基于R语言数据可视化-类别数据可视化
R语言数据可视化 ppt课件

绘图是通过绘图函数结合相应的选项完成的。
ppt课件
9
R绘图功能
demo(graphics):了解R绘图功能 绘图函数包括:
− 高阶绘图函数 High-level Plotting Function • 产生一个新的图区,可能包括坐标轴、标签、标题等。
curve(dnorm(x),add=T)
# 添加曲线
h <- hist(x, plot=F)
# 绘制直方图
ylim <- range(0, h$density, dnorm(0)) #设定纵轴的取值范围
hist(x, freq=F, ylim=ylim) #绘制直方图
curve(dnorm(x),add=T,col="red") #添加曲线
添加图例 添加刻度线 绘制长方形 绘制多边形 添加线段 画箭头 添加外框
ppt课件
14
绘图参数
参数用在函数内部,在没有设定值时使用缺省值。 font = 字体,lty = 线类型,lwd = 线宽度,pch = 点的类型, xlab = 横坐标,ylab = 纵坐标, xlim = 横坐标范围, ylim = 纵坐标范围, 也可以对整个要绘制图形的各种参数进行设定
− 低阶绘图函数 Low-level Plotting Function • 在已有的图上加更多的元素
绘图参数 − 缺省值 − ?par( )
ppt课件
10
高阶绘图函数
plot(x)、plot(x,y) pie(x)
绘制散点图等多种图形,根据数据的 类,调用相应的函数绘图
数据可视化—基于R语言教学大纲

《数据可视化—基于R语言》教学大纲与教学计划 一、课程及教师基本信息课程名称 (中/英文) 数据可视化—基于R语言D a ta V is u a liz a tio n w ith R课程编号 学分 2课程性质 选修 授课对象 本科或研究生 先修课程要统计学任课 教师 信息 姓名 职称 办公时间及地点:办公电话、邮箱地址:助教信息教师简介二、教学目标与课程简介课程教学目标设置本课程的目的在于培养学生使用R语言分析数据和解决实际问题的基本能力。
教学应达到的总体目标是:(1)使学生系统地掌握数据可视化的基本统计方法。
(2)掌握各种数据可视化方法的不同特点、应用条件及适用场合。
(3)熟练使用R语言进行数据可视化,并对可视化的结果进行合理的解释和分析。
课程简介《R语言数据可视化》是为全校本科生(或研究生)开设的一门选修课,教学内容主要包括:数据可视化与R语言、R语言绘图基础、类别数据可视化、分布特征可视化、变量间关系可视化、样本相似性可视化、时间序列可视化等内容。
本课程适合本科适合全校所有学生修读,要求学生已经初步掌握统计学的基本知识。
每周教学时间为2课时,以课堂讲授和课后练习为主。
使用中文教材(参见后文的推荐教材目录),并在讲授过程中结合R软件实现可视化。
作业以实际问题和实际数据为主。
三、考核与考试考核 方式平时考核( %)注:占总成绩的40-60%考核类型 课程作业 课堂表现 期中考试占平时考核比例40 20 0期末考核( %)占60%。
采取实际数据分析报告形式,主要考核学生的理解和应用能力。
要求学生自己收集实际数据,并使用R语言对数据进行可视化分析,写出R代码,撰写完整的可视化分析报告。
学习 要求 学生在课前需要根据教学进度预习教材内容。
课后认真完成指定的作业教。
每周的课外学习时间不应少于3小时。
四、教学计划和教学内容教学 周 章节名称讲授内容和程度教学时数学生学习要求掌握的内容 课后作业第1周 数据可视化与R语言数据可视化的基本问题、R下载、安装和初步使用。
基于R语言的数据分析与可视化平台搭建

基于R语言的数据分析与可视化平台搭建在当今信息爆炸的时代,数据已经成为企业决策和发展的重要支撑。
而R语言作为一种开源的数据分析工具,以其强大的数据处理能力和丰富的可视化功能,受到越来越多数据科学家和分析师的青睐。
本文将介绍如何基于R语言搭建一个高效的数据分析与可视化平台,帮助用户更好地理解数据、发现规律、做出决策。
1. R语言简介R语言是一种专门用于统计计算和图形展示的编程语言,由新西兰奥克兰大学的Ross Ihaka和Robert Gentleman开发而成。
R语言提供了丰富的数据处理、统计分析和图形展示函数,可以满足各种复杂数据分析需求。
同时,R语言拥有庞大的社区支持和丰富的扩展包,用户可以方便地获取各种功能扩展。
2. 数据分析平台搭建步骤2.1 安装R环境首先,我们需要在服务器或个人电脑上安装R环境。
可以从R官网下载最新版本的R,并按照提示进行安装。
2.2 安装RStudioRStudio是一个集成开发环境(IDE),专门用于R语言开发。
它提供了代码编辑、调试、可视化等功能,是使用R语言进行数据分析的理想工具。
安装完成后,打开RStudio并创建一个新的R脚本。
2.3 安装必要的扩展包在RStudio中,我们可以通过install.packages()函数安装需要用到的扩展包。
比如ggplot2用于绘制图表、dplyr用于数据处理、shiny用于构建交互式应用等。
安装完成后,通过library()函数加载这些扩展包。
2.4 导入数据使用read.csv()或其他读取数据的函数导入需要分析的数据集。
在R中,可以处理各种格式的数据,如CSV、Excel、数据库等。
导入数据后,可以通过head()函数查看数据的前几行,了解数据结构。
2.5 数据清洗与处理在进行数据分析之前,通常需要对数据进行清洗和处理。
比如处理缺失值、异常值、重复值等;进行变量转换、合并、筛选等操作。
使用dplyr包提供的函数可以高效地完成这些任务。
R语言PPT课件数据可视化

