第2章多元回归分析
古扎拉蒂《计量经济学基础》第2章

古扎拉蒂 《计量经济学基础》
第二章 双变量回归分析: 一些基本思想
主讲老师:李庆海
2.1 本章要点
●一些基本概念 ●总体回归函数 ●“线性”函数的定义 ●PRF的随机设定 ●随机干扰项的意义
●样本回归函数
2.2 重难点导学
一、一些基本概念
条件概率:给定X的Y的概率,记为P(Y|X)。
条件均值(如图2-1所示)
Y
条件均值
149 101 65
E(Y|Xi)
80
140 220
X
图2-1 总体回归线
总体回归曲线
思考:给定一个X,就对应一个(惟一 的)E(Y|X)。因此,(X,E(Y|X))可以 表示成平面上的一个点。 总体回归曲线(Popular Regression Curve):Y的条件均值的轨迹。即Y对X的回 归。 总体回归曲线的几何意义:当解释变量给 定值时因变量的条件期望值的轨迹。
已知给定X=1,Y取5个不同的值:1、2、3、4、
5。 问:Y取每个值的概率有多大?
古典概率模型:取每个值的概率相等。因此有:
P(Y=1|X=1)=1/5; P(Y=2|X=1)=1/5;
P(Y=3|X=1)=1/5;
P(Y=4|X=1)=1/5; P(Y=5|X=1)=1/5;
词总是指对参数为线性的一种回归(即参数
只以它的1次方出现)。
Y= 1+2X+u, lnY= 1+2lnX+u 是线性的!
Y= 1ln(2X+u)不是线性的!
模型对参数为线性?
模型对变量为线性?
是
不是
是
LRM
LRM
不是
NLRM
气象统计分析与预报方法:08-第二章-回归分析4

▪ 感谢阅读
End Of Curve Estimation
➢非线性回归 2
多项式回归
yi 0 1xi 2 xi2 ... p xip ei
可化为线性的曲线回归 初等函数变换
一般的非线性回归
yi f ( xi , ) ei
用Gauss-Newton 法确定系数向量
感谢阅读
▪ 感谢阅读
▪ 感谢阅读
2.20 162.00 5.09
.79
10.00 12.00 2.48 2.30
8.10 19.00 2.94 2.09
Let Y2=ln(Y), X2=ln(X) Then Y2=ln(b)+b1* ln(X)
14.80 7.90 2.07 2.69
5.5
2.80 178.00 5.18 1.03
参数设置 因变量 自变量
Models (Selection)
中文含义
线性 二次曲线 复合函数 生长曲线 对数函数 三次曲线 S--曲线 指数函数 倒数函数 幂函数 逻辑斯谛函数
其它例子: 1)Y=b0+b1t+b2t2 令:X1=t; X2=t2 则化为线性二元回归方程: Y= b0+b1X1+b2X2 2)Y=a X-b exp(-cX) 取对数:ln(Y)=ln(a)-b*ln(X)-c*X
3.00 135.00
200
11.40
8.90
4.80 6.80 10.20
61.60 39.80 10.00
Example 2:power
100
Observed
Cu b i c
0
P ow er
2
4
6
8
第2章计量经济学回归分析的性质ppt课件

§2.4 数据
一、数据的分类 按照数据与时间的关系,可以分为: ❖ 时间序列数据(time series data) ❖ 横截面数据(cross-section data) ❖ 面板数据(panel data/ pooling data)
实例:我国地区的生产总值
二、数据的来源和质量
❖ 社会科学数据都是非实验所得,存在测量误 差,或出于疏漏或差错 ;
cov(Xt,Yt)
Var(Xt) Var(Yt)
样本相关系数r
rXYˆ
1 T1
(Xt X)(Yt Y)
1 T1
(Xt X)2
1 T1
(Yt Y)2
(Xt X)(Yt Y)
(Xt X)2 (Yt Y)2
性质: (1)r具有对称性 (2)r与原点和尺度都无关
400
200
0 0
X
10
20
30
40
50
完全相关
Y 2
1
X
0
10
20
30
40
50
高度相关
3.0
2.5
Y
2.0
1.5
1.0
0.5
2.0
2.5
3.0
3.5
弱相关
X
4.0
4.5
4
Y 2
0
-2
X -4
-4
-2
0
2
4
零相关
2、按变量个数
200 150 100
50 0 0
Y
X
50
100
150
200
250
非线性相关/负相关
Y 2
1
第2章多元回归分析

