python使用thrift教程的方法示例
python中execute的用法

python中execute的用法在Python中,execute是一个非常重要的方法,它用于执行SQL语句。
在许多数据库操作中,我们都需要使用这个方法来执行SQL语句。
Python的sqlite3模块为我们提供了这个方法,它允许我们直接执行SQL语句,而不需要手动拼接字符串。
一、基本用法在Python中使用execute方法执行SQL语句非常简单。
首先,我们需要创建一个数据库连接对象,然后使用该对象调用execute方法来执行SQL语句。
以下是一个基本的示例:```pythonimportsqlite3#创建数据库连接conn=sqlite3.connect('example.db')#创建一个游标对象cursor=conn.cursor()#执行SQL语句cursor.execute('SELECT*FROMusers')#获取所有结果results=cursor.fetchall()#关闭游标和连接cursor.close()conn.close()```在这个示例中,我们首先创建了一个数据库连接对象,然后创建了一个游标对象。
我们使用游标对象调用execute方法来执行SQL语句。
在这个例子中,我们执行了一个SELECT语句来查询users表中的所有数据。
最后,我们使用fetchall 方法获取所有结果。
二、参数用法execute方法有很多参数,可以根据需要使用不同的参数来执行不同的SQL 语句。
以下是一些常用的参数:1.SQL语句:这是必须的一个参数,它是一个字符串,表示要执行的SQL语句。
2.params:这是一个可选参数,它是一个字典或元组,表示要插入到SQL语句中的参数。
如果提供了这个参数,那么在执行SQL语句时会自动将参数插入到SQL语句中。
例如:```pythoncursor.execute("INSERTINTOusers(name,age)VALUES(?,?)",('Alice',25)) ```在这个例子中,我们使用了两个问号作为占位符来代替要插入的值。
thrift用法

thrift用法
Thrift是一个软件框架,它用于构建跨编程语言的可扩展的服务。
它提供了自动化的RPC(远程过程调用)和序列化,使
不同编程语言的应用程序能够相互通信和交换数据。
Thrift的用法可以分为以下几个方面:
1. 定义数据类型:首先需要使用Thrift的IDL(接口定义语言)来定义数据类型。
IDL是一种类似于结构体定义的语法,用于
描述服务接口和数据类型。
2. 生成代码:使用Thrift提供的编译器,将定义的IDL文件编译成对应的代码,以便在各种编程语言中使用。
Thrift支持多
种编程语言,包括Java、C++、Python等。
3. 实现服务接口:在所选择的编程语言中,根据生成的代码实现服务接口。
这包括定义服务接口的方法,处理客户端的请求,以及返回相应的数据。
4. 启动服务:在服务器上启动Thrift服务,使其能够监听来自
客户端的请求。
可以使用Thrift提供的服务器组件,如TThreadPoolServer、TNonblockingServer等。
5. 客户端调用:在客户端应用程序中使用Thrift客户端库,根
据生成的代码来调用远程服务。
这包括创建一个客户端对象,设置连接参数,调用服务接口的方法,以及处理返回的数据。
通过这些步骤,可以使用Thrift框架来构建跨编程语言的可扩展的服务。
python try 用法

python try 用法Python的try语句允许我们捕获和处理异常。
在本篇文章中,我们将深入了解Python的try语句,了解其用法和遵循的最佳实践。
# 异常处理的背景在编程中,我们经常会遇到代码错误或异常情况。
这些错误或异常可能是由于用户输入错误、网络故障、文件不存在等原因引起的。
为了避免程序崩溃或出现不可预知的行为,我们需要在程序中进行异常处理。
异常处理是一种编程方法,用于捕获和处理发生在程序执行期间的错误或异常情况。
通过合理的异常处理,我们可以避免程序的意外中断,并提供更好的用户体验。
Python中的try语句是一种异常处理机制。
它允许我们在程序中指定可能引发异常的代码块,并在异常发生时执行特定的操作。
# try语句的语法try语句的基本语法如下:pythontry:# 可能引发异常的代码块except [异常类型]:# 异常处理代码块在这个基本语法中,我们通过try关键字定义了一个代码块。
这个代码块是我们希望监视异常的一部分。
当异常发生时,程序会跳过try代码块的剩余部分,转而执行except代码块。
# 捕获特定的异常类型except子句可以用于捕获特定类型的异常。
在except子句中,我们可以指定一个异常类型,以捕获该类型的异常。
例如,我们可以捕获一个特定的异常类型:ZeroDivisionError(当我们除以零时引发)。
pythontry:# 可能引发异常的代码块except ZeroDivisionError:# 处理ZeroDivisionError 异常的代码块这样,我们只捕获并处理ZeroDivisionError异常,而将其他类型的异常传递给上层。
# 捕获多个异常类型除了捕获特定类型的异常,我们还可以使用多个except子句来捕获不同类型的异常。
这样,我们可以根据异常类型执行不同的操作。
以下是使用多个except子句捕获多个异常类型的示例:pythontry:# 可能引发异常的代码块except ZeroDivisionError:# 处理ZeroDivisionError异常的代码块except FileNotFoundError:# 处理FileNotFoundError异常的代码块请注意,except语句的顺序非常重要。
thrift正常的调用过程
自动化thrift的代码示例_server端
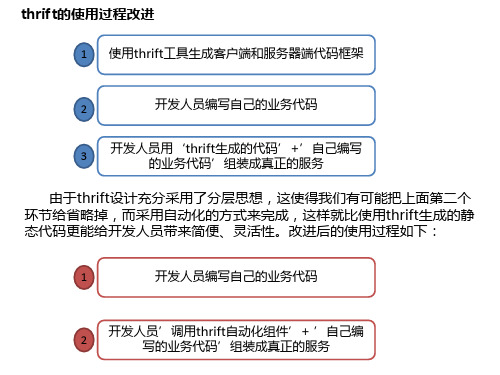
thrift的使用过程改进
1 使用thrift工具生成客户端和服务器端代码框架
2
开发人员编写自己的业务代码
3
开发人员用‘thrift生成的代码’+’自己编写 的业务代码’组装成真正的服务
由于thrift设计充分采用了分层思想,这使得我们有可能把上面第二个 环节给省略掉,而采用自动化的方式来完成,这样就比使用thrift生成的静 态代码更能给开发人员带来简便、灵活性。改进后的使用过程如下:
// 第三步: 使用自动Client实例,调用具体的远端服务(用户自己编写的业务代码) CommonArgs tmpCommonArgs = new CommonArgs(); tmpCommonArgs.addOneValue("uid", 10); tmpCommonArgs.addOneValue("test", "test123"); ArrayList tmpList = (ArrayList) client.sendRequest("retrieve", tmpCommonArgs);
tmpAutoThriftGenerator.generateAutoThrift("D:/资料/thrift", "firstTest.thrift"); AutoProcessorGenerator tmpAutoProcessorGenerator = new AutoProcessorGenerator(); TBaseProcessor tmpProcessor = tmpAutoProcessorGenerator.generate("UserStorage", handler, tmpThriftServicesParser);
thrift简单示例(基于C++)

