使用KETTLE工具在Oracle和Dm7之间迁移数据
使用KETTLE工具在Oracle和Dm7之间迁移数据

使用KETTLE工具在Oracle和Dm7之间迁移数据Kettle是一款开源的ETL工具,用于数据集成、数据迁移和数据清洗等任务。
在使用Kettle工具进行Oracle和DM7之间的数据迁移时,可以按照以下步骤进行操作:1. 配置数据库连接:打开Kettle工具,创建一个新的转换(Transformation),然后点击左侧的“Database Connections”选项卡,选择“Create new connection”来创建一个新的数据库连接。
根据实际情况输入数据库地址、端口、用户名、密码等信息,选择正确的数据库类型分别为Oracle和DM72. 创建源表和目标表:在“Transformation”中,右键点击工作区域,选择“Insert”和“Table Input”来创建一个源表输入步骤,然后在“Table Input”步骤中配置源表的SQL查询语句来选择需要迁移的数据。
接着,右键点击工作区域,选择“Insert”和“Table Output”来创建一个目标表输出步骤,然后在“Table Output”步骤中配置目标表的连接和写入模式。
3. 字段映射和转换:将源表输入步骤和目标表输出步骤之间连接起来,然后右键点击连接线,选择“Mapping”来打开字段映射界面。
在字段映射界面中,将源表字段和目标表字段进行逐一映射,并可以进行一些数据转换操作,例如数据格式转换、字符串拼接等。
4. 数据迁移执行:完成字段映射后,保存转换,并点击工具栏上的“Execute”按钮来执行数据迁移任务。
Kettle工具会自动读取源表数据,并根据字段映射关系将数据插入到目标表中。
在执行过程中,可以查看执行日志和监控执行进度。
5.错误处理和性能优化:如果迁移过程中出现了错误,可以通过配置错误处理步骤来处理错误数据记录或进行错误日志记录。
此外,可以根据需求对转换进行性能优化,例如采用并行执行、增加索引等操作来提高迁移效率。
Oracle数据库的数据迁移方法

数据迁移的一般步骤
对数据库管理人员来说,数据库数据迁移极具挑战性,一旦措施不当,珍贵的数据资源将面临丢失的危险,要成功地实现数据库数据平滑迁移,需要周密计划和充分准备,并按照一定的步骤来完成。
设计数据迁移方案
设计数据迁移方案主要包括以下几个方面工作:研究与数据迁移相关的资料,或在网站上查询相关内容、评估和选择数据迁移的软硬件平台、选择数据迁移方法、选择数据备份和恢复策略、设计数据迁移和测试方案等。
进行数据模拟迁移
根据设计的数据迁移方案,建立一个模拟的数据迁移环境,它既能仿真实际环境又不影响实际数据,然后在数据模拟迁移环境中测试数据迁移的效果。
数据模拟迁移前也应按备份策略备份模拟数据,以便数据迁移后能按恢复策略进行恢复测试。
测试数据模拟迁移
根据设计的数据迁移测试方案测试数据模拟迁移,也就是检查数据模拟迁移后数据和应用软件是否正常,主要包括:数据一致性测试、应用软件执行功能测试、性能测试、数据备份和恢复测试等。
准备实施数据迁移
数据模拟迁移测试成功后,在正式实施数据迁移前还需要做好以下几个方面工作:进行完全数据备份、确定数据迁移方案、安装和配置软硬件等。
正式实施数据迁移
按照确定的数据迁移方案,正式实施数据迁移。
测试数据迁移效果
按照数据迁移测试方案测试数据迁移效果,并对数据迁移后的数据库参数和性能进行调整,使之满足数据迁移后实际应用系统的需要。
移植系统应用软件
将实际应用系统的应用软件移植到数据迁移后的数据库系统上,并使之正常运行。
正式运行应用系统
在正式实施数据迁移成功并且数据库参数和性能达到要求后,就可以正式运行应用系统,并投入实际使用。
实现向Oracle8i数据迁移。
达梦数据库迁移到oracle数据库的方法

达梦数据库迁移到oracle数据库的方法
1. 首先,您需要备份所有达梦数据库。
2. 下一步,您需要安装Oracle数据库并创建一个新的数据库实例。
您可以使用Oracle的官方安装向导或手动安装。
3. 然后,您需要使用Database Migration Assistant for Unicode(DMU)工具来迁移数据。
DMU是一个免费工具,可帮助迁移来自不同数据库的Unicode字符数据。
4. 在DMU中,选择“达梦(Datamars)”作为源数据库,并选择“Oracle”作为目标数据库。
然后,您需要提供达梦数据库的连接详细信息和Oracle数据库的连接详细信息。
5. 您现在可以运行DMU,并等待它完成整个数据迁移过程。
在迁移期间,DMU会自动转换数据类型和字符集,以便与Oracle数据库兼容。
6. 在迁移完成后,您需要验证数据。
您可以使用Oracle数据库中的SQL语句来验证数据是否正确地转换。
7. 最后,您需要调整查询以匹配Oracle的语法。
由于Oracle和达梦之间存在语法差异,因此您需要更改查询以正确地执行它们。
总之,将达梦数据库迁移到Oracle数据库需要一些时间和努力,但通过使用DMU工具和调整查询,您应该能够成功地完成迁移并开始使用Oracle数据库。
【VIP专享】oracle数据迁移方法

