总结与SPSS实践操作
spss实验报告,心得体会

spss实验报告,心得体会篇一:SPSS实验报告SPSS应用——实验报告班级:统计0801班学号:1304080116 姓名: 宋磊指导老师:胡朝明2010.9.8一、实验目的:1、熟悉SPSS操作系统,掌握数据管理界面的简单的操作;2、熟悉SPSS结果窗口的常用操作方法,掌握输出结果在文字处理软件中的使用方法。
掌握常用统计图(线图、条图、饼图、散点、直方图等)的绘制方法;3、熟悉描述性统计图的绘制方法;4、熟悉描述性统计图的一般编辑方法。
掌握相关分析的操作,对显著性水平的基本简单判断。
二、实验要求:1、数据的录入,保存,读取,转化,增加,删除;数据集的合并,拆分,排序。
2、了解描述性统计的作用,并1掌握其SPSS的实现(频数,均值,标准差,中位数,众数,极差)。
3、应用SPSS生成表格和图形,并对表格和图形进行简单的编辑和分析。
4、应用SPSS做一些探索性分析(如方差分析,相关分析)。
三、实验内容:1、使用SPSS进行数据的录入,并保存: 职工基本情况数据:操作步骤如下:打开SPSS软件,然后在数据编辑窗口(Data View)中录入数据,此时变量名默认为var00001,var00002,…,var00007,然后在Variable View窗口中将变量名称更改即可。
具体结果如下图所示:输入后的数据为:将上述的数据进行保存:单击保存即可。
2、读取上述保存文件:选择菜单File--Open—Data;选择数据文件的类型,并输入文件名进行读取,出现如下窗口:选定职工基本情况.sav文件单击打开即可读取数据。
3、对上述数据新增一个变量工龄,其操作步骤为将当前数据单元确定在某变量上,选择菜单Data—Insert Variable,SPSS自动在当前数据单元所在列的前一列插入一2个空列,该列的变量名默认为var00016,数据类型为标准数值型,变量值均是系统缺失值,然后将数据填入修改。
结果如下图所示:篇二:SPSS相关分析实验报告本科教学实验报告(实验)课程名称:数据分析技术系列实验实验报告学生姓名:一、实验室名称:二、实验项目名称:相关分析三、实验原理相关关系是不完全确定的随机关系。
spss统计分析实习心得5篇

spss统计分析实习心得5篇大家知道SPSS吗?SPSS是世界上最早的统计分析软件,SPSS全称为“统计产品与服务解决方案”,是用于统计学分析运算、数据挖掘和预测分析等等。
下面是小编给大家带来的spss统计分析实习心得范文5篇,以供大家参考,我们一起来看看吧!spss统计分析实习心得体会范文1五天的SPSS软件实训终于结束了,虽然实训过程充满了酸甜苦辣,但实训结果却是甜的。
看着小组的课题报告,心里有种说不出来的感触。
高老师在对统计理论及SPSS 软件功能模块的讲解的同时更侧重于统计分析在各项工作中的实际应用,使我们不仅掌握SPSS 软件及技术原理而且学会运用统计方法解决工作和学习中的实际问题这个实训。
我真真正正学到了不少知识,另外,也提高了自己分析问题解决问题的能力。
小组中每个人完成不同的任务,我的任务是用独立样本T检验的方法分析市、县及县以下的分类对社会消费品零售总额的影响,分析方差,均值,P值,显著性如何并进行T检验,得出结论报告。
结果中比较有用的值为差值变量的均值Mean和Sig显著性在初级统计中,通常都要求所分析的数据呈现正态分布。
通过对spss软件对数据的实践处理,我感觉显著性检验问题还是比较简单的,但对具体数据分析的目的性,实用性以及自己在做研究时如何使用,还有待进一步实践和提高。
SPSS 有具体的使用者要求的分析深度,同时是一个可视化的工具,使我们非常容易使用,这样我们可以自己对结果进行检查。
电算化老师曾经说过,学习软件其实只是学习软件的操作流程,而要真正掌握整个软件,就得自己摸索探究,真真正正弄懂它,还要下一定的功夫的。
我也深刻体会到了这点。
前几次实训都是关于会计实验的,虽然时间安排比此次实训紧,任务量大,但实训结束后,基本的试训内容都完全掌握。
而这次实训,虽然时间安排较为轻松,内容也不多,操作起来也有一定的难度,另外受外界因素的影响,根本就听不见看不见老师讲的,即便后来老师一讲就去前面,由于没有条件跟着操作,导致一部分内容总是不熟练,请教同学他们也不会,不过,问题也总会用解决的办法。
spss
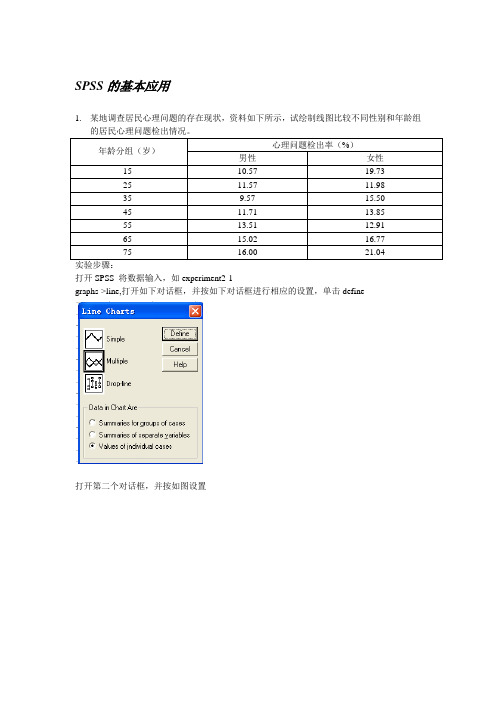
SPSS的基本应用1.某地调查居民心理问题的存在现状,资料如下所示,试绘制线图比较不同性别和年龄组的居民心理问题检出情况。
实验步骤:打开SPSS 将数据输入,如experiment2-1graphs->line,打开如下对话框,并按如下对话框进行相应的设置,单击define打开第二个对话框,并按如图设置单击OK,其线图绘制如下实验结果:通过图形比较分析,可得到以下结论1、女性的心理问题在大部分时间段都比男性高一些2、女性在20-60岁之间心理波动不是很大,女性在25和55岁时的心理问题最小3、男性的心理曲线总体成升高趋势增长,男性在35岁时心理问题最小通过图形,我们还可以发现很多结论,具体问题具体分析,此处只是得出了部分结论2、为研究儿童生长发育的分期,调查1253名1月至7岁儿童的身高(cm),体重(kg),胸围(cm)和坐高(cm)资料。
资料作如下整理:先把一月至七岁化成19个月份段,分月份算出各指标的平均值,将第1月的各指标平均值与出生时的各指标平均值比较,求出月平均值增长率(%),然后第二月起的各月份指标平均值均与前一月比较,亦求出月平均增长率(%),结果见下表。
欲将儿童生长发育分为四期,故指定聚类的类别数为4,请通过聚类打开SPSS 将数据输入,如experiment2-2analyze->classify->k-means cluster打开如下对话框,按如图设置并单击save,选择cluster menbership单击potions选择ANOVA table单击OK得到分类结果保存在experiment2-2result1Quick ClusterInitial Cluster CentersIteration History(a)absolute coordinate change for any center is .000. The current iteration is 2. The minimum distance between initial centers is 10.520.Final Cluster Centers12 3 4 height 11.03 5.47 2.86 .91 weigth50.30 19.30 7.75 1.47 circumferenc e11.81 5.20 2.09 .48 sitheigth 11.277.182.11.66ANOVAThe F tests should be used only for descriptive purposes because the clusters have been chosen to maximize the differences among cases in different clusters. The observedsignificance levels are not corrected for this and thus cannot be interpreted as tests of the hypothesis that the cluster means are equal.Number of Cases in each ClusterCluster 11.000 2 1.000 32.000 415.000 Valid 19.000 Missing.000分类结果中有一个结果反常,通过与上表分类结果对比,第四组最接近第三组的结果 将第四组的weight 值增加0.5,其分类结果如experiment2-2result2Final Cluster Centers通过以上分析儿童生长发育的四个起止区间为第一个发育期间为:第一个月第二个发育期间为:第二个月第三个发育期间为:第三,四,六月第四个发育期间为:剩余的月份实验小结1、第二题感觉分析不是很严谨,但又不知道该怎么做,请老师指导。
Spss实验总结

