我用Python实现了12500张猫狗图像的精准分类
深度学习实验项目一猫狗识别

深度学习实验项⽬⼀猫狗识别项⽬来⾃唐⽼师猫狗识别项⽬及数据集。
项⽬具体实施步骤:1.读取猫狗数据训练集500+500。
2.对读取的图⽚进⾏处理,处理成统⼀⼤⼩格式,分好标签。
3.shuffle⼀下,将猫狗数据掺杂混合,尽可能随机。
4.采⽤CNN⽹络训练测试。
具体代码如下:1.读取训练集。
import pandas as pdimport numpy as npimport osimport globimport matplotlib.pyplot as pltimport cv2 as cv2images = []labels = []img_names = []cls = []train_path="training_data"classes = ['dogs','cats']num_classes = len(classes)image_size=128print('Going to read training images')for fields in classes:index = classes.index(fields)print('Now going to read {} files (Index: {})'.format(fields, index))path = os.path.join(train_path, fields, '*g')files = glob.glob(path)print(len(files))for fl in files:image = cv2.imread(fl)image = cv2.resize(image, (image_size, image_size),0,0, cv2.INTER_LINEAR)image = image.astype(np.float32)image = np.multiply(image, 1.0 / 255.0)images.append(image)label = np.zeros(len(classes))label[index] = 1.0labels.append(label)flbase = os.path.basename(fl)img_names.append(flbase)cls.append(fields)images = np.array(images)labels = np.array(labels)img_names = np.array(img_names)cls = np.array(cls)2.训练数据集。
2022机器学习专项测试试题及答案

2022机器学习专项测试试题及答案1.机器学习的流程包括:分析案例、数据获取、________和模型验证这四个过程。
()A.数据清洗A、数据清洗B.数据分析C.模型训练(正确答案)D.模型搭建2.机器翻译属于下列哪个领域的应用?() *A.自然语言系统(正确答案)A. 自然语言系统(正确答案)B.机器学习C.专家系统D.人类感官模拟3.为了解决如何模拟人类的感性思维, 例如视觉理解、直觉思维、悟性等, 研究者找到一个重要的信息处理的机制是()。
*A.专家系统B.人工神经网络(正确答案)C.模式识别D.智能代理4.要想让机器具有智能, 必须让机器具有知识。
因此, 在人工智能中有一个研究领域, 主要研究计算机如何自动获取知识和技能, 实现自我完善, 这门研究分支学科叫()。
*A. 专家系统A.专家系统B. 机器学习(正确答案)C. 神经网络D. 模式识别5.如下属于机器学习应用的包括()。
*A.自动计算, 通过编程计算 456*457*458*459 的值(正确答案)A. 自动计算,通过编程计算 456*457*458*459 的值(正确答案)A.自动计算,通过编程计算 456*457*458*459 的值(正确答案)B.文字识别, 如通过 OCR 快速获得的图像中出汉字, 保存为文本C.语音输入, 通过话筒将讲话内容转成文本D.麦克风阵列, 如利用灵云该技术实现远场语音交互的电视6.对于神经网络模型, 当样本足够多时, 少量输入样本中带有较大的误差甚至个别错误对模型的输入-输出映射关系影响很小, 这属于()。
*A. 泛化能力A.泛化能力B. 容错能力(正确答案)C. 搜索能力D. 非线性映射能力7.下列选项不属于机器学习研究内容的是() *A. 学习机理A.学习机理B. 自动控制(正确答案)C. 学习方法D. 计算机存储系统8.机器学习的经典定义是: () *A.利用技术进步改善系统自身性能A. 利用技术进步改善系统自身性能B.利用技术进步改善人的能力C.利用经验改善系统自身的性能(正确答案)D.利用经验改善人的能力9.研究某超市销售记录数据后发现, 买啤酒的人很大概率也会购买尿布, 这种属于数据挖掘的那类问题()。
猫狗大战python代码

猫狗大战python代码
猫狗大战是一个经典的图像分类问题,需要将图片中的猫和狗进行区分。
在这篇文章中,我们将介绍如何用Python编写猫狗大战的代码。
首先,我们需要准备数据集。
可以从Kaggle官网上下载猫狗分类数据集,并将其解压缩到指定文件夹下。
我们使用Python中的PIL 库来读取图片,然后将图片转化为Numpy数组。
接下来,我们需要对数据进行预处理。
由于图片大小不一,我们需要将它们缩放到相同的大小。
我们可以使用OpenCV库来实现这个功能。
还需要对图片进行归一化处理,使得每个像素的值都在0到1之间。
接着,我们可以开始构建模型。
我们使用卷积神经网络(Convolutional Neural Network, CNN)来进行分类。
CNN是处理图像数据的一种常用神经网络。
我们使用Keras库来快速地构建CNN模型,其中包括了卷积层、池化层、全连接层等。
最后,我们将训练和测试数据分别输入CNN模型,并对其进行训练和评估。
训练时需要设置训练轮数和批次大小,同时使用交叉熵作为损失函数。
评估时可以使用准确率来评价模型的性能。
在完成上述步骤后,我们就可以得到一个基于CNN的猫狗分类模型,并且使用Python代码进行实现。
通过对模型进行不断的调整和优化,我们可以得到更加准确的分类结果。
- 1 -。
基于Resnet-50的猫狗图像识别

