给出简单的错误提示, 保证顺利完成语法分析过程;4. 4.实验报告要求用文法的形式对语法定义做出详细说明, 说明语法分析程序的工作过程, 说明错误处理的实现。
5.实验原理对文法G进行语法分析, 文法G如下所示:*0. S→a */*1. S→.*2. S→(T)*3. T→SW **4..W→,S.*5. W→ε;6.软件设计与编程#include <stdio.h>#include <stdlib.h>#include <string.h>char str[100]; //存储待分析的句子const char T[ ] = "a^(),#"; //终结符, 分析表的列符const char NT[ ] = "STW"; //非终结符, 分析表的行符/*指向产生式右部符号串*/const char *p[] = {/*0. S→a */ "a",/*1.. S→. *. "^",/*2. S→(T) */ "(T)",/*3. T→SW */ "SW",/*4.. W→,S. */ ",SW",/*5. W→ε; */ ""};//设M[i][j]=x, 通过p[M[i][j]]=p[x]获取右部符号串。
const int M[][6] = {/* a ^ ( ) , # *//*S*/ { 0, 1, 2, -1, -1, -1 },/*T*/ { 3, 3, 3, -1, -1, -1 },/*W*/ { -1, -1,-1, 5, 4, -1 }};void init()//输入待分析的句子{printf("请输入待分析的句子(以$结束): \n");scanf("%s",str);}int lin(char c);//非终结符转换为行号int col(char c);//终结转换为列号bool isNT(char c);//isNT判断是否是非终结符bool isT(char c);//isT判断是否是终结符。
编译原理预测分析实验报告

编译原理实验报告实验题目:预测分析法学院:计算机与通信工程学院专业班级:计算机科学与技术08—2班姓名:学号:预测分析法一、实验目的二、实验要求1、通过该课程设计要学会用消除左递归的方法来使文法满足进行确定自顶向下分析的条件。
2、学会用C/C++高级程序设计语言来设计一个LL(1)分析法的语法分析器;3、通过该课程设计,加深对语法分析理论的理解,培养动手实践的能力。
三、实验代码:#include <stdio.h>#include <tchar.h>#include <string.h>int main(int argc, char* argv[]){char syn[15]; //语法栈int top; //栈顶指针char lookahead; //当前单词char exp[50]; //表达式区int m =0; //表达式指针char s[4][5]={"d","+","*","("}; //表中有空白的符号char string[3]={'E','T','F'}; //表中有同步记号的的非终结符int ll1[7][6]={{1,0,0,1,9,9}, //LL(1)分析表,9表示同步记号,第6行是#,第7行是){0,2,0,0,3,3},{4,9,0,4,9,9},{0,6,5,0,6,6},{8,9,9,7,9,9},{12,12,12,12,12,10},{13,13,13,13,11,13}};int i,j; //表行和列int code; //表项printf("************************语法分析器**********************\n");printf("请输入合法字符串:\n");scanf("%s",exp);top=1;lookahead=exp[m++];syn[0]='#';syn[1]='E';printf("***********************预测分析表*********************\n"); printf("\ti\t *\t +\t (\t )\t #\n");printf(" E\tE—>TE'\t\t\tE—>TE'\n");printf(" E'\t\t\tE'—>+TE'\t E'—>ε\n");printf(" T\tT—>FT'\t\t\tT—>FT'\t\n");printf(" T'\t\tT'—>*FT'\t\t T'—>ε\t\n");printf(" F\tF—>d\t\t\tF—>(E)\n\n");printf("调用规则顺序:\n");while(1){switch(syn[top]) //行{case 'E':i=0;break;case 'e':i=1;break;case 'T':i=2;break;case 't':i=3;break;case 'F':i=4;break;case '#':i=5;break;case ')':i=6;break;}switch(lookahead) //列{case 'd':j=0;break;case '+':j=1;break;case '*':j=2;break;case '(':j=3;break;case ')':j=4;break;case '#':j=5;break;}code=ll1[i][j];if(code==10){ printf("语法分析结束\n");// break;}else{switch(code){case 0:{// printf("出错,用户多输入了%s,跳过%s\n",s[j],s[j]);if(j==0){//lookahead=exp[m++];lookahead=exp[m++];}elselookahead=exp[m++];break;}case 1:{printf("E →TE′\n");syn[top]='e';syn[top+1]='T';top++;break;}case 2:{printf("E′→+TE`\n");syn[top+1]='T';top++;lookahead=exp[m++];break;}case 3:{printf("E′→ε\n");syn[top]='\0';top--;break;}case 4:{printf("T →FT′\n");syn[top]='t';syn[top+1]='F';top++;break;}case 5:{printf("T′→* FT′\n");syn[top+1]='F';top++;lookahead=exp[m++];break;}case 6:{printf("T′→ε\n");syn[top]='\0';top--;break;}case 7:{printf("F →(E)\n");syn[top]=')';syn[top+1]='E';top++;lookahead=exp[m++];break;}case 8:{printf("F →d\n");syn[top]='\0';top--;lookahead=exp[m++];lookahead=exp[m++];break;}case 9:{printf("弹栈,弹出非终结符%c,用户少输入了一个d\n",string[i/2]);syn[top]='\0';top--;break;}case 11:{syn[top]='\0';top--;lookahead=exp[m++];break;}case 13:{printf("弹栈,弹出终结符) ,用户少输入了一个右括号\n");syn[top]='\0';top--;break;}}}}return 0;}实验运行结果:三、总结预测分析法主要是对预测分析表的输出,关键是要理解语法内容和结构。
编译原理课程设计报告-预测分析程序的设计

1课程设计任务书学生姓名: 专业班级:指导教师: 工作单位:题目: 预测分析程序的设计初始条件:1.程序设计语言:主要使用C语言的开发工具, 或者采用LEX、YACC等工具, 也可利用其他熟悉的开发工具。
算法: 可以根据《编译原理》课程所讲授的算法进行设计。
2.要求完成的主要任务: (包括课程设计工作量及其技术要求,说明书撰写等具体要求)3.明确课程设计的目的和重要性, 认真领会课程设计的题目, 读懂课程设计指导书的要求, 学会设计的基本方法与步骤, 学会如何运用前修知识与收集、归纳相关资料解决具体问题的方法。
严格要求自己, 要独立思考, 按时、独立完成课程设计任务。
4.课设任务: 对教材P94中的上下文无关文法, 实现它的预测分析程序, 给出符号串i+i*i的分析过程。
(参考教材P93~96)5.主要功能:对于这个给的LL(1)文法, 假设所有非终结符号P的FIRST集合和FOLLOW集合都是已知的, 构造其预测分析表, 程序显示输出预测分析表, 同时用这个预测分析程序对输入串进行分析, 并给出了栈的变化过程。
进行总体设计, 详细设计:包括算法的设计和数据结构设计。
系统实施、调试, 合理使用出错处理程序。
设计报告: 要求层次清楚、整洁规范、不得相互抄袭。
正文字数不少于0.3万字。
包含内容:①课程设计的题目。
②目录。
③正文: 包括引言、需求分析、总体设计及开发工具的选择, 设计原则(给出语法分析方法及中间代码形式的描述、文法和属性文法的设计), 数据结构与模块说明(功能与流程图)、详细的算法设计、软件调试、软件的测试方法和结果、有关技术的讨论、收获与体会等。
④结束语。
⑤参考文献。
⑥附录: 软件清单(或者附盘)。
时间安排:消化资料、系统调查、形式描述1天系统分析、总体设计、实施计划3天撰写课程设计报告书1天指导教师签名: 2010年 6月 11日系主任(或责任教师)签名: 2010年6月11日目录1引言 (5)2需求分析 (6)2.1问题的提出 (6)2.2问题的解决 (6)2.3解决步骤 (6)3总体设计 (7)3.1概要设计 (7)3.1.1设计原理 (7)3.1.2构造LL(1)分析表 (8)3.2详细设计 (12)3.2.1程序流程图 (12)3.2.2设计要求 (14)3.2.3设计原理 (14)3.2.3.1FIRST(X)(X∈VN VT)的构造 (14)3.2.3.2函数getFIRST(α) (α=X1X2X3…Xn)的构造. 143.2.3.3FOLLOW(A) (A∈VN)的构造 (15)3.2.3.4分析表M【A,a】的构造 (15)3.2.3.5匹配过程的实现 (15)3.3程序设计 (16)3.3.1总体方案设计 (16)3.3.2各模块的实现 (16)4开发工具的选择 (25)5程序测试 (25)6有关技术的讨论 (27)7收获与体会 (28)8参考文献 (29)1引言一个编译程序在对某个源程序完成了词法分析工作之后, 就进入了语法分析阶段, 分析检查源程序是否语法上正确的程序, 并生成相应的内部中间表供下一阶段使用。
编译原理实验报告分析法

