c语言基本简单语法分析器
简单C语言编译器

简单C语言编译器编译器是一种将高级语言转换为机器语言的软件工具。
它是编译原理中的一个重要概念,负责将程序源代码转换成可执行文件。
在这个过程中,编译器会对源代码进行词法分析、语法分析、语义分析和代码优化等操作。
一个简单的C语言编译器包含以下主要组件:1. 词法分析器(Lexer):词法分析器将源代码分割成一个个词素(token),例如关键字、标识符、运算符和常量等。
它可以通过有限自动机(DFA)来实现,也可以使用现有的词法分析工具如Lex。
2. 语法分析器(Parser):语法分析器根据对应的语法规则,将一系列的词素组合成语法树。
它可以通过上下文无关文法(CFG)来实现,例如使用自顶向下的递归下降分析法或自底向上的移入-规约分析法。
3. 语义分析器(Semantic Analyzer):语义分析器对语法树进行语义检查,例如检查变量的声明和使用是否匹配、类型转换是否合法、函数调用是否正确等。
它还可以生成符号表,用于存储程序中的变量、函数和类型等信息。
4. 中间代码生成器(Intermediate Code Generator):中间代码生成器将语法树转换成一种中间表示形式,通常是三地址码、虚拟机指令或者抽象语法树。
该中间表示形式能够方便后续的代码优化和目标代码生成。
5. 代码优化器(Code Optimizer):代码优化器对中间代码进行优化,以提高目标代码的性能。
常见的优化技术包括常量折叠、复写传播、循环展开、函数内联等。
优化器的目标是在不改变程序行为的前提下,尽可能地减少执行时间和存储空间。
6. 目标代码生成器(Code Generator):目标代码生成器将优化后的中间代码转换成机器语言代码。
它可以根据目标平台的特点选择合适的指令集和寻址方式,并生成可以被计算机硬件执行的程序。
7. 符号表管理器(Symbol Table Manager):符号表管理器负责管理程序中的符号表,其中包含了变量、函数和类型等信息。
语法分析器文档

初使化词法分析器
识别出具有独立意义的最小语法单位
辅助性模块
②重要数据结构
·语法树节点类型
struct ExprNode { //语法树节点类型
enum Token_Type OpCode;
union {
struct {
ExprNode *Left, *Right;
} CaseOperator;
struct {
重复此过程,直到所有A产生式的候选项中均不再有公共前缀。
·构造递归下降子程序的方法:
①构造文法的状态转换图并且简化;
②将转换图转化为EBNF表示;
③从EBNmain.cpp)
#include <stdio.h>
#include "parser.h"
·消除左递归算法
输入:无回路文法G
输出:无左递归的等价文法G’
方法:将非终结符合理排序:A1,A2,…,An,然后运用下述过程:
for i in 2..n
loop for j in 1..i-1
loop用AjQ1|Q2|…|Qk的右部替换每个形如AiAj产生式中的Aj,得到新产生式:
计算机网络课程设计:词法分析器

计算机网络课程设计报告班级:计1102姓名:杨勇学号: 41155047词法分析器:一、实验目的调试并完成一个词法分析程序,加深对词法分析原理的理解。
二、实验要求1、待分析的简单语言的词法(1)关键字:begin if then while do end所有关键字都是小写。
(2)运算符和界符::= + –* / <<= <>>>= = ; ( ) #(3)其他单词是标识符(ID)和整型常数(NUM),通过以下正规式定义:ID=letter(letter| digit)*NUM=digit digit *(4)空格由空白、制表符和换行符组成。
空格一般用来分隔ID、NUM,运算符、界符和关键字,词法分析阶段通常被忽略。
2、各种单词符号对应的种别码3、词法分析程序的功能输入:所给文法的源程序字符串。
输出:二元组(syn,token或sum)构成的序列。
其中:syn为单词种别码;token为存放的单词自身字符串;sum为整型常数。
三、C语言程序源代码:#include <stdio.h>#include <string.h>char prog[80],token[8],ch;int syn,p,m,n,sum;char *rwtab[6]={"begin","if","then","while","do","end"}; scaner();main(){p=0;printf("\n please input a string(end with '#'):/n");do{scanf("%c",&ch);prog[p++]=ch;}while(ch!='#');p=0;do{scaner();switch(syn){case 11:printf("( %-10d%5d )\n",sum,syn);break;case -1:printf("you have input a wrong string\n");getch();exit(0);default: printf("( %-10s%5d )\n",token,syn);break;}}while(syn!=0);getch();}scaner(){ sum=0;for(m=0;m<8;m++)token[m++]=NULL;ch=prog[p++];m=0;while((ch==' ')||(ch=='\n'))ch=prog[p++];if(((ch<='z')&&(ch>='a'))||((ch<='Z')&&(ch>='A'))){ while(((ch<='z')&&(ch>='a'))||((ch<='Z')&&(ch>='A'))||((ch>='0')&&(ch<='9'))) {token[m++]=ch;ch=prog[p++];}p--;syn=10;for(n=0;n<6;n++)if(strcmp(token,rwtab[n])==0) { syn=n+1;break;}}else if((ch>='0')&&(ch<='9')) { while((ch>='0')&&(ch<='9')) { sum=sum*10+ch-'0';ch=prog[p++];}p--;syn=11;}else switch(ch){ case '<':token[m++]=ch;ch=prog[p++];if(ch=='=')token[m++]=ch;}else{ syn=20;p--;}break;case '>':token[m++]=ch; ch=prog[p++];if(ch=='='){ syn=24;token[m++]=ch;}else{ syn=23;p--;}break;case '+': token[m++]=ch; ch=prog[p++];if(ch=='+')token[m++]=ch;}else{ syn=13;p--;} break;case '-':token[m++]=ch; ch=prog[p++];if(ch=='-'){ syn=29;token[m++]=ch;}else{ syn=14;p--;} break;case '!':ch=prog[p++];{ syn=21;token[m++]=ch;}else{ syn=31;p--;}break;case '=':token[m++]=ch; ch=prog[p++];if(ch=='='){ syn=25;token[m++]=ch;}else{ syn=18;p--;}break;case '*': syn=15;token[m++]=ch; break;case '/': syn=16; token[m++]=ch; break;case '(': syn=27; token[m++]=ch; break;case ')': syn=28; token[m++]=ch; break;case '{': syn=5; token[m++]=ch; break;case '}': syn=6; token[m++]=ch; break;case ';': syn=26; token[m++]=ch; break;case '\"': syn=30; token[m++]=ch;break;case '#': syn=0;token[m++]=ch;break;case ':':syn=17;token[m++]=ch;break;default: syn=-1;break;}token[m++]='\0';}三、实验结果:1、给定源程序begin x:=9; if x>0 then x:=2*x+1/3; end#输出结果2、源程序(包括上式未有的while、do以及判断错误语句):beginx<=$;whilea<0dob<>9-x;end#输出结果四、总结分析:通过此次实验,让我了解到如何设计、编制并调试词法分析程序,加深对词法分析原理的理解;熟悉了构造词法分析程序的手工方式的相关原理,根据识别语言单词的状态转换图,使用某种高级语言(例如C++语言)直接编写此法分析程序。
用C语言实现简单的词法分析器

