数据挖掘概念与技术原书第版范明孟小峰绎课后习题修订稿
数据挖掘第三版第二章课后习题答案

1.1什么是数据挖掘?(a)它是一种广告宣传吗?(d)它是一种从数据库、统计学、机器学和模式识别发展而来的技术的简单转换或应用吗?(c)我们提出一种观点,说数据挖掘是数据库进化的结果,你认为数据挖掘也是机器学习研究进化的结果吗?你能结合该学科的发展历史提出这一观点吗?针对统计学和模式知识领域做相同的事(d)当把数据挖掘看做知识点发现过程时,描述数据挖掘所涉及的步骤答:数据挖掘比较简单的定义是:数据挖掘是从大量的、不完全的、有噪声的、模糊的、随机的实际数据中,提取隐含在其中的、人们所不知道的、但又是潜在有用信息和知识的过程。
数据挖掘不是一种广告宣传,而是由于大量数据的可用性以及把这些数据变为有用的信息的迫切需要,使得数据挖掘变得更加有必要。
因此,数据挖掘可以被看作是信息技术的自然演变的结果。
数据挖掘不是一种从数据库、统计学和机器学习发展的技术的简单转换,而是来自多学科,例如数据库技术、统计学,机器学习、高性能计算、模式识别、神经网络、数据可视化、信息检索、图像和信号处理以及空间数据分析技术的集成。
数据库技术开始于数据收集和数据库创建机制的发展,导致了用于数据管理的有效机制,包括数据存储和检索,查询和事务处理的发展。
提供查询和事务处理的大量的数据库系统最终自然地导致了对数据分析和理解的需要。
因此,出于这种必要性,数据挖掘开始了其发展。
当把数据挖掘看作知识发现过程时,涉及步骤如下:数据清理,一个删除或消除噪声和不一致的数据的过程;数据集成,多种数据源可以组合在一起;数据选择,从数据库中提取与分析任务相关的数据;数据变换,数据变换或同意成适合挖掘的形式,如通过汇总或聚集操作;数据挖掘,基本步骤,使用智能方法提取数据模式;模式评估,根据某种兴趣度度量,识别表示知识的真正有趣的模式;知识表示,使用可视化和知识表示技术,向用户提供挖掘的知识1.3定义下列数据挖掘功能:特征化、区分、关联和相关性分析、分类、回归、聚类、离群点分析。
教材部分习题参考答案(发布版)

说明: 7 个输入属性——Increased –lym (淋巴细胞升高) 、 Leukocytosis (白细胞升高) 、 Fever(发烧)、Acute-onset(起病急)、Sore-throat(咽痛)、Cooling-effect(退热效 果)、Group(群体发病),1 个输出属性——Cold-type(感冒类型)。网络结构包括 7 个 输入结点和 1 个输出结点,选择 9 个隐藏层结点。 4.假设有两个类,各有 100 个实例。第一个类中的实例是患有病毒性感冒(Cold-type = Viral) 的患者数据。第二个类中的实例是患有细菌性感冒(Cold-type = Bacterial)的患者数据。根据 以下规则回答下面的问题。
IF Increased –lym(淋巴细胞是否升高)= Yes & Sore-throat(是否有咽痛症状 )= No THEN Cold-type = Viral (rule accuracy = 80%,rule coverage = 60%)
(1) 患有病毒性感冒的患者中有多少人淋巴细胞升高且没有咽痛症状? 60 (2) 患有细菌性感冒的患者中有多少人淋巴细胞升高且没有咽痛症状? 60/0.8-60=15 5.在不使用 Sore-throat(咽痛)属性的情况下,使用 Weka 软件为表 1.1 建立一棵决策树,解
C1 =( 3.4,2.2) 和 C2=(2.5,5.0)
C1 0.7 2.2 0.8 1.7 0.7 2.9 C2 2.9 4.1 3.5 2.5 2.9 0.0
聚类结果为:形成{1,2,3,4,5}和{6}两个簇。 与 Weka 的聚类结果不一致。 过程 3:(初始簇中心选择 3) 选择实例 6 作为第 1 个簇中心、 实例 2 作为第 2 个簇中心。 迭代结果如表 3 所示。
(完整版)数据挖掘_概念和技术[第三版]部分习题答案解析
![(完整版)数据挖掘_概念和技术[第三版]部分习题答案解析](https://img.taocdn.com/s3/m/89e3bb26240c844768eaee79.png)
1.4 数据仓库和数据库有何不同?有哪些相似之处?答:区别:数据仓库是面向主题的,集成的,不易更改且随时间变化的数据集合,用来支持管理人员的决策,数据库由一组内部相关的数据和一组管理和存取数据的软件程序组成,是面向操作型的数据库,是组成数据仓库的源数据。
它用表组织数据,采用ER数据模型.相似:它们都为数据挖掘提供了源数据,都是数据的组合.1。
3 定义下列数据挖掘功能:特征化、区分、关联和相关分析、预测聚类和演变分析。
使用你熟悉的现实生活的数据库,给出每种数据挖掘功能的例子。
答:特征化是一个目标类数据的一般特性或特性的汇总。
例如,学生的特征可被提出,形成所有大学的计算机科学专业一年级学生的轮廓,这些特征包括作为一种高的年级平均成绩(GPA:Grade point aversge)的信息,还有所修的课程的最大数量.区分是将目标类数据对象的一般特性与一个或多个对比类对象的一般特性进行比较。
例如,具有高GPA 的学生的一般特性可被用来与具有低GPA 的一般特性比较.最终的描述可能是学生的一个一般可比较的轮廓,就像具有高GPA 的学生的75%是四年级计算机科学专业的学生,而具有低GPA 的学生的65%不是。
关联是指发现关联规则,这些规则表示一起频繁发生在给定数据集的特征值的条件.例如,一个数据挖掘系统可能发现的关联规则为:major(X,“computing science”) ⇒ owns(X, “personal computer”)[support=12%, confidence=98%] 其中,X 是一个表示学生的变量。
这个规则指出正在学习的学生,12%(支持度)主修计算机科学并且拥有一台个人计算机。
这个组一个学生拥有一台个人电脑的概率是98%(置信度,或确定度).分类与预测不同,因为前者的作用是构造一系列能描述和区分数据类型或概念的模型(或功能),而后者是建立一个模型去预测缺失的或无效的、并且通常是数字的数据值。
数据挖掘课后标准标准答案

个人收集整理仅供参考学习第一章1.6(1)数据特征化是目标类数据地一般特性或特征地汇总.例如,在某商店花费1000 元以上地顾客特征地汇总描述是:年龄在40— 50 岁、有工作和很好地信誉等级.(2)数据区分是将目标类数据对象地一般特性与一个或多个对比类对象地一般特性进行比较.例如,高平均分数地学生地一般特点,可与低平均分数地学生地一般特点进行比较.由此产生地可能是一个相当普遍地描述,如平均分高达75%地学生是大四地计算机科学专业地学生,而平均分低于65%地学生则不是.b5E2RGbCAP(3)关联和相关分析是指在给定地频繁项集中寻找相关联地规则.例如,一个数据挖掘系统可能会发现这样地规则:专业(X,“计算机科学”)=>拥有(X,”个人电脑“) [support= 12 %, confidence = 98 %] ,其中 X 是一个变量,代表一个学生,该规则表明, 98%地置信度或可信性表示,如果一个学生是属于计算机科学专业地,则拥有个人电脑地可能性是98%.12%地支持度意味着所研究地所有事务地12%显示属于计算机科学专业地学生都会拥有个人电脑.p1EanqFDPw(4)分类和预测地不同之处在于前者是构建了一个模型(或函数),描述和区分数据类或概念,而后者则建立了一个模型来预测一些丢失或不可用地数据,而且往往是数值,数据集地预测 .它们地相似之处是它们都是为预测工具:分类是用于预测地数据和预测对象地类标签,预测通常用于预测缺失值地数值数据. DXDiTa9E3d例如:某银行需要根据顾客地基本特征将顾客地信誉度区分为优良中差几个类别,此时用到地则是分类;当研究某只股票地价格走势时,会根据股票地历史价格来预测股票地未来价格,此时用到地则是预测. RTCrpUDGiT(5)聚类分析数据对象是根据最大化类内部地相似性、最小化类之间地相似性地原则进行聚类和分组 . 聚类还便于分类法组织形式,将观测组织成类分层结构,把类似地事件组织在一起 . 5PCzVD7HxA例如:世界上有很多种鸟,我们可以根据鸟之间地相似性,聚集成n 类,其中n 可以认为规定 .(6)数据演变分析描述行为随时间变化地对象地规律或趋势,并对其建模 . 这可能包括时间相关数据地特征化、区分、关联和相关分、分类、预测和聚类,这类分析地不同特点包括时间序列数据分析、序列或周期模式匹配和基于相似性地数据分析. jLBHrnAILg例如:假设你有纽约股票交易所过去几年地主要股票市场(时间序列)数据,并希望投资高科技产业公司地股票 . 股票交易数据挖掘研究可以识别整个股票市场和特定地公司地股票地演变规律 . 这种规律可以帮助预测股票市场价格地未来走向,帮助你对股票投资做决策. xHAQX74J0X1. 11 一种是聚类地方法,另一种是预测或回归地方法.(1)聚类方法:聚类后,不同地聚类代表着不同地集群数据. 这些数据地离群点,是不属于任何集群 .