编译原理chapter2词法分析
编译原理-词法分析02-正则表达式

编译原理-词法分析02-正则表达式0.术语rr:正则表达式,表⽰字符串的格式。
L(r)r所匹配的串的集合。
symbol符号L(r)中的元素称为符号。
alphabet字母表表⽰符号的字符的集合。
⽤ ∑ (sigma)表⽰。
元字符metacharacter,元符号metasymbol它们⾮字母表中的字符,是⼀些特殊意义的字符,⽐如,*. 如果要匹配这类符号,则需要使⽤转义符号\。
escape character转义字符⼀般使⽤\表⽰,⽤于匹配元字符。
空串empty string不包含任何字符的串,但它仍然是⼀个匹配。
⽤ε(eplsilon)表⽰空集empty set表⽰正则表达式⽆任何匹配。
regular definition正则定义即正则表达式的名字。
1.正则表达式的定义正则表达式是以下中的⼀种:1. 基本正则表达式由单个字符a(其中a在正规字符的字母表 ∑ 中),以及元字符ε或元字符Φ。
分别表⽰为:L(a) = {a};L(ε) = {ε};L(Φ) = {}.2. r|s格式的表达式:其中r和s均是正则表达式。
在这种情况下:L(r|s) = L(r)|L(s)。
3. rs格式的表达式:其中r是正则表达式。
在这种情况下:L(rs) = L(r)L(s)。
4. r格式的表达式:其中r是正则表达式。
在这种情况下:L(r) = L(r)*。
5. (r)格式的表达式:其中r是正则表达式。
在这种情况下:L((r)) = L(r),因此,括号并不改变语⾔,它们只调整运算的优先级。
注意到这个定义中,|,*,(,),Φ,ε均为元字符。
2.扩展r+ 正闭包,⾄少匹配⼀个. 匹配任意⼀个字符区间匹配如[a-z],[0-9],[A-Za-z]~a或^a 排除匹配r? 可选匹配3.程序语⾔记号的正则表达式numbernat = [0-9]+ #⾃然数signedNat = (+|-)?nat #有符号数number = signedNat("."nat)?(E signedNat)? #数字,包含整数,⼩数,正负数,指数reserved & identifierreserverd = if | while | then | repeat | do ...letter = [a-z]digit = [0-9]identifier = letter(letter|digit)*comment{(~})*} #匹配{ this is a Pascal comment}whitespace解决匹配的⼆义性遵循最长⼦串原理principle of longest。
编译原理_第二章 词法分析(1)

词法分析
主要内容: 词法分析过程涉及的几个问题 模式的形式化描述-正规式与正规集 记号的识别-有限自动机 从正规式到词法分析器 词法分析器生成器简介
2019/2/16
编译原理
1
一、词法分析过程涉及的几个问题
词法分析是编译过程中的第一个阶段。 执行词法分析的程序称为词法分析程序,也称 为词法分析器或扫描器。 任务是:从左至右逐个字符地对源程序进行扫 描,产生一个个单词符号,把字符串形式的源 程序改造成为单词符号串形式的中间程序。 功能是输入源程序,输出单词符号,并检查词 法错误。
2019/2/16
编译原理
7
注意:一个程序语言的保留字、运算符和 界符的个数是确定的,而标识符或常数 的使用则不限定个数。 将产生和识别单词的规则称为模式 (patten)。 按照某个模式(规则)识别出的元素称为记 号(token)。 单词(lexeme)一词是指被识别出元素自 身的值。
编译原理 2
2019/2/16
1、词法分析器的三种工作方式:
词法分析器作为主程序; 词法分析器作为子程序; 并行工作方式
2019/2/16
编译原理
3
图2.1 作为子程序的词法分析器
图2.2 词法分析器进行单独一遍扫描
2019/2/16 4
编译原理
图2.3 并行工作模式
2019/2/16
2019/2/16
编译原理
10
