SSH框架教程
ssh整合框架原理及流程

ssh整合框架原理及流程SSH(Spring、Struts和Hibernate)框架整合的原理和流程如下:原理:1. 控制反转(IoC):IoC是一种设计原则,通过这种原则,对象之间的依赖关系由容器来控制,而非传统的直接操控。
这使得程序代码更加灵活,易于复用。
2. 依赖注入(DI):DI是IoC的一种实现方式。
通过DI,组件之间的依赖关系由容器在运行时决定,并动态地将这种关系注入到组件中。
流程:1. 建立web工程,并将其编码设置为UTF-8。
2. 将整个JSP页面也设置为UTF-8编码格式。
3. 建立三个source folder文件:src(存放源代码)、config(存放所有的配置文件,如Struts、Hibernate和Spring配置文件)、test(存放测试类)。
4. 在WebRoot\WEB-INF\lib中导入相应的jar包。
5. 配置文件。
在这个文件中,Spring容器以监听器的形式与Tomcat整合。
6. Struts负责控制Service(业务逻辑处理类),从而控制Service的生命周期。
这样层与层之间的依赖很强,属于耦合。
7. 使用Spring框架来控制Action对象(Struts中的)和Service类。
这使得两者之间的关系变得松散。
Spring的IoC机制(控制反转和依赖注入)正是用在此处。
8. Spring的AOP应用:事务的处理。
在以往的JDBCTemplate中,事务提交成功、异常处理都是通过Try/Catch来完成。
整合SSH框架的目的是提高软件开发的效率和灵活性,减少代码的冗余和复杂性,使代码更易于维护和扩展。
图解SSH框架配置步骤

图解SSH框架配置步骤核心提示:现在开发的一个项目使用S2SH框架,配置环境用了一两天,现在把当时配置环境时写的文档整理下发出来,也算加强点记忆。
1 开发环境 MyEclipse5.5 JDK 1.6 Java EE 5.0 Tomcat6.0 Struts2.1.6 Spring2.5.6 Hibernate3.3.1 2 为 ssh 做好准备 2.1 下载包 Struts2现在开发的一个项目使用S2SH框架,配置环境用了一两天,现在把当时配置环境时写的文档整理下发出来,也算加强点记忆。
1 开发环境MyEclipse5.5JDK 1.6Java EE 5.0Tomcat6.0Struts2.1.6Spring2.5.6Hibernate3.3.12 为ssh做好准备2.1下载包Struts2.1.6包下载:/download.cgi#struts216Full Distribution:o struts-2.1.6-all.zip (110mb) [PGP] [MD5]Hibernate3.3包下载:https:///6.htmlSpring2.5下载:/download2.2搭建开发环境打开MyEclipse,新建一个web project,如图:注意:J2ee版本设为java ee 5.0点击Finish完成,建好的工程如图:如果你的myeclipse还没有配置一个web服务器,那就进行下面的步骤,这里以tomcat6为例:打开MyEclipse Preferences窗口,展开目录树如下图:设置好你的tomcat6的路径即可,前提你要先安装好tomcat哦。
还有需要注意的一点是,看到目录树tomcat6.x下面的JDK了吗?点击它,也要把tomcat的JDK设为jdk1.6才行,以与myeclipse一致。
好了,工程已经建好了,下面就开始配置struts吧。
配置之前先把struts的包下载下来哦,下载地址上面已经给出了。
(完整版)SSH框架搭建实例教程,毕业课程设计

.SSH的理解及其应用实践1.SSH是什么 (3)2 Spring 介绍理解: (3)2.1简单介绍 (3)2.2各种特性 (3)2.2.1轻量 (3)2.2.2控制反转 (3)2.2.3面向切面 (4)2 .2.4容器 (4)2.2.5框架 (4)2.3总结 (4)3.Hibernate介绍理解: (4)3.1简单介绍 (4)3.2核心接口 (5).3.2.1 Session接口 (5)3.2.2 .SessionFactory接口 (5)3.2.3.Configuration接口 (5)3.2.4.Transaction接口 (5)3.2.5 Query和Criteria接口 (5)4. Struts (6)4.1什么是Struts框架 (6)4.2 Struts 概览 (6)4.2.1Client browser(客户浏览器) (6)4.4 Struts中的Controller(控制器)命令设计模式的实现 (7)4.5 在Struts框架中控制器组件的三个构成部分 (7)4.7 Struts中的Model(模型) (8)5.SSH整合步骤 (8)5.1安装所需软件环境: (8)5.1.1、首先安装JDK,配置Java环境变量 (8)5.1.2安装MyEelipse (8)5.1.3 数据库 (9)5.1.4、 (9)5.2环境配置好了就可以做SSH整合的项目 (9)6.搭建框架并简单应用 (11)6.1准备工作 (11)6.2(建立项目,包结构,导入所需jar文件) (12)6.3撰写资源文件 (15)6.4在com.ssh.utilm 包下添加下列文件 (19)6.5添加hibernate DAO 模板 (20)6.6以上的工作还不够,我们还需要进行WEB方面的配置 (20)7.测试: (23)7.1.ssh.model 包下建立User.java (23)7.2 com.ssh.service 包下建立UserService.java (24)7.3com.ssh.test 下建立Test.java (25)7.4结果 (26)8.结束语 (26)1.SSH是什么新的MVC软件开发模式, SSH(Struts,Spring,Hibernate) Struts进行流程控制,Spring进行业务流转,Hibernate进行数据库操作的封装,这种新的开发模式让我们的开发更加方便、快捷、思路清晰!2 Spring 介绍理解:2.1简单介绍Spring是一个开源框架,它由Rod Johnson创建。
搭建SSH框架步骤.

