SQL Server 关键字
SQLServer常用关键字

SQLServer常⽤关键字SQL 建库建表--1.创建⼀个数据库create database School;--删除数据库drop database School;--创建数据库的时候指定⼀些选项。
create database Schoolon primary(name='School',filename='C:\Program Files\SQL\MSSQL12.MSSQL\MSSQL\DATA\School.mdf',size=5MB,--filegrowth=10MB,filegrowth=10%,--按照⽂件的百分⽐来增长maxsize=100MB)log on(name='School_log',filename='C:\Program Files\SQL\MSSQL12.MSSQL\MSSQL\DATA\School.ldf',size=3MB,filegrowth=3%,maxsize=20MB)--切换数据库use School;TOPselect top10*from student 查询前⼗条select top10percent*from student 查询前10%;Distinctselect distinct*from student 查询不重复Avg Count Sum Min MAxselect AVG(ID) from student 平均数select COUNT(ID) from student 总数select Sum(ID) from student 求和select Max(ID) from student 求最⼤数select Min(ID) from student 求最⼩Where And Orselect*from student where ID>90and ID<100and ID%2=0select*from student where ID>100or ID<10and ID%2!=0模糊查询 Like Not Like % _select*from student where Name like'%三%'查询带有三的select*from student where Name not like'%三%'查询不带有三的select*from student where Name like'三%'查询三开头的select*from student where Name like'%三'查询三结尾的select*from student where Name like'_ 三 %'查询第⼆个为三的Order By where desc asc 排序select * from NT_User order by UserAge 按年龄⼤⼩排序select * from NT_User order by UserAge asc 降序select * from NT_User order by UserAge desc 升序Group By Having 分组(要和聚合函数⼀起使⽤)select UserGender from NT_User group by UserGender 按性别分成三组select UserGender, Count(*) from NT_User group by UserGender 查询三组性别的每个的个数select UserGender,COUNT(*) from NT_User group by UserGender having COUNT(*) >1000 查询三组性别的每个的个数⼤于1000的 Union Union Allselect Name from Student union all select Name from Teacher 两表联查所有的select Name from Student union select Name from Teacher 两表联查去除重复的Select Into Insert Intoselect * into teacher from Student 创建Teacher表并把Student表⾥⾯的数据复制到Teacher表中insert into teacher select * from Student 把Student表⾥⾯的数据复制到Teacher表中Inner Join on 两表联查select A.Content,erName from CLN_Resource as A inner join NT_User as B on erID =erIDselect * from CLN_Resource inner join NT_User on CLN_erID=NT_erID。
SQLServer一些关键字详解(一)

SQLServer⼀些关键字详解(⼀)1.CROSS APPLY 和OUTER APPLYMSDN解释如下(个⼈理解不是很清晰):使⽤ APPLY 运算符可以为实现查询操作的外部表表达式返回的每个⾏调⽤表值函数。
表值函数作为右输⼊,外部表表达式作为左输⼊。
通过对右输⼊求值来获得左输⼊每⼀⾏的计算结果,⽣成的⾏被组合起来作为最终输出。
APPLY 运算符⽣成的列的列表是左输⼊中的列集,后跟右输⼊返回的列的列表。
APPLY 有两种形式:CROSS APPLY 和 OUTER APPLY。
CROSS APPLY 仅返回外部表中通过表值函数⽣成结果集的⾏。
OUTER APPLY 既返回⽣成结果集的⾏,也返回不⽣成结果集的⾏,其中表值函数⽣成的列中的值为 NULL。
⽹上搜集的解释如下(个⼈感觉好理解):SQL Server数据库操作中,在2005以上的版本新增加了⼀个APPLY表运算符的功能。
新增的APPLY表运算符把右表表达式应⽤到左表表达式中的每⼀⾏。
它不像JOIN那样先计算哪个表表达式都可以,APPLY必须先逻辑地计算左表达式。
这种计算输⼊的逻辑顺序允许把右表达式关联到左表表达式。
APPLY有两种形式,⼀个是OUTER APPLY,⼀个是CROSS APPLY,区别在于指定OUTER,意味着结果集中将包含使右表表达式为空的左表表达式中的⾏,⽽指定CROSS,则相反,结果集中不包含使右表表达式为空的左表表达式中的⾏。
注意:若要使⽤ APPLY,数据库兼容级别必须为 90。
下⾯我们做个例⼦:⽐如有个类别表(Category)内容如下:还有个类别明细表(CategoryDetail)内容如下:下⾯我们来看看OUTER APPLY 的查询结果:1SELECT*2FROM dbo.Category a3OUTER APPLY ( SELECT*4FROM dbo.CategoryDetail b5WHERE b.CategoryId = a.Id6 ) AS c ;由上图可看出OUTER APPLY把左表中的信息查出后把右表中的信息也关联出来了,当然当右表的信息为空(NULL)时,OUTER APPLY也会在结果集中显⽰出来.接下来我们看下CROSS APPLY的查询结果:1SELECT*2FROM dbo.Category a3CROSS APPLY ( SELECT*4FROM dbo.CategoryDetail b5WHERE b.CategoryId = a.Id6 ) AS c ;根据这图和上⾯的⽐较可看出,这个返回结果只有两个,Category 表中的Tiger的信息没有带出来,因为在CategoryDetail 表中没有对应的明细.由以上信息可得出,OUTER APPLY 就相当于数学中的并集,⽽CROSS APPLY相当于数学中的交集,关于交集与并集的介绍如下:并集为下图中的所有红⾊部分,即为A和B的全部:交集为下图中的红⾊部分,也就是A和B相交的部分:2.OUTER APPLY 和LEFT JOINLEFT JOIN 关键字会从左表 (Category) 那⾥返回所有的⾏,即使在右表 (CategoryDetail) 中没有匹配的⾏。
SQLServer关键字