y = b0 + b1x1 + b2x2 + . . . bkxk + u
1
Multiple Regression Analysis
y = b0 + b1x1 + b2x2 + . . . bkxk + u
1. Estimation
2
Parallels with Simple Regression
fIrno mthethgeefniersrtalocrdaeser cwointhd iktioinnd, ewpeencdanengtevt akriab1 les,
lwineeasreeeqkueasttiiomnastienskbˆ0,1bˆu1,n k n,obˆwk
tynˆheryebiˆf0orbeˆb,0ˆ1mx1ibnˆ1ixmi1 izebˆtkhxekbˆskuxmik of
The STATA command
Use [path]wage1.dta (insheet using [path]wage1.raw/wage1.txt) Reg wage educ exper tenure Reg lwage educ exper tenure
7
A “Partialling Out” Interpretation
8
“Partialling Out” continued
Previous equation implies that regressing y on x1 and x2 gives same effect of x1 as regressing y on residuals from a regression of x1 on x2
第二章 双变量回归分析(计量经济学,南开大学)
ˆ 和 ˆ 1 2
i
为Yi的线性函数
i 2 i
ˆ
2
xY x
(
xi )Yi 2 x i
k Y
i
i
其中k i
xi xi2 1 xi2
ki k i2
x
2
i
0
2 xi
1 xi2 1 xi2
i
1 xi2
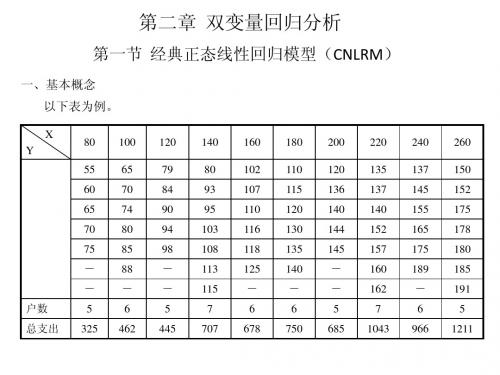
6、样本回归函数(SRF) 由于在大多数情况下,我们只知道变量值得一个样本,要用样本信息的基础 上估计PRF。(表) 样本1
X(收入) Y(支出) 80 55 100 65 120 79 140 80 160 102 180 110 200 120 220 135 240 137 260 150
样本2
ˆ ) VAR( 2
x
2 i
2
2 i
x
ˆ: 对于 1
ˆ Y ˆ X 1 ˆ X Yi 1 2 2 n 1 ˆ X ( 1 2 X i ui ) 2 n u 1 i X k i ui n ˆ ) E[( ui X 方差:VAR( k i ui ) 2 ] 1 n
ˆ ) E( ki E (ui ) 2 2 2 ˆ Y ˆ X 1 2 ( 1 2 X i ui ) ( 1 k i u i ) X 1 u i X k i u i ˆ ) E( 1 1
1 1 2 21
估计量(Estimator):一个估计量又称统计量(statistic),是指一个规则、公式 或方法,以用来根据已知的样本所提供的信息去估计总体参数。在应用中,由估 计量算出的数值称为估计(值)(estimate)。 样本回归函数SRF的随机形式为:
第2章(回归分析)

