人声混响初级教程(Adobe Audition 3.0,Vocaloid2混音可用)
Audition音频编辑及混音技巧详解教程

Audition音频编辑及混音技巧详解教程音频编辑和混音是制作高质量音频作品的关键技能,它们使我们能够在录音室和音乐制作过程中达到惊人的效果。
在本文中,我们将深入探讨Adobe Audition软件中的音频编辑和混音技巧,帮助您提升音频处理的水平。
第一部分:Audition软件的介绍Adobe Audition是一款功能强大的音频编辑和混音软件,它提供了多种功能和工具,使用户能够完全控制音频文件的各个方面。
Audition 的界面简洁而直观,易于使用,使得即使是初学者也能轻松上手。
接下来,我们将讨论Audition中一些常用的编辑和混音技巧。
第二部分:音频编辑技巧1. 剪辑和修剪音频:在Audition中,您可以使用修剪工具剪辑和修剪音频片段,去除无用的部分或错误的录音。
只需要选择要删除的片段,然后按下删除键即可。
2. 清除噪音:Audition提供了强大的噪音清除工具,可以帮助您去除录音中的杂音和背景噪音。
通过选择适当的噪音剖析区域并应用噪音消除效果,您可以获得更清晰和专业的音频。
3. 调整音量和平衡:在编辑音频时,确保音量平衡是至关重要的。
Audition允许您调整音频的整体音量,以及各个频段的平衡。
您可以使用增益效果、均衡器和压缩器等工具来实现这一目标。
第三部分:音频混音技巧1. 使用多轨道混音:Audition中的多轨道编辑功能使您能够将不同的音频轨道组合在一起,创造出丰富多样的声音效果。
您可以将音频片段拖放到不同的轨道上,然后使用淡入淡出、音量平衡和声道平衡等工具进行调整。
2. 添加音效和音乐:为了增强音频的效果,可以在混音过程中添加各种音效和音乐。
Audition提供了众多内置的音效和音乐库,您可以根据需要挑选适合的元素,并将其轻松添加到混音轨道中。
3. 使用混响和回声效果:混响和回声效果可以为音频增添空间感和深度。
通过在Audition中应用合适的混响和回声效果,您可以使音频听起来更加富有层次和立体感。
Adobe Audition 3消除人声技巧二则

Adobe Audition 3.0消除人声技巧二则傻瓜式:方法一:效果- 立体声声像- 声道重混缩- 选择Vocal Cut新建左声道(左100;右-100) 新建右声道(左-100;右100;反相)方法二:效果- 立体声声像- 析取中置通道- Karaoke(效果预置) - 男声.(测试后,在傻瓜式中这种方法效果最好)方法三:编辑- 转换采样类型,在弹出的对话框中选中"通道"选项中的"单声道".再将左声道混合比和右声道混合比分别设置为100%和-100%.优化式,以小齐的对面的女孩看过来.mp3为例步骤一(同傻瓜式方法二一样):初步消除人声。
在多轨视图下将歌曲导入到Adobe Audition 3.0音轨1,双击音块进入编辑模式,如歌曲对面的女孩看过来,在单轨编辑视图模式下,效果- 立体声声像- 析取中置通道- Karaoke(效果预置) - 男声.另存为对面的女孩看过来(伴凑).mp3这里也可以用同傻瓜式方法一一样,完成初频消除人声,不同的歌二种方式都有不同的效果。
步骤二:进一步消除噪音效果- 滤波和均衡–参量均衡器,进行调整,确定并保存。
步骤三:低频补尝消声后,它的音频被衰减了很多。
要对低频进行补尝。
打开原对面的女孩看过来.mp3文件,导入到音轨2中。
同上进入间轨2编辑模式,并打开效果- 滤波和均衡–参量均衡器。
进行如下调节并另存为对面的女孩看过来(BASS).mp3步骤四:多轨合成对音轨1音轨2进行合并,选中音轨1音轨2,在音轨3中右击–合并到新音轨–所选音频剪辑(立体声)把合成的音频另存为就OK了。
顺便说一下,wav格式音质会好一些。
这个要看楼主这个音频到底是什么情况了。
一般的降噪操作都是以牺牲一定的保真度为代价的,但是如果噪声已经远远超过了想要的声音,那么再怎么降噪可是说以现在的技术来讲都是徒劳无功的。
如果噪音不是特别大,并且对声音的质感音色等方面要求不严(也就是只想要听清楚说什么就行),那么可以按照下面的步骤进行:准备工作如图(图中忘了标明顺序:先选择一段噪音,然后双击“降噪”打开对话框,然后再进行各种调节)。
Audition音频 repair及混音技巧介绍

