提取文件夹中所有TXT中所需信息并导入数据库
把数据从txt文件导入到Oracle数据库的实现方法

把数据从txt文件导入到Oracle数据库的实现方法
1、环境配置准备
在导入txt文件到Oracle数据库之前,我们需要配置环境,方可方
便后续的操作:
(1)安装Oracle数据库,并配置好数据库用户及其权限;
(2)安装Oracle的工具sqlldr,这是一个数据导入工具;
(3)在操作系统中,创建一个目录,用于存放sqlldr需要使用的控
制文件,以及要导入数据库的txt文件;
(4)编写好sqlldr需要的控制文件,控制文件可以定义数据的格式,以及要插入到数据库的表结构等;
(5)将要被导入的txt文件存放到上面定义的目录中;
2、编写sqlldr控制文件
sqlldr提供了一种类SQL语句的控制文件,这些控制文件用于描述
如何将txt文件中的数据导入到Oracle数据库中,主要包括以下几方面
的内容:
(1)数据的编码;
(2)要被导入的表名;
(3)每个要被导入的字段的定义,包括其类型、长度等;
(4)数据的分隔符,比如以空格分隔或者以tab分隔等;
(5)进行数据校验,比如检查给定字段的数据是否是满足要求的类型等;
(6)如果数据中有时间字段,可以定义时间的格式;
(7)数据导入失败的记录日志路径;
(8)定义要被导入的字段的映射关系,比如txt文件中的列名与表中的字段没有一一对应;。
Txt文件导入oracle数据库方法

Txt文件导入oracle数据库方法在Oracle数据库中,可以使用SQL*Loader工具或者外部表的方式将文本文件(.txt文件)导入到数据库。
下面我将为你详细介绍这两种方法。
方法一:使用SQL*Loader工具导入txt文件1.创建控制文件控制文件是SQL*Loader用来定义数据导入规则的文件。
它描述了数据文件的格式、目标表的结构,以及导入时的数据转换和验证规则。
例如,假设我们要将一个txt文件中的数据导入到名为EMP的表中,EMP表的结构如下:CREATETABLEEMPEMPNONUMBER(4),ENAMEVARCHAR2(10),JOBVARCHAR2(9),MGRNUMBER(4),HIREDATEDATE,SALNUMBER(7,2),COMMNUMBER(7,2),DEPTNONUMBER(2)我们可以创建一个名为emp.ctl的控制文件,内容如下:LOADDATAINFILE 'emp.txt'APPENDINTOTABLEEMPFIELDS TERMINATED BY ',' optionally enclosed by '"'EMPNO,ENAME,JOB,MGR,HIREDATECHAR"YYYY-MM-DD",SAL,COMM,DEPTNO2.准备数据文件在导入数据之前,需要将数据准备好并保存为一个txt文件(如emp.txt)。
确保数据文件的每一行与控制文件中的字段一一对应,并且字段之间以逗号分隔,如下所示:7902,SMITH,CLERK,7901,1980-12-17,800,,207369,ADAMS,CLERK,7876,1983-01-12,1100,,20...3. 使用SQL*Loader导入数据打开命令行窗口(或终端),输入以下命令导入数据:其中,username是数据库用户名,password是数据库密码,database是数据库实例名。
教你用python提取txt文件中的特定信息并写入Excel

教你⽤python提取txt⽂件中的特定信息并写⼊Excel⽬录问题描述:⼯具:操作:源代码:Reference:总结问题描述:我有⼀个这样的数据集叫test_result_test.txt,⼤概⼏百上千⾏,两⾏数据之间隔⼀个空⾏。
N:505904X:0.969wsecY:0.694wsecN:506038X:4.246wsecY:0.884wsecN:450997X:8.472wsecY:0.615wsec...现在我希望能提取每⼀⾏X:和Y:后⾯的数字,然后保存进Excel做进⼀步的数据处理和分析就拿第⼀⾏来说,我只需要0.969 和0.694。
每⼀⾏三个数字的具体位置是不确定的,因此不能⽤固定的列数去处理,刚好发现split函数能对⽂本进⾏切⽚,所以这⾥我们⽤这个函数来提取需要的数字信息。
split函数语法如下:1、split()函数语法:str.split(str="",num=string.count(str))[n]参数说明:str:表⽰为分隔符,默认为空格,但是不能为空('')。
若字符串中没有分隔符,则把整个字符串作为列表的⼀个元素num:表⽰分割次数。
如果存在参数num,则仅分隔成 num+1 个⼦字符串,并且每⼀个⼦字符串可以赋给新的变量[n]:表⽰选取第n个分⽚注意:当使⽤空格作为分隔符时,对于中间为空的项会⾃动忽略于是对于我们这⾥的⽂本,我们可以先⽤“:”切⽚,把⽂本分成三份,⽐如对于第⼀⾏以“:”进⾏切⽚得到取第三个分⽚进⾏“w”切⽚,得到这⾥的第⼀分⽚就是我们要的X坐标最后我们分析⼀下思路:⾸先定位⽂件位置读取txt⽂件内容,去掉空⾏保存Excel准备⼯作,新建Excel表格,并编辑好标题为写⼊数据就位对于每⼀⾏数据,⾸先⽤‘:'进⾏切⽚,再⽤‘w'切⽚得到想要的数字,然后写⼊Excel保存⼯具:安装好python模块的visual studio 2017包:os,xlwt操作:先import我们所需要的包import osimport xlwt1.找到我们想要处理的⽂件,因此去到指定的位置,定位好⽂件a = os.getcwd() #获取当前⽬录print (a) #打印当前⽬录os.chdir('D:/') #定位到新的⽬录,请根据你⾃⼰⽂件的位置做相应的修改a = os.getcwd() #获取定位之后的⽬录print(a) #打印定位之后的⽬录2.打开我们的txt⽂件查看下⾥⾯的内容(这⼀步可有可⽆)#读取⽬标txt⽂件⾥的内容,并且打印出来显⽰with open('test_result1.txt','r') as raw:for line in raw:print (line)3.去除空⽩⾏并保存#去掉txt⾥⾯的空⽩⾏,并保存到新的⽂件中with open('test_result1.txt','r',encoding = 'utf-8') as fr, open('output.txt','w',encoding= 'utf-8') as fd:for text in fr.readlines():if text.split():fd.write(text)print('success')执⾏完毕同个位置下多了⼀个txt⽂件4. 创建⼀个Excel⽂件#创建⼀个workbook对象,相当于创建⼀个Excel⽂件book = xlwt.Workbook(encoding='utf-8',style_compression=0)'''Workbook类初始化时有encoding和style_compression参数encoding:设置字符编码,⼀般要这样设置:w = Workbook(encoding='utf-8'),就可以在excel中输出中⽂了。
把数据从txt文件导入到数据库的实现方法