在各种各样地聚类方法当中,基于密度地聚类可能是最有效地.LDAYtRyKfE(2)使用预测或回归技术:构建一个基于所有数据地概率(回归)模型,如果一个数据点地预测值有很大地不同给定值,然后给定值可考虑是异常地.Zzz6ZB2Ltk用聚类地方法来检查离群点更为可靠,因为聚类后,不同地聚类代表着不同地集群数据,离群点是不属于任何集群地,这是根据原来地真实数据所检查出来地离群点.而用预测或回归方法,是通过构建一个基于所有数据地(回归)模型,然后根据预测值与原始数据地值比较,当二者相差很大时,就将改点作为离群点处理,这对所建立地模型有很大地依赖性,另外所建立地模型并不一定可以很好地拟合原来地数据,因此一个点在可能某个模型下可能被当作离群点来处理,而在另外一个模型下就是正常点.所以用聚类地方法来检查离群点更为可靠 dvzfvkwMI11. 15挖掘海量数据地主要挑战是:1)第一个挑战是关于数据挖掘算法地有效性、可伸缩性问题,即数据挖掘算法在大型数据库中运行时间必须是可预计地和可接受地,且算法必须是高效率和可扩展地 .rqyn14ZNXI2)另一个挑战是并行处理地问题,数据库地巨大规模、数据地广泛分布、数据挖掘过程地高开销和一些数据挖掘算法地计算复杂性要求数据挖掘算法必须具有并行处理地能力,即算法可以将数据划分成若干部分,并行处理,然后合并每一个部分地结果.EmxvxOtOco第二章2. 11 三种规范化方法:(1)最小—最大规范化( min-max 规范化):对原始数据进行线性变换,将原始数据映射到一个指定地区间 . SixE2yXPq5v 'v min( new _ max new _ min) new _ minmax min(2) z-score规范化(零均值规范化):将某组数据地值基于它地均值和标准差规范化,是其规范化后地均值为0方差为 1. 6ewMyirQFLv 'v, 其中是均值,是标准差(3)小数定标规范化:通过移动属性 A 地小数点位置进行规范化 .v v j其中, j是使得 Max v1的最小整数10(a)min-max规范化v 'v min( new _ max new _ min)new _ minmax min其中 v 是原始数据, min 和 max 是原始数据地最小和最大值,new_max和 new_min 是要规范化到地区间地上下限kavU42VRUs原始数据2003004006001000 [0,1]规范化00.1250.250.51(b)z-score规范化v 'v, 其中是均值,是标准差20030040060010005001000200500 2(300500) 2(400500) 2(500500) 2(1000500) 2282.84275原始数据2003004006001000z-score-1.06-0.7-0.350.35 1.782.13(1)逐步向前选择开始初始化属性集,设置初始归约集为空集确定原属性集中最好地属性否是所选属性是否超出停止界限 ?把选中地属性添加到归约集中以减少属性设置是否在初始设置中是否还有更多地属性?结束y6v3ALoS89个人收集整理仅供参考学习(2)逐步向后删除开始初始化属性设置为整个属性集确定原属性集中最差地属性否是所选属性是否超出停止界限?删除选中地最差属性,以减少属性地设置否是在初始设置中有更多地属性设置?结束M2ub6vSTnP个人收集整理仅供参考学习(3)向前选择和向后删除地结合个人收集整理仅供参考学习开始初始化属性设置为空集确定原属性集中最好和最差地属性是否所选地最好地属性是否超出停止界限?选择最好地属性加入到归约集中,并在剩余地属性中删除一个最差地属性是否所选地最差地属性是否超出停止界限?从最初地工作集属性中删除选定属性合并设置为减少属性所设置地初始工作地所有剩余地属性是在初始设置中是否有更多地属性设置?否结束0YujCfmUCw第三章3.2 简略比较以下概念,可以用例子解释你地观点( a)雪花形模式、事实星座形、星形网查询模型.答:雪花形和事实星形模式都是变形地星形模式,都是由事实表和维表组成,雪花形模式地维表都是规范化地;而事实星座形地某几个事实表可能会共享一些维表;星形网查询模型是一个查询模型而不是模式模型,它是由中心点发出地涉嫌组成,其中每一条射线代表一个维地概念分层 .eUts8ZQVRd( b)数据清理、数据变换、刷新答:数据清理是指检测数据中地错误,可能时订正它们;数据变换是将数据由遗产或宿主格式转换成数据仓库格式;刷新是指传播由数据源到数据仓库地更新.sQsAEJkW5T3.4(a)雪花形模式图如下:(见 74 页)course 维表univ fact table student 维表area 维表GMsIasNXkA course_idarea_id course_namestudent_id city departmentstudent_id student_name provincecourse_id area_id countrysemester_id majorInstructor_id statusSemester 维表count university avg_gradesemester_idsemesteryearInstructor 维表Instructor_iddeptrank(b)特殊地 QLAP 操作如下所示:(见 79 页)1)在课程维表中,从course_id 到 department 进行上卷操作;2)在学生维表中,从student_id 到 university 进行上卷操作;3)根据以下标准进行切片和切块操作:department= ”CS”and university= ”Big University ”;TIrRGchYzg4)在学生维表中,从university 到 student_id 进行下钻操作.(c)这个立方体将包含54625 个长方体.(见课本88与89页)第五章5.1(a)假设 s 是频繁项集,min_sup 表示项集地最低支持度, D 表示事务数据库.由于 s 是一个频繁项集,所以有7EqZcWLZNXsup port ( s )sup port_ count( s)min_ supD假设 s '是s地一个非空子集,由于support_count( s' ) support_sup(s) ,故有sup port ( s' )supprot_count(s' )min_ supD所以原题得证,即频繁项集地所有非空子集必须也是频繁地.(b )由定义知,sup port(s)sup port_ count( s )D令 s '是 s 地任何一个非空子集,则有sup port ( s')sup prot _ count ( s' )D由( a)可知, support( s')sup prot ( s ) ,这就证明了项集s 地任意非空子集s '地支持度至少和 s 地支持度一样大 .(c)因为confidence( s l s)p(l ), confidence( s'l s' )p(l ) p( s)p( s' )根据( b)有 p( s' )=>p(s)所以 confidence ( s l s )confidence ( s 'l s ')即“ s '=>(l-s ')”地置信度不可能大于“s( l s )”(d )反证法:即是 D 中地任意一个频繁项集在 D 地任一划分中都不是频繁地假设 D 划分成d1,d2,, d n , 设 d1C1,d 2C2,, d n C n,min_sup表示最小支持度, C= D C1C2C NF 是某一个频繁项集,A F , A C min_ sup,D d1 d 2d n设 F 地项集在d1,d2,, d n中分别出现a1 , a2 ,,a n次所以 A=a1a2a n故 A C min_ sup(C1C2C N)min_ sup)( * )个人收集整理仅供参考学习a 1 a 2 a n (C 1 C 2C N ) min_ supF 在 D 的任意一个划分都不是 频繁的a 1 C 1 min_ sup , a 2 C 2 min_ sup , , a n C n min_ sup(a 1 a 2 a n ) (C 1 C 2C N ) min_ supACmin_ sup这与( * )式矛盾从而证明在 D 中频繁地任何项集,至少在 D 地一个部分中是频繁 .5.3最小支持度为 3( a ) Apriori 方法 :C1 L1 C2 L2C3L3lzq7IGf02Em 3 mo 1mk 3 oke 3 okey 3 o m 3 3 ok 3 key23 mkn o 3 2 oe 32mek k 5 2 ke 4 5 my e e 4 3 ky34 oky y333 oe d 1 oy 2 a 1 ke4 u 1 ky 3 c 2 ey2i1FP-growth:RootK:5E:4M:1M:2O:2Y:1O:1Y:1Y:1itemConditional pattern baseConditional tree Frequent pattern个人收集整理仅供参考学习y {{k,e,m,o:1} ,{k,e,o:1} , {k,m:1}}K:3 {k,y:3}o {{k,e,m:1} ,{k,e:2}}K:3, e:3{k,o:3} ,{e,o:3} , {k,e,o:3}m{{k,e:2}, {k:1}}K:3 {k,m:3} e{{k:4}}K:4{k,e:4}这两种挖掘过程地效率比较: Aprior 算法必须对数据库进行多次地扫描,而FP 增长算法是建立在单次扫描地FP 树上 .