分布式计算原理与应用大作业2
分布式数据库原理与应用题库

分布式数据库原理与应用题库1. 引言随着互联网的快速发展和大数据时代的到来,数据量的爆炸式增长对数据库的存储和处理能力提出了更高的要求。
传统的单节点数据库已经难以满足这一需求,而分布式数据库应运而生。
本文将介绍分布式数据库的原理和应用,并提供一些应用题供读者练习,加深对该主题的理解。
2. 分布式数据库的原理分布式数据库是将数据存储在多个物理节点上的数据库系统,节点之间通过网络进行通信和协作。
它具有以下几个核心原理:2.1 数据分片和副本为了实现数据的分布式存储和高可用性,分布式数据库将数据进行分片处理,并将每个分片的副本存储在不同的节点上。
这样可以提高数据访问的并发性和容错性。
2.2 数据一致性和并发控制在分布式数据库中,多个节点同时操作数据可能会造成数据的不一致。
因此,分布式数据库需要实现一致性协议来保证数据的一致性,并使用并发控制技术来处理并发操作。
2.3 数据通信和数据同步分布式数据库中的节点通过网络进行数据通信和数据同步。
节点之间的通信可以通过消息传递、RPC(Remote Procedure Call)等方式实现。
数据同步可以通过数据复制和数据冗余等方式实现。
3. 分布式数据库的应用分布式数据库广泛应用于互联网、云计算、物联网等领域,它具有高可用性、可扩展性和容错性等优势。
以下是一些分布式数据库的常见应用案例:3.1 电商平台在电商平台中,用户的购物行为产生了大量的交易数据,而这些数据需要快速地进行存储和分析。
分布式数据库可以实现海量数据的存储和查询,并提供高性能的数据处理能力,从而提高用户的购物体验。
3.2 物联网物联网设备产生的数据通常具有大规模、高并发的特点。
分布式数据库可以实现对这些数据的实时监控和存储,同时提供高可靠性和高性能的数据处理能力。
3.3 金融系统金融系统需要处理大量的交易数据,并保证数据的安全和一致性。
分布式数据库可以有效地管理和存储金融数据,并提供高度可靠的事务处理能力。
深入理解分布式计算的基本原理与方法

深入理解分布式计算的基本原理与方法分布式计算是一种利用多个计算机协同工作来完成一个任务的计算模型。
它将一个大的计算任务分解成多个小的子任务,并将这些子任务分派给多台计算机同时运算,最后将结果进行整合。
分布式计算具有高效、可伸缩、容错等特点,广泛应用于数据处理、科学计算、云计算等领域。
分布式计算的基本原理是任务分解与结果整合。
具体来说,分布式计算将一个大的计算任务分解成多个小的子任务,并将这些子任务分配给不同的计算机节点进行并行计算。
每个计算机节点负责完成自己的子任务,并将运算结果返回。
最后,将各个计算节点的结果进行整合,得到最终的计算结果。
在分布式计算中,有三个关键概念:任务调度、数据通信和容错处理。
任务调度是指如何将任务分解成多个子任务,并将这些子任务分派给计算机节点进行计算。
数据通信是指节点之间如何进行信息交流和数据传输,以便节点可以相互协作完成任务。
容错处理是指如何处理节点故障或通信异常等异常情况,以保证整个分布式系统的稳定性和可靠性。
在分布式计算中,有多种任务调度方式,如静态任务划分、动态任务划分和任务合作。
静态任务划分是指在任务开始之前就将任务划分成多个子任务,并在各个计算机节点上进行并行计算。
动态任务划分是指根据实际运行情况,动态地将任务划分成多个子任务,并动态地分配给计算机节点。
任务合作是指计算机节点之间相互协作,共同完成一个任务,每个节点负责计算任务中的一部分,并将计算结果传递给其他节点进行进一步计算。
数据通信在分布式计算中起着至关重要的作用。
分布式计算系统需要能够进行高效的数据传输和信息交流,以保证节点之间能够及时、准确地进行任务分发和结果传递。
为了实现高效的数据通信,可以采用消息传递机制,即通过消息传递的方式进行节点之间的通信。
消息传递可以分为同步消息传递和异步消息传递两种方式。
同步消息传递是指发送方等待接收方接收完消息后再继续执行,而异步消息传递是指发送方发送消息后立即继续执行,不等待接收方的响应。
分布式计算的原理

分布式计算是一种计算模式,它将一个大型计算任务分解成许多小的、独立的子任务,然后将这些子任务分配给多个计算节点(通常是网络上的多台计算机)进行处理。
每个节点只负责处理任务的一部分,最后将所有节点的处理结果汇总起来,得到最终的计算结果。
分布式计算的原理主要包括以下几个方面:1. 任务分解(Task Decomposition):- 将复杂的、大规模的任务分解成小的、可管理的子任务。
这些子任务可以是独立的,也可以有一定的依赖关系。
2. 并行处理(Parallel Processing):- 在多个计算节点上并行执行这些子任务,以提高计算效率。
每个节点可以同时处理多个子任务,而且在网络条件允许的情况下,节点之间的通信也可以并行进行。
3. 资源分配(Resource Allocation):- 根据每个节点的计算能力和网络条件,合理地分配任务和资源。
这涉及到任务调度算法,它负责决定哪个节点应该执行哪个任务。
4. 数据管理(Data Management):- 管理和分配数据,确保每个节点都能访问到它所需要的数据。
这可能涉及到数据分区、数据复制和一致性维护等问题。
5. 通信协调(Communication and Coordination):- 节点之间需要通过通信来交换信息和协调任务执行。
这包括同步和异步通信机制,以及解决通信中的各种问题,如网络延迟、数据丢失和节点故障等。
6. 容错性(Fault Tolerance):- 分布式系统需要能够处理节点故障和网络分区等异常情况。
这通常通过冗余、备份和恢复机制来实现。
7. 一致性(Consistency):- 确保所有节点最终能够达到一致的计算结果。
在分布式系统中,由于节点之间的独立性,一致性是一个需要特别关注的问题。
8. 负载均衡(Load Balancing):- 动态地调整任务分配,以平衡各个节点的负载,避免某些节点过载而其他节点空闲的情况。
分布式计算的关键优势在于它能够利用分布式资源来提高计算效率和处理能力,同时也能够提高系统的可靠性和容错性。
分布式计算技术的原理与应用