Audition音频 repair及混音技巧介绍Audition音频修复及混音技巧介绍音频修复和混音是音频制作过程中非常关键的环节,它们能够极大地提升音频质量,使之更好地传达音乐、声音或者其他音频内容。
在本文中,我将为您介绍使用Adobe Audition软件进行音频修复和混音的一些技巧和方法。
一、音频修复技巧1. 去除噪音在录音过程中,会出现各种各样的噪音,如电源噪声、电磁干扰、通风扇声等。
使用Audition可以通过选择音频中的噪音部分,然后使用噪音降低或去噪效果器来消除这些噪音。
您可以不断尝试不同参数和效果器,以获得较好的去噪效果。
2. 修复破损音频如果您的音频文件存在损坏或录制不完整的问题,比如某些部分静音、杂音过大等,您可以使用“修复”功能。
该功能可以通过重新采样、插入静音或补充杂音,来修复音频中的问题。
Audition提供了多种修复音频的工具和效果器,您可以灵活运用它们来修复破损音频。
3. 平衡音频频谱当音频在某些频率范围过于强大而使其他频率范围变得不够明显时,可以使用均衡器来平衡音频的频谱。
均衡器可以增强或减弱特定频率上的声音,从而实现音频频谱的平衡。
二、音频混音技巧1. 声音定位和平衡混音时,声音的定位和平衡非常重要。
您可以使用Audition中的“音量平衡”或“均衡器”功能,分别调整音频的左右声道平衡和频率平衡,使声音在空间定位上更加立体而且平衡。
您可以自由尝试不同的效果器参数,以达到满意的音频效果。
2. 添加混响和延迟效果混响和延迟效果可以为音频增加空间感和立体感。
在Audition中,您可以使用混响效果器来模拟不同环境下的混响效果,使音频更加自然。
同时,Audition还提供了多种延迟效果器,您可以使用它们来实现声音的延迟效果,使音频更加丰富多样。
3. 创造立体声效果如果您想为音频创造立体声效果,可以使用Audition中的立体声效果器。
该效果器可以调整声音在立体声场中的位置和深度,使音频听起来更加立体而且逼真。
AdobeAudition 3.0 人声处理的四个步骤
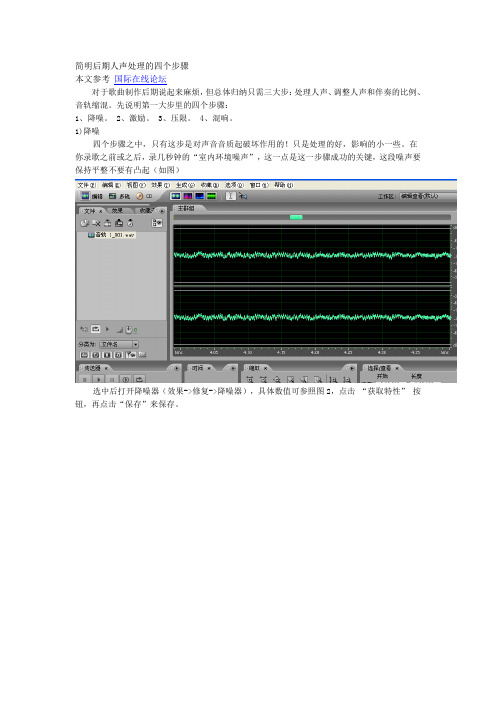
简明后期人声处理的四个步骤
本文参考国际在线论坛
对于歌曲制作后期说起来麻烦,但总体归纳只需三大步:处理人声、调整人声和伴奏的比例、音轨缩混。
先说明第一大步里的四个步骤:
1、降噪。
2、激励。
3、压限。
4、混响。
1)降噪
四个步骤之中,只有这步是对声音音质起破坏作用的!只是处理的好,影响的小一些。
在你录歌之前或之后,录几秒钟的“室内环境噪声”,这一点是这一步骤成功的关键,这段噪声要保持平整不要有凸起(如图)
选中后打开降噪器(效果->修复->降噪器),具体数值可参照图2,点击“获取特性”按钮,再点击“保存”来保存。
干声录制好后,全部选中,打开降噪器,点击“加载”,打开你刚才保存过的文件,单击OK,第一步结束。
2)激励
这步是这四步中最简单的一步,也是必须用插件的一步。
打开BBE ( 效果 -> DirectX插件 -> BBE Sonic Maximizer)
将1、2钮调置“12点”位置(数值为5),3钮调到“3点”位置(数值为4),正确定。
此调法适合大多数需要。
如下图
3)压限
打开“动态处理”(效果–> 振幅和压限 -> 动太处理),预设效果中的Compander 很适合处理人声,可以直接用。
如下图
4)混响
最后一步加混响,用Adobe Audition 3.0的完美混响就可以了,效果 -> 混响–> 完美混响。
使用预设效果中的“Lecture Hall”就可以了. 混响有控制人声远近的作用,一定不要加的过大!“干声”这项就可以控制了,想再小点,就放到100%处。
如何使用Audition进行音频混音与制作

如何使用Audition进行音频混音与制作音频是一种重要的媒体形式,它广泛用于电影制作、音乐制作、广播电视以及各种多媒体项目中。
而Adobe Audition作为一款专业的音频编辑软件,提供了丰富的功能和工具,可以帮助用户进行音频混音与制作。
本文将通过几个章节介绍如何使用Audition进行音频混音与制作。
第一章:Audition简介在开始使用Audition之前,先对它进行简单的介绍。
Audition是Adobe公司开发的一款专业音频编辑软件,它具备强大的多轨道编辑以及混音功能,可以满足不同项目的需求。
它拥有直观的界面,丰富的音频效果和过渡,使用户能够以高质量进行音频混音和制作。
第二章:导入音频文件在使用Audition进行音频混音与制作之前,首先需要导入音频文件。
在Audition的主界面上,可以通过菜单栏中的“文件”选项选择“导入”命令,然后在弹出的对话框中选择需要导入的音频文件并确认即可。
可以导入各种常见的音频格式,如WAV、MP3等。
第三章:多轨道编辑Audition的多轨道编辑功能使用户可以同时处理多个音频轨道,从而实现更复杂的音频制作。
用户可以通过拖放的方式将不同的音频文件拖到不同的轨道上,并可以自由调整它们的位置和顺序。
在每个轨道上,可以进行音量调整、剪辑、淡入淡出等操作。
此外,还可以添加背景音乐、音效或者录制自己的声音。
第四章:音频效果和过渡为了让音频更加丰富和有趣,Audition提供了各种各样的音频效果和过渡效果。
用户可以通过菜单栏中的“效果”选项访问多个音频效果库,如均衡器、压缩器、混响等。
用户可以选择适当的效果并将其应用到特定的音频轨道上。
此外,用户还可以使用过渡效果来实现不同音频片段之间的平滑过渡,使音频听起来更加连贯。
第五章:音频剪辑和修复在音频制作过程中,有时候需要对音频进行剪辑和修复。
Audition提供了丰富的剪辑和修复工具,可以帮助用户进行精确的音频剪辑和修复。
使用Audition进行音频修复和混音处理的技巧