搭建SSH框架步骤一、建数据库二、建Web工程打开Eclipse在工程栏—>鼠标右击New—>选择Web project—>project Name输入Demo;勾起Java 5.0单选按钮—>完成—>在Src文件夹下创建dal、bll、entity、、bll.action三个包以及两个子包。
三、添加框架1. 添加Struts选中所建的Web工程—>鼠标右击选择MyEclipse—>选择Add StrutsCapabilites…—>Struts specification选择Struts1.2;Base package fornew class单击Brouse选择文件路径为dal包;勾掉多选按钮Install StrutsTLDs —>完成2. 添加Spring选中所建的Web工程—>鼠标右击选择MyEclipse—>选择Add SpringCapabilites…—>勾起多选按钮Spring 2.5 Aop Libraries;勾起多选按钮Spring 2.5 Core Libraries;勾起多选按钮Spring 2.5 Persistence Core;勾起多选按钮Spring 2.5 Web Libraries;勾起单选按钮Copy checked Librarycontents…—>单击Browse选择路径为WEB-INF包—>完成3. 添加Hibernate选中所建的Web工程—>鼠标右击选择MyEclipse—>选择Add HibernateCapabilites…—>勾起单选按钮Copy checked Library Jars to…—>选择Spring configuration file—>选择Existing Spring configuration file;SessionFactory Id 输入sessionFactory —>BeanId输入DemoBean;DBDriver选中自己所建的数据库—>勾掉Create Session Factory class? —>完成4. 将SSH架包粘贴到lib文件夹下5. 展开工程中的Referenced Libraries 文件夹(架包文件夹)—>在展开的文件中找到asm-2.23.jar文件—>右击Build path—>选择Remove from Build path —>删除文件asm-2.23.jar四、创建数据单击Eclipse右上角的MyEclipse Hibernate 按钮—>鼠标右键New—> Driver template 下拉选择Microsofe SQLServer 2005;Drever name输入DemoDB;Connection URL 输入jdbc:sqlserver://localhost:1433;User name 输入sa; password输入123456;单击Add JARs 按钮导入jdbc 包;勾起Save password多选按钮—>勾起Display the selected schemas 单选按钮;单击Add按钮导入数据库—>完成—>鼠标右击数据栏刚才所建的数据—>单击Open Connection —>选择dbo —>TABLE—>找到对应的表—>右击Hibernate Reverse Euginnering…—>单击Java src folder 的Brouse按钮选择包entity;勾Creat POJO <>DB…;勾起Java Data Object…;勾起Java Data Access Object…;勾掉Java Data Object…下面的Create abstract class—>在Id Generator 下框中选择native—>勾起Include referenced tables(AB;勾起Include referencing tables(AB;可以给表或者其中的属性起相应的名字,当然也可以不起让其自动生成—>完成五、配置XML文件1.配置Struts-config.xml文件在下面添加标签注:找到Referenced Libraries 包下面的spring-webmvc-struts . jar包复制文件即可。
SSH框架搭建教程

SSH框架搭建教程SSH(Spring + Spring MVC + Hibernate)是一种JavaEE开发的框架组合,被广泛应用于企业级Web应用的开发。
本教程将详细介绍如何搭建SSH框架。
第一步:环境准备第二步:创建Spring项目在搭建SSH框架之前,我们需要先创建一个Spring项目。
在Eclipse中,选择“File -> New -> Project”菜单项,然后选择“Spring -> Spring Project”。
在创建项目的对话框中,选择Maven作为构建工具,并且勾选上“Create a simple project (skip archetype selection)”选项。
填写项目的基本信息后,点击“Finish”按钮开始创建项目。
这样,一个基本的Spring项目就创建完成了。
第三步:配置Spring框架在Spring项目中,我们需要创建一个配置文件(通常称为applicationContext.xml)来配置Spring框架。
该文件可以放在src/main/resources目录下。
在配置文件中,我们需要配置一些基本的Spring设置,例如数据库连接、事务管理等。
此外,我们还需要配置Spring扫描注解的包路径,以便框架能够自动发现和加载注解。
第四步:创建Hibernate实体类和映射文件在SSH框架中,Hibernate用于持久化数据。
我们需要创建相应的实体类来映射数据库表,并且编写Hibernate映射文件来描述实体类和数据库表之间的关系。
实体类可以使用Java的POJO类表示,而映射文件可以使用Hibernate的XML格式编写。
映射文件需要保存在src/main/resources目录下。
第五步:配置Hibernate框架在Spring项目中,我们需要创建一个Hibernate的配置文件(通常称为hibernate.cfg.xml)来配置Hibernate框架。
SSH框架搭建步骤

SSH框架搭建步骤SSH(Struts + Spring + Hibernate)是一种Java Web应用开发框架,结合了三个开源框架Struts、Spring和Hibernate,用于加速和简化开发过程。
下面是SSH框架搭建的详细步骤。
1.环境准备在开始之前,确保你的机器上已经安装了Java JDK、Tomcat服务器、MySQL数据库以及一个IDE(例如Eclipse)。
2.创建项目首先,在IDE中创建一个Java Web项目。
选择动态Web项目模板,并设置项目名称、目标运行时(Tomcat)、目标动态Web模块版本等。
然后,添加Struts、Spring和Hibernate的相关库文件(JAR文件)到项目的类路径中。