SQL Server 2000教程资料SQL Server关键字ADDA LTER TAB LE语句的一个选项,为现有的表添加一个新列。
ALLSELEC T语句的一个选项,用于SE LECT列表中,与UNION操作符和GROUP BY子句一起使用。
在所有这些子句中,ALL选项指定重复行可以出现在结果集中。
A LTE R ALTE R ob ject语句是Tra nsac t-SQL数据定义语言的一部分,修改几个数据库对象的属性。
有5个ALTE R对象语句:ALTE R DATABASE,ALTER T AB LE,ALTE RVI EW,ALT ER T RIGGE R和ALT ER P ROCEDU RE。
AND 布尔操作符。
如果AND操作符连接两个条件,检索两个条件都为真的行。
ANY 用于SE LECT语句的比较操作符。
如果一个内查询的结果含有至少一行满足这个比较,ANY操作符计算的结果为真。
AS用于定义列表达式的相关名字,如SU M(budget)ASsum_of_budgets。
A SC ASCEN DI NG的简写形式,用于SELECT语句的O RDERBY子句中定义升序排序。
AU THO RIZATIO NCREATE SC HEMA语句的一个子句,该子句定义模式对象所有者的ID。
这个标识符必须是数据库中合法的用户帐号。
AVG AV ERAG E的简写形式。
聚集函数AVG计算列中值的平均值,该函数的参数必须是数字。
BACK UP 备份数据库、事务日志或文件组中的一个或多个文件。
对应的Transac t-SQL语句是B ACK UP DAT ABAS E和BAC KUP L OG。
sqlserver sql关键字处理

一、简介SQL(Structured Query Language)是一种特定目的的编程语言,用于管理关系数据库系统。
在SQL Server中,SQL是一种用于查询、修改和管理数据库的重要语言。
SQL关键字是SQL语言中的特定保留字,被用于识别、操作和管理数据库对象。
对于开发人员和数据库管理员来说,了解SQL关键字的处理方法非常重要。
二、SQL关键字的处理方法1. 避免使用关键字作为对象名称在创建数据库表、字段等对象时,应避免使用SQL关键字作为对象名称。
由于SQL关键字是被SQL语法保留的,如果将关键字用作对象名称,可能会导致语法错误和不可预测的行为。
为了避免潜在的问题,应选择具有描述性和唯一性的名称,而不是使用关键字。
2. 使用方括号或引号来转义关键字在SQL Server中,可以使用方括号([])或双引号("")来转义包含关键字的对象名称。
如果需要创建一个名为"order"的表,可以使用方括号或引号将其转义,如下所示:```CREATE TABLE [order] (id INT,name VARCHAR(50));```或者```CREATE TABLE "order" (id INT,name VARCHAR(50));```3. 使用别名在使用SQL关键字时,可以给对象名称或字段名称指定别名。
通过使用别名,可以避免直接使用关键字,减少潜在的错误。
在执行查询时,可以使用别名来代替关键字,如下所示:```SELECT [order].id AS order_id, [order].name AS order_name FROM [order];```4. 使用限定符在SQL语句中,可以使用限定符来明确指定对象的所有者。
通过使用限定符,可以将对象的所有者和对象名称分开,避免与关键字混淆。
可以使用限定符将对象的所有者和对象名称分开,如下所示:```SELECT dbo.[user].id, dbo.[user].nameFROM dbo.[user];```5. 使用转义字符在SQL语句中,可以使用转义字符来转义包含关键字的字符串。
sqlserver关键字大全
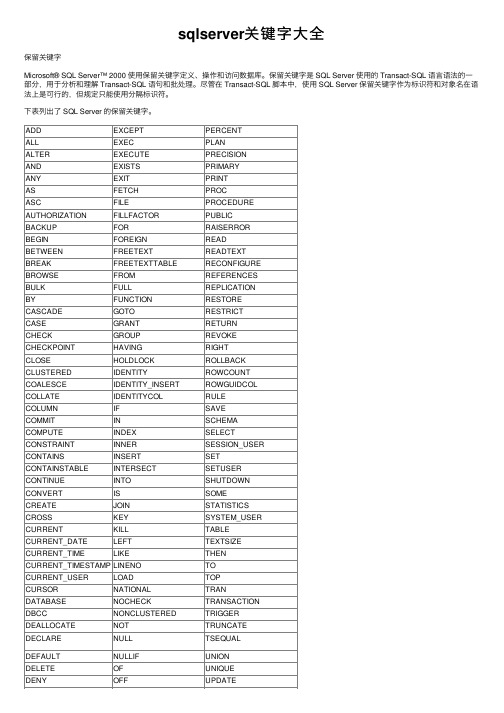
sqlserver关键字⼤全保留关键字Microsoft® SQL Server™ 2000 使⽤保留关键字定义、操作和访问数据库。
保留关键字是 SQL Server 使⽤的 Transact-SQL 语⾔语法的⼀部分,⽤于分析和理解 Transact-SQL 语句和批处理。
尽管在 Transact-SQL 脚本中,使⽤ SQL Server 保留关键字作为标识符和对象名在语法上是可⾏的,但规定只能使⽤分隔标识符。
下表列出了 SQL Server 的保留关键字。
ADD EXCEPT PERCENTALL EXEC PLANALTER EXECUTE PRECISIONAND EXISTS PRIMARYANY EXIT PRINTAS FETCH PROCASC FILE PROCEDUREAUTHORIZATION FILLFACTOR PUBLICBACKUP FOR RAISERRORBEGIN FOREIGN READBETWEEN FREETEXT READTEXTBREAK FREETEXTTABLE RECONFIGUREBROWSE FROM REFERENCESBULK FULL REPLICATIONBY FUNCTION RESTORECASCADE GOTO RESTRICTCASE GRANT RETURNCHECK GROUP REVOKECHECKPOINT HAVING RIGHTCLOSE HOLDLOCK ROLLBACKCLUSTERED IDENTITY ROWCOUNTCOALESCE IDENTITY_INSERT ROWGUIDCOLCOLLATE IDENTITYCOL RULECOLUMN IF SAVECOMMIT IN SCHEMACOMPUTE INDEX SELECTCONSTRAINT INNER SESSION_USERCONTAINS INSERT SETCONTAINSTABLE INTERSECT SETUSERCONTINUE INTO SHUTDOWNCONVERT IS SOMECREATE JOIN STATISTICSCROSS KEY SYSTEM_USERCURRENT KILL TABLECURRENT_DATE LEFT TEXTSIZECURRENT_TIME LIKE THENCURRENT_TIMESTAMP LINENO TOCURRENT_USER LOAD TOPCURSOR NATIONAL TRANDATABASE NOCHECK TRANSACTIONDBCC NONCLUSTERED TRIGGERDEALLOCATE NOT TRUNCATEDECLARE NULL TSEQUALDEFAULT NULLIF UNIONDELETE OF UNIQUEDENY OFF UPDATEDESC OFFSETS UPDATETEXTDESC OFFSETS UPDATETEXTDISK ON USEDISTINCT OPEN USERDISTRIBUTED OPENDATASOURCE VALUESDOUBLE OPENQUERY VARYINGDROP OPENROWSET VIEWDUMMY OPENXML WAITFORDUMP OPTION WHENELSE OR WHEREEND ORDER WHILEERRLVL OUTER WITHESCAPE OVER WRITETEXT另外,SQL-92 标准还定义了保留关键字列表。
sqlserver sql关键字处理 -回复