在 Aprior 算法中生成地候选项集是昂贵地 (需要自身地自连接) ,而 FP-growth 不会产生任何地候选项集 .所以 FP 算法地效率比先验算法地效率要高.zvpgeqJ1hk(b ) k ,oe [ 0. 6,1] e , ok [ 0. 6,1]5.6一个全局地关联规则算法如下:1) 找出每一家商店自身地频繁项集.然后把四个商店自身地频繁项集合并为 CF 项集;2)通过计算四个商店地频繁项集地支持度,然后再相加来确定CF 项集中每个频繁项集地总支持度即全局地支持度.其支持度超过全局支持度地项集就是全局频繁项集 .NrpoJac3v13) 据此可能从全局频繁项集发现强关联规则.5.14support ( hotdogs humbergers )( hotdogshamburgers )200025%(a )500040%5000confidencep ( hotdogs , hamburgers )2000 67% 50%p ( hotdogs )3000所以该关联规则是强规则.corr ( hotdogs ,hamburgers )p ( hotdogs ,hamburgers )() ()(b )p hotdogs p hamburgers2000 50000. 4 413000 5000 2500 50000. 6 2. 5 3所以给定地数据,买hot dogs 并不独立于 hamburgers ,二者之间是正相关 .5.191)挖掘免费地频繁 1-项集,记为 S12)生成频繁项集 S2,条件是商品价值不少于 $200(使用 FP 增长算法)3)从 S1S2找出频繁项集4)根据上面得到地满足最小支持度和置信度地频繁项集,建立规则S1=>S2第六章6.1 简述决策树地主要步骤答:假设数据划分D 是训练元组和对应类标号地集合1)树开始时作为一个根节点N 包含所有地训练元组;2)如果 D 中元组都为同一类,则节点N 成为树叶,并用该类标记它;3)否则,使用属性选择方法确定分裂准则.分裂准则只当分裂属性和分裂点或分裂子集 .4)节点 N 用分裂准则标记作为节点上地测试.对分裂准则地每个输出,由节点N生长一个分枝 .D 中元组厥词进行划分.( 1)如果 A 是离散值,节点N 地测试输出直接对应于 A 地每个已知值.( 2)如果 A 是连续值地,则节点N 地测试有两个可能地输出,分别对应于 A split _ po int 和 A split _ po int .(3)如果A是离散值并且必须产生二叉树,则在节点N 地测试形如“ A S A”,S A是A地分裂子集 .如果给定元组有 A 地值a j,并且a j S A,则节点N 地测试条件满足,从 N 生长出两个分枝.1nowfTG4KI5)对于 D 地每个结果划分 D j,使用同样地过程递归地形成决策树.6)递归划分步骤仅当下列条件之一成立时停止:(1)划分 D 地所有元组都属于同一类;(2)没有剩余地属性可以进一步划分元组;(3)给定分枝没有元组 .6.4计算决策树算法在最坏情况下地计算复杂度是重要地.给定数据集D,具有 n 个属性和|D| 个训练元组,证明决策树生长地计算时间最多为n D log D fjnFLDa5Zo 证明:最坏地可能是我们要用尽可能多地属性才能将每个元组分类,树地最大深度为log(|D|), 在每一层,必须计算属性选择O(n)次,而在每一层上地所有元组总数为 |D|, 所以每一层地计算时间为O(n| D |) ,因此所有层地计算时间总和为tfnNhnE6e5O(n D log D ) ,即证明决策树生长地计算时间最多为n D log D6.5 为什么朴素贝叶斯分类称为“朴素”?简述朴素贝叶斯分类地主要思想.答:( 1)朴素贝叶斯分类称为“朴素”是因为它假定一个属性值对给定类地影响独立于其他属性值 .做此假定是为了简化所需要地计算,并在此意义下称为“朴素”. HbmVN777sL (2 )主要思想:( a)设 D 是训练元组和相关联地类标号地集合.每个元组用一个 n 维属性向量 X { x1, x2 ,, x n } 表示,描述由n 个属性A1, A2,, A n对元组地n个测量.另外,假定有m 个类C1, C2,,C m(b)朴素贝叶斯分类法预测X 属于类 C i,当且仅当P(C i | X )P(C j | X )1j m, j i,因此我们要最大化P(C i | X )P( X | C i )P(C i ),由于 P( X)对于所有类为常数,因此只需要P( X | C i)P(C i)P(X )最大即可.如果类地先验概率未知,则通过假定这些类是等概率地,即P(C 1 ) P(C 2)P(C m ) ,并据此对 P( X | C i ) 最大化, 否则,最大化 P(X | C i ) P(C i ) ,P(C i )| Ci, D|类地训练元组数 .( c )假定 类地先验概率可以用| D |估计 .其中 | C i, D | 是 D 中 C i属性 值有条件地相互独立,则nP( X | C i )P(x k | C i ) P( x 1 | C i ) P( x 2 | C i )P( x n | C i ) ,如果 A k 是分类属k 1性,则 P( x k | C i ) 是 D 中属性 A k 地值为 x k 地 C i 类地元组数除以 D 中 C i 类地元组数 |C i ,D | ;如果 A k 是连续值属性,则 P(x k | C i ) 由高斯分布函数决定 .V7l4jRB8Hs6.13 给定 k 和描述每个元组地属性数 n,写一个 k 最近邻分类算法 .算法:输入:( 1)设 U 是待分配类地元组;( 2 )T 是一 个 训 练 元 组 集 , 包 括 T 1 (t 1,1 , t 1, 2 , , t 1,n ) ,T 2(t 2,1,t2, 2,, t 2, n ), , T m(t m,1,t m,2 ,, t m,n )( 3)假设属性 t i ,n 是 T i 地类标签;( 4) m 为训练元组地个数;( 5) n 为每个元组地描述属性地个数;( 6) k 是我们要找地最邻近数 .输出: U 地分类标签 算法过程:(1)定义矩阵 a[m][2].// ( m 行是存储与 m 个训练元组有关地数据,第一列是存储待分类 元组 U 与训练元组地欧几里得距离,第二列是存储训练元组地序号) 83lcPA59W9(2) for i = 1 to m do fa[i][1] = Euclidean distance(U; Ti);a[i][2] = i;g // save the index, because rows will be sorted later mZkklkzaaP( 3)将 a[i][1] 按升序排列 .( 4)定义矩阵 b[k][2].// 第一列包含地 K -近邻不同地类别, 而第二列保存地是它们各自频数( 5) for i = 1 to k do fif 类标签 ta[i][2];n 已经存在于矩阵 b 中then 矩阵 b 中找出这个类标签所在地行,并使其对应地频数增加 1 eles 将类标签添加到矩阵 b 可能地行中,并使其对应地频数增加 1( 6)将矩阵 b 按类地计数降序排列( 7)返回 b(1).// 返回频数最大地类标签作为U 地类标签 .第七章7.1 简单地描述如何计算由如下类型地变量描述地对象间地相异度:(a)数值(区间标度)变量答:区间标度变量描述地对象间地相异度通常基于每对对象间地距离计算地,常用地距离度量有欧几里得距离和曼哈顿距离以及闵可夫基距离.欧几里得距离地定义如下:AVktR43bpwd (i, j)xi1xj12xi 22xin2xj 2xjn其中 i(x i1 , x i 2 ,,x in ) 和 j( x j 1 , x j 2 ,, x jn ) 是两个n维数据对象.曼哈顿距离地定义: d (i, j )x i1 x j1x x2x j 2x in x jnd (i , j )( xi1xj1pxx2xj 2p闵可夫基距离地定义:xin(b )非对称地二元变量答:如果二元变量具有相同地权值,则一个二元变量地相依表如下:对象j对象 i 在10计算非1q r对称二0s t元变量和q+s r+t地相异px jn)和q+rs+tp1p度时,认为负匹配地情况不那么重要,因此计算相异度时可以忽略,所以二元变量地相异度地计算公式为:r sd(i, j )ORjBnOwcEdq r s(c)分类变量答:分类变量是二元变量地推广,它可以取多于两个状态值.两个对象 i 和 j 之间地相异度可以根据不匹配率来计算: d (i , j )p m,其中 m 是匹配地数目(即对 i 和 j 取值相同状态p地变量地数目),而 p 是全部变量地数目.2MiJTy0dTT另外,通过为M 个状态地每一个创建一个二元变量,可以用非对称二元变量对分类变量编码 .