3. 配置Struts在项目的src目录下创建一个名为struts.xml的配置文件。
在这个文件中,你可以定义你的请求处理流程、Action映射、结果视图等。
可以参考Struts的官方文档和示例来编写配置文件。
4. 配置Spring在src目录下创建一个名为applicationContext.xml的配置文件。
在这个文件中,你可以定义你的Spring的Bean配置、数据库连接池、事务管理器等。
可以参考Spring的官方文档和示例来编写配置文件。
5. 配置Hibernate在src目录下创建一个名为hibernate.cfg.xml的配置文件。
在这个文件中,你可以定义你的数据库连接参数、映射文件、缓存等。
可以参考Hibernate的官方文档和示例来编写配置文件。
6.创建实体类和DAO在src目录下创建实体类和DAO(数据访问对象)类。
实体类对应数据库表,DAO类用于对数据库进行增删改查操作。
你可以使用Hibernate的注解或XML映射来定义实体类和数据库表之间的映射关系。
7.编写业务逻辑在src目录下创建一个名为service的包,并在这个包下编写业务逻辑相关的类。
这些类可以使用Spring的依赖注入功能来调用DAO类,实现对数据库的操作。
SSH框架搭建步骤

SSH框架搭建步骤SSH框架是指Struts2 + Spring + Hibernate三大框架的整合,可以说是目前Java企业级应用开发的主流框架之一、通过整合这三大框架,可以让开发者在项目开发过程中更加高效地实现业务逻辑的开发。
下面将详细介绍SSH框架的搭建步骤。
1.环境准备在进行SSH框架的搭建之前,首先需要确保本地开发环境已经准备好。
需要安装好JDK、Tomcat、Maven等相关软件,并确保配置正确。
2. 创建Maven项目首先我们需要通过Maven创建一个新的项目。
可以使用命令行工具或者IDE中的相关插件来创建Maven项目。
在创建项目时,需要选择相应的依赖库,比如Struts2、Spring、Hibernate等。
3. 配置web.xml在项目的web.xml中配置Struts2的过滤器和监听器,以及Spring监听器。
通过配置这些组件,可以确保在项目启动时正确加载相应的框架组件。
4. 配置Struts2在Struts2的配置文件struts.xml中配置Action和Result等相关信息。
通过配置struts.xml可以实现对请求的拦截和处理,并返回相应的视图结果。
5. 配置Spring在Spring的配置文件中,可以配置相关的Bean以及事务管理等内容。
通过Spring的配置文件,可以实现依赖注入、AOP等功能,方便管理项目中的各个组件。
6. 配置Hibernate在Hibernate的配置文件中,配置数据源、实体映射、缓存等内容。
通过Hibernate的配置文件,可以实现对数据库的访问和操作,实现持久化操作。
7.编写业务逻辑代码在项目中编写业务逻辑代码,包括Action类、Service类、DAO类等。
通过这些类的编写,可以实现对业务逻辑的处理和数据操作。
8.测试和调试在编写完业务逻辑代码后,需要进行测试和调试。
可以通过JUnit等单元测试框架进行测试,确保项目的正常运行。
SSH框架搭建详细图文教程

SSH框架搭建详细图⽂教程⼀、什么是SSH?SSH是JavaEE中三种框架(Struts+Spring+Hibernate)的集成框架,是⽬前⽐较流⾏的⼀种Java Web开源框架。
SSH主要⽤于Java Web的开发。
现在SSH有SSH1和SSH2两种,区别在于Struts的版本是struts1.x还是2.x。
本⽂介绍的是SSH1。
⼆、Struts Spring Hibernate各起什么作⽤?Struts:控制逻辑关系。
Spring:解耦。
Hibernate:操作数据库。
三、学习SSH的⼀些建议SSH适合开发⼀些中、⼤型的企业级⽹站。
功能强⼤,性能也⾼。
但是学习成本也⾼,⿇烦也不少,不擅长做⼩型⽹站或便捷开发。
如果你熟悉Java并准备做动态⽹站的开发,SSH值得学习,如果你不熟悉Java,或没有⼀定的编程经验,只想做个简单的个⼈⽹站或者论坛。
PHP也许更适合你。
四、准备⼯作俗话说:“⼯欲善其事必先利其器”。
让我们看看在搭建SSH前需要准备哪些⼯具吧。
1.JDK[] [] []做Java开发第⼀步当然是Java开发环境了,JDK是必备的,本⽂中⽤的是jdk-8u111。
2.MyEclipse[] [] []搭建SSH最好⽤的开发⼯具了,本⽂中⽤的是MyEclipse 10。
3.MySQL[] [] []完整的动态⽹站需要⼀个数据库。
注意安装时设置的密码千万别忘了。
本⽂中⽤的是MySQL 5.5.53。
4.Navicat for MySQL[] [] []MySQL可视化开发⼯具,主要⽤他来操作数据库。
本⽂中⽤的是Navicat for MySQL 10.1.75.JDBC[] []数据库连接池,这是Java连接数据库必备的jar包。
本⽂中⽤的是mysql-connector-java-5.0.8-bin.jar。
安装顺序:JDK > MyEclipse > MySQL > Navicat for MySQL⽹站结构和开发⼯具作⽤如下图:五、搭建SSH步骤开发⼯具下载安装完毕后,正式进⼊搭建步骤。
ssh框架搭建教程

ssh框架搭建教程SSH 在J2EE项目中表示了3种框架,既Spring + Struts +Hibernate第一步,创建WEB工程,添加struts支持第二步,分包第三步,添加spring支持第四步,添加spring配置文件第五步,在web.xml文件中配置初始化读取参数(spring的配置文件)<context-param><param-name>contextConfigLocation</param-name><param-value>/WEB-INF/applicationContext.xml</param-value> </context-param>第六步,配置spring监听器<listener><listener-class></listener>第七步,在struts-config.xml文件中配置请求处理器,将struts请求委托给spring代理,达到控制反转的目的<controller processorClass=“"></controller>第八步,添加hibernate支持第九步,配置好hibernate以后,在applicationContext.xml文件中会自动生成“数据源”,“sessionFactory”,代码如下:<!-- 配置数据源 --><bean id="dsid" class=""><!