原数据大小:1.5Gexpdp导出操作用时:5分钟impdp导入操作用时:22分钟导出文件大小:588M导出导入环境:单CPU,700M内存,并行度 = 1你不是说这个会更快么?为什么速度跟3.1的imp/exp差不多啊?请看第四部分总结的解释。
1.4 你还敢再快一点么?使用表空间迁移。
将表空间的元数据导出,和数据文件一起,复制到新库。
执行元数据导入。
一般来说,整个导入导出的数据量不到5M。
速度相当快,但使用限制比较多。
导出时间:1分钟导入时间:3分钟导出文件:60M + 数据文件1.5G1.5 如何将数据从linux环境转到windows环境?查看v$transportable_platform,如果数据编码一致,可尝试直接复制数据文件。
否则使用rman或impdp/expdp或imp/exp。
1.6 如果你有一个excel格式的数据表,需要远程更新到客户数据库上,怎么更新?使用pl/sql developer,复制、粘贴、提交。
1.6 如果你需要将正式库的几张表,迁移到测试库来,怎么弄快些?用dblink+脚本,或者使用impdp远程导入二、局部数据的迁移2.1、广域网的迁移2.1.1 pl/sql developer广域网下小数据量的迁移,常用pl/sql developer工具来完成。
在本地打开excel文件,复制数据。
然后通过“远程桌面”,到远程服务器的pl/sql界面上粘贴,就可以了。
操作简单方便。
第一步:在本地复制数据第二步:打开远程桌面第三步:在远程机器的pl/sql里面粘贴数据第四步:保存数据这种方法在小数据量下很好用。
大数据量时,一个表一个表的粘贴比较麻烦,且一粘贴可能就卡在那里了,得等10来分钟。
2.1.2 imp/exp广域网内大数据量的迁移,通常使用imp/exp工具。
先在源库上使用exp工具,导出数据压缩包,通过网络发送到目标数据库。
在目标数据库上再imp。
第一步:本机连接到源库上,执行expExp一般使用直接路径导出,速度可以达到常规路径导出的3倍以上。
oracle 数据迁移方案

Oracle 数据迁移方案1. 简介随着业务的发展和系统的升级,数据迁移已经成为一个不可避免的任务。
在Oracle 数据库中,数据迁移主要包括迁移数据表、迁移数据对象以及导出和导入数据等方面。
本文将介绍一些常用的 Oracle 数据迁移方案。
2. 数据表迁移2.1 导出数据表Oracle 数据表的导出可通过使用expdp命令来实现。
该命令可以将指定的数据表导出为二进制格式的文件,以供后续导入使用。
以下是导出数据表的步骤:1.打开终端或命令行窗口,登录到数据库。
2.运行以下命令导出数据表:expdp username/password@connect_string tables=table1,table2 directory=datapump_dir dumpfile=tables.dmp logfile=tables.log–username/password:登录数据库的用户名和密码。
–connect_string:数据库连接字符串。
–tables:要导出的数据表名称,多个表名之间用逗号分隔。
–directory:导出文件存储的目录。
–dumpfile:导出文件的名称。
–logfile:导出日志文件的名称。
2.2 导入数据表使用impdp命令可以将之前导出的数据表文件导入到目标数据库中。
以下是导入数据表的步骤:1.打开终端或命令行窗口,登录到目标数据库。
2.运行以下命令导入数据表:impdp username/password@connect_string directory=datapump_d ir dumpfile=tables.dmp logfile=import.log–username/password:登录目标数据库的用户名和密码。
–connect_string:目标数据库的连接字符串。
–directory:导出文件存储的目录。
–dumpfile:导出文件的名称。
–logfile:导入日志文件的名称。
Oracle数据库迁移到MySQL(kettle,navicate,sqldeveloper等工具

Oracle数据库迁移到MySQL(kettle,navicate,sqldeveloper等⼯具Oracle 数据库迁移到MySQL (kettle,navicate,sql developer等⼯具1 kettle--第⼀次使⽤kettle玩迁移,有什么不⾜之处和建议,请⼤家指正和建议。
下载软件,官⽹⽐较慢,国内有⼀些镜像下载完成,解压pdi-ce-7.0.0.0-25.zipG:\download\pdi-ce-7.0.0.0-25\data-integration双击Spoon.bat 运⾏提⽰找不到javaw.exe下载jdk安装(这⾥在oracle官⽹上选择相应的进⾏下载安装jdk-8u191-windows-x64.exe),路径C:\Program Files\Java\jdk1.8.0_191添加环境变量 C:\Program Files\Java\jdk1.8.0_191在双击Spoon.bat 运⾏--整库转移数据ojdbc5.jar ojdbc6.jar mysql-connector-java-5.1.47.jar拷贝到kettle的lib路径 G:\download\pdi-ce-7.0.0.0-25\data-integration\lib在启动kettle之前拷贝进去,这⾥重新运⾏--mysql连接--连接oralce,由于oralce是11g r2 rac环境,之前⼀直报错Error connecting to database: (using class oracle.jdbc.driver.OracleDriver)Listener refused the connection with the following error:ORA-12505, TNS:listener does not currently know of SID given in connect descriptor--所以这⾥直接指定⼀个sid,即bol1,选择第⼀个节点,ip是scan ip新建⼀个job,创建2个db的连接,source,target,在菜单中找到[复制多表导向],点击进⾏关联操作⼯具--向导--复制多表导向--点击 finish--开始执⾏--⽇志--登录mysql进⾏查询,发现数据和表已经同步--问题,oracle迁移到mysql的表,字段是number类型,迁移到mysql之后,变成了double类型,数据存储的是整数。
oracle数据库跨平台迁移实施过程

oracle数据库跨平台迁移实施过程Oracle数据库跨平台迁移是将Oracle数据库从一种操作系统迁移到另一种操作系统的过程。
该过程涉及将数据、数据库对象、配置和相关应用程序从原始平台迁移至目标平台,确保迁移后的数据库可以正常运行。
下面是Oracle数据库跨平台迁移的实施过程:1.确定迁移目标和设计迁移策略:首先需要确定迁移的目标操作系统和硬件平台,并根据目标平台的特性来设计迁移策略。
在此阶段,需要考虑目标系统的操作系统版本、硬件配置、网络环境等因素。
2.数据库准备工作:在迁移过程之前,需要进行数据库的准备工作。
包括备份数据库,以防止迁移过程中出现数据丢失,关闭数据库并准备迁移所需的文件。
3. 数据迁移:将数据从原始平台迁移到目标平台。
这可以通过多种方式来实现,包括使用Oracle Data Pump、数据库链接、物理复制等。
根据数据量的大小、迁移时间的限制和网络带宽的限制选择合适的数据迁移方法。
4. 迁移数据库对象:迁移数据库对象,包括表、约束、索引、视图、存储过程等。
通常可以使用Oracle迁移工具或手动将这些对象从原始平台迁移到目标平台。
在迁移过程中要注意兼容性问题,确保目标平台上可以正常使用这些数据库对象。
5. 配置和调整:针对目标平台的特点,进行适当的配置和调整。
例如,配置操作系统、网络、存储以及Oracle数据库本身的参数。
此外,还需要调整数据库的权限和用户,确保数据库在目标平台上能够正常工作。
6.测试和验证:在迁移过程完成后,需要进行测试和验证,确保数据库在目标平台上能够正常运行。
这包括对数据库进行性能测试、功能测试和容量测试等。
7.部署和上线:在完成测试和验证后,可以进行部署和上线工作。
在此过程中,可以将数据库设置为生产状态,并确保数据库能够正常对外提供服务。
8.监控和调优:在数据库迁移完成后,需要定期监控和调优数据库的性能。
包括监控数据库的I/O、CPU和内存使用情况,优化SQL查询和索引,以提高数据库的性能和可靠性。
kettle 批量导入文本数据到mysql、oracle数据库(整改1)

