ETL工具使用说明
ETL使用手册

火龙果 整理ETL使用手册ETL使用手册第一章配置文件结构<loaderJob>//根标签<restartCounter/>//在目标数据库中创建数据表,纪录importDefinition标签重新启动的次数,如果存在表明会抛错.<variables>//接收参数定义<variable/></variables><jdbcDefaultParameters>//默认JDBC连接<jdbcSourceParameters><jdbcSourceParameter/></jdbcSourceParameters><jdbcTargetParameters><jdbcTargetParameter/></jdbcTargetParameters></jdbcDefaultParameters><sql>//执行SQL语句<jdbcTargetParameters><jdbcTargetParameter/></jdbcTargetParameters><sqlStmt><include/></sqlStmt></sql><definitionInclude>//定义包含<include/>//包含多个<definitionInclude>标签文件<echo/>//日志开头要显示的信息<copyTable/>//简单表复制<importDefinition>//导入定义<sortColumns>//确保字段数据唯一<sortColumn/></sortColumns><jdbcParameters>//导入任务定义的JDBC连接<jdbcSourceParameters><jdbcSourceParameter/></jdbcSourceParameters><jdbcTargetParameters><jdbcTargetParameter/></jdbcTargetParameters></jdbcParameters><valueColumns>//直接对应转换列<valueColumn/></valueColumns><transformations>//自定义转换规则<transformation>//转换规则<sourceColumns><sourceColumn/></sourceColumns><targetColumns><targetColumn/></targetColumns><javaScript><include/></javaScript></transformation></transformations><variableColumns><variableColumn/>//将变量值赋给目标字段必须属性override="true"<userIDColumn/>//将当前用户赋给目标字段<timeStampColumn/>//将当前时间赋给目标字段</variableColumns><relationColumns><relationColumn/>//导入外键关系(必须存在对应关系)</relationColumns><constantColumns><constantColumn/>//将固定值(常量)赋给目标字段</constantColumns><counterColumns><counterColumn/>//通过计数器表向目标字段自动增量生成数据(例如:自动加1)<subCounterColumn/><subCounterKeyColumn/></subCounterColumn></counterColumns><tables>//定义目标表<table/></tables></importDefinition></definitionInclude></loaderJob>第二章标签说明<loaderJob>ETL配置文件的根标签。
ETL工具kettl应用说明
Kettle工具在实际中的应用说明一:资源库的设置Kettle提供了两种资源库的选择方式:数据库存放、本地文件存放。
数据库该方式是通过数据库连接直接在数据库里面创建kettle表,表里面记录着你所做的任何保存过的记录以及转换和任务。
此方法是远程存放的方式,具有可多人共享一个资源库的优势,但是也存在资源库不稳定的缺点。
以下就数据库资源库具体怎么实现做一下介绍:第一:在tools选项下面有在资源库选项里面有连接资源库选项,点击之后会出现如下界面:刚开始的时候是没用任何连接的,需要根据自己的需要选择创建。
笔:修改资源库连接加:添加新的资源库叉:删除选中资源库点那个加号图标就可以进入到新建选项页面:在中间的显示栏中:第一行代表着写入到数据库的资源库、第二行代表着保存到本地的资源库。
点击第一行进入如下界面:点击新建按钮将会新建数据库连接,如果已经有你需要的数据库连接也可以选择你需要的。
上面就是新建数据库页面,根据你的需要选择具体的数据库连接方式,填写好完成之后点击一下测试按钮,就可以知道数据库连接是否成功。
到这里,资源库的连接已经做了一半了。
接下来介绍另一半要做的事情。
回到这个页面,填写唯一的ID、名称,然后点击创建或更新按钮,之后会出现一些SQL语句,执行这些语句,如果成功的话就创建成功了,如果失败则要检查一下数据库。
最后点击确定按钮就成功了。
这个时候就可以连接资源库了。
选择你创建的资源库,admin用户的默认密码是admin ,点击OK就行了。
本地接下来简单介绍一下本地资源库,其实是很简单的。
选择第二行。
将会看到如下页面:这个就是本地的页面,比数据库简单多了,选择一下存放路径,给它一个ID号和名称,点击OK就可以了。
资源库建好之后就会进入到主页面了:这个就是主页面了,表面上是空空如也的。
关于资源库的设置就就讲到这里了,关于更多的介绍请参照官方说明文档!二:实现增量更新的方法Kettle工具并没有提供增量更新的选项,这个是要根据你的策略来实现的。
数据集市化etl工具使用说明书

数据集市化etl工具使用说明书数据集市化ETL工具使用说明书一、概述数据集市化ETL工具是一种用于数据集市建设和数据集市化过程中的数据集成、转换和加载的工具。
它可以帮助用户快速、高效地将不同数据源中的数据进行整合、清洗和转换,最终将数据加载到数据集市中,为数据分析和决策提供支持。
二、安装和配置1. 安装:将数据集市化ETL工具的安装包下载到本地,双击运行安装程序,按照提示完成安装过程。
2. 配置:在安装完成后,打开工具,进入配置界面,根据实际需求进行相应配置,包括数据库连接配置、数据源配置等。
三、数据源配置1. 新建数据源:在工具中选择“数据源管理”,点击“新建数据源”按钮,根据实际情况填写数据源名称、类型、地址、端口等信息,并进行测试连接。
2. 编辑数据源:在数据源管理界面,选中需要编辑的数据源,点击“编辑”按钮,对数据源进行相应的修改和配置。