本学期一共学习了七项spss使用方法,分别是数据整理、数据的转换、t检验、方差分析、卡方检验、相关分析与回归方程、图表的制作与编辑。
我觉得spss对我用处非常大,就平时学习来说,我用它计算了几道生物统计题,完成了spss作业和数学建模作业。
因为实验指导书有几个实验实验方法与步骤很不详细,我还练习了写实验方法与步骤,但在写实验感受方面还有所欠缺。
统计学是一门研究随机事件的学科,这类偶然现象是遵循统计规律的,当随机现象是由大量的成份组成,或者随机现象出现大量的次数时,就能体现统计平均规律。
我们只有对数据资料作统计处理,才可能发现它们的内在规律,掌握现象的特征,检验研究的假设,才能得出准确的、可靠的研究结果。
每次实验我开始时都觉得很难,很多时候是因为不知道怎么做表格,比如做卡方检验的时候要交叉值表,一开始我都一直是认为应该把不同因素和不同水平放到不同列里,之后才发现同一因素要写在同一列里,然后在另一列里些他们的水平,这样就会被自动分开。
相关分析我到现在还有一点不明白。
相关分析和回归方程里的那几道题那些应该用相关分析做,那些应该用回归方程做,当然这是统计学方面的问题了。
我以后还要加强对实验结果的解读能力,spss给出的计算结果往往有双侧sig.值等,而我还不太会查表(有个别不清楚查那个表),所以一些题目没有写最终分析。
Spss作为一个工具,本身并无太多原理可言,主要是掌握它的使用方法。
数据输入主要是分为数据列表和变量列表。
和excel最不一样的是变量列表。
变量列表可以对变量名,变量类型作出规定。
而这些尤其是变量类型对后续的统计分析工作有很大影响。
数据整理很重要的一点是排序。
Spss可以先按一个变量排,再在此基础上按另一个变量排。
这是我以前不了解的一个功能。
1.在数据文件中单击菜单项“Data→Sort Cases”,在变量列表中选定按哪(几)个变量的值排序,并用箭头按钮将其移入Sort by矩形框中,单击按纽即会对数据文件中的case进行排序。
spss描述性统计分析实验总结(3篇)

spss描述性统计分析实验总结(3篇)为期半个学期的统计学试验就要完毕了,这段以来我们主要通过excl软件对一些数据进展处理,比方抽样分析,方差分析等,经过这段时间的学习我学到了许多,把握了许多应用软件方面的学问,真正地学与实践相结合,加深学问把握的同时也熬炼了操作力量,回忆整个学习过程我也有许多体会。
统计学是比拟难的一个学科,作为工商专业的一名学生,统计学对于我们又是相当的重要。
因此,每次试验课我都坚持按时到试验室,试验期间仔细听教师讲解,看教师操作,然后自己独立操作数遍,不懂的问题会请教教师和同学,有时也跟同学商议找到更好的解决方法。
几次试验课下来,我感觉我的力量的确提高了不少。
统计学是应用数学的一个分支,主要通过利用概率论建立数学模型,收集所观看系统的数据,进展量化的分析、总结,并进而进展推断和猜测,为相关决策供应依据和参考。
它被广泛的应用在各门学科之上,从物理和社会科学到人文科学,甚至被用来工商业及政府的情报决策之上。
可见统计学的重要性,仔细学习显得相当必要,为以后进入社会有更好的竞争力,也为多把握一门学科,对自己对社会都有好处。
几次的试验课,我每次都有不一样的体会。
个人是理科出来的,对这种数理类的课程原来就很感兴趣,经过书本学问的学习和试验的实践操作更加加深了我的兴趣。
每次做试验后回来,我还会不定时再独立操作几次为了不遗忘操作方法,这样做可以加深我的记忆。
依据记忆曲线的理论,学而时习之才能保证对学问和技能的真正以及把握更久的把握。
就拿最近一次试验来说吧,我们做的是“平均进展速度”的问题,这是个比拟简单的问题,但是放到软件上进展操作就会变得麻烦,书本上只是直接给我们列出了公式,但是对于其中的原理和意义我了解的还不够多,在做试验的时候难免会有许多问题。
不惊奇的是这次试验好多人也都是不明白,操作不好,不像以前几次试验教师讲完我们就差不多把握了,但是这次好像遇到了大麻烦,由于内容比拟多又是一些没接触过的东西。
SPSS操作归纳总结(全)

