建立单词索引实验报告
索引实验报告[精选5篇]
![索引实验报告[精选5篇]](https://img.taocdn.com/s3/m/d3f057f70d22590102020740be1e650e53eacf74.png)
索引实验报告[精选5篇]第一篇:索引实验报告学生实验报告课程名称商务数据库应用实验成绩实验项目名称索引批阅教师实验者学号专业班级实验日期 2012-12-6 一、实验预习报告(实验目的、内容,主要设备、仪器,基本原理、实验步骤等)(可加页)实验目的 1)理解索引的概念和分类。
2)掌握在对象资源管理器中创建和管理索引。
3)掌握 T-SQL 语句创建和管理索引。
实验内容 1)在对象资源管理器中创建、修改和删除索引。
2)在对象资源管理器使用索引。
3)利用 T-SQL 语句创建、修改和删除索引。
4)利用 T-SQL 语句使用索引。
二、实验过程记录(包括实验过程、数据记录、实验现象等)(可加页)1.启动 SQL Server Management Studio,在对象资源管理器中,利用图形化的方法创建下列索引:λ对学生信息表 stu_info 的 name 列创建非聚集索引 idx_name。
λ对学生成绩表 stu_grade 的 stu_id、couse_id 列创建复合索引idx_stu_couse_id。
2.启动 SQL Server Management Studio,在对象资源管理器中,利用图形化的方法对索引idx_name 进行修改,使其成为唯一索引。
3.启动 SQL Server Management Studio,在对象资源管理器中,利用图形化的方法删除索引 idx_stu_couse_id。
4.启动 SQL Server Management Studio,在 SQL 编辑器中,利用 T-SQL 语句 CREATE INDEX命令创建下列索引:λ对课程信息表couse_info 的couse_name 列创建非聚集索引idx_couse_name。
λ对学生成绩表 stu_grade 的 stu_id、couse_id 列创建复合索引idx_stu_couse_id。
5.启动 SQL Server Management Studio,在 SQL 编辑器中,利用 T-SQL 语句对索引idx_couse_name 进行修改,使其成为唯一索引。
C#实验5索引器

实验5 索引器1英汉电子字典实验题目:编写一个简单的英汉电子词典程序,能够将用户输入的英文单词翻译成相应的中文。
假设一个英文单词对应的中文释义有多个。
实验目的:1)理解索引器的概念。
2)掌握索引器的定义及使用。
实验步骤:1)定义一个单词类Word,Word类中包含两个私有字段english、chinese。
其中,字段english表示英文单词,字段chinese表示单词的相应中文释义。
由于一个英文单词相对的中文释义有多个,因此,字段chinese的数据类型必须是一个字符串数组。
2)为Word类定义构造函数,构造函数中,利用英文单词及相应的中文释义初始化Word对象。
3)在Word类中为字段english和chinese提供相应的只读属性。
4)定义一个词典类Dictionary,Dictionary类中包含一个私有字段words。
字段words用于保存期词典中的所有单词,因此,其数据类型必须是Word类数组。
5)为Dictionary类定义构造函数,构造函数中将所有单词保存到字段words中。
6)在Dictionary类中定义一个索引器,该索引器能根据英文单词,返回其中文释义,如果词典中没有该单词,就返回“没有找到该单词”。
7)定义类Test9_1,在其Main方法中接收用户输入,并利用Dictionary类查找相应的中文释义并输出。
8)编译并运行程序,如果发现错误,就改正。
参考答案:运行结果如图所示:2 多边形描述实验题目:定义一个描述多边形的类并验证,要求多边形的顶点坐标能够通过对该类的对象进行索引来访问。
实验目的:1) 理解索引器的概念。
2) 掌握索引器的定义及使用。
实验步骤:1)定义一个点类Point,Point类中包含两个int型私有字段x、y及相应属性,它们用于表示点的坐标。
另外,还应为Point类定义构造函数,并重写方法ToString。
2)定义多边形类Polygon,Polygon类包含一个私有字段points。
课程设计单词簿实验报告

课程设计单词簿实验报告一、教学目标本课程的学习目标包括知识目标、技能目标和情感态度价值观目标。
知识目标要求学生掌握单词簿的基本概念和实验原理,了解实验步骤和数据分析方法。
技能目标要求学生能够独立进行单词簿实验,掌握实验操作技能,并能够分析实验结果。
情感态度价值观目标要求学生培养对科学的兴趣和好奇心,提高实验操作的规范性和准确性,培养团队合作和交流表达能力。
通过分析课程性质、学生特点和教学要求,明确课程目标,将目标分解为具体的学习成果,以便后续的教学设计和评估。
二、教学内容根据课程目标,选择和教学内容,确保内容的科学性和系统性。
制定详细的教学大纲,明确教学内容的安排和进度。
本课程的教学内容主要包括单词簿的基本概念、实验原理、实验步骤和数据分析方法。
教学大纲如下:1.单词簿的基本概念和实验原理2.实验步骤和实验操作技能3.实验结果的数据分析方法三、教学方法选择合适的教学方法,如讲授法、讨论法、案例分析法、实验法等,以激发学生的学习兴趣和主动性。
结合课本内容,采用多种教学方法,丰富学生的学习体验。
1.讲授法:通过教师的讲解,介绍单词簿的基本概念和实验原理,为学生提供理论知识的基础。
2.讨论法:学生进行小组讨论,引导学生思考和探索实验原理和数据分析方法,培养学生的思维能力和团队合作精神。
3.案例分析法:通过分析典型实验案例,让学生理解和应用实验原理和数据分析方法,提高学生的分析和解决问题的能力。
4.实验法:学生进行单词簿实验,培养学生的实验操作技能和实验观察能力,提高学生的实践能力。
四、教学资源选择和准备适当的教学资源,包括教材、参考书、多媒体资料、实验设备等。
教学资源应该能够支持教学内容和教学方法的实施,丰富学生的学习体验。
1.教材:选择一本适合学生年级的单词簿实验教材,提供实验原理、实验步骤和数据分析方法的学习内容。
2.参考书:提供相关的参考书籍,供学生深入学习和拓展知识。
3.多媒体资料:制作多媒体课件和教学视频,帮助学生形象地理解实验原理和数据分析方法。
英语单词学习助手数据结构课设报告