3. 删除数据源:在数据源管理界面,选中需要删除的数据源,点击“删除”按钮,确认删除操作。
四、数据集成1. 新建数据集成任务:在工具中选择“数据集成任务管理”,点击“新建数据集成任务”按钮,根据实际需求填写任务名称、描述等信息。
2. 配置数据源:在数据集成任务管理界面,选择需要配置的数据集成任务,点击“配置数据源”按钮,选择源数据源和目标数据源,并进行字段映射和数据转换等配置。
3. 运行数据集成任务:在数据集成任务管理界面,选择需要运行的数据集成任务,点击“运行”按钮,等待任务执行完成。
五、数据转换1. 数据字段映射:在数据集成任务的配置过程中,可以根据需要进行源字段和目标字段的映射,确保数据能够正确转换和加载。
2. 数据清洗:在数据集成任务的配置过程中,可以进行数据清洗操作,包括数据去重、数据过滤、数据格式化等,以确保数据的质量和准确性。
3. 数据转换:在数据集成任务的配置过程中,可以进行数据转换操作,包括数据合并、数据拆分、数据计算等,以满足不同的业务需求。
ETL工具如何配置数据连接
1.描述ETL工具FineBI的业务包数据通过数据连接从数据库中获取,故首先需要建立数据连接。
2.配置数据连接2.1BI数据配置拥有BI数据配置权限的用户登录ETL工具FineBI系统,一般是管理员,点击数据配置进入ETL工具FineBI的BI数据配置界面,单击数据连接管理,如下图:如果不是ETL工具FineBI的管理员用户想要配置BI数据,需要管理员给其分配BI数据配置的权限,分级权限分配请查看ETL工具FineBI的分级权限分配。
2.2数据连接配置点击ETL工具FineBI的新建数据连接,添加一个数据连接,如下图,数据连接重命名为BIdemo,添加完成之后,数据连接配置框中会新增一个刚刚新建的数据连接:2.3测试连接点击ETL工具FineBI左下角的测试连接按钮,测试该数据连接是否成功,如果连接成功,则会弹出测试连接成功的弹出框,如下图:3.数据库驱动及URL对应表以下列出BI中支持的数据库及对应的连接属性值:数据库类型驱动器URL支持数据库版本Ora cle oracle.jdbc.driver.OracleDriverjdbc:oracle:thin:@ip:1521:databaseNameOracle9i、Oracle10g、Oracle11gOra cle oracle.jdbc.driver.OracleDriverjdbc:oracle:oci:@databaseNameOracle9i、Oracle10g、Oracle11gDB2com.ibm.db2.jcc.DB2Driver jdbc:db2://ip:50000/databaseNameDB2_7.2、DB2_8.1SQLServ er com.microsoft.sqlserver.jdbc.SQLServerDriverjdbc:sqlserver://ip:1433;databaseName=xxxSQLServer2000、2005、2008MySQL com.mysql.jdbc.Driverjdbc:mysql://ip/databaseName?user=root&useUnicode=True&characterEncoding=gb2312MySQL4.0版本以上MySQL org.gjt.mm.mysql.Driverjdbc:mysql://ip/databaseName?user=root&useUnicode=True&characterEncoding=gb2312MySQL4.0版本以上Syb ase com.sybase.jdbc2.jdbc.SybDriverjdbc:sybase:Tds:ip:5000/databaseName?charset=cp936SybaseAcc ess sun.jdbc.odbc.JdbcOdbcDriverjdbc:odbc:Driver={MicrosoftAccess Driver(*.mdb)};DBQ=${ENV_HOME}\..\FRDemo.mdbAccessAcc ess sun.jdbc.odbc.JdbcOdbcDriverjdbc:odbc:Driver={MicrosoftAccess Driver(*.mdb,*accdb)};DBQ=${ENV_HOME}\..\FAccess2007及以上版RDemo.accdb本Der by org.apache.derby.jdbc.ClientDriverjdbc:derby://ip:1527/databaseNameDerbyPostgre org.postgresql.Driverjdbc:postgresql://ip:5432/databaseNamePostgreOthers org.hsqldb.jdbcDriverjdbc:hsqldb:file:[PATH_TO_DB_FILES]Hsql注:在ETL工具FineBI中进行数据连接的时候要注意驱动器支持的数据库版本,如果选择的数据库版本不再上述表格中,那么就需要更换驱动器。
数据仓库中ETL工具的选型与使用

数据仓库中ETL工具的选型与使用随着企业信息化的深入发展,数据仓库在企业的日常运营中扮演着越来越重要的角色。
而在数据仓库建设中,ETL工具起着至关重要的作用。
本文将结合笔者多年的从业经验,深入探讨数据仓库中ETL工具的选型与使用,旨在为读者提供一些有用的参考。
一、ETL工具的概述首先,我们来了解一下ETL工具的概念。
ETL工具是指一类用于将不同来源的数据进行抽取(Extract)、转换(Transform)、加载(Load)等操作的软件。
在数据仓库中,ETL工具类似于“数据加工车间”,可以完成数据的清洗、整合、转换等多种工作。
目前市面上比较流行的ETL工具有很多,例如IBM DataStage、Informatica PowerCenter、Oracle Data Integrator等。
每个ETL工具都有其独特的特点及适用场景,选择一款合适的ETL工具非常关键。
二、ETL工具的选型在ETL工具的选型中,需要考虑以下几个方面:1. 企业规模及需求企业规模及需求是选择ETL工具的首要考虑因素。
对于规模较小的企业,可以选择一些开源的ETL工具,如Kettle和Talend Open Studio。
这些工具具有操作简便、易于掌握、可扩展性强等优点,适合小型企业以及需要快速实现数据仓库的项目。
而若企业具有大规模的数据仓库及数据流转需求,可以考虑一些成熟的商业ETL工具,如IBM DataStage、Informatica PowerCenter、Oracle Data Integrator等。