sqlserver sql关键字处理-回复SQL Server是一个非常流行的关系型数据库管理系统,常用于处理大规模的数据。
在SQL Server中,有一些关键字被保留,这意味着它们不能用作表名、列名或任何其他标识符的名称。
为了在SQL Server中使用这些关键字作为标识符,我们可以使用中括号将其括起来。
SQL Server中的关键字可以分为多个类别,包括保留关键字、特定于Transact-SQL的预定义标识符和其他语言元素。
保留关键字是指在SQL Server中有特定含义的单词或短语,不能用作标识符。
这些关键字用于定义和操作数据库对象,例如表、列、索引等。
一些常见的保留关键字包括SELECT、INSERT、UPDATE、DELETE、CREATE、ALTER、DROP等。
使用中括号可以让我们在命名表或列时不受这些关键字的限制。
Transact-SQL是SQL Server使用的SQL方言,它有一些特定于Transact-SQL的预定义标识符。
这些标识符是SQL Server引入的扩展功能或特定语法要求,它们也可用于各种数据库对象。
其中一些关键字包括TOP、WITH、ROW_NUMBER、OVER等。
同样,使用中括号可以使我们在创建对象时能够使用这些特定于Transact-SQL的预定义标识符。
此外,SQL Server还包含其他一些语言元素,这些元素虽然与SQL语法无关,但仍然需要使用中括号进行处理。
这些包括保留字符、特殊字符和标点符号等。
例如,如果我们想在列名中使用某个特殊字符如“-”,我们可以将其放在中括号中,例如[order-id]。
同样,如果我们想在表名或列名中使用保留字符如空格,也可以使用中括号。
使用中括号来处理SQL关键字非常简单。
无论是在创建表还是在写查询时,只需要在使用关键字作为标识符的地方添加中括号即可。
例如,如果我们要创建一个名为"SELECT"的表,可以使用以下语句:CREATE TABLE [SELECT] ([ID] INT,[Name] VARCHAR(50));使用中括号可以确保我们在SQL Server中正确处理关键字。
sql server top用法

sql server top用法SQL Server TOPTOP是SQL Server中常用的关键字之一,用于指定从查询结果中返回的行数。
通过使用TOP关键字,可以轻松地选择查询结果集的前几行或指定百分比的行数。
以下是一些SQL Server TOP的用法及详细讲解:1. 基本用法使用TOP时,可以在SELECT语句中指定要返回的行数。
例如:SELECT TOP 5 * FROM Customers;上述查询将返回Customers表中的前五行。
2. 结合ORDER BY在使用TOP关键字时,通常需要结合ORDER BY子句以指定返回的行的排序方式。
例如:SELECT TOP 10 * FROM Products ORDER BY Price DESC;上述查询将返回价格最高的10个产品。
3. 百分比TOP使用TOP关键字还可以指定要返回的结果集的百分比。
例如:SELECT TOP 20 PERCENT * FROM Orders;上述查询将返回Orders表中的前20%的行。
4. TOP WITH TIESTOP WITH TIES语句是指在有相等值的情况下,将相等值的行也包括在返回结果中。
例如:SELECT TOP 5 WITH TIES * FROM Orders ORDER BY Quant ity DESC;上述查询将返回数量最大的前5行,并且如果有相等的数量,也会将相等的行包括在内。
5. TOP和子查询TOP关键字还可以与子查询结合使用。
例如:SELECT * FROM Customers WHERE CustomerID IN (SELECT TOP 10 CustomerID FROM Orders);上述查询将返回在Orders表中出现过的前10个顾客的信息。
总之,SQL Server的TOP关键字是一个非常有用的工具,可以帮助我们筛选需要的数据行。
结合ORDER BY子句和其他查询语句,可以更灵活地使用TOP关键字,满足不同的查询需求。
SQL Server 关键字大全

SQL Server 关键字ADD ALTER TABLE(修改表)语句的一个选项,为现有的表添加一个新列。
ALL SELECT(选择,查询(SQL))语句的一个选项,用于SELECT列表中,与UNION操作符和GROUP BY子句一起使用。
在所有这些子句中,ALL选项指定重复行可以出现在结果集中。
ALTER ALTER object(改变对象)语句是Transact-SQL数据定义语言的一部分,修改几个数据库对象的属性。
有5个ALTER对象语句:ALTER DATABASE,ALTER TABLE,ALTERVIEW,ALTER TRIGGER和ALTER PROCEDURE。
AND布尔操作符。
如果AND操作符连接两个条件,检索两个条件都为真的行。
ANY用于SELECT语句的比较操作符。
如果一个内查询的结果含有至少一行满足这个比较,ANY操作符计算的结果为真。
AS用于定义列表达式的相关名字,如SUM(budget) ASsum_of_budgets。
ASC ASCENDING的简写形式,用于SELECT语句的ORDER BY子句中定义升序排序。
AUTHORIZATION CREATE SCHEMA语句的一个子句,该子句定义模式对象所有者的ID。
这个标识符必须是数据库中合法的用户帐号。
AVG AVERAGE的简写形式。
聚集函数AVG计算列中值的平均值,该函数的参数必须是数字。
BACKUP备份数据库、事务日志或文件组中的一个或多个文件。
对应的Transact-SQL语句是BACKUP DATABASE和BACKUP LOG。
BEGIN如果在BEGIN匛ND形式中使用,开始一个Transact-SQL事务。
BEGIN TRANSACTION 语句开始一个事务。
BETWEEN与SELECT语句一起使用的一个操作符,这个操作符用于搜索指定范围的所有值。
BREAK BREAK语句停止块内的语句的执行,并开始这个块后的语句的执行。
SQLServer常用关键字、数据类型和常用语法