课程设计报告题目:英语单词学习助手课程名称:数据结构专业班级:计算机科学与技术1208班学号:U201215033姓名:江振武指导教师:祝建华报告日期:2014年10月29日计算机科学与技术学院任务书☐设计目的:掌握线性表、串、查找表等数据结构的物理存储结构与基本算法,通过解决较复杂的实际问题,提高学生对数据结构知识综合运用的技能与实践能力。
设计内容:以大学英语相关英语文章为语料素材,设计有效的数据结构及其存储结构表示英语单词表,并建立相应的倒排索引,帮助英语学习者在遇到生词时能方便找到生词的相应例句,熟悉其应用语境与地道的用法;设计有效的算法对语料进行清理与分句处理,实现基于索引的快速例句搜索程序。
☐设计要求:(1)输入某一个(或若干个)英语单词,要求返回相应的英语例句。
(2)根据单词与语句建立倒排索引,并且索引要求物化到外存,以文件形式保存,每次启动程序时不必重新建立索引,只需将索引文件导入内存。
(3)采用图形界面,便于输入单词,例句展现直观,界面布局合理。
设计提示:按三步进行:(1)准备英语语料。
寻找英语文章,可下载英语新闻,托福、GRE文章,或大学英语课文等。
(2)处理语料。
对语料进行清理、分句、索引、生成字典。
需要进行取词干的操作,分句可以直接根据标点符号处理。
(3)根据索引进行查询。
支持一个或多个查询,基于对词干的处理,当查go、going 等时也能够有返回。
由于查询的结果是语句,如果直接按照词与文章的关系建立索引,这样需要从文章中找句子,太多的串匹配操作可能导致查询较慢,所以要设计好索引的粒度。
一、问题描述与技术现状分析随着当前形势发展,英语现在随处可见,不管是在书籍还是各种网络上,我们都可以看到英语的踪影,但随之而来面临一个问题,许多英语单词对于初学者很陌生,因此英语单词助手对于他们来说有了莫大的帮助。
随着数据结构课程的结束,我们对C语言编程有了更加深入的了解。
然而通过课程设计,我们对数据结构知识有了更加深刻的理解,牢固掌握其应用方法,并合理灵活地解决一定实际问题,增强和提高综合分析问题与解决问题的能力。
索引和数据完整性实验报告

实验7 索引和数据完整性1、目的与要求(1)掌握索引的使用方法(2)掌握数据完整性的实现方法2、实验内容(1)建立索引(2)数据完整性3、实验步骤(1)建立索引①对yggl数据库的employees表中的departmentid列建立索引。
Use ygglIf exists(select name from sysindexes where name=’depart_ind’Drop index employees.depart_ind)GoCreate index depart_ind on employees(departmentid)②对pxscj数据库的kcb的课程号列建立索引。
(唯一聚集索引)Use pxscjIf exists(select name from sysindexes where name=’kc_id_ind’)Drop index kc_id_indGoCreate unique clustered index kc_in_ind on kcb(课程号)(2)数据完整性①建立一个规则对象,输入4个数字,每一位的范围分别是[0-3][0-9][0-6][0-9],然后把它绑定到book表的book_id字段上,再解除规则,最后删除规则。
Create table book(Book_id char(6) not null primary key,Name varchar(20) not null,Hire_date datetime not null,Cost int check(cost>=0 and cost<=500) null)GoCreate default today as getdate()GoExec sp_binddefault ‘today’,’book.[hire_date]’Go②创建一个表employees5,只含employeeid,name,sex和education列。
单词的检索和计数心得体会

单词的检索和计数心得体会篇一:单词的检索与计数内江师范学院计算机科学学院数据结构课程设计报告课题名称:文本文件单词的检索与计数姓名:学号:专业班级:软件工程系(院):计算机科学学院设计时间: 20XX 年 X 月 X日设计地点:成绩:篇二:文本文件单词的检索与计数(流程图)《数据结构》课程设计报告一、设计时间XX年01月5日-----XX年01月11日二、设计地点实验楼计算机511机房三、设计目的1.巩固和加深对数据结构课程所学知识的理解,了解并掌握数据结构与算法的设计方法;2.初步掌握软件开发过程的问题分析、系统设计、程序编码、测试等基本方法和技能;3.提高综合运用所学的理论知识和方法,独立分析和解决问题的能力; 4.训练用系统的观点和软件开发一般规范进行软件开发,培养软件工作者所应具备的科学的工作方法和作风;5.培养查阅资料,独立思考问题的能力。
四.设计小组成员五.指导老师六.设计课题文本文件单词的检索与计数七.基本思路及关键问题的解决方法(需求分析和概要设计) (一)需求分析:1.建立文本文件建立文本文件的实现思路:(1)定义一个串变量(2)定义文本文件(3)输入文件名,打开该文件(4)循环读入文本行,写入文本文件,其过程如下:While(不是文件输入结束){读入一文本行至串变量;串变量写入文件;输入是否结束输入标志; } (5)关闭文件2.给定单词的计数该功能需要用到前一节中设计的模式匹配算法,逐行扫描文本文件。
匹配一个,计数器加1,直到整个文件扫描结束;然后输出单词的次数。
3 .检索单词出现在文本文件中的行号、次数及其位置4.主控菜单程序的结构(1)头文件包含(2)菜单选择包括: 1、建立文件 2、单词计数 3、单词定位 4、退出程序(3)选择1~4执行相应的操作,其他字符为非法 (二)概要设计:1.建立文本文件:定义一个串变量,定义文本文件,输入文件名,打开该文件,循环读入文本行,写入文本文件,关闭文件。
综合实验十 词索引表的建立