这些工具具有高度可靠性、高性能、强大的数据处理能力等优点,可以满足企业不断发展的需求。
2. 数据量及复杂度数据量及复杂度也是选择ETL工具的一个重要考虑因素。
对于数据量较小、简单的企业,可以选择一些基础的ETL工具,如Microsoft SQL Server Integration Services等。
这些工具主要用于数据提取、转换、加载等基础操作,适合数据量较小及较为简单的企业。
ETL工具介绍解读

ETL工具介绍解读ETL (Extract, Transform, Load) 是一种用于数据集成和转换的工具。
它从多个不同的数据源中提取数据,将其转换为可理解和可分析的格式,然后加载到目标系统中。
ETL 工具的主要功能包括数据抽取、数据转换和数据加载。
通过使用ETL工具,可以更高效地管理和处理海量的数据,为企业提供更准确、可靠和有意义的信息。
1. 数据抽取(Extract):数据抽取是ETL过程的第一步。
在这一步中,ETL工具从各种不同的数据源中抽取数据,包括关系数据库、平面文件、Web服务、主机系统和云存储等。
数据抽取可以是全量的,也可以是增量的,具体取决于数据源和需求。
ETL工具提供了各种选项,以满足不同数据源的需求,并具备高效、稳定和可靠的数据抽取能力。
2. 数据转换(Transform):数据转换是ETL过程的核心步骤。
在这一步中,ETL工具将抽取的数据进行清洗、筛选、聚合、计算和转换等操作,以使其适应目标系统的要求和标准。
数据转换可以包括数据重命名、列合并、数据类型转换、数据标准化、数据验证和数据去重等操作。
ETL工具提供了丰富的数据转换功能,例如提供图形化界面或编写脚本来完成数据转换规则的定义和配置。
3. 数据加载(Load):数据加载是ETL过程的最后一步,将转换后的数据加载到目标系统中。
目标系统可以是关系数据库、数据仓库、数据湖、云存储等。
数据加载可以是批量的,也可以是实时的,取决于数据处理的需求和目标系统的能力。
ETL工具提供了高效和可靠的数据加载功能,确保数据被正确和及时地加载到目标系统中。
除了上述核心功能外,ETL工具还提供了其他的附加功能,增强了数据集成和转换的能力,例如:-数据清洗和质量控制:ETL工具提供了数据清洗和质量控制的功能,以确保数据的准确性和一致性。
这包括去除重复值、修复缺失值、验证数据完整性和一致性等操作。
-数据转换和计算:ETL工具可以进行复杂的数据转换和计算,例如日期处理、文本解析、数学运算、聚合统计等。
etl工具的使用方法(一)

ETL工具的使用方法ETL(Extract, Transform, Load)工具是在数据仓库中广泛使用的一种工具,它能够从各种数据源中提取数据并将这些数据转换成可用的格式,最后加载到数据仓库中。
下面将详细介绍ETL工具的使用方法。
1. 选择合适的ETL工具在使用ETL工具之前,首先需要选择一款合适的工具。
常见的ETL工具包括Informatica PowerCenter、IBM InfoSphere DataStage、Microsoft SQL Server Integration Services(SSIS)等。
每款工具都有自己的特点和适用场景,需要根据具体的需求来选择合适的工具。
2. 设计数据抽取策略在使用ETL工具时,首先需要设计数据抽取策略。
这包括确定数据源、抽取的时间范围、抽取的数据量等。
根据具体的需求和业务场景,可以采用全量抽取或增量抽取的方式。
3. 配置数据连接使用ETL工具需要连接数据源和目标数据库。
在配置数据连接时,需要提供数据源的连接信息,包括数据库类型、主机地址、端口号、用户名、密码等。
同时,还需要配置目标数据库的连接信息。
4. 编写数据转换逻辑数据抽取后,需要进行数据转换。
这包括数据清洗、数据过滤、数据合并、数据格式转换等操作。
在ETL工具中,可以通过可视化的方式来设计数据转换逻辑,也可以使用SQL或脚本语言来编写复杂的转换逻辑。
5. 设计数据加载策略在数据转换完成后,需要设计数据加载策略。
这包括确定数据加载的方式,是全量加载还是增量加载,以及如何处理目标数据库中已有的数据等。
6. 调度任务配置ETL工具的调度任务,可以实现自动化的数据抽取、转换和加载过程。
这包括设置定时任务、监控任务执行情况、处理异常情况等。
7. 监控和优化在ETL工具的使用过程中,需要不断监控任务的执行情况,并对任务进行优化。
这包括优化数据抽取的性能、避免数据丢失或重复加载、优化数据转换和加载的性能等。
八步学会数据迁移:ETL工具kettle使用方法

⼋步学会数据迁移:ETL⼯具kettle使⽤⽅法⼀、⽬的
将不同服务器上的表合并到另外⼀个服务器上。
例如:将服务器1上的表A和服务器2上的表B,合并到服务器3上的表C 要求:表A需要被裁剪(去掉不必要的字段)、表B需要增加⼀些字段
⼆、使⽤⽅法
(1)在服务器3上的数据库中新建⼀张表C(符合实际系统设计的字段)
(2)新建表输⼊,连接服务器1,通过获取SQL语句选择需要使⽤的表,也可以选择⼀些字段
(2)同理,新建表输⼊,连接服务器2,通过获取SQL语句选择需要使⽤的表,也可以选择⼀些字段
(3)新建两个排序记录
(4)选择要排序的字段
(5)新建记录集连接
(6)选择要连接的字段
(7)新建表输出,连接服务器3
1.选择服务器3中的表C
2.获取字段
3.映射字段
(8)运⾏,⼤⼯告成。
开源ETL工具-PentahoKettle使用入门

2. 下载和安装 要运行此工具你必须安装 SUN 公司的 JAVA 运行环境 1.4 或者更高版本, 相关资源你 可以到网络上搜索 JDK 进行下载。设置 JAVA 运行环境变量,JAVA_HOME 和 PATH KETTLE 的下载可以到 /取得最新版本,下载后解压,就可 以直接运行。
第 12页 共 69页
各个组件有不同的用途, 这些组件组合起来可以把数据从数据源经过一系列处理, 最终保存 到目标表。 4.3.3. 添加 TABLE INPUT
鼠标选中左边窗口 INPUT 文件夹下的 TABLE INPUT 组件,然后拖动该组件到右边主窗口中。 如图:
第 13页 共 69页
双击主窗口中 TABLE INPUT 组件,进入 TABLE INPUT 的设置窗口:
第 9页 共 69页
点击左上角的 NEW 按钮或者菜单 FILE->NEW,创建新的 TRANSFORM
主窗口出现一个新的标签页:TRANSFORMATION 1
在主窗口空白处点击右键, 出现菜单, 选择 TRANSFORMATION SETTINGS.进入 TRANSFORMATION SETTINGS 窗口。
JOB 实际上就是 ETL 中的任务流,用于调度 TRANSFORMATION 或者 JOB. 点击左上角的 NEW 按钮或者菜单 FILE->NEW,创建新的 JOB