5.1 低水平绘图命令
第五章 数据可视化
面
(4)箱线图 箱线图通过绘制连续型变量的五个分位数(最大值、最小值、 25%分位数、75%分位数以及中位数)描述变量的分布。绘制例 5.3中数据counts箱线图: >boxplot(counts) 执行结果
第五章 数据可视化
5.1 低水平绘图命令 5.2 高水平绘图命令 5.3 交互绘图命令 习题
>lb <-paste(year,counts,sep=":")
#构造标签
>pie(counts,labels=lb) #画饼图
执行结果
5.1 低水平绘图命令
第五章 数据可视化
面
(2)条形图 条形图就是通过垂直或者水平的条形去展示分类变量的频数。 利用例5.3数据绘制条形图。 >barplot(counts,names.arg=year,col = rainbow(10)) 执行结果
描述 将分面放置在二维网格中 将一维的分面按二维排列
5.2 高水平绘图命令
第五章 数据可视化
分面
【例5.7】按年分组,一列显示。 >p <- ggplot(data=mpg, mapping=aes(x=cty, y=hwy)) >p <-p + geom_point(aes(colour=class,size=displ)) >p<-p+ stat_smooth() >p <- p + geom_point(aes(colour=factor(year),size=displ)) >p <- p + scale_size_continuous(range = c(4, 10)) #增加标度 >p + facet_wrap(~ year, ncol=1) #分面
R语言数据可视化介绍

,
.•.'••.•1
... .
-
• .• • .·}
·· i
' '·
. .3
`. }
•1 • • ·}
.•.}:
.-•. .`..
•- . •
.. . .
-- - ••} ..-.. .. .
-'. }
.
i
.
.•
..... . ..
.... .. .-
-L
.
o-
-- -ቤተ መጻሕፍቲ ባይዱ•
Oi-54
a }W
箱线图
LL-
卜--1 I l--7
lr. 1 lr
lr
l
T
3
w- 仁
已-
订
哀
们 厂
X
(l) 一
卜----亡二D--
过-
1卜- - -I I- --1
。
- L)[.
_0
I
I
I
I
..---10 15 :20 25 关联图
击-
- --
ii---- ----- 笆
。巴后------—-------—----一----血.一一__ ___
4
用plot绘制散点图的参数设置 plot(x$x1,x$x2,
main='科目1与科目2的关系', #设置标题 xlab='科目1',#设置横坐标名称,如果不写则默认为该变量的名称 ylab='科目2',#设置纵坐标名称 xlim=c(50,100),#设置横坐标的范围 ylim=c(50,100),#设置纵坐标的范围 xaxs='r',#xaxs='r', yaxs='i':分别设定 x 和y 轴的形式。 "i"(内部)与 "r"(预设 值) 形式的刻度都会依照资料的范围而自动调整,但是 "r" 形式的刻度会在刻 度范围两边留一些空隙。 yaxs='r', col='red',#设置点的颜色 pch=20 #设置画图的样式,20表示为圆点 )
r语言与数据可视化 读后感

r语言与数据可视化读后感摘要:一、引言二、R语言与数据可视化的关系三、R语言数据可视化的优势四、R语言数据可视化实例五、结论与建议正文:一、引言在当今数据时代,数据分析已成为各行各业发展的必备技能。
作为一门强大的数据处理和分析工具,R语言在数据可视化领域取得了显著的优势。
本文将分享关于R语言与数据可视化的读后感,探讨R语言在数据可视化方面的应用和优势,并通过实例进行说明。
二、R语言与数据可视化的关系R语言是一种开源的统计分析编程语言,被誉为数据科学家的首选工具。
数据可视化是将数据以图形的形式展示出来,有助于更直观地理解和分析数据。
R语言内置了丰富的数据可视化函数和扩展包,可以轻松地实现数据可视化。
三、R语言数据可视化的优势1.丰富的可视化函数:R语言提供了多种基本和高级的可视化函数,如散点图、折线图、柱状图、热力图等,能满足各种数据可视化的需求。
2.易于学习:R语言的语法简洁明了,初学者可以快速上手。
此外,R语言有庞大的用户社区和丰富的学习资源,便于学习和交流。
3.数据处理能力:R语言在数据清洗、转换和建模等方面具有强大功能,可以方便地将数据处理成可视化所需的形式。
4.交互式界面:R语言有丰富的交互式工具,如R Markdown、Shiny 等,可以创建动态的可视化界面,提高数据分析的效率。
四、R语言数据可视化实例以下是一个简单的R语言数据可视化实例:```R# 加载所需库library(ggplot2)# 创建数据data <- data.frame(x = c(1, 2, 3, 4, 5), y = c(2, 4, 1, 3, 5))# 绘制散点图ggplot(data, aes(x = x, y = y)) +geom_point(color = "red", size = 5) +labs(title = "R语言散点图示例", x = "X轴标签", y = "Y轴标签")```该代码将创建一个散点图,展示x和y之间的相关性。
基于R语言数据可视化-类别数据可视化

R 语言
贾俊平
Chap 3
类别数据可视化
3.1 条形图及其变种 3.2 树状图 3.3 马赛克图及其变种 3.4 关联图和独立性检验P值图 3.5 气球图和热图 3.6 南丁格尔玫瑰图 3.7 金字塔图 3.8 饼图及其变种
Chap 3
类别数据可视化
简单条形图 帕 累 托图 并 列条 形 图 堆 叠条 形 图 不等 宽 条 形 图 脊形图
气球图
l 气球图是用气球大小表示数据的图形,它画出的是一个图形 矩阵,其中每个单元格包含一个点(气球),其大小与相应 数据的大小成比例
l 气球图可用于展示由两个类别变量生成的二维列联表,也可 以用于展示具有行名和列名称的其他数据
l 绘图的数据形式是一个数据框或矩阵,数据框中包含至少三 列,第1列对应第1个类别变量,第2列对应第2个类别变量, 第3列是两个类别变量对应的频数或其他数值
35
数据可视化
12/15/2019
3.5
气球图——例题分析
【例3-1】 使 用 ggpubr包 中 的 ggballoonplot 函数可以绘制气 球图
图气球图和热图
36
数据可视化
12/15/2019
3.5
图气球图和热图
气球图——例题分析
【例3-1】 使 用 ggpubr 包中的 ggballoonplo t函数可以绘 制气球图
25
数据可视化
12/15/2019
3.3
马赛克图
马赛克图的变种——筛网图
l 使用sieve函数可以绘制筛网图(sieve plot) l 该图可用于展示二维列联表或多维列联表,图
中矩阵的面积与相应单元格的观测频数成比例, 每个矩形中的多个小正方形(网格)表示该单 元格的观测频数,网格的密度表示观察频数与 期望频数的差异
基于R语言的数据分析与可视化技术研究