综合实验十词索引表的建立一、实验名称词索引表的建立二、实验目的1、熟悉并掌握线性表的顺序存储和链式存储结构的实现与;2、熟悉并掌握字符串的基本操作;3、掌握查找操作在字符串处理中的应用。
三、实验内容及要求:1、实验内容问题描述:信息检索是计算机应用的重要领域之一。
为了提高图书馆数目检索的效率,建立书名关键词索引,可以实现读者快速检索书目的自动化,即读者根据关键词索引表,读者可以方便查询到自己感兴趣的书目。
根据以上问题给出的以下存储结构定义:#define MaxBookNum 1000 //最大书目数#define MaxKeyNum 2500 //索引表最大容量#define MaxLineLen 500 //书目字符串的最大长度#define MaxWordNum 100 //最大次词表的容量typedef struct//定义串的堆存储类型{char *ch;int length;//串长度} HString;typedef struct{char *item[MaxKeyNum+1];int last;} WordListType;//词表类型(顺序表)typedef int elemType;//定义链表的数据类型为整型(书号)typedef struct Lnode//定义索引链表结点{int data;struct Lnode *next;}LNode, *LinkList;typedef struct//定义索引项类型{HString key;//关键字LinkList bnolist;//存放书号索引链表} idxTermType;typedef struct//定义索引表类型(有序表){idxTermType item[MaxKeyNum+1];int last;}idxListType;//全局变量char* buf;//书目串缓存区WordListType wdlist;//词表/*字符串处理函数*/――――――――――定义基本操作的函数说明―――――――――――――/*功能函数*/int StrAssign(HString &T,char* chars);//生成一个值等于串常量chars的串Tint StrCompare(HString s,HString t);//比较字符串s与tvoid InitIdxList(idxListType &idxlist);//初始化索引表,置为空表void GetLine(FILE *f);//从书目文件中读取书目信息void ExtractKeyWord(elemType &bkno);//提取书名关键字到词表,书号存入bknovoid printWordList(WordListType w);//输出词表中所有的关键字int InsertIndexToList(idxListType &indexList,int bkno);//将书号为bkno的书名关键字插入按词表顺序插入索引表indexList中int PutText(FILE *IdxFile, idxListType idxlist);//将生成的索引表indexlist输出到g文件中void GetWord(int i, HString &wd);//返回词表wd中第i个关键字int Locate(idxListType &idxlist, HString wd, int &b);//在索引表idxlist中查找是否存在与wd相同的关键字,若存在,返回在索引表中的//位置,且b=1,若不存在,返回插入位置,且b=0void InsertNewKey(idxListType &idxlist, int i, HString wd);//在索引表idxlist的第i项上插入关键字wd,并初始化书号索引为空链表void Append(LinkList &bnolist,LNode *p);//存放书号索引链表bnolist中插入新的结点,按书号升序排序int InsertBook(idxListType &idxlist, int i, int bno);//在索引表idxlist第i项中插入书号为bno的索引int InsertIndexToList(idxListType &idxlist, int bno);//将书号为bkno的书名关键字插入按词表顺序插入索引表indexList中2、实验要求(1)、用C语言编程实现上述实验内容中的结构定义和算法。
实验报告“计算机网络——搜索引擎”

计算机网络实验报告一、实验名称:搜索引擎的原理与使用技巧二、实验目的:了解网络搜索引擎的基本工作原理;熟悉各种网络搜索引擎的特点和功能;掌握常用网络搜索引擎的使用方法;学会利用网络搜索引擎搜索各种资料;掌握网络搜索引擎提供的新应用;三、实验内容:掌握搜索技巧的必要性:目前全世界的搜索引擎有数千个,其中搜索引擎也可以细分为普通搜索引擎、集成搜索引擎、专业搜索引擎。
一般,搜索引擎均提供分类目录及关键词检索。
而这些搜索引擎的基本用法是在输入框内输入要查找内容的关键字或词,再按搜索或Search等按钮即可。
用户只需通过搜索引擎提供的链接地址,就可以访问到相关信息。
但是用这种方法检索可能会找到许多内容,难以筛选。
首先得了解搜索引擎的分类:网络搜索引擎可以分为:全文搜索引擎和目录搜索引擎。
全文搜索引擎是一种基于关键字的搜索方式,当用户输入要查询的关键字后,检索与用户查询条件相匹配的记录,按一定的排列顺序将结果返回给用户。
它的优点是信息量大、更新及时、不需人工干预,但也有缺点:信息量过多,用户必须从结果中进行筛选。
如我们常用的百度,谷歌等。
目录搜索引擎则以人工方式或者半自动方式搜集信息,人工形成信息摘要,并将信息存储在事先确定好的分类框架中,它的优点是查询信息准确度高,缺点是需要人工维护量大,搜集到的信息少,信息更新不及时。
常用的有hao123网址之家和8684网址导航等。
其次还应了解搜索引擎的工作原理:从互联网上抓取网页:利用能够从互联网上自动收集网页的Spider(蜘蛛)系统程序,自动访问互联网,并沿着任何网页上的所有URL爬到其它网页,重复这过程,并把爬过的所有网页收集回来。
这样我们面对的问题就是如何快速的让自己的网站被搜索引擎检索以及如何不让自己的网站被搜索引擎检索。
可以像搜索引擎登陆自己的站点或在其它重要网站放置到自己网站的链接,例如百度和谷歌的首页网址。
而禁止,因为spider遵守互联网robots协议,可以利用robots.txt文件完全禁止spider访问自己的网站或网站上的部分文件。
建立单词索引实验报告

