第25章 数据泵导入
Oracle10g数据泵的导入导出

从故障中恢复
重启动任务的能力使你可以从某些类型的故障中恢复过来。例如, 清单 5 显示了一个用完了转储文件空间的导出任务的日志文件的结尾部分。然而,什么也没有丢失。该任务只是进入了一个空闲状态,当你连接到该任务并查看状态输出时就可以看到这一点。这个状态不显示任务空闲的原因。要确定这是因为转储文件的空间不够了,则你需要查看日志文件。
启动一个导出任务
你可以使用新的 expdp 实用程序来启动一个导出任务。因为参数与老的 exp 实用程序不同,所以你得熟悉这些新的参数。你可以在命令行中指定参数,但在本文中我使用了参数文件。我想导出我的整个模式( schema ),使用了以下参数:
DUMPFILE=gnis%U.dmp
仅导入那些与密歇根州相关的数据行
不导入原始的存储参数
一开始,我可以在我的导入参数文件中写出以下四行:
DUMPFILE=gnis%U.dmp
DIRECTORY=export_dumps
LOGFILE=gnis_import.log
JOB_NAME=gnis_import
DUMPFILE=export_dumps01:gnis%U.dmp,
export_dumps02:gnis%U.dmp
PARALLEL=2
注意,在这个并行导出任务中,目录名作为文件名的一部分来被指定。
检查状态
你可以随时连接到一个运行中的任务来检查其状态。要连接到一个导出任务,必须执行一条 expdp 命令,使用 ATTACH 参数来指定任务名称。 清单 2 显示了到 GNIS_EXPORT 任务的连接。当你连接到一个任务, expdp 显示该任务的相关信息和当前状态,并为你提供一个 EXPORT> 提示符。
oracle使用数据泵导出和导入

使用数据泵导出和导入几乎所有DBA都熟悉oracle的导出和导入实用程序,它们将数据装载进或卸载出数据库,在oracle database 10g和11g中,你必须使用更通用更强大的数据泵导出和导入(Data Pump Export and Import)实用程序导出和导入数据。
以前的导出和导入实用程序在oracle database 11g中仍然可以使用,但是Oracle强烈建议使用数据泵(Data Pump)技术,因为它提供了更多的高级特性。
例如,你可以中断导出/导入作业,然后恢复它们;可以重新启动已失败的导出和导入作业;可以重映射对象属性以修改对象;可以容易地从另一个会话中监控数据泵的作业,甚至可以在作业过程中修改其属性;使用并行技术很容易快速移动大量的数据;因为oracle提供了针对数据泵技术的API,所以可以容易地在PL/SQL 程序中包含导出/导入作业;可以使用更强大的可移植表空间特性来快速移植大量的数据,甚至可在不同操作系统平台之间移动。
与旧的导出和导入实用程序不同,数据泵程序有一组可以在命令行中使用的参数以及一组只能以交互方式使用的特殊命令,你可以通过在命令行中输入expdp help = y 或者impdp help = y快速获取所有数据泵参数及命令的概述。
一.数据泵技术的优点原有的导出和导入技术基于客户机,而数据泵技术基于服务器。
默认所有的转储,日志和其他文件都建立在服务器上。
以下是数据泵技术的主要优点:1.改进了性能2.重新启动作业的能力3.并行执行的能力4.关联运行作业的能力5.估算空间需求的能力6.操作的网格方式7.细粒度数据导入功能8.重映射能力二.数据泵导出和导入的用途1.将数据从开发环境转到测试环境或产品环境2.在不同的操作系统平台上的oracle数据库直接的传递数据3.在修改重要表之前进行备份4.备份数据库5.把数据库对象从一个表空间移动到另一个表空间6.在数据库直接移植表空间7.提取表或其他对象的DDL注意:数据库不建立完备的备份,因为在导出文件中没有灾难发生时的最新数据。
Oracle数据泵的导入与导出实例详解

Oracle数据泵的导⼊与导出实例详解⽬录前⾔数据泵的导⼊数据泵的导出总结前⾔今天王⼦要分享的内容是关于Oracle的⼀个实战内容,Oracle的数据泵。
⽹上有很多关于此的内容,但很多都是复制粘贴别⼈的,导致很多⼩伙伴想要使⽤的时候不能直接上⼿,所以这篇⽂章⼀定能让你更清晰的理解数据泵。
开始之前王⼦先介绍⼀下⾃⼰的环境,这⾥使⽤的是⽐较常⽤的WIN10系统,Oracle数据库也是安装在本机上的,环境⽐较简单。
数据泵的导⼊导⼊的数据⽂件可能是别⼈导出给你的,也可能是你⾃⼰导出的,王⼦这⾥就是别⼈导出的,⽂件名字是YD.DMP。
在进⾏操作之前,⼀定要问清楚表空间名字,如果表空间命名不统⼀,可能会导致导⼊失败的问题。
所以第⼀步就是建⽴表空间,语句如下:create tablespace VIEWHIGHdatafile 'D:/app/admin/oradata/orcl/VIEWHIGH'size 1M autoextend on next 50M maxsize unlimited;这⾥的datafile路径⼀般选择你本地oracle的数据⽂件路径。
之后,我们可以建⽴⼀个新的⽤户来导⼊数据⽤,这个⽤户名也可以提前问好,最好⽤户名⼀致,否则需要做⼀次⽤户名的映射,这个我们下⽂再说。
建⽴⽤户语句如下:create user DRGS_INITidentified by "vhiadsh"default tablespace VIEWHIGHprofile DEFAULTACCOUNT UNLOCK;建⽴⽤户后需要给⽤户授权,语句如下:--给新建⽤户授DBA权限grant dba to DRGS_INIT;grant unlimited tablespace to DRGS_INIT;接下来我们需要在本地的磁盘中创建⼀个⽂件夹,作为数据泵⽂件夹来使⽤,同时把DMP⽂件放⼊到此⽂件夹下。
数据泵方式导入数据库

管理员权限进入数据库创建一个操作目录 directoryCREATE directory dump_dir ‘/home/oracle/db/’;赋予读写权限GRANT READ,WRITE ON directory dump_dir to 用户名;退出sqlplus使用命令expdp导出数据expdp 用户名/密码 directory=dump_dir dumpfile=文件名.dmp full = y使用impdp导入数据:impdp 用户名/密码 directory=dump_dir dumpfile=文件名.dmp full = y1,导出表Expdp scott/tiger DIRECTORY=DumpDir DUMPFILE=tab.dmp TABLES=dept,emp 2,导出方案Expdp scott/tiger DIRECTORY=DumpDir DUMPFILE=schema.dmp SCHEMAS=system,scott3.导出表空间Expdp system/manager DIRECTORY=DumpDir DUMPFILE=tablespace.dmpTABLESPACES=user01,user024,导出数据库Expdp system/manager DIRECTORY=DumpDir DUMPFILE=full.dmp FULL=Y1, 导入表Impdp scott/tiger DIRECTORY=DumpDir DUMPFILE=tab.dmpTABLES=dept,empImpdp system/manage DIRECTORY=DumpDir DUMPFILE=tab.dmpTABLES=scott.dept,scott.emp REMAP_SCHEMA=SCOTT:SYSTEM第一种方法表示将DEPT和EMP表导入到SCOTT方案中,第二种方法表示将DEPT和EMP表导入的SYSTEM方案中.注意,如果要将表导入到其他方案中,必须指定REMAP SCHEMA选项.。
数据泵