-- 方法注入 --><property name="driverClassName"value=""></property><property name="url"value="jdbc:microsoft:;databaseName=pubs"></property><property name="username" value="sa"></property><property name="password" value="sa"></property> </bean><!-- 将hib中的sessionFactory封装 --><bean id="sfid"class=""><!-- 引用实例化好的数据源 --><property name="dataSource"><ref bean="dsid" /></property><property name="hibernateProperties"><props><!-- 设置数据库方言 --><prop key="hibernate.dialect"></prop><prop key="show_sql">true</prop></props></property></bean>第十步,通过表,反向生成”实体类”,”配置文件”第十一步,当正确添加实体后,在appilcationContext.xml文件中会自动添加实体类的映射<!-- 将hib中的sessionFactory封装 --><bean id="sfid"class=""><!-- 映射表对象 --><property name="mappingResources"><list><value>com/alex/ssh/entity/</list></property></bean>第十二步,修改DAO类的位置,修改配置文件属性值<bean id="Root58DAO" class=""><property name="sessionFactory"><ref bean="sfid" /></property></bean>第十三步,添加service类,反转service Class<!-- 反转service --><bean id="rootService"class=""><property name="dao"><ref bean="Root58DAO"/></property></bean>public void save(RootForm root) {Root58 r = new Root58();r.setUsername(root.getName());r.setUsercity(root.getCity());this.getDao().save(r);}第十四步,添加struts部分(添加jsp,form,action)第十五步,将struts-config.xml文件中action节点的type属性去掉<action name="rootForm"path="/root"/>第十六步,在acpplicationContext.xml文件中代理action类,也是一种控制反转的实现<!-- 反转action name属性的取值与struts配置中的path="/root"一致 --> <bean name="/root" class="" ><property name="service"><ref bean="rootService"/></property></bean>第十七步,运行调试SSH生命周期。
SSH框架搭建流程

SSH框架搭建流程SSH框架是一种集成了Struts、Spring和Hibernate三大框架的web 应用开发框架。
搭建SSH框架可以提高开发效率,提升系统性能,在实际开发中也是非常常见的选择。
本文将介绍SSH框架的搭建流程,以帮助开发人员快速搭建起一个完整的开发环境。
1.准备工作在开始搭建SSH框架之前,首先需要准备好一些工具和环境。
主要包括:(1)安装Java JDK:SSH框架的搭建需要依赖Java环境,因此需要首先安装Java JDK,并配置好JAVA_HOME环境变量。
(2)安装Tomcat服务器:Tomcat是一个常用的Java Web应用服务器,用于部署和运行Web应用程序。
在搭建SSH框架时,需要安装Tomcat服务器,并配置好相应的端口和参数。
(3)安装MySQL数据库:MySQL是一个开源的关系型数据库管理系统,用于存储应用程序的数据。
在搭建SSH框架时,需要安装MySQL数据库,并创建相应的数据库和表结构。
(4)配置开发环境:在开发SSH框架时,需要使用一些开发工具,如Eclipse、IntelliJ IDEA等,并配置好相关的插件和环境。
2.创建SSH项目一般情况下,我们可以使用Maven工具创建SSH项目。
Maven是一个Java项目管理工具,可以帮助我们管理项目的依赖、构建、部署等。
在创建SSH项目时,我们可以选择使用Maven快速搭建项目结构。
首先,在命令行中输入以下命令,创建一个Maven项目:```bash```其中,-DgroupId指定项目的groupId,-DartifactId指定项目的artifactId。
执行该命令后,会在当前目录下创建一个名为my-project的Maven项目。
接着,在项目目录下创建src/main/java、src/main/resources、src/main/webapp等目录,用于存放Java源代码、配置文件和Web资源。
SSH框架搭建教程
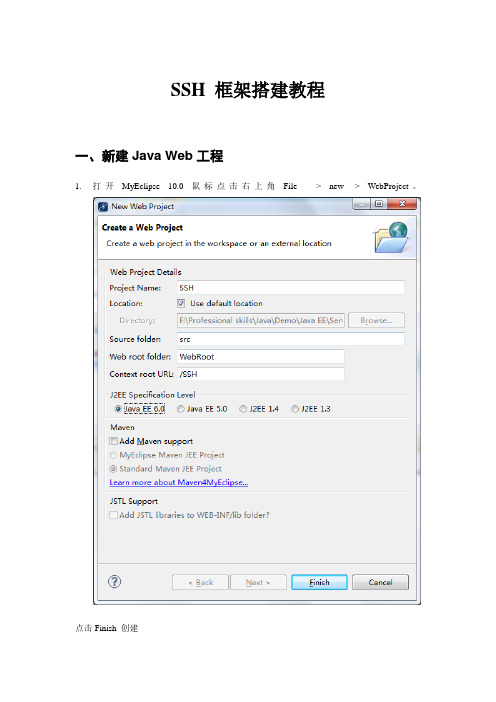
SSH 框架搭建教程一、新建Java Web工程1.打开MyEclipse 10.0 鼠标点击右上角File -> new -> WebProject。
点击Finish 创建2.新建两个package 包,如下:二、配置数据库连接1.点击MyEclipse 右上角图标,如下:MyEclipse旁边这图标2.然后选择MyEclipse Hibernate3.右键选择MyEclipse Derby -> New.. 新建一个数据库连接4.填写数据库连接信息, 这里以Oracle数据库为例,如下:5.6.配置好之后, 点击TestD Driver 进行测试,成功便出现如下7.测试成功之后点击Finish,左边导航会多一个名为SSH 的连接,如下:8.右键点击SSH连接,选择Open connection... 打开连接,打开之后便能看见自己所见的用户及数据库表,如下:9.继续点击MyEclipse 右上角,有个>> 箭头的图标,如下:10.选择MyEclipse Java Enterprise三、配置Spring框架1.右键点击项目名-> MyEclipse -> Add Spring Capabilities2.选择Spring3.0 总共选择5个Jar包,如下图:(选择完5个jar包才能选择窗体最下边的路径)3.继续,Next >4.选择Finish,这样Spring 框架就搭好了四、配置Hibernate框架1.