《高级Java编程技术》课程实验报告院(系)名称:计算机学院专业班级:09计科 3 班学号:姓名:实验题目:实验6字符与字符串实验日期:2011/11/01实验(上机)学时:2一、实验内容、要求1.实验内容:建立单词索引2.要求:编写应用程序,建立一篇文档的单词索引。
应用程序要输入给定文档中所有单词及其在文档中出现的次数的列表,单词按字母顺序排列。
文档是文本文件(文件的内容是ASCⅡ字符),程序的输出结果也保存为ASCⅡ文件。
实现这个程序的主要步骤有:1)创建程序框架。
定义带有数据成员的主类。
为了测试这个主类还要定义Ch9WordConcordance类的框架,它只有一个默认的构造方法。
2)添加打开文件和保存结果的代码。
必要时,对步骤1的类进行扩充。
3)实现Ch9WordConcordance类。
4)去掉临时语句,将各部分连接起来,确定最终的代码。
二、所采用的数据结构如:线性表,二叉树,树,图等。
你在此用到了啥样的数据结构就写啥。
无数据结构。
三、实验的主要模块(或函数)及其功能函数分块及各块主要功能的文字描述1、Ch9WordConcordanceMain主类。
这是一个可实例化的主类,定义stsrt方法来实现顶层控制逻辑。
定义默认的构造方法来创建其他类的实例。
包含的方法及描述如下:(1)实现顶层逻辑控制,main()。
(2)默认构造方法,创建Ch9WordConcordance类和FileManager类的实例。
public Ch9WordConcordanceMain()(3)建立单词列表:private String build(String document)(4)打开文件:private String inputFile()(5)保存文件:private void saveFile(String list)(6)程序开始执行:private void start()2、Ch9WordConcordance类。
数据库实验3:连接查询、索引实验报告

数据库实验3:连接查询、索引实验报告GDOU-B-11-112广东海洋大学学生实验报告书实验名称实验3:连接查询、索引课程名称数据库原理及应用成绩学院(系)信息学院专业软件工程班级学生姓名学号实验地点实验日期实验目的:1.使用内连接2.使用外连接3.索引的创建完成在在GlobalToyz数据库上的查询,按要求完成给出的下列题目,要求写出相应数据库的查询语句(SELECT)。
1.使用连接实现查询,查询订单号为‘000005’的订单订购的玩具的名称及其品牌名称。
(两种连接语法:交叉连接、内连接)SELECT DISTINCT toy.vToyName, brand.cBrandNameFROM OrderDetail AS detail CROSS JOIN Toys AS toy CROSS JOIN ToyBrand AS brandWHERE detail.cOrderNo = '000005' AND detail.cToyId = toy.cT oyId AND toy.cBrandId = brand.cBrandId;SELECT toy.vToyName, brand.cBrandNameFROM OrderDetail AS detail INNER JOIN T oys AS toy ON (detail.cT oyId = toy.cToyId AND detail.cOrderNo = '000005') INNER JOIN ToyBrand AS brand ON toy.cBrandId = brand.cBrandId;2.使用连接实现查询,查询订购了类别为‘Infant’的玩具的订单详情。
SELECT detail.*FROM Category AS cate, Toys AS toy, OrderDetail AS detailWHERE /doc/f511630846.html,ategory = 'infant' AND /doc/f511630846.html,ategoryId = /doc/f511630846.html,ategoryId AND detail.cToyId = toy.cToyId;3.使用连接实现查询,查询订单号为‘000001’的订单的包装描述和附言内容。
简单的英文词典排版系统实验报告

