开源搜索引擎的比较
国内外搜索引擎的特征及其比较

国内搜索引擎的特征及其比较摘要随着信息的剧增,Internet的进一步普及,在浩如烟海的信息高速公路上,根据自己的需求快速准确地需找所需要的信息越来越依赖于借助多种多样的Internet信息检索工具,而搜索引擎是我们平时使用最多的一种。
下面就国内的四个著名搜索引擎来探究它们的特征和区别。
关键字引擎检索查询一百度(http://WWW.baidu.corn)百度由百度网络技术有限公司于1999年底在美国硅谷创建,是目前全球最大的中文搜索引擎。
数据库中收录约3亿个中文网页,平均2周更新一次,对部分网页每天更新。
搜索方式以关键词检索为主,同时可结合分类目录限定检索范围,分基本检索和高级检索两种,支持布尔算符和字段限制符。
特设百度快照功能,供用户迅速查看每条检索结果的内容。
检索时不区分英文字母的大小写,检索结果依相关度排列。
二中文Goog1.(hap://WWW.google.corn)Gcog1.由两位斯坦福大学的博士I丑rry Page和SergeyBrin在1998年创立,是目前世界上最大的搜索引擎。
数据库中收录约1O亿多个中文网页,采用高级的网页级别技术,用户界而出色,有新闻组、图像、新闻等搜索,以搜索相关性高闻名。
检索方式为关键词检索,分为基本检索和高级检索,基本检索以布尔检索为主,高级检索中包括:(1)排除某些站点;(2)限定检索结果于某一特定网站;(3)限定语言类型;(4)相关网页检索,检索结果依检索式相关性排列。
三新浪(http://WWW.sina.com)新浪搜索引擎是面向华人的网上资源查询系统。
提供网站、网页、新闻、软件、游戏等查询服务。
共有16大类目录,1万多个细目和数十万个网站。
搜索方式包括关键词查询和分类目录检索两种。
除基本检索以外,还具备“重新查询”“在结果中再查”和“在结果中去除”三种高级检索,支持布尔逻辑检索,用逻辑算符“And”、“Not”扩大或缩小检索范围,在同一页面上包含目录、网站、新闻标题、新闻全文、频道内容、网页、商品信息、消费场所、中文网址、沪深行情、软件、游戏等各类信息的综合搜索结果,按检索式相关度排列,以日期排序。
常用中文搜索引擎对比

几大常用中文搜索引擎的对比随着互联网的不断发展扩大,网络上中文信息资源和上网的中文用户也大量增加,各类中文搜索引擎更是层出不穷。
以下我选取了Google中文,百度,搜狗,必应这几个常用的中文搜索引擎进行较为粗浅的比较。
先比较一下各搜索引擎的特点。
Google中文:包括网页、图片、新闻搜索,支持个性化搜索及本地搜索,提供论坛、邮箱、日历服务和桌面搜索工具,是万维网上最大的搜索引擎,但Google中文在中国却一直受到百度搜索的压制,最终由于黑客攻击和敏感词过滤问题退出中国内地转至香港。
百度:是全球最大的中文搜索引擎,除网页搜索外,还提供MP3、文档、地图、传情、影视等多样化的搜索服务,率先创造了以贴吧、知道为代表的搜索社区,是目前国内最大的商业化全文搜索引擎。
搜狗:搜狗是全球首个百亿规模中文搜索引擎,收录100亿网页,创造了全球中文网页收录量新高,搜狗以网页搜索为核心,在音乐、新闻、图片、地图等方面提供了垂直搜索服务,通过说吧建立用户间的搜索社区,2010年8月搜狐与阿里巴巴宣布将分拆搜狗成立独立公司,引入战略投资,注资后的搜狗有望成为仅次于百度的中文搜索工具。
必应(bing):必应是微软公司09年新推出的中文搜索引擎。
主打快乐搜索体验。
接着从各方面对比:1.外观排版:Google、百度、搜狗的外观都是以简单的白色背景为主,而必应的背景是一副定期更换的图片,乍看比较新鲜,可是用习惯后我发现搜索引擎还是简洁一点好。
不同于其他3家“相关搜索”出现在搜索结果的底部,必应在网页左侧和底部都出现了“相关搜索”,虽然略显重复,但在一定程度上为用户提供了方便。
2.搜索结果:在这4家引擎同时输入“集美大学诚毅学院”,可以看到Google用时0.10 秒获得约62,900 条结果,百度用时0.018秒找到相关网页约55,000篇,必应没有显示用时找到共50,900 条,搜狗用时0.027 秒只有30,636条。
可见在Google的搜索量大,而百度的时间最短,速度和数量比最好,搜狗略逊一筹3.搜索内容:四家网站的内容更新都比较及时,百度的优势在于很中国化很生活化,符合中国人的习惯。
几个搜索引擎特点比较

