Opencv2.4.9源码分析——GradientBoostedTrees详解
(5条消息)Opencv2.4.9源码分析
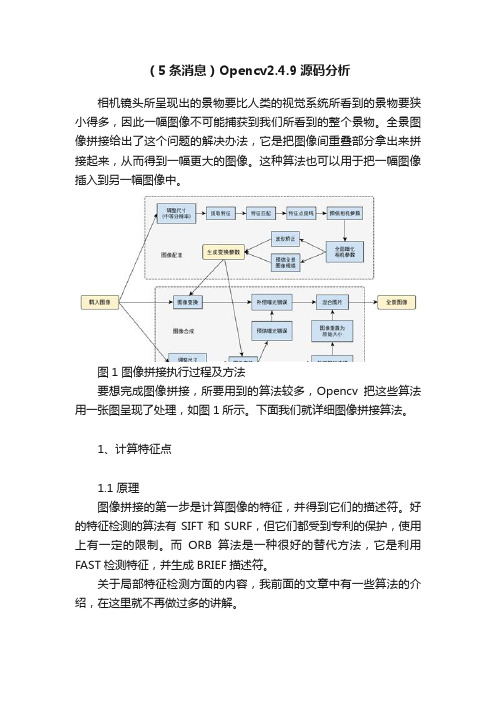
(5条消息)Opencv2.4.9源码分析相机镜头所呈现出的景物要比人类的视觉系统所看到的景物要狭小得多,因此一幅图像不可能捕获到我们所看到的整个景物。
全景图像拼接给出了这个问题的解决办法,它是把图像间重叠部分拿出来拼接起来,从而得到一幅更大的图像。
这种算法也可以用于把一幅图像插入到另一幅图像中。
图1 图像拼接执行过程及方法要想完成图像拼接,所要用到的算法较多,Opencv把这些算法用一张图呈现了处理,如图1所示。
下面我们就详细图像拼接算法。
1、计算特征点1.1 原理图像拼接的第一步是计算图像的特征,并得到它们的描述符。
好的特征检测的算法有SIFT和SURF,但它们都受到专利的保护,使用上有一定的限制。
而ORB算法是一种很好的替代方法,它是利用FAST检测特征,并生成BRIEF描述符。
关于局部特征检测方面的内容,我前面的文章中有一些算法的介绍,在这里就不再做过多的讲解。
1.2 源码Opencv中应用的是SURF算法和ORB算法,详细的内容为:class detail::FeaturesFinder表示寻找图像特征的类:1.class CV_EXPORTS FeaturesFinder2.{3.public:4.virtual ~FeaturesFinder() {}5.//寻找给定图像的特征6.void operator ()(const Mat &image, ImageFeatures &features);7.void operator ()(const Mat &image, ImageFeatures &features, const std::vector<cv::Rect> &rois);8.virtual void collectGarbage() {} //释放已被分配、但还没有被使用的内存9.10.protected:11.//虚函数,根据用户所选取的特征类别,调用不同子类的find函数,目前只实现了SURF特征和ORB特征12.virtual void find(const Mat &image, ImageFeatures &features) = 0;13.};在FeaturesFinder类中,重载( )运算符主要的任务是调用find函数来检测图像特征。
gradientboostingregressor 参数

GradientBoostingRegressor 是Scikit-learn 库中的一个用于回归的机器学习模型。
它基于GradientBoosting 算法,可以用于解决各种回归问题。
以下是GradientBoostingRegressor 的主要参数:1. **base_estimator**: 基学习器的初始估计器。
默认值是None,此时使用决策树作为基学习器。
2. **n_estimators**: 基学习器的数量,即要构建的弱学习器的数量。
默认值是100。
3. **learning_rate**: 学习率,用于控制每个弱学习器的贡献。
默认值是0.1。
4. **max_depth**: 基学习器(决策树)的最大深度。
默认值是3。
5. **min_samples_split**: 基学习器用于分割内部节点的最小样本数。
默认值是2。
6. **min_samples_leaf**: 叶子节点所需的最小样本数。
默认值是1。
7. **max_features**: 基学习器考虑的特征子集的数量或大小。
默认值是'auto',此时会根据数据集的维度来确定最大特征数(对于决策树,最大特征数是输入特征数的平方根)。
8. **random_state**: 随机种子。
默认值是None,此时随机种子由系统时间决定。
9. **subsample**: 用于防止过拟合的样本下采样比例。
默认值是1,表示不进行下采样。
10. **ccp_alpha**: 控制正则化的常数。
默认值是0.0,表示不进行正则化。
11. **validation_fraction**: 用于交叉验证的数据比例。
默认值是0.1,表示使用10% 的数据用于交叉验证。
12. **n_iter_no_change**: 停止训练的条件之一,当提升的变化小于该参数设定的值时,训练将提前结束。
默认值是None,表示没有这个参数。
13. **tol**: 控制收敛的容忍度参数。
opencv2.4.9源码分析——SIFT