⽤C语⾔实现简单的词法分析器词法分析器⼜称扫描器。
词法分析是指将我们编写的⽂本代码流解析为⼀个⼀个的记号,分析得到的记号以供后续语法分析使⽤。
词法分析器的⼯作是低级别的分析:将字符或者字符序列转化成记号.。
要实现的词法分析器单词符号及种别码对照表:单词符号#begin if then while do End+-*/:: =种别码0123456131415161718单词符号<<><=>>==;()Letter(letter|digit)digit digit*种别码2021222324252627281011#include<stdio.h>#include<string.h>char input[200];//存放输⼊字符串char token[5];//存放构成单词符号的字符串char ch; //存放当前读⼊字符int p; //input[]下标int fg; //switch标记int num; //存放整形值//⼆维字符数组,存放关键字char index[6][6]={"begin","if","then","while","do","end"};main(){p=0;printf("please intput string(End with '#'):\n");do{ch=getchar();input[p++]=ch;}while(ch!='#');p=0;do{scaner();switch(fg){case 11:printf("( %d,%d ) ",fg,num);break;case -1:printf("input error\n"); break;default:printf("( %d,%s ) ",fg,token);}}while(fg!=0);getch(); //⽤于让程序停留在显⽰页⾯}/*词法扫描程序:*/scaner(){int m=0;//token[]下标int n;//清空token[]for(n=0;n<5;n++)token[n]=NULL;//获取第⼀个不为0字符ch=input[p++];while(ch==' ')ch=input[p++];//关键字(标识符)处理流程if((ch<='z'&&ch>='a')||(ch<='Z'&&ch>='A')){while((ch<='z'&&ch>='a')||(ch<='Z'&&ch>='A')||(ch<='9'&&ch>='0')){token[m++]=ch;ch=input[p++];}token[m++]='\0';ch=input[--p];fg=10;for(n=0;n<6;n++)if(strcmp(token,index[n])==0)//strcmp()⽐较两个字符串,相等返回0{fg=n+1;break;}}//数字处理流程else if((ch<='9'&&ch>='0')){num=0;while((ch<='9'&&ch>='0')){num=num*10+ch-'0';ch=input[p++];}ch=input[--p];fg=11;}//运算符界符处理流程elseswitch(ch){case '<':m=0;token[m++]=ch;ch=input[p++];if(ch=='>') //产⽣<>{fg=21;token[m++]=ch;}else if(ch=='=') //产⽣<={fg=22;token[m++]=ch;}else{fg=20;ch=input[--p];}break;case '>':token[m++]=ch;ch=input[p++];if(ch=='=') //产⽣>={fg=24;token[m++]=ch;}else //产⽣>{fg=23;ch=input[--p];}break;case ':':token[m++]=ch;ch=input[p++];if(ch=='=') //产⽣:={fg=18;token[m++]=ch;}else //产⽣:{fg=17;ch=input[--p];}break;case '+':fg=13;token[0]=ch;break; case '-':fg=14;token[0]=ch;break; case '*':fg=15;token[0]=ch;break; case '/':fg=16;token[0]=ch;break; case ':=':fg=18;token[0]=ch;break; case '<>':fg=21;token[0]=ch;break; case '<=':fg=22;token[0]=ch;break; case '>=':fg=24;token[0]=ch;break; case '=':fg=25;token[0]=ch;break; case ';':fg=26;token[0]=ch;break; case '(':fg=27;token[0]=ch;break; case ')':fg=28;token[0]=ch;break; case '#':fg=0;token[0]=ch;break; default:fg=-1;}}。
exprtk 解析c代码

