oracle mysql sqlserver
oraclemysqlsqlserver三种数据库查询表获取表数据的前100条数据与排序时。。。

oraclemysqlsqlserver三种数据库查询表获取表数据的前100条数据与排序时。
1.oracle获取表的前100条数据.select * from t_stu_copy where rownum<=100;(从1⾏开始取100⾏数据,第⼀⾏到第100⾏数据)补充:先降序排序再获取第101条到第200条之间的所有记录select * from t_stu_copy order by stuid desc where rownum between 100 and 200 ;---错误select * from t_stu_copy where rownum between 100 and 200 order by stuid desc ;---错误SELECT * FROM(SELECT ROWNUM AS rowno,t.* FROM t_stu_copy t WHERE ROWNUM <= 200 ORDER BY t.stuid ) a WHEREa.rowno > 100;正确或者:select * from t_stu_copy where stuid between 101 and 200;2.mysql获取表的前100条数据.select * from t_stu_copy limit 0,100;(从1⾏开始取100⾏数据,第⼀⾏到第100⾏数据)补充:先降序排序再获取第101条到第200条之间的所有记录select * from t_stu_copy order by stuid limit 100,100;(从101⾏开始取100⾏数据,第101⾏到第200⾏数据)或者:select * from t_stu_copy where stuid between 101 and 200;3.sqlserver获取表的前100条数据.select top 100 * from t_stu_copy ;补充:先降序排序再获取第101条到第200条之间的所有记录(三种⽅法,不过⽅法a与b得到的结果是将第101条到第200条倒过来显⽰罢了)a. select top 100 * from (select top 200 * from t_stu order by stuid) a order by stuid desc;b. select top m * into 临时表(或表变量) from tablename order by columnname set rowcount n select * from 表变量 order by columnname desc.select top 200 * into xxx from t_stu order by stuid set ROWCOUNT 100 select * from xxx order by stuid desc; xxx表⽰临时表变量.c. select * from t_stu where stuid between 101 and 200.。
数据库管理系统比较MySQLvsOraclevsSQLServer

数据库管理系统比较MySQLvsOraclevsSQLServer 数据库管理系统比较:MySQL vs Oracle vs SQL Server引言:数据库管理系统是现代信息技术领域中不可或缺的一环。
随着数据量的急剧增加和数据库应用的广泛应用,选择适合自己需求的数据库管理系统变得至关重要。
在本文中,我们将比较三种常见的数据库管理系统:MySQL、Oracle和SQL Server。
通过对比它们的性能、功能、可扩展性和使用成本,为读者提供一个更好地了解和选择的依据。
一、性能比较在数据库管理系统中,性能是一个至关重要的因素。
下面将对MySQL、Oracle和SQL Server的性能进行比较。
1.1 MySQL性能MySQL是一个轻量级的开源数据库管理系统,以其高性能而闻名。
它采用多线程处理机制和高效的索引算法,能够处理大规模的数据访问和高并发请求。
此外,MySQL还支持垂直和水平扩展,可根据实际需求进行灵活配置和调整。
因此,在对于大多数中小型应用来说,MySQL提供了相对较好的性能。
1.2 Oracle性能Oracle是一个功能强大且成熟的商业数据库管理系统。
它具有出色的性能,并且能够处理大规模的复杂数据模型。
Oracle采用了先进的事务处理机制和高效的查询优化算法,使其在处理高并发访问和复杂查询时具有出色的性能表现。
然而,Oracle的性能和功能也伴随着更高的硬件要求和许可成本。
1.3 SQL Server性能SQL Server是由微软公司开发的关系型数据库管理系统。
它在处理大规模数据时表现出色,并且支持高并发访问和复杂查询。
SQL Server 采用了先进的内存管理和缓存技术,以提高查询速度和响应时间。
此外,SQL Server还具有良好的稳定性和可靠性,适用于中小型企业的应用场景。
综合比较,MySQL适用于中小型应用,对性能要求较高且成本敏感的场景;Oracle适用于大规模企业级应用,对功能和可靠性要求较高的场景;SQL Server适用于中小型企业应用,对性能和稳定性要求较高的场景。
各数据库的数据类型的区别

Oracle、MySQL、SQL Server数据库的数据类型的差异1.Oracle数据库的各种数据类型CHAR 定长的字符型数据,长度<=2000字节VARCHAR2 变长的字符型数据,长度<=4000字节N CHAR 用来存储Unicode字符集的定长字符型数据,长度<=1000字节注意:N字打头的是存储Unicode字符集NVARCHAR2 Unicode字符集的变长字符型数据,长度<=1000字节NUMBER 整型或者浮点型数值DATE 日期数据LONG 2GB的变长字符数据RAW 用来存储非结构化数据的变长字符数据,长度<=2000字节LONG RAW 用来存储非结构化数据的变长字符数据,长度<=2GBROWID 用来存储表中列的物理地址的二进制数据,占用固定的10个字节BLOB 4GB的非结构化的二进制数据CLOB 4GB的字符数据NCLOB 4GB的Unicode字符数据BFILE 把非结构化的二进制数据存储在数据库以外的操作系统文件中UROWID 表示任何类型列地址的二进制数据FLOAT 浮点数2.MySQL数据库的各种数据类型CHAR (M) CHAR数据类型用于表示M长度的字符串。
VARCHAR (M) VARCHAR可以保存可变长度的字符串, VARCHAR数据类型所支持的最大长度也是255个字符。
INT (M) [Unsigned] INT数据类型用于保存从- 2147483647 到2147483648范围之内的任意整数数据。
如果用户使用Unsigned选项,则有效数据范围调整为0-4294967295。
FLOAT [(M,D)] FLOAT数据类型用于表示数值较小的浮点数据,可以提供更加准确的数据精度。
其中,M代表浮点数据的长度(即小数点左右数据长度的总和),D表示浮点数据位于小数点右边的数值位数。
DATE DATE数据类型用于保存日期数据,默认格式为YYYY-MM-DD。
MySQL、Oracle、SqlServer三种数据库的优缺点

MySQL、Oracle、SqlServer三种数据库的优缺点这篇文章主要介绍了sqls erver、Mysql、Oracle三种数据库的优缺点总结,需要的朋友可以参考下。
一、sqlserv er优点:易用性、适合分布式组织的可伸缩性、用于决策支持的数据仓库功能、与许多其他服务器软件紧密关联的集成性、良好的性价比等;为数据管理与分析带来了灵活性,允许单位在快速变化的环境中从容响应,从而获得竞争优势。
从数据管理和分析角度看,将原始数据转化为商业智能和充分利用We b带来的机会非常重要。
作为一个完备的数据库和数据分析包,SQLServ er为快速开发新一代企业级商业应用程序、为企业赢得核心竞争优势打开了胜利之门。
作为重要的基准测试可伸缩性和速度奖的记录保持者,SQLServ er是一个具备完全Web支持的数据库产品,提供了对可扩展标记语言 (XML)的核心支持以及在Inter net上和防火墙外进行查询的能力;缺点:开放性:SQL Server只能windo ws上运行没有丝毫开放性操作系统系统稳定对数据库十分重要Windows9X系列产品偏重于桌面应用NT server只适合小型企业而且wind ows平台靠性安全性和伸缩性非常有限象unix样久经考验尤其处理大数据库;伸缩性并行性:S QL server并行实施和共存模型并成熟难处理日益增多用户数和数据卷伸缩性有限;安全性:没有获得任何安全证书。
性能:SQL Server多用户时性能佳;客户端支持及应用模式:客户端支持及应用模式。
只支持C/S模式,SQL Server C/S结构只支持w indows客户用ADO、DAO、OLEDB、ODBC连接;使用风险:SQL server完全重写代码经历了长期测试断延迟许多功能需要时间来证明并十分兼容;二、Oracle优点:开放性:Oracle能所有主流平台上运行(包括 windows)完全支持所有工业标准采用完全开放策略使客户选择适合解决方案对开发商全力支持;可伸缩性,并行性:Oracle并行服务器通过使组结点共享同簇工作来扩展windo wnt能力提供高用性和高伸缩性簇解决方案wind owsNT能满足需要用户把数据库移U NIXOra c le并行服务器对各种U NIX平台集群机制都有着相当高集成度;安全性:获得最高认证级别的ISO标准认证。
mysql、sqlserver、oracle获取最后一条数据

mysql、sqlserver、oracle获取最后⼀条数据
在⽇常项⽬中经常会遇到查询第⼀条或者最后⼀条数据的情况,针对不同数据库,我整理了mysql、sqlserver、oracle数据库的获取⽅法。
1、mysql 使⽤limit
select * from table order by col limit index,rows;
表在经过col排序后,取从index+1条数据开始的rows条数据。
select * from table order by col limit rows;
表⽰返还前rows条数据,相当于 limit 0,rows
select * from table order by col limit rows,-1;
表⽰查询第rows+1条数据后的所有数据。
2、oracle 使⽤ row_number()over(partition by col1 order by col2)
select row_number()over(partition by col1 order by col2) rnm from table rnm = 1;
表在经过col1分组后根据col2排序,row_number()over返还排序后的结果
3、sql server top
select top n * from table order by col ;
查询表的前n条数据。
select top n percent from table order by col ;
查询前百分之n条数据。
SQL查询前10条记录(SqlServermysqloracle)语法分析

