CH11-其他链表
数据结构(二十四)二叉树的链式存储结构(二叉链表)

数据结构(⼆⼗四)⼆叉树的链式存储结构(⼆叉链表) ⼀、⼆叉树每个结点最多有两个孩⼦,所以为它设计⼀个数据域和两个指针域,称这样的链表叫做⼆叉链表。
⼆、结点结构包括:lchild左孩⼦指针域、data数据域和rchild右孩⼦指针域。
三、⼆叉链表的C语⾔代码实现:#include "string.h"#include "stdio.h"#include "stdlib.h"#include "io.h"#include "math.h"#include "time.h"#define OK 1#define ERROR 0#define TRUE 1#define FALSE 0#define MAXSIZE 100 /* 存储空间初始分配量 */typedef int Status; /* Status是函数的类型,其值是函数结果状态代码,如OK等 *//* ⽤于构造⼆叉树********************************** */int index=1;typedef char String[24]; /* 0号单元存放串的长度 */String str;Status StrAssign(String T,char *chars){int i;if(strlen(chars)>MAXSIZE)return ERROR;else{T[0]=strlen(chars);for(i=1;i<=T[0];i++)T[i]=*(chars+i-1);return OK;}}/* ************************************************ */typedef char TElemType;TElemType Nil=''; /* 字符型以空格符为空 */Status visit(TElemType e){printf("%c ",e);return OK;}typedef struct BiTNode /* 结点结构 */{TElemType data; /* 结点数据 */struct BiTNode *lchild,*rchild; /* 左右孩⼦指针 */}BiTNode,*BiTree;/* 构造空⼆叉树T */Status InitBiTree(BiTree *T){*T=NULL;return OK;}/* 初始条件: ⼆叉树T存在。
习题总

4. 设循环队列的容量为40(序号从0到39),现 经过一系列的入队和出队运算后,有① front=11, rear=19; ② front=19,rear=11;问在这两种情 况下,循环队列中各有元素多少个? 答:用队列长度计算公式: (N+r-f)% N
① L=(40+19-11)% 40=8 ② L=(40+11-19)% 40=32
q=p->next;s=p; while (q!=NULL){ if (p->data = = q->data) {s->next=q->next; delete q;q=s->next;} else s=q;q=q->next; } p=p->next;
}
}
16
第3章 栈和队列
1. 顺序表、栈和队列都是 线性 结构,可以在顺序表的 任何 位置 栈顶 插入和删除元素;对于栈只能在 插入和删除元素;对于队 队尾 队首 列只能在 插入和 删除元素。 2. 栈是一种特殊的线性表,允许插入和删除运算的一端称 为 栈顶 。不允许插入和删除运算的一端称为 栈底 。 3. 队列是被限定为只能在表的一端进行插入运算,在表的另一端 进行删除运算的线性表。 4. 在一个循环队列中,队尾指针指向队尾元素的 后一个位置。 5. 在具有n个单元的循环队列中,队满时共有 n-1 个元素。 6. 向栈中压入元素的操作是先 存入元素 ,后 移动栈顶指针 。 取出元素 7. 从循环队列中删除一个元素时,其操作是 先 , 后 移动队首指针。
13
5. 编写算法,实现单链表的就地逆置,即要求 在原单链表的存储空间内将原表逆置。(带头结点) (a1, a2,…, an)-> (an, an-1,…, a1)
《数据结构》教程c语言版