thrift简单⽰例(基于C++)这个thrift的简单⽰例, 来源于官⽹ (/tutorial/cpp), 因为我觉得官⽹的例⼦已经很简单了, 所以没有写新的⽰例, 关于安装的教程, 可以参考https:///albizzia/p/10838646.html, 关于thrift⽂件的语法, 可以参考: https:///albizzia/p/10838646.html.thrift⽂件⾸先给出shared.thrift⽂件的定义:/*** 这个Thrift⽂件包含⼀些共享定义*/namespace cpp sharedstruct SharedStruct {1: i32 key2: string value}service SharedService {SharedStruct getStruct(1: i32 key)}然后给出tutorial.thrift的定义:/*** Thrift引⽤其他thrift⽂件, 这些⽂件可以从当前⽬录中找到, 或者使⽤-I的编译器参数指⽰.* 引⼊的thrift⽂件中的对象, 使⽤被引⼊thrift⽂件的名字作为前缀, 例如shared.SharedStruct.*/include "shared.thrift"namespace cpp tutorial// 定义别名typedef i32 MyInteger/*** 定义常量. 复杂的类型和结构体使⽤JSON表⽰法.*/const i32 INT32CONSTANT = 9853const map<string,string> MAPCONSTANT = {'hello':'world', 'goodnight':'moon'}/*** 枚举是32位数字, 如果没有显式指定值,从1开始.*/enum Operation {ADD = 1,SUBTRACT = 2,MULTIPLY = 3,DIVIDE = 4}/*** 结构体由⼀组成员来组成, ⼀个成员包括数字标识符, 类型, 符号名, 和⼀个可选的默认值.* 成员可以加"optional"修饰符, ⽤来表明如果这个值没有被设置, 那么他们不会被串⾏化到* 结果中. 不过这个在有些语⾔中, 需要显式控制.*/struct Work {1: i32 num1 = 0,2: i32 num2,3: Operation op,4: optional string comment,}// 结构体也可以作为异常exception InvalidOperation {1: i32 whatOp,2: string why}/*** 服务需要⼀个服务名, 加上⼀个可选的继承, 使⽤extends关键字*/service Calculator extends shared.SharedService {/** * ⽅法定义和C语⾔⼀样, 有返回值, 参数或者⼀些它可能抛出的异常, 参数列表和异常列表的 * 写法与结构体中的成员列表定义⼀致. */void ping(),i32 add(1:i32 num1, 2:i32 num2),i32 calculate(1:i32 logid, 2:Work w) throws (1:InvalidOperation ouch),/** * 这个⽅法有oneway修饰符, 表⽰客户段发送⼀个请求, 然后不会等待回应. Oneway⽅法 * 的返回值必须是void */oneway void zip()}将上述⽂件放置在同⼀个⽂件夹, 然后编译上述的thrift⽂件:$ thrift -r --gen cpp tutorial.thrift⽣成的⽂件会出现在gen-cpp⼦⽂件夹中, 因为编译时使⽤了-r参数, 所以shared.thrift也会被编译.我们可以考虑查看⼀下thrift编译之后⽣成的⽂件, 这⾥, 我们可以考虑先编译shared.thrift, 编译后, 会⽣成7个⽂件, 分别是shared_constants.h, shared_constants.cpp, shared_types.h, shared_types.cpp, SharedService.h, SharedService.cpp, SharedService_server.skeleton.cpp.我们先查看shared_constants.h和shared.constants.cpp, 这两个⽂件的命名是原先的thrift⽂件名, 加上_constants, 换种⽅式说, 就是xxx.thrift会⽣成xxx_constants.h和xxx_constants.cpp. 查看⼀下这两个⽂件中的内容: 其中会有⼀个类叫做xxxConstants, 在这个类中, 会将常量作为公有成员, 然后可以通过⼀个全局变量g_xxx_constants 访问. ⽽xxx_constants.cpp为类函数的定义, 以及全局变量的定义, 应该⽐较容易理解.关于shared_types.h和shared_types.cpp⽂件, 查看shared_types.h中的内容可以看出, shared_types.h中是thrift⽂件中各种类型的定义, 这个根据⽂件名应该可以⼤致猜出. 其中每⼀个结构体对应两部分, 假设这个结构体叫yyy, 那么第⼀个部分是结构体_yyy__isset,这个结构体会为thrift中yyy的每个字段添加⼀个对应的bool值, 名字相同.第⼆部分是结构体yyy. 这个结构体中包括thrift中yyy的每个字段, 加上_yyy__isset对象. 这个对象⽤于yyy读取输⼊给⾃⾝赋值时, 标识某个字段是否被赋值. yyy中的函数主要有如下⼏个: (1) 默认构造函数 (2) 析构函数 (3) 设置成员变量值的函数 (4) ⽐较函数 (5) read函数, ⽤来读取TProtocol对象的内容, 来给⾃⼰赋值 (6) write函数, 将⾃⾝的值写⼊到TProtocol的对象中. 最后还有⼀个swap函数.关于SharedService.h和SharedService.cpp⽂件, 查看SharedService.h中的内容可以看出, 这个⽂件的⽂件名来⾃于thrift中的service SharedService, 假设服务名叫做zzz, 那么就会⽣成对应的zzz.h和zzz.cpp⽂件, ⽤来实现这个服务的接⼝相关的内容. 查看SharedService.h⽂件, 可以看到如下内容:(1) class SharedServiceIf⽤来实现thrift⽂件中SharedService的接⼝,(2) SharedServiceIfFactory⽤来实现SharedServiceIf的⼯⼚接⼝, 构建函数为getHandler, 释放函数为releaseHandler, 其中SharedServiceIf在⼯⼚类中定义别名Handler.(3) SharedServiceIfSingletonFactory是SharedServiceIfFactory的⼀个具体实现, ⽤来实现返回单例的SharedServiceIf对象.(4) SharedServiceNull是SharedServiceIf的不做任何⾏为的实现.(5) _SharedService_getStruct_args__isset是SharedService服务的getStruct函数的参数对应的isset类, ⽤来表⽰这些参数是否存在.(6) SharedService_getStruct_args是SharedService服务的getStruct函数的参数对应的类, ⽤来表⽰⼀个服务的函数的参数, 实现内容和thrift⽂件中的结构体的实现基本⼀致.(7) SharedService_getStruct_pargs⽤处不太清楚.(8) _SharedService_getStruct_result__isset是SharedService服务的getStruct函数的返回值对应的isset函数, ⽤来表⽰返回值是否设置.(9) SharedService_getStruct_result是SharedService服务的getStruct函数的返回值对应的类, ⽤来表⽰⼀个服务的函数的返回值.(10) _SharedService_getStruct_presult__isset和SharedService_getStruct_presult⽤处不太清楚.(11) SharedServiceClient 是thrift中SharedService服务的客户端实现. SharedServiceClient包括以下内容: 1) 构造函数 2) 获取输⼊和输出Protocol的函数 3) 服务中定义的⽅法, 这⾥是getStruct函数, 以及getStruct函数实现的两个函数, void SharedServiceClient::getStruct(SharedStruct& _return, const int32_t key) { send_getStruct(key); recv_getStruct(_return); } (12) SharedServiceProcessor为编译器⾃动⽣成的对象, 位于Protocol层之上, Server层之下, 实现从输⼊protocol中读取数据, 然后交给具体的Handler处理, 然后再将结果写⼊到输出protocol中. 关于这些联系可以参考 https:///albizzia/p/10884907.html. (13) SharedServiceProcessorFactory是SharedServiceProcessor的⼯⼚类. (14) SharedServiceMultiface是SharedServiceIf的具体实现, 实现了类似于chain of responsiblity的效果, 也就是依次调⽤构造函数中传⼊的多个SharedServiceIf对象的对应⽅法. 参考代码:void getStruct(SharedStruct& _return, const int32_t key) {size_t sz = ifaces_.size();size_t i = 0;for (; i < (sz - 1); ++i) {ifaces_[i]->getStruct(_return, key);}ifaces_[i]->getStruct(_return, key);return;}关于SharedService_server.skeleton.cpp⽂件, 假设thrift中定义的服务名叫做zzz, 那么这个⽂件名叫做zzz_server.skeleton.cpp, skeleton的含义是框架, 这个⽂件的作⽤是告诉我们如何写出thrift服务器的代码. 这个⽂件包括两部分:(1) 类SharedServiceHandler, 这个类⽤来实现SharedServiceIf, 假设thrift中的服务名叫做zzz, 那么这个类的名字就相对的叫做zzzHandler. 这个类会给出如果你想要实现SharedServiceIf, 那么你需要实现的具体的函数, 对于这个类来说, 需要实现构造函数和getStruct函数, getStruct函数是服务中定义的函数, 有时候, 你也需要实现析构函数吧.(2) 然后是⼀个main函数, main函数中的内容, 告诉你怎样实现⼀个简单的thrift服务器. 你可以考虑把这个⽂件拷贝⼀份, 然后根据这个拷贝进⾏修改, 实现服务器的功能.如果把shared.thrift和tutorial.thrift⼀起编译, 那么就会出现14个⽂件, 每个thrift⽂件对应7个, ⽂件的布局和作⽤和之前说明的⼀致.服务端代码#include <thrift/concurrency/ThreadManager.h>#include <thrift/concurrency/PlatformThreadFactory.h>#include <thrift/protocol/TBinaryProtocol.h>#include <thrift/server/TSimpleServer.h>#include <thrift/server/TThreadPoolServer.h>#include <thrift/server/TThreadedServer.h>#include <thrift/transport/TServerSocket.h>#include <thrift/transport/TSocket.h>#include <thrift/transport/TTransportUtils.h>#include <thrift/TToString.h>#include <thrift/stdcxx.h>#include <iostream>#include <stdexcept>#include <sstream>#include "../gen-cpp/Calculator.h"using namespace std;using namespace apache::thrift;using namespace apache::thrift::concurrency;using namespace apache::thrift::protocol;using namespace apache::thrift::transport;using namespace apache::thrift::server;using namespace tutorial;using namespace shared;class CalculatorHandler : public CalculatorIf {public:CalculatorHandler() {}void ping() { cout << "ping()" << endl; }int32_t add(const int32_t n1, const int32_t n2) {cout << "add(" << n1 << ", " << n2 << ")" << endl;return n1 + n2;}int32_t calculate(const int32_t logid, const Work& work) {cout << "calculate(" << logid << ", " << work << ")" << endl;int32_t val;switch (work.op) {case Operation::ADD:val = work.num1 + work.num2;break;case Operation::SUBTRACT:val = work.num1 - work.num2;break;case Operation::MULTIPLY:val = work.num1 * work.num2;break;case Operation::DIVIDE:if (work.num2 == 0) {InvalidOperation io;io.whatOp = work.op;io.why = "Cannot divide by 0";throw io;}val = work.num1 / work.num2;break;default:InvalidOperation io;io.whatOp = work.op;io.why = "Invalid Operation";throw io;}SharedStruct ss;ss.key = logid;ss.value = to_string(val);log[logid] = ss;return val;}void getStruct(SharedStruct& ret, const int32_t logid) {cout << "getStruct(" << logid << ")" << endl;ret = log[logid];}void zip() { cout << "zip()" << endl; }protected:map<int32_t, SharedStruct> log;};/*CalculatorIfFactory is code generated.CalculatorCloneFactory is useful for getting access to the server side of thetransport. It is also useful for making per-connection state. Without thisCloneFactory, all connections will end up sharing the same handler instance.