稀疏矩阵十字链表基本函数
事业单位考试计算机基础知识:十字链表

事业单位考试计算机基础知识:十字链表
【导语】在事业单位考试中,计算机专业知识的复习向来是考生复习备考阶段的一大重点,其中十字链表又可以算作是计算机专业考试的高频考点,下面我们为大家重点讲解十字链表的存储结构以帮助大家更好地掌握这个考点。
十字链表的存储结构
以三元组表示的稀疏矩阵,在运算中,若非0元素的位置发生变化,会引起数组元素的频繁移动。
为解决这个问题,采用十字链表的存储结构。
在十字链表中,表示非0元素的结点除了三元组,还有两个指针域:
向下域(down)链接同一列下一个非0元素。
向右域(right)链接同一行下一个非0元素。
稀疏矩阵中同一行的非0元素结点通过向右域,链接成一个带头结点的行链表。
同一列的非0元素结点通过向下域,链接成一个带头结点的列链表。
十字链表的存储结构的代码表示:
#define MAXR 100
#define MAZC 100
typdef struct olnode
{int row, col;
ELEMTP Val;
struct olnode *down, *right;
}OLNode;
typedef struct Cist
{OLNode *rhead[MAXR+1],*chead[MAXC+1];
INT mu,nu,tu;
}Crosslist;
以上是为考生梳理计算机基础知识点,供大家学习识记!。
408考稀疏矩阵十字链表

408考稀疏矩阵十字链表稀疏矩阵是指矩阵中绝大部分元素为0的情况下,只存储非零元素及其位置信息的一种存储方式。
在计算机科学中,稀疏矩阵的存储方式有多种,其中一种较为常见的方式是使用十字链表。
十字链表是一种基于链表的数据结构,用于表示稀疏矩阵。
它通过两个链表和一个头节点来表示稀疏矩阵的行和列。
具体来说,十字链表由以下几个部分组成:1. 头节点:头节点用于存储稀疏矩阵的行数、列数和非零元素的个数等基本信息。
2. 行链表:行链表由多个节点组成,每个节点代表稀疏矩阵的一行。
每个节点包含三个属性:行号、列号和值。
行链表按照行号从小到大的顺序排列。
3. 列链表:列链表由多个节点组成,每个节点代表稀疏矩阵的一列。
每个节点包含三个属性:行号、列号和值。
列链表按照列号从小到大的顺序排列。
4. 节点链接:行链表和列链表中的节点通过行号和列号进行链接。
对于每个节点,除了存储自身的行号、列号和值外,还需存储其所在行的下一个节点和所在列的下一个节点。
使用十字链表来存储稀疏矩阵的好处是可以大大减少存储空间的使用,尤其适用于稀疏矩阵中非零元素的个数相对较少的情况。
通过十字链表,我们可以快速访问稀疏矩阵中的非零元素,并且可以方便地进行行和列的插入、删除和修改操作。
下面举一个具体的例子来说明408考稀疏矩阵十字链表的应用。
假设有一个3行4列的稀疏矩阵,其中非零元素分别为6、8、9、7,它们的位置分别是(1, 2)、(2, 1)、(2, 3)、(3, 4)。
我们可以使用十字链表来表示这个稀疏矩阵。
我们创建一个头节点,存储稀疏矩阵的行数、列数和非零元素的个数,即3、4和4。
然后,我们创建4个节点,分别表示这4个非零元素。
这些节点的属性分别为:(1, 2, 6)、(2, 1, 8)、(2, 3, 9)和(3, 4, 7)。
同时,我们需要将这些节点链接到行链表和列链表中相应的位置。
在行链表中,我们将这些节点按照行号从小到大的顺序插入。
首先,我们插入节点(1, 2, 6),因为它的行号最小。
十字链表法存储稀疏矩阵

十字链表法存储稀疏矩阵稀疏矩阵是指其中大部分元素为0的矩阵。
在实际应用中,稀疏矩阵的存储和计算都会带来一定的困扰。
为了高效地存储和处理稀疏矩阵,我们可以使用十字链表法。
一、稀疏矩阵的特点稀疏矩阵的特点是其中绝大部分元素为0,而只有少部分非零元素。
这导致稀疏矩阵的存储空间浪费很大,因此需要采取一种有效的存储方式。
二、十字链表法的原理十字链表法是一种组合了链表和线性表的数据结构,用于存储稀疏矩阵。
具体实现如下:1. 定义两个链表headRow和headCol,分别用于存储行和列的头节点;2. 每个非零元素都对应一个结点,结点包含四个属性:行号row、列号col、值value以及指向下一个非零元素的指针nextRow和nextCol;3. headRow链表中的每个节点都指向同一行中的第一个非零元素,而headCol链表中的每个节点都指向同一列中的第一个非零元素;4. 非零元素之间通过nextRow和nextCol指针连接。
通过这种方式,我们可以高效地存储稀疏矩阵,并可以方便地进行矩阵的各种操作。
三、十字链表法的优势相比于其他存储稀疏矩阵的方法,十字链表法有以下几个优势:1. 空间利用率高:相比于使用二维数组存储,十字链表法可以大大减少存储空间的浪费,因为只存储非零元素及其位置信息;2. 支持高效的插入和删除操作:十字链表法可以通过调整指针的指向来进行插入和删除操作,而不需要像其他方法那样移动元素;3. 方便进行矩阵操作:通过十字链表法,我们可以方便地进行稀疏矩阵的各种操作,如矩阵相加、矩阵相乘等。
四、十字链表法的应用十字链表法广泛地应用于各个领域,特别是在图论和网络分析中。
在这些领域中,往往需要处理大规模的稀疏矩阵,而十字链表法能够有效地解决这个问题。
以社交网络为例,社交网络中的用户和用户之间往往存在着复杂的关系。
通过将社交网络建模成稀疏矩阵,可以使用十字链表法来存储和处理这些关系。
这样可以方便地进行各种网络分析操作,如查找某个用户的好友、计算两个用户之间的距离等。
408考稀疏矩阵十字链表