SQL查询前10条记录(SqlServer/mysql/oracle)语法分析Sql Server :Sql代码select top X * from table_name --查询前X条记录,可以改成需要的数字。
select top n * from (select top m * from table_name order by column_name ) a order by column_namedesc --查询第N到M条记录。
常用的分页也是这种方式。
例如常用的分页方式:declare @page intdeclare @row intset @page=2 --页数set @row=3 --每页展示行数select top (@row) * from (select top (@row*@page) * from table_name order by id ) a order by iddesc --最基本的分页方式,改变@row和@page达到分页效果MYSQL查询前10条的方法(limit参数的第一个参数n(如下面的0或1)表示前n条记录是不在选择范围内,相当于hibernate的setFirstResult的参数加一;第二个参数表示要选择的记录条数,相当于hibernate的setMaxResult的参数):Sql代码select * from table_name limit 0,10 --通常0是可以省略的,直接写成 limit 10。
0代表从第0条记录后面开始,也就是从第一条开始select * from table_name limit 1,10 --则为从第一条后面的记录开始展示,也就是说从第二条开始。
MySQL查询前5条方法(假设一个表为users表,这里作为子查询时要加入别名不然会出错,还有一点要注意的是order by在limit前面,不然还没出结果前就说要前几条,怎么搞嘛,所以limit要放最后。
SQL获取第一条记录的方法(sqlserver、oracle、mysql数据库)

SQL获取第⼀条记录的⽅法(sqlserver、oracle、mysql数据库)Sqlserver 获取每组中的第⼀条记录在⽇常⽣活⽅⾯,我们经常需要记录⼀些操作,类似于⽇志的操作,最后的记录才是有效数据,⽽且可能它们属于不同的⽅⾯、功能下⾯,从数据库的术语来说,就是查找出每组中的⼀条数据。
下⾯我们要实现的就是在sqlserver中实现从每组中取出第⼀条数据。
例⼦我们要从上⾯获得的有效数据为:对应的sql语句如下所⽰:select * from t1 t where id = (select top 1 id from t1 where grp = t.grp order by createtime desc )下⾯给⼤家介绍oracle查询取出每组中的第⼀条记录oracle查询:取出每组中的第⼀条记录按type字段分组,code排序,取出每组中的第⼀条记录⽅法⼀:select type,min(code) from group_infogroup by type;注意:select 后⾯的列要在group by ⼦句中,或是⽤聚合函数包含,否则会有语法错误。
⽅法⼆:SELECT * FROM(SELECT z.type , z.code ,ROW_NUMBER()OVER(PARTITION BY z.type ORDER BY z.code) AS code_idFROM group_info z)WHERE code_id =1;这⾥涉及到的over()是oracle的分析函数参考sql reference⽂档:Analytic functions compute an aggregate value based on a group of rows. They differ from aggregate functions in that they return multiple rows for each group.Analytic functions are the last set of operations performed in a query except for the final ORDER BY clause. All joins and all WHERE , GROUP BY , and HAVING clauses are completed before the analytic functions are processed. Therefore, analytic functions can appear only in the select list or ORDER BY clause.语法结构:analytic_function ([ arguments ]) OVER(analytic_clause)其中analytic_clause结构包括:[ query_partition_clause ][ order_by_clause [ windowing_clause ] ]也就是:函数名( [ 参数 ] ) over( [ 分区⼦句 ] [ 排序⼦句 [ 滑动窗⼝⼦句 ] ])这⾥PARTITION BY 引导的分区⼦句类似于聚组函数中的group by,排序⼦句可看成是select语句中的order by.mysql 中只获取1条数据SELECT * FROM 表 LIMIT 0, 10LIMIT 接受⼀个或两个数字参数。
SQLServer,MySQL,Oracle三者的区别

SQLServer,MySQL,Oracle三者的区别目录1 Oracle、Sql Server、MySql简介1.1 Oracle1.2 SQL Server1.3 MySQL2 Oracle和MySQL的主要区别2.1 客户端和命令窗口2.2 市场占有率及其他2.3 Oracle也与MySQL操作上的一些区别2.3.1 组函数用法规则2.3.2 自动增长的数据类型处理2.3.3 主键2.3.4 单引号的处理2.3.5 翻页的SQL语句的处理2.3.6 长字符串的处理2.3.7 日期字段的处理2.3.8 空字符的处理2.3.9 字符串的模糊比较1 Oracle、Sql Server、MySql简介返回1.1 OracleOracle 能在所有主流平台上运行(包括Windows)。
完全支持所有的工业标准。
采用完全开放策略。
可以使客户选择最适合的解决方案。
对开发商全力支持,Oracle并行服务器通过使一组结点共享同一簇中的工作来扩展Windows NT的能力,提供高可用性和高伸缩性的簇的解决方案。
如果Windows NT不能满足需要,用户可以把数据库移到UNIX中。
Oracle的并行服务器对各种UNIX平台的集群机制都有着相当高的集成度。
Oracle获得最高认证级别的ISO标准认证.Oracle性能最高,保持开放平台下的TPC-D和TPC-C的世界记录Oracle多层次网络计算,支持多种工业标准,可以用ODBC、JDBC、OCI等网络客户连接。
Oracle 在兼容性、可移植性、可联结性、高生产率上、开放性也存在优点。
Oracle产品采用标准SQL,并经过美国国家标准技术所(NIST)测试。
与 IBM SQL/DS,DB2,INGRES,IDMS/R等兼容。
Oracle的产品可运行于很宽范围的硬件与操作系统平台上。
可以安装在70种以上不同的大、中、小型机上;可在VMS、DOS、UNIX、WINDOWS等多种操作系统下工作。
(word完整版)Oracle-SQLServer-MySQL-MongoDB数据库比较

主流数据库比较目录前言 (3)1. 数据库安装对硬件的要求 (3)1。
1. Oracle (3)1.2. SQL Server (4)1。
3. MySQL (5)2. 数据类型对比 (6)2。
1。
Oracle数据类型 (6)2.2。
SQL Server 数据类型 (7)2。
3。
MySQL 数据类型 (11)3. 三大关系型数据库比较 (14)4。
应用场景 (18)4。
1. Oracle的一般应用 (18)4。
2. MySQL的应用场景 (18)4.3. SQL Server的应用 (19)5. MongoDB-非关系型数据库 (19)5。
1。
MongoDB的应用场景 (19)5.2. MongoDB与MySQL性能比较 (19)5.2。
1. 测试目的 (19)5。
2.2。
测试环境 (19)5。
2.3. 测试结果1:插入速率 (20)5。
2.4. 测试结果2:插入稳定性 (21)5。
2。
5. 测试结果3:读取性能测试 (23)5.2.6。
测试结论 (24)5。
3. MongoDB的优势和缺陷 (25)5。
3。
1。
MongoDB的优势 (25)5。
3。
2. MongoDB的缺陷 (25)前言数据库流行度排行榜来自于美国数据库知识网站DB-engines,在本月(2014—10)的榜单中,前三甲依然是Oracle、MySQL和Microsoft SQL Server.前十名中文档型数据库MongoDB和列式数据库Cassandra作为仅有的两个NoSQl数据库分别位列第五和第十名。
下面就对排名前三甲的关系型数据库(Oracle、MySQL、SqlServer)进行一下对比、以及最受欢迎的非关系型MongoDB.1. 数据库安装对硬件的要求1.1. Oracle以Oracle 11g为例,系统是Windows:硬件要求配置组件最低配置——-—-——--—-—---—-———--————-—-—------—---—-———-----—————-—--— Physical memory (RAM) 1 GB minimumVirtual memory Double the amount of RAMDisk space Total: 4。
SQLServerMySqlOracle语法对比及区别

