简单线性回归模型的统计检验
统计学中的线性回归模型与假设检验

统计学中的线性回归模型与假设检验统计学作为一门研究数据收集、分析和解释的学科,扮演着重要的角色。
其中,线性回归模型和假设检验是统计学中常用的方法。
本文将介绍线性回归模型的基本概念和应用,以及假设检验的原理和实际意义。
一、线性回归模型线性回归模型是一种用于描述两个或多个变量之间关系的统计模型。
它假设自变量和因变量之间存在线性关系,并通过最小化因变量与预测值之间的差异来估计回归系数。
在线性回归模型中,自变量通常表示为X,因变量表示为Y。
模型的基本形式可以表示为Y = β0 + β1X + ε,其中β0和β1是回归系数,ε是误差项。
回归系数表示自变量对因变量的影响程度,误差项表示模型无法解释的随机变动。
线性回归模型的应用非常广泛。
例如,在经济学中,可以使用线性回归模型来研究收入与消费之间的关系;在医学研究中,可以使用线性回归模型来分析药物剂量与治疗效果之间的关系。
通过对数据进行拟合和分析,线性回归模型可以帮助我们理解变量之间的关系,并进行预测和决策。
二、假设检验假设检验是一种统计推断方法,用于判断样本数据与某个假设之间是否存在显著差异。
在假设检验中,我们首先提出一个原假设(H0)和一个备择假设(H1),然后根据样本数据进行统计推断,判断是否拒绝原假设。
在假设检验中,我们通常使用一个统计量来衡量样本数据与原假设之间的差异。
常见的统计量包括t值、F值和卡方值等。
通过计算统计量的概率值(p值),我们可以判断样本数据是否支持原假设。
假设检验在科学研究和实际应用中具有重要意义。
例如,在药物研发中,可以使用假设检验来判断新药物是否比现有药物更有效;在市场营销中,可以使用假设检验来评估不同广告策略的效果。
通过假设检验,我们可以基于数据进行科学决策,提高研究和实践的可靠性。
三、线性回归模型与假设检验的关系线性回归模型和假设检验是统计学中紧密相关的方法。
在线性回归分析中,我们可以使用假设检验来评估回归系数的显著性。
在线性回归模型中,我们通常对回归系数进行假设检验,以确定自变量对因变量的影响是否显著。
简单线性回归分析

简单线性回归分析
简单线性回归分析是一种统计分析方法,用于研究两个变量之间的线性关系。
其中,一个变量被称为因变量或响应变量,另一个变量被称为自变量或解释变量。
简单线性回归通过拟合一条直线来描述两个变量之间的关系,并可以用这条直线来进行预测和推断。
分析简单线性回归模型首先需要进行模型的拟合。
通过拟合可以得到最优的回归系数。
一般使用最小二乘法来拟合模型,最小二乘法的目标是最小化观测值与模型预测值之间的差异的平方和。
拟合模型后,可以进行模型的评估。
评估模型的好坏可以使用各种统计指标,例如残差和决定系数。
残差是观测值与模型预测值之间的差异,用于评估模型对实际数据的拟合效果。
决定系数是评估模型解释观测变异能力的指标,其取值范围为[0,1],值越接近1,说明模型解释变异能力越好。
在模型评估的基础上,可以进行模型的推断。
模型推断包括对回归系数的置信区间估计和假设检验。
通过置信区间估计可以给出回归系数的估计范围,以及回归系数是否显著不等于0。
假设检验可以用于检验回归系数是否显著不等于0,即自变量是否对因变量有显著影响。
简单线性回归分析可以在实际情况中有很多应用。
例如,在市场营销中,可以使用简单线性回归模型来研究广告投入与销售额之间的关系,从而确定广告投入对销售额的影响。
在经济学中,可以使用简单线性回归模型来研究收入与消费之间的关系,从而了解收入对消费的影响。
总结起来,简单线性回归分析是一种重要的统计分析方法,用于研究两个变量之间的线性关系。
通过拟合模型、评估模型和进行推断,可以得到有关两个变量之间关系的重要信息,为实际问题的解决提供有力支持。
简单的斜率检验

简单的斜率检验概述简单的斜率检验是统计学中一种常用的方法,用于检验两组数据之间是否存在显著的差异。
通过计算两组数据的斜率,并进行统计检验,我们可以得出结论是否可以拒绝两组数据没有差异的零假设。
在本文中,将详细介绍简单的斜率检验的原理、步骤以及如何进行结果的解释。
同时,还会给出一些示例和实际应用,帮助读者更好地理解和应用简单的斜率检验。
原理简单的斜率检验是基于线性回归模型的检验方法。
线性回归模型用于描述变量之间的关系,其中有一个自变量(x)和一个因变量(y)。
线性回归模型可以表示为:y = β0 + β1 * x + ε其中,β0和β1是回归系数,代表截距和斜率,ε是误差项。
简单的斜率检验是通过比较两组数据的斜率是否显著不同来判断两组数据之间是否存在差异。
如果两组数据的斜率显著不同,我们可以得出结论认为这两组数据之间存在显著差异。
步骤进行简单的斜率检验需要按照以下步骤进行:1. 设置假设在进行任何统计检验之前,需要明确我们的研究假设。
对于简单的斜率检验,我们关注的是两组数据的斜率是否存在显著差异。
•零假设(H0):两组数据的斜率相等,即β1_A = β1_B•对立假设(H1):两组数据的斜率不相等,即β1_A ≠ β1_B2. 数据准备收集两组数据,并进行数据准备工作。
确保数据的质量和完整性,可以使用统计软件或编程语言进行数据处理和分析。
3. 线性回归模型拟合对每组数据分别进行线性回归模型的拟合。
得到每组数据的截距和斜率。
4. 斜率差异的估计计算两组数据的斜率差异。
可以直接计算斜率的差异β1_A - β1_B,也可以计算斜率的差异的标准差。
5. 斜率差异的显著性检验使用统计方法进行斜率差异的显著性检验。
常用的方法有t检验和Bootstrap法。
•t检验:假设两组数据的斜率差异符合正态分布,可以使用t检验进行显著性检验。
•Bootstrap法:通过重复抽样,计算斜率差异的分布,进而进行显著性检验。
6. 结果解释根据显著性检验的结果,给出对比两组数据斜率差异的结论。
线性回归模型的经典假定及检验修正