SPSS操作归纳总结一、成绩分析(集中量和差异量)如:某校高一甲板40名学生的化学测验分数操作:Analyze——Descriptive Statistics—Frequencies(频数)二、相关量1、积差相关系数如:40名学生的数学和化学成绩操作:Analyze——Correlate(相关)——BIvariate(双变量)结论:在0.01水平上学生的化学成绩与生物成绩相关,也就是说我们有99%的把握说学生的化学成绩与生物成绩密切相关。
分析:若Sig.(2-tailed)的值<0.05,则相关程度密切若Sig.(2-tailed)的值<0.01,则相关程度非常密切若Sig.(2-tailed)的值>0.05,则相关程度不密切2、点双列相关系数如:求若干名考生的生物成绩与性别之间的相关系数,并判断他们之间有无相关关系?操作:Analyze——Correlate(相关)——BIvariate(双变量)分析:Sig.(2-tailed)的值>0.05,则相关程度不密切。
结论:在0.05水平上学生的生物成绩与性别无密切相关,也就是说我们没有95%的把握说学生的生物成绩与性别密切相关,或者说学生的生物成绩和性别无密切关系。
3、等级相关系数如:高考总分与生物等级、化学等级的相关操作:Analyze ——Correlate (相关)——BIvariate (双变量)注:相关系数为负值,说明为负相关,正值为正相关,而且绝对值越大,相关性越大。
该题中男表示为1,女表示为0,该结果为负值,说明女的成绩好,而男的成绩不好。
分析:Sig.(2-tailed)的值>0.05,则相关程度不密切。
结论:在0.05水平上学生的三科总分与物理等级无密切相关,也就是说我们没有95%的把握说学生的三科总分与物理等级密切相关,或者说学生的三科总分与物理等级无密切关系。
补充:“物理等级”转换成“等级数”操作:Transform——Recode——Into different variables三、考试质量的分析1、难度分析(P)Analyze——Descriptive Statistics—Frequencies结论:客观题的难度P ——直接看得分的valid percent主观题的难度P——mean 除以该题的总分值2、区分度分析(1)用相关系数法求试题的区分度某一题的得分与该生总分的相关程度作为该题的区分度。
spss实验报告总结

spss实验报告总结SPSS实验报告总结引言:SPSS(Statistical Package for the Social Sciences)是一款广泛应用于社会科学领域的统计分析软件。
本实验报告将对使用SPSS进行数据分析的过程进行总结,包括实验设计、数据收集、数据处理和结果分析等方面。
实验设计:本次实验旨在研究A市不同年龄段居民的消费习惯。
为此,我们采用了问卷调查的方法,设计了一份包含消费项目和年龄段的问卷,并在A市不同地区随机抽取了500名居民作为样本。
数据收集:在数据收集阶段,我们在A市的各个社区设置了问卷发放点,向居民发放了问卷并进行了解答。
为了提高问卷的有效性,我们还进行了问卷前的预测试,对问卷进行了修改和完善。
数据处理:在数据处理阶段,我们首先对收集到的问卷进行了筛选和整理,剔除了填写不完整或无效的问卷。
然后,我们使用SPSS软件将问卷数据进行了录入和清洗,确保数据的准确性和完整性。
结果分析:在结果分析阶段,我们使用SPSS软件对数据进行了描述性统计和推断性统计分析。
首先,我们计算了不同年龄段居民在各个消费项目上的平均消费金额,并绘制了柱状图进行可视化展示。
然后,我们使用t检验和方差分析等方法,对不同年龄段居民的消费习惯进行了比较和分析。
根据我们的分析结果,我们得出了以下几点结论:1. 不同年龄段居民在消费习惯上存在差异。
年轻人更倾向于消费电子产品和时尚服饰,而中年人更注重家庭生活和教育支出,老年人则更关注健康和养老等方面。
2. 年龄段对消费金额的影响存在显著差异。
通过t检验分析,我们发现不同年龄段居民在某些消费项目上的平均消费金额存在显著差异,这对商家的市场定位和推广活动具有重要意义。
3. 不同地区的消费习惯存在差异。
通过方差分析,我们发现不同地区居民在某些消费项目上的平均消费金额存在显著差异,这可能与地区的经济发展水平和文化背景等因素有关。
结论:通过本次实验,我们利用SPSS软件对A市不同年龄段居民的消费习惯进行了研究和分析。
SpsS实验总结(1)

SpsS实验总结(1)SpsS实验总结SpsS是一种广泛存在于细菌膜上的蛋白质,可以调节膜的渗透性和生长环境的适应性。
在SpsS实验中,我们使用了大肠杆菌作为实验对象,探究了SpsS的功能和作用机制。
以下是本次实验的总结。
实验目的本次实验的目的是探究SpsS对细菌细胞的作用机制,尤其是在逆境环境下的调节功能。
通过实验,了解SpsS在细菌生长与适应中的意义。
实验过程实验过程主要包括以下几个步骤。
1.构建大肠杆菌菌株收集大肠杆菌菌株,并筛选SpsS表达量较高的亚克隆。
再通过PCR扩增和测序确认SpsS基因的序列信息和克隆品质量。
2.制备膜样品将菌株分别培养在LB培养基和M9培养基条件下,分别制取菌体和膜样品。
3.光谱测定使用傅里叶变换红外光谱仪(FTIR)对膜样品进行光谱检测,得到膜样品的红外光谱图谱。
4.电导测定使用电导率计分别测试两组样品在不同温度和pH值下的电导率,观察SpsS对细胞膜渗透性的影响。
5.蛋白免疫印迹将上述两组样品的蛋白通过SDS-PAGE电泳分离并向纸膜上转移,采用免疫印迹的方法检测和定量SpsS的表达量和变化情况。
实验结果通过对实验数据的分析,可以得出以下结论。
1. SpsS的表达与细菌膜的渗透性有关,其表达量越高,细胞膜越容易受到外界环境的影响,渗透性越大。
2. SpsS在调节膜的渗透性时,主要通过改变细胞膜的液态晶体结构和脂质双层间的距离实现。
3. SpsS的活性与细菌所处的环境条件有密切的关系,如温度、pH值、盐度等对其表达和调节功能有一定的影响。
实验总结通过本次实验,我们对SpsS蛋白的功能和调节机制有了一定的了解,进一步认识了细菌在适应不同环境下生存的机制和调节格局。
同时,实验结果也为探究SpsS在生物医学和环境领域的应用奠定了基础。
spss实习报告心得范文

