总体参数的区间估计
简述区间估计的原理和依据

简述区间估计的原理和依据区间估计是统计学中一种常用的推断方法,用于估计总体参数的范围。
它基于样本数据,通过构造一个区间来估计总体参数。
区间估计的原理和依据主要包括置信水平、抽样分布以及中心极限定理。
区间估计的原理基于置信水平的概念。
置信水平是指在重复抽样的情况下,置信区间包含真实总体参数的频率。
常用的置信水平有95%和99%。
例如,当我们使用95%置信水平进行区间估计时,意味着在一百次的抽样中,有95次的置信区间覆盖了真实总体参数。
置信水平越高,区间估计的可靠性越高,但估计的范围也会更大。
区间估计的依据是抽样分布的性质。
在统计学中,我们通常假设样本是从一个符合某种分布的总体中独立抽取得到的。
根据中心极限定理,当样本容量较大时,样本均值的抽样分布近似服从正态分布。
这一性质使得我们可以利用样本均值的分布来进行总体参数的区间估计。
以均值为例,当我们知道样本均值的抽样分布是正态分布时,可以根据该分布的特性计算出一个区间,使得该区间内的样本均值有很高的概率与总体均值接近。
区间估计的步骤一般包括以下几个步骤:1. 确定置信水平:根据具体问题和需求,选择适当的置信水平。
一般常用的置信水平为95%和99%。
2. 收集样本数据:通过抽样方法,收集样本数据。
样本数据应该具有代表性,能够反映总体的特征。
3. 计算样本统计量:根据所需的参数,计算样本统计量,如样本均值、样本比例等。
4. 确定抽样分布:根据中心极限定理,确定样本统计量的抽样分布。
通常情况下,样本均值的抽样分布近似服从正态分布。
5. 构造置信区间:根据抽样分布的性质,计算出一个区间,使得该区间内的样本统计量有较高的概率包含总体参数。
一般情况下,使用样本统计量加减一个标准误差的倍数作为置信区间的边界值。
6. 解释结果:将置信区间的结果进行解释,例如可以说“在95%的置信水平下,总体参数的估计值位于计算得到的置信区间内”。
区间估计是一种基于样本数据进行总体参数估计的方法。
区间估计

常见形式
间估计的区间上、下界通常形式为:“点估计±误差” “总体均值”的区间估计
总体均值:μ 总体方差:σ 样本均值:x =(1/n)×Σ(Xi) 样本方差:s =(1/(n-1))×Σ(Xi-x)^2 符号假设置信水平:1-α 显著水平:α
已知n个样本数据Xi (i=1,2,...,n),如何估计总体的均值? 首先,引入记号: 区间估计σ'=σ/sqrt(n) s'=s/sqrt(n) 然后,分情况讨论: 情况1 小样本(n<30),σ已知,此时区间位于 x ± z(α/2)×σ' 情况2 小样本(n<30),σ未知,此时区间位于 x ± t(α/2)×s' 区间估计情况3 大样本(n≥30),σ已知,此时区间位于 x ± z(α/2)×σ' 情况4 大样本(n≥30),σ未知,此时区间位于 x ± z(α/2)×s' 其中, z(α/2)表示:正态分布的水平α的分位数 t(α/2)表示:T分布的水平α的分位数
置信区间
区间估计有时,对所考虑的置信区间(或上、下限)加上某种一般性限制,在这个前提下寻找最优者。无偏 性是经常用的限制之一,如果一个置信区间(上、下限)包含真值θ的概率,总不小于包含任何假值θ┡的概率, 则称该置信区间(上、下限)是无偏的。同变性(见统计决策理论)也是一个常用的限制。
求置信区间的方法 最常用的求置信区间及置信上、下限的方法有以下几种。
即
费希尔把这个等式解释为:在抽样以前,对于θ落在区间内的可能性本来一无所知,通过抽样,获得了上述 数值,它表达了统计工作者对这个区间的"信任程度",若取b)=-α=uα/2,则得到区间,其信任程度为 1-α。即 当用上述区间作为θ的区间估计时,对于“它能包含被估计的θ”这一点可给予信任的程度为1-α。
吴喜之-统计学基本概念和方法-总体参数的区间估计

x
s
n
15
2
53.87
样本标准差 误差边际
( x x)
n 1
s 6.82 x t 2 2.145* 3.78 n 15
651.73 6.82 14
95%的置信区间为
53.87 ±3.78
即(50.09,57.65)天。
确定样本容量
确定样本容量 误差边际 Z x 2 n
根据选择的在 x1 、x2 、x3
位置的样本均值建立的区间
x 的抽样分布
x 2
95%的所有x的值
3.92 3.92
x1
基于x2 3.92的 区间
基于x1 3.92的 区间
x3
x2
基于x3 3.92的区间(该区间不包含)
上图中,有95%的样本均值落在阴影部分,这个区域的样本 均值±3.92的区间能够包含总体均值。
因此,总体均值的区间的含义为,我们有95%的把握认为, 以样本均值为中心的±3.92的区间能够包含总体均值。 通常,称该区间为置信区间,其对应的置信水平为 1 置信区间的估计包含两个部分:点估计和描述估计精确度 的正负值。也将正负值称为误差边际或极限误差,反映样本估 计量与总体参数之间的最大误差范围。 总结: 已知时的大样本下的区间估计
•
•
q=1-p
n表示样本容量(试验重复次数)
总体比率的区间估计
• 以比率的抽样分布为理论依据,按一定的概
率要求估计总体比率的所在范围就叫做总体比率
的区间估计。
正态近似法
• 当样本容量n比较大,np和nq中较小的那个数
等于或大于5时,二项分布已经接近于正态分布,
此时可以按照正态分布来估计总体比率0.95和
总体参数的区间估计必须具备的三个要素