§2.1 总体与总体回归模型
一、总体与总体回归模型的含义 1.总体回归模型 总体回归模型 对应不同收入水平的60户家庭的每周消费 户家庭的每周消费Y 对应不同收入水平的 户家庭的每周消费
200 160
120
80
40 60 80 100 120 140 160 180 200 220 240 260 280
《计量经济学》王少平 杨继生 欧阳志刚 高教出版社 2010.6
§2.1 总体与总体回归模型
二.总体回归模型中的 Ui 所包含的内容 2.从实际经济行为看 从实际经济行为看Ui 从实际经济行为看
Yi = E (Y X i ) + U i = β 0 + β1 X i + U i
从经济学理论可知, 除收入X外 家庭财富、 从经济学理论可知 除收入 外,家庭财富、 通胀、利率, 通胀、利率,预期等对消费支出产生影响的因 包含在U之中 素,包含在 之中
§2.1 总体与总体回归模型
一、总体与总体回归模型的含义 1. 总体 2. 总体回归模型 二、总体回归模型中 ui所包含的内容 1.从数量上看 ui 从数量上看 2.从实际经济行为看 ui 从实际经济行为看 3.从回归关系看 ui 从回归关系看
《计量经济学》王少平 杨继生 欧阳志刚 高教出版社 2010.6
家庭每周收入X 家庭每周收入
《计量经济学》王少平 杨继生 欧阳志刚 高教出版社 2010.6
§2.1 总体与总体回归模型
一、总体与总体回归模型的含义 1.总体回归模型 总体回归模型
上图说明,收入 从 变化至 变化至280,这一变化 上图说明,收入X从80变化至 说明 , 解释了消费Y的总体的条件期望 均值) 的总体的条件期望( 解释了消费 的总体的条件期望(均值)从65、 、 89等变化至 等变化至173。也就是说,X的变化解释了 等变化至 。也就是说, 的变化解释了 Y的总体的条件期望的变化(总体的平均变 的总体的条件期望的变化( 的总体的条件期望的变化 )。或者说 或者说, 的变化 决定了Y的总体的 的变化, 化)。或者说,X的变化,决定了 的总体的 平均变化。 的变化解释( 平均变化。而X的变化解释(或决定)了Y 的 的变化解释 或决定) 总体的平均变化,这正是回归分析的意义所在。 总体的平均变化,这正是回归分析的意义所在。 因此,称这条线为总体回归模型。 因此,称这条线为总体回归模型。 由于它是一条直线, 由于它是一条直线,故也称为总体回归直线
第2章人工智能技术基本原理2.2回归算法-高中教学同步《信息技术-人工智能初步》(教案
课题
第2章人工智能技术基本原理2.2回归算法
课型
班课
课时
1
授课班级
高一1班
学习目标
理解回归算法的基本概念及其在学习中的应用,包括一元回归和多元回归、线性回归和非线性回归的区别。
掌握回归分析的适用场景,能够区分连续值预测问题与离散值分类问题。
学习回归算法的一般流程,包括数据收集、算法训练、测试和应用。
培养技能:训练学生的数据处理和软件操作能力。
活动四:
巩固练习
素质提升
布置练习题:给出一些与回归分析相关的练习题,如使用其他数据集来练习回归分析。
讨论与反馈:组织课堂讨论,回顾学到的知识,并给予学生反馈。
独立练习:独立完成教师布置的练习题,应用所学知识。
知识回顾:参与讨论,回顾本节课的重点和难点。
巩固知识:通过练习加深对回归算法流程和类型的理解。
文本材料:包括教材、PPT课件和打印的讲义,这些材料中包含有关回归算法的详细说明、公式、实例和应用案例,是传递理论知识的主要媒介。
数据分析工具:如果课程中包含实践操作,可能会使用到数据分析软件(如Excel、Python等),通过实际操作来训练算法并测试结果。
实例数据表:表2.2.2作为一个具体的数据集例子,用于在课堂上展示如何从实际数据中探索变量间的关系。
观察数据:学生先观察表格数据,尝试找出尺寸与价格之间可能存在的关系。
讨论可能的方法:分小组讨论如何使用这些数据来预测未知尺寸的蛋糕价格。
激发兴趣:通过实际问题引起学生的兴趣和好奇心。
引导思考:促使学生从生活实例出发,思考变量间的关系,培养数据分析意识。
活动二:
调动思维
探究新知
医用数据挖掘案例与实践 第2章 多元线性回归分析

在实际应用中,自变量之间可能会存在多重共线性,从而影 响多元线性回归的结果。为此,可以选择对自变量进行筛选 实施多元逐步线性回归,即从多个自变量中找出对因变量真 正有影响的自变量。筛选的方法有前进法(Forward)、后退 法(Backward)和逐步法(Stepwise)等。
12
仍然选用上面的例子,作多元逐步线性回归分析。这里选择逐步筛选法 (Stepwise),如果选择前进法,可以选择“Forward”,如果选择后退法,可 以选择“Backward”。 点开【Option...】按钮,默认筛选变量时入选标准“Entry”为“0.05”,剔除 标准“Removal”为“0.1”。具体操作如见图2.5所示。
图2.5 多元逐步线性回归分析中筛选变量的主对话框和Options子对话框
13
主要输出结果如图2.6~图2.9所示
Model Sum m ary
Model 1
2
R
R Square
.610a
.372
.696b
.484
A djuste d R Square
.347
.441
Std. Error of the Estimate
第二章 多元线性回归分析
1
在医学研究中,常常需要分析变量之间的关系。 比如人的体重与身高和胸围的关系;血压值与年龄、 性别、饮食习惯、吸烟状况和家族史的关系;血糖 水平与年龄、胰岛素、体重指数的关系;肿瘤预后 与患者的肿瘤亚型、肿瘤大小、治疗方式的关系等 等。
此时应采用回归分析的方法来研究变量之间的依存 关系,并对各个因素做出评价,也可用于预测和判 别。
14
如图2.7所示的输出表是对回归模型作的方差分析,同样分为两步,第一步
计量经济学第二章(第二部分)