线性回归模型的经典假定及检验、修正一、线性回归模型的基本假定1、一元线性回归模型一元线性回归模型是最简单的计量经济学模型,在模型中只有一个解释变量,其一般形式是Y =β0+β1X 1+μ其中,Y 为被解释变量,X 为解释变量,β0与β1为待估参数,μ为随机干扰项。
回归分析的主要目的是要通过样本回归函数(模型)尽可能准确地估计总体回归函数(模型)。
为保证函数估计量具有良好的性质,通常对模型提出若干基本假设。
假设1:回归模型是正确设定的。
模型的正确设定主要包括两个方面的内容:(1)模型选择了正确的变量,即未遗漏重要变量,也不含无关变量;(2)模型选择了正确的函数形式,即当被解释变量与解释变量间呈现某种函数形式时,我们所设定的总体回归方程恰为该函数形式。
假设2:解释变量X 是确定性变量,而不是随机变量,在重复抽样中取固定值。
这里假定解释变量为非随机的,可以简化对参数估计性质的讨论。
假设3:解释变量X 在所抽取的样本中具有变异性,而且随着样本容量的无限增加,解释变量X 的样本方差趋于一个非零的有限常数,即∑(X i −X ̅)2n i=1n→Q,n →∞ 在以因果关系为基础的回归分析中,往往就是通过解释变量X 的变化来解释被解释变量Y 的变化的,因此,解释变量X 要有足够的变异性。
对其样本方差的极限为非零有限常数的假设,旨在排除时间序列数据出现持续上升或下降的变量作为解释变量,因为这类数据不仅使大样本统计推断变得无效,而且往往产生伪回归问题。
假设4:随机误差项μ具有给定X 条件下的零均值、同方差以及无序列相关性,即E(μi|X i)=0Var(μi|X i)=σ2Cov(μi,μj|X i,X j)=0, i≠j随机误差项μ的条件零均值假设意味着μ的期望不依赖于X的变化而变化,且总为常数零。
该假设表明μ与X不存在任何形式的相关性,因此该假设成立时也往往称X为外生性解释变量随机误差项μ的条件同方差假设意味着μ的方差不依赖于X的变化而变化,且总为常数σ2。
第二章简单线性回归模型

4000
2037 2210 2325 2419 2522 2665 2799 2887 2913 3038 3167 3310 3510
2754
4500
2277 2388 2526 2681 2887 3050 3189 3353 3534 3710 3834
3039
5000 5500
2469 2924 2889 3338 3090 3650 3156 3802 3300 4087 3321 4298 3654 4312 3842 4413 4074 4165
Yi 与 E(Yi Xi )不应有偏差。若偏
差u i 存在,说明还有其他影响因素。
Xi
X
u i实际代表了排除在模型以外的所有因素对 Y 的影
响。 u i
◆性质 是其期望为 0 有一定分布的随机变量
重要性:随机扰动项的性质决定着计量经济分析结19
果的性质和计量经济方法的选择
引入随机扰动项 u i 的原因
特点:
●总体相关系数只反映总体两个变量 X 和 Y 的线性相关程度 ●对于特定的总体来说,X 和 Y 的数值是既定的,总体相关系
数 是客观存在的特定数值。
●总体的两个变量 X 和 Y的全部数值通常不可能直接观测,所
以总体相关系数一般是未知的。
7
X和Y的样本线性相关系数:
如果只知道 X 和 Y 的样本观测值,则X和Y的样本线性
计量经济学
第二章 一元线性回归模型
1
未来我国旅游需求将快速增长,根据中国政府所制定的 远景目标,到2020年,中国入境旅游人数将达到2.1亿人 次;国际旅游外汇收入580亿美元,国内旅游收入2500亿 美元。到2020年,中国旅游业总收入将超过3000亿美元, 相当于国内生产总值的8%至11%。
一元线性回归模型的统计检验

3. 怎样进行拟合优度检验 (1)总离差平方和的分解 已知有一组样本观测值( Xi ,Yi )(i 1, 2, , n),得到 如下样本回归直线:
Yˆi ˆ0 ˆ1Xi
Y的第i个观测值与样本均值的离差yi Yi Y 可分 解为两部分之和:
yi Yi Y Yi Yˆi Yˆi Y ei yˆi (1)
规则:p值越小,越能拒绝原假设H0.
三、回归系数的置信区间
对参数作出的点估计虽然是无偏估计,但一 次抽样它并不一定等于真实值,所以需要找到包 含真实参数的一个范围,并确定这个范围包含参 数真实值的可靠程度。
在变量的显著性检验中已经知道:
t ˆi i ~ t(n 2) i=0,1
Sˆi
给出置信度1,查自由度为(n 2)的t分布表,
假设检验的步骤: (1)提出原假设和备择假设; (2)根据已知条件选择检验统计量; (3)根据显著性水平确定拒绝域或临界值; (4)计算出统计量的样本值并作出判断。
(2)变量的显著性检验
对于最小二乘估计量ˆ1,已经知道它服从正态分布
ˆ1 ~ N(1,
2
xi2 )
由于真实的 2未知,在用它的无偏估计量ˆ 2
在上述收入——消费支出的例子中,如果给定
=0.01,查表得:
t 2 (n 2) t0.005 (8) 3.355
由于
Sˆ1 0.042
Sˆ0 98.41
于是,计算得到1、0的置信区间分别为:
(0.6345,0.9195)
(-433.32,226.98)
则
TSS RSS ESS
Y的观测值围绕其均值的总离差可分解为两部 分:一部分来自回归线(RSS),另一部分则来自随 机势力(ESS)。因此,我们可以用回归平方和RSS 占Y的总离差平方和TSS的比例来度量样本回归线 与样本观测值的拟合优度。
简单线性回归模型的公式和参数估计方法以及如何利用模型进行