一、EXPDP和IMPDP介绍
1.数据泵导出(Data Dump Export)
数据泵导出的是Oracle Database 10g新增的功能功能,它使用实用工具EXPDP将数据库对象的元数据(对象结构)或数据导出到
1、以sys登录,建目录并将该目录的读写权利授予SCOTT
connect sys/orcl123 as sysdba
create directory dump_dir as 'd:\dump';
grant read,write on directory dump_dir to scott;
impdp scott/tiger directory=dump_dir dumpfile=tab.dmp tables=dept,emp
(2) 将DEPT,EMP表导入到system方案中。
impdp system/orcl123 directory=dump_dir dumpfile=tab.dmp tables=scott.dept,scott.emp remap_schema=scott:sy库是指将存放在转蓄文件中所有的数据库对象及其相关数据装载到数据库中,导入数据库是使用FULL选项来完成的。
注意:导出转蓄文件需要具有DBA角色或是EXP_FULL_DATABASE角色,导入转蓄文件是需要具有DBA角色或是IMP_FULL_DATABASE角
色。
二、使用EXPDP导出数据
EXPDP是服务器端的工具,该工具只能在Oracle服务器端使用,而不能在Oracle客户端使用。数据泵导出包括导出表、导出方案、导出表空间、导出数据库等4种模式。
数据泵导入导出详解

数据泵技术是Oracle Database 10g 中的新技术,它比原来导入/导出(imp,exp)技术快15-45倍。
速度的提高源于使用了并行技术来读写导出转储文件。
expdp使用使用EXPDP工具时,其转储文件只能被存放在DIRECTORY对象对应的OS目录中,而不能直接指定转储文件所在的OS目录。
因此使用EXPDP工具时,,必须首先建立DIRECTORY对象,并且需要为数据库用户授予使用DIRECTORY对象权限。
首先得建DIRECTORY:SQL> conn /as sysdbaSQL> CREATE OR REPLACE DIRECTORY dir_dump AS '/u01/backup/';SQL> GRANT read,write ON DIRECTORY dir_dump TO public;1) 导出scott整个schema--默认导出登陆账号的schema$ expdpscott/tiger@db_esuiteparfile=/orahome/expdp.parexpdp.par内容:DIRECTORY=dir_dumpDUMPFILE=scott_full.dmpLOGFILE=scott_full.log--其他账号登陆, 在参数中指定schemas$ expdp system/oracle@db_esuiteparfile=/orahome/expdp.parexpdp.par内容:DIRECTORY=dir_dumpDUMPFILE=scott_full.dmpLOGFILE=scott_full.logSCHEMAS=SCOTT2) 导出scott下的dept,emp表$ expdpscott/tiger@db_esuiteparfile=/orahome/expdp.par expdp.par内容:DIRECTORY=dir_dumpDUMPFILE=scott.dmpLOGFILE=scott.logTABLES=DEPT,EMP3) 导出scott下除emp之外的表$ expdpscott/tiger@db_esuiteparfile=/orahome/expdp.par expdp.par内容:DIRECTORY=dir_dumpDUMPFILE=scott.dmpLOGFILE=scott.logEXCLUDE=TABLE:"='EMP'"4) 导出scott下的存储过程$ expdpscott/tiger@db_esuiteparfile=/orahome/expdp.par expdp.par内容:DIRECTORY=dir_dumpDUMPFILE=scott.dmpLOGFILE=scott.logINCLUDE=PROCEDURE5) 导出scott下以'E'开头的表$ expdpscott/tiger@db_esuiteparfile=/orahome/expdp.parexpdp.par内容:DIRECTORY=dir_dumpDUMPFILE=scott.dmpLOGFILE=scott.logINCLUDE=TABLE:"LIKE 'E%'" //可以改成NOT LIKE,就导出不以E开头的表6) 带QUERY导出$ expdpscott/tiger@db_esuiteparfile=/orahome/expdp.parexpdp.par内容:DIRECTORY=dir_dumpDUMPFILE=scott.dmpLOGFILE=scott.logTABLES=EMP,DEPTQUERY=EMP:"whereempno>=8000"QUERY=DEPT:"wheredeptno>=10 and deptno<=40"注: 处理这样带查询的多表导出, 如果多表之间有外健关联, 可能需要注意查询条件所筛选的数据是否符合这样的外健约束, 比如EMP中有一栏位是deptno, 是关联dept中的主键, 如果"whereempno>=8000"中得出的deptno=50的话, 那么, 你的dept的条件"wheredeptno>=10 and deptno<=40"就不包含deptno=50的数据, 那么在导入的时候就会出现错误.expdp选项1. ATTACH该选项用于在客户会话与已存在导出作用之间建立关联.语法如下:ATTACH=[schema_name.]job_nameschema_name用于指定方案名,job_name用于指定导出作业名.注意,如果使用ATTACH选项,在命令行除了连接字符串和ATTACH选项外,不能指定任何其他选项,示例如下:expdpscott/tiger ATTACH=scott.export_job2. CONTENT该选项用于指定要导出的内容.默认值为ALL.语法如下:CONTENT={ALL | DATA_ONLY |METADATA_ONLY}当设置CONTENT为ALL 时,将导出对象定义及其所有数据; 为DATA_ONLY时,只导出对象数据; 为METADATA_ONLY时,只导出对象定义,示例如下:expdpscott/tiger DIRECTORY=dump DUMPFILE=a.dumpCONTENT=METADATA_ONLY3. DIRECTORY指定转储文件和日志文件所在的目录.语法如下:DIRECTORY=directory_objectdirectory_object用于指定目录对象名称.需要注意,目录对象是使用CREATE DIRECTORY语句建立的对象,而不是OS 目录,示例如下:expdpscott/tiger DIRECTORY=dump DUMPFILE=a.dump建立目录:CREATE DIRECTORY dump as 'd:dump';查询创建了那些子目录:SELECT * FROM dba_directories;4. DUMPFILE用于指定转储文件的名称,默认名称为expdat.dmp.语法如下:DUMPFILE=[directory_object:]file_name[,….]directory_object用于指定目录对象名,file_name用于指定转储文件名.需要注意,如果不指定directory_object,导出工具会自动使用DIRECTORY选项指定的目录对象,示例如下:expdpscott/tiger DIRECTORY=dump1 DUMPFILE=dump2:a.dmp5. ESTIMATE指定估算被导出表所占用磁盘空间的方法.默认值是BLOCKS.语法如下:EXTIMATE={BLOCKS | STATISTICS}设置为BLOCKS时,oracle会按照目标对象所占用的数据块个数乘以数据块尺寸估算对象占用的空间,设置为STATISTICS时,根据最近统计值估算对象占用空间,示例如下:expdpscott/tiger TABLES=emp ESTIMATE=STATISTICSDIRECTORY=dumpDUMPFILE=a.dump一般情况下, 当用默认值(blocks)时, 日志中估计的文件大小会比实际expdp出来的文件大, 用statistics时会跟实际大小差不多.6. EXTIMATE_ONLY指定是否只估算导出作业所占用的磁盘空间,默认值为N.语法如下:EXTIMATE_ONLY={Y | N}设置为Y时,导出作用只估算对象所占用的磁盘空间,而不会执行导出作业,为N时,不仅估算对象所占用的磁盘空间,还会执行导出操作,示例如下:expdpscott/tiger ESTIMATE_ONLY=y NOLOGFILE=y7. EXCLUDE该选项用于指定执行操作时要排除的对象类型或相关对象.语法如下:EXCLUDE=object_type[:name_clause][,….]object_type用于指定要排除的对象类型,name_clause用于指定要排除的具体对象.EXCLUDE和INCLUDE不能同时使用,示例如下:expdpscott/tiger DIRECTORY=dump DUMPFILE=a.dup EXCLUDE=VIEW在EXPDP的帮助文件中, 可以看到存在EXCLUDE和INCLUDE参数, 这两个参数文档中介绍的命令格式存在问题, 正确用法是:EXCLUDE=OBJECT_TYPE[:name_clause][,...]INCLUDE=OBJECT_TYPE[:name_clause][,...]示例:Expdp<other_parameters> schema=scottexclude=sequence,table:"in('EMP','DEPT')"impdp<other_parameters> schema=scott include = function,package, procedure, table:"='EMP'"有了这些还不够, 由于命令中包含了多个特殊字符, 在不同的操作系统下需要通过转义字符才能使上面的命令顺利执行,如:EXCLUDE=TABLE:"IN('BIGTALE')"8. FILESIZE指定导出文件的最大尺寸,默认为0(表示文件尺寸没有限制).9. FLASHBACK_SCN指定导出特定SCN时刻的表数据.语法如下:FLASHBACK_SCN=scn_valuescn_value用于标识SCN值.FLASHBACK_SCN和FLASHBACK_TIME不能同时使用,示例如下:expdpscott/tiger DIRECTORY=dump DUMPFILE=a.dmpFLASHBACK_SCN=35852310. FLASHBACK_TIME指定导出特定时间点的表数据.语法如下:FLASHBACK_TIME="TO_TIMESTAMP(time_value)"示例如下:expdpscott/tiger DIRECTORY=dump DUMPFILE=a.dmp FLASHBACK_TIME ="TO_TIMESTAMP('25-08-200414:35:00','DD-MM-YYYY HH24:MI:SS')"11. FULL指定数据库模式导出,默认为N.语法如下:FULL={Y | N}为Y时,标识执行数据库导出.12. HELP指定是否显示EXPDP命令行选项的帮助信息,默认为N.当设置为Y时,会显示导出选项的帮助信息,示例如下:expdp help=y13. INCLUDE指定导出时要包含的对象类型及相关对象.语法如下:INCLUDE=object_type[:name_clause][,… ]示例如下:expdpscott/tiger DIRECTORY=dump DUMPFILE=a.dmp INCLUDE=trigger1.1.2 expdp选项14. JOB_NAME指定要导出作用的名称,默认为SYS_XXX.语法如下:JOB_NAME=jobname_string示例如下:expdpscott/tiger DIRECTORY=dump DUMPFILE=a.dmpINCLUDE=triggerJOB_NAME=exp_trigger后面想临时停止expdp任务时可以按Ctrl+C组合键,退出当前交互模式,退出之后导出操作不会停止,这不同于Oracle以前的EXP. 以前的EXP,如果退出交互式模式,就会出错终止导出任务. 在Oracle10g中,由于EXPDP是数据库内部定义的任务,已经与客户端无关. 退出交互之后,会进入export的命令行模式,此时支持status等查看命令:Export> status如果想停止改任务,可以发出stop_job命令:Export>stop_job如果有命令行提示: "是否确实要停止此作业([Y]/N):" 或"Are you sure you wish to stop this job ([yes]/no):", 回答应是yes或者no, 回答是YES以后会退出当前的export界面.接下来可以通过命令行再次连接到这个任务:expdp test/test@acf attach=expfull通过start_job命令重新启动导出:Export>start_jobExport> status15. LOGFILE指定导出日志文件文件的名称,默认名称为export.log.语法如下:LOGFILE=[directory_object:]file_namedirectory_object用于指定目录对象名称,file_name用于指定导出日志文件名.如果不指定directory_object.导出作用会自动使用DIRECTORY的相应选项值,示例如下:expdpscott/tiger DIRECTORY=dump DUMPFILE=a.dmp logfile=a.log16. NETWORK_LINK指定数据库链名,如果要将远程数据库对象导出到本地例程的转储文件中,必须设置该选项.expdp中使用连接字符串和network_link的区别:expdp属于服务端工具,而exp属于客户端工具,expdp生成的文件默认是存放在服务端的,而exp生成的文件是存放在客户端.expdp username/password@connect_string //对于使用这种格式来说,directory使用源数据库创建的,生成的文件存放在服务端。
数据泵IMPDP 导入工具的使用