SQLServerMySqlOracle语法对⽐及区别操作SQLServer Oracle Mysql查看表结构exec sp_help 表名desc 表名在command window看desc 表名或 describe 表名或show columns from 表名;修改数据库名称exec sp_renamedb ‘旧数据库名’,’新数据库名’不详修改表名exec sp_rename ‘旧表明’,’新表明’rename 旧表名 to 新表名alter table 表名 rename to 新表名修改列名exec sp_rename ‘表.旧列名’,’新列名’alter table 表名 rename column 旧列名 to 新列名alter table test change column address address1 varchar(30)--修改表列名删除数据库drop database 数据库名不详Drop database添加表中⼀列alter table 表名 Add 列名数据库类型alter table 表明 add(列名数据类型) 或alter table 表名 Add 列名数据库类型alter table test add column name varchar(10); --添加表列删除表中⼀列alter table 表名 drop column 列名alter table 表名 drop column 列名alter table test drop column name;修改表现有列alter table 表名 alter column 列名新数据库类型⼤⼩alter table 表明 modify(列名数据类型)alter table test modify address char(10) --修改表列类型||alter table test change address address char(40)删除约束alter table 表名 drop constraint约束名完全⼀样添加主键约束alter table 表名add constraint 主键约束名primary key (列名)完全⼀样alter table 表明add primary key (列名)删除主键约束alter table 表名 drop primary key添加唯⼀约束alter table 表名add constraint 唯⼀约束名unique (列名)完全⼀样alter table 表名 add unique (列名)添加默认约束alter table 表名add constraint default (值) for 列名完全⼀样添加检查约束alter table 表名add constraint check (列名 > 10)完全⼀样添加外键约束alter table ⼦表add constraint 外键约束名foreign key(⼦表的列名) references 主表 (列名)on update cascade / on updateaction注意:默认和加 on update action 表⽰更新受限加on update cascade 表⽰更新不受限,多项操作时⽤逗号隔开完全⼀样添加索引约束alter table 表名 add index 索引名 (列名)添加普通索引:create index 索引名 ON 表名 (列名)添加唯⼀索引:create unique索引名 ON 表名 (列名)删除索引drop index 索引名 on 表名alter table 表名 drop index 索引名⾝份: exec sp_grantlog域名\密码’⾝份: exec sp_addlogin ‘登陆’,’密码’SET PASSWORD FOR'username'@'host'= PASSWORD('newpassword');数据库名⾝份: Exec域名密码’,’数据库⽤户名’⾝份: Exec sp_grantdbaccess登陆帐户’,’数据库⽤户名’create user HDEAM_TYMBidentified by ""default tablespace HDEAM_TYMBtemporary tablespace TEMPprofile DEFAULT;mysql>insert intoer(Host,User,Password,ssl_cipher,x509_issuer,x509_subject) values("localhost","pppadmin",password("passwd"),'','','');CREATE USER 'dog'@'localhost' IDENTIFIED BY '123456';CREATE USER 'pig'@'192.168.1.101_' IDENDIFIED BY'123456';CREATE USER 'pig'@'%' IDENTIFIED BY '123456';CREATE USER 'pig'@'%' IDENTIFIED BY '';CREATE USER 'pig'@'%';权限 [on 表明] to 数据库grant dba to HDEAM_TYMB with admin option;-- Grant/Revoke system privilegesgrant unlimited tablespace to HDEAM_TYMBwith admin option;“abc”;grant all privileges on phplampDB.* to phplamp@localhostidentified by '1234';mysql>flush privileges;权限 [on 表名] from 数据REVOKE SELECT ON*.* FROM'pig'@'%';数据库’drop user HDEAM_SBFF cascade;mysql>Delete FROM user Where User="phplamp" andHost="localhost";mysql>flush privileges;⾝份: exec sp_droplogin⾝份: exec sp_revokelogin 登分离数据库:数据库名附加数据库:数据库名,主数据⽂件路径’,⽇志⽂件路径’exp hdeam_product/d3B68Apk29v34Dj@orclfile=E:/tymb.dmp log=E:/tymb.logimp HDEAM_LHSH/HDEAM_LHSH@orcldevfile=E:\TYMBHDEAM_BAK_2013-03-25.dmpfull=Y;mysqldump -h localhost -u root -pmysql oa >d:\oa.sqlmysql -h localhost -u root -p jira<d:\jira.sql:Select *select * from表)Exec Sp_helpExecExec数据库名exec表名exec sp_helpindex注意: 下⾯都是通过( select * from 对象 ) 来查看信息触发器 user_triggers过程 user_procedures查看源代码 user_source查看数据库对象 user_objects查看错误信息 show errors查看索引信息 user_indexes查看分区索引 user_ind_partitions查看有关基于列创建的索引 user_ind_columns查看表空间 -- user_tablespaces查看所有数据库 show databases;查看库所有表 show tables;查看表结构和属性use information_schema;select * from columns where table_name=’表名’查看表源代码show create table 表名;查看存储过程源代show create procedure 过程名查看视图源代码show create procedure 过程名查看视图资代码show create VIEW 视图名查看表的索引show index from 表名查看表的索引show keys from 表明表储蓄过/空过程,函数,视图,表的源代码:对象名::查看序列 -- user_sequences查看同义词 -- user_ind_columns查看⽤户表信息 -- user_tables查看⽤户所有的表信息 user_all_tables查看表的索引show keys from 表明sysdate NOW()varchar2(20)不⼀定要指定具体列名必须指定具体列名标识的开始值, 标识种右)create sequence 序列名1.序列名.nextval 获取下⼀个序列的值2.序列名.currval 获取当前的序列的值: *.mdf =1 :*.ndf >=0 : *.log >=1数据⽂件: *.dbf >=1⽇志⽂件: *.log >=11位置开始查找t字符串(默认从1开始)从pos位置len获取字符串的长度把字符串全部转换成把字符串全部转换成清除左边的空格清楚右边的空格从左边返回指定长度的从右边返回指定长度将s t替换成字符串我的⾳乐我’)A我的⾳乐我的世界EFG2位置开3的字符串,并在该位置索引从1开始substr(char, pos, len) 截取字符串length(char) 返回字符串的长度lower(char) 转换为⼩写upper(char) 转换为⼤写trim() 截取左右空格initcap(char) ⾸字母⼤写ltrim(char,set) 左剪裁rtrim(char,set) 右剪裁replace(char oldchar, newchar) 字符串替换concat(char1, char2) 连接字符串cha(67) 根据ASCII码返回对应的字符lpad()和rpad() 在字符串的左边或右边添加东西需要3个参数第⼀个是字符串第⼆个是返回值的总长度, 第三个是⽤来填充的字符值 as varchar) 不需指定长度to_char(d|n, fmt)将数字或⽇期转换为指定格式的值 as varchar) 不需指定长度值) 必须指to_char(d|n, fmt)将数字或⽇期转换为指定格式的字符串to_date(char,frm)将char 或varchar 转换为⽇期数据类型to_number() 将包含数字的字符转换为number数据类型取绝对值取上界最⼩整取下界最⼤整数取幂四舍五⼊,正数返回1 ,负数返-1求平⽅根获取计算机名称nvl(ex1,ex2)如果ex1为null则返回ex2;如果ex1不为null则返回ex1;nvl2(ex1,ex2,ex3)如果ex1不为null则返回ex2如果ex1为null则返回ex3nullif(ex1,ex2)如果ex1=ex2则返回null 否则返回ex1;聚合)列名) 求这列的平均值列名) 求这列的最⼩值列名) 求这列的最⼤值统计所有的⾏包括重复列名) 统计指定列中⾮空值列名) 统计不是重复右句⽤于将信息表划分,按组进⾏聚合运算avg(列名) 求这列的平均值min(列名) 求这列的最⼩值max(列名) 求这列的最⼤值count(*) 统计所有的⾏包括重复值和空值count(列名) 统计指定列中⾮空值的个数count(distinct 列名) 统计不是重复值的个数group by右句⽤于将信息表划分为组,按组进⾏聚合运算返回当前系统时间返回指+指定部分后的⽇期返回返回指a. add_months(d,n) 返回给指定的⽇期加上指定的⽉数后的⽇期值 selectadd_months(sysdate,2) from dual;b. months_between(d,d) 返回2个⽇期之间的⽉数select months_between (date '2005-05-06',date '2005-9-01') from dual;c. last_day(d) 返回指定⽇期当⽉的最后⼀天的⽇期select last_day(sysdate) from dual;d. round(d, [fmt]) 返回⽇期值⽇期四舍五⼊为格式模型指定的单位 select round(date'2005-09-08','year') from dual; 返回 2005-01-01 selectround(date'2005-09-08','month') from dual; 返回2005-09-01 select round(date'2005-09-08','day')from dual; 返回最靠近的⼀个星期⽇e. next_day(d, day) 返回指定的下⼀个星期⼏的⽇期 select next_day(sysdate,'星期⼆') fromdualf.trunc 语法与round 相同区别:trunc 是只舍不⼊g.extract 提取⽇期时间类型中的特定部分|| 连接字符串⽤于将2个或多个字符串合并成⼀个字符串两个)重复的⾏select orderno from order_master union select orderno from order_detail;b.union all 合并2个查询选定的所有⾏包括重复的⾏c.intersect 返回2个查询都有的⾏d.minus 第1个查询在第2个查询中不存在的数据)个,⾄n-个条)::对1 :)左别名.列名,右别名.列from 左表 as 左别名 inner右表 as 右别名on 左别名.列= 右别名.列名左表名.列名,右表名.列from 左表 ,右表 where 左表.列名 = 右表名.列名左外连接:(返回左表的所有⾏,如null代替,存在则显⽰具体数,显⽰出来的总⾏数由左表决定)左别名.列名,右别名.列名左表 as 左别名 left join 右as 右别名on 左别名.列名 = 右.列名右外连接:(返回右表的所有⾏,如null代替,存在则显⽰具体数,显⽰出来的总⾏数由右表决定)左别名.列名,右别名.列名左表 as 左别名 right join右表 as 右别名on 左别名.列名 =完全⼀样连接分类:1内连接:条件2外连接1)左外连接: left join 或 left outer join2)右外连接:right join 或 right outer join3)完整外连接: Full join 或 Full outer join3交叉连接: from …4. 交叉连接:(返回左右表的所有⾏,如果左表没有与右表匹配的⾏则全部⽤null代替,如果右表没有与左表匹配的⾏则全部⽤null代替,存在则显⽰具体数据,显⽰出来的总⾏数=左表和右表⾏数和决定)Select 左别名.列名,右别名.列名 from 左表 as左别名 right join 右表 as 右别名on 左别名.列名= 右别名.列名完全拷贝: insert into ⽬标表源表部分拷贝: insert into ⽬标表 (列) select 列名 from 源表表不存完全拷贝: select * into 新表源表部分拷贝: select 列名 into 新from 源表拷贝表结构: select * into 新表源表 Where 1=2emp;b.拷贝⼀部分create table temp as select 列1,列2 from 表c.只拷贝⼀个空表(根据⼀个假条件)create table temp as select * from 表 where 1=2d.使⽤列别名: select stu_id, stu_name as "学⽣姓名" from student;A表,B1:⽬标表 set 列 = a.列 froma where a.关联列 = ⽬标表.2:列 = a.列 from 源a , ⽬标表b where a.关联列 =关联列3:⽬标表 set 列 = a.列 froma , ⽬标表b where a.关联列关联列4:⽬标表 set ⽬标表.列 = a.from 源表 a , ⽬标表 b where关联列 = b.关联列5:⽬标表 set⽬标表.列 = a.from 源表 a where a.关联列 =update ⽬标表a, 源表b set a.列 =b.列 where a.关联列 = b.关联列update ⽬标表a, 源表b set a.列 =b.列 where a.关联列 = b.关联列from 源表 a where a.关联列 = .关联列6:update语创建⼀个新表修改表中的列表名 alter column 列新数据库类型⼤⼩添加表中的列表名 Add 列名数据库删除表中的列表名 drop column 列删除表中的记录⽽不删除表的truncate table student只是查看表的结构删除表中的数据及表的结构a.创建⼀个新表create table student(stu_id int, stu_name varchar2(20)) tablespace lijiaob.修改表中的列alter table student modify(stu_name varchar2(40))c.添加表中的列alter table student add(stu_age int)d.删除表中的列alter table student drop column stu_agee.删除表中的记录⽽不删除表的结构truncate table studentf.只是查看表的结构desc studentg.删除表中的数据及表的结构drop table student;:.必须)a. commit 命令(⽤于提交并结束事务处理)commitb.savepoint 保存点类似于标记它将很长的事务处理划分为较⼩的部分他们⽤来标记事务中可以应⽤回滚的点save point savepoint_idc.rollbace work ,rollbackd.回滚到某个保存点rollback to savepoint伪列,但a.rowid(可以唯⼀的标识数据库中的⼀⾏)b.rownum (代表⾏的序号)rownum 不跟> , = , >= 操作使⽤储在,)变量名 = 值变量名 = 列名 from 表明列名 =⽤户)最后⼀个T-SQL错误号最后⼀次插⼊的标识本地服务器的名值’ 只出现在查询分析器中值’,16,1) 能在前台⽤条件) begin … end条件) begin …end else begin表名 where= 值)表名列名 = 值) begin …. enda) if condition then exp_bodyend if;b) if condition then exp_bodyelse exp_body end if;c) if condition then exp_bodyelsif condition then exp_bodyelse exp_body end if;1) loop condition end loop2) while condition Loop exp_body end loop3)for varable in [REVERSE] value1...value2 (varable 变量不需声明 , ... 是范围连接符 )loop exp_body end loop别名=case条件 then 值条件 then 值值表列名值 then 值值 then 值值表a) select case 列名when 值 then 值when 值 then 值else 值end case from 表明b) select casewhen 列名=值 then 值when 列名=值 then 值else 值end case from 表:1.列类型: %TYPEvarable tableName.columnName%TYPE;varable tableName.columnName%TYPE;2.⾏类型: %ROWTYPEvarable tableName%ROWTYPE;3.使⽤⾏类型:varable.列名;异常信息’,16,1) 能在 1)⾃定义异常:a)定义异常:(位 declare和 begin之间)DECLARE varable EXCEPTION;b)显⽰引发异常(为 begin 和 end 之间):RAISE varable;2)处理预定义异常:(位 begin 和 end 之间)EXCEPTIONwhen Too_Many_ROWS thenDBMS_OUTPUT.PUT_LINE('返回多⾏');when others thenDBMS_OUTPUT.PUT_LINE('全部处理');3) 引发应⽤程序错误:RAISE_APPLICATION_ERROR(error_number,error_message);原理: ):(重复⼦查询,不能单)(只执⾏⼀次,能单独执, 查询原理: 从外(外sql⼀次查出sql)到⾥把外不查出来的值传):查询到结果可以作为表来使⼀样切套⼦查询:Select * from AuthorBook a where CopyRight =(select Max(CopyRight) from AuthorBookwhere BookName = a.BopokName)(效率低)>连接查询(效), ⽽连. 右查询有连接查完全⼀样返回多⾏⼀列完全⼀样完全⼀样:只能出现在Group by分组,不能单独使⽤group by 就没有Having完全⼀样完全⼀样相对于mssql oracle显著的书写特点:1.代码⽚段必须放到begin end .. 中2.虚拟表 dual 的使⽤3.每⾏代码强制分号";"结束,包括end4.赋值符号 :=;(select xx into xx from daul;也可以⽤于赋值)5.省略了 as...补充:⼏种关系数据库中字符编码和存储长度需要注意的⼏个问题1.mysql中char(n) varchar(n) 中再utf8编码存储⽅式下数字表⽰的是字符数,但是在其他⽅式下就根据情况定,需要再相应环境下探索⼀下。
浅谈Mysql、SqlServer、Oracle三大数据库的区别