实验目录需求分析———————————— 2 整体设计———————————— 2 详细设计———————————— 4 调试与测试——————————— 6 用户手册———————————— 6 总结—————————————— 6 附录—————————————— 9一需求分析1目的我们所做的程序课题是一个“简单的英文词典排版系统”。
该课题目的在于锻炼我们的自主动手和创新、创造能力, 同时通过自己看书学习文件的输入输出等功能的实现, 提升我们的自学能力。
并通过自己思考程序的算法和函数的组建过程来提升我们的逻辑思维能力, 最后是利用自我程序测试和改进来增加我们对编程的进一步了解, 和提升编程的能力。
其大背景是要为同学提供了一个既动手又动脑, 独立实践的机会, 将课本上的理论知识和实际有机的结合起来, 锻炼同学的分析解决实际问题的能力。
提高学生适应实际, 实践编程的能力。
2 预期达到功能(1) 能输入和显示所打的单词。
(2) 能分辨出单词。
(3) 对重复的单词和已经输入的单词能自动排除。
(4) 能按A-Z的顺序排版。
(5) 能将运行结果以文本形式存储。
(6) 具有添加新单词并重新排版的能力。
(7) 实现以上功能的选择操作3 需解决问题主要解决单词输入到文件和从文件输出以及最后文件保存的问题, 但是我们对C++的学习仍不完全, 这就要求我们提前把课本上的“文件与流”这一章节的相关内容进行自学并应用于其中。
其次我们要解决如何实现查找单词、分辨单词、添加单词以及对单词进行排序的系列问题, 这要求我们能对已学习的内容充分掌握并熟练应用。
二整体设计1 程序设计功能模块图2 程序流程示意图词库文件建立并选择功能添加单词单词排序搜索单词显示单词1)字符排序2) 检查模块三详细设计1 函数功能void write(int r) 将单词写入文件的函数int read() 读取文件函数void zhucaidan() 主菜单函数int paixu() 排序函数void jiancha() 检查单词模块void charu(char*d) 插入单词模块void find(char *s) 查找单词模块void xuanze() 选择菜单模块2 参数说明dic[N][20] N为100, 即但单词库课输入100个单词, 每个单词长度不得大于19*p 为指向Data文件的指针flag, temp 在不同的函数模块中用于不同情况下的结果判断与后续的程序执行s[20], d[20], f[20] char类型的数组s、d和f用于临时的单词输入放置t[20] char类型的数组t是用于临时放置从文件中读取的单词way 是用于switch语句中功能选项的选择i, j, c等是普通的int变量3函数调用1)void xuanze()选择菜单调用的函数: jiancha()检查函数、find(d)查找函数、charu(d)插函数以及zhucaidan()主菜单函数2)void find(char *s) 查找单词模块调用的函数: strcpy复制函数、strcmp比较大小函数、write(r)写入文件函数3)void charu(char*d) 插入单词模块调用的函数: read()读取函数、strcmp比较函数、strcpy复制函数、write(r)写入文件函数、paixu()排序函数、4)void jiancha()检查单词模块调用的函数: write(r)写入文件函数5)int paixu()排序函数调用的函数: read()读取函数、strcmp比较大小函数、strcpy复制函数、write(r)写入文件函数6)int read()读取文件函数调用的函数: write(r)写入文件函数main()主函数调用的函数: jiancha()检查函数、paixu()排序函数、xuanze()菜单选择函数4算法实现1)插入模块void charu(char*d)单词存在情况:先输入单词放置于*d指向的d[20]临时数组中, 再利用for循环和strcmp比较函数看输入的单词是否已经存在, 存在flag=1, 不存在将单词保存break跳出for循环从新输入单词, flag仍等于0;单词不存在情况:若flag=0, 利用strcpy复制函数将新输入的单词复制到单词库已存在单词的后面, 单词个数r增加1;继续输入:利用while语句, 只要继续输入的字符不为0(即输入的为单词, 用户不返回主菜单), 就可以执行while语句继续重复上述的检查单词和保存单词的步骤;2)返回主菜单:3)若输入的字符为0(即用户要返回主菜单), while语句无法执行, 经过从新排序后, 利用return返回调用函数, 即void xuanze()菜单选择函数, 可从新选择功能。
实验十索引的实验报告
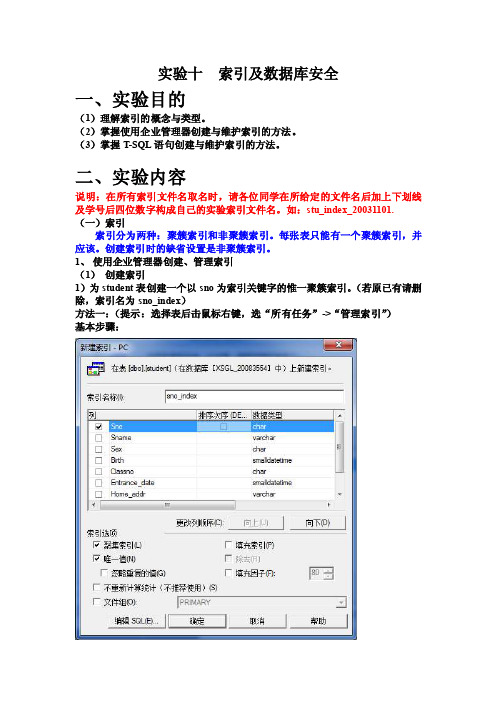
实验十索引及数据库安全一、实验目的(1)理解索引的概念与类型。
(2)掌握使用企业管理器创建与维护索引的方法。
(3)掌握T-SQL语句创建与维护索引的方法。
二、实验内容说明:在所有索引文件名取名时,请各位同学在所给定的文件名后加上下划线及学号后四位数字构成自己的实验索引文件名。
如:stu_index_20031101. (一)索引索引分为两种:聚簇索引和非聚簇索引。
每张表只能有一个聚簇索引,并应该。
创建索引时的缺省设置是非聚簇索引。
1、使用企业管理器创建、管理索引(1)创建索引1)为student表创建一个以sno为索引关键字的惟一聚簇索引。
(若原已有请删除,索引名为sno_index)方法一:(提示:选择表后击鼠标右键,选“所有任务”->“管理索引”)基本步骤:方法二:(提示:选择表后击鼠标右键,选“设计表”->“索引/键”)基本步骤:2)为student表创建以sname,sex为索引关键字的非聚簇索引(对sname以升序来排列,sex以降序排列,并设置填充因子为70%)。
索引名为:ss_index。
基本步骤:(2)重命名索引将索引文件student重新命名为sno_index1。
基本步骤:(3)删除索引将索引文件sno_index1删除。
基本步骤:右击删除即可2、使用T-SQL语句创建、管理索引(1)创建索引1)为SC表创建一个非聚集索引grade_index,索引关键字为grade,升序,填充因子为80%。
(提示:with fillfactor=)T-SQL语句:create index grade_indexon SC(grade)with fillfactor=802)为SC表创建一个惟一性聚集索引sc_index,索引关键字为sno,cno。
提示:用alter table命令也可以删除原有的聚集索引约束或用企业管理器删除。
方法1:用alter table命令创建sc_index索引。
文本文件单词的检索与计数课程设计实验报告