SQL Server 2008常用关键字、数据类型和常用语法常用关键字:SQL server 2008一共大约有180多个关键字。
简要分为主要关键字、辅助关键字和函数类关键字。
本文就常用的这三类关键字进行语法说明和用例。
说明:1、比较好的习惯是,数据库名以D_开头,表名用T_开头,字段名以F_开头,这样可以防止和关键字重名。
2、如果确实用到了系统关键字,就要在关键上加[]方括号,以与关键字进行区别。
例如有一个用户表被命名为USER,则查询该表内容的时候:SELECT * FROM USER语句是错误的,应该是SELECT * FROM [USER]。
因为USER是关键字。
数据类型:SQL Server 2008一共有36种数据类型。
具体如下:常用语法:一、数据库【创建数据库】CREATE DATABASE <dbname>【修改数据库】ALTER DATABASE <dbname>【删除数据库】DROP DATABASE <dbname>二、表结构【创建数据表】1、设定字段是允许空,非空、标识列,自增和主键约束。
CREATE TABLE T_CUSTOMER --表名(CUSTOMERID INT IDENTITY(1,1),--客户ID,标识列,从开始,每次自增COMPANYNAME NVARCHAR(50) NOT NULL,--,如果不显示指明NOT NULL,系统默认是允许空的USERNAME NVARCHAR(10) NOT NULL,--联系人姓名,非空PHONENUMBER CHAR(11) NULL,--联系电话,允许为空CONSTRAINT T_CUSTOMER_PrimaryKey PRIMARY KEY (CUSTOMERID)) --设定USERID为主键,用括号括起来/*每个单词之间是空格隔开,每个字段之间用单引号隔开,整个字段定义部分用括号括起来*//*T_RegUser_PrimaryKey是约束名*/2、设定字段是UNIQUEIDENTIFIER数据类型,唯一性约束,CHECK 约束和默认值约束。
SQL Server 关键字

SQL Server 关键字及其语法Insert into 插入value 值default 默认Null 空update 修改set 设置From 从。
那里where 条件delete 删除Select 查找top 顶部order by 以。
排序Group by 以……分组having 符合(筛选条件)…………. Join 连接left 左right 右between…… and ….在什么之间//模式比配符like 像……..not like 不像……Asc(缺省值) 排序升序Desc排序降序//集合函数查询Count(*):统计元组个数Count(列名):统计一列中值的个数Sum(列名):计算一列值的总和Avg(列名) :计算一列值的平均值Max(列名) :计算一列值的最大值Min(列名) :计算一列值的最小值Table 表DataBase 数据库DBMS数据库管理系统exists 存在not exists不存在If exists(select * from sysdatabases where name=’数据库名’) Drop database 数据库名//判断是否已经有这个数据库,如果有则删除Create Database 数据库名//创建数据库Drop Database数据库名//删除数据库Create table 表名//创建表Drop table表名//删除表//添加约束的语法alter table表名add constraint约束名约束类型具体的约束说明//约束名的取名规则推荐使用:约束类型_约束字段eg.主键(primary key)约束: pk_字段唯一(unique key)约束: uq_字段默认(default key) 约束: df_字段检查(check key)约束: ck_字段外键(foreign key) 约束: fk_字段//删除约束的语法Alter table 表名Drop constraint约束名//向表中添加字段Alter table 表名Add 字段名字段数据类型//对表中删除字段Alter table 表名Drop column字段名//为数据库用户赋予表操作权限的语法为:Grant权限[on 表名] to数据库用户//删除权限的语法:Revoke 权限[on 表名] from 数据库用户//禁用权限的语法:Deny 权限[on 表名] to数据库用户Declare语句//声明局部变量Set/select语句//为局部变量赋值//在select语句里如果要显示平局记录就用with ties 关键字,其中tie 的意思是“与……打成平局”eg.Slect top 10 with ties * from表名//查询不重复记录用关键字distinct(它可以同时指定多个字段,查询的结果就是多个字段同时不重复的记录)Eg.Select distinct 字段名from 表名//在流程控制中开始,结束:begin endGo 批处理In 在……范围内Not in 不在……范围内Begin transaction 开启事务Commit transaction提交事务Rollback transaction回滚事务//创建索引Create index 索引名//删除索引Drop index索引名//创建视图Create view视图名//删除视图Drop view视图名//创建存储过程Create proc存储过程名//删除存储过程Drop proc存储过程名//创建触发器Create trigger触发器名//删除触发器Drop trigger触发器名。
sqlserver数据库 limit的用法和搭配

sqlserver数据库 limit的用法和搭配在SQL Server中,LIMIT关键字是用于限制SELECT查询结果返回的行数的。
在SQL Server中,LIMIT关键字并不直接支持,而是使用TOP关键字来实现类似的功能。
可以使用以下语法:```SELECT TOP <num_rows> column1, column2, ...FROM tableWHERE conditionORDER BY column1, column2, ...```其中,<num_rows>是要返回的行数,column1, column2, ...是要选择的列,table是要查询的表,condition是查询的条件,ORDER BY column1, column2, ...是可选的,用于指定结果的排序顺序。
除了使用TOP关键字外,还可以使用OFFSET FETCH子句来实现分页查询。
OFFSET子句用于指定起始行的偏移量,FETCH子句用于指定要返回的行数。
以下是使用OFFSET FETCH子句的语法:```SELECT column1, column2, ...FROM tableWHERE conditionORDER BY column1, column2, ...OFFSET <offset_rows> ROWSFETCH NEXT <num_rows> ROWS ONLY```其中,<offset_rows>是起始行的偏移量,<num_rows>是要返回的行数。
值得注意的是,OFFSET FETCH子句仅在SQL Server 2012及更高版本中可用。
除了使用这些关键字外,还可以使用其他技术来实现限制查询结果行数的效果,比如使用子查询或使用临时表等。
综上所述,SQL Server中实现类似LIMIT的效果可以通过TOP关键字、OFFSET FETCH子句或其他技术来实现。
sql server事务语法