工业大学实验报告课程编译原理实验名称实验二LL(1)分析法实验目的1.掌握LL(1)分析法的基本原理;2.掌握LL(1)分析表的构造法;3.掌握LL(1)驱动程序的构造法。
一.实验容及要求根据某一文法编制调试LL(1)分析程序,以便对任意输入的符号串进行分析。
本次实验的目的主要是加深对预测分析LL(1)分析法的理解。
对下列文法,用LL(1)分析法对任意输入的符号串进行分析:(1)E->TG(2)G->+TG(3)G->ε(4)T->FS(5)S->*FS(6)S->ε(7)F->(E)(8)F->i程序输入一以#结束的符号串(包括+*()i#),如:i+i*i#。
输出过程如下:步骤分析栈剩余输入串所用产生式1 E i+i*i# E->TG... ... ... ...二.实验过程及结果代码如下:#include<iostream>#include "edge.h"using namespace std;edge::edge(){cin>>left>>right;rlen=right.length();if(NODE.find(left)>NODE.length())NODE+=left;}string edge::getlf(){return left;}string edge::getrg(){return right;}string edge::getfirst(){return first;}string edge::getfollow(){return follow;}string edge::getselect(){return select;}string edge::getro(){string str;str+=right[0];return str;}int edge::getrlen(){return right.length();}void edge::newfirst(string w){int i;for(i=0;i<w.length();i++)if(first.find(w[i])>first.length())first+=w[i];void edge::newfollow(string w){int i;for(i=0;i<w.length();i++)if(follow.find(w[i])>follow.length()&&w[i]!='@')follow+=w[i];}void edge::newselect(string w){int i;for(i=0;i<w.length();i++)if(select.find(w[i])>select.length()&&w[i]!='@')select+=w[i];}void edge::delfirst(){int i=first.find('@');first.erase(i,1);}int SUM;string NODE,ENODE;//计算firstvoid first(edge ni,edge *n,int x){int i,j;for(j=0;j<SUM;j++){if(ni.getlf()==n[j].getlf()){if(NODE.find(n[j].getro())<NODE.length()){for(i=0;i<SUM;i++)if(n[i].getlf()==n[j].getro())first(n[i],n,x);}elsen[x].newfirst(n[j].getro());}}//计算followvoid follow(edge ni,edge *n,int x){int i,j,k,s;string str;for(i=0;i<ni.getrlen();i++){s=NODE.find(ni.getrg()[i]);if(s<NODE.length()&&s>-1) //是非终结符if(i<ni.getrlen()-1) //不在最右for(j=0;j<SUM;j++)if(n[j].getlf().find(ni.getrg()[i])==0){if(NODE.find(ni.getrg()[i+1])<NODE.length()){for(k=0;k<SUM;k++)if(n[k].getlf().find(ni.getrg()[i+1])==0){n[j].newfollow(n[k].getfirst());if(n[k].getfirst().find("@")<n[k].getfirst().length())n[j].newfollow(ni.getfollow());}}else{str.erase();str+=ni.getrg()[i+1];n[j].newfollow(str);}}}}//计算selectvoid select(edge &ni,edge *n){int i,j;if(ENODE.find(ni.getro())<ENODE.length()){ni.newselect(ni.getro());if(ni.getro()=="@")ni.newselect(ni.getfollow());}elsefor(i=0;i<ni.getrlen();i++){for(j=0;j<SUM;j++)if(ni.getrg()[i]==n[j].getlf()[0]){ni.newselect(n[j].getfirst());if(n[j].getfirst().find('@')>n[j].getfirst().length())return;}}}//输出集合void out(string p){int i;if(p.length()==0)return;cout<<"{";for(i=0;i<p.length()-1;i++){cout<<p[i]<<",";}cout<<p[i]<<"}";}//连续输出符号void outfu(int a,string c){int i;for(i=0;i<a;i++)cout<<c;}//输出预测分析表void outgraph(edge *n,string (*yc)[50]){int i,j,k;bool flag;for(i=0;i<ENODE.length();i++){if(ENODE[i]!='@'){outfu(10," ");cout<<ENODE[i];}}outfu(10," ");cout<<"#"<<endl;int x;for(i=0;i<NODE.length();i++){outfu(4," ");cout<<NODE[i];outfu(5," ");for(k=0;k<ENODE.length();k++){flag=1;for(j=0;j<SUM;j++){if(NODE[i]==n[j].getlf()[0]){x=n[j].getselect().find(ENODE[k]);if(x<n[j].getselect().length()&&x>-1){cout<<"->"<<n[j].getrg();yc[i][k]=n[j].getrg();outfu(9-n[j].getrlen()," ");flag=0;}x=n[j].getselect().find('#');if(k==ENODE.length()-1&&x<n[j].getselect().length()&&x>-1){cout<<"->"<<n[j].getrg();yc[i][j]=n[j].getrg();}}}if(flag&&ENODE[k]!='@')outfu(11," ");}cout<<endl;}}//分析符号串int pipei(string &chuan,string &fenxi,string (*yc)[50],int &b) {char ch,a;int x,i,j,k;b++;cout<<endl<<" "<<b;if(b>9)outfu(8," ");elseoutfu(9," ");cout<<fenxi;outfu(26-chuan.length()-fenxi.length()," ");cout<<chuan;outfu(10," ");a=chuan[0];ch=fenxi[fenxi.length()-1];x=ENODE.find(ch);if(x<ENODE.length()&&x>-1){if(ch==a){fenxi.erase(fenxi.length()-1,1);chuan.erase(0,1);cout<<"'"<<a<<"'匹配";if(pipei(chuan,fenxi,yc,b))return 1;elsereturn 0;}elsereturn 0;}else{if(ch=='#'){if(ch==a){cout<<"分析成功"<<endl;return 1;}elsereturn 0;}elseif(ch=='@'){fenxi.erase(fenxi.length()-1,1);if(pipei(chuan,fenxi,yc,b))return 1;elsereturn 0;}else{i=NODE.find(ch);if(a=='#'){x=ENODE.find('@');if(x<ENODE.length()&&x>-1)j=ENODE.length()-1;elsej=ENODE.length();}elsej=ENODE.find(a);if(yc[i][j].length()){cout<<NODE[i]<<"->"<<yc[i][j];fenxi.erase(fenxi.length()-1,1);for(k=yc[i][j].length()-1;k>-1;k--)if(yc[i][j][k]!='@')fenxi+=yc[i][j][k];if(pipei(chuan,fenxi,yc,b))return 1;elsereturn 0;}elsereturn 0;}}}void main(){edge *n;string str,(*yc)[50];int i,j,k;bool flag=0;cout<<"请输入上下文无关文法的总规则数:"<<endl;cin>>SUM;cout<<"请输入具体规则(格式:左部右部,@为空):"<<endl;n=new edge[SUM];for(i=0;i<SUM;i++)for(j=0;j<n[i].getrlen();j++){str=n[i].getrg();if(NODE.find(str[j])>NODE.length()&&ENODE.find(str[j])>ENODE.length()) ENODE+=str[j];}//计算first集合for(i=0;i<SUM;i++){first(n[i],n,i);}//outfu(10,"~*~");cout<<endl;for(i=0;i<SUM;i++)if(n[i].getfirst().find("@")<n[i].getfirst().length()){if(NODE.find(n[i].getro())<NODE.length()){for(k=1;k<n[i].getrlen();k++){if(NODE.find(n[i].getrg()[k])<NODE.length()){for(j=0;j<SUM;j++){if(n[i].getrg()[k]==n[j].getlf()[0]){n[i].newfirst(n[j].getfirst());break;}}if(n[j].getfirst().find("@")>n[j].getfirst().length()){n[i].delfirst();break;}}}}}//计算follow集合for(k=0;k<SUM;k++){for(i=0;i<SUM;i++){if(n[i].getlf()==n[0].getlf())n[i].newfollow("#");follow(n[i],n,i);}for(i=0;i<SUM;i++){for(j=0;j<SUM;j++)if(n[j].getrg().find(n[i].getlf())==n[j].getrlen()-1)n[i].newfollow(n[j].getfollow());}}//计算select集合for(i=0;i<SUM;i++){select(n[i],n);}for(i=0;i<NODE.length();i++){str.erase();for(j=0;j<SUM;j++)if(n[j].getlf()[0]==NODE[i]){if(!str.length())str=n[j].getselect();else{for(k=0;k<n[j].getselect().length();k++)if(str.find(n[j].getselect()[k])<str.length()){flag=1;break;}}}}//输出cout<<endl<<"非终结符";outfu(SUM," ");cout<<"First";outfu(SUM," ");cout<<"Follow"<<endl;outfu(5+SUM,"-*-");cout<<endl;for(i=0;i<NODE.length();i++){for(j=0;j<SUM;j++)if(NODE[i]==n[j].getlf()[0]){outfu(3," ");cout<<NODE[i];outfu(SUM+4," ");out(n[j].getfirst());outfu(SUM+4-2*n[j].getfirst().length()," ");out(n[j].getfollow());cout<<endl;break;}}outfu(5+SUM,"-*-");cout<<endl<<"判定结论:";if(flag){cout<<"该文法不是LL(1)文法!"<<endl;return;}else{cout<<"该文法是LL(1)文法!"<<endl;}//输出预测分析表cout<<endl<<"预测分析表如下:"<<endl;yc=new string[NODE.length()][50];outgraph(n,yc);string chuan,fenxi,fchuan;cout<<endl<<"请输入符号串:";cin>>chuan;fchuan=chuan;fenxi="#";fenxi+=NODE[0];i=0;cout<<endl<<"预测分析过程如下:"<<endl;cout<<"步骤";outfu(7," ");cout<<"分析栈";outfu(10," ");cout<<"剩余输入串";outfu(8," ");cout<<"推导所用产生式或匹配";if(pipei(chuan,fenxi,yc,i))cout<<endl<<"输入串"<<fchuan<<"是该文法的句子!"<<endl;elsecout<<endl<<"输入串"<<fchuan<<"不是该文法的句子!"<<endl;}截屏如下:三.实验中的问题及心得这次实验让我更加熟悉了LL(1)的工作流程以及LL(1)分析表的构造法。
实验 编译原理预测分析表方法试验报告

实验7-8 预测分析表方法一、实验目的理解预测分析表方法的实现原理。
二、实验内容:编写一通用的预测法分析程序,要求有一定的错误处理能力,出错后能够使程序继续运行下去,直到分析过程结束。
可通过不同的文法(通过数据表现)进行测试。
三.实验要求:给定算术表达式文法,编写程序,测试数据。
算术表达式文法E→TE’E’→ +TE’|- TE’|εT→FT’T’→*FT’ |/ FT’ |%FT’|εF→(E) |id|num四.实验过程:1.实验代码:import java.io.*;import javax.swing.JOptionPane;public class predict {int length_vn=5,length_vt=10;static int i,j,i1=0,e_flag=0;public predict() {}static String VN[]={"E","e","T","t","F"};static String VT[]={"+","-","*","/","%","(",")","d","n","#";static String CS[]={"Te","+Te","-Te","$","Ft","*Ft","/Ft"," %Ft","","(E)","d","n"};static String follow[][]={{"#",")"},{"#",")"},{"#",")","+","-"},{"#",")","+","-"},{"#",")","+","-","*","/","% "}};static int analysis_table[][]={{-1,-1,-1,-1,-1,0,-1,0,0,-1} ,{1,2,-1,-1,-1,-1,3,-1,-1,3},{-1,-1,-1,-1,-1,4,-1, 4,4,-1},{8,8,5,6,7,-1,8,-1,-1,8},{-1,-1,-1,-1,-1, 9,-1,10,11,-1}};public void locate(String vn,String vt){for(int a=0;a<5;a++){if(VN[a].equals(vn)){i=a;break;}else i=-1;}for(int b=0;b<10;b++){if(VT[b].equals(vt)){j=b;break;}else j=-1;}}public void equal(int vn,int vt){String cs="";if(analysis_table[vn][vt]==-1) {int a;for(a=0;a<follow[vn].length;a++){if(follow[vn][a].equals(VT[vt]))break;}if(a<follow[vn].length)error1();else error2(vt);}else {cs=CS[analysis_table[vn][vt]];int cs_length=cs.length();char achar[]=new char[cs_length];char bchar[]=new char[cs_length];cs.getChars(0,cs_length,achar,0);for(inta=0,b=cs_length-1;a<cs_length;a++,b--){bchar[b]=achar[a];}String newstr=new String(bchar);in_Stack(newstr);}}public void error1(){System.out.println("出错,弹出栈顶符号");}public void error2(int vt){System.out.println("出错,跳过"+VT[vt]);in_Stack(VN[i]);i1++;}public void error3(String str){System.out.println("错误,不匹配终结符"+str);i1++;}public void in_Stack(String str){try{FileWriter fw = new FileWriter("test.txt", true);PrintWriter pw=new PrintWriter(fw);pw.write(str);pw.close();fw.close();}catch(IOException ef){}}public String out_Stack(){String c="";try{Reader du=new FileReader("test.txt"); BufferedReader br = new BufferedReader(du);c=br.readLine();br.close();du.close();File f1=new File("test.txt");f1.delete();}catch(IOException eio){}c=c.trim();Stringsub_str=c.substring(0,c.length()-1);in_Stack(sub_str);Stringzhand=c.substring(c.length()-1,c.length());return zhand;}public static void main(String args[]){File f=new File("test.txt");f.delete();predict pd=new predict();String fenxi;Stringinput=JOptionPane.showInputDialog("请输入算术表达式:");input=input.trim();char gchar[]=new char[1];pd.in_Stack("#E");fenxi="E";while(i1<input.length()){int a,b,c;fenxi=pd.out_Stack();System.out.println("------------------------------------------------");System.out.print("栈顶元素:"+fenxi+'\t');input.getChars(i1,i1+1,gchar,0);String vt=new String(gchar);vt=vt.trim();System.out.print("当前单词记号:"+vt+ "\t");for(c=0;c<10;c++){if(VT[c].equals(fenxi))break;}for(a=0;a<5;a++){if(VN[a].equals(fenxi)){System.out.print("展开非终结符"+fenxi+"->");for(b=0;b<10;b++){if(VT[b].equals(vt)&&analysis_table[a][ b]!=-1){System.out.print(CS[analysis_table[a][b] ]+"\n");break;}}}}if(c<10&&!fenxi.equals(vt)) pd.error3(fenxi);if(fenxi.equals(vt)){System.out.println("匹配终结符"+fenxi+'\t');i1++;}else {pd.locate(fenxi,vt);pd.equal(i,j);}}System.out.println("结束");}}2.试验测试:给定一符合该文法的句子,如d+n/d,运行预测分析程序,给出分析过程和每一步的分析结果,输出形式如下图:给定一不符合该文法的句子,如dd**n,运行预测分析程序,给出分析和每一步的分析过程,并给出对错误的处理分析过程,输出形式如下图:四、实验总结:1.本次通过试验,我学会了预测分析表的构造方法,即给文法的正规式编号:存放在字符数组中,从0开始编号,正规式的编号即为该正规式在数组中对应的下标。
编译原理非递归预测分析实验报告