分布式计算技术的原理与应用随着计算机技术的不断发展,分布式计算技术已经成为当前计算机领域的一个热门话题。
分布式计算技术将计算机的处理能力分散到许多计算机之中,以达到更快的计算速度和更高的处理效率。
本文将介绍分布式计算技术的原理和应用,帮助读者更好地了解分布式计算技术及其在实际中的应用。
一、分布式计算技术的原理分布式计算技术是指将计算机的处理能力分散到许多计算机之中,使这些计算机能够协同工作,完成比单台计算机更为庞大和复杂的计算任务。
分布式计算技术基于网络通信和数据传输技术,由许多计算节点和一个调度节点组成。
计算节点是指执行计算任务的计算机,调度节点是指负责协调计算任务的计算机。
分布式计算技术的核心原理在于解决如何将大规模计算任务分解为多个小任务,在多台计算机之间进行协同和通信,最终将计算结果汇总到一个单独的结果中。
分布式计算技术的实现需要解决很多问题,例如计算任务如何划分、任务划分后如何在计算节点之间进行协作和通信、如何处理计算节点中的故障等。
分布式计算技术的原理对于计算机科学领域的学者和爱好者来说具有很高的研究价值和应用前景。
二、分布式计算技术的应用1.网格计算网格计算是分布式计算技术的一种应用,从本质上来说,它是分布式计算技术的一种形式。
网格计算技术是指利用网络和分布式计算技术来处理大规模的计算任务。
它可以将多台计算机的处理能力相互协作,加快计算速度,提高计算效率。
网格计算技术可以应用于医学图像处理、气象计算、地矿勘探等领域。
2.云计算云计算是近年来快速发展的一种分布式计算技术。
它是将计算任务和存储数据分散在许多计算机之上,通过网络进行协作和通信,使计算机能够以一种高度可扩展和灵活的方式来运行服务。
云计算可以帮助企业提高业务处理能力,降低成本,缩短开发周期。
云计算的核心是通过虚拟化技术将计算机硬件资源抽象出来,然后按照业务需求进行动态分配。
3.分布式图像处理分布式图像处理是分布式计算技术的一种应用,它可以将大型图像处理任务分解为多个小任务,交给多台计算机协同完成。
分布式计算原理

分布式计算原理分布式计算是一种利用多台计算机协同工作来完成单个任务的计算方式。
它可以将一个大型任务分解成许多小的子任务,然后分配给不同的计算机进行处理,最终将各个计算结果合并在一起,从而完成整个任务。
分布式计算的原理是基于计算机网络和并行计算技术,它可以提高计算效率,提升系统的可靠性和可用性。
首先,分布式计算的原理之一是任务分解和分配。
在分布式计算系统中,一个大型任务会被分解成若干个小的子任务,然后这些子任务会被分配给不同的计算节点进行处理。
这样可以充分利用各个计算节点的计算资源,提高整个系统的计算效率。
其次,分布式计算的原理还包括通信和协调。
在分布式计算系统中,各个计算节点之间需要进行通信和协调,以确保它们能够有效地协同工作。
这就需要设计合适的通信协议和协调机制,以确保各个计算节点之间能够互相通信,协同完成任务。
另外,分布式计算的原理还包括容错和恢复。
在分布式计算系统中,由于涉及多台计算机,可能会出现计算节点故障或通信故障的情况。
因此,需要设计相应的容错和恢复机制,以确保系统能够在出现故障时自动进行恢复,保证系统的可靠性和可用性。
此外,分布式计算的原理还包括数据共享和一致性。
在分布式计算系统中,不同的计算节点可能需要共享数据,因此需要设计合适的数据共享机制,以确保各个计算节点之间能够共享数据,并且保持数据的一致性。
总的来说,分布式计算的原理是基于任务分解和分配、通信和协调、容错和恢复、数据共享和一致性等技术,通过这些技术来实现多台计算机的协同工作,提高计算效率,提升系统的可靠性和可用性。
分布式计算已经广泛应用于各种领域,如云计算、大数据分析、人工智能等,成为了当今计算领域的重要技术之一。
分布式计算原理

分布式计算原理分布式计算是一种通过多台计算机协同工作来完成任务的计算方式。
在分布式计算中,任务被分解为多个子任务,并由不同的计算机节点并行处理这些子任务,最终将结果汇总。
分布式计算的原理主要包括以下几个方面:1.任务划分与分配:将大任务拆分为多个小任务,并将这些小任务分配给不同的计算节点。
任务划分和分配的策略可以根据任务的性质和计算节点的资源情况进行选择,例如根据任务的计算复杂度、数据依赖关系等。
2.通信与协同:分布式计算中的各个计算节点需要进行通信和协同工作,以便相互传递数据和协调任务的执行。
通信可以通过网络进行,节点之间可以发送和接收数据、请求和响应。
协同工作包括任务状态的同步、任务之间的依赖关系管理等。
3.数据分发与共享:对于需要处理大规模数据的任务,数据的分发和共享是分布式计算的关键。
分布式计算系统需要将数据分发到各个计算节点,并在各个节点上进行并行处理。
同时,节点之间需要共享数据,以便协同工作和结果汇总。
4.任务调度与负载均衡:分布式计算系统需要进行任务调度和负载均衡,以充分利用各个计算节点的计算能力和资源,确保任务的高效执行。
任务调度可以考虑节点的负载情况、任务的优先级等因素,负载均衡可以根据节点的计算能力和资源情况对任务进行分配。
5.容错与故障恢复:分布式计算系统需要具备容错和故障恢复的能力,以应对计算节点故障或通信异常等情况。
容错和故障恢复可以采用备份机制、数据冗余、错误检测和纠正等方式来实现,确保计算任务的可靠性和正确性。
总之,分布式计算通过任务划分、通信协同、数据分发共享、任务调度负载均衡、容错故障恢复等原理,实现了多台计算机的协同工作,从而提高了计算效率和处理能力。
分布式计算的原理与应用

