抽象语法树(AST)
abstractprocessor 用法 -回复

abstractprocessor 用法-回复abstractprocessor 用法详解摘要处理器(abstractprocessor)是一种用于生成和处理抽象语法树(AST)的工具。
它是用于编译器和静态代码分析器中的一个重要组件,它可以解析源代码并生成中间表示。
本文将深入介绍abstractprocessor 的用法,从基本概念到实际应用,一步一步回答。
第一步:理解抽象语法树(AST)抽象语法树(AST)是一种树形数据结构,用来表示源代码的结构。
它将源代码分解为抽象的语法单元,例如类、方法、语句、表达式等,以便进行进一步的分析和处理。
AST 通常是编译器中的一个重要中间表示形式,它能够方便地进行静态代码分析、语法检查和代码生成等操作。
第二步:了解abstractprocessorabstractprocessor 是Java 编译器提供的一个工具类,通过它我们可以在编译过程中生成和处理AST。
它是由Java 语言规范定义的一个注解处理器接口,用于处理由特定注解标记的源代码。
abstractprocessor 提供了一组API,用于访问和修改AST,并提供了丰富的工具方法,以便进行静态代码分析和生成等操作。
第三步:编写一个自定义的abstractprocessor要使用abstractprocessor,首先需要编写一个自定义的注解处理器,实现abstractprocessor 接口,并重写其中的方法。
这个注解处理器将负责处理特定注解标记的源代码。
javaimport javax.annotation.processing.*;import ng.model.SourceVersion;import ng.model.element.*;import ng.model.util.ElementFilter;import javax.tools.Diagnostic;import java.util.Set;@SupportedAnnotationTypes("MyAnnotation")public class MyAnnotationProcessor extends AbstractProcessor {@Overridepublic synchronized void init(ProcessingEnvironment processingEnv) {super.init(processingEnv);}@Overridepublic boolean process(Set<? extends TypeElement> annotations, RoundEnvironment roundEnv) {for (TypeElement annotation :ElementFilter.typesIn(roundEnv.getElementsAnnotatedWith(MyAn notation.class))) {处理被MyAnnotation 标记的元素processAnnotation(annotation);}return true;}private void processAnnotation(TypeElement annotation) { 处理注解的逻辑}@Overridepublic SourceVersion getSupportedSourceVersion() {return testSupported();}}上述代码中,我们编写了一个名为`MyAnnotationProcessor` 的自定义注解处理器,它处理了被`MyAnnotation` 注解标记的元素。
gcc 语法树文件解析

gcc 语法树文件解析GCC(GNU Compiler Collection)是一种流行的编译器,它使用一种称为抽象语法树(Abstract Syntax Tree, AST)的数据结构来表示源代码的结构。
AST是源代码的抽象表示,它反映了代码的语法结构,并且可以用于多种目的,例如静态分析、代码生成、重构等。
要解析GCC的语法树文件,你需要使用GCC的内部表示和访问AST的API。
GCC提供了一个称为"libgccjit"的库,它允许你与AST进行交互。
libgccjit是一个用于创建GCC插件的API,它可以让你读取、修改和生成AST。
以下是使用libgccjit解析AST的基本步骤:1. 创建一个GCC插件:首先,你需要创建一个GCC插件,这是使用libgccjit的起点。
插件是一个动态链接库,它与GCC一起加载并执行。
2. 初始化libgccjit:在插件中,你需要初始化libgccjit库,以便能够使用其功能。
这通常涉及到设置一些参数和配置选项。
3. 读取AST文件:你需要加载包含AST的文件。
AST文件是由GCC在编译过程中生成的,通常保存在目标目录下的".tu"文件中。
你可以使用libgccjit提供的函数来打开和读取AST文件。
4. 遍历AST:一旦你加载了AST文件,你可以使用libgccjit提供的API来遍历AST并访问其节点。
AST的结构反映了源代码的语法结构,你可以通过遍历AST来分析和操作代码。
5. 修改AST:如果你需要对AST进行修改,你可以使用libgccjit提供的API来修改节点。
你可以添加、删除或修改节点,以实现你想要的代码变换。
6. 生成新的AST:最后,你可以使用libgccjit生成新的AST。
你可以根据需要创建新的节点和结构,然后将其保存为AST文件或直接编译为目标代码。
需要注意的是,解析和操作AST需要深入理解编译器原理和编程语言语法。
llvm语法树

llvm语法树
LLVM(Low Level Virtual Machine)是一个开源编译器基础设施,它以虚拟机的方式运行中间代码,将高级语言编译成机器码。
在LLVM中,代码被表示为一个抽象语法树(AST)。
AST是代码的抽象表示形式,它忽略了具体语言语法中的细节,而只保留了代码中有用的信息。
在LLVM中,AST是通过Clang这个C/C++编译器生成的。
Clang 具有可靠的语法分析能力,它可以将源代码解析成抽象语法树。
AST节点代表程序中的语言结构,如表达式、语句、函数、类等等。
每个节点都包含了一些元信息,例如节点的类型,子节点等等。
这些信息可以被用来进行优化、分析和代码生成等操作。
LLVM的语法树非常灵活,它可以支持不同的编程语言和编译器前端。
由于它是以抽象方式对代码进行表示,因此对于代码生成器和优化器来说,它们不必关心源代码的语言,只需要关心AST的结构和信息。
这使得LLVM可以实现高效的代码生成和优化,同时也提供了更广泛的语言支持。
总之,LLVM的语法树是一个非常重要的组件,它提供了一个统一的中间表示,使得编译器前端和后端可以更加高效地协作。
它也为编译器的分析和优化提供了基础,使得编译器可以生成更快、更优的代码。
Eclipse AST(抽象语法树)使用指南