数据泵IMPDP 导入工具的使用收藏--=================================--数据泵IMPDP 导入工具的使用--=================================数据的导入导出时数据库经常处理的作业之一,Oracle 提供了IMP和IMPDP以及SQL*Loader等工具来完成数据的导入工作,其中IMP服务于早期的9i之前的版本,在10g及后续版本,Oracle 提供了数据泵高速导入工具,本文主要介绍IMPDP的使用方法,关于高速导出工具请参照:数据泵EXPDP 导出工具的使用。
SQL*Loader请参照:SQL*Loader使用方法。
一、数据泵的体系结构数据泵的体系结构在数据泵EXPDP 导出工具的使用已列出,再此不再赘述。
二、IMPDP支持的接口及导入模式导入接口使用命令行带参数的使用命令行带参数文件使用命令行交互使用database console(GUI)几种常用的导入模式导入表导入方案导入表空间导入数据库传输表空间模式三、演示如何导入1.关于查看impdp的帮助,使用以下命令[oracle@oradb ~]$ impdp -? 或[oracle@oradb ~]$ impdp -help 前者提供帮助信息并开启命令行交互模式2. 导入表--将表dept,emp导入到scott方案中impdp scott/tiger directory=dump_scott dumpfile=tab.dmp tables=dept,emp--将表dept和emp从scott方案导入到system方案中,对于方案的转移,必须使用remap_shcema参数impdp system/manage directory=dump_scott dumpfile=tab.dmptables=scott.dept,scott.emp remap_schema=scott:system3.导入方案--将dump_scott目录下的schema.dmp导入到scott方案中impdp scott/tiger directory=dump_scott dumpfile=schema.dmp schemas=scott--将scott方案中的所有对象转移到system方案中impdp system/redhat directory=dump_scott dumpfile=schema.dmp schemas=scott remap_schema=scott:system4.导入表空间impdp system/redhat directory=dump_scott dumpfile=tablespace.dmp tablespaces=user015.导入数据库impdp system/redhat directory=dump_scott dumpfile=full.dmp full=y6.将数据对象原样导回(演示从Windows客户端来实现,数据库基于Linux系统)从Windows客户端来导出scott.emp表,导出后删除该表,再原样导回C:\>expdp scott/tiger@list2 directory=dump_scott dumpfile=emp.dmp tables=emp C:\>sqlplus scott/tiger@list2SQL*Plus: Release 10.2.0.1.0 - Production on星期一9月20 20:50:35 2010Copyright (c) 1982, 2005, Oracle.All rights reserved.Connected to:Oracle Database 10g Enterprise Edition Release 10.2.0.1.0 - Production With the Partitioning, OLAP and Data Mining optionsSQL>drop table emp;Table dropped.SQL>commit;Commit complete.SQL>select count(1)from emp;select count(1)from emp*ERROR at line 1:ORA-00942:table or view does not existSQL> host impdp scott/tiger@list2 directory=dump_scott dumpfile=emp.dmpSQL>select count(1)from emp;COUNT(1)----------147.将导出的对象使用remap_schema参数转移到不同的方案a.将dept从scott用户导入到system用户下expdp scott/tiger directory=dump_scott dumpfile=dept.dmp tables=dept方法一:impdp system/redhat tables=scott.dept directory=dump_scottdumpfile=dept.dmp remap_schema=scott:system方法二:sql>grant imp_full_database to scott;impdp scott/tiger directory=dump_scott dumpfile=dept.dmp tables=dept remap_schema=scott:system table_exists_action=replaceb.将scott方案下的所有对象导入到system方案下expdp scott/tiger directory=dump_scott dumpfile=allobj.dmp schemas=scott impdp scott/tiger directory=dump_scott dumpfile=allobj.dmpremap_schema=scott:system table_exists_action=replace8.使用remap_datafile参数转移到不同的数据文件(用于不同平台之间存在不同命名方式时)下面的示例首先创建了一个参数文件,参数文件名为payroll.pardirectory=pump_scottfull=ydumpfile=datafile.dmpremap_datafile='db$:[hrdata.payroll]tbs2.f':'/db/hrdata/payroll/tbs2.f' --指明重新映射数据文件impdp scott/tiger PARFILE=payroll.par9.使用remap_tablespace参数转移到不同的表空间impdp scott/scott remap_tablespace=users:tbs1 directory=dpump_scott dumpfile=users.dmp10.并行导入:expdp e/e directory=dump_e dumpfile=a_%u.dmp schemas=e parallel=3impdp e/e directory=dump_e dumpfile=a_%u.dmp schemas=e parallel=3table_exists_action=replace四、数据泵impdp参数:1.REMAP_DATAFILE该选项用于将源数据文件名转变为目标数据文件名,在不同平台之间搬移表空间时需要该选项.REMAP_DATAFILE=source_datafie:target_datafile2.REMAP_SCHEMA该选项用于将源方案的所有对象装载到目标方案中.REMAP_SCHEMA=source_schema:target_schema3.REMAP_TABLESPACE将源表空间的所有对象导入到目标表空间中REMAP_TABLESPACE=source_tablespace:target:tablespace4.REUSE_DATAFILES该选项指定建立表空间时是否覆盖已存在的数据文件.默认为NREUSE_DATAFIELS={Y | N}5.SKIP_UNUSABLE_INDEXES指定导入是是否跳过不可使用的索引,默认为N6,sqlfile 参数允许创建DDL 脚本文件impdp scott/tiger directory=dump_scott dumpfile=a1.dmp sqlfile=c.sql 默认放在directory下,因此不要指定绝对路径7.STREAMS_CONFIGURATION指定是否导入流元数据(Stream Matadata),默认值为Y.8.TABLE_EXISTS_ACTION该选项用于指定当表已经存在时导入作业要执行的操作,默认为SKIPTABBLE_EXISTS_ACTION={SKIP | APPEND |TRUNCATE| FRPLACE }当设置该选项为SKIP时,导入作业会跳过已存在表处理下一个对象;当设置为APPEND时,会追加数据当设置为TRUNCATE时,导入作业会截断表,然后为其追加新数据;当设置为REPLACE时,导入作业会删除已存在表,重建表并追加数据,注意,TRUNCATE选项不适用与簇表和NETWORK_LINK选项9.TRANSFORM该选项用于指定是否修改建立对象的DDL语句TRANSFORM=transform_name:value[:object_type]transform_name用于指定转换名,其中SEGMENT_ATTRIBUTES用于标识段属性(物理属性,存储属性,表空间,日志等信息),STORAGE用于标识段存储属性,VALUE用于指定是否包含段属性或段存储属性,object_type用于指定对象类型.Impdp scott/tiger directory=dump dumpfile=tab.dmptransform=segment_attributes:n:table10.TRANSPORT_DATAFILES该选项用于指定搬移空间时要被导入到目标数据库的数据文件TRANSPORT_DATAFILE=datafile_nameDatafile_name用于指定被复制到目标数据库的数据文件Impdp system/manager DIRECTORY=dump DUMPFILE=tts.dmpTRANSPORT_DATAFILES=’/user01/data/tbs1.f’五、影响数据泵性能的相关参数对下列参数建议如下设置disk_asynch_io=truedb_block_checking=falsedb_block_checksum=false对下列参数建议设置更高的值来提高并发 processessessionsparallel_max_servers对下列参数应尽可能的调大空间大小shared_pool_size undo_tablespace。
数据泵导入建表