几个搜索引擎特点比较By 不走的时钟发表于2006-5-1 14:10:23搜索引擎特点比较在互联网不断走向成熟的今天,新的利润增长点在哪里?Google,百度在纳斯达克的神话,使得越来越多的人将目光投向了搜索引擎行业。
同时在信息大爆炸的时代里,人们对网络信息的处理也越来越借重于许许多多的各种各样的搜索引擎。
在这里,我仅仅是将几个我们较为常用的搜索引擎加以粗略的比较,希望对大家的选择和使用有所帮助。
一、Google首先要讲述的就是世界搜索引擎的老大google了。
Google 依据网络自身结构,清理混沌信息,缜密组织资源。
Google 的搜索服务绝不仅仅是简单的信息目录。
而且Google 目录中收录了10 亿多个网址,这在同类搜索引擎中是首屈一指的。
这些网站的内容是相当涉猎广泛的。
与大多数其它搜索引擎的区别在于:Google 只显示相关的网页,其正文或指向它的链接包含您所输入的所有关键词,而无须再受其它无关结果的烦扰。
Google 不仅能搜索出包含所有关键词的结果,并且还对网页关键词的接近度进行分析。
与大多数其它搜索引擎的又一区别是:Google 按照关键词的接近度确定搜索结果的先后次序,优先考虑关键词较为接近的结果,这样可以为您节省时间,而无须在无关的结果中徘徊。
Google 最擅长于为常见查询找出最准确的搜索结果。
其中“手气不错(tm)”按钮是最有特色的,它会直接带您进入最符合搜索条件的网站,相对省时又方便。
Google 储存网页的快照,当存有网页的服务器暂时出现故障时您仍可浏览该网页的内容。
如果找不到服务器,Google 储存的网页快照也可救急。
虽然网页快照中的信息可能不是最新的,但在网页快照中查找资料要比在实际网页中快得多。
二、百度作为中文搜索引擎的老大,百度也有其及为独到的一面。
其基于字词结合的信息处理方式,就相当巧妙解决了中文信息的理解问题,极大地提高了搜索的准确性和查全率。
百度还支持主流的中文编码标准。
六大搜索引擎的比较

一、界面、广告以及速度搜索引擎在我们日常操作中的使用频率非常高,大家使用它的目的都非常明确,就是用它来搜寻需要的内容,而不会为搜索引擎的页面做过多的停留,因此搜索引擎的界面设计和速度就对我们的使用产生不小的影响,下面来看看这六款搜索引擎在界面和速度上的表现。
谷歌、百度和微软的Live Search,这三大搜索引擎的界面大家都已经相当熟悉,它们有着共同的特点,就是简洁至极:网站LOGO、搜索框和按钮以及个别功能服务链接,除此以外,页面上就没有其他多余和花哨的东西了,给人的感觉非常清爽,界面一目了然,特别是Live Search在不失简洁的同时还通过一些小脚本和背景图片使得页面整体更加美观。
三者使用起来都很方便,并且首页界面上没有任何第三方的广告。
搜索结果页面,三者同样是采用简洁的风格,页面左侧排列着搜索结果,百度搜索结果页面右侧有不少广告,谷歌视关键词的不同也可能出现右侧广告。
Live Search的界面十分简洁且美观百度搜索结果页面右侧的广告与上面三者相比,雅虎全能搜在界面上显得更为活泼、色彩更加多样,并且在首页内容上也更丰富。
首页上除了常规的搜索所需组成部分外,雅虎全能搜还加入了天气预报、邮箱登录的显示区域。
虽然这些占据了一点点页面,但是它们功能实用且不影响正常使用。
雅虎全能搜的搜索主页搜狗搜索的界面可谓结合了谷歌和Live Search:在布局上与谷歌类似,而在细节上与Live Search有着异曲同工之妙;而搜索新军——网易有道的界面与谷歌、百度站在同一阵线,风格、版式都十分一致。
在搜索结果页面中,搜狗搜索页面左侧有少量广告。
总的来说,六款搜索引擎的界面设计都比较合理、美观、大方。
雅虎全能搜的界面稍有不同,加入了天气预报和邮箱模块,而其他五款都尽量精简,其中谷歌、百度和有道趋于一致,采用最简的风格,而Live Search和搜狗在首页的一些细节上多加以了一些修饰。
此外,值得一提的是一些搜索引擎对于Logo文化的重视,在传统的节日或者一些特殊的纪念日时都会将首页的Logo徽标换成与该日子相关的设计。
各种搜索引擎算法的分析和比较

各种搜索引擎算法的分析和比较在互联网上搜索所需信息或资讯,搜索引擎成为了人们必不可少的工具。
然而,搜索引擎的搜索结果是否准确、全面,搜索速度是否快速等方面,关键在于搜索引擎的算法,因此,搜索引擎算法成为了搜索引擎核心竞争力的来源。
目前,主流的搜索引擎包括Google、Baidu、Yahoo、Bing等,但它们的搜索结果和排序结果却存在着很大的差异。
这些搜索引擎的搜索结果背后都有不同的算法,下面将对目前主流的几种搜索引擎的算法进行分析和比较。
1. Google算法Google算法是目前全球最流行的搜索引擎算法,其搜索结果广受用户信任。
Google算法最重要的要素是页面权重(PageRank),其名字最初来源于Google的创始人之一拉里·佩奇的名字。
页面权重是根据页面链接的数量和链接网站的权重计算得到的一个评分系统,也就是所谓的“链接分”。
除此之外,Google还有很多其他的评分规则,比如页面初始状态、页面内部链接等。
可以说,Google的算法非常复杂,它使用了很多技术来确保其搜索引擎结果的质量。
2. Baidu算法Baidu是中国主流的搜索引擎,其搜索算法相较于Google来说较为简单。
Baidu的搜索结果主要依靠页面的标题、关键词、描述等元素,因此其搜索结果的可靠性稍逊于Google。
不过,Baidu的形态分析算法却是非常出色的,可以识别图片和视频等多种形态的信息。
除此之外,Baidu还使用了一些人工智能技术,例如深度学习算法来优化搜索结果。
3. Bing算法Bing是由微软开发的搜索引擎,其搜索结果以关键词匹配为核心来实现。
在关键词匹配的基础上,Bing还使用了一些机器学习和推荐算法来优化搜索结果。
另外,Bing还使用类似Google的页面权重评分系统来实现页面的排序。
除此之外,Bing还注重在搜索结果页面中显示质量较高的结果,而不局限于排序前十的结果。
4. Yahoo算法Yahoo算法是基于文本内容分析的搜索引擎算法。
国外7个源代码库搜索引擎网站