《数据结构》第五版清华大学自动化系李宛洲2004年5月目录第一章数据结构--概念与基本类型 (6)1.1概述 (6)1.1.1数据结构应用对象 (6)1.1.2学习数据结构的基础 (7)1.1.2.1 C语言中的结构体 (7)1.1.2.2 C语言的指针在数据结构中的关联作用 (8)1.1.2.3 C语言的共用体(union)数据类型 (12)1.1.3数据结构定义 (15)1.2线性表 (17)1.2.1 顺序表 (18)1.2.2 链表 (20)1.2.2.1链表的基本结构及概念 (20)1.2.2.2单链表设计 (22)1.2.2.3单链表操作效率 (29)1.2.2.4双链表设计 (30)1.2.2.5链表深入学习 (32)1.2.2.6稀疏矩阵的三元组与十字链表 (36)1.2.3 堆栈 (41)1.2.3.1堆栈结构 (41)1.2.3.2基本操作 (42)1.2.3.3堆栈与递归 (44)1.2.3.4递归与分治算法 (45)1.2.3.5递归与递推 (49)1.2.3.6栈应用 (52)1.2.4 队列 (57)1.2.4.1队列结构 (57)1.2.3.2队列应用 (59)1.3非线性数据结构--树 (64)1.3.1 概念与术语 (64)1.3.1.1引入非线性数据结构的目的 (64)1.3.1.2树的定义与术语 (65)1.3.1.3树的内部节点与叶子节点存储结构问题 (66)1.3.2 二叉树 (66)1.3.2.1二叉树基本概念 (66)1.3.2.2完全二叉树的顺序存储结构 (68)1.3.2.3二叉树遍历 (69)1.3.2.4二叉树唯一性问题 (71)1.3.3 二叉排序树 (72)1.3.3.1基本概念 (72)1.3.3.2程序设计 (73)1.3.4 穿线二叉树 (79)1.3.4.1二叉树的中序线索化 (80)1.3.4.2中序遍历线索化的二叉树 (81)1.3.5 堆 (82)1.3.5.1建堆过程 (83)1.3.5.2在堆中插入节点 (85)1.3.6 哈夫曼树 (86)1.3.6.1最佳检索树 (86)1.3.6.2哈夫曼树结构与算法 (88)1.3.6.3 哈夫曼树应用 (90)1.3.6.4哈夫曼树程序设计 (92)1.3.7 空间数据结构----二叉树深入学习导读 (95)1.3.7.1k-d树概念 (96)1.3.7.2k-d树程序设计初步 (97)1.4非线性数据结构--图 (100)1.4.1图的基本概念 (100)1.4.2图形结构的物理存储方式 (103)1.4.2.1相邻矩阵 (103)1.4.2.2图的邻接表示 (104)1.4.2.3图的多重邻接表示 (106)1.4.3图形结构的遍历 (107)1.4.4无向连通图的最小生成树(minimum-cost spanning tree:MST) (110)1.4.5有向图的最短路径 (113)1.4.5.1单源最短路径(single-source shortest paths) (113)1.4.5.2每对顶点间最短路经(all-pairs shortest paths) (116)1.4.6拓扑排序 (117)第二章检索 (123)2.1顺序检索 (123)2.2对半检索 (124)2.2.1 对半检索与二叉平衡树 (124)2.2.2对半检索思想在链式存储结构中的应用---跳跃表 (127)2.3分块检索 (133)2.4哈希检索 (134)2.4.1哈希函数 (135)2.4.2闭地址散列 (136)2.4.2.1线性探测法和基本聚集问题 (136)2.4.2.2删除操作造成检索链的中断问题 (138)2.4.2.3随机探测法 (139)2.4.2.4平方探测法 (140)2.4.2.5二次聚集问题与双散列探测方法 (141)2.4.3开地址散列 (142)2.4.4哈希表检索效率 (142)第三章排序 (145)3.1交换排序方法 (145)3.1.1直接插入排序 (145)3.1.2冒泡排序 (147)3.1.3 选择排序 (148)3.1.4 树型选择排序 (149)3.2S HELL排序 (150)3.3快速排序 (152)3.4堆排序 (154)3.5归并排序 (156)3.6数据结构小结 (159)3.6.1 数据结构的基本概念 (159)3.6.2 数据结构分类 (159)3.6.2.1数据结构中的指针问题 (160)3.6.2.2线性表的效率问题 (161)3.6.2.3二叉树 (161)3.6.3排序与检索 (161)3.7算法分析的基本概念 (162)3.7.1基本概念 (162)3.7.2上限分析 (164)3.7.3下限分析 (164)3.7.4空间代价与时间代价转换 (165)第6章高级数据结构内容--索引技术 (167)6.1基本概念 (167)6.2线性索引 (168)6.2.1 线性索引 (168)6.2.2 倒排表 (169)6.32-3树 (170)6.3.1 2-3树定义 (172)6.3.2 2-3树节点插入 (173)6.4B+树 (178)6.4.1 B+树定义 (178)6.4.2 B+树插入与删除 (180)6.4.3 B+树实验设计 (182)第一章数据结构--概念与基本类型1.1概述1.1.1数据结构应用对象计算机应用可以分为两大类,一类是科学计算和工业控制,另一类是商业数据处理。
ch树实用学习教程
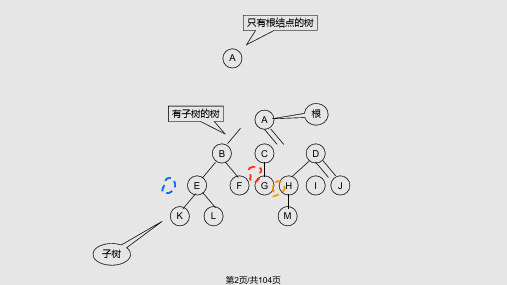
• 几种特殊形式的二叉树
• 满二叉树定义:
一棵深度为k且有2k 1个结点的二叉树称为~
特点:每一层上的结点数都是最大结点数
❖完全二叉树
定义:深度为k,有n个结点的二叉树当且仅当其每一个结点都与深 度为k的满二叉树中编号从1至n的结点一一对应时,称为~
特点 叶子结点只可能在层次最大的两层上出现 对任一结点,若其右分支下子孙的最大层次为L,则其左分支 下子孙的最大层次必为L 或L+1
第34页/共104页
课堂练习
A B
C
D
F E
G
先序遍历: A B C D E G F 中序遍历: C B E G D F A 后序遍历: C G E F D B A 层次遍历: A B C D E F G
第35页/共104页
课堂练习
-
+ a*
/ ef
b-
cd
例:表达式 a + b * (c – d) – e / f
k
k
(第i层的最大结点数 ) 2i1 2k 1
i 1
i 1
第13页/共104页
❖性质3:对任何一棵二叉树T,如果其终端结点数为n0, 度为2的结点数为n2,则n0=n2+1
证明法一: 设二叉树中度为1的结点数为n1,总结点数为n,总度数 为k,则有下列表达式成立: n=n0+n1+n2 k=0*n0+1*n1+2*n2 k=n-1
}BiTNode, *BiTree;
A
B
C
D
EF
G
A^^
B
^C
^
D
^E
^F
^
^G
^
哈希链表的c语言实现

哈希链表的c语言实现哈希链表的C语言实现哈希链表是一种常用的数据结构,用于存储和操作大量的数据。
它结合了哈希表和链表的特点,具有快速查找和高效插入删除的优势。
本文将介绍如何使用C语言实现哈希链表,并详细讲解其原理和操作。
一、哈希链表的原理哈希链表是通过哈希函数将数据的键映射到一个唯一的索引位置,然后使用链表来解决哈希冲突。
哈希函数可以是简单的取模运算,也可以是复杂的算法,关键在于保证映射的唯一性和均匀性。
二、哈希链表的结构在C语言中,我们可以使用结构体来定义哈希链表的节点和链表本身。
节点包含一个键值对,即存储的数据和对应的键,以及一个指向下一个节点的指针。
链表则包含一个指向第一个节点的指针。
```c// 定义哈希链表节点typedef struct Node {int key;int value;struct Node* next;} Node;// 定义哈希链表typedef struct HashTable {int size;Node** table;} HashT able;```三、哈希链表的操作1. 初始化哈希链表在初始化哈希链表时,需要指定链表的大小,并分配相应大小的内存空间。
同时,需要将每个节点的指针初始化为空。
2. 插入节点插入节点时,首先通过哈希函数计算出节点的索引位置,然后将节点插入到对应索引位置的链表中。
如果该位置已经存在节点,则将新节点插入到链表的头部。
3. 查找节点查找节点时,也需要通过哈希函数计算出节点的索引位置,然后遍历链表,找到对应的节点。
如果找到了节点,则返回节点的值;否则,返回空。
删除节点时,首先通过哈希函数计算出节点的索引位置,然后遍历链表,找到对应的节点并删除。
需要注意的是,删除节点时需要维护链表的连续性。
四、示例代码下面是一个简单的示例代码,演示了如何使用C语言实现哈希链表的初始化、插入、查找和删除操作。
```c#include <stdio.h>#include <stdlib.h>// 初始化哈希链表HashTable* initHashTable(int size) {HashTable* ht = (HashTable*)malloc(sizeof(HashTable));ht->size = size;ht->table = (Node**)malloc(sizeof(Node*) * size);for (int i = 0; i < size; i++) {ht->table[i] = NULL;}return ht;}void insertNode(HashTable* ht, int key, int value) { int index = key % ht->size;Node* newNode = (Node*)malloc(sizeof(Node)); newNode->key = key;newNode->value = value;newNode->next = ht->table[index];ht->table[index] = newNode;}// 查找节点int findNode(HashTable* ht, int key) {int index = key % ht->size;Node* cur = ht->table[index];while (cur) {if (cur->key == key) {return cur->value;}cur = cur->next;}return -1;}void deleteNode(HashTable* ht, int key) { int index = key % ht->size;Node* cur = ht->table[index];Node* pre = NULL;while (cur) {if (cur->key == key) {if (pre) {pre->next = cur->next;} else {ht->table[index] = cur->next; }free(cur);return;}pre = cur;cur = cur->next;}}int main() {HashTable* ht = initHashTable(10);insertNode(ht, 1, 10);insertNode(ht, 2, 20);insertNode(ht, 11, 30);printf("%d\n", findNode(ht, 1));printf("%d\n", findNode(ht, 2));printf("%d\n", findNode(ht, 11));deleteNode(ht, 2);printf("%d\n", findNode(ht, 2));free(ht->table);free(ht);return 0;}```五、总结本文介绍了哈希链表的C语言实现,并详细讲解了其原理和操作。
2009年春季江苏省二级c语言试题与答案