编译原理非递归预测分析实验报告一、实验目的本次实验旨在深入理解编译原理中的非递归预测分析方法,通过实际编程实现,掌握其基本原理和应用技巧,提高对编译过程中语法分析阶段的认识和实践能力。
二、实验原理非递归预测分析是一种基于预测分析表的自顶向下语法分析方法。
它通过预测下一个可能的输入符号,并根据语法规则进行相应的处理,从而逐步完成对输入字符串的语法分析。
预测分析表是该方法的核心,它是根据给定的语法规则生成的。
表中的行表示非终结符,列表示终结符或输入符号。
每个表项中存储着相应的分析动作,如匹配、移进、归约等。
在分析过程中,使用一个分析栈来存储当前的语法符号。
从起始符号开始,根据预测分析表和输入符号,不断进行栈操作和符号匹配,直到输入字符串完全被分析或发现语法错误。
三、实验环境本次实验使用的编程语言为_____,开发工具为_____。
四、实验内容1、定义语法规则确定所分析的语法的非终结符和终结符。
以 BNF(巴科斯瑙尔范式)或类似的形式描述语法规则。
2、构建预测分析表根据语法规则,通过计算 First 集和 Follow 集,生成预测分析表。
3、实现分析算法设计非递归的预测分析函数,实现对输入字符串的分析。
在函数中,根据分析栈、预测分析表和输入符号进行相应的操作。
4、处理语法错误设计错误处理机制,能够在发现语法错误时给出相应的提示信息。
五、实验步骤1、分析语法规则仔细研究给定的语法,明确各个语法成分之间的关系。
例如,对于一个简单的算术表达式语法:```E > E + T | TT > T F | FF >( E )| id```其中,E、T、F 是非终结符,+、、(、)、id 是终结符。
2、计算 First 集和 Follow 集First 集:First(X) 表示可以从非终结符 X 推导出来的开头终结符的集合。
例如,First(E) ={(, id },First(T) ={(, id },First(F)={(, id }。
编译原理语法分析器实验报告

编译原理语法分析器实验报告西安邮电大学编译原理实验报告学院名称:计算机学院****:***实验名称:语法分析器的设计与实现班级:计科1405班学号:04141152时间:2017年5月12日把SELECT (i)存放到temp中结果返回1;1.构建好的预测分析表2.语法分析流程图一.实验结果正确运行结果:错误运行结果:二.设计技巧和心得体会这次实验编写了一个语法分析方法的程序,但是在LL(1)分析器的编写中我只达到了最低要求,就是自己手动输入的select集,first集,follow集然后通过程序将预测分析表构造出来,然后自己编写总控程序根据分析表进行分析。
通过本次试验,我能够设计一个简单的语法分析程序,实现对词法分析程序所提供的单词序列进行语法检查和结构分析,进一步掌握常用的语法分析方法。
还能选择最有代表性的语法分析方法,如LL(1) 语法分析程序、算符优先分析程序和LR分析分析程序。
三.源代码package com.LL1;import java.util.ArrayDeque;import java.util.Deque;/*** LL1文法分析器,已经构建好预测分析表,采用Deque实现* Created by HongWeiPC on 2017/5/12.*/public class LL1_Deque {//预测分析表private String[][] analysisTable = new String[][]{{"TE'", "", "", "TE'", "", ""},{"", "+TE'", "", "", "ε", "ε"},{"FT'", "", "", "FT'", "", ""},{"", "ε", "*FT'", "", "ε", "ε"},{"i", "", "", "(E)", "", ""}};//终结符private String[] VT = new String[]{"i", "+", "*", "(", ")", "#"};//非终结符private String[] VN = new String[]{"E", "E'", "T", "T'", "F"};//输入串strTokenprivate StringBuilder strToken = new StringBuilder("i*i+i");//分析栈stackprivate Deque<String> stack = new ArrayDeque<>();//shuru1保存从输入串中读取的一个输入符号,当前符号private String shuru1 = null;//X中保存stack栈顶符号private String X = null;//flag标志预测分析是否成功private boolean flag = true;//记录输入串中当前字符的位置private int cur = 0;//记录步数private int count = 0;public static void main(String[] args) {LL1_Deque ll1 = new LL1_Deque();ll1.init();ll1.totalControlProgram();ll1.printf();}//初始化private void init() {strToken.append("#");stack.push("#");System.out.printf("%-8s %-18s %-17s %s\n", "步骤", "符号栈", "输入串", "所用产生式");stack.push("E");curCharacter();System.out.printf("%-10d %-20s %-20s\n", count, stack.toString(), strToken.substring(cur, strToken.length()));}//读取当前栈顶符号private void stackPeek() {X = stack.peekFirst();}//返回输入串中当前位置的字母private String curCharacter() {shuru1 = String.valueOf(strToken.charAt(cur));return shuru1;}//判断X是否是终结符private boolean XisVT() {for (int i = 0; i < (VT.length - 1); i++) {if (VT[i].equals(X)) {return true;}}return false;}//查找X在非终结符中分析表中的横坐标private String VNTI() {int Ni = 0, Tj = 0;for (int i = 0; i < VN.length; i++) {if (VN[i].equals(X)) {Ni = i;}}for (int j = 0; j < VT.length; j++) {if (VT[j].equals(shuru1)) {Tj = j;}}return analysisTable[Ni][Tj];}//判断M[A,a]={X->X1X2...Xk}//把X1X2...Xk推进栈//X1X2...Xk=ε,不推什么进栈private boolean productionType() {return VNTI() != "";}//推进stack栈private void pushStack() {stack.pop();String M = VNTI();String ch;//处理TE' FT' *FT'特殊情况switch (M) {case "TE'":stack.push("E'");stack.push("T");break;case "FT'":stack.push("T'");stack.push("F");break;case "*FT'":stack.push("T'");stack.push("F");stack.push("*");break;case "+TE'":stack.push("E'");stack.push("T");stack.push("+");break;default:for (int i = (M.length() - 1); i >= 0; i--) {ch = String.valueOf(M.charAt(i));stack.push(ch);}break;}System.out.printf("%-10d %-20s %-20s %s->%s\n", (++count), stack.toString(), strToken.substring(cur, strToken.length()), X, M);}//总控程序private void totalControlProgram() {while (flag) {stackPeek(); //读取当前栈顶符号令X=栈顶符号if (XisVT()) {if (X.equals(shuru1)) {cur++;shuru1 = curCharacter();stack.pop();System.out.printf("%-10d %-20s %-20s \n", (++count), stack.toString(), strToken.substring(cur, strToken.length()));} else {ERROR();}} else if (X.equals("#")) {if (X.equals(shuru1)) {flag = false;} else {ERROR();}} else if (productionType()) {if (VNTI().equals("")) {ERROR();} else if (VNTI().equals("ε")) {stack.pop();System.out.printf("%-10d %-20s %-20s %s->%s\n", (++count), stack.toString(), strToken.substring(cur, strToken.length()), X, VNTI());} else {pushStack();}} else {ERROR();}}}//出现错误private void ERROR() {System.out.println("输入串出现错误,无法进行分析");System.exit(0);}//打印存储分析表private void printf() {if (!flag) {System.out.println("****分析成功啦!****");} else {System.out.println("****分析失败了****");}}}。
预测分析法(编译原理)
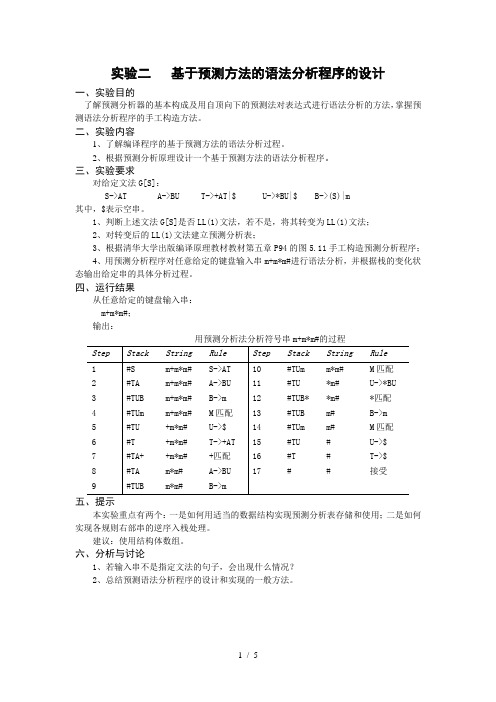
实验二基于预测方法的语法分析程序的设计一、实验目的了解预测分析器的基本构成及用自顶向下的预测法对表达式进行语法分析的方法,掌握预测语法分析程序的手工构造方法。
二、实验内容1、了解编译程序的基于预测方法的语法分析过程。
2、根据预测分析原理设计一个基于预测方法的语法分析程序。
三、实验要求对给定文法G[S]:S->AT A->BU T->+AT|$ U->*BU|$ B->(S)|m其中,$表示空串。
1、判断上述文法G[S]是否LL(1)文法,若不是,将其转变为LL(1)文法;2、对转变后的LL(1)文法建立预测分析表;3、根据清华大学出版编译原理教材教材第五章P94的图5.11手工构造预测分析程序;4、用预测分析程序对任意给定的键盘输入串m+m*m#进行语法分析,并根据栈的变化状态输出给定串的具体分析过程。
四、运行结果从任意给定的键盘输入串:m+m*m#;输出:本实验重点有两个:一是如何用适当的数据结构实现预测分析表存储和使用;二是如何实现各规则右部串的逆序入栈处理。
建议:使用结构体数组。
六、分析与讨论1、若输入串不是指定文法的句子,会出现什么情况?2、总结预测语法分析程序的设计和实现的一般方法。
代码:#include<stdio.h>#include<stdlib.h>#include<string.h>#include<windows.h>struct stack1{char stack[10];}sta[][7]={"\0","+","*","(",")","m","#","S","\0","\0","AT","\0","AT","\0","A","\0","\0","BU","\0","BU","\0","T","+AT","\0","\0","$","\0","$","B","\0","\0","(S)","\0","m","\0","U","$","*BU","\0","$","\0","$"};//struct stack *head;char stack_1[10]={'\0'},stack_2[10]={'\0'},stack_3[10]={'\0'}; int i,j,k,len_1,len_2,len_3,mark=0;void main(){// void c_stack();void analyze_stack();void surplus_str();int rules();// printf("%s\t",sta[0][1].stack);// printf("\n");while(1){// system("cls");mark=0;printf("请输入串:\n");gets(stack_3);if(stack_3[0]=='0')break;stack_1[0]='S';len_3=strlen(stack_3);if(stack_3[len_3-1]!='#'){printf("字符串输入错误,字符串不以#号结束!\n");continue;}printf("分析栈\t\t剩余串\t\t\t\t\t\t规则\n");for(i=0;i<=100;i++){analyze_stack();surplus_str();rules();if(mark==1)break;if(stack_1[0]=='\0'&&stack_3[0]=='#'){printf("#\t\t#\t\t\t\t\t\t成功接受\n");break;}}}}void analyze_stack()//分析栈{printf("#%-15s",stack_1);len_1=strlen(stack_1);}void surplus_str()//剩余串//注意拼写的正确性,写成surlpus_str()报错,unresolved sxternal symbol_surplus_str;{printf("%-48s",stack_3);}int rules()//所用规则{int p,q,h;char temp;// printf("%d",len_1);if(stack_1[len_1-1]==stack_3[0]){printf("%c匹配\n",stack_3[0]);stack_1[len_1-1]='\0';for(h=1;h<=len_3-1;h++)stack_3[h-1]=stack_3[h];stack_3[len_3-1]='\0';}else if(stack_1[len_1-1]<'A'||stack_1[len_1-1]>'Z') {printf("报错\n");mark=1;return 0;}else if(stack_1[len_1-1]>='A'&&stack_1[len_1-1]<='Z') {for(j=1;j<=5;j++){if(stack_1[len_1-1]==sta[j][0].stack[0]){p=j;break;}}if(j>=6){printf("报错\n");mark=1;return 0;}for(k=1;k<=6;k++){if(stack_3[0]==sta[0][k].stack[0]){q=k;break;}}if(k>=7){printf("报错\n");mark=1;return 0;}if(sta[p][q].stack[0]=='\0'){printf("报错\n");mark=1;return 0;}strcpy(stack_2,sta[p][q].stack);len_2=strlen(stack_2);printf("%c->%s\n",stack_1[len_1-1],stack_2); stack_1[len_1-1]='\0';if(stack_2[0]=='$'){}else{for(h=0;h<len_2/2;h++){temp=stack_2[h];stack_2[h]=stack_2[len_2-1-h];stack_2[len_2-1-h]=temp;}strcat(stack_1,stack_2);}}return 0;}。
编译原理非递归预测分析实验报告