ASTVisitor 类提供的 preVisit 方法和 postVisit 方法的缺省实现是什么也不做。子类 可以根据需要来重新实现它们。
acceptChild(visitor, getProperty2());
} visitor.endVisit(this);
// 调用 endVisit( )执行一些节点访问后的操作
从上面的模板可以看出,如果节点包含多个属性,如 CompilationUnit 节点中有 imports
属性和 types 属性等,则按这些属性在源程序中的先后次序来依次访问;如果一个属性为序
要使用这些方法,首先需要创建 AST 类的实例: AST ast = AST.newAST(AST.JLS3);
其中,参数 AST.JLS3 指示所生成的 ast 包含处理 JLS3(Java 语言规范第 3 版)的 AST API。 JLS3 是 Java 语言所有早期版本的超集,JLS3 API 可以用来处理直到 Java SE 6(即 JDK1.6) 的 Java 程序。
在 Eclipse AST 中,与本书的课程设计相关的类主要有以下三部分: z ASTNode 类及其派生类:用于描述各种 AST 节点的类,每个 AST 节点表示一个
Java 源程序中的一个语法结构,例如,一个名字、类型、表达式、语句或声明等。 z AST 类:创建 AST 节点的工厂类,类中包含许多创建各类 AST 节点的工厂方法,
浅析AST抽象语法树及如何利用AST转换JS代码

浅析AST抽象语法树及如何利⽤AST转换JS代码 在学习AST之前,可以结合此篇博客()⼀起看。
抽象语法树(Abstract Syntax Tree)也称为AST语法树,指的是源代码语法所对应的树状结构。
也就是说,对于⼀种具体编程语⾔下的源代码,通过构建语法树的形式将源代码中的语句映射到树中的每⼀个节点上。
如果你查看⽬前任何主流的项⽬中的devDependencies,会发现前些年的不计其数的插件诞⽣。
我们归纳⼀下有:javascript转译、代码压缩、css预处理器、elint、pretiier,等。
有很多js模块我们不会在⽣产环境⽤到,但是它们在我们的开发过程中充当着重要的⾓⾊。
所有的上述⼯具,不管怎样,都建⽴在了AST这个巨⼈的肩膀上。
所有的上述⼯具,不管怎样,都建⽴在了AST这个巨⼈的肩膀上。
⼀、JavaScript语法解析1、什么是AST抽象语法树It is a hierarchical program representation that presents source code structure according to the grammar of a programminglanguage, each AST node corresponds to an item of a source code. 估计很多同学看完这段官⽅的定义⼀脸懵逼,可以通过⼀个简单的例⼦来看语法树具体长什么样⼦。
有如下代码: 我们可以发现,程序代码本⾝可以被映射成为⼀棵语法树(实际上,真正AST每个节点会有更多的信息。
但是,这是⼤体思想。
从纯⽂本中,我们将得到树形结构的数据,每个条⽬和树中的节点⼀⼀对应。
),⽽通过操纵语法树,我们能够精准的获得程序代码中的某个节点。
例如声明语句,赋值语句,⽽这是⽤正则表达式所不能准确体现的地⽅。
JavaScript的语法解析器提供了⼀个,你可以借助于这个⼯具,将JavaScript代码解析为⼀个JSON⽂件表⽰的树状结构。
astnode语法树-概述说明以及解释