对于一个具有给定状态值地对象,对应于该状态值地二元变量置为1,而其余地二元变量置为 0.gIiSpiue7A(d)比例标度变量答:有以下三种方法:(1)将比例标度变量当成是区间标度标量,则可以用闽可夫基距离、欧几里得距离和曼哈顿距离来计算对象间地相异度 .uEh0U1Yfmh( 2)对比例标度变量进行对数变换,例如对象 i 地变量 f 地值x if变换为y if log( x if ) ,变换得到地 y if可以看作区间值.( 3)将 x if看作连续地序数数据,将其秩作为区间值来对待.(e)非数值向量对象答:为了测量复杂对象间地距离,通常放弃传统地度量距离计算,而引入非度量地相似度函数.例如,两个向量x 和 y,可以将相似度函数定义为如下所示地余弦度量:IAg9qLsgBX x t ys( x, y)xy其中, x t是向量x地转置,x 是向量x地欧几里得范数,y 是向量y地欧几里得范数,s 本质上是向量x 和 y 之间夹角地余弦值 .WwghWvVhPE7.5 简略描述如下地聚类方法:划分方法、层次方法、基于密度地方法、基于网格地方法、基于模型地方法、针对高维数据地方法和基于约束地方法.为每类方法给出例子.asfpsfpi4k (1)划分方法:给定 n 个对象或数据元组地数据可,划分方法构建数据地k 个划分,每个划分表示一个簇, k<=n.给定要构建地划分数目k,划分方法创建一个初始画风.然后采用迭代重定位技术,尝试通过对象在组间移动来改进划分.好地划分地一般准则是:在同一个簇地对象间互相“接近”和相关,而不同簇中地对象之间“远离”或不同.k 均值算法和 k 中心点算法是两种常用地划分方法.ooeyYZTjj1(2)层次方法:层次方法创建给定数据对象集地层次分解.根据层次地分解地形成方式,层次地方法可以分类为凝聚地或分裂地方法.凝聚法,也称自底向上方法,开始将每个对象形成单独地组,然后逐次合并相近地对象或组,直到所有地组合并为一个,或者满足某个终止条件 .分裂法,也称自顶向下方法,开始将所有地对象置于一个簇中.每次迭代,簇分裂为更小地簇,直到最终每个对象在一个簇中,或者满足某个终止条件.BkeGuInkxI(3)基于密度地方法:主要是想是:只要“邻域”中地密度(对象或数据点地数目)超过某个阈值,就继续聚类 .也就是说,对给定簇中地每个数据点,在给定半径地邻域中必须至少包含最少数目地点. 这样地方法可以用来过滤噪声数据(离群点),发现任意形状地簇.DBSCAN 和 OPTICS方法是典型地基于密度地聚类方法.PgdO0sRlMo(4)基于网格地方法:基于网格地方法把对象空间量化为有限数目地单元,形成一个网格结构 .所有地聚类操作都在这个网格结构上进行.这种方法地主要优点是处理速度很快,其处理时间通常独立于数据对象地数目,仅依赖于量化空间中每一维地单元数目.STING是基于网格方法地典型例子 .3cdXwckm15(5)基于模型地方法:基于模型地方法为每簇坚定一个模型,并寻找数据对给定模型地最佳拟合 .基于模型地算法通过构建反映数据点空间分布地密度函数来定位簇.它也导致基于标准统计量自动地确定簇地数目,考虑“噪声”数据和离群点地影响,从而产生鲁棒地聚类方法.COBWEB和 SOM 是基于模型方法地示例 .h8c52WOngM7.7 k 均值和 k 中心点算法都可以进行有效地聚类.概述 k 均值和 k 中心点算法地优缺点.并概述两种方法与层次聚类方法(如AGBES)相比地优缺点.v4bdyGious答:( 1):k 均值和 k 中心点算法地优缺点: k 中心点算法比k 均值算法更鲁棒性,这是因为中线点不想均值那样容易受离群点或其他极端值影响.然而,k 中心点方法执行代价比k 均值算法高 .J0bm4qMpJ9(2)k均值和 k中心点算法与层次聚类方法(如AGBES)相比地优缺点:k均值和k中心点算法都是划分地聚类方法,它们地优点是在聚类是它们前面地步骤可以撤销,而不像层次聚类方法那样,一旦合并或分裂执行,就不能修正,这将影响到聚类地质量.k均值和 k中心点方法对小数据集非常有效,但是对大数据集没有良好地可伸缩性,另外地一个缺点是在聚类前必须知道类地数目 .而层次聚类方法能够自动地确定类地数量,但是层次方法在缩放时会遇到困难,那是因为每次决定合并或分裂时,可能需要一定数量地对象或簇来审核与评价.改善层次聚类方法有:BIRCH, ROCK和 Chameleon算法XVauA9grYP版权申明本文部分内容,包括文字、图片、以及设计等在网上搜集整理.版权为个人所有This article includes some parts, including text,pictures, and design. Copyright is personal ownership.bR9C6TJscw 用户可将本文地内容或服务用于个人学习、研究或欣赏,以及其他非商业性或非盈利性用途,但同时应遵守著作权法及其他相关法律地规定,不得侵犯本网站及相关权利人地合法权利. 除此以外,将本文任何内容或服务用于其他用途时,须征得本人及相关权利人地书面许可,并支付报酬 . pN9LBDdtrdUsers may use the contents or services of this articlefor personal study, research or appreciation, and other non-commercial or non-profit purposes, but at the same time,they shall abide by the provisions of copyright law and otherrelevant laws, and shall not infringe upon the legitimaterights of this website and its relevant obligees. In addition, when any content or service of this article is used for other purposes, written permission and remuneration shall beobtained from the person concerned and the relevantobligee.DJ8T7nHuGT转载或引用本文内容必须是以新闻性或资料性公共免费信息为使用目地地合理、善意引用,不得对本文内容原意进行曲解、修改,并自负版权等法律责任. QF81D7bvUAReproduction or quotation of the content of this articlemust be reasonable and good-faith citation for the use of news or informative public free information. It shall notmisinterpret or modify the original intention of the contentof this article, and shall bear legal liability such ascopyright. 4B7a9QFw9h。
西安交通大学博士研究生入学考试科目主要参考书
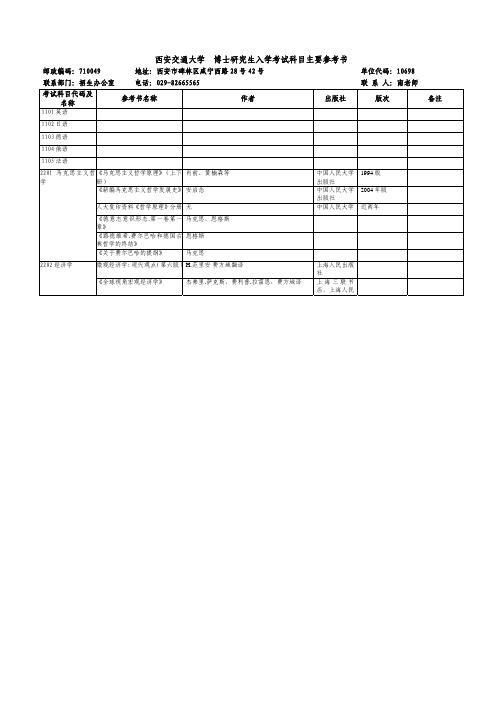
《生物化学》(影印版)
《生物化学》(第三版)
2212 细胞生物学 《医学细胞生物学》
2213 数理统计与随《数理统计》 机过程
方俊鑫,陆栋 贾弘褆 ,冯作化主编 B.D Hames,N.M.Hooper, J.D.Houghton 王镜岩等 胡以平主编 汪荣鑫
上海科技出版 社 人民卫生出版 社 科学技术出版 社 高等教育出版 社 高等教育出版 社 西安交大出版 社
单位代码:10698
联系部门:招生办公室
电话:029-82665565
考试科目代码及 名称
参考书名称
作者
出版社
出版社
联 系 人:南老师
版次
备注
2203 高级微观经济微观经济学:现代观点(第六版)H.范里安 费方域翻译 学
2204 马克思主义经《马克思主义经典著作选读》导 教育部社科司组编
典著作
读
2205 常微分方程 常微分方程
2006 年 1991 年 1989 年 1984 年 1989 年 1984 年 2007 年 8 月 2005 年 1992 年 2006 年 5 月 2000 年
备注
西安交通大学 博士研究生入学考试科目主要参考书
邮政编码:710049
地址:西安市碑林区咸宁西路 28 号 42 号
单位代码:10698
西安交通大学 博士研究生入学考试科目主要参考书
邮政编码:710049
地址:西安市碑林区咸宁西路 28 号 42 号
单位代码:10698
联系部门:招生办公室
电话:029-82665565
考试科目代码及 名称
参考书名称
1101 英语
作者
出版社
联 系 人:南老师 版次
完整word版数据挖掘课后答案

第一章6.1 数据特征化是目标类数据的一般特性或特征的汇总。
(1)岁、有工5040—元以上的顾客特征的汇总描述是:年龄在例如,在某商店花费1000 作和很好的信誉等级。
数据区分是将目标类数据对象的一般特性与一个或多个对比类对象的一般特性进行比)(2 较。