分布式计算的原理与应用随着云计算、人工智能、大数据以及物联网等技术的快速发展,分布式计算作为一种高效、灵活的计算模型,逐渐成为了各行各业的关注焦点。
本文将分析分布式计算的原理以及广泛应用的几个方面,帮助读者对其有更清晰的认识。
一、分布式计算的原理1. 简介:分布式计算指的是将一个计算任务分解为多个子任务,并通过多个计算节点并行地进行处理。
与传统的集中式计算相比,分布式计算具有可靠性高、性能好、可扩展性强、容错性强等特点。
2. 关键技术:a. 数据分割和分发:将原始数据分割成多个子任务,通过分发技术将任务分发到各个计算节点上。
b. 计算节点通信:计算节点之间通过网络进行通信,传递子任务的输入数据和计算结果。
c. 任务调度与管理:由主节点负责任务的划分、分发、收集和汇总。
d. 容错处理:通过备份机制和错误检测机制提高系统的容错性,保证计算的准确性和可靠性。
e. 数据一致性:通过一致性协议和分布式锁等技术实现数据的同步和一致性。
二、分布式计算的应用1. 云计算:分布式计算是云计算的核心技术之一。
云计算平台通过将资源进行虚拟化和分布式管理,实现计算资源的高效利用和动态分配,为用户提供弹性计算、存储和网络服务。
2. 大数据分析:分布式计算能够高效地处理大规模数据。
例如,MapReduce是一种分布式计算框架,通过将任务分解为多个Map和Reduce任务,并在集群中并行处理,实现大规模数据的分布式计算和分析。
3. 并行计算:分布式计算可以将一个复杂的计算任务分解为多个子任务,并在不同的计算节点上并行执行,提高计算效率。
例如,高性能计算领域常用的MPI 编程模型,就是基于分布式计算的。
4. 人工智能:分布式计算对于人工智能的训练和推理具有重要意义。
通过利用分布式计算集群的计算能力,可以加速深度学习模型的训练和推理过程,缩短模型训练的时间。
三、分布式计算的应用步骤1. 任务划分:将一个计算任务分解为多个独立的、可并行计算的子任务。
分布式计算简单易懂实例

分布式计算简单易懂实例分布式计算是一种将计算任务分布到多个计算机节点上执行的技术,通过协同工作完成复杂计算任务。
下面以一个简单的实例来介绍分布式计算的基本原理和过程。
实例:计算斐波那契数列假设我们需要计算斐波那契数列的前20个数,传统的计算方法是采用递归或循环的方式在单机上进行计算。
然而,随着计算任务的规模不断扩大,单机计算的能力可能无法满足需求。
此时,我们可以采用分布式计算的方法来解决问题。
1. 任务划分将计算斐波那契数列的任务划分为多个子任务,每个子任务负责计算斐波那契数列中的一个数。
在这个实例中,我们需要计算斐波那契数列的前20个数,因此可以将任务划分为20个子任务,每个子任务计算一个数。
2. 节点选择选择多个计算机节点来执行分布式计算任务。
这些节点可以是一台计算机的多核处理器,也可以是多台计算机。
在这个实例中,我们假设有4个计算机节点,分别为节点1、节点2、节点3和节点4。
3. 任务分配将子任务分配给各个计算机节点。
在这个实例中,我们可以将前10个子任务分配给节点1,接下来的10个子任务分配给节点2,再接下来的10个子任务分配给节点3和节点4。
4. 计算和结果收集各个节点分别执行分配给自己的子任务,计算出斐波那契数列中的对应数值。
计算完成后,将结果发送给一个结果收集节点。
在这个实例中,我们假设节点1、节点2、节点3和节点4将结果发送给节点5,节点5负责收集结果。
5. 结果合并结果收集节点将收到的结果进行合并,得到完整的斐波那契数列。
在这个实例中,节点5接收到节点1、节点2、节点3和节点4发送的结果后,将它们合并成完整的斐波那契数列。
通过以上步骤,我们采用了分布式计算的方法成功计算出斐波那契数列的前20个数。
这种方法将复杂的计算任务分布到多个节点上执行,提高了计算效率,满足了大规模计算任务的需求。
分布式计算的优势:1. 计算效率高:分布式计算将计算任务分布到多个节点上执行,充分利用了计算机的计算资源,提高了计算效率。
分布式计算理论与实践案例