astnode语法树-概述说明以及解释1.引言1.1 概述概述:AST(Abstract Syntax Tree,抽象语法树)是一种对程序源代码的结构化的抽象表示,它能够描述代码的语法结构和语义信息。
在软件开发和编程领域中,AST被广泛应用于编译器、解释器、代码分析等工具中。
ASTnode语法树是AST的一种具体实现方式,它将源代码解析成节点(node)的形式,每个节点代表源代码中的一个语法结构或表达式。
ASTnode语法树通过构建树形结构来表示源代码的层次结构和语法关系,方便程序分析和处理。
本文将介绍ASTnode语法树的概念、应用和构建方法,希望能够帮助读者更好地理解和应用这一重要的程序表示方式。
1.2 文章结构文章结构部分主要包括以下内容:1. 标题:文章的标题应该具有代表性,能够准确地概括文章的主题和内容。
2. 序言:引入文章的背景和重要性,让读者对文章有一个大致的了解。
3. 正文:主要内容部分,包括对astnode语法树的介绍、应用和构建方法等。
4. 结论:对文章内容进行总结,强调关键信息和观点。
5. 参考文献:列出文章中引用的资料、文献和网址等,方便读者深入了解相关信息。
通过以上部分的安排,将能够使文章结构清晰、逻辑性强,让读者更好地理解和理解文章的内容。
1.3 目的编写本文的目的是为了介绍读者关于astnode语法树的基本概念和应用。
通过本文的阐述,读者将能够了解什么是astnode语法树,以及它在编程领域中的重要性和作用。
同时,我们将深入探讨astnode语法树的构建方法,帮助读者更加深入地理解其内部机制。
通过本文的阐述,我们希望读者能够对astnode语法树有一个清晰的认识,并能够在实际编程中灵活运用这一概念。
最终,我们希望本文能够为读者提供一份全面且易懂的astnode语法树的介绍,为他们在编程领域中的学习和应用提供指导和帮助。
2.正文2.1 什么是astnode语法树在计算机编程和编译原理中,AST(Abstract Syntax Tree)即抽象语法树,是源代码的抽象语法结构的树状表示。
ast课程体系

ast课程体系全文共四篇示例,供读者参考第一篇示例:AST(Abstract Syntax Tree,抽象语法树)是一个在计算机科学中广泛应用的概念,它是一种以树形结构表示程序代码语法结构的方式。
在计算机编程领域中,抽象语法树通常用于编译器和解释器的开发中,将程序代码转换成易于分析和操作的形式,方便进行语法分析、变量作用域分析、类型检查等操作。
AST课程体系是指以抽象语法树为核心内容的教学体系,旨在帮助学习者理解、掌握和应用抽象语法树这一重要概念。
AST课程体系通常包含从基础到高级的各种课程内容,涵盖了抽象语法树的原理、构建、应用等方面,以帮助学生全面掌握这一知识体系。
AST课程体系中常见的课程内容包括但不限于以下几个方面:1. 抽象语法树的介绍:介绍抽象语法树的定义、作用、应用等基本概念,帮助学生理解为什么需要抽象语法树以及它的重要性。
2. 语法分析:介绍常见的语法分析算法,如LL算法、LR算法等,以及如何利用这些算法构建抽象语法树。
3. AST的构建:介绍如何根据源代码构建抽象语法树,包括词法分析、语法分析等步骤,以及如何将抽象语法树表示成数据结构。
4. AST的应用:介绍抽象语法树在编译器、解释器等领域的应用,如代码优化、程序分析、自动化重构等功能,帮助学生了解抽象语法树在实际项目中的价值。
AST课程体系的学习对于编程领域的学生尤为重要。
通过学习AST课程体系,学生可以更深入地了解程序代码的语法结构、语义含义,并能够利用抽象语法树进行程序分析、优化和重构,提高代码质量和开发效率。
AST课程体系应成为编程教育中的重要一环,为学生提供更广阔的学习视野和实践机会。
第二篇示例:AST课程体系是指通过对科学技术的总结和归纳而形成的一套课程体系,旨在培养学生对科学技术的全面理解和运用能力。
AST即是“Applied Science and Technology”的首字母缩写,是一种实用性很强的科学技术课程。
抽象语法树(AST)

抽象语法树(AST)AST描述 在计算机科学中,抽象语法树(AST)或语法树是⽤编程语⾔编写的源代码的抽象语法结构的树表⽰。
树的每个节点表⽰在源代码中出现的构造。
语法是“抽象的”,因为它不代表真实语法中出现的每个细节,⽽只是结构,内容相关的细节。
例如,分组括号在树结构中是隐式的,并且可以通过具有三个分⽀的单个节点来表⽰类似于if-condition-then表达式的句法结构。
这将抽象语法树与传统上指定的解析树区分开来,这些语法树通常由解析器在源代码转换和编译过程中构建。
⼀旦构建,通过后续处理(例如,上下⽂分析)将附加信息添加到AST 。
抽象语法树也⽤于程序分析和程序转换系统。
参考:[维基百科]()解析器Parser JavaScript Parser是把js源码转化为抽象语法树的解析器,⼀般分为词法分析、语法分析及代码⽣成或执⾏。
词法分析 词法分析阶段会把字符串形式的代码转换为令牌(Tokens)流。
可将令牌看作是⼀个扁平的语法⽚段数组。
var answer = 6 * 7;//Tokens[{"type": "Keyword","value": "var","range": [34,37],"loc": {"start": {"line": 2,"column": 0},"end": {"line": 2,"column": 3}}},{"type": "Identifier", "value": "answer", "range": [38,44],"loc": {"start": {"line": 2,"column": 4},"end": {"line": 2,"column": 10 }}},{"type": "Punctuator", "value": "=","range": [45,46],"loc": {"start": {"line": 2,"column": 11 },"end": {"line": 2,"column": 12 }}},{"type": "Numeric", "value": "6","range": [47,48],"loc": {"start": {"line": 2,"column": 13 },"end": {"line": 2,"column": 14 }}},{"type": "Punctuator", "value": "*","range": [49,50],"loc": {"start": {"line": 2,"column": 15 },"end": {"line": 2,"column": 16 }}},{"type": "Numeric", "value": "7","range": [51,52],"loc": {"start": {"line": 2,"column": 17},"end": {"line": 2,"column": 18}}},{"type": "Punctuator","value": ";","range": [52,53],"loc": {"start": {"line": 2,"column": 18},"end": {"line": 2,"column": 19}}}]语法分析 语法分析阶段会把⼀个令牌流转换成抽象语法树(AST)的形式,这个阶段会使⽤令牌中的信息把它们转换成⼀个AST的树结构。
抽象语法树