kettle 批量导入文本数据到mysql、oracle数据库1Kettle 工具Kettle是开源的ETL工具,纯java编写,可以在Windows、Li nux、Unix上运行,数据抽取高效稳定。
Kettle 中文名称叫水壶,该项目的主程序员MATT 希望把各种数据放到一个壶里,然后以一种指定的格式流出。
Kettle中有两种脚本文件,transformation和job,transformati on完成针对数据的基础转换,job则完成整个工作流的控制。
2背景工作中有时会有一种需求,将几百个文件导入的数据库中,这时如果一个一个去导入工作量非常大,而且容易出错不好控制。
使用k ettle 可以非常容易的解决。
2.1转换文件如果有批量文件导入的可以下载本文件获取编辑好的转换。
3使用说明3.1打开下载好的转换文件3.2修改文本文件输入第一步:打开编辑界面第二步:通过通配符选择文件第三步:测验是否可以正常读到文件名第四步:内容设置说明:根据实际填写第五步:字段设置3.3修改插入/ 更新第一步:打开编辑界面第二步:选择数据库连接及需要导入的表第三步:配置数据如果存在是更新还是跳过说明:如果文本字段Field_005 和数据库表server_no 相等,对字段server_no,statis_date 字段不进行更新。
4符:新建数据库连接Mysql jdbc连接为例:第一步:工具-向导-创建数据库连接向导第二步:填写数据库连接名称-选择数据库类型-选择数据库访问类型-NEXT(下一步)第三步:服务器主机名(ip)-数据库端口-数据库名- NEXT(下一步)第四步:输入数据库用户名密码-点击测试-成功后点击Finish。
oracle数据库迁移方案

oracle数据库迁移方案在进行Oracle数据库迁移时,需要考虑到诸多因素,包括数据的完整性、稳定性和安全性。
本文将介绍一种可行的Oracle数据库迁移方案,希望能够对大家有所帮助。
首先,进行数据库迁移前,需要对现有的数据库进行全面的备份。
这一步非常关键,可以保证在迁移过程中出现问题时,能够及时恢复数据,避免造成不必要的损失。
可以选择使用Oracle提供的备份工具,也可以使用第三方备份软件进行备份操作。
其次,确定目标数据库的环境和配置。
在进行数据库迁移时,目标数据库的环境和配置需要与原数据库保持一致,包括操作系统、数据库版本、存储设备等。
如果目标数据库与原数据库的环境有所不同,需要提前进行环境的调整和配置的优化。
接下来,选择合适的迁移工具。
Oracle提供了多种数据库迁移工具,包括Data Pump、Transportable Tablespaces等。
根据实际情况选择合适的迁移工具,并对迁移工具进行详细的配置和参数设置。
然后,进行数据迁移操作。
在进行数据迁移时,需要确保数据的完整性和一致性。
可以选择全量迁移或增量迁移的方式,根据实际情况选择合适的迁移策略。
在迁移过程中,需要对迁移的数据进行验证和测试,确保数据的准确性和完整性。
最后,进行数据库的验证和性能调优。
在完成数据迁移后,需要对目标数据库进行全面的验证和性能调优。
可以使用Oracle提供的性能调优工具,对数据库的性能进行优化和调整,确保数据库的稳定性和高效性。
综上所述,Oracle数据库迁移是一个复杂的过程,需要对各个环节进行详细的规划和操作。
通过本文介绍的迁移方案,希望能够帮助大家顺利完成数据库迁移操作,确保数据的安全和稳定。
祝大家在数据库迁移的过程中顺利完成,谢谢!。
ORACLE数据库迁移方案