使用Audition进行音频修复和混音处理的技巧第一章:Audition的功能介绍Adobe Audition是一款专业音频编辑和处理软件,广泛应用于音频制作、修复和混音等领域。
它提供了一系列强大的工具和效果,帮助用户轻松实现音频修复和混音效果。
第二章:音频修复技巧1. 降噪处理:通过Audition的降噪效果,可以有效去除录音中的背景噪音。
首先,在音频文件中选择需要降噪的部分,然后打开“降噪”面板,调整相关参数,如噪音削弱和频谱阈值等,最后点击“应用”按钮完成操作。
2. 去鼻音处理:在录音中,有时会出现鼻音的问题。
Audition提供了一个去鼻音效果,可以将鼻音部分进行修复。
选择需要去除鼻音的音频段落,在“效果”菜单中选择“去鼻音”,调整相关参数,如“去鼻音强度”和“去鼻音频带”等,然后点击“应用”按钮。
3. 修复音频裂音:Audition提供了修复音频裂音的效果。
选择有裂音的音频段落,在“效果”菜单中选择“修复音频裂音”,调整参数,如“裂音处理”和“光滑度”等,最后点击“应用”按钮。
第三章:混音处理技巧1. 音频剪辑:Audition的剪辑功能可以帮助用户对音频进行切割和调整。
选中要剪辑的音频段落,点击“剪切”按钮,然后在需要插入的地方点击“粘贴”按钮即可完成剪辑。
同时,用户可以调整音频段落的起始和结束点,以达到理想的效果。
2. 重叠淡入淡出:混音时,重叠淡入淡出是一个重要的技巧。
在Audition中,选中两个音频段,点击“效果”菜单中的“重叠淡入淡出”,调整参数,如“淡入时间”和“淡出时间”等,然后点击“应用”按钮。
3. 混响效果:混响是一种常用的音频效果,用于给声音增加空间感和立体感。
在Audition中,选择需要添加混响效果的音频段,点击“效果”菜单中的“混响和残響”,调整参数,如“混响室类型”和“混响时间”等,最后点击“应用”按钮。
第四章:导入和导出音频文件1. 导入音频文件:在Audition中,可以通过“文件”菜单中的“导入”选项,或者直接拖拽音频文件到软件界面来导入音频文件。
(完整版)audition人声处理技巧

audition人声处理技巧人声音源的频谱分布比较特殊,就其发音方式而言,他有三个部分:一个是由声带震动所产生的乐音,此部分的发音最为灵活,不同音高、不同发音方式所产生的频谱变化也很大;二是鼻腔的形状较为稳定,因而其共鸣所产生的谐音频谱分布变化不大;三是口腔气流在齿缝间的摩擦声,这种齿音与声带震动所产生的乐音基本无关。
频率均衡可以大致的将这三部分频谱分离出来。
用于调节鼻音的频率段在500Hz,以下均衡的中点频率一般在80~150Hz,均衡带宽为4个倍频程。
例如,可以将100Hz定为频率均衡的中点,均衡曲线应从100~400Hz平缓的过渡,均衡增益的调节范围可以为+10Db~ -6dB。
这里应提醒大家的是:进行此项调整的监听音箱不得使用低频发音很弱的小箱子,以避免鼻音被无意过分加重。
人声乐音的频谱随音调的变化也很大,所以调节乐音的均衡曲线应非常平缓,均衡的中点频率可在1000~3400Hz,均衡带宽为六个倍频程。
此一频段控制着歌唱发音的明亮感,向上调节可温和地提升人声的亮度。
然而如需降低人声的明亮度,情况就会更复杂一些。
一般音感过分明亮的人声大多都是2500Hz附近的频谱较强,这里我们可用均衡带宽为1/2倍频程,均衡增益为-4dB左右的均衡处理,在2500Hz附近寻找一个效果最好的频点即可。
人声齿音的频谱分布在4kHz以上。
由于此频段亦包含部分乐音频谱,所以建议调节齿音的频段应为6~16KHz,均衡带宽为3个倍频程,均衡中点频率一般在10~12KHz,均衡增益最大向上可调至+10Db;如需向下降低人声齿音的响度,则应使用均衡带宽为1/2倍频程,均衡中点频率为6800Hz的均衡处理,其均衡增益最低可向下降至-10Db。
由以上分析可以看出,对人声进行频率均衡处理时,为突出某一音感而进行的频段提升,都尽量使用曲线平缓的宽频带均衡。
这是为了使人声鼻音、乐音、齿音三部分的频谱分布均匀连贯,以使其发音自然、顺畅。
利用AdobeAudition进行音频编辑和混音的技巧

利用AdobeAudition进行音频编辑和混音的技巧利用Adobe Audition进行音频编辑和混音的技巧音频编辑和混音是音乐创作和音频制作过程中至关重要的环节。
随着技术的不断发展,我们可以利用各种软件工具来进行音频编辑和混音。
而Adobe Audition作为一款专业的音频编辑软件,提供了丰富的功能和工具来实现音频的处理和创作。
本文将介绍一些利用Adobe Audition进行音频编辑和混音的基本技巧,帮助初学者顺利入门。
一、录制和导入音频文件在开始进行音频编辑和混音之前,首先需要进行音频文件的录制或导入。
Adobe Audition支持各种常见音频格式,包括WAV、MP3、AIFF等。
你可以通过内置的录音功能直接录制音频,也可以点击“文件”-“导入”来将已有的音频文件导入到软件中进行处理。
二、音频修复和增强在音频编辑和混音过程中,通常会遇到一些音频质量不佳的问题,比如噪音、杂音、嘶嗓等。
Adobe Audition提供了一系列的音频修复和增强工具,可以帮助我们将音频处理得更加清晰和高质量。
1. 噪音消除:通过选择“效果”-“降噪”来减少音频中的背景噪音。
Adobe Audition会根据音频的特征自动识别并降低噪音水平。
2. 音频增强:通过选择“效果”-“均衡器”来调整音频的频率响应,改善音频的整体音质。
你可以根据需要增加低音、中音或高音等。
三、基本音频编辑技巧1. 剪切和拼接:在进行音频编辑时,我们可能需要对音频进行剪切和拼接。
选中要剪切的部分,点击剪贴板上的剪切按钮,然后将光标移动到要拼接的位置,点击剪贴板上的粘贴按钮即可完成剪切和拼接操作。
2. 淡入淡出:淡入淡出是音频编辑中常用的技巧,可以使音频的开头和结尾更加平滑。
选中要添加淡入或淡出效果的部分,点击“效果”-“淡入淡出”来选择合适的效果。
3. 音量调整:音量调整是音频编辑中一个基本操作,可以对音频的音量进行调整。
选中要调整音量的部分,点击“效果”-“增益”来进行音量调整。
Adobe Audition效果器之混响

