邮箱采集:八爪鱼数据采集器图文详解
八爪鱼采集器采集数据的基本方法和流程

八爪鱼采集器采集数据的基本方法和流程下载提示:该文档是本店铺精心编制而成的,希望大家下载后,能够帮助大家解决实际问题。
文档下载后可定制修改,请根据实际需要进行调整和使用,谢谢!本店铺为大家提供各种类型的实用资料,如教育随笔、日记赏析、句子摘抄、古诗大全、经典美文、话题作文、工作总结、词语解析、文案摘录、其他资料等等,想了解不同资料格式和写法,敬请关注!Download tips: This document is carefully compiled by this editor. I hope that after you download it, it can help you solve practical problems. The document can be customized and modified after downloading, please adjust and use it according to actual needs, thank you! In addition, this shop provides you with various types of practical materials, such as educational essays, diary appreciation, sentence excerpts, ancient poems, classic articles, topic composition, work summary, word parsing, copy excerpts, other materials and so on, want to know different data formats and writing methods, please pay attention!一、概述八爪鱼采集器是一款功能强大的数据采集工具,能够帮助用户快速高效地获取所需数据。
【八爪鱼采集教程】提取数据如何使用备用位置

【八爪鱼采集教程】提取数据如何使用备用位置八爪鱼提取字段时,默认每个字段都是在页面里固定的位置,但是某些特殊情况,当某字段在不同的页面是不同的位置时,也可以用八爪鱼的备选位置功能。
当需要提取的字段在网页两个不同位置,即一个Xpath无法定位到该字段时,我们便需要使用备选功能。
下面为你演示如何设置备选位置:示例网站:https:///12079776060.htmlhttps://item.jd.hk/1958056917.html步骤一:自定义采集任务→输入网址提取数据使用备用位置-图1提取数据使用备用位置-图2步骤二:提取元素字段(商品名、店铺名)提取数据使用备用位置-图3步骤三:保存并启动 直接单机运行可以看到第二个网页店铺名空白,提取不到提取数据使用备用位置-图4这时我们回到流程界面,手动运行一下规则。
提取数据使用备用位置-图5提取数据使用备用位置-图6发现第一个网页的字段2可以提取到,第二个网页则为空白,提取不到。
说明两个网页店铺名的字段Xpath不一样,我们用第一个网页的Xpath提取不到第二个网页的信息。
这时我们需要用到备用位置。
步骤四:选中店铺名字段→点击自定义字段→自定义定位元素方式→设置备用位置提取数据使用备用位置-图7 提取数据使用备用位置-图8提取数据使用备用位置-图9提取数据使用备用位置-图10说明:点击需要设置备用位置的元素,选择将这个元素设为备选即可。
也可以自己通过Xpath 进行修改。
提取数据使用备用位置-图11提取数据使用备用位置-图12单机运行一次,发现可以采集到,设置备用位置成功。
提取数据使用备用位置-图13相关采集教程:淘宝评论采集新浪微博数据采集搜狗微信文章采集八爪鱼——70万用户选择的网页数据采集器。
1、操作简单,任何人都可以用:无需技术背景,会上网就能采集。
完全可视化流程,点击鼠标完成操作,2分钟即可快速入门。
2、功能强大,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布流、Ajax脚本异步加载数据的网页,均可经过简单设置进行采集。
八爪鱼软件地图采集图文攻略