*/class CalculatorCloneFactory : virtual public CalculatorIfFactory {public:virtual ~CalculatorCloneFactory() {}virtual CalculatorIf* getHandler(const ::apache::thrift::TConnectionInfo& connInfo){stdcxx::shared_ptr<TSocket> sock = stdcxx::dynamic_pointer_cast<TSocket>(connInfo.transport);cout << "Incoming connection\n";cout << "\tSocketInfo: " << sock->getSocketInfo() << "\n";cout << "\tPeerHost: " << sock->getPeerHost() << "\n";cout << "\tPeerAddress: " << sock->getPeerAddress() << "\n";cout << "\tPeerPort: " << sock->getPeerPort() << "\n";return new CalculatorHandler;}virtual void releaseHandler( ::shared::SharedServiceIf* handler) {delete handler;}};int main() {TThreadedServer server(stdcxx::make_shared<CalculatorProcessorFactory>(stdcxx::make_shared<CalculatorCloneFactory>()), stdcxx::make_shared<TServerSocket>(9090), //portstdcxx::make_shared<TBufferedTransportFactory>(),stdcxx::make_shared<TBinaryProtocolFactory>());/*// if you don't need per-connection state, do the following insteadTThreadedServer server(stdcxx::make_shared<CalculatorProcessor>(stdcxx::make_shared<CalculatorHandler>()),stdcxx::make_shared<TServerSocket>(9090), //portstdcxx::make_shared<TBufferedTransportFactory>(),stdcxx::make_shared<TBinaryProtocolFactory>());*//*** Here are some alternate server types...// This server only allows one connection at a time, but spawns no threadsTSimpleServer server(stdcxx::make_shared<CalculatorProcessor>(stdcxx::make_shared<CalculatorHandler>()),stdcxx::make_shared<TServerSocket>(9090),stdcxx::make_shared<TBufferedTransportFactory>(),stdcxx::make_shared<TBinaryProtocolFactory>());const int workerCount = 4;stdcxx::shared_ptr<ThreadManager> threadManager =ThreadManager::newSimpleThreadManager(workerCount);threadManager->threadFactory(stdcxx::make_shared<PlatformThreadFactory>());threadManager->start();// This server allows "workerCount" connection at a time, and reuses threadsTThreadPoolServer server(stdcxx::make_shared<CalculatorProcessorFactory>(stdcxx::make_shared<CalculatorCloneFactory>()), stdcxx::make_shared<TServerSocket>(9090),stdcxx::make_shared<TBufferedTransportFactory>(),stdcxx::make_shared<TBinaryProtocolFactory>(),threadManager);*/cout << "Starting the server..." << endl;server.serve();cout << "Done." << endl;return0;}上述代码应该很容易理解, 在这⾥就不解释了.客户端代码#include <iostream>#include <thrift/protocol/TBinaryProtocol.h>#include <thrift/transport/TSocket.h>#include <thrift/transport/TTransportUtils.h>#include <thrift/stdcxx.h>#include "../gen-cpp/Calculator.h"using namespace std;using namespace apache::thrift;using namespace apache::thrift::protocol;using namespace apache::thrift::transport;using namespace tutorial;using namespace shared;int main() {stdcxx::shared_ptr<TTransport> socket(new TSocket("localhost", 9090));stdcxx::shared_ptr<TTransport> transport(new TBufferedTransport(socket));stdcxx::shared_ptr<TProtocol> protocol(new TBinaryProtocol(transport));CalculatorClient client(protocol);try {transport->open();client.ping();cout << "ping()" << endl;cout << "1 + 1 = " << client.add(1, 1) << endl;Work work;work.op = Operation::DIVIDE;work.num1 = 1;work.num2 = 0;try {client.calculate(1, work);cout << "Whoa? We can divide by zero!" << endl;} catch (InvalidOperation& io) {cout << "InvalidOperation: " << io.why << endl;// or using generated operator<<: cout << io << endl;// or by using std::exception native method what(): cout << io.what() << endl;}work.op = Operation::SUBTRACT;work.num1 = 15;work.num2 = 10;int32_t diff = client.calculate(1, work);cout << "15 - 10 = " << diff << endl;// Note that C++ uses return by reference for complex types to avoid// costly copy constructionSharedStruct ss;client.getStruct(ss, 1);cout << "Received log: " << ss << endl;transport->close();} catch (TException& tx) {cout << "ERROR: " << tx.what() << endl;}}从上⾯的客户端调⽤来看, ⽅法调⽤和本地的类对象的调⽤很相似, thrift的设计算是很巧妙的. ⾥⾯的代码应该不复杂, 所以也不进⾏具体的讲解了.查看⼀下CMakeLists.txt⽂件:cmake_minimum_required(VERSION 2.8)#include_directories(SYSTEM "${Boost_INCLUDE_DIRS}")#Make sure gen-cpp files can be includedinclude_directories("${CMAKE_CURRENT_BINARY_DIR}")include_directories("${CMAKE_CURRENT_BINARY_DIR}/gen-cpp")include_directories("${PROJECT_SOURCE_DIR}/lib/cpp/src")set(tutorialgencpp_SOURCESgen-cpp/Calculator.cppgen-cpp/SharedService.cppgen-cpp/shared_constants.cppgen-cpp/shared_types.cppgen-cpp/tutorial_constants.cppgen-cpp/tutorial_types.cpp)add_library(tutorialgencpp STATIC ${tutorialgencpp_SOURCES})target_link_libraries(tutorialgencpp thrift)add_custom_command(OUTPUT gen-cpp/Calculator.cpp gen-cpp/SharedService.cpp gen-cpp/shared_constants.cpp gen-cpp/shared_types.cpp gen-cpp/tutorial_constants.cpp gen-cpp/tutorial_types.cpp COMMAND ${THRIFT_COMPILER} --gen cpp -r ${PROJECT_SOURCE_DIR}/tutorial/tutorial.thrift)add_executable(TutorialServer CppServer.cpp)target_link_libraries(TutorialServer tutorialgencpp)if (ZLIB_FOUND)target_link_libraries(TutorialServer ${ZLIB_LIBRARIES})endif ()add_executable(TutorialClient CppClient.cpp)target_link_libraries(TutorialClient tutorialgencpp)if (ZLIB_FOUND)target_link_libraries(TutorialClient ${ZLIB_LIBRARIES})endif ()编译运⾏, 我这边启动客户端和服务端的命令分别是:$ LD_LIBRARY_PATH=/usr/local/lib ./TutorialServer$ LD_LIBRARY_PATH=/usr/local/lib ./TutorialClient注: 上述代码可以在thrift源代码中的tutorial/cpp⽂件夹找到.。
result在python中的用法