江苏省高校计算机等级考试命题研究院2009年春季江苏省二级c语言试题与答案江苏省高校计算机等级考试2009年春季考试试题第二部分 C程序设计21.以下定义和声明中,语法均有错误的是____(21)_________①int j(int x){}②int f(int f){} ③int 2x=1; ④struet for{int x;};A.②③ B.③④ C.①④ D.①②③④22.设有定义和声明如下:#define d 2int x=5;float Y =3.83;char c='d';以下表达式中有语法错误的是_(22)______A.x++ B.y++ C.c++ D.d++23.以下选项中,不能表示函数功能的表达式是___(23)______。
A.s=(X>0)?1:(X<0)?-1:0 B.s=X<0?-1:(X>0?1:0)C.s=X<=0?-1:(X==0?0:1) D.s=x>0?1:x==0?0:-124.以下语句中有语法错误的是____(24)______ 。
A.printf("%d",0e); B.printf("%f",0e2);C.printf("%d",Ox2); D.printf("%s","0x2");25.以下函数定义中正确的是___(25)_________ 。
A.double fun(double x,double y){}B.double fun(double x;double Y){}C.double fun(double x,double Y);{}D.double fun(double X,Y){}26.若需要通过调用f函数得到一个数的平方值,以下f函数定义中不能实现该功能的是_____(26)______ 。
数据结构中链表的插入和删除方法研究

指 薹 — 叵丑 露 驱 —
图2
j 指譬 卜 继
数据结构 的定义 :
Ty e f sr c p de tu tDLn de o
存放指 向其他结点 的地址值 。下面介绍常用的两个链表 。 '
11 单链 表 .
数据域
( ee y e aa lmtp d t;
u i p itr Th rfr , we n lz t e n eto a d eein sng one. ee oe a ay e h is rin n d lto meh d i l ke l t, f o t h cu o he r be to s n i d i s i n s nd u te r x f t p o lm, a d n
・
3 ・ 6
Co p tr Er m u e a No 9 01 . 2 1
数 据 结构 中链 表 的插入 和 删 除方 法研 究
马春侠 ’ 文 贺 ,宋
( 天津_ _ 大学 工程教 学实习训练 中心, 1 . z, -k l 天津 3 06 ;. 0102 天津工业大学 研 究生院)
摘 要 :链表 是数据 结构 中的重要概念 , 用指针处理链表是教 学中的一个难点 。为此 , 利 对链 表的插入 、 删除 方法进行 了的分析 , 出了问题 的关键 , 找 总结 了操作过程 中的 实现方法和技巧 , 以帮助学生学习和 理解该部 分知 识。 关键词 :链表 ;指针 ;插入 ;删除
中图分类号 : P 0 . T 3 16 文献标识码 : A 文章编号 :0 6 8 2 (0 1 0 — 6 0 10 — 2 82 1 )9 3 — 3
St udy f Li ke Lit ns r i a Dee i n e h o n d s I e ton nd l to M t ods n i Da a t u t e t S r c ur
链表的反转与合并掌握链表反转和合并操作的实现

链表的反转与合并掌握链表反转和合并操作的实现链表是一种常见的数据结构,它由一系列节点组成,每个节点包含一个数据元素和一个指向下一个节点的指针。
链表的反转和合并是链表操作中常见且重要的操作,在很多编程问题中都有应用。
本文将介绍链表的反转和合并操作的实现方法。
一、链表的反转链表的反转是指将链表中节点的顺序反向排列。
例如,对于链表1→2→3→4→5,反转后的链表为5→4→3→2→1。
实现链表的反转有两种常见的方法:迭代法和递归法。
1. 迭代法迭代法的实现思路是,从链表头节点开始,依次遍历每个节点,将该节点的指针指向前一个节点。
具体步骤如下:1)定义三个指针:当前节点指针cur、前一个节点指针prev、下一个节点指针next。
2)遍历链表,将当前节点的指针指向前一个节点,然后更新prev、cur和next指针的位置。
3)重复上述步骤,直到遍历到链表末尾。
以下是迭代法的实现代码示例(使用Python语言):```pythondef reverse_list(head):prev = Nonecur = headwhile cur:next = cur.nextcur.next = prevprev = curcur = nextreturn prev```2. 递归法递归法的实现思路是,从链表的尾节点开始,依次反转每个节点。
具体步骤如下:1)递归地反转除最后一个节点外的链表。
2)将当前节点的指针指向前一个节点。
3)返回反转后的链表的头节点。
以下是递归法的实现代码示例(使用Python语言):```pythondef reverse_list(head):if not head or not head.next:return headnew_head = reverse_list(head.next)head.next.next = headhead.next = Nonereturn new_head```二、链表的合并链表的合并是指将两个有序链表按照一定的规则合并成一个有序链表。
2022年安徽师范大学计算机科学与技术专业《数据结构与算法》科目期末试卷A(有答案)