效果器之混响篇效果器之混响篇--理论基础想象一下有一个人在着色大理石墙壁、地板和房顶的大房间里唱歌,声音都是怎样传播的?而麦克风又是怎样拾音的?歌声会在墙壁、地板和房顶反射,最开始声音会遇到麦克风,然后然后是地板和天花板,因为他们距离歌手最近,之后是歌手两侧的墙壁,最后才是他身子前后的墙壁。
这还没完,声音的传播不会就此停止,他会继续反射。
每准他先通过天花板反射,撞到了墙壁,转了一圈然后又回到了麦克风那里。
这种声音反射返回麦克风的时间是和房间的大小成比例的。
声音大概是每毫秒传播30厘米(1英尺),当歌手象上图中那样处在房间的中间位置,那么声音在经过他两侧的墙壁反射后将在20ms后回来,经过他身子前后反射的声音在40ms后也会回到麦克风那里,这些都是早期反射(Early Reflections),在这之后就属于后期反射(Late Reflections),再往后反射声音越来越密最终确立了一个混响声场,感觉已经辨认不出反射声就说明混响声场已经建立起来了。
因为这个房间的材料是着色大理石,而且房间内没有任何物品,所以他的混响时间大约是2.21秒。
这种房间没有什么分散声音的因素,如果将建筑材料换成石头,再放上一些物品,声音会散步到各个方向,他聚集的混响自然与空房间不一样。
图中的歌手面前的麦克风在拾音时,最先是第一次反射声,之后是早期反射声、后期反射声,直到混响声场的建立所经历的混响时间大约是2.21秒。
但是利用混响时间计算器你可以计算房间在不同频率下的混响时间。
最上图那个房间在不同频率下的混响时间图表就是下图那样:上面说的2.21秒的混响时间是在1000Hz的情况下,而在250Hz是3.09秒,换句话说250Hz 时的衰减比1000Hz要长。
有些混响软件允许你单独控制高低频率下的混响时间,还有些通过EQ来调整高低频。
现在的录音设备(软硬都算)如此的先进,你完全可以用他们得到完美的混响。
本文参考SAE的《Effects--Reverberation》一文编译,有说的不对的翻译的不准确的望您指出效果器之混响篇--实例混响是一个很常用的效果器,同时混响又是我们生活中经常见到的一种现象。
AdobeAudition30多轨界面后期混音处理

8.3 插入素材
8.3.4 插入视频中的音频
• 首先确定插入点 , 然后执行 【Insert( 插入)】 | 【Audio From Video(视频中的声音)】,则弹出 【Insert Audio From Video(视频中的声音)】对 话框,选择要提取声音的视频文件名称,单击 【Open(打开)】按钮,此视频文件的声音就被提 取出来,并在轨道中显示其波形。
8.1 多轨混音概述
8.1.1 动漫游戏音乐与多轨混音
• 在一个完整的动漫游戏音频作品中,必然会使用较 多的轨道,有的轨道承载着主题音乐,有时又需要 动作轨道,一会儿又跟着会话轨道,还有可能出现 演示死亡的音轨。
8.1 多轨混音概述
8.1.2 多轨混音与工程文件
• 在每个轨道上都可以插入若干不同的音频文件、 MIDI、视频文件和视频中的声音。
• 3、删除轨道
8.2 基本轨道控制
8.2.3 命名、移动轨道
• 为轨道命名的方法: • 方法一:在多轨界面中的【Main(主面板)】中,
单击轨道左侧的轨道名处,该轨道的名称进入编辑 状态,您直接输入新的轨道名称即可。
8.2 基本轨道控制
8.2.3 命名、移动轨道
• 为轨道命名的方法: • 方法二:切换到【Mixer(混音台)】面板,单击轨
8.4 安排、布置音频块
8.4.2 移动音频块
• 方法二:单击工具栏中【移动/拷贝音频块工具】按 钮,然后拖动鼠标,则移动所选音频块。
8.4 安排、布置音频块
8.4.3 组合音频块
• 1、组合
8.4 安排、布置音频块
8.4.3 组合音频块
• 1、组合方法一:首先用鼠标同时选中“AA”和“BB” 两个声音波形,然后执行【Clip(音频块)】|【 Group Clips(组合音频块)】命令,此时,两个波 形音频块的颜色变成一样,同时在每个音频块的左 下角都出现了 图标。
使用Audition进行音频编辑和混音处理