右键点击项目名-> MyEclipse -> Add Hibernate Capabilities 见下图:2.Next >3.默认, 继续Next >4.默认, 继续Next >DB Driver 选择第二步创建的数据库连接5.继续,Next > 如下图:如果需要,可以创建SessionFactory,也可以不创建,这里选择不创建6.继续,Finish 这样,Hibernate 就配置完成,如下图:五、配置Status框架1.相对来说,配置Status框架就没有这么复杂了,右键点击项目名-> MyEclipse -> Add Status Capabilities 见下图:这里我们选择Status 2.12.继续, Next > 如下图:这里需要选择如下两个Jar包3.继续, Finish, 这样SSH框架就搭建完成,接下来反向生成DAO与实体类六、反向生成Bean与DAO类1.点击MyEclipse 右上角MyEclipse Hibernate,如下图:2.打开创建的数据库连接,如下:3.选择你要生成的数据库表,如果需要选择多张表,请按住Ctrl进行选择,这里我选择LG 下边的TABLE,LG是数据库的用户名如下图:4.上图有三张表,有两张是系统表,不予理会,这里我们选择USERS表,5.右键点击USERS -> Hibernate Reverse Engineering6.选择Java src folder 选择当前项目的src目录7.Java Package 选择bean 包,也就是存放实体类的包8.接下来,如下图:9.这里直接Finish10.生成后,如下图:11.这里会自动把DAO 放在Bean包里,可以将生成在bean包中的DAO类剪切到dao包下,也可以删掉,创建自己的DAO类。
SSH框架的搭建详细图文教程

SSH框架的搭建详细图⽂教程转载-6.在MySQL中新建⼀个表,⽤来测试数据我在这⾥准备做⼀个注册登录功能,所以在test⾥建了⼀个user表,表⾥的字段有id、username、password、nickname四个字段。
nickname⽤来测试中⽂是否乱码。
SQL语句:CREATE TABLE `user` (`id` bigint(20) unsigned NOT NULL auto_increment COMMENT 'ID',`username` varchar(40) character set utf8 NOT NULL COMMENT '⽤户名',`password` varchar(40) collate utf8_unicode_ci NOT NULL COMMENT '密码',`nickname` varchar(40) character set utf8 NOT NULL COMMENT '昵称',PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8 COLLATE=utf8_unicode_ciCOMMENT='⽤户信息表';SSH框架搭建步骤:1. 新建⼀个项⽬。
打开MyEclipse,新建⼀个Web项⽬,起名就叫SSH,点击完成,若弹出提⽰点Yes即可。
2.添加Struts框架。
右键这个项⽬,选择MyEclipse->Add StrutsCapabilities。
在弹出的菜单中把包的路径改⼀下, Base package for new classes选项中的路径com.yourcompany.struts改成com.ssh.struts, 点击完成。
展开WebRoot中的WEB-INF⽂件夹,看到⽬录结构如下图,证明Struts框架添加完成。
ssh框架开发流程

ssh框架开发流程SSH框架开发流程。
SSH框架是指Struts、Spring、Hibernate三大开源框架的整合,它们分别解决了Web层、业务逻辑层和数据访问层的开发问题。
在实际开发中,SSH框架已经成为了Java企业级应用开发的主流技术之一。
下面我们将详细介绍SSH框架的开发流程。
1. 环境搭建。
在进行SSH框架开发之前,首先需要搭建好相应的开发环境。
我们需要安装好JDK、Tomcat、Maven等开发工具,并且配置好相应的环境变量。
另外,还需要引入Struts、Spring、Hibernate等框架的jar包,并且进行相应的配置。
2. 创建项目。
在环境搭建完成之后,我们可以开始创建SSH项目。
通过Maven创建一个新的Web项目,然后在项目中引入Struts、Spring、Hibernate等框架的依赖。
接着,我们需要配置web.xml、struts.xml、spring.xml、hibernate.cfg.xml等配置文件,以及相应的数据库连接配置。
3. 编写实体类。
在项目创建完成之后,我们需要编写实体类来映射数据库中的表结构。
通过Hibernate的注解或者XML配置来定义实体类与数据库表的映射关系,确保实体类与数据库表字段的一一对应。
4. 编写DAO层。
接下来,我们需要编写DAO层的代码,用于实现数据访问的功能。
在Hibernate中,我们可以使用HibernateTemplate或者SessionFactory来进行数据库操作,实现数据的增删改查等功能。
5. 编写Service层。
在DAO层编写完成之后,我们需要编写Service层的代码,用于实现业务逻辑的处理。
在Service层中,我们可以调用DAO层的方法来实现业务逻辑的处理,并且可以进行事务管理等操作。
6. 编写Controller层。
最后,我们需要编写Controller层的代码,用于接收用户的请求并且进行相应的处理。
在Struts框架中,我们可以通过Action来处理用户的请求,并且可以将请求转发到相应的JSP页面进行展示。
ssh框架开发的使用流程

SSH框架开发的使用流程
1. 简介
SSH框架是一种结合了Spring、Struts和Hibernate三个开源框架的一种开发模式,它能够提供简洁、高效的企业级应用开发环境。
本文将介绍SSH框架的使用流程。
2. 准备工作
在使用SSH框架进行开发之前,需要进行一些准备工作:
•安装Java开发环境:确保计算机上已安装Java JDK。
•下载相关框架:从官网下载并解压Spring、Struts和Hibernate的最新版本。
•配置开发环境:将框架的jar文件导入到开发工具(如Eclipse)的项目中,并配置相关的Java类路径。
3. 创建项目
使用SSH框架进行开发,首先需要创建一个新的项目。
按照以下步骤创建SSH 项目:
1.在开发环境中创建一个新的Java项目。
2.导入Spring、Struts和Hibernate相关的jar文件。
3.配置项目的web.xml文件,设置项目的入口类和相关的配置文件路
径。
4.创建一个包用于存放Java类文件。
4. 配置Spring