2022年安徽师范大学计算机科学与技术专业《数据结构与算法》科目期末试卷A(有答案)一、选择题1、已知广义表LS=((a,b,c),(d,e,f)),用head和tail数取出LS中原子e的运算是()。
A.head(tail(LS))B.tail(head(LS))C.head(tail(head(tail(LS))))D.head(tail(tail(head(LS))))2、设有一个10阶的对称矩阵A,采用压缩存储方式,以行序为主存储, a11为第一元素,其存储地址为1,每个元素占一个地址空间,则a85的地址为()。
A.13B.33C.18D.403、静态链表中指针表示的是()。
A.下一元素的地址B.内存储器的地址C.下一元素在数组中的位置D.左链或右链指向的元素的地址4、动态存储管理系统中,通常可有()种不同的分配策略。
A.1B.2C.3D.45、在用邻接表表示图时,拓扑排序算法时间复杂度为()。
A.O(n)B.O(n+e)C.O(n*n)D.O(n*n*n)6、下列关于无向连通图特性的叙述中,正确的是()。
Ⅰ.所有的顶点的度之和为偶数Ⅱ.边数大于顶点个数减1 Ⅲ.至少有一个顶点的度为1A.只有Ⅰ B.只有Ⅱ C.Ⅰ和Ⅱ D.Ⅰ和Ⅲ7、下列选项中,不能构成折半查找中关键字比较序列的是()。
A.500,200,450,180 B.500,450,200,180C.180,500,200,450 D.180,200,500,4508、设X是树T中的一个非根结点,B是T所对应的二叉树。
在B中,X是其双亲的右孩子,下列结论正确的是()。
A.在树T中,X是其双亲的第一个孩子B.在树T中,X一定无右兄弟C.在树T中,X一定是叶结点D.在树T中,X一定有左兄弟9、每个结点的度或者为0或者为2的二叉树称为正则二叉树。
n个结点的正则二叉树中有()个叶子。
A.log2nB.(n-1)/2C.log2n+1D.(n+1)/210、就平均性能而言,目前最好的内排序方法是()排序法。
离散数学课件总复习之习题讲解

4 c8
25 c2
10 c5
11 c6
36 c7
7 3 c3 11 4 c8 17 6 c4 10 c5 7 3 c3
11
5 c1
6 c4
25 c2
11 c6
36 c7
5 c1
22 11
4 c8
25 c2
36 c7 5 c1
17
11 c6 10 c5 7 3 c3 4 c8
6 c4
25 c2
36 c7 11 5 c1 61
6 c4
11 10 c6 c5
3 c3
c7 01
4 c8
c8 1111
c5 110
c6 101
电文总码数:4×5+ 2×25+ 4×3+ 4×6+ 3×10+ 3×11+ 2×36+ 4×4=257
P295 6.9
设散列表为 HT[13] ,散列函数 H(key)=key%13 ,用闭散列法解决冲突, 对下列关键码序列12,23,45,57,20,03,78,31,15,36造表。 (1)采用线性探查法寻找下一个空位,画出相应的散列表,并计算等概率 下搜索成功的平均搜索长度和搜索不成功的平均搜索长度。 ( 2 )采用双散列法寻找下一个空位,再散列函数 RH(key)=(7*key)%10+1 , 寻找下一个空位的公式为 Hi=( Hi-1+RH(key))% 13,H1=H(key) 。画出 相应的散列表,并计算等概率下搜索成功的平均搜索长度。 温习:
20122012年秋季年秋季各内容重点题型讲解各内容重点题型讲解容容比比示例例题示例例题线性表线性表1515p86222p86222栈和队列栈和队列1515p133322p133322数组矩阵和串数组矩阵和串1010p185413p185413二叉树堆二叉树堆huffmanhuffman2020p248518p2485185205201010p29569p295691100p393810p393810p395824p395824搜索结构搜索结构2020p343715p343715排序排序p44092p44092p86222p86222设在一个带附加头结点的单链表中所有元素结点的数据值按递增顺序排列试编写一个函数删除表中所有大于min小于max的元素若存firstppqq温习
2010&2009年春江苏省二级考试C语言真题和答案

2010年春第二部分C语言程序设计一.选择题21.C语言规定,在一个源程序中main函数的位置()A.必须在最开始B.必须在在最后C.必须在预处理命令的后面D.可以在其他函数之前或之后22.以下选项中,()是C语言的关键字A.printfB.includeC.funD.default23.已知有声明“int a=3,b=4,c;”,则执行语句“c=1/2*(a+b);”后,c的值为()A.0B.3C.3.5D.424.设指针变量占2个字节的内存空间,若有声明“char *p=”123”;int c;”,则执行语句“c=sizeof(p);”后,c的值为()A.1B.2C.3D.425.已知有声明“int a=3,b=4;”,下列表达式中合法的是()A.a+b=7B.a=∣b∣C.a=b=0D.(a++)++26.已知有声明“char s[20]=”hello”;”,在程序运行过程中,若要想使数组s中的内容修改为”Good”,则以下语句中能够实现此功能的是()A.s=”Good‟;B.s[20]=”Good”;C.strcat(s,”Good”);D.strcpy(s,”Good”);27. 已知有声明“int a[4][4]={{1,2,3,4},{5,6,7,8},{9,10,11,12},{13,14,15,16}};”,若需要引用值为12的数组元素,则下列选项中错误的是()A.*(a+2)+3B.*(*(a+2)+3)C.*(a[2]+3)D.a[2][3]28. 已知有声明“int n;float x,y;”,则执行语句“y=n=x=3.89;”后,y的值为()A.3B.3.0C.3.89D.4.029. 已知有声明“int a=12,b=15,c;”,则执行表达式“c=(a||(b-=a))”后,变量b和c的值分别为()A.3 , 1B.15 , 12C.15 , 1D.3 , 1230.下列叙述中,正确的是()A.C语言中的文件是流式文件,因此只能顺序存取文件中的数据。
编写算法:实现带头结点单链表的逆置算法