抽象语法树在计算机科学中,抽象语法树(Abstract Syntax Tree,AST),或简称语法树(Syntax tree),是源代码语法结构的一种抽象表示。
它以树状的形式表现编程语言的语法结构,树上的每个节点都表示源代码中的一种结构。
基本信息⑴中文名称:抽象语法树⑵本质:树状表现形式⑶外文名称:abstract syntax tree⑷应用:计算机科学⑸缩写:AST⑹相对:具体语法树简介⑴之所求民尝晚以说语法是"抽象"的,是因为这里的语法并不会表示出真实语法中出现的每个细节。
比如,嵌套括号被隐含在树的结构腊邀删中,并没有以节点的形式呈现;而类似于if-condition-then这样的条件跳转语句,可以使用带有两个分支的节点来表示。
⑵和抽象语法树相对付射宙的是具体语法树(通常称作分析树)。
一般的,在源代码的翻译和编译过程中,语法分析器创建出分析树。
一旦AST被创建出来,在后续的处理过程中,比如语义分析阶段,会添加一些信息。
语法分析器⑴在计算机科学和语言学中,语法分析(英语:syntactic analysis,也叫parsing)元抹桨是根遥击据某种给定的形式文法对由单词序列(如英语单词序列)构成的输入文本进行分析并确定其语法结构的一种过程。
⑵语法分析器(parser)通常是作主整霉为编译器或解释器的组件出现的,它的作用是进行语法检查、并构建由输入的单词组成的数据结构(一般是语法分析树、抽象语法树等层次化的数据结构)。
语法分析器通常使用一个独立的词法分析器从输入字符流中分离出一个个的"单词",并将单词流作为其输入。
实际开发中,语法分析器可以手工编写,也可以使用工具(半)自动生成。
语法分析器分类语法分析器的任务主要是确定是否可以以及如何从语法的起始符号推导出输入符号串(输入文本),主要可以通过两种方式完成:⑴自顶向下分析:根据形式语法规则,在语法分析树的自顶向下展开中搜索输入符号串可能的最左推导。
ast基础值 -回复

ast基础值-回复AST基础值(AST Primitive Values)是指在编程语言中表示原子类型的值。
原子类型是不可分解的基本数据类型,它们不再可以被继续分解或合并。
AST基础值描述了这些原子类型的特性和使用方式。
在本文中,我们将逐步探讨AST基础值的概念和其在编程语言中的作用。
第一部分:什么是AST基础值?AST是抽象语法树(Abstract Syntax Tree)的缩写,它是一种用于表示编程语言结构的树形数据结构。
AST基础值是AST中的叶节点,它们是不可再分解的最小单元。
在各种编程语言中,AST基础值包括但不限于以下几种类型:1. 布尔值(Boolean):用来表示真或假的逻辑值。
在AST中,布尔值通常用true或false来表示。
2. 数字(Number):表示数值的基本类型。
数字可以分为整数和浮点数两种。
在AST中,我们可以用整数或小数来表示数字,比如0、1、2.5等。
3. 字符串(String):用来表示一串文本字符的类型。
字符串在AST 中被表示为文本序列,比如"hello"或"world"。
以上三种AST基础值是绝大多数编程语言都支持的基本类型。
除此之外,不同的编程语言还可能支持其他基础值类型,比如日期时间、空值(null)等。
第二部分:AST基础值的特性和用途AST基础值具有以下几个特性和用途:1. 不可更改性:AST基础值是不可变的,这意味着一旦创建,就无法再修改。
这是由于AST的树形结构性质决定的。
不可更改性使得基础值可以被安全地共享和重用。
2. 值的计算和比较:我们可以对AST基础值进行计算和比较操作。
例如,对于数字类型,我们可以进行加减乘除等算术运算;对于布尔类型,我们可以进行与或非等逻辑运算;对于字符串类型,我们可以进行拼接、截取等操作。
3. 类型检查与转换:AST基础值可以用于类型检查和类型转换。
在编程中,我们经常需要判断一个值的类型,或者将一个类型的值转换为另一个类型。
ast原理与混淆还原