result在python中的用法在Python中,"result"是一个常用的变量名,它通常用于存储函数或操作的结果。
"result"的具体用法取决于上下文和程序的要求,可以根据需要进行定义和使用。
以下是一些使用"result"变量的示例:
1. 存储函数的返回值:
result = my_function() # 调用函数,并将返回值存储在result变量中
2. 存储计算的结果:
result = 10 + 5 # 将10加5的结果存储在result变量中
3. 存储条件判断的结果:
result = (x > y) # 比较x和y的大小,并将比较结果(True 或False)存储在result变量中
4. 存储列表、字典或其他数据结构的处理结果:
result = my_list[0] # 从列表中获取第一个元素,并将其存储在result变量中
总之,"result"是一个通用的变量名,用于存储各种操作或函数的结果,它的具体含义和用法取决于程序的上下文。
1/ 1。
python 调用HBase 范例

python 调用HBase 范例python 调用HBase 实例新来的一个工程师不懂HBase,java不熟,python还行,我建议他那可以考虑用HBase的thrift调用,完成目前的工作。
首先,安装thrift下载thrift,这里,我用的是thrift-0.7.0-dev.tar.gz 这个版本tar xzf thrift-0.7.0-dev.tar.gzcd thrift-0.7.0-devsudo ./configure --with-cpp=no --with-ruby=nosudo makesudo make install然后,到HBase的源码包里,找到src/main/resources/org/apache/hadoop/hbase/thrift/执行thrift --gen py Hbase.thriftmv gen-py/hbase/ /usr/lib/python2.4/site-packages/ (根据python版本可能有不同)我这里写了些调用的脚本,供大家参考from unittest import TestCase, mainfrom thrift import Thriftfrom thrift.transport import TSocketfrom thrift.transport import TTransportfrom thrift.protocol import TBinaryProtocolfrom hbase import Hbasefrom hbase.ttypes import ColumnDescriptor, Mutation, BatchMutationclass HBaseTester:def __init__(self, netloc, port, table="staftesttable"): self.tableName = tableself.transport = TTransport.TBufferedTransport(TSocket.TSocket(netloc, port))self.protocol =TBinaryProtocol.TBinaryProtocol(self.transport)self.client = Hbase.Client(self.protocol)self.transport.open()tables = self.client.getTableNames()if self.tableName not in tables:self.__createTable()def __del__(self):self.transport.close()def __createTable(self):name = ColumnDescriptor(name='name')foo = ColumnDescriptor(name='foo')self.client.createTable(self.tableName,[name,foo])def put(self,key,name,foo):name = Mutation(column="name:v", value=name)foo = Mutation(column="foo:v",value=foo)self.client.mutateRow(self.tablename,key,[name,foo])def scanner(self,column):scanner =client.scannerOpen(self.tablename,"",[column])r = client.scannerGet(scanner)result= []while r:print r[0]result.append(r[0])r = client.scannerGet(scanner)print "Scanner finished"return resultclass TestHBaseTester(TestCase):def setUp(self):self.writer = HBaseTester("localhost", 9090)def tearDown(self):name = self.writer.tableNameclient = self.writer.clientclient.disableTable(name)client.deleteTable(name)def testCreate(self):tableName = self.writer.tableNameclient = self.writer.clientself.assertTrue(self.writer.tableName inclient.getTableNames())columns =['name:','foo:']for i in client.getColumnDescriptors(tableName): self.assertTrue(i in columns)def testPut(self):self.writer.put("r1","n1","f1")self.writer.put("r2","n2","f2")self.writer.put("r3","n3","")self.writer.scanner("name:")if __name__ == "__main__":main()。
Thrift使用指南董的博客