(2) 单词自身的值。 单词自身的值是编译中其它阶段所需要的信息。 对于单词符号来说: 如果一个种别只含有一个单词符号,那么对于这个单词符号,其 种别编码就完全代表了它自身的值。 如果一个种别含有多个单词符号,那么对于它的每个单词符号, 除了给出种别编码之外还应给出单词符号自身的值,以便把同一 种类的单词区别开来。 注意:标识符自身的值就是标识符自身的字符串,而常数自身的 值是常数本身的二进制数值。此外,我们也可用指向某类表格中 一个特定项目的指针来区分同类中的不同单词。 例如,对于标识符,可以用它在符号表的入口指针作为它自身的 值;而常数也可用它在常数表的入口指针作为它自身的值。
编译原理中的词法分析与语法分析原理解析

编译原理中的词法分析与语法分析原理解析编译原理是计算机科学中的重要课程,它研究的是如何将源程序翻译成目标程序的过程。
而词法分析和语法分析则是编译过程中的两个重要阶段,它们负责将源程序转换成抽象语法树,为接下来的语义分析和代码生成阶段做准备。
本文将从词法分析和语法分析的原理、方法和实现技术角度进行详细解析,以期对读者有所帮助。
一、词法分析的原理1.词法分析的定义词法分析(Lexical Analysis)是编译过程中的第一个阶段,它负责将源程序中的字符流转换成标记流的过程。
源程序中的字符流是没有结构的,而编程语言是有一定结构的,因此需要通过词法分析将源程序中的字符流转换成有意义的标记流,以便之后的语法分析和语义分析的进行。
在词法分析的过程中,会将源程序中的字符划分成一系列的标记(Token),每个标记都包含了一定的语义信息,比如关键字、标识符、常量等等。
2.词法分析的原理词法分析的原理主要是通过有限状态自动机(Finite State Automaton,FSA)来实现的。
有限状态自动机是一个数学模型,它描述了一个自动机可以处于的所有可能的状态以及状态之间的转移关系。
在词法分析过程中,会将源程序中的字符逐个读取,并根据当前的状态和字符的输入来确定下一个状态。
最终,当字符读取完毕时,自动机会处于某一状态,这个状态就代表了当前的标记。
3.词法分析的实现技术词法分析的实现技术主要有两种,一种是手工实现,另一种是使用词法分析器生成工具。
手工实现词法分析器的过程通常需要编写一系列的正则表达式来描述不同类型的标记,并通过有限状态自动机来实现这些正则表达式的匹配过程。
这个过程需要大量的人力和时间,而且容易出错。
而使用词法分析器生成工具则可以自动生成词法分析器的代码,开发者只需要定义好源程序中的各种标记,然后通过这些工具自动生成对应的词法分析器。
常见的词法分析器生成工具有Lex和Flex等。
二、语法分析的原理1.语法分析的定义语法分析(Syntax Analysis)是编译过程中的第二个阶段,它负责将词法分析得到的标记流转换成抽象语法树的过程。
编译原理教程课后习题答案第二章
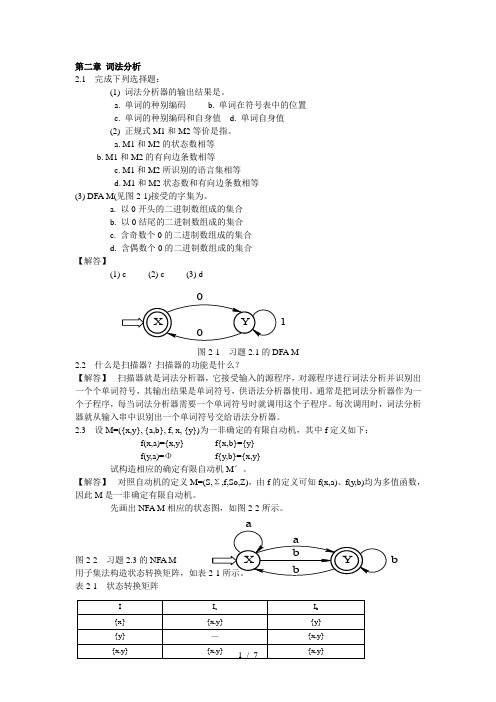
第二章 词法分析2.1 完成下列选择题:(1) 词法分析器的输出结果是。
a. 单词的种别编码b. 单词在符号表中的位置c. 单词的种别编码和自身值d. 单词自身值(2) 正规式M1和M2等价是指。
a. M1和M2的状态数相等b. M1和M2的有向边条数相等c. M1和M2所识别的语言集相等d. M1和M2状态数和有向边条数相等(3) DFA M(见图2-1)接受的字集为。
a. 以0开头的二进制数组成的集合b. 以0结尾的二进制数组成的集合c. 含奇数个0的二进制数组成的集合d. 含偶数个0的二进制数组成的集合【解答】(1) c (2) c (3) d图2-1 习题2.1的DFA M2.2 什么是扫描器?扫描器的功能是什么?【解答】 扫描器就是词法分析器,它接受输入的源程序,对源程序进行词法分析并识别出一个个单词符号,其输出结果是单词符号,供语法分析器使用。
通常是把词法分析器作为一个子程序,每当词法分析器需要一个单词符号时就调用这个子程序。
每次调用时,词法分析器就从输入串中识别出一个单词符号交给语法分析器。
2.3 设M=({x,y}, {a,b}, f, x, {y})为一非确定的有限自动机,其中f 定义如下:f(x,a)={x,y} f {x,b}={y}f(y,a)=Φ f{y,b}={x,y}试构造相应的确定有限自动机M ′。
【解答】 对照自动机的定义M=(S,Σ,f,So,Z),由f 的定义可知f(x,a)、f(y,b)均为多值函数,因此M 是一非确定有限自动机。
先画出NFA M 相应的状态图,如图2-2所示。