使用八爪鱼采集软件采集百度地图搜索结果图文攻略
八爪鱼采集软件的规则市场内更新了百度地图搜索结果采集,本文主要介绍如何采集的详细图文步骤。
首先还是先去八爪鱼采集器内的规则市场搜索下,百度地图采集的规则,如下图:
搜索到之后,将百度地图的规则下载下来,导入到新任务中。
有的小伙伴们会提到下载的时候需要扣除积分,规则太多则完全不够用啊,其实,积分的获取非常简单,八爪鱼采集器提供了各种免费赚积分的途径,快速查看如何免费赚积分。
下载下来的规则,里面有一个关键词示例,就是“教育”,大家可以自行修改成自己想要查询的关键词,修改办法十分简单,点击流程框内的“输入文字”,在右侧的框内将教育修改成为其他的关键词,点击保存,注意,本处只可放入一个关键词哦。
由于这个地图页面有防采集措施,所以大家就一个关键词一个关键词的采集比较好,建议使用云采集会更有效的突破防采集哦!如果要多个关键词一起修改,则可按下图设置关键词循环。
最后,我们就来一起看下采集的成果吧!采集完毕后可以根据自己的需要将数据保存为EXCEL、TXT、HTML、数据库等多种格式哦。
八爪鱼如何登录采集
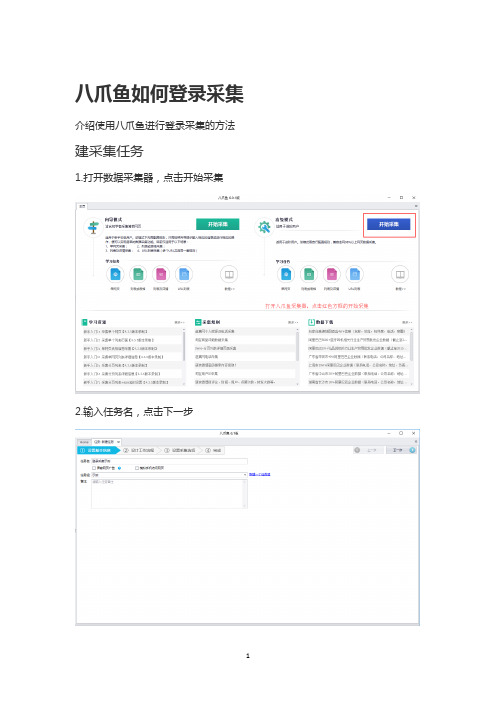
八爪鱼如何登录采集介绍使用八爪鱼进行登录采集的方法建采集任务
1.打开数据采集器,点击开始采集
2.输入任务名,点击下一步
编写采集规则
1.复制你要登录采集的网址
2.在流程设计器里选择打开网页,并拖动到设计器里,粘贴刚刚复制的网址,点击保存并打开网站
3.在下面打开的网址上找到账号输入框并点击右键,执行输入文本操作,如图所示
4.在红色方块指示区域输入登录账号,并点击保存
5.完成账号的保存好,继续右键点击密码输入框,执行输入文本操作,如图所示
6.在红色方框指示区域内输入登录密码,记得点击保存
7.最后一步,鼠标右键点击登录,再选择执行点击元素操作
8.成功登录采集页面,接下来就可以对需要采集的数据进行抓取了。
八爪鱼采集器流程步骤高级选项说明

八爪鱼采集器流程步骤高级选项说明1、打开网页该步骤根据设定的网址打开网页,一般为网页采集流程的第一个步骤,用来打开指定的网站或者网页。
如果有多个类似的网址需要分别打开执行同样的采集流程,则应该放置在循环的内部,并作为第一个子步骤1)页面URL页面URL,一般可以从网页浏览器地址栏中复制得到,如:/ 2)操作名自定义操作名3)超时在网页加载完成前等待的最大时间。
如果网页打开缓慢,或者长时间无法打开,则流程最多等待超时指定的时间,之后无论网页是否加载完成,都直接执行下一步骤。
应尽量避免设置过长的超时时间,因为这会影响采集速度4)阻止弹出用以屏蔽网页弹窗广告,如果打开的网页偶尔会变成另外一个广告页面,则可以使用本选项阻止广告页面弹出5)使用循环配合循环步骤来使用,用以重复打开多个类似的网页,然后执行同样的一套流程,循环打开网页时,应为作为循环步骤的第一个子步骤。
如果勾选此项,则无需手动设置网页地址,网页地址会自动显示循环设定的网址列表的当前循环项6)滚动页面个别网页在打开网页后并没有显示所有数据,需要滚动鼠标滚轮或者拖动页面滚动条到底部,才会加载没有显示的数据,使用此选项在页面加载完成后向下滚动,滚动方式有向下滚动一屏和直接滚动到底部两种7)清理缓存在八爪鱼中,如果需要切换账号,可使用清理浏览器缓存,重新设置其他账号8)自定义cookiecookie指某些网站为了辨别用户身份、进行session 跟踪而储存在用户本地终端上的数据(通常经过加密)。
在八爪鱼中,可以通过做一次预登录获取页面cookie,通过勾选打开网页时使用指定cookie获取登陆后的cookie,从而记住登录状态。