把数据从txt文件导入到数据库的实现方法将数据从txt文件导入到数据库可以通过以下步骤实现:1. 创建数据库表结构:首先需要创建一个与txt文件数据相对应的数据库表结构。
表的列应该与txt文件中的数据字段对应。
可以使用数据库管理工具(如MySQL Workbench)或编程语言中的数据库操作库(如Python的MySQLdb)来创建表结构。
2. 打开txt文件:使用编程语言中的文件操作函数(如Python的open(函数)打开txt文件,并读取其中的数据。
根据txt文件的格式,可以使用逐行读取或一次性读取整个文件的方式来获取数据。
3. 解析数据:对于每一行数据,需要将其解析成各个字段的值。
可以使用字符串操作函数(如split(函数)将一行数据拆分成多个字段值。
如果txt文件中的数据是有结构的,可以使用正则表达式来匹配和提取字段值。
4. 建立数据库连接:使用编程语言中的数据库操作库连接到目标数据库。
根据数据库类型,可以使用不同的库(如Python的MySQLdb库、psycopg2库用于PostgreSQL等)来建立连接。
5.插入数据:将解析得到的数据插入到数据库表中。
使用数据库操作库提供的插入语句(如SQL语句)将数据插入到数据库表中。
可以使用批量插入的方式来提高插入性能,即将多个数据记录一次性插入到数据库中。
6. 关闭文件和数据库连接:在数据导入完成后,关闭txt文件和数据库连接,释放资源。
7. 错误处理:在数据导入的过程中,可能会出现一些错误,如文件不存在、数据格式错误等。
需要进行错误处理,确保数据导入的完整性和正确性。
可以使用异常处理机制(如Python的try-except语句)来捕获和处理错误。
8. 日志记录:为了追踪数据导入的过程和结果,可以添加日志记录功能。
可以使用编程语言中的日志库(如Python的logging库)来记录日志,包括导入开始时间、结束时间、导入的记录数等信息。
总结:将数据从txt文件导入到数据库需要完成文件读取、数据解析、数据库连接、数据插入等步骤。
文本文件导入到数据库中的几种方法

INFILE '/ora9i/fengjie/agent/data/ipaagent200410.txt'
TRUNCATE
INTO TABLE fj_ipa_agent
( DEVNO POSITION(1:20) CHAR,
date_cache -- size (in entries) of date conversion cache(默认1000)
PLEASE NOTE: 命令行参数可以由位置或关键字指定。前者的例子是 'sqlloadscott/tiger foo'; 后一种情况的一个示例是 'sqlldr
其基本工作原理是:首先要针对数据源文件制作一个控制文件,控制文件是用来解释如何对源文件进行解析,其中需要包含源文件的数据格式、目标数据库的字段等信息,一个典型的控制文件为如下形式:
LOAD DATA
INFILE '/ora9i/fengjie/agent/data/ipaagentdetail200410.txt'
readsize -- Size of Read buffer (默认1048576)
external_table -- use external table for load; NOT_USED, GENERATE_ONLY, EXECUTE(默认NOT_USED)
(默认: 常规路径 64, 所有直接路径)
bindsize -- Size of conventional path bind array in bytes(默认256000)
silent -- Suppress messages during run (header,feedback,errors,discards,partitions)
Txt文件导入oracle数据库方法
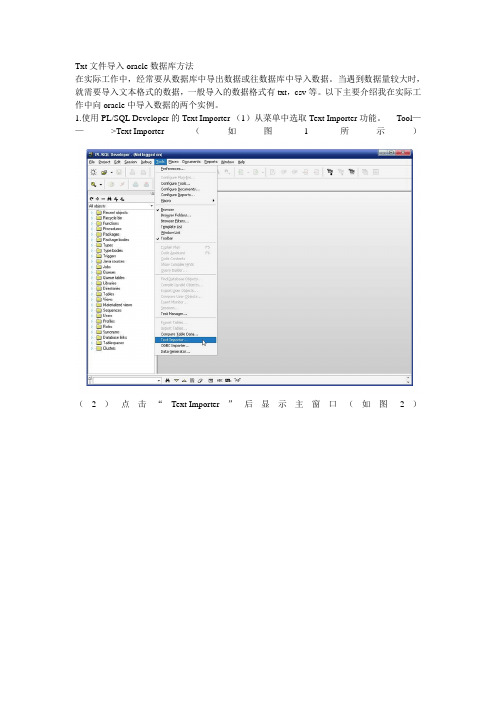
Txt文件导入oracle数据库方法
在实际工作中,经常要从数据库中导出数据或往数据库中导入数据。
当遇到数据量较大时,就需要导入文本格式的数据,一般导入的数据格式有txt,csv等。
以下主要介绍我在实际工作中向oracle中导入数据的两个实例。
1.使用PL/SQL Developer的Text Importer (1)从菜单中选取Text Importer功能。
Tool——>Text Importer(如图1所示)
(2)点击“Text Importer”后显示主窗口(如图2)
3)设置将数据文件导入到哪个数据库中的哪个表中,如图3所示。
(4)设置完成后,点击“Import”按钮,数据开始导入直到数据全部导入到数据库中。
2.使用Power Builder 将txt文件导入到数据库中。
(1)先建表结构
例如:Create Table Temp (subsid varchar(20) not null primary key,subsname(50));如图4所示。
在这里需要说明的是:在建立表的过程中,必须设置主键,否着不允许导入数据。
(2)检索刚建的临时表temp select * from temp
(3)点击“Rows”下的“Import”选项,弹出文件对话框,选择你要加载的数据文件,点击“确定”。
如图5所示。
批量提取指定内容的步骤