图2-2 习题2.3的NFA M 用子集法构造状态转换矩阵,如表表2-1 状态转换矩阵1b将转换矩阵中的所有子集重新命名,形成表2-2所示的状态转换矩阵,即得到 M ′=({0,1,2},{a,b},f,0,{1,2}),其状态转换图如图2-3所示。
表2-2 状态转换矩阵将图2-3所示的DFA M ′最小化。
编译原理与技术 词法分析 (2)
某终态。
识别相同正规集的DFA和NFA: DFA的规模(在状态 数和状态转换上)一般比相应的NFA复杂(可以达到 指数级)
2024/8/6
《编译原理与技术》讲义
16
比较 DFA 和 NFA(3)
e.g.11 识别正规式(0|1)*01的DFA和NFA
0
NFA :
S0
0
S1
1
S2
DFA :
1
1
0
S0
e.g.9 下面DFA M识别的语言L(M)是什么?
S
1
1
S0
S1
1
00 0
00
1
S2
1
S3
2024/8/6
《编译原理与技术》讲义
含偶数个0和偶数个1的0,1串}
1 S0
1 00
1
S2
1
S1 00
S3
S0 偶数个“0”与偶数个“1”的 0,1串
(S1,1)= {S2}
(S2,0)= {S2}
(S2,1)= {S2}
(S3,0)= {S4}
(S3,1)= ∅
(S4,0)= {S4}
(S4,1)= {S4}
2024/8/6
《编译原理与技术》讲义
6
有限自动机的表示
e.g.7 中NFA的状态转换图如下:
0,1
0,1
0
0
S0
S3
S4
1
S1 1
S2 0,1
18
正规式与有限自动机
✓ R= R1 | R2
(1)
Si
fi
R1对应的 NFA,Si为初 态,fi为终态
2024/8/6
Sj
编译原理-词法分析
则。描述词法规则的有效工具是正规式和有限 自动机。
2
3.1 对词法分析器的要求
3.1.1 词法分析器的功能和输出形式
输入源程序,扫描识别, 输出单词符号 程序语言的单词符号一般分为五种:
关 键 字 ( 保 留 字 或 基 本 字 ) : 如 begin,end,if,then,else,while,do等
正规式
正规集
1. ba*
Σ上所有以b为首后跟着
任意多个a的字。
2. a(a|b)*
Σ上所有以a为首的字。
3. (a|b)*(aa|bb)(a|b)* Σ上所有含有两
个相继的a或两个相继的b 的字。
28
正规式与正规集: 例3.2
例3.2: 令Σ={A,B,0,1} , 则:
正规式
正规集
1. (A|B)(A|B|0|1)* 体
字母或数字 0 字母 1 其他 2 *
16
状态转换图识别字符串: 例
识别标识符的状态转换图。其中0为初态,2 为终态。
状态2是终态,它意味着到此已经识别出一个 标识符。终态上打个*号,表示多读进了一个 不属于标识符部分的字符,应把它退还给输入 串。如果在状态0时输入字符不为“字母”, 则意味着这个转换图不工作。
24
正规式定义
正规表达式
正规表达式对应的正规集
1. ,
{},
2. a
{a}
3. 若 r, s
L( r ) , L(s)
则 选择 rs
L( r ) L(s)
连接 r ∙ s
L( r ) ∙ L(s)
闭包 r *
第2章 词法分析-编译原理及实践教程(第3版)-黄贤英-清华大学出版社

=> 0 >
1=
2
>
3=
4
其他
Hale Waihona Puke 其他6*5*
识别>、>=、>>、>>=四个单词的状态转换图
数值型常量的识别
0~9
1~9
=> 0
1
其他
* 2
0
十进制整型数
=> 0
0~7 0 3 其他 4 *
八进制整型数
=> 0 0
0~9
0~9 |a~f
|a~f |A~F
3 x/X 5 |A~F 6 其他 7 *
十六进制整型数
字母或数字
* 0 字母 1 其它 2
识别标识符的转换图
一个状态图可用于识别一定的字符串,大多数程序 设计语言的单词符号都可以用转换图来识别。
字母或数字
* 0 字母 1 其它 2
识别过程是:从初始状态0开始,若读入一个字母, 转入1状态,若再读入字母或数字,仍处于1状态, 否则转向2状态,结束一个标识符的识别过程。状 态上的*表示多读入一个符号。
错误处理程序
源 程 序
词
语
语
法
法
义
分
分
分
析单 析 语
器
词 记
器
法 单
析 器
语 法 单
中 间 代 码 生 成 器
中 间 代
代 码 优 化
器
中 间 代
目 标 代 码 生 成
器
目 标 代 码
号
位
位