赵春江
/zhaocj
一、SIFT 算法
SIFT (尺度不变特征变换, Scale‐Invariant Feature Transform) 是在计算机视觉领域中检测 和描述图像中局部特征的算法,该算法于 1999 年被 David Lowe 提出,并于 2004 年进行了 补充和完善。该算法应用很广,如目标识别,自动导航,图像拼接,三维建模,手势识别, 视频跟踪等。不幸的是,该算法已经在美国申请了专利,专利拥有者为 Lowe 所在的加拿大 不列颠哥伦比亚大学,因此我们不能随意使用它。 用 SIFT 算法所检测到的特征是局部的,而且该特征对于图像的尺度和旋转能够保持不 变性。同时,这些特征对于亮度变化具有很强的鲁棒性,对于噪声和视角的微小变化也能保 持一定的稳定性。SIFT 特征还具有很强的可区分性,它们很容易被提取出来,并且即使在低 概率的不匹配情况下也能够正确的识别出目标来。因此鲁棒性和可区分性是 SIFT 算法最主 要的特点。 SIFT 算法分为 4 个阶段: 1、尺度空间极值检测:该阶段是在图像的全部尺度和全部位置上进行搜索,并通过应 用高斯差分函数可以有效地识别出尺度不变性和旋转不变性的潜在特征点来; 2、特征点的定位:在每个候选特征点上,一个精细的模型被拟合出来用于确定特性点 的位置和尺度。而特征点的最后选取依赖的是它们的稳定程度; 3、方向角度的确定:基于图像的局部梯度方向,为每个特性点分配一个或多个方向角 度。所有后续的操作都是相对于所确定下来的特征点的角度、尺度和位置的基础上进行的, 因此特征点具有这些角度、尺度和位置的不变性; 4、特征点的描述符:在所选定的尺度空间内,测量特征点邻域区域的局部图像梯度, 将这些梯度转换成一种允许局部较大程度的形状变形和亮度变化的描述符形式。 下面就详细阐述 SIFT 算法的这 4 个阶段: 1、尺度空间极值检测 特征点检测的第一步是能够识别出目标的位置和尺度, 对于同一个目标在不同的视角下 这些位置和尺度可以被重复的分配。并且这些检测到的位置是不随图像尺度的变化而改变 的, 因为它们是通过搜索所有尺度上的稳定特征得到的, 所应用的工具就是被称为尺度空间 的连续尺度函数。
Opencv2.4.9源码分析——MSCR

Opencv2.4.9源码分析——MSCR前面我们介绍了MSER方法,但该方法不适用于对彩色图像的区域检测。
为此,Forssen于2007年提出了针对彩色图像的最大稳定极值区域的检测方法——MSCR(Maximally Stable Colour Regions)。
MSCR的检测方法是基于凝聚聚类(AgglomerativeClustering)算法,它把图像中的每个像素作为对象,通过某种相似度准则,依次逐层的进行合并形成簇,即先合并相似度大的对象,再合并相似度小的对象,直到满足某种终止条件为止。
这一过程在MSCR中被称为进化过程,即逐步合并图像中的像素,从而形成斑点区域。
MSCR中所使用的相似度准则是卡方距离(Chi-squared distance):其中,x和y分别为彩色图像中的两个不同像素,下标k表示不同的通道,例如红、绿、蓝三个颜色通道。
因此公式1是一种颜色相似度的度量。
MSCR通过邻域像素之间的颜色相似度来进行聚类合并,邻域关系可以是水平垂直间邻域,也可以是还包括对角线间邻域。
OpenCV使用的是水平垂直间邻域,即当前像素与其右侧像素通过公式1得到一个相似度值,再与其下面像素通过公式1得到另一个相似度值。
所以一般来说,每个像素都有两个相似度值,但图像的最右侧一列和最下面一行只有一个相似度值。
因此对于一个大小为L×M的彩色图像来说,一共有2×L×M-L-M个相似度值。
我们把这些相似度值放入一个列表中,由于该相似度是邻域之间的相似度,类似于求图像的边缘,所以该列表也称为边缘列表。
在凝聚聚类算法中,是需要逐层进行合并的。
在MSCR中合并的层次也称为进化步长,用t 来表示,t∈[0…T],根据经验值,T一般为200,即一共进行200步的进化过程。
在每一层,都对应一个不同的颜色相似度阈值dthr,在该层只选取那些颜色相似度小于该阈值的像素进行合并。
每一层的阈值是不同,并且随着t的增加,阈值也增加,因此达到了合并的区域面积逐步增加的目的。
opencv2.4.9源码分析——SURF

Opencv2.4.9源码分析——SURF赵春江/zhaocj一、SURF 算法SURF (Speeded Up Robust Features)是一种具有鲁棒性的局部特征检测算法,它首先由Herbert Bay 等人于2006年提出,并在2008年进行了完善。
其实该算法是Herbert Bay 在博士期间的研究内容,并作为博士毕业论文的一部分发表。
SURF 算法的部分灵感来自于SIFT 算法,但正如它的名字一样,该算法除了具有重复性高的检测器和可区分性好的描述符特点外,还具有很强的鲁棒性以及更高的运算速度,如Bay 所述,SURF 至少比SIFT 快3倍以上,综合性能要优于SIFT 算法。
与SIFT 算法一样,SURF 算法也在美国申请了专利。
之所以SURF 算法有如此优异的表现,尤其是在效率上,是因为该算法一方面在保证正确性的前提下进行了适当的简化和近似,另一方面它多次运用积分图像(integral image )的概念。
在讲解SURF 算法之前,我们先来介绍一下积分图像。
积分图像很早就被应用在计算机图形学中,但直到2001年才由Viola 和Jones 应用到计算机视觉领域中。
积分图像I Σ(x , y )的大小尺寸与原图像I (x , y )的大小尺寸相等,而积分图像在(x , y )处的值等于原图像中横坐标小于等于x 并且纵坐标也小于等于y 的所有像素灰度值之和,也就是在原图像中,从其左上角到(x , y )处所构成的矩形区域内所有像素灰度值之和,即, ,(1) 事实上,积分图像的计算十分简单,只需要对原图像进行一次扫描,就可以得到一幅完整的积分图像,它的计算公式有几种,下列公式是其中的一种:, , 1, , 1 1, 1(2)其中,I Σ(x -1, y )、I Σ(x , y -1)和I Σ(x -1, y -1)都是在计算I Σ(x , y )之前得到的值。
利用积分图像可以计算原图像中任意矩形内像素灰度值之和。
Opencv2.4.9源码分析——Cascade Classification(三)