一、概述总体参数的区间估计是统计学中一个重要的概念,在实际应用中具有广泛的应用。
区间估计的目的是利用样本数据对总体参数进行估计,以确定参数的取值范围。
在进行区间估计时,需要考虑三个重要的要素,以确保估计结果的准确性和可靠性。
二、总体参数的定义在统计学中,总体参数指的是对整个总体的某一特征进行描述的指标。
例如总体均值、总体比例等。
总体参数通常是未知的,需要通过样本数据来进行估计。
区间估计就是利用样本数据对总体参数进行估计,给出一个区间,以确定参数的取值范围。
三、区间估计的三个要素1. 置信水平置信水平是区间估计中非常重要的一个要素。
它指的是对总体参数估计的准确程度的度量,通常用1-α来表示,其中α称为显著性水平,通常取0.05或0.01。
置信水平越高,说明对总体参数的估计越可信。
在实际应用中,常用的置信水平为95或99。
2. 样本容量样本容量是另一个影响区间估计结果的重要要素。
样本容量的大小直接影响了估计结果的精确度。
通常来说,样本容量越大,估计结果越精确。
在进行区间估计时,一般需要根据置信水平和总体参数的方差来确定合适的样本容量。
3. 统计分布在进行区间估计时,需要考虑所使用的统计分布。
常用的统计分布包括正态分布、t分布、F分布等。
选择合适的统计分布对区间估计的结果具有重要影响。
通常在实际应用中,根据样本容量和总体参数的分布情况来选择合适的统计分布。
四、区间估计的计算方法区间估计的计算方法通常包括以下几个步骤:1. 确定置信水平,通常取95或99。
2. 根据置信水平和总体参数的分布情况,选择合适的统计分布。
3. 根据样本数据计算得到统计量的值。
比如样本均值、样本比例等。
4. 根据统计量的值,计算得到区间估计的上限和下限。
通常使用公式:点估计值±临界值×标准误差。
五、实际应用区间估计在实际应用中具有广泛的应用,比如医学研究、市场调研、经济预测等领域。
在这些领域中,通常需要对总体参数进行估计,以确定参数的取值范围。
7.8 两个正态总体参数的区间估计

2 1
2 2
)
1
nm
因此,均值差1−2的置信水平1−α的置信区间为
(( X Y ) z 2
2 1
n
2 2
m
,(X
Y
)
z
2
2 1
2 2
)
nm
两个正态总体参数的区间估计
2.均值差1−2的置信区间 (方差12 =22 = 2,但 2 未知情形)
易知 ( X Y ) (1 2 ) ( X Y ) (1 2 ) ~ N (0,1)
枢轴量 T X Y (1 2 ) ~ t(n m 2)
S 1 n 1 m
根据 t分布的性质,取分位数tα/2 (n+m−2) 有
P{|
X Y (1 2 )
S 1 n 1 m
|
t
2(n
m
2)}
1
因此,均值差1−2的置信水平1−α置信区间为
2
(2n)=
2 0.05
(18)=28.869,12
2 (2n)
2 0.95
(18)
9.39
计算得:2nX 1062 1/λ 的置信水平为0.90的置信区间为 ( 1062 , 1062) (36.787,113.099)
28.869 9.39
两个正态总体参数的区间估计
2
,
2 2
m
)
由正态分布的性质可得
X
Y
~
N (1
2
,
2 1
总体参数的区间估计

三、总体参数的区间估计
图5-10 “探索”对话框
图5-11 “探索:统计量”对话框
三、总体参数的区间估计
单击“统计量”按钮,弹出“探索:统计量”对话框,如图5-11所示。 该对话框中有如下四个复选框: (1)描述性:输出均值、中位数、众数、标准误、方差、标准差、极小值 、极大值、全距、四分位距、峰度系数和偏度系数的标准误差等。此处能够设 置置信区间,默认为90%(α=0.1),可根据需要进行调整。 (2)M 最大似然确定数。 (3)界外值:输出五个最大值和五个最小值。 (4)百分位数:输出第5%、10%、25%、50%、75%、90%、95%位数 。
三、总体参数的区间估计
【例5-17】 某餐馆随机抽查了50位顾客的消费额(单位:元)为 18 27 38 26 30 45 22 31 27 26 35 46 20 35 24 26 34 48 19 28 46 19 32 36 44 24 32 45 36 21 47 26 28 31 42 45 36 24 28 27 32 36 47 53 22 24 32 46 26 27 在90%的概率保证下,采用点估计和区间估计的方法推断餐馆顾客的平均消 费额。 解:执行“分析”→“描述统计”→“探索”命令,打开“探索”对话框。由于本例只 有消费额一个变量,且需要对消费额进行探索性分析,故选中左侧列表框中的“消 费额”选项,将其移入“因变量列表”框中,如图5-10所示。
解:已知n=31,α=0.01,=10.2;σ=2.4,z0.005=2.58,由于总 体方差已知,为大样本,可以利用式(5-23)来进行计算。
即(9.088,11.312 该学生每天的伙食费在显著性水平为99%时的置信区间为( 9.088,11.312)。
区间估计法估测总体平均值