在主窗口空白处点击右键,出现菜单,选择 JOB SETTINGS
进入 JOB SETTING 窗口。
第 21页 共 69页
A. B. C.
第 14页 共 69页
1) 2) 3)
按照命名规范设置 STEP NAME 在 CONNECTION 下拉框,选择源表所在的数据源,如果没有则新建数据源,参考”设置 资料库”节的新建数据源说明 点击 GET SQL SELECT STATEMENT 按钮,进入源表选择窗口:
ETL说明文档

ETL是将业务系统的数据经过抽取、清洗转换之后加载到数据仓库的过程,目的是将企业中的分散、零乱、标准不统一的数据整合到一起,为企业的决策提供分析的依据ETL是BI项目最重要的一个环节,通常情况下ETL会花掉整个项目的1/3的时间,E TL设计的好坏直接关接到BI项目的成败。
ETL也是一个长期的过程,只有不断的发现问题并解决问题,才能使ETL运行效率更高,为项目后期开发提供准确的数据。
ETL的设计分三部分:数据抽取、数据的清洗转换、数据的加载。
在设计ETL的时候也是从这三部分出发。
数据的抽取是从各个不同的数据源抽取到ODS中(这个过程也可以做一些数据的清洗和转换),在抽取的过程中需要挑选不同的抽取方法,尽可能的提高ETL的运行效率。
ETL三个部分中,花费时间最长的是T(清洗、转换)的部分,一般情况下这部分工作量是整个ETL的2/3。
数据的加载一般在数据清洗完了之后直接写入DW中去。
ETL的实现有多种方法,常用的有三种,第一种是借助ETL工具如Oracle的OWB、SQL server 2000的DTS、SQL Server2005的SSIS服务、informatic等实现,第二种是SQL方式实现,第三种是ETL工具和SQL相结合。
前两种方法各有优缺点,借助工具可以快速的建立起ETL工程,屏蔽复杂的编码任务,提高速度,降低难度,但是欠缺灵活性。
SQL的方法优点是灵活,提高ETL运行效率,但是编码复杂,对技术要求比较高。
第三种是综合了前面二种的优点,极大的提高ETL的开发速度和效率。
数据的抽取数据的抽取需要在调研阶段做大量工作,首先要搞清楚以下几个问题:数据是从几个业务系统中来?各个业务系统的数据库服务器运行什么DBMS?是否存在手工数据,手工数据量有多大?是否存在非结构化的数据?等等类似问题,当收集完这些信息之后才可以进行数据抽取的设计。
1、与存放DW的数据库系统相同的数据源处理方法这一类数源在设计比较容易,一般情况下,DBMS(包括SQLServer,Oracle)都会提供数据库链接功能,在DW数据库服务器和原业务系统之间建立直接的链接关系就可以写Se lect 语句直接访问。
ETL工具操作手册

ETL工具操作手册浙江慧优科技有限公司版本号:V1.02016/11/30ETL工具操作手册目录第一章.ETL简介 (I)第一章.ETL简介➢ETL工具采用JA V A编写,支持关系型数据库(ORACLE,DB2,MySQL,MS Server,Sybase等数据库)的输入输出,也支持NOSQL(Mongodb,CouchDB等NoSQL系列数据库) 大数据处理,以及关系型和非关系型数据库之间的转换。
➢通过http请求,支持解析xml,json格式的数据解析➢利用JS脚本引擎、转换引擎、流程引擎、调度引擎,使各种信息孤岛的数据变得简易操作,大大提高异构系统互联的工作效率;完美实现与业务系统的“零编码”,即配即用;强大的图形化和接口设计、部署、监管的智能化,减轻数据交换和应用的工作负担,提高系统互联的工作效率第二章.数据库到数据库的数据采集1.选择文件-新建-转换,鼠标点击主对象树,切换至相应界面。
右键转换一可以为这个转换进行命名,性能监控。
如图:IETL工具操作手册II ETL工具操作手册2.双击DB连接新建数据库连接,一般会建源数据库连接以及目标数据库连接,根据实际情况来定。
这里我们建立了2个数据库连接,一个是源数据库162以及目标数据库为我本地的。
如图:IIIETL工具操作手册3.点击切换至核心对象-输入下的表输入拖至配置界面上,选择源数据库,以及源数据表,可以自动获取SQL语句查询,筛选条件可以根据实际情况来定义。
点击预览,可以预览SQL查询出来的数据,也可以进行判断SQL语句是否正确。
IVETL工具操作手册4.选择表输出,将子节点的表输出拖至配置界面,双击表输出,选择目标数据库,数据表。
如图5.点击运行即可测试当前配置是否正确。
在步骤、日志、或者执行历史中,可以查看流程是否正确,也可以查看报错的节点,错误信息。
VETL工具操作手册6. 配置定时任务,点击文件-新建-作业-通用下的start,双击配置界面中的start 界面定时任务的配置。
ETL工具介绍解读

ETL工具介绍解读ETL指的是Extract(提取)、Transform(转换)和Load(加载)。
ETL工具是一种用于将数据从源系统中提取、进行转换和加载到目标系统中的软件工具。
它们在数据仓库和商业智能项目中起到至关重要的作用。
本文将介绍ETL工具的定义、功能和一些常见的ETL工具。
ETL工具是一种用于实现ETL过程的软件工具。
ETL过程是将数据从源系统中提取出来,对数据进行清洗、转换和整合,再将转换后的数据加载到目标系统中的过程。
ETL工具可以帮助开发人员自动化这个过程,并提供一系列功能和工具来简化数据转换和数据加载的步骤。
1. 数据提取(Extract):ETL工具可以连接到多个源系统,并提取数据到一个目标位置。
它们能够从数据库、文件、Web API等各种源系统中提取数据,并提供强大的数据提取功能,如增量提取、全量提取、增量更新等。
2. 数据转换(Transform):ETL工具可以对提取出来的数据进行各种转换操作,以满足目标系统的需求。
这包括数据清洗、数据合并、数据重构、数据规范化、数据格式转换等。
ETL工具通常提供了可视化的转换操作界面,使开发人员能够轻松创建和管理转换规则。
3. 数据加载(Load):ETL工具可以将经过转换的数据加载到目标系统中,如数据仓库、数据集市、数据湖等。
它们提供了各种加载功能,如全量加载、增量加载、替换加载等,以及错误处理机制,如重试、异常处理、日志记录等。