Opencv2.4.9源码分析——CascadeClassification(三)下面我们以车牌识别为例,具体讲解OpenCV的级联分类器的用法。
在这里我们只对蓝底白字的普通车牌进行识别判断,对于其他车牌不在考虑范围内。
而且车牌是正面照,略微倾斜可以,倾斜程度太大也是不在识别范围内的。
我们通过不同渠道共收集了1545幅符合要求的带有车牌图像的照片(很遗憾,我只能得到这么多车牌照片,如果能再多一些就更好了!),通过ACDSee软件手工把车牌图像从照片中剪切出来,并统一保存为jpg格式。
为便于后续处理,我们把文件名按照数字顺序命名,如图8所示。
然后我们把这些车牌图像保存到pos文件夹内。
图8 蓝底白字车牌图像需要注意的是,在这里我们没有必要把车牌图像缩放成统一的尺寸(即正样本图像的大小),更没有必要把它们转换成灰度图像,这些工作完全可以由系统完成。
我们只需要告诉系统车牌图像文件、车牌的位置,以及车牌的尺寸大小即可。
为了高效的完成上述工作,我们编写了以下代码:[cpp] view plain copy 在CODE上查看代码片派生到我的代码片#include "opencv2/core/core.hpp"#include "opencv2/highgui/highgui.hpp"#include "opencv2/imgproc/imgproc.hpp"#include <iostream>#include <fstream>#include <string>using namespace cv;using namespace std;int main( int argc, char** argv ){ofstream postxt("pos.txt",ios::out); //创建pox.txt文件if ( !postxt.is_open() ){cout<<"can not creat pos txt file!";return false;}//N表示车牌图像的总数,c表示最终可以利用的车牌样本图像的数量int N = 1545, c = 0;int width, height, i;String filename;Mat posimage;for(i=0;i<N;i++) //遍历所有车牌图像{filename = to_string(i) + ".jpg"; //得到当前车牌图像的文件名posimage = imread("pos\\" + filename); //打开当前车牌图像if ( posimage.empty() ){cout<<"can not open "+ filename +" file!"<<endl;continue;}width = posimage.size().width; //当前车牌图像的宽height = posimage.size().height; //当前车牌图像的高//如果当前车牌图像的宽小于60,或高小于20,则剔除该车牌图像if(width < 60 || height < 20){cout<<filename +" too small!"<<endl;continue;}//把当前车牌图像的信息写入pos.txt文件内postxt<<"pos/" + filename + " 1 0 0 " + to_string(width) + " " + to_string(height)<<endl;c++; //累计}cout<<c; //终端输出c值postxt.close(); //关闭pos.txt文件return 0;}执行完该程序后,在终端输出得到的c值为1390,这说明有155(1545-1390)个车牌图像由于尺寸过小而被剔除。
Opencv2.4.9函数HoughLinesP分析

Opencv2.4.9函数HoughLinesP分析标准霍夫变换本质上是把图像映射到它的参数空间上,它需要计算所有的M个边缘点,这样它的运算量和所需内存空间都会很⼤。
如果在输⼊图像中只是处理m(m<M)个边缘点,则这m个边缘点的选取是具有⼀定概率性的,因此该⽅法被称为概率霍夫变换(Probabilistic Hough Transform)。
该⽅法还有⼀个重要的特点就是能够检测出线端,即能够检测出图像中直线的两个端点,确切地定位图像中的直线。
HoughLinesP函数就是利⽤概率霍夫变换来检测直线的。
它的⼀般步骤为:1、随机抽取图像中的⼀个特征点,即边缘点,如果该点已经被标定为是某⼀条直线上的点,则继续在剩下的边缘点中随机抽取⼀个边缘点,直到所有边缘点都抽取完了为⽌;2、对该点进⾏霍夫变换,并进⾏累加和计算;3、选取在霍夫空间内值最⼤的点,如果该点⼤于阈值的,则进⾏步骤4,否则回到步骤1;4、根据霍夫变换得到的最⼤值,从该点出发,沿着直线的⽅向位移,从⽽找到直线的两个端点;5、计算直线的长度,如果⼤于某个阈值,则被认为是好的直线输出,回到步骤1。
HoughLinesP函数的原型为:void HoughLinesP(InputArray image,OutputArray lines, double rho, double theta, int threshold, doubleminLineLength=0,double maxLineGap=0 )image为输⼊图像,要求是8位单通道图像lines为输出的直线向量,每条线⽤4个元素表⽰,即直线的两个端点的4个坐标值rho和theta分别为距离和⾓度的分辨率threshold为阈值,即步骤3中的阈值minLineLength为最⼩直线长度,在步骤5中要⽤到,即如果⼩于该值,则不被认为是⼀条直线maxLineGap为最⼤直线间隙,在步骤4中要⽤到,即如果有两条线段是在⼀条直线上,但它们之间因为有间隙,所以被认为是两个线段,如果这个间隙⼤于该值,则被认为是两条线段,否则是⼀条。
Opencv2.4.9源码分析——Neural Networks