spss实习报告心得范文spss实习报告心得【1】本科的时候有概率统计和数理分析的基础,但是从来没有接触过应用统计分析的东西,SPSS也只是听说过,从来没有学过。
一直以为这一块儿会比较难,这学期最初学的时候,因为没有认真看老师给的英文教材,课下也没有认真搜集相关资料,所以学起来有些吃力,总感觉听起来一头雾水。
老师说最后的考核是通过提交学习报告,然后我从图书馆里借了些教材查了些资料,发现很多问题都弄清楚了。
结合软件和书上的例子,实战一下,发现SPSS的功能相当强大。
最后总结出这篇报告,以巩固所学。
SPSS,全称是Statistical Product and Service Solutions,即“统计产品与服务解决方案”软件,是IBM公司推出的一系列用于统计学分析运算、数据挖掘、预测分析和决策支持任务的软件产品及相关服务的总称,也是世界上公认的三大数据分析软件之一。
SPSS具有统计分析功能强大、操作界面友好、与其他软件交互性好等特点,被广泛应用于经济管理、医疗卫生、自然科学等各个领域。
具体到管理方面,SPSS也是一个进行数据分析和预测的强大工具。
这门课中也会用到AMOS软件。
关于SPSS的书,很多都是首先介绍软件的。
这个软件易于安装,我装的是19。
0的,虽然20。
0有一些改变和优化,但是主体都是一样的,而且都是可视化界面,用起来很方面且容易上手。
所以,我学习的重点是卡方检验和T检验、方差分析、相关分析、回归分析、因子分析、结构方程模型等方法的适用范围、应用价值、计算方式、结果的解释和表述。
首先是T检验这一部分。
由于参数检验的基础不牢固,这部分也是最初开始接触应用统计的东西,学起来很多东西拿不准,比如说原假设默认的是什么。
结果出来后依然分不清楚是接受原假设还是拒绝原假设。
不过现在弄懂了。
这部分很有用的是T检验。
T检验应用于当样本数较小时,且样本取自正态总体同时做两样本均数比较时,还要求两样本的总体方差相等时,已知一个总体均数u,可得到一个样本均数及该样本标准差,样本来自正态或近似正态总体。
SPSS实训总结

课程实训系部:管理工程系专业:营销与策划班级:营销102学号:姓名:实训课程名称:SPSS指导教师:邓丽丽课程实训周次:17周起始日期2011年12月19日-2011年12月23日目录一、实训目的:了解什么是SPSS: (3)二、实训内容:了解SPSS的操作方法 (4)三、实训的意义: (5)四、EXCEL与SPSS 的区别: (6)一、实训目的:了解什么是SPSS:SPSS软件,社会科学统计包(SPSS)(Statistical Package for the Social Sciences),在2000年SPSS公司重新定义了产品的名称。
正式改名为(Statistical Product and Service Solutions)。
意为“统计产品与服务解决方案”。
SPSS现在的最新版本为11.03,大小约为200M。
他是世界上最早的统计分析软件,由美国斯坦福大学的三位研究生于20世纪60年代末研制,同时成立了SPSS公司,并于1975年在芝加哥组建了SPSS总部。
在最新的11版中,SPSS 一共由十个模块组成,其中SPSS Base为基本模块,其余九个模块为Advanced Models、Regression Models、Tables、Trends、Categories、Conjoint、Exact Tests、Missing Value Analysis和Maps,分别用于完成某一方面的统计分析功能,他们均需要挂接在Base上运行。
除此之外,SPSS 11完全版还包括SPSS Smart Viewer和SPSS Report Writer两个软件,他们并未整合进来,但功能上完全是SPSS的辅助软件。
二、实训内容:了解SPSS的操作方法使用Windows的窗口方式展示各种管理和分析数据方法的功能,对话框展示出各种功能选择项。
用户只要掌握一定的Windows操作技能,粗通统计分析原理,就可以使用该软件为特定的科研工作服务。
spss实验报告心得体会 实验报告心得体会

SPSS实验报告心得体会引言在进行SPSS实验的过程中,我深深地感受到了数据分析的重要性和SPSS软件的便捷性。
通过实验报告的撰写,我进一步加深了对实验数据的理解和分析。
实验目的本次实验的目的是通过使用SPSS软件对实验数据进行分析,探究变量之间的相关性,并归纳总结出一定的结论。
实验步骤1.收集实验数据2.导入数据到SPSS软件3.数据预处理4.变量分析5.数据可视化6.结果分析7.结论总结收集实验数据在本次实验中,我们采集了100个样本数据,包括年龄、性别、收入等变量。
导入数据到SPSS软件通过SPSS软件的数据导入功能,我成功地将实验数据导入到了软件中。
数据预处理在进行数据分析之前,我首先需要对数据进行预处理,包括数据清洗、缺失值处理等操作。
通过SPSS软件提供的功能,我轻松地完成了这些操作,为后续的分析做好了准备。
变量分析在进行变量分析时,我采用了相关性分析和回归分析两种方法。
相关性分析通过相关性分析,我可以了解不同变量之间的相关关系。
通过SPSS软件的相关性分析功能,我得到了变量之间的相关系数矩阵,并根据相关系数的大小判断了变量之间的相关强弱。
回归分析通过回归分析,我可以了解变量之间的因果关系。
通过SPSS软件的回归分析功能,我得到了回归方程和各个变量的回归系数,进一步深入分析了变量之间的关系。
数据可视化在进行数据可视化时,我使用了SPSS软件提供的图表绘制功能,包括柱状图、折线图、散点图等。
通过可视化的方式,我可以更直观地展示实验数据的特征和变化趋势。
结果分析根据变量分析和数据可视化的结果,我得出了以下结论:1.年龄与收入呈现正相关关系,年龄越大,收入越高。
2.性别对收入没有显著影响。
3.受教育程度与收入呈现正相关关系,受教育程度越高,收入越高。
结论总结通过本次SPSS实验,我不仅熟悉了SPSS软件的使用,还深入了解了数据分析的过程和方法。
实验报告的撰写过程让我更系统地整理和总结了实验结果,提高了我的数据分析和文档写作能力。
spss16.0操作总结