2.3检索单词出现在文本文件中得行号、次数及其位置
逐行扫描文本文件。扫描一个单词,单词数加1,匹配一个,计数器加1,输出该单词数,行数到底
以此,行数加1,单词数清零,直到整个文件扫描结束;然后输出单词得次数,行号,第几个单词。
检索单词得出现在文本文件中得行号,次数以及位置
3详细设计
ﻩﻩﻩmemset(S、ch,'\0',256);
ﻩﻩfgets(S、ch,100,fp);
ﻩﻩﻩﻩS、length=strlen(S、ch);
ﻩﻩk=0;//初始化开始检索位置
ﻩﻩwhile(k<S、length-1)//检索整个主串S
ﻩﻩﻩ{
ﻩj=PartPosition(S,T,k);
ﻩﻩﻩif(j<0)
(5) 关闭文件
1、2给定单词得计数
该功能需要用到前一节中设计得模式匹配算法,逐行扫描文本文件。匹配一个,计数器加1,直到整个文件扫描结束;然后输出单词得次数。 ﻫ1、3 检索单词出现在文本文件中得行号、次数及其位置
1、4 主控菜单程序得结构
(1) 头文件包含
(2) 菜单选择包括:
1、 建立文件 ﻫ2、 单词计数
ﻩyn=getchar();
}
fclose(fp);//关闭文件
printf("建立文件结束!");
}
ﻩvoid SubStrCount()
ﻩ{
FILE*fp;
ﻩﻩSString S,T;//定义两个串变量
ﻩchar fname[10];
ﻩinti=0,j,k;
printf("输入文本文件名: ");
voidCreatTextFile()
索引的使用实验报告

一、实验目的1. 理解索引的概念和作用。
2. 掌握创建、删除和管理索引的方法。
3. 通过实际操作,验证索引对数据库查询性能的影响。
二、实验环境1. 操作系统:Windows 102. 数据库管理系统:MySQL 5.73. 实验数据:模拟学生信息表(包含学生ID、姓名、年龄、性别、班级ID等字段)三、实验内容1. 创建索引2. 查询性能测试3. 删除索引4. 索引重建与优化四、实验步骤1. 创建索引(1)创建学生信息表```sqlCREATE TABLE student (id INT AUTO_INCREMENT PRIMARY KEY,name VARCHAR(20),age INT,gender ENUM('男', '女'),class_id INT);```(2)创建索引```sql-- 创建学生ID索引CREATE INDEX idx_student_id ON student(id);-- 创建学生姓名索引CREATE INDEX idx_student_name ON student(name);-- 创建学生年龄索引CREATE INDEX idx_student_age ON student(age);-- 创建学生性别索引CREATE INDEX idx_student_gender ON student(gender);-- 创建学生班级ID索引CREATE INDEX idx_student_class_id ON student(class_id); ```2. 查询性能测试(1)测试创建索引前的查询性能```sql-- 查询学生信息表中所有学生信息SELECT FROM student;-- 查询年龄大于18岁的学生信息SELECT FROM student WHERE age > 18;-- 查询班级ID为1的学生信息SELECT FROM student WHERE class_id = 1;```(2)测试创建索引后的查询性能```sql-- 查询学生信息表中所有学生信息SELECT FROM student;-- 查询年龄大于18岁的学生信息SELECT FROM student WHERE age > 18;-- 查询班级ID为1的学生信息SELECT FROM student WHERE class_id = 1;```3. 删除索引```sql-- 删除学生ID索引DROP INDEX idx_student_id ON student;-- 删除学生姓名索引DROP INDEX idx_student_name ON student;-- 删除学生年龄索引DROP INDEX idx_student_age ON student;-- 删除学生性别索引DROP INDEX idx_student_gender ON student; -- 删除学生班级ID索引DROP INDEX idx_student_class_id ON student;```4. 索引重建与优化(1)重建索引```sql-- 重建学生ID索引ALTER TABLE student DROP INDEX idx_student_id;ALTER TABLE student ADD INDEX idx_student_id(id);-- 重建学生姓名索引ALTER TABLE student DROP INDEX idx_student_name;ALTER TABLE student ADD INDEX idx_student_name(name);-- 重建学生年龄索引ALTER TABLE student DROP INDEX idx_student_age;ALTER TABLE student ADD INDEX idx_student_age(age);-- 重建学生性别索引ALTER TABLE student DROP INDEX idx_student_gender;ALTER TABLE student ADD INDEX idx_student_gender(gender);-- 重建学生班级ID索引ALTER TABLE student DROP INDEX idx_student_class_id;ALTER TABLE student ADD INDEX idx_student_class_id(class_id); ```(2)优化索引```sql-- 优化学生ID索引OPTIMIZE TABLE student;```五、实验结果与分析1. 实验结果(1)创建索引前后的查询性能对比通过实验可以发现,创建索引后,查询性能得到了显著提升。
索引的应用实验报告