其中,有k个解释变量;k+1个回归参数
3
计量经济学 第二章B
同 上
(2)矩阵形式: Y XB N Y1 Y2 Y ... Y n 1 1 X ... 1 0 u1 1 u2 , B , N ... ... u n 1 k (k 1) 1 n n 1 X 11 X 12 ... X 1n X 21 X 22 ... X 2n ... ... ... ... X k1 X k2 ... X kn n (k 1)
2
(2)当 R
2
k n -1
时,
R
2
<0 ,此时, 使
2
用 R 将失去意义。因此, R 只适
2
用于Y与解释变量整体相关程度较的
情况。
34
计量经济学 第二章B
四、回归方程的显著性检验
(1) 提出原假设 (2) 构造统计量 H 0 : 1 2 ... k 0 F ESS/k RSS/n (3) 对于给定的显著性水平 (4)判定方程的显著性, 若 F F , 则拒绝原假设 若 F F ,则接受原假设 H 0,即模型的线性关系 F 检验; - k -1 ~ F(k, n - k - 1) ( 在 H 0 成立时) F
不管其质量的好坏,而所要求的样本容量
的下限。
20
计量经济学 第二章B
同 上
ˆ 由 B ( X X)
-1
ˆ X Y 中看到,要使 B
存在,
必须保证(XˊX)-1存在,因此,必须满
足|XˊX|≠0 ,即XˊX为满秩矩阵,而
应用回归分析_第2章课后习题参考答案.

应用回归分析_第2章课后习题参考答案1. 简答题1.1 什么是回归分析?回归分析是一种统计建模方法,用于研究自变量与因变量之间的关系。
它通过建立数学模型,根据已知的自变量和因变量数据,预测因变量与自变量之间的关系,并进行相关的推断和预测。
1.2 什么是简单线性回归和多元线性回归?简单线性回归是指只包含一个自变量和一个因变量的回归模型,通过拟合一条直线来描述两者之间的关系。
多元线性回归是指包含多个自变量和一个因变量的回归模型,通过拟合一个超平面来描述多个自变量和因变量之间的关系。
1.3 什么是残差?残差是指回归模型中,观测值与模型预测值之间的差异。
在回归分析中,我们希望最小化残差,使得模型与观测数据的拟合效果更好。
1.4 什么是拟合优度?拟合优度是用来评估回归模型对观测数据的拟合程度的指标。
一般使用R方(Coefficient of Determination)来表示拟合优度,其值范围为0到1,值越接近1表示模型拟合效果越好。
2. 计算题2.1 简单线性回归假设我们有一组数据,其中X为自变量,Y为因变量,如下所示:X Y13253749511我们想要建立一个简单线性回归模型,计算X与Y之间的线性关系。
首先,我们需要计算拟合直线的斜率和截距。
根据简单线性回归模型的公式Y = β0 + β1*X,我们可以通过最小二乘法计算出斜率和截距的估计值。
首先,计算X和Y的均值:mean_x = (1 + 2 + 3 + 4 + 5) / 5 = 3mean_y = (3 + 5 + 7 + 9 + 11) / 5 = 7然后,计算X和Y的方差:var_x = ((1-3)^2 + (2-3)^2 + (3-3)^2 + (4-3)^2 + (5-3)^2) / 5 = 2var_y = ((3-7)^2 + (5-7)^2 + (7-7)^2 + (9-7)^2 + (11-7)^2) / 5 = 8接下来,计算X和Y的协方差:cov_xy = ((1-3) * (3-7) + (2-3) * (5-7) + (3-3) * (7-7) + (4-3) * (9-7) + (5-3) * (11-7)) / 5 = 4根据最小二乘法的公式:β1 = cov_xy / var_x = 4 / 2 = 2β0 = mean_y - β1 * mean_x = 7 - (2 * 3) = 1因此,拟合直线的方程为:Y = 1 + 2X。
第二章 回归分析与相关分析(2)