区间估计法估测总体平均值
区间估计是一种统计方法,可以用来估计总体参数的值,其中之一是总体平均值。
区间估计法估测总体平均值的过程如下:
首先,我们需要收集一个来自总体的简单随机样本,并计算样本平均值$\bar{x}$ 和样本标准差$s$。
然后,我们可以使用以下公式来计算总体平均值$\mu$ 的区间估计:
$$ \bar{x} \pm t_{\alpha/2} \frac{s}{\sqrt{n}} $$
其中,$n$ 是样本容量,$t_{\alpha/2}$ 是自由度为$n-1$ 的$t$ 分布表中$\alpha/2$ 处的t 值。
$\alpha$ 是置信水平,通常取0.95 或0.99。
上述公式表示,我们可以通过样本平均值$\bar{x}$ 加减一个误差范围来估计总体平均值$\mu$。
误差范围的计算方法是:$t_{\alpha/2} \frac{s}{\sqrt{n}}$。
其中,$t_{\alpha/2}$ 表示在给定置信水平下,自由度为$n-1$ 的$t$ 分布表中的t 值,$s$ 是样本标准差,$\sqrt{n}$ 是样本容量的平方根。
最后,我们可以得到置信水平为$\alpha$ 的总体平均值的区间估计为:
$$ (\bar{x} - t_{\alpha/2} \frac{s}{\sqrt{n}},\ \bar{x} + t_{\alpha/2}
\frac{s}{\sqrt{n}}) $$
这个区间包含了总体平均值$\mu$ 的真实值的可能性为$1-\alpha$,其中$\alpha$ 是在计算过程中预先指定的置信水平。
专题20 单个总体参数的区间估计

解:(1)总体N , 2 的的置信水平为1的双侧
置信区间分两种情况:
2已知时,为 X
n
z 2 , X &#
t
2
它们都关于X 对称,所以
(n 1), X + 区间长度
S n
t
2 (n
1)
11.46 7.54
置信下限 9.5 (11.46 9.5) 7.54; 3.92. 17
本X1,..., X n的观测值,若样本均值x 9.5,且参数
的置信水平为1 的双侧置信区间的置信上限
为11.46.(其中(1.96) 0.975) (1)求该双侧置信区间的置信下限及区间长度l;
(2)若已知 4,为使双侧置信区间的置信度达
到0.95, 且区间长度不超过l,求最小样本容量n.
16
22
总结: (1)正确理解置信区间的含义, (2)正确运用置信区间的公式
确定参数
2已知 2未知
的置信区间.
2
23
21
解:总体X ~ B(1, p),均值 p,方差 2 p(1 p), p的置信度为1 的近似置信区间为
X z /2S / n , X z /2S / n
n
650,
pˆ
x
52 650
0.08,
s2
pˆ (1
pˆ )
0.0736,
查表知 z0.025 1.96,代入得(0.059,0.101).
常取a 和b 满足
P此(G时( X,1,P...,XˆL
n
(
; ) a)
X1,, X
n)
P(G(X11,...,2X,
n
;
)
b)
2
.
参数估计之点估计和区间估计

作者 | CDA数据分析师参数估计(parameter estimation)是根据从总体中抽取的样本估计总体分布中包含的未知参数的方法。
人们常常需要根据手中的数据,分析或推断数据反映的本质规律。
即根据样本数据如何选择统计量去推断总体的分布或数字特征等。
统计推断是数理统计研究的核心问题。
所谓统计推断是指根据样本对总体分布或分布的数字特征等作出合理的推断。
它是统计推断的一种基本形式,分为点估计和区间估计两部分。
一、点估计点估计是依据样本估计总体分布中所含的未知参数或未知参数的函数。
简单的来说,指直接以样本指标来估计总体指标,也叫定值估计。
通常它们是总体的某个特征值,如数学期望、方差和相关系数等。
点估计问题就是要构造一个只依赖于样本的量,作为未知参数或未知参数的函数的估计值。
构造点估计常用的方法是:①矩估计法,用样本矩估计总体矩②最大似然估计法。
利用样本分布密度构造似然函数来求出参数的最大似然估计。
③最小二乘法。
主要用于线性统计模型中的参数估计问题。
④贝叶斯估计法。
可以用来估计未知参数的估计量很多,于是产生了怎样选择一个优良估计量的问题。
首先必须对优良性定出准则,这种准则是不唯一的,可以根据实际问题和理论研究的方便进行选择。
优良性准则有两大类:一类是小样本准则,即在样本大小固定时的优良性准则;另一类是大样本准则,即在样本大小趋于无穷时的优良性准则。
最重要的小样本优良性准则是无偏性及与此相关的一致最小方差无偏估计,其次有容许性准则,最小化最大准则,最优同变准则等。
大样本优良性准则有相合性、最优渐近正态估计和渐近有效估计等。
下面介绍一下最常用的矩估计法和最大似然估计法。
1、矩估计法矩估计法也称“矩法估计”,就是利用样本矩来估计总体中相应的参数。
它是由英国统计学家皮尔逊Pearson于1894年提出的,也是最古老的一种估计法之一。
对于随机变量来说,矩是其最广泛,最常用的数字特征,主要有中心矩和原点矩。
由辛钦大数定律知,简单随机样本的原点矩依概率收敛到相应的总体原点矩,这就启发我们想到用样本矩替换总体矩,进而找出未知参数的估计,基于这种思想求估计量的方法称为矩法。
参数的区间估计