浅谈Mysql、SqlServer、Oracle三⼤数据库的区别⼀、MySQL优点:1. 体积⼩、速度快、总体拥有成本低,开源;2. ⽀持多种操作系统;3. 是开源数据库,提供的接⼝⽀持多种语⾔连接操作;MySQL的核⼼程序采⽤完全的多线程编程。
线程是轻量级的进程,它可以灵活地为⽤户提供服务,⽽不过多的系统资源。
⽤多线程和C语⾔实现的mysql能很容易充分利⽤CPU;MySql有⼀个⾮常灵活⽽且安全的权限和⼝令系统。
当客户与MySql服务器连接时,他们之间所有的⼝令传送被加密,⽽且MySql⽀持主机认证;⽀持ODBC for Windows,⽀持所有的ODBC 2.5函数和其他许多函数,可以⽤Access连接MySql服务器,使得应⽤被扩展;⽀持⼤型的数据库,可以⽅便地⽀持上千万条记录的数据库。
作为⼀个开放源代码的数据库,可以针对不同的应⽤进⾏相应的修改;拥有⼀个⾮常快速⽽且稳定的基于线程的内存分配系统,可以持续使⽤⾯不必担⼼其稳定性;MySQL同时提供⾼度多样性,能够提供很多不同的使⽤者介⾯,包括命令⾏客户端操作,⽹页浏览器,以及各式各样的程序语⾔介⾯,例如C+,Perl,Java,PHP,以及Python。
你可以使⽤事先包装好的客户端,或者⼲脆⾃⼰写⼀个合适的应⽤程序。
MySQL可⽤于Unix,Windows,以及OS/2等平台,因此它可以⽤在个⼈电脑或者是服务器上。
缺点:1. 不⽀持热备份;2. MySQL最⼤的缺点是其安全系统,主要是复杂⽽⾮标准,另外只有到调⽤mysqladmin来重读⽤户权限时才发⽣改变;3. 没有⼀种存储过程(Stored Procedure)语⾔,这是对习惯于企业级数据库的程序员的最⼤限制;4. MySQL的价格随平台和安装⽅式变化。
Linux的MySQL如果由⽤户⾃⼰或系统管理员⽽不是第三⽅安装则是免费的,第三⽅案则必须付许可费。
Unix或linux ⾃⾏安装免费、Unix或Linux 第三⽅安装收费。
mysql,oracle,sqlserver中的默认事务隔离级别查看,更改