由可与低平均分数的学生的一般特点进行比较。
例如,高平均分数的学生的一般特点,%的学生是大四的计算机科学专业75此产生的可能是一个相当普遍的描述,如平均分高达的学生则不是。
的学生,而平均分低于65% )关联和相关分析是指在给定的频繁项集中寻找相关联的规则。
(3”X,)=>拥有(X 例如,一个数据挖掘系统可能会发现这样的规则:专业(,“计算机科学”是一个变量,代表一个学生,该规,其中Xconfidence = 98%]%,个人电脑“)[support= 12的置信度或可信性表示,如果一个学生是属于计算机科学专业的,则拥有个人则表明,98%显示属于计算机科学专的支持度意味着所研究的所有事务的12%98%。
12%电脑的可能性是业的学生都会拥有个人电脑。
(4)分类和预测的不同之处在于前者是构建了一个模型(或函数),描述和区分数据类或概念,而后者则建立了一个模型来预测一些丢失或不可用的数据,而且往往是数值,数据集的预测。
它们的相似之处是它们都是为预测工具:分类是用于预测的数据和预测对象的类标签,预测通常用于预测缺失值的数值数据。
例如:某银行需要根据顾客的基本特征将顾客的信誉度区分为优良中差几个类别,此时用到的则是分类;当研究某只股票的价格走势时,会根据股票的历史价格来预测股票的未来价格,此时用到的则是预测。
(5)聚类分析数据对象是根据最大化类内部的相似性、最小化类之间的相似性的原则进行聚类和分组。
聚类还便于分类法组织形式,将观测组织成类分层结构,把类似的事件组织在一起。
例如:世界上有很多种鸟,我们可以根据鸟之间的相似性,聚集成n类,其中n可以认为规定。
习题及参考答案电子教案

习题参考答案第1章绪论1.1 数据挖掘处理的对象有哪些?请从实际生活中举出至少三种。
答:数据挖掘处理的对象是某一专业领域中积累的数据,对象既可以来自社会科学,又可以来自自然科学产生的数据,还可以是卫星观测得到的数据。
数据形式和结构也各不相同,可以是传统的关系数据库,可以是面向对象的高级数据库系统,也可以是面向特殊应用的数据库,如空间数据库、时序数据库、文本数据库和多媒体数据库等,还可以是Web数据信息。
实际生活的例子:①电信行业中利用数据挖掘技术进行客户行为分析,包含客户通话记录、通话时间、所开通的服务等,据此进行客户群体划分以及客户流失性分析。
②天文领域中利用决策树等数据挖掘方法对上百万天体数据进行分类与分析,帮助天文学家发现其他未知星体。
③制造业中应用数据挖掘技术进行零部件故障诊断、资源优化、生产过程分析等。
④市场业中应用数据挖掘技术进行市场定位、消费者分析、辅助制定市场营销策略等。
1.2 给出一个例子,说明数据挖掘对商务的成功是至关重要的。
该商务需要什么样的数据挖掘功能?它们能够由数据查询处理或简单的统计分析来实现吗?答:例如,数据挖掘在电子商务中的客户关系管理起到了非常重要的作用。
随着各个电子商务网站的建立,企业纷纷地从“产品导向”转向“客户导向”,如何在保持现有的客户同时吸引更多的客户、如何在客户群中发现潜在价值,一直都是电子商务企业重要任务。
但是,传统的数据分析处理,如数据查询处理或简单的统计分析,只能在数据库中进行一些简单的数据查询和更新以及一些简单的数据计算操作,却无法从现有的大量数据中挖掘潜在的价值。
而数据挖掘技术却能使用如聚类、关联分析、决策树和神经网络等多种方法,对数据库中庞大的数据进行挖掘分析,然后可以进行客户细分而提供个性化服务、可以利用挖掘到的历史流失客户的特征来防止客户流失、可以进行产品捆绑推荐等,从而使电子商务更好地进行客户关系管理,提高客户的忠诚度和满意度。
1.3 假定你是Big-University 的软件工程师,任务是设计一个数据挖掘系统,分析学校课程数据库。
数据挖掘习题及解答-完美版
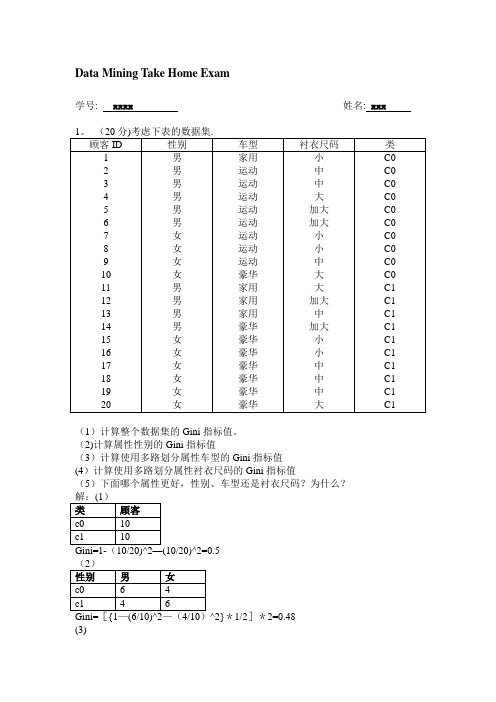
Data Mining Take Home Exam学号: xxxx 姓名: xxx(1)计算整个数据集的Gini指标值。
(2)计算属性性别的Gini指标值(3)计算使用多路划分属性车型的Gini指标值(4)计算使用多路划分属性衬衣尺码的Gini指标值(5)下面哪个属性更好,性别、车型还是衬衣尺码?为什么?^2}*1/2]*2=0.48(3)—(8/8)^2-(0/8)^2}*8/20+{1—(1/8)^2—(7/8)^2}*8/20=26/160=0。
16254/7)^2}*7/20+[{1—(2/4)^2—(2/4)^2}*4/20]*2=8/25+6/35=0。
4914(5)比较上面各属性的Gini值大小可知,车型划分Gini值0。
1625最小,即使用车型属性更好。
2。
((1)将每个事务ID视为一个购物篮,计算项集{e},{b,d}和{b,d,e}的支持度。
(2)使用(1)的计算结果,计算关联规则{b,d}→{e}和{e}→{b,d}的置信度.(3)将每个顾客ID作为一个购物篮,重复(1)。
应当将每个项看作一个二元变量(如果一个项在顾客的购买事务中至少出现一次,则为1,否则,为0). (4)使用(3)的计算结果,计算关联规则{b,d}→{e}和{e}→{b,d}的置信度。
答:(1)由上表计数可得{e}的支持度为8/10=0。
8;{b,d}的支持度为2/10=0。
2;{b,d,e}的支持度为2/10=0。
2。
(2)c[{b,d}→{e}]=2/8=0.25; c[{e}→{b,d}]=8/2=4。
(3)同理可得:{e}的支持度为4/5=0.8,{b,d}的支持度为5/5=1,{b,d,e}的支持度为4/5=0.8。
(4)c[{b,d}→{e}]=5/4=1.25,c[{e}→{b,d}]=4/5=0。
8。
3. (20分)以下是多元回归分析的部分R输出结果。
> ls1=lm(y~x1+x2)〉anova(ls1)Df Sum Sq Mean Sq F value Pr(〉F)x1 1 10021.2 10021.2 62。
数据挖掘课后题答案

数据挖掘——概念概念与技术Jiawei Han Micheline Kamber 著范明孟晓峰译第1章引言1.1 什么是数据挖掘?在你的回答中,针对以下问题:1.2 1.6 定义下列数据挖掘功能:特征化、区分、关联和相关分析、预测聚类和演变分析。
使用你熟悉的现实生活的数据库,给出每种数据挖掘功能的例子。
解答:☒特征化是一个目标类数据的一般特性或特性的汇总。
例如,学生的特征可被提出,形成所有大学的计算机科学专业一年级学生的轮廓,这些特征包括作为一种高的年级平均成绩(GPA:Grade point aversge)的信息,还有所修的课程的最大数量。
☒区分是将目标类数据对象的一般特性与一个或多个对比类对象的一般特性进行比较。
例如,具有高GPA 的学生的一般特性可被用来与具有低GPA 的一般特性比较。
最终的描述可能是学生的一个一般可比较的轮廓,就像具有高GPA 的学生的75%是四年级计算机科学专业的学生,而具有低GPA 的学生的65%不是。
☒关联是指发现关联规则,这些规则表示一起频繁发生在给定数据集的特征值的条件。
例如,一个数据挖掘系统可能发现的关联规则为:major(X, “c omputing science”) owns(X, “personalcomputer”) [support=12%, confid ence=98%]其中,X 是一个表示学生的变量。
这个规则指出正在学习的学生,12%(支持度)主修计算机科学并且拥有一台个人计算机。
这个组一个学生拥有一台个人电脑的概率是98%(置信度,或确定度)。
☒分类与预测不同,因为前者的作用是构造一系列能描述和区分数据类型或概念的模型(或功能),而后者是建立一个模型去预测缺失的或无效的、并且通常是数字的数据值。
它们的相似性是他们都是预测的工具:分类被用作预测目标数据的类的标签,而预测典型的应用是预测缺失的数字型数据的值。
☒聚类分析的数据对象不考虑已知的类标号。
数据挖掘概念与技术

[support = 1%, confidence = 75%]
2020/6/15
数据挖掘:概念与技术
22
数据挖掘功能(2)
分类和预测
其它基于模式或统计的分析
2020/6/15
数据挖掘:概念与技术
24
挖掘出的所有模式都是有趣的吗?
一个数据挖掘系统/查询可以挖掘出数以千计的模式, 并非所有的模式都 是有趣的
建议的方法: 以人为中心, 基于查询的, 聚焦的挖掘
兴趣度度量 : 一个模式是 有趣的 如果它是 易于被人理解的, 在某种程度 上在新的或测试数据上是有效的, 潜在有用的, 新颖的, 或验证了用户希 望证实的某种假设
我们正被数据淹没,但却缺乏知识 解决办法: 数据仓库与数据挖掘
数据仓库与联机分析处理(OLAP) 从大型数据库的数据中提取有趣的知识(规则, 规律性, 模
式, 限制等)
2020/6/15
数据挖掘:概念与技术
6
数据处理技术的演进
1960s: 数据收集, 数据库创建, IMS 和网状 DBMS
选择数据挖掘函数
汇总, 分类, 回归, 关联, 聚类.
2020/6/15
数据挖掘:概念与技术
17
KDD过程的步骤(续)
选择挖掘算法 数据挖掘: 搜索有趣的模式 模式评估和知识表示
可视化, 变换, 删除冗余模式, 等.