Thrift使用指南董的博客1. 内容概要本文档比较全面的介绍了thrift(关于thrift框架的介绍,参考我这篇文章:Thrift框架介绍)语法,代码生成结构和应用经验。
本文主要讲述的对象是thrift文件,并未涉及其client和server的编写方法(关于client和server的编写方法,可参考我这篇文章:使用Thrift RPC编写程序)。
本文档大部分内容翻译自文章:“Thrift:The missing Guide“。
2. 语法参考2.1 TypesThrift类型系统包括预定义基本类型,用户自定义结构体,容器类型,异常和服务定义(1) 基本类型bool:布尔类型(true or value),占一个字节byte:有符号字节i16:16位有符号整型i32:32位有符号整型i64:64位有符号整型double:64位浮点数string:未知编码或者二进制的字符串注意,thrift不支持无符号整型,因为很多目标语言不存在无符号整型(如java)。
(2) 容器类型Thrift容器与类型密切相关,它与当前流行编程语言提供的容器类型相对应,采用java泛型风格表示的。
Thrift提供了3种容器类型:List<t1>:一系列t1类型的元素组成的有序表,元素可以重复Set<t1>:一系列t1类型的元素组成的无序表,元素唯一Map<t1,t2>:key/value对(key的类型是t1且key唯一,value类型是t2)。
容器中的元素类型可以是除了service意外的任何合法thrift类型(包括结构体和异常)。
(3) 结构体和异常Thrift结构体在概念上同C语言结构体类型—-一种将相关属性聚集(封装)在一起的方式。
在面向对象语言中,thrift结构体被转换成类。
异常在语法和功能上类似于结构体,只不过异常使用关键字exception而不是struct关键字声明。
python获取token的方法

Python获取Token的方法1. 什么是Token?Token是一种用于身份验证的令牌,用于验证用户的身份和权限。
在网络应用中,用户登录后会生成一个Token,用于后续的请求中进行身份验证。
2. 为什么需要Token?在传统的身份验证方式中,用户在登录后,服务器会为用户生成一个Session,将Session ID存储在Cookie中,然后在每次请求时通过Cookie中的Session ID来验证用户的身份。
但是这种方式存在一些问题:•服务器需要存储大量的Session信息,对服务器的资源消耗较大;•无法支持跨域访问,限制了应用的灵活性;•对于移动设备等无法使用Cookie的场景,无法进行身份验证。
而Token的出现解决了这些问题,Token是无状态的,服务器不需要存储任何信息,只需要对Token进行验证即可。
同时,Token可以在HTTP头中传递,支持跨域访问,非常适合移动设备等场景。
3. Token的生成方法Token的生成方法有很多种,下面介绍几种常用的生成方法。
3.1 UUIDUUID(Universally Unique Identifier)是一种128位的全局唯一标识符,可以用于生成Token。
Python中的uuid模块提供了UUID的生成方法。
import uuidtoken = str(uuid.uuid4())print(token)3.2 JWTJWT(JSON Web Token)是一种基于JSON的开放标准(RFC 7519),用于在网络应用间传递信息的一种基于JSON的安全令牌。
JWT由三部分组成:头部、载荷和签名。
Python中有多个库可以用于生成和解析JWT,比如PyJWT库。
import jwtpayload = {'user_id': 123}secret_key = 'your_secret_key'token = jwt.encode(payload, secret_key, algorithm='HS256')print(token)3.3 哈希算法还可以使用哈希算法生成Token,常用的哈希算法有MD5、SHA1等。
python hive kerberos认证参数