Opencv2.4.9源码分析——NeuralNetworks一、原理神经网络(Neural Networks)是一种模仿生物神经系统的机器学习算法。
该算法的提出最早可追述至上个世纪四十年代,这几乎与电子计算机的历史同步。
但它的发展并非一帆风顺,也经历了初创阶段—黄金阶段—停滞阶段—复兴阶段,直到目前的高速发展阶段。
年初由Google公司开发的神经网络围棋——AlphaGo击败世界围棋冠军李世石,使神经网络技术更是受到世人的注目,因为它的意义要远大于1997年IBM的超级计算机——深蓝击败国际象棋大师卡斯帕罗夫。
与生物神经系统相似,人工神经网络也是由若干个神经元构成。
如图1所示,x1、x2、…xn 为该神经元的输入,y为该神经元的输出。
显然,不同的输入对神经元的作用是不同的,因此用权值w1、w2、…wn来表示这种影响程度的不同。
神经元内部包括两个部分,第一个部分是对输入的加权求和,第二个部分是对求和的结果进行“激活”,得到输出。
加权求和的公式为:对于MLP,我们可以用Backprop(backward propagation oferrors,误差的反向传播,简称BP)算法实现它的建模,该算法具有结构简单、易于实现等特点。
Backprop算法是一种监督的机器学习算法,输入层的神经元数量一般为样本的特征属性的数量,输出层的神经元的数量一般为样本的所有的可能目标值的数量,如果是分类问题,则为样本的分类数量,因此,与其他机器学习算法不同,在MLP中,样本对应的响应值应该是一个相量,相量的维数与输出层的神经元的数量一致。
而隐含层的层数以及各层神经元的数量则根据实际情况进行选取。
Backprop算法的核心思想是:通过前向通路(箭头的方向)得到误差,再把该误差反向传播实现权值w的修正。
MLP的误差可以用平方误差函数来进行表示。
设某个样本x对应的目标值为t,样本x有n 个特征属性,即x={x1, x2,…,xn},目标值t有J种可能的值,即t={t1, t2,…,tJ},因此该MLP 的输入层(即第一层)一共有n个神经元,输出层(即第L层,设MLP一共有L层)一共有J个神经元。
Opencv2.4.9源码分析——Random Trees

Opencv2.4.9源码分析——RandomTrees一、原理随机森林(Random Forest)的思想最早是由Ho于1995年首次提出,后来Breiman完整系统的发展了该算法,并命名为随机森林,而且他和他的博士学生兼同事Cutler把Random Forest注册成了商标,这可能也是OpenCV把该算法命名为Random Trees的原因吧。
一片森林是由许多棵树木组成,森林中的每棵树可以说是彼此不相关,也就是说每棵树木的生长完全是由自身条件决定的,只有保持森林的多样性,森林才能更好的生长下去。
随机森林算法与真实的森林相类似,它是由许多决策树组成,每棵决策树之间是不相关的。
而随机森林算法的独特性就体现在“随机”这两个字上:通过随机抽取得到不同的样本来构建每棵决策树;决策树每个节点的最佳分叉属性是从由随机得到的特征属性集合中选取。
下面就详细介绍这两次随机过程。
虽然在生成每棵决策树的时候,使用的是相同的参数,但使用的是不同的训练集合,这些训练集合是从全体训练样本中随机得到的,这一过程称之为bootstrap过程,得到的随机子集称之为bootstrap集合,而在bootstrap集合的基础上聚集得到的学习模型的过程称之为Bagging (Bootstrap aggregating),那些不在bootstrap集合中的样本称之为OOB(Out Of Bag)。
Bootstrap过程为:从全部N个样本中,有放回的随机抽取S次(在Opencv中,S=N),由于是有放回的抽取,所以肯定会出现同一个样本被抽取多次的现象,因此即使S=N,也会存在OOB。
我们可以计算OOB样本所占比率:每个样本被抽取的概率为1/N,未被抽取的概率为(1-1/N),抽取S次仍然没有被抽到的概率就为(1-1/N)S,如果S和N都趋于无穷大,则(1-1/N)S≈e-1=0.368,即OOB样本所占全部样本约为36.8%,被抽取到的样本为63.2%。
Opencv2.4.9源码分析——SimpleBlobDetector汇总

Opencv2.4.9源码分析——SimpleBlobDetectorOpenCV中提供了SimpleBlobDetector的特征点检测方法,正如它的名称,该算法使用最简单的方式来检测斑点类的特征点。
下面我们就来分析一下该算法。
首先通过一系列连续的阈值把输入的灰度图像转换为一个二值图像的集合,阈值范围为[T1,T2],步长为t,则所有阈值为:T1,T1+t,T1+2t,T1+3t,……,T2 (1)第二步是利用Suzuki提出的算法通过检测每一幅二值图像的边界的方式提取出每一幅二值图像的连通区域,我们可以认为由边界所围成的不同的连通区域就是该二值图像的斑点;第三步是根据所有二值图像斑点的中心坐标对二值图像斑点进行分类,从而形成灰度图像的斑点,属于一类的那些二值图像斑点最终形成灰度图像的斑点,具体来说就是,灰度图像的斑点是由中心坐标间的距离小于阈值Tb的那些二值图像斑点所组成的,即这些二值图像斑点属于该灰度图像斑点;最后就是确定灰度图像斑点的信息——位置和尺寸。
位置是属于该灰度图像斑点的所有二值图像斑点中心坐标的加权和,即公式2,权值q等于该二值图像斑点的惯性率的平方,它的含义是二值图像的斑点的形状越接近圆形,越是我们所希望的斑点,因此对灰度图像斑点位置的贡献就越大。
尺寸则是属于该灰度图像斑点的所有二值图像斑点中面积大小居中的半径长度。
其中,H表示该斑点的凸壳面积在计算斑点的面积,中心处的坐标,尤其是惯性率时,都可以应用图像矩的方法。
下面我们就介绍该方法。
矩在统计学中被用来反映随机变量的分布情况,推广到力学中,它被用来描述空间物体的质量分布。
同样的道理,如果我们将图像的灰度值看作是一个二维的密度分布函数,那么矩方法即可用于图像处理领域。
设f(x,y)是一幅数字图像,则它的矩Mij为:下面给出SimpleBlobDetector的源码分析。
我们先来看看SimpleBlobDetector类的默认参数的设置:[cpp] view plain copy 在CODE上查看代码片派生到我的代码片SimpleBlobDetector::Params::Params(){thresholdStep = 10; //二值化的阈值步长,即公式1的tminThreshold = 50; //二值化的起始阈值,即公式1的T1maxThreshold = 220; //二值化的终止阈值,即公式1的T2//重复的最小次数,只有属于灰度图像斑点的那些二值图像斑点数量大于该值时,该灰度图像斑点才被认为是特征点minRepeatability = 2;//最小的斑点距离,不同二值图像的斑点间距离小于该值时,被认为是同一个位置的斑点,否则是不同位置上的斑点minDistBetweenBlobs = 10;filterByColor = true; //斑点颜色的限制变量blobColor = 0; //表示只提取黑色斑点;如果该变量为255,表示只提取白色斑点filterByArea = true; //斑点面积的限制变量minArea = 25; //斑点的最小面积maxArea = 5000; //斑点的最大面积filterByCircularity = false; //斑点圆度的限制变量,默认是不限制minCircularity = 0.8f; //斑点的最小圆度//斑点的最大圆度,所能表示的float类型的最大值maxCircularity = std::numeric_limits<float>::max();filterByInertia = true; //斑点惯性率的限制变量//minInertiaRatio = 0.6;minInertiaRatio = 0.1f; //斑点的最小惯性率maxInertiaRatio = std::numeric_limits<float>::max(); //斑点的最大惯性率filterByConvexity = true; //斑点凸度的限制变量//minConvexity = 0.8;minConvexity = 0.95f; //斑点的最小凸度maxConvexity = std::numeric_limits<float>::max(); //斑点的最大凸度}我们再来介绍检测二值图像斑点的函数findBlobs。
基于梯度提升树的回归预测模型