使用Audition进行音频编辑和混音处理音频编辑和混音处理是音频制作过程中的重要环节。
在众多的音频处理软件中,Adobe Audition是一款功能强大、操作简便的专业音频编辑和混音软件。
本文将介绍如何使用Audition进行音频编辑和混音处理,并探讨其应用场景和一些技巧。
一、Audition的基本介绍和安装Adobe Audition是一款专为音频制作而设计的软件,它具有强大的音频编辑、修复和混音功能,适用于音乐制作、广播、电视和电影制作等方面。
它的操作界面简洁直观,同时配备了丰富的音频处理工具和特效插件,为用户提供了良好的创作和处理环境。
在安装Audition之前,需要确保计算机的硬件配置满足软件运行要求。
安装过程相对简单,只需要按照软件的指引进行操作即可完成。
安装完毕后,打开软件,我们将进入到Audition的主界面。
二、音频编辑功能的应用1. 录制音频在Audition中,我们可以使用内建录音设备录制音频。
点击主界面中的“录制”按钮,选择录音设备和录音位深,并设置好音频输入和输出设备。
接下来,点击“录音”按钮开始录制音频。
录制完毕后,我们可以进行后续的编辑和处理。
2. 剪切和合并音频文件Audition提供了精确的音频剪切工具,可以将音频文件按照需要剪切成多个片段,并对每个片段进行单独的处理。
另外,Audition还可以将多个音频文件合并成一个文件,方便后续处理和保存。
3. 清理和修复音频有时候我们会遇到录音中过多的环境噪音或者录制设备的问题导致的音频不清晰。
Audition提供了一系列的音频修复工具,如降噪、去除杂音和修复音频失真等。
通过这些工具,我们可以提高音频的质量和可听性。
4. 添加特效和混响效果Audition还内置了大量的音频特效插件和混响效果,可以通过对音频添加这些效果来改变音频的音色和空间感。
比如,我们可以通过添加均衡器来调整音频的频谱平衡,通过添加压缩器来改善音频的动态范围等。
如何使用Audition进行音频剪辑和混音

如何使用Audition进行音频剪辑和混音第一章:Audition简介1.1 Audition的定义和作用1.2 Audition的基本功能和特点1.3 Audition的用户群体和应用领域第二章:音频剪辑的基本操作2.1 导入音频文件2.2 基本编辑工具的使用2.3 剪切、复制和粘贴音频片段2.4 调整音频的音量和音调2.5 音频的淡入淡出处理2.6 使用特效和音频过渡效果第三章:音频混音的技巧3.1 混音概述与基本原理3.2 声道调整和平衡3.3 音频效果器的应用3.4 人声和背景音乐的平衡处理3.5 混响效果和环绕音效的添加第四章:高级音频处理技术4.1 噪音去除和音频修复4.2 音频的多轨道处理4.3 频率平衡和均衡器的运用4.4 音频切割和合并技术4.5 音频格式转换和导出设置第五章:Audition的扩展功能与应用5.1 音频录制与处理参数设置5.2 使用批量处理功能提高工作效率 5.3 应用Audition制作播客或广播节目 5.4 音频剪辑与视频剪辑的结合第六章:实际案例分析6.1 电影配乐剪辑与混音实例6.2 广播节目制作案例6.3 采访录音剪辑与后期处理6.4 音频书籍制作与音效处理第七章:常见问题解决方法7.1 在剪辑过程中出现噪音的处理方法7.2 如何调整音频的声音大小7.3 导出音频文件时的设置技巧7.4 音频剪辑与混音遇到的常见错误第八章:小结与展望8.1 Audition的应用前景与发展趋势8.2 对于音频剪辑与混音技术的思考8.3 各类专业人士对Audition的评价通过以上章节的介绍,读者可以了解到Audition软件的基本功能和特点,以及如何使用该软件进行音频剪辑和混音。
包括音频剪辑的基本操作、音频混音的技巧、高级音频处理技术、Audition 的扩展功能与应用等方面的内容。
此外,还通过实际案例分析和常见问题解决方法,帮助读者更好地掌握Audition的使用技巧。
如何用Audition进行人声处理 让你的声音更有磁性

人声音源的频谱分布比较特殊,就其发音方式而言,他有三个部分:一个是由声带震动所产生的乐音,此部分的发音最为灵活,不同音高、不同发音方式所产生的频谱变化也很大;二是鼻腔的形状较为稳定,因而其共鸣所产生的谐音频谱分布变化不大;三是口腔气流在齿缝间的摩擦声,这种齿音与声带震动所产生的乐音基本无关。
频率均衡可以大致的将这三部分频谱分离出来。
用语调节鼻音的频率段在500Hz,以下均衡的中点频率一般在80~150Hz,均衡带宽为4个倍频程。
例如,可以将100Hz定为频率均衡的中点,均衡曲线应从100~400Hz平缓的过渡,均衡增益的调节范围可以为+10Db~ -6dB。
这里应提醒大家的是:进行此项调整的监听音箱不得使用低频发音很弱的小箱子,以避免鼻音被无意过分加重。
人声乐音的频谱随音调的变化也很大,所以调节乐音的均衡曲线应非常平缓,均衡的中点频率可在1000~3400Hz,均衡带宽为六个倍频程。
此一频段控制着歌唱发音的明亮感,向上调节可温和地提升人声的亮度。
然而如需降低人声的明亮度,情况就会更复杂一些。
一般音感过分明亮的人声大多都是2500Hz附近的频谱较强,这里我们可用均衡带宽为1/2倍频程,均衡增益为-4dB左右的均衡处理,在2500Hz附近寻找一个效果最好的频点即可。
人声齿音的频谱分布在4kHz以上。
由于此频段亦包含部分乐音频谱,所以建议调节齿音的频段应为6~16KHz,均衡带宽为3个倍频程,均衡中点频率一般在10~12KHz,均衡增益最大向上可调至+10Db;如需向下降低人声齿音的响度,则应使用均衡带宽为1/2倍频程,均衡中点频率为6800Hz 的均衡处理,其均衡增益最低可向下降至-10Db。
由以上分析可以看出,对人声进行频率均衡处理时,为突出某一音感而进行的频段提升,都尽量使用曲线平缓的宽频带均衡。
这是为了使人声鼻音、乐音、齿音三部分的频谱分布均匀连贯,以使其发音自然、顺畅。
从理论上讲,应使人声在发任何音时,其响度都保持恒定。
如何使用AdobeAudition进行音频混音与后期制作