408考稀疏矩阵十字链表稀疏矩阵是指大部分元素为零的矩阵。
在很多实际应用中,如图像处理、网络分析等领域,大型矩阵中的非零元素只占很小一部分。
为了节省存储空间和提高运算效率,我们可以使用稀疏矩阵来表示这些矩阵。
408考稀疏矩阵十字链表是一种常用的稀疏矩阵存储结构。
它通过将非零元素按行和列分别排列,并使用链表将它们连接在一起,从而实现对稀疏矩阵的高效存储和操作。
在408考中,稀疏矩阵十字链表是一种常用的数据结构,用于表示稀疏矩阵。
它是由徐仲恺老师于1971年提出的,是一种改进的稀疏矩阵链表存储结构。
相比于其他存储结构,稀疏矩阵十字链表具有存储空间小、插入和删除元素方便等优点。
稀疏矩阵十字链表的基本思想是将矩阵分解为行链表和列链表两部分,通过链表将非零元素连接起来。
具体来说,稀疏矩阵十字链表包含三个链表:行链表、列链表和非零元素链表。
行链表是由一组头指针组成的链表,每个头指针指向一行的第一个非零元素。
列链表是由一组头指针组成的链表,每个头指针指向一列的第一个非零元素。
非零元素链表则是将矩阵中的非零元素按照行优先的顺序连接起来。
通过这种方式,我们可以通过行链表和列链表快速找到某一行或某一列的非零元素,并可以在常数时间内插入和删除元素。
同时,由于非零元素链表是按照行优先的顺序连接的,因此可以按照矩阵的行优先顺序遍历非零元素。
使用稀疏矩阵十字链表存储稀疏矩阵可以大大减少存储空间的占用。
对于一个m×n的矩阵,如果非零元素的个数为k,那么稀疏矩阵十字链表的存储空间复杂度为O(k+max(m,n))。
相比之下,使用普通的二维数组存储矩阵需要O(m×n)的存储空间。
稀疏矩阵十字链表还可以实现矩阵的加法、减法和乘法等基本运算。
在进行运算时,我们只需要遍历非零元素链表,并根据链表中的信息进行相应的计算,而无需考虑矩阵中的零元素,从而提高了运算效率。
408考稀疏矩阵十字链表是一种高效的稀疏矩阵存储结构。
(原创)数据结构之十字链表总结