AST原理与混淆还原1. 引言在软件开发和信息安全领域,AST(抽象语法树)是一种常用的数据结构,用于表示源代码的结构和语义。
AST可以帮助程序员理解代码的结构,进行代码分析和优化,也可以用于实现代码混淆和还原。
代码混淆是一种保护源代码的技术,通过对代码进行变换和重构,使得代码难以阅读和理解,从而增加攻击者分析和逆向工程的难度。
而代码还原则是将经过混淆的代码恢复成原始的可读性较高的代码,便于理解和维护。
本文将详细介绍AST的基本原理,以及与代码混淆和还原相关的技术和方法。
2. AST基本原理2.1 什么是ASTAST(Abstract Syntax Tree,抽象语法树)是一种数据结构,用于表示源代码的结构和语义。
AST是一个树形结构,每个节点代表源代码中的一个语法结构,比如表达式、语句、函数等。
节点之间通过父子关系和兄弟关系连接起来,形成一棵树。
AST可以帮助我们理解代码的结构和语义,进行代码分析和优化。
AST可以通过解析源代码得到,也可以通过源代码的抽象语法定义手动构建。
2.2 AST的构建过程构建AST的过程通常包括以下几个步骤:1.词法分析:将源代码分割成一个个的词法单元,比如变量名、关键字、运算符等。
2.语法分析:根据词法单元构建语法树,即AST。
语法分析的过程中,会根据语法规则进行语法检查和错误提示。
3.语义分析:对AST进行语义分析,检查代码的合法性和语义错误。
语义分析的过程中,会进行类型检查、作用域分析等。
4.优化:对AST进行优化,改进代码的性能和可读性。
优化的方式包括常量折叠、死代码消除、循环展开等。
5.代码生成:根据AST生成目标代码,比如机器码、字节码等。
2.3 AST的应用AST在软件开发和信息安全领域有着广泛的应用。
在软件开发中,AST可以帮助我们理解代码的结构和语义,进行代码分析和优化。
比如,可以通过AST检测代码中的潜在问题,如空指针引用、死循环等;还可以通过AST进行代码重构,改进代码的可读性和性能。
逆向ast常用方法

逆向ast常用方法全文共四篇示例,供读者参考第一篇示例:逆向AST(Abstract Syntax Tree,抽象语法树)是一种用于程序分析和转换的工具,它将程序源代码表示为一棵树形结构,其中每个节点代表一个语法单元。
逆向AST则是指通过解析目标代码的AST来了解代码的结构和逻辑,以便进行代码审查、安全分析或反编译等操作。
在进行逆向AST分析时,常用的方法包括但不限于以下几种:1. AST解析工具AST解析工具是进行逆向AST分析的基础工具,通过解析目标代码生成对应的AST树。
常用的AST解析工具包括ANTLR(ANother Tool for Language Recognition)、JavaCC(Java Compiler Compiler)和Yacc(Yet Another Compiler Compiler)等。
这些工具可以根据特定语法规则自动生成对应的AST树,为后续的逆向分析提供基础支持。
2. AST遍历技术AST遍历技术是指对生成的AST树进行深度或广度优先遍历,以便获取树中的各个节点和子节点的信息。
通过AST遍历技术,可以实现对代码中的各种语法结构进行分析和提取,如变量、函数、条件语句等。
遍历过程中可以采用递归、迭代或回溯等方法,根据需求获取不同级别的信息。
3. AST节点分析AST节点分析是指对AST树中的各个节点进行深入分析,了解每个节点所代表的语法单元及其关系。
通过AST节点分析,可以发现代码中隐藏的逻辑结构和潜在的安全问题,如未初始化的变量、未校验的用户输入等。
分析过程中需要结合具体语言规范和代码风格,准确识别每个节点的含义和作用。
4. AST模式匹配AST模式匹配是指根据预定义的模式对AST树进行匹配和检索,找到符合条件的节点或子树。
通过AST模式匹配,可以实现对特定代码模式的匹配和替换,如查找所有的循环结构或异常处理代码,并进行统一修改。
模式匹配可以提高逆向AST分析的效率和准确度,避免手动分析带来的繁琐和错误。
ast 中逻辑运算符处理

ast 中逻辑运算符处理AST(抽象语法树)是一种用于表示程序语言结构的树状数据结构。
在AST中,逻辑运算符用于处理逻辑表达式,其中包括与(&&)、或(||)和非(!)运算符。
本文将深入探讨AST中逻辑运算符的处理方式。
一、与运算符(&&)与运算符用于判断两个表达式是否同时为真。
在AST中,与运算符的处理方式是对左右两个表达式进行求值,并将结果进行与操作。
如果左右两个表达式都为真,则整个逻辑表达式的结果为真;否则,结果为假。
二、或运算符(||)或运算符用于判断两个表达式是否至少有一个为真。
在AST中,或运算符的处理方式是对左右两个表达式进行求值,并将结果进行或操作。
如果左右两个表达式至少有一个为真,则整个逻辑表达式的结果为真;否则,结果为假。
三、非运算符(!)非运算符用于对一个表达式的结果进行取反。
在AST中,非运算符的处理方式是对表达式进行求值,并将结果取反。
如果表达式为真,则取反后结果为假;如果表达式为假,则取反后结果为真。
逻辑运算符在程序中经常用于判断条件,根据不同的情况执行不同的代码块。
在AST中,逻辑运算符的处理方式可以帮助编译器生成相应的代码,实现条件判断的功能。
例如,在以下代码中:```pythonif (x > 0 && y < 0) {// do something}```AST会对逻辑表达式进行解析和求值。
首先,对于x > 0这个表达式,编译器会计算x的值,然后判断是否大于0;接着,对于y < 0这个表达式,编译器会计算y的值,然后判断是否小于0。
最后,编译器会对两个表达式的结果进行与操作,判断整个逻辑表达式是否为真。
如果为真,则执行if语句块中的代码;否则,跳过该代码块。
逻辑运算符在程序中的应用非常广泛,可以用于条件判断、循环控制等方面。
在AST中,逻辑运算符的处理方式使得编译器能够按照预期的逻辑进行代码生成,从而实现程序的正确执行。
go ast 语法解析