编写算法:实现带头结点单链表的逆置算法引言单链表是一种常见的数据结构,它由一系列节点组成,每个节点包含两部分:数据域和指针域。
其中,数据域用于存储数据,指针域用于指向下一个节点。
在单链表中,头结点是第一个节点之前的一个特殊节点,它不存储任何数据。
逆置(或反转)单链表是将原始链表中的节点顺序颠倒过来。
例如,给定一个单链表:1 -> 2 -> 3 -> 4 -> nullptr,逆置后的结果为:4 -> 3 -> 2 -> 1 -> nullptr。
本文将介绍如何实现带头结点单链表的逆置算法,并给出相应的C++代码实现。
算法思路要实现带头结点单链表的逆置算法,可以使用迭代或递归两种方法。
迭代方法迭代方法通过遍历原始链表中的每个节点,并修改其指针域来实现逆置。
具体步骤如下:1.如果链表为空或只有一个节点,则直接返回。
2.定义三个指针:prev、curr和next。
–prev指向当前节点的前一个节点(初始时为nullptr);–curr指向当前节点;–next指向当前节点的下一个节点。
3.进行循环,直到curr指向nullptr为止:–将curr的指针域修改为prev;–将prev指向curr;–将curr指向next;–将next指向下一个节点。
4.修改头结点的指针域为nullptr,将prev作为新的头结点。
递归方法递归方法通过逐层调用函数来实现逆置。
具体步骤如下:1.如果链表为空或只有一个节点,则直接返回。
2.定义一个递归函数reverseList,该函数接收一个参数:当前节点head。
3.递归终止条件:如果当前节点或当前节点的下一个节点为空,则返回当前节点。
4.在递归调用前,先逆置从下一个节点开始的子链表,并将返回结果保存在变量newHead中。
5.将当前节点的下一个节点的指针域修改为当前节点(即将子链表的尾部连接到当前节点)。
6.将当前节点的指针域修改为空(即将当前节点作为新链表的尾部)。
(完整word版)数据结构(c语言版)课后习题答案完整版资料

第1章绪论5.选择题:CCBDCA6.试分析下面各程序段的时间复杂度。
(1)O(1)(2)O(m*n)(3)O(n2)(4)O(log3n)(5)因为x++共执行了n—1+n—2+……+1= n(n—1)/2,所以执行时间为O(n2)(6)O(n)第2章线性表1.选择题babadbcabdcddac2.算法设计题(6)设计一个算法,通过一趟遍历在单链表中确定值最大的结点。
ElemType Max (LinkList L ){if(L—〉next==NULL) return NULL;pmax=L-〉next;//假定第一个结点中数据具有最大值p=L-〉next—>next;while(p != NULL ){//如果下一个结点存在if(p->data > pmax—>data) pmax=p;p=p->next;}return pmax-〉data;(7)设计一个算法,通过遍历一趟,将链表中所有结点的链接方向逆转,仍利用原表的存储空间.void inverse(LinkList &L) {// 逆置带头结点的单链表Lp=L-〉next;L->next=NULL;while (p){q=p—>next;// q指向*p的后继p->next=L—>next;L—>next=p; // *p插入在头结点之后p = q;}}(10)已知长度为n的线性表A采用顺序存储结构,请写一时间复杂度为O(n)、空间复杂度为O(1)的算法,该算法删除线性表中所有值为item的数据元素.[题目分析]在顺序存储的线性表上删除元素,通常要涉及到一系列元素的移动(删第i个元素,第i+1至第n个元素要依次前移)。
本题要求删除线性表中所有值为item的数据元素,并未要求元素间的相对位置不变。
因此可以考虑设头尾两个指针(i=1,j=n),从两端向中间移动,凡遇到值item的数据元素时,直接将右端元素左移至值为item的数据元素位置。
ch32v307dma例程用法

ch32v307dma例程用法CH32V307DMA例程用法介绍CH32V307DMA是一种高性能的DMA控制器。
通过使用CH32V307DMA,您可以快速、高效地实现数据传输和数据处理,提高系统的性能和效率。
本文将介绍CH32V307DMA的一些常见用法,并详细解释其用法和特点。
基本用法1.初始化DMA控制器:首先,您需要初始化DMA控制器,将其配置为您需要的参数。
可以通过写入寄存器来设置源地址、目标地址、传输长度和其他相关参数。
2.启动DMA传输:在初始化DMA控制器后,您需要使用合适的触发条件来启动DMA传输。
例如,可以使用外部触发信号、软件触发或定时触发等方式来启动DMA传输。
3.数据传输完成中断处理:在DMA传输完成后,可以通过中断方式来处理传输完成的事件。
您可以在中断服务程序中处理传输完成的数据,或者进行其他必要的操作。
高级用法多通道DMA传输1.配置多个通道:CH32V307DMA支持多个DMA通道,并且可以独立配置每个通道的参数。
您可以选择使用多个通道同时进行数据传输,以提高系统的吞吐量和效率。
2.优先级设置:如果您同时使用多个DMA通道,可以通过设置优先级来确定数据传输的顺序。
可以将更重要或紧急的任务分配给优先级较高的通道,确保其先于其他通道进行数据传输。
3.共享资源管理:在使用多个DMA通道时,需要注意资源的管理和竞争情况。
您可以使用信号量或其他同步机制来确保不同通道之间的数据不会产生冲突或重叠。
循环传输1.设置循环模式:CH32V307DMA支持循环传输模式,可以在传输完成后自动重新启动传输。
您可以根据需要将DMA控制器配置为循环模式,并设置循环次数或条件。
2.数据处理和更新:在循环过程中,您可以在每个循环结束后对传输的数据进行处理和更新。
例如,可以对缓冲区中的数据进行处理、更新或修改,以满足特定的需求。
3.停止和重新启动:在需要停止循环传输时,您可以通过设置相关寄存器来停止DMA传输。
ch11_集合、比较和转换_什么是集合

——什么是集合 ——
集合的概念
什么是集合?
– 集合又可以叫做容器,按照字面意思来理解, , 就是用来存放数据的容器. – 集合有点类似于数组,同样是用来存放连续 数据的,但集合的功能比数组更为强大. – 集合与数组最大区别在于,数组一旦定义以 后就无法改变其大小,而集合却可以动态的 改变其大小.
集合是如何实现的
实现Get函数
public int Get(int index) { return array[index]; }
集合是如何实现的
实现Delete函数
public void Delete(int index) { for (int i=index; i<currentSize-1; i++) { array[i] = array[i+1]; } currentSize--; }
索引器
索引器是一种特殊类型的属性,可以把 它添加到一个类中,以提供类似于数组 的访问,使对类的访问就像对数组的访 问一样.
索引器
索引器的定义:
class <类名> { public <类型> this[int index] { get { // 读取器 } set { // 写入器 } } }
集合的使用方式
集合使用示例
static void Main() { ArrayList list = new ArrayList(); for (int i=0; i<10; i++) { list.Add(0); } for (int i=0; i<10; i++) { Console.WriteLine(list[i]); } }
微机题库之编程