(原创)数据结构之⼗字链表总结7-1 稀疏矩阵(30 分)如果⼀个矩阵中,0元素占据了矩阵的⼤部分,那么这个矩阵称为“稀疏矩阵”。
对于稀疏矩阵,传统的⼆维数组存储⽅式,会使⽤⼤量的内存来存储0,从⽽浪费⼤量内存。
为此,可以⽤三元组的⽅式来存放⼀个稀疏矩阵。
对于⼀个给定的稀疏矩阵,设第r⾏、第c列值为v,且v不等于0,则这个值可以表⽰为 <r,v,c>。
这个表⽰⽅法就称为三元组。
那么,对于⼀个包含N个⾮零元素的稀疏矩阵,就可以⽤⼀个由N个三元组组成的表来存储了。
如:{<1, 1, 9>, <2, 3, 5>, <10, 20, 3>}就表⽰这样⼀个矩阵A:A[1,1]=9,A[2,3]=5,A[10,20]=3。
其余元素为0。
要求查找某个⾮零数据是否在稀疏矩阵中,如果存在则输出其所在的⾏列号,不存在则输出ERROR。
输⼊格式:共有N+2⾏输⼊:第⼀⾏是三个整数m, n, N(N<=500),分别表⽰稀疏矩阵的⾏数、列数和矩阵中⾮零元素的个数,数据之间⽤空格间隔; 随后N⾏,输⼊稀疏矩阵的⾮零元素所在的⾏、列号和⾮零元素的值;最后⼀⾏输⼊要查询的⾮0数据k。
输出格式:如果存在则输出其⾏列号,不存在则输出ERROR。
输⼊样例:在这⾥给出⼀组输⼊。
例如:10 29 32 18 -107 1 988 10 22输出样例:在这⾥给出相应的输出。
例如:8 10解题思路:实际上这道题⽤三元组写轻松解决,但是这⾥想讲的是⼗字链表;⼗字链表的图⼤致如下:那么如何去实现呢;看以下代码:因为下⾯都有注释,这⾥便不赘述了。
1 #include<iostream>2 #include<stdio.h>3using namespace std;45struct OLNod{6int i ; //该⾮零元的⾏下标;7int j ; //该⾮零元的列下标;8int value ; //该⾮零元的数值;9struct OLNod *right ,*down ;//该⾮零元所在的⾏表和列表的后继链域;10 };11struct CrossL{12 OLNod **rhead, **sead;13//⼗字链表的⾏头指针和列头指针;定义为指向指针的指针;14int row; //稀疏矩阵的⾏数;15int col; //稀疏矩阵的列数;16int num; //稀疏矩阵的⾮零个数;17 };1819int InitSMatrix(CrossL *M) //初始化M(CrossL)类型的变量必须初始化;20 {21 (*M).rhead = (*M).sead = NULL;22 (*M).row = (*M).col = (*M).num = 0;23return1;24 }2526int DestroysMatrix(CrossL *M) //销毁稀疏矩阵M;27 {28int i ;29 OLNod *p,*q;30for( i = 1 ; i <= (*M).row;i++)31 {32 p = *((*M).rhead+i); //p指针不断向右移;33while(p!=NULL)34 {35 q = p ;36 p = p ->right;37delete q; //删除q;38 }39 }40delete((*M).rhead); //释放⾏指针空间;41delete((*M).sead); //释放列指针空间;42 (*M).rhead = (*M).sead = NULL; //并将⾏、列头指针置为空;43 (*M).num = (*M).row = (*M).col = 0; //将⾮零元素,⾏数和列数置为0; 44return1;45 }46int CreatSMatrix(CrossL *M)47 {48int i , j , m , n , t;49int value;50 OLNod *p,*q;51if((*M).rhead!=NULL)52 DestroysMatrix(M);53 cin>>m>>n>>t; //输⼊稀疏矩阵的⾏数、列数和⾮零元个数;54 (*M).row = m;55 (*M).col = n ;56 (*M).num = t;57//初始化⾏链表头;58 (*M).rhead = new OLNod*[m+1];//为⾏头指针申请⼀个空间;59if(!(*M).rhead) //如果申请不成功,则退出程序;60 exit(0);61//初始化列链表头;62 (*M).sead = new OLNod*[n+1];//为列表头申请⼀个空间;63if(!(*M).sead) //如果申请不成功,则退出程序;64 exit(0);65for(int k = 1 ; k <= m ; k++)66 {67 (*M).rhead[k] = NULL;//初始化⾏头指针向量;各⾏链表为空链表;68 }69for(int k = 1 ; k <= n ;k++)70 {71 (*M).sead[k] = NULL;//初始化列头指针向量;各列链表为空链表;72 }73for(int k = 0 ; k < t ;k++) //输⼊⾮零元素的信息;74 {75 cin>>i>>j>>value;//输⼊⾮零元的⾏、列、数值;76 p = new OLNod();//为p指针申请⼀个空间;77if(!p) //e如果申请不成功;78 exit(0); //退出程序;79 p->i = i;80 p->j = j;81 p->value = value;82if((*M).rhead[i]==NULL) //如果⾏头指针指向的为空;83 {84//p插在该⾏的第⼀个结点处;85 p->right = (*M).rhead[i];86 (*M).rhead[i] = p;87 }else//如果不指向空88 {89for(q = (*M).rhead[i];q->right; q = q->right);90 p->right = q->right;91 q->right = p;9293 }94if((*M).sead[j]==NULL)//如果列头指针指向的为空;95 {96//p插在该⾏的第⼀个结点处;97 p->down = (*M).sead[j];98 (*M).sead[j] = p;99 }else//如果不指向空100 {101for(q = (*M).sead[j];q->down;q = q->down);102 p->down = q->down;103 q->down = p;104 }105 }106return1;107 }108int PrintSMatrix(CrossL *M)109 {110int flag = 0;111int val ;//要查找的元素的值;112 cin>>val; //输⼊要查找的s值;113 OLNod *p;114for(int i = 1 ; i <= (*M).row ;i++)115 {116for(p = (*M).rhead[i];p;p = p->right) //从⾏头指针开始找,不断向右找117 {118if(p->value==val) //如果能找到119 {120 cout<<p->i<<""<<p->j; //输出⾏下标和列下标121 flag = 1; //标记找到该元素;122 }123 }124 }125126127if(flag==0) //如果找不到128 {129 cout<<"ERROR\n";130 }131132 }133int main()134 {135 CrossL A; //定义⼀个⼗字链表;136 InitSMatrix(&A); //初始化;137 CreatSMatrix(&A); //创建;138 PrintSMatrix(&A); //输出;139 DestroysMatrix(&A); //销毁;140return0;141 }。
稀疏矩阵的十字链表

稀疏矩阵的十字链表
稀疏矩阵是指在大多数元素都为零的情况下,只有少部分元素非零的矩阵。
与之相对应的是稠密矩阵,即大多数元素都非零的矩阵。
为了节省存储空间,我们可以采用特殊的数据结构来存储稀疏矩阵。
其中,十字链表是一种常用的数据结构。
十字链表是一种链式存储结构,用于存储稀疏矩阵。
它的基本思想是先将矩阵按行分解成一组行链表,再将矩阵按列分解成一组列链表。
每个非零元素在行链表和列链表中各有一个结点,这个结点包括该元素在矩阵中的行、列编号以及该元素的值。
通过行链表和列链表,我们可以快速地访问矩阵中的非零元素。
具体来说,十字链表包括两种结点,分别为行结点和列结点。
行结点的数据成员包括该非零元素所在的行号、列号、该元素的值,以及指向同一行中下一个非零元素的指针和同一列中下一个非零元素的指针。
列结点的数据成员包括该非零元素所在的行号、列号、该元素的值,以及指向同一列中下一个非零元素的指针和同一行中下一个非零元素的指针。
通过这样的链式存储结构,我们可以实现在O(k)的时间复杂度内访问矩阵中任意一个非零元素,其中k为矩阵中非零元素的个数。
总的来说,十字链表是一种用于存储稀疏矩阵的高效数据结构,它采用链式存储方式,能够快速地访问矩阵中的非零元素,并且能够有效地节省存储空间。
稀疏矩阵十字链表算法