exprtk 解析c代码exprtk 解析 C 代码C 语言是一种广泛应用于嵌入式系统以及计算机科学领域的编程语言。
C 代码的解析和分析是构建编译器、调试器和其他工具的基础。
在本文中,我们将介绍 exprtk(Expression Toolkit)作为一个用于解析C 代码的开源工具。
exprtk 是一个功能强大的 C++ 数值表达式解析库,它被设计用于解析和计算数学表达式,适用于数值计算、符号计算、自动微分等多个领域。
同时,由于 C 语言的语法与数学表达式有着紧密的联系,我们也可以将其用于解析 C 代码。
exprtk 的设计思路是将表达式解析和计算的功能封装为一个易于使用且高效的库。
它提供了丰富的表达式语法和操作符,支持大部分 C 语言中的数学运算,包括加减乘除、取余、取反等等。
使用 exprtk 解析 C 代码,可以实现诸如变量提取、函数调用、表达式求值等功能。
在解析 C 代码之前,我们首先需要进行词法分析和语法分析,将代码转换为符号序列和语法树。
exprtk 提供了基本的词法分析器和语法分析器,可以方便地将 C 代码转换为表达式。
我们可以通过逐个读取代码的字符,识别变量、常量、操作符和其他关键字,并将其串联起来生成表达式。
以一个简单的示例来说明如何使用 exprtk 解析 C 代码。
假设我们要解析以下的 C 代码片段:int main() {int a = 1;int b = 2;int c = a + b;return c;}```首先,我们需要定义变量和函数。
可以使用 exprtk 提供的 context 类来管理变量和函数的定义。
例如,我们定义一个 context 对象 `ctx`,然后使用 `ctx.set_variable()` 和 `ctx.set_function()` 分别设置变量和函数的名称和值,如下所示:```cppexprtk::symbol_table<double> symbol_table;exprtk::expression<double> expression;symbol_table.add_variable("a", a);symbol_table.add_variable("b", b);symbol_table.add_variable("c", c);exprtk::parser<double> parser;pile(code, expression);在这个例子中,我们将变量 `a`、`b` 和 `c` 分别映射到 C 代码中的变量。
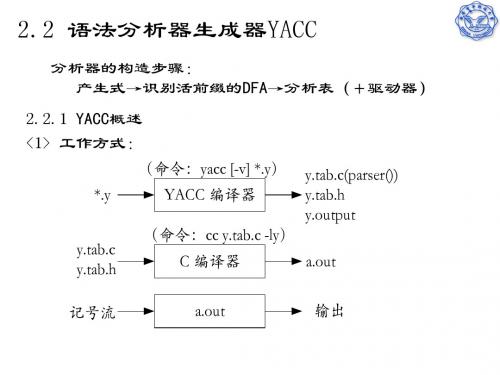
语法分析器生成器YACC
E : num num
再分析3++5
5
分析器动作 移进 num,转向state 3 按(2)“E : num”归约,goto State 1 移进 +,转向State 4 移进error,转向 state 2 按(3)“E : error”归约,goto State 5, 按(1)“E : E‘+’E”归约,goto State 1 移进 +,转向State 4 移进 num,转向 State 3 按(2)“E : num”归约,goto State 5 按(1)“E : E‘+’E”归约,goto State 1 接受
2.2.3.2 YACC对语义的支持
分析器工作原理:
记号流 归约前栈顶 归约后栈顶 $3 E $2 + $1($$) E ... ... 驱动器 分析表 输出
语义栈对语法制导翻译提供直接支持。语义栈的 类型决定了文法符号的属性,语义栈类型表示能力的 强弱决定了YACC的能力。
<1> YACC默认的语义值类型 YACC语义栈与yylval同类型,并以终结符的yylval 值作为栈中的初值。因为yylval的默认类型为整型,所 以,当用户所需文法符号的语义类型是整型时,无需定 义它的类型。如在下述表达式的产生式中: E :E '+' E | E '*' E | num ; { $$=$1+$3;} { $$=$1*$3;}
2.2.1 YACC概述
利用YACC进行语法分析器设计的关键,也是如何编写 YACC源程序。 下边首先介绍YACC源程序的基本结构,然后着重讨论 YACC的产生式、YACC解决产生式冲突的方法、以及YACC对语 义的支持和对错误的处理等。
C语言编译原理词法分析和语法分析

C语言编译原理词法分析和语法分析编程语言的编写和使用离不开编译器的支持,而编译器的核心功能之一就是对代码进行词法分析和语法分析。
C语言作为一种常用的高级编程语言,也有着自己的词法分析和语法分析规则。
一、词法分析词法分析是编译器的第一阶段,也是将源代码拆分为一个个独立单词(token)的过程。
在C语言中,常见的单词包括关键字(如if、while等)、标识符(如变量名)、常量(如数字、字符常量)等。
词法分析器会根据预定义的规则对源代码进行扫描,并将扫描到的单词转化为对应的符号表示。
词法分析的过程可以通过有限自动机来实现,其中包括各种状态和状态转换规则。
词法分析器通常会使用正则表达式和有限自动机的方法来进行实现。
通过词法分析,源代码可以被分解为一个个符号,为后续的语法分析提供基础。
二、语法分析语法分析是编译器的第二阶段,也是将词法分析得到的单词序列转换为一棵具有语法结构的抽象语法树(AST)的过程。
在C语言中,语法分析器会根据C语言的文法规则,逐句解析源代码,并生成相应的语法树。
C语言的语法规则相对复杂,其中包括了各种语句、表达式、声明等。
语法分析的过程主要通过递归下降分析法、LR分析法等来实现。
语法分析器会根据文法规则建立语法树的分析过程,对每个语法结构进行逐步推导和分析,最终生成一棵完整的语法树。
三、编译器中的词法分析和语法分析在编译器中实现词法分析和语法分析是一项重要的技术任务。
编译器通常会将词法分析和语法分析整合在一起,形成一个完整的前端。
在C语言编译器中,词法分析和语法分析器会根据C语言的词法规则和文法规则,对源代码进行解析,并生成相应的中间表示形式,如语法树或者中间代码。
词法分析和语法分析的结果会成为后续编译器中各个阶段的输入,如语义分析、中间代码生成、目标代码生成等。
编译器的优化和错误处理也与词法分析和语法分析有密切关系。
因此,对词法分析和语法分析的理解和实现对于编译器开发者而言是非常重要的。
C语言编译原理编译过程和编译器的工作原理

C语言编译原理编译过程和编译器的工作原理C语言是一种广泛使用的计算机编程语言,它具有高效性和可移植性的特点。
在C语言程序的运行之前,需要通过编译器将源代码翻译成机器可以执行的目标代码。
编译器是一种专门用于将高级语言源代码转换为机器语言的程序。
编译过程分为四个主要阶段,包括词法分析、语法分析、语义分析和代码生成。
下面我们逐一介绍这些阶段的工作原理。
1. 词法分析词法分析是编译过程的第一步,它将源代码分解成一系列的词法单元,如标识符、常量、运算符等。
这些词法单元存储在符号表中,以便后续的分析和转换。
2. 语法分析语法分析的目标是将词法单元按照语法规则组织成一个语法树,以便进一步的分析和优化。
语法分析器使用文法规则来判断输入的字符串是否符合语法规范,并根据语法规则生成语法树。
3. 语义分析语义分析阶段对语法树进行分析并在合适的地方插入语义动作。
语义动作是一些与语义相关的处理操作,用于检查和修正代码的语义错误,并生成中间代码或目标代码。
4. 代码生成代码生成是编译过程的最后一个阶段,它将中间代码或语法树翻译为目标代码,使得计算机可以直接执行。
代码生成阶段涉及到指令的选择、寄存器分配、数据位置的确定等一系列的优化操作,以提高程序的性能和效率。
编译器是实现编译过程的工具。
它接收源代码作为输入,并将其转换为目标代码或可执行文件作为输出。
编译器工作原理可以简单概括为:读取源代码、进行词法分析和语法分析、生成中间代码、进行优化、生成目标代码。
编译器在编译过程中还涉及到符号表管理、错误处理、优化算法等方面的工作。
符号表用于管理程序中的标识符、常量、变量等信息;错误处理机制用于检测和纠正程序中的错误;优化算法用于提高程序的性能和效率,例如常量折叠、无用代码删除等。
总结起来,C语言编译过程涉及到词法分析、语法分析、语义分析和代码生成等阶段,每个阶段都有特定的工作原理和任务。
编译器作为实现编译过程的工具,负责将源代码转换为机器可以执行的目标代码。
词法分析实验报告