第二章 回归分析与相关分析§3 多元线性回归分析在现实地理系统中,任何事物的变化都是多种因素影响的结果,一因多果、一果多因的情况比比皆是。
为了处理一果多因的因果关系问题,我们需要掌握多元线性回归知识。
本节着重讲述二元线性回归分析。
至于三元以上,基本原理可以依此类推。
1 基本模型二元线性回归模型可以表为2211x b x b a y ++=, (3-1)式中a 、b 1、b 2为待定的偏回归参数(partial regression coefficient )。
理论上的预测模型为i i i x b x b a y2211ˆ++=. (3-2) 原则上讲,式(3-2)中的参数a 、b 1、b 2与式(3-1)中的a 、b 1、b 2是有区别的:式(3-1)的是真实的系数值,式(3-2)的是计算的系数值。
但为了方便起见,我们不作符号上的区分。
实测数据的模型可以表作d yd x b x b a y i i i i i ±=±++=ˆ2211, (3-3) 从而i i i i i i x b x b a y yy d 2211ˆ---=-=. (3-4) 令min )(12221112→---==∑∑==ni i i i n i i x b x b a y d S . (3-5)为求极值,分别对a 、b 1、b 2求偏导,并令其为零,可得0)(22211=---=∂∂∑ii i i x b x b a y a S, (3-6) 0)(2122111=---=∂∂∑i ii i i x x b x b a y b S, (3-7)0)(2222111=---=∂∂∑i ii i i x x b x b a y b S. (3-8) 上面三式可以化为正规方程形式⎪⎪⎩⎪⎪⎨⎧=++=++=++∑∑∑∑∑∑∑∑∑∑∑i i i i i ii i i i i i i i i y x x b x x b x a y x x x b x b x a y x b x b an 22222112121221112211. (3-9) 根据线性代数的有关原理,可令∑∑∑∑∑∑∑∑∑=222122121121iiiiiiiiiii i i x x x y x xx x y x xx y A , ∑∑∑∑∑∑∑∑=2222211121ii iiiiiii i i x y x xx x y x x x y nB ,∑∑∑∑∑∑∑∑=iiiiii iiii i yx x x x yx x x yx n B 2212121112, ∑∑∑∑∑∑∑∑=222122121121iiiiiiii i i xx x xx x x x x x nC .借助Cramer 法则容易得到C Aa =,C B b 11=,CB b 12=. (3-10) 2 回归结果的检验检验的类型与一元线性回归相似,包括相关系数检验、标准误差检验、F 检验、t 检验和DW 检验。
第二章双变量回归分析基本概念

第七节 样本回归函数(SRF)
对应(2.3.2)的SRF
Yˆi ˆ1 ˆ2 Xi 其中 Yˆ读为Y-帽,是 E(Y 的Xi估) 计量。
• 注意,一个估计量(estimator),又称(样本)统计量 (statistic),是指一个规则或公式或方法。在一项应用中, 由估计量算出的一个具体的数值,称为估计值 (estimate) 。
1-12
第七节 样本回归函数(SRF)
总体是观测不到的,大多数情况下,对应于一个 解释变量X,只能观测到被解释变量Y的一个值。
• 我们只能得到对应于某些固定X 值的Y 值的一个(有限 个)样本。
1-13
第七节 样本回归函数(SRF)
样本回归函数(sample regression function, SRF)
(2.3.1)
PRF的形式是一个经验问题,线性方程是常
用的形式:
E(Y Xi ) f ( Xi ) 1 2 Xi (2.3.2)
• 其中 1 和 2为未知但却固定的参数,称为回归系 数( regression coefficient)。1 和 2 分别称为截距
和斜率系数。方程(2.3.2)本身则称为线性总体回归 函数或简称线性总体回归。
Yi 1 2 X i ui
(2.5.2)
(2.5.2)为PFR的随机设定形式,与(2.3.2)等价。
1-11
第六节 随机扰动项的意义
为什么要引入随机扰动项?
• 理论的含糊性 • 数据的缺失 • 变量的解释力(核心变量与周边变量) • 人类行为的内在随机性 • 糟糕的替代变量(永久消费与当前消费等) • 节省原则 • 错误的函数形式
• 父母身高、子女身高 • 儿女的身高趋向人口总体平均,普遍回归定律(law of
第二章回归分析中的几个基本概念