sql server事务语法SQL Server 中的事务语法包括以下几个关键字和语句:1. BEGIN TRANSACTION:用于开始一个新的事务。
例如:BEGIN TRANSACTION;2. COMMIT TRANSACTION:用于提交当前的事务,将事务中的所有操作永久保存到数据库中。
例如:COMMIT TRANSACTION;3. ROLLBACK TRANSACTION:用于回滚当前的事务,取消事务中的所有操作,恢复到事务开始之前的状态。
例如:ROLLBACK TRANSACTION;4. SAVE TRANSACTION:用于在事务中创建一个保存点,可以在之后的操作中回滚到该保存点。
例如:SAVE TRANSACTION savepoint_name;5. SET TRANSACTION:用于设置事务的隔离级别和其他属性。
例如:SET TRANSACTION ISOLATION LEVEL READ COMMITTED;在使用这些语句时,需要注意以下几点:每个 BEGIN TRANSACTION 都必须有对应的 COMMIT 或ROLLBACK,否则会导致数据库中出现未提交的事务,造成数据不一致。
事务可以嵌套,即在一个事务中可以包含另一个事务。
事务可以使用保存点来实现部分回滚,即只回滚到指定的保存点。
事务的隔离级别可以通过 SET TRANSACTION 来设置,包括READ UNCOMMITTED、READ COMMITTED、REPEATABLE READ、SERIALIZABLE 等级别。
总之,SQL Server 中的事务语法可以帮助开发人员确保数据库操作的一致性和完整性,避免数据丢失和不一致的情况发生。
通过合理地运用事务,可以有效地管理数据库中的数据操作。
sql ser ver 中 returns用法

sql ser ver 中returns用法SQL Server中的returns用法在SQL Server中,returns是一个非常重要的关键字,它用于指定存储过程、函数或触发器的返回类型。
SQL Server中的returns关键字起到定义返回值类型的作用,并且可以帮助开发人员更好地处理和处理返回值。
在本文中,我们将逐步讨论SQL Server中returns关键字的用法,并提供相关示例来帮助理解。
第一步:定义返回类型在SQL Server中,定义存储过程、函数或触发器的返回类型是非常重要的。
使用returns关键字可以指定返回类型,以便在调用这些对象时能够根据返回类型进行处理。
下面是定义存储过程返回类型的示例:CREATE PROCEDURE GetEmployeeNameEmployeeID INTASBEGINSELECT EmployeeName FROM Employees WHERE EmployeeID = EmployeeIDENDGO在上述示例中,我们使用returns关键字指定了存储过程的返回类型,即EmployeeName。
此返回类型将在存储过程执行时返回给调用方。
第二步:处理返回值在成功定义存储过程、函数或触发器的返回类型后,我们需要相应地处理返回值。
需要根据返回类型的不同,使用不同的方法来处理它们。
以下是三种最常见的处理返回值的方法:1. 使用存储过程来处理返回值的示例:DECLARE Result VARCHAR(50)EXEC Result = GetEmployeeName EmployeeID = 101PRINT 'Employee Name: ' + Result在上述示例中,我们通过将存储过程返回值赋给一个变量来获取存储过程的返回值。
然后,我们可以使用这个变量来进行进一步处理或打印。
2. 使用函数来处理返回值的示例:CREATE FUNCTION GetTotalSales ()RETURNS DECIMAL(10,2)ASBEGINDECLARE TotalSales DECIMAL(10,2)统计销售总额的逻辑代码RETURN TotalSalesEND在上述示例中,我们定义了一个返回DECIMAL(10,2)类型的函数。
sqlserver distinct用法

sqlserver distinct用法标题:SQL Server DISTINCT 用法详解:从基础到高级应用摘要:本文将详细介绍SQL Server 中DISTINCT 关键字的用法。
从基础的概念开始,逐步深入讨论DISTINCT 在SQL 查询中的应用,包括单列DISTINCT、多列DISTINCT、DISTINCT 搭配聚合函数、DISTINCT 和SELECT 子句等功能。
我们还将讨论DISTINCT 运行效率和最佳实践。
无论您是初学者还是有经验的数据库开发人员,本文都将为您提供宝贵的知识和指导。
目录:1. 引言1.1 SQL Server 简介1.2 DISTINCT 的作用2. 单列DISTINCT2.1 基本语法2.2 示例及解析3. 多列DISTINCT3.1 基本语法3.2 示例及解析4. DISTINCT 搭配聚合函数4.1 基本语法4.2 示例及解析5. DISTINCT 和SELECT 子句5.1 基本语法5.2 示例及解析6. DISTINCT 运行效率与最佳实践6.1 索引的影响6.2 数据量的影响6.3 使用临时表进行优化6.4 如何评估DISTINCT 查询的性能7. 结论7.1 总结7.2 推荐资源1. 引言:1.1 SQL Server 简介SQL Server 是由微软公司开发的一种关系数据库管理系统(RDBMS),广泛应用于企业级应用程序的数据存储和管理。
它支持SQL(结构化查询语言)作为标准查询语言,用于对数据库进行查询、插入、更新和删除等操作。
1.2 DISTINCT 的作用DISTINCT 是SQL 查询语句中的关键字,用于去重查询结果集中的重复行,返回唯一的值。
DISTINCT 用于SELECT 语句,它可以应用于单个列或多个列。
通过消除结果集中的重复值,DISTINCT 可以帮助我们更好地理解和分析数据。
2. 单列DISTINCT:2.1 基本语法:SELECT DISTINCT column_nameFROM table_name;2.2 示例及解析:假设我们有一个名为"Customers" 的表,其中包含名为"Country" 的列,我们想要获取不重复的国家列表。
sql server 逻辑判断表达式