批量提取指定内容的步骤
要批量提取指定内容,可以按照以下步骤进行操作:
1. 收集待处理的文档或数据集:收集包含要提取内容的文档或数据集,并保存在一个文件夹或数据库中。
2. 确定要提取的内容:确定要提取的具体内容,例如日期、姓名、地址等。
这个步骤非常重要,因为它会影响后续的提取过程。
3. 选择合适的工具或技术:根据要提取的内容类型,选择适合的工具或技术进行批量提取。
例如,如果要提取的是文本中的关键词,可以使用自然语言处理技术;如果要提取的是结构化数据,可以使用数据挖掘工具。
4. 编写代码或使用现有工具:根据选择的工具或技术,编写代码或使用现有的提取工具进行批量提取。
如果没有编程经验,可以考虑寻找现有的软件或工具来完成任务。
5. 测试和验证:对提取结果进行测试和验证,确保提取的内容准确无误。
可以随机选择几个样本进行人工验证,以确保提取的准确性和完整性。
6. 批量提取并保存结果:将编写的代码应用于整个文档或数据集,并批量提取需要的内容。
将提取的结果保存在适当的格式中,例如CSV文件或数据库。
7. 数据清洗和整理:根据需要,对提取的结果进行数据清洗和整理,例如删除重复项、规范化格式等。
8. 分析和应用结果:根据实际需要,对提取的结果进行进一步的分析和应用。
可以使用各种统计、机器学习或数据可视化技术进行分析,从中提取有用的信息。
以上是一般的批量提取指定内容的步骤,具体的实施过程可能会因不同的情况而有所变化。
将TXT文件导入sqlserver数据库

将TXT⽂件导⼊sqlserver数据库数据库已存在旧表名 old_table,列名old_column_name。
将TXT⽂件导⼊数据库已存在旧表old_table中,导⼊过程中需注意数据源中列名可全部不修改或全部修改列名为old_column_name(与old_table中列名⼀致)。
情景⼆:将源TXT⽂件导⼊数据库,默认时以源TXT⽂件名建新表sourceFile_table;导⼊过程中需修改数据源中列名为 custom_column_name(⾃定义列名)数据库右键》任务》导⼊数据(I)...》 --或者-- 开始》程序》Microsoft Visual Studio2008》导⼊和导出数据(**位)》SQLServer导⼊和导出向导》下⼀步》选择数据源数据源:平⾯⽂件源常规⽂件名(i): 浏览选择TXT⽂件区域设置(L): 中⽂代码页(C): 65001(UTF-8) : 源TXT⽂件编码⽅式为UTF-8936(ANSI/OEM-简体中⽂ GBK): 源TXT⽂件编码⽅式为ANSI 格式(M): 带分隔符⽂本限定符(Q): <⽆>标题⾏分隔符(R): {CR}{LF}要跳过的标题⾏数(S): 可⾃定义列⾏分隔符(O): {CR}{LF}列分隔符(C): 制表符{t}⾼级列名Name列名(可修改) ColumnDelimiter制表符{t}DataType据⽬标表的字段类型定义OutputColumnWidth可⾃定义TextQualified True预览要跳过的数据⾏数(A): 可⾃定义下⼀步》选择⽬标⽬标(D): SQL Server Native Client 10.0服务器名称(S): 需⼿动输⼊“⽬标服务器名称”使⽤SQL Server ⾝份验证(Q)⽤户名(U):需⼿动输⼊密码(P): 需⼿动输⼊数据库(T): 选择已建的数据库下⼀步》选择源表和源视图表和视图(T):源⽬标双击》列映射(可编辑)》当主键id⾃增时,选中启⽤标识插⼊单击》下拉框》可选择⽬标表为(已存在表old_table 或者默认时以源TXT⽂件名sourceFile_table建⽴新表)》下⼀步》下⼀步》完成-------------------------------------------问题⼀:将源TXT⽂件sourceFile_table.txt,导⼊数据库已存在表old_table原因:源TXT⽂件sourceFile_table.txt中数据类型为varchar(50),数据库已存在表old_table中数据类型为nvarchar(50)解决⽅法:修改表old_table中,对应字段数据类型为varchar(50)-------------------------------------------问题⼆:将TXT⽂件导⼊ sqlserver数据库后,字段值中⽂乱码原因:源TXT⽂件编码⽅式,和数据库编码⽅式不⼀致解决⽅法:⽂件转码⽅法1.源TXT⽂件》右键打开》⽂件另存为》编码(E):**》保存⽅法2.源TXT⽂件sourceFile_table.txt、备份⽂件backupFile_table.txt》将源⽂件使⽤转码⼯具转换》将备份⽂件中数据复制到源⽂件中。
MySQL中的批量数据导入导出方法和工具