0 引言人工神经网络(Artificial Neural Networks,简称ANN)以神经元作为基本的运算单元,会对输入数据先进行线性变换z=wx+b,随后将变换后的数据进行非线性变换a=g(z),其中g()函数为非线性函数,也叫做激活函数(activation function)。
激活函数的选择有很多种,较常用的有ReLu和leaky ReLu。
激活函数的作用主要是对通过的信号进行筛选,选择让不让当前信号通过或者以多大通过,并且将数据变成非线性的。
对于线性变换中使用的权重,越大的权重表示对神经元而言数据带来越大的影响,当权重取负数时,表示神经元对输入数据产生抑制效果。
对权重的修改可以改变神经元的计算,对神经网络的训练就是通过反向传播算法来修改网络权重。
从本质上而言,ANN是对自然界中现存的一些算法的拟合。
卷积神经网络(Convolutional Neural Network)是ANN的一种典型结构,属于前馈神经网络,通常用来处理图片类型的数据。
卷积神经网络向前传播计算输出的过程就是前馈的过程,这个过程只进行前向传播计算输出,前一层的输出作为后一层的输入,一直到最后一层得到输出结果,在前向传播过程中并不对网络参数进行调整。
在神经网络的反向传播(Back Propagation)过程中,通过对损失函数的计算,将误差从最后一层向前传播,对每一层的参数进行修改,调整整个网络的权值参数。
从本质上来说,CNN能够将输入映射到输出,给定输入和损失函数,构建好网络结构之后,卷积神经网络能够自动进行权重的更新学习。
和ANN类似,CNN 也是多层结构,每个卷积层可以看作由很多个二维平面类型的卷积核构成,每个卷积核由多个神经元构成。
CNN中的每个卷积层通常设置n个卷积核,使得特征图可以共享权重,相对于全连接的神经网络大大减小了参数数目,加快了运算速度[3]。
典型的CNN结构由特征抽取器(filter)和池化层(pooling layer)构成。
基于卷积神经网络的宠物猫品种分类研究
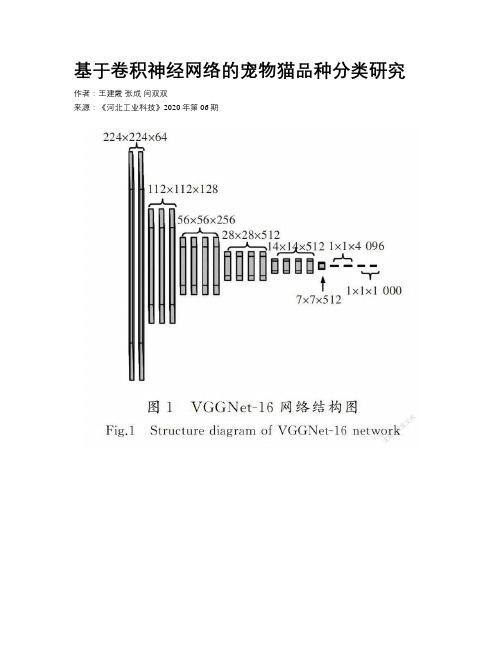
基于卷积神经网络的宠物猫品种分类研究作者:王建霞张成闫双双来源:《河北工业科技》2020年第06期摘要:为了提高宠物猫品种分类的准确率,提出了一种卷积神经网络融合的方法进行特征提取。
首先,基于堆叠卷积自动编码器的域自适应技术,采用反卷积操作丰富特征图;其次,利用Inception结构增加网络的宽度来提取多尺度信息的特征图;最后,使用Softmox函数对图像进行分类,在Oxford-ⅢT数据集中进行实验分析。
实验结果表明,利用改进后的模型对宠物猫进行分类,准确率高于对比模型,达到了84.56%,损失值为0.015 0。
所提出的卷积神经网络融合方法不仅能通过丰富特征图、加深网络深度更好地表达特征,还能提高分类性能和收敛性能,较好地解决了宠物品种识别中由宠物相似所带来的识别率低的问题,还可以推广应用到其他图像相似问题的应用场景中。
关键词:计算机图像处理;深度学习;卷积神经网络;反卷积;宠物猫分类中图分类号: TP319 文献标识码: Adoi: 10.7535/hbgykj.2020yx06004Research on pet cat breed classification based onconvolutional neural networkWANG Jianxia, ZHANG Cheng, YAN Shuangshuang(College of Information Science and Engineering, Hebei University of Science and Technology, Shijiazhuang, Hebei 050018, China)Abstract:In order to improve the accuracy of pet cat breed classification, a convolutional neural network fusion method was proposed for feature extraction. Firstly, based on the domain adaptive technology of the stacked convolutional autoencoder, the deconvolution operation was used to enrich the feature map; Secondly, the Inception structure was used to increase the width of the network to extract the feature map of multi-scale information; Finally, the images were classified by the Softmox function and were experimentally analyzed in the Oxford-ⅢT data set. The experimental results show that the accuracy of classifying pet cats by using the improved model is higher than that of the comparison model, reaching 84.56%, and the loss value is 0.015 0 . The proposed convolutional neural network fusion method can not only enrich feature maps and deepen the network depth to better express features, but also improve the classification performance and convergence performance. The method can better solve the problem of low recognition rate caused by pet similarity in pet breed recognition, and can also be extended to the application scenarios of other image similarity problems.Keywords:computer image processing; deep learning; convolutional neural network; deconvolution; pet cat classification宠物是人们为了消除孤寂或者出于娱乐而饲养的动物,有些工具型宠物还能够帮助人们。
基于卷积神经网络的宠物识别

Computer Science and Application 计算机科学与应用, 2019, 9(6), 1055-1060Published Online June 2019 in Hans. /journal/csahttps:///10.12677/csa.2019.96119Pet Recognition Based on ConvolutionalNeural NetworkWei Zhao, Xianchi Yu, Zekun Xu, Hua Guo, Tan LiNortheast Forestry University, Harbin HeilongjiangReceived: May 31st, 2019; accepted: Jun. 11th, 2019; published: Jun. 18th, 2019AbstractPets have become an integral part of people’s daily life. More and more people will raise pets. With the continuous improvement of people’s intelligence and the comprehensive development of smart home, pet management also puts forward higher requirements, so the research of pet rec-ognition technology has high practical significance. This paper presents a real-time pet recogni-tion technology based on neural network, which uses Opencv, Pycharm, Python and neural net-work to monitor and classify pet faces. The PET images collected in real time are processed and compared with the trained models, which overcomes the problems of low efficiency and low suc-cess rate of pet recognition in the past.KeywordsPet Identification, Neural Network, Smart Home基于卷积神经网络的宠物识别赵伟,于显驰,徐泽堃,郭 华,李 覃东北林业大学,黑龙江哈尔滨收稿日期:2019年5月31日;录用日期:2019年6月11日;发布日期:2019年6月18日摘要宠物在人们的生活当中,已经变成了人们日常生活不可分割的一部分,越来越多的人会去饲养宠物,伴随着人们智能化的不断提升,智能家居的全面发展,也对于宠物的管理提出了更高的要求,所以对于宠物识别技术的研究也有着很高的实际意义。
resnet18实现猫狗分类

resnet18实现猫狗分类先简单说⼀下整体流程,利⽤pytorch训练模型并转化为onnx格式,然后配置好dlinfer,利⽤cv22infer在cv22平台量化序列化模型,展开推理1训练模型1.1处理数据集参考图⽚下载地址:1.1.1⾸先继承写⼀个继承⾃dataset的类#继承了Dataset的类class DogCat(data.Dataset):def__init__(self, root, transform=None, train=True, test=False):'''root表⽰⽤于训练的图⽚地址,前70%⽤于训练,后30%⽤于测试'''self.test =testself.train =trainself.transform =transformimgs =[os.path.join(root, img) for img in os.listdir(root)] #imgs是⼀个list,list中放(编号,图⽚地址)if self.test:#如果是test集imgs =sorted(imgs, key=lambda x: int(x.split('.')[-2].split('/')[-1]))else: #如果是train集imgs =sorted(imgs, key=lambda x: int(x.split('.')[-2]))imgs_num =len(imgs)if self.test:self.imgs =imgselse:random.shuffle(imgs)if self.train:self.imgs =imgs[:int(0.7*imgs_num)]#self.imgs表⽰前百分之七⼗的图⽚else:self.imgs =imgs[int(0.7*imgs_num):]#self.imgs表⽰除了前百分之七⼗的图⽚# 作为迭代器必须有的⽅法,可以⽤[]符号读取数据def__getitem__(self, index):img_path =self.imgs[index]if self.test:label =int(self.imgs[index].split('.')[-2].split('/')[-1])else:label =1if'dog'in img_path.split('/')[-1] else0# 狗的label设为1,猫的设为0data =Image.open(img_path)data =self.transform(data)return data, labeldef__len__(self):return len(self.imgs)1.1.2把传⼊的图⽚集转换为Tensor并且改变格式# 对数据集训练集的处理transform_train = pose([transforms.Resize((256, 256)), # 先调整图⽚⼤⼩⾄256x256transforms.RandomCrop((224, 224)), # 再随机裁剪到224x224transforms.RandomHorizontalFlip(), # 随机的图像⽔平翻转,通俗讲就是图像的左右对调transforms.ToTensor(), #图⽚转换为Tensortransforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.2225)) # 归⼀化,数值是⽤ImageNet给出的数值])# 对数据集验证集的处理transform_val = pose([transform_val = pose([transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225)),])device = torch.device('cuda'if torch.cuda.is_available() else'cpu') # 若能使⽤cuda,则使⽤cudatrainset = DogCat('/mnt/ssd0/zhangwentao/train', transform=transform_train)#这是我图⽚的地址valset = DogCat('/mnt/ssd0/zhangwentao/train', transform=transform_val)#继承了dataset dataset ⼀捆有多⼤数据顺序多线程输⼊,=0表⽰单线程trainloader = torch.utils.data.DataLoader(trainset, batch_size=20, shuffle=True, num_workers=0)valloader = torch.utils.data.DataLoader(valset, batch_size=20, shuffle=False, num_workers=0)1.2修改⽹络模型class Net(nn.Module):'''pytorch的resnet18接⼝的最后⼀层fc层的输出维度是1000。
pycharm课程设计猫狗分类