sql server 逻辑判断表达式在SQL Server中,逻辑判断表达式常用于WHERE子句或CASE语句中,用于进行条件判断和逻辑运算。
逻辑判断表达式包括以下几种常见的运算符和关键字:1. 等于:`=` 或 `==`例如:`column_name = value`2. 不等于:`<>` 或 `!=`例如:`column_name <> value`3. 大于:`>`例如:`column_name > value`4. 小于:`<`例如:`column_name < value`5. 大于等于:`>=`例如:`column_name >= value`6. 小于等于:`<=`例如:`column_name <= value`7. 逻辑与:`AND` 或 `&&`例如:`condition1 AND condition2`8. 逻辑或:`OR` 或 `||`例如:`condition1 OR condition2`9. 逻辑非:`NOT` 或 `!`例如:`NOT condition`10. 包含:`LIKE`例如:`column_name LIKE pattern`注意:`LIKE`可以与`%`和`_`通配符一起使用,分别表示任意字符和单个字符的匹配。
11. 在范围内:`BETWEEN`例如:`column_name BETWEEN value1 AND value2`12. 在列表中:`IN`例如:`column_name IN (value1, value2, ...)`13. 空值判断:`IS NULL` 或 `IS NOT NULL`例如:`column_name IS NULL`这些逻辑判断表达式可以根据实际需求进行组合和嵌套,以实现复杂的条件判断和逻辑运算。
sql ser ver 中 returns用法 -回复

sql ser ver 中returns用法-回复SQL Server 中的RETURNS 用法在SQL Server 数据库中,返回结果集是一项非常重要的功能。
通过使用RETURNS 关键字,我们可以定义存储过程、函数、触发器等数据库对象的返回类型。
本文将逐步解释SQL Server 中RETURNS 关键字的用法和功能。
第一步:理解RETURNS 关键字的含义在SQL Server 中,RETURNS 是声明一个函数、存储过程或触发器返回的数据类型的关键字。
这个关键字用于指定函数返回的结果集的数据类型。
通过使用RETURNS 关键字,我们可以确保返回结果符合指定的数据类型,从而提高查询结果的准确性和可靠性。
第二步:理解RETURNS 关键字的语法在SQL Server 中,RETURNS 关键字通常与CREATE FUNCTION 或CREATE PROCEDURE 语句一起使用,用于确定函数或存储过程返回的结果集数据类型。
下面是一个使用RETURNS 关键字的示例:CREATE FUNCTION dbo.GetCustomerCount()RETURNS INTASBEGINDECLARE @CustomerCount INTSELECT @CustomerCount = COUNT(*) FROM CustomersRETURN @CustomerCountEND在上面的示例中,通过使用RETURNS 关键字,我们声明了函数GetCustomerCount 返回一个INT 类型的结果集。
第三步:返回多个结果集在某些情况下,我们可能需要从一个函数或存储过程返回多个结果集。
在SQL Server 中,我们可以使用多个RETURNS 语句来实现这一点。
下面是一个返回多个结果集的示例:CREATE PROCEDURE dbo.GetCustomerInfoASBEGINSELECT * FROM CustomersSELECT * FROM OrdersSELECT * FROM ProductsEND在上面的示例中,存储过程GetCustomerInfo 通过使用三个SELECT 语句来返回三个不同的结果集。
sqlserver排序语句

sqlserver排序语句SQLServer排序语句是SQL服务器中最常用的语句之一,它可以使用户以特定的顺序显示查询结果,从而使用户可以方便地进行数据分析。
本文将详细介绍SQL Server排序语句,具体涵盖关键字、语法以及典型例子等内容。
一、SQL Server排序语句的关键字SQL Server排序语句使用ORDER BY关键字进行排序,它是一个紧密结合的关键字,并且必须在语句的最后出现。
ORDER BY关键字可以控制如何显示查询结果,通过它可以指定要使用的排序字段及排序方式,这是一种强大的排序功能。
二、SQL Server排序语句的语法SQL Server排序语句的语法如下:SELECT段列表FROM据表WHERE件ORDER BY序字段 [ASC | DESC];其中,SELECT字段列表用于指定要查询的字段;FROM数据表用于指定要查询的表;WHERE条件用于指定查询条件;ORDER BY排序字段用于指定排序要求,并可以指定ASC升序或DESC降序排序。
三、SQL Server排序语句的典型例子下面是SQL Server排序语句的一个典型例子:SELECT name,ageFROM student_infoWHERE age>20ORDER BY age DESC;本例中,我们查询大于20岁的student_info表中name和age 字段,并根据age字段以降序排序。
四、总结本文介绍了SQL Server排序语句的关键字、语法以及典型例子等内容。
SQL Server排序语句是SQL Server中最常用的语句之一,它可以使用户以特定的顺序显示查询结果,从而使用户能够方便地进行数据分析。
通过ORDER BY关键字,开发人员可以方便地定义查询结果的排序顺序。
SQL Server排序语句能够极大地帮助开发人员进行数据分析,并能够满足不同应用场景的实际需求。
sql server top用法(一)

sql server top用法(一)SQL Server TOP在SQL Server中,TOP是一个常用的关键字,用于限制从查询结果中返回的行数。
TOP的用法可以在SELECT语句中指定要返回的行数。
以下是一些常用的TOP用法:1.返回前N行数据SELECT TOP N column1, column2, ...FROM table_name;这个例子会返回表中的前N行数据,其中N是一个正整数。
你可以在SELECT语句中指定要返回的列。
2.返回百分比比例的数据SELECT TOP N PERCENT column1, column2, ...FROM table_name;这个例子会返回表中的前N%的数据,其中N是一个0到100之间的小数。
3.与ORDER BY一起使用SELECT TOP N column1, column2, ...FROM table_nameORDER BY column_name;这个例子会返回按指定列排序后的前N行数据。
你可以在ORDER BY子句中指定升序(ASC)或降序(DESC)排序。
4.返回重复值最多的前N行数据SELECT TOP N column1, column2, ...FROM table_nameGROUP BY column_nameORDER BY COUNT(column_name) DESC;这个例子会返回按指定列分组并按重复值数量降序排序后的前N行数据。
总结:TOP关键字是在SQL Server中用于限制查询结果行数的常用工具,可以通过SELECT TOP N来返回前N行数据,也可以与ORDER BY结合按指定列排序,还可以用于返回一定比例的数据或按重复值数量排序返回数据。
以上是一些常见的TOP用法,在实际操作中可以根据不同的需求灵活运用。
SQLServer与MySql区别(关键字和语法)