在SSH框架中,Spring用于管理对象的创建和依赖注入。
按照以下步骤配置Spring:
1.在项目中创建一个Spring配置文件,通常命名为
applicationContext.xml。
2.在配置文件中定义需要管理的Java对象,使用<bean>标签指定对象
的类名和属性。
3.配置数据源,Spring可以通过数据源连接到数据库。
例如,以下是Spring配置文件的示例:
```xml <bean id=。
ssh框架开发流程

ssh框架开发流程SSH框架开发流程。
SSH框架是指Struts2 + Spring + Hibernate的整合开发框架,是目前Java企业级应用开发中比较流行的一种开发模式。
它将Struts2的MVC设计模式、Spring的IoC(控制反转)和AOP(面向切面编程)功能、Hibernate的ORM(对象关系映射)功能有机地结合在一起,为企业级应用的开发提供了一种高效、规范的解决方案。
下面将介绍SSH框架的开发流程。
1. 环境准备。
在进行SSH框架开发之前,首先需要搭建好相应的开发环境。
通常情况下,我们会选择使用Eclipse作为开发工具,同时需要安装好Tomcat作为应用服务器,以及配置好MySQL等数据库。
另外,还需要下载好Struts2、Spring和Hibernate的相关jar包,并将它们加入到项目的构建路径中。
2. 创建项目。
在环境准备完成后,接下来需要创建一个SSH框架的项目。
可以通过Eclipse的新建项目向导来创建一个Dynamic Web Project,然后在项目中引入Struts2、Spring和Hibernate的配置文件,以及相关的jar包。
接着可以创建相应的实体类、DAO(数据访问对象)、Service和Action等各层的代码文件。
3. 配置文件。
在项目创建完成后,需要进行各个框架配置文件的编写。
在Struts2中,需要编写struts.xml配置文件,配置Action的映射关系;在Spring中,需要编写applicationContext.xml配置文件,配置Bean的定义和依赖注入;在Hibernate中,需要编写hibernate.cfg.xml配置文件,配置数据库连接信息和实体类的映射关系。
4. 编写业务逻辑。
在配置文件编写完成后,可以开始编写业务逻辑代码。
首先需要编写实体类,用于映射数据库中的表结构;然后编写DAO接口和DAO实现类,用于数据库操作;接着编写Service接口和Service实现类,用于业务逻辑处理;最后编写Action类,用于处理用户请求并调用相应的Service方法。
SSH框架教程

SSH框架的学习一,Struts 21 为什么要学习Struts框架?1>Struts框架的好处:简化开发工作量,提高开发效率;采用了优秀的MVC思想2>如何学习:先掌握框架的使用,在了解内涵2 MVC模式在javaWeb中的应用1>MVC思想是根据组件职责不同,将系统分为三部分组成--M(Model) 负责业务处理--V(View) 负责与用户交互--C(Controller) 负责协调试图部分和模型部分协同工作2> 为什么使用MVC:易于扩展和升级3 Struts框架的处理流程浏览器发出struts请求—>请求进入struts控制器—>struts控制器解析XML配置文件—>控制器根据不同请求,调用不同的Action—>Action 调用DAO处理请求返回结果—>控制器根据结果调用试图组件,响应给用户4 Struts 历史Struts框架分为Struts1和Struts2 两者没有必然联系,Struts2 是以WebWork 框架核心(Xwork)为基础构建起来的5 Struts 基本使用1>引入核心开发包五个:commons-logging-1.0.4.jar ( 主要用于日志处理)struts2-spring-plugin-2.0.14.jar ( struts2整合spring需要的包)2>在web.xml 中配置struts控制器org.apache.struts2.dispatcher.ng.filter.StrutsPrepareAndExcuteFilter3>根据要求编写Action 和JSP Action要继承ActionSupport4>在struts.xml定义Action和请求对应关系6 struts.xml 基本配置可以放在src下面1><struts> 根元素里面包含多个<package>元素2><package> 主要是为了将Action分组定义name用于指定包名;extends一般指定struts-default(在struts-default.xml中定义),里面包括struts2运行所需的必要组件3><action name=”” class=”” method=””>4><result> 一个<action>可以包括多个<result> 主要用于试图响应5>下面一个例子:7 为列表添加分页功能例如每页2个page =1;pageSize=2;int begin=(page-1)*pageSize+1;int end=page*pageSize;eg: select * from ( select rownum rn , c.* form COST c ) where rn between 1 and 6;8 利用Struts2标签+OGNL技术1>OGNL: (Object-Graph Navigation Language)对象图导航语言,主要用于访问对象的数据和方法。
ssh框架原理及流程

ssh框架原理及流程SSH框架原理及流程。
SSH框架是指Struts+Spring+Hibernate的整合开发框架,它将三大开源框架整合在一起,使它们可以协同工作,相辅相成,为JavaEE开发提供了一种完整的解决方案。
本文将介绍SSH框架的原理及流程。
首先,我们来了解一下SSH框架的原理。
SSH框架是由Struts 作为MVC的Web层框架、Spring作为业务逻辑和数据访问层的IoC 容器和AOP框架、Hibernate作为持久层的ORM框架组成。
这三者分别负责不同的功能,通过整合,实现了各自的优势互补,形成了一个完整的开发框架。
其中,Struts负责接收用户请求,调度控制器和视图,Spring负责管理业务逻辑和数据访问,Hibernate负责持久化数据,实现了业务逻辑和数据访问的分离。
接下来,我们来看一下SSH框架的流程。
首先,用户发送请求到Struts的Action,Action接收请求后调用业务逻辑层的Service,Service再调用数据访问层的DAO,DAO通过Hibernate 实现对数据库的操作。
在这个过程中,Spring负责注入Service和DAO,管理事务,控制事务的提交和回滚。
最终,数据经过DAO和Hibernate的处理后返回到Action,由Struts将数据展示给用户。