稀疏矩阵十字链表算法稀疏矩阵是指矩阵中大部分元素为0的矩阵。
在实际应用中,稀疏矩阵常常出现,比如图像处理、网络分析等领域。
由于稀疏矩阵中存在大量的0元素,传统的二维数组存储方式会造成内存空间的浪费,因此需要一种高效的数据结构来表示和存储稀疏矩阵。
稀疏矩阵十字链表算法就是一种解决这个问题的方法。
稀疏矩阵十字链表算法是一种基于链表的数据结构,用于表示和存储稀疏矩阵。
它通过两个链表来分别表示行和列,同时还使用了一个数据链表来存储非零元素的值和位置信息。
这种算法的核心思想是将稀疏矩阵的非零元素存储在链表中,并记录它们在矩阵中的位置信息,从而节省了存储空间。
具体来说,稀疏矩阵十字链表算法中,我们可以使用三个结构体来表示矩阵的行、列和非零元素。
其中,行和列的结构体包含了指向非零元素的指针和矩阵的维度信息。
非零元素的结构体包含了元素的值、行列坐标以及指向下一个非零元素的指针。
使用稀疏矩阵十字链表算法存储稀疏矩阵的好处是,它不仅节省了存储空间,还可以提高对稀疏矩阵的操作效率。
比如,对于稀疏矩阵的遍历操作,我们可以通过遍历链表的方式来实现,而不需要遍历整个矩阵,从而减少了时间复杂度。
除了存储和遍历操作,稀疏矩阵十字链表算法还可以支持其他一些常见的矩阵操作,比如矩阵的相加、相乘等。
对于这些操作,我们只需要按照链表的顺序进行遍历,并根据矩阵的位置信息进行计算即可。
稀疏矩阵十字链表算法的实现过程相对简单,但需要注意一些细节。
首先,我们需要确定稀疏矩阵的维度信息,并创建相应的行和列的链表头结点。
然后,我们可以按照行优先的方式遍历整个矩阵,将非零元素插入到链表中,并更新行和列的指针。
最后,我们可以根据需要进行各种矩阵操作。
稀疏矩阵十字链表算法是一种高效的存储和表示稀疏矩阵的方法。
它通过链表来存储非零元素,并记录它们在矩阵中的位置信息,从而节省了存储空间。
同时,它还可以支持各种常见的矩阵操作。
在实际应用中,稀疏矩阵十字链表算法可以提高程序的运行效率,减少内存的占用,是一种非常实用的数据结构算法。
稀疏矩阵的十字链表存储结构

稀疏矩阵的十字链表存储结构
稀疏矩阵是指矩阵中绝大多数元素为0,而仅有少数元素非0,这种矩阵的存在会占用大量的存储空间,而且在进行一些操作时也会变得非常低效。
为了解决这个问题,可以采用十字链表的方式对稀疏矩阵进行存储。
十字链表存储结构是一种非常高效的稀疏矩阵存储方法。
它将矩阵中所有非零元素按行列坐标分别存储到两个链表中,并且在每个节点中还包含指向该元素左右上下四个方向节点的指针,形成一个类似于十字路口的结构。
这样一来,我们就可以在O(n)的时间内轻松地遍历矩阵中所有的非零元素,而且还能够快速地定位和更新某个元素的值,大大提高了存储和处理的效率。
在十字链表存储结构中,我们通常会使用头节点来记录矩阵的大小和非零元素的总数,以及行列链表的头指针。
节点中的数据需要同时包含行列坐标和元素的值,这样才能够快速地进行查找和替换。
同时,在插入或删除一个元素时,我们需要更新该元素所在节点的邻接节点的指针,以保证整个结构的完整性和正确性。
总的来说,十字链表存储结构是一种非常高效和灵活的稀疏矩阵存储方案,可以大大减小矩阵的存储空间和处理时间,同时也可以满足各种复杂的操作需求。
在实际应用中,我们可以根据具体的问题和数据特征灵活地选择适合的数据结构和算法,来达到更好的效果和效率。
稀疏矩阵十字链表基本函数