mysql,oracle,sqlserver中的默认事务隔离级别查看,更改未提交读(隔离事务的最低级别,只能保证不读取物理上损坏的数据)已提交读(数据库引擎的默认级别)可重复读可序列化(隔离事务的最⾼级别,事务之间完全隔离)可串⾏化⽐较严谨,级别⾼;MySQLmysql默认的事务处理级别是'REPEATABLE-READ',也就是可重复读1.查看当前会话隔离级别select @@tx_isolation;2.查看系统当前隔离级别select @@global.tx_isolation;3.设置当前会话隔离级别set session transaction isolatin level repeatable read;4.设置系统当前隔离级别set global transaction isolation level repeatable read;Oracleoracle数据库⽀持READ COMMITTED 和 SERIALIZABLE这两种事务隔离级别。
默认系统事务隔离级别是READ COMMITTED,也就是读已提交1.查看系统默认事务隔离级别,也是当前会话隔离级别--⾸先创建⼀个事务declaretrans_id Varchar2(100);begintrans_id := dbms_transaction.local_transaction_id( TRUE );end;--查看事务隔离级别SELECT s.sid, s.serial#, CASE BITAND(t.flag, POWER(2, 28)) WHEN 0 THEN 'READ COMMITTED' ELSE 'SERIALIZABLE' END AS isolation_levelFROM v$transaction tJOIN v$session s ON t.addr = s.taddr AND s.sid = sys_context('USERENV', 'SID');SQL Server默认系统事务隔离级别是read committed,也就是读已提交1.查看系统当前隔离级别DBCC USEROPTIONSisolation level 这⼀项的 Value 既是当前的隔离级别设置值2.设置系统当前隔离级别SET TRANSACTION ISOLATION LEVEL Read UnCommitted;其中Read UnCommitted为需要设置的值。
mysqloraclesqlserver三大数据库的数据类型列表
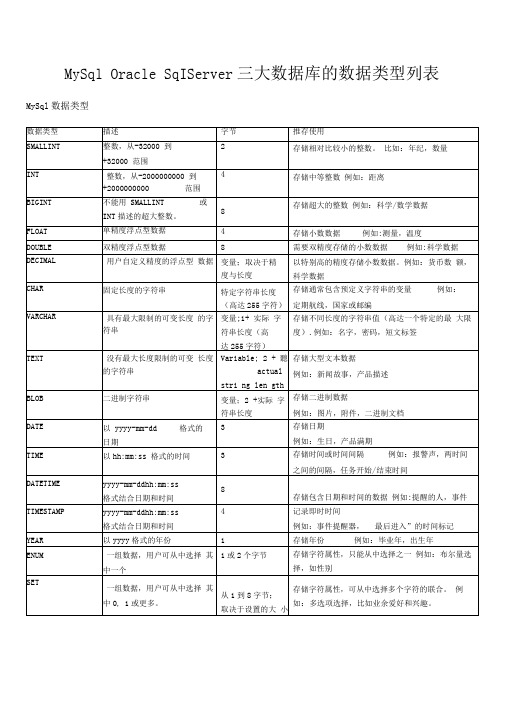
MySql Oracle SqIServer三大数据库的数据类型列表MySql数据类型Oracle数据类型、概述在ORACLE8中定义了:标量(SCALAR、复合(COMPOSITE、引用(REFERENCE和LOB四种数据类型,下面详细介绍它们的特性。
二、标量(SCALAR合法的标量类型与数据库的列所使用的类型相同,此外它还有一些扩展。
它又分为七个组:数字、字符、行、日期、行标识、布尔和可信。
数字,它有三种基本类型--NUMBER、PLS_INTEGEF和BINARY_INTENER NUMBER可以描述整数或实数,而PLS_INTEGEf和BINARY_INTENER^能描述整数。
NUMBER,是以十进制格式进行存储的,它便于存储,但是在计算上,系统会自动的将它转换成为二进制进行运算的。
它的定义方式是NUMBER( P, S),P是精度,最大38位,S是刻度范围,可在-84...127间取值。
例如:NUMBER( 5, 2)可以用来存储表示-999.99...999.99间的数值。
P、S可以在定义是省略,例如:NUMBER( 5)、NUMBER 等;BINARY_INTENER|来描述不存储在数据库中,但是需要用来计算的带符号的整数值。
它以2的补码二进制形式表述。
循环计数器经常使用这种类型。
PLS_INTEGEf和口BINARY_INTENER隹一区别是在计算当中发生溢出时,BINARY_INTENERS的变量会被自动指派给一个NUMBER型而不会出错,PLS_INTEGE型的变量将会发生错误。
字符,包括CHAR VARCHAR2 (VARCHAR、LONG NCHAR和NVARCHAR2几种类型。
CHAR描述定长的字符串,如果实际值不够定义的长度,系统将以空格填充。
它的声明方式如下CHAR( L) , L 为字符串长度,缺省为1,作为变量最大32767个字符,作为数据存储在ORACLE8中最大为2000。
MySQL+SQLSERVER+ORACLE获取数据库表名及字段名总结

MySQL,SQLSERVER,ORACLE获取数据库表名及字段名等总结2009年10月21日星期三 17:373、ORACLE获取表名:USER_TAB_COLS中记录了用户表的列信息。
下面是别人写的:SELECT USER_TAB_COLS.TABLE_NAME as 表名,USER_TAB_COLS.COLUMN_NAME as 列名,USER_TAB_COLS.DATA_TYPE as 数据类型,USER_TAB_COLS.DATA_LENGTH as 长度,USER_TAB_COLS.NULLABLE as 是否为空,USER_TAB_COLS.COLUMN_ID as 列序号,user_col_ments as 备注FROM USER_TAB_COLSinner join user_col_comments on user_col_comments.TABLE_NAME =USER_TAB_COLS.TABLE_NAMEand user_col_comments.COLUMN_NAME = USER_TAB_COLS.COLUMN_NAMEandUSER_TAB_COLS.TABLE_NAME='T_COMPANY_DETAIL'--------------(2).selectA.column_name 字段名,A.data_type 数据类型,A.data_length 长度,A.data_precision 整数位,A.Data_Scale 小数位,A.nullable 允许空值,A.Data_default 缺省值,ments 备注fromuser_tab_columns A,user_col_comments BwhereA.Table_Name =B.Table_Nameand A.Column_Name = B.Column_Nameand A.Table_Name = 'T_COMPANY_DETAIL'1、MySQL获取表名:用“show tables”命令。
使用SQL语句查询MySQL,SQLServer,Oracle所有数据库名和表名,字段名

使⽤SQL语句查询MySQL,SQLServer,Oracle所有数据库名和表名,字段名MySQL中查询所有数据库名和表名查询所有数据库show databases;查询指定数据库中所有表名select table_name from information_schema.tables where table_schema='database_name' and table_type='base table';查询指定表中的所有字段名select column_name from information_schema.columns where table_schema='database_name' and table_name='table_name';查询指定表中的所有字段名和字段类型select column_name,data_type from information_schema.columns where table_schema='database_name' and table_name='table_name';SQLServer中查询所有数据库名和表名查询所有数据库select * from sysdatabases;查询当前数据库中所有表名select * from sysobjects where xtype='U';xtype='U':表⽰所有⽤户表,xtype='S':表⽰所有系统表。
查询指定表中的所有字段名select name from syscolumns where id=Object_Id('table_name');查询指定表中的所有字段名和字段类型select , from syscolumns sc,systypes st where sc.xtype=st.xtype and sc.id in(select id from sysobjects where xtype='U' and name='table_name');Oracle中查询所有数据库名和表名查询所有数据库由于Oralce没有库名,只有表空间,所以Oracle没有提供数据库名称查询⽀持,只提供了表空间名称查询。
oracle mysql sqlserver 查看当前所有数据库及数据库基本操作命令

oracle mysql sqlserver 查看当前所有数据库及数据库基本操作命令1.oracle(1)启动监听lsnrctl start;(2)进入sqlplus界面sqlplus /nologSQL>conn sys/jiaxiaoai@orcl as sysdba;(3)启动数据库实例SQL>startup;(4)查看当前所有的数据库select * from v$database;或select name from v$database;(5)查看哪些用户拥有sysdba、sysoper权限select * from V_$PWFILE_USERS;show user;查看当前数据库连接用户(6)进入某个数据库:database 数据库名;查看数据库结构:desc v$database;(7)查看所有用户实例:select * from v$instance;或select instance_name from v$instance;(8)查看当前库的所有数据表select * from all_tables;select table_name from all_tables;select table_name from user_tables;select table_name from all_tables where owner='用户名';(9)查看表结构desc 表名;(10)增加数据库用户create user 用户名identified by 密码default tablespace users Temporary TAB LESPACE Temp;(11)用户授权grant connect,resource,dba to 用户名;grant sysdba to 用户名;(12)更改数据库用户密码alter user 用户名identified by 密码;2.mysql(1)显示所有数据库show database;(2)显示所有表show tables;(3)显示表结构desc 表名;3.sqlserver查询所有表:select * from sysobjects where xtype=“U”。
数据库迁移及区别比较(Oracle,Sql Server,MySql)

数据库迁移及及区别(Oracle,MySQL,SQLServer)/brightmart徐亮,2011-4-1导言:最近的数据超市项目需要从SQLServer迁移到MySql。
在之前并没有很多数据库迁移方面的经验,所以也不知道迁移需要花费多久,都要做什么工作。
通过几天的工作,项目已经顺利迁移到MySql上。
该文档总结了迁移的经验,同时也方便以后数据库迁移。
1、数据库迁移需要做的工作1.1 建表脚本修改1.2 数据导入(编码、数据类型设置)1.3 项目中的SQL修改1.4 数据库连接(驱动)1.5 连接项目中的程序,测试并修改程序2、常用数据库中在开发方面的不同2.1 数据类型2.2 自增2.3 分页2.4 内置函数2.5 模糊查询3、ORM工具与迁移使用hibernate、ibatis,在数据库迁移中的不同效率4、各数据库的不同数据类型比较及参考资料4.1、MySQL中的建表SQL4.2、Java到SQL数据类型影射表4.3、MySql与Oracle数据类型的相互转化4.4、ORACLE与SQLSERVER、MYSQL的数据类型对照表1、数据库迁移需要做的工作1、1 数据库建表脚本的修改1.1.1 由于各种数据库的数据类型并不相同,需要更改部分数据类型。
1.1.2 在MySQL脚本里暂不能给日期数据设置当前时间,字段如:registertime(注册时间);需在程序中设置当前日期,再保存进数据库或将registertime设置为时间戳(timestamp)1.1.3 在MySQL里的表和字段的注释,见【5】中的建表语句。
1、2 将数据导入到目标数据库的中(其中可以需要修改数据类型)1.2.1设置数据库的编码,防止中文乱码1)、最简单的修改方法,就是修改mysql的my.ini文件中的字符集键值,如:default-character-set = utf8(character_set_server = utf8)修改完后,重启mysql的服务,service mysql restart2)、还有一种修改字符集的方法,就是使用mysql的命令,如:mysql> SET character_set_client = utf8 ;mysql> SET character_set_connection = utf8 ;mysql> SET character_set_database = utf8 ;mysql> SET character_set_results = utf8 ;mysql> SET character_set_server = utf8 ;mysql> SET collation_connection = utf8 ;mysql> SET collation_database = utf8 ; mysql> SET collation_server = utf8 ;如果:没有设置前两条,可以通过以下方式实现编码:a 建数据库时设置数据库支持的编码:create database datmart charset=utf8;b 使用数据库datmart use datmart;c 插入中文数据时,需要先设置:set names utf8;d 将数据导入sourced:\datmart.sql(每个见表语句后加:ENGINE=MyISAM DEFAULT CHARSET=utf8;)1.2.2 数据类型即使MySQL中有bit,但SQLServer中的bit类型(取0或1,分别对应了bool的true和false)的变量在MySQL中,不能顺利导入。
oracle、sqlserver、mysql常用函数对比[to_char、to_numbe。。。