分布式计算理论与实践案例分布式计算是一种计算模型,旨在通过将计算任务分散到多个计算机上来提高计算效率和可靠性。
它在如今的计算领域中扮演着重要角色,可以应用于各种领域,包括大数据处理、云计算、人工智能等。
本文将介绍分布式计算的理论和提供一些实践案例。
一、分布式计算理论概述分布式计算的核心概念是将一个大的计算任务分解成多个小的子任务,并将这些子任务分配到多个计算节点上进行并行计算。
分布式计算可以通过有效地利用计算资源来提高计算速度、处理大规模数据和实现容错性。
以下是分布式计算的关键要素和理论基础。
1.1 高性能计算分布式计算的一个主要目标是提高计算资源的利用率和计算性能。
高性能计算包括并行计算和分布式计算两个层面。
并行计算是指同时在多个处理器或计算机上执行多个计算任务,通过分割计算任务并行处理来提高计算速度。
而分布式计算更广泛,它将任务分配到多个计算节点上进行协同计算,以进一步提高计算性能。
1.2 数据传输与通信在分布式计算中,数据传输和通信是关键问题。
由于计算任务被分布在多个计算节点上,节点之间需要通过网络进行数据传输和通信。
因此,高效的数据传输和通信机制对于分布式计算的性能至关重要。
常见的技术包括基于消息传递的通信模型、远程过程调用(RPC)和分布式文件系统。
1.3 负载均衡负载均衡是指将多个任务或计算负载分配到分布式系统中的各个节点上,以确保每个节点的负载均衡,并最大限度地提高系统性能。
负载均衡算法可以根据节点的计算能力、通信状况、负载情况等因素来动态调整任务的分配。
常见的负载均衡算法包括轮询调度、最小负载和最短作业优先等。
二、分布式计算实践案例2.1 HadoopHadoop是一个开源的分布式计算框架,被广泛应用于大数据处理和分析。
它使用Hadoop分布式文件系统(HDFS)来存储大规模数据,并通过分布式计算框架MapReduce来进行并行计算。
Hadoop的核心思想是将数据分割成小的数据块,并将这些数据块分布在多个计算节点上进行计算和存储。
分布式数据库原理与应用题库

分布式数据库原理与应用题库目录1.介绍2.分布式数据库的原理– 2.1 分布式数据库的概念– 2.2 分布式数据库的特点– 2.3 分布式数据库的架构– 2.4 分布式数据库的优势与挑战3.分布式数据库的应用场景4.分布式数据库的常见问题及解决方案5.总结1. 介绍随着数据量的不断增长和用户对数据的高可用性和低延迟的需求,传统的集中式数据库已经无法满足大规模数据存储和查询的需求。
为了解决这一问题,分布式数据库应运而生。
分布式数据库将数据分散存储在多个节点上,并通过协调和管理这些节点之间的数据访问,实现高性能、高可用性的数据存储和查询。
2. 分布式数据库的原理2.1 分布式数据库的概念分布式数据库是指将数据分散存储在多个节点上的数据库系统。
每个节点都拥有自己的计算和存储资源,节点之间通过网络连接,协同工作以实现数据的存储和查询。
2.2 分布式数据库的特点分布式数据库具有以下几个特点:•高可用性:分布式数据库能够将数据冗余存储在多个节点上,当一个节点发生故障时,系统可以自动切换到其他可用节点,保证数据的可用性。
•可扩展性:分布式数据库可以通过增加节点来实现水平扩展,提升系统的处理能力和存储容量。
•分布透明:用户无需关心数据存储在哪个节点上,可以直接对整个分布式数据库进行读写操作。
•数据一致性:分布式数据库通过一致性协议实现数据的一致性,避免数据冲突和不一致。
•并发控制:分布式数据库需要考虑多个节点之间的并发访问,通过事务管理和锁机制实现并发控制。
•性能优化:分布式数据库通过数据划分和数据复制等技术来提高系统的性能和响应速度。
2.3 分布式数据库的架构分布式数据库的架构通常采用主从架构或者多主架构。
•主从架构:在主从架构中,一个节点被指定为主节点,负责接收和处理用户的写操作,其他节点作为从节点,负责读取和复制数据。
主节点将写操作的结果复制到从节点,从节点可以提供更高的读取性能和可用性。
•多主架构:在多主架构中,所有节点都可以处理写操作,通过复制机制将数据同步到其他节点,实现数据的一致性。
分布式系统的原理与应用

分布式系统的原理与应用分布式系统是由多个独立的计算机节点组成的系统,这些节点通过网络进行通信和协作,共同完成一系列任务。
它的设计目标是提高系统的性能、可靠性和可扩展性。
本文将介绍分布式系统的原理和应用。
一、分布式系统的原理分布式系统的原理涉及以下几个方面:1. 网络通信:分布式系统依赖于网络进行节点之间的通信。
常见的通信协议有TCP/IP和UDP。
节点之间通过消息传递的方式进行通信,可以采用同步和异步两种方式。
2. 分布式计算:分布式系统的核心是分布式计算。
节点之间可以共享计算和存储资源,通过任务划分和并行计算,提高系统的整体性能。
常见的分布式计算模型有客户端/服务器模型、对等网络模型和基于消息传递的模型。
3. 数据一致性:分布式系统中的数据通常分布在不同的节点上,数据的一致性是一个重要的问题。
一致性模型包括强一致性、弱一致性和最终一致性。
常用的一致性协议有Paxos和Raft。
4. 容错机制:分布式系统中的节点可能会出现故障,为了保证系统的可靠性,需要引入容错机制。
常见的容错技术包括冗余备份、故障检测和恢复、容错算法等。
二、分布式系统的应用分布式系统的应用广泛,涵盖了各个领域。
以下是一些常见的应用场景:1. 云计算:云计算是一种基于分布式系统的计算模型,可以提供按需的计算、存储和服务。
云计算平台如亚马逊AWS和微软Azure都是基于分布式系统架构构建的。
2. 大数据处理:由于数据量越来越大,传统的集中式系统无法满足处理数据的需求。
分布式系统可以将数据分布在多个节点上,通过并行计算和分布式存储,高效地处理大数据。
3. 分布式数据库:分布式数据库将数据存储在多个节点上,并提供分布式查询和事务处理能力。
常见的分布式数据库有Google的Spanner和Facebook的Cassandra。
4. 分布式文件系统:分布式文件系统将文件存储在多个节点上,通过副本和冗余备份来提高数据的可靠性和可用性。
常见的分布式文件系统有Hadoop的HDFS和谷歌的GFS。
分布式计算工作原理