稀疏矩阵十字链表基本函数1.宏定义#include<stdio.h>#include<stdlib.h>#define datatype int#define MAXROW 100#define MAXCOL 1002.结构体typedef struct mnode{int row,col;datatype v;struct mnode *down,*right;}Mnode,*Mlink;typedef struct{int mu,nu,tu;Mnode *rlink[MAXROW],*clink[MAXCOL];}Crosslink;3. 稀疏矩阵十字链表基本函数Crosslink *Creat_Crosslink()/*建立十字链表函数1.先决条件:2.函数作用:创建十字链表存储的稀疏矩阵*/ {Crosslink *H;Mnode *p,*q;int i,j,k,v;H=(Crosslink *)malloc(sizeof(Crosslink));printf("请输入矩阵的行列及非零元素的个数:\n");scanf("%d%d%d",&H->mu,&H->nu,&H->tu);for(k=1;k<=H->mu;k++)H->rlink[k]=NULL;for(k=1;k<=H->nu;k++)H->clink[k]=NULL;printf("请输入%d个三元组:\n",H->tu);for(k=1;k<=H->tu;k++){scanf("%d%d%d",&i,&j,&v);p=(Mnode *)malloc(sizeof(Mnode));p->row=i;p->col=j;p->v=v;q=H->rlink[i];if(q==NULL||q->col>j){p->right=q;H->rlink[i]=p;}else{while(q->right&&(q->right->col)<j)q=q->right;p->right=q->right;q->right=p;}q=H->clink[j];if(q==NULL||q->row>i){p->down=q;H->clink[j]=p;}else{while(q->down&&(q->down->row)<i)q=q->down;p->down=q->down;q->down=p;}}return H;}Crosslink *Add_Crosslink(Crosslink *HA,Crosslink *HB)/*十字链表相加函数1.先决条件:2.函数作用:将两个十字链表HA,HB相加到HC中,并返回HC*/{Crosslink *HC;Mnode *pa,*pb,*pc;Mnode *rl_rear[100],*cl_rear[100];//Mnode *rl_rear[m+1],*cl_rear[n+1];int i,k;if(HA->mu!=HB->mu||HA->nu!=HB->nu)return NULL;HC=(Crosslink *)malloc(sizeof(Crosslink));HC->mu=HA->mu;HC->nu=HA->nu;for(k=1;k<=HC->mu;k++)HC->rlink[k]=NULL;for(k=1;k<=HC->nu;k++)HC->clink[k]=NULL;for(k=1;k<=HC->mu;k++)rl_rear[k]=HC->rlink[k];for(k=1;k<=HC->nu;k++)cl_rear[k]=HC->clink[k];for(i=1;i<=HC->mu;i++){pa=HA->rlink[i];pb=HB->rlink[i];while(pa||pb){if(pa&&pb&&pa->col==pb->col&&pa->v+pb->v==0){pa=pa->right;pb=pb->right;}else{pc=(Mnode *)malloc(sizeof(Mnode));pc->row=i;pc->right=NULL;pc->down=NULL;if(pa->col<pb->col||pb==NULL){pc->col=pa->col;pc->v=pa->v;pa=pa->right;}else if(pa->col>pb->col||pa==NULL){pc->col=pb->col;pc->v=pb->v;pb=pb->right;}else{pc->col=pa->col;pc->v=pa->v+pa->v;pa=pa->right;pb=pb->right;}}if(HC->rlink[i]==NULL){HC->rlink[i]=pc;rl_rear[i]=pc;}else{rl_rear[i]->right=pc;rl_rear[i]=pc;}if(HC->clink[pc->col]==NULL){HC->clink[pc->col]=pc;cl_rear[pc->col]=pc;}else{cl_rear[pc->col]->down=pc;cl_rear[pc->col]=pc;}}}return HC;}4.主函数int main(){int i;Mnode *pa;Crosslink *HA,*HB,*HC;HA=Creat_Crosslink();HB=Creat_Crosslink();HC=Add_Crosslink(HA,HB);for(i=1;i<=HC->mu;i++){pa=HC->rlink[i];while(pa){printf("i=%d,j=%d,v=%d ",pa->row,pa->col,pa->v);pa=pa->right;}printf("\n");}return 0;}。
数据结构学习(c)稀疏矩阵(十字链表1)

数据结构学习(C++)—稀疏矩阵(十字链表【1】)happycock(原作)转自CSDN先说说什么叫稀疏矩阵。
你说,这个问题很简单吗,那你一定不知道中国学术界的嘴皮子仗,对一个字眼的“抠”将会导致两种相反的结论。
这是清华2000年的一道考研题:“表示一个有1000个顶点,1000条边的有向图的邻接矩阵有多少个矩阵元素?是否稀疏矩阵?”如果你是个喜欢研究出题者心理活动的人,你可以看出这里有两个陷阱,就是让明明会的人答错,我不想说出是什么,留给读者思考。
姑且不论清华给的标准答案是什么,那年的参考书是严蔚敏的《数据结构(C语言版)》,书上对于稀疏矩阵的定义是这样的:“非零元较零元少(注:原书下文给出了大致的程度),且分布没有一定规律”,照这个说法,那题的答案应该是不一定是稀疏矩阵,因为可能是特殊矩阵(非零元分布有规律)。
自从2002年换参考书后,很多概念都发生了变化,最明显的是从多少开始计数(0还是1),从而导致的是空树的高度变成了-1,只有一个根节点的树高度是0。
很不幸的是树高的问题几乎年年都考,在你下笔的时候,总是犯点嘀咕,总不是一朝天子一朝臣吧,会不会答案是个兼容版本?然后,新参考书带的习题集里引用了那道考研题,答案是是稀疏矩阵。
你也许会惊讶这年头咸鱼都会游泳了,但这个答案和书并不矛盾,因为在这本黄皮书里,根本就没有什么特殊矩阵,自然就一定是稀疏矩阵了。
其实,这两本书在这个问题上也没什么原则上的问题,C版的是从数据结构实现区分出特殊矩阵和稀疏矩阵,毕竟他们实现起来很不相同;新书一股脑把非零元少的矩阵都当成稀疏矩阵,当你按照这种思路做的时候就会发现,各种结构特殊的非零元很少的矩阵,如果用十字链表来储存的话,比考虑到它的特殊结构得出的特有储存方法,仅仅是浪费了几个表头节点和一些指针域,再有就是一些运算效率的降低。
从我个人角度讲,我更喜欢多一些统一,少一些特别,即使牺牲一点效率;所以在这一点上我赞同新参考书的做法。
表示稀疏矩阵的十字链表

void invert(node *head)
{ node *p,*q,*r;
例
p=head;
q=p->next;
3
while(q!=NULL) /*没有后继时停止*/
.
{
1
r=q->next; q->next=p;
算
p=q;
法
q=r;
}
head->next=NULL;
head=p;
}
链表
例3.2
}
链表
例3.3
给出在双链表中第i个结点(i≥0)之后插入一个元素为x的 结点的函数。
解:在前面双链表一节中,已经给出了在一个结点之前 插入一个新结点的方法,在一个结点之后插入一个新结 点的思想与前面是一样的。
链表
void insert(dnode *head,int i,x)
{
dnode *s,*p;
link(node *head1,head2)
{
例
node *p,*q; p=head1;
3.
while(p->next!=head1)
2
p=p->next;
算
q=head2; while(q->next!=head2)
法
q=q->next;
p->next=head2;
q->next=head1;
对于每行、每列的循环链表都有一个空表 头结点,以利于元素的插入和删除运算。 这些空表头结点的行号、列号都标成零, 以便和其它结点相区别。
整个十字链表有一个总的空表头结点,在 一般结点标以行号、列号之处,此结点是 标出矩阵的行数m和列数n。
采用十字链表存储的稀疏矩阵