简单线性回归模型的公式和参数估计方法以及如何利用模型进行数据预测一、简单线性回归模型的公式及含义在统计学中,线性回归模型是一种用来分析两个变量之间关系的方法。
简单线性回归模型特指只有一个自变量和一个因变量的情况。
下面我们将介绍简单线性回归模型的公式以及各个参数的含义。
假设我们有一个自变量X和一个因变量Y,简单线性回归模型可以表示为:Y = α + βX + ε其中,Y表示因变量,X表示自变量,α表示截距项(即当X等于0时,Y的值),β表示斜率(即X每增加1单位时,Y的增加量),ε表示误差项,它表示模型无法解释的随机项。
通过对观测数据进行拟合,我们可以估计出α和β的值,从而建立起自变量和因变量之间的关系。
二、参数的估计方法为了求得模型中的参数α和β,我们需要采用适当的估计方法。
最常用的方法是最小二乘法。
最小二乘法的核心思想是将观测数据与模型的预测值之间的误差最小化。
具体来说,对于给定的一组观测数据(Xi,Yi),我们可以计算出模型的预测值Yi_hat:Yi_hat = α + βXi然后,我们计算每个观测值的预测误差ei:ei = Yi - Yi_hat最小二乘法就是要找到一组参数α和β,使得所有观测值的预测误差平方和最小:min Σei^2 = min Σ(Yi - α - βXi)^2通过对误差平方和进行求导,并令偏导数为0,可以得到参数α和β的估计值。
三、利用模型进行数据预测一旦我们估计出了简单线性回归模型中的参数α和β,就可以利用这个模型对未来的数据进行预测。
假设我们有一个新的自变量的取值X_new,那么根据模型,我们可以用以下公式计算对应的因变量的预测值Y_new_hat:Y_new_hat = α + βX_new这样,我们就可以利用模型来进行数据的预测了。
四、总结简单线性回归模型是一种分析两个变量关系的有效方法。
在模型中,参数α表示截距项,β表示斜率,通过最小二乘法估计这些参数的值。
线性回归模型检验方法拓展-三大检验

第四章线性回归模型检验方法拓展——三大检验作为统计推断的核心内容,除了估计未知参数以外,对参数的假设检验是实证分析中的一个重要方面。
对模型进行各种检验的目的是,改善模型的设定以确保基本假设和估计方法比较适合于数据,同时也是对有关理论有效性的验证。
一、假设检验的基本理论及准则假设检验的理论依据是“小概率事件原理”,它的一般步骤是(1)建立两个相对(互相排斥)的假设(零假设和备择假设)。
(2)在零假设条件下,寻求用于检验的统计量及其分布。
(3)得出拒绝或接受零假设的判别规则。
另一方面,对于任何的检验过程,都有可能犯错误,即所谓的第一类错误P(拒绝H|H0为真)=α和第二类错误P(接受H|H0不真)=β在下图,粉红色部分表示P(拒绝H0|H0为真)=α。
黄色部分表示P(接受H0|H0不真)=β。
而犯这两类错误的概率是一种此消彼长的情况,于是如何控制这两个概率,使它们尽可能的都小,就成了寻找优良的检验方法的关键。
下面简要介绍假设检验的有关基本理论。
参数显著性检验的思路是,已知总体的分布(,)F X θ,其中θ是未知参数。
总体真实分布完全由未知参数θ的取值所决定。
对θ提出某种假设001000:(:,)H H θθθθθθθθ=≠><或,从总体中抽取一个容量为n 的样本,确定一个统计量及其分布,决定一个拒绝域W ,使得0()P W θα=,或者对样本观测数据X ,0()P X W θα∈≤。
α是显著性水平,即犯第一类错误的概率。
既然犯两类错误的概率不能同时被控制,所以通常的做法是,限制犯第一类错误的概率,使犯第二类错误的概率尽可能的小,即在0()P X W θα∈≤ 0θ∈Θ的条件下,使得()P X W θ∈,0θ∈Θ-Θ达到最大,或1()P X W θ-∈,0θ∈Θ-Θ达到最小。
其中()P X W θ∈表示总体分布为(,)F X θ时,事件W ∈{X }的概率,0Θ为零假设集合(0Θ只含一个点时成为简单原假设,否则称为复杂原假设)。
一元线性回归模型的统计检验

预测分析
学习如何对新数据进行预测,进行误差分析,并利用置信区间来评估预测的 准确性。
模型选择
学习方差分析、逐步回归和信息准则等方法,探讨如何选择最佳的一元线性 回归模型。
实例分析
通过应用案例深入理解一元线性回归模型的统计检验,展示实际数据的应用和模型的术论文和研究报告等参考文献,帮助学习者进一步深入研 究一元线性回归模型的统计检验。
参数估计
掌握OLS估计法,解释回归系数的含义,了解拟合优度,并且能够根据参数估计法对一元线性回归模型 进行参数的估计。
模型检验
进行残差分析,检验模型是否符合要求,学习诊断性检验,发现模型中的问题并作出相应的调整。
显著性检验
学习t检验、p值和显著性水平的概念,了解在一元线性回归模型中如何进行 显著性检验。
一元线性回归模型的统计 检验
了解一元线性回归模型的统计检验。包括定义与介绍,相关理论,假设检验, 样本数据,参数估计,模型检验,显著性检验,预测分析,模型选择,实例 分析。
相关理论
了解线性回归方程、残差、误差、相关系数等相关理论,掌握它们在一元线性回归模型中的含义和应用。
样本数据
学习数据的收集、处理和描述,实现对一元线性回归模型的数据样本分析, 为后续的参数估计和模型检验打下基础。
Q& A
解答学生对于一元线性回归模型的统计检验相关问题,确保学生对所学内容的充分理解。
总结
对本次PPT的主要内容进行概括,总结重点和难点,帮助学习者回顾和巩固所 学知识。
答疑环节
解答学生在本次PPT学习中的遗留问题和疑惑,确保学生能够全面理解一元线 性回归模型的统计检验。
§2.3 一元线性回归模型的统计检验