获取的当前页面cookie,可以通过点击查看cookie9)重试如果网页没有按照成功打开预期页面,例如显示服务器错误(500),访问频率太快等,或者跳转到其他正常执行不应该出现的页面,可以使用本选项进行重试,但必须配合以下几个重试参数执行,请注意以下几种判断的情况任意一种出现都会导致重试①当前网页的网址/文本/xpath,包含/不包含如果当前页面网址/文本/xpath总是出现/不出现某个特殊内容,则使用此选项可以判断有没有打开预期页面,需要重试②最大重试次数为了避免无限制重复尝试,请使用本选项限制最大重复尝试的次数,如果重试到达最大允许的次数,任然没有成功,则流程将停止重试,继续执行下一步骤③时间间隔在两次重试之间等待的时间,一般情况下,当打开网页出错时,立即重试很有可能是同样的错误,适当等待则可能成功打开预期网页,但应该尽量避免设置过长的等待时间,因为这会影响采集速度2、点击元素该步骤对网页上指定的元素执行鼠标左键单击动作,比如点击按钮,点击超链接等1)操作名自定义操作名2)执行前等待对此步骤设置执行前等待,即等待设置的时间后,再进行此步骤3)或者出现元素或者出现元素,配合执行前等待使用,在其中输入元素的xpath可以在出现该元素的时候结束执行前的等待。
八爪鱼采集器使用入门教程

三、提取数据
正式的采集步骤
四、点击元素 循环本身是不会有任何执行操作的,如果要实现循环翻页,则 需要一个点击元素来和循环产生联动
流程设计步骤
流程设计步骤: 在八爪鱼采集器中,一共有11个流程设计操作,其中分为基本步骤和进阶步骤,划分为以下: 基本步骤: 基本步骤本身是应用较多的流程设计操作,通常来说,要实现一个网页的数据快 速整理与采集,这些步骤是必不可少的,基本步骤如下: 1)打开网页 2)点击元素 3)循环 4)提取数据 进阶步骤: 进阶步骤,是指除基本步骤外,我们需要通过下列操作来辅助完成我们的数据采 集,例如:有时候我们采集的数据需要先输入文本才能进行采集,进阶步骤如下: 1)输入文字 2)识别验证码 3)切换下拉选项 4)判断条件 5)移动鼠标到元素上 6)结束循环 7)结束流程
操作基本信息及高级选项
在八爪鱼中,流程操作由基本信息与高级选项两部分组成 一、基本信息: 基本信息一般会将该操作流程的基本信息显示出来,例如:打开网页会显示你打开网页的URL, 点击元素会显示你点击的元素文本等 二、高级选项: 高级选项,可以设置一些额外的选项设置,以便辅助规则正确有效执行,例如:执行前等待、元素 在iframe里等
二、任务规则:
任务规则,就是指根据特定的网页,按人用浏览器去访问网页的过程制定好的自动化任务程 序,一般来说,一个类型相似的网站对应一个任务规则 三、任务状态: 1)任务生命周期:可执行状态、等待状态、运行中状态、已完成状态、已停止状态 2)运行中状态:1)本地采集状态、云采集状态
八爪鱼图片采集攻略

八爪鱼采集软件批量图片采集攻略瀑布流网站、AJAX网页等技术和网站技术架构和网页结构都与以往传统的网站有所区别,如何对这类型网站进行网页数据采集,下面,本文就来详细介绍下,这类型网站时使用八爪鱼采集器的详细操作步骤。
以“东大门”这个站为采集范例,来说明下图片采集要如何实现。
先来看下这个网站的特殊之处,首先,页面上的图片不是一次加载完成,而需要滚动多次才会滚动到底部,这类型的网站像新浪微博也是类似情况,当然也有的瀑布流网站是一直加载无法见底的,这个情况另外介绍。
其次,产品详情页不能通过点击标题进入,而需要点击图片才能进入。
针对以上两点问题,在使用八爪鱼采集器采集图片等信息的时候,在设置规则的时候需要注意以下几点:1、打开网页的时候,需要设置AJAX网页加载,以便确保数据采集的时候不会遗漏,像东大门这个示范站,我们实际滚动大约需要4次,所以我们在AJAX加载到底部,滚动次数可以设置为4次或5次均可,次数可以适当的比实际的滚动次数稍微多一两次!2、由于我们采集时需要点击图片才能进入到产品详情页,在建立元素循环列表的时候,需要将图片链接设置为列表项,如下图所示,我们需要点击A标签取到图片的链接地址,并以此链接为循环列表,添加元素到列表的时候,每次都需要点击A标签,2-3次添加之后系统会将所有选中的图片链接自动读取出来。
3、采集图片的URL,按第二步的操作进入到详情页后,就是提取数据了,对于产品名称和价格,都是文本形式,提取非常简单,而对于图片,会需要先采集到图片本身的URL,再进行转换,采集办法如下图所示,选中图片后,在弹出的对话框中可选中IMG标签,选择图片的超链接进行采集。
4、设置完成后,保存,来看下采集的战果!URL、产品名称、价格均已采集下来,我们导出为EXCEL格式的文件。
5、将图片的URL转换为图片批量下载下来,相关的工具再八爪鱼数据采集器论坛可以免费下载。