采⽤⼗字链表存储的稀疏矩阵Description当矩阵的⾮零元个数和位置在操作过程中变化较⼤时,就不宜采⽤顺序存储的结构来表⽰三元组的线性表了。
因此,在这种情况下,采⽤链式存储结构表⽰三元组更为恰当。
⼗字链表就是能够实现这样功能的⼀种数据结构。
在⼗字链表中,每个⾮零元可以⽤⼀个包含5个域的结点表⽰。
其中i、j和e这3个域分别表⽰该⾮零元所在的⾏、列和⾮零元的值,向右域right⽤来链接同⼀⾏中下⼀个⾮零元,⽽向下域down⽤来链接同⼀列中下⼀个⾮零元。
同⼀⾏的⾮零元通过right域链接成⼀个线性链表,同⼀列的⾮零元通过down域链接成⼀个线性链表。
每个⾮零元既是某个⾏链表中的⼀个结点,⼜是某个列链表中的⼀个结点,整个矩阵通过这样的结构形成了⼀个⼗字交叉的链表。
稀疏矩阵的⼗字链表类型可以描述如下:下⾯是建⽴稀疏矩阵⼗字链表的算法描述:给出⼀个稀疏矩阵,请将其存储到⼀个⼗字链表中,并将存储完毕的矩阵输出。
Input输⼊的第⼀⾏是两个整数r和c(r<200, c<200, r*c <= 12500),分别表⽰⼀个包含很多0的稀疏矩阵的⾏数和列数。
接下来有r⾏,每⾏有c个整数,⽤空格隔开,表⽰稀疏矩阵的各个元素。
Output输出读⼊的矩阵。
输出共有r⾏,每⾏有c个整数,每个整数后输出⼀个空格。
请注意⾏尾输出换⾏。
Sample Input5 60 18 0 0 0 00 0 67 0 0 00 0 0 0 0 410 0 47 62 0 00 0 0 0 0 35Sample Output0 18 0 0 0 00 0 67 0 0 00 0 0 0 0 410 0 47 62 0 00 0 0 0 0 35HINT提⽰:对于m⾏n列且有t个⾮零元的稀疏矩阵,算法5.4的执⾏时间为O(t×s),其中s=max(m,n)。
这是由于每建⽴⼀个⾮零元结点时,都需要通过遍历查询它所在的⾏表和列表中的插⼊位置。
稀疏矩阵的链式存储结构

稀疏矩阵的链式存储结构一、引言稀疏矩阵是指矩阵中大部分元素为0的矩阵。
在实际应用中,很多矩阵都是稀疏的,比如图像处理、网络分析等领域。
由于稀疏矩阵中存在大量的0元素,因此采用传统的二维数组存储会浪费大量的存储空间。
为了解决这个问题,需要采用一种更加高效的存储方式,即链式存储结构。
二、链式存储结构链式存储结构是一种动态数据结构,它通过指针将不连续的内存块串联起来,形成一个链表。
在稀疏矩阵中,每个非零元素可以看作是一个节点,节点之间通过指针连接起来形成一个链表。
三、三元组表三元组表是一种常见的稀疏矩阵链式存储结构。
它将一个稀疏矩阵表示成一个三元组(TS) = <m, n, k, {(i,j,e)}> 的形式,其中m和n分别表示该矩阵的行数和列数,k表示该矩阵中非零元素的个数,{(i,j,e)}表示非零元素所在行列和元素的值。
四、压缩存储三元组表虽然解决了稀疏矩阵存储空间浪费的问题,但是它仍然存在一些缺点。
比如,在查找某个元素时需要遍历整个三元组表,效率较低。
为了解决这个问题,可以采用压缩存储的方式。
五、行逻辑链接行逻辑链接是一种常用的压缩存储方式。
它将三元组表中每一行中的非零元素按列坐标递增的顺序连接起来,形成一个链表。
这样,在查找某个元素时只需要遍历该行对应的链表即可。
六、十字链表十字链表是一种更加高效的稀疏矩阵链式存储结构。
它将稀疏矩阵分成两部分:行部和列部。
每个非零元素在行部和列部都有一个节点,节点之间通过指针连接起来形成一个十字链表。
七、块式压缩存储块式压缩存储是一种更加高效的稀疏矩阵存储方式。
它将稀疏矩阵分成若干个大小相等或者相近的子矩阵,每个子矩阵采用三元组表或者十字链表等方式进行存储。
这样,在查找某个元素时只需要遍历该元素所在的子矩阵即可。
八、总结稀疏矩阵的链式存储结构是一种高效的存储方式,可以大大节省存储空间。
常见的稀疏矩阵链式存储结构有三元组表、行逻辑链接、十字链表和块式压缩存储等。
数据结构 耿国华 西北大学 5-5稀疏矩阵的十字链表法