词法分析实验报告词法分析是编译原理中的一个重要概念,它是编译器中的第一个阶段,也是最基础的一个阶段。
词法分析器将输入的源代码转化为一系列的标记(Token),这些标记是语法分析器后续分析的基本单元。
在本次实验中,我们使用C语言编写了一个简单的词法分析器。
该词法分析器可以识别常见的C语言关键字(如if、while、for等)、运算符(如+、-、*、/等)、标识符、常量等,并将它们转化为相应的标记。
实验过程中,我们使用了C++编程语言来实现词法分析器。
在主函数中,我们首先读取输入的源代码文件,并将其逐个字符地进行扫描。
扫描过程中,我们利用一些常见的正则表达式来匹配每个标记,并将其转化为相应的Token。
在匹配完成后,我们将Token存储在一个Token序列中,以便后续的语法分析器使用。
实验过程中,我们遇到了一些困难。
一是字符匹配的问题,在处理运算符等特殊字符时,需要对转义字符进行特殊处理。
二是标识符的识别问题,我们需要判断一个字符是否属于标识符中的某一部分,而不能将其单独当作一个标记。
为了解决这个问题,我们采用了状态机的方法,维护一个标识符的状态,根据状态的变化来判断是否识别到了一个完整的标识符。
在实验结果中,我们成功地将源代码转化为了一系列的标记。
这些标记可以用于后序的语法分析和语义分析等过程中。
同时,我们也发现了一些问题,如在处理注释时可能会出现误判等。
针对这些问题,我们可以进一步改进词法分析器,提高其准确性和鲁棒性。
总的来说,通过本次实验,我们深入理解了词法分析的原理和过程,并成功地实现了一个简单的词法分析器。
通过这个实验,我们对编译原理有了更深入的了解,并提高了自己的编程能力。
LR(0)语法分析

淮阴工学院编译原理课程设计报告选题名称:LR(0) 语法分析系(院):计算机工程学院专业:计算机科学与技术班级:计算机1075(单招)姓名:赵俊丽学号: 1071308114指导老师:于长辉王文豪高丽夏森学年学期:2009 ~2010 学年第 2 学期设计任务书指导教师(签章):年月日编译原理课程设计报告摘要:编译程序是现代计算机系统的基本组成部分之一,语法分析是编译程序的核心部分,识别由语法分析给出的单词符号序列是否是给定文法的正确句子,把词法记号流按语言的语法结构层次地分组,以形成语法短语。
一个编译程序的工作过程一般可以划分为五个阶段:词法分析、语法分析、语义分析与中间代码生成、优化、目标代码生成。
LR(0)是一种自底向上的语法分析方法,是已知的最一般的无回溯的移近—归约方法,这一方法能够识别所有能用上下文无关文法描述的程序语言的结构.本文主要讨论LR(0)语法分析的构造.着重分析LR(0)分析器的一般原理、实现思想、基本设计方法以及主要实现技术和工具。
操作员录入合法的LR(0)文法,则自动生成LR(0)分析表,并对任一输入串进行分析。
判断其是否是给定文法的句子。
还可以对输入的句子进行语法分析。
关键词:自底向上分析;移进;规约目录1课题综述 (1)1.1课题来源 (1)1.2意义 (1)1.3预期目标 (1)1.4面对的问题 (2)2系统分析 (3)2.1涉及的基础知识 (3)2.2 总体方案 (5)3 系统设计 (5)3.1 算法描述 (6)3.3 详细流程图 (9)4代码编写 (10)5程序调试 (15)总结 (19)致谢 (20)参考文献 (21)1课题综述1.1课题来源编译器设计的编译程序涉及到编译五个阶段中的三个,即词法分析器、语法分析器和中间代码生成器。
编译程序的输出结果包括词法分析后的二元式序列、变量名表、状态栈分析过程显示及四元式序列程序。
整个编译程序分为三部分:词法分析部分、语法分析处理及四元式生成部分、输出显示部分。
用C语言编写的简单编译器

用C语言编写的简单编译器编译器是软件开发中不可或缺的工具,它可以将高级语言编写的源代码转换成计算机能够理解和执行的机器码。
在本文中,我们将介绍如何用C语言编写一个简单的编译器,让读者了解编译器的基本原理和实现方法。
一、概述编译器是由多个模块组成的,每个模块负责完成不同的任务。
在我们的简单编译器中,我们将实现以下几个基本模块:1. 词法分析器(Lexer):将源代码分解成一个个的词法单元,比如标识符、关键字和运算符等。
词法分析器是编译器的第一个模块,它会读取源代码,并生成一个个的词法单元序列供后续处理。
2. 语法分析器(Parser):根据词法单元序列构建语法分析树,通过语法规则判断源代码是否符合语法规范。
语法分析器会进行递归下降或者使用其他算法进行语法分析,并将结果存储在语法分析树中。
3. 语义分析器(Semantic Analyzer):对语法分析树进行分析,并进行语义检查,比如类型检查、符号表管理等。
语义分析器负责捕捉源代码中可能存在的语义错误,并提供错误提示和修复建议。
4. 中间代码生成器(Intermediate Code Generator):将语法分析树转换成中间代码表示,比如三地址代码、虚拟机代码等。
中间代码生成器是连接语义分析和目标代码生成的桥梁。
5. 目标代码生成器(Codegen):将中间代码转换成目标机器的机器码,并生成可执行文件。
目标代码生成器负责将中间代码翻译成目标机器能够执行的代码,并进行优化以提高执行效率。
二、实现步骤下面以一个简单的四则运算表达式为例,介绍我们的编译器的实现步骤:1. 首先,我们需要定义词法分析器,它会从源代码中逐个读取字符,并根据一定的规则进行词法单元的生成。
在这个例子中,我们可以定义的词法单元有:数字、加号、减号、乘号和除号等。
2. 接下来,我们定义语法分析器,在这个例子中,我们可以使用递归下降的方法来进行语法分析。
我们需要定义一个函数来处理每个非终结符,比如表达式、项和因子等,并根据定义的语法规则进行递归调用。
编译原理实验词法分析器与语法分析器实现