国外7个源代码库搜索引擎网站转——国外7个源代码/库搜索引擎网站2011-10-25 16:16 146人阅读评论(0) 收藏举报现如今编程似乎成为一种潮流,程序员越来越多,任何一个程序员都必须学习至少一门编程语言,但是学习编程语言总是不那么容易的,前些时候在SitePoint社区进行的如何更好的学习编程语言的讨论中,大家一致认为认真学习别人的代码是一种非常有效的方法,以下七个源代码搜索引擎网站是由网友们提供的、寻找源代码最高效的地方!让我们一起来了解一下吧!1 . GitHubGitHub是非常受欢迎的开源代码库和版本控制服务提供者,前段时间推出了一项新的源代码搜索服务,虽然GitHub才刚刚进入源代码搜索服务领域不久,但是GitHub已经成为了这一领域非常受欢迎的搜索服务提供者,并且已经拥有了数以亿计的代码储存量,正如一篇博客中提到的,GitHub中的确有”很多东西”!2 . KrugleKrugle声称他们的搜索包含超过25亿行代码,这一数量使他们成为互联网上最大的源代码搜索引擎之一,并且还称他们的搜索结果包含了全球三分之一开发者的源代码!同时他们还分别为全球多家大型公司或企业,如Amazone、IBM、、、Yahoo!等提供企业级的代码搜索服务!3 . KodersKoders号称其能够搜索的代码数目超过10亿行,并且深受Ruby 程序员的青睐!在Koders被黑鸭软件公司(Black Duck Software)收购之后,该网站关于Ruby的搜索比过去四年的总和激增了20倍,超过了该站PHP、Perl和Python的搜索数目!并且Ruby已成为该网站继Java、 C/C、和 C#之后搜索次数最多的语言。
4 . CodaesCodaes在这个源代码搜索领域似乎并不起眼,能够搜索到的代码数量也只有2.5亿条,究其原因可能是该网站的搜索服务发展似乎已经停滞好几年了。
Codaes主要关注的是关于Linux方面的C/C++项目代码,但这在今天似乎有些过时了!除非这就是你要找的内容,否则除此之外你有更好的搜索选择。
21款开源搜索引擎项目介绍

21款开源搜索引擎项目介绍搜索引擎的主流语言是Java,要研究和开发搜索引擎,最好从Lucene开始,下面介绍一些开源搜索引擎系统,包含开源Web搜索引擎和开源桌面搜索引擎。
Lucene一个全文搜索引擎工具包,但只支持文本文件以及少量语种的索引;通过Lucene提供的接口,我们可以自己开发具体语言的分词器,针对具体文档的文本解析器等;Lucene是索引数据结构事实上的标准;Apache Lucene是一个基于Java全文搜索引擎,利用它可以轻易地为Java软件加入全文搜寻功能。
Lucene的最主要工作是替文件的每一个字作索引,索引让搜寻的效率比传统的逐字比较大大提高,Lucen提供一组解读,过滤,分析文件,编排和使用索引的API,它的强大之处除了高效和简单外,是最重要的是使使用者可以随时应自已需要自订其功能。
Sphider Sphider是一个轻量级,采用PHP开发的web spider和搜索引擎,使用mysql来存储数据。
可以利用它来为自己的网站添加搜索功能。
Sphider非常小,易于安装和修改,已经有数千网站在使用它。
RiSearch PHPRiSearch PHP是一个高效,功能强大的搜索引擎,特别适用于中小型网站。
RiSearch PHP非常快,它能够在不到1秒钟内搜索5000-10000个页面。
RiSearch是一个索引搜索引擎,这就意味着它先将你的网站做索引并建立一个数据库来存储你网站所有页面的关键词以便快速搜索。
Risearch是全文搜索引擎脚本,它把所有的关键词都编成一个文档索引除了配置文件里面的定义排除的关键词。
RiSearch使用经典的反向索引算法(与大型的搜索引擎相同),这就是为什么它会比其它搜索引擎快的原因。
Xapian使用C++编写,提供绑定程序使得其他语言能够方便地使用它;便于进行二次开发PhpDigPhpDig是一个采用PHP开发的Web爬虫和搜索引擎。
通过对动态和静态页面进行索引建立一个词汇表。
opensearch数据库原理

OpenSearch 数据库原理OpenSearch 是一个开源的分布式搜索引擎,它基于Apache Lucene 构建。
OpenSearch 提供了强大的搜索功能,包括全文搜索、结构化搜索、地理搜索等。
它还支持多种数据源,包括关系型数据库、NoSQL 数据库、文件系统等。
OpenSearch 的基本原理是将数据索引到一个分布式的倒排索引中。
倒排索引是一种数据结构,它将词语映射到包含该词语的文档的列表。
当用户进行搜索时,OpenSearch 会将搜索词语查询倒排索引,并返回包含该词语的所有文档的列表。
OpenSearch 的索引过程分为两步:1. 分词:将文档中的词语拆分成单个的词元。
2. 索引:将词元添加到倒排索引中。
OpenSearch 的搜索过程分为三步:1. 查询解析:将用户输入的搜索词语解析成一个查询表达式。
2. 查询执行:将查询表达式应用于倒排索引,并返回包含查询词语的所有文档的列表。
3. 结果排序:对返回的文档列表进行排序,并返回最相关的文档。
OpenSearch 还支持多种聚合功能,可以对搜索结果进行分组和统计。
聚合功能包括:求和:计算文档中某个字段的值的总和。
平均值:计算文档中某个字段的值的平均值。
最大值:计算文档中某个字段的值的最大值。
最小值:计算文档中某个字段的值的最小值。
计数:计算文档中某个字段的值出现的次数。
OpenSearch 是一个功能强大的搜索引擎,它可以用于构建各种各样的搜索应用程序。
OpenSearch 的开源特性也使其非常灵活,可以根据不同的需求进行定制。
OpenSearch 的优点开源:OpenSearch 是一个开源的搜索引擎,这意味着它可以免费使用和修改。
分布式:OpenSearch 是一个分布式的搜索引擎,这意味着它可以横向扩展以满足不断增长的搜索需求。
可扩展:OpenSearch 是一个可扩展的搜索引擎,这意味着它可以随着数据量的增加而扩展。
高性能:OpenSearch 是一个高性能的搜索引擎,这意味着它可以快速地处理搜索请求。
各种开源数据库详细比较