编译原理非递归预测分析实验报告一、实验目的本次实验的主要目的是深入理解编译原理中的非递归预测分析方法,并通过实际编程实现,掌握其在语法分析中的应用。
二、实验环境操作系统:Windows 10编程语言:Python开发工具:PyCharm三、实验原理非递归预测分析是一种自顶向下的语法分析方法,它基于 LL(1) 文法。
LL(1) 文法要求对于每个非终结符,其产生式的各个候选式所能推出的首终结符集互不相交,并且对于每个产生式,能够准确预测出在当前输入符号下应该选择哪个候选式进行推导。
非递归预测分析通过构建预测分析表来指导分析过程。
预测分析表的行表示非终结符,列表示输入符号,表中的元素则是相应的产生式或者“出错”信息。
在分析过程中,使用一个分析栈来存储待处理的符号。
从输入字符串的第一个符号开始,根据预测分析表和分析栈的状态进行推导,直到输入字符串被完全匹配或者发现语法错误。
四、实验内容1、定义文法首先,我们需要定义一个给定的文法。
以下是一个简单的算术表达式文法示例:```E > E + T | TT > T F | FF >( E )| id```2、计算 FIRST 集和 FOLLOW 集为了构建预测分析表,需要计算文法中每个非终结符的 FIRST 集和FOLLOW 集。
FIRST 集:FIRST(X) 表示可以从非终结符 X 推导出来的串的首终结符集合。
FOLLOW 集:FOLLOW(X) 表示在文法的某个句型中,紧跟在非终结符 X 后面的终结符集合。
以上述文法为例,计算得到的 FIRST 集和 FOLLOW 集如下:FIRST(E) ={(, id}FIRST(T) ={(, id}FIRST(F) ={(, id}FOLLOW(E) ={$,)}FOLLOW(T) ={+,$,)}FOLLOW(F) ={,+,$,)}3、构建预测分析表根据计算得到的 FIRST 集和 FOLLOW 集,构建预测分析表。
语法分析_预测分析法_实验报告

}
else if ( IsSymbolEnd(StackGet()) )
{
//栈顶为开始符
ProcessEnd();
}
else
{
//栈顶为非终结符
ProcessN();
}
}
void ProcessEnd()
{
if (StackGet() != ComingToken())
{
//非正常结尾
}
}
/*
*
*将产生式反向入栈
**/
void StackPushProfom(int buf[], int length)
{
int i;
_ASSERT(length > 0);
for (i = length - 1; i >= 0; i--)
{
StackPush(buf[i]);
}
}
/**
*由当前栈顶符及当前输入符取得产生式
}
}
void ProcessT()
{
if (StackGet() == ComingToken())
{
//match success, pop stack
StackPop();
//get next token
NextToken();
}
else
{
Leave(ANA_ERROR_UNEXPECTED_VALUE);
SELECT(F→( E )) SELECT(F→i)
= { ( } { i }
=
因而改写后的文法为LL(1)文法,可使用预测分析法自顶向下分析。
3)预测分析表
对每个表达式求其SELECT集。
编译原理预测分析法C语言的实验报告

题目:编写识别由下列文法所定义的表达式的预测分析程序。
E→E+T | E-T | TT→T*F | T/F |FF→(E) | i输入:每行含一个表达式的文本文件。
输出:分析成功或不成功信息。
(题目来源:编译原理实验(三)--预测(LL(1))分析法的实现)解答:(1)分析a) ∵E=>E+T=>E+T*F=>E+T*(E)即有E=>E+T*(E)存在左递归。
用直接改写法消除左递归,得到如下:E →TE’ E’ →+TE’ | −TE’|εT →FT’ T’ →*FT’ | /FT’|εF → (E) | i对于以上改进的方法。
可得:对于E’:FIRST( E’ )=FIRST(+TE’)∪FIRST(-TE’)∪{ε}={+,−,ε}对于T’:FIRST( T’ )=FIRST(*FT’)∪FIRST(/FT’)∪{ε}={*,∕,ε} 而且:FIRST( E ) = FIRST( T ) = FIRST( F )=FIRST((E))∪FIRST(i)={(,i }由此我们容易得出各非终结符的FOLLOW集合如下:FOLLOW( E )= { ),#}FOLLOW(E’)= FOLLOW(E)={ ),#}FOLLOW( T )= FIRST(E’)\ε∪FOLLOW(E’)={+,−,),#}FOLLOW( T’ ) = FOLLOW( T ) ={+,−,),#}FOLLOW( F )=FIRST(T’)\ε∪FOLLOW(T’)={*,∕,+,−,),#}由以上FOLLOW集可以我们可以得出SELECT集如下:对E SELECT(E→TE’)=FIRST(TE’)=FIRST(T)={ (,i }对E’ SELECT(E’ →+TE’)={ + }SELECT(E’ →−TE’)={ − }SELECT(E’ →ε)={ε,),#}对T SELECT(T→FT’)={(,i}对T’ SELECT(T’ →*FT’)={ * }SELECT(T’ →∕FT’)={ ∕ }SELECT(T’ →ε)={ε,+,−,),#}对F SELECT(F→(E) )={ ( }SELECT(F→i)={ i }∴SELECT(E’ →+TE’)∩SELECT(E’ →−TE’)∩SELECT(E’ →ε)=ΦSELECT(T’ →*FT’)∩SELECT(T’ →∕FT’)∩SELECT(T’ →ε)=ΦSELECT(F→(E) )∩SELECT(F→i)= Φ由上可知,有相同左部产生式的SELECT集合的交集为空,所以文法是LL(1)文法。
编译原理实验二 预测分析法

实验二预测分析法一、实验项目名称预测分析法二、实验目的根据某一LL(1)文法编制调试预测分析程序,以便对任意输入的符号串进行分析。
本次实验的目的主要是加深对预测分析法的理解。
三、实验环境Win8系统,VC++6.0软件,C语言开发工具四、实验内容本次实验的LL(1)文法为表达式文法:E→E+T | TT→T*F | FF→i | (E)编写识别表达式文法的合法句子的预测分析程序,对输入的任意符号串,给出分析过程及分析结果。
分析过程要求输出步骤、分析栈、剩余输入串和所用产生式。
如果该符号串不是表达式文法的合法句子,要给出尽量详细的错误提示。
五、实验步骤首先将终结符和非终结符以及预测分析表计算出来,并保存到数组中然后对输入的字符进行分析,将一个个终结符进行分配在分配的过程中输出每一步步骤对错误处,显示步骤数和错误字符六、源程序清单、测试数据、结果源程序:#include<iostream.h>#include<stdio.h>#include<string>using namespace std;char zhong[6]={'i','+','*','(',')','#'};char fzhong[5]={'E','R','T','Y','F'};char shu[20];1//R代表E' Y代表T'string biao[5][6]={{"TR","","","TR","",""},{"","+TR","","","@","@"}, //@代表空{"FY","","","FY","",""},{"","@","*FY","","@","@"},{"i","","","(E)","",""}};#define N 20;typedef char type;typedef struct{type *base;type *top;int stacksize;}sqstack;void initstack(sqstack &s){s.base=new type[2];if(!s.base)cout<<"错误";s.top=s.base;s.stacksize=N;}void push(sqstack &s,type e){if(s.top-s.base==s.stacksize)cout<<"栈满";*s.top++=e;}void pop(sqstack &s,type &e){if(s.top==s.base)cout<<"栈空";e=*--s.top;}type gettop(sqstack s){if(s.top==s.base)cout<<"栈空";return *(s.top-1);}int find1(char x){for(int i=0;i<5;i++){if(x==fzhong[i]){break;}}return i;}int find2(char x){for(int i=0;i<6;i++){if(x==zhong[i]){break;}}return i;}void showstack(sqstack fen){char a;sqstack x;initstack(x);while(fen.top!=fen.base){pop(fen,a);push(x,a);}3while(x.top!=x.base){pop(x,a);cout<<a;}}void fenxi(sqstack &fen){string str;int i=0,row=1,j;char ch1,ch2;// ch1=gettop(fen);while(1){if(gettop(fen)==shu[i]&&gettop(fen)!='#'){cout<<endl<<row++<<" ";showstack(fen);j=i;cout<<" ";while(shu[j]!='#'){cout<<shu[j];j++;}cout<<"# "<<shu[i]<<"被分配"<<endl;i++;pop(fen,ch2);}else if(gettop(fen)=='#'){cout<<row<<" # # 被接受";break;}else{str=biao[find1(gettop(fen))][find2(shu[i])];if(biao[find1(gettop(fen))][find2(shu[i])]==""){cout<<"第"<<row<<"行出现错误"<<gettop(fen)<<"与"<<shu[i]<<"无对应的关系"<<endl;break;}else if(biao[find1(gettop(fen))][find2(shu[i])]=="@"){cout<<row<<" ";showstack(fen);j=i;cout<<" ";while(shu[j]!='#'){cout<<shu[j];j++;}cout<<"# "<<gettop(fen)<<"->";for(j=0;j<str.length();j++){ cout<<str.at(j);}cout<<endl;row++;pop(fen,ch2);j=0;}else{cout<<row<<" ";showstack(fen);j=i;cout<<" ";while(shu[j]!='#'){cout<<shu[j];j++;}cout<<"# "<<gettop(fen)<<"->";5for(j=0;j<str.length();j++){ cout<<str.at(j);}row++;pop(fen,ch2);j=str.length()-1;while(j>=0){push(fen,str.at(j));j--;}cout<<endl;}}}}void main(){cout<<"这里是预测分析法程序测试!!!"<<endl;cout<<"请输入一串仅含i,+,*,(,)的字符串,并以#结束"<<endl;char a;sqstack fen;int i=0;while(a!='#'){cin>>a;shu[i]=a;i++;}cout<<"对输入串:"<<shu<<"的分析过程"<<endl;initstack(fen);push(fen,'#');push(fen,'E');fenxi(fen);}运行结果截图:测试一:测试二:7测试三:(错误测试)七、实验小结和思考预测分析法相对于RL法简单很多,而且预测分析表已经得到。
编译原理预测分析程序的实现