分布式计算工作原理
分布式计算是指将一个复杂的任务分解为多个由不同计算机执行的独
立任务,最后将所有任务的结果结合在一起,以完成总体任务的计算方式。
分布式计算的优势在于可以充分利用计算机系统的可用资源,节省计算时间,降低系统维护成本。
1)计算管理器(调度器):该部分在分布式计算系统中扮演着一个
总控制的角色,其功能是对分布式计算系统中的每一个任务的调度管理,
包括任务的分发,运行,收集等。
它接收用户输入的计算请求,然后将这
些请求拆分成若干个小任务,将这些小任务分发到各个计算节点,指派计
算机节点对任务进行处理,并对各计算节点进行监控,直至计算完成。
2)计算节点:计算节点是指参与分布式计算的实际计算机,它接受
计算管理器的发出的任务,然后根据数据和算法,计算出结果并将该结果
发送给调度器。
3)存储和通信系统:存储和通信系统负责管理、利用分布式计算系
统中的所有存储资源和通信资源,它包含一个网络协议层,用于实现计算
节点之间的通信与信息共享。
分布式作业2
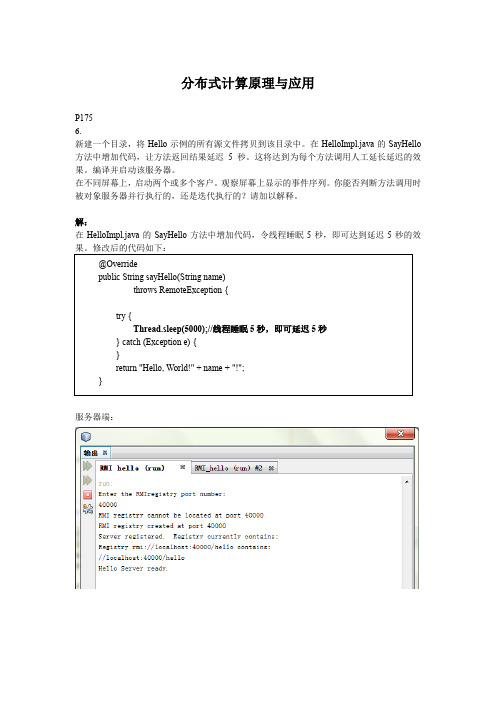
分布式计算原理与应用P1756.新建一个目录,将Hello示例的所有源文件拷贝到该目录中。
在HelloImpl.java的SayHello 方法中增加代码,让方法返回结果延迟5秒。
这将达到为每个方法调用人工延长延迟的效果。
编译并启动该服务器。
在不同屏幕上,启动两个或多个客户。
观察屏幕上显示的事件序列。
你能否判断方法调用时被对象服务器并行执行的,还是迭代执行的?请加以解释。
解:在HelloImpl.java的SayHello方法中增加代码,令线程睡眠5秒,即可达到延迟5秒的效果。
修改后的代码如下:服务器端:@Overridepublic String sayHello(String name)throws RemoteException {try {Thread.sleep(5000);//线程睡眠5秒,即可延迟5秒} catch (Exception e) {}return "Hello, World!" + name + "!";}客户端1:客户端2:经过多轮测试,启动多个客户端时,结果显示的顺序与启动顺序并不完全一致,说明该方法调用时并行执行的。
8.使用RMI实现Daytime服务器和客户程序包。
解:(1)DaytimeInterface接口/** DaytimeInterface接口*/package RMI_DAYTIME;import java.rmi.Remote;import java.rmi.RemoteException;/**** @author XiaoTianCai*/public interface DaytimeInterface extends Remote {public String sayTime(String name) throws RemoteException;}(2)DaytimeImpl接口实现类/** DaytimeImpl接口实现类*/package RMI_DAYTIME;import java.rmi.RemoteException;import java.rmi.server.UnicastRemoteObject;import java.util.Date;/*** @author XiaoTianCai*/public class DaytimeImpl extends UnicastRemoteObject implements DaytimeInterface {public DaytimeImpl() throws RemoteException {super();}@Overridepublic String sayTime(String name) throws RemoteException {Date timestamp=new Date(); //获取当前时间return "Daytime:" + timestamp.toString() + "!";}}(3)DaytimeServer服务器端/** DaytimeServer服务器端*/package RMI_DAYTIME;import java.io.BufferedReader;import java.io.InputStreamReader;import .MalformedURLException;import java.rmi.Naming;import java.rmi.RemoteException;import java.rmi.registry.LocateRegistry;import java.rmi.registry.Registry;/*** @author XiaoTianCai*/public class DaytimeServer {public static void main(String args[]) {InputStreamReader is = new InputStreamReader(System.in);BufferedReader br = new BufferedReader(is);String portNum, registryURL;try {//注册服务器不在运行状态时,用户指定端口启动RMI注册服务器System.out.println("Enter the RMIregistry port number:");portNum = (br.readLine()).trim();int RMIPortNum = Integer.parseInt(portNum);startRegistry(RMIPortNum);//以URL的形式将分布式对象的引用存储到注册表当中DaytimeImpl exportedObj = new DaytimeImpl();registryURL = "rmi://localhost:" + portNum + "/saytime";Naming.rebind(registryURL, exportedObj);System.out.println("Serve registered. Registry currently contains:");// list names currently in the registrylistRegistry(registryURL);System.out.println("Daytime Server ready.");} catch (Exception e) {System.out.println("Exception in DaytimeServer.main:" + e);}}// This method starts a RMI registry on the local host, if it// does not already exists at the specified port number.private static void startRegistry(int RMIPortNum) throws RemoteException { try {Registry registry = LocateRegistry.getRegistry(RMIPortNum);registry.list();// This call will throw an exception// if the registry does not already exist} catch (RemoteException e) {// No valid registry at that port.System.out.println("RMI registry cannot be located at port " + RMIPortNum);Registry registry = LocateRegistry.createRegistry(RMIPortNum);System.out.println("RMI registry created at port " + RMIPortNum);}} // end startRegistry// This method lists the names registered with a Registry objectprivate static void listRegistry(String registryURL) throws RemoteException, MalformedURLException {System.out.println("Registry " + registryURL + " contains: ");String[] name = Naming.list(registryURL);for (int i = 0; i < name.length; i++) {System.out.println(name[i]);}}//end listRegistry} // end class(4)DaytimeClient客户端/** DaytimeClient客户端*/package RMI_DAYTIME;import java.io.BufferedReader;import java.io.InputStreamReader;import java.rmi.Naming;import java.util.Date;/*** @author XiaoTianCai*/public class DaytimeClient {public static void main(String args[]) {try {int RMIPort;String hostName;InputStreamReader is = new InputStreamReader(System.in);BufferedReader br = new BufferedReader(is);System.out.println("Enter the RMIRegistry host name:");hostName = br.readLine();System.out.println("Enter the RMIRegistry port number:");String portNum = br.readLine();RMIPort = Integer.parseInt(portNum);String registryURL = "rmi://" + hostName + ":" + portNum + "/saytime";// find the remote object and cast it to an interface objectDaytimeInterface d = (DaytimeInterface) Naming.lookup(registryURL);System.out.println("Lookup completed.");//invoke the remote methodDate timestamp = new Date();String message = d.sayTime(timestamp.toString());System.out.println("DaytimeClient:" + message);} catch (Exception e) {System.out.println("Exception in DaytimeClient:" + e);}} //end main}//end class运行截图:服务器端:客户端:。
分布式计算原理与应用(DistributedComputing)第二章精品PPT课件