各种开源数据库的详细比较(2011-01-13 16:33:33)标签:分类:5作为当今最流行的开放源码数据库之一,MySQL数据库为用户提供了一个相对简单的解决方案,适用于广泛的应用程序部署,能够降低用户的TCO。
MySQL是一个多线程、结构化查询语言(SQL)数据库服务器。
MySQL的执行性能高,运行速度快,容易使用。
MySQL包括以下几个关键优势:◆ 可靠的性能和服务MySQL向公众提供所有数据库服务器软件的早期版本,都是利用开放源码进行为期几个月的测试之后才发布作为生产之用。
◆ 易于使用和部署MySQL的结构体系易于定制,运行速度快,其独特的多存储引擎结构为企业客户提供了灵活性,为数据库管理系统带来紧致性和稳定性,易于部署。
◆ 自由获得源码可以随时访问MySQL源代码,其策略确保了自由性,避免锁定某家公司或平台。
◆ 跨平台支持MySQL可用于20多种不同平台,包括主要的Linux系统、Mac OS X、Unix和Windows◆ 可信赖的开发力量MySQL拥有大量的用户基础,也拥有高素质、有经验的开发团队。
◆ 满足企业需求MySQL结构体系简单易用,运行速度极快,能够处理企业数据库绝大多数的应用需求。
2008年12月8日,Sun Microsystems公司宣布,正式对外提供MySQL 软件——这是全球最受欢迎的开源数据库MySQL的一个极其重要的新版本。
MySQL GA版现通过以下三种模式提供,以满足不同用户的各种特殊需求:◆MySQL Community Server —— Sun的MySQL 数据库的免费开源版。
这一GPL 许可的全功能软件的目标用户是个人技术用户,他不需要商业支持或是享有优惠的机上服务。
◆MySQL Enterprise Server ——它作为MySQL Enterprise订购的一部分来提供,它最可靠、最安全,提供的是MySQL数据库的最新版本,其目标用户是有法人的IT用户。
垂直搜索与开源软件

信息 ,如 何精 确 定位 所需 求 的信 前行业细分的情况下,专有 的垂直 性 ,有着更为优秀的定制开发 的功
搜 索 引擎 更 能 满 足 某一 特 定 行 业 的 能 ,互联 网企业在应用开源软件的 但 是 ,随 着 互 联 网 应 用 的 不 需 求 。 ”
同时 ,也能根据 自身的技术实力 ,
上 ,你可以不会使用聊天工具 ,可 垂直 搜索 引擎 。与传统 的通用搜索 开源软件低廉的成本恰好能很好的 以不会收发 E i,但 绝不可 以不 引擎相 比,垂直搜索更 能快速 、精 解决这样 的问题 。 mal
会使用 搜索 引擎 。面对 错综复杂 的 确 的定 位 到 特 定 的 信息 ,尤 其 在 目 的开放
盛行起 来。 20 0 5年 ,Go ge 司全 球 副 o l公
一
心 内容 。 吴 柏 林 也 向 记 者 证 实 了 这 么 种情 况 : 我 们除 了最核 心的一 “
什么是垂直搜索?垂直搜索是 总 裁 李开 复 在 开 源 中国 开 源 世 界高 针对某一 个行业 的专业搜索 引擎 ,
峰论坛上发表 了关于 《 没有开 源就 部 分业 务使 用 商业 软件之 外 ,其
是搜索引擎 的细分和延伸 ,是对 网 没有 G o l o ge的今天》的一 个讲话 , 余 的 都 使 用 开 源 软 件 。 可 以 这 么 页库中的某类专 门的信息进行一次 Go g e 样搜索 引擎 巨头背后的 说 ,我 们能够 使用 开 源软件 的地 o l这 整合 ,定 向分字段抽取 出需要的数 支撑系统浮出了水面 ,那就是万千 方 就 绝 不 会 考 虑 使 用 商 业 软 件 据进 行处理后再以某 种形式返 回给 的开源软件。
维普资讯
■ 评析 O ean brt svi o
五大学术搜索引擎比较

2 0 1 5年 1 1 月
谢
奇等 : 五 大 学 术 搜 索 引 擎 比较
第 1 1 期( 总 2 1 7期 )
百 度学 术 的收 录 范 围 : 收 录 了全球 7 0万个 站 点
的3 . 5亿 学 术 资 源 , 包 括 国 内 中文 站 点 知 网 、 维普 、
万 方 .以及外 文学 术 站点 P u b Me d 、 S p i r n g e r 、 I E E E
2 0 1 5年 1 1 月
NO V. 20l 5
情 报 探 索
I n f o r ma t i o n Re s e a r e h
第 1 1期 ( 总2 1 7 期)
No . 1 1 ( S e r i a l No . 2 1 7 )
五大学术搜索引擎比较 水
谢 奇 李 立 立 毕 玉侠
X i e Q i L i L i l i B i Y u x i a ( 1 . S h e n y a n g P h a r m a c e u t i c a l U n i v e r s i t y L i b r a r y , S h e n y a n g L i a o n i n g 1 1 0 0 1 5 ) ( 2 . S h e n y a n g A o x i n Q&M S t o m a t o l o g y H o s p i t a l , S h e n y a n g L i a o n i n g 1 1 0 0 1 3 )
超 星百 链 云 ( 简 称百 链 , h t t p : / / w w w . b l y u n . c o n) 是 超 星公 司推 出 的图 书馆 整合 门户 ,利 用互 联 网搜 索 引擎技 术预 先对 海 量 的 中外 文 文献元 数 据进 行整
各个搜索引擎的优缺点