整个流程中,各个组件各司其职,协同工作,实现了一个完整的开发流程。
在实际开发中,SSH框架的应用可以极大地提高开发效率和代码质量。
Struts提供了良好的MVC分离,使得前端开发更加清晰,易于维护;Spring提供了依赖注入和面向切面编程,使得业务逻辑的开发更加简洁,易于测试;Hibernate提供了对象关系映射,使得数据访问更加方便,避免了手写SQL语句的繁琐。
整合后的SSH 框架,不仅继承了各个框架的优点,还解决了各个框架之间的兼容性和整合性问题,使得开发更加高效、灵活和可维护。
总的来说,SSH框架的原理是将Struts、Spring和Hibernate 整合在一起,各司其职,相互配合,形成一个完整的开发框架;而SSH框架的流程是用户请求经过Struts、Spring和Hibernate的处理,最终返回给用户,各个组件之间相互协作,实现了一个完整的开发流程。
SSH框架运行流程

SSH框架运行流程1.初始化阶段:在初始化阶段,SSH框架会加载配置文件、创建核心对象和建立组件之间的关联关系。
1.1加载配置文件:1.2创建核心对象:1.3建立组件关联:2.请求处理阶段:在请求处理阶段,SSH框架根据请求的URL找到相应的处理器,并将请求参数传递给处理器进行处理。
2.1客户端发送请求:客户端通过浏览器向服务器发送请求,请求的URL中包含了需要调用的方法和相应的参数。
2.2URL映射:2.3参数绑定:2.4方法调用:处理器会调用相应的方法,并将参数传递给方法进行处理。
2.5数据库操作:如果需要进行数据库操作,如增删改查等,处理器会通过Hibernate 框架进行数据库访问。
3.结果返回阶段:在结果返回阶段,SSH框架将处理结果返回给客户端,通常是通过页面展示或异步请求返回数据。
3.1视图解析:如果处理器返回的是页面,SSH框架会根据配置文件中定义的视图解析器,将逻辑视图转换为具体的物理视图。
3.2页面渲染:3.3异步请求返回数据:如果处理器返回的是异步请求的数据,SSH框架会将数据封装成JSON 或XML格式,并通过HTTP协议返回给客户端。
总结:SSH框架的运行流程可以概括为初始化、请求处理和结果返回三个阶段。
在初始化阶段,SSH框架会加载配置文件、创建核心对象和建立组件之间的关联关系;在请求处理阶段,SSH框架根据请求的URL找到相应的处理器,并将请求参数传递给处理器进行处理;在结果返回阶段,SSH框架将处理结果返回给客户端,通常是通过页面展示或异步请求返回数据。
这个流程使得开发者能够快速开发出高质量的Java Web应用程序。
ssh框架流程

ssh框架流程
x
1. 客户机发送SSH请求:客户机向服务器发送SSH请求,告诉服务器客户机想要建立一个安全的连接。
2. 服务器回复并发送密钥:服务器接收客户机发送的SSH请求,回复客户机,并向客户机发送一个公开密钥,客户机此时可以使用服务器发送的公开密钥来确认服务器的身份。
3. 客户机发送数字签名:客户机使用服务器发送的公开密钥进行数字签名操作,并将数字签名发送给服务器。
4. 服务器验证数字签名:服务器接收客户机发送的数字签名,并使用服务器本身的私有密钥进行签名验证,如果签名验证成功,则表示客户机发送的数字签名来源于客户机。
5. 双方设置会话密钥:双方采用Diffie- Hellman算法协商出一个共享会话密钥,用于加密传输数据。
6. 通信传输:双方采用会话密钥进行加密传输数据,传输过程中对双方的数据包进行安全的加密传输。
7. 会话结束:当客户机完成所有的会话操作后,会话结束,双方都可以断开连接。
- 1 -。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
SSH框架的学习一,Struts 21 为什么要学习Struts框架?1>Struts框架的好处:简化开发工作量,提高开发效率;采用了优秀的MVC思想2>如何学习:先掌握框架的使用,在了解内涵2 MVC模式在javaWeb中的应用1>MVC思想是根据组件职责不同,将系统分为三部分组成--M(Model) 负责业务处理--V(View) 负责与用户交互--C(Controller) 负责协调试图部分和模型部分协同工作2> 为什么使用MVC:易于扩展和升级3 Struts框架的处理流程浏览器发出struts请求—>请求进入struts控制器—>struts控制器解析XML配置文件—>控制器根据不同请求,调用不同的Action—>Action 调用DAO处理请求返回结果—>控制器根据结果调用试图组件,响应给用户4 Struts 历史Struts框架分为Struts1和Struts2 两者没有必然联系,Struts2 是以WebWork 框架核心(Xwork)为基础构建起来的5 Struts 基本使用1>引入核心开发包五个:commons-logging-1.0.4.jar ( 主要用于日志处理)struts2-spring-plugin-2.0.14.jar ( struts2整合spring需要的包)2>在web.xml 中配置struts控制器org.apache.struts2.dispatcher.ng.filter.StrutsPrepareAndExcuteFilter3>根据要求编写Action 和JSP Action要继承ActionSupport4>在struts.xml定义Action和请求对应关系6 struts.xml 基本配置可以放在src下面1><struts> 根元素里面包含多个<package>元素2><package> 主要是为了将Action分组定义name用于指定包名;extends一般指定struts-default(在struts-default.xml中定义),里面包括struts2运行所需的必要组件3><action name=”” class=”” method=””>4><result> 一个<action>可以包括多个<result> 主要用于试图响应5>下面一个例子:7 为列表添加分页功能例如每页2个page =1;pageSize=2;int begin=(page-1)*pageSize+1;int end=page*pageSize;eg: select * from ( select rownum rn , c.* form COST c ) where rn between 1 and 6;8 利用Struts2标签+OGNL技术1>OGNL: (Object-Graph Navigation Language)对象图导航语言,主要用于访问对象的数据和方法。