基于梯度提升树的回归预测模型回归预测模型是数据分析和机器学习中常用的一种方法,用于预测连续型变量的值。
在回归预测模型中,梯度提升树(Gradient Boosted Trees)是一种强大且灵活的算法。
本文将介绍梯度提升树的原理和应用,并通过实例演示其在回归预测中的性能。
梯度提升树是通过集成多个决策树来构建预测模型的,并利用梯度下降算法来不断优化模型的拟合能力。
具体而言,梯度提升树通过逐步迭代的方式,每次迭代都对之前模型的残差进行拟合。
在每一轮迭代中,梯度提升树根据之前模型的预测结果和真实值之间的误差计算一个伪残差,然后让新的模型来拟合这个伪残差。
在构建梯度提升树模型时,需要确定一些关键参数。
其中包括决策树的深度、学习率和迭代次数等。
决策树的深度用于控制模型的复杂度,过深的决策树可能产生过拟合问题,而过浅的决策树可能无法很好地拟合数据。
学习率则是用于控制每一轮迭代的权重衰减程度,在更新新模型时起到调整模型拟合幅度的作用。
迭代次数决定了梯度提升树的模型复杂度和拟合能力,过多的迭代次数可能导致过拟合。
除了关键参数的选择,梯度提升树的特点还包括灵活性和稳健性。
通过集成多个决策树,梯度提升树能够适应各种类型的数据和非线性关系,对异常值和噪声也有较好的鲁棒性。
梯度提升树在回归预测中的应用非常广泛。
它可以用于预测房价、股票价格、销售额等连续型变量。
以预测房价为例,我们可以收集一系列与房价相关的特征,如房屋大小、地理位置、建筑年份等,并将这些特征作为输入变量,房价作为输出变量。
通过训练梯度提升树模型,我们可以使用已知特征来预测未知房价。
这种模型可以帮助房地产开发商、投资者和买卖双方做出更明智的决策。
除了回归预测,梯度提升树还可以应用于分类问题。
在分类问题中,输入变量和输出变量都是离散型的。
梯度提升树通过构建多个决策树,将输入变量映射到离散的输出变量,从而实现分类任务。
总结起来,基于梯度提升树的回归预测模型是一种强大而灵活的算法。
python gradientboostingclassifier参数详解

GradientBoostingClassifier 是Python 中scikit-learn 库中的一个梯度提升分类器。
它是一种高效的,灵活的,以及可扩展的机器学习算法,可以用于解决分类问题。
下面是一些常用的参数:1. base_estimator:基本估计器,即弱学习器。
它是一个用于创建弱分类器的类或者元组。
默认值是DecisionTreeRegressor(决策树回归器),也可以选择其他适合的弱学习器。
2. n_estimators:弱学习器的数量,即梯度提升树的数量。
默认值是100。
3. learning_rate:学习率。
它决定了每个弱学习器在减小错误时的权重。
默认值是0.1。
4. max_depth:每个弱学习器的最大深度。
默认值是3。
5. min_samples_split:一个节点在被考虑分裂前必须具有的最小样本数。
默认值是2。
6. min_samples_leaf:叶子节点必须具有的最小样本数。
默认值是1。
7. max_features:用于选择特征的最多特征数。
默认值是'auto',即sqrt(n_features)。
8. subsample:提升过程中使用的样本的比例。
默认值是0.85。
9. ccp_alpha:控制正则化的强度。
默认值是0.0001。
10. label_weights:标签的权重字典或列表。
默认值是None,这意味着所有标签都被平等对待。
11. random_state:随机种子。
默认值是None,这意味着每次运行算法时都会生成不同的随机数。
12. presort:是否在训练前对数据集进行排序。
默认值是True,这将通过内存使用量较小的代价带来速度的提升。
13. warm_start:如果设置为True,则可以重复训练模型,每次训练时添加一个额外的弱学习器。
默认值是False。
这只是GradientBoostingClassifier 的一部分参数,你可以查阅scikit-learn 的官方文档以获取更全面的参数列表和详细解释。
Opencv2.4.9源码分析——Extremely randomized trees