数据泵导入建表数据泵是Oracle数据库中的一个重要工具,通过该工具可以将数据从一个数据库传输到另一个数据库,同时还可以通过数据泵将数据库中的数据导出,并保存为一个文件,以备日后使用。
数据泵还可以被用来对表进行导入、导出和重建等操作。
在这篇文章中,我们将介绍如何使用数据泵导入建表。
步骤一:导出数据文件在进行数据导入之前,我们需要先将数据从源数据库导出。
可以使用数据泵的expdp命令将数据导出为一个dump文件。
例如,通过以下命令将指定的数据导出到个人电脑的F盘根目录:expdp system/oracle@orcl schemas=scottdumpfile=f:\scott.dmp其中,system/oracle是登录源数据库的用户名和密码;orcl是源数据库的服务名,schemas参数指定了要导出的Schema;dumpfile 指定了dump文件的保存路径和文件名。
步骤二:创建目录导出数据后,我们需要使用Oracle的SQL命令创建一个导入目录,以便在接下来的步骤中使用。
例如:SQL> create directory imp_dir as 'f:\';其中,imp_dir是导入目录的名称,f:\是导出的dump文件的保存路径。
步骤三:导入数据一旦目录被创建之后,我们就可以使用数据泵的impdp命令将数据导入到目标数据库中。
例如:impdp system/oracle@orcl directory=imp_dirdumpfile=scott.dmp schemas=scott remap_schema=scott:scott1 在此命令中,system/oracle是目标数据库的用户名和密码;orcl是目标数据库的服务名;directory指定了导入目录的名称;dumpfile指定了导出的dump文件的名称;schemas参数指定了要导入的schema;remap_schema参数可以让我们将导出时原本的schema名称修改为新的名称。
数据泵导入导出

在开始我就说了,这里没有指定Job name。 所以系统自动给我们生成了一个:SYS_EXPORT_FULL_02。
默认是从SYS_EXPORT_FULL_01开始,因为我之前有一个没有运行的Job,所以这里从2开始了。
3.1.2指定Job_name
[oracle@qs-dmm-rh2 ~]$ expdp \'/ as sysdba\' directory=backup full=y dumpfile=fullexp3.dmp logfile=fullexp3.log parallel=2 job_name=diriJob;
20 bl
11 rows selected.
3. 开始测试
3.1 FULL=Y全库导出
3.1.1不指定Job_name
[oracle@qs-dmm-rh2 ~]$ expdp \'/ as sysdba\' directory=backup full=y dumpfile=fullexp.dmp logfile=fullexp.log parallel=2;
******************************************************************************
Dump file set for SYS.SYS_EXPORT_FULL_02 is:
/u01/backup/fullexp.dmp
OWNER DIRECTORY_NAME DIRECTORY_PATH
----- ------------------------- ------------------------------------------------
数据泵导入导出步骤(从sqlplus登录到导入过程)