1、在DS段中有一个从TABLE开始的由160个字符组成的链表,设计一个程序,实现对此表进行搜索,找到第一个非0元素后,将此单元和下一单元清0。
解:MOV CX, SEG TABLEMOV DS, CX ;将段地址送DSMOV SI, OFFSET TABLE ;表偏移量送SIMOV CX, 160 ;字节数XOR AL, ALNEXT: CMP AL, [SI]JNE EXIT1INC SILOOP NEXTEXIT1: MOV [SI], ALINC SIMOV [SI], AL2、试编写一个程序段,实现将BX中的数除以10,结果仍放在BX中。
解:MOV CL,0AHMOV AX,BXIDIV CLMOV BX,AX3、用串操作指令设计实现以下功能的程序段:首先将100H个数从2170H处搬到1000H处,然后,从中检索相等于AL中字符的单元,并将此单元值换成空格符。
解: BUFF1 EQU 1000HBUFF2 EQU 2170HSTART:MOV SI,OFFSET BUFF2LEA DI,BUFF1MOV CX,100HCYCLE:MOV AL,[SI]MOV [DI],ALINC SIINC DILOOP CYCLEANOTHER:MOV DI,OFFSET BUFF1MOV CX,100CLDAGE:SCASBDEC CXJZ FINJNZ AGEJMP OVERFIN:MOV [DI],20HCMP CX,0JNZ AGEOVER:RET4、用循环控制指令设计程序段,从60H 个元素中寻找一个最大值,结果放在AL中。
解:MOV SI, OFFSET DATA1 ; 将数据起始地址送SIMOV CX, 5FH ; 有60H-1次循环MOV AL, [SI] ; 将第一个元素放AL中COMPARE: INC SICMP AL, [SI]JL XCHMAXJMP NEXTXCHMAX: MOV AL, [SI]NEXT: LOOP COMPARE5、编程序将一个存储块的内容复制到另一个存储块,进入存储段时,SI中为源区起始地址的偏移量,DI中为目的区起始地址的偏移量,CX中为复制的字节数。
单链表操作实验报告

线性表一、实验目的1. 了解线性表的逻辑结构特征,以及这种特性在计算机内的两种存储结构。
2. 掌握线性表的顺序存储结构的定义及其C语言实现。
3. 掌握线性表的链式村粗结构——单链表的定义及其C语言实现。
4. 掌握线性表在顺序存储结构即顺序表中的各种基本操作。
5. 掌握线性表在链式存储结构——单链表中的各种基本操作。
二、实验要求1. 认真阅读和掌握本实验的程序。
2. 上机运行本程序。
)3. 保存和打印出程序的运行结果,并结合程序进行分析。
4. 按照对顺序表和单链表的操作需要,重新改写主程序并运行,打印出文件清单和运行结果三、实验内容请编写C程序,利用链式存储方式来实现线性表的创建、插入、删除和查找等操作。
具体地说,就是要根据键盘输入的数据建立一个单链表,并输出该单链表;然后根据屏幕菜单的选择,可以进行数据的插入或删除,并在插入或删除数据后,再输出单链表;然后在屏幕菜单中选择0,即可结束程序的运行。
四、解题思路本实验要求分别写出在带头结点的单链表中第i(从1开始计数)个位置之后插入元素、创建带头结点的单链表中删除第i个位置的元素、顺序输出单链表的内容等的算法。
五、程序清单#include<>#include<>#include<>typedef int ElemType;~typedef struct LNode{ ElemType data;struct LNode *next;}LNode;LNode *L;LNode *creat_L();void out_L(LNode *L);void insert_L(LNode *L,int i,ElemType e);ElemType delete_L(LNode *L,int i);int locat_L(LNode *L,ElemType e);$void main(){ int i,k,loc;ElemType e,x;char ch;do{ printf("\n");printf("\n 1.建立单链表");printf("\n 2.插入元素");printf("\n 3.删除元素");printf("\n 4.查找元素");printf("\n 0.结束程序运行");.printf("\n======================================");printf("\n 请输入您的选择(1,2,3,4,0)");scanf("%d",&k);switch(k){ case 1:{ L=creat_L();out_L(L);}break;case 2:{ printf("\n请输入插入位置:");scanf("%d",&i);printf("\n请输入要插入元素的值:");scanf("%d",&e);&insert_L(L,i,e);out_L(L);}break;case 3:{ printf("\n请输入要删除元素的位置:");scanf("%d",&i);x=delete_L(L,i);out_L(L);if(x!=-1){printf("\n删除的元素为:%d\n",x);printf("删除%d后的单链表为:\n",x);out_L(L);|}else printf("\n要删除的元素不存在!");}break;case 4:{ printf("\n请输入要查找的元素值:");scanf("%d",&e);loc=locat_L(L,e);if(loc==-1) printf("\n为找到指定元素!"); else printf("\n已找到,元素位置是%d",loc);}break;}printf("\n----------------");)}while(k>=1&&k<5);printf("\n 按回车键,返回...\n");ch=getchar();}LNode *creat_L(){ LNode *h,*p,*s; ElemType x;h=(LNode *)malloc(sizeof(LNode));h->next=NULL;p=h;printf("\n请输入第一个数据元素:");,scanf("%d",&x);while(x!=-999){ s=(LNode *)malloc (sizeof(LNode));s->data=x; s->next=NULL;p->next=s; p=s;printf("请输入下一个数据:(输入-999表示结束。
linux 链表 实例

linux 链表实例一、链表概述链表是一种常见的数据结构,主要由一系列节点组成。
每个节点包含两个部分:数据域和指针域。
数据域用于存储数据,指针域用于存储下一个节点的地址。
链表的头部和尾部分别用头指针和尾指针表示。
链表的头指针通常指向第一个节点,尾指针指向最后一个节点或者NULL。
二、链表节点结构体定义在Linux 系统中,我们可以使用结构体来定义链表节点。
以下是一个简单的链表节点结构体定义:```ctypedef struct Node {int data; // 数据域,存储节点数据struct Node *next; // 指针域,指向下一个节点} Node;```三、链表操作实例3.1 链表创建创建链表的常见方法是使用循环逐个初始化节点。
以下是一个创建链表的示例:```code *create_list(int num) {Node *head = NULL, *tail = NULL;for (int i = 0; i < num; i++) {Node *new_node = (Node *) malloc(sizeof(Node));new_node->data = i + 1;new_node->next = NULL;if (head == NULL) {head = new_node;tail = new_node;} else {tail->next = new_node;tail = new_node;}}return head;}```3.2 链表插入在链表的尾部插入节点,以下是一个插入节点的示例:```cvoid insert_node(Node **head, int data) {Node *new_node = (Node *) malloc(sizeof(Node));new_node->data = data;new_node->next = NULL;if (*head == NULL) {*head = new_node;} else {Node *temp = *head;while (temp->next != NULL) {temp = temp->next;}temp->next = new_node;}}```3.3 链表删除根据节点值删除链表中的节点,以下是一个删除节点的示例:```cvoid delete_node(Node **head, int data) {if (*head == NULL) {return;}Node *temp = *head;while (temp->next != NULL && temp->next->data != data) { temp = temp->next;if (temp->next == NULL) {return;}if (temp->next->next == NULL) {free(temp->next);temp->next = NULL;} else {Node *next_node = temp->next->next;free(temp->next);temp->next = next_node;}}```3.4 链表遍历以下是一个遍历链表的示例:```cvoid traverse_list(Node *head) {Node *temp = head;while (temp != NULL) {printf("%d -> ", temp->data);temp = temp->next;printf("NULL");}```四、总结与拓展本文介绍了Linux 系统中链表的基本操作,包括链表的创建、插入、删除和遍历。
尾插法创建链表