( β$i t α × s β$ , β$i + t α × s β$ )
2 i 2 i
在上述收入-消费支出例中,如果给定α =0.01, 在上述收入-消费支出例中,如果给定α =0.01, 收入 例中 查表得: 查表得:
t α (n 2) = t0.005 (8) = 3.355
2
1
由于
S β = 0.042
βi βi s β
i
~ t ( n 2)
P(tα < t < tα ) = 1α
2 2
即
P(t α <
2
β$i βi
s β$
i
< tα ) = 1 α
2
$ tα ×s <β <β +tα ×s ) =1α $ P(β $ $ i i i β β
2 i 2 i
(1- 的置信度下, (1-α)的置信度下, βi的置信区间是
可构造如下t 对于一元线性回归方程中的β0,可构造如下 统计量进行显著性检验: 统计量进行显著性检验:
t=
β0 β0 2 ∑Xi2 n∑xi2 σ
=
β0 Sβ
0
~ t(n 2)
在上述收入-消费支出例中,首先计算σ 在上述收入-消费支出例中,首先计算σ2的估计值 收入 例中
σ2 = ei2 ∑ n 2 = (yi y)2 β12 ∑(xi x)2 ∑ n 2 =13402
§2.3 一元线性回归模型的统 计检验
一、拟合优度检验 二、变量的显著性检验 三、参数的置信区间
一、拟合优度检验
含义: 含义:对样本回归直线与样本观测值之 间拟合程度的检验。 间拟合程度的检验。 指标:判定系数(可决系数) 指标:判定系数(可决系数)R2
回归分析中的变量间关系检验方法(八)

回归分析中的变量间关系检验方法回归分析是统计学中常用的一种数据分析方法,它用来研究一个或多个自变量对因变量的影响程度。
在回归分析中,变量间关系检验是非常重要的一环,它可以帮助我们确定自变量和因变量之间的关系是否显著,从而对回归模型的准确性进行评估。
一、Pearson相关系数Pearson相关系数是一种用来衡量两个连续变量之间线性相关程度的统计量。
在回归分析中,我们可以使用Pearson相关系数来检验自变量和因变量之间的线性相关性,从而确定是否适合进行线性回归分析。
如果Pearson相关系数接近1或-1,表明两个变量之间存在较强的线性相关性;如果接近0,则表明两个变量之间不存在线性相关性。
在实际应用中,我们可以使用统计软件计算Pearson相关系数并进行显著性检验,以确定相关性是否达到显著水平。
二、t检验在回归分析中,t检验可以用来检验自变量的系数是否显著。
在简单线性回归模型中,t检验可以用来检验自变量的回归系数是否等于0,从而判断自变量对因变量的影响是否显著。
在多元线性回归模型中,t检验可以用来检验自变量的系数是否等于0,从而确定各个自变量对因变量的影响是否显著。
通常情况下,我们会对t检验的p值进行判定,如果p值小于显著性水平(通常为),则认为自变量的系数显著,反之则不显著。
三、F检验F检验是用来检验回归模型整体拟合程度的一种统计方法。
在回归分析中,我们可以使用F检验来检验回归方程的显著性,从而确定自变量对因变量的整体影响是否显著。
F检验的原假设是回归方程的系数都等于0,备择假设是回归方程的系数不全为0。
如果F检验的p值小于显著性水平(通常为),则可以拒绝原假设,认为回归方程显著,自变量对因变量的整体影响是显著的。
四、残差分析在回归分析中,残差是指观测值与回归方程预测值之间的差异。
残差分析可以帮助我们检验回归模型的假设是否成立,从而评估回归模型的拟合效果。
通常情况下,我们会对残差进行正态性检验和独立性检验,以确定回归模型的适用性。
第二章 简单线性回归模型

Y 的条件均值
E (Y X i )
55
75
95
115
135
155
175
195
215
235
之间的对应关系是: 家庭可支配收入 X 与平均消费支出 E ( Y X i ) 之间的对应关系是:
E ( Y X i ) = 15 + 2 X 3
i
的条件期望表示为解释变量的某种函数称为总体函数。 这种把总体应变量 Y 的条件期望表示为解释变量的某种函数称为总体函数。简记 PRF。 为 PRF。
(三)回归与相关的联系与区别
两者的区别在于: 用途不同—— ——相关分析是用相关系数去度量变量之间线性 (1)用途不同——相关分析是用相关系数去度量变量之间线性 关联的程度,而回归分析却要根据解释变量的确定值, 关联的程度,而回归分析却要根据解释变量的确定值,去估计和预测 被解释变量的平均值; 被解释变量的平均值; 变量性质不同—— ——相关分析中把相互联系的变量都作为随 (2)变量性质不同——相关分析中把相互联系的变量都作为随 机变量, 机变量, 而在回归分析中, 而在回归分析中, 假定解释变量在重复抽样中具有固定数值, 假定解释变量在重复抽样中具有固定数值, 是非随机的,被解释变量才是随机变量。 是非随机的,被解释变量才是随机变量。 对变量的因果关系处理不同—— ——回归分析是在变量因果关 (3)对变量的因果关系处理不同——回归分析是在变量因果关 系确定的基础上研究解释变量对被解释变量的具体影响,对变量的处 系确定的基础上研究解释变量对被解释变量的具体影响, 理是不对称的, 而在相关分析中, 把相互联系的变量都作为随机变量, 理是不对称的, 而在相关分析中, 把相互联系的变量都作为随机变量, 是对称的。 是对称的。
统计学中的回归分析方法