SQL Server 和MySql 语法和关键字的区别——用于SQLServer到MySql的转换(1)mysql的ifnull()函数对应sql的isnull()函数;(2)mysql的存储过程中变量的定义去掉@;(3)mysql的每句结束要用";"(4)SQLServer存储过程的AS在MySql中需要用begin .....end替换(5)字符串连接用concat()函数;如SQLServer: Temp=’select * from ’+’tablename’+…+…MySql:Temp=concat(’select * from’, ’tablecname’,…,…)(6)mysql的uuid()对应sql的GUID();(7)MySql的out对应SQLServer的output,且mysql 的out要放在变量的前面,SQLServer的output放在变量后面MySql out,in,inout的区别——MySQL 存储过程“in”参数:跟C 语言的函数参数的值传递类似,MySQL 存储过程内部可能会修改此参数,但对in 类型参数的修改,对调用者(caller)来说是不可见的(not visible)。
MySQL 存储过程“out”参数:从存储过程内部传值给调用者。
在存储过程内部,该参数初始值为null,无论调用者是否给存储过程参数设置值。
MySQL 存储过程inout 参数跟out 类似,都可以从存储过程内部传值给调用者。
不同的是:调用者还可以通过inout 参数传递值给存储过程。
(8)MySQL的if语句为if (条件) thenend if;或者If (条件) thenElseEnd if或者If(条件)thenElseif (注意不能写成Else if )Elseif…End if(9)Mysql的Execute对应SqlServer的exec;(注意:必须像下面这样调用)Set @cnt=’select * from 表名’;Prepare str from @cnt;Execute str;(10)MySql存储过程调用其他存储过程用callCall函数名(即SQLServer的存储过程名)(’参数1’,’参数2’,……)(11) mysql的日期○1获得当前日期函数:curdate(),current_date()○2获得当前时间函数:curtime();○3获得当前日期+时间:now();○4MySQL dayof... 函数:dayofweek(), dayofmonth(), dayofyear()分别返回日期参数,在一周、一月、一年中的位置。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
SQL Server 关键字ADD ALTER TABLE语句的一个选项,为现有的表添加一个新列。
ALL SELECT语句的一个选项,用于SELECT列表中,与UNION操作符和GROUP BY子句一起使用。
在所有这些子句中,ALL选项指定重复行可以出现在结果集中。
ALTER ALTER object语句是Transact-SQL数据定义语言的一部分,修改几个数据库对象的属性。
有5个ALTER对象语句:ALTERDATABASE,ALTER TABLE,ALTERVIEW,ALTERTRIGGER和ALTER PROCEDURE。
AND 布尔操作符。
如果AND操作符连接两个条件,检索两个条件都为真的行。
ANY 用于SELECT语句的比较操作符。
如果一个内查询的结果含有至少一行满足这个比较,ANY操作符计算的结果为真。
AS 用于定义列表达式的相关名字,如SUM(budget)ASsum_of_budgets。
ASC ASCENDING的简写形式,用于SELECT语句的ORDER BY子句中定义升序排序。
AUTHORIZATION CREATE SCHEMA语句的一个子句,该子句定义模式对象所有者的ID。
这个标识符必须是数据库中合法的用户帐号。
AVG AVERAGE的简写形式。
聚集函数AVG计算列中值的平均值,该函数的参数必须是数字。
BACKUP 备份数据库、事务日志或文件组中的一个或多个文件。
对应的Transact-SQL语句是BACKUP DATABASE和BACKUPLOG。
BEGIN 如果在BEGIN匛ND形式中使用,开始一个Transact-SQL事务。
BEGIN TRANSACTION语句开始一个事务。
BETWEEN 与SELECT语句一起使用的一个操作符,这个操作符用于搜索指定范围的所有值。
BREAK BREAK语句停止块内的语句的执行,并开始这个块后的语句的执行。
通常与WHILE语句一起使用。
BROWSE FOR BROWSE子句用作SELECT语句的一部分,指定在查看数据时可以更新。
BULK BULK INSERT语句把数据文件复制到用户定义格式的表中。
BY GROUP BY和ORDER BY子句的一部分。
CASCADE CASCADE子句与DENY语句一起使用,指定权限从一个用户帐号拒绝,以及由第一个用户帐号授予权限的所有其他用户帐号都被拒绝。
CASE CASE表达式用于SELECT语句和UPDATE语句,评价一个条件列表,并返回某个可能的结果表达式。
CHECK 用于CREATE TABLE和ALTER TABLE,定义声明的表约束。
也用于CREATE VIEW语句中,作为WITH CHECKOPTION的一部分,限制只插入(或修改)满足查询条件的那些行。
CHECKPOINT CHECKPOINT语句强制被修改但还没有写到磁盘的所有页面写到磁盘上。
CLOSE CLOSE语句关闭一个打开的光标。
CLUSTERED CREATE INDEX语句的一个选项,创建一个具有行的顺序与索引顺序相同的属性的索引。
也用于UNIQUE和PRIMARYKEY子句(在CREATE TABLE和ALTERTABLE语句中)定义同样的属性。
COALESCE 返回参数中第一个非空表达式的系统函数。
COLUMN ALTER TABLE语句中ALTER COLUMN和DROPCOLUMN子句的一部分。
ALTER COLUMN子句修改列的属性,而DROP COLUMN子句删除存在的一个列。
COMMIT COMMIT TRANSACTION语句标记成功事务的结束。
COMMITTED SET TRANSACTION ISOLATION LEVEL语句的READCOMMITTED选项的一部分。
如果指定READCOMMITTED,在数据被读时,对数据保持共享锁。
COMPUTE SELECT语句的一个子句。
它使用聚集函数计算汇总值,在结果集中作为附加的行出现。