pycharm课程设计猫狗分类一、课程目标知识目标:1. 让学生掌握Python编程基础,了解PyCharm集成开发环境的使用;2. 让学生掌握计算机视觉基础,了解图片分类的原理;3. 让学生掌握卷积神经网络(CNN)的基本结构及其在图像分类中的应用;4. 让学生掌握猫狗分类任务的实现方法,了解数据集的划分和使用。
技能目标:1. 培养学生运用Python编程解决问题的能力;2. 培养学生运用PyCharm进行项目开发的能力;3. 培养学生运用计算机视觉技术处理图像问题的能力;4. 培养学生运用CNN进行图像分类的能力。
情感态度价值观目标:1. 培养学生对人工智能技术的兴趣和热情,激发学生探索未知领域的欲望;2. 培养学生具备团队协作精神,学会与他人共同解决问题;3. 培养学生具备良好的编程习惯,注重代码的可读性和可维护性;4. 培养学生具备客观、严谨的科学态度,勇于面对挑战,克服困难。
本课程针对的学生特点为具备一定的Python编程基础,对人工智能和计算机视觉感兴趣。
课程性质为实践性较强的编程课程,教学要求学生在掌握理论知识的基础上,注重实践操作,将所学知识应用于实际项目中。
通过本课程的学习,学生将能够独立完成猫狗分类任务,提高编程和解决问题的能力。
二、教学内容1. Python编程基础回顾:变量、数据类型、条件语句、循环语句、函数等基本概念;2. PyCharm集成开发环境介绍:安装与配置、基本操作、调试技巧等;3. 计算机视觉基础:图像处理基础、特征提取、卷积运算等;4. 卷积神经网络(CNN)原理:网络结构、卷积层、池化层、全连接层等;5. 猫狗分类任务实现:- 数据集准备:收集猫狗图片,进行数据清洗、标注和划分;- 模型搭建:使用TensorFlow或Keras库搭建CNN模型;- 模型训练与优化:设置训练参数,进行模型训练,调整优化器、学习率等;- 模型评估与测试:评估模型性能,进行测试集预测,分析分类结果;6. 课程总结与拓展:总结猫狗分类任务的学习过程,探讨人工智能在现实生活中的应用。
python之tensorflow手把手实例讲解猫狗识别实现

python之tensorflow⼿把⼿实例讲解猫狗识别实现⽬录⼀,猫狗数据集数⽬构成⼆,数据导⼊三,数据集构建四,模型搭建五,模型训练六,模型测试作为tensorflow初学的⼤三学⽣,本次课程作业的使⽤猫狗数据集做⼀个⼆分类模型。
⼀,猫狗数据集数⽬构成train cats:1000 ,dogs:1000test cats: 500,dogs:500validation cats:500,dogs:500⼆,数据导⼊train_dir = 'Data/train'test_dir = 'Data/test'validation_dir = 'Data/validation'train_datagen = ImageDataGenerator(rescale=1/255,rotation_range=10,width_shift_range=0.2, #图⽚⽔平偏移的⾓度height_shift_range=0.2, #图⽚数值偏移的⾓度shear_range=0.2, #剪切强度zoom_range=0.2, #随机缩放的幅度horizontal_flip=True, #是否进⾏随机⽔平翻转# fill_mode='nearest')train_generator = train_datagen.flow_from_directory(train_dir,(224,224),batch_size=1,class_mode='binary',shuffle=False)test_datagen = ImageDataGenerator(rescale=1/255)test_generator = test_datagen.flow_from_directory(test_dir,(224,224),batch_size=1,class_mode='binary',shuffle=True)validation_datagen = ImageDataGenerator(rescale=1/255)validation_generator = validation_datagen.flow_from_directory(validation_dir,(224,224),batch_size=1,class_mode='binary')print(train_datagen)print(test_datagen)print(train_datagen)三,数据集构建我这⾥是将ImageDataGenerator类⾥的数据提取出来,将数据与标签分别存放在两个列表,后⾯在转为np.array,也可以使⽤model.fit_generator,我将数据放在内存为了后续调参数时模型训练能更快读取到数据,不⽤每次训练⼀整轮都去读⼀次数据(应该是这样的…我是这样理解…)注意我这⾥的数据集构建后,三种数据都是存放在内存中的,我电脑内存是16g的可以存放下。
猫狗分类CNN

猫狗分类CNN猫狗分类CNN实验环境编译器:win10+python3.7.4+pycharm2018库: anaconda+pytorch+tensorflow+tensorboardX硬件 gpu(可以没有)性能:accuracy:准确度⼤概稳定在0.6左右。
这是在⼆分类的情况下。
如果测试⾃⼰的图⽚,也就是存既不是猫也不是狗的概率的话,肯恶搞准确度会更低。
loss:约为0.02Ⅰ、解决⽅法⼀、数据集的预处理1.训练集1.1.1 初始化:提取路径和标签这个问题是kaggle竞赛的⼀个赛题。
所以数据集也是由官⽅提供的。
训练集内容如下图我们可以看到,它的命名规则是分类.序号.jpg所以我们就只要建⽴两个list,⼀个存路径,⼀个存标签self.list_img = []self.list_label = [] # 0:cat,1:dog然后打开训练集,循环遍历⾥⾯的图⽚dir = train_path + '/' #train_path为训练集⽂件夹for file in os.listdir(dir):self.list_img.append(dir + file)self.data_size += 1name = file.split(sep='.') #以'.'为界限,分割⽂件名# one-hotif name[0] == 'cat':self.list_label.append(0)else:self.list_label.append(1)采⽤one-hot编码,这样对后期计算损失函数⽐较友好。
1.1.2 处理图⽚思路:打开图⽚-->重新设置图⽚⼤⼩-->转换图⽚为tensor的形式-->返回tensor和标签img = Image.open(self.list_img[item]) #item为选中的图⽚序号img = img.resize((IMAGE_H, IMAGE_W)) #重新设置图⽚⼤⼩img = np.array(img)[:, :, :3]label = self.list_label[item]return self.transform(img), torch.LongTensor([label])其中transform函数的⽅法是transforms.ToTensor()2.测试集1.2.1初始化:这是⼤赛提供的测试集。
Python深度学习pytorch实现图像分类数据集

Python深度学习pytorch实现图像分类数据集⽬录读取数据集读取⼩批量整合所有组件⽬前⼴泛使⽤的图像分类数据集之⼀是MNIST数据集。
如今,MNIST数据集更像是⼀个健全的检查,⽽不是⼀个基准。
为了提⾼难度,我们将在接下来的章节中讨论在2017年发布的性质相似但相对复杂的Fashion-MNIST数据集。
import torchimport torchvisionfrom torch.utils import datafrom torchvision import transformsfrom d2l import torch as d2le_svg_display()读取数据集我们可以通过框架中的内置函数将Fashion-MNIST数据集下载并读取到内存中。
# 通过ToTensor实例将图像数据从PIL类型变换成32位浮点数格式# 并除以255使得所有像素的数值均在0到1之间trans = transforms.ToTensor()mnist_train = torchvision.datasets.FashionMNIST(root="../data", train=True, transform=trans, download=True)mnist_test = torchvisino.datasets.FashionMNIST(root="../data", train=False, transform=trans, download=True)Fashion-MNIST由10个类别的图像组成,每个类别由训练集中的6000张图像和测试集中的1000张图像组成。
测试数据集(test dataset)不会⽤于训练,只⽤于评估模型性能。
训练集和测试集分别包含60000和10000张图像。
len(mnist_train), len(mnist_test)(60000, 10000)每个输⼊图像的⾼度和宽度均为28像素。
图像分类综述