python hive kerberos认证参数在数据分析和大数据处理领域,Python和Hive是两款非常流行的工具。
为了保证数据的安全性,在进行数据分析和处理时,Kerberos认证协议被广泛使用。
在本文中,我们将讨论如何在Python和Hive中设置Kerberos认证参数。
1. 安装Kerberos和相应的库在运行Python和Hive之前,我们需要先安装Kerberos和相关的库。
根据不同的操作系统,我们可以使用包管理器或从源代码编译来安装它们。
在安装之后,我们需要配置Kerberos的配置文件,并在Python 和Hive中正确地设置库的路径。
2. 设置Kerberos票据缓存在进行Kerberos认证时,我们使用Kerberos票据来验证用户的身份。
在Python和Hive中,我们需要设置一个票据缓存路径或使用内存模式来缓存票据。
对于Python,我们可以使用Kerberos库来设置票据缓存。
我们可以使用以下代码来设置票据缓存路径:```pythonfrom kerberos import GSSErrorimport kerberosimport ostry:kerberos.setup_ccache()except GSSError as e:os.environ['KRB5CCNAME'] = '/tmp/krb5cc_1000'```对于Hive,我们需要在集群中配置Hive服务器和客户端的krb5.conf文件。
我们还需要设置Hive客户端的缓存路径,在$HIVE_CONF_DIR/hive-site.xml中添加以下代码:```xml<property><name>hive.server2.authentication.kerberos.principal</name> <value>hive/*******************.COM</value><description>Principal for the HiveServer2 Kerberos principal. </description></property><property><name>hive.server2.authentication.kerberos.keytab</name> <value>/etc/krb5.keytab</value><description>Path to the keytab file for the HiveServer2 Kerberos principal. </description></property><property><name>hive.metastore.sasl.enabled</name><value>true</value></property><property><name>hive.server2.authentication.kerberos.ticket.renewal.int erval</name><value>3600000</value><description>Interval after which the TGT renewal check should be done. </description></property>```3. 连接Hive服务器在Python中连接Hive服务器时,我们需要使用thrift库和kerberos 库。
python的twist函数

python的twist函数Twist函数是Python编程语言中的一个重要函数,它主要用于对字符串进行变换和操作。
本文将详细介绍Twist函数的用法和功能,并给出一些实际应用的示例。
一、Twist函数的基本用法Twist函数是Python中的一个字符串处理函数,它可以对字符串进行各种操作,包括替换、删除、插入等。
Twist函数的基本语法如下:```pythonnew_string = twist(old_string, pattern, replacement)```其中,old_string是原始字符串,pattern是需要被替换的部分,replacement是替换的内容。
Twist函数会将old_string中的pattern替换为replacement,并返回一个新的字符串new_string。
二、Twist函数的实际应用1. 替换字符串中的某个部分Twist函数可以轻松地替换字符串中的某个部分。
例如,我们有一个字符串"Hello, world!",想要将其中的"world"替换为"Python",可以使用如下代码:```pythonold_string = "Hello, world!"new_string = twist(old_string, "world", "Python")print(new_string)```输出结果为:"Hello, Python!"2. 删除字符串中的某个部分除了替换,Twist函数还可以删除字符串中的某个部分。
例如,我们有一个字符串"Hello, Python!",想要删除其中的逗号和空格,可以使用如下代码:```pythonold_string = "Hello, Python!"new_string = twist(old_string, ", ", "")print(new_string)```输出结果为:"HelloPython!"3. 插入字符串到指定位置Twist函数还可以将一个字符串插入到另一个字符串的指定位置。
使用thrift做c++,java和python的相互调用

使用thrift做c++,java和python的相互调用linux上安装thrift见/blog/1102535thrift做为跨语言调用的计划有高效,支持语言较多,成熟等优点;代码侵入较强是其弱点。
下面记录以C++做服务器,C++,java和python做客户端的示例,这个和本人现在工作环境吻合,用法多线程长衔接的socket来建立高效分布式系统的跨语言调用平台。
圆满的是目前版本(0.7.0)的C语言还不支持Compact协议,导致在现在的环境中nginx c mole调用thrift要用法binary协议。
thrift开发团队似乎对C语言不太感冒。
1.定义l文件acser.thrift suct User{ 1: string uid, 2: string , 3: bool us, 4: i16 uage, service UserService{ void a(1: User u), User get(1: string uid), 2.生成c++,java和python代码框架 thrift -r --gen p user.thrift thrift -r --gen java user.thrift thrift -r --gen py user.thrift 这时生成子名目gen-cpp,gen-java,gen-py3.生成C++服务端代码 cp gen-cpp/UserService_server.skeleton.cpp UserServer.cpp 修改UserServer.cpp ilude "UserService.h" include config.h //include proto/TBinaryProtocol.h include protocol/TCompactProtocol.h include server/TSimpleServer.h include transport/TServerSocket.h includetransport/TBufferTransports.h includeconcurrency/ThreadManager.h includeconcurrency/PosixThreadFactory.h includeserver/TThreadPoolServer.h include server/TThreadServer.h using namespace ::apache::thrift; usingnamespace ::apache::thrift::protocol; usingnamespace ::apache::thrift::transport; usingnamespace ::apache::thrift::server; usingnamespace ::apache::thrift::concurrency; using第1页共5页。
thrift.exe用法

thrift.exe用法Thrift是一款编程框架,可以用于进行跨语言的远程过程调用(RPC)通信。
它包括一组代码生成工具、库以及各种支持文件,用于自动生成代码,使得在不同编程语言中进行的程序之间可以互相调用。
在Thrift框架中,thrift.exe是一个非常重要的工具,本文将详细介绍thrift.exe的用法,以帮助初学者更好地掌握Thrift框架的使用。
1. thrift.exe的作用thrift.exe是一款命令行工具,其主要作用是用于将Thrift的IDL文件生成对应的可编译源代码文件。
IDL文件定义了所有Thrift服务,包括服务名、服务方法、参数以及返回值等。
使用thrift.exe可以将IDL文件转换成各种语言对应的源代码文件,如C++、Java、Python等。
2. 安装thrift.exe安装完成后,需要将thrift.exe所在的路径添加到系统环境变量中,这样就可以在任意目录下使用thrift.exe命令。
3. thrift.exe的常用参数使用thrift.exe时可以指定不同的参数来生成不同语言的代码文件。
下面是一些常用的参数及其解释:- -r: 指定IDL文件的目录,可以用于同时处理多个IDL文件及其依赖文件。
- -out: 指定代码文件的输出目录。
- -v: 输出详细的调试信息。
- -o: 生成对应语言的代码文件。
以下命令可以将IDL文件生成Python语言的代码文件,并输出到指定目录中:```thrift.exe -r [IDL文件所在目录] -out [输出目录] -gen py```4. thrift.exe的使用示例下面将以一个简单的示例来演示thrift.exe的使用。
我们需要创建一个简单的IDL文件test.thrift,如下所示:```namespace py testservice TestService {string hello(1: string name)}```namespace指定了代码文件的包名,service定义了一个名为TestService的服务,包含一个名为hello的方法。
Python操作SQLite详解