ASCII 固定列:下一步→fixed ,no→下一步→下一步→保存非固定列:下一步→delimited ,yes→下一步→选分隔符→保存数据拆分:compare groups 各分组的观测量数据所得的结果放在一起比较。
数据合并:增加观测量:data→merge→add cases集中量数【操作】quartiles ,mean ,median ,mode ,std.deviation ,skewness ,kurtosis ;histogram ,with normal【报告】平均值,标准差,智商小于100的占总数的7%差异量数【操作】range【报告】平均值,标准差,最小值~最大值探索分析【操作】outliers (极端值)极端值:0.6745为截距;X 为原始分数;Mdn 为“原始数据的中位数”;各分数与Mdn 差的绝对值数列;Mdn AD 为”绝对值数的中位数”。
Z 绝对值≧3.5时为极端值。
【报告】各组人数,平均值,标准差。
两组成绩存在一定的差异。
单样本t 检验【对象】一个样本的均值与总体均值或某个已知的观测量之间差异的显著性【操作】one-sample t test ,将要分析的变量选入变量框,text value 中设定总体均值【报告】t 检验结果显示,这个班的数学成绩与平均成绩之间差异不显著,t ,df ,p 。
独立样本t 检验【对象】两个不相干样本在相同变量上的观测量均值之间的差异显著性,要求正态分布、方差齐、样本间独立【观察】levene 的sig 不显著,报告上面一行的t 检验结果,显著则报告下一行。
【报告】教学效果的独立样本t 检验结果显示,方差分析齐性不显著,即两组的方差齐。
方法1与方法2的消息效果之间存在显著差异(t ,df ,p ),即方法1明显优于方法2. 配对样本t 检验【对象】两个相关样本观测量的均值差异或同一个样本的两次观测量均值之间的差异【报告】xxxx 配对样本t 检验结果显示,入学后一年的智商要显著高于入学时的智商,t ,df ,p 。
spss统计软件实习总结

教学实习是贯彻统计教学⼤纲的教学计划的⼿段,不仅是⼩内教学的延续,⽽且是校内教学的总结。
实习的⽬的就是使同学们的理论更加扎实、专业技能操作更加过硬。
同时,培养良好的就业观和职业道德。
通过本次实习需要了解和掌握: spss软件的基本操作,对spss所分析的各项数据的理解。
我国普查⼯作开展的现状及普查⼯作的意义和基本流程。
政府统计的基本流程和⾏业统计与政府统计相互协调的关系。
了解⼯作中如何进⾏数据的收集、整理以及统计分析报告的撰写的⽅法 这次实习内容分为两个阶段,第⼀部分是上机实习,主要学习SPSS软件的操作技能,以及关于此软件的⼀些理论,以及它在统计⼯作中的重要作⽤。
具体包括: (1) SPSS基本理论知识; (2) SPSS的相关分析、线性回归分析、⾮参数检验、聚类分析等; (3) 利⽤SPSS软件进⾏参数检验和⾮参数检验以及绘制统计图表; 第⼆部分是听专家讲座,主要包括: (1) 了解有关政府统计,(2) ⾏业统计⼯作的流程; (3) 了解政府统计的现状、内容、程序、职能、以及⾏业统计的现状,(4) 既林业 统计⼯作的特点、内程序,以及存在的⼀些问题; (5) 了解政府统计和⾏业统计之间的协调关系,(6) 以及各部门之间的配合; 了解统计报表、统计数据的搜集和贯彻的整个过程。
本次实习要解决的问题: 1. 统计分析软件spss的操作技能问题。
2. 统计分析软件spss所做数据应如何理解。
3. 统计分析报告的撰写。
4. 普查⼯作意义及具体步骤。
5. 政府统计的基本流程、统计数据的上报⼯作。
本次实习要取得的效果: 1. 提⾼对统计这门学科的兴趣和认识。
2. 对spss软件有⼀个系统的认识并熟练掌握spss的操作。
3. 了解普查⼯作的意义及基本流程。
4. 了解政府统计现状及基本流程。
实习结果 通过本次的教学实习,使我们对统计⼯作有了⼀个初步的认识,以及统计软件在统计⼯作中应⽤的重要性和⽅便性,认识实习的⽬的认识实习的⽬的就在于让同学们初步了解企业的基本情况,了解信息收集,处理过程加强感性认识,为以后专业理论课程的学习特别是毕业设计奠定必要的实践基础。
SPSS实验报告总结一.docx

湖南涉外经济学院实验报告课程名称:应用统计软件分析(SPSS)专业班级:姓名学号:指导教师:职称:副研究员实验日期:成绩评定指导教师签字日期签字学生实验报告实验序号一、实验目的及要求实验目的实验要求通过本次实验,使学生熟练掌握转换菜单和数据菜单的具体功能及操作,熟练应用两个菜单中的计算变量、重新编码、选择个案、个案排序、分类汇总等几个主要过程能够根据相关要求选用正确的过程对变量或者文件进行管理和操作,得到结果,并能对得出的结果进行解释。
二、实验描述及实验过程一、下载数据(以下情况选一种):(一)分地区(31 个省市区)环境污染治理投资数据(2014 年)环境污染治理投资总额(亿元 ),城市环境基础设施建设投资额(亿元 ) ,城市燃气建设投资额 (亿元 ) ,城市集中供热建设投资额(亿元 ),城市排水建设投资额(亿元 ),城市园林绿化建设投资额(亿元 ),城市市容环境卫生建设投资额(亿元 )工业污染源治理投资(万元 )实建设项目“三同时”环保投资额(亿元 )(二)分地区(31 个省市区)经济发展总体数据(2014 年)验国民总收入,国内生产总值,第一产业增加值,第二产业增加值,第三产业增加值,人均国内生产总值,人口总量,城镇失业率,基尼系数等描 (三 )各省市房地产开发 2014 年相关数据投资额,房地产开发企业个数,从业人员数,收入,税金,利润,资产,负债,平均销述售价格,等等。
(四)各省市科技2014 年相关数据包括 GDP,研发投入,研发投入强度(研发投入/GDP),R&D 研发人员,专利授权数,发明专利授权量。
(五)查找相关行业(钢铁行业、水泥行业、医药制造、工程机械、汽车制造业、旅游酒店行业、航空、电子商务企业等)上市公司2015 年度数据。
包括销售收入、利润、固定资产净值、总资产利润率、营业利润率、销售净利率、净资产收益率、流动比率、资产负债率、主营业务收入增长率、营收账款周转率、存货周转率、流动资产周转率等。
论文写作中如何利用SPSS进行数据分析与报告撰写