统计学中的回归分析方法回归分析是一种常用的统计学方法,旨在分析变量之间的关系并预测一个变量如何受其他变量的影响。
回归分析可以用于描述和探索变量之间的关系,也可以应用于预测和解释数据。
在统计学中,有多种回归分析方法可供选择,本文将介绍其中几种常见的方法。
一、简单线性回归分析方法简单线性回归是最基本、最常见的回归分析方法。
它探究了两个变量之间的线性关系。
简单线性回归模型的方程为:Y = β0 + β1X + ε,其中Y是因变量,X是自变量,β0和β1是回归系数,ε是残差项。
简单线性回归的目标是通过拟合直线来最小化残差平方和,从而找到最佳拟合线。
二、多元线性回归分析方法多元线性回归是简单线性回归的扩展形式,适用于多个自变量与一个因变量之间的关系分析。
多元线性回归模型的方程为:Y = β0 +β1X1 + β2X2 + ... + βnXn + ε,其中X1, X2, ..., Xn是自变量,β0, β1,β2, ..., βn是回归系数,ε是残差项。
多元线性回归的目标是通过拟合超平面来最小化残差平方和,从而找到最佳拟合超平面。
三、逻辑回归分析方法逻辑回归是一种广义线性回归模型,主要用于处理二分类问题。
逻辑回归将线性回归模型的输出通过逻辑函数(如Sigmoid函数)映射到概率范围内,从而实现分类预测。
逻辑回归模型的方程为:P(Y=1|X) =1 / (1 + exp(-β0 - β1X)),其中P(Y=1|X)是给定X条件下Y=1的概率,β0和β1是回归系数。
逻辑回归的目标是通过最大似然估计来拟合回归系数,从而实现对未知样本的分类预测。
四、岭回归分析方法岭回归是一种用于处理多重共线性问题的回归分析方法。
多重共线性是指自变量之间存在高度相关性,这会导致估计出的回归系数不稳定。
岭回归通过在最小二乘法的目标函数中引入一个正则化项(L2范数),从而降低回归系数的方差。
岭回归模型的方程为:Y = β0 +β1X1 + β2X2 + ... + βnXn + ε + λ∑(β^2),其中λ是正则化参数,∑(β^2)是回归系数的平方和。
实验报告简单线性回归分析

西南科技大学Southwest University of Science and Technology经济管理学院计量经济学实验报告——多元线性回归的检验专业班级:姓名: 学号: 任课教师: 成绩:简单线性回归模型的处理实验目的:掌握多元回归参数的估计和检验的处理方法。
实验要求:学会建立模型,估计模型中的未知参数等。
试验用软件:Eviews实验原理:线性回归模型的最小二乘估计、回归系数的估计和检验。
实验内容:1、实验用样本数据:运用Eviews软件,建立1990-2001年中国国内生产总值X和深圳市收入Y的回归模型,做简单线性回归分析,并对回归结果进行检验。
以研究我国国内生产总值对深圳市收入的影响。
经过简单的回归分析后得出表EQ1:Depe ndent Variable: Y Method: Least Squares Date: 11/27/11 Time: 14:02 Sample: 1990 2001 In cluded observati ons: 12 VariableCoefficientStd. Error t-Statistic Prob.C -3.611151 4.161790 -0.867692 0.4059 X0.134582 0.003867 34.80013 0.0000 R-squared0.991810 Mean depe ndent var 119.8793 Adjusted R-squared 0.990991 S.D. dependent var 79.361247.02733 S.E. of regressi on7.532484 Akaike infocriteri on8Sum squared resid 567.3831 Schwarz criteri on 7.1081561211.0490.00000Log likelihood-40.16403F-statisticDurbin-Wats on stat 2.051640 Prob(F-statistic)其中拟合优度为:0.991810有很强的线性关系2、实验步骤: 1、 回归分析:(1) 在 Objects 菜单中点击 New objects ,在 New objects 选择 Group ,并以GROUP01定义文件名,点击 OK 出现数据编辑窗口,, 按顺序键入数据。
计量经济学的2.3 一元线性回归模型的统计检验