基于R语言的数据分析与可视化技术研究一、引言随着大数据时代的到来,数据分析和可视化技术在各个领域中扮演着越来越重要的角色。
而R语言作为一种开源的数据分析工具,以其强大的数据处理能力和丰富的可视化功能,受到了越来越多数据科学家和分析师的青睐。
本文将探讨基于R语言的数据分析与可视化技术在实际应用中的研究和发展。
二、R语言简介R语言是一种专门用于统计计算和图形展示的编程语言和软件环境。
它提供了丰富的数据处理、统计分析和图形展示函数,使得用户可以方便地进行数据分析和可视化。
R语言具有开源、跨平台、易学易用等特点,因此在学术界和工业界都得到了广泛应用。
三、数据分析技术1. 数据清洗在进行数据分析之前,首先需要对原始数据进行清洗和预处理。
R语言提供了各种函数和包,可以帮助用户进行数据清洗,包括缺失值处理、异常值检测、数据转换等操作。
2. 统计分析R语言内置了大量的统计分析函数,可以进行描述性统计、假设检验、回归分析等操作。
用户可以通过调用这些函数,快速对数据进行统计分析,并得出结论。
3. 机器学习除了传统的统计方法,R语言还支持各种机器学习算法,如决策树、支持向量机、神经网络等。
用户可以利用这些算法构建预测模型,对未来事件进行预测。
四、可视化技术1. 基本图形R语言提供了丰富多样的绘图函数,用户可以轻松绘制各种基本图形,如散点图、折线图、柱状图等。
这些图形可以直观地展示数据的分布和趋势。
2. 高级可视化除了基本图形外,R语言还支持绘制高级可视化图形,如热力图、雷达图、网络图等。
这些图形可以更加生动地展示数据之间的关系和规律。
3. 交互式可视化随着Web技术的发展,交互式可视化成为了一种新的趋势。
R语言也提供了各种交互式可视化包,用户可以通过添加交互功能,使得图形更具互动性。
五、案例研究为了更好地说明基于R语言的数据分析与可视化技术在实际应用中的价值,我们以某电商平台销售数据为例进行案例研究。
通过对销售数据进行清洗、统计分析和可视化处理,我们可以发现销售额随时间变化的趋势、不同产品类别的销售情况等信息。
基于R语言的数据可视化与分析平台建设

基于R语言的数据可视化与分析平台建设一、引言随着大数据时代的到来,数据分析和可视化变得越来越重要。
R语言作为一种开源的数据分析工具,具有强大的数据处理和可视化能力,因此在数据科学领域得到了广泛应用。
本文将介绍如何基于R语言搭建一个高效的数据可视化与分析平台,帮助用户更好地理解和利用数据。
二、环境搭建在搭建数据可视化与分析平台之前,首先需要搭建好R语言的开发环境。
用户可以选择在本地安装R语言的开发环境,也可以选择使用在线的R编程平台。
无论是本地还是在线环境,都需要安装相关的R 包和工具,以便进行数据处理和可视化操作。
三、数据导入与处理在搭建平台的过程中,首要任务是导入数据并进行必要的处理。
R语言提供了丰富的数据导入函数,可以轻松导入各种格式的数据文件,如CSV、Excel等。
同时,R语言也提供了强大的数据处理函数,用户可以对数据进行清洗、筛选、聚合等操作,以便后续的分析和可视化。
四、数据可视化数据可视化是数据分析过程中至关重要的一环。
通过可视化手段,用户可以直观地展示数据的特征和规律,帮助用户更好地理解数据。
在R语言中,有许多优秀的可视化包,如ggplot2、plotly等,用户可以根据需求选择合适的包来创建各种类型的图表,如折线图、柱状图、散点图等。
五、统计分析除了数据可视化外,统计分析也是数据分析平台不可或缺的一部分。
R语言作为一种统计计算工具,提供了丰富的统计函数和算法,用户可以利用这些函数进行描述性统计、假设检验、回归分析等操作。
通过统计分析,用户可以深入挖掘数据背后的规律和关联性。
六、交互式应用开发为了提升用户体验和操作便捷性,可以考虑开发交互式应用来展示数据分析结果。
在R语言中,Shiny包提供了快速开发交互式Web应用的能力,用户可以通过简单的代码编写实现交互式应用的功能。
这样用户不仅可以通过静态图表展示数据结果,还可以通过交互式应用进行动态探索和交互操作。
七、部署与分享当平台搭建完成后,需要考虑如何部署和分享给其他用户。
【原创】R语言数据可视化分析报告(附代码数据)
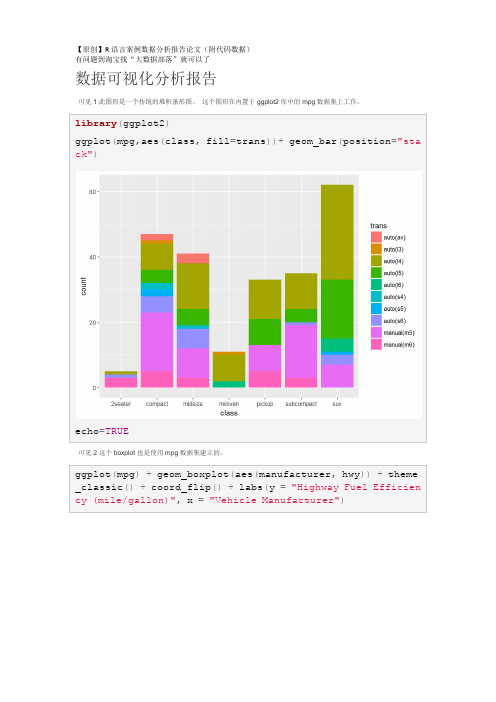
Vis 3这个图形是用另一个数据集菱形建立的,也是内置在ggplot2包中的数据集。
library(ggthemes)
ggplot(diamonds)+geom_density(aes(price,fill=cut,color=cut),alpha=0.4,size=0.5)+labs(title='Diamond Price Density',x='Diamond Price (USD)',y='Density')+theme_economist()
library(ggplot2)
ggplot(mpg,aes(class,fill=trans))+geom_bar(position="stack")
echo=TRUE
可见2这个boxplot也是使用mpg数据集建立的。
ggplot(mpg)+geom_boxplot(aes(manufacturer,hwy))+theme_classic()+coord_flip()+labs(y="Highway Fuel Efficiency (mile/gallon)",x="Vehicle Manufacturer")
echo=TRUE
另外,我正在使用ggplot2软件包来将线性模型拟合到框架内的所有数据上。
ggplot(iris,aes(Sepal.Length,Petal.Length))+geom_point()+geom_smooth(method=lm)+theme_minimal()+theme(panel.grid.major=element_line(size=1),panel.grid.minor=element_line(size=0.7))+labs(title='relationship between Petal and Sepal Length',x='Iris Sepal Length',y='Iris Petal Length')
基于R语言的财务数据可视化方法应用研究