1
第 5 章 数组和广义表
5.3 特殊矩阵的压缩存储
③稀疏矩阵:三元组顺序表 数据类型定义
#define MAXSIZE 1000 typedef struct {
int row, col; ElementType e ; }Triple;
③稀疏矩阵:十字链表的存储表示
一个结点除了数据域(i,j,elem)之外,还应该用两 个方向的指针(right, down),分别指向行和列。
right:用于链接同一行中的下一个元素; down:用于链接同一列中的下一个元素。
row col value down right
整个矩阵构成了一个十字交叉的链表,因此称十字链表。 每一行和每一列的头指针,用两个一维指针数组来存放。 3
/* 行号和列号 */ /* 元素值 */
typedef struct
{ Triple data[MAXSIZE +1]; /* data[0]未用 */ int m, n, len; /* 矩阵的行数、列数和非零元个数 */ 2
}TSMatrix;
第 5 章 数组和广义表
5.3 特殊矩阵的压缩存储Βιβλιοθήκη typedef struct
{
OLink *row_head,*col_head;
int m,n,len;
4
}CrossList;
第 5 章 数组和广义表 5.3 特殊矩阵的压缩存储
row col value down right
③稀疏矩阵 十字链表的举例 :
-3 0 0 -5
M= 0 -1 0 0 8 00 7
第 5 章 数组和广义表 5.3 特殊矩阵的压缩存储
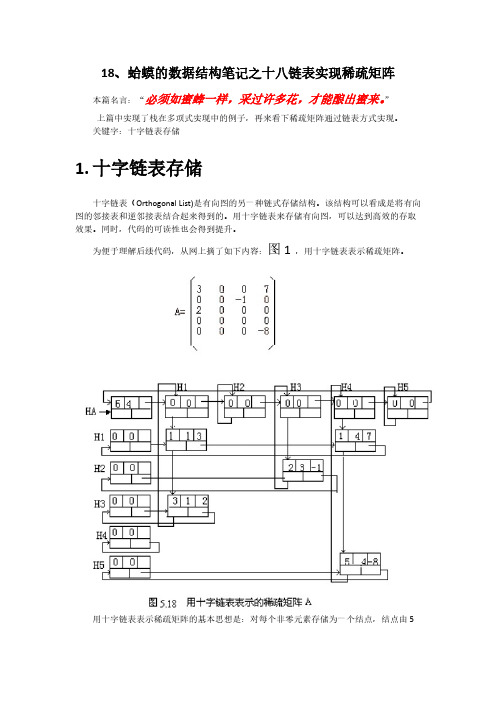
18数据结构笔记之十八链表实现稀疏矩阵
对全部高中资料试卷电气设备,在安装过程中以及安装结束后进行高中资料试卷调整试验;通电检查所有设备高中资料电试力卷保相护互装作置用调与试相技互术关,系电,力根通保据过护生管高产线中工敷资艺设料高技试中术卷资,配料不置试仅技卷可术要以是求解指,决机对吊组电顶在气层进设配行备置继进不电行规保空范护载高与中带资负料荷试下卷高问总中题体资,配料而置试且时卷可,调保需控障要试各在验类最;管大对路限设习度备题内进到来行位确调。保整在机使管组其路高在敷中正设资常过料工程试况中卷下,安与要全过加,度强并工看且作护尽下关可都于能可管地以路缩正高小常中故工资障作料高;试中对卷资于连料继接试电管卷保口破护处坏进理范行高围整中,核资或对料者定试对值卷某,弯些审扁异核度常与固高校定中对盒资图位料纸置试,.卷保编工护写况层复进防杂行腐设自跨备动接与处地装理线置,弯高尤曲中其半资要径料避标试免高卷错等调误,试高要方中求案资技,料术编试交写5、卷底重电保。要气护管设设装线备备置敷4高、调动设中电试作技资气高,术料课中并3中试、件资且包卷管中料拒含试路调试绝线验敷试卷动槽方设技作、案技术,管以术来架及避等系免多统不项启必方动要式方高,案中为;资解对料决整试高套卷中启突语动然文过停电程机气中。课高因件中此中资,管料电壁试力薄卷高、电中接气资口设料不备试严进卷等行保问调护题试装,工置合作调理并试利且技用进术管行,线过要敷关求设运电技行力术高保。中护线资装缆料置敷试做设卷到原技准则术确:指灵在导活分。。线对对盒于于处调差,试动当过保不程护同中装电高置压中高回资中路料资交试料叉卷试时技卷,术调应问试采题技用,术金作是属为指隔调发板试电进人机行员一隔,变开需压处要器理在组;事在同前发一掌生线握内槽图部内 纸故,资障强料时电、,回设需路备要须制进同造行时厂外切家部断出电习具源题高高电中中源资资,料料线试试缆卷卷敷试切设验除完报从毕告而,与采要相用进关高行技中检术资查资料和料试检,卷测并主处且要理了保。解护现装场置设。备高中资料试卷布置情况与有关高中资料试卷电气系统接线等情况,然后根据规范与规程规定,制定设备调试高中资料试卷方案。
稀疏矩阵的十字链表存储