Go语言中的AST(抽象语法树)是源代码的抽象语法结构的树状表现形式,它
以树状的形式表现了源代码的语法结构,树上的每个节点都表示源代码中的一种结构。
要解析Go语言的AST,需要使用Go语言的标准库中的go/ast包。
go/ast包提供了一组函数和类型,用于从源代码中提取AST,并对AST进行遍历和分析。
以下是一个简单的示例,演示如何使用go/ast包来解析Go语言的AST:
在上面的示例中,我们首先使用parser.ParseFile函数解析了一个名为"example.go"的源文件,返回一个AST树的根节点。
然后,我们使用ast.Inspect 函数来遍历AST树,并对每个节点进行打印输出。
AST中的每个节点都实现了ast.Node接口,可以使用fmt.Printf函数结合%T 格式化参数来打印节点的信息。
输出结果将显示节点的类型和结构。
通过遍历AST,可以对Go语言的源代码进行各种分析和处理,例如语义分析、代码生成、重构等。
抽象语法树
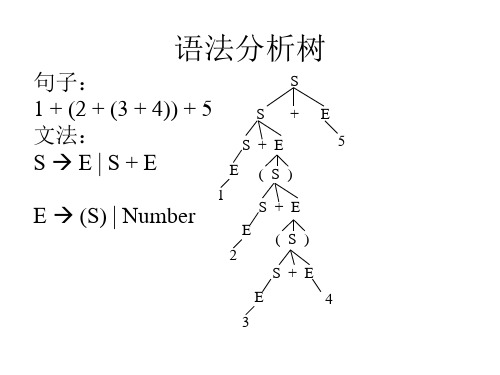
4 3
抽象语法树
1 + 2 * (3 + 4) + 5
+
SE|S+E ET|E*T
+
* 5
+
T (S) | Number
12
4 3
抽象语法树
1 + 2 * (3 + 4) + 5
+
SE|S+E ET|E*T
+
* 5
+
T (S) | Number
12
DONE!
4 3
从抽象语法树如何进行翻译
SE|S+E ET|E*T T (S) | Number
S +E S+E
5 E *+
12
4 3
抽象语法树
1 + 2 * (3 + 4) + 5
S
SE|S+E ET|E*T T (S) | Number
S +E S+*
5 +
12
4 3
抽象语法树
1 + 2 * (3 + 4) + 5
S
SE|S+E ET|E*T T (S) | Number
个非终结符,使用一个 3
结点表示。
抽象语法树
1 + 2 * (3 + 4) + 5
S
SE|S+E ET|E*T
S +E
S+E 5
E*T
T (S) | Number
12
产生式右部具有几个算
S+E
符的规则可以归约为一
Babel(抽象语法树,又称AST)