将URL地址导入工具即可将图片转换下来!经过以上简单的5步,AJAX网页上的瀑布流图片就采集下来了,当然,如果你要进行多页采集,只需要再第2步的设置一次翻页循环即可,翻页循环的相关视频教程可直接点此查看。
八爪鱼采集器新手入门必备的知识点(7.0版)18页PPT
八爪鱼采集器是一款模拟人的思维去访问网页
文档的互联网数据采集器。通过设计工作流程,可以 实现采集的程序自动化,以达到快速的对网页数据进 行收集整合,完成用户数据采集的目的。
深圳视界信息技术有限公司
界面简介
-八爪鱼界面功能介绍
深圳视界信息技术有限公司
界面简介
-智能模式介绍
深圳视界信息技术有限公司
界面简介
常用步骤:
常用步骤本身是应用较多的流程设计操作,通常来说,要实现一个网页的数据快速整理
与采集,这些步骤是必不可少的,基本步骤如下: 1)打开网页 2)点击元素 3)循环 4)提取数据
进阶步骤:
进阶步骤,是指除基本步骤外,我们需要通过下列操作来辅助完成我们的数据采集,进 阶步骤如下:
1)输入文字 3)切换下拉选项 5)移动鼠标到元素上
7)结束流程
2)识别验证码 4)判断条件 6)结束循环
深圳视界信息技术有限公司
实战演练
新浪财经 vip.stock.finance.sina/q/go.php/vIR_RatingNewest/index.phtml?p =1
58同城 bj.58/waiyu/30390652277055x.shtml?adtype=1&entinfo=303906 52277055_0&adact=3&psid=167579685196837197191772083&i uType=q_1&ClickID=2&PGTID=0d303871-0000-4c8d-427b904ef31bbe7d
结语: 实践出真知,八爪鱼让数据触手可及
深圳视界信息技术有限公司
实战演练
一、打开网页:
八爪鱼产品使用手册

八爪鱼产品使用手册目录1关于八爪鱼 (2)2Cookie (更多内容详见Cookie 视频) (2)2.1 Cookie诞生 (2)2.2 Cookie概述 (2)2.3 Cookie工作原理 (3)3Xpath、Html (3)3.1 Xpath、Html概念 (3)3.2 Html结构 (4)3.3 Html标签、元素、节点 (4)3.4 Html常见标签 (5)3.5 Html常见属性 (6)3.6 Xml、Xpath、Html关系和区别 (7)4常见问题 (7)5常见软件操作教程 (10)5.1 采集单个网页 (10)5.2 采集单个列表页面 (10)5.3 单网页表格信息采集 (10)5.4 采集单网页列表详细信息 (10)5.5 采集分页列表 (10)5.6 采集分页列表详细信息 (10)5.7 采集分页列表+ajax延时设置 (10)5.8 单个文本输入及各种登录方式采集 (11)5.9 Cookie登录 (11)5.10 文本循环输入 (11)5.11 循环切换下拉框 (11)5.12 xpath入门1 (11)5.13 xpath入门2 (11)5.14 一二页重复循环采集 (11)关于八爪鱼八爪鱼·大数据,通过自主创新研发,以分布式云平台架构为产品核心,帮助客户通过在极短的时间内,通过简单操作即可获取想要的数据,并以结构化数据展示,为企业数据挖掘与数据分析提供基础数据源。
于2015年1月,获得国家重点软件企业上市公司“拓尔思”投资。
Cookie (更多内容详见Cookie 视频)Cookie诞生当某个用户打开浏览器发出页面请求时,web服务器只是进行简单相应,然后就关闭与该用户的连接。
所以当用户每发起一个打开网页请求到web服务器的时候,无论是否是第一次打开同一个网页,web服务器都会把这个请求当作第一次来对待,那这样的缺陷可想而知,比如每次打开登录页面的时候都需要输入用户名、密码。
八爪鱼爬虫采集方法
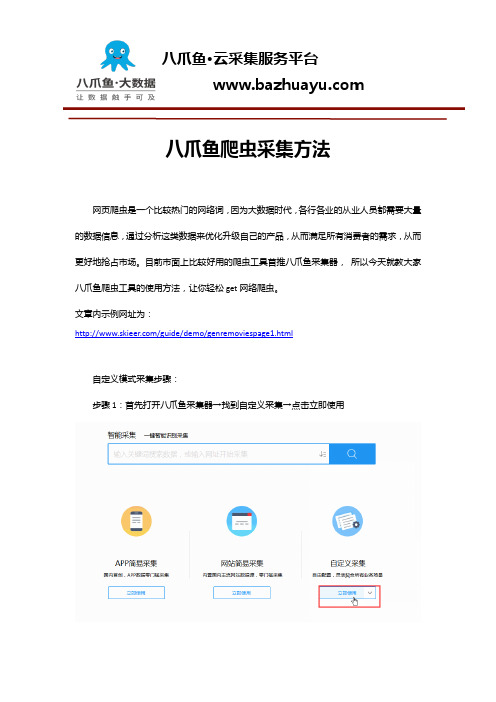
八爪鱼爬虫采集方法网页爬虫是一个比较热门的网络词,因为大数据时代,各行各业的从业人员都需要大量的数据信息,通过分析这类数据来优化升级自己的产品,从而满足所有消费者的需求,从而更好地抢占市场。
目前市面上比较好用的爬虫工具首推八爪鱼采集器,所以今天就教大家八爪鱼爬虫工具的使用方法,让你轻松get网络爬虫。