ORACLE数据库迁移方案Oracle数据库是一个关系型数据库管理系统,具有强大的功能和稳定性。
数据库迁移是将一个数据库从一个环境迁移到另一个环境的过程,需要精心计划和执行。
下面是一个Oracle数据库迁移的方案,包括迁移的准备工作、迁移工具的选择、数据的备份和恢复、测试和验证以及最终的迁移步骤。
1.迁移的准备工作:a.了解源数据库的技术规格、版本和架构,确定目标数据库的技术规格和版本要求。
b.确定迁移的目标和目标环境的可用性和稳定性。
c.评估迁移过程中可能出现的风险和问题,并准备应对措施。
d.编制详细的迁移计划和时间表。
2.迁移工具的选择:a.选择适合的迁移工具,根据实际情况选择在线迁移工具或离线迁移工具。
b. 如果迁移数据量大,可以选择使用Oracle Data Pump工具进行数据迁移。
c. 如果需要进行数据转换,可以选择使用Oracle SQL Developer工具进行数据迁移。
3.数据备份和恢复:a.在迁移之前,对源数据库进行备份,以防迁移过程中出现数据丢失或损坏的情况。
b.在迁移过程中,定期进行数据恢复测试,确保备份的完整性和可用性。
c.在迁移完成后,对目标数据库进行数据恢复测试,验证数据是否完整和正确。
4.测试和验证:a.在目标环境中创建一个与源数据库相似的测试环境,进行迁移过程的测试和验证。
b.在测试环境中进行功能和性能测试,确保迁移后的数据库能够正常运行和满足需求。
c.在迁移过程中,根据测试结果做出必要的调整和改进。
5.最终迁移步骤:a.在迁移之前,关闭源数据库,确保所有的数据都已经写入磁盘。
b.将源数据库的数据文件、日志文件和控制文件复制到目标环境中,并创建与源数据库相同的目录结构和权限。
c.在目标环境中,根据源数据库的配置文件创建新的数据库实例。
d.在目标环境中启动数据库实例,并将数据文件和日志文件导入到目标数据库。
e.在目标数据库中配置和测试用户连接,确保数据库能够正常运行。
Kettle进行数据迁移
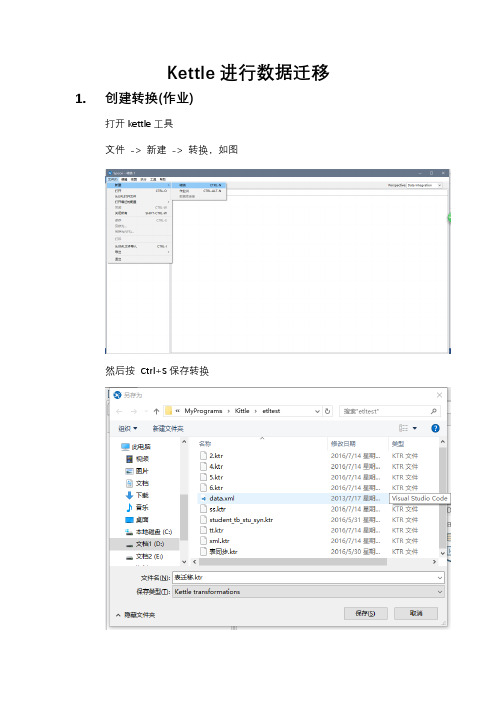
Kettle进行数据迁移1.创建转换(作业)打开kettle工具文件-> 新建-> 转换,如图然后按Ctrl+S保存转换2.创建数据库连接点击左侧的主对象树-> DB连接-> 右键-> 新建然后按照下图所示配置Oracle的数据库连接点击中下方的【测试】,若出现类似下图的连接成功提示则可以点击下方的【确认】保存此连接如果是错误提示的话,首先确认有没有下载该数据库的jdbc驱动的jar包,并复制到kettle安装目录的lib目录下,然后重启kettle程序,然后检查填写是否错误或者服务器端配置等等问题接下来配置MS SQL Server的连接3.添加组件配置好数据库连接之后,接下来添加完成此转换需要的组件,点击左侧的核心对象,如下图所示在输入的子级中找到表输入,输出的子级中找到表输出并拖到工作区中,如下图然后连接表输入与表输出4.配置组件双击表输入,在数据库连接中选择sql server的连接,如下图然后点击[获取SQL查询语句…] ,选择需要迁移的表点击确定然后点击否把下图的表名复制一下然后点击确定保存表输入的配置接下来双击表输出进行配置在数据库连接中选择oracle的连接,并在目标表中粘贴刚在复制的表名(要保证目标数据库中没有此表,有的话也要保证表结构相同,否则要先删除表或者换个表名)然后点击确定完成表输出的配置5.创建表在kettle界面中上方如下图所示的区域点击图标,会出现创建目标表的SQL语句点击下方的【执行SQL】,弹出下图所示对话框则表示目标表创建完成6.运行转换点击下图所示位置的运行此转换然后在弹出的窗口中点击启动之后会看到执行结果说明执行成功了,此表已经迁移完成7.注意事项在本例中的表迁移仅仅是对数据进行迁移,表的主键, 外键或者与其他表的关联信息并不会迁移过去,还需要待后期自行去目标数据库配置。
利用 kettle 实现数据迁移的实验总结

数据迁移是指将数据从一个系统或评台移动到另一个系统或评台的过程。
在进行数据迁移时,我们通常需要借助一些工具来帮助我们高效地完成数据迁移任务。
Kettle 是一款功能强大的开源数据集成工具,它可以帮助用户实现数据的抽取、转换和加载(ETL)操作,非常适用于数据迁移的实施。
在本文中,我们将结合我们的实际经验,对利用Kettle 实现数据迁移的实验进行总结,并共享一些经验和教训。
一、实验背景1.1 实验目的在进行数据迁移的实验之前,我们首先需要明确实验的目的和意义。
数据迁移的目的通常是为了将数据从一个系统迁移到另一个系统,实现数据的共享、备份或者更新等操作。
我们希望通过本次实验,探索并验证 Kettle 工具在数据迁移中的实际效用,为以后的项目工作提供参考和借鉴。
1.2 实验环境在进行实验之前,我们需要搭建相应的实验环境,以确保实验的顺利进行。
在本次实验中,我们使用了一台装有 Windows 操作系统的服务器,并在上面成功安装了Kettle 工具。
我们还准备了两个数据源,分别用于模拟数据的来源和目的地,以便进行数据迁移的实验。
二、实验过程2.1 数据抽取在进行数据迁移之前,我们首先需要从数据源中抽取需要迁移的数据。
在本次实验中,我们使用 Kettle 工具的数据抽取功能,成功地将源数据抽取到 Kettle 中,并对数据进行了初步的清洗和处理。
通过Kettle 的直观界面和丰富的抽取组件,我们轻松地完成了数据抽取的工作,为后续的数据转换和加载操作奠定了基础。
2.2 数据转换在数据抽取之后,我们往往需要对数据进行一定的转换和处理,以满足目的系统的要求。
在本次实验中,我们利用 Kettle 的数据转换功能,对抽取得到的数据进行了格式化、清洗和加工操作。
Kettle 提供了丰富的转换组件和灵活的数据转换规则,让我们能够快速地实现各种复杂的数据转换需求。
Kettle 还支持可视化的数据转换设计,让我们可以直观地了解数据转换的过程和结果。
详细讲解Oracle数据库的数据迁移方法