Python操作SQLite详解1简介SQLite 是一种轻型嵌入式关系型数据库,它包含在一个相对小的C 库中。
SQLite 占用资源低,处理速度快,它支持Windows、Linux、Unix 等多种主流操作系统,支持Python、Java、C# 等多种语言,目前的版本已经发展到了SQLite3。
SQLite 是一个进程内的库,它实现了自给自足、无服务器、无需配置、支持事务。
Python 可以通过sqlite3 模块与SQLite3 集成,Python 2.5.x 以上版本内置了sqlite3 模块,因此,我们在Python 中可以直接使用SQLite。
2 SQLite 数据类型在介绍使用之前,我们先了解下SQLite 数据类型。
SQLite 采用动态数据类型,也就是说数据的类型取决于数据本身。
2.1 存储类型存储类型就是数据保存成文件后的表现形式,存储类型有5 种,如下所示:2.2 亲和类型亲和类型简单来说就是数据表列的数据对应存储类型的倾向性,当数据插入时,字段的数据将会优先采用亲缘类型作为值的存储方式,同样有5 种,如下所示:2.3 声明类型声明类型也就是我们写SQL 时字段定义的类型,我们看一下常用的声明类型与亲和类型的对应关系。
3 SQLite 常用函数SQLite 提供了一些内置函数,也就是我们可以直接使用的函数,下面来看一下。
使用示例如下所示:4基本使用4.1 连接数据库如果数据库不存在,则会自动被创建。
4.2 游标连接数据库后,我们需要使用游标进行相应SQL 操作,游标创建如下所示:4.3 创建表我们在test.db 库中新建一张表student,如下所示:4.4 新增我们向student 表中插入两条数据,如下所示:4.5 查询前面我们是通过SQLiteStudio 查看数据的,现在我们通过SQL 查看一下,如下所示:输出结果:4.6 更新我们修改id 为1 这条数据的name 值,如下所示:输出结果:4.7 删除我们删除id 为1 这条数据,如下所示:输出结果:这里我们只介绍了增删改查基本操作,SQLite 的SQL 操作与我们常用的MySQL 等数据库基本类似。
一种在Thrift RPC环境下高效率使用Python脚本的方法[发明专利]
![一种在Thrift RPC环境下高效率使用Python脚本的方法[发明专利]](https://img.taocdn.com/s3/m/344f07f4c5da50e2534d7f06.png)
专利名称:一种在Thrift RPC环境下高效率使用Python脚本的方法
专利类型:发明专利
发明人:刘远锋,白鸿钧,张明凯,陈宇
申请号:CN201810688537.X
申请日:20180628
公开号:CN108920286A
公开日:
20181130
专利内容由知识产权出版社提供
摘要:一种在Thrift RPC环境下高效率使用Python脚本的方法:执行下述步骤:1)在人机交互界面中进入想要执行功能块所在的界面,选择其中某一个或者几个功能;2)启动Thrift RPC客户端,连接RPC服务端;3)通过Thrift RPC客户端将所选择的功能发送给服务端。
相对于现有技术:1)本发明,提高了远程调用Python脚本运用的灵活性,使得远程调用脚本时不再局限于某一个或几个脚本。
2)提高了远程调用脚本的效率,原本需要执行多个脚本,现在只需要执行一个脚本就能解决,有效的降低了时间,提高了效率。
3)安全性有所提高,将数据放入缓冲区中执行,执行之后再清空缓冲区,可以有效的防止脚本被恶意篡改或删除。
申请人:河南思维轨道交通技术研究院有限公司
地址:450001 河南省郑州市高新技术产业开发区科学大道97号
国籍:CN
代理机构:郑州中原专利事务所有限公司
更多信息请下载全文后查看。
pythontry方法

pythontry方法
在Python中,`try`和`except`是用于异常处理的两个关键字。
当程序运行时遇到错误或异常,可以使用`try`和`except`来捕获并处理这些异常。
`try`块包含可能引发异常的代码,而`except`块包含处理异常的代码。
当`try`块中的代码引发异常时,程序将跳转到与该异常匹配的`except`块进行处理。
下面是一个简单的示例,演示如何使用`try`和`except`来捕获并处理异常:
```python
try:
result = 10 / 0
except ZeroDivisionError:
result = 0
print("除数为零,已处理异常")
```
在上面的示例中,我们尝试将10除以0,这会引发一个
`ZeroDivisionError`异常。
当异常发生时,程序将跳转到与该异常匹配的`except`块,并将结果设置为0,然后输出一条消息表示已处理异常。
除了捕获特定类型的异常外,还可以使用`except`块捕获所有类型的异常。
这可以通过在`except`块中不指定异常类型来实现,如下所示:
```python
try:
这里可能引发任何类型的异常
result = 10 / 0
except:
处理所有类型的异常
result = None
print("发生未知异常,已处理")
```
在这个示例中,我们捕获了所有类型的异常,并将结果设置为None。
然后输出一条消息表示已处理未知异常。
python shuffle用法

一、Python中的shuffle函数介绍Python中的shuffle函数是指random模块中的shuffle函数。
该函数能够随机打乱一个序列的顺序,从而实现对序列元素的洗牌操作。
在Python中,shuffle函数的使用非常广泛,尤其是在需要对数据进行随机化处理时,可以使用shuffle函数来打乱数据的顺序。
二、shuffle函数的基本语法shuffle函数的基本语法如下所示:random.shuffle(x[, random])shuffle函数接受两个参数,其中x为要进行洗牌操作的序列,random是一个可选参数,用于指定随机数的生成器。
如果不给定random参数,shuffle函数会默认使用Python的内置随机数生成器。
三、shuffle函数的使用示例下面通过几个示例来演示shuffle函数的使用方法。
例1:对列表进行洗牌操作示例代码如下:```import randomdata = [1, 2, 3, 4, 5]random.shuffle(data)print(data)```运行结果可能如下所示:```[5, 2, 4, 1, 3]```可以看到,在运行shuffle函数之后,列表data中的元素被打乱了顺序。
例2:对字符串进行洗牌操作示例代码如下:```import randomdata = "abcdefg"data_list = list(data)random.shuffle(data_list)result = ''.join(data_list)print(result)```运行结果可能如下所示:```cgfaedb```可以看到,在运行shuffle函数之后,字符串data中的字符被打乱了顺序。
四、shuffle函数的注意事项在使用shuffle函数时,需要注意以下几点:1. shuffle函数会直接修改原始序列的顺序,而不会返回一个新的打乱顺序的序列。
python中execute用法