码
码
表格管理程序
2.1 词法分析器概述
• 功能:
源程序
词法分析程序 Token串 语法分析程序
编译原理第二章词法分析
1
5
6
7
a
8
b
9
2.3 有 限 自 动 机
A = {0, 1, 2, 4, 7} B = {1, 2, 3, 4, 6, 7, 8} 状态 A
2.3 有 限 自 动 机
2.3.1 不确定的有限自动机(简称NFA)
• • • • •
一个数学模型,它包括: 状态集合S; 输入符号集合; 转换函数move : S ({}) P(S); 状态s0是开始状态; F S是接受状态集合。 a
识别语言 (a|b)*ab 的NFA 开始
子集构造法 • DFA的一个状态是NFA的一个状态集合 • 读了输入a1 a2 … an后, NFA能到达的所有状态:s1, s2, …, sk,则 DFA到达状态{s1, s2, …, sk} a 开始
0
b
a
1
b
2
2.3 有 限 自 动 机
2.3.3 NFA到DFA的变换
• DFA是NFA的特例,对于每个NFA M都存在一个DFA M’ ,使L(M)=L(M’)。 • 定义对状态集合I的两个运算:
2.3.2 确定的有限自动机(简称DFA) 一个数学模型,包括:
• 状态集合S; • 输入字母表; • 转换函数move : S S; • 唯一的初态 s S; b • 终态集合F S; 识别语言 (a|b)*ab 的DFA
开始 0 a
b b a
1
2
a
2.3 有 限 自 动 机
0
0
开始
1
1
2
3
4
2.3 有 限 自 动 机
• 例:识别 ={0,1}上能被能5整除的二进制数
《编译原理教程》第二章词法分析

通过优化正则表达式来减少DFA的状态数量和转 移边的数量,从而提高分析效率。例如,可以使 用贪婪匹配、非贪婪匹配、预读等技术来优化正 则表达式。
使用字符类和快速映射
将字符映射到相应的字符类,可以减少比较次数 和查表时间,提高分析效率。
并行处理和分布式处理
使用并行处理或分布式处理的方法来提高词法分 析器的处理能力和效率。例如,可以使用多线程 或多进程来处理多个输入字符串,或者使用分布 式系统来处理大规模的输入数据。
06
典型案例分析与实践
案例一:简单算术表达式词法分析
词法单元定义
定义算术表达式中的各类词法单元,如数字、 运算符等。
正则表达式描述
使用正则表达式描述各类词法单元的模式。
词法分析器实现
编写词法分析器,将输入的算术表达式拆分 为一个个的词法单元。
案例二:C语言子集词法分析
词法规则定义
定义C语言子集中的词法规则,包括关键字、标识符、 常量、运算符等。
词法分析的准确性对编译器的正确性和效率至关重要,因为任何错误或遗漏的词素都可 能导致编译失败或生成错误的代码。
本章学习目标和要求
掌握词法分析的基本概念和原理 ,了解词法分析器的作用和工作 流程。
了解词法分析中的常见问题和解 决方法,如处理空白、注释和特 殊字符等。
学习词法规则的定义和描述方法 ,能够编写简单的词法规则。
DFA与NFA之间转换关系
NFA转换为DFA
通过子集构造法可以将NFA转换为等价的DFA。该方法将NFA的状态集划分为不相交的 子集,每个子集代表DFA的一个状态。转换后的DFA具有与原始NFA相同的语言识别能
力。
DFA转换为NFA
任何DFA都可以直接看作是一个特殊的NFA,其中每个转移都是确定的,并且没有ε-转 移。因此,将DFA转换为NFA是简单的,只需保留原始DFA的结构即可。
编译原理第2章-词法分析(3)

College of Computer Science & Technology
• 例1:
2.3 有限自动机
a
0a 1b 2a 3 b
• 该自动机接受的语言是 • L = {aba, abaa, abab, abaab, abaaab, abaabb, ……} • 等价于正则表达式aba(a|b)*定义的语言
Compiler Construction Principles & Implementation Techniques
-11-
College of Computer Science & Technology
2.3 有限自动机
• 例3: 若DFA M只有一个状态,既是开始状态又是终止状态 ,则DFA M定义的串集是L() = {}
-16-
2.3 有限自动机