图像分类综述⼀、图像分类介绍 什么是图像分类,核⼼是从给定的分类集合中给图像分配⼀个标签的任务。
实际上,这意味着我们的任务是分析⼀个输⼊图像并返回⼀个将图像分类的标签。
标签来⾃预定义的可能类别集。
⽰例:我们假定⼀个可能的类别集categories = {dog, cat, eagle},之后我们提供⼀张图1给分类系统: 这⾥的⽬标是根据输⼊图像,从类别集中分配⼀个类别,这⾥为dog,我们的分类系统也可以根据概率给图像分配多个标签,如dog:95%,cat:4%,eagle:1%。
图像分类的任务就是给定⼀个图像,正确给出该图像所属的类别。
对于超级强⼤的⼈类视觉系统来说,判别出⼀个图像的类别是件很容易的事,但是对于计算机来说,并不能像⼈眼那样⼀下获得图像的语义信息。
计算机能看到的只是⼀个个像素的数值,对于⼀个RGB图像来说,假设图像的尺⼨是32*32,那么机器看到的就是⼀个形状为3*32*32的矩阵,或者更正式地称其为“张量”(“张量”简单来说就是⾼维的矩阵),那么机器的任务其实也就是寻找⼀个函数关系,这个函数关系能够将这些像素的数值映射到⼀个具体的类别(类别可以⽤某个数值表⽰)。
⼆、应⽤场景 图像分类更适⽤于图像中待分类的物体是单⼀的,如上图1中待分类物体是单⼀的,如果图像中包含多个⽬标物,如下图3,可以使⽤多标签分类或者⽬标检测算法。
三、传统图像分类算法 通常完整建⽴图像识别模型⼀般包括底层特征学习、特征编码、空间约束、分类器设计、模型融合等⼏个阶段,如图4所⽰。
1). 底层特征提取: 通常从图像中按照固定步长、尺度提取⼤量局部特征描述。
常⽤的局部特征包括SIFT(Scale-Invariant Feature Transform, 尺度不变特征转换) 、HOG(Histogram of Oriented Gradient, ⽅向梯度直⽅图) 、LBP(Local Bianray Pattern, 局部⼆值模式)等,⼀般也采⽤多种特征描述,防⽌丢失过多的有⽤信息。
Python中的分类问题解决方法和应用

Python中的分类问题解决方法和应用1. Python中的分类问题在机器学习中,分类问题是常见的问题之一。
分类问题指的是把一个事物或者一个概念划归到某一个事先确定好的类别中去。
如图像识别中,将图像划归到某一类别中,如猫、狗、树。
分类问题是机器学习中的一种监督学习,即数据集中已经标注好了类别,模型通过学习已有的数据,来准确地预测新的数据是属于哪个类别。
Python是一款高效、易用且开放的编程语言,广泛应用于数据科学和机器学习领域。
Python中有一些常见的分类问题解决方法,如逻辑回归、决策树、朴素贝叶斯、支持向量机等等。
这些解决方法都有各自的优劣势,并且适用于不同的分类问题。
2.解决方法及应用2.1逻辑回归逻辑回归是一种基于概率模型的分类方法,它主要用于解决二分类问题。
逻辑回归利用逻辑函数或Sigmoid函数,将数据映射到0-1之间的区间,即判定一个数据属于哪个类别的概率。
逻辑回归的优点是计算速度快,易于理解,缺点是只能解决二分类问题。
逻辑回归在Python中有许多的实现,比如使用sklearn包的逻辑回归分类器,或者使用tensorflow搭建神经网络来实现逻辑回归。
2.2决策树决策树是一种常用的非参数分类方法,它将数据集切分成小的数据集,每个小数据集可以采用相同的方法进行处理。
决策树分类器是一种树形结构分类器,它通过一系列的决策来实现分类。
决策树的优点是易于理解、计算代价低,缺点是容易过拟合,无法处理连续型变量。
在Python中,使用sklearn包的决策树分类器或其他的包如xgboost、lightGBM等来实现决策树分类器。
2.3朴素贝叶斯朴素贝叶斯(Naive Bayes)是一种基于贝叶斯定理的分类方法,它的基本思想是假设各个特征之间相互独立,计算每个特征在不同类别下的概率。
朴素贝叶斯的优点是计算简单、不需要进行复杂的数据预处理,缺点是对于复杂的分类问题考虑因素较少,精度可能会受到一定影响。
如何用Python实现12500张猫狗图像的精准分类?
如何用Python实现12500张猫狗图像的精准分类?本文经授权转载自“51CTO技术栈”作者:AhmedBesbes,张盛强翻译编辑:陶家龙、孙淑娟在这篇文章中,我们将展示如何建立一个深度神经网络,能做到以 90% 的精度来对图像进行分类,而在深度神经网络,特别是卷积神经网络兴起之前,这还是一个非常困难的问题。
深度学习是目前人工智能领域里最让人兴奋的话题之一了,它基于生物学领域的概念发展而来,现如今是一系列算法的集合。
事实已经证明深度学习在计算机视觉、自然语言处理、语音识别等很多的领域里都可以起到非常好的效果。
在过去的6 年里,深度学习已经应用到非常广泛的领域,很多最近的技术突破,都和深度学习相关。
这里仅举几个例子:特斯拉的自动驾驶汽车、Facebook 的照片标注系统、像 Siri 或 Cortana 这样的虚拟助手、聊天机器人、能进行物体识别的相机,这些技术突破都要归功于深度学习。
在这么多的领域里,深度学习在语言理解、图像分析这种认知任务上的表现已经达到了我们人类的水平。
如何构建一个在图像分类任务上能达到 90% 精度的深度神经网络?这个问题看似非常简单,但在深度神经网络特别是卷积神经网络(CNN)兴起之前,这是一个被计算机科学家们研究了很多年的棘手问题。
本文分为以下三个部分进行讲解:展示数据集和用例,并且解释这个图像分类任务的复杂度。
搭建一个深度学习专用环境,这个环境搭建在AWS 的基于GPU 的 EC2 服务上。
训练两个深度学习模型:第一个模型是使用 Keras 和 TensorFlow 从头开始端到端的流程,另一个模型使用是已经在大型数据集上预训练好的神经网络。
一个有趣的实例:给猫和狗的图像分类有很多的图像数据集是专门用来给深度学习模型进行基准测试的,我在这篇文章中用到的数据集来自 Cat vs Dogs Kaggle competition,这份数据集包含了大量狗和猫的带有标签的图片。
PYQT5+Pytorch的猫狗分类(从数据集制作-网络模型搭建和训练-界面演示)

PYQT5+Pytorch的猫狗分类(从数据集制作-⽹络模型搭建和训练-界⾯演⽰)1.猫狗数据集制作利⽤python爬⾍爬取⽹上的猫狗图⽚,有关python爬取图⽚参考了这篇⽂章https:///zhangjunp3/article/details/79665750有关python爬取图⽚代码如下1# 导⼊需要的库2import requests3import os4import json567# 爬取百度图⽚,解析页⾯的函数8def getManyPages(keyword, pages):9'''10参数keyword:要下载的影像关键词11参数pages:需要下载的页⾯数12'''13 params = []1415for i in range(30, 30 * pages + 30, 30):16 params.append({17'tn': 'resultjson_com',18'ipn': 'rj',19'ct': 201326592,20'is': '',21'fp': 'result',22'queryWord': keyword,23'cl': 2,24'lm': -1,25'ie': 'utf-8',26'oe': 'utf-8',27'adpicid': '',28'st': -1,29'z': '',30'ic': 0,31'word': keyword,32's': '',33'se': '',34'tab': '',35'width': '',36'height': '',37'face': 0,38'istype': 2,39'qc': '',40'nc': 1,41'fr': '',42'pn': i,43'rn': 30,44'gsm': '1e',45'1488942260214': ''46 })47 url = 'https:///search/acjson'48 urls = []49for i in params:50try:51 urls.append(requests.get(url, params=i).json().get('data'))52except json.decoder.JSONDecodeError:53print("解析出错")54return urls555657# 下载图⽚并保存58def getImg(dataList, localPath):59'''60参数datallist:下载图⽚的地址集61参数localPath:保存下载图⽚的路径62'''63if not os.path.exists(localPath): # 判断是否存在保存路径,如果不存在就创建64 os.mkdir(localPath)65 x = 066for list in dataList:67for i in list:68if i.get('thumbURL') != None:69print('正在下载:%s' % i.get('thumbURL'))70 ir = requests.get(i.get('thumbURL'))71 open(localPath + '%d.jpg' % x, 'wb').write(ir.content)72 x += 173else:74print('图⽚链接不存在')757677# 根据关键词⽪卡丘来下载图⽚78if__name__ == '__main__':79 dataList = getManyPages('狗', 40) # 参数1:关键字,参数2:要下载的页数80 getImg(dataList, './dataset/dog/') # 参数2:指定保存的路径在这⾥与原⽂章不同之处是加了这段代码。
Python机器学习之基于Pytorch实现猫狗分类