编译原理实验词法分析器与语法分析器实现词法分析器与语法分析器是编译器的两个重要组成部分,它们在编译过程中扮演着至关重要的角色。
词法分析器负责将源代码转化为一个个标记(token)序列,而语法分析器则根据词法分析器生成的标记序列构建语法树,验证源代码的语法正确性。
本实验旨在实现一个简单的词法分析器和语法分析器。
实验一:词法分析器实现在实现词法分析器之前,需要定义所需词法项的规则。
以C语言为例,常见的词法项包括关键字(如int、if、for等)、标识符、运算符(如+、-、*、/等)、常量(如整数、浮点数等)和分隔符(如括号、逗号等)。
接下来,我们来实现一个简单的C语言词法分析器。
1. 定义词法项的规则在C语言中,关键字和标识符由字母、数字和下划线组成,且首字符不能为数字。
运算符包括各种数学运算符和逻辑运算符。
常量包括整数和浮点数。
分隔符包括括号、逗号等。
2. 实现词法分析器的代码下面是一个简单的C语言词法分析器的实现代码:```pythondef lexer(source_code):keywords = ['int', 'if', 'for'] # 关键字列表operators = ['+', '-', '*', '/'] # 运算符列表separators = ['(', ')', '{', '}', ',', ';'] # 分隔符列表tokens = [] # 标记序列列表current_token = '' # 当前标记for char in source_code:if char.isspace(): # 如果是空格,则忽略continueelif char.isalpha(): # 如果是字母,则可能是关键字或标识符的一部分current_token += charelif char.isdigit(): # 如果是数字,则可能是常量的一部分current_token += charelif char in operators or char in separators: # 如果是运算符或分隔符,则当前标记结束if current_token:tokens.append(current_token)current_token = ''tokens.append(char)else: # 如果是其他字符,则当前标记结束if current_token:tokens.append(current_token)current_token = ''return tokens```以上代码通过遍历源代码的字符,根据定义的规则生成一个个标记,存储在`tokens`列表中。
编译原理实验——flex语法实现简单词法分析器

flex提供的2个全局变量:
yytext:刚刚匹配到的字符串 yyleng:刚刚匹配到的字符串的长度
代码段如下(注意:规则行务必没有缩进,且对应的动作必须在同一行开始):
%{ #include <stdio.h> #include <string.h>
%}
ALPHA [a-zA-Z] ID {ALPHA}+[a-zA-Z0-9_]* KEY begin|if|then|while|do|end NUM [\-]?[1-9][0-9]*|0
四、实验结果
1. 用管理员身份打开cmd窗口 2. 进入到该代码文本文件所在的文件夹内 3. 然后输入下面两行命令,完成对代码的编译生成。
flex test.l //此后会生成C文件lex.yy.c gcc lex.yy.c //使用gcc编译成可执行文件 4. 我这里生成的是a.exe文件,在窗口中输入a.exe或a回车,运行该文件 即可输入字符串来验证结果。
2.3 词法分析程序的功能: 输入:所给文法的源程序字符串。 输出:二元组(syn,token或num)构成的序列。 其中:syn为单词种别码; token为存放的单词自身字符串; num为整型常数。 例如:对源程序begin x:=9; if x>9 then x:=2*x+1/3; end #的Pascal源文件,经过词法分析后输出如下序列: (1,begin)(10,x)(18,:=)(11,9)(26,;)(2,if)…
printf("(4,%s)",yytext);
else if(yytext[0]=='d')
printf("(5,%s)",yytext);
C语言的代码生成与自动生成工具

C语言的代码生成与自动生成工具C语言是一种广泛应用于系统开发和嵌入式设备编程的编程语言。
然而,编写大量的C代码可能是一项繁琐且耗时的任务。
为了简化开发过程,提高效率,许多开发人员选择使用代码生成和自动生成工具来生成C代码。
本文将介绍一些常用的C语言代码生成和自动生成工具,包括它们的特点、优势以及如何使用它们来提高开发效率。
1. CMake1.1 特点•跨平台:CMake可以生成针对不同操作系统和编译器的构建文件,方便在不同平台上进行开发和构建。
•灵活性:CMake使用一种类似于脚本的语言来描述构建过程,允许开发人员自定义构建规则和选项。
•高效性:CMake使用自动依赖分析和增量构建机制,减少了不必要的重新构建,提高了构建过程的效率。
1.2 使用方法1.创建一个CMakeLists.txt文件,在其中描述项目的源代码文件、依赖项以及构建选项。
2.执行cmake命令生成平台特定的构建文件(如Makefile或VisualStudio项目文件)。
3.使用生成的构建文件进行编译和构建。
2. YACC/Bison2.1 特点•语法分析:YACC/Bison是一种用于生成解析器的工具,可以根据语法规则自动生成对应的语法分析器。
•高度可定制:开发人员可以通过定义自己的语法规则来创建特定领域的解析器,方便进行语法分析和处理。
•与Lex/Flex集成:YACC/Bison通常与Lex/Flex配合使用,前者负责生成语法解析器,后者负责生成词法分析器。
2.2 使用方法1.创建一个包含语法规则的.y文件。
2.使用yacc或bison命令对.y文件进行分析,生成对应的语法解析器。
3.将生成的解析器与词法分析器集成,用于分析和处理代码。
3. CMocka3.1 特点•单元测试:CMocka是一个用于C语言的单元测试框架,可以方便地进行单元测试和断言。
•轻量级:CMocka是一个轻量级框架,易于学习和使用。
•丰富的功能:CMocka提供了丰富的断言和测试辅助函数,可以方便地对代码进行测试和验证。
实验5-LL(1)语法分析程序的设计与实现(C语言)