Babel(抽象语法树,⼜称AST)1. 你了解过Babel吗?了解过抽象语法树,⼜称AST,有学习过,也写过⼀个基于AST的,先是词法解析token,然后⽣产抽象语法树,然后更改抽象语法树,当然这是插件做的事情,最后根据新的AST⽣成代码。
2. 写过Babel插件吗没有,只是看过相关⽂档3. 如果让你写⼀个插件,你能写的出来吗?应该可以吧...遂卒....开玩笑的,既然提到了,⼜没回答上来什么,哎哟我这暴脾⽓,⼀想到今晚就睡不着,连夜把它撸了。
那么我们来从零写个插件吧。
写⼀个预计算简单表达式的插件预览Before:const result = 1 + 2 + 3 + 4 + 5;After:const result = 15;以上的例⼦可能⼤家不会经常遇到,因为傻x才会这么写,但是有可能你会这么写setTimeout(function(){// do something}, 1000 * 2) // 插件要做的事,就是把 1000 * 2 替换成 2000前提条件开⼯再写代码之前,你需要明⽩Babel它的原理,简单点说: Babel解析成AST,然后插件更改AST,最后由Babel输出代码那么Babel的插件模块需要你暴露⼀个function,function内返回visitormodule.export = function(babel){return {visitor:{}}}visitor是对各类型的AST节点做处理的地⽅,那么我们怎么知道Babel⽣成了的AST有哪些节点呢?很简单,你可以把Babel转换的结果打印出来,或者这⾥有传送门:这⾥我们看到const result = 1 + 2中的1 + 1是⼀个BinaryExpression节点,那么在visitor中,我们就处理这个节点var babel = require('babel-core');var t = require('babel-types');const visitor = {BinaryExpression(path) {const node = path.node;let result;// 判断表达式两边,是否都是数字if (t.isNumericLiteral(node.left) && t.isNumericLiteral(node.right)) {// 根据不同的操作符作运算switch (node.operator) {case "+":result = node.left.value + node.right.value;breakcase "-":result = node.left.value - node.right.value;break;case "*":result = node.left.value * node.right.value;break;case "/":result = node.left.value / node.right.value;break;case "**":let i = right;while (--i) {result = result || node.left.value;result = result - node.left.value;}break;default:}}// 如果上⾯的运算有结果的话if (result !== undefined) {// 把表达式节点替换成number字⾯量path.replaceWith(t.numericLiteral(result));}}};module.exports = function (babel) {return {visitor};}插件写好了,我们运⾏下插件试试const babel = require("babel-core");const result = babel.transform("const result = 1 + 2;",{plugins:[require("./index")]});console.log(result.code); // const result = 3;与预期⼀致,那么转换const result = 1 + 2 + 3 + 4 + 5;呢?结果是: const result = 3 + 3 + 4 + 5;这就奇怪了,为什么只计算了1 + 2之后,就没有继续往下运算了吗?我们看⼀下这个表达式的AST树你会发现Babel解析成表达式⾥⾯再嵌套表达式。
AST抽象语法树JavaScript版

AST抽象语法树JavaScript版在javascript世界中,你可以认为抽象语法树(AST)是最底层。
再往下,就是关于转换和编译的“⿊魔法”领域了。
现在,我们拆解⼀个简单的add函数function add(a, b) {return a + b}⾸先,我们拿到的这个语法块,是⼀个FunctionDeclaration(函数定义)对象。
⽤⼒拆开,它成了三块:⼀个id,就是它的名字,即add两个params,就是它的参数,即[a, b]⼀块body,也就是⼤括号内的⼀堆东西add没办法继续拆下去了,它是⼀个最基础Identifier(标志)对象,⽤来作为函数的唯⼀标志。
{name: 'add'type: 'identifier'...}params继续拆下去,其实是两个Identifier组成的数组。
之后也没办法拆下去了。
[{name: 'a'type: 'identifier'...},{name: 'b'type: 'identifier'...}]接下来,我们继续拆开body我们发现,body其实是⼀个BlockStatement(块状域)对象,⽤来表⽰是{return a + b}打开Blockstatement,⾥⾯藏着⼀个ReturnStatement(Return域)对象,⽤来表⽰return a + b继续打开ReturnStatement,⾥⾯是⼀个BinaryExpression(⼆项式)对象,⽤来表⽰a + b继续打开BinaryExpression,它成了三部分,left,operator,rightoperator即+left⾥⾯装的,是Identifier对象aright⾥⾯装的,是Identifer对象b就这样,我们把⼀个简单的add函数拆解完毕。
抽象语法树(Abstract Syntax Tree),的确是⼀种标准的树结构。
ast原理与混淆还原

ast原理与混淆还原
(最新版)
目录
1.AST 原理
2.AST 混淆
3.AST 还原
4.总结
正文
1.AST 原理
AST(Abstract Syntax Tree,抽象语法树)是一种用于表示源代码结构的树形数据结构。
在编译器或解释器中,源代码首先会被解析成抽象语法树,然后通过不同的后端实现进行代码生成或直接执行。
AST 是源代码的中间表示形式,它可以反映出源代码的语法结构和语义信息,但并不包含具体的数据类型和值。
2.AST 混淆
AST 混淆是指对源代码的抽象语法树进行变换,使其在保持原有功能的前提下,变得难以理解和阅读。
混淆可以提高代码的安全性,防止源代码被轻易地分析和逆向工程。
AST 混淆通常包括以下几种操作:- 重命名变量、函数和类名,使它们更具有迷惑性;
- 添加或删除一些无用代码,使分析者难以追踪代码的执行路径;
- 替换运算符和表达式,使代码更难以理解;
- 修改控制流程,使代码的执行顺序更加复杂。
3.AST 还原
AST 还原是指将混淆后的抽象语法树恢复到原始状态,使其易于理解
和阅读。
AST 还原可以帮助程序员分析混淆的代码,找出其中的逻辑错误或漏洞。
AST 还原通常需要进行以下操作:
- 识别变量、函数和类名的原始含义;
- 删除无用代码;
- 恢复原始的运算符和表达式;
- 恢复原始的控制流程。
4.总结
AST 原理、混淆和还原是编译器和解释器领域的重要概念。
理解 AST 原理有助于编写高效的代码分析工具,而 AST 混淆和还原则可以在保护代码安全和提高代码可读性之间找到平衡。
calcite 原理