MySQL中的批量数据导入导出方法和工具MySQL是一个常用的关系型数据库管理系统,用于存储和管理大量的数据。
在日常工作中,我们经常需要将数据从一个数据库导入到另一个数据库,或者将数据导出到其他格式的文件中。
本文将介绍MySQL中的批量数据导入导出方法和工具。
一、批量数据导入方法1. LOAD DATA INFILE语句LOAD DATA INFILE语句是MySQL中常用的批量数据导入方法之一。
它可以将一个文本文件中的数据批量导入到数据库表中。
使用LOAD DATA INFILE语句导入数据的步骤如下:首先,创建一个文本文件,文件中每一行表示一条记录,记录中的列值使用制表符或逗号进行分隔。
然后,在MySQL数据库中创建一个目标表,用于存储导入的数据。
目标表的结构需要和文本文件中的数据保持一致。
接下来,在MySQL的命令行界面或数据库管理工具中执行LOAD DATA INFILE语句,指定导入的文本文件和目标表。
示例代码如下:LOAD DATA INFILE 'data.txt' INTO TABLE table_nameFIELDS TERMINATED BY '\t' (column1, column2, column3);其中,'data.txt'为导入的文本文件的路径,table_name为目标表的名称,\t表示制表符作为字段的分隔符,column1、column2和column3分别是目标表的列。
2. 使用MySQL的命令行工具除了LOAD DATA INFILE语句,MySQL的命令行工具也提供了另一种批量导入数据的方法。
使用该方法的步骤如下:首先,创建一个文本文件,文件中每一行表示一条记录,记录中的列值使用制表符或逗号进行分隔。
然后,使用命令行工具登录MySQL数据库。
接下来,执行以下命令导入数据:mysql> USE database_name; -- 切换到目标数据库mysql> SET AUTOCOMMIT=0; -- 关闭自动提交mysql> SET UNIQUE_CHECKS=0; -- 关闭唯一性检查mysql> SET FOREIGN_KEY_CHECKS=0; -- 关闭外键检查mysql> LOAD DATA INFILE 'data.txt' INTO TABLE table_name-> FIELDS TERMINATED BY '\t' LINES TERMINATED BY '\n'; -- 指定导入的文件和分隔符mysql> COMMIT; -- 提交导入的数据mysql> SET UNIQUE_CHECKS=1; -- 打开唯一性检查mysql> SET FOREIGN_KEY_CHECKS=1; -- 打开外键检查其中,database_name为目标数据库的名称,table_name为目标表的名称,data.txt为导入的文本文件的路径,\t表示制表符作为字段的分隔符,\n表示换行符作为记录的分隔符。
批量提取记事本内容的方法

批量提取记事本内容的方法:
在处理大量记事本文件时,可能需要批量提取这些文件的内容。
下面将介绍一种批量提取记事本内容的方法,该方法主要借助一款软件工具来实现。
一、准备阶段
收集所有需要提取内容的记事本文件,确保这些文件都保存在同一个文件夹下。
确保计算机上已安装好文本处理软件或具有批量处理功能的工具,如“我的ABC软件工具箱”等。
这些工具可以帮助我们更高效地批量提取记事本内容。
二、批量提取记事本内容
打开所选的软件工具,并进入“批量生成文件路径清单”的功能中。
这个功能可以将所有文件的路径统一导出和提取出来,并保存成我们想要的格式文件。
在软件界面中,将所有需要生成清单的记事本文件一次性添加到列表中。
这意味着在后续生成的txt记事本中,会包含这些文件的所有路径和内容。
添加完文件后,单击下一步。
此时,软件会提示我们选择一个清单的格式。
由于我们需要批量提取记事本内容,所以选择txt格式。
选择完txt格式后,单击下一步。
软件会自动识别所选的txt格式,并开始扫描所选择的所有记事本文件的路径。
这个过程可能需要一些时间,取决于文件数量和文件大小。
扫描完成后,软件会将所有记事本文件的路径和内容批量导出到我们选择的txt记事本中。
此时,可以打开这个txt记事本查看所有提取出的内容。
通过以上步骤,我们可以轻松实现批量提取记事本内容的目的。
这种方法不仅提高了处理效率,还避免了手动打开和复制粘贴的繁琐操作。
同时,借助专业的软件工具,我们可以更好地管理和利用大量的记事本文件。
提取文件夹中所有txt中所需信息并导入数据库