实验五LL(1)文法识别程序设计一、实验目的通过LL(1)文法识别程序的设计理解自顶向下的语法分析思想。
二、实验重难点FIRST集合、FOLLOW集合、SELECT集合元素的求解,预测分析表的构造。
三、实验内容与要求实验内容:1.阅读并理解实验案例中LL(1)文法判别的程序实现;2.参考实验案例,完成简单的LL(1)文法判别程序设计。
四、实验学时4课时五、实验设备与环境C语言编译环境六、实验案例1.实验要求参考教材93页预测分析方法,94页图5.11 预测分析程序框图,编写表达式文法的识别程序。
要求对输入的LL(1)文法字符串,程序能自动判断所给字符串是否为所给文法的句子,并能给出分析过程。
表达式文法为:E→E+T|TT→T*F|FF→i|(E)2.参考代码为了更好的理解代码,建议将图5.11做如下标注:/* 程序名称: LL(1)语法分析程序 *//* E->E+T|T *//* T->T*F|F *//* F->(E)|i *//*目的: 对输入LL(1)文法字符串,本程序能自动判断所给字符串是否为所给文法的句子,并能给出分析过程。
/********************************************//* 程序相关说明 *//* A=E' B=T' *//* 预测分析表中列号、行号 *//* 0=E 1=E' 2=T 3=T' 4=F *//* 0=i 1=+ 2=* 3=( 4=) 5=# *//************************************/#include"iostream"#include "stdio.h"#include "malloc.h"#include "conio.h"/*定义链表这种数据类型参见:*/struct Lchar{char char_ch;struct Lchar *next;}Lchar,*p,*h,*temp,*top,*base;/*p指向终结符线性链表的头结点,h指向动态建成的终结符线性链表节点,top和base分别指向非终结符堆栈的顶和底*/char curchar; //存放当前待比较的字符:终结符char curtocmp; //存放当前栈顶的字符:非终结符int right;int table[5][6]={{1,0,0,1,0,0},{0,1,0,0,1,1},{1,0,0,1,0,0},{0,1,1,0,1,1},{1,0,0,1,0,0}};/*存放预测分析表,1表示有产生式,0表示无产生式。
编译原理课程(词法分析器及语法分析器)

编译原理实验报告词法分析器与语法分析器I. 问题描述设计、编制并调试一个词法分析子程序,完成识别语言单词的任务;设计、编制、调试一个语法分析程序,并用它对词法分析程序所提供的单词序列进行语法检查和结构分析。
ii. 设计简要描述界面需求:为了更加形象的模拟过程,此实验使用图形界面。
要求从图形界面上输入输入串,点击词法分析,可以将词法分析后识别的单词符号显示,点击语法分析,可以将语法分析的堆栈过程显示,并且显示结果(是否是符合文法的句子),清空则可以将所有置空。
功能分析:1、由用户输入输入串;2、用户点击“词法分析”,可以将词法分析后识别的单词符号显示。
3、用户点击语法分析,可以将语法分析的堆栈过程显示,并且显示结果(是否是符合文法的句子)4、用户点击清空,则将界面所有组件置为空思路描述:一、设计构想:本实验决定编写一个简易C语言的词法分析器和语法分析器。
使其能够识别while,if等关键字,可以判断赋值语句、条件语句、循环语句。
二、文法分析1、需要识别的关键字及其识别码有:关键字识别码关键字识别码关键字识别码main 0 - 11 ;22int 1 * 12 > 23char 2 / 13 < 24if 3 ( 14 >= 25else 4 ) 15 <= 26for 5 [ 16 == 27while 6 ] 17 != 28ID 7 { 18 ERROR -1NUM 8 } 19= 9 , 20+ 10 : 212、文法〈程序〉→ main()〈语句块〉〈语句块〉→{〈语句串〉}〈语句串〉→〈语句〉;〈语句串〉|〈语句〉;〈语句〉→〈赋值语句〉|〈条件语句〉|〈循环语句〉〈赋值语句〉→ ID =〈表达式〉;〈条件语句〉→ if〈条件〉〈语句块〉〈循环语句〉→ while〈条件〉〈语句块〉〈条件〉→(〈表达式〉〈关系符〉〈表达式〉)〈表达式〉→〈表达式〉〈运算符〉〈表达式〉|(〈表达式〉)|ID|NUM〈运算符〉→+|-|*|/〈关系符〉→<|<=|>|>=|=|!>转化为符号表示:S→ main() K|空K→ { C }C→Y;C |空Y→F | T | XF→ ID = BT→ if J KX→ while J KJ→( B G B )B→ B Z B |( B )| ID | NUMZ→ + | - | * | /G→< | <= | > | >= | == | !>表示含义:S:程序 K:语句块 C:语句串 Y:语句 F :赋值语句T:条件语句 X:循环语句 J:条件 B:表达式 I:项 Z :运算符G:关系符3、LL(1)分析表(1),求出first集及follow集:FIRST(S)={mian}FIRST(K)={{}FIRST(C)= FIRST(Y)= {ID,if,while,空};FIRST(Y)= FIRST(F)+ FIRST(T)+ FIRST(X)={ID,if,while};FIRST(F)={ID};FIRST(T)={if};FIRST(X)={while};FIRST(J)= FIRST(B)={};FIRST(B)={(,ID,NUM };FIRST(Z)={+,-,*,/}FIRST(G)={<,<= ,>,>=,==,!= };FOLLO W(S)={#};FOLLO W(K)={;};FOLLO W(C)={}};FOLLO W(Y)={;}FOLLO W(F)={;};FOLLO W(T)={;};FOLLO W(X)={;};FOLLO W(J)={{,;};FOLLO W(B)={+,-,*,/,),<,<= ,>,>=,==,!=,;};FOLLO W(B’)={+,-,*,/,),<,<= ,>,>=,==,!=,;};FOLLO W(Z)={(,ID,NUM };FOLLO W(G)={(,ID,NUM };(2)消除左递归,拆分文法关系并编号0、S→ 空1、S→ main() K2、K→ { C }3、C→Y;C4、C→空5、Y→ F6、Y→ T7、Y→ X8、F→ ID = B9、T→ if J K10、X→ while J K11、J→( B G B )12、 B→( B )B'13、B→ ID B'14、B→ NUM B'15、B'→ BZB B'16、B'→空17、Z→ +18、Z→ -19、Z→ *20、Z→ /21、 G→ <22、 G→ <=23、 G→ >24、 G→ >=25、 G→ ==26、 G→ !=(3)构造LL(1)分析表(注:在表中用上一步的编号表示所需要的产生式)main 空( ) { } ; = if while ID num + - * / < <= > >= == != #iii. 详细设计描述 项目构架:各函数功能介绍:1、word.wordList 包(存储了关键字):word :此类是定义了存储关键字的结构:包括String 型的关键字,和int 型的识别符。
编译原理实验报告词法分析器语法分析器