In practice, the synchronization requires system support.
8
Distributed Computing, M. L. Liu
- Distributed computing requires information to be exchanged among independent processes.
2
Distributed Computing, M. L. Liu
IPC – unicast and multicast
- Distributed computing systems make use of these facilities to provide application programming interface which allows IPC to be programmed at a higher level of abstraction.
3
Distributed Computing, M. L. Liu
Unicast vs. Multicast
P2
P2
P3 ... P4
m m mm
P1
unicast
4
P1
multicast
Distributed Computing, M. L. Liu
Interprocess Communications in Distributed Computing
7
Distributed Computing, M. L. Liu
分布式计算原理

分布式计算原理
分布式计算是指将一个大型的计算任务分解成许多小的计算子任务,然后由多个通信的计算机并行处理这些子任务,使整个系统能够
高效地完成计算任务。
这种计算模式被广泛应用于大数据处理、人工
智能、科学计算和云计算等领域。
分布式计算系统通常由多个节点组成,每个节点都有自己的计算
资源和存储资源。
这些节点之间通过高速网络进行通信,协同完成计
算任务。
分布式计算系统具有高可靠性、易扩展性和高效性等优点。
在分布式计算系统中,任务分配是一个重要的环节。
首先,将大
的任务分解成许多小的子任务,然后根据每个节点的计算能力、存储
能力和网络带宽等因素,将这些子任务分配给不同的节点。
分配任务
的算法是分布式计算系统的核心,它既要考虑任务分配的均衡性,又
要考虑节点之间的负载均衡。
另外,为了保证分布式计算系统的高效性,需要对节点之间的通
信进行优化。
一般来说,分布式计算系统采用消息传递的方式进行通信。
消息传递可以通过共享内存或者网络数据传输实现。
在实际应用中,需要根据任务的特点来选择不同的通信方式,以获得最佳的效果。
总之,分布式计算是现代计算机科学的重要发展方向之一。
通过
将单个计算机的资源组合起来,形成更大、更强大的计算机集群,能
够显著提高计算效率,为科学研究和商业应用带来巨大的价值。
分布式计算在大数据处理中的应用(二)

分布式计算在大数据处理中的应用近年来,随着互联网技术的快速发展,大数据的规模和复杂度不断增加,传统的计算方式已经无法满足对大数据的处理需求。
而分布式计算作为一种能够并行处理大规模数据的技术,正逐渐成为大数据处理的关键工具。
一、分布式计算的概念和特点分布式计算是指将计算任务分解为若干个子任务,并将这些子任务分配给分布在不同计算节点上的多台计算机进行并行计算的一种计算模型。
它的特点包括高并发性、高扩展性、高可靠性和高灵活性。
相比于传统的集中式计算,分布式计算能够充分利用多台计算机的处理能力,显著提高计算速度和效率。
二、分布式计算在大数据处理中的应用1. 数据的分发与并行计算在传统的集中式计算环境下,大数据的处理往往需要花费大量的时间和计算资源。
而分布式计算可以将数据分发到多个计算节点上进行并行处理,极大地缩短了计算时间。
例如,对于某个需要对大数据集进行复杂计算的任务,可以使用MapReduce模型将任务分为多个子任务,分发到不同的计算节点上进行并行计算,最后将结果进行合并,大大提高了计算效率。
2. 分布式存储与数据管理大数据处理不仅需要高效的计算能力,还需要强大的存储和数据管理能力。
分布式计算技术可以实现大规模数据的分布式存储和管理,提供高性能的读写能力和数据冗余备份。
通过将数据分布在多个节点上,可以实现数据的高可用性和容错性。
同时,采用分布式存储技术还能够大幅度缩减单台计算机的存储压力,从而降低成本。
3. 多源数据融合与分析在大数据处理中,通常需要从不同的数据源获取数据,并对这些数据进行融合和分析。
分布式计算可以实现多源数据的并行获取、融合和分析。
通过将不同的数据源分配到不同的计算节点上,可以并行地获取和处理数据,提高数据融合的效率。
同时,采用分布式计算还能够支持复杂的数据分析算法,如机器学习和深度学习等,实现对大数据的高效分析和挖掘。
三、分布式计算在大数据处理中的挑战尽管分布式计算在大数据处理中具有许多优势,但也面临着一些挑战。
分布式计算的原理与应用