1、首先建立目录:create directory 目录名称as '数据库服务器上的一个目录',如:create directory 别名as 'd:\服务器目录名';将导入或导出的文件放在这个目录下2、导出及导入以SID=orcl,导出dmp的账号为test,导入dmp的账号为test为例。
若将数据从sfz中导出:expdp test/test@orcl directory=别名dumpfile=导出文件名导入到test中:impdp test/test@orcl directory=别名dumpfile=导出文件名.dmp导入到处用户名不一样时,做个映射,一样时,不用写remap_schema=test:test111g版本导出,导入到10g具体如下:导出脚本(11G):expdp test109/test109@orcl directory=expdp dumpfile=test10930bak.dmp logfile=mydb.log filesize=200m full=y version=10.2.0.1.0version号一定要哈导入脚本(10G):impdp shl1017/shl1017 directory=expdpdumpfile=TEST10930BAK.dmp version=10.2.0.1.0 REMAP_SCHEMA=test109:shl1017各参数对应的数据你根据自己的修改下2015-11-24下午数据泵方式导入zh.dmp过程:1、建立目录(expnc_dir为别名)create directory expnc_dir as 'E:\ncdatabak';2、导入数据impdp system/oracle@orcl directory=expnc_dir dumpfile=zh.dmp;3、根据错误日志文件(E:\ncdatabak目录下),建立用户、临时空间、用户空间a、删除用户及空间(再次导入的时候使用)drop user zh cascade;DROP TABLESPACE EAS_D_ZH_STANDARD INCLUDING CONTENTS AND DATAFILES;DROP TABLESPACE temp_zh INCLUDING CONTENTS AND DATAFILES;b、建立空间create tablespace EAS_D_ZH_STANDARDlogging datafile 'D:\app\Administrator\oradata\orcl\EAS_D_ZH_STANDARD.dbf'size 5gautoextend onnext 100m maxsize UNLIMITEDextent management local;c、建临时空间create temporary tablespace temp_zhtempfile 'D:\app\Administrator\oradata\orcl\temp_zh.dbf'size 100mautoextend onnext 32m maxsize UNLIMITEDextent management local;d、修改自动增长的太小alter database datafile 'D:\app\Administrator\oradata\orcl\EAS_D_ZH_STANDARD.dbf' autoextend on next 100m maxsize UNLIMITED;e、建用户create user zh identified by zhdefault tablespace EAS_D_ZH_STANDARDtemporary tablespace temp_zh;f、授权grant dba,connect,resource to zhg、导入数据impdpzh/zh directory=expnc_dir dumpfile=ZH.dmpremap_schema=zh:zhremap_tablespace=EAS_D_ZH_STANDARD:EAS_D_ZH_STANDARD(注意不带;)或impdp zh/zh@orcl directory=expnc_dir dumpfile=zh.dmp;注意:a、temp表空间不能自动扩展,所以建了一个有自动扩展的空间temp_zhb、出错的时候需要删除用户、表空间、临时空间再重新建立、再导入Oracle命令(一):Oracle登录命令()1、运行SQLPLUS工具C:\Users\wd-pc>sqlplus2、直接进入SQLPLUS命令提示符C:\Users\wd-pc>sqlplus /nolog3、以OS身份连接C:\Users\wd-pc>sqlplus / as sysdba 或SQL>connect / as sysdba4、普通用户登录C:\Users\wd-pc>sqlplus scott/123456 或SQL>connect scott/123456 或SQL>connect scott/123456@servername5、以管理员登录C:\Users\wd-pc>sqlplus sys/123456 as sysdba或SQL>connect sys/123456 as sysdba6、切换用户SQL>conn hr/123456注:conn同connect7、退出exitOracle数据导入导出imp/exp sp2-0734:未知的命令开头'imp 忽略了剩余行默认分类sp2-0734:未知的命令开头'imp 忽略了剩余行默认分类应该是在cmd的dos命令提示符下执行,而不是在sqlplus里面。
数据泵导入方法详解

extent management local autoallocate
segment space management auto;
---创建用户
CREATE USER FJK IDENTIFIED BY salis DEFAULT TABLESPACE FJK TEMPORARY TABLESPACE TEMP PROFILE DEFAULT;
---- 删除用户
drop user FJK cascade;
--删除表空间
DROP TABLESPACE FJK INCLUDING CONTENTS AND DATAFILES;
----创建表空间
create tablespace FJK
datafile 'E:\app\Administrator\oradata\yanhui\FJK.dbf' size 50M
---CMD导入数据库语句
impdp FJK/salis@YANHUI schemas=FJK directory=DMPDIR dumpfile=FJK.dmp logfile=FJK.log
GRANT CONNECT TO FJK;
GRANT DBA TO FJK;
GRANT RESOURCE TO FJK;
grant create any view to FJK;
GRANT CREATE ANY TABLE TO FJK;
GRANT SELECT ANY TABLE TO FJK;
GRANT COMMENT ANY TABLE TO FJK;
第25章 数据泵导出

数据泵备份与恢复
FLASHBACK_SCN:允许在导出数据库时使用数据库闪回特性,此 时EXPDP使用规定的SCN进行闪回。 FULL:说明是否导出整个数据库对象,如果该参数为Y,说明导出数 据库的所有对象。 INCLUDE:说明要导出的特定对象类型,此时会导出该参数指定的 对象和与它们有依赖关系的对象。 JOB_NAME:为了便于管理运行的EXPDP作业设置当前作业的名字。 系统默认的命名格式为sys_operation_mode_nn。如导出SCOTT 用户的元数据,此时的作业名字为 "SCOTT"."SYS_EXPORT_SCHEMA_01"。 LOGFILE:说明在导出操作时记录导出过程的日志文件名,其默认名 为export.log,和导出文件保存在相同的目录下,即directory参数 指定的目录。 PARALLEL:说明在导出作业时最大的线程数,实现导出作业的并行 处理。也可以在作业运行总使用ATTACH改变并行度,PARALLEL参 数的默认值为1,表示使用单线程导出单独个备份文件,如果设置多 个工作线程,则要指定相同数量的备份文件,这样多个线程可以同时 写多个备份文件。给出一个例子,设置并行度为2。
数据泵备份与恢复
交互式参数 ADD_FILE:向导出备份文件集中增加文件以增加目录空间。 如在一个作业运行期间输入CTRL+C组合键切换到交互式导出 提示EXPORT>。如果该作业因为备份文件的空间不足导致停 止,可以使用ADD_FILE命令增加文件到导出目录中。 Export>add_file = data_dump_dir:expdata02.dmp; STOP_JOB:停止运行的数据泵作业,数据库服务器端的导出 数据服务器进程终止。 START_JOB:重新恢复由于某种意外导致停止的数据泵作业。 KILL_JOB:杀死客户机进程和数据泵作业(服务器进程)。 CONTINUE_CLIENT:退出交互方式(EXPORT方式)恢复 正在运行地导出数据泵作业,实际的数据泵作业不受影响。 EXIT_CLIENT:停止交互式会话并终止客户机会话,但是实 际的数据泵作业不受影响,此时用户可以在当前窗口中继续其 他操作
数据泵导入导出