实验二预测分析表一、实验目的预测分析表的实现二、实验内容设有文法G:E→TE’E’→+TE’|εT→FT’T’→*FT’|εF→(E)|i;根据文法编写预测表分析总控程序,分析句子是否为该文法的句型。
当输入字符串:+i时,分析字符串是否为文法的句型三、实验步骤(详细的实验步骤)(1)文法E→TE’E’→+TE’|εT→FT’T’→*FT’|εF→(E)|i;(2)FIRST集FIRST(E)={(,i};FIRST(E’)={+, ε};FIRST(T)={(,i};FIRST(T’)={ *, ε};FIRST(F)={(,i};(3)FALLOW集FOLLOW(E)={),#};FOLLOW(E’)={),#};FOLLOW(T)={+,),#};FOLLOW(T’)={+,),#};FOLLOW(F)={*,+,),#};(4)预测分析表(5)分析过程步骤符号栈输入串应用句型0#E i1*i2+i3#1#E’T i1*i2+i3#E->TE’2#E’T’F i1*i2+i3#E->TE’3#E’T’i i1*i2+i3#F->i4# E’T’i1*i2+i3#5# E’T’F**i2+i3#T’->*FT’6# E’T’F*i2+i3#7# E’T’i i2+i3#F->i8# E’T’i2+i3#9#E’+i3#T’->ε10# E’T++i3#E’->+TE’11#E’T+i3#12# E’T’F i3#T->FT’13# E’T’i i3#F->i14# E’T’i3#15# E’#T’->ε16# #E’->ε(6)程序伪代码BEGIN首先把‘#’然后把文法开始符号推进STACK栈;把第一个输入符号读进a;FLAG:=TRUE;WHILE FLAG DOBEGIN把STACK栈顶符号托出去并放在X中;IF X属于VT THENIF X=a THEN 把下一输入符号读进a;ELSE ERROR;ELSE IF X=’#’ THENIF X=a THEN FLAG:=FALSE ELSE ERROR;ELSE IF M[A,a]={X->X1X2…Xk} THEN把Xk,X(k-1),…,X1一一推进栈ELSE ERROR;END OF WHILESTOPEND(7)运行结果截图注:为了将E和E’区分开,所以就有e来表示E’,因为在处理中E’会被当成两个字符来处理,所以就简化的表示了。
编译原理LL(1)分析实验报告

青岛科技大学LL(1)分析编译原理实验报告学生班级__________________________学生学号__________________________学生姓名________________________________年 ___月 ___日一、实验目的LL(1)分析法的基本思想是:自项向下分析时从左向右扫描输入串,分析过程中将采用最左推导,并且只需向右看一个符号就可决定如何推导。
通过对给定的文法构造预测分析表和实现某个符号串的分析,掌握LL(1)分析法的基本思想和实现过程。
二、实验要求设计一个给定的LL(1)分析表,输入一个句子,能根据LL(1)分析表输出与句子相应的语法数。
能对语法数生成过程进行模拟。
三、实验内容(1)给定表达式文法为:G(E’): E’→#E# E→E+T | T T→T*F |F F→(E)|i(2)分析的句子为:(i+i)*i四、模块流程五、程序代码#include<iostream>#include<stdio.h>#include <string>#include <stack>using namespace std;char Vt[]={'i','+','*','(',')','#'}; /*终结符*/char Vn[]={'E','e','T','t','F'}; /*非终结符*/ int LENVt=sizeof(Vt);void showstack(stack <char> st) //从栈底开始显示栈中的内容{int i,j;char ch[100];j=st.size();for(i=0;i<j;i++){ch[i]=st.top();st.pop();}for(i=j-1;i>=0;i--){cout<<ch[i];st.push(ch[i]);}}int find(char c,char array[],int n) //查找函数,返回布尔值{int i;int flag=0;for(i=0;i<n;i++){if(c==array[i])flag=1;}return flag;}int location(char c,char array[]) //定位函数,指出字符所在位置,即将字母转换为数组下标值{int i;for(i=0;c!=array[i];i++);return i;}void error(){cout<<" 出错!"<<endl;}void analyse(char Vn[],char Vt[],string M[5][6],string str){int i,j,p,q,h,flag=1;char a,X;stack <char> st; //定义堆栈st.push('#');st.push(Vn[0]); //#与识别符号入栈j=0; //j指向输入串的指针h=1;a=str[j];cout<<"步骤"<<"分析栈"<<"剩余输入串"<<" 所用产生式"<<endl;while(flag==1){cout<<h<<" "; //显示步骤h++;showstack(st); //显示分析栈中内容cout<<" ";for(i=j;i<str.size();i++) cout<<str[i]; //显示剩余字符串X=st.top(); //取栈顶符号放入X if(find(X,Vt,LENVt)==1) //X是终结符if(X==a) //分析栈的栈顶元素和剩余输入串的第一个元素相比较if (X!='#'){cout<<" "<<X<<"匹配"<<endl;st.pop();a=str[++j]; //读入输入串的下一字符}else{ cout<<" "<<"acc!"<<endl<<endl; flag=0;}else{error();break;}else{p=location(X,Vn); //实现下标的转换(非终结符转换为行下标)q=location(a,Vt); //实现下标的转换(终结符转换为列下标)string S1("NULL"),S2("null");if(M[p][q]==S1 || M[p][q]==S2) //查找二维数组中的产生式{error();break;} //对应项为空,则出错else{string str0=M[p][q];cout<<" "<<X<<"-->"<<str0<<endl; //显示对应的产生式st.pop();if(str0!="$") //$代表"空"字符for(i=str0.size()-1;i>=0;i--) st.push(str0[i]);//产生式右端逆序进栈}}}}main(){string M[5][6]={"Te" ,"NULL","NULL","Te", "NULL","NULL","NULL","+Te" ,"NULL","NULL","$", "$","Ft", "NULL","NULL","Ft", "NULL","NULL","NULL","$", "*Ft", "NULL","$", "$","i", "NULL","NULL","(E)", "NULL","NULL"}; //预测分析表j string str;int errflag,i;cout<<"文法:E->E+T|T T->T*F|F F->(E)|i"<<endl;cout<<"请输入分析串(以#结束):"<<endl;do{ errflag=0;cin>>str;for(i=0;i<str.size();i++)if(!find(str[i],Vt,LENVt)){ cout<<"输入串中包含有非终结符"<<str[i]<<"(输入错误)!"<<endl;errflag=1;}} while(errflag==1); //判断输入串的合法性analyse(Vn, Vt, M,str);return 0;}六、实验结果七、实验总结。
合肥工业大学编译原理实验报告(完整代码版)