常见的ETL工具1. Informatica PowerCenter:Informatica PowerCenter是最常用的商业ETL工具之一、它提供了强大的数据提取、转换和加载功能,支持大规模数据集成和处理。
它还提供了丰富的连接器,可以连接到各种异构数据源。
Informatica PowerCenter有一个用户友好的可视化界面,企业可以通过拖放和设置相应的连接以及转换规则来创建ETL流程。
2. Talend:Talend是一个开源的ETL工具,具有强大的数据集成和转换功能。
ETLPLUS工具说明
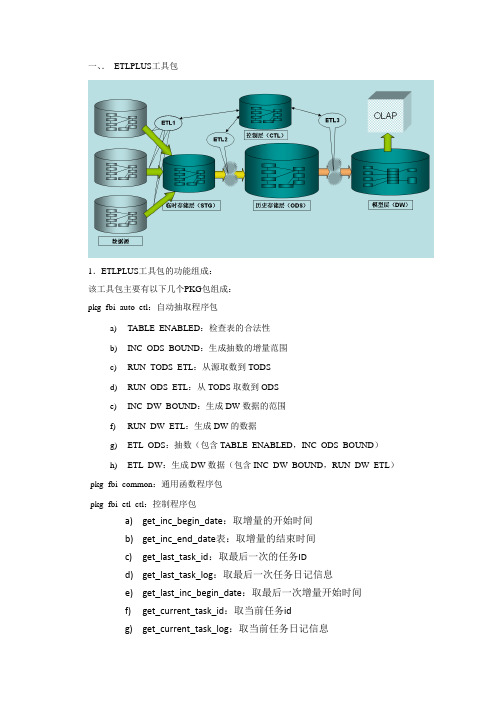
一、.ETLPLUS工具包1.ETLPLUS工具包的功能组成:该工具包主要有以下几个PKG包组成:pkg_fbi_auto_etl:自动抽取程序包a)TABLE_ENABLED:检查表的合法性b)INC_ODS_BOUND:生成抽数的增量范围c)RUN_TODS_ETL:从源取数到TODSd)RUN_ODS_ETL:从TODS取数到ODSe)INC_DW_BOUND:生成DW数据的范围f)RUN_DW_ETL:生成DW的数据g)ETL_ODS:抽数(包含TABLE_ENABLED,INC_ODS_BOUND)h)ETL_DW:生成DW数据(包含INC_DW_BOUND,RUN_DW_ETL)pkg_fbi_common:通用函数程序包pkg_fbi_etl_ctl:控制程序包a)get_inc_begin_date:取增量的开始时间b)get_inc_end_date表:取增量的结束时间c)get_last_task_id:取最后一次的任务IDd)get_last_task_log:取最后一次任务日记信息e)get_last_inc_begin_date:取最后一次增量开始时间f)get_current_task_id:取当前任务idg)get_current_task_log:取当前任务日记信息h)write_log:写当前任务的日记信息i)start_task:开始当前etl任务j)stop_task:结束当前etl任务pkg_fbi_etl_loger:提供相关日记的写方法和取方法pkg_fbi_etl_utils:公共的工具包,提供相关系统函数以上该ETLPLUS工具包的核心功能组成部分2.使用该工具包的关键表及配置方法auto_etl_col_list 该表是实现抽取中列替换的作用列转换配置信息如下:目的表的模式名目的表名目的列名源的类型(con_c,con_d,con_n:常量,字符,时间,数值;var:pl/sql中的变量或常量运行时给出; col:同一源表的其他列)源的值(字符常量用''包起来)当前活动标志(y:活动需要处理;n:不处理)auto_etl_dw_list该表是配置DW程序处理顺序及增量获取范围信息auto_etl_dw_tmp该表辅助表不需要手工配置auto_etl_inc_control_dw 记录DW增量控制信息不需要手工配置auto_etl_inc_control_ods记录ODS增量控制信息不需要手工配置auto_etl_ms_list 该表是实现主从表抽取配置通过对主从业务表信息配置,可以支持从表的自动增量抽取过程,配置表信息如下:源主表schema名称源主表表名称源主表列名称源从表schema名称源从表表名称源从表列名称当前活动标志(y:活动需要处理;n:不处理)auto_etl_table_list该表是配置自动抽取表信息的核心表增量类型(st源表有时间戳【源表必须有主键或唯一性索引,来进行临时层到历史层的增量数据的删除操作】;dt源表没有时间戳,有业务时间【临时层到历史存储层的删除操作可以用时间段或主键删除】;dte源表没有时间戳,也无业务时间,可以和dt类型表作关联后得到业务时间;all完全抽取,无增量概念)当前活动标志(y:需要处理;n:不处理)源分类;作分类抽取用,支持like参数调用抽取顺序,可null,null时按表名顺序抽取增量时间先前推的天数,st类型一般是小数,解决系统时间差异;dt类型一般是天数,表示更新历史多少天的数据临时层到历史层增量时采用的删除数据的方式(pk,主键或唯一性约束列作删除,st类必须是此情况,dt,dte,all可以用此方式删除;dt,业务时间删除,dt,dte可以用此方式删除,all不能选此方式;tr,truncate历史表,st、dt、dte、all都可用此方式,用此方式历史层只保存增量数据,all类型一般用此方式)当需要全跑的时候,是否truncate表中数据,y-truncate,n-delete保留历史最大集速度慢源的dblink名(非oracle用透明网关处理)源表的schema源系统表名临时层表中记录更新标志的列(时间戳列或业务列,对于dte,all类型的可以null)临时存储schema临时存储表名历史存储schema历史存储表名ods表是否用来计算dw的增量范围(y是,一般st、dt才填y;n不是)算dw增量范围的业务时间字段,st类型的填业务时间列,dt类型的一般与source_inc_col值相同检查pk删除方式的主键或唯一索引是否存在,系统自动检查表存在否或是否存在主键或唯一性索引说明(程序填)备注信息etl_log 该表记录抽取过程中所有重要信息:包括抽取是否成功,异常原因等等以上红色标记的信息都是需要关注的核心配置抽取程序提供信息,自动完成增量抽取和流程控制,配置表信息如下3.如何调用该工具包beginpkg_fbi_etl_ctl.start_task;-- 开始ETL任务,在CTL.ETL_TASK中生成任务ID(此ID贯串一次ETL任务);PKG_FBI_AUTO_ETL.ETL_ODS('N','N','$ALL$','$ALL$','$ALL$');--抽取源数据到ODS层--是否只生成代码--是否全量抽取,级别高于内部配置--源分类--HSS owner name--HSS table namePKG_FBI_AUTO_ETL.ETL_DW('N','N','$ALL$','$ALL$','$ALL$');--抽取ODS数据进入DW层pkg_fbi_etl_ctl.stop_task;-- 结束ETL任务end;以上是整个工具包的组成,抽取配置,抽取执行处理的全部过程,对实施人员来说只要能正确配置红色标记的部分,就可以完成抽取工作。