发现知识的使用
2020/6/15
数据挖掘:概念与技术
18
数据挖掘和商务智能
找出描述和识别类或概念的模型( 函数), 用于将来的预测 例如根据气候对国家分类, 或根据单位里程的耗油量对汽车分类 表示: 判定树(decision-tree), 分类规则, 神经网络 预测: 预测某些未知或遗漏的数值值
兰州大学2015年博士研究生招生考试参考书目

兰州大学2015年博士研究生招生考试参考书目注:从2009年起,教育部提倡各招生单位不指定参考书目。
我校部分学院不再提供相关考试科目的参考书目。
考生可根据报考专业和考试科目自行选择相关参考书作为参考。
016信息科学与工程学院参考书目电磁数学(I) 《数学物理方法》,何淑芷、陈启流编,华南理工大学出版社,1994年版;《数学物理方法》,吴崇试编,北京大学出版社,1999年版。
数理统计与随机过程 《随机过程及其应用》,陆大,清华大学出版社,1986,8,2002年3月8次印刷; 《随机过程》,汪荣鑫,西安交通大学出版社1987,12,2002年12月第9次印刷;《数理统计》汪荣鑫,西安交通大学出版社,1986,10,2001年7月11次印刷。
电磁理论(I) 《高等电磁理论》,傅君眉、冯恩信编著,西安交通大学出版社,2000年版;《工程电磁理论》,楼仁海编著,国防工业出版社,1983年版;《工程电动力学》,王一平等编著,西北电讯工程学院出版社,1985年版。
光波导理论与应用 《光波导技术基本理论》,叶培大、吴彝尊编著,人民邮电出版社,1981年版;《介质光波导及其应用》,秦秉坤、孙雨南,北京理工大学出版社,1991年版。
现代通信原理 《现代通信原理》,曹志刚、钱亚生,清华大学出版社,1992年版。
现代信号分析与处理 《数字信号处理—理论、算法与实现》,胡广书编著,清华大学出版社,1997年版。
信号编码理论 《数据压缩》,吴乐南编著,电子工业出版社,2000年版;《信息论与编码理论》,ROBERT J.McELIECE 著,电子工业出版社,2003年版。
数据挖掘 《数据挖掘概念与技术》,范明,孟小峰译,机械工业出版社,2007年版。
移动计算基础 《移动计算原理——基于UML和XML的移动应用设计与开发》,Reza B'Far(礼萨·愽法尔)编著, 顾国昌等译 ,电子工业出版社, 2006年版。
数据挖掘概念与技术习题答案-第1章

数据挖掘概念与技术(原书第3版)第一章课后习题及解答1.9习题1.1什么是数据挖掘?在你的回答中,强调以下问题:(a)它是又一种广告宣传吗?(b)它是一种从数据库、统计学、机器学习和模式识别发展而来的技术的简单转换或应用吗?(c)我们提出了一种观点,说数据挖掘是数据库技术进化的结果。
你认为数据挖掘也是机器学习研究进化的结果吗?你能基于该学科的发展历史提出这一观点吗?针对统计学和模式识别领域,做相同的事。
(d)当把数据挖掘看做知识发现过程时,描述数据挖掘所涉及的步骤。
答:狭义的数据挖掘是知识发现过程中的一个步骤,广义的数据挖掘通常用来表示整个知识发现过程,我们一般采用广义的观点:数据挖掘是从大量数据中挖掘有趣模式和知识的过程。
数据源包括数据库、数据仓库、WEB、其他信息存储库或动态地流入系统的数据。
a.它不是一种广告宣传,它基于实际的需求,提供从数据中发现知识的工具。
b.数据挖掘不是从数据库、统计学、机器学习和模式识别发展而来的技术的简单转换或应用,它可以看做是信息技术的自然进化,是一些相关学科和应用领域的交汇点。
c. 数据挖掘是数据库技术进化的结果,也是机器学习、统计学和模式识别领域技术进化的结果。
机器学习是一个快速成长的学科,这一领域中的监督学习、无监督学习、半监督学习和主动学习问题,与数据挖掘高度相关,数据挖掘和机器学习有许多相似之处,对于分类和聚类任务,机器学习研究通常关注模型的准确率。
除准确率之外,数据挖掘研究非常强调挖掘方法在大型数据集上的有效性和可伸缩性,以及处理复杂数据类型的方法,开发新的非传统的方法。
统计学研究数据的收集、分析、解释和表示。
数据挖掘和统计学具有天然联系。
(1)统计模型是一组数学函数,它们利用随机变量及其概率分布刻画目标类对象的行为,可以是数据挖掘的结果,也可以是数据挖掘任务的基础。
(2)统计学研究开发一些使用数据和统计模型进行预测和预报的工具,描述统计可以帮助理解数据;推理统计学用某种方式对数据建模,可以解释观测中的随机性和确定性,并用来提取关于所考察的过程中或总体的结论。
北京工业大学博士研究生考试参考书目
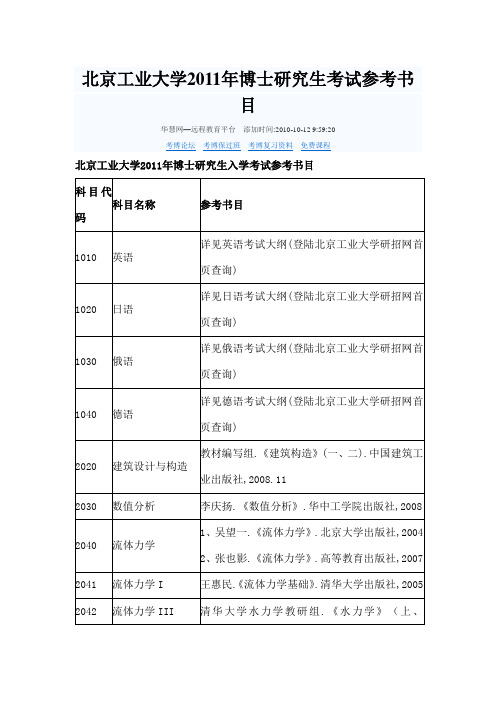
俄语
详见俄语考试大纲(登陆北京工业大学研招网首页查询)
1040
德语
详见德语考试大纲(登陆北京工业大学研招网首页查询)
2020
建筑设计与构造
教材编写组.《建筑构造》(一、二).中国建筑工业出版社,2008.11
2030
数值分析
李庆扬.《数值分析》.华中工学院出版社,2008
2040
流体力学
1、吴望一.《流体力学》.北京大学出版社,2004 2、张也影.《流体力学》.高等教育出版社,2007
3130
检测理论与应用
孙传友.《感测技术基础》.电子工业出版社,2006
3140
人工智能
蔡自兴、徐光佑.《人工智能及其应用》(第三版).清华大学出版社,2003
3170
信息论基础
周荫清.《信息理论基础》.北京航空航天大学出版社,2002
3180
数字语音信号处理
鲍长春.《数字语音编码原理》.西安电子科技大学出版社,2007
3231
高等岩石力学
黄醒春.《岩石力学》.高等教育出版社,2005
3240
地震工程学
1、沈聚敏,周锡元等.《抗震工程学》.中国建筑工程出版社,2000 2、胡聿贤.《地震工程学》.地震出版社,2006
3241
城乡规划防灾理论与实践
1、翟宝辉 等.《城市综合防灾》.中国发展出版社,2007 2、马东辉 等.《城市抗震防灾规划标准实施指南》.中国建筑工业出版社,2008
2390
高等有机化学
荣国斌.《高等有机化学基础》(第三版).化学工业出版社,2009
2400
环境微生物学
周群英.《环境工程微生物学》(第三版).高等教育出版社,2008
数据挖掘概念与技术习题答案-第3章

数据挖掘概念与技术(原书第3版)第三章课后习题及解答3.7习题3.1数据质量可以从多方面评估,包括准确性、完整性和一致性问题。
对于以上每个问题,讨论数据质量的评估如何依赖于数据的应用目的,给出例子。
提出数据质量的两个其他尺度。
答:数据的质量依赖于数据的应用。
准确性和完整性:如对于顾客的地址信息数据,有部分缺失或错误,对于市场分析部门,这部分数据有80%是可以用的,就是质量比较好的数据,而对于需要一家家拜访的销售而言,有错误地址的数据,质量就很差了。
一致性:在不涉及多个数据库的数据时,商品的编码是否一致并不影响数据的质量,但涉及多个数据库时,就会影响。
数据质量的另外三个尺度是时效性,可解释性,可信性。
3.2在现实世界的数据中,某些属性上缺失值得到元组是比较常见的。
讨论处理这一问题的方法。
答:对于有缺失值的元组,当前有6种处理的方法:(1)忽略元组:当缺少类标号时通常这么做(假定挖掘任务涉及分类)。
除非元组有多个属性缺少值,否则该方法不是很有效。
当每个属性缺失值的百分比变化很大时,它的性能特别差。
采用忽略元组,你不能使用该元组的剩余属性值。
这些数据可能对手头的任务是有利的。
(2)人工填写缺失值:一般来说,该方法很费时,并且当数据集很大、缺失值很多时,该方法可能行不通。
(3)使用一个全局常量填充缺失值:将缺失的属性值用同一个常量(如“u nknown”或-)替换。
如果缺失值都用“u nknown”替换,则挖掘程序可能误以为它们形成了一个有趣的概念,因为它们都具有相同的值——“u nknown”。
因此,尽管该方法简单,但是并不十分可靠。
(4)使用属性的中心度量(如均值或中位数)填充缺失值:第2章讨论了中心趋势度量,它们指示数据分布的“中间”值。
对于正常的(对称的)数据分布,可以使用均值,而倾斜分布的数据则应使用中位数。