Opencv2.4.9源码分析——Extremelyrandomized trees一、原理ET或Extra-Trees(Extremely randomized trees,极端随机树)是由PierreGeurts等人于2006年提出。
该算法与随机森林算法十分相似,都是由许多决策树构成。
但该算法与随机森林有两点主要的区别:1、随机森林应用的是Bagging模型,而ET是使用所有的训练样本得到每棵决策树,也就是每棵决策树应用的是相同的全部训练样本;2、随机森林是在一个随机子集内得到最佳分叉属性,而ET是完全随机的得到分叉值,从而实现对决策树进行分叉的。
对于第2点的不同,我们再做详细的介绍。
我们仅以二叉树为例,当特征属性是类别的形式时,随机选择具有某些类别的样本为左分支,而把具有其他类别的样本作为右分支;当特征属性是数值的形式时,随机选择一个处于该特征属性的最大值和最小值之间的任意数,当样本的该特征属性值大于该值时,作为左分支,当小于该值时,作为右分支。
这样就实现了在该特征属性下把样本随机分配到两个分支上的目的。
然后计算此时的分叉值(如果特征属性是类别的形式,可以应用基尼指数;如果特征属性是数值的形式,可以应用均方误差)。
遍历节点内的所有特征属性,按上述方法得到所有特征属性的分叉值,我们选择分叉值最大的那种形式实现对该节点的分叉。
从上面的介绍可以看出,这种方法比随机森林的随机性更强。
对于某棵决策树,由于它的最佳分叉属性是随机选择的,因此用它的预测结果往往是不准确的,但多棵决策树组合在一起,就可以达到很好的预测效果。
当ET构建好了以后,我们也可以应用全部的训练样本来得到该ET的预测误差。
这是因为尽管构建决策树和预测应用的是同一个训练样本集,但由于最佳分叉属性是随机选择的,所以我们仍然会得到完全不同的预测结果,用该预测结果就可以与样本的真实响应值比较,从而得到预测误差。
如果与随机森林相类比的话,在ET中,全部训练样本都是OOB样本,所以计算ET的预测误差,也就是计算这个OOB误差。
梯度提升树实现代码

梯度提升树实现代码梯度提升树是一种迭代学习的模型,使用了前向学习算法,弱学习器限定为 CART 回归树。
其实现代码如下:```pythonimport numpy as np# 定义损失函数def square_loss(r):return r ** 2# 定义梯度提升树函数def gbdt(X, y, num_rounds, learning_rate):# 初始化模型为0f = np.zeros(X.shape[0])for m in range(num_rounds):# 计算残差r = y - f# 找到残差最小的特征和对应的分割点s, t = np.min(X, axis=0)# 构建当前模型f = f + learning_rate * np.sign(s) * np.maximum(t - X[:, s], 0)# 更新残差r = y - freturn f# 生成示例数据X = np.linspace(0, 2, 100).reshape(-1, 1)y = 2 * X + 1 + np.random.randn(100)# 设置参数num_rounds = 10learning_rate = 0.1# 训练模型final_model = gbdt(X, y, num_rounds, learning_rate)# 打印模型print(final_model)```在这个示例代码中,定义了`square_loss`函数作为损失函数,它是平方损失函数。
`gbdt`函数实现了梯度提升树算法,其中使用了前向学习算法,并且弱学习器限定为 CART 回归树。
在`gbdt`函数中,初始化模型为0,然后通过循环迭代`num_rounds`次来构建梯度提升树模型。
在每次迭代中,计算当前模型的残差`r`,找到残差最小的特征和对应的分割点,构建当前模型并更新残差。
最后,返回最终的模型。
示例数据`X`是一个包含100个样本的一维数组,`y`是对应的目标值。
Opencv2.4.9源码分析——Cascade Classification(二)

Opencv2.4.9源码分析——CascadeClassification(二)训练级联分类器的源码在OpenCV/sources/app/traincascade目录下。
首先我们给出级联分类器的特征类型的相关类和函数。
CvHaarFeatureParams、CvLBPFeatureParams和CvHOGFeatureParams分别表示HAAR状特征、LBP特征和HOG特征的参数类,它们都继承于CvFeatureParams:[cpp] view plain copy 在CODE上查看代码片派生到我的代码片class CvFeatureParams : public CvParams{public://级联分类器能够使用三种特征类型用于训练样本:HAAR、LBP和HOGenum { HAAR = 0, LBP = 1, HOG = 2 };//缺省构造函数,赋值maxCatCount为0,featSize为1CvFeatureParams();//初始化maxCatCount和featSizevirtual void init( const CvFeatureParams& fp );//表示向params.xml文件写入一些信息:maxCatCount和featSize的值virtual void write( cv::FileStorage &fs ) const;//表示从params.xml文件内读取一些信息:maxCatCount和featSize的值virtual bool read( const cv::FileNode &node );//构建相应的特征参数,即级联分类器具体使用哪种特征,如果输入参数featureType=0,则应用HAAR,该函数返回CvHaarFeatureParams的指针;如果featureType=1,则应用LBP,该函数返回CvLBPFeatureParams的指针;如果featureType=2,则应用HOG,该函数返回CvHOGFeatureParams的指针。
梯度增强算法python代码实现

梯度增强算法python代码实现梯度增强(Gradient Boosting)是一种集成学习方法,通过迭代地训练一系列弱学习器(通常是决策树),每次都在前一次训练的基础上进行优化。
在Python 中,你可以使用scikit-learn 库来实现梯度增强算法。
下面是一个简单的梯度增强分类器的示例代码:from sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_splitfrom sklearn.ensemble import GradientBoostingClassifierfrom sklearn.metrics import accuracy_score# 加载数据集data = load_iris()X = data.datay = data.target# 划分训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 创建梯度增强分类器gb_classifier = GradientBoostingClassifier(n_estimators=100, learning_rate=0.1, random_state=42)# 训练模型gb_classifier.fit(X_train, y_train)# 在测试集上进行预测y_pred = gb_classifier.predict(X_test)# 计算准确率accuracy = accuracy_score(y_test, y_pred)print("Accuracy:", accuracy)在这个示例中,我们首先加载了Iris 数据集,并将其划分为训练集和测试集。
然后,我们使用scikit-learn 中的GradientBoostingClassifier 创建了一个梯度增强分类器。
openCV之头文件分析