计算机与信息学院之欧侯瑞魂创作创作时间:二零二一年六月三十日编译原理实验陈说专业班级信息平安13-1班学生姓名及学号马骏 2013211869课程教学班号任课教师李宏芒实验指导教师李宏芒实验地址实验楼机房2015 ~2016 学年第二学期实验1 词法分析设计一、实验目的通过本实验的编程实践, 使学生了解词法分析的任务, 掌握词法分析法式设计的原理和构造方法, 使学生对编译的基本概念、原理和方法有完整的和清楚的理解, 并能正确地、熟练地运用二、实验要求1、编程时注意编程风格:空行的使用、注释的使用、缩进的使用等.2、将标识符填写的相应符号表须提供给编译法式的以后各阶段使用.3、根据测试数据进行测试.测试实例应包括以下三个部份:全部合法的输入.各种组合的非法输入.由记号组成的句子.4、词法分析法式设计要求输出形式:例:输入VC++语言的实例法式:If i=0 then n++;a﹤= 3b %);输出形式为:单词二元序列类型位置(行, 列)(单词种别, 单词属性)for (1,for ) 关键字(1, 1)i ( 6,i ) 标识符(1, 2)= ( 4, = ) 关系运算符(1, 3) 120 ( 5, 0 ) 常数(1, 4)then ( 1, then) 关键字(1, 5)n (6,n ) 标识符(1, 6)++ Error Error (1, 7);( 2, ; ) 分界符(1, 8)a (6,a ) 标识符(2, 1)﹤= (4,<= ) 关系运算符(2, 2)3b Error Error (2, 4)% Error Error (2, 4)) ( 2, ) ) 分界符(2, 5);( 2, ; ) 分界符(2, 6)三、实验内容用 VC++/VB/JAVA 语言实现对 C 语言子集的源法式进行词法分析.通过输入源法式从左到右对字符串进行扫描和分解, 依次输出各个单词的内部编码及单词符号自身值;若遇到毛病则显示“Error”, 然后跳过毛病部份继续显示;同时进行标识符挂号符号表的管理.以下是实现词法分析设计的主要工作:(1)从源法式文件中读入字符.(2)统计行数和列数用于毛病单词的定位.(3)删除空格类字符, 包括回车、制表符空格.(4)按拼写单词, 并用(内码, 属性)二元式暗示.(属性值——token的机内暗示)(5)如果发现毛病则陈说犯错 7(6)根据需要是否填写标识符表供以后各阶段使用.四、实验步伐1、根据流程图编写出各个模块的源法式代码上机调试.2、编制好源法式后, 设计若干用例对系统进行全面的上机测试, 并通过所设计的词法分析法式;直至能够获得完全满意的结果.3、书写实验陈说;实验陈说正文的内容:功能描述:该法式具有什么功能?法式结构描述:函数调用格式、参数含义、返回值描述、函数功能;函数之间的调用关系图.详细的算法描述(法式总体执行流程图) .给出软件的测试方法和测试结果.实验总结(设计的特点、缺乏、收获与体会).五、实验截图输入If i=0 then n++;a<= 3b %);六、核心代码#include<iostream>#include<string>#include<fstream>#include <sstream>using namespace std;const char* salaryfile="salaryfile.txt";const int max=40;stringid[max]={"do","end","for","if","printf","scanf","then"," while"};//关键字表string s[max]={",",";","(",")","[","]","+","-","*","/","<","<=","=",">",">=","<>"};//分界符表算数运算符表关系运算符表string k[max];// 标识符string ci[max];// 常数int fjfpoint=5;//分界符表尾int mathpoint=9;//算数运算符表尾int cipointer=0;//常数表尾int idpointer=0;//关键字表尾int kpointer=0;//标识符表尾int fjf;//0 不是分界符 1是int rowy=1;//识别输入行位置int rowx=1;//识别输入列位置int outkey=0;//打印控制 0为数字后有字母其他可以void searcht(int i,string m)//根据已识另外首字母识别字符串{//cout<<"enter searcht!!"<<endl;int x;if(i==0)//首字符是字母识别关键字{//cout<<" a word!!"<<endl;for(x=0;x<max;x++){if(id[x]==m){cout<<"(1,"<<id[x]<<")"<<" 关键字("<<rowy<<","<<rowx<<")"<<endl;break;}}if(x==max)//不是关键字再识别标识符{for(x=0;x<max;x++){if(k[x]==m){cout<<"(6,"<<m<<") "<<"标识符("<<rowy<<","<<rowx<<")"<<endl;break;}}if(x==max)//标识符表没有时拔出标识符{cout<<"(6,"<<m<<") "<<"标识符("<<rowy<<","<<rowx<<")"<<endl;k[kpointer]=m;kpointer++;}}}if(i==1)//识别常数{//cout<<" a number!!"<<endl;for(x=0;x<max;x++){if(ci[x]==m){cout<<"(5,"<<x<<")"<<endl;break;}}if(x==max){cout<<"(5,"<<m<<") 常数("<<rowy<<","<<rowx<<")"<<endl;ci[cipointer]=m;cipointer++;}}if(i==2)//识别分界符算数运算符关系运算符{//cout<<" a signal!!"<<endl;for(x=0;x<max;x++){if(s[x]==m)break;}//x--;if(x<6){fjf=1;}if(x>5&&x<10){if(outkey==1){cout<<"(3,"<<s[x]<<") 算数运算符("<<rowy<<","<<rowx<<")"<<endl;outkey=0;}fjf=0;}if(x>9&&x<max-1){if(outkey==1){cout<<"(4,"<<s[x]<<") 关系运算符("<<rowy<<","<<rowx<<")"<<endl;outkey=0;}fjf=0;}if(x==max){if(outkey==1){cout<<"Error Error ("<<rowy<<","<<rowx<<")"<<endl; outkey=0;}fjf=0;}}};void wordlook(char t,string sn)//识别首字符, 分类识别字符串{if(t>=48&&t<=57)searcht(1,sn);else{if((t>64&&t<91)||(t>96&&t<123))searcht(0,sn);else searcht(2,sn);}};void split(string s)//分割字符串{//cout<<s<<endl;string now[max];string sn;int nowpointer=0;int i=0;int x;int sign=2;//非法数字标识表记标帜int diannumber=0;//数中点的个数for(x=0;x<s.length();x++){if((s[x]>64&&s[x]<91)||(s[x]>96&&s[x]<123)||(s[x]>=48&&s [x]<=57)||(x>0&&s[x]==46&&sign==1))//判断数字后跟字母还是字母后有数字{if(i==0){if(s[x]>=48&&s[x]<=57)sign=1;else sign=2;}else{if(sign==1){if(s[x]>=48&&s[x]<=57||s[x]==46){if(s[x]==46){if(diannumber==0)diannumber++;else sign=0;}}else sign=0;}}i++;if(x==(s.length()-1)){sn=s.substr(x-i+1,i);if(i>0){// cout<<sn<<" i="<<i<<endl;cout<<sn<<" ";if(sign==0)//数字后有字母的情况cout<<" Error Error ("<<rowy<<","<<rowx<<")"<<endl;else //字母开头的字符串{// cout<<" true"<<endl;wordlook(sn[0],sn);rowx++;}}}}else{if(x>0&&(s[x-1]>64&&s[x-1]<91)||(s[x-1]>96&&s[x-1]<123)||(s[x-1]>=48&&s[x-1]<=57))//遇到分界符运算符如果前面是数字或字母{sn=s.substr(x-i,i);if(i>0){// cout<<sn<<" i="<<i<<endl;cout<<sn<<" ";if(sign==0)cout<<" Error Error ("<<rowy<<","<<rowx<<")"<<endl;else{// cout<<" true"<<endl;wordlook(sn[0],sn);rowx++;}}i=0;}string ll=s.substr(x,1);//判断是运算符还是分界符wordlook(s[x],ll);if(fjf==0)//是运算符{i++;if((s[x+1]>64&&s[x+1]<91)||(s[x+1]>96&&s[x+1]<123)||(s[x +1]>=48&&s[x+1]<=57))//如果后面是数字或字母{sn=s.substr(x-i+1,i);// cout<<sn<<"运算符 i="<<i<<endl;cout<<sn<<" ";outkey=1;wordlook(sn[0],sn);rowx++;i=0;}}if(fjf==1){if((s[x-1]>64&&s[x-1]<91)||(s[x-1]>96&&s[x-1]<123)||(s[x-1]>=48&&s[x-1]<=57))//如果前面是数字或字母 {}else if(i>0){sn=s.substr(x-i,i);// cout<<sn<<"运算符 i="<<i<<endl;cout<<sn<<" ";outkey=1;wordlook(sn[0],sn);rowx++;i=0;}cout<<s[x]<<" (2,"<<s[x]<<") 分界符("<<rowy<<","<<rowx<<")"<<endl;rowx++;/* if(ll==";"){rowy++;rowx=1;}*/}}};int main(){int x;string instring;//读入一行string sn;/*getline(cin,sn);// string带空格输入cout<<sn<<endl;char t=sn[0];if(t>=48&&t<=57)searcht(1,sn);else{if((t>64&&t<91)||(t>96&&t<123))searcht(0,sn);else searcht(2,sn);}*/ifstream inputfile;//in file stream inputfile.open(salaryfile);//inputfile>>noskipws;if(!inputfile){cout<<"no file"<<endl;}string pp;while(!inputfile.eof()){getline(inputfile,pp); istringstream istr(pp);string ppword;while(istr>>ppword)//依照空格分割字符串{split(ppword);}int begin = 0;//去失落字符串的所有空格begin = pp.find(" ",begin); //查找空格在str中第一次呈现的位置while(begin != -1) //暗示字符串中存在空格{pp.WordStr(begin, 1, ""); // 用空串替换str中从begin开始的1个字符begin = pp.find(" ",begin); //查找空格在替换后的str中第一次呈现的位置}*///cout<<"good "<<pp<<endl;//rowx++;rowy++;//换行rowx=1;}return 0;}七、实验总结通过本次试验使我不单对词法分析器有了更深的了解, 而且提高了编程能力, 希望在以后的学习中可以解决词法分析更多的问题.实验2 LL(1)分析法一、实验目的通过完成预测分析法的语法分析法式, 了解预测分析法和递归子法式法的区别和联系.使学生了解语法分析的功能, 掌握语法分析法式设计的原理和构造方法, 训练学生掌握开发应用法式的基本方法.有利于提高学生的专业素质, 为培养适应社会多方面需要的能力.二、实验要求1、编程时注意编程风格:空行的使用、注释的使用、缩进的使用等.2、如果遇到毛病的表达式, 应输犯毛病提示信息.3、对下列文法, 用 LL(1)分析法对任意输入的符号串进行分析:(1)E->TG(2)G->+TG|—TG(3)G->ε(4)T->FS(5)S->*FS|/FS(6)S->ε(7)F->(E)(8)F->i三、实验内容根据某一文法编制调试 LL ( 1 )分析法式, 以便对任意输入的符号串进行分析.构造预测分析表, 并利用分析表和一个栈来实现对上述法式设计语言的分析法式.分析法的功能是利用 LL(1)控制法式根据显示栈栈顶内容、向前看符号以及 LL(1)分析表, 对输入符号串自上而下的分析过程.四、实验步伐1、根据流程图编写出各个模块的源法式代码上机调试.2、编制好源法式后, 设计若干用例对系统进行全面的上机测试, 并通过所设计的 LL(1)分析法式;直至能够获得完全满意的结果.3、书写实验陈说;实验陈说正文的内容:写出 LL(1)分析法的思想及写出符合 LL(1)分析法的文法.法式结构描述:函数调用格式、参数含义、返回值描述、函数功能;函数之间的调用关系图.详细的算法描述(法式执行流程图) .给出软件的测试方法和测试结果.实验总结(设计的特点、缺乏、收获与体会).五、实验截图六、核心代码#include<iostream>#include<string>using namespace std;string pp;//输出字符串string hh="\r\n";//换行const int max=50;int endfu[max];//终止符序号表int endfupointer=8;char endfureal[max]={'+','-','*','/','(','i',')','#'};int unendfu[max];int unendfupointer=5;char unendfureal[max]={'E','G','T','S','F'};string makemath[max]={"E->TG","G->+TG","G->-TG","G->$","T->FS","S->*FS","S->/FS","S->$","F->(E)","F->i"};//0 E->TG,1 G->+TG,2 G->-TG,3 G->$,4 T->FS,5 S->*FS,6 S->/FS,7 S->$,8 F->(E),9 F->i//$代表空串string behavior[max]={"初始化","POP"};int smarttable[max][max];//分析表int checkendfu(char fu)//查终结符序号{int x;for(x=0;x<endfupointer;x++){if(endfureal[x]==fu){break;}}if(x<endfupointer)return x;else return -1;};int checkunendfu(char fu)//查非终结符序号{int x;for(x=0;x<unendfupointer;x++){if(unendfureal[x]==fu)break;}if(x<unendfupointer)return x;else return-1;};string checkmakemath(int x)//查发生式表{return makemath[x];};int checksmarttable(int x,int y)//查分析表{return smarttable[x][y];};class smartbox{public:smartbox(){box[0]='#';box[1]='E';boxpointer=1;}void push(char fu){boxpointer++;box[boxpointer]=fu;}char pop(){char a=box[boxpointer];if(a!='#'){//cout<<"pop: "<<boxpointer<<" "<<a<<endl; //stringstream oss;/*pp=pp+"pop: ";char buffer[max];sprintf(buffer,"%d",boxpointer);string s=buffer;pp=pp+" ";pp=pp+s;pp=pp+hh;*/boxpointer--;return a;}}void check(){if(checkendfu(box[boxpointer])!=-1){char a;//cout<<box[boxpointer]<<checkendfu(box[boxpointer])<<" ";//char buffer[max];//sprintf(buffer//pp=pp+box[boxpointer];//pp=pp+checkendfu(box[boxpointer]);//pp=pp+" ";a=pop();//cout<<"out "<<a<<endl;。
编译原理-实验报告3-LL1