论文写作中如何利用SPSS进行数据分析与报告撰写在论文写作中,数据分析是一个至关重要的环节。
而SPSS作为一个强大的统计分析工具,被广泛应用于研究领域。
本文将介绍如何利用SPSS进行数据分析,并撰写相应的报告。
一、数据收集与录入在进行数据分析之前,首先需要完成数据的收集与录入。
在收集数据时,需明确需要哪些数据变量以及相应的测量方式。
然后,可以通过问卷调查、实验观察等方法获得相应的数据。
在收集到数据后,需要将其录入SPSS软件中。
SPSS提供了一个数据视图用于数据录入,可以手动输入数据值。
在录入数据时,需要注意数据的合法性,确保数据的准确性与完整性。
二、数据清洗与预处理数据清洗与预处理是数据分析的关键步骤之一。
数据清洗包括删除无效数据、处理缺失值、异常值处理等。
在SPSS中,可以使用数据转换或计算变量来执行这些操作。
例如,可以使用“转换”-"计算变量"来创建新变量,并通过函数计算对应的数值。
在完成数据清洗后,需要进行数据预处理。
对于连续变量,可以进行数据标准化和离散化处理;对于分类变量,可以进行哑变量处理。
在SPSS中,可以利用“转换”菜单下的“重新编码”功能来实现。
三、数据分析在完成数据清洗和预处理后,可以进行数据分析。
常见的数据分析方法包括描述性统计、相关分析、方差分析、回归分析等。
1. 描述性统计描述性统计是对数据进行总结和描述的一种分析方法。
通过计算数据的中心趋势(均值、中位数)、离散程度(标准差、方差)等指标,可以对数据的分布特征有一个初步了解。
在SPSS中,可以通过“分析”菜单下的“描述统计”功能进行描述性统计分析。
选择相关变量,SPSS会自动生成统计报告,包括均值、标准差、最大值、最小值等信息。
2. 相关分析相关分析用于研究变量之间的相关关系。
通过计算相关系数,可以判断变量之间的关联程度。
在SPSS中,可以通过“分析”菜单下的“相关”功能进行相关分析。
在相关分析中,可以选择想要分析的变量,SPSS会输出相关系数矩阵,通过观察相关系数的大小和正负,可以初步了解变量之间的相关情况。
SPSS多元线性回归解析总结计划实例操作步骤

SPSS 统计剖析多元线性回归剖析方法操作与剖析实验目的:引入 1998~2008年上海市城市人口密度、城市居民人均可支配收入、五年以上均匀年贷款利率和房子空置率作为变量,来研究上海房价的改动要素。
实验变量:以年份、商品房均匀售价(元 / 平方米)、上海市城市人口密度 (人/ 平方公里 )、城市居民人均可支配收入 (元)、五年以上均匀年贷款利率 (%)和房子空置率 (%)作为变量。
实验方法:多元线性回归剖析法软件:操作过程:第一步:导入 Excel数据文件1. open data document——open data——open;2. Opening excel data source——OK.第二步:1.在最上边菜单里面选中Analyze——Regression——Linear ,Dependent(因变量)选择商品房均匀售价,Independents(自变量)选择城市人口密度、城市居民人均可支配收入、五年以上均匀年贷款利率、房子空置率;Method 选择 Stepwise.进入以下界面:2.点击右边 Statistics,勾选 Regression Coefficients(回归系数)选项组中的Estimates;勾选 Residuals(残差)选项组中的 Durbin-Watson、Casewise diagnostics 默认;接着选择 Model fit 、Collinearity diagnotics;点击 Continue.3.点击右边 Plots,选择 *ZPRED(标准化展望值)作为纵轴变量,选择DEPENDNT(因变量)作为横轴变量;勾选选项组中的Standardized Residual Plots(标准化残差图)中的 Histogram、Normal probability plot ;点击 Continue.4.点击右边 Save,勾选 Predicted Vaniues(展望值)和 Residuals(残差)选项组中的 Unstandardized;点击 Continue.5.点击右边 Options,默认,点击 Continue.6.返回主对话框,单击OK.输出结果剖析:1.引入 / 剔除变量表Variables Entered/Removed aModel Variables Entered Variables Removed Method1城市人口密度(人 /平方公里 ).Stepwise (Criteria:Probability-of-F-to-enter<= .050,Probability-of-F-to-remove >= .100).2城市居民人均可支配收入(元).Stepwise (Criteria:Probability-of-F-to-enter<= .050,Probability-of-F-to-remove >= .100).a. Dependent Variable: 商品房均匀售价(元/ 平方米)该表显示模型最初引入变量城市人口密度(人/ 平方公里 ),第二个引入模型的是变量城市居民人均可支配收入(元),没有变量被剔除。
spss实验报告总结