参数的区间估计1. 参数的概念参数是指一种描述总体特性的量,通常用符号表示。
以样本均值为例,我们通常用$\bar{x}$表示样本均值,用$\mu$表示总体均值,$\bar{x}$就是关于$\mu$的一个参数。
2. 区间估计的基本思想区间估计是通过样本的统计量来估计总体的参数,因为样本数据毕竟是有限的,所以估计值与真实值之间必然存在误差。
为了消除这种误差,我们采用确定一个区间的方法,即“置信区间”。
置信区间是指用样本数据计算出来的一个范围,其含义是真实的总体参数值有一定的置信水平(置信度)落在这个区间内。
①确定信赖水平(置信度)$1-\alpha$,$\alpha$称为显著性水平。
②根据样本均值选择合适的经验公式或理论公式来计算样本估计量的标准误差。
③根据置信度$1-\alpha$,查找$t$分布表或正态分布表,得到置信水平为$1-\alpha$的$t$值或$z$值。
④根据样本容量和总体方差是否已知,确定区间估计公式。
⑤根据置信度和样本数据计算出置信区间。
下面具体介绍区间估计的步骤:A. 确定总体所服从的概率分布总体可以服从正态分布、泊松分布、二项分布等概率分布,其中正态分布是最为常用的一种分布。
B. 确定样本容量$n$样本容量$n$的大小直接影响到置信区间的精度,当样本容量越大,置信区间的长度就越短。
一般观测数据越多,则样本容量越大。
C. 确定置信度$1-\alpha$置信度是指总体参数落在某一特定区间内的概率,一般取$95\%$或$99\%$。
D. 求出样本均值$\bar{x}$样本均值$\bar{x}$是样本中所有元素值的总和除以样本容量$n$,即$\bar{x}=\frac{\sum_{i=1}^nx_i}{n}$E. 求出样本方差$s^2$若总体标准差未知,用样本标准差$s$代替,$S(\bar{x})=\frac{s}{\sqrt{n}}$G. 选择合适的分布当总体服从正态分布,$\frac{\bar{x}-\mu}{\frac{\sigma}{\sqrt{n}}}$服从标准正态分布;当总体未知且样本容量$n$较小($n<30$),$\frac{\bar{x}-\mu}{\frac{s}{\sqrt{n}}}$服从$t$分布。
区间估计在统计学中的重要性解析

区间估计在统计学中的重要性解析统计学是一门应用广泛的学科,它研究如何收集、整理、分析和解释数据。
在统计学中,区间估计是一种重要的方法,用于估计总体参数的范围。
本文将对区间估计的概念、应用和重要性进行解析。
一、区间估计的概念区间估计是统计学中一种用于估计总体参数的方法。
总体参数是指用于描述总体特征的数值,例如总体均值、总体比例等。
由于总体参数很难直接获得,因此需要通过样本来进行估计。
区间估计通过样本统计量和抽样分布的性质,给出一个参数范围,称为置信区间,该区间内有一定的概率包含真实的总体参数值。
二、区间估计的应用区间估计在实际应用中具有广泛的用途。
例如,在医学研究中,研究人员可以利用区间估计来估计某种药物的治疗效果。
他们可以通过随机选择一部分患者,给予药物治疗,并通过对比实验组和对照组的数据,利用区间估计来估计药物的疗效范围。
在市场调研中,区间估计也被广泛应用。
研究人员可以通过抽取一部分消费者的意见和反馈,利用区间估计来估计市场上某种产品的受欢迎程度。
这样可以帮助企业制定更加准确的市场策略。
三、区间估计的重要性区间估计在统计学中具有重要的地位和作用。
首先,区间估计提供了一个参数范围,而不是一个点估计。
这样可以更加客观地反映估计的不确定性。
如果只提供一个点估计,可能会忽略了估计的误差范围,导致结果的不准确。
其次,区间估计可以通过置信水平来控制估计的准确性。
置信水平是指在重复抽样下,置信区间包含真实参数的概率。
常见的置信水平有95%和99%。
通过选择不同的置信水平,可以控制估计的准确性和可靠性。
此外,区间估计还可以用于假设检验。
假设检验是统计学中常用的方法,用于判断样本数据是否支持某个假设。
在假设检验中,可以利用区间估计来判断总体参数是否在某个范围内。
如果置信区间与假设的范围重叠,说明数据支持该假设;反之,说明数据不支持该假设。
最后,区间估计还可以帮助决策者进行决策。
在实际应用中,决策者往往需要面对不确定性和风险。
正态总体参数的区间估计