<%@LANGUAGE="VBSCRIPT" CODEPAGE="65001"%><!--#include file="Connections/" --><!DOCTYPE html PUBLIC "-//W3C//DTD XHTML Transitional//EN" ""><html xmlns=""><head><meta http-equiv="Content-Type" content="text/html; charset=utf-8" /> <title>提取数据</title></head><body><%Set fso = ("")on error resume nextSet objFolder=("C:\Jerry\ASP\WEB\wwwroot\getdata")Set objFiles='循环输出文件夹path下的文件的文件名For each objFile in objFiles '取相关值txtname=""name1=""school=""sex=""qq=""msn=""telephone=""if ="Text Document" then"<br>"+ & "<br>"txtname='判断是不是有相同的文件名Set rs2 = ("")sql="select * from where txtname="&txtname sql,objConn,1,3if =true then'读取文档dim fsodim pathset fso=("")path =set file = (path,1,true)if not thenline=end if'提取姓名("姓名:")n=instr(line,"帐号 <#>")m=instr(line,"装扮主页 <修改资料")if m=0 then'提取物修改资料这块的账户姓名line=right(line,len(line)-n-13)i=instr(line,"\x{")if i<5 and i<>0 thenname1=mid(line,1,i-1)elsename1=mid(line,1,3)end ifname1+"<br>"elseline=right(line,len(line)-m-127)i=instr(line,"\x{")if i<5 thenname1=mid(line,1,i-1) elsename1=mid(line,1,3)end ifname1+"<br>"end if'提取所在学校str2="所在学校:"str3="生日:"str4="<"str5=">"m=Instr(line,str3)if n<>0 thenschool=mid(line,n+11,m-n-11)"所在学校:"+school+"<br>"'提取了所在大学end if'提取生日line=right(line,len(line)-m+1)n=Instr(line,str4)year1=mid(line,1+9,n-10)'提取了年份line=right(line,len(line)-n)n=Instr(line,str5)m=instr(line,str4)month1=mid(line,n+1,m-n-1)'提取了月份line=right(line,len(line)-m)m=instr(line,str4)day1=mid(line,n+1,m-n-1)'提取了日birthdate=replace(year1&month1&day1," ","")("生日:"+birthdate+"<br>")'显示生日'提取了性别n=instr(line,"性别 :")m=instr(line,"生日 :")sex=mid(line,n+10,1)"性别:"+sex+"<br>"'提取联系方式n=instr(line,"QQ :")m=instr(line,"MSN :")k=instr(line,"电话号 :")j=instr(line,"个人网站 :")if n<>0and m<>0 and k=0 then'只有QQ 和MSN的情况"QQ:"+qq+"<br>"'提取了QQmsn=mid(line,m+10,j-m-10)"MSN:"+msn+"<br>"'提取了msnelseif n<>0 and m=0 and k<>0 then'只有QQ和电话号码的情况qq=mid(line,n+10,k-n-10)"QQ:"+qq+"<br>"'提取了QQtelephone=mid(line,k+10,j-k-10)"电话号:"+telephone+"<br>"'提取了电话号elseif n<>0 and m=0 and k=0then'只有QQ的情况qq=mid(line,n+10,j-n-10)"QQ:"+qq+"<br>"'提取了QQelseif n<>0 and m<>0 and k<>0 then'QQ MSN 电话号码都有的情况qq=mid(line,n+10,m-n-10)"QQ:"+qq+"<br>"'提取了QQ"MSN:"+msn+"<br>"'提取了MSNtelephone=mid(line,k+10,j-k-10)"电话号:"+telephone+"<br>"'提取了电话号码elseif n=0 and m<>0 and k=0 then'只有MSN的情况msn=mid(line,m+10,j-m-10)"MSN:"+msn+"<br>"'提取了MSNelseif n=0 and m<>0 and k<>0 then'只有MSN 电话号的情况msn=mid(line,m+10,k-m-10)"MSN:"+msn+"<br>"'提取了MSNtelephone=mid(line,k+10,j-k-10)"电话号:"+telephone+"<br>"'提取了电话号elseif n=0 and m=0 and k<>0 then'只有电话号的情况telephone=mid(line,k+10,j-k-10)"电话号:"+telephone+"<br>"'提取了电话号end if'去除空格qq=replace(qq," ","")msn=replace(msn," ","")telephone=replace(telephone," ","")'将记录插入数据库中set cmd=("")query="insert intodata1(txtname,name,school,birthdate,sex,qq,msn,telephone)values('"&txtname&"','"&name1&"','"&school&"','"&birthdate&"','"&sex&"','"&qq &"','"&msn&"','"&telephone&"')"(query)else("数据库中已经存在该文档名称的数据,请不要重复添加!") end ifend ifNextSet objFolder=nothingSet fso=nothing '释放对象%></body> </html>。
将文本数据导入到ORACLE数据库的方法

将文本数据导入到ORACLE数据库的方法
1. 使用命令行工具 sqlldr:
sqlldr 是 ORACLE 提供的一个命令行工具,可以用于将文本数据导入到 ORACLE 数据库。
以下是使用 sqlldr 导入数据的步骤:
a.创建一个控制文件,控制文件描述了文本数据的结构和如何导入数据库。
例如,可以指定字段的名称、类型和顺序等。
b. 使用 sqlldr 命令加载数据,命令格式如下:
2. 使用外部表(External Table):
外部表是ORACLE数据库的一种特殊对象,它将外部文件(如文本文件)映射为数据库表的一部分。
以下是使用外部表导入数据的步骤:
a.创建外部表,指定外部文件的位置和格式。
例如,可以使用ANIZATIONEXTERNAL语句创建外部表。
b.使用INSERT...SELECT语句将外部表中的数据插入到其他数据库表中。
3.使用ORACLEDATAPUMP工具:
ORACLEDATAPUMP是ORACLE提供的一个工具,可以方便地导入和导出数据库对象和数据。
以下是使用ORACLEDATAPUMP工具导入数据的步骤:
a. 使用 expdp 命令导出数据,命令格式如下:
b.创建一个目标表,用于接收导入的数据。
c. 使用 impdp 命令导入数据,命令格式如下:
4.使用ETL工具:
总结起来,将文本数据导入到 ORACLE 数据库的方法包括使用sqlldr 命令行工具、外部表、ORACLE DATA PUMP 工具和 ETL 工具。
根据具体情况选择合适的方法进行数据导入。
数据库数据导入与导出的技巧与方法