详细讲解Oracle数据库的数据迁移方法(1)随着数据库管理系统和操作系统平台的更新换代的速度的加快,数据库管理员经常需要在两个不同的数据库之间或在两种不同的系统平台之间进行数据迁移。
本文介绍了数据库数据迁移的一般步骤以及实现向Oracle8i数据库进行数据迁移的几种方法,并对它们的优缺点做了对比分析。
在开发环境向运行环境转换、低版本数据库向高版本数据库转换以及两个不同数据库之间进行转换时,数据库中的数据(包括结构定义)需要被转移并使之正常运行,这就是数据库中的数据迁移。
对于中小型数据库,如Foxpro 中的*.dbf,这种迁移非常简单,一般只需通过简单的Copy就能完成。
但对于大型数据库系统,如Oracle 数据库,数据迁移就不那么简单了,它需要利用一定的技术和经验,有步骤按计划地完成。
数据迁移的一般步骤对数据库管理人员来说,数据库数据迁移极具挑战性,一旦措施不当,珍贵的数据资源将面临丢失的危险,要成功地实现数据库数据平滑迁移,需要周密计划和充分准备,并按照一定的步骤来完成。
设计数据迁移方案设计数据迁移方案主要包括以下几个方面工作:研究与数据迁移相关的资料,或在网站上查询相关内容、评估和选择数据迁移的软硬件平台、选择数据迁移方法、选择数据备份和恢复策略、设计数据迁移和测试方案等。
进行数据模拟迁移根据设计的数据迁移方案,建立一个模拟的数据迁移环境,它既能仿真实际环境又不影响实际数据,然后在数据模拟迁移环境中测试数据迁移的效果。
数据模拟迁移前也应按备份策略备份模拟数据,以便数据迁移后能按恢复策略进行恢复测试。
测试数据模拟迁移根据设计的数据迁移测试方案测试数据模拟迁移,也就是检查数据模拟迁移后数据和应用软件是否正常,主要包括:数据一致性测试、应用软件执行功能测试、性能测试、数据备份和恢复测试等。
准备实施数据迁移数据模拟迁移测试成功后,在正式实施数据迁移前还需要做好以下几个方面工作:进行完全数据备份、确定数据迁移方案、安装和配置软硬件等。
Oracle数据库迁移指南