Python机器学习之基于Pytorch实现猫狗分类⽬录⼀、环境配置⼆、数据集的准备三、猫狗分类的实例四、实现分类预测测试五、参考资料⼀、环境配置安装Anaconda具体安装过程,请配置Pytorchpip install -i https:///simple torchpip install -i https:///simple torchvision⼆、数据集的准备1.数据集的下载2.数据集的分类将下载的数据集进⾏解压操作,然后进⾏分类分类如下(每个⽂件夹下包括cats和dogs⽂件夹)三、猫狗分类的实例导⼊相应的库# 导⼊库import torch.nn.functional as Fimport torch.optim as optimimport torchimport torch.nn as nnimport torch.nn.parallelimport torch.optimimport torch.utils.dataimport torch.utils.data.distributedimport torchvision.transforms as transformsimport torchvision.datasets as datasets设置超参数# 设置超参数#每次的个数BATCH_SIZE = 20#迭代次数EPOCHS = 10#采⽤cpu还是gpu进⾏计算DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu')图像处理与图像增强# 数据预处理transform = pose([transforms.Resize(100),transforms.RandomVerticalFlip(),transforms.RandomCrop(50),transforms.RandomResizedCrop(150),transforms.ColorJitter(brightness=0.5, contrast=0.5, hue=0.5),transforms.ToTensor(),transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])])读取数据集和导⼊数据# 读取数据dataset_train = datasets.ImageFolder('E:\\Cat_And_Dog\\kaggle\\cats_and_dogs_small\\train', transform) print(dataset_train.imgs)# 对应⽂件夹的labelprint(dataset_train.class_to_idx)dataset_test = datasets.ImageFolder('E:\\Cat_And_Dog\\kaggle\\cats_and_dogs_small\\validation', transform) # 对应⽂件夹的labelprint(dataset_test.class_to_idx)# 导⼊数据train_loader = torch.utils.data.DataLoader(dataset_train, batch_size=BATCH_SIZE, shuffle=True)test_loader = torch.utils.data.DataLoader(dataset_test, batch_size=BATCH_SIZE, shuffle=True)定义⽹络模型# 定义⽹络class ConvNet(nn.Module):def __init__(self):super(ConvNet, self).__init__()self.conv1 = nn.Conv2d(3, 32, 3)self.max_pool1 = nn.MaxPool2d(2)self.conv2 = nn.Conv2d(32, 64, 3)self.max_pool2 = nn.MaxPool2d(2)self.conv3 = nn.Conv2d(64, 64, 3)self.conv4 = nn.Conv2d(64, 64, 3)self.max_pool3 = nn.MaxPool2d(2)self.conv5 = nn.Conv2d(64, 128, 3)self.conv6 = nn.Conv2d(128, 128, 3)self.max_pool4 = nn.MaxPool2d(2)self.fc1 = nn.Linear(4608, 512)self.fc2 = nn.Linear(512, 1)def forward(self, x):in_size = x.size(0)x = self.conv1(x)x = F.relu(x)x = self.max_pool1(x)x = self.conv2(x)x = F.relu(x)x = self.max_pool2(x)x = self.conv3(x)x = F.relu(x)x = self.conv4(x)x = F.relu(x)x = self.max_pool3(x)x = self.conv5(x)x = F.relu(x)x = self.conv6(x)x = F.relu(x)x = self.max_pool4(x)# 展开x = x.view(in_size, -1)x = self.fc1(x)x = F.relu(x)x = self.fc2(x)x = torch.sigmoid(x)return xmodellr = 1e-4# 实例化模型并且移动到GPUmodel = ConvNet().to(DEVICE)# 选择简单暴⼒的Adam优化器,学习率调低optimizer = optim.Adam(model.parameters(), lr=modellr)调整学习率def adjust_learning_rate(optimizer, epoch):"""Sets the learning rate to the initial LR decayed by 10 every 30 epochs"""modellrnew = modellr * (0.1 ** (epoch // 5))print("lr:",modellrnew)for param_group in optimizer.param_groups:param_group['lr'] = modellrnew定义训练过程# 定义训练过程def train(model, device, train_loader, optimizer, epoch):model.train()for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device).float().unsqueeze(1)optimizer.zero_grad()output = model(data)# print(output)loss = F.binary_cross_entropy(output, target)loss.backward()optimizer.step()if (batch_idx + 1) % 10 == 0:print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(epoch, (batch_idx + 1) * len(data), len(train_loader.dataset),100. * (batch_idx + 1) / len(train_loader), loss.item()))# 定义测试过程def val(model, device, test_loader):model.eval()test_loss = 0correct = 0with torch.no_grad():for data, target in test_loader:data, target = data.to(device), target.to(device).float().unsqueeze(1)output = model(data)# print(output)test_loss += F.binary_cross_entropy(output, target, reduction='mean').item() pred = torch.tensor([[1] if num[0] >= 0.5 else [0] for num in output]).to(device) correct += pred.eq(target.long()).sum().item()print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(test_loss, correct, len(test_loader.dataset),100. * correct / len(test_loader.dataset)))定义保存模型和训练# 训练for epoch in range(1, EPOCHS + 1):adjust_learning_rate(optimizer, epoch)train(model, DEVICE, train_loader, optimizer, epoch)val(model, DEVICE, test_loader)torch.save(model, 'E:\\Cat_And_Dog\\kaggle\\model.pth')训练结果四、实现分类预测测试准备预测的图⽚进⾏测试from __future__ import print_function, division from PIL import Imagefrom torchvision import transformsimport torch.nn.functional as Fimport torchimport torch.nn as nnimport torch.nn.parallel# 定义⽹络class ConvNet(nn.Module):def __init__(self):super(ConvNet, self).__init__()self.conv1 = nn.Conv2d(3, 32, 3)self.max_pool1 = nn.MaxPool2d(2)self.conv2 = nn.Conv2d(32, 64, 3)self.max_pool2 = nn.MaxPool2d(2)self.conv3 = nn.Conv2d(64, 64, 3)self.conv4 = nn.Conv2d(64, 64, 3)self.max_pool3 = nn.MaxPool2d(2)self.conv5 = nn.Conv2d(64, 128, 3)self.conv6 = nn.Conv2d(128, 128, 3)self.max_pool4 = nn.MaxPool2d(2)self.fc1 = nn.Linear(4608, 512)self.fc2 = nn.Linear(512, 1)def forward(self, x):in_size = x.size(0)x = self.conv1(x)x = F.relu(x)x = self.max_pool1(x)x = self.conv2(x)x = F.relu(x)x = self.max_pool2(x)x = self.conv3(x)x = F.relu(x)x = self.conv4(x)x = F.relu(x)x = self.max_pool3(x)x = self.conv5(x)x = self.conv6(x)x = F.relu(x)x = self.max_pool4(x)# 展开x = x.view(in_size, -1)x = self.fc1(x)x = F.relu(x)x = self.fc2(x)x = torch.sigmoid(x)return x# 模型存储路径model_save_path = 'E:\\Cat_And_Dog\\kaggle\\model.pth'# ------------------------ 加载数据 --------------------------- ## Data augmentation and normalization for training# Just normalization for validation# 定义预训练变换# 数据预处理transform_test = pose([transforms.Resize(100),transforms.RandomVerticalFlip(),transforms.RandomCrop(50),transforms.RandomResizedCrop(150),transforms.ColorJitter(brightness=0.5, contrast=0.5, hue=0.5),transforms.ToTensor(),transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])])class_names = ['cat', 'dog'] # 这个顺序很重要,要和训练时候的类名顺序⼀致device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")# ------------------------ 载⼊模型并且训练 --------------------------- #model = torch.load(model_save_path)model.eval()# print(model)image_PIL = Image.open('E:\\Cat_And_Dog\\kaggle\\cats_and_dogs_small\\test\\cats\\cat.1500.jpg')#image_tensor = transform_test(image_PIL)# 以下语句等效于 image_tensor = torch.unsqueeze(image_tensor, 0)image_tensor.unsqueeze_(0)# 没有这句话会报错image_tensor = image_tensor.to(device)out = model(image_tensor)pred = torch.tensor([[1] if num[0] >= 0.5 else [0] for num in out]).to(device)print(class_names[pred])预测结果实际训练的过程来看,整体看准确度不⾼。
Python通过TensorFlow卷积神经网络实现猫狗识别