各个搜索引擎的优缺点百度搜索引擎优点:1、知识交流功能强,可以实现互动、知识的共享。
2、强大的地图导航功能,方便路线的查询。
3、对于中国人的阅读和浏览更为熟悉,服务更加本土化。
4、提供RSS(简易信息聚合)新闻订阅服务。
5、提供历史和各省市新闻查阅。
6、图片格式多样化,基本上都有。
7、百度还提供搜索flash的功能。
8、如果无法打开某个搜索结果,或者打开速度特别慢,“百度快照”能帮您解决问题。
每个被收录的网页,在百度上都存有一个纯文本的备份,称为“百度快照”。
不过,百度只保留文本内容。
9、提供高级搜索语法搜索功能。
10、提供错别字提醒、英汉互译词典、计算器和度量衡转换、拼音提示、股票与列车时刻表和飞机航班查询等功能。
缺点:1、由于知识来源广,重复的内容多而繁杂。
2、页面布局不合理,页面没有充分利用。
3、更新时间迅速的优势没有充分发挥。
4、商业味太重,你搜索的关键字的首页基本都价排名出价高的企业占据了,很难找到你需要的真正自然搜索的结果,百度的搜索排名技术不够权威;5、搜索结果中广告、垃圾网站和死链比较多。
Google搜索引擎优点:1、容量大和范围广:其数据库如今是最大的,包括了PDF、DOC、PS及其他许多文件类型。
2、易用性较强。
3、根据站点的链接数和权威性进行相关性排序。
4、网页缓存归档,浏览过的网页被编入索引。
5、还有其他数据库:Google群组、新闻和目录等数据库。
缺点:1、网页排版不新颖,美观度不高。
2、搜索特性有限,没有嵌套搜索,没有截词搜索,不支持全部的布尔逻辑检索。
3、链接搜索不完整。
死链率比较高,中文网站检索的更新频率不够高,不能及时淘汰过时的链接。
4、只能把网页的前101KB和PDF的大约前120KB编入索引。
5、可能会在不告诉你的情况下,检索复数单数、同义词和语法变体。
雅虎搜索引擎优点:1、搜索引擎数据库庞大而且新颖。
2、包括页面的缓存拷贝。
3、也包括指向雅虎目录的链接。
4、支持全部的布尔逻辑检索。
常见开源规则引擎对比分析

常见开源规则引擎对比分析开源规则引擎是一种用于管理和执行规则的软件工具。
它们可以帮助开发人员更轻松地实现业务逻辑,并提供一种灵活的方法来动态地配置和管理规则。
在本文中,我们将对常见的开源规则引擎进行对比分析,以帮助读者选择适合自己项目的规则引擎。
以下是对比分析的一些关键指标:1.功能和语法:不同的规则引擎提供不同的功能和语法。
一些规则引擎提供基本的规则匹配和执行功能,而其他规则引擎提供更复杂的功能,如规则优先级、条件和动作的组合以及规则的版本控制。
选择规则引擎时,需要评估其功能和语法是否满足项目的要求。
2.性能:规则引擎的性能是评估其执行规则的速度和效率的重要指标。
一些规则引擎在处理大量规则时可能性能下降,而其他规则引擎在这方面表现更好。
因此,需要根据项目的需求评估规则引擎的性能。
3.扩展性:扩展性是指规则引擎能否与其他系统集成以及在不同环境下运行。
一些规则引擎提供了易于集成的API和插件机制,使其可以与其他系统无缝连接。
同时,一些规则引擎支持云部署,可以在大规模分布式环境中运行。
因此,评估规则引擎的扩展性对于项目的成功实施非常重要。
4.社区支持和文档:一种活跃和热情的社区支持是开源项目的重要组成部分。
开源规则引擎通常有其自己的社区,可以提供技术支持、问题解答和开发指导。
此外,规则引擎的文档和教程也是开发人员了解和学习该工具的重要资源。
基于以上指标,我们对以下几个常见的开源规则引擎进行比较:1. Drools:Drools 是一个Java规则引擎,具有强大的规则匹配和执行引擎。
它提供了广泛的规则语法和表达方式,支持规则动态加载和修改,并具有高性能和可扩展性。
Drools 还有一个活跃的社区,并提供了详尽的文档和指南。
2. Jess:Jess 是一个基于Java的规则引擎,拥有强大的推理能力和灵活的语法。
它支持基于规则的编程和基于事件的规则执行,能够快速地处理大量的规则。
然而,Jess 的学习曲线较陡,并且该项目的社区支持相对较小。
比较Google、百度、Excite等搜索引擎的异同