spss实验报告总结《SPSS实验报告总结》在社会科学研究中,SPSS(统计包装软件)是一个常用的数据分析工具。
通过SPSS,研究人员可以对收集到的数据进行统计分析,从而得出科学可靠的研究结论。
本文将通过对一项实验的SPSS分析,总结实验结果并进行讨论。
实验目的是研究不同学习方法对学生考试成绩的影响。
实验设计了两组学习方法,分别是传统课堂教学和在线学习课程。
参与实验的学生被随机分配到两组,并在相同的学习时间内接受不同的教学方式。
最后,他们的考试成绩被记录下来,用以分析两种学习方法的效果。
通过SPSS对实验数据进行分析,得出了以下结论:1. 传统课堂教学组的平均成绩为85分,标准差为5分;在线学习课程组的平均成绩为78分,标准差为6分。
通过t检验发现,两组成绩之间存在显著差异(t=2.34,p<0.05)。
2. 通过方差分析(ANOVA)进一步比较了不同学习方法对学生成绩的影响。
结果显示,学习方法对成绩有显著影响(F=5.67,p<0.01),说明传统课堂教学在提高学生成绩方面更为有效。
基于以上分析结果,我们得出了以下结论:1. 传统课堂教学对学生成绩有显著影响,能够帮助学生取得更好的成绩。
这可能是因为传统课堂教学更加互动和个性化,能够更好地满足学生的学习需求。
2. 在线学习课程在提高学生成绩方面效果不如传统课堂教学。
这可能是因为在线学习缺乏面对面的交流和互动,学生的学习动力和效果受到了一定的影响。
通过SPSS的数据分析,我们得以客观地评估了两种学习方法对学生成绩的影响,为教育教学实践提供了科学依据。
同时,我们也意识到了在线学习的一些不足之处,为今后的教学改进提供了一定的启示。
希望本研究能够为教育教学领域的决策者和从业者提供一些参考,促进教学方法的不断创新和提高。
SPSS统计软件实训报告

SPSS统计软件实训报告一、引言SPSS(Statistical Product and Service Solutions)统计软件是一种常用的统计分析软件,被广泛应用于数据分析和统计研究领域。
本报告旨在总结并分析在SPSS实训课程中所学到的基本操作和统计分析方法。
二、实训内容在SPSS统计软件实训中,我们学习了以下主要内容: 1. SPSS软件的安装和介绍; 2. 数据输入和修改; 3. 数据清洗和处理; 4. 描述性统计分析; 5. 参数检验和非参数检验; 6. 方差分析; 7. 相关分析; 8. 回归分析等。
三、实训过程1. SPSS软件的安装和介绍我们首先安装了SPSS统计软件,并对其界面和基本功能进行了介绍。
SPSS软件提供了直观的用户界面,可以进行数据输入、数据处理和统计分析等操作。
2. 数据输入和修改为了方便后续的统计分析,我们学习了数据的输入和修改方法。
在SPSS软件中,我们可以手动输入数据,也可以从Excel等其他文件中导入数据。
此外,我们还学习了如何修改数据,包括添加变量、删除变量、重命名变量等操作。
3. 数据清洗和处理在实际应用中,数据往往存在一些错误或缺失。
为了保证统计分析的准确性,我们需要对数据进行清洗和处理。
SPSS软件提供了一系列的数据清洗工具,如删除重复数据、替换缺失值、筛选数据等。
4. 描述性统计分析描述性统计分析是对收集到的数据进行总结和描述的方法。
我们学习了如何计算数据的均值、中位数、众数、标准差等统计量。
通过绘制直方图、箱线图等图表,我们可以对数据的分布进行可视化展示。
5. 参数检验和非参数检验参数检验和非参数检验是统计分析中常用的两种方法,用于判断样本间差异是否显著。
我们学习了t检验、方差分析、卡方检验等方法,并通过SPSS软件进行了实际操作。
6. 方差分析方差分析是用于比较三个或三个以上样本均值是否存在显著差异的方法。
我们学习了单因素方差分析和多因素方差分析,并通过SPSS软件进行了实际分析。
spss数据分析总结.

spss数据分析总结2018-01-15下面就是小编为您收集整理的spss数据分析总结的相关文章,希望可以帮到您,如果你觉得不错的话可以分享给更多小伙伴哦!篇一:spss数据分析总结实验一 SPSS基本操作一、实验目的1.熟悉SPSS的菜单和窗口界面,熟悉SPSS各种参数的设置; 2.掌握SPSS的数据管理功能。
二、实验内容及步骤(一)数据的输入和保存 1. SPSS界面当打开SPSS后,展现在我们面前的界面如下:请注意窗口顶部显示为“SPSS for Windows Data Editor”,表明现在所看到的是SPSS的数据管理窗口。
这是一个典型的Windows软件界面,有菜单栏、工具栏。
该界面和EXCEL极为相似,很多操作也与EXCEL类似,同学们可以自己试试。
2.定义变量选择菜单Data==>Define Variable。
系统弹出定义变量对话框如下:对话框最上方为变量名,现在显示为“VAR00001”,这是系统的默认变量名;往下是变量情况描述,可以看到系统默认该变量为数值型,长度为8,有两位小数位,尚无缺失值,显示对齐方式为右对齐;第三部分为四个设置更改按钮,分别可以设定变量类型、标签、缺失值和列显示格式;第四部分实际上是用来定义变量属于数值变量、有序分类变量还是无序分类变量,现在系统默认新变量为数值变量;最下方则依次是确定、取消和帮助按钮。
假如有两组数据如下:GROUP 1: 0.84 1.05 1.20 1.20 1.39 1.53 1.67 1.80 1.87 2.07 2.11 GROUP 2: 0.54 0.64 0.64 0.75 0.76 0.81 1.16 1.20 1.34 1.35 1.48 1.56 1.87先来建立分组变量GROUP。
请将变量名改为GROUP,然后单击OK按钮。
现在SPSS的数据管理窗口如下所示:第一列的名称已经改为了“group”,这就是我们所定义的新变量“group”。
spss数据分析总结汇报