第⼆章回归分析中的⼏个基本概念第四章⼀、练习题(⼀)简答题1、多元线性回归模型的基本假设是什么?试说明在证明最⼩⼆乘估计量的⽆偏性和有效性的过程中,哪些基本假设起了作⽤?2、多元线性回归模型与⼀元线性回归模型有哪些区别?3、某地区通过⼀个样本容量为722的调查数据得到劳动⼒受教育的⼀个回归⽅程为fedu medu sibs edu 210.0131.0094.036.10++-=R 2=0.214式中,edu 为劳动⼒受教育年数,sibs 为该劳动⼒家庭中兄弟姐妹的个数,medu 与fedu 分别为母亲与⽗亲受到教育的年数。
问(1)若medu 与fedu 保持不变,为了使预测的受教育⽔平减少⼀年,需要sibs 增加多少?(2)请对medu 的系数给予适当的解释。
(3)如果两个劳动⼒都没有兄弟姐妹,但其中⼀个的⽗母受教育的年数为12年,另⼀个的⽗母受教育的年数为16年,则两⼈受教育的年数预期相差多少? 4、以企业研发⽀出(R&D )占销售额的⽐重为被解释变量(Y ),以企业销售额(X1)与利润占销售额的⽐重(X2)为解释变量,⼀个有32容量的样本企业的估计结果如下:099.0)046.0()22.0()37.1(05.0)log(32.0472.0221=++=R X X Y其中括号中为系数估计值的标准差。
(1)解释log(X1)的系数。
如果X1增加10%,估计Y 会变化多少个百分点?这在经济上是⼀个很⼤的影响吗?(2)针对R&D 强度随销售额的增加⽽提⾼这⼀备择假设,检验它不虽X1⽽变化的假设。
分别在5%和10%的显著性⽔平上进⾏这个检验。
(3)利润占销售额的⽐重X2对R&D 强度Y 是否在统计上有显著的影响? 5、什么是正规⽅程组?分别⽤⾮矩阵形式和矩阵形式写出模型:i ki k i i i u x x x y +++++=ββββΛ22110,n i ,,2,1Λ=的正规⽅程组,及其推导过程。
第二章(简单线性回归模型)2-1答案

2.1回归分析与回归函数一、判断题1. 总体回归直线是解释变量取各给定值时被解释变量条件期望的轨迹。
(T )2. 线性回归是指解释变量和被解释变量之间呈现线性关系。
( F )3. 随机变量的条件期望与非条件期望是一回事。
(F )4、总体回归函数给出了对应于每一个自变量的因变量的值。
(F )二、单项选择题1.变量之间的关系可以分为两大类,它们是( A )。
A .函数关系与相关关系B .线性相关关系和非线性相关关系C .正相关关系和负相关关系D .简单相关关系和复杂相关关系2.相关关系是指( D )。
A .变量间的非独立关系B .变量间的因果关系C .变量间的函数关系D .变量间不确定性的依存关系3.进行相关分析时的两个变量( A )。
A .都是随机变量B .都不是随机变量C .一个是随机变量,一个不是随机变量D .随机的或非随机都可以4.回归分析中定义的( B )。
A.解释变量和被解释变量都是随机变量B.解释变量为非随机变量,被解释变量为随机变量C.解释变量和被解释变量都为非随机变量D.解释变量为随机变量,被解释变量为非随机变量5.表示x 和y 之间真实线性关系的总体回归模型是( C )。
A .01ˆˆˆt t Y X ββ=+B .01()t t E Y X ββ=+C .01t t t Y X u ββ=++D .01t t Y X ββ=+6.一元线性样本回归直线可以表示为( C )A .i i X Y u i 10++=ββ B. i 10X )(Y E i ββ+=C. i i e X Y ++=∧∧i 10ββ D. i 10X i Y ββ+=∧7.对于i 01i i ˆˆY =X +e ββ+,以ˆσ表示估计标准误差,r 表示相关系数,则有( D)。
A .ˆ0r=1σ=时,B .ˆ0r=-1σ=时,C .ˆ0r=0σ=时,D .ˆ0r=1r=-1σ=时,或8.相关系数r 的取值范围是( D )。
第二章回归分析中的几个基本概念

第二章回归分析中的几个基本概念1. 回归模型(Regression Model):回归模型是回归分析的基础,用来描述两个或多个变量之间的关系。
回归模型通常包括一个或多个自变量和一个或多个因变量。
常用的回归模型有线性回归模型和非线性回归模型。
线性回归模型是最简单的回归模型,其中自变量和因变量之间的关系可以用一条直线来表示。
线性回归模型的表达式为:Y=β0+β1*X1+β2*X2+...+βn*Xn+ε其中,Y表示因变量,X1、X2、…、Xn表示自变量,β0、β1、β2、…、βn表示回归系数,ε表示误差项。
2. 回归系数(Regression Coefficients):回归系数是回归模型中自变量的系数,用来描述自变量对因变量的影响程度。
回归系数可以通过最小二乘法估计得到,最小二乘法试图找到一组系数,使得模型的预测值和实际观测值的误差平方和最小。
回归系数的符号表示了自变量与因变量之间的方向关系。
如果回归系数为正,表示自变量的增加会使因变量增加,即存在正向关系;如果回归系数为负,表示自变量的增加会使因变量减少,即存在负向关系。
3. 拟合优度(Goodness-of-fit):拟合优度是用来评估回归模型对样本数据的拟合程度。
通常使用R方(R-squared)来度量拟合优度。
R 方的取值范围在0到1之间,越接近1表示模型对数据的拟合程度越好。
R方的解释是,回归模型中自变量的变异能够解释因变量的变异的比例。
例如,如果R方为0.8,表示模型中自变量解释了因变量80%的变异,剩下的20%可能由其他未考虑的因素引起。
4. 显著性检验(Significance Test):显著性检验用于判断回归模型中自变量的系数是否显著不为零,即自变量是否对因变量有显著影响。
常用的方法是计算t值和p值进行检验。
t值是回归系数除以其标准误得到的统计量。
p值是t值对应的双侧检验的概率。
如果p值小于给定的显著性水平(通常是0.05),则可以拒绝原假设,即认为回归系数显著不为零,即自变量对因变量有显著影响。
计量经济学-第2章 双变量回归分析:一些基本概念