总体均值μ的区间估计是一种基于抽样 调查的方法,通过样本均值和标准差 来估计总体均值的范围,常用t分布或z 分布计算置信区间。
详细描述
在进行总体均值μ的区间估计时,首先 需要收集样本数据,计算样本均值和 标准差。然后,根据样本数据的大小 和置信水平,选择适当的分布(如t分 布或z分布)来计算置信区间。最后, 根据置信区间的大小和分布特性,可 以得出总体均值μ的可能取值范围。
正态分布的性质
集中性
正态分布的曲线关于均值μ对称。
均匀变动性
随着x的增大,f(x)逐渐减小,但速 度逐渐减慢。
随机变动性
在μ两侧对称的位置上,离μ越远, f(x)越小。
正态分布在生活中的应用
金融
正态分布在金融领域的应用十分 广泛,如股票价格、收益率等金 融变量的分布通常被假定为正态 分布。
生物医学
THANKS
感谢观看
实例二:总体方差的区间估计
总结词
在正态分布下,总体方差的区间估计可以通过样本方 差和样本大小来计算。
详细描述
当总体服从正态分布时,根据中心极限定理,样本方差 近似服从卡方分布。因此,总体方差σ²的置信区间可以 通过以下公式计算:$[s^2 cdot frac{n - 1}{n} cdot F^{-1}(1 - frac{alpha}{2}), s^2 cdot frac{n - 1}{n} cdot F^{-1}(1 - frac{alpha}{2})]$,其中$s^2$是样本 方差,$n$是样本容量,$F^{-1}$是自由度为1的卡方 分布的逆函数,$alpha$是显著性水平。
详细描述
当总体服从正态分布时,根据中心极限定理,样本均值 近似服从正态分布。因此,总体均值μ的置信区间可以通 过以下公式计算:$[bar{x} - frac{s}{sqrt{n}} cdot Phi^{-1}(1 - frac{alpha}{2}), bar{x} + frac{s}{sqrt{n}} cdot Phi^{-1}(1 - frac{alpha}{2})]$,其中$bar{x}$是样 本均值,$s$是样本标准差,$n$是样本容量,$Phi^{1}$是标准正态分布的逆函数,$alpha$是显著性水平。
7.9 单正态总体参数的区间估计(1)

概率论与数理统计
07
参数估计
问题
如何让与θ的误差体现在估计中?ˆθ•湖中鱼数的真值[ ]对给定的置信水平(置信度)1-α
办法称为未知参数θ的置信度为1-α的置信区间.12
ˆˆ(,)θθ置信下限(X 1, X 2, …, X n )和置信上限(X 1, X 2, …, X n )1ˆθ2
ˆθ12
ˆˆ()1P θθθα<<≥−使含义若1-α=0.95,抽样100次中约有95个包含θ.12
ˆˆ(,)θθ
单个正态总体均值的区间估计σ2已知μ的置信度为1-α的置信区间为2~(,)
X N n
σμ/2()1/X P u n
αμασ−<=−/2/2()1P X u X u n n αασσμα−<<+=−/2/2(,);X u X u n n αασσ−+/2()
X u n ασ±2~(0,1)n X N σμ−
➢置信区间长度注➢相同置信水平下,置信区间选取不唯一.
l = 2σn u α/2 /2/2(,)
X u X u n n αασσ−+单个正态总体均值的区间估计
例滚珠直径X ~N (μ, 0.0006),从某天生产的滚珠中随机抽取6个,测得直径为(单位:mm) 1.46 1.51 1.49 1.48 1.52 1.51
求μ 的置信度为95%的置信区间.解/2/2(,)
X u X u n n αασσ−+单个正态总体均值的区间估计
1.495x =,0.05α=,
0.05/20.025 1.96u u ==0.0006(1.495 1.96)6±⨯(1.4754,1.5146)=。
正态总体参数的区间估计
, 0
2
2 ( 1 , ) 2
已知
≥0
2
2
2
2
2
( n 1)
( n 1)
]
正态总体均值和方差的假设检验 检 验 法
H H
0
1
检验统计量
自 由 度
拒绝域
| |
2
条件
0
≠ 0
> 0 < 0
=
x 0
μ
检 验
≤ 0
≥ 0
0
n
0
, 0
2
已知
0
| t | t
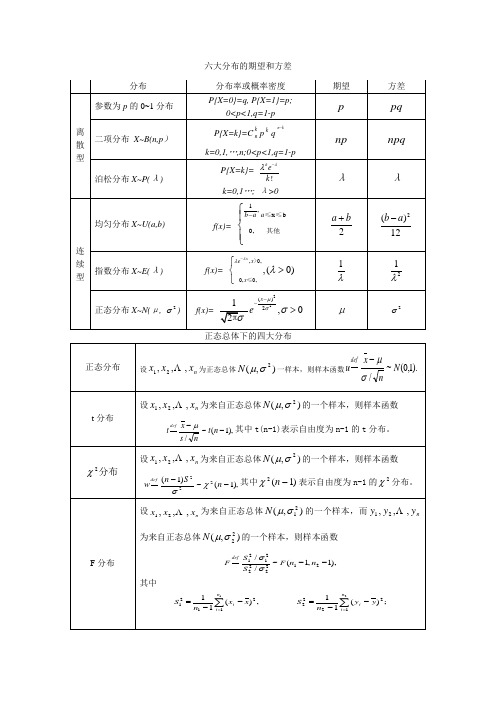
六大分布的期望和方差 分布 参数为 p 的 0~1 分布 离 散 型 分布率或概率密度 P{X=0}=q, P{X=1}=p; 0<p<1,q=1-p P{X=k}=C n p q k=0,1,…,n;0<p<1,q=1-p 泊松分布 X~P(λ ) P{X=k}=
e
k
期望
方差
p np λ
设 x 1 , x 2 , , x n 为来自正态总体 N ( , ) 的一个样本,则样本函数
2
t 分布
def
t
x s/ n
~ t ( n 1 ),
其中 t(n-1)表示自由度为 n-1 的 t 分布。
2
设 x 1 , x 2 , , x n 为来自正态总体 N ( , ) 的一个样本,则样本函数
n
μ = t=
(x )
(x ) s ( n 1) s
2
[x u [x t [
2
正态总体参数的区间估计