CONSTRAINT 用于CREATE TABLE和ALTER TABLE语句的选项,指定4个完整性约束中的一个:UNIQUE,PRIMARY KEY,CHECK和FOREIGN KEY。
CONTAINS 全文检索中的谓词,用于搜索含有基于字符的数据类型的列。
CONTAINSTABLE 全文检索中的谓词,返回含有基于字符的数据类型的列中的0个或多个数据行。
CONTINUE CONTINUE语句停止块内的语句的执行,并重新开始该块内的第一条语句的执行。
通常与WHILE语句一起使用。
CONVERT 显式地把一个数据类型的表达式转换成另一个数据类型的系统函数。
COUNT 有两种形式的聚集函数:COUNT(DISTINCT(表达式))和COUNT(*)。
第一种形式计算表达式中值的数目,而第二种形式统计表中的行数。
CREATE CREATE object语句是Transact-SQL数据定义语言的一部分。
有9个CREATE object语句:CREATEDATABASE,CREATE TABLE,CREATE VIEW,CREATETRIGGER,CREATE PROCEDURE,CREATE SCHEMA,CREATEINDEX,CREATE RULE和CREATE DEFAULT(还有不属于DDL的CREATE STATISTICS语句)。
CROSS SELECT语句的CROSS JOIN选项的一部分,用于明确定义两个表的迪卡尔乘积。
CURRENT 用于UPDATE (DELETE)语句,定义行的定位修改(删除)。
这意味着行的修改(删除)在光标的当前位置发生。
CURRENT_DATE 系统函数,返回当前日期。
CURRENT_TIME 系统函数,返回当前时间。
CURRENT_TIMESTAMP 系统函数,返回当前日期和时间。
CURRENT_USER 系统函数,返回当前用户。
CURSOR DECLARE CURSOR语句的一部分。
这条语句定义查询的光标,用于构造结果集。
DATABASE 作为DDL语句CREATE DATABASE,ALTERDATABASE和DROP DATABASE的一部分或备份语句BACKUPDATABASE和RESTORE DATABASE的一部分出现。
DBCC 包括几个语句,检查(和恢复)数据库及其对象的物理一致性和逻辑一致性。
DEALLOCATE DEALLOCATE语句删除一个存在的光标的引用。
DECLARE DECLARE语句定义一个或多个本地变量。
也是DECLARECURSOR语句的一部分,用于定义查询的一个光标,用来构造结果集。
DEFAULT 指定“默认”约束或“默认”文件组。
默认约束可以在CREATETABLE或ALTER TABLE语句中指定,而默认文件组可以在CREATE TABLE或ALTER DATABASE语句中指定。
DELETE 从表中删除行的Transact-SQL语句。
也可以用作CREATETRIGGER或ALTER TRIGGER语句的一部分,定义行的删除将激活该触发器。
最后,在FRANT,DENY和REVOKE语句中用于权限。
DENY 用于定义权限的3条语句之一,防止用户通过从用户帐号删除现有的权限来执行动作,或者防止用户通过组(角色)成员关系获得权限。
DESC DESCENDING的简写。
在SELECT语句的ORDER BY子句中用于定义降序顺序。
DISK 在BACKUP和RESTORE语句中用于定义备份的介质。
DISTINCT 在SELECT语句的SELECT列表中用于定义仅唯一的行在结果集中显示。
也用于聚集函数COUNT中,达到相同的效果。
DISTRIBUTED BEGIN DISTRIBUTED TRANSACTION语句的一部分,指定分布式事务的开始由Microsoft分布式事务协调器控制。
DOUBLE Microsoft Access的标准数据类型,对应于SQL Server中的FLOAT数据类型(为从Microsoft Access到SQL Server的迁移而支持)。
DROP DROP object语句是Transact-SQL数据定义语言的一部分。
有9个DROP object语句:DROP DATABASE,DROPTABLE,DROP VIEW,DROP TRIGGER,DROPPROCEDURE,DROP SCHEMA,DROP INDEX,DROPRULE和DROPDEFAULT。
DUMP DUMP DATABASE和DUMP TRANSACTION语句的一部分,进行数据库和事务日志的备份副本。
SQL Server 7支持这两个语句,是为了向后兼容。
ELSE IF…ELSE语句的一部分。
ELSE引入一个或多个Transact-SQL语句,在IF部分的条件不满足时执行。
END 结束BEGIN…END块或CASE表达式。
ESCAPE ESCAPE选项是SELECT语句的LIKE谓词的一部分。
这个选项指定转义符,改写一个通配符的含义,使它解释为普通字符。
EXEC(EXECUTE)EXECUTE语句执行一个系统存储过程,用户定义的过程,或扩展存储过程。
还有EXECUTE对象权限,用于授予、取消或拒绝存储过程的权限。
EXISTS EXISTS函数以一个子查询作为参数,如果该子查询返回一行或多行,它就返回真。
EXIT EXIT命令退出isql和osql实用程序的用户会话。
FETCH Transact-SQL语句FETCH从结果集中检索特定的行,该结果集是使用光标声明和查询的。
FILE 作为ALTER DATABASE和BACKUP语句的几个选项的一部分出现。
FILLFACTOR 创建索引时,定义每个索引页的存储百分比。
可以与CREATETABLE,ALTER TABLE和CREATE INDEX语句一起使用。
FLOPPY 在BACKUP和RESTORE语句中用于指定软盘作为备份的介质(为了向后兼容)。
FOR 作为ALTER TABLE和CREATE TABLE语句的NOTFORREPLICATION选项的一部分出现。
FOREIGN 完整性约束的一部分,定义和修改CREATE TABLE和ALTERTABLE语句中的外部关键字。
FREETEXT 全文检索中的一个谓词,用于搜索含有基于字符的数据类型的列中满足搜索条件中字的含义的值。
FREETEXTTABLE 在搜索含有基于字符的数据类型的列中满足搜索条件中字的含义的值的全文检索中,返回0行或多行的一个表。
FROM 指定在DELETE,SELECT或UPDATE语句中使用的表或视图。
FULL 用作FULL OUTER JOIN的一部分,定义两个表的全外连接。