导出:Expdp work/work@lxgh DIRECTORY=DATA_PUMP_DIR DUMPFILE=test2.dmplogfile=test2.log导出的包目录,有二种方式可以找到,第一种方式最简单,导出完成后,最后会有导出包存放的目录,或查看日志也会有记录。
第二种方式是通过语句查询,用PLsql登录后,执行下面的语句:SELECT * FROM dba_directories;结果中查找DATA_PUMP_DIR对应的地址,就是导出包存放的位置了。
第二步:在需要导入的数据库中建好相应的表空间(一致),用户(一致)等,如果有就不需要执行此步骤。
第三步:导入数据用数据泵导入数据,先将导出的数据包放在需导入库的DATA_PUMP_DIR 对应的目录下,然后直接执行下面的语句就可以了:Impdp work/work@orcl DIRECTORY=DATA_PUMP_DIR DUMPFILE=xtdb.Dmpfull=y (这个是全部导入的语句)导入执行完后,也有相应的日志可以查看,导入是否成功。
如果日志报ORA-39082: Object type VIEW:"YXT"."V_ZK_CAPITALASSERTS" created with compilation warnings 这一类错误,就说明在导入过程中,有些函数、视图和存储过程编译失败,可以执行如下语句查看:select owner,object_name,object_type,statusFROM dba_objectswhere status !='VALID'and owner not in('SYS','SYSTEM')然后把编译失败的OBJECT重新编译,可以在SQLPLUS DEVELOP中右键点击重新编译,或者执行如下语句:alter function F_GET_COST_AMOUNT_DATE_ALL compile;alter PROCEDURE P_DR_ESTI_INCOMES_CDI_HOSP compile;即可解决备注:一定要在导入之前在库里建好相关的存贮过程,ORCLLNK和HRP_ZK_LINK以及HRLINK要不编译不过去而且报错。
Oracle数据泵方式导入导出

一、EXPDP和IMPDP使用说明Oracle Database 10g引入了最新的数据泵(Data Pump)技术,数据泵导出导入(EXPDP和IMPDP)的作用1)实现逻辑备份和逻辑恢复.2)在数据库用户之间移动对象.3)在数据库之间移动对象4)实现表空间搬移.二、数据泵导出导入与传统导出导入的区别在10g之前,传统的导出和导入分别使用EXP工具和IMP工具,从10g开始,不仅保留了原有的EXP和IMP工具,还提供了数据泵导出导入工具EXPDP和IMPDP.使用EXPDP和IMPDP时应该注意的事项:1) EXP和IMP是客户端工具程序,它们既可以在可以客户端使用,也可以在服务端使用。
2) EXPDP和IMPDP是服务端的工具程序,他们只能在ORACLE服务端使用,不能在客户端使用。
3) IMP只适用于EXP导出文件,不适用于EXPDP导出文件;IMPDP只适用于EXPDP导出文件,而不适用于EXP导出文件。
数据泵导出包括导出表,导出方案,导出表空间,导出数据库4种方式.【pump特点】与原有的export和import使用程序相比,oracle的data pump工具的功能特点如下:1) 在导出或者导入作业中,能够控制用于此作业的并行线程的数量。
2) 支持在网络上进行导出导入,而不需要是使用转储文件集。
3) 如果作业失败或者停止,能够重新启动一个data pump作业。
并且能够挂起恢复导出导入作业。
4) 通过一个客户端程序能够连接或者脱离一个运行的作业。
5) 空间估算能力,而不需要实际执行导出。
6) 可以指定导出导入对象的数据库版本。
允许对导出导入对象进行版本控制,以便与低版本数据库兼容。
三、导入导出操作1.导出数据1.1在数据库服务端,用system用户通过sqlplus命令登录到oracle,sqlplus logis/logis@logis_local;1.2在oracle中创建目录,如下:CREATE DIRECTORY LOGIS_EXP_DIR AS 'd:\data';注意:d:\data 这个目录必须是磁盘上实际存在的,可以是其他目录名称和路径。
数据泵导入导出操作方法

--设置为不限制密码效期
Alter Profile Default Limit Password_Life_Time Unlimited;
--在原服务器上导出数据泵数据
--完成后编译无效对象
grant exp_full_database to SYSTEM;
grant imp_full_database to SYSTEM;
--设置为不限制大小写
Alter System Set sec_case_sensitive_logon = false scope=both;
--设置为可以导出空表
execute DBMS_AUTO_TASK_ADMIN.DISABLE;
--设置为不限制大小写
Alter System Set sec_case_sensitive_logon = false scope=both;
--设置为可以导出空表
Alter System Set deferred_segment_creation=false scope=both;
---在原服务器(WINDOWN服务器)上D盘创建一个DataBak目录
sqlplus sys/oracle@orcl as sysdba
--创建数据泵目录
CreaaBak';
--授权用户
Grant read,write on directory dp to system;
--设置为不限制密码效期
Alter Profile Default Limit Password_Life_Time Unlimited;
Data pump数据泵导入导出

Data pump数据泵导入导出从oracle10g开始引入了data pump数据泵功能,它是一种基于服务器的数据提取和恢复的实用程序,与传统export和import使用程序相比其在功能和传输性能上有很大提升。
Data pump的所有工作通过数据库的实例来完成,可以通过建立多个Data pump工作进程来并行处理这些工作,提高导入导出性能;data pump工作在服务端,可以通过调整并行度来加快或减少资源消耗,同时可以快速装入或卸载数据。
使用data pump步骤如下:首先要为创建和读取的数据文件及日志文件创建一个目录,这个目录对应的是服务端的目录,同时,将要访问data pump文件的用户必须要拥有该目录的读写权限。
下面将创建一个名为BAK的目录,并授予system用户对此目录的读写权限。
同时需要在系统目录下创建相应的\u01\backup目录。
使用datapump导出方法有很多种,举两个常用例子:1)schema导出expdp [用户名]/[密码]@[主机字符窜] schemas=[用户名] directory=BAK dumpfile=xxx.dmp logfile=xxx.log2)数据库全库导出expdp [用户名]/[密码]@[主机字符窜] full=y directory=BAK dumpfile=xxx.dmp logfile=xxx.logdata pump导入1)schema导入impdp [用户名]/[密码]@[主机字符窜] schemas=[用户名] directory=BAK dumpfile=xxx.dmp logfile=xxx.log2)数据库全库导入impdp [用户名]/[密码]@[主机字符窜] full=y directory=BAK dumpfile=xxx.dmp logfile=xxx.log南京宝云教育。
数据泵导入语句