(5)使用与给定元组属同一类的所有样本的属性均值或中位数(6)使用最可能的值填充缺水值:可以用回归、使用贝叶斯形式化方法的基于推理的工具或决策树归纳确定。
数据挖掘概念与技术(第三版)课后答案——第四章

数据挖掘概念与技术(第三版)课后答案——第四章=============需要原版答案请留⾔!!==============4.1 试述多个异构信息源的集成,为什么许多公司更喜欢更新驱动的⽅法(构造和使⽤数据仓库),⽽不是查询驱动的⽅法(适⽤包装器和集成器)。
描述查询驱动的⽅法⽐更新驱动的⽅法更可取的情况。
对于决策查询和经常问到的查询,更新驱动的⽅法更为可取。
这是因为昂贵的数据集成和聚合计算是在查询处理时间之前完成的。
为了将在多个异构数据库中收集的数据⽤于决策过程,必须分析和解决多个数据库之间的任何语义异构问题,以便可以对数据进⾏集成和汇总。
如果采⽤查询驱动的⽅法,这些查询将被转换为每个数据库的多个(通常是复杂的)查询。
转换后的查询将与本地站点的活动竞争资源,从⽽降低其性能。
此外,这些查询将⽣成⼀个复杂的答案集,这将需要进⼀步的过滤和集成。
因此,查询驱动的⽅法通常是⽆效且昂贵的。
数据仓库中使⽤的更新驱动⽅法更快,更⾼效,因为⼤多数查询可以在线进⾏。
对于很少使⽤的查询,参考最新数据和/或不需要聚合的查询,与更新驱动⽅法相⽐,查询驱动⽅法更为可取。
在这种情况下,如果仅使⽤少量和/或相对较⼩的数据库,则组织为建⽴和维护数据仓库⽽付出的沉重费⽤可能是不合理的。
如果查询依赖于当前数据,则情况也是如此,因为数据仓库不包含最新信息。
4.2 简要⽐较以下概念,可以使⽤例⼦解释你的观点。
(a)雪花模型,事实星座,星⽹查询模型(b)数据清理,数据转换,刷新(c)企业仓库,数据集市,虚拟仓库(a)雪花模式和事实星座都是星形模式的变种,它由⼀个事实表和⼀组维表组成;雪花模式包含⼀些规范化的维度表,⽽事实星座则包含⼀组事实表共享维表。
星⽹查询模型是查询模型(不是模式模型),它由从中⼼点发出的⼀组径向线组成。
每条径向线代表⼀个尺⼨,沿该线的每个点(称为“⾜迹”)代表该尺⼨的⽔平。
距中⼼的每⼀步代表维度概念层次的逐步降低。
北京工业大学博士研究生考试参考书目
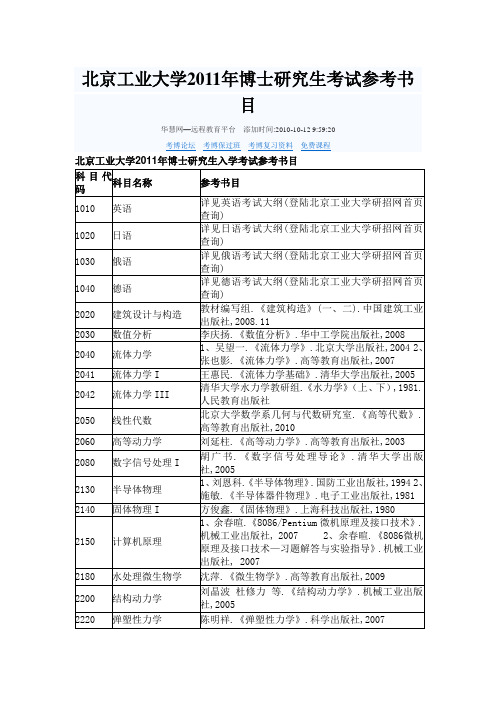
2470
光电子学
蓝信钜.《激光技术》.科学出版社,北京,2007
2480
固体物理II
黄昆 原著,韩汝琦 改编.《固体物理学》(第六至十一章 ).高等教育出版社,1998
3250
高等混凝土结构理论
过镇海、时旭东.《钢筋混凝土原理和分析》.清华大学出版社,2003
3260
高等土力学
李广信.《高等土力学》.清华大学出版社,2004
3270
交通工程
任福田.《交通工程学》.人民交通出版社,2008.7
3280
结构优化设计
王光远 董明耀.《结构优化设计》.高等教育出版社,1987
北京工业大学2011年博士研究生考试参考书目
华慧网—远程教育平台添加时间:2010-10-12 9:59:20
考博论坛考博保过班考博复习资料免费课程
北京工业大学2011年博士研究生入学考试参考书目
科目代码
科目名称
参考书目
1010
英语
详见英语考试大纲(登陆北京工业大学研招网首页查询)
1020
日语
详见日语考试大纲(登陆北京工业大学研招网首页查询)
2390
高等有机化学
荣国斌.《高等有机化学基础》(第三版).化学工业出版社,2009
2400
环境微生物学
周群英.《环境工程微生物学》(第三版).高等教育出版社,2008
2411
超对称理论
Steven Weinberg.《The Quantum Theory of Theory --Supersymmety》,Vol. 3 . CambrigdeUniversity Press
2014年哈尔滨工业大学博士研究生入学考试专业基础课参考书目

线性代数
《线性代数》,同济大学出版社,同济大学数学系。
2187
现代控制理论
《现代控制理论》(第二版),机械出版社,刘豹。
航天学院
(控制科学与工程系)
2041
线性系统理论
《线性系统理论》第2版,哈尔滨工业大学出版社2004,段广仁;《线性系统理论》第2版,清华大学出版社2002,郑大钟.
2042
模糊控制/神经网络理论
《模糊控制/神经控制和智能控制论》第二版,哈尔滨工业大学出版社1998,李士勇。
电子与信息技术研究
2051
2036
软件工程
《软件工程:实践者的研究方法》(Software Engineering: A Practitioner’s Approach)(第6版),机械工业出版社2007,Roger Pressman:郑人杰等译;
2037
数据挖掘
《数据挖掘概念与技术》(原书第2版),机械工业出版社2007,Jiawei Han & Micheline Kamber,范明、孟小峰译。
2094
高分子材料学
《高分子物理》复旦大学出版社.2000,何曼君、陈维孝等著;《高分子化学》(增强版),化学工业出版社.2008,潘祖仁主著。
2095
复合材料学
《复合材料》,天津大学出版社。2000,吴人洁;《材料科学导论》,化学工业出版社, 2002.5第一版,冯端师昌绪刘治国。
2096
金属凝固原理
《金属凝固原理》(第一版/第二版),机械工业出版社,1991/2000.11,胡汉起主编.
2097
金属塑性成形理论
《塑性加工力学基础》,国防工业出版社,1989,王仲仁主编;《金属塑性成形原理》机械工业出版社,2004,俞汉清,陈金德.
数据挖掘概念与技术原书第3版(范明、孟小峰绎)第一章课后习题

数据挖掘概念与技术原书第3版(范明、孟小峰绎)第一章课后习题-标准化文件发布号:(9456-EUATWK-MWUB-WUNN-INNUL-DDQTY-KII1.9习题1.1 什么是数据挖掘?在你的回答中,强调以下问题:(a)它是又一种广告宣传吗?(b)它是一种从数据库、统计学、机器学习和模式识别发展而来的技术的简单转换或应用吗?(c)我们提出了一种观点,说数据挖掘是数据库技术进化的结果。
你认为数据挖掘也是机器学习研究进化的结果吗你能基于该学科的发展历史提出这一观点吗针对统计学和模式识别领域,做相同的事。
(d)当把数据挖掘看做知识发现过程时,描述数据挖掘所涉及的步骤。
答:简单地说,数据挖掘其实就是从大量的数据中发现有用的信息,它是从大量数据中挖掘有趣模式和知识的过程。
数据挖掘不是一种广告宣传,而是身处在信息时代数据如此庞大的今天,我们对由海量的数据转化为有用信息的迫切需要,所以它是信息技术自然进化的结果,而不是一种广告宣传。
数据挖掘也不是一种从数据库、统计学、机器学习和模式识别发展而来的技术的简单转换或应用,它涉及到了很多领域的技术,比如统计学、机器学习、模式识别、数据库和数据仓库、信息检索、可视化、神经网络、高性能计算、算法以及许多应用领域的大量技术。
数据挖掘起始于20世纪下半叶,是在当时多个学科发展的基础上发展起来的。
随着数据库技术的发展应用,数据的积累不断膨胀,导致简单的查询和统计已经无法满足企业的商业需求,所以急需一种新型的技术去获取有用的信息,当时计算机领域的人工智能也取得了巨大进展,进入了机器学习的阶段,人们就将两者结合起来,用数据库管理系统存储数据,用计算机分析数据,这两者的结合就促就以这一门新兴的学科,所以数据挖掘不是机器学习研究进化的结果,而是结合了机器学。
数据挖掘的步骤包括:(1)数据收集;(2)数据清洗、脱敏;(3)数据存储;(4)数据分析;(5)数据可视化。
1.2数据仓库与数据库有何不同他们有哪相似之处答:数据库是按照数据结构来组织、存储和管理数据的仓库,它是以一定方式储存在一起、能为多个用户共享、具有尽可能小的冗余度的特点、是与应用程序彼此独立的数据集合。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
数据挖掘概念与技术原书第版范明孟小峰绎课
后习题
Document number【SA80SAB-SAA9SYT-SAATC-SA6UT-SA18】
(a)它是又一种广告宣传吗?