Oracle 数据库迁移指南Oracle 数据库迁移指南我们常需要对数据进行迁移,迁移到更加高级的主机上,迁移到远程的机房上或者迁 移到不同的平台下.在 Oracle DBA 的日常任务中,数据库迁移也是一项非常重要的工作. 为此,我们对 Oracle 数据库迁移方面的技巧以及策略进行了一定的总结,并列举出一些 在迁移过程中常见的错误,供大家参考,希望能为 DBA 在进行数据库迁移时提供一些灵感.Oracle 数据库迁移基础知识在开始展开数据库迁移工作之前,你必须对这部分任务的基础内容有一个较为详细的 了解,正所谓"不打无准备之仗",在这一部分中,我们将对 Oracle 数据库迁移一些较 为基础的知识进行介绍. 初学者的数据迁移问题 Oracle 数据库迁移几种方式 Oracle 数据库迁移与就地升级方法讨论Oracle 专家建议Oracle 数据库迁移是一项十分复杂的工程,因此相关经验是很重要的.在这一部分中, 我们将汇总 Oracle 专家针对具体问题的经验与心得,这对于 DBA 来说是相当有价值的参 考. 升级过程中的数据迁移,代码迁移和性能调优问题 使用 Oracle 可传输表空间进行数据库迁移 使用 RMAN 转换命令对 Oracle 数据库进行迁移 从 Unix 到 Linux 的 Oracle 数据库迁移/升级TT 数据库技术专题之"Oracle 数据库迁移指南"Page 2 of 23迁移基于 Oracle 数据库的应用到开源数据库 升级过程中加速启动迁移程序 48 小时迁移 2TB 数据库迁移过程中的常见错误Oracle 有着丰富的错误代码库,无数 Oracle DBA 都饱受这些错误代码的折磨,当然 在进行数据库迁移时也不例外,在这里我们总结了一些比较常见的 Oracle 数据库迁移错 误,读者可以引以为戒. 数据库迁移过程中出现 OIP-00005 错误 数据库迁移中的 ORA-01034 错误 迁出数据库时出现 ORA-06550 错误TT 数据库技术专题之"Oracle 数据库迁移指南"Page 3 of 23初学者的数据迁移问题问:您好!我在数据迁移领域是个新手.我们有多个 Oracle 数据库.为了更好地组 织所有东西(数据,应用等),给用户提供统一的服务,我们正在寻求各种可选的措施. 我有几个问题: 1. 什么情况下,我们应该把数据放到一个数据库里? 2. 集成数据库,应用和展现层的优缺点是什么?各自合适的时机是什么情况? 任何有关的建议都可以.非常感谢. 答:有一些问题你要先搞清楚: 1. 这些数据库之间有任何形式的关联吗? 2. 你用到跨多数据库的事务了吗? 3. 这些数据库的用途是什么(例如 DSS,或者 OLTP,或者混合模式)? 如果问题(1)和(或者)问题(2)的回答是"是",并且数据库的负载都差不多的 话,我建议最好合并数据库.即便负载不一样,你可以用资源管理器检查各自占用资源. 曾经在一个网站上,我用了五个独立但有业务关联关系的数据库组成了一个非常大的数据 仓库.我把这五个数据库合并到了一起(保留它们属于不同的 schema).合并后的数据库 尽管大,但是易于管理,而且大部分查询和加载数据处理的性能得到了改善.(作者:Harish Harbham 译者:冯昀晖 来源:TT 中国)原文标题:初学者的数据迁移问题 链接:/showcontent_21402.htmTT 数据库技术专题之"Oracle 数据库迁移指南"Page 4 of 23Oracle 数据库迁移几种方式我们常需要对数据进行迁移,迁移到更加高级的主机上,迁移到远程的机房上,迁移 到不同的平台下 一,exp/imp: 这也算是最常用最简单的方法了,一般是基于应用的 owner 级做导出导入. 操作方法为:在新库建立好 owner 和表空间,停老库的应用,在老库做 exp user/pwd owner=XXX file=exp_xxx.dmp log=exp_xxx.log buffer=6000000,传 dmp 文件到新库, 在新库做 imp user/pwd fromuser=XXX touser=XXX file=exp_xxx.dmp log=imp_xxx.log ignore=y. 优缺点:优点是可以跨平台使用;缺点是停机时间长,停机时间为从 exp 到网络传输 到新库,再加上 imp 的时间. 二,存储迁移: 这种情况下,数据文件,控制文件,日志文件,spfile 都在存储上(一般情况下是裸 设备),我们可以直接把存储挂到新机器上,然后在新机器上启动数据库. 操作方法:将老库的 pfile(因为里面有指向裸设备的 spfile 链接),tnsnames.ora, listener.ora,密码文件传到新库的对应位置.将存储切至新机,或者用文件拷贝或 dd 的方式复制数据文件,启动数据库. 优缺点:优点是该迁移方式非常简单,主要的工作是主机工程师的工作,dba 只需配 合即可,停机时间为当库,切存储,起库的时间.缺点是要求新老库都是同一平台,是相 同的数据库版本. 三,利用 data guard 迁移: 用 dg 我们不仅可以用来做容灾,物理的 dg 我们还可以作为迁移的方式.TT 数据库技术专题之"Oracle 数据库迁移指南"Page 5 of 23操作方法:可见 /study-note/dg-created-by-rman/或者 /study-note/create-dg-by-rman-one-datafile-by-onedatafile/或者其他相关网文.注意 switch over 之后,可以将 dg 拆掉,去掉 log_archive_dest_2,FAL_SERVER,FAL_CLIENT,standby_file_management 参数.另外 还要注意如果用 rman 做 dg,注意手工添加 tempfile. 优缺点:优点是停机时间短,停机时间为 switch over 的时间.缺点:主机必须双份, 存储必须双份. 四,用 rman 做迁移: rman 比较适合于跨文件系统的迁移,如同平台下的不同文件系统. 操作方法: 1.停第三方的归档备份,如 legato 或 dp 2.backup 数据库: 在一次周末的课程试验中,频繁的看到 Data file init write 等待事件. 在这里做一点记录说明,以下是来自跟踪文件的记录信息:WAIT #2: nam='Data file init write' ela= 13031 count=1 intr=256 timeout=1 obj#=51706 tim=6068271611 WAIT #2: nam='Data file init write' ela= 118163 count=1 intr=256 timeout=1 obj#=51706 tim=6068392491 WAIT #2: nam='Data file init write' ela= 94036 count=1 intr=256 timeout=1 obj#=51706 tim=6068490286 WAIT #2: nam='Data file init write' ela= 52412 count=1 intr=256 timeout=1 obj#=51706 tim=6068545333TT 数据库技术专题之"Oracle 数据库迁移指南"Page 6 of 23WAIT #2: nam='Data file init write' ela= 4 count=0 intr=32 timeout=214748364 7 obj#=51706 tim=6068545596 WAIT #2: nam='Data file init write' ela= 26 count=1 intr=32 timeout=21474836 47 obj#=51706 tim=6068545641 WAIT #2: nam='Data file init write' ela= 101743 count=1 intr=256 timeout=1 obj#=51706 tim=6068648487 WAIT #2: nam='Data file init write' ela= 44854 count=1 intr=256 timeout=1 obj#=51706 tim=6068694281 WAIT #2: nam='Data file init write' ela= 52841 count=1 intr=256 timeout=1 obj#=51706 tim=6068748054 WAIT #2: nam='Data file init write' ela= 48984 count=1 intr=256 timeout=1 obj#=51706 tim=6068798310 WAIT #2: nam='Data file init write' ela= 3 count=0 intr=32 timeout=214748364 7 obj#=51706 tim=6068798365 WAIT #2: nam='Data file init write' ela= 26 count=1 intr=32 timeout=21474836 47 obj#=51706 tim=6068798409 WAIT #2: nam='Data file init write' ela= 101899 count=1 intr=256 timeout=1 obj#=51706 tim=6068900931 WAIT #2: nam='Data file init write' ela= 21 count=1 intr=32 timeout=2147483647 obj#=51706 tim=6068901053测试数据库是 Oracle10g 10.2.0.3,实际上这个等待事件也是从 Oracle 10g 开始引 入的,用来标识表空间或数据文件扩展时的等待. Oracle 需要将系统块格式化为 Oracle 数据块,然后才能提供数据库使用. 在这个流程处理中,Oracle 经过如下三个步骤: 1.扩展数据文件 select file# from file$ where ts#=:1TT 数据库技术专题之"Oracle 数据库迁移指南"Page 7 of 232.更新用户空间限额 update tsq$ set blocks=:3,maxblocks=:4,grantor#=:5,priv1=:6,priv2=:7,priv3=:8 where ts#=:1 and user#=:2 3.扩展数据段 update seg$ set type#=:4,blocks=:5,extents=:6,minexts=:7,maxexts=:8,extsize=:9,extpct=:10,user #=:11,iniexts=:12,lists=decode(:13, 65535, NULL, :13),groups=decode(:14, 65535, NULL, :14), cachehint=:15, hwmincr=:16, spare1=DECODE(:17,0,NULL,:17),scanhint=:18 where ts#=:1 and file#=:2 and block#=:3 这就是 Oracle10g 中空间扩展时内部流程.TT 数据库技术专题之"Oracle 数据库迁移指南"Page 8 of 23Oracle 数据库迁移与就地升级方法讨论进行 Oracle 数据库升级时,有两种方法可以考虑.有些管理员倾向于选择"就地升 级"方式,就是在现有版本基础上,在同一台机器上安装最新的升级版本.有些管理员则 选择进行数据库"迁移"来完成升级,最新版本的数据库安装在一台新硬件上,你需要做 的是把原有的数据迁移到新的数据库当中.乍一看来,就地升级的方法好像能更简单更迅 速地完成升级工作,但是这种方法也有自己的缺点. 首先,就地升级所需要的停机时间比较长,在整个升级过程中,Oracle 数据库都处于 不可用状态.而且测试就地升级的过程比较困难,数据库管理员需要处理大量的实时数据, 在测试升级过程时还需要把数据库设置成脱机状态.其次,就地升级往往会导致性能的衰 减.新版本的软件对硬件的需求会增加,而不更换硬件就自然会导致性能的下降. 就地升级相对来说比较难以复原,如果在升级过程中出现重大问题或数据损坏时,想 要复原旧的数据库或恢复到升级前的状态就需要一个漫长的备份恢复过程.总而言之,就 地升级需要投入更多的时间和人力物力,不太容易预算其成本,在遇到故障问题时可回旋 的余地也比较小.节省下来的硬件更新成本往往花在了人力上,有时升级需要的钱都超过 了更换硬件的预算. 在进行迁移升级时,虽然会在硬件上花费一些钱,但是这绝对是物有所值的.很明显, 迁移升级最大的优势就是速度.新硬件的速度肯定比原有的要快得多.而且还有一点就是 新硬件都在保修期内,自然会比老硬件更可靠. 新硬件往往也可以进行升级.比如,随着新服务器的部署,上面的操作系统,驱动程 序和相关软件都是最新版本的,这就会让性能更加优越,还可以实现更多的功能.另外, 新硬件有着更好的嵌入式管理能力,比如 Intel's VPRO 和其它一些远程控制特性. 新硬件为升级过程提供了一个清晰路径,这无疑对整个升级过程十分有利.因为旧的 硬件不需要做任何修改,在升级过程中如果出现什么问题,旧的数据库也不会受到影响. 新硬件还可以为升级提供一个测试环境,并对升级的可行性做出评估.在权衡以上两种升 级方法之后,相信大多数的管理员会倾向于选择更新硬件的迁移升级方法.TT 数据库技术专题之"Oracle 数据库迁移指南"Page 9 of 23(作者:Frank Ohlhorst 译者:孙瑞 来源:TT 中国)原文标题:Oracle 数据库迁移与就地升级方法讨论 链接:/showcontent_22919.htmTT 数据库技术专题之"Oracle 数据库迁移指南"Page 10 of 23升级过程中的数据迁移、代码迁移和性能调优问题问:我们正在准备迁移到Oracle 10 RAC。
Kettle开发使用手册