比较Google、百度、Excite等搜索引擎的异同一搜索引擎的概念搜索引擎是指根据一定的策略、运用特定的计算机程序从互联网搜集信息,在对信息进行组织和处理后,为用户提供检索服务,将用户检索相关的信息展示给用户的系统。
搜索引擎包括全文索引、目录索引、元搜索引擎、垂直搜索引擎、集合式搜索引擎、门户搜索引擎与免费链接列表等。
百度、谷歌、Excite等是搜索引擎的代表。
二搜索引擎的分类1.全文索引全文搜索引擎是名副其实的搜索引擎,国外代表有Google,国内则有著名的百度搜索。
它们从互联网提取各个网站的信息(以网页文字为主),建立起数据库,并能检索与用户查询条件相匹配的记录,按一定的排列顺序返回结果。
根据搜索结果来源的不同,全文搜索引擎可分为两类,一类拥有自己的检索程序(Indexer),俗称“蜘蛛”(Spider)程序或“机器人”(Robot)程序,能自建网页数据库,搜索结果直接从自身的数据库中调用,上面提到的Google和百度就属于此类;另一类则是租用其他搜索引擎的数据库,并按自定的格式排列搜索结果,如Lycos搜索引擎。
2.目录索引目录索引虽然有搜索功能,但严格意义上不能称为真正的搜索引擎,只是按目录分类的网站链接列表而已。
用户完全可以按照分类目录找到所需要的信息,不依靠关键词(Keywords)进行查询。
目录索引中最具代表性的莫过于大名鼎鼎的Yahoo!、新浪分类目录搜索。
3.元搜索引擎元搜索引擎(META Search Engine)接受用户查询请求后,同时在多个搜索引擎上搜索,并将结果返回给用户。
著名的元搜索引擎有InfoSpace、Dogpile、Vivisimo等,中文元搜索引擎中具代表性的是搜星搜索引擎。
在搜索结果排列方面,有的直接按来源排列搜索结果,如Dogpile;有的则按自定的规则将结果重新排列组合,如Vivisimo。
其他非主流搜索引擎形式(1)集合式搜索引擎:该搜索引擎类似元搜索引擎,区别在于它并非同时调用多个搜索引擎进行搜索,而是由用户从提供的若干搜索引擎中选择,如HotBot在2002年底推出的搜索引擎。
三大搜索引擎对比分析表
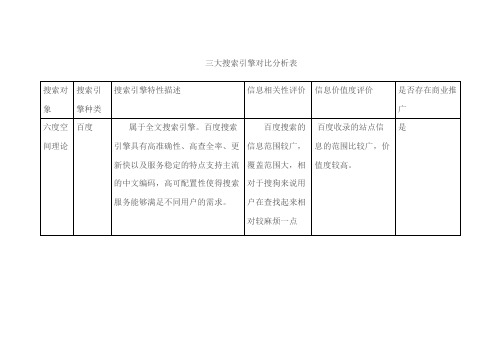
三大搜索引擎对比分析表
六度空间理论:
六度空间理论是一个数学领域的猜想,名为Six Degrees of Separation,中文翻译包括以下几种:六度分割理论或小世界理论等。
理论指出:你和任何一个陌生人之间所间隔的人不会超过六个,也就是说,最多通过六个人你就能够认识任何一个陌生人。
这就是六度分割理论,也叫小世界理论。
这种现象,并不是说任何人与人之间的联系都必须要通过六个层次才会产生联系,而是表达了这样一个重要的概念:任何两位素不相识的人之间,通过一定的联系方式,总能够产生必然联系或关系。
显然,随着联系方式和联系能力的不同,实现个人期望的机遇将产生明显的区别。
手持移动电视市场:
移动电视是指采用数字广播技术(主要指地面传输技术)播出,接收终端一是安装在公交汽车、地铁、城铁、出租车、商务车和其他公共场所的电视系统,二是手持接收设备(如手机、笔记本、PMP、超便携PC等)等满足移动人
群收视需求的电视系统。
本文主要讨论支持第二类的移动终端,即手持移动电视的技术应用状况。
目前手持移动电视产品中占绝对数量的是手机电视。
33款可用来抓数据的开源爬虫软件工具

33款可用来抓数据的开源爬虫软件工具要玩大数据,没有数据怎么玩?这里推荐一些33款开源爬虫软件给大家。
爬虫,即网络爬虫,是一种自动获取网页内容的程序。
是搜索引擎的重要组成部分,因此搜索引擎优化很大程度上就是针对爬虫而做出的优化。
网络爬虫是一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成。
传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。
聚焦爬虫的工作流程较为复杂,需要根据一定的网页分析算法过滤与主题无关的链接,保留有用的链接并将其放入等待抓取的URL队列。
然后,它将根据一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到达到系统的某一条件时停止。
另外,所有被爬虫抓取的网页将会被系统存贮,进行一定的分析、过滤,并建立索引,以便之后的查询和检索;对于聚焦爬虫来说,这一过程所得到的分析结果还可能对以后的抓取过程给出反馈和指导。
世界上已经成型的爬虫软件多达上百种,本文对较为知名及常见的开源爬虫软件进行梳理,按开发语言进行汇总。
虽然搜索引擎也有爬虫,但本次我汇总的只是爬虫软件,而非大型、复杂的搜索引擎,因为很多兄弟只是想爬取数据,而非运营一个搜索引擎。
Java爬虫1、ArachnidArachnid是一个基于Java的web spider框架.它包含一个简单的HTML剖析器能够分析包含HTML内容的输入流.通过实现Arachnid 的子类就能够开发一个简单的Web spiders并能够在Web站上的每个页面被解析之后增加几行代码调用。
Arachnid的下载包中包含两个spider应用程序例子用于演示如何使用该框架。
特点:微型爬虫框架,含有一个小型HTML解析器许可证:GPL2、crawlzillacrawlzilla 是一个帮你轻松建立搜索引擎的自由软件,有了它,你就不用依靠商业公司的搜索引擎,也不用再烦恼公司內部网站资料索引的问题。
搜索引擎Google、Bing及Baidu的比较