oracle、sqlserver、mysql常⽤函数对⽐[to_char、to_numbe。
oracle --> mysqlto_char(sysdate,'yyyy-mm-dd')-->date_format(sysdate(),'%Y-%m-%d');to_date(sysdate,'yyyy-mm-dd')-->STR_TO_DATE(sysdate(),'%Y-%m-%d');1.oracle(1)使⽤TO_CHAR函数处理数字TO_CHAR(number, '格式')TO_CHAR(salary,’$99,999.99’);(2)使⽤TO_CHAR函数处理⽇期TO_CHAR(date,’格式’);to_char(sysdate,'q') 季to_char(sysdate,'yyyy')年to_char(sysdate,'mm')⽉to_char(sysdate,'dd')⽇to_char(sysdate,'d')星期中的第⼏天to_char(sysdate,'DAY')星期⼏to_char(sysdate,'ddd')⼀年中的第⼏天(3)TO_NUMBER使⽤TO_NUMBER函数将字符转换为数字TO_NUMBER(char[, '格式'])(4) TO_DATE使⽤TO_DATE函数将字符转换为⽇期TO_DATE(char[, '格式'])------------------------------------------------------------------------------------------2.sql1)类型转换:Cast()类型转换,例:Cast(@startdate as datetime),Cast(name as nvarchar)2)⽇期截取:Datepart()返回代表指定⽇期的指定⽇期部分的整数,例:Datepart(Dd,@startdate)--取⽇,Datepart(Month,@startdate)--取⽉,Datepart(Yy,@startdate)--取年3)⽇期操作:Dateadd()在向⼀个⽇期加上⼀个段时间的基础上,返回新的datetime类型。
MySQL、Oracle、SqlServer三种数据库的优缺点

MySQL、Oracle、SqlServer三种数据库的优缺点MySql数据库:优点: 1.⽀持5000万条记录的数据仓库2.适应于所有的平台3.是开源软件,版本更新较快4.性能很出⾊。
纯粹就性能⽽⾔,MySQL是相当出⾊的,因为它包含⼀个缺省桌⾯格式MyISAM。
MyISAM数据库与磁盘⾮常地兼容⽽不占⽤过多的CPU和内存。
MySQL可以运⾏于Windows 系统⽽不会发⽣冲突,在UNIX或类似UNIX系统上运⾏则更好。
你还可以通过使⽤64位处理器来获取额外的⼀些性能。
因为MySQL在内部⾥很多时候都使⽤64位的整数处理。
5.价格便宜缺点:缺乏⼀些存储程序的功能,⽐如MyISAM引擎联⽀持交换功能MsSqlserver数据库:优点: 1.真正的客户机/服务器体系结构2.图形化的⽤户界⾯,使系统管理和数据库管理更加直观、简单3.丰富的编程接⼝⼯具,为⽤户进⾏程序设计提供了更⼤的选择余地4.与WinNT完全集成,利⽤了NT的许多功能,如发送和接受消息,管理登录安全性等,SQL Server也可以很好地与Microsoft BackOffice产品集成。
5.有很好的伸缩性,可以跨平台使⽤。
6.提供数据仓库功能,这个功能只在Oracle和其他昂贵的DBMS中才有。
Oracle数据库:优点: 1.Oracle的稳定性要⽐Sql server好。
2.Oracle在导数据⼯具sqlload.exe功能⽐Sqlserver的Bcp功能强⼤,Oracle可以按照条件把⽂本⽂件数据导⼊.3.Oracle的安全机制⽐Sql server好。
4.Sql server的易⽤性和友好性⽅⾯要⽐Oracle好。
5.在处理⼤数据⽅⾯Oracle会更稳定⼀些。
6.Sql Server在数据导出⽅⾯功能更强⼀些。
7.处理速度⽅⾯⽐Oracle快⼀些,和两者的协议有关.缺点:价格昂贵。
SQL语句大全(mysql,sqlserver,oracle)