数据泵导入语句
1. 你知道数据泵导入语句有多神奇吗?就像魔法一样,能把大量数据瞬间转移!比如从一个数据库快速导入到另一个数据库中,哇塞,太厉害了吧!
2. 数据泵导入语句,这可是个厉害的家伙呀!就好比是数据世界里的搬运工,能把数据轻松挪来挪去。
就像把一堆文件从一个文件夹移到另一个文件夹那么简单,真的好神奇啊!
3. 嘿,你想过数据泵导入语句能带来多大的便利吗?简直就像是给数据插上了翅膀,让它们自由飞翔到该去的地方!比如把大量客户信息导入新系统,这效率,杠杠的!
4. 数据泵导入语句,那可真是个宝贝啊!它就像一把钥匙,能打开数据流动的大门。
比如说把旧系统的数据导入新系统,一下子就搞定了,多牛啊!
5. 哇哦,数据泵导入语句啊,这可是个超级实用的工具呢!就如同是数据海洋中的引航员,指引着数据准确到达目的地。
像把销售数据导入分析系统,太方便啦!
6. 数据泵导入语句,你可别小瞧它呀!它就像是一个神奇的魔法棒,轻轻一挥,数据就乖乖听话啦。
比如把员工信息导入人力资源系统,简单得很呢!
7. 嘿,数据泵导入语句是不是很厉害呢?简直就是数据迁移的小能手啊!就像把一堆玩具从一个箱子搬到另一个箱子,轻松加愉快!比如把产品数据导入电商平台,一下子就搞定咯!
8. 数据泵导入语句,那可真是太重要啦!它就像一条纽带,连接着不同的数据世界。
比如把库存数据导入管理系统,这作用,太大啦!
9. 哇,数据泵导入语句,这可真是个不可或缺的东西呀!它就像是数据世界里的快递员,使命必达。
像把财务数据导入报表系统,快速又准确!
10. 数据泵导入语句,你真的了解它的强大吗?它就像一个超级英雄,拯救数据于危难之中。
比如把用户数据导入新平台,厉害得不要不要的!。
使用数据泵方式导入导出oracle数据(不导出附件表)
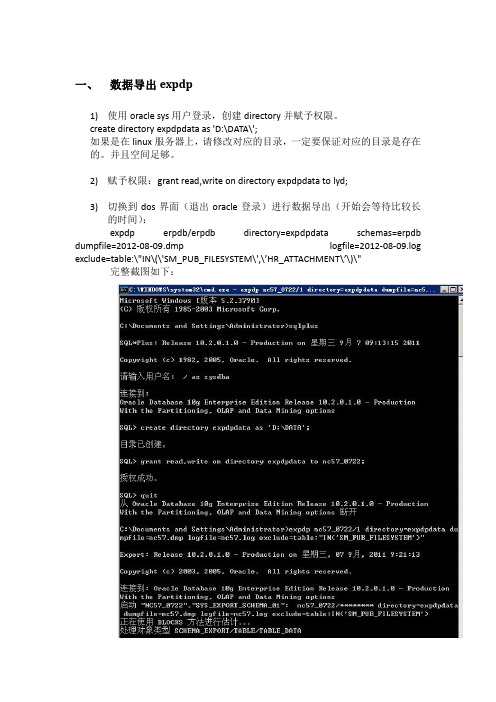
一、数据导出expdp1)使用oracle sys用户登录,创建directory并赋予权限。
create directory expdpdata as 'D:\DATA\';如果是在linux服务器上,请修改对应的目录,一定要保证对应的目录是存在的。
并且空间足够。
2)赋予权限:grant read,write on directory expdpdata to lyd;3)切换到dos界面(退出oracle登录)进行数据导出(开始会等待比较长的时间):expdp erpdb/erpdb directory=expdpdata schemas=erpdb dumpfile=2012-08-09.dmp logfile=2012-08-09.log exclude=table:\"IN\(\'SM_PUB_FILESYSTEM\',\’HR_ATTACHMENT\’\)\"完整截图如下:二、数据导入impdp导入时也需要和导出一样创建对应的目录和授权,将dmp文件放到创建的目录下。
1)导到指定用户下:impdp scott/tiger DIRECTORY=dpdata1 DUMPFILE=expdp.dmp SCHEMAS=scott;2)改变表的owner:impdp system/manager DIRECTORY=dpdata1 DUMPFILE=expdp.dmp TABLES=scott.dept REMAP_SCHEMA=scott:system;3)导入表空间:impdp system/manager DIRECTORY=dpdata1 DUMPFILE=tablespace.dmp TABLESPACES=example;4)导入数据库:impdb system/manager DIRECTORY=dump_dir DUMPFILE=full.dmp FULL=y;5)追加数据:impdp system/manager DIRECTORY=dpdata1 DUMPFILE=expdp.dmp SCHEMAS=system TABLE_EXISTS_ACTION=append;。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
数据泵备份与恢复
数据泵导入(IMPDP)数据库实例 (3)导入指定的表 使用IMPDP导入特定的表使用TABLES参数,该参数后是要导 入的表对象的列表,如果有多个表使用,逗号分隔。我们使用 了参数TABLE_EXISTS_ACTION参数,设置 TABLE_EXISTS_ACTION=REPLACE,如果该表存在则先删 除在加载数据。 例子25-38 导入特定的表对象。 D:\>impdp scott/tiger@orcl dumpfile=pump_dir:MYDB_TBS_USERSANDSYSTEM_ 01.DAT nologfile=y tables= emp table_exists_action=replace
数据泵备份与恢复
数据泵导入(IMPDP)数据库实例 (2)导入表空间 使用IMPDP导入特定的表空间时,需要有备份表空间文件,需要使用 TABLESPACES参数说明要导入的表空间名,此时实际上是导入表空 间中的所有数据库对象,当然这些工作都由IMPDP自己操作完成,由 于表空间中有表对象,如果当前的数据库中的表空间已有相应的表对 象,则最好告诉IMPDP该怎么做,此时需要参数 TABLE_EXITS_ACTION参数,它的默认值为SKIP即如果表已经存 在则跳过。我们建议使用REPLACE或TRUNCATE,前者表示重建表, 后者表示删除掉当前表中的数据,然后使用备份文件中的表数据进行 加载,但是会跳过所有相关元数据。如下例所示。 例子: 使用IMPDP导入特定的表空间 D:\>impdp system/oracle@orcl dumpfile=pump_dir:MYDB_TBS_USERSANDSYSTEM_01.DA T logfile= tablespaces=users table_exists_action=replace
数据泵备份与恢复
(3)导入作业参数 JOB_NAME:说明导入作业名,IMPDP提供了很多可管理性如停止 作业和恢复作业,附加(ATTACH)到特定的作业,都需要作业名来 关联导入作业。 PRALLEL:说明当前导入作业的线程数。该值的默认值为1。 STATUS:监视导入作业的状态频率,该参数的默认值为0 (4)导入方式参数 TABLES:说明允许导入指定的表,如果有多个表使用逗号分隔开, 同时也导入与这些表有依赖关系的对象,如索引、触发器和函数等。 SCHEMAS:说明要导入的模式列表,要使用该参数登录数据库的用 户必须拥有imp_full_database的权限。 TABLESPACES:说明要导入的表空间的列表,在导入这些表空间的 同时也要求导入与表空间有依赖关系的所有数据库对象。 FULL:说明要导入整个数据库。该参数的默认值为n。
数据泵备份与恢复
(9)交互模式参数 数据泵导入的交互参数和数据泵导出的交互参数功能是一样的,在数 据泵导入参数中没有ADD_FILE参数,它只对数据泵导出程序有效, 而其他参数以及切换到交互模式数据泵导入与导出是一样的。 PARALLEL:说明当前作业的活跃WORKER数量。 CONTINUE_CLIENT:在切换到交互模式后,返回记录模式。 EXIT_CLIENT:退出客户登录模式,但是不终止导入作业。 KILL_JOB:分离或删除当前导入作业。 START_JOB:在导入作业被意外终止后,可以重启或恢复当前作业。 STATUS:监视当前导入作业的状态,该参数是一个整数值,默认值 为0,如果设置STATUS=5,说明每5秒钟刷新一次导入作业的状态 信息。 STOP_JOB:关闭当前执行的作业并退出客户端,如果有多个导入作 业,则顺序关闭这些作业。如果设置STOP_JOB=IMMEDIATE将立 即关闭数据泵作业。