spss数据分析总结汇报尊敬的领导/老师/评审专业人士:我荣幸地向您汇报一项基于SPSS数据分析的研究工作。
本次研究旨在探究XXX领域的XXXX。
我们采用了SPSS软件对收集的数据进行了多个统计分析方法的处理和解读。
以下是对数据分析结果的总结和分析。
首先,我们对收集到的数据进行了描述性统计。
通过计算每个变量的均值、标准差、最小值和最大值,我们得到了对整体研究样本的整体把握。
例如,对于XXX变量,我们发现其平均值为XX,标准差为XX,最小值为XX,最大值为XX。
这些结果为后续的进一步分析提供了基础。
接下来,我们进行了相关性分析。
通过计算Pearson相关系数,我们研究了不同变量之间的关联程度。
我们发现XXX变量与XXX变量之间的相关系数为XX,表明二者存在正相关。
这一发现为我们理解这两个变量之间的关系提供了线索。
此外,我们还进行了回归分析。
在进行回归分析时,我们选择了XXXX模型,并检验了模型的拟合程度。
我们发现,模型的拟合度(例如,R平方值)为XX,表明该模型能够解释总体数据的XX%。
此外,我们还计算了回归系数,并进行了显著性检验,发现XXX变量对于解释因变量的变异有着显著影响。
这一结果为我们理解因变量与自变量之间的关系提供了重要线索。
最后,我们进行了差异性分析。
通过采用独立样本t检验,我们比较了不同组别之间的平均差异。
我们发现,XXX组和XXX组在XXX变量上存在显著差异(t = XX,p < 0.05),表明两组在该变量上存在明显的差异。
通过以上分析,我们得出了以下结论:XXX。
这些结论为我们对研究问题的理解提供了基础,并且具有实践和理论意义。
然而,我们也要注意到本研究的不足之处。
首先,研究样本可能存在一定的局限性,因此,结果在总体上的泛化能力有限。
其次,我们的研究可能还需要更多的数据和更全面的指标来支持我们的结论。
在未来的研究中,我们建议考虑收集更多的样本数据,并结合其他的统计方法进行深入分析。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
One-Sample Kolmogorov-Smirnov Test
N
Normal Parametersa,b
Mean
Std. Deviation
Most Extreme Differences
Absolute Positive
Negative
Kolmogorov-Smirnov Z
Asymp. Sig. (2-tailed)
Std.
Std. Error
Deviation
Mean
95% Confidence Interval of the
Difference
Lower
Upper
.22903
.06906 .03431 .34205
t 2.725
df 10
Sig. (2-tailed)
.021
例3-6 为比较两种方法对乳酸饮料中脂肪含 量测定结果是否不同,随机抽取了10份乳酸
Valid Missing
2.5 5 25 50 75 95 97.5
120 0
120.9217 120.4000
5.16524 26.680
.151 .221 -.278 .438 25.20 108.40 133.60 110.0575 112.5200 117.5500 120.4000 124.3750 129.8900 131.4900
0.978
0.517
0.750
0.454
差值d (4)=(2)(3)
0.260 0.082 0.174 0.316 0.350 0.461 0.296
Std. Deviation
1.92039
Std. Error Mean
.48010
VAR00001
t 2.322
One-Sample Test Test Value = 4.882
df 15Sig. (2-来自ailed).035Mean Difference
1.11488
95% Confidence
1
VAR00002
Mean 6.7118
6.5236
N 11
11
Std. Deviation
.42497
.46120
Std. Error Mean .12813
.13906
Paired Samples Test
Pair 1 VAR00001 - VAR00002
Mean .18818
Paired Differences
1.某工厂附属医院2003年随机调查了该厂120名健康 职工餐后两小时的血糖值(mmol/L)结果如下:
St at ist ic s
x N
Mean Median Std. Deviation Variance Skewness Std. Error of Skewness Kurtosis Std. Error of Kurtosis Percentiles
总结
未知总体标准差,已知样本标准差 单样本
已知样本均数x、标准差s、例数n和总体均数u0。
配对设计
已知对子的平均差值d、差值的标准差sd和对子 数n。
成组设计
已知两样本均数x1与x2 、对应的标准差s1、s2和 对应的例数n1、n2。
例:已知一般无肝肾疾患的健康人群尿素氮 均值为4.882 (mol/L) 。 16名脂肪肝患者的尿素氮(mol/L) 的测定 值为5.74,5.75,4.26,6.24, 5.36, 8.68,6.47,5.24,4.13,11.8,5.57, 5.61,4.37,4.59, 5.18,6.96。 问脂肪肝患者尿素氮测定值的均数是否高于 健康人?
Valid Missing
5 25 50 75 95
119 0
4.6521 4.8000 .79786
.637 -.713 .222 -.377 .440 3.1000 4.1000 4.8000 5.3000 5.7000
思考题1
资料分哪三类? 对数值型资料进行描述首先应知道资料的
分布情况,如何采用SPSS统计软件实现对 资料分布情况的了解? 描述集中趋势和离散趋势的指标有哪些? 会阅读SPSS软件结果。
Interval of the
Difference
Lower
Upper
.0916
2.1382
配对t检验
某医生为了比较甲、乙两种药物降血脂的 效果,将性别相同,年龄、营养状况、血 清总胆固醇等相近的高血脂患者配成对子, 每对中随机抽一人服甲药,另一人服乙药, 治疗一个疗程后,测得血清胆固醇含量 (mmol/L),见下表
对子编号
1 2 3 4 5 6 7 8 9 10 11 合计
甲药(2)乙药(3) 差值d(4) d2
6.02
5.89
0.13
0.0169
7.02
6.81
0.21
0.0441
6.78
6.45
0.33
0.1089
6.58
6.02
0.56
0.3136
7.11
7.33
-0.22
0.0484
7.34
7.16
饮料制品,分别用脂肪酸水解法和哥特里 -罗紫法测定其结果如表3-5第(1)~(3)栏。 问两法测定结果是否不同?
编号 (1) 1 2 3 4 5 6 7 8 9 10
哥特里-罗紫法 脂肪酸水解法
(2)
(3)
0.840
0.580
0.591
0.509
0.674
0.500
0.632
0.316
0.687
0.337
a. Test distribution is Normal.
b. Calculated from data.
VAR00001 16
5.9969 1.92039
.239 .239 -.165 .955 .322
VAR00001
One-Sample Statistics
N 16
Mean 5.9969
St at ist ic s
VAR00001 N
Mean Median Std. Deviation Variance Skewness Std. Error of Skewness Kurtosis Std. Error of Kurtosis Range Minimum Maximum Percentiles
0.18
0.0324
6.76
6.55
0.21
0.0441
6.77
6.31
0.46
0.2116
6.54
6.58
-0.04
0.0016
5.96
6.01
-0.05
0.0025
6.95
6.65
0.30
0.0900
——
——
2.07
0.9141
Paired Samples Statistics
Pair VAR00001