计算机硬件实验室实验报告根据某一文法编制调试LL(1)分析程序,以便对任意输入的符号串进行分析。
本次实验的目的主要是加深对预测分析LL(1)分析法的理解。
二、实验要求:对下列文法,用LL(1)分析法对任意输入的符号串进行分析:(1)E->TG(2)G->+TG|—TG(3)G->ε(4)T->FS(5)S->*FS|/FS(6)S->ε(7)F->(E)(8)F->i输出的格式如下:(1)LL(1)分析程序,编制人:姓名,学号,班级(2)输入一以#结束的符号串(包括+—*/()i#):在此位置输入符号串(3)输出过程如下:步骤分析栈剩余输入串所用产生式1 E i+i*i# E->TG(4)输入符号串为非法符号串(或者为合法符号串)备注:(1)在“所用产生式”一列中如果对应有推导则写出所用产生式;如果为匹配终结符则写明匹配的终结符;如分析异常出错则写为“分析出错”;若成功结束则写为“分析成功”。
(2) 在此位置输入符号串为用户自行输入的符号串。
(3)上述描述的输出过程只是其中一部分的。
注意:1.表达式中允许使用运算符(+-*/)、分割符(括号)、字符i,结束符#;2.如果遇到错误的表达式,应输出错误提示信息(该信息越详细越好);三、实验过程:1.模块设计:将程序分成合理的多个模块(函数),每个模块做具体的同一事情。
2.写出(画出)设计方案:模块关系简图、流程图、全局变量、函数接口等。
3.程序编写(1)定义部分:定义常量、变量、数据结构。
(2)初始化:设立LL(1)分析表、初始化变量空间(包括堆栈、结构体、数组、临时变量等);(3)控制部分:从键盘输入一个表达式符号串;(4)利用LL(1)分析算法进行表达式处理:根据LL(1)分析表对表达式符号串进行堆栈(或其他)操作,输出分析结果,如果遇到错误则显示错误信息。
四、实验结果:(1)写出程序流程图(2)给出运行结果示例程序:注意:本示例只要修改分析的句子即可,不要改写文法/*LL(1)分析法源程序,只能在VC++中运行*/#include<stdio.h>#include<stdlib.h>#include<string.h>#include<dos.h>char A[20];/*分析栈*/char B[20];/*剩余串*/char v1[20]={'i','+','-','*','/','(',')','#'};/*终结符*/char v2[20]={'E','G','T','S','F'};/*非终结符*/int j=0,b=0,top=0,l;/*L为输入串长度*/typedef struct type/*产生式类型定义*/{char origin;/*大写字符*/char array[5];/*产生式右边字符*/int length;/*字符个数*/}type;type e,t,g,g1,g2,s,s2,s1,f,f1;/*结构体变量*/type C[10][10];/*预测分析表*/void print()/*输出分析栈*/{int a;/*指针*/for(a=0;a<=top+1;a++)printf("%c",A[a]);printf("\t\t");}/*print*/void print1()/*输出剩余串*/{int j;for(j=0;j<b;j++)/*输出对齐符*/printf(" ");for(j=b;j<=l;j++)printf("%c",B[j]);printf("\t\t\t");}/*print1*/void main(){int m,n,k=0,flag=0,finish=0;char ch,x;type cha;/*用来接受C[m][n]*//*把文法产生式赋值结构体*/e.origin='E';strcpy(e.array,"TG");e.length=2;t.origin='T';strcpy(t.array,"FS");t.length=2;g.origin='G';strcpy(g.array,"+TG");g.length=3;g1.origin='G';strcpy(g1.array,"-TG");g1.length=3;g2.origin='G';g2.array[0]='^';g2.length=1;/////////////////////////////////////////////s.origin='S';strcpy(s.array,"*FS");s.length=3;s1.origin='S';strcpy(s1.array,"/FS");s1.length=3;s2.origin='S';s2.array[0]='^';s2.length=1;////////////////////////////////f.origin='F';strcpy(f.array,"(E)");f.length=3;f1.origin='F';f1.array[0]='i';f1.length=1;for(m=0;m<=4;m++)/*初始化分析表*/for(n=0;n<=5;n++)C[m][n].origin='N';/*全部赋为空*//*填充分析表*///char v1[20]={'i','+','-','*','/','(',')','#'};/*终结符*///char v2[20]={'E','G','T','S','F'};/*非终结符*/C[0][0]=e;C[0][5]=e;C[1][1]=g;C[1][2]=g1;C[1][3]=C[1][4]=C[1][7]=g2;C[2][0]=t;C[2][3]=t;C[2][5]=t;C[3][1]=C[3][2]=s2;C[3][3]=s;C[3][4]=s1;C[3][6]=C[3][7]=s2;C[4][0]=f1; C[4][5]=f;printf("LL(1)分析程序,编制人:武普泉,20号,1020562班\n");printf("输入一以#结束的符号串(包括+ - * / () i #):");do/*读入分析串*/{scanf("%c",&ch);if ((ch!='i') &&(ch!='+') &&(ch!='-')&&(ch!='*')&&(ch!='/')&&(ch!='(')&&(ch!=')')&&(ch!='#')) {printf("输入串中有非法字符\n");exit(1);}B[j]=ch;j++;}while(ch!='#');l=j;/*分析串长度*/ch=B[0];/*当前分析字符*/A[top]='#'; A[++top]='E';/*'#','E'进栈*/printf("步骤\t\t分析栈\t\t剩余字符\t\t所用产生式\n");do{x=A[top--];/*x为当前栈顶字符*/printf("%d",k++);printf("\t\t");for(j=0;j<=7;j++)/*判断是否为终结符*/if(x==v1[j]){flag=1;break;}if(flag==1)/*如果是终结符*/{if(x=='#'){finish=1;/*结束标记*/printf("acc!\n");/*接受*/getchar();getchar();exit(1);}/*if*/if(x==ch){print();print1();printf("%c匹配\n",ch);ch=B[++b];/*下一个输入字符*/flag=0;/*恢复标记*/}/*if*/else/*出错处理*/{print();print1();printf("%c出错\n",ch);/*输出出错终结符*/exit(1);}/*else*/}/*if*/else/*非终结符处理*/{for(j=0;j<=4;j++)if(x==v2[j]){m=j;/*行号*/break;}for(j=0;j<=7;j++)if(ch==v1[j]){n=j;/*列号*/break;}cha=C[m][n];if(cha.origin!='N')/*判断是否为空*/{print();print1();printf("%c->",cha.origin);/*输出产生式*/for(j=0;j<cha.length;j++)printf("%c",cha.array[j]);printf("\n");for(j=(cha.length-1);j>=0;j--)/*产生式逆序入栈*/A[++top]=cha.array[j];if(A[top]=='^')/*为空则不进栈*/top--;}/*if*/else/*出错处理*/{print();print1();printf("%c出错\n",x);/*输出出错非终结符*/exit(1);}/*else*/}/*else*/}while(finish==0);}/*main*。
编译原理-预测分析程序的设计与实现-实验报告

3.1目的和Array要求1、掌握LL(1)语法分析的基本原理和方法。
2、掌握相应数据结构的设计方法。
3.2实验环境Windows 7 + DEVC++6.03.3实验准备首先将下列算术表达式文法E-->E+T|TT-->T*F|FF-->(E)|i改写文法为LL(1)文法;构造LL(1)预测分析表。
解:1)该文法为左递归文法,设非终结符A,B;E=〉TAA=〉+TA|εT=>FBB=>*FB|εF=>(E)|i2)计算FIRST,FELLOW,SELECT集:因为A,B,F的的两个产生式的选择集都没有交集,所以,该文法为LL(1)文法。
、3)构造预测分析表4)给出i+i的预测分析过程。
3.4实验内容及步骤1、根据预测分析表编写预测分析程序yuce。
2、编译成功后,提示输入符号串,用回车键查看输出的结果。
3、比较自己分析的结果和屏幕上的输出结果。
3.5实验小结1、得到的经验。
2、遇到的主要问题。
3、改进方案。
自拟LL1文法G[A]:E=>aAEE=>bA=>bAA=>ε1)计算FIRST,FOLLOW,SELECT集。
2)构造预测分析表。
E=>aAE=>abAcE=>abcb3) 给出abcb的预测分析过程。
3)改进代码,其中用e代替εusing namespace std;int main(){string sheet[2][5]={{"aAE","b","","",""}, //预测分析表{"","bAc","e","","e"}};vector<char> S;//分析栈vector<char> Stc;//用户输入栈vector<char> SOS;//空栈string STC;//用于获取用户输入的字符串int YourChoice;do{cout<<endl;S=SOS; //每次执行用空的SOS初始化分析栈S.push_back('#');//将#放到分析栈中S.push_back('E');//将E放到分析栈中STC=""; //将STC设置为空cout<<"请输入您要分析的字符串:";cin>>STC;STC.resize(STC.size()+1);STC[STC.size()-1]='#';//将输入串最后一位设置为#Stc=SOS; //Stc是将STC+#倒序压入的用户输入栈for(int x=STC.size()-1;x>=0;--x)Stc.push_back(STC[x]);string YY="EA";string XX="abce#";while(!(S[S.size()-1]=='#'&&Stc[Stc.size()-1]=='#')){int i=0,j=0;////////////////////查表找到相应规则//////////////////// for(i=0;i<2;++i)if(YY[i]==S[S.size()-1])break;for(j=0;j<5;++j)if(XX[j]==Stc[Stc.size()-1])break;if(i>=5||j>=6) //如果查找超出表{cout<<"出错啦!"<<endl;break;}else if(sheet[i][j]=="") {cout<<"出错啦!"<<endl;break;}else{///////////////分析栈里的压栈与弹栈//////////////////// S.pop_back();for(int k=sheet[i][j].size()-1;k>=0;--k)S.push_back(sheet[i][j][k]);if(S[S.size()-1]==Stc[Stc.size()-1]) //一般规则{S.pop_back();Stc.pop_back();}else if(S[S.size()-1]=='e') //含空串的规则{S.pop_back();if(S[S.size()-1]!='#'&&Stc[Stc.size()-1]!='#'&&S[S.size()-1]==Stc[Stc.size()-1]) {S.pop_back();Stc.pop_back();}}}}if(S[S.size()-1]=='#'&&Stc[Stc.size()-1]=='#')cout<<"分析成功!"<<endl;cout<<"继续分析";}while(cin>>YourChoice&&YourChoice==0);return 0; }。
编译原理预测分析程序的实现