SQL语句大全--语句功能--数据操作SELECT --从数据库表中检索数据行和列-selectINSERT --向数据库表添加新数据行-insertDELETE --从数据库表中删除数据行-deleteUPDATE --更新数据库表中的数据-update--数据定义CREATE TABLE --创建一个数据库表-create tableDROP TABLE --从数据库中删除表-drop tableALTER TABLE --修改数据库表结构-alter tableCREATE VIEW --创建一个视图-create viewDROP VIEW --从数据库中删除视图-drop viewCREATE INDEX --为数据库表创建一个索引-create indexDROP INDEX --从数据库中删除索引-drop indexCREATE PROCEDURE --创建一个存储过程-create procedureDROP PROCEDURE --从数据库中删除存储过程-drop procedure CREATE TRIGGER --创建一个触发器-create triggerDROP TRIGGER --从数据库中删除触发器-drop triggerCREATE SCHEMA --向数据库添加一个新模式-create schema DROP SCHEMA --从数据库中删除一个模式-drop schema CREATE DOMAIN --创建一个数据值域-create domainALTER DOMAIN --改变域定义-alter domainDROP DOMAIN --从数据库中删除一个域-drop domain--数据控制GRANT --授予用户访问权限-grantDENY --拒绝用户访问-denyREVOKE --解除用户访问权限-revoke--事务控制COMMIT --结束当前事务-commitROLLBACK --中止当前事务-rollbackSET TRANSACTION --定义当前事务数据访问特征-set transaction --程序化SQLDECLARE --为查询设定游标-declareEXPLAN --为查询描述数据访问计划-explanOPEN --检索查询结果打开一个游标-openFETCH --检索一行查询结果-fetchCLOSE --关闭游标-clocePREPARE --为动态执行准备SQL 语句-repareEXECUTE --动态地执行SQL 语句-executeDESCRIBE --描述准备好的查询-describe---局部变量---必须以@@开头--IF ELSEdeclare @x int @y int @z intselect @x = 1 @y = 2 @z=3if @x > @yprint 'x > y' --打印字符串'x > y'else if @y > @zprint 'y > z'else print 'z > y'--CASEuse panguupdate employeeset e_wage =casewhen job_level = ’1’ then e_wage*1.08when job_level = ’2’ then e_wage*1.07when job_level = ’3’ then e_wage*1.06else e_wage*1.05end--WHILE CONTINUE BREAKdeclare @x int @y int @c intselect @x = 1 @y=1while @x < 3beginprint @x --打印变量x 的值while @y < 3beginselect @c = 100*@x + @yprint @c --打印变量c 的值select @y = @y + 1endselect @x = @x + 1select @y = 1end--WAITFOR--例等待1 小时2 分零3 秒后才执行SELECT 语句waitfor delay ’01:02:03’select * from employee--例等到晚上11 点零8 分后才执行SELECT 语句waitfor time ’23:08:00’select * from employee***SELECT***select *(列名) from table_name(表名) where column_name operator valueex:(宿主)select * from stock_information where stockid = str(nid)stockname = 'str_name'stockname like '% find this %'stockname like '[a-zA-Z]%' --------- ([]指定值的范围)stockname like '[^F-M]%' --------- (^排除指定范围)--------- 只能在使用like关键字的where子句中使用通配符)or stockpath = 'stock_path'or stocknumber < 1000and stockindex = 24not stock*** = 'man'stocknumber between 20 and 100stocknumber in(10,20,30)order by stockid desc(asc) --------- 排序,desc-降序,asc-升序order by 1,2 --------- by列号stockname = (select stockname from stock_information where stockid = 4)--------- 子查询--------- 除非能确保内层select只返回一个行的值,--------- 否则应在外层where子句中用一个in限定符select distinct column_name form table_name --------- distinct指定检索独有的列值,不重复select stocknumber ,"stocknumber + 10" = stocknumber + 10 from table_nameselect stockname , "stocknumber" = count(*) from table_name group by stockname--------- group by 将表按行分组,指定列中有相同的值having count(*) = 2 --------- having选定指定的组select *from table1, table2where table1.id *= table2.id -------- 左外部连接,table1中有的而table2中没有得以null表示table1.id =* table2.id -------- 右外部连接select stockname from table1union [all] ----- union合并查询结果集,all-保留重复行select stockname from table2***insert***insert into table_name (Stock_name,Stock_number) value ("xxx","xxxx")value (select Stockname , Stocknumber from Stock_table2)---value为select语句***update***update table_name set Stockname = "xxx" [where Stockid = 3]Stockname = defaultStockname = nullStocknumber = Stockname + 4***delete***delete from table_name where Stockid = 3truncate table_name ----------- 删除表中所有行,仍保持表的完整性drop table table_name --------------- 完全删除表***alter table*** --- 修改数据库表结构alter table database.owner.table_name add column_name char(2) null .....sp_help table_name ---- 显示表已有特征create table table_name (name char(20), age smallint, lname varchar(30))insert into table_name select ......... ----- 实现删除列的方法(创建新表)alter table table_name drop constraint Stockname_default ---- 删除Stockname的default约束***function(/*常用函数*/)***----统计函数----AVG --求平均值COUNT --统计数目MAX --求最大值MIN --求最小值SUM --求和--AVGuse panguselect avg(e_wage) as dept_avgWagefrom employeegroup by dept_id--MAX--求工资最高的员工姓名use panguselect e_namefrom employeewhere e_wage =(select max(e_wage)from employee)--STDEV()--STDEV()函数返回表达式中所有数据的标准差--STDEVP()--STDEVP()函数返回总体标准差--VAR()--VAR()函数返回表达式中所有值的统计变异数--VARP()--VARP()函数返回总体变异数----算术函数----/***三角函数***/SIN(float_expression) --返回以弧度表示的角的正弦COS(float_expression) --返回以弧度表示的角的余弦TAN(float_expression) --返回以弧度表示的角的正切COT(float_expression) --返回以弧度表示的角的余切/***反三角函数***/ASIN(float_expression) --返回正弦是FLOAT 值的以弧度表示的角ACOS(float_expression) --返回余弦是FLOAT 值的以弧度表示的角ATAN(float_expression) --返回正切是FLOAT 值的以弧度表示的角ATAN2(float_expression1,float_expression2)--返回正切是float_expression1 /float_expres-sion2的以弧度表示的角DEGREES(numeric_expression)--把弧度转换为角度返回与表达式相同的数据类型可为--INTEGER/MONEY/REAL/FLOAT 类型RADIANS(numeric_expression) --把角度转换为弧度返回与表达式相同的数据类型可为--INTEGER/MONEY/REAL/FLOAT 类型EXP(float_expression) --返回表达式的指数值LOG(float_expression) --返回表达式的自然对数值LOG10(float_expression)--返回表达式的以10 为底的对数值SQRT(float_expression) --返回表达式的平方根/***取近似值函数***/CEILING(numeric_expression) --返回>=表达式的最小整数返回的数据类型与表达式相同可为--INTEGER/MONEY/REAL/FLOAT 类型FLOOR(numeric_expression) --返回<=表达式的最小整数返回的数据类型与表达式相同可为--INTEGER/MONEY/REAL/FLOAT 类型ROUND(numeric_expression) --返回以integer_expression 为精度的四舍五入值返回的数据--类型与表达式相同可为INTEGER/MONEY/REAL/FLOAT 类型ABS(numeric_expression) --返回表达式的绝对值返回的数据类型与表达式相同可为--INTEGER/MONEY/REAL/FLOAT 类型SIGN(numeric_expression) --测试参数的正负号返回0 零值1 正数或-1 负数返回的数据类型--与表达式相同可为INTEGER/MONEY/REAL/FLOAT 类型PI() --返回值为π 即3.1415926535897936RAND([integer_expression]) --用任选的[integer_expression]做种子值得出0-1 间的随机浮点数----字符串函数----ASCII() --函数返回字符表达式最左端字符的ASCII 码值CHAR() --函数用于将ASCII 码转换为字符--如果没有输入0 ~ 255 之间的ASCII 码值CHAR 函数会返回一个NULL 值LOWER() --函数把字符串全部转换为小写UPPER() --函数把字符串全部转换为大写STR() --函数把数值型数据转换为字符型数据LTRIM() --函数把字符串头部的空格去掉RTRIM() --函数把字符串尾部的空格去掉LEFT(),RIGHT(),SUBSTRING() --函数返回部分字符串CHARINDEX(),PATINDEX() --函数返回字符串中某个指定的子串出现的开始位置SOUNDEX() --函数返回一个四位字符码--SOUNDEX函数可用来查找声音相似的字符串但SOUNDEX函数对数字和汉字均只返回0 值DIFFERENCE() --函数返回由SOUNDEX 函数返回的两个字符表达式的值的差异--0 两个SOUNDEX 函数返回值的第一个字符不同--1 两个SOUNDEX 函数返回值的第一个字符相同--2 两个SOUNDEX 函数返回值的第一二个字符相同--3 两个SOUNDEX 函数返回值的第一二三个字符相同--4 两个SOUNDEX 函数返回值完全相同QUOTENAME() --函数返回被特定字符括起来的字符串/*select quotename('abc', '{') quotename('abc')运行结果如下----------------------------------{{abc} [abc]*/REPLICATE() --函数返回一个重复character_expression 指定次数的字符串/*select replicate('abc', 3) replicate( 'abc', -2)运行结果如下----------- -----------abcabcabc NULL*/REVERSE() --函数将指定的字符串的字符排列顺序颠倒REPLACE() --函数返回被替换了指定子串的字符串/*select replace('abc123g', '123', 'def')运行结果如下----------- -----------abcdefg*/SPACE() --函数返回一个有指定长度的空白字符串STUFF() --函数用另一子串替换字符串指定位置长度的子串----数据类型转换函数----CAST() 函数语法如下CAST() (<expression> AS <data_ type>[ length ])CONVERT() 函数语法如下CONVERT() (<data_ type>[ length ], <expression> [, style])select cast(100+99 as char) convert(varchar(12), getdate())运行结果如下------------------------------ ------------199 Jan 15 2000----日期函数----DAY() --函数返回date_expression 中的日期值MONTH() --函数返回date_expression 中的月份值YEAR() --函数返回date_expression 中的年份值DATEADD(<datepart> ,<number> ,<date>)--函数返回指定日期date 加上指定的额外日期间隔number 产生的新日期DATEDIFF(<datepart> ,<number> ,<date>)--函数返回两个指定日期在datepart 方面的不同之处DATENAME(<datepart> , <date>) --函数以字符串的形式返回日期的指定部分DATEPART(<datepart> , <date>) --函数以整数值的形式返回日期的指定部分GETDATE() --函数以DATETIME 的缺省格式返回系统当前的日期和时间----系统函数----APP_NAME() --函数返回当前执行的应用程序的名称COALESCE() --函数返回众多表达式中第一个非NULL 表达式的值COL_LENGTH(<'table_name'>, <'column_name'>) --函数返回表中指定字段的长度值COL_NAME(<table_id>, <column_id>) --函数返回表中指定字段的名称即列名DATALENGTH() --函数返回数据表达式的数据的实际长度DB_ID(['database_name']) --函数返回数据库的编号DB_NAME(database_id) --函数返回数据库的名称HOST_ID() --函数返回服务器端计算机的名称HOST_NAME() --函数返回服务器端计算机的名称IDENTITY(<data_type>[, seed