第19讲 正态总体参数的区间估计教学目的:理解区间估计的概念,掌握各种条件下对一个正态总体的均值和方差进行区间估计的方法。
教学重点:置信区间的确定。
教学难点:对置信区间的理解。
教学时数: 2学时。
教学过程:第六章 参数估计§6.3正态总体参数的区间估计1. 区间估计的概念我们已经讨论了参数的点估计,但是对于一个估计量,人们在测量或计算时,常不以得到近似值为满足,还需估计误差,即要求知道近似值的精确程度。
因此,对于未知参数θ,除了求出它的点估计ˆθ外,我们还希望估计出一个范围,并希望知道这个范围包含参数θ真值的可信程度。
设ˆθ为未知参数θ的估计量,其误差小于某个正数ε的概率为1(01)αα-<<,即ˆ{||}1P θθεα-<=-或αεθθεθ-=+<<-1)ˆˆ(P这表明,随机区间)ˆ,ˆ(εθεθ+-包含参数θ真值的概率(可信程度)为1α-,则这个区间)ˆ,ˆ(εθεθ+-就称为置信区间,1α-称为置信水平。
定义 设总体X 的分布中含有一个未知参数θ。
若对于给定的概率1(01)αα-<<,存在两个统计量1112(,,,)n X X X θθ= 与2212(,,,)n X X X θθ= ,使得12{}1P θθθα<<=-则随机区间12(,)θθ称为参数θ的置信水平为1α-的置信区间,1θ称为置信下限,2θ称为置信上限,1α-称为置信水平。
注(1)置信区间的含义:若反复抽样多次(各次的样本容量相等,均为n ),每一组样本值确定一个区间12(,)θθ,每个这样的区间要么包含θ的真值,要么不包含θ的真值。
按伯努利大数定理,在这么多的区间中,包含θ真值的约占100(1)%α-,不包含θ真值的约仅占100%α。
例如:若0.01α=,反复抽样1000次,则得到的1000个区间中,不包含θ真值的约为10个。
(2)置信区间的长度表示估计结果的精确性,而置信水平表示估计结果的可靠性。
区间估计的名词解释

区间估计的名词解释在统计学中,区间估计是一种通过样本数据确定未知参数真值范围的方法。
其目的是通过一定的置信水平,给出一个包含真实参数的区间。
这个方法常用于不确定性问题的解决,例如预测总体均值、比率或方差等。
一、区间估计的基本原理区间估计的基本原理是建立在样本与总体之间的关系基础上的。
当我们从总体中取出一个样本并计算它们的统计量时,我们可以通过这些统计量来推断总体参数的范围。
具体来说,以估计总体均值为例,假设我们要估计总体均值μ,并且我们有一个样本数据集。
我们首先计算样本的平均值x,然后计算标准误差(standard error)或标准差(standard deviation)。
标准误差是样本平均值的标准差,而标准差是总体的标准差。
接下来,我们可以选择一个置信水平,通常为95%或99%。
置信水平表示我们对于真实参数落在估计的区间内的置信程度。
置信水平越高,估计的区间范围就会越大。
然后,我们可以使用统计分布的性质,例如正态分布或t分布,来计算区间估计的下限和上限。
这些分布的性质可以帮助我们确定参数的范围。
最后,我们得到了一个置信区间,这个区间代表了我们对于总体参数真值的估计范围。
例如,我们可以得出一个96%的置信区间为[10.2, 20.7],这意味着我们有96%的置信度认为总体均值落在这个区间内。
二、区间估计的应用区间估计在实际应用中起着至关重要的作用。
它为我们提供了对于未知参数的范围估计,以便我们能够更好地理解和解释数据。
在市场调研中,区间估计常用于估计产品销量、顾客满意度等指标。
通过对样本数据进行统计分析和区间估计,我们可以预测产品的市场接受度和潜在销量范围。
在医学研究中,区间估计可用于确定药物疗效和副作用的范围。
通过对临床试验中的样本数据进行统计分析和区间估计,我们可以更好地评估药物对公众健康的影响。
在质量控制中,区间估计可以帮助我们确定生产过程的质量指标范围。
通过对产品样本数据进行统计分析和区间估计,我们可以判断产品是否符合标准要求或有潜在问题。
6-5非正态总体参数的区间估计