题目:基于R语言的财务数据可视化方法应用研究课程名称R语言实训学生学号201学生姓名孙所在班级2018级指导教师撰写时间成绩摘要在大数据时代,生活中的许多方面都因数据而改变,财务数据分析工作也不例外,其思维方式和技术方法等方面必须有所变化。
目前,财务数据的表现形式仍然以各种财务法规、准则规定的报告形式主,其内容必须要接受过一定的专业训练才能解读。
因此,财务数据的可视化被提上了日程。
本文基于R语言在数据可视化方面的优势,通过案例分析的形式探究R语言在财务数据可视化方法研究中的可行性,通过R语言动态数据可视化技术进行财务数据分析,发现隐藏在企业内部的财务险,帮助企业管理者或股东更直观地发现数据中隐藏的秘密,以更好的服务于企业的经营决策。
鉴于企业在国民经济中的重要地位,研究R语言在财务数据可视化方面的作用,对于提高综合国力也有积极的作用本文主要分为四个章节,主要介绍了R语言在财务数据可视化分析方法,通过在苏宁易购财务数据分析的作用,充分的展示R语言在财务数据分析中的优势,以进一步论证R语言在财务数据可视化的可行性,进而达到推广R语言在企业财务数据可视化方面的目的通过对理论的研究和案例的分析,笔者认为R语言在财务数据可视化中的优势是显著的,希望未来可以得到推广关键词:R语言;数据可视化;财务分析目录题目:基于R语言的财务数据可视化方法应用研究 (1)摘要 (2)第1章绪论 (5)1.1本文研究背景及意义 (5)1.1.1研究背景 (5)1.1.2研究意义 (6)1.2国内外研究现状 (6)1.2.1数据可视化研究现状 (6)1.2.2 R语言在财务数据可视化中的应用 (8)1.3本文主要内容及结构安排 (9)1.3.1本文主要内容 (9)1.3.2本文结构安排 (10)第2章财务数据可视化的工具及理论 (11)2.1 R语言概述 (11)2.1.1R语言的主要特点 (11)2.1.2 R语言在财务数据可视化分析中的主要方法 (12)2.2财务数据可视化相关理论 (14)2.2.1财务数据可视化概念 (14)2.2.2财务数据分析方法 (15)2.3财务数据分析理论 (16)2.4主成分分析理论 (16)2.5本章小结 (17)第3章R语言在苏宁易购财务数据可视化的应用案例 (18)3.1案例公司背景介绍 (18)3.2可视化应用案例 (19)3.2.1运用R语言对苏宁易购偿债能力分析 (19)3.2.2运用R语言对苏宁易购营运能力分析 (21)3.2.3运用R语言对苏宁易购盈利能力分析 (22)3.3 基于脸谱图运用R语言的苏宁易购财务分析 (23)3.3.1基于主成分分析法的财务指标量化 (23)3.3.2基于脸谱图的苏宁易购财务分析 (26)3.4本章小结 (29)第4章基于R语言的财务数据可视化未来发展策略 (30)4.1影响财务数据可视化发展的主要因素 (30)4.2财务数据可视化发展的策略 (30)4.2.1可视化技术与管理相结合 (30)4.2.2整合现有资源,做好技术储备 (31)4.2.3重视财务人员跨专业知识整合 (31)4.3本章小结 (32)结论 (33)参考文献 (34)第1章绪论1.1本文研究背景及意义1.1.1研究背景目前的市场竞争中,对信息的各个方面进行分析都是提高企业竞争力的有效手段,而对企业经营的各项财务数据加以分析,已经成为当今企业管理中不可或缺的一部分。
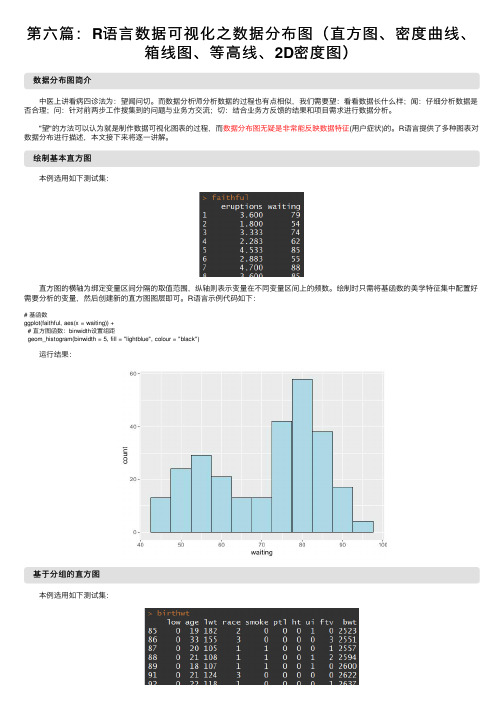
第六篇:R语言数据可视化之数据分布图(直方图、密度曲线、箱线图、等高线、2D密度图)
第六篇:R语⾔数据可视化之数据分布图(直⽅图、密度曲线、箱线图、等⾼线、2D密度图)数据分布图简介中医上讲看病四诊法为:望闻问切。
⽽数据分析师分析数据的过程也有点相似,我们需要望:看看数据长什么样;闻:仔细分析数据是否合理;问:针对前两步⼯作搜集到的问题与业务⽅交流;切:结合业务⽅反馈的结果和项⽬需求进⾏数据分析。
"望"的⽅法可以认为就是制作数据可视化图表的过程,⽽数据分布图⽆疑是⾮常能反映数据特征(⽤户症状)的。
R语⾔提供了多种图表对数据分布进⾏描述,本⽂接下来将逐⼀讲解。
绘制基本直⽅图本例选⽤如下测试集:直⽅图的横轴为绑定变量区间分隔的取值范围,纵轴则表⽰变量在不同变量区间上的频数。
绘制时只需将基函数的美学特征集中配置好需要分析的变量,然后创建新的直⽅图图层即可。
R语⾔⽰例代码如下:# 基函数ggplot(faithful, aes(x = waiting)) +# 直⽅图函数:binwidth设置组距geom_histogram(binwidth = 5, fill = "lightblue", colour = "black")运⾏结果:基于分组的直⽅图本例选⽤如下测试集:直⽅图的分组图和本系列前⾯⼀些博⽂中讲的⼀些分组图不同,它不能进⾏⽔平⽅向的堆积 - 这样看不出频数变化趋势;也不能进⾏垂直⽅向的堆积 - 这样同样看不出趋势。
这⾥采⽤⼀种新的堆积⽅法:重叠堆积,R语⾔实现代码如下:# 预处理:将smoke变量转换为因⼦类型birthwt$smoke = factor(birthwt$smoke)# 基函数:x设置⽬标变量ggplot(birthwt, aes(x = bwt, fill = smoke)) +# 直⽅图函数:position设置堆积模式为重叠geom_histogram(position = "identity", alpha = 0.4)运⾏结果:也可以采⽤分⾯的⽅法,R语⾔实现代码如下:# 预处理1:将smoke变量转换为因⼦类型birthwt$smoke = factor(birthwt$smoke)# 预处理2:改变因⼦⽔平名称birthwt$smoke = revalue(birthwt$smoke, c("0" = "No Smoke", "1" = "Smoke"))# 基函数ggplot(birthwt, aes(x = bwt)) +# 直⽅图函数geom_histogram(fill = "lightblue", colour = "black") +# 分⾯函数:纵向分⾯facet_grid(smoke ~ .)运⾏结果:绘制密度曲线本例选⽤如下测试集:密度曲线表达的意思和直⽅图很相似,因此密度曲线的绘制⽅法和直⽅图也⼏乎是相同的。
基于R语言数据可视化-其他可视化图形