编译原理实验报告实验一一、实验名称:词法分析器的设计二、实验目的:1,词法分析器能够识别简单语言的单词符号2,识别出并输出简单语言的基本字.标示符.无符号整数.运算符.和界符。
三、实验要求:给出一个简单语言单词符号的种别编码词法分析器四、实验原理:1、词法分析程序的算法思想算法的基本任务是从字符串表示的源程序中识别出具有独立意义的单词符号,其基本思想是根据扫描到单词符号的第一个字符的种类,拼出相应的单词符号。
2、程序流程图(1)主程序(2)扫描子程序3五、实验内容:1、实验分析编写程序时,先定义几个全局变量a[]、token[](均为字符串数组),c,s( char型),i,j,k(int型),a[]用来存放输入的字符串,token[]另一个则用来帮助识别单词符号,s用来表示正在分析的字符。
字符串输入之后,逐个分析输入字符,判断其是否‘#’,若是表示字符串输入分析完毕,结束分析程序,若否则通过int digit(char c)、int letter(char c)判断其是数字,字符还是算术符,分别为用以判断数字或字符的情况,算术符的判断可以在switch语句中进行,还要通过函数int lookup(char token[])来判断标识符和保留字。
2 实验词法分析器源程序:#include <>#include <>#include <>int i,j,k;char c,s,a[20],token[20]={'0'};int letter(char s){if((s>=97)&&(s<=122)) return(1);else return(0);}int digit(char s){if((s>=48)&&(s<=57)) return(1);else return(0);}void get(){s=a[i];i=i+1;}void retract(){i=i-1;}int lookup(char token[20]){if(strcmp(token,"while")==0) return(1);else if(strcmp(token,"if")==0) return(2);else if(strcmp(token,"else")==0) return(3);else if(strcmp(token,"switch")==0) return(4);else if(strcmp(token,"case")==0) return(5);else return(0);}void main(){printf("please input string :\n");i=0;do{i=i+1;scanf("%c",&a[i]);}while(a[i]!='#');i=1;j=0;get();while(s!='#'){ memset(token,0,20);switch(s){case 'a':case 'b':case 'c':case 'd':case 'e':case 'f':case 'g':case 'h':case 'i':case 'j':case 'k':case 'l':case 'm':case 'n':case 'o':case 'q':case 'r':case 's':case 't':case 'u':case 'v':case 'w':case 'x':case 'y':case 'z':while(letter(s)||digit(s)){token[j]=s;j=j+1;get();}retract();k=lookup(token);if(k==0)printf("(%d,%s)",6,token);else printf("(%d,-)",k);break;case '0':case '2':case '3':case '4':case '5':case '6':case '7':case '8':case '9':while(digit(s)){token[j]=s;j=j+1;get();}retract();printf("%d,%s",7,token);break;case '+':printf("('+',NULL)");break;case '-':printf("('-',null)");break; case '*':printf("('*',null)");break;case '<':get();if(s=='=') printf("(relop,LE)");else{retract();printf("(relop,LT)");}break;case '=':get();if(s=='=')printf("(relop,EQ)");else{retract();printf("('=',null)");}break;case ';':printf("(;,null)");break;case ' ':break;default:printf("!\n");}j=0;get();} }六:实验结果:实验二一、实验名称:语法分析器的设计二、实验目的:用C语言编写对一个算术表达式实现语法分析的语法分析程序,并以四元式的形式输出,以加深对语法语义分析原理的理解,掌握语法分析程序的实现方法和技术。
编译原理课程设计_词法语法分析器