College of Computer Science & Technology
• 例9: 使用DFA定义程序设计语言的标识符
标识符构成特点: •由字母a~z, A~Z和数字0~9构成 •x, Xy, x123, xYz 接受 •23x, 12_x, _x 拒绝
letter
k
default : return false;
Compiler Construction Principles & Implementation Techniques
-19-
DFA的实现-基于转换图
College of Computer Science & Technology
• 对于每个终止状态,增加一个分支,如果当前字符是字符 串的结束符#,则接受;
Compiler Construction Principles & Implementation Techniques
贵州大学_编译原理课件第二章(编译原理完整版)

下一页 最后一页
退出
• 字母表是组成字符串的所有字符的集合。换句话说,字 符串中的所有字符取自字母表
• 定义中强调两个有限,因为计算机的表示能力有限 : <1> 字母表是有限的,即字母表中元素是有限多个;
<2> 字符串的长度是有限的,即字符串中字符个数是有限 多个。
• 由于字符串的有序性,使得以字符串作为元素的集合, 与一般意义下的集合有所不同,反映在集合运算上,强
➢ 实现方法:
最后一页 退出
– 作为单独的一遍:把字符流的源程序变为单词序列,输 出在一个中间文件上,这个文件作为语法分析程序的输
入而继续编译过程。
– 作为语法分析的子程序:当语法分析程序需要一个单词 时,调用该子程序;词法分析程序每得到一次调用,便
从源程序文件中读入一些字符,直到识别出一个单词或 直到下一单词的第一个字符为止。
便。运算符可采用一符一种的分法,但也可以把具
有一定共性的运算符视为一种。至于界符一般用一
符一种的分法
2.1.2 词法记号的属性
目 录 ➢ 如果一个记号只含一个单词符号,那么,对于这个
第一页 单词符号,记号就完全代表它自身了。若一个记号
上一页 下一页
含有多个单词符号,那么,对于它的每个单词符号, 除了给出记号之外,还应给出有关单词符号的属性 信息。
上一页
fi (a == f (x) ) …
下一页 ➢在实数是a.b格式下,可以发现下面紧急方式的错误恢复
➢错误修补
2.2 词法记号的描述与识别
目 录 ➢ 2.2.1 串和语言
第一页 上一页
– 从词法分析的角度看程序设计语言,它是由记号组成的 集合。
– 定义2.1 语言L是有限字母表∑上有限长度字符串的集合。
编译原理词法2(NFA、DFA的确定化和化简)

2.4 正规表达式到有限自动机的构造
例2.8 求正规表达式(a|b) *(aa|bb) (a|b) *对应的DFA M [解答] (3) 划分的最终结果为 {0} 、{1}、{2}、{3,4,5,6};
对其进行重命名:0、1、2、3 (4) 得到新的状态转换矩阵和化简后的DFA,如下所示:
S ab 0 12 1 32 2 13 3 33
f(s1, b) ={s2 } f(s2, a) = Ф
f(s2, b) ={ s1 }
状态转换图: b
s0 bb
a
s1 b
s2
状态转换矩阵:
∑
f
a
b
s0 {s2} {s0,s2} S s1 Ф {s2}
s2 Ф {s1}
2.3 正规表达式与优先自动机简介
2.3.2:有限自动机(识别的语言) – 对于一个自动机FA 而言,如果存在一条从初始状态到终止状 态的通路,通路上有向边所识别的字符依次连接所得到的字 符串为α, 则称α可以为FA 所接受或者α为FA 所识别 – FA 所能识别的字符串集为FA 所识别的语言,记为L(M) – FA的等价:对于任意两个FA M和 FA M’, 如果L(M)=L(M’), 则称M和M’等价 – 对于任意一个NFA M,一定存在一个DFA M’与其等价
2.3 正规表达式与优先自动机简介
2.3.2:有限自动机 – 1、确定有限自动机(DFA): • DFA是一个五元组,Md= (S, ∑, f, s0 , Z) ,其中: (1) S是一个有限状态集合,它的每个元素称为一个状态 (2) ∑是一个有穷字母表,它的每个元素称为一个输入字符 (3)f是一个从S×∑至S的单值映射,也叫状态转移函数 (4)s0∈S 是唯一的初态 (5) Z S 是一个终态集