一、实验目的1. 理解索引的概念及其在数据库中的应用。
2. 掌握创建、删除和修改索引的方法。
3. 通过实验验证索引对数据库查询性能的影响。
二、实验环境1. 操作系统:Windows 102. 数据库管理系统:MySQL 5.73. 数据库:实验数据库三、实验内容1. 创建索引2. 删除索引3. 修改索引4. 索引对查询性能的影响四、实验步骤1. 创建索引(1)创建实验数据库```sqlCREATE DATABASE experiment;USE experiment;```(2)创建实验表```sqlCREATE TABLE students (id INT AUTO_INCREMENT PRIMARY KEY,name VARCHAR(50),age INT,class VARCHAR(50));```(3)向实验表中插入数据```sqlINSERT INTO students (name, age, class) VALUES ('张三', 20, '计算机科学与技术');INSERT INTO students (name, age, class) VALUES ('李四', 21, '软件工程');INSERT INTO students (name, age, class) VALUES ('王五', 22, '计算机科学与技术');INSERT INTO students (name, age, class) VALUES ('赵六', 23, '软件工程');INSERT INTO students (name, age, class) VALUES ('孙七', 24, '计算机科学与技术');```(4)创建索引```sql-- 根据姓名创建索引CREATE INDEX idx_name ON students (name);-- 根据年龄创建索引CREATE INDEX idx_age ON students (age);-- 根据班级创建索引CREATE INDEX idx_class ON students (class);```2. 删除索引```sql-- 删除姓名索引DROP INDEX idx_name ON students;-- 删除年龄索引DROP INDEX idx_age ON students;-- 删除班级索引DROP INDEX idx_class ON students;```3. 修改索引```sql-- 修改姓名索引为唯一索引ALTER TABLE students ADD UNIQUE INDEX idx_name_unique (name); ```4. 索引对查询性能的影响(1)查询姓名为“张三”的记录```sql-- 使用索引查询SELECT FROM students WHERE name = '张三';-- 不使用索引查询SELECT FROM students WHERE name = '张三' LIMIT 1;```(2)查询年龄为20岁的记录```sql-- 使用索引查询SELECT FROM students WHERE age = 20;-- 不使用索引查询SELECT FROM students WHERE age = 20 LIMIT 1;```五、实验结果与分析1. 创建索引后,查询姓名为“张三”的记录速度明显提高,说明索引可以加快查询速度。
实验报告搜索引擎

一、实验目的1. 了解搜索引擎的基本原理和运作方式;2. 掌握搜索引擎的使用方法,提高信息检索效率;3. 分析搜索引擎的优势与不足,为我国搜索引擎的发展提供参考。
二、实验内容1. 搜索引擎的基本原理2. 搜索引擎的使用方法3. 搜索引擎的优势与不足三、实验过程1. 搜索引擎的基本原理(1)搜索引擎的工作流程搜索引擎主要分为三个阶段:爬虫、索引和搜索。
1)爬虫:搜索引擎的爬虫程序会从互联网上抓取网页,并将其存储到数据库中。
2)索引:搜索引擎会对抓取到的网页进行分析,提取关键词、标题、摘要等信息,建立索引。
3)搜索:用户输入关键词后,搜索引擎会根据索引快速找到相关网页,并展示给用户。
(2)搜索引擎的排名算法搜索引擎的排名算法主要包括以下几种:1)基于关键词匹配:搜索引擎会根据用户输入的关键词,从索引中找到包含该关键词的网页。
2)基于网页质量:搜索引擎会根据网页的质量、更新频率等因素,对网页进行排序。
3)基于用户行为:搜索引擎会根据用户在网站上的行为,如点击、停留时间等,对网页进行排序。
2. 搜索引擎的使用方法(1)关键词搜索:用户在搜索框中输入关键词,点击搜索按钮,即可获取相关网页。
(2)高级搜索:部分搜索引擎提供高级搜索功能,用户可以通过限定搜索范围、时间、语言等条件,提高搜索精度。
(3)搜索技巧:为了提高搜索效果,用户可以运用以下技巧:1)使用精确匹配:将关键词用引号括起来,如“搜索引擎原理”。
2)使用逻辑运算符:使用“与”、“或”、“非”等逻辑运算符,对关键词进行组合。
3)使用通配符:使用“”代表任意字符,如“搜索引擎”。
3. 搜索引擎的优势与不足(1)优势1)信息量大:搜索引擎可以覆盖全球范围内的网页,提供丰富的信息资源。
2)速度快:搜索引擎通过索引和排名算法,能够快速找到相关网页。
3)方便快捷:用户只需输入关键词,即可获取所需信息。
(2)不足1)信息质量参差不齐:由于搜索引擎无法对网页进行严格审查,导致部分虚假、低质量信息混入搜索结果。
(2021年整理)文本文件单词的检索与计数课程设计实验报告