ˆ ˆ P( ) 1
如果存在这样一个区间,称之为置信区间 (confidence interval); 1-称为置信系数(置信度) (confidence coefficient), 称为显著性水平(level of significance)(或犯第I类错误的概率,即拒真的概 率);置信区间的端点称为置信限(confidence limit) 或临界值(critical values)。置信区间以外的区间称 4 为临界域
由于置信区间一定程度地给出了样本参数估计 值与总体参数真值的“接近”程度,因此置信区间 越小越好。 (i t s , i t s )
2 i 2 i
要缩小置信区间,需要减小 (1)增大样本容量n,因为在同样的置信水平 下, n越大,t分布表中的临界值越小;同时,增大样本 容量,还可使样本参数估计量的标准差减小;
5
如何构造参数值的估计区间? 通过构造已知分布的统计量
6
构造统计量(1)
回顾: 在正态性假定下
以上统计量服从自由度为n-2的x2分布,n为样本量
7
构造统计量(2)
ˆ ˆ 0 和 1 服从正态分布
ˆ E ( 0 )= 0
ˆ E ( 1 )=1
Var 0) (ˆ
X
i 1 n i 1
§2.3 一元线性回归模型的统 计检验
一、参数的区间估计 二、拟合优度检验 三、参数的假设检验 (对教材内容作了扩充)
1
一、参数的区间估计
参数的两种估计:点估计和区间估计
点估计
通过样本数据得到参数的一个估计值。
(如:最小二乘估计、最大似然估计)
点估计不足:
(1)点估计给出在给定样本下估计出的参数的可能取值,但 它并没有指出在一次抽样中样本参数值到底离总体参数的真 值有多“近”。 (2)虽然在重复抽样中估计值的均值可能会等于真值,但由 于抽样波动,单一估计值很可能不同于真值。 2
EViews计量经济学实验报告-简单线性回归模型分析
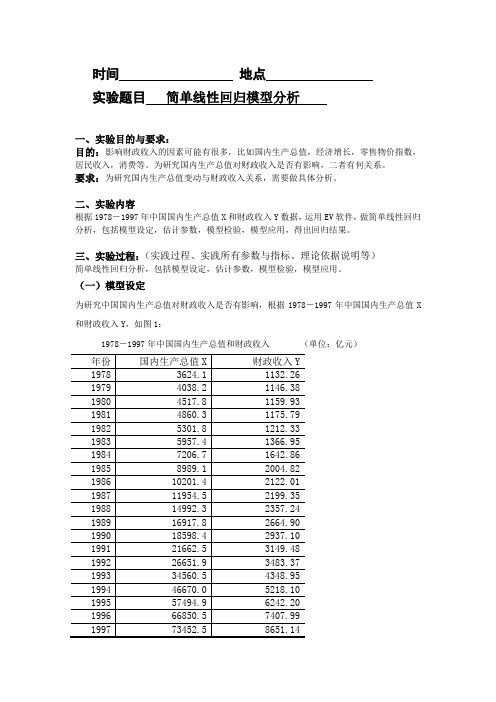
时间地点实验题目简单线性回归模型分析一、实验目的与要求:目的:影响财政收入的因素可能有很多,比如国内生产总值,经济增长,零售物价指数,居民收入,消费等。
为研究国内生产总值对财政收入是否有影响,二者有何关系。
要求:为研究国内生产总值变动与财政收入关系,需要做具体分析。
二、实验内容根据1978-1997年中国国内生产总值X和财政收入Y数据,运用EV软件,做简单线性回归分析,包括模型设定,估计参数,模型检验,模型应用,得出回归结果。
三、实验过程:(实践过程、实践所有参数与指标、理论依据说明等)简单线性回归分析,包括模型设定,估计参数,模型检验,模型应用。
(一)模型设定为研究中国国内生产总值对财政收入是否有影响,根据1978-1997年中国国内生产总值X 和财政收入Y,如图1:1978-1997年中国国内生产总值和财政收入(单位:亿元)根据以上数据,作财政收入Y 和国内生产总值X 的散点图,如图2:从散点图可以看出,财政收入Y 和国内生产总值X 大体呈现为线性关系,所以建立的计量经济模型为以下线性模型:01i i i Y X u ββ=++(二)估计参数1、双击“Eviews ”,进入主页。
输入数据:点击主菜单中的File/Open /EV Workfile —Excel —GDP.xls;2、在EV 主页界面点击“Quick ”菜单,点击“Estimate Equation ”,出现“Equation Specification ”对话框,选择OLS 估计,输入“y c x ”,点击“OK ”。
即出现回归结果图3:图3. 回归结果Dependent Variable: Y Method: Least Squares Date: 10/10/10 Time: 02:02 Sample: 1978 1997 Included observations: 20Variable Coefficient Std. Error t-Statistic Prob. C 857.8375 67.12578 12.77955 0.0000 X0.1000360.00217246.049100.0000R-squared 0.991583 Mean dependent var 3081.158 Adjusted R-squared 0.991115 S.D. dependent var 2212.591 S.E. of regression 208.5553 Akaike info criterion 13.61293 Sum squared resid 782915.7 Schwarz criterion 13.71250 Log likelihood -134.1293 F-statistic 2120.520 Durbin-Watson stat0.864032 Prob(F-statistic)0.000000参数估计结果为:i Y = 857.8375 + 0.100036i X(67.12578) (0.002172)t =(12.77955) (46.04910)2r =0.991583 F=2120.520 S.E.=208.5553 DW=0.8640323、在“Equation ”框中,点击“Resids ”,出现回归结果的图形(图4):剩余值(Residual )、实际值(Actual )、拟合值(Fitted ).(三)模型检验1、 经济意义检验回归模型为:Y = 857.8375 + 0.100036*X (其中Y 为财政收入,i X 为国内生产总值;)所估计的参数2ˆ =0.100036,说明国内生产总值每增加1亿元,财政收入平均增加0.100036亿元。
回归分析与相关性检验方法

回归分析与相关性检验方法引言回归分析和相关性检验方法是统计学中常用的两种分析方法。
它们主要用于研究变量之间的关联程度和预测某一变量对其他变量的影响。
在实际应用中,回归分析和相关性检验方法具有广泛的应用领域,例如经济学、医学、社会科学等。
本文将对回归分析和相关性检验方法进行详细介绍,并给出相应的案例应用。
一、回归分析回归分析是一种统计学方法,用于研究因变量和一个或多个自变量之间关系的强度和方向。
回归分析有两种基本类型:简单线性回归和多元线性回归。
1. 简单线性回归简单线性回归是指当因变量和自变量之间存在一种线性关系时使用的回归分析方法。
简单线性回归的模型可以表示为:$y = \\beta_0 + \\beta_1x + \\epsilon$,其中y表示因变量,x表示自变量,$\\beta_0$和$\\beta_1$是回归系数,表示截距和斜率,$\\epsilon$表示误差项。
简单线性回归的关键是通过最小二乘法估计回归系数,然后进行显著性检验和模型拟合度的评估。
通过显著性检验可以确定回归系数是否显著不为零,进而得出自变量对因变量的影响是否显著。
2. 多元线性回归多元线性回归是指当因变量和多个自变量之间存在一种线性关系时使用的回归分析方法。
多元线性回归的模型可以表示为:$y = \\beta_0 + \\beta_1x_1 +\\beta_2x_2 + ... + \\beta_nx_n + \\epsilon$,其中y表示因变量,x1,x2,...,x n表示自变量,$\\beta_0, \\beta_1, \\beta_2, ..., \\beta_n$表示回归系数,$\\epsilon$表示误差项。
多元线性回归的关键也是通过最小二乘法估计回归系数,并进行显著性检验和模型拟合度的评估。
多元线性回归可以通过检验回归系数的显著性,判断各个自变量是否对因变量产生显著影响。
二、相关性检验方法相关性检验方法是用于检测变量之间关系的非参数统计学方法。
计量经济学中的各种检验