3916.7
2899.7
1000.4
总支出 37425.4
居住 生活用品及服务 交通通信 教育文化娱乐 医疗保健 其他用品及服务 Total
8
数据可视化
6/10/2020
8.2
和弦图
和弦图
和 弦 图 ( chord diagram ) 也 可 以 称 为 圆 形 图 (circular plot),它是显示矩阵、数据框或二维 列联表中各组别数据间相互关系的可视化图形
其节点数据(组别或类别)沿圆周径向排列,节 点之间使用不同宽度的弧线链接
和弦图是用圆形来表达数据流量的分布结构,可 用于不同组别之间的关系或相似性比较
9
数据可视化
6/10/2020
8.2
和弦图
瀑布图——例题分析 【例8-1】 由 circlize 包 中 的 chordDiagram函数绘制 的和弦图
0.76
27
数据可视化
6/10/2020
8.7
出版物中的图表
绘制表格——例题分析
【例8-1】 计算出相关系数矩阵后再绘制出文本表格
食品烟酒 衣着 居住 生活用品及服务 交通通信 教育文化娱乐 医疗保健 其他用品及服务
食品烟酒 1 0.32 0.69
0.29
0.51
0.77
0.66
0.88
衣着 0.32 1 0.57
8.6
词云图
词云图——例题分析
使 用 wordcloud2 自 带 的 数 据 集 demoFreqC , 由 letterCloud 函数绘制的以词语“R可视化”展示的词云图
22
数据可视化
6/10/2020
8.6
词云图
原创R语言线性回归案例数据分析可视化报告附代码数据

原创R语言线性回归案例数据分析可视化报告附代码数据在数据分析领域,线性回归是一种常用的数据建模和预测方法。
本文将使用R语言进行一个原创的线性回归案例分析,并通过数据可视化的方式呈现分析结果。
下面是我们的文本分析报告,同时包含相关的代码数据(由于篇幅限制,只呈现部分相关代码和数据)。
请您详细阅读以下内容。
1. 数据概述本次案例我们选用了一个关于房屋价格的数据集,数据包含了房屋面积、房间数量、地理位置等多个维度的信息。
我们的目标是分析这些因素与房屋价格之间的关系,并进行可视化展示。
2. 数据预处理在开始回归分析之前,我们需要对数据进行预处理,包括数据清洗和特征选择。
在这个案例中,我们通过删除空值和异常值来清洗数据,并选择了面积和房间数量两个特征作为自变量进行回归分析。
以下是示例代码:```R# 导入数据data <- read.csv("house_data.csv")# 清洗数据data <- na.omit(data)# 删除异常数据data <- data[data$area < 5000 & data$rooms < 10, ]# 特征选择features <- c("area", "rooms")target <- "price"```3. 线性回归模型建立我们使用R语言中的lm()函数建立线性回归模型,并通过summary()函数输出模型摘要信息。
以下是相关代码:```R# 线性回归模型建立model <- lm(data[, target] ~ ., data = data[, features])# 输出模型摘要信息summary(model)```回归模型摘要信息包含了拟合优度、自变量系数、截距等重要信息,用于评估模型的拟合效果和各个因素对因变量的影响程度。
基于R语言的主成分分析结果解释与可视化

基于R语言的主成分分析结果解释与可视化主成分分析(PCA)是一种常用的降维技术,用于将高维数据转变为低维数据,同时保留数据的重要信息。
本文将基于R语言对主成分分析结果进行解释与可视化。
首先,我们需要加载相关的R包,并导入数据集。
假设我们有一个包含多个变量的数据集,命名为"dataset.csv",其中每一行代表一个样本,每一列代表一个变量。
通过以下代码导入数据集:```R# 加载相关的R包library(ggplot2)library(dplyr)library(FactoMineR)library(FactoExtra)# 导入数据集dataset <- read.csv("dataset.csv", header = TRUE)```接下来,我们可以对数据进行主成分分析。
使用`prcomp`函数可以进行主成分分析,并设置`scale = TRUE`对数据进行标准化:```R# 主成分分析pca <- prcomp(dataset, scale = TRUE)```主成分分析会生成一些重要的结果,包括主成分得分、主成分贡献率、特征向量等。
我们可以通过以下代码来获取这些结果:```R# 提取主成分得分scores <- as.data.frame(pca$x)# 提取主成分贡献率contributions <- pca$sdev^2 / sum(pca$sdev^2)# 提取特征向量loadings <- pca$rotation```得分是指每个样本在主成分上的投影值,可以用来表示样本在不同主成分上的位置。
贡献率是指每个主成分对总方差的贡献程度,可以用来衡量主成分的重要性。
特征向量表示每个变量在主成分上的权重,可以用来解释主成分与原始变量之间的关系。
接下来,我们可以对主成分分析的结果进行解释与可视化。
首先,我们可以使用散点图来展示样本在不同主成分上的位置。
R语言数据分析与可视化教程