Kettle 开发使用手册Kettle 开发使用手册2 0 1 7 年 4 月版本历史说明版本作者日期备注1.0彭伟峰2017.04.111. Kettle 介绍1.1. 什么是 KettleKettle 是纯 Java编写的、免费开源的 ETL工具,主要用于抽取 (Extraction)、转换 (Transformation)、和装载(Loading)数据。
Kettle中文名称叫水壶,该项目的主程序员 MATT希望把各种数据放到一个壶里,然后以一种指定的格式流出。
在这种思想的设计下,Kettle 广泛用于不同数据库之间的数据抽取,例如Mysql 数据库的数据传到 Oracle ,Oracle 数据库的数据传到 Greenplum数据库。
1.2. Kettle的安装Kettle 工具是不需要安装的,直接网上下载解压就可以运行了。
不过它依赖于Java,需要本地有 JDK环境,如果是安装 4.2 或 5.4 版本, JDK需要 1.5 以上的版本,推荐 1.6 或 1.7 的 JDK。
运行 Kettle直接双击里面的批处理文件spoon.bat 就行了,如图 1.1 所示:图1.12. Kettle 脚本开发2.1. 建立资源库( repository 仓库)Repository仓库是用来存储所有kettle文件的文件系统,由于数据交换平台服务器管理 kettle文件也是用Repository仓库,因此我们这边本地的kettle开发环境也是要用到该资源库。
建立资源库的方式是工具-->资源库- ->连接资源库,这时候弹出一个窗口,我们点击右上角的“+”号,跟着点击下面的kettlefile repository选项,按确定,如图 2.1 所示:图2.1跟着在右上角选择一个目录,建议在kettle路径下新建repository文件夹,再选择这个文件夹作为根目录,名称和描述可以任意写,如图 2.2 所示:图2.2建完后会 kettle工具会自动连接到repository资源库,每次打开kettle 也会弹出一个窗口让你先连接到资源库。
kettle多表关联循环分页迁移数据的完整例子

kettle多表关联循环分页迁移数据的完整例子在这篇文章中,我们将探讨kettle多表关联循环分页迁移数据的完整例子。
我们将以从简到繁、由浅入深的方式来讨论这个主题,以便读者能更深入地理解。
这个主题将涉及Kettle工具的使用技巧,包括多表关联和分页迁移数据,希望通过文章能够为读者带来有价值的信息和启发。
1. 理解Kettle的基本概念让我们简单介绍一下Kettle。
Kettle是一款开源的ETL工具,它能够帮助用户实现数据抽取、转换和加载的功能。
用户可以通过Kettle将数据从一个地方抽取出来,在转换之后加载到另一个地方。
Kettle提供了可视化的图形界面,让用户可以通过拖拽和连接组件来设计数据处理流程,非常适合数据工程师和分析师使用。
2. 多表关联在实际的数据迁移工作中,经常需要处理多个表之间的关联。
Kettle 提供了方便的方式来实现多表关联。
在我们的例子中,我们将演示如何使用Kettle来处理多个表之间的关联关系,以及如何将相关数据进行整合和迁移。
3. 循环处理数据另一个常见的需求是对数据进行循环处理。
我们可能需要对一个大表进行分页处理,以便将数据分批迁移至目标数据库。
Kettle提供了很好的支持来实现这个功能,我们将在后文详细介绍。
4. 分页迁移数据我们将利用前面介绍的多表关联和循环处理的技巧,来完成一个完整的例子:分页迁移数据。
我们将以实际的案例来演示如何使用Kettle 工具来处理这个任务,以便读者能够更直观地理解。
在这个例子中,我们假设有两个关联的表A和B,我们需要将它们的数据按照一定的条件和顺序进行分页迁移。
我们将逐步介绍如何使用Kettle来处理这个需求,包括设计数据处理流程、设置参数和条件、以及监控和优化运行结果。
总结回顾通过本文的介绍,我们希望读者能够更全面、深刻和灵活地掌握Kettle工具中多表关联、循环处理和分页迁移数据的技巧和方法。
Kettle作为一款强大的ETL工具,能够帮助用户高效地处理各种复杂的数据迁移任务,同时也需要用户有一定的技术功底和经验来更好地发挥其功能。
Oracle 跨操作系统 迁移 说明