感谢观看
供更好的服务;随着技术的不断发展未来的搜索引擎将更加强大功能更为强 大;从用户角度出发给用户带来更为方便的使用体验才获得消费 者数据通过研究消费者的搜其搜索引擎是该国最受欢迎的搜索引擎之 一。Bdu在中国的市场份额几乎是其他所有搜索引擎的总和。Bdu拥有丰富的中文 资源和本土人才库资源网络;与国外的技术强国相比本土资源的拥有量绝对优势; 基于数据基础的机器自适应算法已经逐渐成为全球各大搜索引擎的主流;技术驱 动是未来搜索引擎发展关键Bdu是拥有中文语义识别和图片识别
1、Google
Google是最流行的搜索引擎,提供全球最强大的搜索算法和最丰富的搜索结 果。Google的搜索结果通常非常准确,而且其广告和赞助商链接相对较少。 Google提供许多有用的功能,例如翻译、图片搜索、地图视图等。此外,Google 还提供Gmail、Google Drive、Google Docs等实用的工具,这些工具可以与其 他Google产品无缝集成。
3、Yahoo
Yahoo是另一个流行的搜索引擎,它提供基于Bing的搜索结果。Yahoo搜索结 果的质量和广告数量略低于Google和Bing。此外,Yahoo还提供一些有用的功能, 例如天气预报、新闻摘要、电影评分等。Yahoo还提供许多实用的工具,例如 Yahoo Mail、Yahoo Finance等。
此外,G富的结果筛选选项以及与社交媒体和其他中国特色的网站 进行了整合而提高了他们 在互联网上的效率和生产力。这两家搜索引擎还提供了广告服务,允许商家通过 关键词广告在网络上推广他们的产品和服务。虽然这两家搜索引擎的商业模式有 所不同,但他们都为互联网经济做出了重要贡献。
连接人与万物的智能中间下未来的搜索引擎将会变得更为智能 化会更好地满足用户需求并能够根据用户需求为用户提供个性化的服务而实现人 机交互;从这一点上来看未来搜索引擎将会变成一个机器人的角色并且越来越为 智能化可以更好地理解人的语言与人进行对话与交流为用户提
强大的开源全文检索引擎——Sphinx

L c n 可 以嵌 入到 其他应 用使 用。相对 Xa in uee pa
而 言 ,S hn 更 具 有 优 势 : p ix ・开发 团 队活跃 ,社 区支持 活跃 ,文档详 细 ,案例 丰 富 ; ・功 能 更 全 面 ,可 靠 性 更 好 ; ・分 布 式 搜 索 更 灵 活 ;
术 社 区 ,狂 热 的 开 源 爱 好 者 和 传 播 者 ;在 Chn Unx 任 w e 服 务 ia i担 b
器 、PH P、W e 开 发 、互联 网行 业 b
四个 版 面 的资 深 技 术 版 主 。
一 责任编辑:高松 ( a s n @c d e) g o o g s nn t 2 O1 0 127 1 3
作 为 一 款 高 性 能 的 全 文 检 索 引擎 , S hn P to 、R b 、Jv 、CC +、C 等 ; 同 时 ,还 p ix yh n u y a a /+ 撑 支持使用S L 法进行查询 。 Q 语
・基 于 c++开 发 , 相 对 于 基 于 J v 的 a a
有 主 流 的 Li u 、 BS n x D、 M a OS、 S l r s c o ai 、
1 26 程序 员
・提供对互 联网黄金搭档 P . S L的完 HPMy Q
口, 可 以作 为 My QL 储 引擎 使 用 , 自身 也 可 S 存
L c n , 绝 对 称 得 上 短 小 精 干 , 同 时 支 持 在 所 美 结 合 ,提 供 了P 扩 展 和 P 代 码 的 查 询 接 ue e HP HP
从 2 0 年 开 始 ,我 们 基 于 S hn 开 发 了 专 用 性 。 06 p ix 门针对 中文环境 使用 的版本 一
开源拍照搜题