R语言数据分析与可视化教程R语言是一种常用于数据分析和可视化的编程语言,具有广泛的应用领域。
本教程将介绍R语言的基本概念、常用函数和工具,帮助读者快速上手数据分析和可视化。
1. R语言基础R语言是一种开源的统计分析工具,因其丰富的函数库和灵活的数据处理能力而备受青睐。
首先,我们需要学习R语言的基本语法和操作。
以下是一些常用的命令和操作符:- 变量赋值:使用<-或=符号将数据赋给变量。
- 数据类型:R支持多种数据类型,如数字、字符、逻辑等。
- 数据结构:包括向量、矩阵、数组、列表和数据框等。
- 条件语句:使用if-else语句进行条件判断。
- 循环语句:使用for和while语句进行循环操作。
- 函数定义:使用自定义函数提高代码的可复用性。
2. 数据导入与处理在数据分析中,我们经常需要导入外部数据,并对数据进行预处理。
R语言提供了多种数据导入和处理的方法,以下是常用的函数和技巧:- read.table():用于导入文本文件。
- read.csv():用于导入CSV文件。
- read_excel():用于导入Excel文件。
- subset():用于筛选数据。
- merge():用于合并数据。
- aggregate():用于数据聚合。
- na.omit():用于去除缺失值。
3. 数据分析R语言拥有丰富的数据分析库,可以进行各种统计分析和建模操作。
以下是常用的数据分析函数和技巧:- summary():用于描述性统计分析。
- t.test():用于执行t检验。
- cor.test():用于执行相关性检验。
- lm():用于执行线性回归。
- glm():用于执行广义线性模型。
- kmeans():用于执行聚类分析。
- randomForest():用于执行随机森林算法。
4. 数据可视化数据可视化是数据分析的重要环节,可以帮助我们更好地理解数据和分析结果。
R语言提供了多种数据可视化工具和函数,以下是常用的绘图函数和技巧:- plot():用于绘制散点图、折线图和柱状图等。
基于R语言的主成分分析结果可视化方法与实例分析

基于R语言的主成分分析结果可视化方法与实例分析主成分分析(Principal Component Analysis,简称PCA)是一种常用的多变量数据降维和数据可视化方法。
它可以将高维数据集转化为低维空间,保留数据集的主要信息,便于观察和分析。
R语言是一种强大的统计分析工具,具有丰富的PCA函数和可视化包,可以帮助我们实现主成分分析结果的可视化。
下面我将介绍基于R语言的主成分分析结果可视化方法,并通过一个实例来说明。
首先,我们需要使用R语言加载相关的库和数据集。
在R中,我们可以使用"ggplot2"包来进行数据可视化,使用"FactoMineR"包来进行主成分分析。
```R#加载所需包library(ggplot2)library(FactoMineR)#加载数据集data <- read.csv("data.csv") #将数据集命名为"data.csv"```接下来,我们可以进行主成分分析并获取结果。
在R中,我们可以使用"PCA"函数来进行主成分分析。
```R#主成分分析pca <- PCA(data)```主成分分析会生成一系列的主成分和它们的贡献度。
我们可以通过"dimdesc"函数查看主成分的描述信息。
```R#查看主成分描述dimdesc(pca)```通过"dimdesc"函数,我们可以得到每个主成分对应的原始变量,并且可以查看它们的权重和贡献度。
接下来,我们可以选择性地选择几个主成分进行可视化分析。
在R中,我们可以使用"fviz_pca_ind"函数进行样本的主成分分析结果可视化。
```R#样本主成分分析结果可视化fviz_pca_ind(pca, axes = c(1, 2), geom.ind = "point", col.ind = "blue", pointsize = 2, title = "PCA - Individus")```"fviz_pca_ind"函数中,参数"axes"指定了我们要可视化的主成分,"geom.ind"指定了个体的几何表达方式,"col.ind"和"pointsize"分别指定了个体的颜色和大小。
《数据可视化分析—基于R语言》—教学大纲

《数据可视化分析—基于R语言》—教学大纲教学大纲《数据可视化分析—基于R语言》(第2版)一.课程概述1.1课程背景和目标1.2教学方法和学习方式1.3考核方式二.基础知识介绍2.1R语言简介和环境搭建2.2基本数据类型和数据结构2.3数据处理和数据清洗三.数据可视化基础3.1可视化概念和原则3.2常见的可视化图表类型3.3合适的可视化图表选择3.4基本绘图函数的使用四.单变量数据可视化4.1频数统计图和直方图4.2核密度估计图4.3箱线图五.双变量数据可视化5.1散点图5.2折线图和面积图5.3箱线图和小提琴图5.4相关分析图六.多变量数据可视化6.1散点图矩阵6.2平行坐标图6.3树状图和热力图6.4气泡图和雷达图七.数据可视化设计7.1颜色选择和使用技巧7.2字体选择和布局设计7.3图表的美化和注解添加八.交互式数据可视化8.1 ggplot2包介绍8.2 ggplot2包的使用方法8.3制作交互式可视化图表九.地理数据可视化9.1空间数据的处理和可视化9.2制作地图和地理信息图表9.3地图上添加标记和注释十.时间序列数据可视化10.1时间序列数据的处理和可视化方法10.2折线图和面积图的时间序列展示10.3时间序列的季节性和趋势分析十一.大数据可视化11.1大数据可视化的挑战和方法11.2基于R语言的大数据可视化工具11.3大数据可视化案例分析十二.实际案例分析12.1数据可视化的实际应用12.2根据实际案例进行数据可视化分析12.3分析结果的解读和总结十三.课程总结和展望13.1课程回顾和总结13.2学员反馈和建议13.3未来数据可视化发展趋势以上为《数据可视化分析—基于R语言》(第2版)教学大纲的主要内容。
通过本课程的学习,学员将掌握R语言的基本知识和数据处理技巧,了解数据可视化的基本概念和原则,学会使用R语言进行单变量、双变量和多变量数据可视化,掌握数据可视化设计的基本方法,学习交互式数据可视化和地理数据可视化的技术,了解时间序列和大数据的可视化方法。
基于R_语言的可视化技术在食品生产经营主体风险分级数据上的应用