数据库数据导入与导出的技巧与方法随着信息时代的来临,数据成为企业和个人生活中不可或缺的一部分。
有效地管理和处理数据变得至关重要。
数据库是存储和管理大量结构化数据的理想工具,它使得数据的访问、更新和分析变得更加高效和可靠。
然而,数据库的真正价值在于其数据的导入和导出功能。
数据的导入和导出是将现有的数据存储到数据库中或从数据库中提取数据的过程。
在本文中,我们将介绍一些数据库数据导入和导出的技巧和方法,帮助您更好地管理和利用您的数据。
一、导入数据的技巧与方法1. 使用数据库管理软件数据库管理软件(例如MySQL Workbench、Navicat等)通常提供了直观且易于使用的界面,使得数据导入过程更加简单。
这些软件通常具有导入向导,可以快速指导用户导入各种数据格式。
首先,您需要选择要导入的数据文件(如CSV、Excel等),然后选择目标数据表和字段映射关系。
最后,您可以预览和验证导入数据,并执行导入操作。
2. 使用SQL语句对于一些精通SQL语句的用户来说,使用SQL语句直接导入数据也是一个不错的选择。
您可以使用LOAD DATA INFILE语句将文本文件导入到数据库中,该语句可以根据指定的格式将文件中的数据导入到指定的数据表中。
此方式适用于大批量数据导入,速度较快且能够保留数据的完整性。
3. 使用ETL工具ETL(Extract Transform Load)工具是一种用于将数据从一个数据库(或文件)提取出来,然后经过一系列的清洗和转换处理后,再加载到另一个数据库(或文件)中的工具。
常见的ETL工具如Talend、Pentaho等。
这些工具提供了可视化的界面和强大的数据处理能力,能够满足复杂的数据导入需求。
二、导出数据的技巧与方法1. 使用数据库管理软件数据库管理软件往往也提供了数据导出的功能。
您可以选择要导出的数据表和字段,然后指定导出的格式(如CSV、Excel、SQL等),最后执行导出操作。
python读取一个目录下所有txt里面的内容方法

python读取⼀个⽬录下所有txt⾥⾯的内容⽅法实例如下所⽰:import osallFileNum = 0def printPath(level, path):global allFileNum'''''打印⼀个⽬录下的所有⽂件夹和⽂件'''# 所有⽂件夹,第⼀个字段是次⽬录的级别dirList = []# 所有⽂件fileList = []# 返回⼀个列表,其中包含在⽬录条⽬的名称files = os.listdir(path)# 先添加⽬录级别dirList.append(str(level))for f in files:if(os.path.isdir(path + '/' + f)):# 排除隐藏⽂件夹。
因为隐藏⽂件夹过多if(f[0] == '.'):passelse:# 添加⾮隐藏⽂件夹dirList.append(f)if(os.path.isfile(path + '/' + f)):# 添加⽂件fileList.append(f)# 当⼀个标志使⽤,⽂件夹列表第⼀个级别不打印i_dl = 0for dl in dirList:if(i_dl == 0):i_dl = i_dl + 1else:# 打印⾄控制台,不是第⼀个的⽬录print('-' * (int(dirList[0])), dl )# 打印⽬录下的所有⽂件夹和⽂件,⽬录级别+1printPath((int(dirList[0]) + 1), path + '/' + dl)for fl in fileList:# 打印⽂件print(fl)f = open('C:/Users/DELL/Desktop/userid3/'+fl)#读取完txt再读txt⾥⾯的类容# print(f.read())# 'a'表⽰附加模式,⽤写⼊模式‘w'要⼩⼼,如果指定⽂件已经存在,python将再返回⽂件对象前清空该⽂件f2 = open("20170610uid.txt",'a')f2.write(f.read())# 以下三⾏是逐⾏读取,跟f2.write(f.read())效果⼀样# alllines = f.readlines()# for eachLine in alllines:# f2.write(eachLine)f2.close()# 随便计算⼀下有多少个⽂件allFileNum = allFileNum + 1print(allFileNum)if __name__ == '__main__':printPath(1, 'C:/Users/DELL/Desktop/userid3/')以上这篇python读取⼀个⽬录下所有txt⾥⾯的内容⽅法就是⼩编分享给⼤家的全部内容了,希望能给⼤家⼀个参考,也希望⼤家多多⽀持。
如何在MySQL中进行数据导入导出

如何在MySQL中进行数据导入导出导入和导出数据是MySQL数据库中非常常见的操作。
在实际的数据库开发和管理中,我们经常需要将数据从一个数据库导出到另一个数据库,或者将数据从文件导入到数据库中。
本文将介绍如何在MySQL中进行数据导入导出的方法和技巧。
一、导出数据1. 使用SELECT语句导出数据最简单的导出数据的方法是使用SELECT语句,通过查询结果将数据导出。
例如,要导出一张名为"users"的表中的所有数据,可以执行以下语句:SELECT * FROM users;执行上述语句后,系统会将查询结果以表格形式展示出来。
可以将结果复制到Excel等工具中进行保存和进一步处理。
2. 使用SELECT INTO OUTFILE语句导出数据SELECT INTO OUTFILE语句提供了将查询结果导出到文件的功能。
可以使用该语句将数据导出为文本文件,便于在其他系统中进行处理。
例如,要将表"users"中的数据导出为文本文件"users.txt",可以执行以下语句:SELECT * INTO OUTFILE '/path/to/users.txt'FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"'FROM users;执行上述语句后,MySQL会将查询结果以CSV格式保存到指定路径的文件中。
3. 使用mysqldump工具导出数据mysqldump是MySQL自带的一个导出工具,可以将整个数据库或单个表导出为SQL脚本或文本文件。
要导出整个数据库,可以执行以下命令:mysqldump -u username -p database > database.sql将"username"替换为实际的用户名,"database"替换为要导出的数据库名。
如何利用Word进行批量提取文本内容