数据泵备份与恢复
数据泵导入(IMPDP)数据库实例 (1)导入整个数据库 导入整个数据库至少需要两个参数,一个是FULL,设置 FULL=Y说明是导入全库,一个是DUMPFILE,说明要导入的 备份文件的目录和名称,当然最好设置JOB_NAME参数,因为 它允许切换到交换模式,允许终止或重启导入会话。如下所示。 例子25-36 使用IMPDP导入整个数据库 D:\>impdp system/oracle@orcl dumpfile=pump_dir:full_db_%u.dat logfile=myfulldb.log parallel= 3 job_name=my_fulldb_impdp full =y
数据泵备份与恢复
(6)转换参数 TRANSFORM:该参数说明在导入数据泵作业时可以选择导入某个对象的存 储参数或其他属性值,如导入表时,不导入该表的存储属性等。 TRANSFORM参数的语法如下所示: TRANSFORM= transform_name:value[:object_type] 下面我们介绍各个部分: 1、transform_name:转换名由四个选项组成,代表四种基本的对象特征。其中 SEGMENT_ATTRIBUTES段属性包括物理属性、存储参数、表空间等,该参 数的值为Y或N,如果选择SETMENT_ATTRIBUTES=Y则说明导入作业包括 对象的这些属性;STORAGE存储属性说明是否导入对象的存储属性,如果 STORAGE=Y说明对象的存储属性作为导入作业的一部分。OID说明是否分 配新的OID给对象表。PCTSPACE:提供一个正数值,可以增加对象的分配 尺寸。 2、value:转换名的值中前三个值即SEGMENT_ATTRIBUTES、STORAGE和 OID默认值为Y,说明默认数据泵导入对象的存储属性,和段属性。而 PCTSPACE取一个正数值。 3、object_type:对象类型说明需要转换那些类型的对象,这些类型包括表、索 引、表空间以及约束等。
数据泵备份与恢复
数据泵导入参数 (2)过滤参数 INCLUDE:说明要导入的特定对象,如只导入表,此时会导入和导入特定对象有依赖关 系的对象如索引、触发器等。 下面是使用INCLUDE参数的例子,说明只允许导入表对象,且只有两个表可以导入。 INCLUDE=TABLE: "IN (‘EMP’,’DEPT’) " 也可以使用QUERY参数过滤要导入的表数据,此时数据泵导入作业使用外部表数据方法 访问数据,而不是采用直接路径方法。如下所示。 INCLUDE=TABLE: "IN (‘EMP’,’DEPT’) " QUERY=EMP: "WHERE sal>3000 ORDER BY sal" TABLE_EXITS_ACTION:该参数说明当导入的表已经存在时,IMPDP导入程序的行 为,参数TABLE_EXITS_ACTION有四个值,SKIP表示如果该表存在则跳过该表,它 是默认值;APPEND将导入的数据行附加到当前存在的表中;TRUNCATE截断表并从导 入数据文件中重新装载数据;REPLACE删除存在的表然后重建该表并导入数据。 EXCLUDE:在导入操作中排除特定的元数据,如不导入特定的表,此时也不会导入和 排除对象有依赖关系的其他对象。如下所示告诉IMPDP程序不导入表EMP和DEPT。
数据泵备份与恢复
数据泵导入(IMPDP)概述及参数含义 Oracle数据泵导入实用程序(IMPDP)将备份的数据导入到整 个数据库、特定的模式、特定的表或者特定的表空间,使用 IMPDP也可以在不同平台的数据库之间迁移表空间。IMPDP实 用程序通过各种参数支持对数据过滤以及对元数据的过滤,而 元数据的过滤可以有效控制要导入的对象类型,如导入表、索 引还是授权等等。 使用数据泵导入实用程序与数据泵导出实用程序一样可以使用 DIRECTORY、PARFILE、DUMPFILE和LOGFILE等参数,但 是正如ADD_FILE是数据泵导出EXPDP实用程序专有的一样, SQLFILE参数也是数据泵导入IMPDP实用程序所专有的。在执 行数据泵导入作业时,往往需要从备份数据文件中途提取DDL 语句,此时需要使用SQLFILE。
数据泵备份与恢复
数据泵导入参数 (1)目录和文件相关参数 DIRECTORY:说明备份文件、日志文件和SQL文件的目录对象,如果没有定 义目录,则会使用PUMP_DIR的默认值。 DUMPFILE:说明备份文件名,如导入数据时需要多个备份文件,则用逗号 分隔这些文件名,在DUMPFILE参数后可以使用包括目录,如 DUMFILE=PUMP_DIR:BACKUP.DMP,也可以使用替换变量(%U)告诉 IMPDP可以使用多个备份文件。如 DUMPFILE=PUMP_DIR:BACKUP_%U.DMP。 PARFILE:说明参数文件,IMPDP使用外部定义一个参数文件执行导入行为, 该参数文件是本地的,使用时需要告诉IMPDP参数文件的绝对位置。如 D:\IMPDP SYSTEM/ORACLE@ORCL PARFILE=D:\PAR\EXP.PAR LOGFILE:说明使用日志文件保存导入过程的信息,该参数的值是日志文件 的名字名,如LOGFILE =MYLOG.LOG。 NOLOGFILE:说明不使用日志文件记录导入过程,如NOLOGFILE=Y。 SQLFILE:说明从备份文件中提取SQL的DDL语句,并写入该参数设置的文 件中,如SQLFILE=MYSQLFILE.SQL。该文件默认保存在DIRECTORY参 数设置的目录对象中。
数据泵备份与恢复
数据泵导入(IMPDP)数据库实例 (4)导入指定的数据库对象 导入特定的数据库对象使用INCLUDE参数,该例 子中我们从备份文件中恢复SCOTT用户的所有表 和触发器对象,而对于已经存在的表则重建再加载 数据。 D:\>impdp scott/tige_USERSAND SYSTEM_01.DAT nologfile=y include=table,trigger table_exists_action=replace
数据泵备份与恢复
(5)重新映射参数 重新映射使得在数据导入过程中将数据从一个数据库对象移动到另一个数据库对象,可 以映射模式,映射数据文件和映射表空间,映射可以理解为“数据对象移动”。 REMAP_SCHEMA:重新映射模式,可以将对象从一个模式移动到另一个模式, D:\>impdp system/oracle@orcl dumpfile =pump_dir:SHCEMA_SCOTT.DMP remap_schema=scott:linzi 上例将SCOTT模式下的所有数据库对象移动到LINZI模式下,这样使用LINZI模式登录 数据库,就可以使用SCOTT用户的所有数据库对象。我们通过下例验证重映射模式的结 果。 REMAP_DATAFILE:在导入数据时,重新定义数据文件的名称和目录。如下所示。 D:\impdp system/oracle@orcl directory=pump_dir dumpfile=backup_full.dmp remap_datafile='c:\mydb.dbf':'d:\mydb\newdb.dbf REMAP_TABLESPACE:重映射表空间使得将数据对象从一个表空间移动到另一个表空 间。如下所示。 D:\impdp system/oracle@orcl remap_tablespace='users':'mynewusers' directory=pump_dir dumpfile=backup_full.dmp