编译原理 词法分析--2

b T5 a
3.2.5 从化简后的DFA到程序表示
化简后的DFA与程序流程图的关系 自动机可由程序代码表示 方法
实验1
将DFA以状态转换图的形式表现 将每个结点状态及其相应动作设计成一段程序,然后按 照DFA逻辑关系将各结点程序连结,即为‛ DFA的程序 表示‛ 关于状态结点的注意事项
a
1
ε
b
c
2
ε
3
NFA M 所能识别的符号串的全体记为L(M)
NFA与DFA的等价性 DFA是NFA的特例 对于任何两个有穷自动机 M和M‟,如果 L(M)=L(M‟),则称M与M‟是等价的 对于每个NFA M,存在一个与其等价的 DFA M‟
回顾
3.2.3 NFA到DFA的转换
从NFA构造DFA的算法—子集法
第三章 词法分析 (Lexical Analysis) 2
3.1 单词的描述工具
3.2 有穷自动机
3.3 正规式和有穷自动机的等价性
3.4 正规文法和有穷自动机间的转换
3.5 词法分析程序设计原理
3.6 词法分析程序的自动构造工具
回顾---确定的有穷自动机(DFA)
定义:一个DFA M是一个五元组: M=(K,Σ ,f,S,Z) K是一个有穷集,它的每个元素称为一个状态 Σ 是一个有穷字母表,它的每个元素称为一个输 入字符 f是一个从Kⅹ∑→K的单值映射。f(ki,a)=kj 意 味着当前状态为ki 、输入字符为a时,将转换到 下一状态kj S∈K,是唯一的初态 Z K,是一个终态集,终态也称为可接受状态 或结束状态。
B C D E F
编译原理第二章词法分析

目录
• 词法分析概述 • 词法分析器的设计 • 词法分析算法 • 词法分析器生成工具 • 词法分析器应用实例
01
词法分析概述
词法分析的定义
01
词法分析是编译过程中的第一个阶段,也称为词法扫描或词 法扫描器。
02
它负责将源代码从左到右逐个字符地读取,并识别出其中的 各个单词或标记。
03
词法分析器可以帮助数据挖掘系统识别出频繁出现的模式、 关键词和概念,从而为后续的数据分类、聚类和关联规则挖 掘等任务提供支持。
THANKS
感谢观看
词法分析器的实现方式
01 手工编写
通过手工编写代码实现词法分析器,适用于对编 译器原理理解较深且经验丰富的开发者。
02 工具辅助
使用工具如Lex、Flex等自动生成词法分析器的代 码,适用于快速开发简单的词法分析器。
03 编译器生成器
使用编译器生成器如Bison、ANTLR等,可以生 成高效、可维护的词法分析器。
词法分析算法的实现
01
词法分析算法的实现通常包括 将输入的源代码分解成一系列 的单词或标记,并输出相应的 单词或标记序列。
02
实现词法分析算法可以采用扫 描器或词法分析器生成器,如 Lex或Flex等工具。
03
扫描器或词法分析器生成器可 以根据正则表达式定义单词或 标记,并生成相应的代码来识 别和匹配这些单词或标记。
02 词法分析器通常使用词典和规则来识别单词的词 性(名词、动词、形容词等)和短语的结构。
02 通过词法分析,自然语言处理系统可以更好地理 解文本的含义,并为后续的句法分析和语义分析 提供基础。
词法分析器在数据挖掘中的应用
01
《编译原理》课件第2章

种别划分
标识符: 一般统归为一种 常 数: 可统归为一种,也可按整型、实型、布尔型等分
为几种 运算符: 采用一符一种 界 符: 采用一符一种
2.1 词法分析器设计方法
(2)单词自身的值 是编译中其它阶段所需要的信息
对于单词符号来说,如果一个种别只含有一个单词 符号,其种别编码就完全代表了它自身的值。如果一个 种别含有多个单词符号,那么对于它的每个单词符号, 除了给出种别编码之外还应给出单词符号自身的值。
2.1 词法分析器设计方法
对于不含回路的分支状态来说,可以让它对应一个 switch( ) 语句或一组if-else语句。
s=getchar( );
switch(s)
{ case 'a':
case 'b':
…
case 'z':
…;
//实现状态j功能的语句
case '0':
case '1':
…
case '9':
s=getchar ( );
getbe ( );
/*滤除空格*/
switch (s)
{
case 'a':
case 'b':
…
case 'z':
while (letter ( )‖digit ( ))