2>OGNL主要由三部分组成--OGNL引擎:负责解析OGNL表达式,定位数据;--Root根存储区:负责存储要访问的目标对象;--Context变量存储区(Map 类型) 负责存放多个要访问的目标对象;3> OGNL 基本语法:A,访问Root区域对象基本语法:--访问简单数据:属性—> “name”;--访问数组和List集合:属性[index] —> “list[2]”;--访问Map集合:属性.Key —> “map.sex”;--访问方法:属性.方法( ) —> “list.size( )”;--创建List对象:”{ element1, element2}”;--创建Map对象:”#{key1 : value1 , key2 : value2}”;--创建对象: “ new 包名.构造方法” —> “ new int( totalPages )”B,访问Context区域对象基本语法:采用”#key”即可4> OGNL技术在Struts上面的应用在Struts中有一个ValueStack( )值栈数据对象,该对象存储了请求相关的所有的数据信息。
例如request session application action等,struts采用OGNL 工具对ValueStack进行操作。
--- xwork对OGNL进行了部分改造:答:将Root存储区改造成一个栈结构(CompoundRoot),当利用”属性”表达式访问时。
优先对栈顶对象查找,没有再去次栈顶查找,以此类推5>Struts标签的使用利用Struts2标签显示数据,需要为标签指定OGNL表达式,标签利用表达式定位ValueStack中的数据,进行相应的操作--- <debug> : 显示valueStack状态Eg:<s:debug></s:debug>--- <iterator> : 循环集合元素Eg:<s:iterator value=”new int(totalPages)” status=”i”/> 分页中用到了;<s:iterator value=”pageRows” var=”cost”/>注:value :指定循环集合或数组var:指定循环变量,会被存放到ValueStack的Context中。
status:指定循环状态变量,会被存放到ValueStack的Context中,该变量有count属性表示循环了多少个元素(1开始),index表示当前循环元素的索引(0开始)。
--- if…else…标签判断分支:<s:if test=””></s:if> test指定ognl判断表达式Eg:<s:if test=”#cost.status==0”>暂停</s:if><s:else>开通</s:else>--- <s:property value=””/> 显示数据标签value指定ognl表达式Eg:<s:property value=”#cost.id”/>--- <s:date name=”” format=””/> 将数据date格式化输出Eg:<s:date name=”#cost.startTime” format=”yyyy/MM/dd HH:mm:ss” /> 9 Action组件的相关使用1> Action 组件的原理客户发出action请求给struts控制器—> struts控制器会创建ValueStack对象—>struts控制器根据请求创建Action对象,并将Action压入ValueStack 的root栈顶(线程安全,不用考虑并发问题)—>struts控制器将请求相关的Request,Session对象放入到ValueStack的Context区域—>struts控制器执行Action对象的execute方法处理请求—>struts控制器根据execute结果生成响应信息输出—>请求处理完毕,销毁ValueStack和Action对象。
2>Action属性注入在<action>配置中,为Action对象的属性指定初始值,使用格式如下<action name=”” class=”” method=””><param name=”属性名”>属性值</param><result></result></action>注意:type类型如果你想再见跳转的页面需要Action的数据的话要用dispatcher,如果用redirect时候,将所有的数据删除了,jsp页面中也不能获取到应有的值了。
10 Result组件的相关使用1> 作用:负责生成响应试图内容。
Struts2框架提供了多种不同的Result组件类型,用于做不同形式响应,例如json数据响应,流数据响应,jsp页面响应等。
2> Result组件相关配置---声明定义<package><result-types><result-type name=”result类型” class=”result组件实现类”/> </result-types></package>3> Result组件相关配置---使用定义<action><result name=”action返回的标识符” type = “result类型”></result> </action>4> 掌握经常使用的Result组件--Jsp试图--dispatcher:以转发方式调用Jsp页面--redirect:以重定向方式调用Jsp页面<result name=”” type=”dispatcher/redirect”>Jsp页面</result>--Action试图--chain:以转发方式调用下一个Action--redirectAction:以重定向方式调用下一个Action相同命名空间的调用:<result type=”chain/redirectAction”>请求名</result>跨命名空间的调用:<result type=”chain/redirectAction”><param name=”actionName”>请求名</param><param name=”namespace”>/命名空间名</param></result>5> JSON Result组件主要负责Action的属性以JSON字符串格式输出,JSON Result的使用步骤:---引入struts2-json-plugin.jar。
---将<package>元素的extends继承”json-default”;---<result>使用配置---只返回Action中一个属性:<result type=”json”><param name=”root”>属性名</param></result>---返回Action中多个属性:<result type=”json”><param name=”includeProperties”>属性名1,属性名2,属性名3</param></result>---返回Action中的所以属性值<result type=” json” ></result>11 拦截器组件Struts2组件提供了大量的拦截器组件,如果不能满足开发者需求,可以自行定义,一般利用拦截器封装一些通用性的功能,例如请求参数给action赋值,文件上传,权限检查等;1> 拦截器的作用:拦截器可以在Action 和Result组件调用之前执行,也可以在其之后执行。