文章内示例网址为:/guide/demo/genremoviespage1.html自定义模式采集步骤:步骤1:首先打开八爪鱼采集器→找到自定义采集→点击立即使用自定义模式-图1步骤2:输入网址→设置翻页循环→设置字段提取→修改字段名→对规则进行手动检查→选择采集类型启动采集自定义模式-图2:输入网址自定义模式-图3:设置翻页循环自定义模式-图4:创建循环列表自定义模式-图5:提取字段自定义模式-图6:修改字段名注意点:1.设置翻页循环:观察网页底部有没有翻页图标,如果有并且需要翻页则点击翻页图标,操作提示中循环点击下一页表示循环翻页,可以在循环中设置翻页次数,设置几次则采集网页最新内容几页。
采集该链接的文本选项则会出现提取数据步骤,提取下一页对应的文本;点击采集该链接地址步骤选项会出现提取数据步骤,提取当前字段对应的链接地址。
点击该链接则会出现点击元素步骤,点击该元素一次。
2.设置字段提取:先对网页内容进行分区块,思路为循环各区块,再从循环到的区块中提取每个字段内容,所以设置时先点击2-3各区块,八爪鱼会自动选中剩余所有区块,点击采集以下元素文本会出现循环提取数据步骤,实现对区块的循环采集,但是此时每个区块循环时只会将区块内文字合并为一条提取,此时我们删除该字段并手动添加需要提取的所有字段;点击循环点击每个元素则会出现循环点击元素步骤,对每个区块进行一次点击,该示例中区块点击没有效果,所以该示例中循环点击不存在效果。
如果选择错误,或者出现的内容列表不是你需要的,可以在操作提示中点击区块后的垃圾桶图标进行删除操作,或者点击取消选择,重新设置。
八爪鱼采集器使用进阶教程

循环
基本信息:
•循环列表 循环操作的列表元素
高级选项:
•执行前等待 流程步骤执行前等待时间 •或者出现元素 填写Xpath路径,配合执行前等待 一起使用 •元素在Iframe里 填写Iframe的Xpath,解决框架网页 问题 •循环方式 五种循环方式,解决各种循环场景 •满足以下条件时退出循环 限制循环次数
八爪鱼默认生成操作,即便不设置,在特定流 程步骤中,也会隐式生效,例如:流程开始、结束流程
打开网页
基本信息:
•页面Url 打开网页的网址
高级选项:
•阻止弹窗 阻止弹出窗口 •使用循环 配合URL循环一起使用 •滚动页面 内置浏览器滚动次数与方式 •缓存设置 1.清除缓存 2.Cookie •激活重试 按条件尝试重新打开网页
点击元素
基本信息:
•要点击元素 点击元素基本信息
高级选项:
•使用循环 配合单个元素循环、不固定元素列 表、固定元素列表循环一起使用 •开新标签 新标签打开网页页面 •滚动页面 内置浏览器滚动次数与方式 •AJAX加载 页面自动刷新时间,AJAX超时为 设置时间 定位锚点 设置后页面自动跳置锚点 •激活重试 按条件尝试重新打开网页
翻页问题
死循环翻页 死循环翻页,一般都是由点击翻页的自定义定位 元素方式中的XPath路径不精准导致的,此时我们需 要根据网页特点,来修改Xpath,教程。 •提取为空 如果网页能正常打开,提取为空一般有下列两种 情况: 1)IFRAME IFRAME问题教程 2)Xpath不精准 Xpath不精准,导致部分数据提取不到,这时我 们需要观察网页结构进行修改Xpath Xpath基础教程 观看完后,尝试自己解决,如果未能解决,可以 到Xpath板块进行发帖咨询
企业信息采集器使用方法

企业信息采集器使用方法一般企业都会密切关注行业或者竞争对手的实时动态,而且有的企业还会有企业信息收集分析部门,不定时地为企业的决策者提供准确的数据分析报表。
这时候企业信息的采集就变得尤为重要了,企业信息采集器可选八爪鱼采集器操作简单采集效率高。
本文介绍使用八爪鱼采集天眼查企业信息(以家装公司为例)的方法采集网站:https:///search?key=%E5%AE%B6%E8%A3%85%E5%85%AC%E5%8F%B8&c heckFrom=searchBox步骤1:创建采集任务1)打开八爪鱼软件,选择自定义采集下拉框中的向导模式开始采集2)粘贴地址链接,然后点击“下一步”步骤2:创建翻页设置1)打开网页以后,勾选左边第二栏“网页列表中每个链接页的详细内容”,然后选择“下一步”2)之后在列表中选中公司的链接,配置列表里就会有相应的文字显示然后接着选中第二条,上面的列表框里就会自动显示剩下的链接,接着选择“下一步”3)这时需要设置一下翻页选项,勾选第二个“需要翻页”,并选中页面底部的翻页按钮,以创建翻页设置。