食品科技基于R语言的可视化技术在食品生产经营主体风险分级数据上的应用应轩宇,蔡 强*,纪 伟(浙江清华长三角研究院,浙江嘉兴 314006)摘 要:为了探索数据可视化技术在食品生产经营主体风险分级中的应用,本文基于R语言及ggplot2、plotly、shiny等扩展包构建食品生产经营主体风险分级数据可视化系统,实现区域整体状况、主体风险信息、风险识别、时间趋势比较等的全面展示与人机交互。
该数据可视化技术有助于动态、快速、直观地开展食品生产经营主体的风险评价,强化风险表征,辅助监管决策。
关键词:食品安全;风险分级;数据可视化;R语言Application of Visualization Technology in Risk Classification of Food Operators Based on R LanguageYING Xuanyu, CAI Qiang*, JI Wei(Yangtze Delta Region Institute of Tsinghua University, Zhejiang, Jiaxing 314006, China) Abstract: In order to explore the application of data visualization technology in the risk classification of food production and management entities, this paper builds a risk classification data visualization system for food production and management entities based on R language and ggplot2, plotly, shiny and other extension packages. To realize the comprehensive display and human-computer interaction of the overall situation of the region, subject risk information, risk identification, time trend comparison, etc. The data visualization technology is helpful to dynamically, quickly and intuitively carry out the risk assessment of food production and management entities, strengthen the risk characterization, and assist the regulatory decision-making.Keywords: food safety; risk classification; data visualization; R language食品生产经营主体风险分级是指市场监督管理部门结合食品生产经营者的食品类别、业态规模、管理能力、记录情况等,按照指标量化评价,动态划分食品生产经营者风险等级,统筹监管资源与能力,对食品生产经营者实施差异化、精准化监督管理,有助于强化食品生产经营风险管理,优化监管资源配置,科学有效地实施监管,落实食品安全监管责任,保障食品安全[1-2]。
基于R语言数据可视化-分布特征可视化