2 a n u ,
2
2 b (2nX u ) ,
2
总体服从指数分布 未知参数 的置信水平为1 的置信区间是 1 1 1 1 ˆ ˆ ( 1 , 2 ) ( (1 u ) , (1 u ) ).
X n
2
c nX 2 .
X
n
2
概率论与数理统计教程(第四版)
[例2] 从一批电子元件中,抽取 50个样品,测得它们 设电子元件的使用寿命 的使用寿命的均值为1200小时, 服从指数分布e( ) , 求未知参数 的置信水平为 0.99 的置信区间.
解:由题设有 n 50 , x 1200. 已给置信水平1 0.99 ,
0.01 , 查附表得 u2 u0.005 t0.005 () 2.58. 由此得
目录
上一页
下一页
返回
结束
[例1]从一批产品中抽取 200个样品, 发现其中 9 个次品, 求这批产品的次品率 p 的置信水平为90%的置信区间. 解: 设随机变量 0 , 若取得正品; X 1 , 若取得次品. p ( x ; p ) p x (1 p )1 x , 概率函数为 则 X 服从 "0 1" 分布, x 0或1, 其中 p 是这批产品的次品率. 按题意, 样本容量 n 200 ,样本观测值 x1 , x2 ,, x200 中恰有 9 个 1 与 191个 0 , 所以 1 200 9 x xi 200 0.045. 200 i 1
则未知参数 p 的置信水平为1 的置信区间是
b b 2 4ac b b 2 4ac ( p1 , p2 ) ( ˆ ˆ , ). 2a 2a
第4节正态总体参数的区间估计

3
, 给定 ,0 1 , 定义 设是总体的一个未知参数
确定两个统计量
ˆ , ˆ 分别称为置信下限和置信上限. 区间. 1 2
ˆ , ˆ ]为 的 置信水平为 1 的 置信 则称区间 [ 1 2
1.75 1.96 1.96 0.49, n 50
所以 的置信区间为
(4.10 0.49, 4.10 0.49 ) (3.61, 4.59 ) .
10
例3 在上例中 , 为使 的置信水平是 0.95 的置信区间
的长度 L 1.5, 求样本容量 .
, u0.025 1.96, 1.75, 解 0.05
u / 2
x
X | | u / 2 X u / 2 X u / 2 / n n n
于是所求 的置信区间为 ( X u 有时简记为 ( X u / 2
2
n
, X u 2 ), n n
7
).
2 某厂生产滚珠,直径 X 服从正态分布 N ( , ). 例1 为了估计 , 抽检 6 个滚珠, 测得直径为 ( mm) : 14.70, 15.21,14.90,14.91,15.32,15.32,
对给定的置信水平 1 ,
按标准正态分布的 水平双侧分位数的定义,
查正态分布表得 u 2 ,
6
1.
已知时 的置信区间
2
/2
( x)
X U ~ N (0,1) , / n
1
O
/2
X P{ | | u 2 } 1 , n
区间估计的原理