如何使用AdobeAudition进行音频混音与后期制作Chapter 1: Introduction to Adobe AuditionAdobe Audition is a powerful digital audio workstation that offers a wide range of tools and features for audio mixing and post-production. With its user-friendly interface and professional-grade capabilities, it has become a popular choice among musicians, producers, and sound engineers.In this guide, we will explore how to use Adobe Audition for audio mixing and post-production, covering various aspects of the software and providing practical tips and techniques.Chapter 2: Getting Started with Adobe AuditionBefore diving into the world of audio mixing and post-production, it's essential to familiarize yourself with the basic functionalities and interface of Adobe Audition. This chapter will walk you through the essential steps of setting up your workspace, importing audio files, and understanding different audio tracks.Chapter 3: Editing and Arranging Audio ClipsOne of the fundamental aspects of audio post-production is editing and arranging audio clips. This chapter will cover various techniques for editing audio in Adobe Audition, including cutting, copying,pasting, and fading audio clips. Additionally, we will explore how to arrange audio clips on the timeline for seamless playback.Chapter 4: Mixing Audio TracksMixing audio tracks is a crucial step in the post-production process, as it involves adjusting the volume, panning, and applying effects to create a balanced and cohesive sound. In this chapter, we will delve into the techniques of mixing audio tracks in Adobe Audition, including using the mixer window, applying EQ and compression, and automating volume changes.Chapter 5: Applying Effects and FiltersAdobe Audition offers a vast array of built-in effects and filters that can enhance the quality and creativity of your audio. In this chapter, we will explore different types of effects and filters, such as reverb, delay, chorus, and equalization. We will also discuss how to apply and customize these effects for specific audio tracks.Chapter 6: Noise Reduction and RestorationAudio recordings often come with unwanted background noise and imperfections. Adobe Audition provides powerful noise reduction and restoration tools to minimize these issues and enhance the overall audio quality. This chapter will guide you through the process of reducing noise, removing pops and clicks, and restoring audio using Adobe Audition's advanced features.Chapter 7: Mixing in Multichannel AudioMultichannel audio is widely used in film, television, and gaming industries to create immersive soundscapes. Understanding how to mix and edit multichannel audio is essential for professionals in these fields. In this chapter, we will explore Adobe Audition's capabilities in working with multichannel audio, including assigning audio to different speakers and creating surround sound effects.Chapter 8: Finalizing the Audio MixAfter completing the mixing process, it's time to finalize the audio mix for distribution. In this chapter, we will cover the essential steps of exporting audio files, choosing the appropriate file format and settings, and ensuring the compatibility and quality of the final output. We will also discuss the importance of mastering and provide tips for achieving professional-sounding results.Chapter 9: Advanced Techniques and Workflow OptimizationFor seasoned users of Adobe Audition, this chapter will delve into advanced techniques and workflow optimization. Topics covered will include utilizing keyboard shortcuts, creating templates for common tasks, integrating third-party plugins, and exploring additional features and functionalities within Adobe Audition.Conclusion:Using Adobe Audition for audio mixing and post-production can elevate the quality and creativity of your audio projects. With its comprehensive set of tools and features, professionals in various industries can utilize this powerful software to achieve professional-grade results. By following the guidelines and techniques outlined in this guide, you will be able to harness the full potential of Adobe Audition and unleash your creativity in the world of audio production.。
学会使用Audition进行音频编辑和混音技术

学会使用Audition进行音频编辑和混音技术一、 Audition音频编辑和混音技术简介Adobe Audition是一款强大的音频编辑和混音软件,提供了丰富的工具和功能,可以满足专业音频处理需要。
本文将介绍Audition的基本操作和一些常用的编辑和混音技术。
二、 Audition的基本操作1. 安装和界面介绍在安装Audition后,打开软件,会看到一个直观的用户界面。
界面上方是菜单栏,左侧是工具栏,在中间是编辑窗口,右边是修正和效果面板。
熟悉界面布局对于学习和使用Audition非常重要。
2. 创建和导入音频文件点击“文件”菜单,选择“新建”可以创建一个新的音频文件。
也可以通过“文件”菜单中的“导入”选项导入已有音频文件。
Audition 支持多种音频格式,包括mp3、wav、aiff等。
3. 基本编辑功能Audition提供了一系列基本的编辑功能,如剪切、复制、粘贴和删除。
可以通过选中音频段落,在编辑窗口中点击鼠标右键弹出菜单来操作。
4. 渐入渐出效果对于音频的开头和结尾,经常需要添加渐入渐出效果,使音频过渡更加自然。
通过选中音频段落,在菜单栏中选择“效果”-“渐入渐出”,可以添加渐入渐出效果。
5. 混音音轨在Audition中,可以分别创建多个音轨,并在每个音轨上添加不同的音频。
通过音轨的叠加和调整,可以实现混音效果。
在界面底部的音轨栏中,有添加音轨、删除音轨和调整音轨顺序的按钮。
6. 音频修正和音效处理Audition提供了强大的音频修正和音效处理功能。
例如,可以使用降噪工具降低噪音,使用均衡器调整音频的频率响应,还可以添加各种音效和混响。
7. 导出和保存音频文件编辑完音频后,可以通过“文件”菜单中的“导出”选项将文件保存为不同的音频格式。
还可以选择导出的音频质量和参数。
三、 Audition音频编辑技术1. 去除杂音在录制音频时,常常会有各种杂音,如电流噪音、风噪音等。
Audition提供了多种降噪工具,可以有效去除这些杂音。
AU3.0专业教程-第6章-单轨界面中进行后期的音频效果处理