9
数据可视化
12/15/2019
4.1
直方图与核密度图
直方图——堆叠直方图——例题分析
【例4-1】
堆叠直方图 ( stacked histogram) 是将按因子 水平分类的 直方图堆叠 在一起的一 种图形。比 如,我们按 “质 量 等 级 ” 这一因子来 绘 制 AQI的 直 方图并堆叠 在一起
数绘制的按质 量等级分类来 绘制点图
37
数据可视化
12/15/2019
4.3
点图和带状图
带状图 l 带 状 图 ( stripchart) 又 称 平 行 散 点 图 ( parallel
scatterplot) l 它与点图类似,用于产生一维(one dimensional)
散点图 l 当样本数据较少时,可作为直方图和箱线图的替
25
数据可视化
12/15/2019
4.2
箱线图和小提琴图
箱线图——例题分析
【例4-1】 graphics包 中 的 boxplot函 数绘制的6项 空气污染指 标的箱线图
26
数据可视化
12/15/2019
4.2
箱线图和小提琴图
箱线图——例题分析
【例4-1】 对数变换和 标准化变换 后的6项空气 污染指标的 箱线图
【 例 4-1】 ( 数 据 : data4_1.csv) 。 空 气 质 量 指 数 ( Air Quality Index,AQI)用来描述空气质量状况,指数的数值 越大说明空气污染状况越严重。参与空气质量评价的主要 污染物有细颗粒物(PM 2.5)、可吸入颗粒物(PM10)、 二氧化硫(SO2)、一氧化碳(CO)、二氧化氮(NO2)、 臭氧浓度(O3)等6项。根据空气质量指数将空气质量分 为6级:优(0-50),良(51-100),轻度污染(101-150), 中度污染(151-200),重度污染(201-300),严重污染 (300以上);分别用绿色、黄色、橙色、红色、紫色、褐 红色表示。表4-1是2018年1月1日~12月31日北京市的空气 质量数据
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
520
plot_frq 函 数 绘 500
(26.0%)
制的条形图
250
0
不满意
满意
中立
满意度
6
数据可视化
6/10/2020
3.1
条形图及其变种
简单条形图和帕累托图——帕累托图
帕累托图(Pareto plot)是将各类别的频数降序排 列后绘制的条形图
以意大利经济学家V.Pareto的名字命名的 帕累托图可以看作简单条形图的一个变种,利用
9
数据可视化
6/10/2020
3.1
条形图及其变种
并列条形图和堆叠条形图——例题分析
【例3-1】
使 用 barplot 结 合 BarText 函 数 绘制的条形图
人数 0 200 400 600 800
人数 0 100 200 300 400
男
女
482
338
322
280
340 238
1-2次
3-5次
使 用 epade 包 中 的 bar.plot.ade 函 数 绘 制的3D条形图。默 认参数beside=TRUE, 绘制并列条形图, 设 置 beside=FALSE 可绘制堆叠条形图
人数
0
200 400 600 800 1000
p: 0.0036 10.4% 8.6% 11.9%
1-2次
p: <0.0001 14.6% 9.8% 15.8%
0.0 0.2 0.4 0.6 0.8 1.0
0.0 0.2 0.4 0.6 0.8 1.0 网购次数
1-2次 3-5次 6次 以 上
女
性别
男
不满意
满意 满意度
中立
不满意
满意 满意度
中立
16
数据可视化
6/10/2020
3.1
条形图及其变种
脊形图——例题分析
【例3-1】
使
用
ggiraphExtra
包中的
1-2次
不满意
满意
中立
不满意 满意度
满意
中立
17
数据可视化
6/10/2020
3.2
树状图
树状图
将各类别的层次结构画成树状图的形式,称为树状 图(dendrogram)或分层树状图
有条形树状图和矩形树状图,可以看做是条形图的 另一个变种
主要用来展示各类别变量之间的层次结构关系,尤 其适合展示3个及3个以上类别变量的情形(也可以 用于展示两个类别变量)
该图很容易看出哪类频数出现得最多,哪类频数 出现得最少。
7
数据可视化
6/10/2020
3.1
条形图及其变种
简单条形图和帕累托图——帕累托图
800 1000
【例3-1】 barplot 函 数 绘 制的帕累托图
600
累积分布曲线 800
680 520
0.4 0.5 0.6 0.7 0.8 0.9 1.0
条形树状图 矩形树状图
条形图及其变种 树状图
马赛克图 马赛克图变种
马赛克图及其变种
关联图 独立性检验P值图
关联图和独立性 检验P值图
3
Chap 3
数据可视化
气球图和热图
气球图
热
图
南丁格尔玫瑰图 玫 瑰 图
金 字 塔 图 金字塔图
饼图及其变种
饼图和扇形图 环形图和弧形
6/10/2020
3.1
条形图及其变种
38.1% (n=320)
中立
性别 男 女 Total
11
数据可视化
6/10/2020
3.1
条形图及其变种
并列条形图和堆叠条形图——例题分析
【例3-1】
使 用 epade 包 中 的 bar.plot.ade 函 数 绘 制的3D条形图。默 认参数beside=TRUE, 绘制并列条形图, 设 置 beside=FALSE 可绘制堆叠条形图
• 使用treemap包中的 treemap函数可以绘制树 状图
21
数据可视化
6/10/2020
3.2
树状图
矩形树状图——例题分析
【例3-1】
矩形树状图(treemap)是 将多个类别变量的层次结 构绘制在一个表示总频数 的大的矩形中,每个子类 用不同大小的矩形嵌套在 这个大的矩形中。嵌套矩 形表示各子类别的频数, 其大小与相应的子类频数 成比例。
人数 0 100 200 300 400 500
性别与满意度的条形图
p: 0.0047
男女
p: <0.0001
p: 0.13
22.0% 18.0%
18.0% 8.0%
18.0% 16.0%
不满意
满意 满意度
中立
12
数据可视化
6/10/2020
3.1
条形图及其变种
并列条形图和堆叠条形图——例题分析
【例3-1】
数据可视化
R 语言
贾俊平
Chap 3
类别数据可视化
3.1 条形图及其变种 3.2 树状图 3.3 马赛克图及其变种 3.4 关联图和独立性检验P值图 3.5 气球图和热图 3.6 南丁格尔玫瑰图 3.7 金字塔图 3.8 饼图及其变种
Chap 3
类别数据可视化
简单条形图 帕累托图 并列条形图 堆叠条形图 不等宽条形图 脊形图
并列条形图中,一个类别变量作为坐标轴,另一个类别变量各类别频 数的条形并列摆放;堆叠条形图中,一个类别变量作为坐标轴,另一 个类别变量各类别的频数按比例堆叠在同一个条中
使用barplot函数默认绘制堆叠条形图,设置参数beside=TRUE可绘制并 列条形图。使用DescTools包中的BarText函数、plotrix包中的barlabels函 数可以给条形图添加标签
累积频率
人数
400
200
0
不满意
中立
满意
满意度
8
数据可视化
6/10/2020
3.1
条形图及其变种
并列条形图和堆叠条形图
绘制两个类别变量的条形图时,可以使用原始数据绘图,也可以先生 成二维列联表再绘图
根据绘制方式不同有并列条形图(juxtaposed bar plot)和堆叠条形图 (stacked bar plot)等
ggSpine 函 数
绘制按第3个
类别变量分
面的脊形图
网购次数
3-5次
6次以上
性别:男 N=840
29.4%
30.6%
25.9%
38.1%
33.8%
40.9%
32.5%
35.6%
33.1%
性别:女 N=1160
31.6%
29.2%
26.7%
40.7%
39.2%
45.0%
27.7%
31.7%
28.3%
18
数据可视化
6/10/2020
3.2
树状图
条形树状图——例题分析
【例3-1】
使用plotrix包中的 plot.dendrite 函 数 和 sizetree 函 数 可 以绘制出不同式 样的树状图。 plot.dendrite 绘 制 的条形树状图
女 1160
男 840
性别
6次以上 340 3-5次 482 1-2次 338
简单条形图和帕累托图——条形图
条形图(bar plot)是用一定宽度和高度的矩形表 示各类别频数多少的图形
主要用于展示类别变数据的频数分布
绘制条形图时,各类别可以放在X轴(横轴),也 可以放在Y轴(纵轴)
类别放在X轴的条形图称为垂直条形图(vertical bar plot)或柱形图,类别放在Y轴的条形图称为 水平条形图(horizontal bar plot)
中 立 (162)
不 满 意 (139) 满 意 (105) 中 立 (96)
满意度
20
数据可视化
6/10/2020
3.2
树状图
矩形树状图——例题分析
【例3-1】
矩形树状图(treemap)是 将多个类别变量的层次结 构绘制在一个表示总频数 的大的矩形中,每个子类 用不同大小的矩形嵌套在 这个大的矩形中。嵌套矩 形表示各子类别的频数, 其大小与相应的子类频数 成比例。
6次以上 238 3-5次 322 1-2次 280
网购次数
中立 96 满意 105
不满意 139 中立 162 满意 141
不满意 179 中立 102 满意 114
不满意 122 中立 83 满意 49
不满意 106 中立 131 满意 54
不满意 137 中立 106 满意 57
不满意 117
1-2次
3-5次
6次 以 上
人数
网购次数
(c) 垂 直 条 形 图
人数
0 200 400 600 800
不满意
满意 满意度
中立
5
数据可视化
6/10/2020
3.1
条形图及其变种
简单条形图和帕累托图——简单条形图——例题分析
【例3-1】
800 (40.0%)
750
680
sjPlot 包 中 的
(34.0%)
满意度
19
数据可视化
6/10/2020
3.2
树状图
大小树状图——例题分析
【例3-1】
使用sizetree函数 男 (840)
可以绘制出另一
种形式的树状图,
称为大小树
女 (1160)
( size tree ) 或
规模树 性别