步骤3 :提取所需信息1)之后选择我们需要的内容,如下图红框所示,分别选中需要提取的信息2)然后在页面上方的列表中对选择的字段进行自定义修改,并选择“下一步”步骤4:数据采集及导出1)最后启动本地采集,采集完成之后选择合适的方式导出 2)导出之后数据如下图所示相关采集教程:黄页88企业信息采集:/tutorial/hottutorial/qyxx/huangye88Xpath 入门教程1,以采集黄页88企业信息举例:/tutorial/xpathrm1黄页88企业名录采集方法:/tutorial/hy88cj顺企网企业黄页采集详细步骤:/tutorial/sqwcj-7114黄页企业信息采集详细教程步骤:/tutorial/qyxxcj-7企业信息采集软件:/tutorial/qyxxcj使用八爪鱼采集天眼查企业信息(以家装公司为例):/tutorial/tycqyxxcj企业信息采集教程,以采集企查查企业名录为例:/tutorial/qichachacj企查查企业邮箱采集:/tutorial/qccqyemailcj。
八爪鱼爬虫模拟登录抓取数据

八爪鱼使用cookie登陆网站采集数据(7.0版本)本文给大家演示,通过记录Cookie登录网站,再进行数据采集的方式。
Cookie:某些网站为了辨别用户身份、进行session 跟踪而储存在用户本地终端上的数据(通常经过加密)。
在八爪鱼里,有些网站是需要登陆账号之后,才能进行采集数据。
我们需要先做一个登录流程,登陆进网站,然后获取登陆后的Cookie,记住登陆状态,浏览器即会自动打开登陆后要采集的网址。
登录网址:https:///示例网址:https:///list?spm=a217f.8051907.312344.10.Xesvx1&style=grid&selle r_type=taobao&cps=yes&cat=50000671我们需要先创建一个登录流程:在登录网址里面,输入用户名、密码,登陆网站。
然后获取登陆后的Cookie,记住登陆状态。
步骤1:打开网页1)登陆八爪鱼7.0采集器,点击新建任务,选择“自定义采集”,进入到任务配置页面2)然后输入登录网址,点击“保存网址”,系统会进入到流程设计页面并自动打开前面输入的登录网址Cookie 登录方法(7.0)-图1步骤2:登录网站1)在浏览器中,用鼠标点击用户名输入框,输入自己的用户名。
用同样的方式输入密码Cookie登录方法(7.0)-图22)在浏览器中,用鼠标点击登陆按钮,在右边弹出的提示框里选择“点击该按钮”(或直接按键盘上的enter键也可)Cookie登录方法(7.0)-图33)浏览器会自动登陆,打开我们最终需要采集数据的网址。
这时登陆流程便做好了步骤3:新建“打开网页”1)打开“流程”。
在流程设计器中,拖入一个打开网页的步骤2)输入最终要采集的网址URL,点击“确定”。
八爪鱼浏览器以登录后的状态打开了此URLCookie登录方法(7.0)-图43)在拖入“打开网页”的步骤之后,默认超时时间是空白的。
QQ采集图文详解-八爪鱼采集

现在QQ采集时,QQ本身有很多限制,很多网站会希望能快速有效的将QQ群及QQ号码能收集到并导出,这里我们给大家介绍通过免费采集软件-八爪鱼采集器如何快速的实现这点。
1、打开采集器,登陆进去之后,找到菜单项【采集规则】一项,双击打开,在【规则市场】中找到规则名称为:QQ群-群成员-QQ号邮箱采集的规则,点击产品名称进入规则下载页,首次使用的用户需要先下载此规则,已经下载过此规则的用户可以调过,无需再次下载。
2、进入到软件主页,双击【快速开始】选项,在左上角菜单栏双击【导入任务】选项,将刚下载好的规则导入进去,为了方便管理任务,你可以新建一个任务分组比如QQ号码采集,方便记忆,这个分组名称可以任意建立命名。
3、在【我的任务】中找到刚刚导入的规则任务名称,双击点击开始运行。
注意,规则导入过一次之后,下次再使用此规则,打开软件后直接进入该步骤即可,无需再次运行第一步和第二步。