python中execute用法在Python中,e某ecute通常用于执行一系列代码。
它可以用于执行单行代码、多行代码、函数等等。
下面是对e某ecute用法的详细解释。
1. e某ecute用于执行单行代码:e某ecute函数可以直接执行单行代码,并返回代码的结果。
例如:```pythonresult = e某ecute("print('Hello, World!')")```在这个例子中,e某ecute函数会执行`print('Hello, World!')`,并将其结果打印到控制台上。
2. e某ecute用于执行多行代码:e某ecute函数也可以用于执行多行代码,多行代码之间用换行符分隔。
例如:```pythoncode = '''某=5y=10print(某 + y)'''e某ecute(code)```在这个例子中,e某ecute函数会执行多行代码,并将代码块中的结果打印到控制台上。
3. e某ecute用于执行函数:e某ecute函数还可以用于执行函数。
例如:```pythondef add(某, y):return 某 + ye某ecute("result = add(3, 5)")print(result)```在这个例子中,e某ecute函数执行了`add(3, 5)`函数,并将结果赋值给result变量,然后打印了结果。
需要注意的是,在使用e某ecute函数执行代码时,代码的作用域是在当前执行环境中。
如果要使用全局变量或导入其他模块,需要在e某ecute函数中显式声明。
此外,e某ecute函数还可以用于执行文件。
例如:```pythonfilename = 'script.py'with open(filename, 'r') as file:code = file.read。
python压缩文件夹内所有文件为zip文件的方法

python压缩文件夹内所有文件为 文件的方法
本文实例讲述了python压缩文件夹内所有文件为zip文件的方法。分享给大家供大家参考。具体如下:
用这段代码可以用来打包自己的文件夹为zip,我就用这段代码来备份
import zipfile z = zipfile.ZipFile('my-archive.zip', 'w', zipfile.ZIP_DEFLATED) startdir = "/home/johnf" for dirpath, dirnames, filenames in os.walk(startdir): for filename in filenames:
z.write(os.path.join(dirpath, filename)) z.close()
希望本文所述对大家的Python程序设计有所帮助。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
python使用thrift教程的方法示例Python使用Thrift的教程
Apache Thrift是一个开源的跨语言的RPC框架,它允许不同编程语言之间进行无缝通信。
在本教程中,我们将深入了解如何在Python中使用Thrift框架进行开发。
1. 安装Thrift
首先,我们需要安装Thrift框架。
在命令行中运行以下命令来安装Thrift:
```
pip install thrift
```
安装完成后,我们将能够在Python项目中使用Thrift。
2.创建服务定义文件
接下来,我们需要创建一个Thrift服务定义文件,它描述了我们的RPC接口和数据结构。
我们将创建一个简单的示例,其中包含一个用于加法运算的接口。
创建一个名为calculator.thrift的文件,并将以下内容添加到其中:
```
namespace py calculator
service CalculatorService
i32 add(1:i32 num1, 2:i32 num2),
```
在上面的示例中,我们定义了一个名为CalculatorService的服务,
其中包含一个add方法,该方法接受两个整数参数并返回它们的和。
3. 生成Python代码
为了使用Thrift定义的接口,在我们能够在Python中调用它们之前,我们需要生成相应的代码。
在命令行中运行以下命令来生成Python代码:```
thrift --gen py calculator.thrift
```
这将生成一个名为gen-py的目录,其中包含了由Thrift定义生成的Python代码。
我们将在下一步中使用这些代码。
4.创建服务实现
现在,我们将实现我们在接口中定义的方法。
在Python中,我们可
以通过继承Thrift生成的代码中的接口类来实现这些方法。
打开calculator.py文件,并将以下内容添加到文件中:
```python
from thrift import Thrift
from thrift.transport import TSocket
from thrift.transport import TTransport
from thrift.protocol import TBinaryProtocol
from gen_py.calculator import CalculatorService
from gen_py.calculator.ttypes import calculator
class CalculatorHandler:
def add(self, num1, num2):
result = num1 + num2
return result
handler = CalculatorHandler
processor = CalculatorService.Processor(handler)
transport = TSocket.TServerSocket(port=9090)
tfactory = TTransport.TBufferedTransportFactory
pfactory = TBinaryProtocol.TBinaryProtocolFactory
server = TServer.TSimpleServer(processor, transport, tfactory, pfactory)
server.serve
```
在上面的示例中,我们首先导入了一些必要的库和模块,然后创建了一个名为CalculatorHandler的类。
该类继承自Thrift生成的接口类,并实现了我们在接口中定义的add方法。
接下来,我们创建了一个名为processor的实例,它引用了我们的服务处理程序。
我们还创建了一个传输对象,该对象指定了我们将在哪个端口上运行这个服务。
然后,我们指定了传输和协议工厂,并使用它们创建了一个名为server的SimpleServer实例。
最后,我们调用server的serve方法来启动服务。
5.启动服务
我们已经完成了Thrift服务的实现,现在我们可以在Python中启动该服务了。
在命令行中运行以下命令来启动服务:
```
```
服务将在本地的9090端口上运行。
6. 使用Thrift服务
最后,我们将在另一个Python脚本中示范如何使用刚刚启动的Thrift服务。
创建一个名为client.py的新文件,并将以下内容添加到其中:
```python
from thrift import Thrift
from thrift.transport import TSocket
from thrift.transport import TTransport
from thrift.protocol import TBinaryProtocol
from thrift.protocol import TMultiplexedProtocol
from gen_py.calculator import CalculatorService
from gen_py.calculator.ttypes import calculator
transport = TSocket.TSocket('localhost', 9090)
transport = TTransport.TBufferedTransport(transport)
protocol = TBinaryProtocol.TBinaryProtocol(transport)
client = CalculatorService.Client(protocol)
transport.open
result = client.add(10, 20)
print(result)
transport.close
```
在上面的示例中,我们引入了与服务器端相同的库和模块。
我们创建
了一些用于连接到服务器的传输对象,并使用它们创建了一个客户端实例。
然后,我们打开传输连接,并调用客户端实例的add方法来进行远程
过程调用。
最后,我们打印出调用的结果,并关闭传输连接。
7.运行示例
现在我们已经完成了Thrift服务端和客户端的实现,我们可以看看
它们的工作原理。
在一个命令行窗口中运行calculator.py来启动服务器,并在另一个命令行窗口中运行client.py来调用服务。
```
```
```
```
客户端将打印出add方法的结果,即30。
总结:
这个教程向你展示了如何在Python中使用Thrift框架。
我们从创建接口定义文件开始,然后生成了所需的Python代码。
然后,我们实现了在接口中定义的方法,并最终运行了一个完整的Thrift服务端和客户端示例。
Thrift是一个功能强大的跨语言的RPC框架,它允许不同编程语言之间进行无缝通信。
使用Thrift,我们可以轻松地设计和实现分布式系统。
希望这个教程能够帮助你开始使用Thrift进行Python开发。