{
concatenation ( );
/*将当前读入的字符送入token数组*/
getchar ( );
大多数程序语言的单词符号都可以用状态转换图予以识 别。作为一个综合例子,我们来构造一个C语言子集的简单 词法分析器。
C语言子集的单词符号表示
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
正规式、记号名和属性
空白时词法分析器不返回记号给分析器
ws
__
__
while
while
__
do
do
__
id
id
符号表条目的指针
number
number
数表条目的指针
relop
relop
LT、LE、EQ、NE、GT或GE < < <> > >
9
letter
10
other
*
11 return(installId( ))
简略了
【例2.8】 number digit+ (.digit+)? (E (+ | )? digit+)?
E
digit
digit
digit digit
开始
12
digit
13
.
digit
14
15
E
+/ digit
16
17
约定: (1)闭包运算(算符*)有最高的优先级并且是左结合的运算, (2)连接运算(两个正规式并列)的优先级次之且也是左结合的运算, (3)选择运算(算符|)的优先级最低且仍然是左结合的运算。
【例2.3】 令字母表 = {a, b},那么
正规式
语言
•a|b
{a, b}
• (a | b) ( | b )
标识符 age
记号名 if for
relation id
number literal
词法记号、模式、词法单元
记号的例子
词法单元(单词)列举
模式的非形式描述
if for < , <= , = , … sum, count, D5
字符i, f 字符f, o, r < 或 <= 或 = 或 … 由字母开头的字母数字串
3.1, 10, 2.8 E12 “seg. error”
任何数值常数
引号“和”之间任意不含 引号本身的字符串
• 历史上词法定义中的一些问题
• 忽略空格带来的困难
Fortran
DO 8 I 3. 75 等同于 DO8I 3. 75
DO 8 I 3, 75
循环,8语句标号循环体结束
• 关键字不保留
正规定义的名字:黑体字
【例2.5】无符号数(整数和浮点数)集合,例1946 ,
11.28 , 63.6E8 , 1.999E-6,下面是这个串集合的正规定
义
整数部分 小数部分 指数部分
digit 0 | 1 | … | 9 digits digit digit*
optional_fraction .digits|
✓下面是定义字母表Σ上正规式的规则,和每条规则相联系的是被定义的正规式所表 示的语言描述。
(1)ε是正规式,它表示{ε}。 (2)如果a是Σ上的符号,那么a可以作为正规式,它表示语言{a}。 (3)假设r和s都是正规式,它们分别表示语言语言L(r)和语言L(s),那么( r )|( s )、( r )( s ) 、( r )*和( r )都是正规式,分别表示语言L(r) L(s) 、L(r) L(s)、(L(r))*和 L(r) 。
的记号和属性值:
id,指向符号表中position条目的指针 assign_op id,指向符号表中initial条目的指针 add_op id,指向符号表中rate条目的指针 mul_ op number,整数值60
2.1.3 词法错误
• 词法分析器对源程序采取非常局部的观点
• 例:难以发现下面的错误
IF THEN THEN THEN=ELSE;ELSE …
• 关键字、保留字和标准标识符的区别
• 保留字是语言预先确定了含义的词法单元
• 标准标识符也是预先确定了含义的标识符,但程序可以重新声明它的 含义
2.1.2 词法记号的属性
【例2.1】 语句 position = initial + rate 60
do do relop < | < = | = | < > | > | > = letter A | B | … | Z | a | b | … | z digit 0 | 1 | … | 9 id letter (letter | digit )* number digit+ (.digit+)? (E (+ | )? digit+)?