6.3 降低噪音
6.3.4 噪声降低器
• 1、确认噪音波形。
6.3 降低噪音
6.3.4 噪声降低器
• 2、采集噪音样本。
6.3 降低噪音
6.3.4 噪声降低器
• 3、降低噪音。
6.4 延迟效果
• 6.4.1 延迟与回声 • 6.4.2 Modulation(调整) • 6.4.3 Reverb(混响)效果
• 一般地,库面板中的【Effects(效果)】面板 (如图6-1)和菜单栏中的【Effects(效果)】 菜单都可以为声音添加特效。
6.1 关于Audition3.0效果器的基础知识
• 效果对话框,可以在预设列表中选择一种预设, 或者直接调整具体参数。
6.1 关于Audition3.0效果器的基础知识
正确
错误
显示答案
4.8 练习题
6、判断题
【Mastering Rack】可以为声音添加任何特效。
正确
错误误
显示答案
第六章 在Adobe Audition3.0的单轨界面中进行后期的音频效果处理
• 6.1 关于Audition3.0效果器的基础知识 • 6.2 改变波形振幅 • 6.3 降低噪音 • 6.4 延迟效果 • 6.5 时间拉伸/变速变调 • 6.6 消除人声
6.1 关于Audition3.0效果器的基础知识
6.4 延迟效果
6.4.2 Modulation(调整)
• 1、Chorus(合唱)
6.4 延迟效果
6.4.2 Modulation(调整)
• 2、Flanger(镶边)效果
6.4 延迟效果
6.4.1 延迟与回声
• 3、Sweeping Phaser(变化的相位)效果
au怎么给声音加混响?AU飘渺混响效果的设置技巧
au怎么给声⾳加混响?AU飘渺混响效果的设置技巧
在我们⽇常学习⽣活⼯作中,经常会⽤到⾳频剪辑软件来处理⽂件,有时候需要设置飘渺混响效果,该怎么设置au的⾳频混响效果呢?下⾯我们就来看看详细的教程。
Adobe Audition 2019 ⾳频编辑软件 v12.1.5.3 直装版
类型:⾳频处理
⼤⼩:411.32MB
语⾔:简体中⽂
时间:2019-10-04
查看详情
1、⾸先在电脑中打开AU软件,点击左上⽅区域,将需要的⾳频导⼊。
2、在弹出的导⼊⽂件窗⼝中,选择需要的⾳频素材⽂件,然后点击打开。
3、点击软件左⽅⾓,将左侧导⼊的⾳频素材拖动,到右侧编辑区内。
4、点击顶部⼯具栏中的“效果”——“混响”——“混响”。
5、在弹出的预设窗⼝中,将预设设置为“飘渺”,然后点击“应⽤”按钮。
6、剪辑完成后,将处理好的素材导出为想要的格式即可。
以上就是AU中设置飘渺混响效果的技巧,希望⼤家喜欢,请继续关注。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
(如有人要转载此帖请注明原出处/read.php?tid=10972115)
本来是打算写一个音频后期的详细教程,不过由于种种原因这个计划搁浅了,于是只好挑一个重点的部分来写.
嗯...好像大多数人对于后期混音都比较惧怕...我刚开始时也是这样,走了无数弯路,不过呢...在别人的指导下我终于有所顿悟...嗯...我把我学到的大概讲一下吧,希望同学们少走弯路.
本文所使用的音频处理平台为Adobe Audition 3.0,所使用的插件除了Au自带的外还有Waves水银包(经常做音频后期处理的同学应该都有这套插件吧)和iZotope Zone(著名的母带处理插件,别名"臭氧").
重点讲一下对轨的技巧和效果器的连接方式,参数方面就不讲了,感觉越讲会越糊涂,而且有一些参数我也没搞明白,参数也不是绝对的,自己慢慢摸索可能更好.
1.对轨
对轨除了听以外还要看,看什么?看波形.导入音频文件后将其插入到多轨界面下的轨道中,首先要做的是将原唱歌曲和歌曲伴奏对齐,翻唱人声是比对原唱来对轨的,而不是去对伴奏.
原唱和伴奏对齐的要点是找鼓点,鼓点的波形通常较为突出,如果没有鼓点也要找相对明显的乐器声点.
波形大致对其后将鼓点部分继续放大,可以看到一些不规则的波形,波峰很明显,将波峰对齐~OK
接下来是将翻唱的人声干音和原唱对齐,可以比对音节的起头和音节的波峰,如果有些长音节难以辨别还可以去比对短音节.对齐后就可以准备将人声和伴奏混缩了.
2.添加辅助输出BUS(即总线,BUS这个词在计算机领域里有"总线"的意思) 关于后面要说到的总线轨,主控轨和多轨效果格架,如果想深入了解的去看这里
/playlist/playindex.do?lid=8474438&iid=50261269&cid=25
/playlist/playindex.do?lid=8474438&iid=50261257&cid=25
多轨界面下右键点击一个空白的音频轨,选择第一项插入,然后可以看到要添加的内容,最下面是几个轨道类型,选择总线轨,连续添加3个,将得到总线轨A,B,C,这3个总线轨后面有用.
3.添加效果格架
先点击图示中的fx(效果)按键转换到效果格架添加模式,然后点击图示中音轨1(我的音轨1是翻唱的人声轨,音轨2是伴奏轨)的那个类似播放的三角按键,这时会弹出效果器列表,点击效果格架,弹出效果格架界面.
同样的,点击界面左边的三角按键给音轨1(人声轨)插入常用的压缩效果器,比如waves里的C4或C1,如果要两个都用的话C4要放在C1前面,这两个压缩器的作用是平衡音量,只不过由于算法不同而各有侧重,C4更偏向于调整音量,C1偏向于调整人声特性,使音量变化的同时还可以增加人声的穿透力.
同样的方法,在总线轨A里插入任意一款EQ效果器(EQ即均衡equalize的英文缩写),视情况还可以插入waves里的RDeEsser效果器,其作用是消除人声中类似嘶嘶声的齿音,注意如果要用RDeEsser的话EQ必须放在RDeEsser前面.总线轨B里插入任意一款延时效果器,总线轨C里插入任意一款混响效果器.