尾插法创建链表介绍过了头插法,再来介绍⼀下尾插法。
假如我们现在要在链表中插⼊⼀些数据:1、2、3、4、5,并从键盘输⼊这些数据,最后插⼊到链表中的数据的顺序和输⼊数据的顺序是⼀致的,即{1,2,3,4,5},因为尾插法每次都是在末尾部插⼊数据的,先插⼊1,此时表中数据为{1};接着在尾部插⼊2,此时表中数据数据为{1,2};再在尾部插⼊3,此时表中数据数据为{1,2,3};以此类推,最后,表中数据的顺序和你输⼊的顺序是⼀致的。
找了⼀张尾插法的图,来看⼀下具体是怎么实现的吧可以看到,每次新加⼊的结点都是插⼊在了最后⼀个节点后⾯,所以叫尾插法,同时将其next置空。
同样地,尾插法创建链表也分为两种情况。
⼀种是已知节点个数,还有⼀种是未知节点个数。
下⾯⽤代码来展⽰⼀下先说⼀下已知结点个数的情况,看代码1 #include<stdio.h>2 #include<stdlib.h>3#define N 10 //结点个数4 typedef struct LNode5 {6int data;7struct LNode *next;8 }LNode,*LinkList;91011 LinkList creat_Linklist() //已知节点个数,并且不带头结点12 {13 LNode *head=NULL,*s,*rear=NULL; //尾插法需要⽤到尾指针,rear是尾指针14for(int i=1;i<=N;i++)15 {16 s=(LinkList)malloc(sizeof( LNode));17 scanf("%d",&s->data);18 s->next=NULL; //把当前结点next置空NULL19if(i==1) //⽤来标记插⼊的节点是否为第⼀个节点,是的话就让头结点head指向第⼀个节点20 head=s;21else22 rear->next=s; //不是头结点的话就让上⼀个节点的next指向当前结点23 rear=s; //尾指针rear指向当前节点24 }25return head; //返回头指针26 }27int main()28 {29 LinkList p;30 p=creat_Linklist(); //没有头结点,p指向表中的第⼀个节点31while(p!=NULL)32 {33 printf("%d ",p->data);34 p=p->next ;35 }36 printf("\n");37return0;38 }结果如下:再说⼀下未知结点个数的情况,看代码1 #include<stdio.h>2 #include<stdlib.h>3 typedef struct LNode4 {5int data;6struct LNode *next;7 }LNode,*LinkList;89 LinkList create_Linklist( ) //未知结点个数,并且带头结点10 {11 LNode *head=NULL,*s,*rear=NULL; //尾插法需要⽤到尾指针,rear是尾指针12int e;char ch;13 head=(LinkList)malloc(sizeof( LNode));14 head->next=NULL;15 rear=head;do{scanf("%d",&e);19 s=(LinkList)malloc(sizeof( LNode));20 s->data=e;21 s->next=NULL; //把当前结点next置空NULL22 rear->next=s; //s操作上⼀个结点,让上⼀个节点的next指向当前结点23 rear=s; //尾指针指向当前结点}while((ch=getchar())!='\n');26return head; //返回头指针27 }28int main()29 {30 LinkList p;31 p=create_Linklist( );32 p=p->next; //有头结点,让p跳过头结点,指向表中的第⼀个节点33while(p!=NULL)34 {35 printf("%d ",p->data);36 p=p->next ;37 }38 printf("\n");39return0;40 }结果如下:其实尾插法创建链表的时候,头结点可有可⽆,根据需要来选择。
2022年广西民族大学计算机科学与技术专业《数据结构与算法》科目期末试卷A(有答案)