编译原理课程设计Course Design of Compiling(课程代码3273526)半期题目:词法和语法分析器实验学期:大三第二学期学生班级:2014级软件四班学生学号:2014112218学生姓名:何华均任课教师:丁光耀信息科学与技术学院2017.6课程设计1-C语言词法分析器1.题目C语言词法分析2.内容选一个能正常运行的c语言程序,以该程序出现的字符作为单词符号集,不用处理c语言的所有单词符号。
将解析到的单词符号对应的二元组输出到文件中保存可以将扫描缓冲区与输入缓冲区合成一个缓冲区,一次性输入源程序后就可以进行预处理了3.设计目的掌握词法分析算法,设计、编制并调试一个词法分析程序,加深对词法分析原理的理解4.设计环境(电脑语言环境)语言环境:C语言CPU:i7HQ6700内存:8G5.概要设计(单词符号表,状态转换图)5.1 词法分析器的结构词法分析程序的功能:输入:所给文法的源程序字符串。
输出:二元组(syn,token或sum)构成的序列。
词法分析程序可以单独为一个程序;也可以作为整个编译程序的一个子程序,当需要一个单词时,就调用此法分析子程序返回一个单词.为便于程序实现,假设每个单词间都有界符或运算符或空格隔开,并引入下面的全局变量及子程序:1) ch 存放最新读进的源程序字符2) strToken 存放构成单词符号的字符串3) Buffer 字符缓冲区4)struct keyType 存放保留字的符号和种别5.3 状态转换图6.详细设计(数据结构,子程序)算法思想:首先设置3个变量:①strToken用来存放构成单词符号的字符串;②ch 用来字符;③struct keyType用来存放单词符号的种别码。
扫描子程序主要部分流程如下图所示。
7.程序清单// ConsoleApplication1.cpp : 定义控制台应用程序的入口点。
//#include"stdafx.h"#include"stdio.h"#include"stdlib.h"#include"conio.h"#include"string.h"#define N 47char ch;char strToken[20];//存放构成单词符号的字符串char buffer[1024]; //字符缓冲区struct keyType {char keyname[256];int value;}Key[N] = { { "$ID",0 },{ "$INT",1 },{ "auto",2 },{ "break",3 },{ "case",4 }, { "char",5 },{ "const",6 },{ "continue",7 },{ "default",8 },{ "do",9 }, { "double",10 },{ "else",11 },{ "enum",12 },{ "extern",13 },{ "float",14 }, { "for",15 },{ "goto",16 },{ "if",17 },{ "int",18 },{ "long",19 },{ "register",20 }, { "return",21 },{ "short",22 },{ "signed",23 },{ "sizeof",24 },{ "static",25 }, { "struct",26 },{ "switch",27 },{ "typedef",28 },{ "union",29 },{ "unsigned",30 }, { "void",31 },{ "volatile",32 },{ "while",33 },{ "=",34 },{ "+",35 },{ "-",36 },{ "*",37 }, { "/",38 },{ "%",39 },{ ",",40 },{ ";",41 },{ "(",42 },{ ")",43 },{ "?",44 },{ "clear", 45 },{ "#",46 } };void GetChar() //读一个字符到ch中{int i;if (strlen(buffer)>0) {ch = buffer[0];for (i = 0; i<256; i++)buffer[i] = buffer[i + 1];}elsech = '\0';}void GetBC()//读一个非空白字符到ch中{int i;while (strlen(buffer)) {i = 0;ch = buffer[i];for (; i<256; i++) buffer[i] = buffer[i + 1];if (ch != ' '&&ch != '\n'&&ch != '\0') break;}}void ConCat()//把ch连接到strToken之后{char temp[2];temp[0] = ch;temp[1] = '\0';strcat(strToken, temp);}bool Letter()//判断ch是否为字母{if (ch >= 'A'&&ch <= 'Z' || ch >= 'a'&&ch <= 'z')return true;elsereturn false;}bool Digit()//判断ch是否为数字{if (ch >= '0'&&ch <= '9')return true;elsereturn false;}int Reserve()//用strToken中的字符查找保留字表,并返回保留字种别码,若返回0,则非保留字{int i;for (i = 0; i<N; i++)if (strcmp(strToken, Key[i].keyname) == 0)return Key[i].value;return 0;}void Retract()//把ch中的字符回送到缓冲区{int i;if (ch != '\0') {buffer[256] = '\0';for (i = 255; i>0; i--)buffer[i] = buffer[i - 1];buffer[0] = ch;}ch = '\0';}keyType ReturnWord(){strcpy(strToken, "\0");int c;keyType tempkey;GetBC();if (ch >= 'A'&&ch <= 'Z' || ch >= 'a'&&ch <= 'z') { ConCat();GetChar();while (Letter() || Digit()) {ConCat();GetChar();}Retract();c = Reserve();strcpy(tempkey.keyname, strToken);if (c == 0)tempkey.value = 0;elsetempkey.value = Key[c].value;}else if (ch >= '0'&&ch <= '9') {ConCat();GetChar();while (Digit()) {ConCat();GetChar();}Retract();strcpy(tempkey.keyname, strToken);tempkey.value = 1;}else {ConCat();strcpy(tempkey.keyname, strToken);tempkey.value = Reserve();}return tempkey;}/*主函数*/int main() {//文件操作FILE *fp;if ((fp = fopen("E:\\作业\\编译原理\\Ccode.txt", "r")) == NULL) { printf("cannot open file/n"); exit(1);}while (!feof(fp)) {if (fgets(buffer, 250, fp) != NULL){printf("E:\\作业\\编译原理\\Ccode.txt\n");}}keyType temp;printf("单词\t种别号\n");while (strlen(buffer)) {temp = ReturnWord();printf("%s\t %d\n\n", temp.keyname, temp.value);}printf("the end!\n");getch();return 0;}8.运行结果E:/作业/编译原理/Code.txt运行结果九、 实验体会通过本次次法分析设计实验,我加深了对词法分析过程的理解。
lll算法 c语言

lll算法 c语言
LL算法是一种语法分析算法,主要用于解析上下文无关文法。
在C语言中,LL算法可以用来构建语法解析器,帮助程序员解析代码。
本文将介绍LL算法的基本原理和C语言实现,以及如何使用LL 算法构建一个简单的语法解析器。
LL算法中,LL代表Left-to-right, Leftmost derivation。
这意味着算法从左到右扫描输入的字符,并尝试找到最左侧的推导路径。
LL算法的一个重要特点是它只需要一次向前看一个字符就能够确定
应该采取哪个产生式进行推导。
在C语言中,LL算法可以用递归下降分析器来实现。
递归下降
分析器是一种自顶向下的语法分析器,它将文法规则翻译成一组递归函数,每个函数表示一个非终结符。
递归下降分析器从语法树的根节点开始,递归地调用各个函数,直到生成整个语法树。
使用LL算法构建语法解析器的步骤如下:
1. 定义文法规则并将其转换为LL(1)文法。
2. 实现递归下降分析器,将每个非终结符映射为一个函数。
3. 从输入中读取字符,并调用递归下降分析器函数解析输入。
4. 根据解析结果生成语法树或报告语法错误。
LL算法和递归下降分析器是C语言中常用的语法分析技术。
掌
握这些技术可以帮助程序员更好地理解和解析代码,推进程序的开发进程。
- 1 -。
C语言基本语法

若:a为1,b为0, 则
printf("%d \t %d \t",a,b); printf("%d \n%d \n",a,b);
输出: 1 0 0
1
28
转义字符表示法
29
转义字符举例
\ddd \xhhh \101 \141 \60 \x41 \x61 \x30 表示1到3个八进制数字对应ASCII字符 表示1到3个十六进制数字对应ASCII字符 表示 'A' 八进制101十进制的65 表示 'a' 表示 '0' 表示 'A' 十六进制41十进制的65 表示 'a' 表示 '0' 若:a ='\101' ,b ='\141',c=' \60'; 若:x ='\x41',y ='\x61',z='\x30';
例
x+y x%y 2*x-ya>b x=a+=3 x>y && a>b a=2,a+3,a++ --i
7
一、C语言的基本元素--5
5. 分隔符
用来分隔标识符间或标识符与 关键字间的符号 分隔符内容:空格字符、水平制表符、垂直制表符、 换行符、换页符及注释和逗号等,也称为空白字符。 分隔规则:在相邻的变量、关键字和常量、函数之 间需要用一个或多个空白字符(其效果是一样的) 将其分开 。 逗号也是分隔符,用于相邻同类项之间的分隔。例 如编程计算1+2案例中定义变量语句: int x=1, y=2, z;
6
一、C语言的基本元素--4