人声先经过插入音轨1的效果器处理,再输出至总线A并经插入总线A的效果器处理,经过两次处理后人声即获得所需效果(这时原始的人声信号已经发生变化),每次处理时所获得的效果都称为插入式效果.
4.人声轨辅助输出
点击fx按键旁边的输入/输出按键将界面切换回去,如图示,在音轨1处有一个向左的箭头,这就是输出选项,所有轨道默认都是输出到主控轨(也叫master轨,母线,即直接输出到电脑的声卡).
将音轨1(人声轨)的输出改为总线A.
5.总线A分别发送至总线B和总线C
点击fx旁边的发送按键,将界面转为发送模式,可以看到总线A的S1(发送1)路线为无(其他轨道默认也都是无),将其设置为总线B.
注意右侧有1个很小的滑块和上下两个箭头,点向下的箭头切换到S2(发送2),将S2发送设置为总线C.
这时人声先输出至总线A,再由总线A分别发送至总线B和总线C,通过总线B和C所插入的延时及混响效果器实时处理后所获得的效果称为发送式效果.
6.打开混音器调节音量配比
将界面切换到混音器界面,播放一下听听看,会发现总线B和C没有声音,那是因为总线A发送至总线B和C的电平为负无穷大.如图示,将总线A的S1和S2的发送电平都改为最大值15.再播放会发现有声音了.
接下来是调节各轨的音量配比,直接拖动界面里的那些推子,调到自己满意为止(这是混音最关键的一步,过程可能会很漫长,千万不要急躁),主控轨的推子可以限制总体音量,避免产生爆音.在混音器界面下可以边播放边调节界面里的各项参数,称为动态调节.在这里同样可以更改效果器格架.由于总线B和总线C所加载的效果器是采用发送式效果,因此调节总线B和总线C的音量时只会影响延时效果和混响效果的音量,基础人声的音量并不会改变,这便是发送式效果的优点.
7.给主控规(master轨)添加效果器(这里所获得的效果是插入式效果)
经过第6步调整后的效果通常都已经比较满意了,但仔细听可能还会有一些细微的问题,这时就需要在最后给主控轨添加专用的效果器来处理了,目的是为了使人声和伴奏尽可能完美地融合在一起,切记主控轨的效果器不可在前面第3步时添加,如果在前面添加了就会影响到第6步的音量配比调节.可以添加waves里的L2或者iZotope Zone(臭氧),任选一款即可,追求完美的建议使用臭氧.
8.混缩
全部调整完后切换回主群组界面将人声和伴奏混缩~~~~完工
附逻辑关系图
最后主控轨总共得到4条音频信号,分别是:
1.经过压缩和EQ处理的人声(原始人声经过插入式效果处理后被改变,这一信号是被改变的基础人声信号)
2.通过混响器后得到的混响声(经过发送式效果处理后获得的仅是一个效果信号,不包含人声)
3.带有延时的效果声(同第2条)
4.伴奏(原始信号)
讲一下插入式效果和发送式效果的区别.
插入式效果如字面意思,就是在人声音轨中直接插入效果器,得到的声音是经过效果器处理后的声音,特点是直接对人声音轨产生影响,即改变了人声音轨的内容.
发送式效果如字面意思,是将人声音轨发送到一条总线(该总线已加载一个效果器),经过该总线处理后所获得的效果将与人声音轨一并输出至主控轨,特点是人声音轨的内容并不会被改变,特别适合做混响等效果.以文中的例子来讲,如果你在混音器界面里将总线C的音量拉到最低,那么播放的时候人声还是有的,但是混响的效果就没有了,而将音量拉高混响声也会变大.
还不明白的我再举个例子.假设一个演员要登上舞台,那么化妆师要为演员化妆,直接改变演员的形象(插入式效果),服装设计师要为演员设计服装,而设计服装就需要演员的一些资料数据,接下来把演员的资料数据给服装设计师(相当于发送过程,这一过程没有直接对演员产生影响),然后服装设计师设计出服装给演员穿上(发送式效果).可以这样理解,发送式效果所获得的效果信号就相当于套在演员(经过处理的基础人声信号)身上的衣服.
以上内容也是别人教我的,很实用,他学的专业就是这方面,为什么要按这样的步骤具体我不解释了,太麻烦.
很多混音产生问题主要是混响器和延时器以插入方式加入到音轨之中(插入式效果),这是混
音大忌,其实我之前也一直都在犯这样的错,好在现在终于明白正确的方法了.
补充一下,以文中步骤为例,如果混响和延时是插入式效果的话那么步骤就是第2步只添加一条总线A,混响和延时效果器在第3步时直接加在人声轨或总线A上,只有一条总线A的话第5步也就不需要了,也就是没有"发送"这一过程.
关于需不需要再添加其他的效果器这得视情况定,效果器加得越多问题可能越多,本着能少加尽量少加的原则,人声(压缩器),总线A(EQ,RDeEsser消除齿音实质上也是调整EQ),总线B(延时),总线C(混响),主控轨(L2或臭氧),这是最基本的5个.如果要添加额外的效果器的话是以插入式效果直接加在人声轨上,发送式效果一般情况下只有延时和混响需要.
也许有人会问,都是插入式效果为什么不直接把EQ也添加在人声轨上呢?人声轨不是也可以发送到其他总线吗?为什么要特意添加一个总线A呢?这里需要注意,压缩和EQ处理的是两类完全不同的参数,如果都放在一起的话不方便调节,分开的话在混音器界面还可以调节音量配比.
另外,如果是多人合唱有多个人声轨,那么分别给每个人声轨插入压缩器后,再让所有人声轨都输出到总线A,这也就是总线(BUS)的含义,可以形象地理解为将所有人都装入一辆巴士中,然后所有人都共用总线A所插入的EQ(这时在混音器界面调节总线A的音量时所有的人声音量都会产生变化),接着再将总线A分别发送至总线B(延时)和总线C(混响).当然,如果你觉得所有人声共用一个EQ参数不爽的话还可以替每个人声单独设置一条EQ总线,然后将所有EQ总线汇总至另一条总线,再发送至延时总线和混响总线(也可以不汇总,每条EQ总线单独分别发送至延时和混响总线,但这比较麻烦,不建议这样做).
附合唱逻辑关系图
共用EQ
独立EQ The End。