ETLPLUS使用指南

ETLPLUS使用指南ETLPLUS是一款功能强大的ETL(Extract, Transform, Load)工具,用于数据抽取、转换和加载。
本使用指南将帮助用户了解ETLPLUS的基本概念、主要功能和操作步骤,以便能够高效地使用该工具。
一、基本概念1. 数据抽取(Extract):从各种不同的数据源(如数据库、文件、Web服务等)中提取数据。
2. 数据转换(Transform):对抽取的数据进行清洗、删除重复值、数据格式转换、数据筛选、字段计算等操作,以便满足分析和报表的需求。
3. 数据加载(Load):将转换后的数据加载到目标数据仓库、数据库或数据集市中,以便进行进一步的分析和应用。
二、主要功能1. 数据源连接:ETLPLUS支持连接到各种不同类型的数据源,包括关系型数据库、非关系型数据库、文件、Web服务等。
2.数据抽取:通过简单的配置,可以轻松从各种数据源中提取数据,支持增量抽取和全量抽取。
3.数据转换:提供多种数据转换操作,包括数据清洗、数据格式转换、数据筛选、字段计算、数据合并等功能。
4.数据加载:支持将转换后的数据加载到各种目标数据仓库、数据库或数据集市中,支持增量加载和全量加载。
5.调度管理:ETLPLUS提供了强大的调度管理功能,可以设置定时任务,自动执行数据抽取、转换和加载的操作。
6.数据质量管理:通过内置的数据质量规则和异常监测功能,可以对数据进行质量评估和监控,帮助用户发现数据异常和数据质量问题。
7.数据集市管理:ETLPLUS支持构建和管理数据集市,将不同数据源的数据集成到一个集市中,方便用户进行一站式的数据分析和查询。
三、操作步骤1.连接数据源:在ETLPLUS中设置数据库连接信息,包括数据库类型、地址、端口、用户名和密码等。
2.创建任务:点击“新建任务”按钮,设置任务名称、描述和类型(增量抽取、全量抽取、增量加载、全量加载)。
3.设置数据源:选择数据源类型,并配置数据源的相关参数,例如数据库表名、查询条件、文件路径等。
ETL工具使用说明

ETL工具使用说明ETL工具是指用于从源系统中提取数据、对数据进行清洗、转换和加载到目标系统中的一类软件工具,是数据仓库和业务智能系统中的核心组件之一、它能帮助企业将分散、杂乱的数据整合到一个集中的数据仓库中,为企业的数据分析、决策和报告提供基础支持。
本文将简要介绍ETL工具的使用说明,主要包括以下几个方面:一、ETL工具的基本概念ETL是Extract、Transform和Load的缩写,分别表示提取、转换和加载。
提取是指将数据从源系统中获取出来;转换是指对数据进行清洗、整理、计算等操作;加载是指将经过转换后的数据加载到目标系统中。
二、ETL工具的功能特点1. 数据源连接:ETL工具能够连接多种不同类型的数据源,如关系型数据库、平面文件、Web服务、NoSQL数据库等。
2.数据提取:ETL工具支持从多个数据源中提取数据,并支持增量提取、全量提取和增量更新等模式。
3.数据清洗:ETL工具提供丰富的数据清洗功能,如数据去重、数据过滤、数据转换、数据合并等,能够保证数据的质量和一致性。
4.数据转换:ETL工具提供强大的数据转换功能,包括数据的拆分、合并、汇总、计算、格式化等操作,能够满足不同的数据处理需求。
5.数据加载:ETL工具支持将处理后的数据加载到目标系统中,如数据仓库、数据湖、数据集市等,保证数据的及时性和准确性。
6.数据质量管理:ETL工具能够对数据进行质量检查和验证,并提供数据质量报告和异常处理功能。
7.任务调度和监控:ETL工具提供任务调度和监控功能,能够自动执行数据集成任务,并监控任务的执行情况和效果。
8.可视化开发:ETL工具提供可视化开发环境,支持图形化设计和配置,减少编码工作量,提高开发效率。
三、ETL工具的基本使用步骤1.数据源定义:首先需要定义数据源连接信息,包括数据源类型、连接字符串、用户名、密码等。
可以通过界面输入或者配置文件方式定义。
2.数据提取:根据业务需求选择相应的数据提取方式,支持增量提取、全量提取、增量更新等多种模式。
etl的简单用法

etl的简单用法ETL(Extract, Transform, Load)是一种常用的数据处理方法,用于从源数据中提取需要的数据,对数据进行转换和清洗,最后将数据加载到目标系统中。
以下是ETL的简单用法:1. 提取(Extract):从源系统中获取需要的数据。
可以通过查询数据库、读取文件、API调用等方式进行数据提取。
2. 转换(Transform):对提取的数据进行转换和清洗。
包括数据格式转换、字段计算、数据合并、数据过滤等操作,以使数据符合目标系统的要求。
3. 加载(Load):将转换后的数据加载到目标系统中。
可以是数据库、数据仓库、数据分析工具等,以供后续的业务分析和决策使用。
简单的ETL操作可以使用各种编程语言或者ETL工具来实现。
常用的ETL工具包括Talend、Informatica、Pentaho等,这些工具提供了可视化的界面和丰富的数据处理功能,可以大大简化ETL的实施过程。
在具体的ETL实施过程中,可以按照以下流程进行操作:1. 分析需求:明确需要提取哪些数据,目标系统的数据结构和要求,以及转换的逻辑和规则。
2. 数据源接入:连接到源系统,提取需要的数据。
可以使用各种方式,如数据库连接、文件读取等。
3. 数据转换:将提取的数据进行清洗、转换和计算。
根据需求进行字段选择、数据过滤、数据转换等操作。
可以使用各种脚本或者可视化工具来实现。
4. 数据加载:将转换后的数据加载到目标系统中,确保数据的完整性和正确性。
可以使用数据库的插入、更新等操作来实现数据的加载。
5. 验证和测试:对ETL过程进行验证和测试,确保数据的正确性和可用性。
6. 定期执行:根据需求,设定ETL任务的执行时间和频率,确保数据的及时更新和准确性。
需要注意的是,在实施ETL过程中,还需要考虑到数据的安全性、性能优化、错误处理和日志记录等方面的问题,以确保ETL过程的可靠性和稳定性。
数据库的数据集成与ETL工具使用