如何利用Word进行批量提取文本内容引言近年来,随着信息技术的迅速发展,大量的文本数据被产生和积累。
在处理这些文本数据时,我们经常需要从大量的文档中提取出特定的信息,以满足需求。
Microsoft Word作为一种广泛使用的文本编辑和处理软件,具备了批量提取文本内容的强大能力。
本文将介绍如何利用Word进行批量提取文本内容,并按照以下几个方面进行阐述:预处理文档、使用通配符进行搜索、利用宏自动提取以及利用自定义属性批量提取。
一、预处理文档在进行批量提取文本内容之前,我们需要对文档进行一些预处理操作,以确保提取结果的准确性和统一性。
首先,我们应该将多个需要提取的文档保存在同一个文件夹中,便于后续的批量处理。
其次,为了提高搜索效率,我们需要将文档的内容整理为统一的格式,包括字体、字号、样式等。
此外,还可以通过Word的自动格式功能,自动根据一定的规则给文档进行编号、分段和标记,以便后续的批量提取工作。
二、使用通配符进行搜索在Word中,可以利用通配符进行搜索,以便快速定位和提取特定的文本内容。
通配符是一种模式匹配符,用于表示特定的字符或字符串。
通过在搜索功能中使用通配符,可以根据需要提取出匹配特定模式的文本内容。
例如,如果想提取出所有以“special”开头的单词,在搜索框中输入“special*”即可。
同样,通配符还可以用于匹配特定的字符长度,如“sp??ial”表示匹配中间有两个任意字符的“special”字符串。
通过灵活运用通配符,可以提取符合特定模式的文本内容,提高提取效率。
三、利用宏进行自动提取在Word中,宏是一种自动化操作工具,可以根据预设的规则和操作,快速进行大量的文本处理工作。
通过录制和编辑宏,可以实现批量提取文本内容的自动化。
首先,我们可以使用“录制宏”功能将一次性的提取操作录制下来,然后通过“编辑宏”功能进一步优化和扩展宏的功能。
例如,我们可以编写一个宏,通过指定标记或者样式来提取文档中的各种信息,并将它们保存到一个新的文档或者整理成一张表格。
java中高效获取txt所有文本内容的方法

java中高效获取txt所有文本内容的方法Java中高效获取txt所有文本内容的方法在Java编程中,我们经常需要读取文件的内容并进行处理。
在某些情况下,我们需要读取一个txt文件的所有文本内容,并且希望能够以高效的方式实现。
本文将介绍一种高效获取txt所有文本内容的方法,并逐步回答中括号内的问题。
第一步:使用Java的File类首先,我们需要使用Java的File类来表示我们要读取的txt文件。
File类提供了很多与文件相关的常用方法,比如判断文件是否存在、获取文件路径等。
javaFile file = new File("file.txt");在上面的代码中,我们创建了一个名为file的File对象,表示文件名为file.txt的文本文件。
你可以将file.txt替换为你要读取的txt文件名。
问题1:如何创建File类对象?答:通过在File类的构造函数中传入文件名(包括路径)来创建File对象。
问题2:如何表示要读取的txt文件的路径?答:可以使用相对路径或绝对路径来表示要读取的txt文件的路径。
相对路径是相对于当前Java程序的工作目录的路径,而绝对路径是该txt文件在文件系统中的完整路径。
第二步:使用Java的BufferedReader类接下来,我们需要使用Java的BufferedReader类来读取txt文件的内容。
BufferedReader类提供了按行读取文本内容的方法,非常适合读取txt 文件。
javatry {BufferedReader reader = new BufferedReader(new FileReader(file));String line;while ((line = reader.readLine()) != null) {处理文本内容}reader.close();} catch (IOException e) {e.printStackTrace();}在上面的代码中,我们首先创建一个BufferedReader对象reader,它使用FileReader对象来读取文件内容。
批量导入文本数据操作方法