需要说明的问题
在实际应用中,我们往往希望所建立模型的决定 系数或修正的决定系数越大越好。但应注意,决 定系数只是对模型拟合优度的度量,决定系数或 修正的决定系数越大,只能说明列入模型的解释 变量对被解释变量整体的影响程度很大,并不能 说明模型中各个解释变量对被解释变量的影响程 度显著。因此在选择模型时,不能单纯地凭决定 系数的高低来断定模型的优劣,有时从模型的经 济意义和整体可靠程度的角度出发,可以适当降 低对决定系数的要求。
拟合优度检验和F检验的关系
F检验和拟合优度检验都是把总变差TSS分 解为回归平方和与残差平方和,并在这一 分解的基础上构造统计量进行的检验。区 别在于前者有精确的分布而后者没有。一 般来说,模型对观测值的拟合程度越高, 模型总体线性关系的显著性越强。
拟合优度检验和F检验的关系
F显著==>拟合优度必然显著
这两准则均要求仅当所增n 加n的解释变量能够减少 AIC值或SC值时才在原模型中增加该解释变量。
回归模型的总体显著性检验
拟合优度检验可以说明模型对样本数据的 近似情况。模型的总体显著性检验则一般 用来检验全部解释变量对被解释变量的共 同影响是否显著。
回归模型的总体显著性检验
检验全部解释变量对被解释变量的共同影响是否显著,或者说,检验回
TSS=RSS+ESS 被解释变量Y总的变动(差异)=解释变量
X引起的变动(差异)+除X以外的因素引 起的变动(差异) 如果X引起的变动在Y的总变动中占很大比 例,那么X很好地解释了Y;否则,X不能 很好地解释Y。
第三节 一元线性回归模型的统计检验

二、模型的显著性检验
模型的显著性检验,就是检验模型对总体的 近似程度。最常用的检验方法是F检验或者R 检验。 1. F检验 ∑( yi y ) 2 / k F= ~ F (k , n k 1) 2 ∑ ei / n k 1
给定的显著水平
α,可由F分布表查得临界值,进行判断:
若 F0 > Fα ,可以认为模型的线性关系是显著的; 若 F0 ≤ Fα ,则接受 H ,认为模型的线性关系不显著,回 0 归模型无效。
方程的显著性检验, 方程的显著性检验,旨在对模型中被解释变 量与解释变量之间的线性关系在总体上是否显著 成立作出推断。 成立作出推断。
1、方程显著性的 检验 、方程显著性的F检验
即检验模型
Yi=β0+β1X1i+β2X2i+ … +βkXki+i i=1,2, …,n
中的参数βj是否显著不为0。 可提出如下原假设与备择假设: H0: β0=β1=β2= … =βk=0 H1: βj不全为0
注意: 注意:一个有趣的现象
(Y Y ) = (Y Y ) + (Y Y ) (Y Y ) ≠ (Y Y ) + (Y Y ) ∑ (Y Y ) = ∑ (Y Y ) + ∑ (Y Y )
i i i i 2 2 2 i i i i 2 2 i i i i
2
TSS=ESS+RSS Y的观测值围绕其均值的总离差 总离差(total variation) 总离差 可分解为两部分:一部分来自回归线 一部分来自回归线(ESS),另一部 一部分来自回归线 , 分则来自随机因素的影响(RSS)。 分则来自随机因素的影响 在给定样本中,TSS不变, 如果实际观测点离样本回归线越近,则ESS在 TSS中占的比重越大,因此 拟合优度:回归平方和ESS/Y的总离差TSS 拟合优度:回归平方和ESS/Y的总离差TSS ESS/Y的总离差
简单线性回归模型的统计检验