calcite 原理Calcite:实现数据复杂性管理,建立一种标准模型以支持任意外部查询系统的灵活查询Calcite是Apache开源团队开发的一个流行的SQL解析器,它提供了一种抽象和统一的接口,能够将SQL语句在各种不同的数据库之间进行转换,从而实现多种特性的数据访问。
以下是Calcite的原理和主要功能:一、SQL解析器1、抽象语法树(AST):Calcite将输入的SQL语句解析成抽象语法树(Abstract Syntax Tree),这个语法树是标准化(normalized)的,其中每一个步骤都只和实际的SQL语句没有关系。
2、验证:Calcite也会检查SQL语句是否符合语法规则,以确认该语句是否可以执行。
3、属性分析:Calcite会对SQL语句进行类型检查,确认对象,函数和运算的类型是否正确。
4、优化:Calcite会对语句进行多种优化,比如去除无用的运算,排列查询中的操作顺序,组合多个查询以及执行时的索引优化。
二、查询转换1、SQL流:Calcite可以根据数据源的不同,将抽象语法树转换成具体的SQL语句,Calcite也会根据每个数据源的特点,将更优化查询,以提高性能。
2、表达式树:Calcite把AST转换成一棵表达式树(expression tree),这棵树有时也称为“查询树”。
这棵树将SQL转换为可执行查询所需的各种结构。
三、结果1、虚拟列:Calcite可以为表和查询创建虚拟列,以允许将查询分解为若干步骤。
2、元数据:Calcite可以为查询和表以及各种其他结构添加元数据(metadata),这些元数据是查询的一部分,也可以用于表达式树中,以确保查询执行结果的正确性。
3、结果检查:Calcite还可以对结果进行验证,确保查询的结果是符合预期的。
总之,Calcite是一个功能强大的SQL解析器,它可以把SQL语句转换成抽象语法树、表达式树,以及添加元数据和虚拟列,这些都可以帮助我们更好的操作数据库,提高开发效率和性能。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
抽象语法树(AST)
抽象语法树(AST)
最近在做一个类JA V A语言的编译器,整个开发过程,用抽象语法树(Abstract SyntaxTree,AST)作为程序的一种中间表示,所以首先就要学会建立相对应源代码的AST和访问AST。
Eclipse AST是Eclipse JDT的一个重要组成部分,定义在包org.eclipse.jdt.core.dom中,用来表示JA V A语言中的所有语法结构。
Eclipse AST的总体结构
1、org.eclipse.jdt.core.dom.AST(AST节点类)
Eclipse AST的工厂类,用于创建表示各种语法结构的节点。
2、org.eclipse.jdt.core.dom.ASTNode及其派生类(AST类)用于表示JA V A语言中的所有语法结构,在实际使用中常作为AST上的节点出现。
3、org.eclipse.jdt.core.dom.ASTVisitor(ASTVisitor类)Eclipse AST的访问者类,定义了统一的访问AST中各个节点的方法。
详细介绍:
一、AST节点类
整体结构包括CompilationUnit类(编译单元)、TypeDeclaration类(类型声明)、MethodDeclaration类(方法声明);
语句包括Block类(语句块)、ExpressionStatement类(表达式)、IfStatement(if语句)、WhileStatement类(while语句)、EmptyStatement类(空语句)、BreakStatement类和ContinueStatement类;
表达式包括MethodInvocation类(方法调用)、Assignment
类(赋值表达式)(“=”、“+=”、“-=”、“*=”、“/=”)、InfixExpression类(中缀表达式)(“+”、“-”、“*”、“/”、“%”、“==”、“!=”、“<"、“<=”、“>=”、“&&”、“||”。
)、PrefixExpression类(前缀表达式)(“+”PLUS “-”MINUS “!”NOT)、ParenthesizedExpression类(带括号的表达式)、NumberLiteral类(整数)、Name类(simple)、MethodInvocation类(方法调用)。
二、AST类
关键是创建编译单元节点,创建类AST的实例。
AST ast = AST.newAST(JLS3);
三、ASTVisitor类
它提供与节点类有关的visit()方法和endVisit()法,与节点类无关的preVisit()方法和postVisit()方法。
boolean visit( T node):这类方法如果返回true,则接着访问
子节点。
如果返回false,则不再访问子节点。
void endVisit(T node):这类方法在节点node的子节点已经被访问或者是在visit(node)返回false后调用。
void preVisit():这类方法在visit(node)之前被调用。
void postVisit():这类方法在endVisit(node)之后被调用。
在做简单解释器过程中,分析句子时我主要用到了上面的visit()和endVisit()方法,其中visit()方法是比较好理解的,主要是endVisit()方法在没有特定语法分析树的情况下分析是比较抽象的,所以下面我举几个例子分析。
endVisit()在node的子节点已被访问后调用型:
a、赋值语句分析为例:
i1 = 1;
i4 = i1;
它们对应语法树结构:
Expressionstatement
Assignment。