openCV之头文件分析我们利用openCV开源库进行项目开发时,往往要牵涉到头文件的添加问题,而o penCV中头文件众多,该如何选择呢?下面对openCV2.4.10的头文件进行一个简单的梳理,以便能够快速的添加对应的头文件。
1、首先看下opencv文件夹中的头文件其中cv.h中包含的头文件:#include "opencv2/core/core_c.h"#include "opencv2/core/core.hpp"#include "opencv2/imgproc/imgproc_c.h"#include "opencv2/imgproc/imgproc.hpp"#include "opencv2/video/tracking.hpp"#include "opencv2/features2d/features2d.hpp"#include "opencv2/flann/flann.hpp"#include "opencv2/calib3d/calib3d.hpp"#include "opencv2/objdetect/objdetect.hpp"#include "opencv2/legacy/compat.hpp"cv.hpp中包含头文件:#include <cv.h>也就是说cv.hpp是包含cv.h的,程序中凡用到cv.h的地方都可以用cv.hpp 替换,那么为什么又要设置hpp文件呢?hpp是Header Plus Plus的简写,与 *.h 文件类似。
但与之不同的是,*.hpp将*.cpp中的实现代码也写入其中,使得定义与实现都包含在同一文件中。
这样做带来的好处显而易见,无需再将cpp文件添加到项目中编译,减少了编译次数,也不用发布烦人的lib,dll 文件,因此非常适合用来编写公用的开源库。
grnboost2原理