t分布
P(t)
P(t
2
t
ˆ1 1 seˆ(ˆ1)
t ) 1
2
95%
拒绝域
2
t (n 2)
接受域 0
2
拒绝域
t (n 2)
t
假如 0.05,t 2.1009 P(2.1009 t* 2.1009) 95%
2
16
举例:一元线性模型中,i (i=1,2)的置信区间: 在变量的显著性检验中已经知道:
在实际计算可决系数时,在 ˆ1 已经估计出后:
R 2
ˆ12
xi2
y
2 i
在例2.2收入-消费支出例中,
R2 1
ei2 yi2
1 76650 5870212.5
0.9869
注:可决系数是一个非负的统计量。它也是随
着抽样的不同而不同。为此,对可决系数的统计 可靠性也应进行检验,这将在第3章中进行。
Yˆi ˆ0 ˆ1 X i
yi Yi Y (Yi Yˆi ) (Yˆi Y ) ei yˆi
3
如果Yi=Ŷi 即实际观测值落在样本回归“线”上,则拟合最好。
可以认为,“离差”全部来自回归线,而与“残差”无关。 4
对于所有样本点,则需考虑这些点与样本均值离 差的平方和,可以证明:
偏估计ˆ 2 ei2 直接代替 2 来计算参数估计量的标准误差: n2
seˆ(ˆ1) ˆ
n
X
2 i
xi2
seˆ(ˆ2 )
ˆ
xi2
12
(2)在小样本情况下,若用无偏估计 ^2代替 去2
估计标准误差,则进行标准变化的统计量不再服从正
态分布,而是服从自由度为n-2的t分布
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
可编辑ppt
1
1、拟合优度检验
拟合优度检验:对样本回归直线与样本 观测值之间拟合程度的检验。
度量拟合优度的指标:判定系数(可决 系数)R2
问题:采用普通最小二乘估计方法,已 经保证了模型最好地拟合了样本观测值, 为什么还要检验拟合程度?
可编辑ppt
2
2、总离差平方和的分解
已知由一组样本观测值(Xi,Yi),i=1,2…,n得到如下 样本回归直线
n
X
2 i
x
2 i
s eˆ ( ˆ 2 )
ˆ
x
2 i
可编辑ppt
12
(2)在小样本情况下,若用无偏估计 ^ 2 代替 2 去 估计标准误差,则进行标准变化的统计量不再服从正
态分布,而是服从自由度为n-2的t分布
一 般 情 况 下 , 对 ˆ 1 与 ˆ 2 变 换 后 服 从 自 由 度 为 n - 2 的 t 分 布 :
可编辑ppt
15
t分布
P (t)
P(t 2tsˆe 1 ˆ( ˆ 1)1t 2)195%
拒绝域
2
t (n 2)
接受域 0
2
拒绝域
t (n 2)
t
假如0.05,t 2.1009 P ( 2 .1 0 0 9 t* 2 .1 0 0 9 ) 9 5 %
2
可编辑ppt
16
举例:一元线性模型中,i (i=1,2)的置信区间: 在变量的显著性检验中已经知道:
x
2 i
^
^
1 Y2 X
^^
因为 1 , 2 是关于Y 的线性函数,而Y是关于随机扰动项 ui的线 ^^
性函数,所以 1 , 2 也是ui的线性函数,且服从正态分布
^
1 ~N(1,2 n
Xxi2i2)
^
2 ~ N(2,
2
) xi2
可编辑ppt
10
1 、 经 过 标 准 变 化 的 服 Z 1,Z 2 从 标 准 正 态 分 布
Yˆi ˆ0ˆ1Xi
y i Y i Y ( Y i Y ˆ i) ( Y ˆ i Y ) e i y ˆ i
可编辑ppt
3
如果Yi=Ŷi 即实际观测值落在样本回归“线”上,则拟合最好。
可以认为,“离差”全部来自回归线,而与“残差”无关。
可编辑ppt
4
对于所有样本点,则需考虑这些点与样本均值离 差的平方和,可以证明:
可编辑ppt
7
在 实 际 计 算 可 决 系 数 时 , 在 ˆ 1 已 经 估 计 出 后 :
R2
ˆ12
xi2 yi2
在例2.2收入-消费支出例中,
R 21 e yii2 2158 7 7 6 0 6 2 5 1 0 2.50.9869
注:可决系数是一个非负的统计量。它也是 随着抽样的不同而不同。为此,对可决系数的统 计可靠性也应进行检验,这将在第3章中进行。
ˆ1 与 ˆ 2 均 服 从 正 态 分 布 , 且 :
ˆ 1 ~ N ( 1 , 2 n
X
2 i
)
x
2 i
ˆ 2 ~ N ( 2 ,
2
)
x
2 i
将其作标准化变换,有
Z 1 ( ˆ 1 1 ) / s e ( ˆ 1 )
ˆ 1 1 ~ N ( 0 ,1 )
2
X
2 i
n
x
2 i
记 T Sy S i2(Y i Y )2 总体平方和(Total Sum
of Squares)
E SS y ˆi2(Y ˆi Y )2 回归平方和(Explained
Sum of Squares)
R SS e i2(Y i Y ˆi)2 残差平方和(Residual
Sum of Squares )
值。这种方法就是参数检验的置信区间估计。
可编辑ppt
14
P (ˆ ˆ ) 1
如果存在这样一个区间,称之为置信区间 (confidence interval); 1-称为置信系数(置信度) (confidence coefficient), 称为显著性水平(level of significance ) ; 置 信 区 间 的 端 点 称 为 置 信 限 (confidence limit)或临界值(critical values)。
假设检验可以通过一次抽样的结果检验总体参 数可能的假设值的范围(如是否为零),但它并没 有指出在一次抽样中样本参数值到底离总体参数的 真值有多“近”。
要判断样本参数的估计值在多大程度上可以
“近似”地替代总体参数的真值,往往需要通过构
造一个以样本参数的估计值为中心的“区间”,来
考察它以多大的可能性(概率)包含着真实的参数
Z2
( ˆ 2
2 ) / 2
~
N ( 0 ,1)
x
2 i
可编辑ppt
11
( 1) 当 总 体 回 归 函 数 中 随 机 扰 动 项 的 方 差 2 未 知 时 , 用 其 无
偏
估
计
ˆ 2
e
2 i
直
接
代
替
2来
计
算
参
数
估
计
量
的
标
准
误
差
:
n2
s eˆ ( ˆ 1 ) ˆ
可编辑ppt
6
3、可决系数R2统计量
R 2 E S S 1 R S S 1 e i 2
T S S
T S S
y i 2
称 R2 为(样本)可决系数/判定系数(coefficient of determination)。
可决系数的取值范围:[0,1]
R2越接近1,说明实际观测点离样本线越近,拟 合优度越高,模型的解释程度越高。
可编辑ppt
8
第四节 回归系数的区间估计和假设检验
• 一、OLS估计的分布性质 • 二、回归系数的区间估计 • 三、回归系数的假设检验
可编辑ppt
9
一、OLS估计的分布性质
^^
1 , 2 是关于样本观测值Yi的线性函数
^ 2
xiyi xi2
xiYi xi2
kiYi k i
xi
可编辑ppt
5
TSS=ESS+RSS
Y的观测值围绕其均值的总离差(total variation) 可分解为两部分:一部分来自回归线(ESS),另一部 分则来自随机势力(RSS)。
在给定样本中,TSS不变, 如果实际观测点离样本回归线越近,则ESS在
TSS中占的比重越大,因此 拟合优度:回归平方和ESS/Y的总离差TSS
ˆ1 1 s eˆ ( ˆ1 )
~
t(n
2)
ˆ 2 2 s eˆ ( ˆ 2 )
~
t(n
2)
在大样本的情况下,可近似看作服从正态分布:
ˆ 1 1 s eˆ ( ˆ 1 )
~
N
( 0 ,1 )
ˆ 2 2 s eˆ ( ˆ 2 )
~
N
( 0 ,1 )
可编辑ppt
13
二、回归系数的区间估计