样本回归函数(SRF,The Sample Regression Function)
表2.1是一个总体,这是一个假定的总体,在现 实的经济生活中总体的所有观测值往往是不能够全部 获得的。
在大多数情况下,我们只有对应于某些固定的 X的Y值的一个样本。比如,对于表2.1的总体我们只知 道如下的抽取的样本:
120
180
145
200
135
220
145
240
175
260
那么,我们能否从上表的样本数据预测整个总体 中对应于选定X的平均的消费支出Y呢?或者说,能 否估计出PRF?
根据表2.4和表2.5可以得到如下的散点图。
SRF1是根据第一个样本画的;而SRF2是根据第 二个样本画的。图中的回归线叫样本回归线 (sample regression lines)
如:
E(Y | Xi ) 1 2 Xi2
是一个LRM(linear regression model)
PRF的随机设定
我们现在再回到表2.1和图2.1,可见,随着家庭收 入↑,家庭消费支出平均地看也会↑;但是对具体的某一 个家庭的消费支出却不一定随收水平↑而↑
给定收入水平 X i 的个别家庭的消费支出,聚集在收 入为X i 的所有家庭的平均消费支出的周围,也就是围绕 着它的条件均值
“永久消费”和“永久收入”是两个抽象的概念, 不可以观测,实际上,只能用可以观测到的当前消费 Y ( current consumption ) 和 当 前 收 入 X ( current income),或者n个时期的平均值去替代。这便有个 测量误差。∴干扰项ui也用来代表测量误差
节省原则:
做回归模型,在许可的范围内尽量节省——减少 变量的个数。这也有个“投入产出”的问题。当然, 不能为了简单而省去有关的和重要的变量
多元回归分析与协方差分析