Python通过TensorFlow卷积神经⽹络实现猫狗识别这份数据集来源于Kaggle,数据集有12500只猫和12500只狗。
在这⾥简单介绍下整体思路1. 处理数据2. 设计神经⽹络3. 进⾏训练测试1. 数据处理将图⽚数据处理为 tf 能够识别的数据格式,并将数据设计批次。
第⼀步get_files() ⽅法读取图⽚,然后根据图⽚名,添加猫狗 label,然后再将 image和label 放到数组中,打乱顺序返回将第⼀步处理好的图⽚和label 数组转化为 tensorflow 能够识别的格式,然后将图⽚裁剪和补充进⾏标准化处理,分批次返回。
新建数据处理⽂件,⽂件名input_data.pyimport tensorflow as tfimport osimport numpy as npdef get_files(file_dir):cats = []label_cats = []dogs = []label_dogs = []for file in os.listdir(file_dir):name = file.split(sep='.')if 'cat' in name[0]:cats.append(file_dir + file)label_cats.append(0)else:if 'dog' in name[0]:dogs.append(file_dir + file)label_dogs.append(1)image_list = np.hstack((cats,dogs))label_list = np.hstack((label_cats,label_dogs))# print('There are %d cats\nThere are %d dogs' %(len(cats), len(dogs)))# 多个种类分别的时候需要把多个种类放在⼀起,打乱顺序,这⾥不需要# 把标签和图⽚都放倒⼀个 temp 中然后打乱顺序,然后取出来temp = np.array([image_list,label_list])temp = temp.transpose()# 打乱顺序np.random.shuffle(temp)# 取出第⼀个元素作为 image 第⼆个元素作为 labelimage_list = list(temp[:,0])label_list = list(temp[:,1])label_list = [int(i) for i in label_list]return image_list,label_list# 测试 get_files# imgs , label = get_files('/Users/yangyibo/GitWork/pythonLean/AI/猫狗识别/testImg/')# for i in imgs:# print("img:",i)# for i in label:# print('label:',i)# 测试 get_files end# image_W ,image_H 指定图⽚⼤⼩,batch_size 每批读取的个数,capacity队列中最多容纳元素的个数def get_batch(image,label,image_W,image_H,batch_size,capacity):# 转换数据为 ts 能识别的格式image = tf.cast(image,tf.string)label = tf.cast(label, tf.int32)# 将image 和 label 放倒队列⾥input_queue = tf.train.slice_input_producer([image,label])label = input_queue[1]# 读取图⽚的全部信息image_contents = tf.read_file(input_queue[0])# 把图⽚解码,channels =3 为彩⾊图⽚, r,g ,b ⿊⽩图⽚为 1 ,也可以理解为图⽚的厚度image = tf.image.decode_jpeg(image_contents,channels =3)# 将图⽚以图⽚中⼼进⾏裁剪或者扩充为指定的image_W,image_Himage = tf.image.resize_image_with_crop_or_pad(image, image_W, image_H)# 对数据进⾏标准化,标准化,就是减去它的均值,除以他的⽅差image = tf.image.per_image_standardization(image)# ⽣成批次 num_threads 有多少个线程根据电脑配置设置 capacity 队列中最多容纳图⽚的个数 tf.train.shuffle_batch 打乱顺序,image_batch, label_batch = tf.train.batch([image, label],batch_size = batch_size, num_threads = 64, capacity = capacity) # 重新定义下 label_batch 的形状label_batch = tf.reshape(label_batch , [batch_size])# 转化图⽚image_batch = tf.cast(image_batch,tf.float32)return image_batch, label_batch# test get_batch# import matplotlib.pyplot as plt# BATCH_SIZE = 2# CAPACITY = 256# IMG_W = 208# IMG_H = 208# train_dir = '/Users/yangyibo/GitWork/pythonLean/AI/猫狗识别/testImg/'# image_list, label_list = get_files(train_dir)# image_batch, label_batch = get_batch(image_list, label_list, IMG_W, IMG_H, BATCH_SIZE, CAPACITY)# with tf.Session() as sess:# i = 0# # Coordinator 和 start_queue_runners 监控 queue 的状态,不停的⼊队出队# coord = tf.train.Coordinator()# threads = tf.train.start_queue_runners(coord=coord)# # coord.should_stop() 返回 true 时也就是数据读完了应该调⽤ coord.request_stop()# try:# while not coord.should_stop() and i<1:# # 测试⼀个步# img, label = sess.run([image_batch, label_batch])# for j in np.arange(BATCH_SIZE):# print('label: %d' %label[j])# # 因为是个4D 的数据所以第⼀个为索引其他的为冒号就⾏了# plt.imshow(img[j,:,:,:])# plt.show()# i+=1# # 队列中没有数据# except tf.errors.OutOfRangeError:# print('done!')# finally:# coord.request_stop()# coord.join(threads)# sess.close()2. 设计神经⽹络利⽤卷积神经⽹路处理,⽹络结构为# conv1 卷积层 1# pooling1_lrn 池化层 1# conv2 卷积层 2# pooling2_lrn 池化层 2# local3 全连接层 1# local4 全连接层 2# softmax 全连接层 3新建神经⽹络⽂件,⽂件名model.py#coding=utf-8import tensorflow as tfdef inference(images, batch_size, n_classes):with tf.variable_scope('conv1') as scope:# 卷积盒的为 3*3 的卷积盒,图⽚厚度是3,输出是16个featuremapweights = tf.get_variable('weights',shape=[3, 3, 3, 16],dtype=tf.float32,initializer=tf.truncated_normal_initializer(stddev=0.1, dtype=tf.float32))biases = tf.get_variable('biases',shape=[16],dtype=tf.float32,initializer=tf.constant_initializer(0.1))conv = tf.nn.conv2d(images, weights, strides=[1, 1, 1, 1], padding='SAME')pre_activation = tf.nn.bias_add(conv, biases)conv1 = tf.nn.relu(pre_activation, name=)with tf.variable_scope('pooling1_lrn') as scope:pool1 = tf.nn.max_pool(conv1, ksize=[1, 3, 3, 1], strides=[1, 2, 2, 1], padding='SAME', name='pooling1')norm1 = tf.nn.lrn(pool1, depth_radius=4, bias=1.0, alpha=0.001 / 9.0, beta=0.75, name='norm1')with tf.variable_scope('conv2') as scope:weights = tf.get_variable('weights',shape=[3, 3, 16, 16],dtype=tf.float32,initializer=tf.truncated_normal_initializer(stddev=0.1, dtype=tf.float32))biases = tf.get_variable('biases',shape=[16],dtype=tf.float32,initializer=tf.constant_initializer(0.1))conv = tf.nn.conv2d(norm1, weights, strides=[1, 1, 1, 1], padding='SAME')pre_activation = tf.nn.bias_add(conv, biases)conv2 = tf.nn.relu(pre_activation, name='conv2')# pool2 and norm2with tf.variable_scope('pooling2_lrn') as scope:norm2 = tf.nn.lrn(conv2, depth_radius=4, bias=1.0, alpha=0.001 / 9.0, beta=0.75, name='norm2')pool2 = tf.nn.max_pool(norm2, ksize=[1, 3, 3, 1], strides=[1, 1, 1, 1], padding='SAME', name='pooling2') with tf.variable_scope('local3') as scope:reshape = tf.reshape(pool2, shape=[batch_size, -1])dim = reshape.get_shape()[1].valueweights = tf.get_variable('weights',shape=[dim, 128],dtype=tf.float32,initializer=tf.truncated_normal_initializer(stddev=0.005, dtype=tf.float32))biases = tf.get_variable('biases',shape=[128],dtype=tf.float32,initializer=tf.constant_initializer(0.1))local3 = tf.nn.relu(tf.matmul(reshape, weights) + biases, name=)# local4with tf.variable_scope('local4') as scope:weights = tf.get_variable('weights',shape=[128, 128],dtype=tf.float32,initializer=tf.truncated_normal_initializer(stddev=0.005, dtype=tf.float32))biases = tf.get_variable('biases',shape=[128],dtype=tf.float32,initializer=tf.constant_initializer(0.1))local4 = tf.nn.relu(tf.matmul(local3, weights) + biases, name='local4')# softmaxwith tf.variable_scope('softmax_linear') as scope:weights = tf.get_variable('softmax_linear',shape=[128, n_classes],dtype=tf.float32,initializer=tf.truncated_normal_initializer(stddev=0.005, dtype=tf.float32))biases = tf.get_variable('biases',shape=[n_classes],dtype=tf.float32,initializer=tf.constant_initializer(0.1))softmax_linear = tf.add(tf.matmul(local4, weights), biases, name='softmax_linear')return softmax_lineardef losses(logits, labels):with tf.variable_scope('loss') as scope:cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits \(logits=logits, labels=labels, name='xentropy_per_example')loss = tf.reduce_mean(cross_entropy, name='loss')tf.summary.scalar( + '/loss', loss)return lossdef trainning(loss, learning_rate):with _scope('optimizer'):optimizer = tf.train.AdamOptimizer(learning_rate= learning_rate)global_step = tf.Variable(0, name='global_step', trainable=False)train_op = optimizer.minimize(loss, global_step= global_step)return train_opdef evaluation(logits, labels):with tf.variable_scope('accuracy') as scope:correct = tf.nn.in_top_k(logits, labels, 1)correct = tf.cast(correct, tf.float16)accuracy = tf.reduce_mean(correct)tf.summary.scalar( + '/accuracy', accuracy)return accuracy3. 训练数据,并将训练的模型存储import osimport numpy as npimport tensorflow as tfimport input_dataimport modelN_CLASSES = 2 # 2个输出神经元,[1,0]或者[0,1]猫和狗的概率IMG_W = 208 # 重新定义图⽚的⼤⼩,图⽚如果过⼤则训练⽐较慢IMG_H = 208BATCH_SIZE = 32 #每批数据的⼤⼩CAPACITY = 256MAX_STEP = 15000 # 训练的步数,应当 >= 10000learning_rate = 0.0001 # 学习率,建议刚开始的 learning_rate <= 0.0001def run_training():# 数据集train_dir = '/Users/yangyibo/GitWork/pythonLean/AI/猫狗识别/img/' #My dir--20170727-csq#logs_train_dir 存放训练模型的过程的数据,在tensorboard 中查看logs_train_dir = '/Users/yangyibo/GitWork/pythonLean/AI/猫狗识别/saveNet/'# 获取图⽚和标签集train, train_label = input_data.get_files(train_dir)# ⽣成批次train_batch, train_label_batch = input_data.get_batch(train,train_label,IMG_W,IMG_H,BATCH_SIZE,CAPACITY)# 进⼊模型train_logits = model.inference(train_batch, BATCH_SIZE, N_CLASSES)# 获取 losstrain_loss = model.losses(train_logits, train_label_batch)# 训练train_op = model.trainning(train_loss, learning_rate)# 获取准确率train__acc = model.evaluation(train_logits, train_label_batch)# 合并 summarysummary_op = tf.summary.merge_all()sess = tf.Session()# 保存summarytrain_writer = tf.summary.FileWriter(logs_train_dir, sess.graph)saver = tf.train.Saver()sess.run(tf.global_variables_initializer())coord = tf.train.Coordinator()threads = tf.train.start_queue_runners(sess=sess, coord=coord)try:for step in np.arange(MAX_STEP):if coord.should_stop():break_, tra_loss, tra_acc = sess.run([train_op, train_loss, train__acc])if step % 50 == 0:print('Step %d, train loss = %.2f, train accuracy = %.2f%%' %(step, tra_loss, tra_acc*100.0))summary_str = sess.run(summary_op)train_writer.add_summary(summary_str, step)if step % 2000 == 0 or (step + 1) == MAX_STEP:# 每隔2000步保存⼀下模型,模型保存在 checkpoint_path 中checkpoint_path = os.path.join(logs_train_dir, 'model.ckpt')saver.save(sess, checkpoint_path, global_step=step)except tf.errors.OutOfRangeError:print('Done training -- epoch limit reached')finally:coord.request_stop()coord.join(threads)sess.close()# trainrun_training()关于保存的模型怎么使⽤将在下⼀篇⽂章中展⽰。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