区间估计的基本原理区间估计是统计学中一种常用的方法,用来根据样本数据推断总体参数的取值范围。
它通过计算置信区间来表示参数估计值的可信度,并提供了一种统计量范围的估计方法。
在这个过程中,我们关注的是总体参数的不确定性。
置信区间的定义置信区间是指在一定置信水平下,总体参数的可信范围。
置信水平通常采用符号(1−α)表示,其中α是一个介于0和1之间的数,表示置信水平的显著性水平。
例如,当α=0.05时,我们说我们有95%的置信度来估计总体参数。
置信区间的上界和下界称为置信限。
区间估计的步骤进行区间估计时,我们需要按照以下步骤进行:1.收集样本数据:从总体中随机抽取一部分样本进行观察和测量,得到样本数据。
2.选择合适的统计分布:根据所研究的问题和样本数据的性质,选择适当的统计分布来建立数学模型。
3.计算统计量:根据所选择的统计分布,利用样本数据计算出一个统计量,该统计量用于估计总体参数。
常用的统计量有样本均值、样本比例、样本方差等。
4.构建置信区间:根据所选择的统计分布和计算出的统计量,采用适当的方法构建置信区间。
5.解释和应用结果:根据置信区间的结果进行解释,并根据实际应用情况进行结果的应用和决策。
构建置信区间的方法在构建置信区间时,常用的方法有以下几种:1.正态分布的方法:当样本容量大于30,或当样本容量较小但总体近似服从正态分布时,可以使用正态分布的方法进行区间估计。
2.t分布的方法:当样本容量较小且总体不服从正态分布时,可以使用t分布的方法进行区间估计。
t分布相较于正态分布,具有较宽的尾部,适合用于较小样本的情况。
3.二项分布的方法:当样本数据为二项分布时,可以使用二项分布的方法进行区间估计。
二项分布常用于估计样本比例的置信区间。
4.Poisson分布的方法:当样本数据符合泊松分布时,可以使用Poisson分布的方法进行区间估计。
5.其他分布的方法:根据具体问题的要求,选择适当的分布进行区间估计。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
因为
ˆ (1 P ˆ) P SP ˆ n
0.1 (1 0.1) 0.0077 1500
上一张 下一张 主 页Fra bibliotek退 出
所以该地区老年人结核病患病率ρ 的95%、 99%置信区间为:
0.1 1.96 0.0077 0.1 1.96 0.0077
0.1 2.58 0.0077 0.1 2.58 0.0077
越高。
上一张 下一张 主 页 退 出
常用的置信度为95%和99%,故由(5-13)
式可得总体平均数μ 的95%和99%的置信区间如
下:
( x t 0.05 S x x t 0.05 S5-14 x ) ( 5-15 ) x t 0.01S x x t 0.01 S x
P( x t a S x x t a S x ) 1 a
称为置信半径; ta S x
(5-13)式称为总体平均数μ 置信度为1-a的置
信区间。其中
x和 ta S x
分别称为置信下限和置信上限; 置信上、下限 x ta S x
之差称为置信距,置信距越小,估计的精确度就
ˆ 其中, P 为样本百分数, 为样本百分数标准 S ˆ P
误, 的计算公式为: SP ˆ
SP ˆ ˆ (1 P ˆ P ) 5-18) ( n
上一张 下一张 主 页 退 出
【例5.10】 调查某地1500老年人,患结核病
的有150人,求该地区老年人结核病患病率的
95%、99%置信区间。
ˆ ,采用正态分布近似法求 由于>1000, >1% P 置信区间。
上一张 下一张 主 页 退 出
ˆ 只是总体百分数 ρ 的点估计值。 P
当 n 1000 , 99%置信区间为:
ˆ 时 , 1 %总 体 ρ 的95%、 P
ˆ 1.96S ˆ P ˆ 1.96 ( 5-16 ) P S ˆ P P
ˆ 2.58S ˆ P ˆ 2.58 ( 5-17 ) P S ˆ P P
上一张 下一张 主 页 退 出
所以该免疫球蛋白总体平均数μ 的95%置信 区间为
1.02 1.38
又因为
99%置信半径为
99%置信下限为 99%置信上限为
t 0.01(df ) S x 3.25 0.08 0.26
x t 0.01(df ) S x 1.2 0.26 0.94
即
8.01% 11.99%
8.49% 11.15%
上一张 下一张 主 页 退 出
例9 10名患者某免疫球蛋白测值为1.5、 1.2、 1.3、 1.4、 1.8、0.9、1.0、1.1、 1.6、 1.2(单 位),求该免疫球蛋白总体平均数的置信区间。
上一张 下一张 主 页 退 出
经计算得 由
, x 1 .2
,0.08 Sx
,查 df n 1 10 1 t9值 表
上一张 下一张 主 页 退 出
区间估计是在一定概率保证下指出总体参数 的可能范围,所给出的可能范围叫 置 信 区 间
(confidence interval),给出的概率保证称为
置 信 度 或 置 信概 率 (confidence probability)。本节介绍正态总体平均数和二项 总体百分数P的区间估计。
总体参数的区间估计
所谓参数估计就是用样本统计量来估计总 体参数,有 点估计 (point estimation)和区 间估计 (interval estimation) 之分。
将样本统计量直接作为总体相应参数的估 计值叫点估计。点估计只给出了未知参数估计 值的大小,没有考虑试验误差的影响,也没有 指出估计的可靠程度。
上一张 下一张 主 页 退 出
一、正态总体平均数的置信区间
设有一来自正态总体的样本,包含n个观测
xn 值 x1 , x2 ,, ,样本平均数
误
Sx S
x ,标准 x n
。总体平均数为 μ。 n
因为 t ( x 服从自由度为 n-1的 t分布。双 ) Sx 侧概率为a时,有:
P(t a t t a ) 1 a ,也就是说 t在区间
t a , t a 内取值的
可能性为1-a,即:
x P(t a ta ) 1 a Sx
上一张 下一张 主 页 退 出
对
x ta ta 变形得: Sx
5-13) x t a S x x t a( Sx 亦即
x t 0.01(df ) S x 1.2 0.26 1.46
上一张 下一张 主 页 退 出
所以该免疫球蛋白总体平均数μ 的99%置信
区间为
0.94(kg) 1.46(kg)
二、二项总体百分数ρ 的置信区间
样本百分数 百分数的置信区间则是在一定置信度下对总体百 分数作出区间估计。求总体数的置信区间有两种 方法:正态近似法和查表法,这里仅介绍正态近 似法。
t 0.01(9),因此 3.250
得 t 0.05(9) 2.262 ,
95%置信半径为 95%置信下限为
t 0.05(df ) S x 2.262 0.08 0.18
x t 0.05(df ) S x 1.2 0.18 1.02
95%置信上限为
x t 0.05(df ) S x 1.2 0.18 1.38