实验二预测分析表一、实验目的预测分析表的实现二、实验内容设有文法G:E→TE’E’→+TE’|εT→FT’T’→*FT’|εF→(E)|i;根据文法编写预测表分析总控程序,分析句子是否为该文法的句型。
当输入字符串: +i时,分析字符串是否为文法的句型三、实验步骤(详细的实验步骤)(1)文法E→TE’E’→+TE’|εT→FT’T’→*FT’|εF→(E)|i;(2)FIRST集FIRST(E)={(,i};FIRST(E’)={+, ε};FIRST(T)={(,i};FIRST(T’)={ *, ε};FIRST(F)={(,i};(3)FALLOW集FOLLOW(E)={),#};FOLLOW(E’)={),#};FOLLOW(T)={+,),#};FOLLOW(T’)={+,),#};FOLLOW(F)={*,+,),#};(4)预测分析表(5)分析过程步骤符号栈输入串应用句型0 #E i1*i2+i3#1 #E’T i1*i2+i3# E->TE’2 #E’T’F i1*i2+i3# E->TE’3 #E’T’i i1*i2+i3# F->i4 # E’T’i1*i2+i3#5 # E’T’F* *i2+i3# T’->*FT’6 # E’T’F *i2+i3#7 # E’T’i i2+i3# F->i8 # E’T’ i2+i3#9 #E’ +i3# T’->ε10 # E’T+ +i3# E’->+TE’11 #E’T +i3#12 # E’T’F i3# T->FT’13 # E’T’i i3# F->i14 # E’T’ i3#15 # E’ # T’->ε16 # # E’->ε(6)程序伪代码BEGIN首先把‘#’然后把文法开始符号推进STACK栈;把第一个输入符号读进a;FLAG:=TRUE;WHILE FLAG DOBEGIN把STACK栈顶符号托出去并放在X中;IF X属于VT THENIF X=a THEN 把下一输入符号读进a;ELSE ERROR;ELSE IF X=’#’ THENIF X=a THEN FLAG:=FALSE ELSE ERROR;ELSE IF M[A,a]={X->X1X2…Xk} THEN把Xk,X(k-1),…,X1一一推进栈ELSE ERROR;END OF WHILESTOPEND(7)运行结果截图注:为了将E和E’区分开,所以就有e来表示E’,因为在处理中E’会被当成两个字符来处理,所以就简化的表示了。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
预测分析表方法一、实验目的理解预测分析表方法的实现原理。
二、实验内容:编写一通用的预测法分析程序,要求有一定的错误处理能力,出错后能够使程序继续运行下去,直到分析过程结束。
可通过不同的文法(通过数据表现)进行测试。
二、实验内容提示1.算法数据构造:构造终结符数组:char Vt[10][5]={ “id ”,” +”……};构造非终结符数组: char Vn[10]={ };构造 follow 集数组: char *follow[10][10]={ } (可将 follow 集与预测分析表合并存放)数据构造示例(使用的预测分析表构造方法 1 ):/*data1.h 简单算术表达式数据 */char VN[10][5]={ "E","E'","T","T'" ,"F" }; //非终结符表int length_vn=5; // 非终结符的个数char VT[15][5]={ "id" ,"+" ,"*" ,"(" ,")" ,"#" }; // 终结符表int length_vt=6; // 终结符的个数char Fa[15][10]={ "TE'" ,"+TE'" ,"" ,"FT'" ,"*FT'" ,"" ,"(E)" ,"id" };// 产生式表 :0:E->TE' 1:E'->+TE' 2:E'-> 空// 3:T->FT' 4:T'->*FT' 5:T'-> 空 6:F->(E)7:F->idint analysis_table[10][11]={0,-1,-1,0,-2,-2,0,0,0,0,0,-1,1,-1,-1,2,2,0,0,0,0,0,3,-2,-1,3,-2,-2,0,0,0,0,0,-1,5, 4,-1,5, 5,0,0,0,0,0, 7,-2,-2,6,-2,-2,0,0,0,0,0};//预测分析表,-1表示出错,-2表示该行终结符的follow集合,用于错误处理,正数表示产生式在数组Fa中的编号, 0表示多余的列( 1)预测分析表的构造方法 1 给文法的正规式编号:存放在字符数组中,从 0 开始编号,正规式的编号即为该正规式在数组中对应的下标。
如上述 Fa 数组表示存储产生式。
构造正规式数组:char P[10][10]={ “ E->TE '”,” E' ->+TE ,……(正规式可只存储右半部分,如E->TE '可存储为TE',正规式中的符号可替换,如可将E'改为M )构造预测分析表: int analyze_table[10][10]={ } // 数组元素值存放正规式的编号, -1 表示出错(2)预测分析表的构造方法 2可使用三维数组Char analyze_table[10][10][10]={ }或Char *analyze_table[10][10]={ }2.针对预测分析表构造方法 1 的查预测分析表的方法提示:(1)查非终结符表得到非终结符的序号 no1(2)查终结符表得到终结符的序号 no2( 3)根据 no1 和 no2 查预测分析表得到对应正规式的序号no3=analyze_table[no1][no2] ,如果 no3=-1 表示出错。
(4)根据 no3 查找对应的正规式 Fa[no3]( 5)对正规式进行处理3.错误处理机制紧急方式的错误恢复方法(抛弃某些符号,继续向下分析)可认为输入串中缺少 A表示的结构),继续分析。
------------ 错误编号为1(2 )栈顶为非终结符 A,串中当前单词不属于FOLLOW ( A),则可使串指针下移一个位置(认为输入串中当前单词多余) ,继续分析。
---------- 错误编号为 2( 3)栈顶为终结符,且不等于串中当前单词,则从栈中弹出此终结符(认为输入串中缺少当前单词)或者将串指针下移一个位置(认为串中当前单词多余) 。
在程序中可选择上述两种观点中的一种进行处理。
---------- 错误编号 3因此 error ()函数的编写方式可按如下方式处理Error ( int errornum ){If (errornum==1 ) ............Else if (errornum==2 ) ...........Else ..........// 或者可用 choose case 语句处理}4.增加了错误处理的预测分析程序预测分析程序的算法:将“ #”和文法开始符依次压入栈中;把第一个输入符号读入 a ;do{把栈顶符号弹出并放入 x 中;if(x € VT)-2 表示 a follow (x )else error(3);} elseif(M[x,a] =“ x f y1y2 …yk ”){按逆序依次把yk 、yk-1 、…、y1压入栈中;输出"x f y1y2 …yk ”;}else if a follow (x) error(1); else error (2);//在前述的数据定义中查表为 }while(x!=“ # ”)三•实验要求给定算术表达式文法,编写程序。
测试数据: 1 .算术表达式文法E f TE 'E ' f +TE '卜 TE ' | & T f FT 'T' f *FT' |/ FT ' |%FT ' | £F f (E) |id |n um孑F i y y F 41 > ・丄}} > > > -- > >一> --一一一J -一一*一JAE TF T一E rF T- F T E t^^itl洛+谒id符”符id语士匚±匚士匚摩匚士匚“住匚士匚庁匚厅匚丙匚士匚冬冬冬+1口冬冬吉冬空、土口冬土□冬吉冬冬,却二SN―-SN--Sh|」SMJ心士£J玄」总丁£一2"H-上^—£■士■』」:」匚」厂尸十二「二L椁^-二-二厂J?--yL厂utL~rr^N -----T7T7T7®4/42^r74/_®幵Sr3开呼开开東驚四展四展四驚结二一-二去・干巳-—pid$ tress any key to continueTEFTld>*号> >M T」符二E T FT頁TEs^id符矗丛善r+击口丄口士口^-n吉吉悅线线共结n结碁皱统—JLLLthr^x-11二-J^F.^M^LrrE—二二二■二**二一二一隽开幵配开开克出覆结idid给定一符合该文法的句子,如id+id*id$ ,运行预测分析程序,给出分析过程和每一步的分析结果。
输出形式参考下图($为结束符)札頂元素当前单词记号动作动作ress an</ key €o continue#in clude<stdio.h>i->id#include<string.h> #include<stdlib.h>#define TT 0char aa[20]=" ";int pp=0;# if TTchar VN[5]={'E','e','T','t','F'}; // 非终结符表int length_vn=5; // 非终结符的个数char VT[10]={'*','l','m','+','-','(',')','i','n','#'}; // 终 结 符 表 l->/ m->%n->numint length_vt=10; // 终结符的个数charFa[12][6]={"Te","+Te","-Te","NULL","Ft","*Ft","nFt","mFt","NULL","(E)","i","n"};// 产生式表 :0:E->Te 1:e->+Te 2:e->-Te 3:e-> 空charF[12][6]={"E->","e->","e->","e->","T->","t->","t->","t->","t->","F->","F->","F->"};int analysis_table[5][10]={-2,-2,-2,-2,-2,0,-1,0,0,-1,-2,-2,-2,1,2,-2,3,-2,-2,3,-2,-2,-2,-1,-1,4,-1,4,4,-1, 5,6,7,8,8,-2,8,-2,-2,8,-1,-1,-1,-1,-1,9,-1,10,11,-1};# elsechar VN[4]={'A','Z','B','Y'}; // 非终结符表int length_vn=4; // 非终结符的个数char VT[5]={'a','l','d','b','#'}; // 终结符表int length_vt=5; // 终结符的个数char Fa[6][6]={"aZ","ABl","NULL","dY","bY","NULL"};char F[6][6]={"A->","Z->","B->","Y->"};int analysis_table[4][5]={0,-2,-1,-2,-1,1,-2,2,-2,2,-2,-1,3,-2,-2,-2,5,-2,4,-2};# endifchar stack[50];int top=-1;void initscanner() // 程序初始化:输入并打开源程序文件{int i=0;FILE *fp;if((fp=fopen("a.txt","r"))==NULL)printf("Open error!");exit(0);}char ch=fgetc(fp);while(ch!=EOF){aa[i]=ch;i++;ch=fgetc(fp);}fclose(fp);}void push(char a){top++;stack[top]=a;}char pop(){return stack[top--];}int includevt(char x)for(int i=0;i<length_vt;i++){if(VT[i]==x) return 1;}return 0;}int includean(char x,char a){int i,j;for(i=0;i<length_vn;i++)if(VN[i]==x) break;for( j=0;j<length_vt;j++)if(VT[j]==a) break;return analysis_table[i][j]; }void destory(){int flag=0;int flagg=0;push('#'); // 将 "#" 和文法开始符依次压入栈中push(VN[0]);char x;do{if(flag==0)x=pop(); // 把栈顶符号弹出并放入 x 中 flag=0;printf("%c\t\t\t%c\t",x,a);if(includevt(a)==1){if(includevt(x)==1){if(x==a){if(a=='#'){flagg=1;printf(" 结束 \n");}else printf(" 匹配终结符 %c\n",x);pp++;a=aa[pp]; // 将下一输入符号读入 a;else{flag=1;printf(" 出错,跳过 %c\n",a);pp++;a=aa[pp];}}else if(includean(x,a)>=0){int h=includean(x,a);printf(" 展开非终结符 %s%s\n",F[h],Fa[h]);int k;for(k=0;k<10;k++)if(Fa[h][k]=='\0') break;if(k==4){//printf("+++++++++++pop %c \n",x);}elsewhile(k!=0) //按逆序依次把yk、yk?1、…、y1压入栈中k--;push(Fa[h][k]);}}}else if(includean(x,a)==-1){flag=1;printf(" 出错 ,从栈顶弹出 %c\n",x);x=pop();}else{flag=1;printf(" 出错 ,跳过 %c\n",a);pp++;a=aa[pp];}}elseflag=1;printf(” 出错,跳过%c\n",a);pp++;a=aa[pp];}}while(x!='#');if(flagg==0){printf("%c\t\t\t%c\t",x,a);printf(" 结束 \n");}}int main(){printf(" 请输入 1 or 0:\n");//scanf("%d",TT);printf(" 语法分析工程如下 :\n");initscanner();printf(" 要分析的语句是 :%s\n",aa);动作 \n");\n");printf(" 语法分析工程如下 :\n");printf(" 栈顶元素 \t\t 当前单词记号 \t\t\tprintf("destory(); return 0;。