批量导入文本数据操作方法
批量导入文本数据可以通过以下几种方法进行操作:
1. 手动导入:可以通过文件管理器或命令行界面手动选择要导入的文本文件,然后逐个文件导入数据。
这种方法适用于少量文本文件的情况。
2. 使用数据导入工具:如果需要导入大量的文本文件,可以使用数据导入工具或脚本来自动化导入过程。
这些工具可以读取指定的目录中的所有文本文件,并将其逐个导入数据库或其他数据存储系统。
3. 使用编程语言进行导入:如果需要对导入的文本数据进行处理或转换,可以使用编程语言如Python、Java或R来完成导入操作。
通过编写代码,可以使用文件读取功能和数据库连接工具来读取文本文件并将数据导入到数据库中。
需要注意的是,批量导入文本数据操作的具体步骤和方法会根据使用的工具、数据库或编程语言而有所不同。
因此,根据具体的需求和环境,选择合适的方法来进行批量导入文本数据操作。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
<%@LANGUAGE="VBSCRIPT" CODEPAGE="65001"%><!--#include file="Connections/conn.asp" --><!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "/TR/xhtml1/DTD/xhtml1-transitional.dtd"><html xmlns="/1999/xhtml"><head><meta http-equiv="Content-Type" content="text/html; charset=utf-8" /> <title>提取数据</title></head><body><%Set fso = Server.CreateObject("Scripting.FileSystemObject")on error resume nextSet objFolder=fso.GetFolder("C:\Jerry\ASP\WEB\wwwroot\getdata") Set objFiles=objFolder.Files'循环输出文件夹path下的文件的文件名For each objFile in objFiles '取相关值txtname=""name1=""school=""sex=""qq=""msn=""telephone=""if objFile.Type="Text Document" thenResponse.Write "<br>"+ & "<br>"txtname='判断是否有相同的文件名Set rs2 = Server.CreateObject("ADODB.Recordset")sql="select * from dbo.data1 where txtname="&txtnamers2.Open sql,objConn,1,3if rs2.eof=true then'读取文档dim fsodim pathset fso=server.createobject("scripting.filesystemobject")path = objFile.Pathset file = fso.opentextfile(path,1,true)if not file.atendofstream thenline=file.ReadAllend if'提取姓名response.write ("姓名:")n=instr(line,"帐号 <#>")m=instr(line,"装扮主页</store/view/home?wc=10000>修改资料")if m=0 then'提取物修改资料这块的账户姓名line=right(line,len(line)-n-13)i=instr(line,"\x{")if i<5 and i<>0 thenname1=mid(line,1,i-1) elsename1=mid(line,1,3)end ifresponse.write name1+"<br>" elseline=right(line,len(line)-m-127)i=instr(line,"\x{")if i<5 thenname1=mid(line,1,i-1) elsename1=mid(line,1,3)end ifresponse.write name1+"<br>" end if'提取所在学校str2="所在学校:"str3="生日:"str4="<"str5=">"n=Instr(line,str2)m=Instr(line,str3)if n<>0 thenschool=mid(line,n+11,m-n-11)response.write "所在学校:"+school+"<br>"'提取了所在大学end if'提取生日line=right(line,len(line)-m+1)n=Instr(line,str4)year1=mid(line,1+9,n-10)'提取了年份line=right(line,len(line)-n)n=Instr(line,str5)m=instr(line,str4)month1=mid(line,n+1,m-n-1)'提取了月份line=right(line,len(line)-m)n=Instr(line,str5)m=instr(line,str4)day1=mid(line,n+1,m-n-1)'提取了日birthdate=replace(year1&month1&day1," ","")response.Write ("生日:"+birthdate+"<br>")'显示生日'提取了性别n=instr(line,"性别 :")m=instr(line,"生日 :")sex=mid(line,n+10,1)response.Write "性别:"+sex+"<br>"'提取联系方式n=instr(line,"QQ :")m=instr(line,"MSN :")k=instr(line,"手机号 :")j=instr(line,"个人网站 :")if n<>0and m<>0 and k=0 then'只有QQ 和MSN的情况qq=mid(line,n+10,m-n-10)response.Write "QQ:"+qq+"<br>"'提取了QQmsn=mid(line,m+10,j-m-10)response.Write "MSN:"+msn+"<br>"'提取了msnelseif n<>0 and m=0 and k<>0 then'只有QQ和手机号码的情况qq=mid(line,n+10,k-n-10)response.Write "QQ:"+qq+"<br>"'提取了QQtelephone=mid(line,k+10,j-k-10)response.Write "手机号:"+telephone+"<br>"'提取了手机号elseif n<>0 and m=0 and k=0then'只有QQ的情况qq=mid(line,n+10,j-n-10)response.Write "QQ:"+qq+"<br>"'提取了QQelseif n<>0 and m<>0 and k<>0 then'QQ MSN 手机号码都有的情况qq=mid(line,n+10,m-n-10)response.Write "QQ:"+qq+"<br>"'提取了QQmsn=mid(line,m+10,k-m-10)response.Write "MSN:"+msn+"<br>"'提取了MSNtelephone=mid(line,k+10,j-k-10)response.Write "手机号:"+telephone+"<br>"'提取了手机号码elseif n=0 and m<>0 and k=0 then'只有MSN的情况msn=mid(line,m+10,j-m-10)response.Write "MSN:"+msn+"<br>"'提取了MSNelseif n=0 and m<>0 and k<>0 then'只有MSN 手机号的情况msn=mid(line,m+10,k-m-10)response.Write "MSN:"+msn+"<br>"'提取了MSNtelephone=mid(line,k+10,j-k-10)response.Write "手机号:"+telephone+"<br>"'提取了手机号elseif n=0 and m=0 and k<>0 then'只有手机号的情况telephone=mid(line,k+10,j-k-10)response.Write "手机号:"+telephone+"<br>"'提取了手机号end if'去除空格qq=replace(qq," ","")msn=replace(msn," ","")telephone=replace(telephone," ","")'将记录插入数据库中set cmd=Server.CreateObject("mand")query="insert into data1(txtname,name,school,birthdate,sex,qq,msn,telephone)values('"&txtname&"','"&name1&"','"&school&"','"&birthdate&"','"&sex&"','"&qq&"','"&msn&" ','"&telephone&"')"objConn.execute(query)elseresponse.Write("数据库中已经存在该文档名称的数据,请不要重复添加!")end ifrs2.closeend ifNextSet objFolder=nothingSet fso=nothing '释放对象%></body></html>。