2022年广西民族大学计算机科学与技术专业《数据结构与算法》科目期末试卷A(有答案)一、选择题1、n个结点的完全有向图含有边的数目()。
A.n*nB.n(n+1)C.n/2D.n*(n-1)2、有一个100*90的稀疏矩阵,非0元素有10个,设每个整型数占2字节,则用三元组表示该矩阵时,所需的字节数是()。
A.60B.66C.18000D.333、某线性表中最常用的操作是在最后一个元素之后插入一个元素和删除第一个元素,则采用()存储方式最节省运算时间。
A.单链表B.仅有头指针的单循环链表C.双链表D.仅有尾指针的单循环链表4、下面关于串的叙述中,不正确的是()。
A.串是字符的有限序列B.空串是由空格构成的串C.模式匹配是串的一种重要运算D.串既可以采用顺序存储,也可以采用链式存储5、用不带头结点的单链表存储队列,其队头指针指向队头结点,队尾指针指向队尾结点,则在进行出队操作时()。
A.仅修改队头指针B.仅修改队尾指针C.队头、队尾指针都可能要修改D.队头、队尾指针都要修改6、若元素a,b,c,d,e,f依次进栈,允许进栈、退栈操作交替进行,但不允许连续三次进行退栈操作,则不可能得到的出栈序列是()。
7、已知关键字序列5,8,12,19,28,20,15,22是小根堆(最小堆),插入关键字3,调整后的小根堆是()。
A.3,5,12,8,28,20,15,22,19B.3,5,12,19,20,15,22,8,28C.3,8,12,5,20,15,22,28,19D.3,12,5,8,28,20,15,22,198、设X是树T中的一个非根结点,B是T所对应的二叉树。
在B中,X是其双亲的右孩子,下列结论正确的是()。
A.在树T中,X是其双亲的第一个孩子B.在树T中,X一定无右兄弟C.在树T中,X一定是叶结点D.在树T中,X一定有左兄弟9、有关二叉树下列说法正确的是()。
A.二叉树的度为2B.一棵二叉树的度可以小于2C.二叉树中至少有一个结点的度为2D.二叉树中任何一个结点的度都为210、对n个记录的线性表进行快速排序为减少算法的递归深度,以下叙述正确的是()。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
c
ptrc myDegree 3 myTerms
data 0 0 next
稀疏多项式链式实现
多项式加法操作
a
myDegree 5 myTerms
A( x) = 5 + 6 x 3 + 2 x 5
B( x) = x 3 − 2 x 5 + 13x 7
ptra ptra
data 0 0 next
data 5 0 next data 1 3 next data 5 0 next
data 6 3 next
ptrb
data 2 5 next
ptrb
b
myDegree 7 myTerms
data 0 0 next
data -2 5 next data 7 3 next
data 13 7 next
ptrc
c
myDegree 3 myTerms
data 0 0 next
稀疏多项式链式实现
C++ list
3、List 操作示例
// Assignment // Ways to delete from a list ila = ld; lc = ld; lb.end(), 66666); // find is an algorithm = find(lb.begin(), // Ways to insert if (i != lb.end()) into a list list<int>::iterator i; i = lb.begin(); i++; i++; //迭代器指针 迭代器指针 { lb.insert(i,"66666 found -- will erase it\n"; lb.erase(i); cout << 66666); cout << lb << endl; lb.insert(i,3, 555); cout << lb << endl; } lb.insert(i, array, list<int>::iterator j lb << endl; i= lb.begin(); i++; array + 3); cout << = lb.end(); --j; --j; i = --j; i --; i--; lb.push_back(888); lb << endl; lb.erase(i,j); cout << lb.push_front(111); cout << lb << endl; lb.pop_back(); lb.pop_front(); cout << lb << endl;
data 0 0 next data 5 0 next data 1 99 next
myDegree 99 myTerms
使用系数-幂对使用系数-幂对系数 指针域组成节点 指针域组成节点 链表来表示多 的链表来表示多 项式。 项式。
稀疏多项式链式实现
Polynomial 类定义
template <class CoefType> class Polynomial { private: class Term // Term class { public: CoefType coef; int expo; }; class Node //Node class { public: Term data; Node * next; Node(CoefType co = 0, int ex = 0, Node * ptr = 0) { data.coef = co; data.expo = ex; next = ptr; } }; typedef Node * NodePointer; public: //Function members private: int myDegree; NodePointer myTerms; };
B( x) = x 3 − 2 x 5 + 13x 7
data 0 0 next
data 5 0 next data 1 3
ptrc
data 6 3 next data -2 5 next
data 2 5 next data 13 7 next
ptrb
b
myDegree 7 myTerms
data 0 0 next
preptr first
?
9
17
22
26
34
插入第1 插入第1个节点
newptr
5
பைடு நூலகம்
newptr->next=preptr->next; preptr->next=newptr;
带头节点的链表
preptr first ptr ptr
?
9
17
22
26
34
删除第1 删除第1个节点
preptr->next=ptr->next; delete ptr; ptr=preptr->next;
data 2 5 next data 13 7 next
ptrb
b
myDegree 7 myTerms
data 0 0 next
next
c
myDegree 0 myTerms
data 0 0 next
稀疏多项式链式实现
多项式加法操作
a
myDegree 5 myTerms
A( x) = 5 + 6 x 3 + 2 x 5 ptra ptra
data 2 5 next
ptrb
b
myDegree 7 myTerms
data 0 0 next
data 13 7 next
ptrc ptrc
ptrb
c
myDegree 7 myTerms
data 0 0 next
data 13 7 next
C ( x) = 5 + 7 x 3 + 13x 7
双向链表
头节点数据部分未定义,可以存放和 头节点数据部分未定义, 列表相关的信息。 列表相关的信息。
稀疏多项式链式实现
一元多项式P(x) 一元多项式P(x): P(x):
P( x) = a0 + a1 x + a2 x 2 + ... + an x n
myDegree 5 myCoeffs 5 7 0 -8 0 4 0 0 0 0 0 1 2 3 4 5 6 7 8 9
多项式类: 多项式类: (Polynomial)
一般没有大量 零系数可以 的零系数可以 用数组描述
P( x) = 5 + 7 x − 8 x 3 + 4 x 5
稀疏多项式链式实现
P( x) = 5 + x 99
myDegree 99 myCoeffs 5 0 0 0 0 0 0 0 0 0 … 0 1 0 1 2 3 4 5 6 7 8 9… 99
双向链表是指在前驱和后继方向都能游历(遍历)的线性链表。 双向链表是指在前驱和后继方向都能游历(遍历)的线性链表。
节点除了数据部分外,还包含2个指针域 节点除了数据部分外,还包含2
前驱 data 后继
用这样的节点构建的链表称为双向链表 用这样的节点构建的链表称为双向链表
last first
mySize 5
ptr->next->prev=ptr->prev; ptr->prev->next=ptr->next; delete ptr;
17 20 22
ptr
C++ list
List与其他容器的比较 1、List与其他容器的比较 属性
直接/随机访问([]) 直接/随机访问([]) 顺序访问 在前端插入和删除 在任意点插入和删除 在尾端插入和删除 时间开销
9
17
22
26
34
双向链表 基本操作: 基本操作:注意额外链的处理
插入节点
先设置被插入节点的前指针和后指针 分别指向它的前驱和后继。 分别指向它的前驱和后继。 然后,设置其前驱节点的后指针和其 然后, 后继节点的前指针指向这个新节点。 后继节点的前指针指向这个新节点。
newptr predptr
17
data 0 0 next
data 5 0 next data 1 3 next data 5 0 next
data 6 3 next
ptrb
data 2 5 next data 13 7 next
ptrc
ptrb
b
myDegree 7 myTerms
data 0 0 next
data -2 5 next data 7 3 next
22
20
注意先 后顺序
newptr->prev=predptr; newptr->next=predptr->next; predptr->next->pre=newptr; predptr->next=newptr;
双向链表 基本操作: 基本操作:注意额外链的处理 删除节点
重置被删除节点的前驱节点 重置被删除节点的前驱节点 的后指指针和它的后继节点 的后指指针和它的后继节点 和它的 的前指指针。 的前指指针。
大量零系数的多 大量零系数的多 零系数 项式会造成数组 空间的浪费。 空间的浪费。
数组元素类型由 int改为 改为Term int改为Term
myDegree 99 myTerms 5 0 0