GRNBoost2原理解释1. 引言GRNBoost2(Gene Regulatory Network Boosting 2)是一种用于推断基因调控网络(Gene Regulatory Network,GRN)的机器学习方法。
GRNBoost2是基于梯度增强树(Gradient Boosting Tree)的算法,旨在从基因表达数据中预测基因之间的调控关系。
在本文中,我们将详细解释GRNBoost2的基本原理,包括梯度增强树的工作原理、特征选择和模型训练的过程。
2. 梯度增强树(Gradient Boosting Tree)梯度增强树是一种集成学习方法,通过迭代训练多个决策树来提高预测性能。
它的基本思想是通过反复迭代来训练一系列弱分类器(决策树),每个弱分类器都试图纠正前面所有弱分类器的错误。
最终的预测结果是将所有弱分类器的预测结果加权求和得到的。
梯度增强树的训练过程可以简要概括为以下几个步骤:2.1 初始化模型首先,初始化一个弱分类器(决策树)作为初始模型。
通常情况下,初始模型是一个简单的树,其中每个叶节点都有相同的预测值。
2.2 计算残差使用当前模型对训练数据进行预测,并计算预测值与真实值之间的残差。
残差表示当前模型无法很好地拟合训练数据的部分。
2.3 训练新的弱分类器使用残差作为目标变量,训练一个新的弱分类器。
这个弱分类器的目标是尽可能减小残差,使得模型能够更好地拟合训练数据。
2.4 更新模型将新的弱分类器与现有模型相加,更新模型。
这样,模型会逐步改进,每个新的弱分类器都试图纠正前面所有弱分类器的错误。
2.5 重复迭代重复执行步骤2.2至2.4,直到达到指定的迭代次数或模型性能满足预设条件。
3. GRNBoost2的基本原理GRNBoost2是基于梯度增强树的算法,用于推断基因调控网络。
它的基本原理如下:3.1 输入数据准备GRNBoost2的输入数据是基因表达数据,其中包含多个基因在不同条件下的表达水平。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Opencv2.4.9源码分析——GradientBoosted Trees一、原理梯度提升树(GBT,Gradient Boosted Trees,或称为梯度提升决策树)算法是由Friedman 于1999年首次完整的提出,该算法可以实现回归、分类和排序。
GBT的优点是特征属性无需进行归一化处理,预测速度快,可以应用不同的损失函数等。
从它的名字就可以看出,GBT包括三个机器学习的优化算法:决策树方法、提升方法和梯度下降法。
前两种算法在我以前的文章中都有详细的介绍,在这里我只做简单描述。
决策树是一个由根节点、中间节点、叶节点和分支构成的树状模型,分支代表着数据的走向,中间节点包含着训练时产生的分叉决策准则,叶节点代表着最终的数据分类结果或回归值,在预测的过程中,数据从根节点出发,沿着分支在到达中间节点时,根据该节点的决策准则实现分叉,最终到达叶节点,完成分类或回归。
提升算法是由一系列“弱学习器”构成,这些弱学习器通过某种线性组合实现一个强学习器,虽然这些弱学习器的分类或回归效果可能仅仅比随机分类或回归要好一点,但最终的强学习器却可以得到一个很好的预测结果。
二、源码分析下面介绍OpenCV的GBT源码。
首先给出GBT算法所需参数的结构体CvGBTreesParams:[cpp] view plain copy 在CODE上查看代码片派生到我的代码片CvGBTreesParams::CvGBTreesParams( int _loss_function_type, int _weak_count,float _shrinkage, float _subsample_portion,int _max_depth, bool _use_surrogates ): CvDTreeParams( 3, 10, 0, false, 10, 0, false, false, 0 ){loss_function_type = _loss_function_type;weak_count = _weak_count;shrinkage = _shrinkage;subsample_portion = _subsample_portion;max_depth = _max_depth;use_surrogates = _use_surrogates;}loss_function_type表示损失函数的类型,CvGBTrees::SQUARED_LOSS为平方损失函数,CvGBTrees::ABSOLUTE_LOSS为绝对值损失函数,CvGBTrees::HUBER_LOSS为Huber损失函数,CvGBTrees::DEVIANCE_LOSS为偏差损失函数,前三种用于回归问题,后一种用于分类问题weak_count表示GBT的优化迭代次数,对于回归问题来说,weak_count也就是决策树的数量,对于分类问题来说,weak_count×K为决策树的数量,K表示类别数量shrinkage表示收缩因子vsubsample_portion表示训练样本占全部样本的比例,为不大于1的正数max_depth表示决策树的最大深度use_surrogates表示是否使用替代分叉节点,为true,表示使用替代分叉节点CvDTreeParams结构详见我的关于决策树的文章CvGBTrees类的一个构造函数:[cpp] view plain copy 在CODE上查看代码片派生到我的代码片CvGBTrees::CvGBTrees( const cv::Mat& trainData, int tflag,const cv::Mat& responses, const cv::Mat& varIdx,const cv::Mat& sampleIdx, const cv::Mat& varType,const cv::Mat& missingDataMask,CvGBTreesParams _params ){data = 0; //表示样本数据集合weak = 0; //表示一个弱学习器default_model_name = "my_boost_tree";// orig_response表示样本的响应值,sum_response表示拟合函数Fm(x),sum_response_tmp表示Fm+1(x)orig_response = sum_response = sum_response_tmp = 0;// subsample_train和subsample_test分别表示训练样本集和测试样本集subsample_train = subsample_test = 0;// missing表示缺失的特征属性,sample_idx表示真正用到的样本的索引missing = sample_idx = 0;class_labels = 0; //表示类别标签class_count = 1; //表示类别的数量delta = 0.0f; //表示Huber损失函数中的参数δclear(); //清除一些全局变量和已有的所有弱学习器//GBT算法的学习train(trainData, tflag, responses, varIdx, sampleIdx, varType, missingDataMask, _params, false);}GBT算法的学习构建函数:[cpp] view plain copy 在CODE上查看代码片派生到我的代码片boolCvGBTrees::train( const CvMat* _train_data, int _tflag,const CvMat* _responses, const CvMat* _var_idx,const CvMat* _sample_idx, const CvMat* _var_type,const CvMat* _missing_mask,CvGBTreesParams _params, bool /*_update*/ ) //update is not supported//_train_data表示样本数据集合//_tflag表示样本矩阵的存储格式//_responses表示样本的响应值//_var_idx表示要用到的特征属性的索引//_sample_idx表示要用到的样本的索引//_var_type表示特征属性的类型,是连续值还是离散值//_missing_mask表示缺失的特征属性的掩码//_params表示构建GBT模型的一些必要参数{CvMemStorage* storage = 0; //开辟一块内存空间params = _params; //构建GBT模型所需的参数bool is_regression = problem_type(); //表示该GBT模型是否用于回归问题clear(); //清空一些全局变量和已有的所有弱学习器/*n - count of samplesm - count of variables*/int n = _train_data->rows; //n表示训练样本的数量int m = _train_data->cols; //m表示样本的特征属性的数量//如果参数_tflag为CV_ROW_SAMPLE,则表示训练样本以行的形式储存的,即_train_data矩阵的每一行为一个样本,那么n和m无需交换;否则如果_tflag为CV_COL_SAMPLE,则表示样本是以列的形式储存的,那么n和m就需要交换。
总之,在后面的程序中,n表示训练样本的数量,m表示样本的特征属性的数量if (_tflag != CV_ROW_SAMPLE){int tmp;CV_SW AP(n,m,tmp);}// new_responses表示每个样本的伪响应值,因为构建GBT决策树使用的是伪响应值CvMat* new_responses = cvCreateMat( n, 1, CV_32F);cvZero(new_responses); //伪响应值初始为零//实例化CvDTreeTrainData类,并通过该类内的set_data函数设置用于决策树的训练样本数据datadata = new CvDTreeTrainData( _train_data, _tflag, new_responses, _var_idx,_sample_idx, _var_type, _missing_mask, _params, true, true );if (_missing_mask) //如果给出了缺失特征属性的掩码{missing = cvCreateMat(_missing_mask->rows, _missing_mask->cols,_missing_mask->type); //初始化missingcvCopy( _missing_mask, missing); //赋值_missing_mask给missing }//初始化orig_response矩阵的大小,该变量表示样本的原始真实响应值orig_response = cvCreateMat( 1, n, CV_32F );//step表示样本响应值的步长int step = (_responses->cols > _responses->rows) ? 1 : _responses->step / CV_ELEM_SIZE(_responses->type);//根据样本响应值_responses的数据类型,为orig_response赋值switch (CV_MAT_TYPE(_responses->type)){case CV_32FC1: //32位浮点型数据{for (int i=0; i<n; ++i)orig_response->data.fl[i] = _responses->data.fl[i*step];}; break;case CV_32SC1: //32位整型数据{for (int i=0; i<n; ++i)orig_response->data.fl[i] = (float) _responses->data.i[i*step];}; break;default: //其他数据类型报错CV_Error(CV_StsUnmatchedFormats, "Response should be a 32fC1 or 32sC1 vector.");}if (!is_regression) //如果构建的GBT模型是用于分类问题{class_count = 0; //表示样本类别的数量//为每个样本定义一个掩码,用于判断样本的类别unsigned char * mask = new unsigned char[n];memset(mask, 0, n); //掩码清零// compute the count of different output classesfor (int i=0; i<n; ++i) //遍历所有样本,得到类别的数量//如果当前样本的掩码没有被置1,则说明当前样本属于新的类别if (!mask[i]){class_count++; //样本类别数加1//判断当前样本以后的所有样本的响应值是否与当前样本的响应值相同,即是否属于同一类,如果是同一类,则把样本掩码置1,说明它不再是新的类别for (int j=i; j<n; ++j)if (int(orig_response->data.fl[j]) == int(orig_response->data.fl[i]))mask[j] = 1;}delete[] mask; //删除mask变量//初始化样本类别标签,并赋首地址指针class_labels = cvCreateMat(1, class_count, CV_32S);class_labels->data.i[0] = int(orig_response->data.fl[0]);int j = 1; //表示所有样本类别标签的索引值for (int i=1; i<n; ++i) //遍历所有样本,为样本类别标签赋值{int k = 0; //表示已得到的样本类别标签的索引值//while循环用于判断是否有新的类别标签出现。