4、按照提示,点击下一步,进入到【设计工作流程】页面,此步骤如果你需要再已有的规则上进行修改,可以在此页面进行配置或修改新的规则,如果无需修改,直接点击下一步进入下一流程。
5、【设置执行计划】页面,你可以设置采集的相关选项,如果你打算使用云采集,还可以设置启动的时间,系统会自动按照该时间进行采集,云采集还能将每次下载的数据自动去重,自动过滤你之前已经下载过的数据。
如果你不打算采取云采集,直接点击【下一步】进入下一流程6、任务配置完成页,你可以选择【检查任务】进入QQ数据采集运行检查,任务检查时点击运行按钮,即可开始QQ采集,在此,需要你登陆要采集的QQ号码,系统即可自动开始运行,任务检查完毕,你也可以将数据直接导出7、在任务配置完成页,你也可以选择【完成】设置【云采集】或【单机采集】,云采集系统会自动根据你的设置定时定量完成采集和去重工作。
八爪鱼采集器如何循环采集数据PPT课件

四、固定元素列表循环
适用情况:网页上要采集的元素是固定数目的。1) 每一页的元素数目固定;2)采集特定数目的元素。 实现方式:通过固定因素列表循环,循环页面内 的固定元素。 定位方式:使用xpath定位,一条xpath对应循环 列表中的一个元素。 示例网址:/
三、单个元素循环
适用情况:需循环点击页面内的某个按钮。例如: 循环点击下一页按钮进行翻页。
实现方式:通过单个元素循环方式,达到循环点 击下一页按钮进行翻页目的。
定位方式:使用xpath定位,在当前页始终能定 位到下一页按钮。
示例网址: /guide/demo/genrem oviespage1.html
五、不固定元素列表循环
适用情况:网页上要采集的元素不是固定数目。 每个页面上元素数目不固定:一页存在同类元 素7个,另一页存在同类元素10个......
实现方式:通过不固定因素列表循环,循环页 面内的不固定数目的元素。
定位方式:使用xpath定位,一条xpath对应 循环列表中的多个元素。
示例网址: /?utm_source=link&spm =u-LscBIm_2J9tMeMj.psy_111
应用:循环下翻下拉框
适用情况:网页中存在可以下拉并选择元素的 下拉框,需要先循环选择下拉框中的元素,再 进行数据采集。 循环选择下拉框中所有元素或循环选择下拉框 中某些特定元素。 示例网址:/
The End
谢谢大家
有的网页点击搜索按钮后页面会发生变化能正常采集到第一个关键词的数据则打开网页步骤需放在文本循环内示例网址
八爪鱼 让数据触手可及
视频教程PPT
五大循环方式
一、URL循环 二、文本循环 三、单个元素循环 四、固定元素列表循环 五、不固定元素列表循环
八爪鱼采集器使用方法图解

八爪鱼采集器使用方法
图解
文档编制序号:[KKIDT-LLE0828-LLETD298-POI08]
八爪鱼采集器使用方法图解:
1、打开八爪鱼采集器的客户端,登陆软件之后新建一个任务,打开你要采集的网站地址。
这里我自己示范的原创设计手稿的采集。
2、进入到设计工作流程环节,在界面浏览器那输入你要采集的网址,点击打开,你就能看到你要采集的网站界面,由于这个网址存在多页内容需要采集,我们再设置采集规则的时候,可以先建立翻页循环,先把鼠标选择页面上的【下一页】按钮,在弹出的任务对话框,选择高级选项中的【循环点击下一页】,软件会自动建立一个翻页循环。
3、建好翻页循环好,就是采集当前页上的内容,我要采集图片的URL,就选中一个图片,然后单击,软件会自动弹出对话框,先建立一个元素循环列表。
当前页面的所有元素都被抓取后,循环列表则建立完成。
4、设置要抓取的内容,选择元素循环列表中的任意一个元素,在浏览器内找到该元素对应的图片,点击后弹出对话框,选择【抓取这个元素的图片地址】为字段1,同时我为了方便识别,还抓取了字段2为图片标题名称,设置原理同图片地址。
5、检查一下,翻页循环框应该将产品循环框嵌套在内,表示,先抓取完当前一整页的图片URL后再翻页。
6、设置执行计划后,就可以开始采集了,单击采集的话,直接点击【完成】步骤下的【检查任务】,开始运行任务。
采集完毕后可以直接下载成EXCEL的文件。
7、将URL转换为图片,这里用八爪鱼图片转换工具,将EXCEL导入之
后,就可以自动等待系统将图片下载下来了!