increment]) [AS column_name])--IDENTITY() 函数只在SELECT INTO 语句中使用用于插入一个identity column列到新表中/*select identity(int, 1, 1) as column_nameinto newtablefrom oldtable*/ISDATE() --函数判断所给定的表达式是否为合理日期ISNULL(<check_expression>, <replacement_value>) --函数将表达式中的NULL 值用指定值替换ISNUMERIC() --函数判断所给定的表达式是否为合理的数值NEWID() --函数返回一个UNIQUEIDENTIFIER 类型的数值NULLIF(<expression1>, <expression2>)--NULLIF 函数在expression1 与expression2 相等时返回NULL 值若不相等时则返回expression1 的值sql中的保留字action add aggregate allalter after and asasc avg avg_row_length auto_incrementbetween bigint bit binaryblob bool both bycascade case char characterchange check checksum columncolumns comment constraint createcross current_date current_time current_timestampdata database databases datedatetime day day_hour day_minuteday_second dayofmonth dayofweek dayofyeardec decimal default delayeddelay_key_write delete desc describedistinct distinctrow double dropend else escape escapedenclosed enum explain existsfields file first floatfloat4 float8 flush foreignfrom for full functionglobal grant grants grouphaving heap high_priority hourhour_minute hour_second hosts identifiedignore in index infileinner insert insert_id intinteger interval int1 int2int3 int4 int8 intoif is isam joinkey keys kill last_insert_idleading left length likelines limit load locallock logs long longbloblongtext low_priority max max_rowsmatch mediumblob mediumtext mediumintmiddleint min_rows minute minute_secondmodify month monthname myisamnatural numeric no notnull on optimize optionoptionally or order outeroutfile pack_keys partial passwordprecision primary procedure processprocesslist privileges read realreferences reload regexp renamereplace restrict returns revokerlike row rows secondselect set show shutdownsmallint soname sql_big_tables sql_big_selectssql_low_priority_updates sql_log_off sql_log_update sql_select_limitsql_small_result sql_big_result sql_warnings straight_joinstarting status string tabletables temporary terminated textthen time timestamp tinyblobtinytext tinyint trailing totype use using uniqueunlock unsigned update usagevalues varchar variables varyingvarbinary with write whenwhere year year_month zerofill常用SQL命令和ASP编程在进行数据库操作时,无非就是添加、删除、修改,这得设计到一些常用的SQL语句,如下:SQL常用命令使用方法:(1) 数据记录筛选:sql="select * from 数据表where 字段名=字段值order by 字段名[desc]"sql="select * from 数据表where 字段名like %字段值% order by 字段名[desc]"sql="select top 10 * from 数据表where 字段名order by 字段名[desc]"sql="select * from 数据表where 字段名in (值1,值2,值3)"sql="select * from 数据表where 字段名between 值1 and 值2"(2) 更新数据记录:sql="update 数据表set 字段名=字段值where 条件表达式"sql="update 数据表set 字段1=值1,字段2=值2 …… 字段n=值n where 条件表达式" (3) 删除数据记录:sql="delete from 数据表where 条件表达式"sql="delete from 数据表" (将数据表所有记录删除)(4) 添加数据记录:sql="insert into 数据表(字段1,字段2,字段3 …) valuess (值1,值2,值3 …)"sql="insert into 目标数据表select * from 源数据表" (把源数据表的记录添加到目标数据表) (5) 数据记录统计函数:AVG(字段名) 得出一个表格栏平均值COUNT(*|字段名) 对数据行数的统计或对某一栏有值的数据行数统计MAX(字段名) 取得一个表格栏最大的值MIN(字段名) 取得一个表格栏最小的值SUM(字段名) 把数据栏的值相加引用以上函数的方法:sql="select sum(字段名) as 别名from 数据表where 条件表达式"set rs=conn.excute(sql)用rs("别名") 获取统的计值,其它函数运用同上。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
mysql比较小,易于安装维护和管理,操作简单,最重要的是它是三个中唯一一个开源数据库,但目前也属于Oracle公司的产品了。
对于中小型应用都可以支持,如果没记错的话最大并发好像是6000,性能不错。
一般php程序比较喜欢用mysql,我做java也喜欢用。
sqlserver是微软的产品,对 .net程序支持比较好,对于一般的应用来说都够用了。
基本上.net阵营中很少使用sqlserver以外的数据库产品。
oracle是oracle的数据库产品,它体积比较庞大(现在的sqlserver体积也很庞大),可以在同一机器上运行多个实例,一般用来开发大型应用(例如分布式)。
比如我们知道,联通用的就是oracle。
oracle对java支持的很好1.类型转换--Oracle select to_number('123') from dual; --123;select to_char(33) from dual; --33;select to_date('2004-11-27','yyyy/mm/dd') from dual;--2004-11-27--Mysql select cast('123'as signed integer); --123select cast(33 as char(2)); --33;select to_days('2000-01-01'); --730485--SqlServer select cast('123'as decimal(30,2));--123.00select cast(33 as char(2)); --33;select convert(varchar(12) , getdate(), 120)2.四舍五入函数区别--Oracle select round(12.86*10)/10 from dual; --12.9--Mysql select format(12.89,1); --12.9--SqlServer select round(12.89,1); --12.93.日期时间函数--Oracle select sysdate from dual; --日期时间--Mysql select sysdate(); --日期时间select current_date(); --日期--SqlServer select getdate(); --日期时间select datediff(day,'2010-01-01',cast(getdate() as varchar(10)));--日期相差天数4.Decode函数--Oracle select decode(sign(12),1,1,0,0,-1) from dual;--1--Mysql/SqlServer select case when sign(12)=1 then 1 when sign(12)=0 then 0 else -1 end;--15.判空函数--Oracle select nvl(1,0) from dual; --1--Mysql select ifnull(1,0); --1--SqlServer select isnull(1,0); --16.字符串连接函数--Oracle select'1'||'2'from dual; --12select concat('1','2'); --12--Mysql select concat('1','2'); --12--SqlServer select'1'+'2'; --127.记录限制函数--Oracle select 1 from dual where rownum <= 10;--Mysql select 1 from dual limit 10;--SqlServer select top 10 18.字符串截取函数--Oracle select substr('12345',1,3) from dual;--Mysql/SqlServer select substring('12345',1,3);8.把多行转换成一合并列--Oracle select wm_concat(列名) from dual; --多行记录转换成一列之间用,分割--Mysql/SqlServer select group_concat(列名);9、中文排序--Oracle select * from dual orderby NLSSORT('CD.F_NAME_CH',NLS_SORT=SCHINESE_PINYIN_M) desc; --中文拼音排序1)按笔画排序select * from Table order by nlssort(columnName,'NLS_SORT=SCHINESE_STROKE_M') 2)按部首排序select * from Table order by nlssort(columnName,'NLS_SORT=SCHINESE_RADICAL_M') 3)按拼音排序select * from Table order by nlssort(columnName,'NLS_SORT=SCHINESE_PINYIN_M'); --Mysql select * from dual NLSSORT order by CONVERT(‘F_NAME_CH' USING GBK) desc ;如果数据表tbl的某字段name的字符编码是latin1_swedish_ci;select * from `tbl` order by birary(name) asc如果数据表tbl的某字段name的字符编码是utf8_general_ci;SELECT name FROM `tbl` WHERE 1ORDER BY CONVERT( name USING gbk ) COLLATE gbk_chinese_ci ASC--SqlServer1)中文的笔画顺序排序Select * From [Table_Name] Order By [Column_Name] Collate Chinese_PRC_Stroke_ci_as 2)按拼音排序Select * From [Table_Name] ORDER BY [Column_Name] COLLATE Chinese_PRC_CS_AS_KS_WSMySQL和SQLServer的比较对于程序开发人员而言,目前使用最流行的两种后台数据库即为MySQL和SQLServer。
这两者最基本的相似之处在于数据存储和属于查询系统。
你可以使用sql来访问这两种数据库的数据,因为它们都支持ansi-sql。
还有,这两种数据库系统都支持二进制关键词和关键索引,这就大大地加快了查询速度。
同时,二者也都提供支持xml的各种格式。
除了在显而易见的软件价格上的区别之外,这两个产品还有什么明显的区别吗?在这二者之间你是如何选择的?让我们看看这两个产品的主要的不同之处,包括发行费用,性能以及它们的安全性。
根本的区别是它们遵循的基本原则二者所遵循的基本原则是它们的主要区别:开放vs保守。
SQLServer服务器的狭隘的,保守的存储引擎与MySQL服务器的可扩展,开放的存储引擎绝然不同。
虽然你可以使用SQLServer服务器的 sybase引擎,但MySQL能够提供更多种的选择,如myisam, heap, innodb, and berkeley db。
MySQL不完全支持陌生的关键词,所以它比SQLServer服务器要少一些相关的数据库。
同时,MySQL也缺乏一些存储程序的功能,比如 myisam引擎联支持交换功能。
发行费用:MySQL不全是免费,但很便宜当提及发行的费用,这两个产品采用两种绝然不同的决策。
对于SQLServer服务器,获取一个免费的开发费用最常的方式是购买微软的office或者visual studio的费用。
但是,如果你想用于商业产品的开发,你必须还要购买sql server standard edition。
学校或非赢利的企业可以不考虑这一附加的费用。
性能:先进的MySQL纯粹就性能而言,MySQL是相当出色的,因为它包含一个缺省桌面格式myisam。
myisam 数据库与磁盘非常地兼容而不占用过多的cpu和内存。
MySQL可以运行于windows系统而不会发生冲突,在unix或类似unix系统上运行则更好。
你还可以通过使用64位处理器来获取额外的一些性能。
因为MySQL在内部里很多时候都使用64位的整数处理。
Yahoo!商业网站就使用MySQL 作为后台数据库。
当提及软件的性能,SQLServer服务器的稳定性要比它的竞争对手强很多。
但是,这些特性也要付出代价的。
比如,必须增加额外复杂操作,磁盘存储,内存损耗等等。
如果你的硬件和软件不能充分支持SQLServer服务器,我建议你最好选择其他如dbms数据库,因为这样你会得到更好的结果。
安全功能MySQL有一个用于改变数据的二进制日志。
因为它是二进制,这一日志能够快速地从主机上复制数据到客户机上。
即使服务器崩溃,这一二进制日志也会保持完整,而且复制的部分也不会受到损坏。
在 SQLServer服务器中,你也可以记录SQLServer的有关查询,但这需要付出很高的代价。
安全性这两个产品都有自己完整的安全机制。
只要你遵循这些安全机制,一般程序都不会出现什么问题。
这两者都使用缺省的ip端口,但是有时候很不幸,这些ip也会被一些黑客闯入。
当然,你也可以自己设置这些ip端口。
恢复性:先进的sql服务器恢复性也是 MySQL的一个特点,这主要表现在myisam配置中。
这种方式有它固有的缺欠,如果你不慎损坏数据库,结果可能会导致所有的数据丢失。
然而,对于 SQLServer服务器而言就表现得很稳键。
SQLServer服务器能够时刻监测数据交换点并能够把数据库损坏的过程保存下来。
根据需要决定你的选择对于这两种数据库,如果非要让我说出到底哪一种更加出色,也许我会让你失望。
以我的观点,任一对你的工作有帮助的数据库都是很好的数据库,没有哪一个数据库是绝对的出色,也没有哪一个数据库是绝对的差劲。