R 第2章 词法分析
• 词法分析器的任务是把构成源程序的字符流翻译成词法记号流。 • 构造词法分析器的一种简单办法是用状态转换图来描述元词法记号的
结构,然后手工把这种状态转换图翻译成为识别词法记号的程序。
本章内容
✓ 词法分析器:把构成源程序的字符流翻译成记号流,还可以完成 和用户接口的一些任务
✓ 围绕词法分析器的生成展开 ✓ 介绍正规式、状态转换图和有限自动机概念
r* = r+ | r+ = rr* • 零个或一个实例。一元后缀“?”的意思是“零个或一个实例”。
r? = r | • 字符组。[ abc ](其中a、b、c是字母表的符号)表示正规式
a | b | c。缩写字符组[ a-z ]表示正规式a | b | ... | z
letter_ A | B | … | Z | a | b | … | z | _ digit 0 | 1 | … | 9 id letter_(letter_ |digit)*
18
1946 11.28 63.6E8 1.999E-6
other
other
other
*
19
return( installNum( ) )
填入并返回数值的记号
无符号数的转换图
• 空白的转换图
delim blank | tab | newline ws delim+
delim
开始
delim
other
形式化描述
2.2.1 串和语言
✓字母表:符号的有限集合, 例: = { 0, 1}
✓串:符号的有穷序列,例:0,1,11,10010,0110,
串s的长度是出现在s中符号的个数,写做|s|
✓语言:字母表上的一个串集,例: {, 0, 00, 000, …}, {}, ,{1,10, 11, 100,101, …}
不便于计算机处理
语言的运算 并: 连接: 幂: 闭包: 正闭包:
L M = {s | s L 或 s M } LM = {st | s L 且 t M} L0是{},Li是Li-1L L = L0 L1 L2 … L+ = L1 L2 …
2.2.2 正规式
✓正规式(又称正规表达式、正则表达式)是按照一组定义规则,由较简单的正规 式构成的,每个正规式r表示一个语言L(r)。这些定义规则说明L(r)如何从r的子正 规式所表示的语言中构造出来。
2.1 词法记号及属性
• 词法分析是编译的第一阶段,它的主要任务是扫描输入字符流,产生 词法分析的词法记号序列。
源程序
子程序
词法分析器
记号(token) 取下一个记号
主程序
语法分析器
符号表
词法分析器和语法分析器的相互作用
2.1.1 词法记号、模式、词法单元
• 词法记号。词法记号(简称记号)是由记号名和属性值构成的二元组 ,属性值不是必须项。记号名是代表一类词法单元的抽象名字,例如
简化表示
letter_ [A - Z a - z _] digit 0 | 1 | … | 9 id letter_(letter_ |digit)*
[0-9]
2.2.4 状态转换图
进一步考虑如何构造词法分析器
【例2.6】某语言while语句中可能出现的部分记号描述。 while while ==
【例2.2】 L: { A, B, …, Z, a, b, …, z }, D: { 0, 1, …, 9 }
L D是字母和数字的集合 LD是所有由一个字母后跟随一个数字组成的串的集合 L6是所有由6个字母组成的串的集合 L*是所有字母串(包括)的集合 L(L D )*是以字母开头的所有字母数字串的集合 D+ 是不含空串的数字串的集合
{aa, ab, ba, bb}
• aa | ab | ba | bb • a* • (a | b)*
{aa, ab, ba, bb} 由字母a构成的所有串集,包括空串 由a和b构成的所有串集,包括空串
正规式的代数规律
r|s=s|r r | ( s | t )= ( r | s ) | t ( rs ) t = r ( st ) r ( s | t )= rs | rt ;( s | t )r = sr | tr
• 绘制状态转换图(简称转换图)是构造词法分析器的第一 步。状态转换图描绘词法分析器被语法分析器调用时,词 法分析器为下一个记号所做的动作。
关系算符的转换图
=
2 return(relop, LE)
1
>
3 return(relop, NE)
<
开始 0
=
other
4 * return(relop, LT)
起名字 正规式
d1 r1 d2 r2 ...
dn rn 的定义序列,各个di的名字都不同,每个ri都是 {d1, d2, …, di-1 } 上的正规式。
【例2.4】C语言的标识符是字母、数字和下划线组成的串, 下面是C语言的标识符的正规定义。
letter_ A | B | … | Z | a | b | … | z | _ digit 0 | 1 | … | 9 id letter_(letter_ |digit)*