开源拍照搜题
开源拍照搜题是一种利用开源技术进行拍照搜题的方法。
通过利用开源的图像识别、文字识别、搜索引擎等技术,实现从照片中提取问题,并利用搜索引擎搜索答案的功能。
开源拍照搜题的具体实现流程如下:
1. 图像识别:使用开源的图像识别库,如OpenCV、TensorFlow等,对拍摄的照片进行图像识别,提取出问题相
关的图片区域。
2. 文字识别:利用开源的文字识别库,如Tesseract-OCR等,
对提取出的图片区域进行文字识别,将问题文本提取出来。
3. 搜索引擎:利用开源的搜索引擎API,如Google搜索API、百度搜索API等,将通过文字识别提取的问题文本输入搜索
引擎进行答案搜索。
4. 答案展示:将搜索引擎返回的答案展示给用户,以便用户查看答案。
需要注意的是,开源拍照搜题的准确性和效果受限于图像识别和文字识别的准确性。
因此,在实际应用中,需要使用准确性较高的图像识别和文字识别算法,并对算法进行优化和调整,以提高准确性和搜索结果的质量。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
开源搜索引擎的比较
1.Nutch
简介:
Nutch是一个用java实现的基于Lucene的开源搜索引擎框架,主要包括爬虫和查询两部
分组成。
Nutch所使用的数据文件主要有以下三种:1)是webDb,保存网页链接结构信息,只在爬虫工作中使用。
2)是segment,存储网页内容及其索引,以产生的时间来命名。
segment文件内容包括CrawlDatum、Content、ParseData、ParseText四个部分,其中CrawlDatum保存抓取的基本信息,content保存html脚本,ParseData和ParseText这两个部分是对原内容的解析结果。
3)是index,即索引文件,它把各个segment的信息进行了整合。
爬虫的搜索策略是采用广度优先方式抓取网页,且只获取并保存可索引的内
容。
Nutch0.7需要java1.4以上的版本,nutch1.0需要java1.6。
特点:
1、遵循robots.txt,当爬虫访问一个站点时,会首先检查该站点根目录下是
否存在robots.txt,如果存在,搜索机器人就会按照该文件中的内容来确定访问的范围;如果该文件不存在,所有的搜索蜘蛛将能够访问网站上所有没有被口令
保护的页面。
2、采用基于Hadoop的分布式处理模型,支持分布式的实现。
3、Nutch可以修剪内容,或者对内容格式进行转换。
4、Nutch使用插件机制,可以很好的被用户定制和集
成。
5、Nutch采用了多线程技术。
6、将爬取和建索引整合在了一起,爬取内容的存储方式是其自己定义的segment,不便于对爬取的内容进行再次处理,需要进行一定的修改。
7、因为加入了对页面分析,
建索引等功能其效率与heritrix相比要相对较低。
全国注册建筑师、建造师考试备考资料历年真题考试心得模拟试题2.Heritrix
简介:
Heritrix是一个用Java实现的基于整个web的可扩展的开源爬虫框架。
Heritrix主要由三大部件:范围部件,边界部件,处理器链组成。
范围部件主要按照规则决定将哪个URI 入队;边界部件跟踪哪个预定的URI将被收集,和已经被收集的URI,选择下一个URI,剔除已经处理过的URI;处理器链包含若干处理器获取URI,分析结果,将它们传回给边界部件。
采用广度优先算法进行爬取。
heritrix用来获取完整的、精确的、站点内容的深度复制。
包括获取图像以及其他非文本内容。
抓取并存储相关的内容。
对内容来者不拒,不对页面进行内容上的修改。
重新爬行对相同的URL不针对先前的进行替换。
特点:
1、各个部件都具有较高的可扩展的,通过对各个部件的修改可以实现自己的抓取逻辑。
2、可以进行多种的配置,包括可设置输出日志,归档文件和临时文件的位置;可设置下载的最大字节,最大数量的下载文档,和最大的下载时间;可设置工作线程数量;可设置所利用的带宽的上界;可在设置之后一定时间重新选择;包含一些可设置的过滤机制,表达方式,URI路径深度选择等等。
3、采用多线程技术。
4、保存的内容是原始的内容,采用镜像方式存储,即按照斜杠所划分出的层次结构进行存储,同时也会爬取图片等信息。
5、同样也遵守robots.txt规范。
6、在硬件和系统失败时,恢复能力很差。
3.WebSPHINX
简介:
WebSPHINX是一个Java类包和Web爬虫的交互式开发环境。
WebSPHINX由两部分组成:爬虫工作平台和WebSPHINX类包。
爬虫工作台提供接口实现对爬虫的配置;类包则提供对爬虫进行扩展需要的一些支持。
其工作原理为从一个基点网站出发,遍历其中的所有有用信息,同时抽去其中的链接信息放入队列,以待有空闲蠕虫(worm)时,从队列中读取,发出request 请求,继续进行信息抽取和链接入队列的工作。
特点:
1、保存网页的原始内容。
2、采用多线程技术。
3、采用广度优先遍历算法进行爬取。
4、支持HTML解析,URL过滤,页面配置,模式匹配等等。
5、适用于爬取小规模的网页,例如爬取单一的个人站点。
4.Weblech
简介:
WebLech是一个用Java实现的功能强大的Web站点下载与镜像工具。
它支持按功能需求来下载web站点并能够尽可能模仿标准Web浏览器的行为。
WebLech有一个功能控制台并采用多线程操作。
特点:
1、支持多线程技术。
2、可维持网页的链接信息,可配置性较强,配置较为灵活,可设置需获取的网页文件的类型、起始地址、抓取策略等14 项内容。
3、采用广度优先遍历算法爬取网页。
4、保存网页的原始内容。
5.Jspider
简介:
JSpider是一个完全用Java实现的可配置和定制的Web Spider引擎.你可以利用它来检查网站的错误(内在的服务器错误等),网站内外部链接检查,分析网站的结构(可创建一个网站地图),下载整个Web站点,你还可以写一个JSpider插件来扩展你所需要的功能。
Jspider主要由规则、插件和事件过滤器三部分组成,规则决定获取和处理什么资源;插件可以根据配置叠加和替换功能模块;事件过滤器选择处理什么事件或则独立的插件。
特点:
1、扩展性较强,容易实现对爬虫功能的扩展。
2、目前只支持下载HTML,不支持下载动态网页。
3、保存原始网页内容。
6.Spindle
简介:
spindle是一个构建在Lucene工具包之上的Web索引和搜索工具.它包括一个用于创建索引的HTTPspider和一个用于搜索这些索引的搜索类。
spindle项目提供了一组JSP标签库使得那些基于JSP的站点不需要开发任何Java类就能够增加搜索功能。
该项目长期没有更新且功能不完善。
7.Jobo
简介:
JoBo是一个用于下载整个Web站点的简单工具。
它本质是一个WebSpider。
与其它下载工具相比较它的主要优势是能够自动填充form(如:自动登录)和使用cookies来处理
session。
JoBo还有灵活的下载规则(如:通过网页的URL,大小,MIME类型等)来限制下载。
8.Snoics-reptile
简介:
snoics-reptile是用纯Java开发的,用来进行网站镜像抓取的工具,可以使用配制文件中提供的URL入口,把这个网站所有的能用浏览器通过GET的方式获取到的资源全部抓取到本地,包括网页和各种类型的文件,如:图片、flash、mp3、zip、rar、exe等文件。
可以将整个网站完整地下传至硬盘内,并能保持原有的网站结构精确不变。
只需要把抓取下来的网站放到web服务器(如:Apache)中,就可以实现完整的网站镜像。
9.Arachnid
简介:
Arachnid是一个基于Java的webspider框架.它包含一个简单的HTML剖析器能够分析包含HTML内容的输入流.通过实现Arachnid的子类就能够开发一个简单的Webspiders并能够在Web站上的每个页面被解析之后增加几行代码调用。
(注:可编辑下载,若有不当之处,请指正,谢谢!)。