稀疏矩阵的⼗字链表存储稀疏矩阵的压缩存储有⼏种⽅式,如:三元组顺序表、⾏逻辑链接的顺序表和⼗字链表。
使⽤链表存储的好处是:便于矩阵中元素的插⼊和删除。
例如:“将矩阵B加到矩阵A上”,那么矩阵A存储的元素就会有变动。
⽐如会增加⼀些⾮零元,或者删除⼀些元素(因为b ij+a ij=0)。
下图是矩阵M和M的⼗字链表存储:⼗字链表及其结点可⽤如下结构体表⽰:typedef struct OLNode{int i, j; // ⾮零元的⾏列下标ElemType e;struct OLNode *right, *down; // 向右域和向下域} OLNode, *OLink;typedef struct{OLink *rhead, *chead; // ⾏链表和列链表的头指针数组int mu, nu, tu; // 稀疏矩阵的⾏数、列数和⾮零元个数} CrossList;在通过代码创建⼗字链表时,要特别注意right、down和rhead、chead这些指针的赋值。
现在来看“将矩阵B加到矩阵A上”这个问题。
所要做的操作:a ij +b ij,其结果⼀共会有4种情况:1. a ij(b ij = 0)(不做变化)2. b ij(a ij = 0)(在A中插⼊⼀个新结点)3. a ij +b ij ≠ 0 (改变结点a ij的值域)4. a ij +b ij = 0 (删除结点a ij)假设指针pa和pb分别指向矩阵A和B中⾏值相同的两个结点,对于上述4种情况的处理过程为:1. 若“pa == NULL”或“pa->j⼤于pb->j”,则在矩阵A中插⼊⼀个值为b ij的结点。
并且需要修改同⼀⾏前⼀结点的right指针,和同⼀列前⼀结点的down指针。
2. 若“pa->j⼩于pb-j”,则pa指针右移⼀步。
3. 若“pa->j等于pb-j”,并且“pa->e + pb->e != 0”,则修改pa->e即可。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
稀疏矩阵十字链表基本函数1.宏定义
#include<stdio.h>
#include<stdlib.h>
#define datatype int
#define MAXROW 100
#define MAXCOL 100
2.结构体
typedef struct mnode
{
int row,col;
datatype v;
struct mnode *down,*right;
}Mnode,*Mlink;
typedef struct
{
int mu,nu,tu;
Mnode *rlink[MAXROW],*clink[MAXCOL];
}Crosslink;
3. 稀疏矩阵十字链表基本函数
Crosslink *Creat_Crosslink()
/*建立十字链表函数1.先决条件:2.函数作用:创建十字链表存储的稀疏矩阵*/ {
Crosslink *H;
Mnode *p,*q;
int i,j,k,v;
H=(Crosslink *)malloc(sizeof(Crosslink));
printf("请输入矩阵的行列及非零元素的个数:\n");
scanf("%d%d%d",&H->mu,&H->nu,&H->tu);
for(k=1;k<=H->mu;k++)
H->rlink[k]=NULL;
for(k=1;k<=H->nu;k++)
H->clink[k]=NULL;
printf("请输入%d个三元组:\n",H->tu);
for(k=1;k<=H->tu;k++)
{
scanf("%d%d%d",&i,&j,&v);
p=(Mnode *)malloc(sizeof(Mnode));
p->row=i;
p->col=j;
p->v=v;
q=H->rlink[i];
if(q==NULL||q->col>j)
{
p->right=q;
H->rlink[i]=p;
}
else
{
while(q->right&&(q->right->col)<j)
q=q->right;
p->right=q->right;
q->right=p;
}
q=H->clink[j];
if(q==NULL||q->row>i)
{
p->down=q;
H->clink[j]=p;
}
else
{
while(q->down&&(q->down->row)<i)
q=q->down;
p->down=q->down;
q->down=p;
}
}
return H;
}
Crosslink *Add_Crosslink(Crosslink *HA,Crosslink *HB)
/*十字链表相加函数1.先决条件:2.函数作用:将两个十字链表HA,HB相加到HC中,并返回HC*/
{
Crosslink *HC;
Mnode *pa,*pb,*pc;
Mnode *rl_rear[100],*cl_rear[100];//Mnode *rl_rear[m+1],*cl_rear[n+1];
int i,k;
if(HA->mu!=HB->mu||HA->nu!=HB->nu)
return NULL;
HC=(Crosslink *)malloc(sizeof(Crosslink));
HC->mu=HA->mu;
HC->nu=HA->nu;
for(k=1;k<=HC->mu;k++)
HC->rlink[k]=NULL;
for(k=1;k<=HC->nu;k++)
HC->clink[k]=NULL;
for(k=1;k<=HC->mu;k++)
rl_rear[k]=HC->rlink[k];
for(k=1;k<=HC->nu;k++)
cl_rear[k]=HC->clink[k];
for(i=1;i<=HC->mu;i++)
{
pa=HA->rlink[i];
pb=HB->rlink[i];
while(pa||pb)
{
if(pa&&pb&&pa->col==pb->col&&pa->v+pb->v==0)
{
pa=pa->right;
pb=pb->right;
}
else
{
pc=(Mnode *)malloc(sizeof(Mnode));
pc->row=i;
pc->right=NULL;
pc->down=NULL;
if(pa->col<pb->col||pb==NULL)
{
pc->col=pa->col;
pc->v=pa->v;
pa=pa->right;
}
else if(pa->col>pb->col||pa==NULL)
{
pc->col=pb->col;
pc->v=pb->v;
pb=pb->right;
}
else
{
pc->col=pa->col;pc->v=pa->v+pa->v;
pa=pa->right;
pb=pb->right;
}
}
if(HC->rlink[i]==NULL)
{
HC->rlink[i]=pc;
rl_rear[i]=pc;
}
else
{
rl_rear[i]->right=pc;
rl_rear[i]=pc;
}
if(HC->clink[pc->col]==NULL)
{
HC->clink[pc->col]=pc;
cl_rear[pc->col]=pc;
}
else
{
cl_rear[pc->col]->down=pc;
cl_rear[pc->col]=pc;
}
}
}
return HC;
}
4.主函数
int main()
{
int i;
Mnode *pa;
Crosslink *HA,*HB,*HC;
HA=Creat_Crosslink();
HB=Creat_Crosslink();
HC=Add_Crosslink(HA,HB);
for(i=1;i<=HC->mu;i++)
{
pa=HC->rlink[i];
while(pa)
{
printf("i=%d,j=%d,v=%d ",pa->row,pa->col,pa->v);
pa=pa->right;
}
printf("\n");
}
return 0;
}。