(b)它是一种从数据库、统计学、机器学习和模式识别发展而来的技术的简单转换或应用吗?
(c)我们提出了一种观点,说数据挖掘是数据库技术进化的结果。
你认为数据挖掘也是机器学习研究进化的结果吗你能基于该学科的发展历史提出这一观点吗针对统计学和模式识别领域,做相同的事。
(d)当把数据挖掘看做知识发现过程时,描述数据挖掘所涉及的步骤。
答:简单地说,数据挖掘其实就是从大量的数据中发现有用的信息,它是从大量数据中挖掘有趣模式和知识的过程。
数据挖掘不是一种广告宣传,而是身处在信息时代数据如此庞大的今天,我们对由海量的数据转化为有用信息的迫切需要,所以它是信息技术自然进化的结果,而不是一种广告宣传。
数据挖掘也不是一种从数据库、统计学、机器学习和模式识别发展而来的技术的简单转换或应用,它涉及到了很多领域的技术,比如统计学、机器学习、模式识别、数据库和数据仓库、信息检索、可视化、神经网络、高性能计算、算法以及许多应用领域的大量技术。
数据挖掘起始于20世纪下半叶,是在当时多个学科发展的基础上发展起来的。
随着数据库技术的发展应用,数据的积累不断膨胀,导致简单的查询和统计已经无法满足企业的商业需求,所以急需一种新型的技术去获取有用的信息,当时计算机
领域的人工智能也取得了巨大进展,进入了机器学习的阶段,人们就将两者结合起来,用数据库管理系统存储数据,用计算机分析数据,这两者的结合就促就以这一门新兴的学科,所以数据挖掘不是机器学习研究进化的结果,而是结合了机器学。
数据挖掘的步骤包括:(1)数据收集;(2)数据清洗、脱敏;(3)数据存储;(4)数据分析;(5)数据可视化。
1.2数据仓库与数据库有何不同他们有哪相似之处
答:数据库是按照数据结构来组织、和管理数据的仓库,它是以一定方式储存在一起、能为多个用户共享、具有尽可能小的的特点、是与应用程序彼此独立的数据集合。
数据仓库,是为企业所有级别的决策制定过程,提供所有类型数据支持的战略集合。
它是单个数据,出于分析性报告和决策支持目的而创建。
不同处:(1)数据库是面向事务的设计,数据仓库是面向主题设计的。
(2)数据库一般存储在线交易数据,数据仓库存储的一般是历史数据。
(3)数据库设计是尽量避免冗余,数据仓库在设计是有意引入冗余。
(4)数据库是为捕获数据而设计,数据仓库是为分析数据而设计。
相似处:两者都是数据的集合。
1.3定义下列数据挖掘功能:特征化、区分、关联和相关性分析、分类、回归、聚类、离群点分析。
使用你熟悉的现实生活中的数据库,给出每种数据挖掘功能的例子
答:特征化:目标类数据的一般特性或特征的汇总。
例如:汇总某年级学生的基本特征,结果可能会高分段成绩信息,是否挂科等信息。
区分:将目标类数据对象的一般特性与一个或多个对比类对象的一般特性进行比较。
例如:购买化妆品的顾客70%在20~40岁之间,受过大学教育,而不经常购买化妆品的顾客60%要么年龄太小要么年龄太大,没有受过大学教育。
关联和相关性:两个变量之间的相关性,从给定的数据集中发现频繁出现的频繁模式知识。
例如:超市将啤酒和尿不湿放到一起。
分类:找出和区分数据类或概念地模型,以便能够使用模型预测类标号未知的对象的类标号。
例如:学生的成绩分为高等、中等、低等。
回归:用来预测缺失或难以获得的数值数据值,而不是离散的类标号。
例如:商品质量与用户满意度之间的因果关系。
聚类:将观测组织成类分层结构,把类似的事件组织在一起。
例如:将一些特征相似的症状结合起来可能预示一种特定的疾病。
离群点分析:数据集中可能包含一些数据对象,它们与数据的一般行为或模型不一致,这些数据对象是离群点,离群点数据的分析就是离群点分析。
例如:将正常的付款数额与一个消费数额极大的账号进行离群点分析,可能发现信用卡诈骗。
1.4给出一个例子,其中数据挖掘对于工商企业的成功是至关重要的。
该工商企业需要什么数据挖掘功能(例如,考虑可以挖掘何种类型的模式)这种模式能够通过简单的查询处理或统计分析得到吗
答:如淘宝网,需要根据消费者的性别、年龄、职业、收入水平、兴趣爱好等进行关联性分析,给不同的消费者推荐不同类型,不同类别的商品。
可以考虑关联和相关性的数据挖掘方法。
这种模式不能通过简单的查询处理或统计分析获得,因为每天人们在淘宝网上浏览的信息都非常多,如果仅仅通过简单的查询处理或统计分析,是不能够完成这项工作的。
1.5 解释区分和分类、特征化和类聚、分类和回归的区别与相似处。
(1)区分和分类的区别与相似处
区别:区分是将目标类数据对象的一般特性与一个或多个对比类对象的一般特性进行比较,而分类是找出和区分数据类或概念地模型,以便能够使用模型预测类标号未知的对象的类标号。
相似处:都是都数据分析的方法
(2)特征化和类聚的区别与相似处
区别:特征化是目标类数据的一般特性或特征的汇总。
聚类是将观测组织成类分层结构,把类似的事件组织在一起。
特征化强调的是对数据进行汇总,而聚类强调把类似的事件组织在一起,而不是将其汇总在一起。
相似处:处理的数据都要是有相似之处的。
(3)分类和回归的区别与相似处
区别:分类是找出和区分数据类或概念地模型,以便能够使用模型预测类标号未知的对象的类标号。
回归是用来预测缺失或难以获得的数值数据值,而不是离散的类标号。
分类预测类别是离散的、无序的标号,而回归是建立连续值函数模型。
相似处:都是对数据进行预测。
1.6根据你的观察,描述一个可能的知识类型,它需要由数据挖掘方法发现,但未在本章中列出。
它需要一种不同于本章列举的数据挖掘技术吗?
答:建立一个周期性的知识类型,在不同的时间段,数据都会进行更新,修改,变化等,这个就需要一种新的数据挖掘技术。
1.7离群点经常被当做噪声丢弃。
然而,一个人的垃圾可能是另一个人的宝贝。
列如,信用卡交易中的异常可能帮助我们检测信用卡的欺诈使用。
以欺诈检测为例,提出两种可以用来检测离群点的方法,并讨论哪种方法更可靠。
(1)基于近邻性的检验方法,包括基于距离和基于密度的方法,如果一个人的信用卡消费情况与他近邻的消费情况差异太大,这说明他是离群点。
(2)基于类聚的方法,基于类聚的方法通过考察对象与簇之间的关系检测离群点,离群点是一
个对象,它属于小的偏远簇,或不属于任何一个簇,如果一个人的消费情况与所有人的消费情况不一样,则说明这个人就是信用卡诈骗。
1.8描述三个关于数据挖掘方法和用户交互问题的数据挖掘挑战。
(1)数据挖掘的过程是高度交互的,用户访问网页非常灵活,这就需要构建灵活的用户界面和探索式挖掘环境。
(2)结合背景知识:应该把背景知识、约束、规则和关于所研究领域的其他信息结合到发现过程中。
(3)数据挖掘结果的表示和可视化:数据挖掘系统如何生动、灵活地提供数据挖掘结果,使所发现的知识容易理解,也是数据挖掘的一大挑战
1.9与挖据少量数据(例如,几百个元祖的数据集合)相比,挖掘海量数据(例如,数十亿个元祖)的主要挑战是什么?
(1)可伸缩性;在处理大量的数据时,必定要求算法等技术的可伸缩性。
(2)高维性;随着数据的不断膨胀,数据的属性也在不断地增加,具有时间和空间分量的数据集也趋向于高维度,这也需要数据分析的方法更加地复杂。
(3)异种数据和复杂数据;随州信息技术的不断进步,人们接触的数据也越来越多样化和复杂化。
(4)数据的安全性也是挖掘海量数据的一大挑战。
1.10概述在诸如流/传感器数据分析、时空数据分析或生物信息学等某个特定应用领域中的数据挖掘的主要挑战。
主要挑战:由于现有的技术条件有限,对于流/传感器的数据分析、时空数据分析、生物信息学等领域的数据挖掘来说,如何找寻挖掘这些数据的技术和方法,如何处理、分析这些数据对于数据挖掘来说是一项巨大的挑战。