我用Python实现了12500张猫狗图像的精准分类在这篇文章中,我们将展示如何建立一个深度神经网络,能做到以90% 的精度来对图像进行分类,而在深度神经网络,特别是卷积神经网络兴起之前,这还是一个非常困难的问题。
深度学习是目前人工智能领域里最让人兴奋的话题之一了,它基于生物学领域的概念发展而来,现如今是一系列算法的集合。
事实已经证明深度学习在计算机视觉、自然语言处理、语音识别等很多的领域里都可以起到非常好的效果。
在过去的 6 年里,深度学习已经应用到非常广泛的领域,很多最近的技术突破,都和深度学习相关。
这里仅举几个例子:特斯拉的自动驾驶汽车、Facebook 的照片标注系统、像Siri 或Cortana 这样的虚拟助手、聊天机器人、能进行物体识别的相机,这些技术突破都要归功于深度学习。
在这么多的领域里,深度学习在语言理解、图像分析这种认知任务上的表现已经达到了我们人类的水平。
如何构建一个在图像分类任务上能达到90% 精度的深度神经网络?这个问题看似非常简单,但在深度神经网络特别是卷积神经网络(CNN)兴起之前,这是一个被计算机科学家们研究了很多年的棘手问题。
本文分为以下三个部分进行讲解:展示数据集和用例,并且解释这个图像分类任务的复杂度。
搭建一个深度学习专用环境,这个环境搭建在AWS 的基于GPU 的EC2 服务上。
训练两个深度学习模型:第一个模型是使用Keras 和TensorFlow 从头开始端到端的流程,另一个模型使用是已经在大型数据集上预训练好的神经网络。
一个有趣的实例:给猫和狗的图像分类有很多的图像数据集是专门用来给深度学习模型进行基准测试的,我在这篇文章中用到的数据集来自Cat vs Dogs Kaggle competition,这份数据集包含了大量狗和猫的带有标签的图片。
和每一个Kaggle 比赛一样,这份数据集也包含两个文件夹:训练文件夹:它包含了25000 张猫和狗的图片,每张图片都含有标签,这个标签是作为文件名的一部分。
我们将用这个文件夹来训练和评估我们的模型。
测试文件夹:它包含了12500 张图片,每张图片都以数字来命名。
对于这份数据集中的每幅图片来说,我们的模型都要预测这张图片上是狗还是猫(1= 狗,0= 猫)。
事实上,这些数据也被Kaggle 用来对模型进行打分,然后在排行榜上排名。
我们观察一下这些图片的特点,这些图片各种各样,分辨率也各不相同。
图片中的猫和狗形状、所处位置、体表颜色各不一样。
它们的姿态不同,有的在坐着而有的则不是,它们的情绪可能是开心的也可能是伤心的,猫可能在睡觉,而狗可能在汪汪地叫着。
照片可能以任一焦距从任意角度拍下。
这些图片有着无限种可能,对于我们人类来说在一系列不同种类的照片中识别出一个场景中的宠物自然是毫不费力的事情,然而这对于一台机器来说可不是一件小事。
实际上,如果要机器实现自动分类,那么我们需要知道如何强有力地描绘出猫和狗的特征,也就是说为什么我们认为这张图片中的是猫,而那张图片中的却是狗。
这个需要描绘每个动物的内在特征。
深度神经网络在图像分类任务上效果很好的原因是,它们有着能够自动学习多重抽象层的能力,这些抽象层在给定一个分类任务后又可以对每个类别给出更简单的特征表示。
深度神经网络可以识别极端变化的模式,在扭曲的图像和经过简单的几何变换的图像上也有着很好的鲁棒性。
让我们来看看深度神经网络如何来处理这个问题的。
配置深度学习环境深度学习的计算量非常大,当你在自己的电脑上跑一个深度学习模型时,你就能深刻地体会到这一点。
但是如果你使用GPUs,训练速度将会大幅加快,因为GPUs 在处理像矩阵乘法这样的并行计算任务时非常高效,而神经网络又几乎充斥着矩阵乘法运算,所以计算性能会得到令人难以置信的提升。
我自己的电脑上并没有一个强劲的GPU,因此我选择使用一个亚马逊云服务(AWS) 上的虚拟机,这个虚拟机名为p2.xlarge,它是亚马逊EC2 的一部分。
这个虚拟机的配置包含一个12GB 显存的英伟达GPU、一个61GB 的RAM、4 个vCPU 和2496 个CUDA 核。
可以看到这是一台性能巨兽,让人高兴的是,我们每小时仅需花费0.9 美元就可以使用它。
当然,你还可以选择其他配置更好的虚拟机,但对于我们现在将要处理的任务来说,一台p2.xlarge 虚拟机已经绰绰有余了。
我的虚拟机工作在Deep Learning AMI CUDA 8 Ubuntu Version 系统上,现在让我们对这个系统有一个更清楚的了解吧。
这个系统基于一个Ubuntu 16.04 服务器,已经包装好了所有的我们需要的深度学习框架(TensorFlow,Theano,Caffe,Keras),并且安装好了GPU 驱动(听说自己安装驱动是噩梦般的体验)。
如果你对AWS 不熟悉的话,你可以参考下面的两篇文章:https://blog.keras.io/running-jupyter-notebooks-on-gpu-on-aws-a-starter-guide.htmlhttps:///keras-with-gpu-on-a mazon-ec2-a-step-by-step-instruction-4f90364e49ac这两篇文章可以让你知道两点:建立并连接到一个EC2 虚拟机。
配置网络以便远程访问jupyter notebook。
用TensorFlow 和Keras 建立一个猫/狗图片分类器环境配置好后,我们开始着手建立一个可以将猫狗图片分类的卷积神经网络,并使用到深度学习框架TensorFlow 和Keras。
先介绍下Keras:Keras 是一个高层神经网络API,它由纯Python 编写而成并基于Tensorflow、Theano 以及CNTK 后端,Keras 为支持快速实验而生,能够把你的idea 迅速转换为结果。
从头开始搭建一个卷积神经网络首先,我们设置一个端到端的pipeline 训练CNN,将经历如下几步:数据准备和增强、架构设计、训练和评估。
我们将绘制训练集和测试集上的损失和准确度指标图表,这将使我们能够更直观地评估模型在训练中的改进变化。
数据准备在开始之前要做的第一件事是从Kaggle 上下载并解压训练数据集。
我们必须重新组织数据以便让Keras 更容易地处理它们。
我们创建一个data 文件夹,并在其中创建两个子文件夹:trainvalidation在上面的两个文件夹之下,每个文件夹依然包含两个子文件夹:catsdogs最后我们得到下面的文件结构:data/train/dogs/dog001.jpgdog002.jpg...cats/cat001.jpgcat002.jpg...validation/dogs/dog001.jpgdog002.jpg...cats/cat001.jpgcat002.jpg这个文件结构让我们的模型知道从哪个文件夹中获取到图像和训练或测试用的标签。
这里提供了一个函数允许你来重新构建这个文件树,它有 2 个参数:图像的总数目、测试集r 的比重。
我使用了:n:25000(整个数据集的大小)r:0.2ratio = 0.2n =25000organize_datasets(path_to_data='./train/',n=n, ratio=ratio) 现在让我们装载Keras 和它的依赖包吧:图像生成器和数据增强在训练模型时,我们不会将整个数据集装载进内存,因为这种做法并不高效,特别是你使用的还是你自己本地的机器。
我们将用到ImageDataGenerator 类,这个类可以无限制地从训练集和测试集中批量地引入图像流。
在ImageDataGenerator 类中,我们将在每个批次引入随机修改。
这个过程我们称之为数据增强(dataaugmentation)。
它可以生成更多的图片使得我们的模型不会看见两张完全相同的图片。
这种方法可以防止过拟合,也有助于模型保持更好的泛化性。
我们要创建两个ImageDataGenerator 对象。
train_datagen 对应训练集,val_datagen 对应测试集,两者都会对图像进行缩放,train_datagen 还将做一些其他的修改。
基于前面的两个对象,我们接着创建两个文件生成器:train_generatorvalidation_generator每个生成器在实时数据增强的作用下,在目录处可以生成批量的图像数据。
这样,数据将会无限制地循环生成。
模型结构我将使用拥有 3 个卷积/池化层和 2 个全连接层的CNN。
3 个卷积层将分别使用32,32,64 的 3 * 3的滤波器(fiter)。
在两个全连接层,我使用了dropout 来避免过拟合。
我使用随机梯度下降法进行优化,参数learning rate 为0.01,momentum 为0.9。
Keras 提供了一个非常方便的方法来展示模型的全貌。
对每一层,我们可以看到输出的形状和可训练参数的个数。
在开始拟合模型前,检查一下是个明智的选择。
model.summary()下面让我们看一下网络的结构。
结构可视化在训练模型前,我定义了两个将在训练时调用的回调函数(callback function):一个用于在损失函数无法改进在测试数据的效果时,提前停止训练。
一个用于存储每个时期的损失和精确度指标:这可以用来绘制训练错误图表。
我还使用了keras-tqdm,这是一个和keras 完美整合的非常棒的进度条。
它可以让我们非常容易地监视模型的训练过程。
要想使用它,你仅需要从keras_tqdm 中加载TQDMNotebookCallback 类,然后将它作为第三个回调函数传递进去。
下面的图在一个简单的样例上展示了keras-tqdm 的效果。
关于训练过程,还有几点要说的:我们使用fit_generator 方法,它是一个将生成器作为输入的变体(标准拟合方法)。
我们训练模型的时间超过50 个epoch。
这个模型运行时的计算量非常大:如果你在自己的电脑上跑,每个epoch 会花费15 分钟的时间。
如果你和我一样在EC2 上的p2.xlarge 虚拟机上跑,每个epoch 需要花费2 分钟的时间。
分类结果我们在模型运行34 个epoch 后达到了89.4% 的准确率(下文展示训练/测试错误和准确率),考虑到我没有花费很多时间来设计网络结构,这已经是一个很好的结果了。
现在我们可以将模型保存,以备以后使用。
model.save(`./models/model4.h5)下面我们在同一张图上绘制训练和测试中的损失指标值:当在两个连续的epoch 中,测试损失值没有改善时,我们就中止训练过程。