数据库的数据集成与ETL工具使用随着企业数据量的不断增长和信息化建设的推进,各个部门和业务系统中的数据产生的数量也呈现爆发式增长。
在这种情况下,如何高效地管理和利用各个部门和系统中的数据,成为了每个企业都需要面对的挑战。
数据库的数据集成和ETL工具的使用,可以帮助企业解决数据流动的问题,提升数据的价值和利用效率。
一、数据库的数据集成是什么?数据库的数据集成是将多个数据库中的数据整合到一个数据库中,并消除重复和冗余数据,实现不同数据库之间的数据交互和共享。
通过数据集成,可以实现企业内部不同部门之间的数据整合,以及与外部合作伙伴的数据交流。
数据集成的目标是实现数据的一致性、准确性和完整性,提供一个统一的数据视图。
数据库的数据集成有以下几种方法:1. ETL(抽取、转换、加载):通过抽取数据、对数据进行转换处理,最后加载到目标数据库中。
这是一种常用且广泛应用的方法,能够保证数据的一致性和完整性;2. 数据复制:将源数据库中的数据复制到目标数据库中,保持数据的一致性;3. 数据虚拟化:通过虚拟的方式将不同源的数据统一进行管理和访问,实现数据的集成和共享;4. 数据仓库:将源数据库中的数据抽取到数据仓库中,并进行事实表和维度表的建模和关联,实现数据的集成和分析。
二、ETL工具的使用ETL是一种常用的数据集成方法,它包括抽取(Extract)、转换(Transform)、加载(Load)三个步骤,通过这三个步骤从源数据库中抽取数据,对数据进行转换处理,最终加载到目标数据库中。
ETL工具是用于执行ETL过程的工具,它提供了数据抽取、转换和加载的功能,帮助用户简化和自动化数据集成的流程。
下面介绍几个常用的ETL工具。
1. Informatica PowerCenterInformatica PowerCenter是一套强大的ETL工具,它具有良好的用户界面和灵活的设计功能。
该工具支持从多种数据源中抽取数据,并且具备强大的数据处理和转换能力,可以帮助用户高效地完成数据集成和数据处理操作。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
实验一:表到表的数据转换实验目的:将SQLServer数据库中user表的数据传输到Oracle数据库中TABLE_USER表中,当发现重复数据时,先删除旧数据,再插入新数据。
传输过程中无任何数据转换。
源字段目标字段user.id TABLE_USER.ID TABLE_实验数据:源:SQLServer数据库user表,共有3条数据,如下图:目标:Oracle数据库TABLE_USER表,无数据,如下图:预期结果:源表中的3条数据逐一添加到目标表中。
实验过程:1、在“文件”菜单中,选择“转换”,新建一个转换方案2、在“输入”目录中,拖拽添加一个“表输入”对象3、双击新建的对象,编辑该对象A、输入合理、易懂的步骤名称B、点击数据库连接右边的“新建”按钮,新建一个数据库连接4、新建一个SQLServer数据库连接A、连接类型选择:MS SQL ServerB、依次填写主机名、数据库名、实例名、端口号、登录用户名、登录密码C、点击“Test”按钮,进行连接测试,如连接成功,则弹出成功提示框连接成功,弹出下面提示框:5、点击“获取SQL查询语句”按钮,选择源表6、在弹出的表选择画面上,选择源表,这里选择user表,点击“OK”按钮7、可以看到相应的查询SQL文,点击“预览”按钮,可以查看数据8、数据显示窗口9、点击“确定”按钮,完成输入对象的配置10、从“输出”目录中,拖拽添加一个“删除”对象,将鼠标放置在输入对象上,按住“Shift”键,同时按住鼠标左键,拉动箭头,建立输入源到删除目标的指向关系。
* 建立本步骤的目的,是先删除具有相同主键的旧数据,防止传输数据时,出现主键重复错误。
11、双击“删除”对象,编辑该对象A、输入合理、易懂的步骤名称B、点击“新建”按钮,建立新的数据库连接(因为目标表是Oracle类型的,所以需要新建连接。
如果目标表和输入表属于同一个数据库连接,可以直接从“数据库连接”下拉菜单中选择。
)12、建立新的Oracle数据库连接A、输入连接名B、依次输入主机名、数据库名、端口号、登录用户名、登录密码C、点击“Test”按钮,测试连接是否成功D、点击“OK”按钮连接成功的情况下,弹出以下提示框:13、点击“目标表”右侧的“浏览”按钮,选择待删除记录的目标表14、在表选择窗口中,选择待删除记录的表,这里选择“TABLE_USER”表,点击“OK”按钮15、设置“查询值所需的关键字”,然后点击“确定”按钮A、表字段:ID(目标表主键)B、比较符:=C、流里的字段1:id(源表主键)这里的含义是:当目标表字段“ID”出现与源表中字段“id”相等的记录时,删除目标表中的该条记录,防止数据插入时,出现主键重复错误。
16、复制并粘贴之前建立的输入对象,如图:17、从“输出”目录中,拖拽添加一个“表输出”对象,将鼠标放置在输入对象上,按住“Shift”键,同时按住鼠标左键,拉动箭头,建立输入源到输出目标的指向关系。
如图:18、双击“表输出”对象,编辑该对象A、输入合理、易懂的步骤名称B、数据库连接选择“Oracle”C、目标表选择“TABLE_USER”D、选中“Specify database fields”E、切换标签到“Database fields”F、点击“Enter field mapping”按钮19、选择源表到目标表的映射关系,然后点击“Add”按钮建立完映射关系后的结果,如图所示:20、点击“确定”按钮21、至此,一个完整的表到表数据传输步骤就建立完毕了。
22、保存该过程为一个*.ktr文件(一个符合xml标准的文件),然后执行该过程,如图,点击上方的“绿色三角”点击“启动”按钮23、执行后结果:成功执行的日志:可以看到,目标表中新添加了3条数据。
实验二:视图到表的数据转换实验目的:将SQLServer数据库中userview视图的数据传输到Oracle数据库中TABLE_USER表中,传输过程中没有数据转换。
源字段目标字段userview.id TABLE_USER.ID TABLE_实验数据:源:SQLServer数据库userview视图,共有3条数据,如下图:目标:Oracle数据库TABLE_USER表,无任何数据,如下图:预期结果:TABLE_USER表中新添加3条记录。