当 某 人 为 A 型 血 时 , 令 X1=1、X2=X3=0; 当 某 人 为 B 型 血 时 , 令 X2=1、
X1=X3=0; 当 某 人 为 AB 型 血 时 , 令 X3=1、X1=X2=0; 当 某 人 为 O 型 血 时 , 令
X1=X2=X3=0。
h
5
5.变量筛选
研究者根据专业知识和经验所选定的全部自变量并非对因变量都是
第2章 多元线性回归分析
第 1 节
多元线性回归分析的概述
回归分析中所涉及的变量常分为自变量与因变量。 当因变量是非时间的 连续性变量(自变量可包括连续性的和离散性的)时,欲研究变量之间的依存 关系,多元线性回归分析是一个有力的研究工具。
但从科学性角度来说,回归问题也应从试验设计入手考虑。因为这样做 不仅可以减少回归分析中可能遇到的很多麻烦,而且,可用较少的试验次数取 得较多的信息。
h
10
例
看书上有关协方
差分析的实例!
h
11
、…、k代表k个水平的取值,是不够合理的。因为这隐含着承认各等级之
间的间隔是相等的,其实质是假定该因素的各水平对因变量的影响作用几乎
是
相
同
ቤተ መጻሕፍቲ ባይዱ
的
。
比较妥当的做法是引入k-1个哑变量(Dummy Variables),每个哑变量
取 值 为 0 或 1 。 现 以 ABO 血 型 系 统 为 例 , 说 明 产 生 哑 变 量 的 具 体 法 。
(2) 配 伍 组 设 计 的 协 方 差 分 析 模 型 为 ∶
MODEL Y=X A B /
SS3;
(3)两因素析因设计的协方差分析模型为∶ MODEL Y=X A B A*B
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Consider the case wherek 2, i.e.
yˆ bˆ0 bˆ1x1 bˆ2 x2 , then
bˆ1 rˆi1yi
rˆi12 , w hererˆi1 are
the residuals from the estimated
regression xˆ1 ˆ0 ˆ2 xˆ2
yi y2 is the totalsum of squares(SST) yˆi y2 is the explained sum of squares(SSE) uˆi2 is the residualsum of squares(SSR)
Then SST SSE SSR
13
Goodness-of-Fit (continued)
What determines the person to commit crime? (the dependent variable is the number of times the man was arrested during 1986, narr86)
第二章 多元回归分析:估计
y = b0 + b1x1 + b2x2 + . . . bkxk + u
1
Multiple Regression Analysis
y = b0 + b1x1 + b2x2 + . . . bkxk + u
1. Estimation
2
Parallels with Simple Regression
This means only the part of xi1 that is uncorrelated with xi2 are being related to yi so we’re estimating the effect of x1 on y after x2 has been “partialled out”
line. The population regression line is
E( y | x) b0 b1x1 b2 x2 L bk xk
5
Interpreting Multiple Regression
yˆ bˆ0 bˆ1x1 bˆ2 x2 ... bˆk xk , so yˆ bˆ1x1 bˆ2x2 ... bˆk xk ,
How do we think about how well our sample regression line fits our sample data?
Can compute the fraction of the total sum of squares (SST) that is explained by the model, call this the R-squared of regression
The STATA command
Use [path]wage1.dta (insheet using [path]wage1.raw/wage1.txt) Reg wage educ exper tenure Reg lwage educ exper tenure
7
A “Partialling Out” Interpretation
yˆ bˆ0 bˆ1x1 bˆ2x2 L bˆk xk
The above estimated equation is called the OLS regression line or the sample regression function (SRF)
the above equation is the estimated equation, is
Now, we first regress educ on exper and tenure to patial out the exper and tenure’s effects. Then we regress wage on the residuals of educ on exper and tenure. Whether we get the same result.?
The estimated equations without tenure
wage=3.3910.644educ+0.070exper log(wage)=0.2170.098educ+0.0103exper
wage=0.9050.541educ log(wage)=0.5840.083educ
so holding x2,...,xk fixed implies that
yˆ bˆ1x1, that is each b has
a ceteris paribus interpretation
6
An Example (Wooldridge, p76)
The determination of wage (dollars per hour), wage:
educ=13.575-0.0738exper+0.048tenure wage=5.896+0.599resid log(wage)=1.623+0.092resid
We can see that the coefficient of resid is the same of the coefficien of the variable educ in the first estimated equation. And the same to log(wage) in the second equation.
wage=b0b1educ+b2exper+b3tenure+u log(wage)=b0b1educ+b2exper+b3tenure+u
The estimated equation as below:
wage=2.8730.599educ+0.022exper+0.169tenure log(wage)=0.2840.092educ+0.0041exper+0.022tenure
R2 = SSE/SST = 1 – SSR/SST
14
Goodness-of-Fit (continued)
We can also think of R2 as being equal to
the squaredcorrelation coefficient between
the actual yi and the values yˆi
8
“Partialling Out” continued
Previous equation implies that regressing y on x1 and x2 gives same effect of x1 as regressing y on residuals from a regression of x1 on x2
assumption, so now assume that E(u|x1,x2, …,xk) = 0 Still minimizing the sum of squared residuals,
so have k+1 first order conditions
3
Obtaining OLS Estimates
12
Goodness-of-Fit
We can thinkof each observation as being made up of an explained part, and an unexplained part, yi yˆi uˆi Wethen define the following :
10
Simple vs Multiple Reg Estimate
Compare thesimple regression ~y b~0 b~1x1 with themultiple regression yˆ bˆ0 bˆ1x1 bˆ2x2 Generally, b~1 bˆ1 unless : bˆ2 0 (i.e. no partial effectof x2 ) OR
fIrnomthethgeefniersrtalocrdaeser cwointhdiktioinnd, ewpeencdanengtevtakriab1les,
lwtiynˆhneeerasyebreiˆf0eeoqkrbeuˆeb,0aˆs1mttxiio1mibnnˆ1aisxLmtiie1niszkbeLˆb0ˆtk,h1xbeˆkb1uˆs,nkKuxkmink,oboˆwkf ns0inqsubtˆha0re,ebedˆ1q,ruKeistii,dobˆunka:ls:
x y inn1
ii11 i1 i
yi
bˆ0bˆ0
bˆ1bxˆi11xi1 L L
bˆkbxˆkikxik2
0
n xi2 yi bˆ0 bˆ1xi1 L bˆk xik 0
i 1
M
n 0.
i 1
4
Obtaining OLS Estimates, cont.
9
The wage determinations
The estimated equation as below:
wage=2.8730.599educ+0.022exper+0.169tenure log(wage)=0.2840.092educ+0.0041exper+0.022tenure
not the really equation. The really equation is
population regression line which we don’t know.