8、。
八爪鱼采集器高阶教程

八爪鱼采集器高阶教程手动创建翻页循环及下一页死循环解决方法手动创建翻页循环相信很多朋友都碰到过这种情况,明明是一个翻页按钮,但是点击后没有创建翻页人选项,很多人会以为这种网页就不能做翻页了,其实这种类型的网页我们可以通过手动创建出一个翻页循环来解决。
接下来就教大家如何手动创建翻页循环。
首先我们打开一个无法自动创建翻页的网页,如图中所示,当我们点击下一页按钮后,跳出的执行框中并没有循环点击的选项出现;针对这种类型的网页,我们可以通过下面几个简单的步骤进行循环翻页的手动创建:1)选择点击这个元素,添加一个点击步骤到流程中系统添加点击步骤到流程中后,点击自定义,进入自定义定位方式界面2)将图中红色方框中下一页的Xpath复制出来,然后把创建的点击步骤删除,因为我们让系统自动创建点击步骤只是为了得到下一页的Xpath,如果是懂Xpath的朋友可以省掉这个步骤。
自动生成的XPath只能对应当前网页,翻页后的页面格式有可能不能应对,所以需要自己修改。
3)接下来我们创翻页循环,先拖一个循环步骤到流程中,打开高级选项,勾选点击单个元素,将之前复制的下一页人Xpath填到单个元素输入框中,点击保存。
4)拖入一个点击步骤到,打开高级选项,勾选上点击当前循环中设置的元素,点击保存。
翻页循环就建好了,这种类型的翻页问题就可以通过上面介绍的方法解决。
接下来我们再看一下:下一页死循环的问题。
下一页死循环解决方法什么是下一页死循环?有些网站可能在我们用系统做好的规则进行采集的时候,明明已经采集到最后一页了,就是不终止跳出循环,一直在最后一页循环采集,这种情况其实是由于xpath定位不对导致的,这种翻页情况我们称为下一页死循环,它可以通过我们对xpath的修改来解决。
当我们采集出现问题的时候,我们可以通过规则流程来找到问题所在。
下面的规则是直接按照新手入门的步骤做的如上图:浏览器中要采集的数据已经在最后一页了,可以我们在循环列表中依旧能找到下一页的按钮,代表一直都可以点击这个按钮进行采集,循环是结束不了的点开循环列表的高级设置按钮,可以看到下一页的xpath如下图所示:把这个xpath复制到火狐浏览器的Firebug里面进行定位,我们发现在第一页是的确可以定位下一页的,可以看到这个xpath在火狐里面每一页都能定位,再看一下第一页(class="nex t")和第四页(class="no_next")里面源码的区别可以看到第一页和第三页下一页的class属性是不一样的,我们只需要前面几页的下一页能正确定位,但是最后一页是不需要的,这样可以直接用class来区别。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
2dg0f7c9b 99彩
黔驴技穷要奋斗,江郎才尽须学习。一笔代
将邮箱采集规则直接导入到任务中 前去【我的任务】找到任务标题,双击点击
开始运行,基本信息设置可以修改也可以不修
改,这个地方只是对任务做个备注。然后点击【下 一步】
黔驴技穷要奋斗,江郎才尽须学习。一笔代
设计流程页面,你可以再红框标出来的地方
修改你想要采集的邮箱搜索条件及网址即可
设置执行计划,在此步骤,云采集的可以根
据自己的实际采集频率设置,单击采集则无需改 动他的设置项,直接进入下一步即可。
黔驴技穷要奋斗,江郎才尽须学习。一笔代
设置完成后,如果需要云采集,则选择【完
成】按钮,如果是单机直接采集,则可直接点击 【检查任务】进入单机执行页面,点击上的运行
按钮,即可看到数据采集的情况,运行完成之后,
邮件营销很多企业会用到,企业常常会需要
采集数量庞大的邮箱地址,下面我们就来介绍 下,使用八爪鱼采集器,快速的采集组,根据自己的习
黔驴技穷要奋斗,江郎才尽须学习。一笔代
惯设立任务组名称。 前去软件内的规则市场,搜索“邮箱"关键
词,找到邮箱采集的规则,点击下载规则 点击【快速开始】按钮,选择【导入任务】,