实验过程:1、在“文件”菜单中,选择“转换”,新建一个转换方案2、在“输入”目录中,拖拽添加一个“表输入”对象3、双击新建的对象,编辑该对象A、输入合理、易懂的步骤名称B、点击数据库连接右边的“新建”按钮,新建一个数据库连接4、新建一个SQLServer数据库连接A、连接类型选择:MS SQL ServerB、依次填写主机名、数据库名、实例名、端口号、登录用户名、登录密码C、点击“Test”按钮,进行连接测试,如连接成功,则弹出成功提示框连接成功,弹出下面提示框:5、点击“获取SQL查询语句”按钮,选择源视图6、在弹出的表选择画面上,选择源视图,这里选择userview视图,点击“OK”按钮7、可以看到相应的查询SQL文,点击“预览”按钮,可以查看数据8、数据显示窗口9、点击“确定”按钮,完成输入对象的配置10、从“输出”目录中,拖拽添加一个“删除”对象,将鼠标放置在输入对象上,按住“Shift”键,同时按住鼠标左键,拉动箭头,建立输入源到删除目标的指向关系。
* 建立本步骤的目的,是先删除具有相同主键的旧数据,防止传输数据时,出现主键重复错误。
11、双击“删除”对象,编辑该对象A、输入合理、易懂的步骤名称B、点击“新建”按钮,建立新的数据库连接(因为目标表是Oracle类型的,所以需要新建连接。
如果目标表和输入表属于同一个数据库连接,可以直接从“数据库连接”下拉菜单中选择。
)12、建立新的Oracle数据库连接A、输入连接名B、依次输入主机名、数据库名、端口号、登录用户名、登录密码C、点击“Test”按钮,测试连接是否成功D、点击“OK”按钮连接成功的情况下,弹出以下提示框:13、点击“目标表”右侧的“浏览”按钮,选择待删除记录的目标表14、在表选择窗口中,选择待删除记录的表,这里选择“TABLE_USER”表,点击“OK”按钮15、设置“查询值所需的关键字”,然后点击“确定”按钮A、表字段:ID(目标表主键)B、比较符:=C、流里的字段1:id(源表主键)这里的含义是:当目标表字段“ID”出现与源表中字段“id”相等的记录时,删除目标表中的该条记录,防止数据插入时,出现主键重复错误。
16、复制并粘贴之前建立的输入对象,如图:17、从“输出”目录中,拖拽添加一个“表输出”对象,将鼠标放置在输入对象上,按住“Shift”键,同时按住鼠标左键,拉动箭头,建立输入源到输出目标的指向关系。
如图:18、双击“表输出”对象,编辑该对象A、输入合理、易懂的步骤名称B、数据库连接选择“Oracle”C、目标表选择“TABLE_USER”D、选中“Specify database fields”E、切换标签到“Database fields”F、点击“Enter field mapping”按钮19、选择源表到目标表的映射关系,然后点击“Add”按钮建立完映射关系后的结果,如图所示:20、点击“确定”按钮21、至此,一个完整的表到表数据传输步骤就建立完毕了。
22、保存该过程为一个*.ktr文件(一个符合xml标准的文件),然后执行该过程,如图,点击上方的“绿色三角”点击“启动”按钮23、执行后结果:可以看到,该表中新添加了3条数据。
实验三:值映射实验目的:将SQLServer数据库中userview视图的数据分别传输到Oracle数据库中TABLE_USER表和TABLE_USERINFO中,传输过程中有数据转换。
源字段目标字段userview.id TABLE_USER.ID、TABLE_USERINFO.ID TABLE_userview.age TABLE_USERINFO.ARGuserview.birthday TABLE_USERINFO.BIRTHDAYuserview.card TABLE_USERINFO.CARD实验数据:源:SQLServer数据库userview视图,共有3条数据,其中姓名为“张三”的记录,名字改成了“张三_新”,如下图:目标:Oracle数据库TABLE_USER表,共有3条通过实验二添加的数据,3条记录的名字分别为张三、李四、王五,如下图:目标:Oracle数据库TABLE_USERINFO表,无任何数据,如下图:预期结果:TABLE_USER表中仍然为3条记录,其中,姓名为“张三”的记录,应更新为“张三_新”;TABLE_USERINFO表中新添加3条记录。
实验过程:1、在“文件”菜单中,选择“转换”,新建一个转换方案2、在“输入”目录中,拖拽添加一个“表输入”对象3、双击新建的对象,编辑该对象A、输入合理、易懂的步骤名称B、点击数据库连接右边的“新建”按钮,新建一个数据库连接4、新建一个SQLServer数据库连接A、连接类型选择:MS SQL ServerB、依次填写主机名、数据库名、实例名、端口号、登录用户名、登录密码C、点击“Test”按钮,进行连接测试,如连接成功,则弹出成功提示框连接成功,弹出下面提示框:5、点击“获取SQL查询语句”按钮,选择源视图6、在弹出的表选择画面上,选择源视图,这里选择userview视图,点击“OK”按钮7、可以看到相应的查询SQL文,点击“预览”按钮,可以查看数据8、数据显示窗口9、点击“确定”按钮,完成输入对象的配置10、从“输出”目录中,拖拽添加两个“删除”对象(因为本次实验的目标表为两个),将鼠标放置在输入对象上,按住“Shift”键,同时按住鼠标左键,拉动箭头,分别建立输入源到两个删除目标的指向关系。
* 建立本步骤的目的,是先删除具有相同主键的旧数据,防止传输数据时,出现主键重复错误。
11、双击第一个“删除”对象,编辑该对象,建立针对TABLE_USER表的删除步骤A、输入合理、易懂的步骤名称B、点击“新建”按钮,建立新的数据库连接(因为目标表是Oracle类型的,所以需要新建连接。
如果目标表和输入表属于同一个数据库连接,可以直接从“数据库连接”下拉菜单中选择。
)12、建立新的Oracle数据库连接A、输入连接名B、依次输入主机名、数据库名、端口号、登录用户名、登录密码C、点击“Test”按钮,测试连接是否成功D、点击“OK”按钮连接成功的情况下,弹出以下提示框:。