分布式计算的原理与应用随着数字时代的到来,数据和信息的数字化处理不断加速。
人类面临的问题推动着计算机技术的不断发展。
分布式计算作为一种新型的计算形式,应运而生,承担着处理海量数据的重任。
本文将介绍分布式计算的原理和应用。
一、分布式计算的原理分布式计算是指将一个大型计算任务分解成许多小的计算子任务,在位于不同地点的多台计算机上分别进行计算,并最终将计算结果进行汇总,得到最终的结果。
分布式计算依赖于网络通信技术和计算机并行处理技术,可实现海量数据的高效计算。
分布式计算的核心是任务分发。
它首先将大型的计算任务分解成多个小的计算子任务,然后通过互联网将这些小的计算子任务分发给不同的计算节点。
每一个计算节点会独立地计算它所分配到的计算子任务,并将计算结果返回给任务管理者。
任务管理者会在接收到所有计算节点的计算结果之后,对它们进行合并得到最终的结果。
在分布式计算中,任务管理者可以根据需要增加或减少计算节点。
计算节点可以是任何联网的计算机或功能节点,它们共同完成整个分布式计算任务。
每个节点通常只负责部分计算任务,减轻了单个计算机的计算负担,提高了整个系统的可靠性和稳定性。
由于所有的计算节点都可以进行并行计算,因此可以大大提高计算速度和效率。
同时,这也为计算任务的许多问题提供了解决方案,例如可扩展性、可靠性、容错性、负载均衡等。
同时,分布式计算还可以充分利用各节点的计算能力,每个节点可以运行不同操作系统、不同编程语言、不同硬件平台的应用程序。
这样,分布式应用可以采用最优的方案来完成计算任务,提高了计算的效率和准确性。
二、分布式计算的应用1. 网络搜索引擎分布式计算技术被广泛应用于网络搜索引擎领域。
例如,Google是一个典型的分布式搜索引擎,它的数据处理中心包含大量的计算服务器。
当用户查询一个搜索词时,这个查询会先进入Google的主服务器,并向所有的数据处理中心分发该查询请求。
数据处理中心将查询分发给各自的子节点进行并行计算,得到搜索结果。
分布式计算技术在大规模数据处理中的应用教程

分布式计算技术在大规模数据处理中的应用教程随着互联网的普及和科技的不断发展,大规模数据处理的需求不断增加。
传统的数据处理方法已经无法满足这种需求,因此分布式计算技术应运而生。
本文将详细介绍分布式计算技术在大规模数据处理中的应用,帮助读者了解并应用这一重要的技术。
第一部分:分布式计算技术基础知识1. 分布式计算的概念和原理- 分布式计算是将一个大型任务分解成多个小任务,并由多台计算机协同完成的一种计算模式。
- 分布式计算的原理包括任务划分、任务分配、任务执行和结果合并等步骤。
2. 常用的分布式计算框架- Hadoop:是最流行的开源分布式计算框架之一,它通过HDFS(分布式文件系统)和MapReduce(分布式计算模型)实现数据存储和计算。
- Spark:是一个快速、通用的大规模数据处理引擎,支持内存计算,可以与Hadoop集成,提供更高效的数据处理能力。
- Flink:是一个流式处理框架,能够实时处理大规模数据,并提供了丰富的查询和计算功能。
第二部分:分布式计算技术在大规模数据处理中的应用1. 数据存储和管理- 分布式文件系统:通过将数据分布在多个计算节点上,提供高容量、高可靠性和高扩展性的数据存储解决方案。
- 数据库管理系统:使用分布式数据库可以提高数据访问的并发性和可扩展性,支持大规模数据的快速检索和处理。
2. 数据处理和分析- 大规模数据批处理:使用分布式计算框架(如Hadoop和Spark)可以对大规模数据进行分布式的批处理,实现高效的数据清洗、转换和计算。
- 流式数据处理:通过分布式流处理框架(如Flink)可以实现对实时的大规模数据流进行高效的处理和分析。
- 图计算:分布式计算技术可以应用于大规模图计算,用于社交网络分析、推荐系统和网络安全等领域。
3. 机器学习和人工智能- 分布式机器学习:将机器学习算法应用于分布式计算环境中,可以加速模型训练和优化,并处理更大规模的数据集。
- 深度学习:使用分布式计算技术可以应对深度神经网络训练中的计算和存储需求,提高学习速度和模型效果。
分布式计算原理与应用大作业2