关于跨OS 的DB 迁移,MOS 上有相关的文章说明:[ID 733205.1]。
To migrate an existing Oracle database (NOT BINARIES) from one Operating System platform to another (i.e. Windows to Solaris) ,This can occur as part of an Oracle version upgrade (Oracle 8i .. Oracle 11G) or within the same Oracle version: (Oracle 10.2 to Oracle 10.2).--可以将Oracle DB 从一个操作系统迁移到另一个操作系统,比如从windows 到Solaris,注意这里的迁移仅仅是数据的迁移,不包含DB 的安装介质。
这个迁移可以是不同DB版本的迁移,比如从8i 到11g,也可以是相同版本的迁移,比如从10.2 到10.2.Changes within an Operating System (ie: Linux,Windows or Solaris from 32 bit to 64 bit) are not considered cross platform migrations and are performed as normal version upgrades/wordsize conversions.--改变操作系统不用考虑系统的平台,可以按照正常的db version upgrades 和wordsize的改变来操作。
1解决方法There is no migration utility (Script or DBUA) to perform a cross platform migration of an Oracle Database.--没有迁移工具如脚本或者DBUA来执行跨OS的数据迁移。
oracle常用的数据库迁移方法

oracle常用的数据库迁移方法Oracle是一种常用的关系型数据库管理系统,为了满足不同需求,很多时候需要将数据库迁移到其他环境或系统中。
本文将介绍几种常用的Oracle数据库迁移方法。
一、数据泵导入导出数据泵是Oracle提供的一种高效的数据迁移工具,可以将表、视图、存储过程等数据库对象以及数据导出为二进制文件,再通过数据泵导入工具将数据导入到目标数据库中。
数据泵导出可以使用expdp命令,导出的文件可以包含完整的数据库对象和数据,也可以只导出指定的对象。
数据泵导入可以使用impdp命令,将导出的文件恢复到目标数据库中。
二、物理备份恢复物理备份恢复是一种将源数据库的物理文件备份并复制到目标数据库的方法。
这种方法适用于需要将整个数据库迁移到其他环境的情况。
在源数据库上执行备份命令,将数据库的物理文件备份到指定位置。
将备份文件复制到目标数据库服务器上。
在目标数据库上执行恢复命令,将备份文件恢复到目标数据库中。
三、逻辑备份恢复逻辑备份恢复是一种将源数据库中的逻辑数据导出为可读的文本文件,再通过导入工具将数据导入到目标数据库中的方法。
在源数据库上执行逻辑备份命令,将数据导出为文本文件。
将备份文件复制到目标数据库服务器上。
在目标数据库上执行导入命令,将备份文件导入到目标数据库中。
四、数据库链接数据库链接是一种在不同数据库之间进行数据传输和共享的方法。
可以在目标数据库中创建一个链接,链接到源数据库,然后通过SQL语句将数据从源数据库传输到目标数据库。
在目标数据库中创建一个数据库链接,链接到源数据库。
通过SQL语句查询源数据库中的数据,并将数据插入到目标数据库中。
五、GoldenGate数据复制GoldenGate是Oracle提供的一种高性能数据复制工具,可以将源数据库的数据实时复制到目标数据库中。
这种方法适用于需要实时同步数据的场景。
在源数据库和目标数据库上分别安装和配置GoldenGate软件。
在源数据库上配置数据抽取进程,将数据抽取到中间文件。
ORACLE 数据库在不同计算机上的迁移(克隆数据库)

ORACLE 数据库在不同计算机上的迁移(克隆数据库)描述:一台联想台式机上安装了oracle11g,建立了自己的数据库,现在想在宿舍DELL笔记本电脑上克隆这个数据库。
1 在目标机器上安装数据库,密码一致数据库名字一致。
2 登陆sys as sysdba 这时数据库自动启动3 shutdown immediate 关闭数据库,startup nomount,这时系统释放掉控制文件和数据文件,就是在这时完成替换。
4 复制数据文件和redo文件到目标机相应目录下原先的文件全部删除(数据目录下)我的是在C:\app\Administrator\oradata\orcl\目录下5 重建控制文件,主要就是让数据库系统知道有哪些数据文件,文件路径(指定的文件都应该有存在,否则会报错,这就是4在前的原因)如果不重建,会报控制文件太旧的错误,所以重建控制文件时必须的;6set linesize 400;col file# for 99;col name for a100;col status for a20;select file#,name,status from v$datafile;///////SQL> set linesize 400;SQL> col file# for 99;SQL> col name for a100;SQL> col status for a20;SQL> select file#,name,status from v$datafile;FILE# NAME STATUS----- ---------------------------------------------------------------------------------------------------- -------------1 D:\APP\ADMINISTRATOR\ORADATA\ORCL\SYSTEM01.DBF SYSTEM2 D:\APP\ADMINISTRATOR\ORADATA\ORCL\SYSAUX01.DBF RECOVER3 D:\APP\ADMINISTRATOR\ORADATA\ORCL\UNDOTBS01.DBF RECOVER4 D:\APP\ADMINISTRATOR\ORADATA\ORCL\USERS01.DBF RECOVER5 D:\APP\ADMINISTRATOR\ORADATA\ORCL\MILKWAY_TBS_01 RECOVER6 D:\APP\ADMINISTRATOR\ORADATA\ORCL\MILKWAY_TBS_02 RECOVER找到文件编号7 SQL> recover datafile 1;SQL> recover datafile 2;.....最好把所有的数据文件都恢复一边,不管提示是否为RECOVER状态8 alter database open;搞定9 cmd 命令窗口下最好来一下set ORACLE_SID=orcl; 大小写敏感shutdown normal ;好不容易搞定,第一次关闭用normal ,慢点值得,免得丢失10 sys as sysdba 如果发现是连接到空闲进程,用startup open即可。