(完整)文本文件单词的检索与计数课程设计实验报告编辑整理:尊敬的读者朋友们:这里是精品文档编辑中心,本文档内容是由我和我的同事精心编辑整理后发布的,发布之前我们对文中内容进行仔细校对,但是难免会有疏漏的地方,但是任然希望((完整)文本文件单词的检索与计数课程设计实验报告)的内容能够给您的工作和学习带来便利。
同时也真诚的希望收到您的建议和反馈,这将是我们进步的源泉,前进的动力。
本文可编辑可修改,如果觉得对您有帮助请收藏以便随时查阅,最后祝您生活愉快业绩进步,以下为(完整)文本文件单词的检索与计数课程设计实验报告的全部内容。
文件检索1需求分析1.1 建立文本文件建立文本文件的实现思路(1)定义一个串变量(2)定义文本文件(3)输入文件名,打开该文件(4)循环读入文本行,写入文本文件,其过程如下:While(不是文件输入结束){读入一文本行至串变量;串变量写入文件;输入是否结束输入标志;}(5)关闭文件1。
2给定单词的计数该功能需要用到前一节中设计的模式匹配算法,逐行扫描文本文件。
匹配一个,计数器加1,直到整个文件扫描结束;然后输出单词的次数。
1。
3 检索单词出现在文本文件中的行号、次数及其位置1。
4 主控菜单程序的结构(1)头文件包含(2) 菜单选择包括:1、建立文件2、单词计数3、单词定位4、退出程序(3)选择1~4执行相应的操作,其他字符为非法2.概要设计2。
流程图2.1建立文本文件定义一个串变量,定义文本文件,输入文件名,打开该文件,循环读入文本行,写入文本文件, 关闭文件。
建立文本文件的思路过程2.2给定单词的计数逐行扫描文本文件。
匹配一个,计数器加1,直到整个文件扫描结束;然后输出单词的次数。
给定单词计数的过程2.3检索单词出现在文本文件中的行号、次数及其位置逐行扫描文本文件。
扫描一个单词,单词数加1,匹配一个,计数器加1,输出该单词数,行数到底以此,行数加1,单词数清零,直到整个文件扫描结束;然后输出单词的次数,行号,第几个单词。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
《高级Java编程技术》课程实验报告
院(系)名称:计算机学院专业班级:09计科 3 班
学号:姓名:
实验题目:实验6字符与字符串
实验日期:2011/11/01实验(上机)学时:2
一、实验内容、要求
1.实验内容:建立单词索引
2.要求:
编写应用程序,建立一篇文档的单词索引。
应用程序要输入给定文档中所有单词及其在文档中出现的次数的列表,单词按字母顺序排列。
文档
是文本文件(文件的内容是ASCⅡ字符),程序的输出结果也保存为ASCⅡ
文件。
实现这个程序的主要步骤有:
1)创建程序框架。
定义带有数据成员的主类。
为了测试这个主类还
要定义Ch9WordConcordance类的框架,它只有一个默认的构造
方法。
2)添加打开文件和保存结果的代码。
必要时,对步骤1的类进行扩充。
3)实现Ch9WordConcordance类。
4)去掉临时语句,将各部分连接起来,确定最终的代码。
二、所采用的数据结构
如:线性表,二叉树,树,图等。
你在此用到了啥样的数据结构就写啥。
无数据结构。
三、实验的主要模块(或函数)及其功能
函数分块及各块主要功能的文字描述
1、Ch9WordConcordanceMain主类。
这是一个可实例化的主类,定义
stsrt方法来实现顶层控制逻辑。
定义默认的构造方法来创建其他类的实例。
包含的方法及描述如下:
(1)实现顶层逻辑控制,main()。
(2)默认构造方法,创建Ch9WordConcordance类和FileManager类的实例。
public Ch9WordConcordanceMain()
(3)建立单词列表:private String build(String document)
(4)打开文件:private String inputFile()
(5)保存文件:private void saveFile(String list)
(6)程序开始执行:private void start()
2、Ch9WordConcordance类。
该类的实例利用Pattern和Matcher类进行单词提取。
包含的方法和描述如下:
(1)默认的构造方法,创建WordList类和Pattern的实例:public Ch9WordConcordance()
(2)对打开的文件内容进行单词获取:
public String build(String document)
3、FileManager类。
实现打开文件和保存文件。
包含的方法和描述如下:
(1)打开文本文件filename,将其内容作为字符串返回:
public String openFile(String filename) throws
FileNotFoundException,IOException
(2)打开最终用户所选择的文本文件,将其内容作为字符串返回。
选择文件时使用标准的文件打开对话框:
public String openFile() throws FileNotFoundException,
IOException
(3)讲字符串data保存到文件filename中:
public void saveFile(String filename, String data) throws IOException
(4)讲字符串data保存到最终用户所选择的文件中,使用标准的文件保存对话框:
public void saveFile(String data) throws IOException
4、WordList类。
支持单词列表的维护。
每次从文档中提取出一个单词
时,就将它写入单词列表。
如果单词列表已经有这个单词时,这将它的数量加1。
包含的方法及描述如下:
(1)增加给定单词的数量。
如果单词已在列表中,则将它的数量加1;
如果单词不在列表中,那么将它添加到列表中,数量设为1.:
public void add(String word)
(2)将单词索引作为一个字符串返回,单词索引以单词的首字母顺序排列,每行包含一个单词及其数量:
public String getConcordance()
(3)清空内部数据结构,以便创建新的单词列表。
在每次处理新的文档之前,必须调用该方法:
public void reset()
四、主要模块(或函数)的算法思想和程序框图
具体算法实现文字描述或框图:
主类:Ch9WordConcordanceMain main( ) start( ) inputFile() 调用FileManager 类的openFile()
显示了一个打开文件的对话框
build(document) 调用Ch9WordConcordance 类的build(document) 对打开文档的内容进行单词模式匹配 Run the program? N Y 退出程序。
调用WordList 类的add(document.substring(matcher.start(), matcher.end())) 调用WordList 类的getConcordance() 获取记录中所有的记录项 saveFile(wordList) 调用FileManager 类的saveFile()
显示了一个保存文件的对话框
Run the program ?
谢谢使用程序。
Y N
五、程序运行时的输入数据(随机产生的数据要求输出显示),输出结果
1、选择是否运行程序:
2、选择是,打开一个打开文件的对话框,选择了一个在我的文档的文本文件lizebing.txt:
3、打开一个保存文件的对话框,选择了保存在我的文档的lizebing1.txt:
4、询问是否继续运行程序:
6、选择否退出程序。
7、这是打开lizebing.txt文件中的内容:
8、打开文本文件1lizebing1.txt可以看到从lizebing.txt文档中索取的单词列表:。