(3)命令:测试 PC 与 reader 之间的连通 test
<Elpas> <Type>Command</Type> <Subtype>Test</Subtype> < DeviceId >00:11:11:11:44:55</ DeviceId > <ClearStats>1</ClearStats> <Repeat>Close</Repeat> <RequestId>12345</RequestId>
后可以验证“确认”(acknowledge)已经被 Reader 接收。 PacketId: 此标签值用来跟踪徽章标签消息的编号。由于使用 UDP 协议,PC 使用此
标签值来发现以太网的通讯问题和可能丢失的消息。
下面若干 XML 消息供模拟仿真使用: Reader 收集的数据,并发送到 PC (1)徽章消息 <Elpas> <Type>BadgeMessage</Type> <DeviceId>00:11:22:33:44:55</DeviceId> <HostMAC>00:11:11:11:44:55</HostMAC> <Motion>1</Motion> <Battery>1</Battery> <Buttons>3</Buttons> <Id>00D330</Id> <RSSI>221</RSSI> <Noise>43</Noise> <PacketId>4567</PacketId>
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
2、写一个多播应用程序:多个进程使用多播通讯进行一次选举,有两个候选人(Jones 和 Smith),每一个进程通过多播消息进行投票(消息内容:投票者和投票)。每一个进程能够跟踪 每一位候选人的得票计数(包括它自己的投票)。在选举结束时(多播组的所有成员完成了投 票),每一个进程独立地进行得票计算,然后在它的屏幕上显示投票结果(例如,Jones10, Smith 5)。画出应用程序的体系结构图及组件间的调用关系图(UML)。编写应用程序,并调试。
并回答如下问题:(实现 30 分,回答下列问题 10 分,共计 40 分)
a、投票程序如何允许参与者加入一个多播组?
b、投票程序如何同步选举的开始,以保证每一个进程准备好接受多播组的任何成员的投票。
c、运行程序中,每一个进程独立的得票统计都一样吗?同学可以假定得票统计一直彼此一致吗? 请解释。
d、什么 Java 可靠多播服务,什么是 Java 不可靠多播服务。
1、分别采用 Java Socket API 、RMI 技术和 CORBA 实现远程词典应用,场景描述: 假设有一台应用服务器以 Socket API /RMI/CORBA 的方式向客户端提供英汉互译词典的服务。
请同学们尝试完成服务器端程序的编码和一个客户端应用的编码,并分别部署到两台计算机上进 行测试。画出应用程序的体系结构图及组件间的调用关系图(UML)。编写应用程序,并调试。 试阐述开发应用程序时如何选择 Socket API 、RMI 与 CORBA。服务接口声明如下。(Socket 实现 15 分,RMI 实现 15 分,CORBA 10 分,共计 40 分)
public interface Translator {
/**
*
* @param str 需要被翻译的单词
* @return 英汉互译后的内容,如果词典中不包含此单词返回 null
*/
public String translate(String str);
}
说明: 服务器端词典的容量不是考察的重点,可以使用数据库技术也可以使用 Map 在内存中保存少
<RawData>DE5394614900</RawData> <Group>19</Group> <Data>FE</Data> </Elpas> (2)徽章事件 <Elpas> <Type>BadgeEvent</Type> <DeviceId>00:11:22:33:44:55</DeviceId> <HostMAC>00:11:11:11:44:55</HostMAC> <Time>22:10:59</Time> <Id>00D330</Id> <EventType>Motion</EventType> <EventValue>1</EventValue> <Data>111</Data> </Elpas> (3)系统事件 <Elpas> <Type>SystemEvent</Type> <Subtype>Supervision</Subtype> <DeviceId>00:11:22:33:44:55</DeviceId> <HostMAC>00:11:11:11:44:55</HostMAC> <Time>18:49:36</Time> <Tamper>0</Tamper> <Voltage>0</Voltage> <DeviceIp>192.168.1.34</DeviceIp> <Messages>1289</Messages> <CRCErrors>0</CRCErrors> <NoAnswer>0</NoAnswer> </Elpas> (4)系统事件 <Elpas> <Type>SystemEvent</Type>
Reader 回应
<Elpas> <Type>Command</Type> <Subtype>Activate</Subtype> <DeviceId>00:11:22:33:44:55</DeviceId> <HostMAC>00:11:11:11:44:55</HostMAC> <RequestID>12345</RequestID>
Trouble Tamper High Noise Level
Low Voltage Bus Capacity Exceeded
Send Command
RS-485 Error
Lost Away
Receiver Error
Description
Device cover is open Current noise level is above normal, may cause a badge message loss Device voltage dropped below the critical level An attempt to connect more than 16 devices to the RS-485 bus Device has failed to send ACK in response to Activation command Communication problems between RF reader and one of his slave devices Device didn't send any unicast messages for a specific period of time RF receiver failure
</Elpas>
(3)命令:测试 PC 与 reader 之间的连通 test
<Elpas> <Type>Command</Type> <Subtype>Test</Subtype> < DeviceId >00:11:11:11:44:55</ DeviceId > <ClearStats>1</ClearStats> <Repeat>Close</Repeat> <RequestId>12345</RequestId>
标准(unicast) Incoming: 7777;Outgoing: 7778 主动 RFID 网络如下图所示: Nhomakorabea功能简介
1) 读写器(Controller,也称为 Reader)产生的消息 Controller 产生消息,并将消息发送到计算机 PC。这些消息是最常见的信息。 a. 徽章消息(Badge Messages):Controller 把接收到的每一条徽章消息发送到 PC,此消 息是系统中最基本的信息。 b. 徽章事件(Badge Events):与徽章消息相对应的是徽章事件,当以下状态之一发生变 化,Controller 把接收到的徽章事件发送到 PC。 Button press/Button release Motion/motionless Low Battery Badge lost, badge first seen c. 系统事件(System Events) Supervision Troubles Trouble description:
上述的基本功能都有一个 XML 实现
基本的 XML 标签:
Device Id: 唯一标识源或目标设备。 以太网设备:以太网 MAC 地址,例如:00:11:22:33:44:55
HostMac:消息源是从设备,则此标签的值是指主设备 SlaveId:消息目的地址是从设备,此标签值标识从设备 Type: 消息类型 (IPChange, Set parameters,Get Parameters,command) Subtype: 有关消息类型的额外信息 RequestId: 一些 PC 命令需要进行确认,这个标签值唯一地标识这样的命令:PC 稍
<EventData>123</EventData>
<EventMessage>Tamper</EventMessage>
</Elpas>
PC 发送到 Reader 上的命令
(1)命令:复位 reset <Elpas>
<Type>Command</Type> <SlaveId>00:11:11:11:44:55</SlaveId> <Subtype>Reset</Subtype> <Param>All</Param> <RequestId>12345</RequestId> </Elpas>
<Subtype>Trouble</Subtype>
<DeviceId>00:11:22:33:44:55</DeviceId>
<HostMAC>00:11:11:11:44:55</HostMAC>
<Time>23:45:47</Time>